BAB 2
TINJAUAN PUSTAKA
2.1. Kecerdasan Buatan
Bagian dari teknik kompetitif yang lain dari kecerdasan buatan (Sistem pendukung keputusan, Sistem pakar, Komputer vision) seperti fuzzy logic, genetik algorithm sama halnya dengan metode statistik dan analitik, Jaringan syaraf tiruan sangat kuat dalam menyelesaikan masalah kompleks dan masalah non linear. Alasan mengapa JST banyak digunakan karena dapat menunjukkan beberapa keuntungan antara lain pembelajaran yang memperlihatkan beberapa kemampuan dari generalisasi pelatihan data.
2.2. Jaringan Syaraf Tiruan
Jaringan syaraf tiruan salah satu mesin pembelajaran yang sangat terkenal dan telah digunakan secara luas pada berbagai permasalahan, yang melibatkan pembangunan algoritma yang memungkin komputer untuk belajar (Negnevitsky, 2005).
Jaringan syaraf tiruan merupakan suatu sistem informasi yang cara kerjanya memiliki kesamaan tertentu dengan jaringan syaraf biologi (Fausett, 1994). Jaringan syaraf tiruan dikembangkan sebagai model matematis dari syaraf biologis dengan berdasarkan asumsi bahwa :
1. Pemrosesan terjadi pada elemen – elemen sederhana yang disebut neuron. 2. Sinyal penghubungkan antar neuron melalui penghubung
3. Setiap penghubung memiliki bobot yang akan mengalikan sinyal yang lewat.
4. Setiap neuron memiliki fungsi aktivasi yang akan menentukan nilai sinyal output.
Setiap neuron memiliki internal state yang disebut dengan fungsi aktivasi. Fungsi aktivasi merupakan fungsi dari input yang diterima neuron. Satu neuron akan mengirimkan sinyal ke neuron-neuron yang lain (Setiawan, 2003)
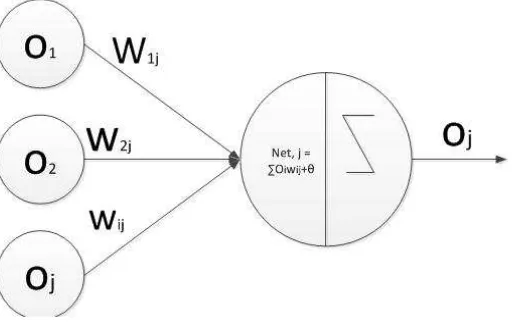
Secara sederhana Jaringan syaraf tiruan terdiri dari modul yang saling keterkaitan disebut juga dengan neuron dimana analogi dari syaraf biologi pada otak. Struktur Neuron pada JST digambarkan sebagai berikut :
Gambar 2.1 Struktur Neuron Sumber : Fausset (1994)
Gambar 2.1 memperlihatkan bahwa jaringan syaraf tiruan terdiri dari satuan-satuan pemroses berupa neuron. Y sebagai output menerima input dari x1, x2, x3,…….xn dengan
bobot W1, W2, W3,……..Wn. Hasil penjumlahan seluruh impuls neuron dibandingkan
dengan nilai ambang tertentu melalui fungsi aktivasi f setiap neuron.
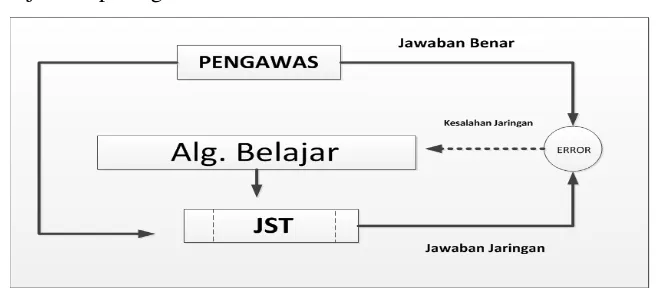
Sebagaian besar jaringan syaraf melakukan penyeseuain bobot-bobotnya selama proses pelatihan. Pelatihan dapat berupa pelatihan terbimbing (Supervised training) dimana diperlukan pasangan masukan – sasaran untuk tiap pola yang dilatihnya.Jenis kedua adalah pelatihan tak terbimbing (unsurpersived training). Pada metode ini, penyesuaian bobot tidak perlu disertai sasaran. Sebuah jaringan syaraf tiruan mempunyai tiga karakteristik, yaitu :
1. Arsitektur Jaringan
neuron pada lapisan berikutnya. Adapun arsitektur dari Jaringan Syaraf tiruan antara lain :
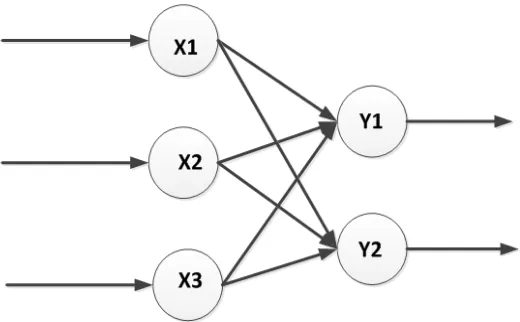
a. Jaringan Satu Lapis (Single layer network)
Pada jaringan satu lapis, hanya memiliki satu lapisan input dan lapisan output. Pada jaringan ini sinyal masukan langsung diolah menjadi sinyal keluaran , tanpa melalui hidden layer seperti contoh yang ditujukkan pada Gambar 2.2. Pada jaringan satu lapis dapat ditambahkan dengan bias yang merupakan bobot koneksi dari unit aktivasinya selalu 1
Gambar 2.2 Jaringan satu lapis Sumber : Supriyadi (2012)
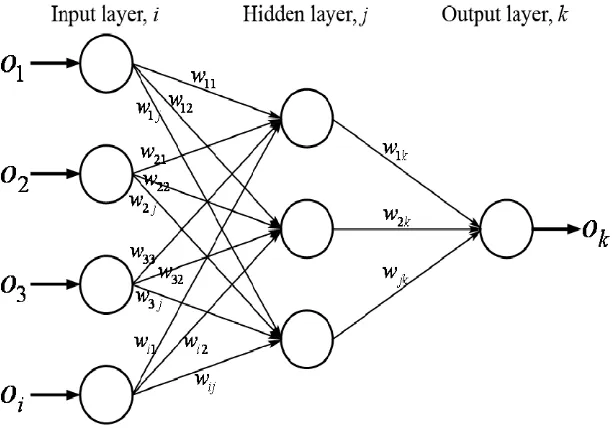
b. Jaringan Lapis Banyak (multi layer net)
Jaringan lapis banyak terdiri dari satu lapisan input, satu lapisan output dan satu atau lebih hidden layer yang terletak diantara lapisan input dan lapisan output seperti yang ditunjukkan pada gambar 2. 3. Jaringan dengan banyak lapisan dapat dimanfaatkan untuk menyelesaikan
Gambar 2.3 Jaringan lapis banyak Sumber : Hamid (2011)
Multi layer net juga dikenal setara Multilayer Feedforward Neural Network (MLFNN) adalah salah satu yang banyak digunakan pada model jaringan syaraf tiruan. Oleh karena arsitektur dan perbandingan algoritma yang sederhana (Popescuet al., 2009), dapat juga digunakan sebagai fungsi pembangkit secara menyeluruh, bahkan dapat digunakan untuk jenis aplikasi yang besar
Multi layer perceptron tersusun oleh seperangkat sensor yang dikelompokkan dalam tiga tingkatan lapisan yang terdiri dari input layer, satu atau lebih perantara atau hidden layer dan lapisan output layer yang mengkalkulasikan keluaran dari jaringan. Semua lapisan berurutan terhubung secara lengkap. Hubungan antara modul berbatasan lapisan relay sinyal keluaran dari satu lapisan ke berikutnya. Sebagai contoh, gambar diatas mempunyai 4 vektor dimensi, di ikuti oleh 3 lapisan tersembunyi dan yang terakhir lapisan keluaran dimana terdiri dari 1 modul. Jaringan JSTdisebut dengan sebagai
jaringan 4-3-1.
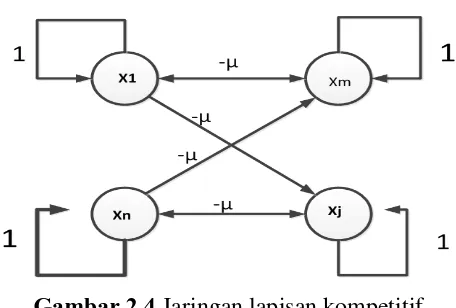
c. Jaringan dengan lapisan kompetitif
Pada lapisan kompetitif hubungan antar neuron tidak diperlihatkan
Gambar 2.4 Jaringan lapisan kompetitif Sumber :Supriyadi (2012)
2. Konsep Pembelajaran Jaringan Syaraf Tiruan
Sistem Jaringan syaraf tiruan mempunyai ciri utama yaitu kemampuannya untuk belajar dari contoh atau pengalaman terdahulu. Sistem dapat berfungsi dengan baik tanpa dilakukan pembuatan program seperti pada sistem komputer konvensional akan tetapi dengan pelatihan. Fungsi JST ditentukan oleh bobot penghubungnya dan didasarkan pada fungsi masukan keluarannya.
Bobot – bobot koneksi dapat berupa variabel yang ditentukan pada saat perancangan, tetapi juga jaringan yang harus mencari sendiri besarnya bobot – bobot yang sesuai. Proses penyesuaian bobot inilah jaringan syaraf tiruan disebut pross pelatihan. Proses pembelajaran di bagi atas dua yaitu :
a. Proses belajar terbimbing
Algoritma pembelajaran terbimbing memerlukan keluaran / target yang telah
terdapat dalam paket belajarnya. Diagram dari konsep belajar terbimbing ditunjukkan pada gambar 2.5
Gambar 2.5 Proses belajar terbimbing
Sumber :Supriyadi (2012)
b. Proses belajar tidak terbimbing (unsupervised learning)
Pada algoritma pembelajaran tak terbimbing, jaringan akan mengubah bobot-bobotnya, sehingga tanggapan terhadap masukan tanpa memerlukan keluaran acuan/ target. Tujuan pembelajaran ini adalah mengelompokkan unit-unit yang hampir sama dalam suatu area tertentu. Pembelajaran ini cocok untuk pengelompokan pola
2.2.1. Fungsi Aktivasi
Fungsi aktivasi yang juga dikenal sebagai fungsi pemindahan adalah fungsi untuk menentukan output dari penjumlahan fungsi dari input bobot pada neuron (Engelbrecht, 2007), fungsi tersebut dapat berbentuk linear dan non linear. Ada beberapa fungsi aktivasi yang sering digunakan dalam syaraf tiruan, antara lain :
a. Fungsi Linear
Fungsi linear menyiapkan output yang seimbang untuk total bobot output
y = f(x) = x (2.1)
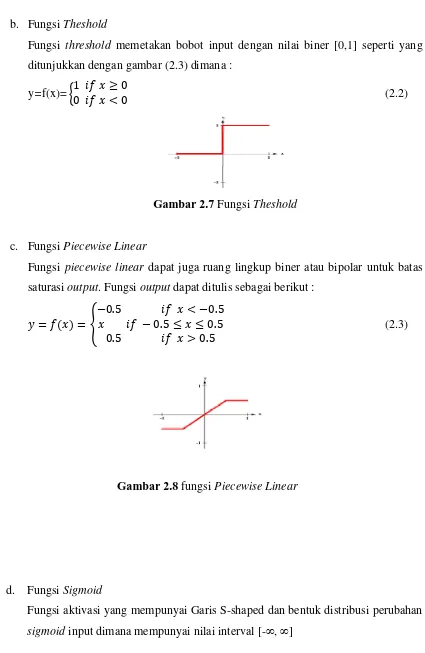
b. Fungsi Theshold
Fungsi threshold memetakan bobot input dengan nilai biner [0,1] seperti yang ditunjukkan dengan gambar (2.3) dimana :
y=f(x)= 1 ≥ 0
0 < 0 (2.2)
Gambar 2.7 Fungsi Theshold
c. Fungsi Piecewise Linear
Fungsi piecewise linear dapat juga ruang lingkup biner atau bipolar untuk batas saturasi output. Fungsi output dapat ditulis sebagai berikut :
= = −0.5 < −0.5 − 0.5 ≤ ≤ 0.5
0.5 > 0.5 (2.3)
Gambar 2.8 fungsi Piecewise Linear
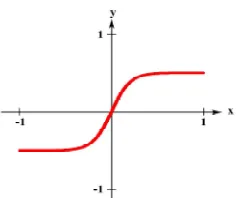
d. Fungsi Sigmoid
Fungsi aktivasi yang mempunyai Garis S-shaped dan bentuk distribusi perubahan sigmoid input dimana mempunyai nilai interval [- , ]
Gambar 2.9 Fungsi sigmoid
Fungsi aktivasi adalah salah satu parameter yang terpenting dalam jaringan syaraf tiruan. Fungsi ini tidak hanya untuk penentuan garis, disamping nilai fungsi aktivasi juga menunjukkan jumlah masukan dari node (Engelbrecht, 2007). Oleh karena pemilihan fungsi aktivasi tidak dapat secara sembarangan dipilih sebab sangat besar berdampak pada perfoma jaringan syarat tiruan.
2.3. Backpropagation
Backpropagation (BP) merupakan Jaringan syaraf tiruan multi-layer. Penemuannya mengatasi kelemahan JST dengan layer tunggal yang mengakibatkan perkembangan JST
sempat tersendat disekitar tahun 1970.Algoritma BP merupakan generalisasi aturan delta (Widrow-Hoff), yaitu menerapkan metode gradient descent untuk meminimalkan error kuadrat total dari keluaran yang dihitung oleh jaringan.
Salah satu metode pelatihan dalam jaringan syaraf tiruanadalahpelatihan terbimbing (supervised learning). Jaringan syaraf tiruan Backpropagationmerupakan metode yangmenggunakan supervised learning.Padapelatihan terbimbing diperlukan sejumlahmasukan dan target yang berfungsi untukmelatih jaringan hingga diperoleh bobot yangdiinginkan.Pada setiap kali pelatihan, suatu inputdiberikan ke jaringan. Jaringan akan memprosesdan mengeluarkan keluaran. Selisih antarakeluaran jaringan dengan target merupakanerror. Jaringan akanmemodifikasi bobot sesuai dengan errortersebut.
supervised learning terdapat pasangan data input dan output yang dipakai untuk melatih JST hingga diperoleh bobot penimbang (weight) yang diinginkan.
2.4. Algoritma Backpropagation
Pelatihan algoritma backpropagation meliputi 2 fase yaitu
a. Fasepropagsi maju (feedforward) pola pelatihan masukan. b. Fase propasi mundur (backpropagation) dari error yang terkait. c. Fase modifikasi bobot
PenempatanBackpropagation metode gradient descent berusaha memperkecil error pada jaringan dengan memindahkan kebawah kurva error gradient. Algoritma jenis ini banyak digunakan serta dikombinasikan dengan yang lain dan diterapkan pada banyak
aplikasi yang berbeda (alsmadiet al, 2009)
Selama fase maju algoritma ini memetakan nilai masukan untuk mendapatkan
keluaran yang diharapkan.Untuk menghasilkan keluaran pola maka didapatkan dari rekapitulasi bobot masukan dan dipetakan untuk fungsi aktivasi jaringan. Keluaran dapat dihitung sebagai berikut
= !" (2.5)
# $%&. = ' ( )*+ + - (2.6)
dengan :
oj : input dari j unit
wij : bobot yang dihubungkan dari unit I ke unit j
anet,j : jaringan keluaran untuk j unit
j : bias untuk j unit
. =/'0
12 &1− 1 / (2.7)
dengan,
n : angka pada modul keluaran didalam lapisan output tk : keluaran yang dikendaki dari keluaran unit k
ok : keluaran jaringan dari keluaran unit k
2.4.1. Fase Propagasi Maju
Selama propagasi maju, sinyal masukan (x1) dipropagasikan ke layer tersembunyi
menggunakan fungsi aktivasi yang ditentukan.Keluaran dari unit tersembuyi (Z1) tersebut
selanjutnya dipropagasi maju lagi ke layer tersembunyi berikutnya dengan fungsi aktivasi yang telah ditentukan. Dan seterusnya hingga menghasilkan keluaran jaringan (yk).
Berikutnya, keluaran jaringan (yk) dibandingkan dengan target yang harus dicapai
(tk)..Jika erro lebih kecil dari batas toleransi yang ditentukan, maka iterasi dihentikan.
Jika error masih lebih besar dari batas toleransi, maka bobot setiap garis dari jaringan akan dimodifikasi untuk mengurangi error.
2.4.2. Fase Propagasi Mundur
Berdasarkan kesalahan tk- ykdihitung faktor k(k= 1, ..., m) yang dipakai untuk
mendistribusikan kesalahan di unit Yke semua unit tersembunyi yang terhubung langsung dengan yk. kjuga dipakai untuk mengubah bobot garis yang berhubungan
langsung dengan unit keluaran.
Dengan cara yang sama, dihitung faktor jdi setiap layer tersembunyi sebagai
dasar perubahan bobot semua garis yang berasal dari unit tersembunyi di layer di bawahnya. Dan seterusnya hingga semua faktor di unit tersembunyi yang terhubung langsung dengan unit masukan.
2.4.3. Fase Modifikasi Bobot
Ketiga fase tersebut diulang-ulang hingga kondisi penghentian dipenuhi.Umumnya kondisi penghentian yang sering dipakai adalah jumlah interasi atau kesalahan. Iterasi akan dihentikan jika jumlah iterasi yang dilakukan sudah melebihi jumlah maksimum iterasi yang ditetapkan, atau jika error yang terjadi sudah lebih kecil dari batas toleransi yang ditetapkan.
2.4.4. Prosedur Pelatihan
Menurut Fausset (1994) langkah prosedur pelatihan sebagai berikut :
Langkah 0 : Inisialisasi bobot keterhubungan antara neuron dengan menggunakan bilangan acak kecil (-0.5 sampai +0.5).
Langkah 1 : Kerjakan langkah 2 sampai langkah 9 selama kondisi berhenti yang ditentukan tidak dipenuhi.
Langkah 2 : Kerjakan langkah 3 sampai langkah 8 untuk setiappasangan pelatihan.
Propagasi maju
Langkah 3 : Setiap unit masukan (xi,i = 1,…., n) menerima sinyal masukan xi,dan
menyebarkannya ke seluruh unit pada lapisan tersembunyi
Langkah 4 : Setiap unit tersembunyi (xi, I = 1,…….,p) jumlahkan bobot sinyal masukannya :
3_ $5 = 6 5+ '0*2 * 6*5 (2.8) voj = bias pada unit tersembunyi j aplikasikan fungsi aktivasinya untuk
menghilangkan sinyal keluarannya, zj = f (z_inj), dan kirimkan sinyal
ini keseluruh unit pada lapisan diatasnya (unit keluaran)
Langkah 5 : tiap unit keluaran (yk, k = 1,…….m) jumlahkanbobot sinyal masukannya :
(2.9) wok = bias pada unit keluaran k dan aplikasikan fungsi aktivasinya
untuk menghitung sinyal keluarannya, yk = f(y_ink)
Langkah 6 : Tiap unit keluaran (yk, k = 1,…..,m) menerima pola target yang saling berhubungan pada masukan pola pelatihan, hitung kesalahan informasinya,
71 = &1 − 1 ′ *09 (2.10) hitung koreksi bobotnya (digunakan untuk mempengaruhi wjknantinya),
∆(51 = ; 7135 (2.11) hitung koreksi biasnya (digunakan untuk mempengaruhi woknantinya)
∆( 12 ; 71 (2.12) Dankirimkan k ke unit-unit pada lapisan dibawahnya,
Langkah 7 : Setiap unit lapisan tersembunyi (zj, j = 1,…..p) jumlah hasil
perubahanmasukannya (dari unit-unit lapisan diatasnya),
7_ $5 = '<12 71(51 (2.13) kalikan dengan turunan fungsi aktivasinya untuk menghitung informasi kesalahannya,
75 = 7_ $5 ′ 3_ $5)
hitung koreksi bobotnya (digunakan untuk memperbaharui vojnanti)
(2.15) hitung koreksi bias
(2.16) Langkah 8 : Update bobot dan bias pada hubungan antar lapisan
(2.17)
(2.18) Langkah 9 : Tes kondisi terhenti
Jika stop condition telah terpenuhi, maka pelatihan dapat dihentikan. Ada dua
cara yang dapat dilakukan untuk menentukan stopping condition (test kondisi
berhenti), yaitu :
Cara 1 : membatasi jumlah iterasi yang ingin dilakukan (satu iterasi
merupakan perulangan langkah 3 sampai dengan langkah 8
untuk semua training data yang ada)
yang dikendaki pada training data dengan output yang
dihasilkan oleh jaringan.
2.4.5. Prosedur Pengujian
Setelah pelatihan, jaringan syaraf backpropagation diaplikasikan dengan hanya
menggunakan tahap perambatan maju dari algoritma pelatihan. Prosedur aplikasinya
adalah sebagai berikut :
Langkah 0 : Inisialisasi bobot (dari algoritma pelatihan)
Langkah 1 : Untuk tiap vektor masukan, lakukan langkah 2-4
Langkah 2 : = = 1, … … . $ : atur aktivasi unit masukan xi
Langkah 3 : = = 1, … . . , @:
3*05 = 6B5 'GDHICDEDF (2.18)
352J K_*0F (2.19)
Langkah 4 : _DG9 = (L1+ '052 35 MF9 (2.20)
12J N_DG9 (2.21)
Langkah 5 : Jika 1 ≥ 0,5 O#P# 1 = 1, %QR% 1= 0
Adapun notasi – notasi yang digunakan pada algoritma backpropagation adalah ;
X Data training untuk input
x = ( x1,…,xi,…,xn )
t Data training untuk output (target/desired output)
t = ( t1,…,tk,…,tm )
Learning rate, yaitu parameter yang mengontrol perubahan bobot selama
pelatihan. Jika learning rate besar, jaringan semakin cepat belajar, tetapi
hasilnya kurang akurat. Learning rate biasanya dipilih antara 0 dan 1
Xi Unit input ke-i. untuk unit input, sinyal yang masuk dan keluar pada
suatu unit dilambangkan dengan variabel yang sama, yaitu xi
Zj Hidden unit ke-j. sinyalinput pada Zjdilambangkan dengan
3
*0output (aktivasi) untuk Zj dilambangkan dengan zj
Voj Bias untuk hidden unit ke-j
Vij Bobot antara unit input ke-i dan hidden unit ke-j
Yk Unit output ke-k. sinyalinput ke Yk dilambangkan *0
9
.Sinyal
output(aktivasi) untuk Yk dilambangkan dengan yk
Wok Bias untuk unit output ke-k
Wjk Bobot antara hidden unit ke-j dan unit output ke-k
k Faktor koreksi error untuk bobot Wjk
j Faktor koreksi error untuk bobot Vij
2.5. Syarat Parameter
Backpropagation menggunakan dua parameter yaitu learning rate dan momentum
coefficient. Kedua parameter tersebut digunakan untuk mengawasi perubahan bobot
selama arah turunan paling terjal dan untuk mematikan osilasi (Zweiriet al, 2003).
a. Learning rate
Learning rate salah satu yang paling efektif untuk mempercepat converge
dari pembelajaran Backpropagation dimana nilai yang diberikan antara
0,1 . ini adalah yang sangat penting untuk mengawasi variabel neuron
perubahan bobot untuk masing iterasi selama proses pelatihan dan oleh sebab
itu mempengaruhi laju converge. Kenyataan kecepatan converge sangat
berpengaruh pada pemilihan nilai learning rate.
Learning rate juga menjadi pertimbangan penting dalam kinerja jaringan
saraf yang ditentukan oleh bagaimana kita merubah bobot-bobot ‘w’ pada
tiap langkah, jika learning rate terlalu kecil algoritma akan memakan waktu
lama menuju konvergen, dan sebaliknya jika learning rate terlalu besar maka
algoritma menjadi divergen.
b. Momentum coeffisiens
Satu lagi pendekatan yang efektif terhadap percepatan konvergensi dan
stabilitas langkah pembelajaran dengan menambahkan beberapa koefisien
momentum pada jaringan. Nilai koefisien momentum yang biasa digunakan
dalam interval 0,1. Penambahan parameter momentum coeffisiens dapat
Dengan momentum m, bobot diperbaharui pada waktu t yang diberikan
menjadi. Dimana 0 < m < 1 adalah sebuah parameter global baru yang harus
ditentukan secara trial dan error. Momentum ini menambahkan sebuah
perkalian dengan bobot sebelumnya pada bobot saat ini. Pada saat gradient
tidak terlalu banyak bergerak, ini akan meningkatkan ukuran langkah yang
diambil menuju nilaiminimum.
2.6. Riset Terkait
Hamed et al. (2008) untuk mengatasi masalah local minimal dengan membandingkan
penggunakan algoritma genetika untuk menentukan nilai yang optimal untuk
mendapatkan parameter yang tepat seperti laju pembelajaran dan momentum serta
pengoptimuman bobot. Selain itu juga meggunakan teknik pengoptimun yaitu algoritma
Particle Swarm Optimization (PSO) dan diterapkan pada aplikasi Backpropagation
untuk mempercepat proses pembelajaran dan klasifikasi yang akurat.
Adapun langkah yan digunakan adalah :
a. Perubahan NN menggunakan PSO
1. Menentukan pola pelatihan
2. menentukan arsitektur NN
3. Menentukan NN dan parameter PSO
4. Mulai pelatihan
4. Menerapkan Keluaran Genetik Algoritms untuk BPNN
5. Mulai pelatihan
c. kedua output dibandingkan dan dianalisis
Hamid et al. (2011) mengajukan modifikasi yang baru pada pembelajaran
algoritma backpropagation dengan memperkenalkan Adaptive gain together dengan
adaptive momentum dan adaptive learning rate ke dalam proses perubahan bobot,
memberikan converge rate yang lebih baik dan mendapatkan solusi yang baik untuk
perbandingan waktu dibandingkan dengan backpropapagation konvensional.
Ernest & Tony (2011) meneliti algoritma momentum windowed dimana
meningkatkan kecepatan diatas standar momentum. Momentum windowed dirancang
untuk menetapkan lebarnya bobot yang lalu dengan bobot yang baru di update pada
masing-masing koneksi Neural Network. Momentum windowed memberikan kecepatan
yang signifikan pada serangkaian aplikasi yang sama atau tingkat keakuratan.
2.7. Perbedaan dengan riset yang Lain
Berdasarkan riset yang telah dilakukan, peneliti membuat beberapa perbedaan dalam
penelitian ini, yaitu;
1. Untuk mengatasi lambatnya konvergensi pada algoritma backpropagation
menggunakan parameter Acelarated adaptive learning rate dan Momentum
coeffisien.
2. Data yang digunakan data set dari Data Benmark yaitu Blood Transfusion
Service Center tahun 2007, di mana akan dibagi menjadi dua dataset training
dan dataset testing.
2.8. Kontribusi Riset
Dalam penelitian ini, diharapkan akan didapatkan parameter yang tepat untuk
mempercepat pembelajaran pada Backpropagation sehingga penggunaan algoritma