BAB 2
LANDASAN TEORI
2.1Audio
Audio atau suara merupakan gelombang yang mengandung sejumlah komponen penting (amplitudo, panjang gelombang dan frekuensi) yang dapat menyebabkan
suara yang satu berbeda dari suara lain. Amplitudo adalah kekuatan atau daya
gelombang sinyal. Tinggi gelombang yang bisa dilihat sebagai grafik, Gelombang
yang lebih tinggi diinterpretasikan sebagai volume yang lebih tinggi, Suara beramplitudo lebih besar akan terdengar lebih keras. Frekuensi adalah jumlah dari
siklus yang terjadi dalam satu detik. Satuan dari frekuensi adalah Hertz atau disingkat
Hz. Getaran gelombang suara yang cepat membuat frekuensi semakin tinggi.
Misalnya, bila menyanyi dalam pita suara tinggi memaksa tali suara untuk bergetar
secara cepat. Suara dengan frekuensi lebih besar akan terdengar lebih tinggi[10].
Gelombang suara adalah gelombang yang dihasilkan dari sebuah benda yang
bergetar. Sebagai contoh, senar gitar yang dipetik, gitar akan bergetar dan getaran ini
merambat di udara, atau air, atau material lainnya. Satu-satunya tempat dimana suara
tak dapat merambat adalah ruangan hampa udara. Gelombang suara ini memiliki
lembah dan bukit, satu buah lembah dan bukit akan menghasilkan satu siklus atau
periode. Siklus ini berlangsung berulang-ulang, yang membawa pada konsep
frekuensi.
Telinga manusia dapat mendengar bunyi antara 20 Hz hingga 20 kHz
(20.000 Hz) sesuai batasan sinyal audio. Karena pada dasarnya sinyal suara adalah
sinyal yang dapat diterima oleh telinga manusia. Angka 20 Hz sebagai frekuensi suara
dapat didengar. Gelombang suara bervariasi sebagaimana variasi tekanan media
perantara seperti udara. Suara diciptakan oleh getaran dari suatu obyek, yang
menyebabkan udara disekitarnya bergetar. Getaran udara ini kemudian menyebabkan
gendang telinga manusia bergetar, yang kemudian oleh otak dianggap sebagai suara.
2.1.1Audio Digital
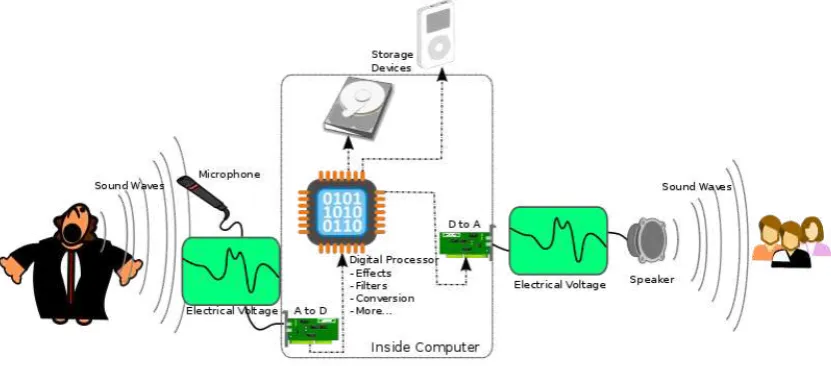
Audio digital merupakan versi digital dari suara analog. Pengubahan suara analog
menjadi suara digital membutuhkan suatu alat yang disebut Analog to Digital Converter (ADC). ADC akan mengubah amplitudo sebuah gelombang analog ke dalam waktu interval (sampel) sehingga menghasilkan penyajian digital dari suara[1].
Gambar 2.1 Ilustrasi proses suara analog ke digital dan sebaliknya
Sumber: http://en.wikipedia.org/wiki/File:A-D-A_Flow.svg
Berlawanan dengan ADC, Digital to Analog Converter (DAC) akan mengubah suara digital ke alat suara analog (speaker). Audio digital merupakan penyajian dari suara asli. Dengan kata lain, audio digital merupakan sampel suara. Kualitas
perekaman digital bergantung pada seberapa sering sampel diambil (angka sampling
atau frekuensi dihitung dalam kiloHertz atau seribu sampel per detik). Tiga frekuensi
sampling yang paling sering digunakan dalam multimedia adalah kualitas CD
sampel 8 bit menyediakan 256 unit deskripsi jarak dinamis atau amplitudo (level suara
dalam satu waktu). Ukuran file dari audio digital bergantung pada angka sampling, resolusi dan channel-nya (Stereo atau Mono).
Kualitas perekaman digital bergantung pada seberapa sering sampel diambil
dan berapa banyak angka yang digunakan untuk menyajikan nilai dari tiap sampel
(bitdepth, ukuran sampel, resolusi, jarak dinamis). Semakin sering sampel diambil, semakin banyak data yang disimpan mengenai sampel, semakin bagus resolusi dan
kualitas suara yang ditangkap ketika diputar. Artinya, kualitas suara akan semakin
tinggi. Semakin tinggi kualitas suara, semakin besar pula ukuran file yang dihasilkan.
Resolusi audio (8 bit atau 16 bit) menentukan akurasi proses digital dari suara.
Penggunaan bit yang lebih besar untuk ukuran sampel akan menghasilkan hasil
rekaman yang menyerupai versi aslinya.
2.1.2Format File Audio
2.1.2.1File WAV
WAV adalah format file audio standar Microsoft dan IBM untuk personal computer
(PC), biasanya menggunakan pengkodean PCM (Pulse Code Modulation). WAV adalah data tidak terkompres sehingga seluruh sampel audio disimpan semuanya di
harddisk. Perangkat lunak yang dapat menciptakan WAV dari sinyal analog misalnya
adalah Windows Sound Recorder. WAV jarang sekali digunakan di internet karena
ukurannya yang relatif besar dengan batasan maksimal untuk file WAV adalah 2GB.
Secara umum data audio digital dari WAV memiliki karakteristik yang dapat
dinyatakan dengan parameter-parameter berikut:
a. Laju sampel (sampling rate) dalam sampel/detik, misalnya 22050 atau 44100 sampel/detik.
b. Jumlah bit tiap sampel, misalnya 8 atau 16 bit.
Parameter-parameter tersebut menyatakan pengaturan yang digunakan oleh
ADC pada saat data audio direkam. Biasanya laju sampel juga dinyatakan dengan
satuan Hz atau kHz. Sebagai gambaran, data audio digital yang tersimpan dalam CD
audio memiliki karakteristik laju sampel 44100 Hz, 16 bit per sampel, dan 2 kanal
(stereo), yang berarti setiap satu detik suara tersusun dari 44100 sampel, dan setiap
sampel tersimpan dalam data sebesar 16-bit atau 2 byte. Laju sampel selalu
dinyatakan untuk setiap satu kanal (channel). Jadi misalkan suatu data audio digital memiliki 2 kanal (channel) dengan laju sampel 8000 sampel/detik, maka di dalam setiap detiknya akan terdapat 16000 sampel.
File WAV menggunakan struktur standar RIFF Microsoft yang
mengelompokkan isi file (sampel format, sampel audio digital, dan lain sebagainya)
menjadi “Chunk” yang terpisah, setiap bagian mempunyai header dan byte data masing- masing. Header Chunk menetapkan jenis dan ukuran dari byte data Chunk. Dengan metoda pengaturan seperti ini maka program yang tidak mengenali jenis
Chunk yang khusus dapat dengan mudah melewati bagian Chunk ini dan melanjutkan langkah memproses Chunk yang dikenalnya.
Tabel 2.1 Field-field pada struktur format file WAV Field Keterangan
Fomat Menunjukkan type format data dan memiliki nilai WAVE_FORMAT_PCM.
NumChannels Menunjukkan banyaknya kanal yang ada di dalam data waveform audio. Untuk mono
menggunakan satu kanal sedangkan untuk
stereo menggunakan dua kanal.
SampleRate Menunjukkan besarnya sample rate dalam sample per detik.
ByteRate Menunjukkan rata-rata laju transfer data, dalam byte per detik. Misalnya untuk PCM 16-bit stereo pada 44.1 kHz, ByteRate
bernilai 176400 (2 kanal * 2 byte per sample * 44100).
BlockAlign Menunjukkan banyaknya byte yang digunakan untuk satu buah sample. Misalnya untuk PCM 16-bit mono,
BlockAlign akan bernilai 2
2.1.2.2File MP3
MPEG-1 audio layer III atau yang lebih dikenal dengan MP3, adalah pengkodean
dalam digital audio dan juga merupakan format kompresi audio yang memiliki sifat
“menghilangkan”. Istilah menghilangkan yang dimaksud adalah kompresi audio ke
dalam format mp3 menghilangkan aspek-aspek yang tidak signifikan pada
pendengaran manusia untuk mengurangi besarnya file audio.
Sejarah MP3 dimulai dari tahun 1991 saat proposal dari Phillips (Belanda),
CCET (Perancis), dan Institut für Rundfunktechnik (Jerman) memenangkan proyek
untuk DAB (Digital Audio Broadcast). Produk mereka seperti Musicam (lebih dikenal dengan layer 2) terpilih karena kesederhanaan, ketahanan terhadap kesalahan, dan
perhitungan komputasi yang sederhana untuk melakukan pengkodean yang
menghasilkan keluaran yang memiliki kualitas tinggi. Pada akhirnya ide dan teknologi
yang digunakan dikembangkan menjadi MPEG-1 audio layer 3. MP3 adalah
pengembangan dari teknologi sebelumnya sehingga dengan ukuran yang lebih kecil
Spesifikasi dari layer-layer sebagai berikut:
a. Layer 1: paling baik pada 384 kbit/s.
b. Layer 2: paling baik pada 256...384 kbit/s, sangat baik pada 224...256
kbit/, baik pada 192...224 kbit/s 3.
c. Layer 3: paling baik pada 224...320 kbit/s, sangat baik pada 192...224
kbit/s, baik pada 128...192 kbit/s.
Kompresi yang dilakukan oleh MP3 seperti yang telah disebutkan, tidak
mempertahankan bentuk asli dari sinyal input. Melainkan yang dilakukan adalah
menghilangkan suara-suara yang keberadaannya kurang/tidak signifikan bagi sistem
pendengaran manusia. Proses yang dilakukan adalah menggunakan model dari sistem
pendengaran manusia dan menentukan bagian yang terdengar bagi sistem
pendengaran manusia. Setelah itu sinyal input yang memiliki domain waktu dibagi
menjadi blok-blok dan ditransformasi menjadi domain frekuensi. Kemudian model
dari sistem pendengaran manusia dibandingkan dengan sinyal input dan dilakukan
proses penyaringan yang menghasilkan sinyal dengan range frekuensi yang signifikan
bagi sistem pendengaran manusia. Proses tersebut adalah proses konvolusi dua sinyal
yaitu sinyal input dan sinyal model sistem pendengaran manusia. Langkah terakhir
adalah kuantisasi data, dimana data yang terkumpul setelah penyaringan akan
dikumpulkan menjadi satu keluaran dan dilakukan pengkodean dengan hasil akhir file
dengan format MP3
2.2Song Recognition
Song dalam bahasa Indonesia diartikan sebagai lagu dan Recognition berarti pengenalan sehingga Song Recognition dapat diartikan sebagai pengenalan pada media suara yakni lagu. Pada dasarnya setiap lagu memiliki karakteristik yang
berbeda-beda antara lagu yang satu dengan yang lainnya layaknya sidik jari manusia.
Pengenalan lagu dapat dipandang sebagai ringkasan pendek dari suatu objek lagu.
ringkasan tersebut diolah sedemikian rupa menjadi sekumpulan kode yang disebut
bisa didapatkan. Secara pendengaran manusia, lagu yang diperdengarkan terlihat sama
namun sebenarnya beda. Hash inilah yang akan membedakannya.
Pengenalan lagu membandingkan hash yang dihasilkan dari rekaman dengan
yang ada pada basis data. Hal ini terlihat seperti kriptografi, namun kriptografi agak
sensitif dalam kesetaraan perhitungan matematika. Satu bit saja berbeda akan
menghasilkan perbedaan. Sedangkan pengenalan lagu membutuhkan kesamaan
persepsi yakni, lagu yang diperdengarkan memiliki gangguan seperti sinyal yang
buruk (gangguan suara disekitar) tetapi masih diakui sebagai lagu asli[4].
Pengenalan lagu didasarkan pada lagu yang memang dari penyanyi aslinya
bukan lagu yang dibawakan ulang oleh penyanyi lain meskipun lirik dan melodi sama.
Lagu yang dibawakan ulang tersebut sudah memiliki karakteristik yang berbeda
dengan lagu asli tetapi dalam beberapa hal masih bisa memiliki kesamaan. Ini
ditunjukkan pada penyanyi asli membawakan lagunya secara langsung dan
membawakan lagunya.
Istilah lain untuk pengenalan lagu diantaranya pencocokan kuat, hashing kuat atau persepsi, tanda tangan digital berbasis konten dan identifikasi lagu berbasis
konten. Bidang yang relevan dengan pengenalan lagu yang meliputi pencarian
informasi, pencocokan pola, pemrosesan sinyal, database, dan kriptografi.
2.2.1Parameter Song Recognition
Dalam Song Recognition, terdapat beberapa parameter yang digunakan sebagai acuan[4]. Parameter-parameter yang paling utama adalah sebagai berikut:
1. Ketahanan
Rekaman lagu masih bisa diidentifikasi bila degradasi sinyalnya buruk. Untuk
Sebaliknya, pada lagu yang memiliki degradasi buruk masih mengarah ke hasil
yang sangat mirip.
2. Kehandalan
Seberapa sering lagu yang diidentifikasi hasilnya salah. Misalnya, "The
Rolling Stones-Angie" yang diidentifikasi sebagai "Beatles-Yesterday".
Tingkat di mana kejadian ini biasanya mengacu pada tingkat positif yang
salah.
3. Ukuran
Berapa banyak penyimpanan yang dibutuhkan untuk Song Recognition. Untuk mengaktifkan pencarian cepat, proses Song Recognition biasanya disimpan dalam memori RAM. Oleh karena itu ukuran Song Recognition, biasanya dinyatakan dalam bit per detik atau bit per lagu, menentukan batas besar
sumber daya memori yang dibutuhkan untuk server basis data Song Recognition.
4. Granular
Berapa detik durasi lagu yang diperlukan untuk mengidentifikasi lagu.
Granular adalah parameter yang dapat bergantung pada aplikasi.
5. Kecepatan pencarian dan skalabilitas
Berapa lama waktu yang diperlukan untuk menemukan lagu dalam basis data.
Bagaimana jika basis data berisi ribuan lagu. Untuk pengembangan komersil
dari sistem Song Recognition, kecepatan pencarian dan skalabilitas merupakan parameter kunci. Kecepatan pencarian harus dalam urutan milidetik untuk
sebuah database yang berisi lebih dari 100.000 lagu hanya menggunakan
sumber daya komputasi yang terbatas (misalnya PC dengan speksifikasi
rendah).
Kelima parameter dasar memiliki dampak yang besar pada satu sama lain.
mengekstrak lagu lebih besar untuk mendapatkan keandalan yang sama. Hal ini
dikarenakan tingkat positif berbanding terbalik dengan ukuran Song Recognition. Contoh lain yaitu, kecepatan pencarian umumnya meningkat ketika salah satu desain
Song Recognition lebih kuat. Hal ini dikarenakan bahwa pencarian lagu adalah pencarian kedekatan. Yaitu serupa (atau paling mirip) lagu harus ditemukan. Oleh
karena itu kecepatan pencarian dapat ditingkatkan.
2.2.2Rancangan Song Recognition
Secara umum, proses yang dilakukan dalam Song Recognition dengan menggunakan algoritma Fast Fourier Transform dapat dilihat pada Gambar 2.3.
Gambar 2.3 Cara kerja umum aplikasi Song Recognition[2]
2.3Sinyal Domain Waktu dan Sinyal Domain Frekuensi
Kebanyakan dari sinyal dalam prakteknya adalah sinyal domain waktu. Oleh karena
itu, apapun sinyal yang diukur adalah fungsi waktu, dimana ketika diplot salah satu
sumbu dengan variabel waktu maka variabel lainnya adalah amplitudo. Ketika diplot,
sinyal domain waktu berupa gelombang berjalan yang direpresentasikan pada waktu
terhadap amplitudo dari sinyal. Amplitudo pada sinyal domain waktu menunjukan
keras lemahnya sinyal yang diterima. Sehingga, sinyal yang diterima tidak memiliki
karakteristik yang berbeda tiap waktunya.
Pada sinyal domain frekuensi, ketika diplot berupa spektrum dengan penyajian
frekuensi terhadap magnitudo. Informasi yang penting tersembunyi di dalam frekuensi
sinyal. Spektrum frekuensi sinyal pada dasarnya adalah komponen frekuensi (spektral
frekuensi) sinyal yang menunjukkan frekuensi apa yang muncul. Frekuensi
menunjukkan tingkat perubahan. Jika suatu variabel sering berubah, maka disebut
berfrekuensi tinggi. Namun, jika tidak sering berubah, maka disebut berfrekuensi
rendah. Jika variabel tersebut tidak berubah sama sekali, maka disebut tidak
mempunyai frekuensi (nol frekuensi). Magnitudo pada sinyal domain frekuensi
menunjukkan tinggi rendahnya sinyal yang diterima. Dengan kata lain, keras
lemahnya sinyal tidak mempengaruhi frekuensi yang didalamnya. Sinyal domain
frekuensi dapat dikembalikan ke sinyal domain waktu.
Gambar 2.4 Gelombang sinus sinyal domain waktu[5]
2.4Transformasi Fourier
Proses penting dalam pemrosesan sinyal digital adalah menganalisis suatu sinyal input
maupun output untuk mengetahui karakteristik sistem fisis tertentu dari sinyal. Proses
analisis dan sintesis dalam domain waktu memerlukan analisis cukup panjang dengan
melibatkan turunan dari fungsi, yang dapat menimbulkan ketidaktelitian hasil analisis.
Analisis dan sintesis sinyal akan lebih mudah dilakukan pada domain frekuensi,
karena besaran yang paling menentukan suatu sinyal adalah frekuensi. Oleh karena
itu, untuk dapat bekerja pada domain frekuensi dibutuhkan suatu formulasi yang tepat
sehingga proses manipulasi sinyal sesuai dengan kenyataan. Salah satu teknik untuk
menganalisis sinyal adalah mentransformasikan (alih bentuk) sinyal yang semula
analog menjadi diskrit dalam domain waktu, dan kemudian diubah ke dalam domain
frekuensi.
Transformasi Fourier adalah suatu model transformasi yang memindahkan
sinyal domain spasial atau sinyal domain waktu menjadi sinyal domain frekuensi. Di
dalam pengolahan suara, transformasi fourier banyak digunakan untuk mengubah
domain spasial pada suara menjadi domain frekuensi. Analisa-analisa dalam domain
frekuensi banyak digunakan seperti filtering. Dengan menggunakan transformasi fourier, sinyal atau suara dapat dilihat sebagai suatu objek dalam domain frekuensi.
2.4.1Transformasi Fourier Diskrit
Transformasi Fourier Diskrit (Discrete Fourier Transform - DFT) adalah prosedur yang paling umum dan kuat pada bidang pemrosesan sinyal digital. DFT
memungkinkan untuk menganalisis, memanipulasi, dan mensintesis sinyal dengan
cara yang tidak mungkin dilakukan dalam pemrosesan sinyal analog[5]. Meskipun
sekarang digunakan dalam hampir setiap bidang teknik. Aplikasi yang menggunakan
DFT terus berkembang sebagai utilitas yang menjadikan DFT lebih mudah untuk
dimengerti. Karena itu, pemahaman yang kuat tentang DFT adalah wajib bagi siapa
𝑋(𝑓) = � 𝑥[𝑡].𝑒−𝑗2𝜋𝑓𝑡 𝑑𝑡
DFT merupakan prosedur matematika yang digunakan untuk menentukan
harmonik atau frekuensi yang merupakan isi dari urutan sinyal diskrit. Urutan sinyal
diskrit adalah urutan nilai yang diperoleh dari sampling periodik sinyal kontinu dalam
domain waktu. DFT berasal dari fungsi Transformasi Fourier X(f) yang didefinisikan:
(2.1)
Dimana:
X(f) = urutan ke-f komponen output (X(0), X(1),…,X(N-1))
f = indeks output dalam domain frekuensi (0, 1, …, N-1)
x(t) = urutan ke-t sampel input (x(0), x(1), …, x(N-1))
n = indeks sampel input dalam domain waktu (0, 1, …, N-1)
j = bilangan imajiner (√−1 ) π = derajat (180o
)
e = basis logaritma natural (2.718281828459…)
Dalam bidang pemrosesan sinyal kontinu, Persamaan 2.1 digunakan untuk
mengubah fungsi domain waktu kontinu x(t) menjadi fungsi domain frekuensi kontinu
X(f). Fungsi X(f) memungkinkan untuk menentukan kandungan isi frekuensi dari
beberapa sinyal dan menjadikan beragam analisis sinyal dan pengolahan yang dipakai
di bidang teknik dan fisika. Dengan munculnya komputer digital, ilmuwan di bidang
pengolahan digital berhasil mendefenisikan DFT sebagai urutan sinyal diskrit domain
frekuensi X(m), dimana:
(2.2)
Dimana:
N = jumlah sampel input
X(m) = urutan ke-m komponen output DFT (X(0), X(1),…,X(N-1))
m = indeks output DFT dalam domain frekuensi (0, 1, …, N-1)
x(n) = urutan ke-n sampel input (x(0), x(1), …, x(N-1))
𝑋(𝑚) = � 𝑥(𝑛). [ 𝑁−1
𝑛=0
𝑐𝑜𝑠 (2𝜋𝑛𝑚/𝑁) – 𝑗𝑠𝑖𝑛 (2𝜋𝑛𝑚/𝑁)]
j = bilangan imajiner (√−1 ) π = derajat (180o
)
e = basis logaritma natural (≈2.718281828459…)
Persamaan 2.2 kemudian dihubungkan dengan rumusan Euler 𝑒−𝑗𝜃 = cos (θ) –
j sin (θ), sehingga setara dengan:
(2.3)
Dimana:
N = jumlah sampel input
X(m) = urutan ke-m komponen output DFT (X(0), X(1),…,X(N-1))
m = indeks output DFT dalam domain frekuensi (0, 1, …, N-1)
x(n) = urutan ke-n sampel input (x(0), x(1), …, x(N-1))
n = indeks sampel input dalam domain waktu (0, 1, …, N-1)
j = konstanta bilangan imajiner (√−1 ) π = derajat (180o
)
Meski lebih rumit daripada Persamaan 2.2, Persamaan 2.3 lebih mudah untuk
dipahami. Konstanta j = √−1 hanya membantu membandingkan hubungan fase di
dalam berbagai komponen sinusoidal dari sinyal. Nilai N merupakan parameter
penting karena menentukan berapa banyak sampel masukan yang diperlukan, hasil
domain frekuensi dan jumlah waktu proses yang diperlukan untuk menghitung N-titik
DFT. Diperlukan N-perkalian kompleks dan N-1 sebagai tambahan. Kemudian, setiap
perkalian membutuhkan N-perkalian riil, sehingga untuk menghitung seluruh nilai N
(X(0), X(1), …, X(N-1)) memerlukan N2 perkalian. Hal ini menyebabkan perhitungan
DFT memakan waktu yang lama jika jumlah sampel yang akan diproses dalam jumlah
2.4.2Fast Fourier Transform
Meskipun DFT memainkan peranan yang penting sebagai prosedur matematis untuk
menentukan isi frekuensi dari urutan domain waktu, namun sangat tidak efisien.
Jumlah titik dalam DFT meningkat menjadi ratusan atau ribuan, sehingga
jumlah-jumlah yang dihitung menjadi tidak dapat ditentukan. Pada tahun 1965 sebuah
makalah diterbitkan oleh Cooley dan Tukey menjelaskan algoritma yang sangat
efisien untuk menerapkan DFT[3]. Algoritma yang sekarang dikenal sebagai Fast Fourier Transform (FFT). Sebelum munculnya FFT, seribu titik DFT membutuhkan waktu begitu lama untuk melakukan perhitungan yang pada saat itu masih terbatas
pada komputer-komputer berspesifikasi rendah. Gagasan Cooley dan Tukey, dan
perkembangan industri semikonduktor menjadikan jumlah N-titik DFT semisal
1024-titik, dapat dilakukan dalam beberapa detik saja pada komputer berspesifikasi
rendah[5].
Meskipun telah banyak bermacam-macam algoritma FFT yang dikembangkan,
algoritma FFT radix-2 merupakan proses yang sangat efisien untuk melakukan DFT
yang memiliki kendala pada ukuran jumlah titik dipangkatkan dua. FFT radix-2
menghilangkan redundansi dan mengurangi jumlah operasi aritmatika yang
diperlukan. Sebuah DFT 8-titik, harus melakukan N2 atau 64 perkalian kompleks.
Sedangkan FFT melakukan (N/2)log2N yang memberikan penurunan yang signifikan
dari N2 perkalian kompleks. Ketika N = 512 maka DFT memerlukan 200 kali
perkalian kompleks dari yang diperlukan oleh FFT.
Gambar 2.6 Perbandingan jumlah perkalian kompleks DFT dengan FFT[5] 65536
0 200 400 600 800 1000 1200
FFT beroperasi dimulai dengan menguraikan (dekomposisi) sinyal domain
waktu titik N ke N sinyal domain waktu hingga masing-masing terdiri dari satu titik.
Selanjutnya menghitung N frekuensi spektrum yang berkorespondensi dengan N
sinyal domain waktu. Terakhir, spektrum N disintesis menjadi spektrum frekuensi
tunggal.
Gambar 2.7 Diagram Alir FFT[9]
Dalam proses dekomposisi diperlukan tahapan Log2N. Sebagai contoh, sinyal
16 titik (24) memerlukan 4 tahapan, sinyal 512 titik (29) membutuhkan 9 tahap, sinyal
4096 titik (212) membutuhkan 12 tahapan. Dalam Gambar 2.8, sinyal 16 titik terurai
melalui empat tahap yang terpisah. Tahap pertama memisahkan sinyal 16 titik menjadi
dua sinyal masing-masing terdiri dari 8 titik. Tahap kedua menguraikan data menjadi
empat sinyal terdiri dari 4 titik. Pola ini berlanjut sampai sinyal N terdiri dari satu
titik. Dekomposisi digunakan setiap kali sinyal dipecah menjadi dua, yaitu sinyal
Gambar 2.8 Contoh dekomposisi sinyal domain waktu yang digunakan di FFT[9]
Setelah dekomposisi, dilakukan Pengurutan Pembalikan Bit (Bit Reversal Sorting), yaitu menata ulang urutan sampel sinyal domain waktu N dengan menghitung dalam biner dengan bit membalik dari kiri ke kanan. Asumsi N adalah
kelipatan dari 2, yaitu N = 2r untuk beberapa bilangan bulat r=1, 2, dst. Algoritma FFT
memecah sampel menjadi dua bagian yaitu bagian genap dan bagian ganjil.
𝑋(𝑚) = � 𝑥[2𝑛].
Persamaan 2.2 dibagi menjadi bagian ganjil dan bagian genap sebagai berikut:
(2.4)
Dimana:
N = jumlah sampel input
X(m) = urutan ke-m komponen output FFT (X(0), X(1),…,X(N-1))
m = indeks output FFT dalam domain frekuensi (0, 1, …, N-1)
x(2n) = urutan ke-n sampel input genap(x(0), x(2), …,x(N-2))
x(2n+1) = urutan ke-n sampel input ganjil(x(1), x(3), …,x(N-1))
n = indeks sampel input dalam domain waktu (0, 1, …, N/2-1)
j = konstanta bilangan imajiner (√−1 ) π = derajat (180o
)
e = basis logaritma natural (≈2.718281828459…)
Karena rumusan yang didapat panjang, sehingga digunakan notasi standar
untuk menyederhanakannya. Didefenisikan WN = 𝑒−𝑗2𝜋/𝑁 yang merepresentasikan nth
root of unity. Persamaan 2.4 dapat ditulis:
(2.5)
Karena 𝑊𝑁2 = 𝑒−𝑗2𝜋2/𝑁 = 𝑒−𝑗2𝜋/(𝑁/2), kemudian subsitusikan 𝑊𝑁2 = 𝑊𝑁/2.
Sehingga menjadi:
(2.6)
Sintesis domain frekuensi membutuhkan tiga perulangan. Perulangan luar
Perulangan bagian tengah bergerak melalui masing-masing spektrum frekuensi
individu dalam tahap sedang dikerjakan (masing-masing kotak pada setiap tingkat).
Dalam pemrosesan sinyal digital dikenal istilah butterfly. Butterfly digunakan untuk menggambarkan peruraian (decimation) yang terjadi. Karena tampilannya yang bersayap maka disebut butterfly. Butterfly adalah elemen komputasi dasar FFT, mengubah dua poin kompleks menjadi dua poin kompleks lainnya. Ada dua jenis
peruraian, peruraian dalam waktu (decimation in time-DIT) dan peruraian dalam frekuensi (decimation in frekuensi-DIF). Gambar dari butterfly dasar untuk kedua jenis peruraian tersebut dapat dilihat pada Gambar 2.9 dan Gambar 2.10.
Gambar 2.9 FFT butterfly dasar untuk peruraian dalam waktu[5]
Gambar 2.10 FFT butterfly dasar untuk peruraian dalam frekuensi[5]
Perulangan paling dalam menggunakan butterfly untuk menghitung poin dalam setiap spektrum frekuensi (perulangan melalui sampel dalam setiap kotak). Gambar
2.11 menunjukkan implemetasi FFT dari empat spektrum dua titik dan dua spektrum
empat titik. Gambar 2.11 terbentuk dari pola dasar pada Gambar 2.9 berulang-ulang.
WN𝑘
A = a + b
B = (a – b).WN𝑘 WN𝑘
a
b
A = a + WN𝑘.b
B = a - WN𝑘.b
a
Gambar 2.11 FFT sintesis butterfly[5]
2.5Hashing
Hashing adalah transformasi aritmatik sebuah string dari karakter menjadi nilai yang merepresentasikan string aslinya. Menurut bahasa, hashing berarti memenggal dan kemudian menggabungkan. Hashing digunakan sebagai metode untuk menyimpan data dalam sebuah array agar penyimpanan data, pencarian data, penambahan data dan penghapusan data dapat dilakukan dengan cepat. Ide dasarnya adalah menghitung
posisi record yang dicari dalam array, bukan membandingkan record dengan isi pada array. Fungsi yang mengembalikan nilai atau kunci disebut fungsi hash (hash function) dan array yang digunakan disebut tabel hash (hash table). Hash table
sebuah field kunci unik berupa bilangan (hash) yang merupakan representasi dari
record tersebut.
Fungsi hash menyimpan nilai asli atau kunci pada alamat yang sama dengan nilai hash-nya. Pada pencarian suatu nilai pada tabel hash, yang pertama dilakukan adalah menghitung nilai hash dari kunci atau nilai aslinya, kemudian membandingkan kunci atau nilai asli dengan isi pada memori yang beralamat nomor hash-nya. Dengan cara ini, pencarian suatu nilai dapat dilakukan dengan cepat tanpa harus memeriksa
seluruh isi tabel satu per satu.
Selain digunakan pada penyimpanan data, fungsi hash juga digunakan pada algoritma enkripsi sidik jari digital (fingerprint) untuk mengautentifikasi pengirim dan penerima pesan. Sidik jari digital diperoleh dengan fungsi hash, kemudian nilai hash
dan tanda pesan yang asli dikirim kepada penerima pesan. Dengan menggunakan
fungsi hash yang sama dengan pengirim pesan, penerima pesan mentransformasikan pesan yang diterima. Nilai hash yang diperoleh oleh penerima pesan kemudian dibandingkan dengan nilai hash yang dikirim pengirim pesan.
Kedua nilai hash harus sama dan pasti ada masalah jika tidak sama. Hashing
selalu merupakan fungsi satu arah. Fungsi hash yang ideal tidak bisa diperoleh dengan melakukan reverse engineering dengan menganalisa nilai hash. Fungsi hash yang ideal juga seharusnya tidak menghasilkan nilai hash yang sama dari beberapa nilai yang berbeda. Jika hal yang seperti ini terjadi, inilah yang disebut dengan bentrokan
![Gambar 2.2 Format file WAV[12]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/4.595.210.422.431.725/gambar-format-file-wav.webp)

![Gambar 2.3 Cara kerja umum aplikasi Song Recognition[2]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/9.595.128.529.344.487/gambar-cara-kerja-umum-aplikasi-song-recognition.webp)
![Gambar 2.4 Gelombang sinus sinyal domain waktu[5]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/10.595.185.446.562.732/gambar-gelombang-sinus-sinyal-domain-waktu.webp)
![Gambar 2.6 Perbandingan jumlah perkalian kompleks DFT dengan FFT[5]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/14.595.149.490.569.736/gambar-perbandingan-jumlah-perkalian-kompleks-dft-dengan-fft.webp)
![Gambar 2.7 Diagram Alir FFT[9]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/15.595.158.506.185.538/gambar-diagram-alir-fft.webp)
![Gambar 2.8 Contoh dekomposisi sinyal domain waktu yang digunakan di FFT[9]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/16.595.200.433.433.708/gambar-contoh-dekomposisi-sinyal-domain-waktu-yang-digunakan.webp)
![Gambar 2.9 FFT butterfly dasar untuk peruraian dalam waktu[5]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/18.595.204.490.452.533/gambar-fft-butterfly-dasar-untuk-peruraian-dalam-waktu.webp)
![Gambar 2.11 FFT sintesis butterfly[5]](https://thumb-ap.123doks.com/thumbv2/123dok/3900279.1856960/19.595.166.466.82.461/gambar-fft-sintesis-butterfly.webp)
