PENERAPAN CHARACTER N-GRAM UNTUK SENTIMENT
ANALYSIS REVIEW HOTEL MENGGUNAKAN
ALGORITMA NAIVE BAYES
Elly Indrayuni 1) Mochamad Wahyudi 2) 1)Sistem Informasi, ST MI K N u sa Ma n d i r i Ja k a r t a Jl. Damai No. 8, Warung Jati Barat (Margasatwa), Jakarta Selatan
email: [email protected]
2)
Ilmu Komputer, ST M I K Nu sa Ma n d i r i Ja k a r t a Jl. Damai No. 8, Warung Jati Barat (Margasatwa), Jakarta Selatan
email: [email protected]
ABSTRACT
Tourism is one of the objects most likely to be developed and promoted through the website. Hotel is one of the most important tourism product to be considered both in terms of facilities, services or mileage and travel. We have had many travel websites that provide the facility for internet users write opinions and personal experiences online. Before deciding to determine who will be selected hotel, visitors should read the opinion or the results of a review of the experience of other visitors. This certainly requires a long time. Sentiment analysis or opinion mining is one solution to overcome the problem of classifying opinions or reviews into positive or negative opinion automatically. The technique used in this study is Naive Bayes. Naive Bayes has the advantages of simple, fast and has high accuracy. Application of character n-gram features on this study is expected to increase the value of the accuracy of the method. N-grams are considered to reduce the difference between positive and negative class classification so as to increase the average accuracy of the end of an algorithm. The results of sentiment classification in this study consists of two label classes, namely positive and negative. The accuracy of the resulting value will be the benchmark to find the best test model for sentiment classification case. The evaluation was done using 10 fold cross validation. Measurement accuracy is measured by the confusion matrix and ROC curves. The results showed an increase in accuracy of 2% for Naive Bayes algorithm from 82.67% to 84.67% after the application of character n-gram features.
Keywords: Sentiment Analysis, Opinion Mining, Review, Naive Bayes, N-gram
PENDAHULUAN
Pariwisata merupakan salah satu objek yang berpeluang besar untuk dikembangkan dan dipromosikan melalui website. Dengan memanfaatkan perkembangan teknologi informasi dan website, memungkinkan para pengelola dunia pariwisata untuk memberikan informasi lebih detail tentang produk pariwisata yang ditawarkan. Banyak orang yang memeriksa pendapat dari pembeli lain sebelum membeli produk untuk membuat pilihan yang tepat [15]. Misalnya, pendapat dan pengalaman yang ditulis oleh wisatawan pada platform web lain pada saat liburan. Hotel merupakan salah satu produk pariwisata yang sangat penting untuk dipertimbangkan baik dari segi fasilitas, pelayanan ataupun jarak tempuh perjalanan wisata. Saat ini sudah banyak website wisata yang menyediakan fasilitas untuk pengguna internet menuliskan opini dan pengalaman pribadinya secara online. Sebelum memutuskan untuk menentukan hotel untuk menginap sebaiknya wisatawan mengetahui dengan detail informasi mengenai hotel tersebut, hal ini dapat diperoleh dengan membaca opini atau hasil review dari pengalaman wisatawan lain yang tentunya membutuhkan waktu yang cukup lama.
Analisa sentimen atau opinion mining adalah studi komputasi mengenai pendapat, perilaku dan emosi seseorang terhadap entitas. Entitas tersebut dapat menggambarkan individu, kejadian atau topik[10]. Opinion mining tidak memperhatikan topik dari teks tersebut tetapi lebih fokus kepada ekspresi yang digambarkan dari teks opini tersebut. Hal ini menentukan komentar dalam forum online, blog, atau komentar yang berkaitan dengan topik tertentu (produk, buku, film, dan lain-lain) termasuk opini positif, negatif atau netral [9]. Oleh karena itu, analisa sentimen atau opinion mining merupakan salah satu solusi mengatasi masalah untuk mengelompokan opini atau review menjadi opini positif atau negatif secara otomatis.
Penelitian tentang klasifikasi sentimen terhadap review film telah dilakukan oleh Dhande dan Patnaik (2014) dengan menggunakan algoritma Naive Bayes, Neural Network, dan Naive Bayes Neural Classifier. Dari hasil penelitian akhir yang diuji menggunakan ketiga algoritma tersebut menyebutkan bahwa Naive Bayes menghasilkan akurasi yang lebih tinggi dibandingkan Neural Network. Dan algoritma Naive Bayes Neural Classifier yang merupakan penggabungan antara metode Naive Bayes dan Neural Network
menghasilkan akurasi yang paling tinggi diantara kedua algoritma tersebut. Naive Bayes memiliki beberapa keunggulan seperti sederhana, cepat dan akurasi yang tinggi.
Penelitian lain yang pernah dilakukan Kang, Yoo, dan Han (2012) adalah analisa sentimen pada review restoran menggunakan algoritma Naive Bayes dengan fitur unigrams dan bigrams untuk meningkatkan akurasi Naive Bayes. Pada penelitian ini dengan menerapkan metode senti leksikon yaitu fitur unigrams dan bigrams, menunjukan bahwa selisih akurasi antara class positif dan negatif sekitar 3,6% dibandingkan dengan penggunaan Naive Bayes saja.
Metodologi n-gram banyak digunakan dalam pemodelan bahasa statistik untuk tujuan memprediksi kata berikutnya yang diberikan kata-kata sebelumnya. Model bahasa n-gram membuat asumsi bahwa probabilitas kata berikutnya tergantung pada n - 1 kata terakhir.
Pada penelitian ini penulis menggunakan algoritma Naive Bayes dan penerapan character n-gram pada algoritma Naive Bayes untuk mendapatkan nilai akurasi tertinggi dengan membandingkan hasil akurasi kedua model tersebut.
Identifikasi masalah dari penelitian ini antara lain:
1. Banyak website yang menyediakan informasi tentang perjalanan wisata dan sistem booking hotel secara online seperti pada website tripadvisor.com, virtualtourist.com sehingga diperlukan sebuah aplikasi untuk menganalisa review.
2. Bagaimana tingkat akurasi yang dihasilkan algoritma Naive Bayes sebagai algoritma paling sederhana untuk klasifikasi sentimen review. 3. Bagaimana tingkat akurasi yang dihasilkan setelah
penerapan character n-gram pada algoritma Naive Bayes.
Dengan banyaknya algoritma yang sering digunakan pada analisa sentimen, masalah penelitian hanya dibatasi pada klasifikasi sentimen untuk review hotel menggunakan algoritma Naive Bayes. Dan kemudian menerapkan fitur character n-gram pada tahap preprocessing algoritma Naive Bayes.
Tujuan dari penelitian ini adalah untuk membuktikan pengaruh penerapan character n-gram pada tahap preprocessing berdasarkan tingkat akurasi yang dihasilkan dalam mengklasifikasikan analisa sentimen review hotel menggunakan algoritma Naive Bayes.
Manfaat penelitian ini, diantaranya:
a. Manfaat praktis penelitian ini adalah membantu para wisatawan dalam mengambil keputusan saat ingin melakukan pemesanan atau booking hotel yang sesuai dengan keinginannya agar lebih efisien dibandingkan jika harus membaca review yang memakan waktu cukup lama.
b. Manfaat teoritis penelitian ini adalah memberikan bukti secara empiris untuk teori yang berkaitan
dengan analisa sentimen atau opinion mining dan penerapan character n-gram pada algoritma Naive Bayes dalam pengklasifikasian opini atau review sehingga dapat dijadikan sumbangan pemikiran untuk pengembangan teori berikutnya.
Opinion mining atau juga dikenal sebagai analisa sentimen adalah proses yang bertujuan untuk menentukan apakah polaritas kumpulan teks tulisan (dokumen, kalimat, paragraph, dll) cenderung ke arah positif, negatif, atau netral [8]. Analisa sentimen adalah teknik komputasi pendapat, perasaan dan subjektivitas teks [10].
Preprocessing data adalah proses pembersihan dan mempersiapkan teks untuk klasifikasi [5]. Seluruh proses melibatkan beberapa langkah: membersihkan teks online, penghapusan ruang spasi, memperluas singkatan, kata dasar (stemming), penghapusan kata henti (stopword removal), penanganan negasi dan terakhir seleksi fitur.
N-gram didefinisikan sebagai sub-urutan n karakter dari kata diberikan. Misalnya, ''mountain'' dapat diwakili dengan character n-gram yang ditunjukkan pada tabel berikut [3].
Tabel 1. Contoh Penerapan Character N-gram
n Character n-gram samples 2-Grams (n=2) mo-ou-un-nt-ta-ai-in
3-Grams (n=3) mou-oun-unt-nta-tai-ain 4-Grams (n=4) moun-ount-unta-ntai-tain
Naive Bayes adalah model sederhana untuk klasifikasi. Model ini bekerja dengan baik untuk klasifikasi teks. Model ini merupakan bentuk sederhana dari Bayesian Network, dimana semua atribut independen diberi nilai kelas variabel. Naïve Bayes memiliki beberapa keunggulan seperti sederhana, cepat dan akurasi yang tinggi [1].
Banyak peneliti telah melakukan klasifikasi sentimen dengan menggunakan Naive Bayes. Namun klasifikasi ini memiliki keterbatasan utama yang tidak mungkin selalu memenuhi asumsi independensi antara atribut. Dan ini mempengaruhi tingkat akurasi klasifikasi.
K-fold Cross-validation merupakan teknik validasi dengan membagi data awal secara acak kedalam k bagian yang saling terpisah atau “fold” [6]. Grafik Receiver Operating Characteristics (ROC) adalah teknik untuk memvisualisasikan, mengorganisasikan dan memilih pengklasifikasi berdasarkan kinerja mereka [2]. Kurva ROC digunakan untuk mengukur nilai Area Under Curve (AUC). Kurva ROC memiliki properti yang menarik: mereka tidak sensitif terhadap perubahan distribusi kelas. Jika proporsi positif terhadap kasus negatif berubah dalam satu set tes, kurva ROC tidak akan berubah. Untuk melihat mengapa demikian, dapat dilihat pada confusion matrix [13]
.
Gambar 1. Confusion Matrix
Berikut adalah persamaan model confusion matrix: a. Nilai akurasi (acc) adalah proporsi jumlah prediksi
yang benar.
Accuracy = TP +TN 0 (13.1) TP + TN + FP + FN
b. Sensitivity digunakan untuk membandingkan proporsi tp terhadap tupel yang positif.
Sensitivity = TP (13.2) TP + FN
c. Specificity digunakan untuk membandingan proporsi tn terhadap tupel yang negatif.
Specificity = TN 0 (13.3) TN + FP
d. PPV (positive predictive value) adalah proporsi kasus dengan hasil diagnosa positif.
ppv = TP 0 (13.4) TP + FP
e. NPV (negative predictive value) adalah proporsi kasus dengan hasil diagnosa negatif.
npv = TN 0 (13.5) TN + FN
Ada beberapa penelitian yang menggunakan algoritma Naive Bayes sebagai pengklasifikasian dalam klasifikasi teks sentimen pada review online.
Tabel 2. State of the art Penelitian Sentiment Analysis
Judul Pre-processing Feature Selection Classifie r Senti-lexicon and improve Naive Bayes algorithms for sentiment analysis of restaurant reviews (Kang, Yoo, dan Han, 2012)
POS tagger Feature Extraction Unigrams, Bigrams Naive Bayes Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network (Ghiassi, Skinner, dan Zimbra, 2013) Removing stopwords, stemming, transforming the data into the vector space, term weighting N-gram Dynamic Artificial Neural Network (DAN2), SVM Analyzing Sentiment of Movie Bag of Words Model - Naive Bayes dan Review Data using Naive Bayes Neural Classifier (Dhande dan Patnaik, 2014) Neural Network
Kerangka pemikiran yang penulis usulkan dalam penelitian ini dapat dilihat pada Gambar 2.
Gambar 2. Kerangka Pemikiran
Hipotesis penelitian ini adalah diduga penerapan fitur character n-gram pada tahap preprocessing mampu meningkatkan nilai akurasi untuk permasalahan klasifikasi sentimen review hotel.
PEMBAHASAN
Data review hotel diambil dari situs
www.tripadvisor.com. Pengumpulan data training
untuk review hotel berupa file berekstensi .txt. Setelah itu file-file tersebut dipisahkan ke dalam folder positif untuk data review opini positif dan folder negatif untuk data review opini negatif. Pada penelitian ini, penulis menggunakan 300 data review hotel yang terdiri dari 150 review untuk opini positif dan 150 review untuk opini negatif.
Ada beberapa tahap preprocessing yang digunakan, antara lain: 1. Tokenization. Pada proses tokenize ini, semua tanda baca, simbol, atau apapun yang bukan huruf dihilangkan sehingga menjadi sekumpulan kata secara utuh. 2. Filter Stopword. Pada tahap ini terjadi penghapusan kata-kata yang tidak relevan, seperti the, for, of , dan sebagainya sehingga dihasilkan sekumpulan teks yang memiliki arti dan berkaitan dengan klasifikasi sentimen. Metode yang diusulkan adalah penggunaan algoritma Naive Bayes untuk klasifikasi sentimen, dengan menggunakan character n-gram pada tahap preprocessing.
1. Hasil Eksperimen dan Pengujian Metode Algoritma Naive Bayes
Pengklasifikasian teks menggunakan Naive Bayes melalui proses yang cukup sederhana.
Sumber : Hasil Penelitian (2015)
Gambar 3. Desain Model Algoritma Naive Bayes
Pada klasifikasi sentiment ini digunakan beberapa kata yang menjadi atribut sebagai penentuan data review hotel tersebut termasuk kategori opini positif atau opini negatif antara lain seperti good, amazing dan delicious untuk mewakili opini positif. Sedangkan atribut yang mewakili opini negatif adalah worst, broken dan terrible.
Tabel 3. Tabel Vector Label Class Hasil Klasifikasi
Sumber : Hasil Penelitian (2015)
Hasil akurasi pengklasifikasian teks opini dengan menggunakan algoritma Naive Bayes dapat dilihat pada tabel berikut ini:
Tabel 4. Eksperimen Penentuan Nilai Training Cycles
Naive Bayes
NB
Accuracy 82.67%
AUC 0.556
Sumber : Hasil Penelitian (2015)
Hasil Eksperimen dan Pengujian Metode Algoritma Naive Bayes dengan Character N-gram
Dengan penerapan character N-gram diharapkan dapat meningkatkan hasil akurasi. Pada eksperimen ini, akan diterapkan nilai character N-gram sebesar 2, 3, dan 4 untuk mendapatkan nilai akurasi terbaik. Berikut adalah hasil percobaan untuk klasifikasi teks menggunakan Naive Bayes dengan penerapan character N-gram.
Tabel 5. Eksperimen Penentuan Nilai Training Cycles
Naive Bayes dengan Character N-gram
NB + N-gram
N-gram 2 3 4
Accuracy 84.33% 83.67% 84.67%
AUC 0.559 0.548 0.638
Sumber : Hasil Penelitian (2015)
Metode pengujian validasi hasil menggunakan cross validation.
Sumber : Hasil Penelitian (2015)
Gambar 4. Model Pengujian K-Fold Cross Validation
Berikut hasil pengolahan data review jika digambarkan pada tabel confusion matrix.
Tabel 6. Model Confusion Matrix untuk Naive Bayes
Accuracy : 82.67% True positif True negative Class Precission Prediksi positif 130 32 80.25% Prediksi negative 20 118 85.51% Class Recall 86.67% 78.67% Sumber : Hasil Penelitian (2015)
Berdasarkan tabel confusion matrix menunjukkan bahwa jumlah true positive (tp) adalah 130 opini, false negative (fn) sebanyak 32 opini. Berikutnya 118 opini untuk true negative (tn) dan 20 opini untuk false positif (fp). Nilai accuracy, sensitivity, specificity, ppv dan npv hasilnya dapat dilihat pada tabel berikut.
Tabel 7. Nilai accuracy, sensitivity, specificity, ppv dan
npv algoritma Naive Bayes
% (dalam persen) Accuracy 82.67 Sensitivity 80.25 Specificity 85.51 Ppv 86.67 Npv 78.67
Sumber : Hasil Penelitian (2015)
Dari eksperimen pengolahan 300 data training menggunakan Naive Bayes diperoleh tampilan kurva ROC dengan nilai AUC (Area Under Curve) sebesar 0.556 dan diagnosa hasil Poor Classification.
Sumber : Hasil Penelitian (2015)
Gambar 5. Nilai AUC dalam Kurva ROC Naive Bayes
Berikut tampilan data hasil pengolahan pada tabel confusion matrix.
Tabel 8. Model Confusion Matrix untuk Naive Bayes dengan Character N-gram
Accuracy : 84.67% True positif True negative Class Precission Prediksi positif 132 28 82.50% Prediksi negative 18 122 87.14% Class Recall 88.00% 81.33% Sumber : Hasil Penelitian (2015)
Berdasarkan tabel confusion matrix menunjukkan bahwa nilai akurasi mencapai 84.67% dengan jumlah true positive (tp) adalah 132 opini, false negative (fn) sebanyak 28 opini. Berikutnya 122 opini untuk true negative (tn) dan 18 opini untuk false positif (fp). Nilai accuracy, sensitivity, specificity, ppv dan npv hasilnya dapat diperoleh pada tabel berikut.
Tabel 9. Nilai accuracy, sensitivity, specificity, ppv dan
npv algoritma Naive Bayes dengan Character N-gram
% (dalam persen) Accuracy 84.67 Sensitivity 82.50 Specificity 87.14 Ppv 88.00 Npv 81.33
Sumber : Hasil Penelitian (2015)
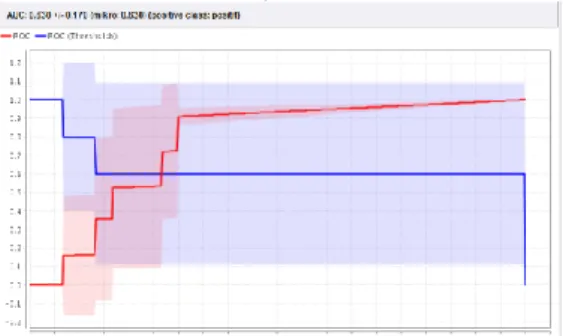
Dari eksperimen pengolahan 300 data training menggunakan Naive Bayes dengan penerapan character N-gram= 4, diperoleh tampilan kurva ROC dengan nilai AUC sebesar 0.638 dan diagnosa hasil Fair Classification.
Gambar 6. Nilai AUC dalam Kurva ROC Naive Bayes dengan N-gram
4. Analisa Evaluasi dan Validasi Model
Hasil pengujian semua algoritma secara detail dapat dilihat pada tabel berikut ini.
Tabel 10. Pengujian Algoritma Naive Bayes
NB NB, Ngram Accuracy 82.67% 84.67%
AUC 0.556 0.638
Sumber : Hasil Penelitian (2015)
Berdasarkan evaluasi menggunakan confusion matrix maupun ROC curve terbukti bahwa penerapan Character N-gram pada proses preprocessing dapat meningkatkan nilai akurasi
algoritma Naive Bayes. Hasil pengujian algoritma Naive Bayes dengan menggunakan Character N-gram pada proses preprocessing memiliki nilai akurasi yang lebih tinggi dibandingkan dengan algortima Naive Bayes saja tanpa Character N-gram. Nilai akurasi untuk model algoritma Naive Bayes sebesar 82.67% dan nilai akurasi untuk model algoritma Naive Bayes dengan length Character N-gram = 4 meningkat menjadi 84.67% dengan selisih akurasi 2%. Pada Curve ROC dapat dilihat nilai AUC untuk algoritma Naive Bayes sebesar 0.556 yang masih tergolong Poor Classification. Namun pada algoritma Naive Bayes dengan Character N-gram nilai AUC pun meningkat menjadi 0.638 dengan selisih 0.082 dan diagnosa hasil Fair Classification. 7. Implikasi Penelitian
Implikasi penelitian mengarahkan pada tiga aspek, yaitu:1. Aspek Sistem. Dengan adanya sentimen analisis untuk pengklasifikasian opini pada review hotel ini dapat membantu wisatawan ataupun pengunjung dalam menentukan pilihan hotel yang sesuai dengan keinginan atau kebutuhannya tanpa harus membaca review yang banyak dan waktu yang lama. 2. Aspek Manajerial. Secara manejerial hasil klasifikasi sentimen dapat digunakan pihak manajemen hotel untuk mengetahui review yang ditulis oleh pengunjung tersebut bersifat positif atau negatif agar menjadi bahan evaluasi untuk meningkatkan fasilitas atau pelayanan. 3. Penelitian Lanjutan. Penelitian ini dapat dikembangkan untuk klasifikasi teks ataupun dokumen. Data yang digunakan tidak hanya berasal dari review yang berisi opini, namun data dapat diambil dari review yang bersifat summary atau ringkasan, ataupun berdasarkan status pribadi seperti tweet atau media sosial lainnya. Penelitian ini juga dapat dikembangkan dengan algoritma aturan klasifikasi yang lain seperti algoritma Support Vector Machine, Neural Network, K-Nearest Neighbours, ataupun dengan menggunakan seleksi fitur sepeti Genetic Algorithm.
KESIMPULAN
Berdasarkan pengujian model menggunakan algoritma Naive Bayes pada eksperimen yang telah dilakukan ada beberapa hal yang dihasilkan, antara lain:1. Algoritma Naive Bayes yang merupakan algoritma paling sederhana yang terbukti menghasilkan nilai akurasi hingga 82.67%. 2. Penerapan character N-gram pada tahap preprocessing algoritma Naive Bayes membuat nilai akurasi meningkat hingga 2%, yaitu menjadi 84.67%. Dari uraian diatas, dapat disimpulkan bahwa penerapan character N-gram pada tahap preprocessing algoritma Naive Bayes untuk klasifikasi sentimen review hotel dapat meningkatkan nilai rata-rata akurasi sehingga secara keseluruhan diperoleh kesimpulan bahwa penerapan character
N-gram pada algoritma Naive Bayes merupakan model pengujian algoritma yang memiliki unjuk kerja lebih baik jika dibandingkan penggunaan algoritma Naïve Bayes saja untuk permasalahan klasifikasi sentimen review hotel.
DAFTAR PUSTAKA
[1] Dhande, L. L., dan Patnaik, G. K., (2014). Analyzing Sentiment of Movie Review Data using Naive Bayes Neural Classifier. International Journal of Emerging Trends & Technology in Computer Science (IJETTCS), vol (3) Issue 4. ISSN 2278-6856.
[2] Fawcett, Tom. (2005). An introduction to ROC Analysis. Pattern Recognition Letters, 27, 861-874. doi:10.1016/j.patrec.2005.10.010
[3] Gencosman, B. C., Ozmutlu, H. C., dan Ozmutlu, S. (2014). Character n-gram application for automatic new topic identification. Information Processing and Management, 50, 821-856. doi:10.1016/j.ipm.2014.06.005
[4] Ghiassi, M., Skinner, J., dan Zimbra, D. (2013). Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network. Expert Systems with
Applications, 40, 6266-6282.
doi:10.1016/j.eswa.2013.05.057
[5] Haddi, E., Liu, X., dan Shi, Y. (2013). The Role of Text Pre-processing in Sentiment Analysis. Procedia Computer Science, 17, 26-32. doi:10.1016/j.procs.2013.05.005
[6] Han, J., & Kamber, M. (2007). Data Mining Concepts and Techniques. San Francisco: Diane Cerra.
[7] Kang, H., Yoo, J.S., dan Han, D. (2012). Senti-lexicon and improved Naive Bayes algorithms for sentiment analysis of restaurant reviews. Expert Systems with Applications, 39, 6000-6010. doi:10.1016/j.eswa.2011.11.107
[8] Kontopoulos, E., Berberidis, C., Dergiades, T., dan Bassiliades, N. (2013). Ontology-based sentiment analysis of twitter post. Expert Systems with Applications, 40, 4065-4074. doi:10.1016/j.eswa.2013.01.001
[9] Martinez, I. P., Sanchez, F. G., Garcia, R. V., Moreno, V., Fraga, A., Cervantez, J. L. S.
(2014). Feature-based opinion mining through ontologies. Expert Systems with Applications, 41, 5995-6008. doi:10.1016/j.eswa.2014.03.022 [10] Medhat, W., Hassan, A., dan Korashy, H. (2014).
Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal. doi:10.1016/j.asej.2014.04.011
[11] Mitra, V., Wang, C. J., dan Banerjee, S. (2007). Text classification: A least square support vector machine approach. Applied Soft Computing, 7, 908-914. doi:10.1016/j.asoc.2006.04.002
[12] Maimon, O. (2010). Data Mining And Knowledge Discovery Handbook. New York Dordrecht Heidelberg London: Springer.
[13] Moraes, R., Valiati, J. F., dan Gavião Neto, W. P. (2013). Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Systems with Applications, 40(2), 621–633. doi:10.1016/j.eswa.2012.07.059 [14] Patil, G., Galande, V., Kekan, V., dan Dange, K.
(2014). Sentiment Analysis using Support Vector Machine. International Journal of Innovative Research in Computer and Communication Engineering.
[15] Taylor, E. M., Velasquez, J. D., Marquez, F. B., dan Matsuo, Y., (2013). Indentifying Customer Preferences about Tourism Products using an Aspect-Based Opinion Mining Approach. Procedia Computer Science, 22, 182-191. doi:10.1016/j.procs.2013.09.094
[16] Witten, H. I., Frank, E., & Hall, M. A. (2011). Data Mining Practical Machine Learning Tools And Technique. Burlington: Elsevier Inc
[17] Ye, Q., Zhang, Z., dan Law, R. (2009). Sentiment classification of online reviews to travel destinations by supervised machine learning approaches. Expert Systems with Applications, 36(3), 6527–6535. doi:10.1016/j.eswa.2008.07.035
[18] Zhang, L., Hua, K., Wang, H., Qian, G., dan Zhang, L. (2014). Sentiment Analysis on Reviews of Mobile Users. Procedia Computer
Science, 34, 458–465.