SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Matematika
Oleh:
BANI ADI NUGROHO 023114023
PROGRAM STUDI MATEMATIKA JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SANATA DHARMA
“Lakukan lebih dari sekadar melihat, perhatikan”.
“Lakukan lebih dari sekadar membaca, seraplah”.
“Lakukan lebih dari sekadar mendengar, simaklah”.
“Lakukan lebih dari sekadar berpikir, pikirkan dengan mendalam”.
“Lakukan lebih dari sekadar bicara, katakan sesuatu”.
( John H. Roades )
Skripsi ini kupersembahkan kepada
Allah Bapa di Surga dan Bunda Maria yang mahakasih,
Orang tuaku dan adek-adekku tercinta.
Almamterku tercinta Universitas Sanata Dharma
dibuat sedemikian hingga meminimalkan ukuran sampel yang dibutuhkan dalam penelitian. Ada tiga keputusan yang bisa dibuat yaitu menolak hipotesis, menerima hipotesis, atau melanjutkan penelitian dengan mengambil sebuah pengamatan lagi. Proses pengujian berhenti bila terjadi keputusan menerima atau menolak hipotesis. Karena pengujian dilakukan langkah demi langkah sampai pengamatan ke-n dan banyaknya pengamatan tergantung hasil uji sekuensial pengamatan sebelumnya, maka banyaknya pengamatan adalah variabel random yang nilainya tidak dapat ditentukan sebelumnya.
decisions at any stage of the experiment so it can minimize sample size which is needed in the experiment. There are three decision can be made, i.e., reject the hypothesa, accept the hypotesa, or continue the experiment by take one more observation again. Process will be terminate if one of the decision i.e. accept or reject the hypotesa is made. The test is done step by step until the n of observation, depends on the outcome of the last sequential test, theerefore the number of obsevation is not predetermined.
Dalam penulisan skripsi ini, penulis banyak menemui hambatan dan kesulitan. Namun, berkat bantuan dan dukungan dari banyak pihak, akhirnya skripsi ini dapat terselesaikan. Oleh karena itu penulis ingin mengucapkan terima kasih kepada:
1. Ibu Enny Murwaningtyas, S.Si, M.Si, selaku dosen pembimbing skripsi yang telah meluangkan waktu, pikiran, serta sabar dalam membimbing penulis selama penyusunan skripsi ini.
2. Bapak Ir. Ig. Aris Dwiatmoko, M.Sc, selaku Dekan FMIPA dan dosen pembimbing akademik yang selalu setia memberikan nasehat dan saran untuk penulis.
3. Bapak Y.G. Hartono, M. Sc, selaku Ketua Program Studi Matematika yang telah banyak membantu dan memberikan saran.
4. Bapak dan Ibu Dosen FMIPA yang telah memberikan bekal ilmu yang sangat berguna bagi penulis.
5. Mas Tukijo, Ibu Linda, dan Ibu Suwarni yang telah memberikan pelayanan administrasi selama penulis kuliah.
6. Perpustakaan USD dan staf yang telah memberikan fasilitas dan kemudahan kepada penulis.
7. Kedua orang tuaku tercinta, adekku (Gethuk dan Bulus) yang selalu memberikan dukungan dalam segala hal.
Lenta, Deby, Lia, Dani, Asih, Rita, Wuri, Aning, Feliks, Nunung, Desy, Deon, Chea, Palem yang selalu kompak dalam melewati kebersamaan di Matematika. 10.Kost Kodok Ijo n’ Friends: Oky, Sumin, Gondronk, Didiet, Topan, Feliks, Tepe, Rt, Doghox, Robert yang selalu ceria berbagi kebersamaan dan selalu memberikan dukungan kepada penulis, serta Pak Harwani sekeluarga yang tidak pernah cape’ menghadapi kenakalan dan keisengan penulis.
11.Kakak angkatan 1998-2001 dan Adek-adek angkatan 2003-2006 yang memberikan warna kehidupan kepada penulis selama kuliah.
12.Mbak Indah yang memberikan nasehat dan mau membagi pengalamannya dalam menulis skripsi.
13.Mas Kariyaman yang memberikan semangat dan berbagi pengalaman hidup. 14.Merry atas pinjaman buku-bukunya, Djembat atas dukungan dan semangat
yang diberikan, Katrin atas saran-sarannya, mehonk atas kekonyolannya. 15.Marwan dan keluarga yang selalu mendukung dalam segala hal.
16.Mr. Pow, Babi, Djaran, Bayu, Jacky, Trimbil, Djeruk, Senthot, Isaac, Khuri, djarir, Ucup, Era, Tika, Mia, Vina atas persahabatan masa SMA yang masih terjaga hingga sekarang.
17.Iyha’ yang selalu mendukung dan mendoakanku, Ary yang selalu memberi semangat, dan Siti yang nun jauh disana, thanks atas semuanya.
membantu penulis dalam penulisan skripsi ini yang tidak disebutkan disini.
Yogyakarta, April 2007
Penulis
HALAMAN PERSETUJUAN PEMBIMBING... iii
HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA... v
HALAMAN PERSEMBAHAN... vi
ABSTRAK... vii
ABSTRACT... viii
KATA PENGANTAR... x
DAFTAR ISI... xi
BAB I. PENDAHULUAN... 1
A. Latar Belakang Masalah... 1
B. Rumusan Masalah... 3
C. Pembatasan Masalah... 3
D. Tujuan Penulisan... 4
E. Metode Penulisan... 4
F. Manfaat Penulisan... 4
G. Sistematika Penulisan... 4
BAB II. LANDASAN TEORI... 6
A. Variabel Random dan Distribusi Probabilitas... 6
B. Distribusi Binomial... 7
C. Populasi dan Sampel... 8
BAB III. UJI SEKUENSIAL UNTUK PROPORSI... 19
A. Uji Hipotesis dan Statistik Uji... 22
B. Kriteria Uji... 27
C. Hubungan Antara α,β,A, dan B... 28
D. Penentuan Konstanta A dan B... 31
E. Fungsi Karakteristik Operasi... 42
F. Fungsi Rataan Ukuran Sampel... 59
BAB IV. APLIKASI UJI SEKUENSIAL UNTUK PROPORSI... 70
BAB V. PENUTUP... 80
A. Kesimpulan... 80
B. Saran... 81
DAFTAR PUSTAKA... 82
A. Latar Belakang Masalah
Inferensi statistik adalah salah satu cabang ilmu pengetahuan yang membahas tentang penarikan kesimpulan mengenai suatu populasi berdasarkan pengamatan terhadap sampelnya. Saat ini begitu banyak bidang kehidupan yang memanfaatkan proses inferensi statistik untuk pengambilan keputusan mengenai permasalahan yang dihadapi. Misal dalam hal pengendalian mutu suatu produk. Perusahaan berharap produk itu sesuai dengan standar mutu yang telah ditetapkan, maka harus dilakukan pengendalian mutu yang melibatkan proses dalam inferensi statistik. Proses inferensi statistik di sini dibutuhkan dalam pengambilan keputusan apakah produk yang dihasilkan layak atau tidak untuk dipasarkan dan seberapa perlu meningkatkan faktor produksi (misal: mutu bahan baku, modal, mesin produksi) agar produk sesuai dengan standar mutu yang diharapkan..
Untuk cara-cara pengujian hipotesis yang biasa, ukuran sampel yang digunakan besarnya telah ditentukan terlebih dahulu. Penentuannya dapat dilakukan berdasarkan besar resiko penolakan hipotesis yang seharusnya diterima dan penerimaan hipotesis yang seharusnya ditolak. Dengan kata lain, berdasarkan pada nilai-nilai α dan β yang mau diterima. Dalam kenyataannya, cara demikian sering mengakibatkan ukuran sampel cukup besar sehingga ditinjau dari segi biaya tidaklah ekonomis. Tentu saja hal ini tidak akan menjadikan persoalan apabila harga bahan yang diteliti murah dan biaya untuk melakukan pengujian tersebut tidak mahal, sehingga ukuran sampel yang minimum tidak menjadi penting.
Kecuali alasan-alasan diatas, uji sekuensial sangat menguntungkan apabila:
1. Tiap obyek dapat diuji sendiri-sendiri.
2. Waktu reaksi perlakuan terhadap obyek cukup pendek.
3. Keadaan tidak mengijinkan untuk melakukan pengujian terhadap lebih dari satu obyek sekaligus.
4. Tejadinya obyek atau kasus sangat jarang.
B. Perumusan Masalah
Permasalahan yang dibahas dalam skripsi ini dapat dirumuskan sebagai berikut:
1. Bagaimanakah bentuk hipotesis statistik untuk uji sekuensial?
2. Bagaimanakah cara menentukan daerah kritis untuk uji sekuensial?
3. Bagaimana penyusunan rencana samplingnya?
4. Seperti apakah bentuk fungsi karakteristik operasi untuk uji sekuensial?
5. Bagaimana rata-rata ukuran sampelnya?
C. Pembatasan Masalah
Dalam skripsi ini dibatasi oleh beberapa hal sebagai berikut:
1. Skripsi ini hanya akan membahas tentang uji sekuensial terutama uji sekuensial untuk parameter tunggal. p
2. Teorema limit pusat tidak dibuktikan.
3. Nilai L
( )
p untuk nilai p=0 yang berkaitan dengan h=+∞ dan nilai p=1yang berkaitan dengan h=−∞ hanya dijabarkan secara logis saja, tidak secara matematis karena membutuhkan kalkulus yang lebih lanjut.
4. Rataan ukuran sampel pada persamaan (3.84) tidak dibuktikan karena membutuhkan kalkulus yang lebih lanjut.
D. Tujuan Penulisan
Tujuan skripsi ini adalah untuk memperdalam pengetahuan tentang uji se-kuensial dan memahami konsep-konsep dasar yang terdapat didalamnya.
E. Metode Penulisan
Penulisan skripsi ini menggunakan metode studi pustaka, yaitu dengan menggunakan buku-buku, jurnal-jurnal, makalah-makalah yang telah dipublikasi-kan, sehingga tidak ditemukan hal yang baru.
F. Manfaat Penulisan
Penulisan skripsi ini diharapkan dapat berguna untuk menambah wawasan tentang uji sekuensial. Uji sekuensial ini memiliki keuntungan jika berada pada kondisi tertentu, sehingga dapat digunakan sebagai alternatif uji statistik ketika dengan kondisi itu lebih menguntungkan untuk menggunakan metode ini.
G. Sistematika Penulisan
Bab II. Landasan Teori , pada bagian ini akan dibahas tentang variabel random dan distribusi probabilitas, distribusi binomial, populasi dan sampel, distribusi sampling, uji hipotesis, dan uji mengenai proporsi.
Bab III. Uji Sekuensial untuk Proporsi, pada bagian ini akan dibahas tentang uji hipotesis dan statistik uji sekuensial, kriteria uji sekuensial, hubungan antara α,β,AdanB, penentuan konstanta A dan B, fungsi karakteristik operasi, dan fungsi rataan ukuran sampelnya.
Bab IV. Aplikasi Uji Sekuensial untuk Proporsi, pada bagian ini akan dibahas penyelesaian masalah tentang lapisan pelindung pada peluru.
A. Variabel Random dan Distribusi Probabilitas
Variabel random, misal X adalah suatu fungsi yang didefinisikan pada ruang sampel S yang memetakan setiap elemen a∈S ke suatu bilangan real. Variabel random ini dinotasikan dengan:
( )
a x a SX = , ∈
a 0ú dengan
( )
aX = Variabel random x = Nilai variabel random
Variabel random diskret adalah variabel random yang nilainya berhingga atau tak berhingga terbilang.
Jika pada sebuah pengamatan probabilitas didaftarkan seluruh keluaran yang mungkin dari variabel random diskret X , yaitu dan kemudian didaftarkan pula nilai probabilitas yang berkaitan dengan keluaran tersebut, yaitu
, ,
n
x x x
x1, 2, 3,K,
(
X x1)
P = P
(
X = x2)
P(
X = x3)
,....,P(
X =xn)
maka telah dibentuk suatudistribusi probabilitas diskret dari variabelX .
Pernyataan f
( )
x disebut sebagai fungsi probabilitas dari variabel random X1. Nilai-nilai dari suatu fungsi probabilitas adalah angka-angka yang berada dalam interval antara 0 dan 1. Jadi nilai nilai fungsi yang mungkin akan selalu berada dalam interval 0≤ f
( )
x ≤12. Jumlah seluruh nilai fungsi probabilitas adalah 1, sehingga
∑
f( )
x =1Jika X menyatakan suatu variabel random diskret yang dapat mengambil
nilai yang masing-masing mempunyai probabilitas
dengan
n
x x x
x1, 2, 3,K,
( ) ( ) ( )
x f x f x f( )
xnf 1 , 2 , 3 ,K, f
( ) ( ) ( )
x1 ,+f x2 ,+f x3 +K,+f( )
xn =1, makanilai harapan dariX yang dinyatakan dengan E
( )
X didefinisikan sebagai:( )
∑
( )
=
= n
i
i if x x X
E
1
B. Distribusi Binomial
Distribusi binomial adalah salah satu distribusi probabilitas diskret yang paling sering digunakan dalam analisis statistik modern. Suatu distribusi binomial dibentuk oleh suatu pengamatan binomial. Pengamatan ini merupakan kali percobaan Bernoulli sehingga harus memenuhi kondisi:
n
1. Jumlah percobaan adalah konstanta yang telah ditentukan sebelumnya. n 2. Setiap pengulangan pengamatan yang biasa disebut percobaan, hanya dapat
menghasilkan satu dari dua keluaran yang mungkin, yaitu sukses atau gagal. 3. Probabilitas sukses pdan probabilitas gagal adalah q=1− pselalu konstan
dalam setiap percobaan.
Dalam sebuah pengamatan binomial dengan kali percobaan, maka probabilitas sukses adalah
n
pdan probabilitas gagal adalah q=1− p. Jika suatu variabel random X menyatakan banyaknya sukses yang terjadi pada n percobaan tersebut, maka dapat dibentuk suatu distribusi probabilitas dengan fungsi probabilitasnya:
(
)
n x n x xb x n p C p q P ; ; = − ; dengan
• x=1,2,3,K,n; n=1,2,3,K; dan 0≤ p≤1
• = kombinasi dari n objek pengamatan dengan setiap pemilihan diambil
n x C
xobjek.
C. Populasi dan Sampel
sampel ini bersifat bebas satu dengan yang lain. Dengan demikian variabel random akan merupakan sampel random berukuran n jika variabel-variabel itu saling bebas dan berdistribusi probabilitas identik.
n
X X
X1, 2,K,
Suatu sampel random berukuran n dari suatu populasi yang mempunyai fungsi probabilitas adalah himpunan n variabel random bebas
yang masing-masing berdistribusi probabilitas
( )
xf X1,X2,K,Xn
( )
x f .Suatu harga yang dihitung dari suatu sampel dinamakan statistik. Karena banyak sampel bisa diambil dari populasi yang sama, maka diharapkan bahwa harga statistik yang dihitung dari masing-masing sampel itu akan berbeda-beda satu dengan yang lain. Sehingga statistik adalah variabel random dan mempunyai distribusi probabilitas.
D. Distribusi Sampling
Distribusi probabilitas suatu statistik dinamakan distribusi sampling harga statistik. Deviasi standar distribusi sampling suatu statistik dinamakan kesalahan standar statistik itu.
Pengertian mengenai distribusi sampling dapat dijelaskan dengan menunjukkan bagaimana distribusi itu dibentuk. Misal ada populasi dengan N elemen dan mempunyai mean μ, variansi σ2, dan proporsi
p, maka dilakukan langkah-langkah sebagai berikut:
1. Diambil sampel random dengan elemen . Selanjutnya dihitung
harga-harga statistik sampel ini, misal mean (diberi lambang
n
X X
X1, 2,K,
1
(dilambangkan ), proporsi (dilambangkan dengan ) dan sebagainya. Setelah itu elemen-elemen yang terambil dalam sampel ini dikembalikan lagi ke dalam populasinya sehingga populasi itu tetap mempunyai N elemen.
2 1
S p
2. Diambil lagi sampel random dengan n elemen, yang lain dengan sampel random yang pertama tadi. Dua sampel dikatakan berbeda apabila minimal ada satu elemen yang berbeda. Dari sampel kedua ini juga dihitung harga-harga statistiknya. Kemudian elemen-elemen yang telah diambil dalam sampel ini dikembalikan lagi ke dalam populasinya, sehingga populasi itu tetap seperti semula.
3. Pekerjaan pengambilan sampel ini dan perhitungan harga-harga statistiknya dilakukan terus menerus sampai semua sampel random berelemen n yang berlainan satu dengan yang lain, yang mungkin dapat diambil dari populasi itu telah dihabiskan. Elemen-elemen sampel (setelah dihitung harga-harga statistiknya) dikembalikan ke dalam populasinya , sebelum sampel berikutnya diambil. Oleh karena itu populasi itu tetap mempunyai N elemen setiap kali sampel random baru diambil.
4. Harga-harga statistik sampel pertama, kedua, ketiga, dan seterusnya ini dikumpulkan. Himpunan-himpunan dari harga statistik ini dinamakan distribusi sampling.
Jika harga –harga statistik ini adalah mean, maka distribusi samplingnya dinamakan distribusi sampling mean, yaitu himpunan harga-harga
} , , ,
yaitu himpunan harga-harga . Jika harga-harga statistik yang dihitung itu harga-harga proporsi, maka distribusi samplingnya dinamakan distribusi sampling proporsi.
} , , ,
{ 2
3 2 2 2
1 S S K
S
Untuk distribusi sampling proporsi, jika dalam sebuah populasi berukuran N yang didalamnya terdapat probabilitas sukses adalah pdan probabilitas gagalnya adalah q=1− p, maka dari sampel random berukuran yang diambil dari populasi itu terdapat nilai proporsinya. Distribusi proporsi-proporsi dari seluruh sampel random berukuran nyang mungkin diambil dari populasi dapat dicari nilai mean dan standar deviasinya sebagai berikut:
n
• Jika populasinya berhingga
p p =
μ
1
− − =
N n N n pq
p
σ
• Jika populasinya tak berhingga
p p =
μ
n pq
p =
σ
dengan :
p
μ = mean dari distribusi sampling proporsi
p
σ = deviasi standar dari distribusi sampling proporsi N = ukuran populasi
Distribusi sampling mempunyai sifat-sifat yang sangat penting terutama dalam hubungannya dengan sampel dan populasi. Sifat-sifat ini sangat perlu untuk diketahui karena peranan distribusi sampling dalam inferensi statistik.
Untuk ukuran sampel n cukup besar berlaku sifat bahwa jika populasi berdistribusi binomial dengan parameter p, maka distribusi sampling proporsinya mendekati distribusi normal. Hal ini dikenal sebagai teorema limit pusat.
E. Hipotesis Statistik
ada hipotesis yang lain yaitu hipotesis nol. Hipotesis alternatif dilambangkan dengan H1dan hipotesis nol dilambangkan dengan H0.
Misal n menyatakan banyaknya pengamatan yang merupakan dasar pengambilan keputusan (menolak hipotesis, menerima hipotesis). Setiap n-pengamatan merupakan sampel berukuran n. Setiap prosedur pengujian adalah suatu aturan untuk menolak hipotesis atau menerima hipotesis berdasarkan sampel. Prosedur pengujiannya merupakan pemecahan semua sampel yang mungkin menjadi dua bagian yang saling lepas, namakan daerah 1 dan daerah 2. hipotesis ditolak apabila sampel berada di daerah 1 dan hipotesis diterima bila sampel berada di daerah 2. Daerah 1 dinamakan daerah kritis. Karena daerah 2 berisi semua sampel yang tidak termasuk di daerah 1, maka daerah 2 diperoleh dari daerah 1. Jadi, pemilihan prosedur pengujian setara dengan penentuan daerah kritis.
Prosedur pengujian hipotesis dalam pengambilan keputusan dapat membawa pada dua kesimpulan yang salah. Keputusan yang diambil untuk menerima atau menolak suatu hipotesis mempunyai resiko kesalahan, yaitu :
• Kesalahan tipe I yaitu menolak sedangkan sebenarnya itu benar. Probabilitas untuk melakukan kesalahan tipe I ini dilambangkan dengan
0
H H0
α.
• Kesalahan tipe II yaitu menerima sedangkan sebenarnya itu salah. Probabilitas melakukan kesalahan tipe II ini dilambangkan dengan
0
H H0
β.
kesalahan tersebut dapat diperkecil secara bersama-sama dengan memperbesar ukuran sampel. Dengan kata lain αdan β dapat diperkecil secara bersama-sama dengan cara memperbesar ukuran sampelnya.
Suatu uji hipotesis statistik yang alternatifnya bersifat satu arah seperti ,
: 0
0 θ =θ H
0 1:θ >θ
H .
Atau ,
: 0
0 θ =θ H
0 1:θ <θ
H .
disebut uji satu arah. Wilayah kritis bagi hipotesis θ >θ0 teletak seluruhnya di bagian kanan. Sedangkan wilayah kritis bagi hipotesis alternatif θ <θ0 terletak seluruhnya di bagian kiri. Dalam pengertian ini, tanda ketaksamaan menunjuk ke wilayah kritisnya.
Uji hipotesis yang alternatifnya bersifat dua arah, yaitu : ,
: 0
0 θ =θ H
0 1:θ ≠θ
H .
disebut uji dua arah, karena wilayah kritisnya dibagi menjadi dua bagian yang ditempatkan di masing-masing ekor distribusi statistiknya. Hipotesis alternatif
0
θ
θ ≠ menyatakan bahwa θ <θ0 atau θ >θ0.
Hipotesis nol, , akan selalu dituliskan dengan tanda kesamaan sehingga menspesifikasi suatu nilai tunggal. Dengan cara demikian, probabilitas melakukan kesalahan tipe I dapat dikendalikan. Apakah akan digunakan uji satu arah atau dua
arah bergantung pada kesimpulan yang akan ditarik bila ditolak. Lokasi wilayah kritisnya dapat ditentukan hanya setelah hipotesis alternatif
dinyatakan.
0 H
1 H
Misal dalam pengujian suatu obat baru, dapat dibuat hipotesis bahwa obat baru itu tidak lebih baik daripada obat-obat serupa yang beredar di pasaran. Diuji melawan hipotesis alternatif bahwa obat baru tersebut lebih unggul. Hipotesis alternatif yang demikian ini selalu menghasilkan uji satu arah dengan wilayah kritisnya di ekor sebelah kanan. Tetapi bila membandingkan suatu teknik mengajar yang baru dengan teknik mengajar yang biasa, maka hipotesis alternatifnya harus memungkinkan bahwa teknik mengajar yang baru tersebut bersifat lebih baik atau lebih buruk daripada teknik mengajar yang biasa. Dengan demikian uji itu bersifat dua arah dengan wilayah kritisnya dibagi dua sama besar di ekor sebelah kiri dan kanan.
Dalam pengujian hipotesis yang statistik ujinya bersifat diskret, wilayah kritisnya dapat ditentukan. Bila α terlalu besar dapat diperbesar ukuran sampelnya untuk mengimbangi membesarnya β . Dalam uji hipotesis yang statistik ujinya bersifat kontinu, biasanya nilai α ditentukan lebih dahulu, baru kemudian menentukan wilayah kritisnya.
Langkah-langkah pengujian hipotesis mengenai parameter populasi θ lawan suatu hipotesis alternatif dapat dituliskan sebagai berikut :
tiap-tiap pernyataan dalam bentuk rentang harga-harga parameter θ model probabilitas itu.
2. - Nyatakan hipotesis nolnya bahwa H0:θ =θ0.
- Pilih hipotesis alternatif yang sesuai, H1:θ ≠θ0, H1:θ <θ0, atauH1:θ >θ0.
3. Tentukan taraf nyata ujinya (α).
4. Pilih statistik uji yang sesuai dan kemudian tentukan wilayah kritisnya. 5. Hitung nilai statistik uji berdasarkan data sampel.
6. Keputusan : tolak bila nilai statistik uji tersebut jatuh dalam wilayah
kritisnya, sedang bila jatuh di luar wilayah kritisnya diterima. 0
H
0 H
F. Uji Mengenai Proporsi
Uji hipotesis mengenai proporsi diperlukan di banyak bidang. Pengujian hipotesis bahwa proporsi keberhasilan dalam suatu percobaan binom sama dengan suatu nilai tertentu. Hal ini berarti bahwa akan diuji hipotesis : dengan p adalah parameter distribusi binomial. Hipotesis alternatifnya dapat yang bersifat satu sisi maupun yang dua sisi.
0
H p= p0
Statistik yang akan digunakan sebagai landasan kriteria pengambilan keputusan adalah variabel random binom X, meski dapat digunakan statistik
n X
Pˆ = sama baiknya. Nilai-nilai X yang jauh dari nilai tengah μ=np0akan membawa pada penolakan hipotesis nol. Untuk menguji hipotesis
0
0:p p
0
1:p p
H < Wilayah kritis berukuran αdiberikan oleh
' α
k x≤
Sedang ' adalah bilangan bulat terbesar yang bersifat α
k
α
α
α = = ≤
≤
∑
= '
0
0 0
'
) ; ; ( )
(
k
x
p n x b p
p bila k X P
Begitu pula untuk menguji hipotesis
0
0:p p
H =
0
1:p p
H >
Wilayah kritis yang berukuran αdiberikan oleh
α
k x≥
Sedang dalam hal ini kαadalah bilangan bulat terkecil yang bersifat
α
α
α = = ≤
≥
∑
=
n
k x
p n x b p
p bila k x
P( 0) ( ; ; 0)
Dan yang terakhir untuk menguji hipotesis
0
0:p p
H =
0
1:p p
H ≠
Wilayah kritis sebesar αdiberikan oleh '
2 α k x≤ dan
2
α
k x≥
Langkah-langkah pengujian proporsi dapat dituliskan sebagai berikut : 1. H0:p= p0
2. H1: alternatifnya adalah p< p0, p> p0, atau p≠ p0 3. Tentukan taraf nyata α
4. Wilayah kritis ' α
k
x≤ , bila hipotesis alternatifnya p< p0
α
k
x≤ , bila hipotesis alternatifnya p> p0 '
2 α k
x≤ dan 2
α
k
x≥ , bila hipotesis alternatifnya p≠ p0 5. Perhitungan : hitunglah x yaitu banyaknya keberhasilan
6. Keputusan : Tolak bila x jatuh dalam wilayah kritis ; bila tidak demikian
terima .
0 H
Dalam uji hipotesis biasa, banyaknya pengamatan yaitu ukuran sampel, diperlakukan sebagai konstanta. Jadi dalam hal ini bisa ditentukan berapa besarnya ukuran sampel yang akan diteliti sebagai dasar pengambilan keputusan.
Uji sekuensial mempunyai ciri khusus yang membedakannya dari uji biasa, yaitu banyaknya pengamatan yang diperlukan tergantung dari hasil uji terhadap pengamatan sebelumnya. Misalnya ingin diamati sebuah populasi di suatu tempat. Diambil sampel pertama, kemudian diproses dengan aturan dalam uji sekuensial. Keputusan apakah akan menambah pengamatan dengan sampel kedua ditentukan oleh hasil proses uji sekuensial tehadap pengamatan pertama tadi. Proses penambahan sampel pengamatan ini akan berlanjut sampai diperoleh keputusan yang sesuai dengan aturan dalam uji sekuensial. Jadi berdasar dari ciri tersebut, maka mengakibatkan besarnya sampel untuk pengamatan tidak dapat ditentukan sebelumnya, sehingga merupakan variabel random.
Metode sekuensial untuk menguji hipotesis mempunyai beberapa aturan. Pertama lakukan pengamatan tehadap objek penelitian, kemudian diproses berdasarkan aturan dalam uji sekuensial yaitu:
0 H
1. Menerima H0 2. Menolak H0
Keputusan yang diambil berdasarkan pada hasil uji sekuensial pengamatan ke- . Jika keputusan (1) atau keputusan (2) diperoleh maka proses berakhir. Jika keputusan (3) yang diperoleh maka harus dilakukan pengamatan yang kedua. Selanjutnya setelah dilakukan pengamatan yang kedua, diproses lagi untuk memperoleh satu dari tiga keputusan yang ada. Jika kembali diperoleh keputusan (3), maka harus dilakukan lagi pengamatan yang ketiga. Proses ini akan berlanjut terus sampai diperoleh keputusan (1) atau (2). Hal ini menyebabkan banyaknya n pengamatan tergantung dari hasil uji sekuensial terhadap pengamatan sebelumnya,.
m
(
m=1,2,3,K)
)
Untuk setiap bilangan bulat , dimisalkan adalah kumpulan semua
sampel berukuran m yang mungkin. Sampel dinotasikan
(
)
.Himpunan dapat dipandang sebagai ruang berdimensi m dengan setiap sampel merupakan satu vektor di . Aturan dalam pengambilan keputusan untuk setiap tahap pengambilan keputusan dapat dipandang sebagai pemecahan ruang menjadi tiga bagian yang saling lepas, yaitu: dan
dengan . Lakukan pengamatan pertama . Hipotesis
diterima bila , ditolak bila , lanjutkan dengan pengamatan
kedua bila . Hipotesis diterima atau ditolak atau lanjutkan dengan
pengamatan ketiga bila di atau . Jika
m Mm
m x1,x2,...xm
m
M
(
x1,x2,...xm Mmm
M 0, 1,
m m R R
m
R Rm ∪Rm ∪Rm =Mm
1 0
1 x
0
H x1∈R10 x1∈R11
2
x x1∈R1 H0
(
x1,x2)
, , 1 2 02 R
R R2
(
x1,x2)
di maka lanjutkan dengan pengamatan ketiga. Proses lagi apakah2 R
(
x1,x2,x3)
berada di, atau , demikian seterusnya sampai diperoleh keputusan (1) atau 1
3 0 3,R
keputusan (2). Jadi uji sekuensial ditentukan oleh dengan
Himpunan saling lepas dan gabungannya merupakan ruang sampel
, maka cukup didefinisikan dua dari tiga himpunan dan .
, , 1 0
m m R
R Rm m=1,2,3,K
, , 1
0
m m R R Rm
m
M Rm0,R1m, Rm
Sampel
(
x1,x2,...xm)
kita sebut tidak efektif jika dalam sampel tersebutmemuat sampel
(
x1,x2,...,xm')
dengan m'<m, sehingga sampel(
)
berada di atau . Suatu sampel yang bukan sampel tak efektif dinamakan sampel efektif. Pada uji sekuensial selalu diperoleh sampel efektif untuk setiap tahap percobaan. Jadi dalam mendefinisikan himpunan dan bisa diabaikan adanya sampel yang tidak efektif. Jika sampel tak efektif tidak pernah terjadi selama proses sekuensial, cukup untuk mendefinisikan letak setiap sampel efektif harus berada di salah satu dari atau ,' 2
1,x ,...,xm
x 0
'
m
R R1m'
, , 1 0
m m R
R Rm
(
x1,x2,...xm)
, ,1 0
m m R
R Rm
Contoh 3.1
Misalkan satu partai barang diajukan untuk menjalani pemeriksaan. Tiap unit dikelompokkan atas rusak atau tak rusak. Proporsi rusak tidak diketahui. Partai diterima bila dengan ' suatu bilangan diketahui. Bila , partai barang ditolak. Jadi diuji hipotesis : '
p
'
p
p≤ p p> p'
0
H p≤ p . Prosedur pengujian merupakan suatu contoh uji sekuensial. Misal suatu bilangan bulat. Jika unit pertama yang diperiksa ternyata tidak ada yang rusak, pemeriksaan barang dihentikan dan partai diterima. Jika untuk suatu nilai
0 H
0
n n0
0 n
m≤ , unit ke- ternyata rusak, maka partai ditolak dan pemeriksaan tidak dilanjutkan. Misal unit-unit
rusak diberi nilai 1 dan unit tak rusak diberi nilai 0. Sampel
(
x1,x2,...xm)
efektifjika dan hanya jika m≤n0, dan x1 =K= xm−1 =0. Penerimaan tidak mungkin dilakukan untuk , dengan kata lain memuat sampel tak efektif untuk
. hanya mengandung satu sampel efektif yaitu . Untuk
sebarang , memuat tepat satu sampel efektif, yaitu 0
n
m< Rm0
0 n m<
0
n
R
(
0,0,K,0)
0 n
m≤ Rm1
(
0,0,K,0,1)
.Himpunan Rm0,R1m, dan Rm
(
m=1,2,3,K)
yang didefinisikan dengan ujisekuensial dapat dipilih dengan berbagai cara dan masalah dasar dalam teori uji sekuensial adalah pemilihan yang layak terhadap himpunan ini.
A. Uji Hipotesis dan Statistik Uji
Dalam rencana sampling yang didasarkan atas pemeriksaan dari suatu partai barang dapat membawa pada keputusan yang salah. Keputusan yang salah itu
terjadi jika 'partai barang ditolak, dengan '
batas toleransi proporsi rusak yang ditentukan dan parameter proporsi rusak yang tidak diketahui. Demikian juga sebaliknya jika proporsi parameter yang tidak diketahui lebih besar dari ' tetapi partai barang diterima. Keputusan yang salah ini dapat dituliskan sebagai :
dengan sama
atau dari
kurang p
p p
p
p
p
Contoh 3.2
Misal ditentukan bahwa proporsi rusak unit barang yang masih bisa ditoleransi adalah 0,2; sehingga nilai p'=0,2. Setelah dilakukan pengamatan ternyata diperoleh bahwa nilai parameter p=0,1, maka diperoleh kesimpulan . Berdasar atas kesimpulan tadi, maka keputusan yang salah akan terjadi jika
ditolak dan diterima.
'
p p<
0 H
1 H
Tentunya tidak diharapkan bahwa proporsi rusak barang melebihi ketentuan yang telah ditetapkan.
Seringkali pemeriksaan terhadap tiap unit barang merupakan hal tidak mungkin dengan alasan barang akan menjadi rusak, biaya terlalu tinggi, dan waktu yang dibutuhkan cukup lama. Oleh karena itu dengan kondisi seperti ini resiko untuk membuat keputusan yang salah masih dapat ditolerir asal tidak melebihi batas yang telah ditetapkan. Untuk merancang sampling yang baik, perlu ditetapkan resiko maksimum dalam membuat keputusan yang salah agar masih dapat ditolerir.
Berdasar pada teori uji sekuensial, jika p= p' adalah mutu partai barang yang diperiksa berada di batas maka keputusan tidak dapat diambil. Untuk
, kecenderungan untuk menolak partai lebih besar dan pilihan ini akan meningkat dengan bertambahnya nilai p. Untuk
'
p p>
'
p
Jika p tidak terlalu jauh diatas , keputusan untuk menerima partai merupakan kesalahan yang dapat diabaikan. Demikian juga jika p tidak terlalu jauh dibawah ', kesalahan menolak partai bukan merupakan kesalahan yang serius. Sehingga secara tidak langsung terdapat dua bilangan yang menjadi batas kesalahan maksimum. Bilangan itu dinotasikan dengan dan sehingga diperoleh
'
p
p
1
p p0
'
0 p
p < sebagai toleransi bawah dan '
1 p
p > sebagai toleransi atas.
Penerimaan partai dianggap sebagai keputusan yang salah jika dan penolakan barang dianggap sebagai keputusan yang salah jika . Jika
tidak terlalu peduli keputusan mana yang dibuat.
1 p p≥
0 p p≤ 1
0 p p
p < <
Setelah dan dipilih, resiko dalam membuat keputusan yang salah dan masih dapat ditolerir dapat dirumuskan dengan probabilitas menolak partai jika
tidak melebihi 0
p p1
0 p
p≤ α. Demikian pula probabilitas untuk menerima partai jika tidak melebihi
1 p
p≥ β.
Jadi resiko yang masih dapat ditolerir dikenali dengan empat bilangan yaitu :
α
, , 1
0 p
p dan β. Pemilihan p0, p1,α dan β bukan merupakan masalah statistika, melainkan dipilih berdasar alasan praktis. Setelah keempat bilangan dipilih dapat ditentukan suatu rencana sampling.
tidak melebihi β diberikan oleh uji sekuensial dengan kekuatan
(
α,β)
untuk menguji p= p0 melawan p= p1. Sehingga dengan kata lain hipotesis pada uji sekuensial dengan kekuatan(
α,β)
dapat dituliskan sebagai berikut:0
0 : p p
H = , melawan
1
1: p p
H =
Misal menyatakan hasil pemeriksaan unit ke-i. Jika unit yang diperiksa
ternyata rusak maka nilai
i
X
1
=
i
X . Misal nilai-nilai ini dimasukkan dalam kategori I. Banyaknya pengamatan yang masuk dalam kategori I dilambangkan dengan . Demikian juga jika unit yang diperiksa ternyata tidak rusak maka nilai
. Nilai-nilai yang tidak rusak ini dimasukkan dalam pengamatan yang bukan termasuk kategori I. Banyaknya pengamatan yang bukan termasuk kategori I dilambangkan dengan . Sehingga jika pengamatan yang dilakukan sebanyak n maka nilai
i
X
1 n 0
=
i
X Xi
2 n
2
1 n
n n= + .
Statistik uji sekuensial adalah sebagai berikut:
( ) ( ) ( )
( )
( ) ( ) ( )
( )
) , ( ) , ( ) , ( ) , (
) , ( ) , ( ) , ( ) , (
0 0
3 0 2 0 1
1 1
3 1 2 1 1
0 3 0 2 0 1 0
1 3 1 2 1 1 1
p X f p X f p X f p X f
p X f p X f p X f p X f
X f X f X f X f
X f X f X f X f S
n n n
n n
K K K
K
= =
(3.1)
dengan
• Sn =statistik uji sekuensial
• f1(Xi)=fungsipeluanguntukp= p1
• n = banyak pengamatan yang dilakukan (sifatnya variabel) satu demi satu sampai langkah ke-n.
Persamaan (3.1) bila ditulis dalam bentuk logaritma menjadi:
n n n n z z z z p X f p X f p X f p X f p X f p X f p X f p X f S + + + + = + + + + = K K 3 2 1 0 1 0 3 1 3 0 2 1 2 0 1 1 1 ) , ( ) , ( ln ) , ( ) , ( ln ) , ( ) , ( ln ) , ( ) , ( ln ln (3.2) dengan ) , ( ) , ( ln 0 1 p X f p X f z i i
i = , dan i = 1,2,...,n (3.3)
Karena variabel random disini hanya mempunyai dua nilai yaitu 0 dan 1, maka probabilitas bahwa
i
X 1
=
i
X sama dengan p. Hal ini dapat ditulis dengan , dengan p merupakan parameter yang tidak diketahuii. Fungsi
probabilitas dari diberikan oleh dengan p
X
P( i =1)=
i
X f(Xi,p)
p p
f(1, )= dan
p p
f(0, )=1− . (3.4) sehingga persamaan 3.3 dapat ditulis sebagai berikut
jadi
⎟⎟ ⎠ ⎞ ⎜⎜
⎝ ⎛
− − +
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ =
+ + + + =
2 1 2
0 1 1
3 2 1
1 1 ln ln
ln
p p n
p p n
z z
z z
Sn K n
(3.6)
Dengan n1 menyatakan banyaknya kejadian Xi =1dan menyatakan banyaknya kejadian
2 n 0
=
i
X , dan n=n1+n2.
B. Kriteria Uji
Dalam prosedur uji sekuensial untuk menguji melawan didefinisikan sebagai berikut:
0
H H1
1. Dipilih dua konstanta positif A dan B denganB< A. Pada tiap tahap
percobaan ( percobaan ke-n ), dihitung probabilitas
n n n
p p S
0 1
= , dengan:
(
1 1) (
2 1)
(
1)
1 f X ,p , f X ,p f X ,p
pn = K n bila H1benar dan
(
1 0) (
2 0)
(
0)
0 f X ,p ,f X ,p f X ,p
p n = K n bila H0benar.
2. jika
B
Sn ≤ (3.7)
proses berhenti dengan keputusan menerima H0. Jika
A
Jika
A S
B< n < (3.9) pengamatan dilanjutkan dengan mengambil pengamatan tambahan.
Konstanta A dan B ditentukan sedemikian hingga αdanβ mempunyai suatu nilai tertentu.
Dari persamaan (3.6) dan (3.7), hipotesisH0diterima bila: B
Sn ln ln ≤
B
p p n
p p
n ln
1 1 ln ln
0 1 2
0 1
1 ⎟⎟≤
⎠ ⎞ ⎜⎜
⎝ ⎛
− − +
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛
(3.10)
Dari persamaan (3.6) dan (3.8), hipotesis H0ditolak bila: A
Sn ln
ln ≥
A
p p n
p p
n ln
1 1 ln ln
0 1 2
0 1
1 ⎟⎟≥
⎠ ⎞ ⎜⎜
⎝ ⎛
− − +
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛
(3.11)
Dari persamaan (3.6) dan (3.9), pengamatan dilanjutkan dengan mengambil pengamatan tambahan bila:
A S
B ln n ln ln < <
A p
p n
p p n
B ln
1 1 ln ln
ln
0 1 2
0 1
1 ⎟⎟<
⎠ ⎞ ⎜⎜
⎝ ⎛
− − +
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛
< (3.12)
C. Hubungan antara α,β,A, dan B
Sampel
(
X1,X2,K,Xn)
merupakan sampel tipe 0 bilaA p p B
m m <
<
0
1 untuk
1 , , 2 ,
1 −
= n
dan B p p
n n ≤
0 1
sampel
(
X1,X2,K,Xn)
dikatakan sampel tipe 1 bilaA p p B
m m <
<
0
1 untuk
1 , , 2 ,
1 −
= n
m K
dan A
p p
n n ≥
0 1
Sampel tipe 0 akan membawa pada penerimaan dan sampel tipe 1 akan
membawa pada penolakan .
0 H
0 H
Untuk suatu sampel tipe 1, probabilitas untuk memperoleh sampel tersebut sekurang-kurangnya A kali lebih besar dibawah dibandingkan dengan . Nilai probabilitas bahwa proses sekuensial akan berakhir dengan penolakan
adalah
1
H H0
0 H
α bila H0benar dan 1−β bila H1 benar. Jadi diperoleh:
α β ≥ A −
1
atau dapat ditulis
α β
− ≤1
A (3.13)
jadi
α β
−
1
merupakan limit atas untuk A.
Limit bawah untuk B dapat diperoleh dengan cara yang sama. Dalam kenyataannya, untuk sebarang sampel
(
X1,X2,K,Xn)
tipe 0 maka probabilitassampel tipe 0 ketika H0 benar. Karena probabilitas dari penerimaan H0 adalah
α
−
1 ketika H0 benar dan β ketika H1 benar, maka diperoleh persamaan:
B
) 1
( α
β ≤ −
atau dapat ditulis
α β
− ≥
1
B (3.14)
jadi
α β
−
1 merupakan limit bawah untuk B.
Pertidaksamaan-pertidaksamaan (3.13) dan (3.14) juga dapat ditulis
A 1 1−β ≤
α
(3.15)
dan
B ≤ −α
β
1 (3.16)
dari pertidaksamaan (3.15) dan (3.16) dapat diturunkan limit atas untukαdanβ sebagai fungsi A atau B.
A 1 lim 1
lim
0
0 →
→ − ≤β
β β
α
A
1
≤
α (3.17)
dan
B
0
01 lim
lim
→ → − ≤α
α α
β
B ≤
Kumpulan
(
α,β)
yang memenuhi pertidaksamaan (3.17) dan (3.18) dapat dapat dinyatakan dalam suatu grafik pada Gambar 3.1. Setiap pasang(
α,β)
dapat dinyatakan sebagai titik pada bidang datar dengan absisαdan ordinatβ.Garis L1:αA=1−β memotong sumbu datar pada
A
1
=
α dan sumbu tegak
1
=
β . Garis L2 :β =B(1−α)memotong sumbu datar pada α =1dan sumbu tegak β = B.
β
α 1
1
B
A
1
Gambar 3.1
D. Penentuan Konstanta A dan B
dan B untuk pengujian dengan kekuatan
(
α,β)
, sehingga pertidaksamaan (3.13) dan (3.14) dapat ditulis sebagai berikut:α β β
α, )≤1−
(
A (3.19)
(
)
α β β α
− ≥
1 ,
B (3.20)
Dengan mengambil
(
1)
(α,β)α β
a = −
danβ(1−α)=b(α,β), maka harus diperiksa akibat-akibat dari penentuan A dan B. Dari pertidaksamaan (3.19) dan (3.20) diperoleh bahwa nilai a(α,β) yang dipilih lebih besar atau sama dengan nilai A(α,β)dan nilai b(α,β) yang dipilih lebih kecil atau sama dengan
) , (α β
B . Dengan mensubtitusikanA=a(α,β) sebagai penggantiA(α,β)dan
) , (α β
b
β α β
α β
α
− = ≤
− ( , ) 1
1 '
1 '
a (3.21) dari pertidaksamaan (3.18) dan (3.20) diperoleh:
α β β
α α
β
− = ≤
− ' ( , ) 1
1 '
b (3.22)
dengan 'α dan β' kesalahan tipe I dan kesalahan tipe II batas A=a
(
α,β)
dan) , (α β
b
B= .
Dari pertidaksamaan (3.21) dan (3.22) diperoleh :
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛
− ≤
⎟⎟ ⎠ ⎞ ⎜⎜
⎝ ⎛
− →
→ β
α β
α
β
β 1 ' lim 1
' lim
0 ' 0
'
β α α
− ≤
1
' (3.23)
dan
⎟ ⎠ ⎞ ⎜ ⎝ ⎛
− ≤
⎟ ⎠ ⎞ ⎜ ⎝ ⎛
− →
→ α
β α
β α
α 1 lim 1
' lim
0 ' 0
'
α β β
− ≤
1
' (3.24)
Dengan mengalikan pertidaksamaan (3.21) dengan
(
1−β)
(
1−β')
maka diperoleh:(
)(
)
(
1)(
1 ' 11 ' 1 ' 1
' β β
β
)
α β β
β
α − −
− ≤ − −
⋅ −
(
1)
(
1 ')
' β α β
α − ≤ −
' '
' α β α αβ
α − ≤ −
0 ' '
'−α β+αβ −α ≤
demikian juga dengan mengalikan pertidaksamaan (3.22) dengan
(
1−α)
(
1−α')
maka diperoleh:(
)(
)
(
1)(
1 ' 11 ' 1 ' 1
' α α
α
)
β α α α
β − −
− ≤ − − −
(
1)
(
1 ')
' α β α
β − ≤ −
β α β αβ
β'− '≤ − ' 0 '
'
'−αβ+α β −β ≤
β (3.26) Dengan menjumlahkan pertidaksamaan (3.25) dan (3.26) maka diperoleh pertidaksamaan:
0 ' '
'−α β+αβ −α ≤
α
0 '
'
'−αβ+α β −β ≤
β
+
0 '
'+β−α −β ≤
α
β α β
α'+ '≤ + (3.27)
Dalam kenyataan, nilaiαdan β terletak antara 0,01 dan 0,05. Jadi,
(
)
αβ
α ≅
−
1
dan β
α
β ≅
− ) 1
( . Hal ini berarti bahwa kenaikan 'α terhadap αatauβ'terhadapβ dapat diabaikan.
Setelah penentuan nilai A dan B dilakukan, maka dari pertidaksamaan (3.10) dan (3.14) diperoleh pertidaksamaan kriteria uji untuk menerima H0 yaitu:
⎟ ⎠ ⎞ ⎜ ⎝ ⎛
− ≤ ⎟⎟ ⎠ ⎞ ⎜⎜
⎝ ⎛
− − +
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛
α β
1 ln 1
1 ln ln
0 1 2
0 1 1
p p n
p p
Dari pertidaksamaan (3.11) dan (3.13), maka kriteria uji untuk menolak adalah: 0 H ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ≥ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ α β 1 ln 1 1 ln ln 0 1 2 0 1 1 p p n p p
n (3.29)
Dari persamaan (3.12) , (3.13) dan (3.14), maka diperoleh pertidaksamaan kriteria uji untuk menambah dengan satu pengmatan lagi yaitu:
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − < ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ < ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − α β α β 1 ln 1 1 ln ln 1 ln 0 1 2 0 1 1 p p n p p
n (3.30)
Nilai-nilai batas untuk kriteria uji dapat dihitung dari:
⎪ ⎪ ⎪ ⎭ ⎪⎪ ⎪ ⎬ ⎫ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ α β α β 1 ln 1 1 ln ln 1 ln 1 1 ln ln 0 1 2 0 1 1 0 1 2 0 1 1 p p n p p n p p n p p n (3.31)
Karena = banyak barang yang rusak diantara n barang yang diambil dan , maka bagian pertama sistem persamaan (3.31) menjadi:
1 n
1
2 n n
n = −
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + 0 1 0 1 0 1 0 1 0 1 1 1 1 ln ln 1 ln 1 1 ln ln 1 1 ln p p p p p p p p p p n n α β (3.32)
Persamaan (3.32) disebut garis batas atas penerimaan dan dinotasikan dengan
. Jika sumbu mendatarnya adalah ndan sumbu tegaknya adalah , maka dari persamaan (3.32) diperoleh kemiringan garis adalah:
0 H
1
g n1
1 g ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = 0 1 0 1 0 1 1 1 log ln 1 1 ln p p p p p p
t (3.33)
Untuk n2 =n−n1 ,bagian kedua sistem persamaan (3.31) menjadi:
(
)
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ α β 1 ln 1 1 ln ln 0 1 1 0 1 1 p p n n p p n ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ α β 1 ln 1 1 ln 1 1 ln ln 0 1 1 0 1 0 1 1 p p n p p n p p n ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ α β 1 ln 1 1 ln 1 1 ln ln 0 1 0 1 0 1 1 p p n p p p p n ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − + 0 1 0 1 0 1 0 1 0 1 1 1 1 ln ln 1 ln 1 1 ln ln 1 1 ln p p p p p p p p p p n n α β (3.34)Persamaan (3.34) disebut garis batas bawah penolakan dan dinotasikan
dengan . Kemiringan garis ini adalah:
0 H
2
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = 0 1 0 1 0 1 1 1 ln ln 1 1 ln p p p p p p
u (3.35)
Dari persamaan (3.33) dan (3.35) diperoleh kesimpulan bahwa garis dan mempunyai kemiringan garis yang sama dan dinotasikan dengan lambang sdan
.
1
g g2
u t s= =
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = 0 1 0 1 0 1 1 1 ln ln 1 1 ln p p p p p p
s (3.36)
Dari persamaan (3.32) diperoleh titik potong dengan sumbu tegak sebagai berikut: 1 n ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − ⋅ + 0 1 0 1 0 1 0 1 0 1 0 1 1 log ln 1 ln 1 1 log ln 1 1 ln 0 p p p p p p p p p p h α β ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = 0 1 0 1 0 1 1 ln ln 1 ln p p p p h α β (3.37)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = 0 1 0 1 1 1 1 ln ln 1 ln p p p p h α β (3.38) Contoh 3.3
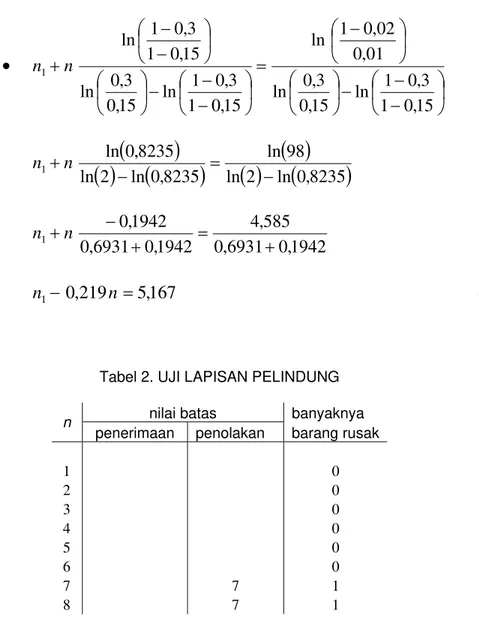
Misal ada partai barang yang banyak sekali yang harus ditentukan berdasarkan sampling apakah partai barang itu bagus atau tidak. Perusahaan menetapkan bahwa keputusan dibuat dengan ketentuan terima partai bsrsng jika proporsi rusaknya kurang atau sama dengan 10% dan tolak partai barang jika proporsi rusaknya lebih atau sama dengan 20%. Resiko kesalahan yang ditetapkan perusahaan untuk kesalahan tipe I sebesar α =0,01 dan resiko kesalahan tipe II sebesarβ =0,05. Dalam merencanakan rencana sampling dari permasalahn ini, ada dua hipotesis yang dihadapi yaitu:
1 , 0
: 0
0 p= p =
H
2 , 0
: 1
1 p= p =
H
berdasar pada rumus persaman (3.31), maka diperoleh persamaan-persamaan:
⎪ ⎪ ⎪ ⎭ ⎪⎪ ⎪ ⎬ ⎫ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ 01 , 0 95 , 0 ln 9 , 0 8 , 0 ln 1 , 0 2 . 0 ln 99 , 0 05 , 0 ln 9 , 0 8 , 0 ln 1 , 0 2 . 0 ln 2 1 2 1 n n n n (3.39)
Setelah sistem persamaan (3.39) disederhanakan, maka diperoleh persamaan:
1
Daerah penerimaan H0 Lanjutkan pengamatan
2
g
1
g
Daerah penolakan H0
Gambar 3.2
n
1
2 n n
n karena
karena n2 =n−n1, sistem persamaan (3.40) dapat ditulis sebagai berikut:
⎪⎭ ⎪ ⎬ ⎫
= −
− = −
9777 , 1 0511 , 0 3521 , 0
2966 , 1 0511 , 0 3521 , 0
1 1
n n
n n
(3.41)
Rencana sampling diperoleh dari rumus pertidaksamaan (3.29) dan (3.30). Jadi diterima jika:
0 H
2966 , 1 0511 , 0 3521 ,
0 n1− n≤−
yang memberikan n1 ≥0,1451n−3,6824 dan batasnya g1:n1 =0,1451n−3,6824 dan tolak H0 jika:
9777 , 1 0511 , 0 3521 ,
0 n1− n≥
yang memberikan n1 ≥0,1451n+5,6168 dan batasnya .
6168 , 5 1451 , 0 : 1
2 n = n+
g
Dalam hal lainnya, sampling masih harus dilanjutkan.
Secara grafik, rencana sampling ini dapat ditunjukkan dalam Gambar 3.2 dengan n= sumbu datar dan = sumbu tegak. n1
Daerah grafik pada Gambar 3.2 dibagi menjadi tiga bagian, yaitu:
• penerimaan H0( di sudut kanan bawah )
• penolakan H0( di bagian atas)
• daerah sampling untuk melanjutkan prosedur dengan menambah sebuah pengamatan lagi (daerah tengah yang dibatasi oleh garis sejajar dan
).
1 g
2 g
Untuk setiap barang yang diperiksa, peristiwa diperoleh barang rusak dijumlahkan pada setiap pengambilan. Peristiwa ini digambarkan pada grafik sebagai titik-titik. Selama titik-titik ini masih berada diantara dan , maka sampling terus dilanjutkan dengan menambah pemeriksaan barang itu satu demi satu. Setelah ada titik yang keluar dari garis-garis batas dan , maka sampling berhenti. Jika titik yang keluar itu jatuh pada daerah penerimaan hipotesis, maka diterima dan dinyatakan bahwa partai barang bagus. Jika titik
yang keluar itu berada di daerah penolakan hipotesis, maka ditolak dan dinyatakan bahwa partai barang jelek.
1
g g2
1
g g2
0 H
0 H
Misal diperoleh hasil pemeriksaan sebagai berikut: Tabel 3.1
n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
1
Atau jika b = barang tak rusak dan j = barang rusak, pemeriksaan dalam tabel (1) dapat ditulis dalam bentuk sebagai berikut:
b b j b j j j b b j b b b j b j b b b j j
10 20 30 40
10 20
Daerah penolakan H0
2
g
1
Daerah penerimaan
g
n
Lanjutkan pengamatan 1
n
Gambar 3.3
0 H
E. Fungsi Karakteristik Operasi
Fungsi karakteristik operasi L
( )
p didefinisikan sebagai probabilitas bahwa proses sekuensial akan berakhir dengan penerimaan H0 bila padalah nilai parameter yang sebenarnya. Fungsi karakteristik operasi ini dapat dinyatakan dengan notasi probabilitas yaitu:( )
p L( )
pL = P (menerima partai | proporsi rusak p) sehingga diperoleh pernyataan sebagai berikut:
( )
0L = P (menerima partai | p=0) = 1
Karena diketahui bahwa proporsi rusak sebenarnya dari partai barang adalah 0 yang berarti tidak ditemukan barang rusak dalam partai barang, maka probabilitas untuk menerima partai barang adalah 1.
Demikian pula untuk:
( )
1L = P (menerima partai | p=1) = 0
Karena diketahui proporsi rusak sebenarnya dari partai barang adalah 1 yang artinya ditemukan semua barang dalam keadaan rusak, maka probabilitas untuk menerima partai adalah 0. Dengan kata lain partai barang ditolak.
Prosedur pengujian H0 : p= p0 melawan H1: p= p1 dipilih sedemikian sehingga:
P (menerima partai bila p= p0) = probabilitas menerima H0 yang benar = 1−α P (menerima partai bila p= p1) = probabilitas menerima H0 yang salah = β dengan demikian diperoleh
( )
p0 =1−α( )
p1 =βL
Misal untuk sebarang nilai pyang diberikan, fungsi probabilitas dari X ditentukan sebagai berikut:
(
)
(
)
( )
(
X p f pX f
p X f p X f
p h
, ,
, )
, (
0 1
⎥ ⎦ ⎤ ⎢
⎣ ⎡ =
∗
)
(3.42)
Untuk setiap nilai p, nilai dari h
( )
p dapat ditentukan sedemikian sehingga . Karena persamaan (3.42) merupakan sebuah fungsi probabilitas dari X, maka ada tepat satu nilai( )
p ≠0h
( )
p ≠0h sedemikian sehingga dipenuhi persamaan:
(
(
)
)
( )
(
,)
1 ,, 0
1 =
⎥ ⎦ ⎤ ⎢
⎣ ⎡
∑
X
p h
p X f p
X f
p X f
(3.43)
Karena h
( )
p ≠0, maka terdapat dua kemungkinan nilai p yaitu atau .( )
p >0h
( )
p <0h
Untuk kasus dengan h
( )
p >0, misal hipotesisHmenyatakan bahwa adalah fungsi probabilitas dari distribusi X yang sebenarnya dan hipotesis(
X p f ,)
∗
H menyatakan bahwa f∗
(
X,p)
adalah fungsi probabilitas dari distribusi X yang sebenarnya. Misal uji sekuensial untuk menguji Hmelawan H∗ adalah sebagai berikut:(
)
(
)
(
X p)
f(
X p)
f
p X f p X f S
n n
, ,
, ,
1 1
K
K ∗
∗ ∗ =
(3.44)
sehingga hipotesisH diterima jika:
(
)
(
)
(
)
(
n)
h( )p nB p X f p X f
p X f p X f
≤
∗ ∗
, ,
, ,
1 1
K K
(3.45)
(
)
(
)
(
)
(
n)
h( )p n A p X f p X f p X f p X f ≥ ∗ ∗ , , , , 1 1 K K (3.46)dan dilanjutkan dengan mengambil sebuah pengamatan lagi jika:
( )
(
)
(
)
(
)
(
n)
h( )p n p h A p X f p X f p X f p X fB < <
∗ ∗ , , , , 1 1 K K (3.47)
Karena , maka dari pertidaksamaan (3.42) dan (3.45) diperoleh pertidaksamaan yang setara yaitu:
( )
p >0h
(
)
(
)
( )
(
)
(
(
)
)
( )(
)
(
)
(
n)
h( )pn p h n n p h B p X f p X f p X f p X f p X f p X f p X f p X f ≤ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ , , , , , , , , 1 0 1 1 0 1 1 1 K K
(
)
(
)
( )(
)
(
)
( )( )p h p h n n p h B p X f p X f p X f p X f ≤ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ 0 1 0 1 1 1 , , , , K
(
)
(
)
( )(
)
(
)
( )( )p h( )p h( )p
h p h n n p h B p X f p X f p X f p X f ≤ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ 0 1 0 1 1 1 , , , , K
(
)
(
)
(
X p)
f(
X p)
B f p X f p X f n n ≤ 0 0 1 1 1 1 , , , , K K (3.48)dari pertidaksamaan (3.42) dan (3.46) diperoleh pertidaksamaan yang setara yaitu:
(
)
(
)
( )
(
)
(
(
)
)
( )(
)
(
)
(
n)
h( )pn p h n n p h A p X f p X f p X f p X f p X f p X f p X f p X f ≥ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ , , , , , , , , 1 0 1 1 0 1 1 1 K K
(
)
(
)
( )(
)
(
)
( )( )p h p h n n p h A p X f p X f p X f p X f ≥ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ 0 1 0 1 1 1 , , , , K
(
)
(
)
( )(
)
(
)
( )( )p h( )p h( )p
(
)
(
)
(
)
(
)
Ap X f p X f p X f p X f n n ≥ 0 0 1 1 1 1 , , , , K K (3.49)
dari pertidaksamaan (3.42) dan (3.7) diperoleh pertidaksamaan yang setara yaitu:
( )
(
)
(
)
( )
(
)
(
(
)
)
( )(
)
(
)
(
n)
h( )pn p h n n p h p h A p X f p X f p X f p X f p X f p X f p X f p X f B < ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ < , , , , , , , , 1 0 1 1 0 1 1 1 K K ( )
(
)
(
)
( )(
)
(
)
( )( )p h p h n n p h p h A p X f p X f p X f p X f
B ⎥ <
⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ < 0 1 0 1 1 1 , , , , K ( ) ( )
(
)
(
)
( )(
)
(
)
( )( )p h( )p h( )p
h p h n n p h p
h h p
A p X f p X f p X f p X f
B ⎥ < ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ < 0 1 0 1 1 1 , , , , K
(
)
(
)
(
X p)
f(
X p)
A f p X f p X f B n n < < 0 0 1 1 1 1 , , , , K K (3.50)Pertidaksamaan ini identik dengan definisi uji sekuensial untuk menguji melawan . Oleh karena itu, jika menuju pada penerimaan
S
0
H H1 S∗ H, maka
menuju pada penerimaan dan jika menuju pada penolakan
S
0
H S∗ H, maka juga
menuju pada penolakan . Sehingga dapat diambil kesimpulan bahwa probabilitas penerimaan jika p adalah nilai parameter sebenarnya yang
dinotasikan dengan adalah sama seperti probabilitas bahwa uji akan berakhir dengan penerimaan
S
0 H
0 H
( )
pL S∗
Hjika f
(
X,p)
adalah fungsi probabilitas dari distribusi X yang sebenarnya. Probabilitas bahwa akan berakhir dengan penerimaan∗ S
HjikaHbenar adalah α'dan probabilitas bahwa akan berakhir dengan penolakan
∗