PEMBANGUNAN SISTEM
DATA MINING
UNTUK DIAGNOSIS PENYAKIT DIABETES
MENGGUNAKAN ALGORITME
CLASSIFICATION
BASED ASSOCIATION
HERWANTO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2006
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis Pembangunan Sistem Data Mining untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme Classification Based Association adalah karya saya sendiri dan belum diajukan dalam bentuk apa pun kepada pergu ruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, September 2006
Herwanto NIM G651034084
PEMBANGUNAN SISTEM
DATA MINING
UNTUK DIAGNOSIS PENYAKIT DIABETES
MENGGUNAKAN ALGORITME
CLASSIFICATION
BASED ASSOCIATION
HERWANTO
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2006
ABSTRAK
HERWANTO. Pembangunan Sistem Data Mining Untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme Classification Based Association. Dibimbing oleh IMAS S. SITANGGANG dan RINDANG KARYADIN.
Basis data rumah sakit umumnya berisi data dalam jumlah besar dengan banyak variasi, tetapi belum dimanfaatkan secara optimal. Diperlukan suatu sistem data mining yang bisa memanfaatkan gunungan data menjadi informasi yang bernilai strategis. Dalam penelitian ini dipelajari bagaimana data bisa digunakan untuk membantu mendiagnosa penyakit, khususnya penyakit diabetes
Data-data pasien yang beresiko menderiita penyakit diabetes dikumpulkan ke dalam data warehouse diabetes. Dua tahapan utama yang dilakukan dalam penelitian ini, yaitu proses pembentukan model klasifikasi dan pembuatan program aplikasi untuk mendeteksi penyakit diabetes.
Dalam proses pembentukan model klasifikasi ada tiga tahapan yang dilakukan. Tahap pertama adalah menangani data-data yang beragam, tidak lengkap, dan tidak konsisten. Kemudian melakukan proses perubahan data kontinyu menjadi data kategori, dimana setiap variabel dikelompokkan ke dalam sejumlah kategori. Tahap berikutnya adalah membuat rule mining dan klasifikasi.
700 pasien dipilih sebagai data training, 400 pasien dengan diagnosa negatif diabetes dan 300 pasien positif diabetes. Pada pembentukan model klasifikasi dipilih 12 variabel yang digunakan untuk menghasilkan aturan yaitu usia, sex dan hasil-hasil pemeriksaan laboratorium. Didapatkan hasil pemeriksaan glukosa darah 2 jam pasca puasa, glukosa urin 2 jam pasca puasa, serta glukosa darah puasa menjadi penentu utama untuk menentukan apakah pasien positif diabetes atau negatif diabetes. Aturan-aturan yang dihasilkan selanjutnya digunakan dalam program aplikasi untuk mendiagnosa pasien apakah positif diabetes atau negatif diabetes.
PRAKATA
Syukur Alhamdulillah penulis panjatkan kepada Allah SWT atas limpahan rahmat dan karuniaNya sehingga penulis akhirnya dapat menyelesaikan karya ilmiah ini. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juni 2005 ini adalah sistem data mining, dengan judul Pembangunan Sistem Data Mining untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme Classification Based Association.
Dalam kesempatan ini penulis ingin menyampaikan ucapan terima kasih dan penghargaan kepada Ibu Imas S Sitanggang, S.Si., M.Kom., dan Bapak Rindang Karyadin S.T., M.Kom. selaku pembimbing yang sejak awal penulisan proposal sampai pada penulisan karya ilmiah ini, telah membimbing dengan penuh keikhlasan, dan kesabaran. Di samping itu penghargaan penulis sampaikan kepada para dosen Program Studi Ilmu Komputer, Sekolah Pascasarjana, Institut Pertanian Bogor, yang telah memberikan wawasan dan pengetahuan baru bagi penulis. Atas do’a, pengorbanan, kesabaran, ketulusan, serta dukungan semangatnya, penulis juga menyampaikan ucapan terima kasih dan rasa hormat yang setulus-tulusnya kepada kedua orang tua, serta seluruh keluarga.
Semoga karya ilmiah ini bermanfaat.
Bogor, September 2006
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 24 May 1962 dari ayah Paridjan dan ibu Parinah. Penulis merupakan putra kelima dari delapan bersaudara.
Pada tahun 1982 penulis lulus dari SMA Negeri 43 Jakarta. Pendidikan sarjana ditempuh pada tahun 1991 di Sekolah Tinggi Manajemen Informatika dan Komputer Gunadarma, jurusan Manajemen Informatika, lulus pada tahun 1996. Kesempatan untuk melanjutkan ke program magister pada Program Studi Ilmu Komputer, Sekolah Pascasarjana IPB diperoleh pada tahun 2004.
Penulis bekerja di Rumah Sakit Pusat Pertamina Jakarta pada bagian Sistem Informasi & Telekomunikasi Elektronika sejak tahun 1997. Bidang yang menjadi tanggung jawab penulis ialah pembangunan dan pengembangan sistem informasi rumah sakit. Pada tahun 2005 penulis dipercaya sebagai kepala bagian Sistem Informasi & Telekomunikasi Elektronika.
Judul Tesis : Pembangunan Sistem Data Mining
Untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme Classification Based Association Nama : Herwanto
NIM : G651034084
Disetujui
Komisi Pembimbing
Imas S Sitanggang, S.Si., M.Kom. Rindang Karyadin, S.T., M.Kom. Ketua Anggota
Diketahui
Ketua Program Studi Ilmu Komputer Dekan Sekolah Pascasarjana
Dr. Sugi Guritman . Dr. Ir. Khairil A. Notodiputro, MS
DAFTAR ISI
Halaman
DAFTAR GAMBAR xi
DAFTAR TABEL xii
DAFTAR LAMPIRAN xiii
I. PENDAHULUAN 1.1 Latar belakang 1
1.2. Tujuan Penelitian 2
1.3. Ruang lingkup 2
1.4. Manfaat Penelitian 3
II. TINJAUAN PUSTAKA 2.1. Diabetes Melitus 4
2.2 Data Warehouse 5
2.2.1. Metodologi Perancangan Data Warehouse 7
2.2.2. Star Schema 8
2.3. Data Mining 10
2.3.1. Klasifikasi dan Prediksi 13
2.3.2. Metodologi Data Mining 14
2.3.3. Teknik Data Mining 16
2.3.4. Membangun Model Prediksi 26
III. BAHAN DAN METODE 3.1. Bahan 29
3.2. Metode 31
3.2.1. Kerangka Pemikiran 31
3.2.2. Tata Laksana 33
IV. PERANCANGAN ARSITEKTUR SISTEM DATA MINING 4.1 Gambaran umum sistem 35
4.2. Pembangunan Data Warehouse 36
4.3. Pembangunan Model Klasifikasi 38
4.4. Antarmuka Pemakai 40
4.5. Basis Pengetahuan 40
Halaman V. IMPLEMENTASI
5.1. Preproses Data 44
5.2. Pembentukan Sampel Positif dan Sampel Negatif 46
5.3. Pembentukan PN Array 47
5.4. Pembentukan Gain 48
5.5. Program Aplikasi 51
VI. PENGUJIAN DAN PEMBAHASAN 6.1. Mekanisme Pengujian 52
6.2. Pelatihan Dengan Data Training 52
6.3. Proses Optimalisasi 58
VII. KESIMPULAN DAN SARAN 7.1. Kesimpulan 64
7.2. Saran 64
DAFTAR PUSTAKA 65
DAFTAR GAMBAR
Halaman
1. Arsitektur Data Warehouse 7
2. Relasi antartabel dimensi dan table fakta sederhana 10 3. Data mining sebagai salah satu tahapan dalam proses
knowledge discovery 11
4. Model proses pembuatan data mining 15
5. Algoritme Appriori 18
6. Algoritme FOIL 22
7. Algoritma PRM 24
8. Metoda startCPAR 25
9. Metoda cparGeneration 25
10. Langkah-langkah membangun model pred iksi 28 11. Kerangka pemikiran pembangunan model
untuk diagnosis penyakit diabetes 32
12. Tahapan Proses data mining 33
13. Model aplikasi diabetes 35
14. Relasi antartabel skema bintang data warehouse diabetes 37 15. Ekstraksi dan Transformasi Basis Data SIM RSPP 38
16. Flowchart Algoritme CPAR 39
17 Grafik Gain data training untuk kelas positip diabetes 55 18. Grafik Gain data training untuk kelas negatip diabetes 55 19. Grafik Gain negatif diabetes setelah proses optimalisasi 60 20. Grafik Gain negatif diabetes setelah proses optimalisasi 60
DAFTAR TABEL
Halaman
1. Transaksi Penjualan Barang 18
2. Karakteristik umum data pasien 30
3. Rata-rata variabel pemeriksaan laboratorium 30 4. Klasifikasi Berat Badan berdasarkan IMT 42
5. Nilai referensi hasil laboratorium 44
6. Kategori untuk tabel sampel_data 45
7. Contoh sampel data 46
8. Sampel positif dari data pada Tabel 7 46
9. Sampel negatif dari data pada Tabel 7 47
10. PN Array 47
11. Kategori dan nilai Gain 48
12. Karakteristik umum data training 53
13. Rata-rata variabel pemeriksaan laboratorium data training 53
14. Perbandingan bobot sampel dan gain 54
15. Aturan yang dihasilkan dengan gain similarity ratio 99% 56 16. Aturan yang dihasilkan dengan gain similarity ratio 80% 56 17. Aturan yang dihasilkan dengan gain similarity ratio 50% 57 18. Aturan yang dihasilkan dengan gain similarity ratio 20% 57 19. Aturan yang dihasilkan dengan gain similarity ratio 10% 58 20. Kategori untuk tabel sampel_data setelah proses optimalisasi 58 21 Aturan setelah proses optimalisasi dengan
Gain similarity ratio 99% 61
22 Aturan setelah proses optimalisasi dengan
Gain similarity ratio 80% 61
23 Aturan setelah proses optimalisasi dengan
Gain similarity ratio 50% 62
24 Aturan setelah proses optimalisasi dengan
Gain similarity ratio 20% 62
25 Aturan setelah proses optimalisasi dengan
DAFTAR LAMPIRAN
Halaman
1. Proses Pasien Rawat Jalan 66
2. Proses Pasien rawat Inap 67
3. Kamus Data Pasien Rawat Jalan dan Pasien Rawat Inap 68
4. Kamus Data Data Warehouse diabetes 74
5. Sampel data positif diabetes dan negatif diabetes 76
6. Tampilan halaman Status Pasien 77
7. Tampilan halaman Anamnes is 77
8. Tampilan halaman Riwayat DM 78
9. Tampilan halaman Anamnesis Keluarga 78
10. Tampilan halaman Pemeriksaan Fisis 79
11. Tampilan halaman Laboratoriu 79
12. Tampilan halaman Pemeriksaan Penunjang 80
13. Tampilan halaman Diagnosis 80
BAB I
PENDAHULUAN
1.1. Latar Belakang
Organisasi Kesehatan Dunia (WHO) memperkirakan, bahwa 177 juta penduduk dunia mengindap diabetes melitus atau biasa disingkat diabetes. Jumlah ini akan meningkat hingga melebihi 300 juta pada tahun 2025. Dr Paul Zimmet, direktur dari International Diabetes Institute (IDI) di Victoria, Australia, meramalkan bahwa diabetes akan menjadi epidemi yang paling dahsyat dalam sejarah manusia. Tetapi data epidemiologi di negara berkembang memang masih belum banyak. Oleh karena itu angka prevalensi yang dapat ditelusuri terutama berasal dari negara maju.
Dengan bertambahnya angka harapan hidup bangsa Indonesia perhatian masalah kesehatan beralih dari penyakit infeksi ke penyakit degeneratif. Selain penyakit jantung koroner dan hipertensi, diabetes merupakan salah satu penyakit degeneratif yang saat ini makin bertambah jumlahnya di Indonesia.
Pola prevalensi diabetes telah mengalami pergeseran. Pada awal tahun 1990 -an umumnya masih tert-anam keyakin-an bahwa diabetes h-anya menyer-ang mereka yang berusia lanjut, dan merupakan “penyakit orang kaya”. Kenyataannya sekarang ini diabetes sudah tidak mengenal perbedaan kelas, diabetes dapat menyerang siapa saja, baik di “gedongan”, daerah kumuh, golongan tua maupun muda. Berbagai faktor genetik, lingkungan dan cara hidup berperan dalam perjalanan penyakit diabetes (Lanny et al, 2004).
Pada dasarnya diabetes dapat dikelompokkan menjadi dua, yaitu diabetes tipe 1 yang terjadi sejak kecil karena cacat sejak lahir, dan diabetes tipe 2 yang berkembang setelah dewasa sebagai akibat gaya hidup yang salah. Diabetes tipe 2 adalah jenis yang paling banyak ditemukan.
Tanpa intervensi yang efektif, jumlah penderita diabetes tipe 2 akan meningkat disebabkan oleh berbagai hal antara lain bertambahnya usia harapan hidup, berkurangnya kematian akibat infeksi dan meningkatnya faktor risiko yang
disebabkan karena cara hidup yang salah seperti kegemukan, kurang gerak dan pola makan tidak sehat.
Berdasarkan hal tersebut untuk meningkatkan upaya menurunkan angka kesakitan dan prevalensi timbulnya komplikasi pada penyakit diabetes maka perlu kiranya dilakukan penelitian-penelitian yang mengarah pada pembuatan sistem yang dapat mendeteksi timbulnya penyakit diabetes sehingga dapat dilakukan upaya prefentif serta upaya rehabilitatif bagi penderita diabetes dengan pendekatan yang menyeluruh, sehingga dampak terjadinya berbagai penyulit menahun, seperti penyakit jantung koroner, penyulit pada mata, ginjal dan syaraf dapat dikurangi.
Salah satu alternatif sebagai solusi dari masalah tersebut adalah membuat suatu sistem data mining yang bisa melakukan penelusuran pada data historis untuk mengidentifikasi pola dan memprediksi trend didasarkan pada sifat-sifat yang teridentifikasi sebelumnya, kemudian memberikan alternatif pengobatan atau pencegahan bila ditemukan indikasi yang mengarah pada timbulnya penyakit diabetes. Informasi yang dihasilkan untuk selanjutnya bisa digunakan oleh edukator diabetes maupun dokter sebagai dasar untuk melakukan tindakan -tindakan yang diperlukan.
1.2. Tujuan Penelitian
Tujuan penelitian ini adalah membuat suatu aplikasi data mining meliputi : 1. Membuat data warehouse diabetes yang akan dijadikan sebagai sumber data
bagi data mining dengan menggunakan star schema.
2. Membuat data mining engine yang dapat melakukan prediksi terhadap penyakit diabetes dengan mengaplikasikan teknik classification-based association.
3. Membuat antarmuka yang memungkinkan pasien diabetes, dokter serta perawat berinteraksi dengan sistem pengobatan diabetes yang terintegrasi.
1.3. Ruang Lingkup
Lingkup penelitian yang dilakukan dalam pembuatan model penanganan diabetes adalah :
1. Sumber data utama bagi pembentukan model berasal dari Sistem Informasi Rumah Sakit Pusat Pertamina (SIM RSPP) dan Sistem Informasi Laboratorium Rumah Sakit Pusat Pertamina (LIS RSPP), dengan data yang akan digunakan adalah data dari tahun 2004 sampai tahun 2005.
2. Setelah melalui proses penyaringan, informasi tersebut dimasukkan ke dalam data warehouse diabetes yang dirancang dengan menggunakan star schema. 3. Penelitian ini akan membuat aplikasi data mining untuk penyakit diabetes.
Teknik data mining yang digunakan adalah classification-based association.
1.4. Manfaat Penelitian
Dengan adanya suatu sistem yang dapat digunakan untuk memprediksi penyakit diabetes, maka terjadinya penyakit ini pada seseorang sedini mungkin dapat diprediksi sehingga dapat dilakukan tindakan antisipasi. Sistem ini nantinya juga bisa digunakan untuk memonitor perkembangan kesehatan penderita diabetes dan efektifitas pengobatan yang telah dilakukan pada pasien diabetes melitus. Sehingga hasil akhir dari penelitian ini diharapkan bisa digunakan baik oleh dokter mapun edukator diabetes melitus dalam mengantisipasi peningkatan jumlah pasien diabetes.
BAB II
TINJAUAN PUSTAKA
2.1. Diabetes Melitus
Diabetes adalah suatu penyakit, dimana tubuh penderitanya tidak secara otomatis mengendalikan tingkat gula (glukosa) dalam darahnya. Pada tubuh yang sehat, pankreas melepas hormon insulin yang bertugas mengangkut gula melalui darah ke otot-otot dan jaringan lain untuk memasok energi. Penderita diabetes tidak bisa memproduksi insulin dalam jumlah yang cukup, atau tubuh tidak mampu menggunakan insulin secara efektif, sehingga terjadilah kelebihan gula di dalam darah. Kelebihan gula yang kronis didalam darah (hiperglikemia) ini menjadi racun bagi tubuh.
Menurut ADA (Americant Diabetes Assosiation) 1998, (Soegondo et al, 2002), diabetes merupakan suatu kelompok penyakit metabolik dengan karakteristik hiperglikemia yang terjadi karena kelainan sekresi in sulin, kerja insulin atau kedua-duanya. Sedang sebelumnya WHO 1980 berkata bahwa diabetes merupakan suatu yang tidak dapat dituangkan dalam satu jawaban yang jelas dan singkat tetapi secara umum dapat dikatakan sebagai suatu kumpulan problema anatomik dan kimiawi yang merupakan akibat dari sejumlah faktor dimana didapat defesiensi insulin absolut atau relatif dan gangguan fungsi insulin
Diabetes dapat digolongkan ke dalam dua tipe, yaitu tipe 1 dan tipe 2. Diabetes tipe 1 adalah bila tubuh perlu pasokan insulin dari luar. Diabetes tipe 1 ini biasanya ditemukan pada penderita yang mulai mengalami diabetes sejak anak-anak atau remaja. Diabetes tipe 2 terjadi jika insulin hasil produksi pankreas tidak cukup, sehingga terjadi gangguan pengiriman gula ke sel tubuh.
Gejala diabetes tipe 1 muncul secara tiba-tiba pada saat usia anak -anak sebagai akibat dari kelainan genetika, sehingga tubuh tidak memproduksi insulin dengan baik. Sedangkan gejala diabetes tipe 2 muncul secara perlahan-lahan sampai menjadi gangguan yang jelas. Gejala -gejala umum pada kedua tipe diabetes hampir sama, antara lain: sering buang air kecil, terus menerus lapar dan
haus, cepat lelah, kehilangan tenaga, luka yang lama sembuh, penglihatan kabur. Dikarenakan munculnya gejala-gejala tersebut pada penderita diabetes tipe 2 adalah perlahan-lahan, maka sering terabaikan dan dianggap sebagai keletihan biasa. Orang yang mempunyai resiko tinggi menderita diabetes melitus adalah 1. Orang dengan riwayat keluarga dengan diabetes
2. Orang obeis ( > 20% berat badan ideal)
3. Umur di atas 40 tahun dengan faktor tersebut di atas 4. Orang dengan tekanan darah tinggi
5. Orang dengan dislipidemia (kolesterol HDL < 35 md/dl dan/atau trigliserida > 250 mg/dl)
6. Semua wanita hamil 24-28 minggu
7. Wanita yang melahirkan bayi > 4.000 gram.
Diabetes melitus jika tidak dikelola dengan baik akan dapat mengakibatkan terjadinya berbagai penyulit menahun, seperti penyakit jantung koroner, penyulit pada mata, ginjal dan syaraf. Jika kadar glukosa darah dapat selalu dikendalikan dengan baik, diharapkan semua penyulit menahun tersebut dapat dicegah, paling sedikit dihambat.
2.2. Data Warehouse
Basis data rumah sakit yang dihasilkan dari sistem informasi rumah sakit umumnya berisi data dalam jumlah besar. Penyaringan serta penyajian informasi-informasi yang relevan dalam basis data yang besar ini adalah pekerjaan yang rumit. Sehingga perlu teknik -teknik tertentu agar proses penyaringan informasi bisa dilakukan secara efesien dan efektif, antara lain dengan membangun data warehouse yang akan berfungsi sebagai pusat penyimpanan data yang terintegrasi sebagai hasil penyaringan data operasional, dan menerapkan data mining yang akan menelusuri pola -pola data untuk tujuan analisis.
Data warehouse bukan prasyarat untuk data mining, tetapi dalam prakteknya tugas data mining dibuat lebih mudah dengan mengakses dari data warehouse. Data warehouse dapat dipandang sebagai tempat penampungan data untuk mendukung pembuatan keputusan strategis. Fungsi dari data warehouse adalah untuk menyimpan data historis yang terintegrasi untuk merefleksikan berbagai
sudut pandang organisasi. Data mining adalah salah satu aplikasi utama bagi data warehouse, dimana fungsi data warehouse adalah untuk menyediakan informasi pada end user untuk mendukung pembuatan keputusan, sedangkan tool data mining menyediakan kemampuan kepada end user untuk menyaring informasi yang tersembunyi.
Data warehouse adalah kumpulan data yang subject oriented, integrated, nonvolatile dan time variant untuk membantu membuat keputusan manajemen (Inmon, 1996). Subject oriented berarti data warehouse diarahkan kepada subyek utama yang akan didefinisikan dalam data model. Subyek-subyek utama ini pada akhirnya akan diimplementasikan secara fisik sebagai sekumpulan tabel-tabel yang saling berelasi dalam data warehouse.
Karakteristik yang kedua pada data warehouse adalah integrasi. Data warehouse bisa bersumber dari banyak aplikasi yang biasanya tidak konsisten baik dalam pemrograman, pembuatan tata nama, pembuatan atribut fisik maupun pembuatan atribut pengukuran. Pada data warehouse keragaman tersebut harus dikonversi dengan memodifikasinya agar didapat format atau struktur data yang sesuai. Karakteristik ketiga dari data warehouse adalah non -volatile. Data yang ada pada data warehouse adalah data historis yang umumnya hanya bisa dibaca, tetapi data tersebut tidak dapat di update. Karakteristik keempat pada data warehouse adalah time variant, dimana key struktur data warehouse selalu mengandung komponen waktu. Komponen waktu merupakan hal yang sangat penting pada data warehouse.
Salah satu aspek yang sangat penting saat merancang data warehouse adalah yang berkaitan dengan granularity. Granularity menunjukkan tingkatan detil yang ditampung dalam unit data dalam data warehouse. Semakin detil tingkatan yang ditampung dalam unit data, semakin rendah tingkat granularity-nya. Sebaliknya semakin kurang detil, tingkat granularity-nya semakin tinggi. Granularity akan berdampak pada volume data yang menempati data warehouse, dan pada saat yang sama juga berdampak pada jenis kueri yang bisa dilakukan. Dengan volume data yang besar membutuhkan kapasitas penyimpanan yang juga besar.
Masalah kedua yang juga penting saat merancang data warehouse adalah partitioning. Partitioning menunjukkan pembagian data ke dalam beberapa unit
yang secara fisik berbeda, yang masing-masing bisa ditangani sendiri-sendiri. Hal ini menjadi penting, karena jika data berada dalam unit yang besar, maka data tersebut akan sulit untuk dikelola. Sedangkan salah satu esensi dari pembentukan data warehouse adalah kemudahan dalam mengakses data.
2.2.1 Metodologi Perancangan Data Warehouse
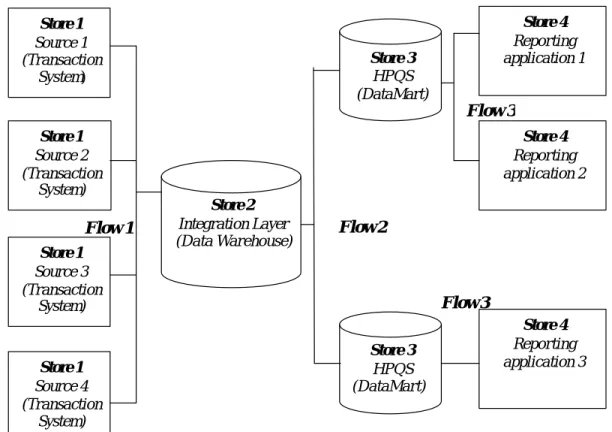
Ada banyak pilihan yang bisa dilakukan ketika merancang data warehouse. Tetapi pendekatan yang paling banyak digunakan adalah dengan menggunakan empat data store dan tiga data flow (Corey et al, 2001), seperti pada Gambar 1.
Data store 1 adalah source system yaitu berbagai sistem aplikasi yang akan menyediakan data bagi data warehouse. Source system ini bisa juga berasal dari
Store 1 Source 1 (Transaction System) Store 1 Source 4 (Transaction System) Store 1 Source 3 (Transaction System) Store 1 Source 2 (Transaction System) Store 2 Integration Layer (Data Warehouse) Store 3 HPQS (DataMart) Store 3 HPQS (DataMart) Store 4 Reporting application 1 Store 4 Reporting application 2 Store 4 Reporting application 3 Flow 1 Flow 2 Flow 3 Flow 3
Gambar 1 Arsitektur data warehouse dengan menggunakan empat data store dan tiga data flow.
luar organisasi. Masing -masing sistem ini mempunyai basis data yang diperlukan oleh end user untuk mengaksesnya.
Flow 1 adalah aliran data dari sumber data ke integration layer. Setelah mengetahui dari mana sumber data berasal, berikutnya perlu mengembangkan mekanisme untuk mendapatkan data tersebut, yaitu dengan melakukan penyaringan data. Tahapan ini disebut juga tahap ekstraksi data. Data yang berasal dari berbagai sumb er diintegrasikan dan/atau ditransformasikan sebelum diletakkan ke dalam data warehouse.
Data store 2 – Integration Layer atau data warehouse adalah basis data yang dinormalisasikan yang berasal dari berbagai sumber yang diletakkan dalam satu tempat. Adapun alasan membangun integration layer antara lain adalah untuk menghindari pengulangan ekstraksi. Beberapa data mart memerlukan data dari sistem yang sama. Jika tidak ada data warehouse, maka setiap data mart harus mengakses setiap sumber. Dengan membangun data warehouse, setiap data mart hanya membaca dari satu sumber yaitu integration layer yang sudah berisi data yang terintegrasi.
Flow 2 merupakan aliran dari dari integration layer ke High Performance Query Structure (HPQS). Pada flow ini data diekstrak dari integration layer dan disisipkan ke data mart. Pada tahapan ini hanya diperlukan Extract, Tranform dan Load (ETL) untuk mempopulasikan data ke data mart.
Data store 3 – HPQS atau data mart adalah basis data dan struktur data yang dibentuk secara khusus untuk mendukung kueri yang diperlukan oleh end user. Basis data ini dikelola oleh engine relational database atau engine multidimensional database. Jika disimpan dalam relational database, maka perancangan basis data data mart umumnya menggunakan star schema
Data Flow 3 merupakan aliran data dari HPQS ke aplikasi. Untuk mendapatkan data dari data mart diperlukan tool kueri. Tool ini umumnya memerlukan SQL untuk memanggil relational database.
Data store 4 menyajikan report yang disimpan dalam basis data.
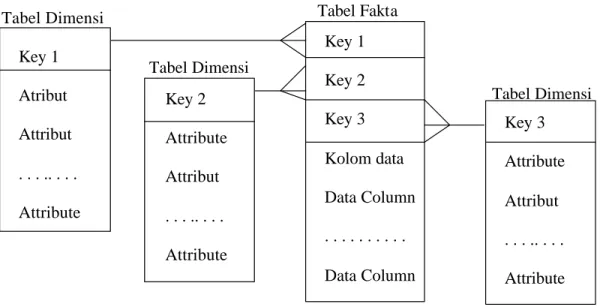
Star schema adalah jenis perancangan basis data yang digunakan untuk mendukung analytical processing. Star schema berisi dua jenis tabel yaitu tabel fakta dan tabel dimensi. Tabel fakta atau disebut juga major table berisi data kuantitatif atau data transaksi sesungguhnya yang ada pada organisasi dimana informasi yang ada didalamnya akan dianalisa. Informasi ini biasanya berupa pengukuran numerikal dan bisa terdiri dari banyak kolom dan jutaan baris. Tabel dimensi atau disebut juga minor table, berisi deskripsi data yang merefleksikan dimensi organisasi.
Perancangan basis data dengan menggunakan star schema ini paling banyak digunakan untuk membangun struktur data pada data mart dalam lingkungan relasional (Corey et al, 2001). Dalam star schema akan dilakukan normalisasi yang minimal untuk tujuan mendapatkan unjuk kerja yang baik.
Untuk merancang tabel fakta dan tabel dimensi terlebih dahulu harus mengetahui transaksi apa yang akan dimodelkan. Setiap record dalam tabel fakta berisi primary key yang dibentuk dari satu atau lebih foreign key; foreign key adalah kolom yang ada dalam satu tabel yang nilainya ditentukan oleh primary key pada tabel lain. Tabel fakta adalah tabel yang sudah dinormalisasikan. Setiap record berisi sejumlah atribut yang semua atributnya hanya mempunyai satu primary key, sehingga dikatakan sudah memenuhi bentuk normal pertama (1NF). Tidak ada grup yang berulang, seluruh atribut hanya bergantung penuh pada primary key (2NF). Tidak ada satupun atribut yang bergantung pada atribut non key (3NF). Contoh relasi antartabel dimensi dan tabel fakta bisa dilihat pada Gambar 2.
Tabel dimensi mempunyai ciri yaitu :
1. Denormalized. Tabel dimensi dibentuk dengan menggabungkan beberapa tabel yang berasal dari berbagai sumber untuk dimasukkan dalam satu tabel denormalized. Tujuannya adalah untuk mengurangi jumlah join yang harus diproses pada kueri, sehingga hal ini akan meningkatkan kinerja basis data. 2. Lebar. Tabel dimensi umumnya lebih lebar dibandingkan dengan tabel dalam
aplikasi basis data. Hal ini berarti tabel dimensi memiliki banyak kolom
3. Pendek. Tabel dimensi umumnya jumlah row-nya lebih sedikit jika dibandingkan tabel fakta
4. Menggunakan surrogate key, yaitu key yang dibuat sendiri dalam data warehouse.
5. Berisi hubungan ke baris-baris tertentu dalam tabel master. Tabel dimensi berisi referensi ke key yang ada pada tabel master untuk mendapatkan record yang diinginkan.
6. Berisi kolom tanggal atau flag tambahan
2.3. Data mining
Data mining merupakan proses pencarian pola dan relasi-relasi yang tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, association rule, clustering, deskripsi dan visualisasi. Berdasarkan aktifitasnya data mining dikelompokkan menjadi dua jenis, yaitu directed data mining dan undirected data mining. Directed data mining digunakan jika sudah diketahui secara pasti apa yang akan diprediksi, sehingga bisa secara langsung menambang data untuk diarahkan pada tujuan tertentu. Misalnya model prediktif yang digunakan untuk membuat prediksi tentang diagnosa penyakit yang belum diketahui. Model prediktif menggunakan pengalaman untuk menentukan bobot dan tingkat kepercayaan. Salah satu kunci Tabel Dimensi Key 1 Atribut Attribut . . . .. . . . Attribute Tabel Fakta Key 1 Key 2 Key 3 Kolom data Data Column . . . Data Column Tabel Dimensi Key 2 Attribute Attribut . . . .. . . . Attribute Tabel Dimensi Key 3 Attribute Attribut . . . .. . . . Attribute
keberhasilan model prediktif adalah adanya data yang cukup dengan hasil yang sudah diketahui untuk mengarahkan/melatih model.
Undirected data mining berkaitan dengan menelusuri pola-pola baru dalam data. Tidak seperti directed data mining, yang sudah mengetahui apa yang akan diprediksi. Pada undirected data mining, ingin diketahui bagaimana model mengusulkan jawaban. Dalam prakteknya data mining sering berisi kombinasi dari keduanya. Misalnya saat membangun predictive model, sering berguna untuk mencari pola dalam data menggunakan teknik undirected.
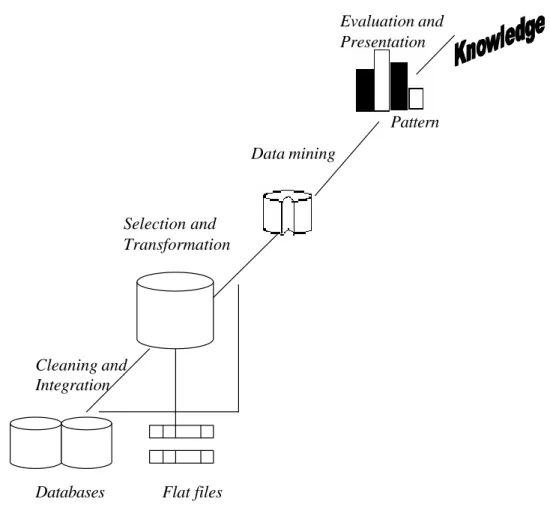
Secara sederhana data mining bisa dikatakan sebagai proses menyaring atau “menambang” pengetahuan dari sejumlah data yang besar. Istilah lain untuk data mining adalah Knowledge Discovery in Database atau KDD. Walaupun sebenarnya data mining sendiri adalah bagian dari tahapan proses dalam KDD, seperti yang terlihat pada Gambar 3 (Han & Kamber, 2001).
Gambar 3 Data mining sebagai salah satu tahapan dalam proses Databases Flat files
Cleaning and Integration Selection and Transformation Data mining Pattern Evaluation and Presentation
Knowledge Discovery
Sumber: Han & Kamber (2001) Tahapan dalam KDD adalah sebagai berikut:
1. Pembersihan data; untuk mengidentifikasi, merubah, membersihkan data yang tidak konsisten atau tidak akurat.
2. Integrasi data; dimana data dari berbagai sumber digabungkan
3. Pemilihan data; dimana data yang relevan untuk melakukan analisis dipilih dari basis data.
4. Transformasi data; dimana data ditransformasikan atau dikonsolidasi ke dalam bentuk yang sesuai untuk mining misalnya dengan melakukan operasi summary atau agregasi.
5. Data mining ; proses yang penting dimana metoda cerdas diterapkan untuk menyaring pola-pola dari data.
6. Evaluasi pola; mengidentifikasikan pola -pola yang benar-benar menarik yang menggambarkan pengetahuan didasarkan pada pengukuran tertentu.
7. Penyajian pengetahuan; dimana teknik -teknik penyajian serta representasi pengetahuan digunakan untuk menyajikan pengetahuan yang dihasilkan dari mining ke user.
Berdasarkan tahapan dalam KDD, arsitektur sistem data mining umumnya mempunyai komponen utama sebagai berikut :
1. Basis data, data warehouse, atau tempat penyimpanan informasi lainnya. Teknik data cleaning dan data integration umumnya diperlukan dalam pembentukan komponen-komponen tersebut.
2. Basis data atau data warehouse server. Basis data atau data warehouse server bertanggungjawab untuk mengambil data yang relevan.
3. Basis pengetahuan. Komponen ini merupakan domain pengetahuan yang digunakan untuk mengarahkan pencarian, atau mengevaluasi kemenarikan pola-pola yang dihasilkan. Pengetahu an tersebut bisa berisi konsep hirarki, yang digunakan untuk menyusun atribut atau nilai-nilai atribut ke dalam tingkatan abstraksi yang berbeda-beda. Pengetahuan seperti keyakinan user, yang bisa digunakan untuk menguji ketertarikan pola -pola didasarkan pada hal-hal yang tidak diharapkannya, dapat juga dimasukkan.
4. Data mining engine. Bagian ini adalah yang paling penting bagi sistem data mining dan idealnya berisi sekumpulan modul-modul fungsional untuk melakukan tugas seperti karakterisasi, asosiasi, klasifikasi, analisis cluster, evaluasi dan analisis deviasi.
5. Modul evaluasi pola. Komponen ini berinteraksi dengan modul-modul data mining sedemikian sehingga menfokuskan pencarian ke arah pola-pola yang menarik. Untuk meng -efisienkan data mining, sangat dianjurkan untuk menekankan evaluasi dari pola-pola yang menarik sedalam mungkin ke dalam proses mining sedemikian sehingga memfokuskan pencarian hanya pada pola -pola yang menarik saja.
6. Antarmuka pengguna. Modul ini berkomunikasi antara user dan sistem data mining, memungkinkan user untuk berinteraksi dengan sistem dengan menulis kueri, menyediakan informasi untuk membantu memfokuskan pencarian, dan melakukan eksplorasi data mining didasarkan pada hasil antara data mining. Selain itu komponen ini memungkinkan user untuk menelusuri basis data dan skema data warehouse atau struktur data, mengevaluasi pola-pola yang dihasilkan dari proses mining, dan menyajikan pola-pola dalam bentuk yang berbeda-beda.
2.3.1. Klasifikasi dan Prediksi
Klasifikasi dan prediksi adalah dua bentuk analisis data yang bisa digunakan untuk mengekstrak model dari data yang berisi kelas-kelas atau untuk memprediks i trend data yang akan datang. Klasifikasi memprediksi data dalam bentuk kategori, sedangkan prediksi memodelkan fungsi-fungsi dari nilai yang kontinyu. Misalnya model klasifikasi bisa dibuat untuk mengelompokkan aplikasi peminjaman pada bank apakah beresiko atau aman, sedangkan model prediksi bisa dibuat untuk memprediksi pengeluaran untuk membeli peralatan komputer dari pelanggan potensial berdasarkan pendapatan dan lokasi tinggalnya.
Klasifikasi data dilakukan dengan dua tahapan. Pada tahap pertama, model dibentuk dengan menentukan kelas-kelas data. Model dibentuk dengan menganalisa database tuples yang dinyatakan dengan atribut. Setiap tuple p memiliki kelas tertentu, yang d inyatakan oleh salah satu atributnya yang disebut
class label atribute. Dalam konteks klasifikasi data tuples disebut juga sample. Data tuples ini membentuk training data set yang selanjutnya dianalisa untuk membangun model. Setiap tuple yang membentuk training set disebut training sample dan secara acak dipilih dari sample population. Karena label kelas dari setiap training sample telah diketahui, maka tahapan ini disebut juga supervised learning. Supervised learning ini kebalikan dari unsupervised learning, dimana pada unsupervised learning label kelas dari setiap training sample tidak diketahui. Pada tahap kedua, model digunakan untuk klasifikasi. Pertama, akurasi model prediksi (atau classifier) ditentukan menggunakan data test. Sample ini secara acak dipilih, independent dengan training sample. Akurasi dari model pada test set adalah prosentase dari sample test set yang diklasifikasikan oleh model dengan benar. Untuk setiap sample test, label kelas yang telah diketehui dibandingkan dengan model kelas prediksi yang telah dilatih untuk sample tersebut. Jika akurasi dari model bisa diterima, maka model bisa digunakan untuk mengklasifikasikan data tuples dimana label kelasnya tidak diketahui. Misalnya, classification rule yang telah dihasilkan dari analisis data dari pelanggan yang ada dapat digunakan untuk memprediksi credit rating dari pelanggan baru.
Prediksi bisa dipandang sebagai pembentukan dan penggunaan model untuk menguji kelas dari sample yang tidak berlabel, atau untuk menguji nilai atau rentang nilai dari suatu atribut. Dalam pandangan ini, klasifikasi dan regresi adalah dua jenis masalah prediksi, dimana klasifikasi digunakan untuk memprediksi nilai-nilai diskrit atau nominal, sedangkan regresi digunakan untuk memprediksi nilai-nilai yang kontinyu. Untuk selanjutnya penggunaan istilah prediction untuk memprediksi kelas yang berlabel disebut classification, dan pengggunaan istilah prediksi untuk memprediksi nilai-nilai yang kontinyu sebagai prediction (Han & Kamber, 2001).
2.3.2 Metodologi Data mining
Ada beberapa konsep yang penting pada data mining. Konsep pertama berkaitan dengan mencari pola di dalam data. Biasanya berupa kumpulan data yang sering muncul. Tetapi secara umum berupa suatu daftar atau pola data yang muncul lebih sering dari yang diharapkan saat dilakukan secara acak. Konsep
yang kedua adalah sampling, yang bertujuan untuk memperoleh keterangan mengenai populasi dengan mengamati hanya sebahagian saja dari populasi itu.
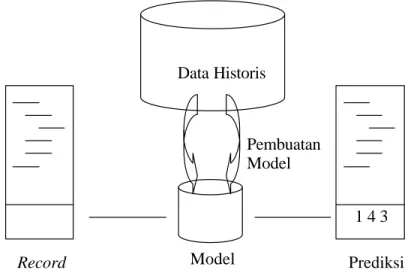
Hal lain yang juga penting yang berhubungan dengan data mining adalah validasi model prediksi yang muncul dari algoritme data mining. Khususnya, jika menemukan pola dalam data, model yang dibangun untuk memprediksi pola tersebut harus juga bisa digunakan untuk memprediksi pola ditempat lain. Akhirnya jika menemukan pola, dan yakin bahwa model tersebut bisa diproduksi, maka seluruh turunan untuk mencari pola atau model tersebut adalah yang terbaik. Model digunakan untuk membuat prediksi tentang suatu record yang menggambarkan keadaan nyata yang baru, dan model terbatas hanya merefleksikan basis data histori dimana model tersebut dibuat, seperti yang ditunjukkan pada Gambar 4.
Model adalah deskripsi dari data historis dimana model tersebut dibangun untuk bisa diterapkan ke data baru dengan tujuan membuat prediksi tentang nilai-nilai yang terputus atau untuk membuat pernyataan tentang nilai-nilai yang diharapkan. Pola adalah suatu kejadian atau kombinasi kejadian dalam suatu basis data yang terjadi atau muncul lebih sering dari yang diharapkan (Berson et al., 2001).
Data Historis Model Pembuatan Model Record Prediksi 1 4 3
Gambar 4 Model proses pembuatan data mining Sumber: Berson et al., 2001.
2.3.3. Teknik Data mining
Ada tiga hal pokok yang harus diperhatikan untuk keberhasilan penerapan data mining, yaitu; teknik data mining, data, dan model data. Teknik adalah pendekatan umum untuk memecahkan masalah, dan biasanya terdapat banyak cara yang bisa digunakan. Masing -masing cara mempunyai algoritmenya sendiri-sendiri. Istilah teknik digunakan untuk menunjukkan pendekatan konseptual untuk menyaring informasi dari data. Algoritme menunjukkan detil tahap demi tahap dari cara tertentu untuk mengimplementasikan suatu teknik.
Data mining bisa berupa predictive atau descriptive. Perbedaan ini menunjukkan tujuan dari penggunaan data mining. Tujuan utama predictive data mining adalah mengotomatisasikan proses pembuatan keputusan dengan membuat model yang punya kemampuan untuk melakukan prediksi atau mengestimasi suatu nilai. Umumnya hasil dalam predictive data mining akan langsung ditindak lanjuti Sehingga tolok ukur yang paling penting pada model adalah akurasinya. Data mining sering juga bersifat descriptive. Tujuan utama descriptive data mining adalah untuk menggali pengertian yang mendalam dari apa yang terjadi di dalam data. Descriptive data mining sering menghasilkan action, tetapi bukan berupa urutan aksi yang bisa diotomatisasikan secara langsung dari hasil model (Berry & Linoff, 2000).
Descriptive mining, yaitu proses untuk menemukan karakteristik penting dari data dalam suatu basis data. Clustering, Association, dan Sequential mining adalah beberapa contoh dari teknik descriptive mining.
Predictive mining, yaitu proses untuk menemukan pola dari data untuk membuat prediksi. Classification, Reg ression dan Deviation adalah teknik dalam predictive mining.
a. Association Rule
Association rule merupakan salah satu teknik data mining yang paling banyak digunakan dalam penelusuran pola pada sistem pembelajaran unsupervised. Metodologi ini akan mengambil seluruh kemungkinan pola-pola yang diamati dalam basis data. Association rule menjelaskan kejadian -kejadian
yang sering muncul dalam suatu kelompok. Misalnya metodologi ini bisa digunakan untuk menganalisa produk-produk mana saja yang sering dibeli oleh seorang pelanggan secara bersamaan (analisa keranjang belanja). Hasil analisis tersebut bisa digunakan untuk menentukan peletakan produk di toko.
Satu itemset adalah himpunan bagian A dari semua kemungkinan item I. Satu itemset yang mengandung i item disebut i-itemset. Prosentase transaksi yang mengandung itemset disebut support. Untuk suatu itemset yang akan diamati, support-nya harus lebih besar atau sama dengan nilai yang dinyatakan oleh user, sehingga itemset tersebut dikatakan sering muncul (frequent).
Bentuk umum aturan asosiasi adalah A1,A2,…,An → B1,B2,…,Bm, yang berarti jika item Ai muncul, item Bj juga muncul dengan peluang tertentu.
Misalkan X adalah itemset. transaksi T dikatakan mengandung X jika dan hanya jika X ⊆ T. Aturan X ⇒ Y menyatakan himpunan basis data transaksi dengan tingkat kepercayaan (confidence) C, jika C% dari transaksi dalam D yang mengandung X juga mengandung Y. Rule X ⇒ Y mempunyai support dalam transaksi set D jika S% dari transaksi dalam basis data berisi X ∪ Y. Tingkat kepercayaan menunjukkan kekuatan implikasi, dan support menunjukkan seringnya pola terjadi dalam rule. Sebagai contoh diberikan aturan : A, B ⇒ C dengan S = 0.01 dan C = 0.8. Hal ini berarti bahwa 80% dari semua pelanggan yang membeli A dan B juga membeli C, dan 1% dari semua pelanggan membeli ketiga item tersebut.
Mining association rule dilakukan dalam dua tahap, yaitu
1. Mencari semua association rule yang mempunyai minimum support Smin
dan minimum confidence Cmin. Itemset dikatakan sering muncul (frequent)
jika Support(A) ≥ Smin.
2. Menggunakan itemset yang besar untuk menentukan association rule untuk basis data yang mempunyai tingkat kepercayaan C di atas nilai minimum yang telah ditentukan (Cmin.).
b. Algoritme Appriori
Algoritme apriori menghitung seringnya itemset muncul dalam basis data melalui beberapa iterasi. Setiap iterasi mempunyai dua tahapan; menentukan
kandidat dan memilih serta menghitung kandidat. Pada tahap pertama iterasi pertama, himpunan yang dihasilkan dari kandidat itemset berisi seluruh 1-itemset, yaitu seluruh item dalam basis data. Pada tahap kedua, algoritme ini menghitung support-nya mencari melalui keseluruhan basis data Pada akhirnya hanya i-itemset dengan batas minimum tertentu saja yang dianggap sering muncul (frequent). Sehingga setelah iterasi pertama, seluruh i-itemset yang sering muncul akan diketahui. Pada iterasi kedua, algoritme appriori mengurangi sekelompok kandidat itemset yang dihasilkan dari iterasi pertama dengan menghapus kandidat itemset yang tidak sering muncul. Penghapusan ini berdasarkan pengamatan yaitu apakah itemset tersebut sering muncul atau tidak.
1. k = 1
2. C1 = I (semua item) 3. While Ck > 0
( a ). Sk = Ck
( b ).Ck+1 = Semua himpunan dengan k=1 elemen yang terbentuk
dengan menggabungkan dua itemset dalam sk
( c ). Ck+1 = Ck+1 ( d ). S = S + Sk ( e ). k ++ 4. return S
Gambar 5. Algoritme Appriori
Tabel 1. Transaksi Penjualan Barang A B C D E
Pelanggan 1 1 0 1 1 0 Pelanggan 2 0 1 1 0 1 Pelanggan 3 1 1 1 0 1 Pelanggan 4 0 1 0 0 0
Misalkan pada tabel 1, akan dicari seluruh itemset dengan minimal support Smin = 50%. Sehingga itemset dianggap sering muncul jika ia terdapat pada paling
tidak di 50% transaksi. Dalam setiap iterasi, algoritme appriori membentuk kandidat set, menghitung jumlah kejadian dari setiap kandidat dan memilih itemset didasarkan pada minimum support yang telah ditentukan sebelumnya yaitu 50%.
Pada tahap pertama iterasi pertama, semua item adalah kandidat. Algoritme appriori hanya menelusuri semua transaksi dalam basis data dan membuat daftar kandidat, yaitu ;
C1 = A, B, C, D, E L1 = A, B, C, D, E
Pada tahap berikutnya , algoritme appriori menghitung terjadinya setiap kandidat dan berdasarkan nilai minimum support Smin, kemudian menentukan itemset yang
sering muncul, setelah tahap ini kandidat berisi: L1 = A, B, C, E
D dikeluarkan karena nilai S = 25%, hanya ada satu transaksi dari keseluruhan empat transaksi..
Untuk menelusuri himpunan itemset, karena himpunan bagian (subset) dari 2-itemset juga mempunyai minimum support yang sama, algoritme appriori menggunakan L1 * L1 untuk membuat kandidat. Operasi * didefinisikan sebagai berikut ;
Lk * Lk = XUY dimana X,Y Ε Lk, (X∩Y=K-1 , Untuk k =1 ⇒ |L1| . |(L1)-1)/2| = 4 . 3/2 = 6
Pada iterasi kedua kandidat berisi :
C2 = A,B, A,C, A,E, B,C, B,E, C,E.
Pada tahap berikutnya , algoritme appriori menghitung terjadinya setiap kandidat dan berdasarkan nilai minimum support Smin, kemudian menentukan itemset yang
sering muncul, setelah tahap ini kandidat berisi: L2 = A,C, B,C, B,E, C,E
Himpunan 3-itemset dihasilkan dari S2 menggunakan operasi yang sudah ditentukan sebelumnya L2 * L2. Langkah praktisnya, dari L2 dengan item yang pertama sama, yaitu B,C, B,E,dinyatakan pertama. Kemudian algoritme appriori akan mencek apakah 2-itemset C,E, yang berisi item kedua dari B,C,
B,E terdapat pada L2 atau tidak. Karena C,E ada dalam L2, maka B,C,E menjadi kandidat 3 -itemset.
Karena tidak ada kandidat 4 -itemset, maka algoritme ini berakhir. c. Membuat Association Rule berdasarkan Frequent Itemset
Tahap kedua dalam penelusuran assosiation rule didasarkan pada seluruh i-itemset yang sering muncul, yang didapat dari tahap pertama. Untuk rule yang mengandung X1, X2, X3 → X4, rule tersebut dianggap bermakna jika kedua itemset tersebut X1, X2, X3, X4 dan X1, X2, X3 adalah frequent. Sehingga tingkat kepercayaan C dari rule tersebut dihitung sebagai hasil bagi dari support itemset, yaitu :
C = S(X1, X2, X3, X4) / S(X1, X2, X3).
Strong association rule adalah rule dengan tingkat kepercayaan C diatas Smin.
Misalkan dari tabel 1 akan dicek apakah association rule (B,C) → E adalah strong rule.
Pertama harus dipilih hubungan support dari tabel L2 dan L3. S(B,C) = 2, S(B,C,E) = 2
C((B,C) → E ) = S(B,C,E)/S(B,C) = 2/2 = 1 (100%)
Karena tingkat kepercayaan adalah maksimal, maka jika transaksi berisi item B dan C maka transaksi tersebut juga berisi item E.
d. Classification-Based Association
Saat ini, salah satu teknik data mining telah dikembangkan adalah dengan menerapkan konsep association rule mining dalam masalah klasifikasi. Ada beberapa metode yang bisa digunakan, antara lain association rule clustering system (ARCS) dan associative classification (Han & Kamber, 2001). Metode ARCS melakukan association rule mining didasarkan pada clustering kemudian menggunakan aturan yang dihasilkan untuk klasifikasi. ARCS, melakukan association rule mining dalam bentuk Aquant1∧ Aquant2 ⇒ Acat, dimana bentuk
Aquant1 dan Aquant2 adalah data test yang atributnya punya rentang nilai, Acat
menunjukkan label kelas untuk atribut kategori yang diberikan dari training data. Metode associative classification mining menghasilkan aturan dalam bentuk condset ⇒ y, dimana condset adalah sekumpulan item dan y adalah label kelas.
Aturan yang sesuai dengan minimum support tertentu disebut frequent. Rule mempunyai support s jika s% dari sample dalam data set yang mengandung condset dan memiliki kelas y. Aturan yang sesuai dengan minimum confidence disebut accurate. Aturan mempunyai confidence c jika c% dari sample dalam data set yang mengandung condset memiliki kelas y. Jika beberapa rule mempunyai condset yang sama, maka rule dengan confidence tertinggi d ipilih sebagai possible rule (PR). Metode associative classification mining menggunakan algoritme association rule, seperti algoritme Appriori untuk menghasilkan association rule, kemudian memilih sekelompok aturan yang mempunyai kualitas tinggi dan menggunakan aturan tersebut untuk memprediksi data. Associative classification masih kurang efisien karena seringkali menghasilkan aturan dalam jumlah yang besar (Yin & Han, 2003).
Metode classification -based association lainnya adalah CPAR (Classification based on Predictive Association Rule). Algoritme ini mengambil ide dari FOIL (First Order Inductive Leaner) dalam menghasilkan aturan dan mengintegrasikannya dengan associative classification.
e. Classification based on Predictive Association Rules (CPAR)
Klasifikasi pada penelitian ini menggunakan association rule. Menurut Yin & Han (2003) algoritme yang efektif untuk digunakan dalam masalah klasifikasi adalah CPAR. Pada algoritme ini klasifikasi diimplementasikan dalam tiga tahap: rule generation, rule evaluation dan classification.
Pada proses rule generation, CPAR membangun rule dengan menambahkan literal satu persatu. Pada setiap tahapan proses, CPAR menghitung Gain dari setiap literal. Setelah masing-masing sampel diproses untuk mendapatkan rule, sampel ini digunakan kembali di dalam perhitungan Gain tetapi dengan mengurangi bobot dengan decay factor. Bobot sampel dikurangi hingga mencapai nilai minimum yang dihitung oleh parameter w yaitu bobot seluruh sampel positif. Bobot seluruh contoh pada awal proses ditetapkan sama dengan 1.
Setelah proses rule generation, CPAR mengevaluasi setiap rule untuk menentukan kekuatan prediksinya. Untuk rule r = p1 ∧p2 ... ∧ pn → c, CPAR
mendefinisikan ekspektasi akurasi sebagai sebagai berikut : L.A = (nc+1) / (ntot+f)
Dimana L.A adalah Laplace accuracy, f adalah jumlah kelas, ntot adalah ju mlah total sampel yang memenuhi body dari aturan, nc adalah jumlah sampel yang memenuhi kelas c.
Klasifikasi berupa sekumpulan aturan untuk setiap kelas, CPAR menggunakan s aturan terbaik setiap kelas, yang dipilih berdasarkan Laplace accuracy.
Ide dasar CPAR berasal dari FOIL yang menggunakan algoritme greedy untuk mempelajari aturan yang membedakan contoh positif dengan contoh negatif. FOIL secara berulang mencari aturan terbaik dan memindahkan seluruh contoh positif yang dicakup oleh aturan sampai seluruh contoh positif dalam data set tercakup. Algoritme FOIL diperlihatkan pada Gambar 6 (Yin & Han ,2003).
Masukan: Training set D = P ∪ N. (P dan N adalah himpunan contoh positif dan contoh negatif)
Keluaran: Himpunan aturan untuk memprediksi label kelas dari contoh. Procedure FOIL
rule set R ←Φ while |P| > 0 N’ ← N, P’ ← P rule r ← empty_rule
while |N| > 0 and r.length < max_rule_length
find the literal p that brings most Gain according to P’ and N’ append p to r
remove from P’ all examples not satisfying r remove from N’ all examples not satisfying r end
R ← R ∪ {r}
Remove from p all examples satisfying r’s body end
return R
Gambar 6. Algoritme FOIL Definisi
• Literal p adalah pasangan nilai atribut, dalam bentuk (Ai,v), dimana Ai adalah
atribut dan v adalah nilai atribut Ai. Tuple t memenuhi literal p = (Ai,v) jika
dan hanya jika ti = v, dimana ti adalah nilai atribut ke-i.
• Aturan r, berbentuk “p1∧p2∧ ... ∧pt⇒ c,” Tuple t memenuhi body dari aturan
r jika dan hanya jika tuple tersebut memenuhi setiap literal dalam rule. Jika t memenuhi body dari r, r memprediksi bahwa t adalah dari kelas c.
Algoritme FOIL pertama kali membaca data masukan berupa himpunan contoh positif dan contoh negatif, menghasilkan keluaran berupa aturan -aturan yang berguna untuk memprediksi label kelas dari contoh positif atau contoh negatif. Pada awal proses himpunan aturan R ditetapkan kosong. Proses pembentukan aturan terus berulang selama jumlah contoh positif lebih besar dari 0, dan selama proses pembentukan aturan algoritme FOIL melakukan penyalinan contoh positif ke contoh positif sementara, contoh negatif ke contoh negatif sementara, membaca atribut contoh positif satu persatu dan menambahkan ke rule list jika nilai Gain sesui dengan yang ditetapkan.
Pada saat memilih literal, FOIL Gain digunakan untuk mengukur informasi yang diperoleh dari penambahan literal tersebut ke current rule. Misalkan terdapat |P| conto h positif dan |N| contoh negatif memenuhi body dari aturan r. Setelah literal p ditambahkan ke r, terdapat |P*| contoh positif dan |N*| contoh negatif yang memenuhi body dari aturan r yang baru. FOIL Gain p didefinisikan sebagai berikut (Yin & Han, 2003).
+ − + = | N | | P | | P | log | * N | | * P | | * P | log | * P | ) p ( Gain
dimana |P| dan |N| adalah jumlah contoh positif dan jumlah contoh negatif yang memenuhi body dari aturan r. |P*| dan |N*| adalah jumlah contoh positif dan jumlah contoh negatif yang memenuhi body dari aturan r yang baru, yang dihasilkan dengan menambahkan p ke r.
Predictive Rule Mining (PRM) adalah suatu algoritme yang memodifikasi FOIL untuk mendapatkan akurasi dan efesiensi yang lebih baik. Pada PRM,
setelah contoh yang benar tercakup dalam aturan, selain mengeluarkannya, bobotnya dikurangi dengan faktor perkalian. Algoritme PRM diperlihatkan pada Gambar 7 (Yin & Han, 2003).
Masukan: Training set D = P ∪ N. (P dan N adalah himpunan contoh positif dan contoh negatif)
Keluaran: Himpunan aturan untuk memprediksi label kelas dari contoh. Procedure Predictive Rule Mining
Set the weight of every example to 1 Rule set R ← φ
Totalweight ← TotalWeight(P) A ← Compute PNArray from D While TotalWeight(P) > δ. totalWeight N’ ← N, P’← P, A’ ← A
Rule r ← emptyrule While true
Find best literal p according to A’ If Gain(p) < min_Gain then break Append p to r
For each example t in P’ ∪ N’ not satifying r’s body Remove t from P’ or N’
Change A’ according to the removal of t End
End
R ← R ∪ {r}
For each example t in P satisfying r’s body t.weight ← α.t.weight
change A according to the weight decreased end
end return R
Gambar 7. Algoritme PRM
Algoritme CPAR merupakan pengembangan dari algoritme PRM. Perbedaan diantara CPAR dan PRM adalah selain hanya memilih atribut yang mempunyai gain terbaik pada setiap iterasi, CPAR dapat memilih sejumlah atribut yang nilai gain-nya hampir sama. Pemilihan atribut tersebut dilakukan dengan menghitung dan menerapkan gain_similarity_ratio. Semua atribut dengan nilai gain lebih besar dari bestGain X gain_similarity_ratio akan dipilih dan diproses
lebih lanjut. Algoritme CPAR diperlihatkan pada Gambar 8 dan Gambar 9 (Coenan, 2004).
Method : startCPAR Parameters : none Global access to : R, C
generate an empty global attributes array A For each c in C
generate global P and N example arrays generate global PN array
determine minimum total weight threshold
while (total weight P > minimum total weight threshold) A’ ? A, N’ ? N, P’ ? P, PN’ ? PN
If no attributes exist with weightings that can produce a gain above minimum break cparGeneration
end loop end loop
Gambar 8. Metoda startCPAR
Method : cparGeneration
Parameters : parameters ante (antecedent) and Cons (consequent) for current rule.
For each a in A
If (a not in antecedent) calculated gain using
information in PN array and add to attribute array End loop
I = “available” column in A with best gain If (A[i][0] <= MIN_BEST_GAIN ) return
loop through attribute array and find attribute a’ with best gain If (best gain <= MIN_BEST_GAIN)
add antecedent ? c to rule list
for all records in P reduce weighting by decay factor and adjust PN array accordingly
return
gainThreshold = bestGain×GAIN_SIMILARITY_RATIO for each a in A
if a available and a.gain > gainThreshold
tempP’ ? P’, tempN’ ? N’, tempA’ ? A’, tempNP’ ? NP’ add a’ to antecedent
remove examples from N’ and P’ that do not contain antecedent and adjust NP array accordingly if (N’ == {})
add antecedent ? c to rule list
for all records in P reduce weighting by decay factor and adjust NP array accordingly
else prmGeneration(antecedent,c)
P’ ? tempP, N’ ? tempN’, A’ ? tempA’, NP’ ? tempNP’ End loop
Gambar 9. Metoda cparGeneration
Pada metoda startCPAR proses dimulai dengan membaca data berupa sekumpulan bilangan array dua dimensi yang setiap kolomnya diberi atribut A dan atribut terakhir menunjukkan kelas. Data masukan selanjutnya dikelompokkan menjadi contoh positif P dan contoh negative N sesuai dengan kelasnya. Bobot contoh positif |P| dan bobot contoh negative |N| setiap atribut dijumlahkan untuk membentuk PN array, berupa array dua dimensi berisi daftar semua atribut, bobot contoh positif, dan bobot contoh negative. Total weight threshold (TWT) dihitung dengan mengalikan jumlah bobot positif dengan konstanta yang selama percobaan ditetapkan sama dengan 0.05.
Proses pembentukan aturan dilakukan berulang-ulang sampai jumlah bobot contoh positif lebih kecil dari TWT. Pada setiap proses dilakukan penyalinan P, N, A dan PN ke P’, N’, A’ dan PN’. Menghitung Gain dan menyisipkan aturan ke rule list. Pada percobaan yang dilakukan konstanta minimum gain adalah 0.7, dan decay factor 1/3.
Membuat Rule Dalam CPAR
Dalam PRM, setiap aturan di-generate dari dataset yang tersisa, memilih hanya literal yang terbaik dan mengabaik an seluruh literal lainnya. CPAR membuat rule s dengan menambahkan literal satu per satu, yang mirip dengan PRM. Pada CPAR setelah menemukan literal terbaik p, literal lainnya q yang Gain-nya mirip dengan p (misalnya hanya berbeda 1%) akan dicari. Selain terus membangun rule dengan menambahkan p ke r, q juga ditambahkan ke current rule r untuk membuat rule baru r’
2.3.4. Membangun Model Prediksi
Secara umum, proses dasar membangun model prediksi adalah sama, apapun teknik data mining yang akan digunakan. Keberhasilan dalam membangun model lebih banyak tergantung pada proses bukan pada teknik yang digunakan, dan
proses tersebut sangat tergantung pada data yang digunakan untuk menghasilkan model .
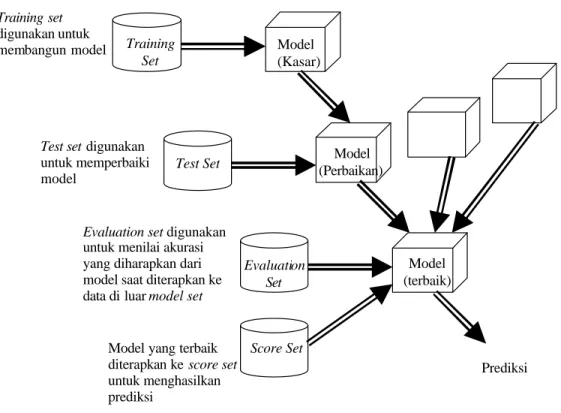
Tantangan utama dalam membangun model prediksi adalah mengumpulkan data awal yang cukup. Dalam preclassified, hasilnya sudah diketahui, dan karenanya preclassified digunakan untuk melatih model, himpunan data tersebut disebut model set. Gambar 10 menggambarkan langkah -langkah dasar dalam membangun model prediksi (Berry & Linoff, 2000). Langkah-langkah tersebut adalah :
1. Model dilatih menggunakan preclassified data, dengan mengambil sebagian data dari data set yang disebut training set. Pada tahap ini, algoritme data mining mencari pola-pola dari nilai yang diprediksi.
2. Model diperbaiki menggunakan himpunan bagian lain dari data yang disebut test set. Model perlu diperbaiki agar tidak hanya bisa bekerja pada training set.
3. Performance model diestimasi atau membandingkan performance beberapa model, dengan menggunakan himpunan data ketiga, yang didapat dari gabungan himpunan data pertama dan kedua, yang disebut evaluation set. 4. Model diterapkan ke score set. Score set bukan preclassified, dan bukan
bagian dari model set. Hasil dari data tersebut tidak diketahui. Predictive score akan digunakan untuk membuat keputusan.
Dataset adalah preclassified data yang digunakan untuk membangun model. Dataset perlu d ipecah ke dalam tiga komponan, training set, test set dan evaluation set.
Training Set Test Set Evaluation Set Score Set Model (Kasar) Model (Perbaikan) Model (terbaik) Prediksi Training set digunakan untuk membangun model
Test set digunakan untuk memperbaiki model
Evaluation set digunakan untuk menilai akurasi yang diharapkan dari model saat diterapkan ke data di luar model set
Model yang terbaik diterapkan ke score set
untuk menghasilkan prediksi
Gambar 10 Langkah -langkah membangun model prediksi Sumber: Berry & Linoff, 2000
BAB III
BAHAN DAN METODE 3.1. BAHAN
Sampel penelitian bersumber dari basis data dalam Sistem Informasi Manajemen Rumah Sakit Pusat Pertamina dan Sistem Informasi Laboratorium Rumah Sakit Pusat Pertamina. Periode pengambilan data dari tanggal 1 oktober 2004 sampai dengan 31 Desember 2005. Data tersebut meliputi:
1. Data pasien yang diduga menderita penyakit diabetes berjumlah 9.919 pasien. Pasien yang dipilih adalah pasien dengan minimal satu kali kunjungannya didiagnosa diabetes, pasien yang melahirkan bayi di atas 4.000 gr, pasien dengan tekanan darah tinggi, pasien dengan berat badan yang termasuk ke dalam kategori obesitas.
2. Data terapi obat serta hasil pemeriksaan laboratorium yang dilakukan pada pasien selama periode 01 Oktober 2004 sampai dengan 31 Desember 2005 baik yang berasal dari rawat jalan maupun rawat inap dikumpulkan.
Persyaratan catatan medis yang dijadikan sampel mengacu pada international classification of deseases tenth revision (ICD 10) dimana penyakit diabetes melitus diberi kode E.10 Insulin -dependent diabetes mellitus, E.11 Non-insulin -dependent diabetes mellitus, E.12 Malnutrition-related diabetes mellitus, E.13 Other specified diabetes mellitus dan E.14 Unspecified diabetes mellitus.
Dari 9.919 pasien yang diduga menderita penyakit diabetes didapat 159.476 record terapi obat dan 211.694 hasil laboratorium. Untuk membentuk data training dan testing, diambil 10 jenis data pemeriksaan hasil laboratorium yang paling banyak dilakukan yaitu Kolesterol Total (CHOL), Trigliserida (TG), Glukosa Urin Puasa (URN), Aseton Urin Puasa (ACTN), Glukosa Darah Puasa (GLUN), Kolesterol HDL (HDL), Kolesterol LDL (LDL), Glukosa Urin 2 jam PP (UPOST), Aseton Urin 2 jam PP (ACTPP). Terdapat 41.958 record hasil pemeriksaan laboratorium yang memenuhi kriteria tersebut.
Banyaknya pasien yang mempunyai catatan medis lengkap adalah 1.386 orang. Rata-rata umur ± standar deviasi (SD) dari data tersebut adalah 59.29 ± 10.25 tahun. Dari data tersebut diperoleh rasio laki-laki : perempuan adalah 4 : 6. Karakteristik umum data yang ditambang dapat dilihat pada Tabel 2, sedangkan rata-rata variabel hasil pemeriksaan laboratorium dapat dilihat pada Tabel 3. Tab el 2 Karakteristik umum data pasien
Data Sex Jumlah
Baris
Prosentase
Setiap Kelas Umur ± SD
Diabetes Laki-laki 121 7.37 59.88 ± 8.31
Perempuan 283 17.24 60.49 ± 8.71
Bukan Daibetes Laki-laki 469 28.56 59.20 ± 10.69
Perempuan 769 46.83 58.81 ± 10.72
Tabel 3 Rata-rata variabel pemeriksaan laboratorium
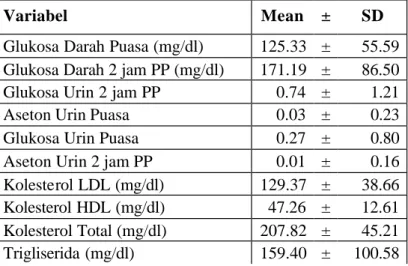
Variabel Mean ± SD
Glukosa Darah Puasa (mg/dl) 125.33 ± 55.59 Glukosa Darah 2 jam PP (mg/dl) 171.19 ± 86.50 Glukosa Urin 2 jam PP 0.74 ± 1.21
Aseton Urin Puasa 0.03 ± 0.23
Glukosa Urin Puasa 0.27 ± 0.80
Aseton Urin 2 jam PP 0.01 ± 0.16 Kolesterol LDL (mg/dl) 129.37 ± 38.66 Kolesterol HDL (mg/dl) 47.26 ± 12.61 Kolesterol Total (mg/dl) 207.82 ± 45.21 Trigliserida (mg/dl) 159.40 ± 100.58
Sumber data yang digunakan dalam penelitian ini selain dari basis data yang sudah tersedia juga berasal dari isian pertanyaan. Pertanyaan yang diajukan ke pasien terdiri dari pemeriksaan fisik meliputi tinggi badan, berat badan dan tekanan darah, serta riwayat diabetes. Riwayat diabetes meliputi awal diagnosis diabetes ditetapkan, riwayat keluarga diabetes, riwayat merokok, riwayat kehamilan, dan pengobatan diabetes yang dilakukan.
3.2. METODE
3.2.1. Kerangka Pemikiran
Meningkatnya penderita penyakit diabetes melitus di beberapa negara berkembang, akibat peningkatan kemakmuran di negara bersangkutan, akhir -akhir ini banyak disoroti. Peningkatan pendapatan per kapita dan perubahan gaya hidup terutama di kota-kota besar, menyebabkan peningkatan prevalansi penyakit degeneratif, seperti jantung koroner, hipertensi, hiperlipidemia, diabetes dan lain-lain. Menghadapi jumlah pasien diabetes melitus yang semakin meningkat, diperlukan peningkatan peran semua tingkat pelayanan kesehatan. Penanggulangan diabetes melitus perlu dilakukan secara tepat dan berkesinambungan dengan keterlibatan program dan sektor terkait.
Atas dasar pemikiran di atas, perlu kiranya dilakukan upaya-upaya penanganan agar dampak negatif penyakit ini dapat diminimalkan, dengan membuat dan menerapkan suatu sistem yang dapat memprediksi timbulnya penyakit diabetes melitus dalam upaya peringatan dini bagi pasien.
Sebagai langkah awal maka perlu adanya studi pustaka berkenaan dengan penyakit diabetes melitus untuk lebih mengenal dan memahami permasalahan penyakit ini. Kemudian dilakukan identifikasi dari permasalahan yang akan diteliti untuk memperjelas permasalahan dan penentuan alternatif solusi. Selanjutnya dilakukan pengumpulan data untuk menentukan parameter-parameter yang dapat menyebabkan timbulnya penyakit diabetes melitus. Sumber data yang dikumpulkan pada penelitian nanti barasal dari SIM RSPP dan LIS RSPP. Data tersebut kemudian akan disimpan dalam suatu data warehouse, yang selanjutnya dibuat suatu model menggunakan teknik classification based association untuk mengetahui keterkaitan antara parameter-parameter yang diduga sebagai penyebab timbulnya gejala penyakit diabetes. Gambar 9 menunjukkan garis besar kerangka pemikiran dari penelitian ini.
Mulai
Identifikasi Masalah
Pengumpulan Data
Pembuatan Clinical Data Warehouse dengan Star Schema
Pembuatan Model Prediksi Penyakit
Diabetes Melitus
Pembuatan Program Aplikasi
Sesuai Harapan Kelayakan Penerapan Selesai Ya Tidak Pengujian
3.2.2. Tata Laksana
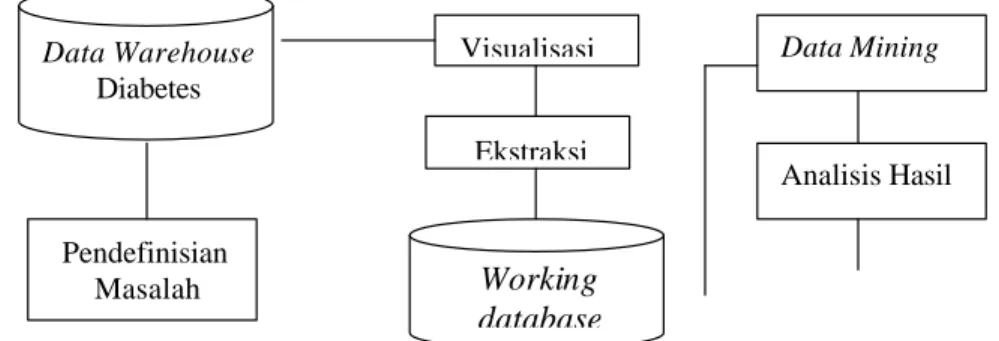
Kegiatan penelitian ini dilakukan dengan dua tahapan utama, yaitu proses pembentukan model klasifikasi dan pembuatan program aplikasi untuk mendeteksi penyakit diabetes. Proses pembentukan model klasifikasi dilakukan berdasarkan urutan proses pada Gambar 12. Proses dimulai dengan pendefinisian masalah serta mempelajari bisnis proses dari sistem yang sedang berjalan. Pada tahap kedua yaitu pembentukan data warehouse diabetes dilakukan melalui dua tahapan yaitu membuat rancangan logik dan rancangan fisik serta melakukan proses Extraction, Transformation, Loading (ETL).
Membuat rancangan logik dan rancangan fisik
Pembuatan rancangan logik dilakukan dengan menentukan jenis in formasi yang dibutuhkan. Salah satu tekniknya adalah dengan menggunakan entity relationship modelling. Perancangan fisik dilakukan dengan menggunakan Structure Query Language (SQL).
Extraction, Transformation, Loading (ETL)
Setelah membuat basis data, langkah selanjutnya adalah melakukan proses Extraction Transformation dan Loading (ETL). Ekstraksi adalah operasi mengekstrak data dari sistem sumber untuk selanjutnya digunakan dalam lingkungan data warehouse. Setelah ekstraksi, data tersebut ditransformasi dan dimuat kedalam data warehouse. Metode ekstraksi yang dipilih adalah full extraction yaitu dengan mengekstrak seluruh data yang ada pada sistem sumber menggunakan export file.
Gambar 11 Kerangka pemikiran pembuatan aplikasi data mining untuk diagnosis penyakit diabetes
Pendefinisian Masalah Data Warehouse Diabetes Visualisasi Ekstraksi Working database Analisis Hasil Data Mining