PENERJEMAHAN BAHASA INDONESIA DAN BAHASA JAWA MENGGUNAKAN
METODE STATISTIK BERBASIS FRASA
Rizky Aditya Nugroho1, Teguh Bharata Adji2, Bimo Sunarfri Hantono3
1Jurusan Teknik Elektro, Fakultas Teknik, Universitas Gadjah Mada Jl. Grafika 2 Yogyakarta 55281
2Jurusan Teknik Elektro, Fakultas Teknik, Universitas Gadjah Mada Jl. Grafika 2 Yogyakarta 55281
3Jurusan Teknik Elektro, Fakultas Teknik, Universitas Gadjah Mada E-mail: [email protected], [email protected], [email protected]
ABSTRACT
Communication is an important part of social live. Inability to communicate can lead to a sense of anxiety . Anxiety in turn can disrupt a person's concentration. Anxiety can disrupt a person's concentration. Population distribution and uneven development in Indonesia cause centralizing to Java island. Much immigrants, especially students on the island of Java, undoubtedly will make inter- ethnic interactions that have different culture, one of them is language. Machine translation becomes part of one of the solutions. Translation Indonesian and Javanese in this paper uses the phrase -based statistical methods by source data taken from the Bible. The amount of data used is 5080 lines with Indonesian and Javanese word count 104 568 to 93 369 for the Javanese and Indonesian. The result shows 44,02 % of evaluation results for Indonesia - Java and 49,77 % for Java - Indonesia, which are both evaluated using BLEU - matric.
Kata Kunci: Indonesian Language, Javanese Language, Statistical Machine Translation, Phrasa-based
ABSTRAK
Komunikasi merupakan bagian penting dalam berkehidupan sosial. Ketidakmampuan dalam berkomunikasi dapat memicu rasa kecemasan. Kecemasan pada akhirnya dapat mengganggu konsentrasi seseorang. Persebaran penduduk dan pembangunan yang tidak merata di Indonesia menyebabkan sentralisasi pada pulau Jawa. Banyaknya pendatang, terutama mahasiswa, di pulau Jawa tidak dapat dipungkiri akan melahirkan interaksi antar-suku yang mempunyai kebudayaan berbeda, salah satunya bahasa. Mesin penerjemah hadir sebagai salah satu solusi. Penerjemahan bahasa Indonesia dan bahasa Jawa pada makalah ini menggunakan metode statistik yang berbasis frasa, dengan sumber data yang diambil dari Alkitab. Banyaknya data yang dipakai adalah 5.080 baris kalimat bahasa Indonesia dan Jawa dengan jumlah kata 104.568 untuk bahasa Jawa dan 93.369 untuk bahasa Indonesia. Hasil penelitian menunjukkan hasil evaluasi 44,02 % untuk Indonesia-Jawa dan 48,77 % untuk Indonesia-Jawa-Indonesia, yang keduanya dievaluasi menggunakan BLEU-matric.
Kata Kunci: Bahasa Indonesia, Bahasa Jawa, Mesin Penerjemah Statistik, Berbasis Frasa
1. PENDAHULUAN 1.1 Latar Belakang
Manusia merupakan sebuah entitas dalam kehidupan sosial, oleh karenanya manusia disebut juga sebagai mahluk sosial. Salah satu media yang digunakan dalam bersosialisasi adalah bahasa. Bahasa mempunyai sifat yang unik, yang berarti bahwa setiap bahasa mengandung ciri khas tersendiri yang tidak dimiliki oleh bahasa lain (Rahardi, 2010). Keunikan itu dapat dilihat dari segi pembentukan kata, pembentukan kalimat, dan pelafalan setiap bahasa.
Indonesia merupakan negara kepulauan dengan luas wilayah mencapai ± 7,9 juta km2 (Setyowati, 2008) dan keberagaman bahasa yang melimpah. Dengan luas wilayah yang begitu luas, persebaran penduduk dan pembangunan daerah yang belum merata masih menjadi masalah. Hal ini berakibat pada sentralisasi suatu daerah, dalam hal ini pulau
Jawa. Pulau Jawa merupakan pulau dengan jumlah penduduk paling banyak di Indonesia. Selain itu, hal tersebut juga mendorong para pendatang, khususnya mahasiswa, untuk datang ke pulau Jawa.
Dengan pulau Jawa sebagai sentra kependudukan dan sentra pembangunan, maka dapat dipahami bahwa interaksi antar-suku merupakan sesuatu yang tak dapat dihindari. Bahasa Indonesia merupakan media yang dapat digunakan dalam interaksi antar-suku. Namun demikian, penggunaan bahasa daerah, dalam hal ini bahasa Jawa, sebagai media komunikasi sehari-hari sering kali dianggap lebih mengikat. Hal ini berimplikasi terhadap penduduk yang belum mampu untuk berbahasa Jawa. Ketidakmampuan dalam berkomunikasi dapat memicu rasa kecemasan (Nurlette, 2014). Kecemasan pada akhirnya dapat mengganggu tingkat konsentrasi seseorang.
52 Mesin penerjemah hadir sebagai salah satu solusi untuk menjembatani interaksi antar-suku. Mesin penerjemah merupakan sebuah media yang memproses perpindahan satu bahasa ke bahasa lain. Pendekatan statistik adalah pendekatan yang digunakan untuk menanggulangi kekurangan dari pendekatan sebelumnya, seperti pendekatan berbasis contoh dan pendekatan berbasis aturan. Keuntungan dari penerapan pendekatan statistik pada mesin penerjemah adalah durasi pengembangan yang lebih cepat (Adji, 2011). Selain itu, dilihat dari sisi keakuratan, mesin penerjemah dengan pendekatan statistik memiliki keakuraran yang lebih baik bila dibandingkan dengan mesin penerjemah dengan pendekatan berbasis aturan.
Makalah ini akan memaparkan sistematika pembuatan sebuah mesin penerjemah bahasa Indonesia dan bahasa Jawa yang menggunakan pendekatan statistik dengan berbasis frasa (phrase based). Selain itu, pada makalah ini juga akan mengevaluasi hasil terjemahan dari mesin penerjemah yang telah dibuat. Hasil tersebut kemudian dapat menjadi tolak ukur, seberapa mumpuni mesin penerjemah dengan pendekatan statistik dalam menerjemahkan bahasa Indonesia dan bahasa Jawa.
1.2 Penelitian Terkait
Telah ada beberapa penelitian yang dilakukan terkait dengan mesin penerjemah bahasa Indonesia dan bahasa daerah. Nurwarsito (2010) dalam penelitiannya membangun aplikasi kamus yang melibatkan bahasa Indonesia, bahasa Jawa, dan bahasa Madura. Ada pula Priharyanto (2012) yang membangun aplikasi penerjemah kata bahasa Indonesia dan bahasa Jawa. Penelitian-penelitian tersebut masih sebatas menerjemahkan antarkata.
Untuk mesin penerjemah antarkalimat bahasa Indonesia dan bahasa Jawa, setidaknya ada dua penelitian yang telah dilakukan. Soyusiowati (2009) mengembangkan aplikasi penerjemah kalimat tunggal bahasa Indonesia ke dalam bahasa daerah Sasak, dan Afifah (2010) yang melakukan penelitian terkait dengan mesin penerjemahan kalimat bahasa Indonesia dan bahasa Jawa. Namun demikian, pendekatan yang digunakan dalam penelitian-penelitian tersebut masih menggunakan pendekatan berbasis aturan (rule based).
Penelitian mengenai mesin penerjemah dengan statistik sebagai pendekatannya dimulai oleh Brown (1990). Pada penelitiannya, Brown melibatkan bahasa Prancis dan bahasa Inggris sebagai bahan penelitian. Selanjutnya, Koehn, dkk. (2003) melakukan penelitian dengan beberapa bahasa Eropa sebagai bahannya. Selain itu, Koehn, dkk. juga menambahkan metode di dalam penelitiannya, yakni berbasis frasa (phrase based). Berikutnya Nusai (2008) yang menerapkan pendekatan statistik untuk mesin penerjemah dengan mengambil bahan bahasa Thailan dan bahasa Inggris.
Sedangkan penelitian yang menggunakan bahasa Indonesia dan juga bahasa daerah sebagai bahan dalam mengembangkan mesin penerjemah statistik relatif sedikit. Tercatat, Adres Ginting (2012) yang telah melakukan penelitian yang mengambil bahasa Indonesia dan bahasa Karo sebagai bahannya.
2. METODOLOGI 2.1. Proses Penelitian
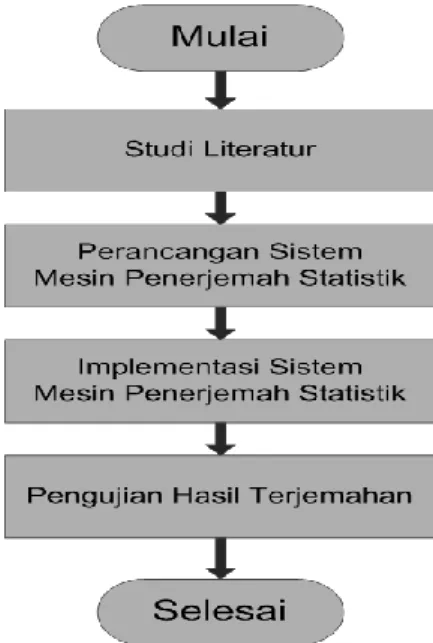
Alur penelitian untuk makalah ini dapat dilihat pada Gambar 1.
Gambar 1. Alur penelitian 2.2. Alat dan Bahan
Untuk alat-alat (tools) yang digunakan dalam mengembangkan mesin penerjemah statistik bahasa Indonesia dan bahasa Jawa adalah :
a. Cygwin
b. Moses (Koehn, 2007), perangkat lunak untuk proses preprosesing dan decoding. c. IRSTLM (Bertoldi, 2010), perangkat lunak
untuk Language Model.
d. Giza++ (Och, 2003), perangkat lunak untuk Translation Model.
e. BLEU (Papineni, 2002), perangkat lunak untuk proses evaluasi.
Sedangkan untuk bahan yang digunakan adalah kumpulan kalimat dari sebagian isi Alkitab yang terdiri dari 5.080 baris kalimat bahasa Indonesia dan Jawa dengan jumlah kata 104.568 untuk bahasa Jawa dan 93.369 untuk bahasa Indonesia. Alkitab yang digunakan, baik Alkitab berbahasa Jawa maupun Alkitab berbahasa Indonesia, ialah Alkitab yang diterbitkan oleh Lembaga Alkitab Indonesia (LAI) tahun 1994. Khusus Alkitab berbahasa Jawa, jenis bahasa Jawa yang dipilih LAI dalam penerbitannya adalah bahasa Jawa yang biasa digunakan sehari-hari. Oleh sebab itu, Alkitab terbitan LAI dipilih sebagai bahan untuk membangun mesin penerjemah statistik bahasa
Indonesia dan bahasa Jawa. Selain itu, kedua jenis bahasa berasal dari sumber yang sama, yakni LAI, yang berarti bahwa keabsahan terjemahannya dapat dipertanggung jawabkan.
2.3. Arsitektur Umum Mesin Penerjemah Statistik (MPS)
Mesin penerjemah statistik secara umum mempunyai arsitektur, yang dapat dilihat pada Gambar 2, dengan beberapa komponen di dalamnya, yakni language model, translation model dan decoder.
Gambar 2. Arsitektur Umum MPS
Language model mempunyai tugas untuk mencari kefasihan (fluency) penerjemahan. Translation model bertugas untuk mencari ketepatan (faithfulness) dari penerjemahan. Sedangkan decoder berfungsi untuk mencari teks pada bahasa target yang memiliki nilai probabilitas paling tinggi dengan pertimbangan language model dan translation model.
3. PEMBAHASAN
3.1. Arsitektur MPS Indonesia - Jawa
Dalam membangun mesin penerjemah statistik bahasa Indonesia dan bahasa Jawa, diawali dengan merancang arsitektur sistem. Arsitektur dari mesin penerjemah statistik bahasa Indonesia dan bahasa Jawa dapat dilihat pada Gambar 3.
Gambar 3. Arsitektur MPS Indonesia - Jawa
Arsitektur ini terdiri dari beberapa fase. Dimulai dari fase preprocessing yang merupakan tahapan awal untuk mempersiapkan corpus parallel. Kemudian dilanjutkan dengan fase training, yakni fase pengolahan corpus parallel untuk memperoleh language model dan translation model. Selanjutnya fase testing, dan diakhiri dengan fase evaluasi.
Preprocessing terdiri dari beberapa bagian, yakni penjajaran kalimat, tokenisasi, cleaning, lowercase filtering, dan truecase. Penjajaran kalimat adalah proses menjajarkan corpus parallel yang awalnya berupa paragraf, seperti yang ditunjukkan pada Tabel 1 menjadi susunan baris kalimat seperti Gambar 4.
Tabel 1. Corpus parallel dalam bentuk paragraf
Bahasa Indonesia Bahasa Jawa Pada mulanya Allah
menciptakan langit dan bumi. Bumi belum berbentuk dan kosong, gelap gulita menutupi samudera raya, dan Roh Allah melayang-layang di atas permukaan air
Ing jaman kuna sing wiwitan mula Gusti Allah nitihake jagad. Bumi kaanane isish ora karu-karuwan, tur sepi banget. Salumahe bumi ketutupan banyu, mangka kaanane peteng ndhedet. Dene Rohe Allah makarya ana ing sandhuwure banyu.
Gambar 4. Penjajaran kalimat
Tokenisasi diperlukan untuk memberi jarak antar kata termasuk juga memberi jarak antara kata dengan tanda baca yang ada. Cleaning adalah proses pemberian batasan panjang kalimat. Cleaning juga berfungsi untuk menghilangkan kalimat-kalimat yang tidak sejajar. Sedangkan lowercase merupakan proses untuk menyeragamkan besar-kecilnya huruf. Proses terakhir di dalam preprocessing adalah trucase. Pada proses ini setiap awal dari tiap kalimat dikonversi ke tempat yang paling mungkin. Selain proses penjajaran kalimat, proses-proses pada preprocessing dilakukan menggunakan perangkat lunak Moses.
Fase berikutnya adalah fase training. Pada fase inilah language model dan translation model dilakukan. Languange model menggunakan
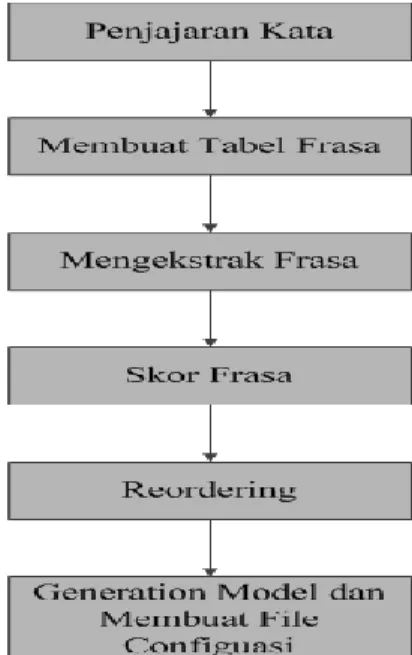
54 perangkat lunak IRSTLM yang telah disatukan ke dalam Moses. Sedangkan untuk translation model digunakan perangkat lunak Giza++ yang didalamnya menerapkan algoritma Expectation Maximitation atau algoritma IBM model. Khusus untuk translation model, pendekatan yang digunakan adalah berbasis frasa, yang di dalamnya terdapat beberapa tahapan seperti yang ditunjukkan pada Gambar 5. Tahapan tersebut dimulai dari penjajaran kata sampai dengan pembuatan berkas konfigurasi (configuration file) yang akan digunakan pada proses decoding.
Gambar 5. Proses pada translation model
Selanjutnya adalah fase testing. Fase testing adalah fase dalam menerjemahkan bahasa sumber ke bahasa target. Masukan berupa kalimat dalam bahasa sumber akan diterjemahkan ke dalam bahasa target. Fase ini juga merupakan fase decoding hasil dari fase training. Dan fase yang terakhir adalah fase pengevaluasian secara automatis dari hasil terjemahan yang diperoleh fase testing.
3.2. Ekperimen dan Hasil
Pada saat melakukan preprocessing cleaning, terdapat beberapa baris kalimat yang terfilter atau dapat dikatakan terbuang, seperti yang ditunjukkan pada Gambar 6. Dari Gambar 6 dapat dilihat bahwa dari masukan kalimat yang berjumlah 5080 baris kalimat setelah melalui proses cleaning berkurang menjadi 4571 baris kalimat. Jumlah baris kalimat yang terbuang mencapai 509 atau 10,02%.
Hal ini disebabkan kalimat yang ada pada Alkitab Jawa tidak selalu paralel dengan pasangan kalimat yang ada pada Alkitab Indonesia. Hal ini dapat dipahami karena terjemahan pada Alkitab sering kali dilakukan dengan penambahan
penjelasan dengan konteks budaya Jawa, sehingga memengaruhi jumlah kata pada terjemahan.
Gambar 6. Hasil cleaning corpus
Penambahan konteks penjelasan yang ada pada Alkitab juga pada akhirnya memengaruhi model terjemahan. Kata “siapa” yang dalam bahasa Jawa berarti “Sapa [dibaca : sopo]”, ketika diterjemahkan menggunakan mesin penerjemah statistik menjadi “sapa sing”, seperti yang ditunjukkan pada Gambar 7.
Gambar 7. Contoh kesalahan terjemahan
Selain itu, kurangnya perbendaharaan kata pada corpus parallel menyebabkan ketidakmampuan mesin penerjemah statistik untuk menerjemahkan. Seperti kata “main” pada bahasa Indonesia, jika diterjemahkan ke dalam bahasa Jawa menjadi “dolan”.
Gambar 8. Ketidakmampuan menerjemahkan karena kurangnya corpus
parallel
Pada Tabel 3 dan Tabel 4 dipaparkan beberapa contoh kalimat yang berhasil diterjemahkan oleh mesin penerjemah statistik baik dari bahasa Indonesia ke bahasa Jawa, dan sebaliknya.
0 50000
1
Jumlah n-gram terpakai
Unigram Bigram Trigram
Tabel 3. Contoh hasil terjemahan bahasa Indonesia – bahasa Jawa
No. Kalimat Keterangan
1. Aku akan pergi ke danau Masukan Kawula bakal lunga
menyang tlaga
Terjemahan
Kawula arep lunga menyang tlaga
Referen
2. Jangan jauh dariku Masukan Aja adoh dariku Terjemahan Aja adoh saka aku Referen 3. Ibu sedang pergi ke pasar Masukan
Ibu lagi padha ana ing pasar Terjemahan Ibu lagi tindhak menyang
pasar
Referen
4. Lempar batu itu ke sungai Masukan Lempar watu mau menyang
bengawan
Terjemahan
Nguncalke watu menyang bengawan
Referen
Tabel 4. Contoh hasil terjemahan bahasa Jawa - bahasa Indonesia
No. Kalimat Keterangan
1. Kawula arep lunga menyang tlaga
Masukan
Aku mau pergi ke danau Terjemahan Aku akan pergi ke danau Referen 2. Aja adoh saka kawula Masukan
Janganlah jauh dari aku Terjemahan Jangan jauh dari aku Referen 3. Mbok e lunga menyang
pasar
Masukan
Mbok e pergi ke pasar Terjemahan Ibu pergi ke pasar Referen 4. Sawaten watu iku menyang
bengawan
Masukan
Sawaten batu itu ke bengawan
Terjemahan
Buanglah batu itu ke sungai Referen Dari contoh terjemahan yang dihasilkan, dapat dilihat ada beberapa kata yang belum mampu terjemahkan secara baik. Hal ini, sekali lagi, disebabkan oleh kurangnya jumlah corpus parallel, dan juga banyaknya kalimat yang tidak terjaga kecocokannya.
Dari hasil percobaan juga diperoleh model n-gram yang paling banyak digunakan adalah bin-gram, yang jumlahnya mencapai 44406 kata. Jumlah keseluruhan n-gram yang digunakan dapat dilihat pada Tabel 5 dan disajikan dalam bentuk grafik yang dapat dilihat pada Gambar 9.
Tabel 5. Jumlah n-gram yang terpakai Model n-gram Jumlah
Unigram 7627
Bigram 44406
Trigram 13357
Gambar 9. Grafik jumlah n-gram yang terpakai 3.3 Evaluasi Automatis
Untuk melihat nilai pengukuran dari hasil terjemahan mesin penerjemah statistik digunakan BLEU-metric. Meskipun terdapat beberapa kesalahan dalam penerjemahan, namun hasil dari evaluasi automatis menunjukkan nilai yang relatif baik. Untuk penerjemahan bahasa Indonesia ke bahasa Jawa diperoleh hasil 44,02 %, dan untuk bahasa Jawa ke dalam bahasa Indonesia diperoleh hasil 48,77 %.
56 Nilai yang diperoleh tersebut lebih tinggi jika dibandingkan dengan penelitian yang pernah dilakukan. Sujaeni (2012) memperoleh nilai tertinggi sebesar 33,26 % untuk penerjemahan bahasa Inggris ke bahasa Indonesia dengan jumlah data 15.000.
4. KESIMPULAN
Dari hasil eksperimen, dapat dilihat bahwa corpus parallel mempunyai peran yang sangat penting untuk menjaga kualitas dari mesin penerjemahan. Dengan corpus parallel yang berasal dari sebagian isi Alkitab, masih banyak pengurangan baris kalimat pada proses cleaning. Penataan corpus parallel diperlukan untuk memperoleh hasil terjemahan yang laik. Penataan ini dapat dilakukan dengan membuat padanan kata dan panjang kalimat yang mendekati sama terhadap kedua korpus.
Meski demikian, menilik hasil evaluasi yang diperoleh dari BLEU-metric, mesin penerjemah statistik bahasa Indonesia dan bahasa Jawa, relatif mempunyai nilai yang baik. Hasil itu menjelaskan bahwa, dengan penataan corpus parallel yang lebih baik, maka penerjemahan bahasa Indonesia dan bahasa Jawa dengan menggunakan pendekatan statistik berbasis frasa akan mempunyai nilai keakuratan yang lebih bagus, baik secara terjemahan maupun nilai evaluasi.
PUSTAKA
Adji, T., B., Astuti, Y., Kusumawardani, S., S., 2011. Statistical-based Machine Translation for Prepositional Phrase Using Link Grammar. Bandung: International Conference on Electrical Engineering and Informatics.
Afifah, N., Santoso, B., Yuliana, M., 2010. Pembuatan Kamus Elektronik Kalimat Bahasa Indonesia dan Bahasa Jawa untuk Aplikasi Mobile Menggunakan Interpolation Search. Surabaya: Seminar Proyek Akhir Jurusan Teknik Telekomunikasi PENS-ITS.
Bertoldi, N., 2010 “IRSTLM Toolkit” Fondazione Bruno Kessler, Le Mans: 5th MT Marathon. Brown, P.F., Cocke, J., Pietra, S.A.D., Pietra,
V.J.D., Jelinek, F., Lafferty, J., Mercer, R.L., Roossin, P.S. 1990. “A Statistical Approach to Machine Translation.” Journal of Computational Linguistics, Volume 16, Nomor 2. [http://www.aclweb.org/anthology/J90-2002, diakses tanggal 5 Agustus 2014]
Ginting, A., Nazori, A., 2012. “Penerjemah Dua Arah Bahasa Indonesia ke Bahasa Daerah (Karo) Menggunakan Teknik Statistical Machine Translation Sebagai Fitur Pada Situs Web Untuk Meningkatkan Web Traffic” Jakarta: Jurnal Telematika MKOM Vol. 4 No. 1.
Koehn, P., Och, F.J., Marcu, D., 2003 “Statistical Phrase-Based Translation” Edmonto: Proceedings of HLT-NAACL, Main Papers.
Koehn, P., Hoang, H., Birch, A., Callison-Burch, C., Federico, M., Bertoldi, N., Cowan, B., Shen, W., Moran, C., Zens, R., Dyer, C., Bojar, O., Constantin, A., Herbst, E., 2007 “Moses: Open Source Toolkit For Statistical Machine Translation”. Prague: Proceedings of 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions.
Nurlette, R., 2014. Gambaran Kecemasan Mahasiswa Asal Maluku Saat Menjalani Masa Perkuliahan di Universitas Jenderal Soedirman Purwokerto. Skripsi tidak diterbitkan. Purwokerto: Fakultas Kedokteran dan Ilmu-Ilmu Kesehatan.
Nurwarsito, H., 2010. Aplikasi Kamus Bahasa Madura-Indonesia-Jawa Online dengan XHTML MP dan WCSS. Skripsi tidak diterbitkan.
Nusai, C., Suzuki, Y., Yamazaki, H. 2008 “Estimting Word Translation Probabilities for Thai – English Machine Translation using EM Algorithm” International Journal of Computational Intelligence, WASET, Volume 4, Nomor 3.
Och, F.J., Ney, H., 2003 “A Systematic Comparation of Various Statistical Alignment Models” Computational Linguistics, Volume 29 No. 1. Papineni, K., Roukos, S., Ward, T., W, Zhu, W.J
2002 “BLUE : A Method for Automatic Evaluation of Machine Translation” Philadelphia: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL).
Priharyanto, I., 2012. Aplikasi Kamus Bahasa Indonesia-Jawa-Jawa Krama Berbasis Android. Skripsi tidak dipublikasikan. Yogyakarta: Jurusan Teknik Informatika Stimik Amikom. Rahardi, K., 2010. Bahasa Indonesia Untuk
Perguruan Tinggi. Jakarta: Penerbit Erlangga. Setyowati, A., 2008. Interferensi Morfologi dan
Sintaksis Bahasa Jawa Dalam Bahasa Indonesia Dalam Kolom “piye, ya?” Harian Suara Merdeka. Skripsi tidak diterbitkan. Semarang: Jurusan Ilmu Sastra Indonesia Fakultas Sastra Universitas Diponegoro.
Soyusiawaty, D., Haspiyan, R., 2009. Aplikasi Kamus Indonesia-Bahasa Sasak Berbasis WAP. Yogyakarta: Seminar Nasional Informatika UPN Veteran.
Sujaini, H., Kuspriyanto, Arman, A., A., Purwarianti, A., 2012. Pengaruh Part-of-Speech Pada Mesin Penerjemah Bahasa Inggris-Indonesia Berbasis Factored Translation Model. Seminar Nasional Aplikasi Teknologi Informasi, Yogyakarta.