ADVISE: Symbolism and External Knowledge for Decoding Advertisements
Keren Ye
Adriana Kovashka
Department of Computer Science
University of Pittsburgh
{yekeren, kovashka}@cs.pitt.eduAbstract
In order to convey the most content in their limited space, advertisements embed references to outside knowledge via symbolism. For example, a motorcycle stands for adventure (a positive property the ad wants associated with the prod-uct being sold), and a gun stands for danger (a negative property to dissuade viewers from undesirable behaviors). We show how to use symbolic references to better under-stand the meaning of an ad. We further show how anchor-ing ad understandanchor-ing in general-purpose object recognition and image captioning can further improve results. We for-mulate the ad understanding task as matching the ad image to human-generated statements that describe the action that the ad prompts and the rationale it provides for this action. We greatly outperform the state of the art in this task. We also show additional applications of our learned represen-tations for ranking the slogans of ads, and clustering ads according to their topic.
1. Introduction
Advertisements are a powerful tool for affecting human behavior. Product ads convince us to make large purchases, e.g. for cars and home appliances, or small but recur-rent purchases, e.g. for laundry detergent. Public service announcements (PSAs) encourage different behaviors, e.g. combating domestic violence or driving safely. To stand out from the rest, ads have to be both eye-catching and memo-rable [74], while also conveying the information that the ad designer wants to impart. All of this must be done in lim-ited space (one image) and time (however many seconds the viewer is willing to spend looking at an ad).
How can ads get the most “bang for their buck”? One technique is to make references to knowledge that viewers already have, in the form of e.g. cultural knowledge, con-ceptual mappings, and symbols that humans have learned [58, 39, 61,38]. These symbolic mappings might come from literature (e.g. a snake symbolizes evil or danger), movies (e.g. motorcycles symbolize adventure or coolness),
danger
motorbike bottle
cool I should buy this drink e ause it’s ex iting.
bottle cool gun
danger cool
A
C
B D
TRAIN
TEST
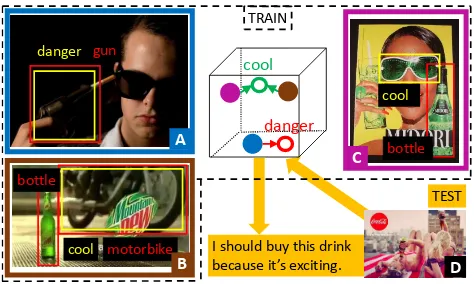
Figure 1. Our key idea: Use symbolic associations shown in yel-low (a gun symbolizes danger; a motorcycle symbolizes coolness) and recognized objects shown in red, to learn an image-text space where each ad maps to the correct statement that describes the message of the ad. The symbol “cool” brings images B and C closer together in the learned space, and further from image A and its associated symbol “danger.” At test time (shown in orange), we use the learned image-text space to retrieve a matching statement for test image D. At test time, the symbol labels arenotprovided.
common sense (a flexed arm symbolizes strength), or even pop culture (Usain Bolt symbolizes speed).
In this paper, we describe how to use symbolic mappings to predict the messages of advertisements. On one hand, we use the symbol bounding boxes and labels from the Ads Dataset of [23] as visual anchors to ideas outside the im-age. On the other hand, we use knowledge sources external to the main task, such as object detection, to better relate ad images to their corresponding messages. These are both forms of using outside knowledge which boil down to learn-ing links between objects and symbolic concepts. We use each type of knowledge in two ways, as a constraint or as an additive component for the learned image representation. We focus on the following multiple-choice task: Given an image and several statements, the system must identify the correct statement to pair with the ad. For example, for test image D in Fig.1, the system might predict the message is “Buy this drink because it’s exciting.” Our method learns
a joint image-text embedding that associates ads with their corresponding messages. The method has three compo-nents: (1) an image embedding which takes into account in-dividual regions in the image, (2) constraints on the learned space computed from symbol labels and object predictions, and (3) an additive expansion of the image representation using a symbol distribution.
In more detail, we first use the symbol bounding boxes from the Ads Dataset [23], without labels, to learn a region proposal network. For each image, we compute its repre-sentation as a weighted average of the reprerepre-sentations of its important regions. It is this representation that we embed in the joint image-text space. Second, we constrain the learned space using the sparse ground-truth symbol labels from the Ads Dataset, and the predictions from a generic captioning method not based on ads [29]. Images that have similar symbol labels and similar predicted captions should project closeby in the learned space. Third, we add an adaptive ad-ditive refinement to our image representation that brings the image representation closer to its corresponding statement. Both the constraints and the additive component depend on external knowledge in the form of symbols and object pre-dictions, i.e. we show two ways to learn an embedding for ads that rely on outside knowledge. We call our method ADVISE:ADsVIsualSemanticEmbedding.
We focus on public service announcements, rather than product (commercial) ads. PSAs tend to be more concep-tual and challenging, often involving multiple steps of rea-soning. Quantitatively, 59% of the product ads in the dataset of [23] are straightforward, i.e. would be nearly solved with traditional recognition advancements. In contrast, only 33% of PSAs use straightforward strategies, while the remain-ing 67% use a number of challengremain-ing non-literal approaches to convey their message. Our method outperforms several relevant baselines, including prior visual-semantic embed-dings [35] and methods for understanding ads [23].
In addition to showing how to use external knowledge to solve ads, we also demonstrate how recent advances in object recognition help with the ad-understanding task. While [23] evaluates basic techniques for ad-understanding, it does not make use of recent advances in computer vi-sion, e.g. region proposals [18, 55, 42, 15], attention [8,73, 70,60, 72,54, 51,43, 13,79, 52], or image-text embeddings [35,6,7,11,16,53].
Note that symbols can be culture-dependent, and the messages of ads might be interpreted differently by different viewers. We do not deal with these nuisance factors. Sym-bols were annotated by workers in the United States, and from the point of view of ad designers, a single message is encoded. It is this message, and this US-based symbolism, that we are interested in predicting.
To summarize, our contributions are as follows:
• We show how to effectively use symbolism to better
understand ads.
• We show how to make use of noisy caption predictions to bridge the gap between the abstract task of predicting the message of an ad, and more accessible information such as the objects present in the image. Detected objects are mapped to symbols via a domain-specific knowledge base.
• We improve the state of the art in understanding ads by 35% in the case of public service announcements, and 30% in the case of product ads.
• We show that for the “abstract” PSAs, conceptual knowledge in the form of symbols helps more, while for the more “straightforward” product ads, use of general-purpose object recognition techniques is more helpful.
The remainder of the paper is organized as follows. We briefly discuss related work in Sec. 2. In Sec. 3.1, we describe the retrieval task on which we focus, and in Sec.3.2, we describe standard triplet embedding using the Ads Dataset. In Sec.3.3, we discuss the representation of an image as a weighted combination of region representa-tions, weighed by their importance via an attention model. In Sec.3.4, we describe how we use external knowledge to constrain the learned space. In Sec.3.5, we develop an op-tional additive refinement of the image representation, again using external knowledge and symbols. In Sec.4, we com-pare our method to state of the art methods, and conduct extensive ablation studies. We conclude in Sec.5.
2. Related Work
Advertisements and multimedia. The most related work to ours is [23] which proposes the problem of decoding ads, formulated as answering the question “Why should I [ac-tion]?” where [action] is what the ad suggests the viewer should do, e.g. buy something or behave a certain way (e.g. help prevent domestic violence). The dataset con-tains 64,832 image ads. Annotations available include the topic (product or subject) of the ad, sentiments and ac-tions the ad prompts, rationales provided for why the action should be done, symbolic mappings (signifier-signified, e.g. motorcycle-adventure), etc. Considering the media domain more broadly, [30] analyze in what light a photograph por-trays a politician, and [31] analyze how the facial features of a political candidate determine the outcome of an elec-tion. Also related is work in parsing infographics, charts and comics [4,33,26]. In contrast to these, our interest is analyzing theimplicitreferences ads were created to make. Vision and language and image-text embeddings. In re-cent years, there is great interest in joint vision-language tasks, e.g. image and video captioning [67,32,10,29,2,73,
this work. [35] uses triplet loss where an image and its cor-responding human-provided caption should be closer in the learned embedding space than image/caption pairs that do not match. [11] propose a bi-directional network to maxi-mize correlation between matching images and text, akin to CCA [19]. [16] utilize the images and texts in Wikipedia articles for self-supervision. While these achieve excellent results, none of them consider images with implicit or ex-plicit persuasive intent, as we do.
External knowledge for vision-language tasks. We pro-pose to use external knowledge for decoding ads, in two ways: via symbols that inherently refer to outside knowl-edge, and by using outside knowledge to learn to detect symbols. [69,68,28, 81, 64] examine the use of knowl-edge bases for answering visual questions. [66] use external sources to diversify their image captioning language model. [49] learn to compose object classifiers by relating similar-ity in semantics to visual similarsimilar-ity. [45,17] use knowledge graphs or hierarchies to aid in object recognition. These works all use mappings that are objectively/scientifically grounded, i.e. lions are related to cats, lions are a type of cat, etc. In contrast, we use cultural associations that arose in the media/literature and are internalized by humans, e.g. motorcycles are associated with adventure.
Region proposals and attention. We make use of region proposals [18,55,42,15] and attention [8,73,70,60,72,
54,51,43,13,79,52]. Region proposals focus the job of an object detector to regions likely to contain objects. At-tention helps focus learning and prediction tasks on regions likely to be relevant to the task; these regions are learned us-ing backpropagation. We show that the regions over which we compute attention must be specific to the domain of ads. Modeling of human attention [25,5,27,37,78] and mem-orability [24,34] are also relevant since ads are created to draw and hold the viewer’s attention [74].
3. Approach
We learn a joint image-text embedding space where we can evaluate the similarity between ad images and ad mes-sages. We use symbols and external knowledge to con-strain and refine this space in three ways. First, rather than consider ad images as a whole, we represent an ad image as a weighted average of the representations of its regions (Sec. 3.3). Second, we enforce that images that have the same symbol labels, or the same detected objects [29], map closeby in the learned space (Sec.3.4). Finally, we propose an additive refinement of the image representation via an attention-masked symbol distribution (Sec.3.5). In Sec.4
we demonstrate the utility of each component.
3.1. Task and dataset
Our goal is to develop a method for understanding ad-vertisements. Concretely, we consider the task of question-answering in the dataset of [23]. The authors formulated ad understanding as answering the question is “Q: Why should I [action]? A: [one-word reason]” An example question-answer pair is “Q: Why should I speak up about domestic violence? A: bad.” The one-word reason is picked from a full-sentence reason, also available in the dataset. We be-lieve that using a single word is insufficient to capture the rhetoric of complex ads, so we slightly modify their task. Rather than a softmax over 1000 words, we ask the sys-tem to pick whichstatementis most appropriate for the im-age. We retrieve statements in the format: “I should [action] because [reason].” Using the same example, the statement would be “I should speak up about domestic violence be-cause being quiet is as bad as committing violence your-self.” Given an image, we rank 50 statements (3 related and 47 unrelated) based on their similarity to the image, in the learned feature space.
3.2. Basic image-text triplet embedding
As a foundation for our approach, we first directly learn an embedding that optimizes for the desired task. We re-quire that in the feature space, the distance between an im-age and its corresponding statement should be smaller than the distance between that image and any other statement, or between other images and that statement. In other words, the loss that is being minimized is
L(v, t;θ) =
wherevindicates the visual embedding we are learning and
tindicates the text embedding,via,v p
i correspond to a different ad. In order to extract visual embeddingvfrom imagex, we first extract the image’s CNN feature (1536-D) from [62], then use a fully connected layer to project it to the 200-D joint embedding feature space. Givenw ∈R200×1536
, the parameter of the fully connected layer,
v=w·CN N(x) (2)
0
Knowledge inference and
symbol embedding +
200D image embedding
Triplet training Region proposal and
attention weighing
Embedding of external knowledge
x1 x2 x3
α1 α2 α3
x
uobj, usymb ysymb
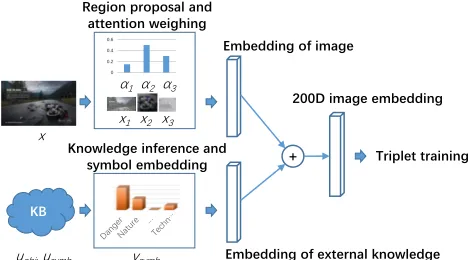
Figure 2. Our image embedding model with knowledge branch. In the main branch (top), multiple image regions are proposed by the region proposal network. Attention weighing is then applied on these regions and the embedding of the image is computed as a weighted sum of the regions’ embedding vectors. The knowledge branch (bottom) predicts the existence of symbols, maps these to 200-D, and adds them to the image embedding (top).
3.3. Embedding using symbol regions
Since ads are carefully designed, they may involve com-plex narratives with several distinct components, i.e. several regions in the ad might need to be interpreted individually first, before we can reason about them jointly to infer the message of the ad. Thus, we represent an image as a collec-tion of its constituent important reasons, using an attencollec-tion module to learn the weights for each region.
We learn a region proposal network using the sym-bol bounding boxes of [23]. The idea is that ads draw the viewer’s attention in a particular way, and the symbol bounding boxes without symbol labels can be used to ap-proximate this. This label-agnostic method is a new use of [23]’s symbolism data that has not been explored before. We use a pre-trained network [42,22,20] and fine-tune it using the symbol bounding box annotations. We show in Sec.4that this fine-tuning is crucial.
To further model the viewer’s attention, we also incorpo-rate the bottom-up attention mechanism [64,1], which is a weighing among region proposals.
In more detail, we extract CNN features for each de-tected ads regionxi, i∈ {1, . . . , K = 10}in the imagex. We then use a fully connected layer to project each region-based feature to: 1) a 200-D embedding vectorvi(Eq.3), and 2) a confidence scoreai saying how much the region should contribute to the final representation (Eq.4). In Eq (3) and Eq (4) w ∈ R200×1536
andwa ∈ R1×1536. The final embedding vectorzis a weighted sum of these region-based vectors weighed by their confidence score (Eq. 5). This intuitive idea was also used in [64] for visual ques-tion answering, but in our case, the attenques-tion distribuques-tion do not depend on questions. In Fig.2, we show how we use bottom-up attention to weigh the different regions.
vi=w·CN N(xi) (3)
ai=wa·CN N(xi) α=sof tmax(a) (4)
z=XK
i=1αivi (5) The loss used to learn the image-text embedding is the same as in Eq. (1), but defined using the region-based image representationzinstead ofv:L(z, t;θ).
We demonstrate that (1) learning a region proposal net-work with attention, and (2) learning from symbol bounding boxes, greatly help the statement retrieval task. In particu-lar, statement ranking results are worse if we use a generic pre-trained region proposal network. We argue that general-purpose object detection models cannot capture nuance in ads since they ignore uncommon or abstract objects.
3.4. Constraints via symbols and captions
In Sec. 3.2, we describe how we learn a joint image-text space using triplet loss defined over pairs of images and their corresponding reason statements. Since symbols provide additional information that humans use to decode ads, we now propose additional constraints to our triplet loss such that two images (and their statements) that were annotated with the same symbol are closer in the learned space than images (and statements) annotated with differ-ent symbols. The extraloss term we use to constrain the training process is shown in Eq (6) wheres is the 200-D embedding of symbol labels.
Lsym(s;θ) =
By applying the new constraints, the model converges faster and the training process becomes more stable. At the same time, we explicitly embed symbol labels in the same feature space as images and statements. These symbols em-bedding vectors serve as entry points for external knowl-edge and shall be further discussed in Sec.3.5.
captions. Theextraloss term we use for constrain the
train-Note that the object/DenseCap embedding model does not share weights with the statements’ embedding model since the meaning of the same surface words may vary in these two different domains.
The same object can be used to make different points, e.g. faces in beauty ads vs domestic violence ads, cars in car ads vs safety ads, etc. Similarly, symbol labels in isolation do not tell the full story of the ad. Thus, we reduce the impact of the symbol-based and object-based constraints by weighing the corresponding loss by 0.1.
Note that [50] also propose to use labels to constrain an embedding space. However, we show in our experiments that it is not sufficient to useanytype of label in the domain of interest. We experiment with another type of label from [23]’s dataset, namely the topic of the ad (e.g. what product it is selling), and show that symbols give a greater benefit.
3.5. Additive external knowledge
In this section, we describe how to make use of external knowledge via a symbol representation that is adaptively added to the image representation to compensate inadequa-cies of the image embedding. This external knowledge can take the form of a mapping between physical objects and implicit concepts, or a classifier mapping pixels to concepts. Assume we are viewing a challenging ad whose mean-ing is not immediately obvious. The only thmean-ing we can do is to use our human experience to find some evidence. For example, do the visual cues remind us of concepts we have seen in other ads? This is how external knowledge helps us to decode the ad. Our model is able to interpret ads in the same way: based on external knowledge base, it infers the abstract symbols. Since the model knows the exact mean-ing of these symbols (since it already knows the embed-ding vectors of these symbols, see Sec. 3.4), it is able to reconstruct the image representation using these symbols’ embedding vectors by weighing them. Fig. 2 (bottom) shows the general idea of the external knowledge branch. It is worth mentioning that our model only uses external knowledge to compensate its own lack of knowledge and it assigns small weights for uninformative symbols.
We propose two ways to additively expand the image representation with external knowledge. Both ways are a form of knowledge base (KB) mapping physical evidence to concepts. The first is to directly train classifiers to
link certain visuals to the symbolic concept. More specifi-cally, we use the 53-waymultilabelsymbol classifierusymb from [23] as 53 individual classifiers. We obtain a sym-bol distributionysymb = sigmoid(usymb·x). We learn a weight αsymbj for each of j ∈ {1, . . . , C = 53} classi-fiers denoting the confidence of the classifier. Therefore, the learned model of the knowledge branch is an tion model weighing the 53 symbol classifiers. The atten-tion weights are adjusted depending on whether a particular symbol is helping in the statement matching task.
The second method is to learn associations between ac-tual objects in the image (surface words for detected ob-jects) and abstract concepts of symbols. For example, what type of ad might I see a “car” in? What about a “rock” or “animal”? We first construct a knowledge base associating object words to symbol words. We compute the similarity in the learned text embedding space between symbol words and DenseCap words, then create a mapping rule (object implies symbol) for each symbol and its five most simi-lar DenseCap words. This results in a 53×V matrixuobj, whereV is the size of the DenseCap vocabulary. Each row contains 5 entries of 1 denoting the mapping rule, andV−5 entries of 0. Examples of learned mappings are shown in Table6.
For a given image, we use [29] to predict the 3 most probable words in the DenseCap vocabulary, and put the results in a multi-hotyobj ∈RV×1vector. We then matrix-multiply to accumulate evidence for the presence of all symbols using the detected objects: ysymb = uobj ·yobj. We associate a weight αsymbjl with each rule in the KB,
j ∈ {1, . . . , C = 53},l ∈ {1, . . . , V}, which explains the
importance of the rule saying to what extent thelthword in the DenseCap vocabulary symbolizes thejthsymbol (e.g. to what extent “rock” is used to illustrate “natural”).
For both methods, we first use the attention weights
αsymbas a mask, then project the 53-D symbol distribution
ysymbinto 200-D, and add it to the image embedding. This additive branch is most helpful when the informa-tion it contains is not already contained in the main image embedding branch. We discovered this happens when the discovered symbols are rare. This poses a learning chal-lenge for our object-to-symbol mapping method. In order to learn attention weights on the full 53×V matrix, we must have enough data, but if we have enough data, the additional branch is not likely to be active. Breaking this dependency is the subject of our future work.
3.6. ADVISE: our final model
VSE on Ads: “I should wear Revlon makeup because it will make me more attractive”
ADVISE (ours): “I
should stop smoking because it doesn't make me pretty”
VSE on Ads: “I should buy Ben & Jerry's ice cream because they treat the cows that give the milk for their ice cream well”
ADVISE (ours): “I should report domestic abuse because ignoring the problem will not make anything better”
Figure 3. The performance of our ADVISE method compared to the strongest baseline, VSE ON ADS. In the first example, the baseline is tricked into thinking this is a beauty ad, as is the intent of the ad designer for creating a more dramatic effect. In the sec-ond example, the baseline may have gotten confused by the purple colors often used in Ben & Jerry’s ads.
4. Experimental Validation
We evaluate to what extent our proposed method is able to match an ad to its intended message (see Sec.3.1). We compare our method to the following approaches from re-cent literature:
• ONE-WORD, the QA method from [23] which uses symbols in a different, less effective way. The goal is to predict a one-word answer to the question “Why should the viewer [action]?”, e.g. “Why should the viewer buy this car?” An answer might be e.g. “reliable” or “fast”. The method combines three features: the VGG embedding of the image, an LSTM embedding of the question, and a dis-tribution over 53 symbols using a symbol classifier. In order to adapt this method to our task, we take the predicted one word, and use Glove similarity to rank the statement options in terms of their similarity to this word.
• the Visual-Semantic Embedding (VSE) from [35], trained using Flickr30K [75] and COCO [41]. Note that more recent image-text joint embedding methods exist, but these use complex architectures [11] or are specialized to particular applications [16,6, 7]. We focus on VSE as a simple general-purpose embedding.
• VSEONADSuses the same method as [35] but trains it on around 39,000 images from the Ads Dataset and more than 111,000 associated statements (training set size varies for different folds), as described in Sec.3.2.
We compute two metrics: Recall@3, which denotes the number of true statements ranked within the Top-3, and Rank, which is the averaged ranking value of the highest-ranked true matching statement (highest rank is 0, which means rank at the first place). We expect a good model to have high Recall@3 and low Rank score.
We use five random splits of the dataset into train/validation/test sets, and show mean results and stan-dard error over a total of 62,468 test cases.
We show the improvement that our method produces over state of the art methods, in Table1. Since public ser-vice announcements (e.g. domestic violence campaigns and anti-bullying campaigns) typically use different strategies
and sentiments than product ads (e.g. ads for cars and cof-fee), we separately show the result for PSAs and products. We observe that our method greatly outperforms the prior relevant research. PSAs in general appear harder than prod-uct ads, consistent with our argument in Sec.1. Compared to VSE [35], our method improves Recall@3 and Rank by
five timesfor PSAs, and three/five times for products. Com-pared to the strongest baseline, VSEONADS, we improve Rank by 35% for PSAs, and 30% for product ads. Note that in Table1we show the better of the two alternative methods in Sec.3.5, namely the symbol classifier. Qualitative results are shown in Fig.3.
We also conduct ablation studies to verify the benefit of the components of our method.
• GENERIC REGION embedding using image regions from a generic region proposal network [22] trained on the COCO [41] detection dataset.
• SYMBOL BOXembedding andATTENTION(Sec.3.3)
• SYMBOL/OBJECTconstraints (Sec.3.4)
• additive knowledge (Sec.3.5), first predicting objects and mapping to symbols (KBOBJECTS) or directly predict-ing symbols via trainpredict-ing data as a KB (KBSYMBOLS)
The results are shown in Table2for PSAs, and Table3
for products. We also show percent improvement of each new component. Improvement is computed with respect to the previous row, except for KB OBJECTSand KB SYM -BOLS, whose improvement is computed with respect to the third-to-last row, i.e. the method on which both KB meth-ods are based. The largest increase in performance comes from focusing on individual regions within the image to un-derstand the ad’s story. This makes sense because ads are carefully designed and multiple elements work together to convey the message. Qualitative examples showing the im-pact of regions are shown in Fig.4. Especially for PSAs, these regions must be learned on the ads domain specifi-cally to further greatly increase performance.
Beyond this, the story that the results tell differs between PSAs and products. Our key idea to rely on external knowl-edge and symbols is more helpful for the challenging, ab-stract PSAs that are the focus of our work. In contrast, general-purpose computer vision techniques help more for product ads that rely on straightforward strategies.
Interestingly, attention helps for product ads, but slightly hurts for PSAs. It appears PSAs tell their “story” holisti-cally, so subselecting individual regions is detrimental.
ob-Recall@3 (Higher↑is better) Rank (Lower↓is better)
Method PSA Product PSA Product
VSE [35] 0.313±0.010 0.504±0.003 10.817±0.177 7.394±0.036 ONE-WORD[23] 0.697±0.017 0.653±0.004 7.934±0.208 6.336±0.036 VSEONADS 1.220±0.018 1.511±0.004 3.139±0.095 2.112±0.019 ADVISE (OURS) 1.507±0.018 1.726±0.004 2.032±0.076 1.474±0.016
Table 1. Our main result. We observe our method greatly outperforms three recent methods in retrieving matching statements for each ad.
% improvement Method Rec@3↑ Rank↓ Rec@3 Rank VSEONADS 1.220 3.139
GENERIC REGION 1.384 2.414 13 23
SYMBOL BOX 1.452 2.159 5 11
+ATTENTION 1.450 2.237 0 -4
+SYMBOL/OBJECT 1.487 2.128 3 5
+ KBOBJECTS 1.488 2.102 0 1
+ KBSYMBOLS 1.507 2.032 1 5
Table 2. Ablation study on PSAs. All external knowledge compo-nents (i.e. all except attention) give a boost over the naive VSE.
% improvement Method Rec@3↑ Rank↓ Rec@3 Rank VSEONADS 1.511 2.112
GENERIC REGION 1.668 1.649 9 22
SYMBOL BOX 1.694 1.549 2 6
+ATTENTION 1.725 1.491 2 4
Table 3. Ablation study on products. General-purpose recognition approaches, e.g. regions and attention, produced the main boost. The symbol-based method components in Sec.3.4and Sec.3.5 pro-duced small or no improvements.
PSA Product
Method Rec@3↑ Rank↓ Rec@3↑ Rank↓
Symbol labels 2 4 0 1
Topic labels 1 4 0 0
Table 4. % improvement for different types of labels as constraints.
ject and symbol words, which can be obtained much more efficiently as they are not image-dependent. Thus, KBOB -JECTSwould likely generalize better to a new domain of ads (or ads in a different culture) where the symbol training data from the Ads Dataset is not available.
In Table4, we show that not any type of label would suf-fice as constraint. In particular, even though the Ads Dataset includes 6 times more topic labels that could be used as constraints compared to symbol labels, symbol labels give much greater benefit. Thus, [50]’s approach is not enough; the type of labels must be carefully chosen.
In Table5, we demonstrate the versatility of our learned embedding, compared to the baselines from Table1. None of the methods were retrained, i.e. we simply used the pre-trained embedding used for the results in Table1. First, we
Ours
Generic
Figure 4. Visualization of region proposals for PSAs. Note how our proposals based on ads focus on relevant regions of the image, e.g. the smoke (which can often be a symbol) and the tip of the cigarette (left), the wound (middle), and the region of damage in the forest (right). The generic COCO boxes straddle the bound-aries of meaningful regions in the ad.
Method Hard stmt (↓) Slogan (↓) Clustering (↑) VSE [35] 9.676 9.564 0.173 ONE-WORD[23] 8.725 7.365 N/A
VSEONADS 4.642 3.108 0.293 ADVISE (OURS) 3.835 2.336 0.356
Table 5. Other tasks that our learned image-text embedding helps with. We show Rank for the first two tasks (lower is better), and homogeneity score [56] for the third task (higher is better). N/A indicates the method does not learn an embedding.
again perform a statement retrieval task, but make the task harder. In particular, all statements that are to be ranked are from the same topic (i.e. all statements are about car safety or about beauty products). The second task uses cre-ative captions that MTurk workers were asked to write for 2000 ads in [23]. We perform a retrieval task among these slogans, using an image as the query. Finally, we check how well an embedding clusters ad images with respect to a ground-truth “clustering” defined by the topics of ads. For example, if two images show faces but one is a domestic violence ad while the other is a beauty ad, would an embed-ding accurately place these ads in different clusters despite their visual similarity? We see that our method greatly out-performs all other embeddings.
• Our ADVISE method greatly exceeds the state of the art for the task of retrieving statements that describe the ad’s message correctly (VSE [35] and ONE-WORD[23]).
• The region embedding greatly improves upon the tra-ditional embedding, even though the latter is trained directly for the task of interest.
• Relying on symbol boxes always helps as symbol boxes indicate how ads draw the viewer’s attention.
• For PSAs, symbol labels as additional constraints help further; importantly, they help not just because they are proxies for the metric learning [50], but because they cap-ture the idea of the ads. In contrast, another type of label that is also from the ads dataset but much more rough (top-ics), does not help as much. Regularizing with external info, e.g. predictions about objects, also provides a benefit.
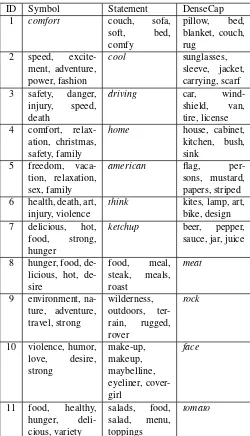
Finally, in Table 6, we show some qualitative results demonstrating the utility of anchoring our learned space with DenseCap predictions. We consider three vocabular-ies: the 53 symbol words from [23], the 27,999 unique words from the action/reason question-answers, and the 823 unique words from the DenseCap annotations. In the learned space, we compute the nearest neighbors for each symbol, statement, and DenseCap word, to establish rough synonymy. This is the knowledge base used in Sec. 3.5. These discovered results can be used as a “dictionary” showing the meaning of ad. In other words, if I see a given object, what should I predict the message of the ad is?
We begin with an intuitive result in the first triplet (ID 1). When an ad designer wants to allude to comfort, they might use objects such as a soft bed, where “soft” is a state-ment word (“Why should I buy this? Because it’s soft.”) In ID 3-6, we demonstrate the evidence in terms of different symbols and different objects, for statements that are given. The first column essentially tells us the meaning of a visual, and the last column tells us how a concept is illustrated. To illustrate “coolness”, one might show sunglasses, and these might refer to adventure. If the statement contains the word “driving,” then perhaps this is a safe driving ad, where visu-als in the ad allude to safety, danger, or speed, while phys-ically the visuals contain cars, tires, and windshields. Ads about “home” show houses and kitchens, but these refer to safety, family, and comfort. Freedom, family and relaxation are “American” concepts alluded to by flags. In ID 6, we see further evidence that PSAs (on health, art and violence) are more conceptual (the viewer needs tothink).
In IDs 8-10, we see the intuitive context and symbol-ism associated with “meat” and “rocks,” and the double role that “faces” can play (in beauty and domestic violence ads). Finally, observe the different role of “tomato” (ID 11) vs “ketchup” (ID 7): the former symbolizes health while the latter is associated with flavor and hotness.
ID Symbol Statement DenseCap 1 comfort couch, sofa,
soft, bed, 6 health, death, art,
injury, violence
think kites, lamp, art, bike, design
8 hunger, food, licious, hot,
de-Table 6. Discovered synonym triplets between symbol words, ac-tion/reason words, and DenseCap words. The single word (the word appearing alone in a table cell, shown in italics) is the query.
5. Conclusion
predic-tions about the memorability or human attention over ads, and use our object-symbol mappings to analyze the vari-ability that the same object category exhibits when used for different ad topics.
References
[1] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang. Bottom-up and top-down atten-tion for image capatten-tioning and VQA.CoRR, abs/1707.07998, 2017.4
[2] L. Anne Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Deep composi-tional captioning: Describing novel object categories without paired training data. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.2 [3] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra,
C. Lawrence Zitnick, and D. Parikh. Vqa: Visual question answering. InThe IEEE International Conference on Com-puter Vision (ICCV), December 2015.2
[4] Z. Bylinskii, S. Alsheikh, S. Madan, A. Recasens, K. Zhong, H. Pfister, F. Durand, and A. Oliva. Understanding info-graphics through textual and visual tag prediction. arXiv preprint arXiv:1709.09215, 2017.2
[5] Z. Bylinskii, A. Recasens, A. Borji, A. Oliva, A. Torralba, and F. Durand. Where should saliency models look next? In European Conference on Computer Vision, pages 809–824. Springer, 2016.3
[6] Y. Cao, M. Long, J. Wang, and S. Liu. Deep visual-semantic quantization for efficient image retrieval. InCVPR, 2017.2, 6
[7] K. Chen, T. Bui, C. Fang, Z. Wang, and R. Nevatia. Amc: Attention guided multi-modal correlation learning for image search. InCVPR, 2017.2,6
[8] L.-C. Chen, Y. Yang, J. Wang, W. Xu, and A. L. Yuille. At-tention to scale: Scale-aware semantic image segmentation. InComputer Vision and Pattern Recognition (CVPR). IEEE, 2016.2,3
[9] T.-H. Chen, Y.-H. Liao, C.-Y. Chuang, W.-T. Hsu, J. Fu, and M. Sun. Show, adapt and tell: Adversarial training of cross-domain image captioner. InThe IEEE International Confer-ence on Computer Vision (ICCV), Oct 2017.2
[10] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Dar-rell. Long-term recurrent convolutional networks for visual recognition and description. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.2
[11] A. Eisenschtat and L. Wolf. Linking image and text with 2-way nets. InCVPR, 2017.2,3,6
[12] F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler. Vse++: Improved visual-semantic embeddings. arXiv preprint arXiv:1707.05612, 2017.3
[13] J. Fu, H. Zheng, and T. Mei. Look closer to see better: recur-rent attention convolutional neural network for fine-grained image recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.2,3
[14] C. Gan, Z. Gan, X. He, J. Gao, and L. Deng. Stylenet: Generating attractive visual captions with styles. In The IEEE Conference on Computer Vision and Pattern Recog-nition (CVPR), July 2017.2
[15] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea-ture hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014.2,3
[16] L. Gomez, Y. Patel, M. Rusinol, D. Karatzas, and C. V. Jawa-har. Self-supervised learning of visual features through em-bedding images into text topic spaces. InCVPR, 2017.2,3, 6
[17] W. Goo, J. Kim, G. Kim, and S. J. Hwang. Taxonomy-regularized semantic deep convolutional neural networks. In European Conference on Computer Vision, pages 86–101. Springer, 2016.3
[18] K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask r-cnn. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017.2,3
[19] H. Hotelling. Relations between two sets of variates. Biometrika, 28(3/4):321–377, 1936.3
[20] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Effi-cient convolutional neural networks for mobile vision appli-cations.arXiv preprint arXiv:1704.04861, 2017.4 [21] R. Hu, J. Andreas, M. Rohrbach, T. Darrell, and K. Saenko.
Learning to reason: End-to-end module networks for visual question answering. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017.2
[22] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolu-tional object detectors. InThe IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), July 2017. 4, 6
[23] Z. Hussain, M. Zhang, X. Zhang, K. Ye, C. Thomas, Z. Agha, N. Ong, and A. Kovashka. Automatic understand-ing of image and video advertisements. InThe IEEE Confer-ence on Computer Vision and Pattern Recognition (CVPR), July 2017.1,2,3,4,5,6,7,8
[24] P. Isola, J. Xiao, D. Parikh, A. Torralba, and A. Oliva. What makes a photograph memorable?IEEE Transactions on Pat-tern Analysis and Machine Intelligence, 36(7):1469–1482, 2014.3
[25] L. Itti, C. Koch, and E. Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on pattern analysis and machine intelligence, 20(11):1254– 1259, 1998.3
[26] M. Iyyer, V. Manjunatha, A. Guha, Y. Vyas, J. Boyd-Graber, H. Daume, III, and L. S. Davis. The amazing mysteries of the gutter: Drawing inferences between panels in comic book narratives. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.2
[28] J. Johnson, B. Hariharan, L. van der Maaten, J. Hoffman, L. Fei-Fei, C. L. Zitnick, and R. Girshick. Inferring and ex-ecuting programs for visual reasoning. InICCV, 2017. 2, 3
[29] J. Johnson, A. Karpathy, and L. Fei-Fei. Densecap: Fully convolutional localization networks for dense captioning. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.2,3,4,5
[30] J. Joo, W. Li, F. F. Steen, and S.-C. Zhu. Visual persua-sion: Inferring communicative intents of images. In Pro-ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.2
[31] J. Joo, F. F. Steen, and S.-C. Zhu. Automated facial trait judg-ment and election outcome prediction: Social dimensions of face. InProceedings of the IEEE International Conference on Computer Vision, pages 3712–3720, 2015.2
[32] A. Karpathy and L. Fei-Fei. Deep visual-semantic align-ments for generating image descriptions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.2
[33] A. Kembhavi, M. Salvato, E. Kolve, M. Seo, H. Hajishirzi, and A. Farhadi. A diagram is worth a dozen images. In European Conference on Computer Vision, pages 235–251. Springer, 2016.2
[34] A. Khosla, A. S. Raju, A. Torralba, and A. Oliva. Un-derstanding and predicting image memorability at a large scale. InProceedings of the IEEE International Conference on Computer Vision, pages 2390–2398, 2015.3
[35] R. Kiros, R. Salakhutdinov, and R. S. Zemel. Unifying visual-semantic embeddings with multimodal neural lan-guage models. arXiv preprint arXiv:1411.2539, 2014. 2, 3,6,7,8
[36] R. Krishna, K. Hata, F. Ren, L. Fei-Fei, and J. Car-los Niebles. Dense-captioning events in videos. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017.2
[37] M. K¨ummerer, T. S. Wallis, and M. Bethge. Deepgaze ii: Reading fixations from deep features trained on object recog-nition.arXiv preprint arXiv:1610.01563, 2016.3
[38] J. H. Leigh and T. G. Gabel. Symbolic interactionism: its ef-fects on consumer behaviour and implications for marketing strategy.Journal of Services Marketing, 6(3):5–16, 1992.1 [39] S. J. Levy. Symbols for sale. Harvard business review,
37(4):117–124, 1959.1
[40] X. Li, D. Hu, and X. Lu. Image2song: Song retrieval via bridging image content and lyric words. InThe IEEE Inter-national Conference on Computer Vision (ICCV), Oct 2017. 2
[41] T. Lin, M. Maire, S. J. Belongie, L. D. Bourdev, R. B. Girshick, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: common objects in context. CoRR, abs/1405.0312, 2014.6
[42] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. InEuropean conference on computer vision, pages 21–37. Springer, 2016.2,3,4
[43] J. Lu, C. Xiong, D. Parikh, and R. Socher. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. InCVPR, 2017.2,3
[44] M. Malinowski, M. Rohrbach, and M. Fritz. Ask your neu-rons: A neural-based approach to answering questions about images. InThe IEEE International Conference on Computer Vision (ICCV), December 2015.2
[45] K. Marino, R. Salakhutdinov, and A. Gupta. The more you know: Using knowledge graphs for image classification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.3
[46] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.3
[47] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, edi-tors,Advances in Neural Information Processing Systems 26, pages 3111–3119. Curran Associates, Inc., 2013.3 [48] T. Mikolov, W.-t. Yih, and G. Zweig. Linguistic regularities
in continuous space word representations. InHLT-NAACL, pages 746–751, 2013.3
[49] I. Misra, A. Gupta, and M. Hebert. From red wine to red tomato: Composition with context. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.3
[50] Y. Movshovitz-Attias, A. Toshev, T. K. Leung, S. Ioffe, and S. Singh. No fuss distance metric learning using proxies. In ICCV, 2017.5,7,8
[51] H. Nam, J.-W. Ha, and J. Kim. Dual attention networks for multimodal reasoning and matching. InCVPR, 2017.2,3 [52] M. Pedersoli, T. Lucas, C. Schmid, and J. Verbeek. Areas
of attention for image captioning. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017.2,3 [53] B. A. Plummer, M. Brown, and S. Lazebnik. Enhancing
video summarization via vision-language embedding. In CVPR, 2017.2
[54] M. Ren and R. S. Zemel. End-to-end instance segmentation with recurrent attention. InThe IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), July 2017. 2, 3
[55] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.2,3
[56] A. Rosenberg and J. Hirschberg. V-measure: A condi-tional entropy-based external cluster evaluation measure. In EMNLP-CoNLL, volume 7, pages 410–420, 2007.7 [57] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A
uni-fied embedding for face recognition and clustering. InThe IEEE Conference on Computer Vision and Pattern Recogni-tion (CVPR), June 2015.3
[59] R. Shetty, M. Rohrbach, L. Anne Hendricks, M. Fritz, and B. Schiele. Speaking the same language: Matching machine to human captions by adversarial training. InThe IEEE Inter-national Conference on Computer Vision (ICCV), Oct 2017. 2
[60] K. J. Shih, S. Singh, and D. Hoiem. Where to look: Focus regions for visual question answering. InComputer Vision and Pattern Recognition (CVPR). IEEE, 2016.2,3 [61] N. E. Spears, J. C. Mowen, and G. Chakraborty.
Sym-bolic role of animals in print advertising: Content analysis and conceptual development.Journal of Business Research, 37(2):87–95, 1996.1
[62] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. InICLR 2016 Workshop, 2016.3 [63] M. Tapaswi, Y. Zhu, R. Stiefelhagen, A. Torralba, R.
Ur-tasun, and S. Fidler. Movieqa: Understanding stories in movies through question-answering. InThe IEEE Confer-ence on Computer Vision and Pattern Recognition (CVPR), June 2016.2
[64] D. Teney, P. Anderson, X. He, and A. v. d. Hengel. Tips and tricks for visual question answering: Learnings from the 2017 challenge. arXiv preprint arXiv:1708.02711, 2017. 2, 3,4
[65] R. Vedantam, S. Bengio, K. Murphy, D. Parikh, and G. Chechik. Context-aware captions from context-agnostic supervision. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.2
[66] S. Venugopalan, L. Anne Hendricks, M. Rohrbach, R. Mooney, T. Darrell, and K. Saenko. Captioning images with diverse objects. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.2,3 [67] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and
tell: A neural image caption generator. InProceedings of the IEEE conference on computer vision and pattern recog-nition, pages 3156–3164, 2015. 2
[68] P. Wang, Q. Wu, C. Shen, A. Dick, and A. van den Hengel. Fvqa: fact-based visual question answering. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 2017.2, 3
[69] Q. Wu, P. Wang, C. Shen, A. Dick, and A. van den Hen-gel. Ask me anything: Free-form visual question answering based on knowledge from external sources. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.2,3
[70] H. Xu and K. Saenko. Ask, attend and answer: Exploring question-guided spatial attention for visual question answer-ing. InEuropean Conference on Computer Vision (ECCV). Springer, 2016.2,3
[71] L. Yang, K. Tang, J. Yang, and L.-J. Li. Dense captioning with joint inference and visual context. InThe IEEE Confer-ence on Computer Vision and Pattern Recognition (CVPR), July 2017.2
[72] Z. Yang, X. He, J. Gao, L. Deng, and A. Smola. Stacked at-tention networks for image question answering. InComputer Vision and Pattern Recognition (CVPR). IEEE, 2016.2,3
[73] Q. You, H. Jin, Z. Wang, C. Fang, and J. Luo. Image caption-ing with semantic attention. InComputer Vision and Pattern Recognition (CVPR). IEEE, 2016.2,3
[74] C. E. Young. The advertising research handbook. Ideas in Flight, 2005.1,3
[75] P. Young, A. Lai, M. Hodosh, and J. Hockenmaier. From im-age descriptions to visual denotations: New similarity met-rics for semantic inference over event descriptions. Transac-tions of the Association for Computational Linguistics, 2:67– 78, 2014.6
[76] L. Yu, E. Park, A. C. Berg, and T. L. Berg. Visual madlibs: Fill in the blank description generation and question answer-ing. InThe IEEE International Conference on Computer Vi-sion (ICCV), December 2015.2
[77] Y. Yu, J. Choi, Y. Kim, K. Yoo, S.-H. Lee, and G. Kim. Su-pervising neural attention models for video captioning by hu-man gaze data. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.2
[78] J. Zhang and S. Sclaroff. Exploiting surroundedness for saliency detection: a boolean map approach. IEEE transactions on pattern analysis and machine intelligence, 38(5):889–902, 2016.3
[79] H. Zheng, J. Fu, T. Mei, and J. Luo. Learning multi-attention convolutional neural network for fine-grained image recog-nition. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017.2,3
[80] Y. Zhu, O. Groth, M. Bernstein, and L. Fei-Fei. Visual7w: Grounded question answering in images. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.2