KLASIFIKASI STATUS GIZI ORANG DEWASA
MENGGUNAKAN ALGORITMA NAÏVE BAYES
(STUDI KASUS KLINIK BHAKTI MULIA CIKARANG)
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Sarjana Satu (S1) pada Program Studi Teknik Informatika
Oleh:
TIARA DESWARA PUNGKAS 311410268
PROGRAM STUDI TEKNOLOGI INFORMASI
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
2018
KLASIFIKASI STATUS GIZI ORANG DEWASA
MENGGUNAKAN ALGORITMA NAÏVE BAYES
(STUDI KASUS KLINIK BHAKTI MULIA CIKARANG)
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Sarjana Satu (S1) pada Program Studi Teknik Informatika
Oleh:
TIARA DESWARA PUNGKAS 311410268
PROGRAM STUDI TEKNOLOGI INFORMASI
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
2018
vii
DAFTAR ISI
PERSETUJUAN ... Error! Bookmark not defined. PENGESAHAN ... Error! Bookmark not defined.
PERNYATAAN KEASLIAN PENELITIAN ... iv
KATA PENGANTAR ... v
DAFTAR ISI ... vii
DAFTAR TABEL ... x DAFTAR GAMBAR ... xi ABSTRAK ... xiii ABSTRACT ... xii BAB I PENDAHULUAN ... 1 1.1. Latar Belakang ... 1 1.2. Identifikasi Masalah ... 2 1.3. Batasan Masalah ... 3 1.4. Rumusan Masalah ... 3
1.5. Tujuan dan Manfaat ... 4
1.5.1 Tujuan ... 4
1.5.2 Manfaat ... 4
1.6. Sistematika Penulisan ... 5
viii 2.1. Kajian Pustaka ... 7 2.2. Dasar Teori ... 10 2.2.1 Data Mining ... 10 2.2.2 Naïve Bayes ... 13 2.2.3 Klasifikasi ... 15 2.2.4 Status Gizi ... 17 2.2.5 Cross Validation ... 18
BAB III METODE PENELITIAN... 19
3.1. Sejarah Singkat Klinik ... 19
3.2. Objek Penelitian ... 19
3.3. Pengumpulan Data ... 20
3.4. Peralatan Penelitian ... 24
3.5. Metode yang Diusulkan ... 26
3.6. Waktu Penelitian ... 26
BAB IV HASIL DAN PEMBAHASAN ... 28
4.1. Hasil ... 28
4.1.1 Analisis Preprocessing Data ... 28
4.1.2 Pengujian Algoritma Naïve Bayes ... 30
4.1.3 Pengujian Model yang Sudah Dibuat ... 31
4.2. Pembahasan ... 32
ix
5.1. Kesimpulan ... 34 5.2. Saran ... 34 DAFTAR PUSTAKA ... 36
x
DAFTAR TABEL
Tabel 2.1 Penelitian Sebelumnya yang Relevan ... 9
Tabel 3.1 Dataset Status Gizi ... 20
Tabel 3.2 Data Asli Status Gizi ... 22
Tabel 3 3 Data Status Gizi Setelah di Cleaning ... 23
Tabel 3 4 Data Status Gizi Setelah di Transformation ... 24
Tabel 3.5 Kegiatan Penelitian ... 27
Tabel 4.1 Training data yang sudah diolah ... 29
Tabel 4.2 Testing data yang telah diolah ... 29
xi
DAFTAR GAMBAR
Gambar 3.1 Alur Pengolahan Data ... 21
Gambar 3 2 Alur Metode yang Diusulkan ... 26
Gambar 4.1 Permodelan Naïve Bayes ... 30
Gambar 4.2 Hasil Result Naïve Bayes ... 30
Gambar 4.3 Data Statistic ... 31
Gambar 4.4 Proses Pengujian ... 31
Gambar 4.5 Proses Cross Validation ... 32
xii
ABSTRAK
Status gizi adalah keadaan yang diakibatkan oleh keseimbangan antara asupan zat gizi dari makanan dan kebutuhan zat gizi oleh tubuh. Status gizi orang dewasa terkadang kurang stabil dan banyak pola makan yang tidak teratur. Untuk mengetahui status gizi orang dewasa, maka dilakukan penelitian status gizi pada orang dewasa. Oleh karena itu, penelitian ini dibuat dengan algoritma naïve bayes untuk menentukan status gizi orang dewasa. Naïve bayes adalah teknik prediksi berbasis probabilitas sederhana yang berdasarkan pada penerapan teorema bayes, dan hasil akhirnya akan dilihat dari nilai yang paling tepat atau akurat, sehingga algoritma ini dianggap cukup baik dalam melakukan probabilitas untuk menentukan hasil. Pada penelitian ini, algoritma naïve bayes digunakan untuk menentukan status gizi orang dewasa. Data diklasifikasikan menjadi tiga, yaitu Normal, Kurang, dan Obesitas. Uji coba ini dilakukan dengan 150 data, dan hasil akurasi yang didapat sebesar 88,67%.
xiii
ABSTRACT
Nutritional status is a condition caused by a balance between nutrient intake from food and nutritional needs by the body. The nutritional status of adults is sometimes less stable and there are many irregular eating patterns. To find out the nutritional status of adults, research on nutritional status in adults is carried out. Therefore, this study was made with a naïve bayes algorithm to determine the nutritional status of adults. Naïve Bayes is a simple probability-based prediction technique that is based on the application of the Bayes theorem, and the end result will be seen from the most appropriate or accurate value, so that this algorithm is considered to be good enough in performing probabilities to determine results. In this study, a naïve bayes algorithm was used to determine the nutritional status of adults. Data are classified into three, namely Normal, Less, and Obesity. This trial was conducted with 150 data, and the results of the accuracy obtained were 88.67%.
Keyworad: Nutritional Status, Classification, Data Mining, Naïve Bayes Algorithm
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Status gizi adalah salah satu unsur penting dalam membentuk status kesehatan. Status gizi (nutritional satus) adalah keadaan yang diakibatkan oleh keseimbangan antara asupan zat gizi dari makanan dan kebutuhan zat gizi oleh tubuh. Status gizi sangat dipengaruhi oleh asupan gizi, karena suatu ukuran mengnai kondisi tubuh seseorang yang dapat dilihat dari makanan yang dikonsumsi dan penggunaan zat-zat gizi di dalam tubuh. Status gizi suatu tanda-tanda penampilan seseorang akibat keseimbangan antar pemasukan dan pengeluaran zat gizi yang berasal dari pangan yang dikonsumsi pada suatu saat berdasarkan kategori dan indikator yang digunakan. Seseorang diidentifikasi status gizi normal apabila terdapat keseimbangan antara jumlah energi yang masuk ke dalam tubuh dan energi yang di keluarkan dari luar tubuh sesuai dengan kebutuhan individu. Energi yang masuk ke dalam tubuh dapat berasal dari karbohidrat, protein, lemak dan zat gizi lainnya. Pemanfaatan zat gizi dalam tubuh dipengaruhi oleh dua faktor, yaitu primer dan sekunder. Faktor primer adalah keadaan yang mempengaruhi asupan gizi dikarenakan susunan makanan yang dikonsumsi tidak tepat, sedangkan faktor sekunder adalah zat gizi tidak mencukupi kebutuhan tubuh karena adanya gangguan pada pemanfaatan zat gizi dalam tubuh. Status gizi orang dewasa terkadang kurang stabil, dan banyak pola makan yang tidak teratur. Status gizi orang dewasa biasanya diukur dengan antropometri.
2
Klinik Bhakti Mulia adalah klinik yang melayani pengobatan umum untuk masyarakat yang berlokasi di Jl. Sindang Jaya RT/RW 003/007 No. 20, Desa Karang Asih Pilar Cikarang Utara, Kabupaten Bekasi, Kode Pos 17530. Klinik Bhakti Mulia berdiri pada tahun 1984. Klinik ini didirikan karena belum adanya klinik yang melayani pengobatan umum yang tersedia khususnya di daerah Cikarang Utara, sehingga pemilik klinik berinisiatif mendirikan klinik ini untuk membantu pengobatan di daerah tersebut. Pada klinik Bhakti Mulia, untuk menilai status gizi seseorang menggunakan antropometri.
Pengukuran antropometri tidak lah salah, namun sering sekali terjadi kerancuan dalam pengukurannya. Akan tetapi, untuk usia dewasa sekarang ini menggunakan perhitungan Indeks Massa Tubuh (IMT). Indeks Massa Tubuh (IMT) merupakan alat atau cara yang sederhana untuk memantau status gizi orang dewasa. Namun, pengukuran ini sering terjadi kerancuan. Pegawai klinik sesekali pernah mengalami perhitungan yang rancu atau lebih tepatnya perhitungan yang tidak akurat. Jadi, harus ada suatu metode yang dapat memperhitung keakuratannya.
Status gizi orang dewasa pada klinik Bhakti Mulia akan menggunakan Teknik data mining yang akan digunakan untuk mengetahui klasifikasi status gizi orang dewasa pada klinik Bhakti Mulia, salah satunya menggunakan algoritma
Naïve Bayes. Algoritma ini memanfaatkan nilai probabilitas yang akurat.
1.2. Identifikasi Masalah
Berdasarkan latar belakang yang telah di sampaikan, identifikasi masalah sebagai berikut ;
3
1. Pihak klinik kesulitan dalam mengukur status gizi orang dewasa karena belum ada metode perhitungan untuk memantau status gizi orang dewasa. 2. Pihak klinik kesulitan dalam menentukan nilai akurasi yang baik untuk
status gizi orang dewasa.
3. Pihak klinik kesulitan dalam menentukan klasifikasi status gizi orang dewasa.
1.3. Batasan Masalah
Agar pembahasan lebih focus pada permasalahan yang ada, maka diperlukan pembatasan masalah ;
1. Mencari penyebab keakurasian yang tidak tepat dalam menentukan nilai akurasi status gizi orang dewasa.
2. Menentukan algoritma terbaik dalam penilaian status gizi orang dewasa agar dapat memberikan nilai yang akurat.
3. Menerapkan algoritma naïve bayes untuk menentukan klasifikasi status gizi yang lebih baik dan tepat.
1.4. Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah didapatkan, maka rumusan masalahnya sebagai berikut ;
1. Bagaimana pihak klinik mengukur atau melakukan perhitungan status gizi orang dewasa?
2. Bagaimana untuk mendapatkan nilai akurasi yang baik dan tepat untuk status gizi orang dewasa?
4
3. Bagaimana algoritma naïve bayes dapat memberikan nilai akurasi yang baik dan tepat dari status gizi orang dewasa?.
1.5. Tujuan dan Manfaat 1.5.1 Tujuan
Berdasarkan rumusan masalah yang sudah di uraikan maka di dapatkan tujuan sebagai berikut :
1. Penelitian ini dilakukan agar pihak klinik mampu melakukan perhitungan status gizi orang dewasa dengan baik dan tepat.
2. Dapat memberikan keakuratan yang baik bagi status gizi orang dewasa menggunakan metode data mining.
3. Penelitian ini menggunakan algoritma naïve bayes, agar nilai akurasi yang didapat baik dan benar.
1.5.2 Manfaat
Jika tercapainya tujuan di atas, maka penelitian ini memberikan manfaat sebagai berikut ;
1. Bagi Mahasiswa
a. Menambah pengetahuan, wawasan, dan peningkatan ilmu kesehatan untuk lebih menjaga kesehatan tubuh
b. Menerapkan ilmu pada bidang Teknik Informatika dengan kajian data mining serta sebagai salah satu syarat kelulusan gelar S1 program studi Teknik Informatika di STT Pelita Bangsa
5
a. Diharapkan dapat dipergunakan sebagai bahan acuan dalam melakukan penelitian lebih lanjut tentang status gizi orang dewasa menggunakan perhitungan algoritma
b. Menambah literatur atau sumber kajian di perpustakaan STT Pelita Bangsa
3. Bagi Perusahaan
a. Dapat dijadikan informasi secara dini untuk menentukan akurasi yang baik bagi penilaian status gizi orang dewasa
b. Lebih percaya diri lagi untuk menentukan status gizi pada pasien 1.6. Sistematika Penulisan
Untuk mempermudah dan memahami laporan penulisan dan pembahasan skripsi ini, penulis membuat sistematika penulisan sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, identifikasi masalah, rumusan masalah, pembatasan masalah, tujuan dan manfaat masalah, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisikan teori – teori kajian pustaka yang akan menjadi landasan dasar sebagai acuan dalam melakukan penelitian ini. Tidak lupa pada bab ini dirumuskan kerangka berpikir serta mengkaji dari penelitian – penelitian terdahulu baik yang berkaitan langsung maupun yang masih ada kaitannya dalam pembahasan penelitian ini.
6
BAB III METODE PENELITIAN
Bab ini akan menjelaskan tentang langkah – langkah penelitian yang akan dilakukan mulai dari persiapan data, objek yang akan menjadi bahan penelitian, serta metode yang digunakan dalam melakukan penelitian ini.
BAB IV HASIL DAN PEMBAHASAN
Bab ini akan menjelaskan tentang hasil serta pembahasan dari penelitian yang sudah dilakukan bab ini merupakan inti sari dari penelitian yang dilakukan serta menghasilkan karya seni penelitian. BAB V PENUTUP
Bab ini berisikan kesimpulan dan saran dari penelitian yang sudah dilakukan secara keseluruhan serta memberikan beberapa saran sebagai acuan apabila ada yang akan melanjutkan penelitian ataupun ingin mengembangkan penelitian ini.
7
BAB II
TINJAUAN PUSTAKA
2.1. Kajian Pustaka
Beberapa penelitian tentang penerapan data mining ataupun yang mendekati penelitian tersebut.
Klasifikasi status gizi balita menggunakan naïve bayes classification (Putra, 2018). Penelitian ini bertujuan untuk memudahkan penentuan status gizi balita menggunakan data mining dengan algoritma naïve bayes classification (NBC). Penelitian ini menggunakan data 17 balita dengan rentang waktu 2 tahun pengukuran. Total data yang digunakan berjumlah 408 data. Dilakukan dua kali pengujian data, pertama dengan perbandingan 60:40 dan kedua 80:20 data training dan data testing. Hasil penelitian menunjukkan akurasi sebesar 93,1%. Dengan kata lain NBC dikategorikan baik untuk pengujian status gizi balita.
Komparasi algoritma C.45 dan backpropagation untuk klasifikasi status gizi balita berdasarkan indeks antropometri Bb/U dan BB/PB (Purwati, Agustina, & S, 2017). Penelitian ini bertujuan melakukan komparasi algoritma C.45 dan Backpropagation untuk klasifikasi staus gizi balita berdasarkan indeks antropometri BB/U dan BB/PB yang akan menghasilkan status sangat kurus, kurus, normal, dan gemuk. Hasil dari penelitian ini diperoleh metode yang paling akurat untuk klasifikasi status gizi balita yaitu menggunakan metode algoritma Backpropagation dengan accuracy sebesar 96,08% dan kappa 0,907. Sedangkan pada algoritma C.45 diperoleh nilai accuracy sebesar 88,24% dan kappa 0,725.
8
Analisa rekam medis untuk menentukan status gizi anak balita menggunakan naïve bayes classifier (Pramitarini, Purnama, & Purnomo, 2013). Penelitian ini melakukan pencarian pola status gizi yang sering dialami oleh pasien balita yang mana bisa dideteksi dari informasi yang terkandung dalam kumpulan rekam medis. Pencarian pola akan dilakukan dengan menerapkan metode klasifikasi dengan algoritma naïve bayes dengan jumlah data bersih sebanyak 198 data. Hasil dari penelitian ini adalah mengklasifikasikan data yang ada sesuai dengan intepretasinya. Pengujiannya dilakukan dengan membagi data sampel yang ada menjadi 70:30, 50:50, dan 30:70. Untuk uji validitasnya diperoleh jika 70:30 maka besar nilai akurasinya 88%. Jika 50:50 maka besar nilai akurasinya 55% dan jika 30:70 maka besar nilai akurasinya 28%.
Sistem pendukung keputusan penentuan status gizi balita menggunakan metode Naïve Bayes (Wahyudi, 2018). Penelitian ini menilai status gizi balita menggunakan metode Naïve Bayes pada sistem pendukung keputusan. Hasil dari penelitian ini, menunjukkan metode Naïve Bayes bisa diimplementasikan dengan sistem pendukung keputusan, kinerja pada sistem ini menunjukkan nilai sebesar 86,7%.
Penerapan metode Naïve Bayes untuk klasifikasi status gizi (Zubair & Muksin, 2018). Penelitian ini menggunakan metode Naïve Bayes Classifier. Penelitian ini langsung menguji hasil dari akurasi yang didapat, hasilnya menunjukkan bahwa penelitian ini memiliki nilai akurasi 98% sebaiagi akurasi terbaik.
Implementasi Naïve Bayes Classifier untuk diagnosa status gizi balita (Hariri & Pamungkas, 2016). Penelitian ini melakukan probabilitas pada setiap
9
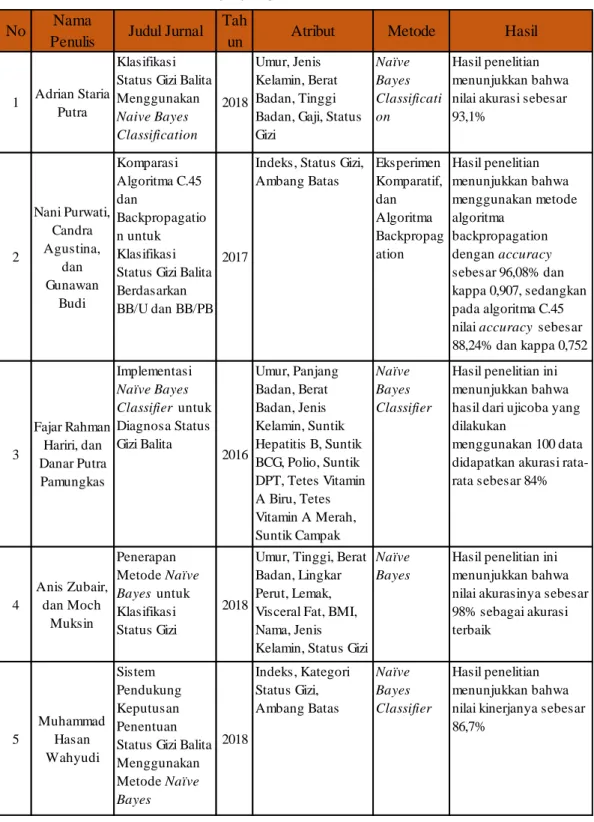
class yang paling tertinggi, agar algoritma bisa merasa cukup baik untuk melakukan probabilitas dalam menentukan hasil. Hasil yang didapat dari uji coba yang dilakukan dari 100 data, mendapatkan nilai rata – rata akurasi sebesar 84%. Tabel 2.1 Penelitian Sebelumnya yang Relevan
No Nama
Penulis Judul Jurnal Tah
un Atribut Metode Hasil
1 Adrian Staria Putra
Klasifikasi Status Gizi Balita Menggunakan Naive Bayes Classification 2018 Umur, Jenis Kelamin, Berat Badan, Tinggi Badan, Gaji, Status Gizi Naïve Bayes Classificati on Hasil penelitian menunjukkan bahwa nilai akurasi sebesar 93,1% 2 Nani Purwati, Candra Agustina, dan Gunawan Budi Komparasi Algoritma C.45 dan Backpropagatio n untuk Klasifikasi Status Gizi Balita Berdasarkan BB/U dan BB/PB
2017
Indeks, Status Gizi, Ambang Batas Eksperimen Komparatif, dan Algoritma Backpropag ation Hasil penelitian menunjukkan bahwa menggunakan metode algoritma backpropagation dengan accuracy sebesar 96,08% dan kappa 0,907, sedangkan pada algoritma C.45 nilai accuracy sebesar 88,24% dan kappa 0,752 3 Fajar Rahman Hariri, dan Danar Putra Pamungkas Implementasi Naïve Bayes Classifier untuk Diagnosa Status Gizi Balita 2016 Umur, Panjang Badan, Berat Badan, Jenis Kelamin, Suntik Hepatitis B, Suntik BCG, Polio, Suntik DPT, Tetes Vitamin A Biru, Tetes Vitamin A Merah, Suntik Campak Naïve Bayes Classifier
Hasil penelitian ini menunjukkan bahwa hasil dari ujicoba yang dilakukan
menggunakan 100 data didapatkan akurasi rata-rata sebesar 84% 4 Anis Zubair, dan Moch Muksin Penerapan Metode Naïve Bayes untuk Klasifikasi Status Gizi 2018
Umur, Tinggi, Berat Badan, Lingkar Perut, Lemak, Visceral Fat, BMI, Nama, Jenis Kelamin, Status Gizi
Naïve Bayes
Hasil penelitian ini menunjukkan bahwa nilai akurasinya sebesar 98% sebagai akurasi terbaik 5 Muhammad Hasan Wahyudi Sistem Pendukung Keputusan Penentuan Status Gizi Balita Menggunakan Metode Naïve Bayes 2018 Indeks, Kategori Status Gizi, Ambang Batas Naïve Bayes Classifier Hasil penelitian menunjukkan bahwa nilai kinerjanya sebesar 86,7%
10
2.2. Dasar Teori
Dasar teori yang ada merupakan salah satu landasan untuk menguatkan penelitian yang akan dilakukan. Pengertian serta sejarah dari teori maupun algoritma yang digunakan dalam penelitian ini akan dijabarkan pada bab ini, mengenai sejarah dari algoritma naïve bayes, pengertian tentang data mining serta fungsi dan kegunaannya, kelebihan serta kekurangan dari algoritma naïve bayes, klasifikasi, status gizi, serta beberapa teori pendukung lainnya sebagai landasan penelitian ini.
2.2.1 Data Mining
“Data mining merupakan data yang tersimpan dalam waktu yang lama, kemudian data tersebut dikumpulkan, ternyata setelah di analisis data tersebut memiliki pola tertentu. Data mining biasanya berisi tentatng statistik, ekonomi, ramalan cuaca, serta berbagai jenis data lainnya yang berhubungan dengan pekerjaan. Data mining merupakan pelajaran apa yang telah terjadi dimasa lalu kemudian akan diterapkan dimasa yang akan datang agar memperoleh hasil yang lebih baik. Secara khusus, koleksi metode yang dikenal sebagai data mining menawarkan metodologi dan solusi teknis untuk mengatasi analisis data medis dan kontruksi prediksi model” (Naparin, 2016).
“Data mining merupakan proses pengekstraksian informasi dari sekumpulan data yang sangat besar melalui penggunaan algoritma dan teknik penarikan dalam bidang statistik, pembelajaran mesin, dan sistem manajemen basis data. Data
mining adalah proses menganalisa data dari perspektif yang berbeda dan
11
meningkatkan keuntungan, memperkecil biaya pengeluaran, atau bahkan kedunya” (Saleh, 2015).
“Data mining merupakan proses ataupun kegiatan untuk mengumpulkan data yang berukuran besar kemudian mengekstraksi data tersebut menjadi informasi – informasi yang nantinya dapat digunakan” (Fadlan, Ningsih, & Windarto, 2018).
“Data mining adalah proses seleksi, eksplorasi, dan pemodelan dari sejumlah besar data untuk menemukan pola atau kecenderungan yang biasanya tidak disadari keberadaannya. Data mining dapat dikatakan sebagai proses mengekstrak pengetahuan dari sejumlah besar data yang tersedia. Pengetahuan yang dihasilkan dari proses data mining harus baru, mudah dimengerti, dan bermanfaat. Dalam data mining, data disimpan secara elektronik dan diproses secara otomatis oleh komputer menggunakan teknik dan perhitungan tertentu” (Pramadhani & Setiadi, 2014).
Tahapn – tahapan dalam data mining dibagi menjadi beberapa tahap (Saleh, 2015), antara lain :
1. Pembersiihan Data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan.
2. Integrasi Data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
12
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari
database.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Tidak semua data dapat diproses secara langsung, karena tidak setiap data memiliki karakteristiknya masing – masing, sebab ada bebebrapa data yang memerlukan sebuah transformasi data.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. Beberapa metode yang dapat digunakan berdasarkan pengelompokan data mining.
6. Evaluasi Pola (Pattern Evaluation)
Untuk mengidentifikasi pola – pola menarik kedalam pengetahuan yang ditemukan, sehingga dapat diketahui proses yang dilakukan sudah akurat atau belum.
7. Presentasi Pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
“Data mining merupakan proses pencarian pola dan relasi – relasi yang tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, association rule, clustering, dan deskripsi.
13
Berdasarkan aktifitasnya data mining dikelompokan menjadi dua jenis, yaitu
directeddata mining dan undirected data mining” (Nugraha, Dodu, & Chandra,
2017) .
“Data mining adalah bagian dari proses penemuan pengetahuan terbesar yang meliputi tugas preprocessing seperti data extraction, data cleaning, data
fusion, data reduction, dan feature construction, dan juga meliputi tugas post processing seperti pattern and model interpretation, hypothesis confirmation, dan
sebagainya. Proses data mining ini cenderung berulang dan interaktif” (Nugroho, T, M, & Si, 2016).
“Data mining merupakan sebagai proses menemukan dan membaca pola dalam data sehingga dapat digunakan sebagai alat untuk membantu menemukan informasi yang sangat penting dari data tersebut” (Purwati et al., 2017).
“Data mining adalah suatu proses menemukan hubungan yang berarti, pola dan kecendrungan dengan memeriksa sekumpulan besar data yang tersimpan dengan menggunakan Teknik pengenalan pola” (Putra, 2018).
2.2.2 Naïve Bayes
“Naïve bayes adalah salah satu algoritma pembelajaran induktif yang paling efektif dan efisien untuk machine learning dan data mining. Pervorma naïve bayes yang kompetitif dalam proses klasifikasi walaupun menggunakan asumsi keidependenan atribut (tidak ada kaitan antar atribut). Asumsi keidependenan atribut ini pada data sebenarnya jarang terjadi, namun walaupun asumsi keidependenan atribut tersebut dilanggar performa pengklasifikasian naïve bayes cukup tinggi” (Syarli, 2016).
14
“Naïve bayes merupakan teknik prediksi berbasis probabiitas sederhana yang berdasarkan pada penerapan teorema Bayes dengan asumsi independensi yang kuat. Dengan kata lain, dalam Naïve bayes menggunakan model fitur independen, maksud independen yang kuat pada fitur adalah bahwa data tidak berkaitan dengan data yang lain dalam kasus yang sama ataupun atribut yang lain” (Fadlan et al., 2018).
“Naïve bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai teorema bayes” (Syarli, 2016).
Rumus dari theorem bayes sendiri ialah :
𝑃(𝑋|𝐻)𝑃(𝐻)
𝑃(𝐻|𝑋) =
𝑃(𝑋) Keterangan :
X : Data dengan kelas yang belum diketahui
H : Hipotesis data x merupakan suatu kelas spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (posteriori probabilty P(H) : Probabilitas hipotesis H (prior probabilty)
P(X|H) : Probabilitas X berdasar kondisi pada hipotesis H P(X) : Probabilitas X
Berdasarkan persamaan theorem bayes maka inilah rumus naïve bayes
15
𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖)
𝑃(𝐶𝑖|𝑋) =
𝑃(𝑋) Keterangan :
X : Data dengan kelas yang belum diketahui
Ci : Hipotesis data x merupakan suatu kelas spesifik
P(Ci|X) : Probabilitas hipotesis Ci berdasarkan kondisi X (posteriori probability) P(Ci) : Probabilitas hipotesis Ci (prior probabilty)
P(X|Ci) : Probabilitas X berdasar kondisi pada hipotesis Ci P(X) : Probabilitas X
“Naïve Bayes merupakan sebuah pengklasifikasian probabilistik sederhana
yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan. Algoritma menggunakan teorema bayes dan mengasumsikan semua atribut independent atau tidak saling ketergantungan yang diberikan nilai pada variabel kelas” (Saleh, 2015).
“Naïve Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik. Memprediksi peluang di masa depan berdasarkan pada pengalaman di masa sebelumnya” (Naparin, 2016).
2.2.3 Klasifikasi
“Klasifikasi adalah salah satu masalah mendasar dan tugas utama dalam data mining, dalam klasifikasi sebuah pengklasifikasi dibuat dari sekumpulan data latih dengan kelas yang telah ditentukan sebelumnya. Performa pengklasifikasi biasanya diukur dengan ketepatan atau tingkat galat” (Syarli, 2016).
16
“Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Dalam mencapai tujuan tersebut, proses klasifikasi membentuk suatu model yang mampu membedakan data kedalam kelas- kelas yang berbeda berdasarkan aturan atau fungsi tertentu. Model itu sendiri bisa berupa aturan “jika-maka”, berupa pohon keputusan, atau formula matematis” (Fadlan et al., 2018).
“Klasifikasi adalah metode dalam Data Mining yang paling sering digunakan untuk menyelesaikan problem-problem di dunia nyata. Sebagai salah satu yang terpopuler dalam keluarga yang menggunakan teknik
‘machine-learning’, classification mempelajari pola-pola dari data historis (sekumpulan
informasi –seperti ciri-ciri, variabel-variabel, fitur-fitur – pada berbagai karakteristik item-item yang sudah diberi label sebelumnya) dengan tujuan untuk menempatkan instans (object-object) baru (dengan label yang tak diketahui sebelumnya) ke dalam kelompok atau kelas masing-masing” (Rahman & Firdaus, 2016).
“Klasifikasi adalah suatu pengklasifikasian yang terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah, dan beberapa contoh yang menentukan kelas” (Nugraha et al., 2017).
“Klasifikasi merupakan pembagian data dalam beberapa kelompok yang sudah ditentukan sebelumnya” (Naparin, 2016).
17
2.2.4 Status Gizi
“Status gizi adalah suatu ukuran mengenai kondisi tubuh seseorang yang dapat dilihat dari makanan yang dikonsumsi dan penggunaan zat – zat gizi di dalam tubuh. Status gizi dibagi menjadi tiga kategori, yaitu status gizi kurang, gizi normal, dan gizi lebih” (Purwati et al., 2017).
“Status gizi adalah keadaan ketika seseorang memiliki asupan dan kebutuhan zat gizi yang seimbang dan berguna untuk tumbuh kembang. Zat gizi ini juga berguna sebagai pemeliharaan kesehatan, serta penyembuh bagi mereka yang sakit dan juga proses biologis lainnya yang bekerja di dalam tubuh” (Zubair & Muksin, 2018).
“Status gizi adalah ukuran keberhasilan dalam pemenuhan nutrisi untuk anak yang diindikasikan oleh berat badan dan tinggi badan anak. Status gizi juga didefinisikan sebagai status kesehatan yang dihasilkan oleh keseimbangan antara kebutuhan dan masukan nutrient (nutrisi)” (Hariri & Pamungkas, 2016).
“Status gizi kurang atau lebih sering disebut undernutrition merupakan keadaan gizi seseorang dimana jumlah energi yang masuk lebih sedik dari energi yang dikeluarkan. Hal ini dapat terjadi karena jumlah energi yang masuk lebih sedikit dari anjuran kebutuhan individu” (Purwati et al., 2017).
“Status gizi merupakan keadaan kesehatan tubuh seseorang yang diakibatkan oleh konsumsi, penyerapan, dan penggunaan zat gizi makanan. Status gizi seseorang tersebut dapat diukur dan dinilai untuk mengetahui apakah status gizinya tergolong normal atau tidak normal” (Rahmawati, 2017).
18
“Staus gizi merupakan keadaan kesehatan tubuh seseorang atau sekelompok orang yang diakibatkan oleh konsumsi, penyerapan (absorption), dan penggunaan (utilization) zat gizi makanan. Status gizi seseorang atau sekelompok orang dapat digunakan untuk mengetahui apakah seseorang atau sekelompok orang tersebut keadaan gizinya baik atau sebaliknya” (Riyadi, Khomsan, S, A, & Mudjajanto, 2006).
2.2.5 Cross Validation
“Cross validation merupakan suatu metode evaluasi, dimana pada metode ini data yang digunakan dalam jumlah yang sama untuk training dan tepat satu kali untuk testing. Cross validation memiliki beberapa pendekatan, salah satunya adalah Hold – Out. Hold – Hout merupakan metode untuk memecah dataset mennjadi dua bagian terpisah, yaitu set data latih dan set data uji” (Nugroho et al., 2016)
“Croos validation adalah suatu pengkelompokan data pada setip kelas yang diwakili dalam proporsi yang tepa tantara data training dan data testing. Data dibagi secara acak pada masing – masing kelas dengan perbandingan yang sama. Untuk mengurangi bias yang disebabkan oleh sampel tertentu, seluruh proses
training dan testing diulang beberapa kali dengan sampel yang berbeda tingkat
kesalahan pada iterasi yang berbeda akan dihitung rata – rata nya untuk menghasilkan error rate secara keseluruhan. Model yang memberikan rata – rata kesalahan terkecil adalah model yang terbaik” (Menarianti, 2015)
19
BAB III
METODE PENELITIAN
3.1. Sejarah Singkat Klinik
Klinik Bhakti Mulia adalah klinik yang melayani pengobatan umum untuk masyarakat yang berlokasi di Jl. Sindang Jaya RT/RW 003/007 No. 20, Desa Karang Asih Pilar Cikarang Utara, Kabupaten Bekasi, Kode Pos 17530. Klinik Bhakti Mulia berdiri pada tahun 1984. Klinik ini didirikan karena belum adanya klinik yang melayani pengobatan umum yang tersedia khususnya di daerah Cikarang Utara, sehingga pemilik klinik berinisiatif mendirikan klinik ini untuk membantu pengobatan di daerah tersebut. Pada klinik Bhakti Mulia, untuk menilai status gizi seseorang menggunakan antropometri.
3.2. Objek Penelitian
Objek penelitian yang digunakan ialah kinerja dari algoritma Naïve Bayes untuk memprediksi tingkat status gizi orang dewasa terhadap pasien klinik Bhakti Mulia dengan dataset yang diambil dari beberapa data pasien. Data yang diambil berupa dataset status gizi orang dewasa yang akan diakurasi kebenarannya.
Perhitungan status gizi orang dewasa setiap tahunnya mengalami peningkatan, karena kurangnya informasi secara akurat dalam menentukan status gizi orang dewasa, maka dari itu penelitian ini dilakukan untuk mengurangi ketidak akuratan dalam perhitungan status gizi orang dewasa menggunakan algoritma Naïve Bayes.
20
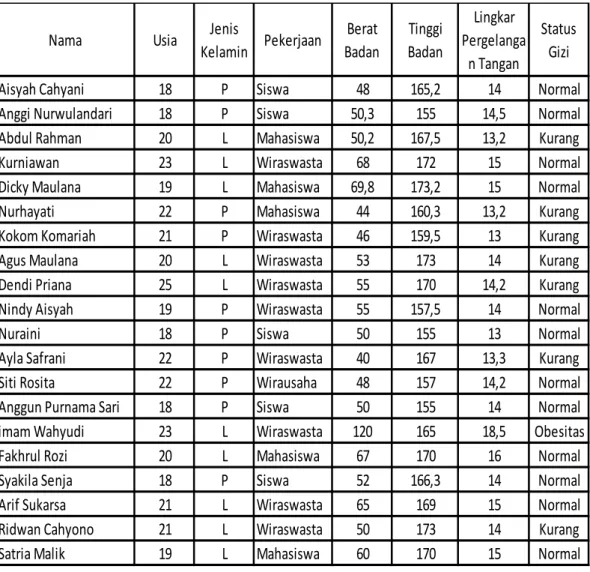
Data yang diambil berupa dataset status gizi orang dewasa dari klinik Bhakti Mulia Cikarang dengan 8 atribut, yaitu nama, usia, jenis kelamin, pekerjaan, berat badan, tinggi badan, lingkar pergelangan tangan, dan status gizi. 3.3. Pengumpulan Data
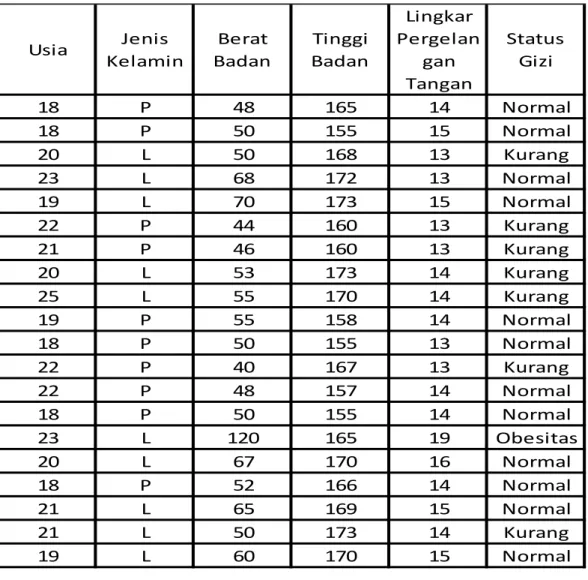
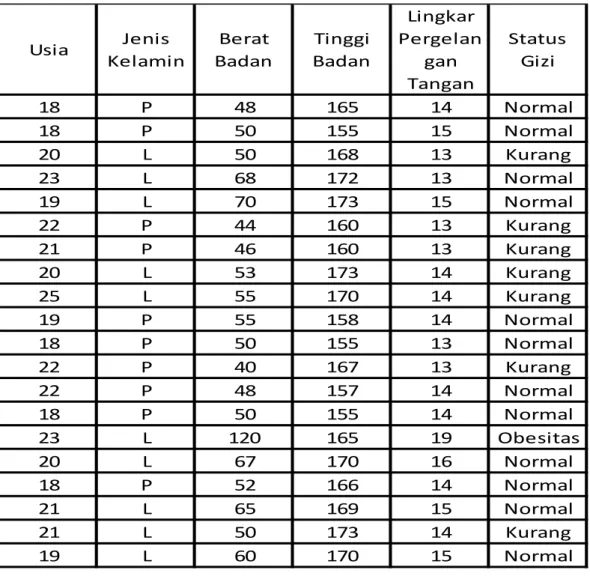
Pengumpulan data dalam penelitian ini menggunakan metode pengumpulan data primer. Data primer adalah data yang diperoleh secara langsung pada sumbernya. Sumber data yang digunakan penelitian ini berasal dari data publik yaitu dataset klinik Bhakti Mulia dengan jumlah 150 data. Berikut tabel 3.1 menunjukkan table sebagian dari dataset status gizi :
Tabel 3.1 Dataset Status Gizi
Nama Usia Jenis
Kelamin Pekerjaan Berat Badan Tinggi Badan Lingkar Pergelanga n Tangan Status Gizi Aisyah Cahyani 18 P Siswa 48 165,2 14 Normal Anggi Nurwulandari 18 P Siswa 50,3 155 14,5 Normal Abdul Rahman 20 L Mahasiswa 50,2 167,5 13,2 Kurang Kurniawan 23 L Wiraswasta 68 172 15 Normal Dicky Maulana 19 L Mahasiswa 69,8 173,2 15 Normal Nurhayati 22 P Mahasiswa 44 160,3 13,2 Kurang Kokom Komariah 21 P Wiraswasta 46 159,5 13 Kurang Agus Maulana 20 L Wiraswasta 53 173 14 Kurang Dendi Priana 25 L Wiraswasta 55 170 14,2 Kurang Nindy Aisyah 19 P Wiraswasta 55 157,5 14 Normal Nuraini 18 P Siswa 50 155 13 Normal Ayla Safrani 22 P Wiraswasta 40 167 13,3 Kurang Siti Rosita 22 P Wirausaha 48 157 14,2 Normal Anggun Purnama Sari 18 P Siswa 50 155 14 Normal imam Wahyudi 23 L Wiraswasta 120 165 18,5 Obesitas Fakhrul Rozi 20 L Mahasiswa 67 170 16 Normal Syakila Senja 18 P Siswa 52 166,3 14 Normal Arif Sukarsa 21 L Wiraswasta 65 169 15 Normal Ridwan Cahyono 21 L Wiraswasta 50 173 14 Kurang Satria Malik 19 L Mahasiswa 60 170 15 Normal
21
3.3.1 Analisa Pengolahan Data
Berikut ini adalah langkah – langkah dari analisa pengolahan data yang akan dilakukan :
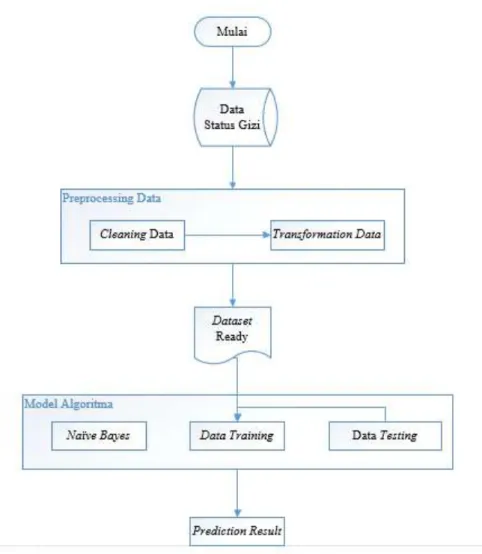
Mulai Data Mentah Seleksi Data
Data Status Gizi yang Sudah Diolah
Proses Mining Selesai
Gambar 3.1 Alur Pengolahan Data a. Seleksi Data
Pada tahap ini akan dilakukan penyeleksian terhadap data yang kurang relevan terhadap penelitian (menghilangkan atau menghapus data). Setelah diseleksi, dilakukan penggabungan seluruh data yang telah diperoleh. Setelah itu data akan disimpan dalam satu file sesuai dengan kriteria atributnya.
b. Penerapan Teknik Mining
Pada tahap ini data menjadi sangat relevan, dari berbagai data akan diklasifikasikan ke beberapa tipe dari data tersebut dengan metode Naïve Bayes. 3.4. Analisi Data
Dataset yang akan digunakan dalam penelitian ini adalah data asli dari klinik Bhakti Mulia Cikarang dengan status gizi orang dewasa, beserta
22
keterangannya. Berikut ini adalah sebagian dari data yang akan dijadikan dataset dengan beberapa tahapan :
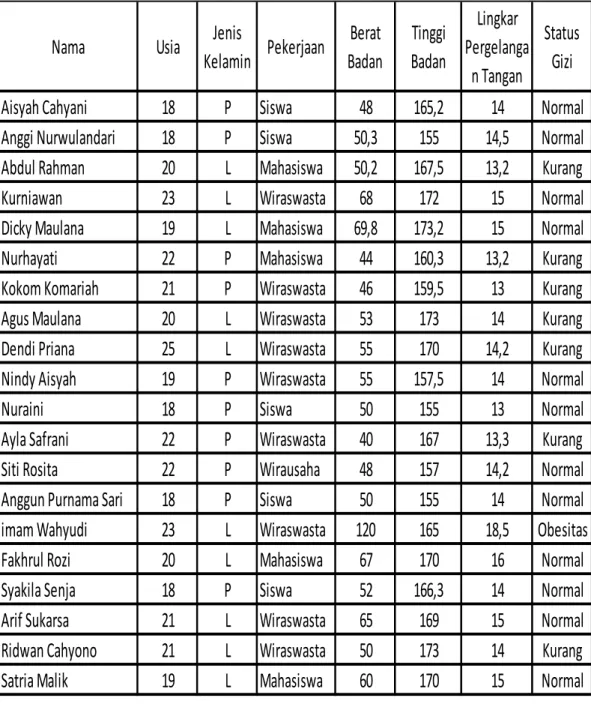
1. Cleaning Data
Cleaning data diperlukan untuk menghilangkan beberapa atribut yang tidak
dibutuhkan sebagai dataset dalam pengujian yang akan dilakukan. Tabel 3.2 Data Asli Status Gizi
Nama
Usia
Jenis
Kelamin
Pekerjaan
Berat
Badan
Tinggi
Badan
Lingkar
Pergelanga
n Tangan
Status
Gizi
Aisyah Cahyani
18
P
Siswa
48
165,2
14
Normal
Anggi Nurwulandari
18
P
Siswa
50,3
155
14,5
Normal
Abdul Rahman
20
L
Mahasiswa
50,2
167,5
13,2
Kurang
Kurniawan
23
L
Wiraswasta
68
172
15
Normal
Dicky Maulana
19
L
Mahasiswa
69,8
173,2
15
Normal
Nurhayati
22
P
Mahasiswa
44
160,3
13,2
Kurang
Kokom Komariah
21
P
Wiraswasta
46
159,5
13
Kurang
Agus Maulana
20
L
Wiraswasta
53
173
14
Kurang
Dendi Priana
25
L
Wiraswasta
55
170
14,2
Kurang
Nindy Aisyah
19
P
Wiraswasta
55
157,5
14
Normal
Nuraini
18
P
Siswa
50
155
13
Normal
Ayla Safrani
22
P
Wiraswasta
40
167
13,3
Kurang
Siti Rosita
22
P
Wirausaha
48
157
14,2
Normal
Anggun Purnama Sari
18
P
Siswa
50
155
14
Normal
imam Wahyudi
23
L
Wiraswasta
120
165
18,5
Obesitas
Fakhrul Rozi
20
L
Mahasiswa
67
170
16
Normal
Syakila Senja
18
P
Siswa
52
166,3
14
Normal
Arif Sukarsa
21
L
Wiraswasta
65
169
15
Normal
Ridwan Cahyono
21
L
Wiraswasta
50
173
14
Kurang
23
Berikut ini merupakan tabel hasil dari cleaning data dari status gizi orang dewasa yang telah dilakukan :
Tabel 3 3 Data Status Gizi Setelah di Cleaning
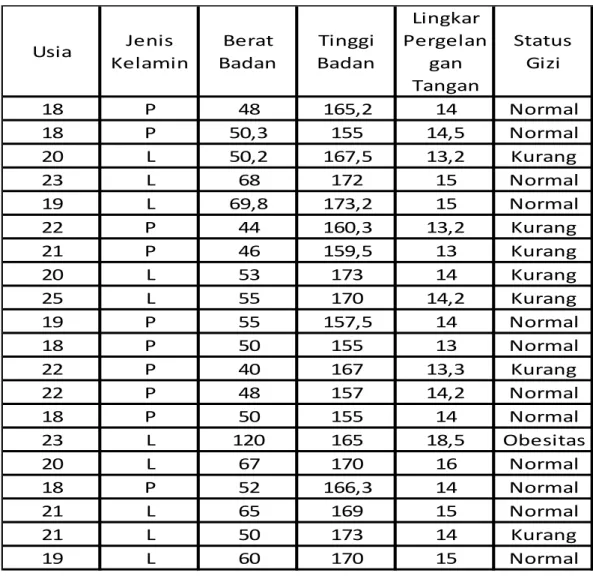
2. Transformation Data
“Transformation data dilakukan untuk mengubah bentuk dan format data. Hal ini tentunya sangat membantu memudahkan pengguna dalam proses mining ataupun memahami hasil yang didapat” (). Jadi, transformation data itu mengubah format untuk mempermudah proses mining. Berikut merupakan data yang sudah di transformasikan : Usia Jenis Kelamin Berat Badan Tinggi Badan Lingkar Pergelan gan Tangan Status Gizi 18 P 48 165,2 14 Normal 18 P 50,3 155 14,5 Normal 20 L 50,2 167,5 13,2 Kurang 23 L 68 172 15 Normal 19 L 69,8 173,2 15 Normal 22 P 44 160,3 13,2 Kurang 21 P 46 159,5 13 Kurang 20 L 53 173 14 Kurang 25 L 55 170 14,2 Kurang 19 P 55 157,5 14 Normal 18 P 50 155 13 Normal 22 P 40 167 13,3 Kurang 22 P 48 157 14,2 Normal 18 P 50 155 14 Normal 23 L 120 165 18,5 Obesitas 20 L 67 170 16 Normal 18 P 52 166,3 14 Normal 21 L 65 169 15 Normal 21 L 50 173 14 Kurang 19 L 60 170 15 Normal
24
Tabel 3 4 Data Status Gizi Setelah di Transformation
3.4. Peralatan Penelitian
Penelitian yang dilakukan memerlukan peralatan untuk mendukung pelaksanaan penelitian. Peralatan – peralatan tersebut berupa kebutuhan software (perangkat lunak) dan hardware (perangkat keras). Berikut kebutuhan yang diperlukan antara lain, yaitu :
1. Perangkat Keras
Berikut adalah perangkat keras yang diggunakan dalam penelitian ini dengan laptop Acer dengan spesifikasi, antara lain :
Usia Jenis Kelamin Berat Badan Tinggi Badan Lingkar Pergelan gan Tangan Status Gizi 18 P 48 165 14 Normal 18 P 50 155 15 Normal 20 L 50 168 13 Kurang 23 L 68 172 13 Normal 19 L 70 173 15 Normal 22 P 44 160 13 Kurang 21 P 46 160 13 Kurang 20 L 53 173 14 Kurang 25 L 55 170 14 Kurang 19 P 55 158 14 Normal 18 P 50 155 13 Normal 22 P 40 167 13 Kurang 22 P 48 157 14 Normal 18 P 50 155 14 Normal 23 L 120 165 19 Obesitas 20 L 67 170 16 Normal 18 P 52 166 14 Normal 21 L 65 169 15 Normal 21 L 50 173 14 Kurang 19 L 60 170 15 Normal
25
a. Processor AMD E1-1200 APU with Radeon(tm) HD Graphics 1,40 GHz
b. RAM 2,00 GB
c. 64-bit Operating System, x64-based processor 2. Perangkat Lunak
Adapun perangkat lunak yang digunakan untuk menjalankan aplikasi tersebut, sebagai berikut ;
a. Sistem Operasi Windows 2010 Ultimate 64-bit b. Microsoft Word 2013
c. Microsoft Excel 2013
d. RappidMiner Studio Educational 9.0.2 e. Mendeley Dekstop Version 1.19.1 f. PDF Xchange Viewer Version 1.5
26
3.5. Metode yang Diusulkan
Gambar 3 2 Alur Metode yang Diusulkan 3.6. Waktu Penelitian
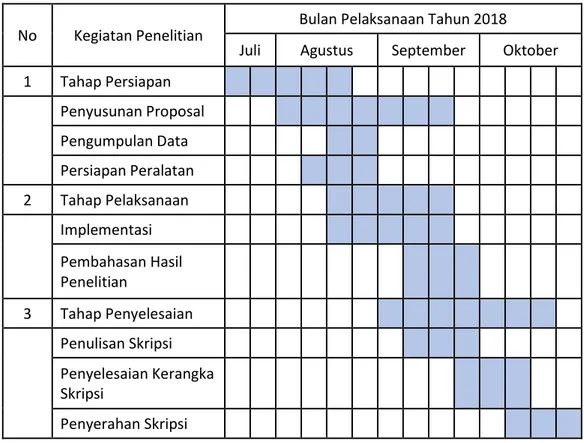
Tahap – tahap dalam kegiatan penelitian ini meliputi, tahap persiapan, tahap pelaksanaan, dan tahap penyelesaian. Adapun waktu penelitian dimulai pada bulan juli sampai dengan oktober 2018. Berikut adalah table perincian tahap – tahap penelitian :
27
Tabel 3.5 Kegiatan Penelitian
No Kegiatan Penelitian Bulan Pelaksanaan Tahun 2018
Juli Agustus September Oktober 1 Tahap Persiapan Penyusunan Proposal Pengumpulan Data Persiapan Peralatan 2 Tahap Pelaksanaan Implementasi Pembahasan Hasil Penelitian 3 Tahap Penyelesaian Penulisan Skripsi Penyelesaian Kerangka Skripsi Penyerahan Skripsi
28
BAB IV
HASIL DAN PEMBAHASAN
Pada bab ini menjelaskan hasil dan pembahasan hasil penelitian yang telah dilakukan. Hasil penelitian ini berdasarkan pada metode yang telah dijabarkan pada bab sebelumnya.
4.1. Hasil
Hasil penelitian dilakukan dengan menggunakan tools RappidMiner 9.0.2 dengan jumlah dataset yang sudah ditentukan yaitu 150 data dengan parameter yang berbeda. Pada penelitian ini, pengujian dilakukan dengan menerapkan algoritma Naïve Bayes dengan menggunakan 20 data untuk dijadikan data
training.
4.1.1 Analisis Preprocessing Data
Data ini memiliki atribut seperti usia, tinggi badan, berat badan, jenis kelamin, lingkar pergelangan tangan, dan status gizi. Berikut ini adalah tabel training dari dataset status gizi orang dewasa, dibawah ini ada sebagian dari data training (20 data dari 150) dan data testing (hanya 10 dari 20 data).
29
Tabel 4.1 Training data yang sudah diolah
Tabel 4.2 Testing data yang telah diolah
Usia Jenis Kelamin Berat Badan Tinggi Badan Lingkar Pergelan gan Tangan Status Gizi 18 P 48 165 14 Normal 18 P 50 155 15 Normal 20 L 50 168 13 Kurang 23 L 68 172 13 Normal 19 L 70 173 15 Normal 22 P 44 160 13 Kurang 21 P 46 160 13 Kurang 20 L 53 173 14 Kurang 25 L 55 170 14 Kurang 19 P 55 158 14 Normal 18 P 50 155 13 Normal 22 P 40 167 13 Kurang 22 P 48 157 14 Normal 18 P 50 155 14 Normal 23 L 120 165 19 Obesitas 20 L 67 170 16 Normal 18 P 52 166 14 Normal 21 L 65 169 15 Normal 21 L 50 173 14 Kurang 19 L 60 170 15 Normal Usia Jenis Kelamin Berat Badan Tinggi Badan Lingkar Pergelan gan Tangan Status Gizi 18 P 48 165 14 Normal 18 P 50 155 15 Normal 20 L 50 168 13 Kurang 23 L 68 172 13 Normal 19 L 70 173 15 Normal 22 P 44 160 13 Kurang 21 P 46 160 13 Kurang 20 L 53 173 14 Kurang 25 L 55 170 14 Kurang 19 P 55 158 14 Normal
30
4.1.2 Pengujian Algoritma Naïve Bayes
Berikut ini adalah pengolahan data dengan menggunakan algoritma naïve
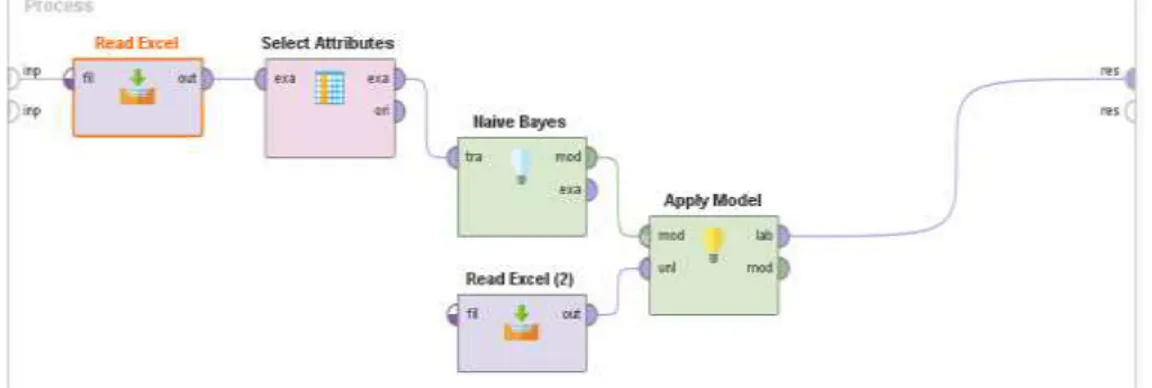
bayes pada RapidMiner ;
Gambar 4.1 Permodelan Naïve Bayes
Permodelan di atas memasukan data training dan data testing, kemudian di
run dan akan muncul hasil dari data training dan testing, dan hasil dari prediksi
seperti pada gambar di bawah ini ;
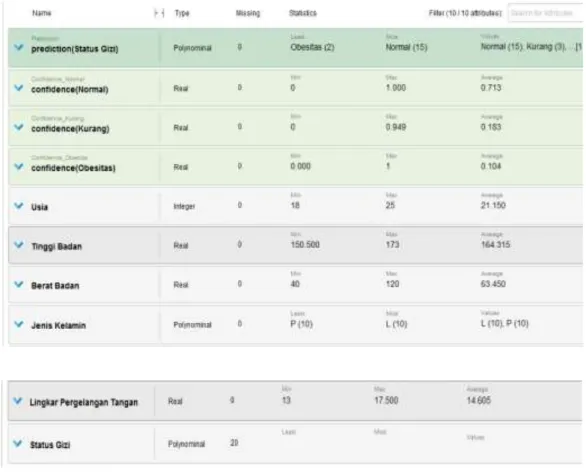
31
Gambar 4.3 Data Statistic 4.1.3 Pengujian Model yang Sudah Dibuat
Berikut ini adalah pengujian model yang akan dihitung tingkat akurasinya menggunakan RapidMiner ;
32
Gambar di atas merupakan model proses pengujian yang terdapat data
training pada model retrive, kemudian dalam proses cross validation didalamnya
terdapat performance dimana ada training dan juga testing seperti pada gambar di bawah ini ;
Gambar 4.5 Proses Cross Validation
Terakhir dibagian testing terdapat model performance, fimana model ini digunakan untuk mengevaluasi hasil algoritma naïve bayes dengan akurasi seperti di bawah ini ;
Gambar 4.6 Accuracy 4.2. Pembahasan
Penelitian ini dilakukan dengan data mining algoritma Naïve Bayes menggunakan data training dan data testing untuk pengujian dengan menggunakan aplikasi RapidMiner. Preprocessing data menggunakan teknik
33
Berikut ini merupakan preprocessing data yang akan menghasilkan data seperti pada tabel 4.1 data ini bisa disebut juga data mentah ataupun data asli, karena data ini belum bisa dijadikan data nilai yang akurat untuk pengujian Tabel 4.3 Data asli status gizi
Nama Usi a Jenis Kelami n Pekerjaan Berat Bada n Tinggi Bada n Lingkar Pergelanga n Tangan Status Gizi Aisyah
Cahyani 18 P Siswa 48 165,2 14 Normal
Anggi
Nurwulandari 18 P Siswa 50,3 155 14,5 Normal
Abdul
Rahman 20 L Mahasiswa 50,2 167,5 13,2 Kurang
Kurniawan 23 L
Wiraswast
a 68 172 15 Normal
Dicky
Maulana 19 L Mahasiswa 69,8 173,2 15 Normal
Nurhayati 22 P Mahasiswa 44 160,3 13,2 Kurang
Kokom Komariah 21 P Wiraswast a 46 159,5 13 Kurang Agus Maulana 20 L Wiraswast a 53 173 14 Kurang Dendi Priana 25 L Wiraswast a 55 170 14,2 Kurang Nindy Aisyah 19 P Wiraswast a 55 157,5 14 Normal
Nuraini 18 P Siswa 50 155 13 Normal
Ayla Safrani 22 P
Wiraswast
a 40 167 13,3 Kurang
Siti Rosita 22 P Wirausaha 48 157 14,2 Normal
Anggun
Purnama Sari 18 P Siswa 50 155 14 Normal
imam Wahyudi 23 L Wiraswast a 120 165 18,5 Obesita s
Fakhrul Rozi 20 L Mahasiswa 67 170 16 Normal
Syakila Senja 18 P Siswa 52 166,3 14 Normal
Arif Sukarsa 21 L Wiraswast a 65 169 15 Normal Ridwan Cahyono 21 L Wiraswast a 50 173 14 Kurang
34
BAB V
PENUTUP
5.1. Kesimpulan
Berdasarkan penjelasan penelitian yang telah diuraikan di bab –bab sebelumnya, yaitu tentang klasifikasi status gizi orang dewasa menggunakan algoritma Naïve Bayes dapat diambil kesimpulan sebagai berikut ;
1. Berdasarkan data dari status gizi orang dewasa menghasilkan nilai akurasi dengan menggunakan algoritma Naïve Bayes dimana pada tahapan tersebut perlu fokus dalam menyiapkan sebuah data agar bersih dari segala noise data yang ada sehingga proses klasifikasi dapat berjalan dengan baik dan akurat.
2. Berdasarkan hasil pengujian untuk penilaian akurasi status gizi orang dewasa menggunakan algoritma Naïve Bayes, data yang digunakan yaitu menggunakan atribut nama, usia, jenis kelamin, pekerjaan, berat badan, tinggi badan, lingkar pergelangan tangan, dan status gizi untuk menentukan nilai akurasi status gizi.
3. Berdasarkan penelitian yang sudah dilakukan algoritma Naïve Bayes nilai akurasi yang didapat sebesar 88,67% maka algoritma Naïve Bayes akurat dalam perhitungan status gizi orang dewasa.
5.2. Saran
Berdasarkan hasil penelitian yang telah dilakukan, penulis memberikan beberapa saran yang dapat digunakan pada penelitian kedepannya yaitu ;
35
1. Pada penelitian selanjutnya disarankan untuk menggunakan perhitungan status gizi dengan algoritma yang berbeda.
2. Penelitian ini tidak terimplementasi pada system aplikasi, maka pada penelitian selanjutnya disarankan untuk membuat sistem aplikasi status gizi orang dewasa.
3. Penelitian selanjutnya bisa menggunakan perbandingan dengan algoritma yang lain untuk menguji hasil akurasi yang didapat.
36
DAFTAR PUSTAKA
Fadlan, C., Ningsih, S., & Windarto, A. P. (2018). Penerapan Metode Naive
Bayes dalam Klasifikasi Kelayakan Keluarga Penerima Beras Rastra. Jutim, 3(1), 1–8.
Hariri, F. R., & Pamungkas, D. P. (2016). Implementasi Naive Bayes Classifier
untuk Diagnosa Status Gizi Balita. Seminar Nasional Teknologi Informasi Dan Multimedia 2016, 6–7.
Jaenal, M. (2018). Analisis efektivitas kinerja particle swarm optimization dalam
meningkatkan performansi algoritma naïve bayes. Skripsi STT Pelita Bangsa
: Kab. Bekasi.
Menarianti, I. (2015). Klasifikasi data mining dalam menentukan pemberian
kredit bagi nasabah koperasi. Jurnal Ilmu Teknosains, 1(1).
Naparin, H. (2016). Klasifikasi Peminatan Siswa SMA Menggunakan Metode
Naive Bayes. Systemic, 02(01), 25–32.
Nugraha, D. W., Dodu, A. Y. E., & Chandra, N. (2017). Klasifikasi penyakit
stroke menggunakan metode Naive Bayes Classifier. SemanTik, 3(2), 13–22.
Nugroho, D., T, F. N. S., M, D. T., & Si, S. (2016). Prediksi Penyakit
Menggunakan Genetic Algorithm ( GA ) dan Naive Bayes Untuk Data Berdimensi Tinggi Prediction of Disease Using Genetic Algorithm ( GA ) and Naive Bayes For Data High Dimension. E-Proceeding of Engineering, 3(2), 3889–3899.
Pramadhani, A. E., & Setiadi, T. (2014). Penerapan Data Mining untuk
Klasifikasi Prediksi Penyakit ISPA ( Infeksi Saluran Pernapasan Akut ) dengan Algoritma Decision Tree ( ID3 ). Jurnal Sarjana Teknik Informatika,
37
2.
Pusnawati, E. (2018). Penerapan algoritma naive bayes dalam menentukan merek
mobil terlaris. Skripsi STT Pelita Bangsa : Kab. Bekasi.
Pramitarini, Y., Purnama, I. K. E., & Purnomo, M. H. (2013). Analisa Rekam
Medis untuk Menentukan Status Gizi Anak Balita Menggunakan Naive Bayes Classifier. Prosiding Seminar Nasional Manajemen Teknologi XVII, 1–8.
Purwati, N., Agustina, C., & S, G. B. (2017). Komparasi Algoritma C . 45 Dan
Backpropagation Untuk Klasifikasi Status Gizi Balita Berdasarkan Indeks Antropometri Bb / U Dan BB / PB. Journal Speed, 9(3), 26–33.
Putra, A. S. (2018). Klasifikasi Status Gizi Balita Menggunakan Naive Bayes
Classification (Studi Kasus Posyandu Ngudi Luhur).
Rahman, F., & Firdaus, I. (2016). Penerapan Data Mining Metode Naive Bayes
untuk Prediksi Hasil Belajar Siswa Sekolah Menengah Pertama ( SMP ). Al Ulum Sains Dan Teknologi, 1(2), 76–78.
Rahmawati, T. (2017). Hubungan Asupan Zat Gizi Dengan Status Gizi
Mahasiswa Gizi Semester 3 Stikes PKU Muhammadiyah Surakarta. Profesi, 14(2), 49–57.
Riyadi, H., Khomsan, A., S, D., A, F., & Mudjajanto, E. S. (2006). Studi tentang
status gizi pada rumahtangga miskin dan tidak miskin. Gizi Indon, 1.
Saleh, A. (2015). Implementasi Metode Klasifikasi Naïve Bayes Dalam
Memprediksi Besarnya Penggunaan Listrik Rumah Tangga. Citee Journal, 2(3), 207–217.
38
Data Mahasiswa Baru Perguruan Tinggi ). Jurnal Ilmiah Ilmu Komputer, 2(1).
Wahyudi, M. H. (2018). Sistem pendukung keputusan penentuan status gizi balita
menggunakan metode naïve bayes. Universitas Amikom Yogyakarta, 25–30.
Zubair, A., & Muksin, M. (2018). Penerapan metode naive bayes untuk klasifikasi
status gizi (studi kasus di klinik bromo malang). Fakultas Teknologi Informasi, 1204–1208.
39