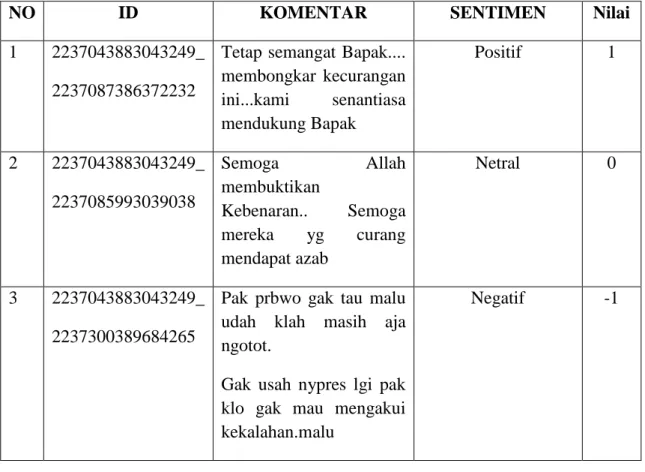
SISTEM ANALISIS SENTIMEN PADA FANPAGE FACEBOOK KANDIDAT PRESIDEN 2019-2024
SKRIPSI
MEISSY AYU MAISARAH 151401031
PROGRAM STUDI S-1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2020
SISTEM ANALISIS SENTIMEN PADA FANPAGE FACEBOOK KANDIDAT PRESIDEN 2019-2024
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Ilmu Komputer
MEISSY AYU MAISARAH 151401031
PROGRAM STUDI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2020
PERSETUJUAN
Judul : SISTEM ANALISIS SENTIMEN PADA FANPAGE
FACEBOOK KANDIDAT PRESIDEN 2019-2024
Kategori : SKRIPSI
Nama : MEISSY AYU MAISARAH
Nomor Induk Mahasiswa : 151401031
Program Studi : SARJANA (S1) ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 9 Januari 2020
Komisi Pembimbing :
Diketahui/Disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
Dr. Poltak Sihombing, M.Kom NIP. 196203171991031001
Dosen Pembimbing II
Dr. Maya Silvi Lydia, M. Sc NIP. 197401272002122001
Dosen Pembimbing I
Amalia ST., M.T
NIP. 197812212014042001
PERNYATAAN
SISTEM ANALISIS SENTIMEN PADA FANPAGE FACEBOOK KANDIDAT PRESIDEN 2019-2024
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Januari 2020
Meissy Ayu Maisarah 151401031
PENGHARGAAN
Puji syukur kita sampaikan kehadirat Allah SWT yang telah memberikan rahmat serta karunia-Nya sehingga penulis dapat menyelesaikan skripsi ini dengan sebaik-baiknya.
Pada dasarnya penyusunan skripsi merupakan syarat mutlak yang harus dipenuhi untuk menyelesaikan pendidikan dan menyandang gelar Sarjana Komputer pada Program Studi S1 Ilmu Komputer Fasilkom-TI Universitas Sumatera Utara.
Tidak dapat dipungkiri, skripsi ini dapat selesai karena bantuan, semangat, motivasi, dan kerjasama yang diterima penulis dari orang-orang terdekat terutama kedua orang tua penulis. Oleh karena itu, pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada berbagai pihak yang terkait, antara lain :
1. Prof. Dr. Runtung Sitepu, SH, M.Hum selaku Rektor Universitas Sumatera Utara.
2. Prof. Dr. Opim Salim Sitompul M.Sc selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Dr. Poltak Sihombing, M.Kom selaku Ketua Program Studi S1 Ilmu Komputer Fakultas Ilmu komputer dan Teknologi Informasi Universitas Sumatera Utara.
4. Ibu Amalia ST., M.T selaku dosen pembimbing I yang senantiasa memberikan bimbingan, motivasi, kritik, dan saran kepada penulis selama proses pengerjaan skripsi ini.
5. Ibu Dr. Maya Silvi Lydia, M. Sc selaku dosen pembimbing II yang telah memberikan arahan dan bimbingan kepada penulis dalam penyempurnaan skripsi ini.
6. Seluruh staf pengajar dan pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi USU.
7. Ayahanda Muhammad Zaini, Ibunda tercinta Rohani dan Kakak Suci Indah Sari dan Rini Mulia Sari dan Abang Andriansyah Putra Ramadhan dan Yopie Haris Fandi yang tanpa lelah memberi kasih sayang, perhatian, dukungan, dan doa terbaik untuk penulis dalam pengerjaan skripsi.
8. Sahabat seperjuangan Aftika Wulandari yang menjadi tempat berkeluh-kesah,
9. Sahabat tercinta Nurdiana Rizka yang selalu memberikan bantuan dan memberikan semangat kepada penulis selama mengerjakan skripsi.
10. Teman – teman Pejuang Skripsi Gusvita Amalia Nisa, Mayrisa, Sinta Awalisa Sinaga, Balya, Ahmad Alfin, Kartika Anggraini dan Ulfa Natalia Siahaan yang kerap menemani dan memberikan semangat selama pengerjaan skripsi.
11. Teman - teman yang baik hatinya Balya dan Zikri yang telah membantu penulis mengerjakan program skripsi.
12. Keluarga Kom A 2015 Ilmu Komputer Universitas Sumatera Utara yang banyak memberi motivasi kepada penulis dalam pengerjaan skripsi ini.
13. Teman-teman stambuk 2015, kakak abang senior dan adik-adik junior yang selalu memberi semangat kepada penulis
14. Dan semua pihak yang telah membantu yang tidak dapat disebutkan satu per satu.
Terima kasih kepada semua pihak, semoga semua kebaikan, perhatian, bantuan serta dukungan yang telah diberikan kepada penulis semoga mendapatkan balasan yang setimpal dari Allah swt. Semoga Skripsi ini dapat bermanfaat bagi orang banyak.
Medan, Januari 2020
Penulis
ABSTRAK
Fanpage kandidat presiden merupakan media untuk berkomunikasi dan bertukar informasi dengan simpatisannya. Selain itu, fanpage juga seharusnya berisi lebih banyak sentimen positif dengan asumsi bahwa pengikut halaman adalah orang yang mendukung. Namun ada beberapa oposisi yang tidak sependapat sehingga timbul sentimen negatif. Dalam penelitian ini, penulis akan melakukan analisis sentimen berdasarkan komentar yang terdapat dalam fanpage kandidat presiden dengan menerapkan proses text mining dan algoritma Support Vector Machine (SVM) dan K- Nearest Neighbours (K-NN) untuk mengklasifikasikan apakah teks termasuk dalam sentimen positif, negatif dan netral. Penulis menggunakan kurang lebih 6000 komentar dari masing-masing fanpage kandidat presiden sebagai data latih yang akan diklasifikasikan sentimennya. Data diklasifikasikan secara manual dengan mengelompokkan menjadi kelas sentimen postif, negatif dan netral kemudian secara otomatis data latih akan mengambil beberapa data untuk data uji dan menguji kemampuan sistem. Hasil penelitian berupa persentase akurasi menggunakan 2 algoritma. Algoritma K-Nearest Neighbours terbukti mendapatkan nilai akurasi lebih tinggi dari algoritma Support Vector Machine yaitu pada fanpage Joko Widodo dan Ma’ruf Amin akurasi yang diperoleh algoritma K-Nearest Neighbours sebesar 94 % sedangkan algoritma Support Vector Machine sebesar 47%. Pada fanpage Prabowo Subianto dan Sandiaga Uno akurasi yang diperoleh algoritma K-Nearest Neighbours sebesar 96% sedangkan algoritma Support Vector Machine sebesar 65%.
Kata kunci: Facebook, Fanpage, Komentar, Sentimen, Sentimen Analisis, Support Vector Machine, K-Nearest Neighbours
SENTIMENT ANALYSIS SYSTEM IN FACEBOOK FANPAGE CANDIDATE PRESIDENT 2019-2024
ABSTRACT
The presidential candidate's fanpage is a medium for communicating and exchanging information with sympathizers. In addition, the fanpage should also contain more positive sentiment assuming that the followers of the page are people who support.
But there are some opposition that disagrees so that negative sentiment arises. In this study, the author will conduct sentiment analysis based on comments contained in the presidential candidate fanpage by applying the text mining process and the Support Vector Machine (SVM) algorithm and K-Nearest Neighbors (K-NN) to classify whether the text is included in positive, negative sentiments and neutral. The author uses approximately 6000 comments from each presidential candidate fanpage as training data to be classified sentiment. Data is classified manually by grouping into positive, negative and neutral sentiment classes and then automatically training data will take some data for test data and test the ability of the system. The results of this research are percentage accuracy using 2 algorithms. The K-Nearest Neighbors algorithm is proven to get higher accuracy values than the Support Vector Machine algorithm, which is on the Joko Widodo and Ma'ruf Amin fanpage, the accuracy obtained by the K-Nearest Neighbors algorithm is 94% while the Support Vector Machine algorithm is 47%. In the fanpage of Prabowo Subianto and Sandiaga Uno the accuracy obtained by the K-Nearest Neighbours algorithm is 96% while the Support Vector Machine algorithm is 65%.
Keywords: Facebook, Fanpage, Comments, Sentiments, Sentiment Analysis, Support Vector Machine, K-Nearest Neighbors
DAFTAR ISI
PERSETUJUAN ... ii
PERNYATAAN ... iii
PENGHARGAAN ... iv
ABSTRAK ... vi
ABSTRACT ... vii
DAFTAR ISI ... viii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Batasan Masalah ... 2
1.4 Tujuan Penelitian ... 3
1.5 Manfaat Penelitian ... 3
1.6 Metode Penelitian ... 3
1.7 Sistematika Penulisan ... 4
BAB 2 LANDASAN TEORI ... 6
2.1. Text Mining ... 6
2.2. Machine Learning ... 8
2.3. Facebook ... 9
2.4 Analisis Sentimen ... 11
2.5 Algoritma Support Vector Machine (SVM) ... 17
2.6 Algoritma K-Nearest Neighbours (K-NN) ... 22
2.7 Power Query ... 24
2.8 Penelitian yang Relevan ... 24
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 28
3.1. Analisis Sistem ... 28 Halaman
3.1.1. Analisis Masalah ... 28
3.1.2. Analisis Kebutuhan ... 29
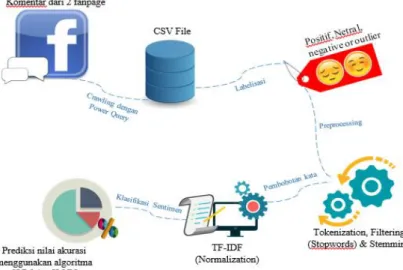
3.2. General Arsitektur Sistem ... 30
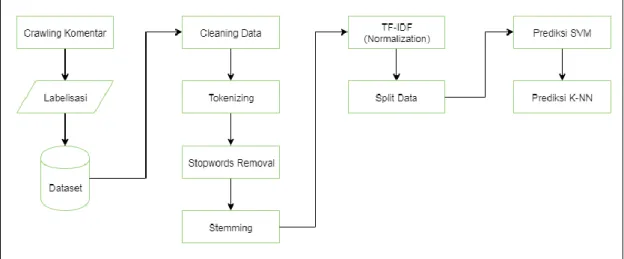
3.3. Perancangan Sistem ... 31
3.3.1. Crawling Komentar ... 32
3.3.2. Labelisasi ... 33
3.3.3. Cleaning ... 34
3.3.4. Case Folding ... 35
3.3.5. Tokenizing ... 36
3.3.6. Stopwords Removal ... 38
3.3.7. Stemming ... 39
3.3.8. TF-IDF (Normalization) ... 40
3.3.9. Split Data ... 45
3.3.10.Prediksi Algoritma Support Vector Machine (SVM) ... 46
3.3.11.Prediksi Algoritma K-Nearest Neigbours (K-NN) ... 49
3.3.12.Confusion Matrix ... 53
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 55
4.1. Implementasi Sistem ... 55
4.1.1. Spesifikasi Kebutuhan Perangkat Keras ... 55
4.1.2. Spesifikasi Kebutuhan Perangkat Lunak ... 55
4.2. Implementasi Sistem Analisis Sentimen ... 56
4.2.1. Power Query... 56
4.2.2. Anaconda Navigator... 57
4.2.3. Crawling ... 58
4.2.4. Labelisasi ... 60
4.2.5. Cleaning Data ... 61
4.2.6. Case Folding ... 61
4.2.7. Tokenizing ... 62
4.2.8. Stopwords Removal ... 62
4.2.9. Stemming ... 62
4.2.10.Visualisasi ... 63
4.2.11.TF-IDF (Normalization) ... 67
4.2.12.Split Data ... 67
4.2.13. Klasifikasi SVM dan K-NN ... 68
4.2.14. Prediksi Menggunakan Confusion Matrix ... 71
4.3. Pengujian Sistem ... 73
BAB 5 KESIMPULAN DAN SARAN ... 76
5.1. Kesimpulan ... 76
5.2. Saran ... 76
DAFTAR PUSTAKA ... 78
DAFTAR TABEL
Tabel 2.1 Rangkuman Penelitian Terdahulu ... 24
Tabel 3.1 Contoh Labelisasi Fanpage Joko Widodo dan Ma'ruf Amin ... 32
Tabel 3.2 Contoh Labelisasi Fanpage Prabowo Subianto dan Sandiaga Uno ... 32
Tabel 3.3 Perhitungan Term Frequency (TF) ... 41
Tabel 3.4 Perhitungan Nilai TF-IDF ... 43
Tabel 3.5 Perhitungan Kesamaan Kata ... 50
Tabel 3.6 Confusion Matrix ... 52
Tabel 4.1 Hasil Pengujian Sistem Menggunakan Algoritma Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN) pada Fanpage Facebook Kandidat 01 .... 72
Tabel 4.2 Hasil Pengujian Sistem Menggunakan Algoritma Support Vector Machine (SVM) pada K-Nearest Neighbours (K-NN) Fanpage Facebook Kandidat 02 ... 73
Tabel 4.3 Perbandingan Persentase Akurasi ... 74 Halaman
DAFTAR GAMBAR
Gambar 2.1 Proses Text Mining ... 6
Gambar 2.2 Tampilan Setelah Log-in Facebook ... 10
Gambar 2.3 Confusion Matrix ... 16
Gambar 2.4 Hyperplane pada SVM ... 18
Gambar 2.5 Klasifikasi Multi-kelas ... 20
Gambar 2.6 Algoritma K-Nearest Neighbours ... 22
Gambar 3.1 Diagram Ishikawa ... 27
Gambar 3.2 General Arsitektur Sistem ... 29
Gambar 3.3 Proses Perancangan Sistem ... 30
Gambar 3.4 Crawling Komentar ... 31
Gambar 3.5 Crawling dengan Power Query ... 31
Gambar 3.6 Flowchart Cleaning ... 33
Gambar 3.7 Pseudocode Cleaning ... 33
Gambar 3.8 Flowchart Case Folding ... 34
Gambar 3.9 Pseudocode Case Folding ... 35
Gambar 3.10 Flowchart Tokenizing ... 35
Gambar 3.11 Pseudocode Tokenizing ... 36
Gambar 3.12 Flowchart Stopwords Removal ... 37
Gambar 3.13 Pseudocode Stopwords Removal ... 37
Gambar 3.14 Flowchart Stemming ... 38
Gambar 3.15 Pseudocode Stemming ... 39
Gambar 3.16 Flowchart TF-IDF ... 40
Gambar 3.17 Pseudocode TF-IDF ... 41
Gambar 3.18 Split Data ... 44
Gambar 3.19 Pseudocode Split data ... 45
Gambar 3.20 Flowchart Algoritma SVM ... 46
Gambar 3.21 Pseudocode Algoritma SVM ... 47
Gambar 3.22 Flowchart Algoritma K-Nearest Neighbours (K-NN) ... 48
Gambar 3.23 Pseudocode Algoritma K-NN ... 49 Halaman
Gambar 3.24 Pseudocode Confusion Matrix ... 52
Gambar 4.1 Microsoft Excel dengan Power Query ... 55
Gambar 4.2 Anaconda Navigator ... 56
Gambar 4.3 Jupyter Notebook ... 56
Gambar 4.4 Proses Crawling (1) ... 57
Gambar 4.5 Proses Crawling (2) ... 58
Gambar 4.6 Proses Crawling (3) ... 58
Gambar 4.7 Proses Crawling (4) ... 59
Gambar 4.8 Dataset Crawling Fanpage Paslon 01 ... 59
Gambar 4.9 Dataset Crawling Fanpage Paslon 02 ... 60
Gambar 4.10 Cleaning Data ... 60
Gambar 4.11 Case Folding ... 60
Gambar 4.12 Tokenizing ... 61
Gambar 4.13 Stopwords Removal ... 61
Gambar 4.14 Stemming ... 61
Gambar 4.15 Jumlah Banyak Kata ... 62
Gambar 4.16 Pencarian Kata Tertentu ... 62
Gambar 4.17 Diagram Visualisasi Kepadatan Kata... 63
Gambar 4.18 Tampilan WordCloud ... 64
Gambar 4.19 Persentase Kemunculan Kata ... 65
Gambar 4.20 Nilai TF-IDF ... 65
Gambar 4.21 Split Data ... 66
Gambar 4.22 Persentase Klasifikasi Sentimen ... 66
Gambar 4.23 Algoritma SVM ... 67
Gambar 4.24 Persentase Akurasi Algoritma SVM Paslon 01 ... 67
Gambar 4.25 Persentase Akurasi Algoritma SVM Paslon 02 ... 67
Gambar 4.26 Algoritma K-NN ... 68
Gambar 4.27 Persentase Akurasi Algoritma K-NN Paslon 01 ... 68
Gambar 4.28 Persentase Akurasi Algoritma K-NN Paslon 02 ... 68
Gambar 4.29 (a) dan gambar 4.29 (b) Diagram Confusion Matrix Algoritma SVM . 68 Gambar 4.30 (a) dan gambar 4.30 (b) Data Frame Confusion Matrix Algoritma SVM ... 69
Gambar 4.31 (a) dan gambar 4.31 (b) Diagram Confusion Matrix Algoritma K-NN 69 Gambar 4.32 (a) dan gambar 4.32 (b) Data Frame Confusion Matrix Algoritma K-NN ... 70
DAFTAR LAMPIRAN
Lampiran 1 LISTING PROGRAM ... A-1 Lampiran 2 CURRICULUM VITAE ... B-1 Halaman
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Indonesia merupakan negara yang menggunakan sistem pemerintahan presidensial dan sistem politik yang demokrasi. Contohnya seperti diadakannya suatu pemilihan umum terhadap presiden suatu negara yang menganut demokrasi biasanya diselenggarakan secara periodik. Opini masyarakat saat ini merupakan suatu pertimbangan untuk memilih seorang tokoh politik yang akan maju menjadi pemimpin negara. Dahulu masyarakat mengungkapkan opini dengan menerbitkan tulisan melalui media cetak. Namun, dengan perkembangan teknologi saat ini masyarakat dapat lebih mudah menyampaikan opininya menggunakan sosial media (Nurhuda et al., 2014).
Sosial media saat ini sering digunakan masyarakat untuk sarana berekspresi dan kebebasan berpendapat, salah satunya terkait masalah pemilihan calon presiden tahun ini. Dalam hak kebebasan berpendapat, prinsip bebas dan bertanggung jawab artinya adalah pendapat yang kita keluarkan itu berisi ide dan pikiran tanpa ada tekanan dari siapapun dan bertanggung jawab atas pendapat kita berdasarkan niat yang baik dan sesuai dengan norma dan UU-ITE yang berlaku. Sosial media yang sering digunakan masyarakat saat ini adalah Facebook.
Facebook adalah sosial media yang populer di seluruh dunia. Pada Bulan Oktober 2012 mencapai 1 miliar pengguna aktif bulanan (1 miliar pengguna mengakses dalam waktu 1 bulan) dan lebih dari 550 juta pengguna aktif harian (Ortigosa et al., 2014).
Facebook memiliki data yang beraneka ragam bentuknya, mulai data teks, data gambar/foto, data suara bahkan data dalam bentuk video. Komentar oleh para pengguna facebook adalah jenis data yang perlu dilakukan analisis (Rachmat, A., &
Lukito, Y., 2016).
Untuk menarik perhatian masyarakat dalam beropini para pendukung presiden membuat fanpage pada facebook untuk memberikan informasi seputar kampanye yang dilakukan oleh kandidat presiden. Fanpage dari kandidat presiden ini seharusnya berisi lebih banyak sentimen yang positif dengan asumsi followers fanpage adalah masyarakat yang mendukung namun ada beberapa oposisi tidak sependapat sehingga
facebook) dari masing-masing fanpage kandidat presiden untuk dilakukan analisis sentimen.
Isi komentar fanpage dapat mengekspresikan mood pengguna, hal ini bersifat penilaian subjektif atau opini. Opini melalui fanpage inilah yang dapat dimanfaatkan untuk melihat bagaimana sentimen mengenai opini seseorang terhadap tokoh politik yang akan maju sebagai calon presiden Indonesia tahun 2019 (Nurhuda et al., 2014).
Komentar pada fanpage calon presiden merupakan dataset yang akan digunakan pada penelitian ini. Dataset yang lengkap, konsisten dalam setiap datanya, variable jelas, menarik dan mudah dimengerti adalah ciri dataset yang baik untuk digunakan (Rachmat, A., & Lukito, Y., 2016).
Algoritma analisis sentimen yang digunakan pada penelitian ini yaitu Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN) untuk memprediksi nilai akurasi dari komentar positif, netral dan negatif dari komentar fanpage facebook dari kandidat presiden. Hasil dari pengolahan data analisis sentimen ini juga dapat dijadikan tolak ukur dalam menentukan calon presiden serta melihat sentimen masyarakat di media fanpage facebook. terhadap tokoh politik yang maju dalam pemilihan umum tahun 2019.
1.2 Rumusan Masalah
Fanpage facebook untuk kandidat presiden merupakan suatu media untuk memberikan informasi kepada semua simpatisan dan juga media dukungan dari simpatisan kepada kandidat presiden. Seharusnya pada fanpage berisi opini positif kepada kandidat presiden, namun banyaknya oposisi yang menyusup membuat opini negatif juga muncul. Untuk itu dibutuhkan suatu klasifikasi sentimen untuk melihat pola sentimen yang ada di kedua fanpage kandidat presiden.
1.3 Batasan Masalah
Adapun beberapa batasan masalah yang akan diterapkan pada penelitian antara lain:
1. Dataset berupa komentar dari 2 Fanpage Facebook kandidat presiden yang didapatkan dari tools mengunakan Power Query.
2. Dataset hanya berupa teks untuk menganalisis sentimen.
3. Dataset yang akan digunakan kurang lebih 6000 komentar dari masing-masing Fanpage Facebook calon kandidat presiden.
4. Menggunakan algoritma Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN) untuk analisis klasifikasi.
5. Menggunakan bahasa pemrograman python dan pada pembuatan sistem.
1.4 Tujuan Penelitian
Adapun tujuan penelitian adalah untuk memetakan sentimen positif, netral dan negatif masyarakat terhadap kandidat Presiden 2019-2024 menggunakan metode terbaik untuk mendapatkan hasil akurasi dengan tingkat error rate paling rendah yang berguna untuk memberi informasi dan pengetahuan yang dapat dijadikan acuan dalam banyak hal sesuai dengan tujuan penerapan sistemnya.
1.5 Manfaat Penelitian
Beberapa manfaat yang didapatkan dari penelitian ini antara lain:
1. Untuk mendapatkan informasi yang akurat seputar calon kandidat Presiden yang berasal dari kumpulan pendapat masyarakat.
2. Mengetahui karakteristik pendapat masyarakat secara lebih detail untuk mengurangi kesalahpahaman dalam mengartikan maksud pendapat.
3. Hasil dari pengolahan data sentimen dapat dijadikan sebagai tolak ukur untuk mengetahui inti dari objek sentimen yang sedang dibicarakan.
1.6 Metode Penelitian
Metodologi penelitian ini antara lain:
1. Observasi dan Mengumpulkan Data
Dilakukan pengumpulan berbagai informasi yang berkenaan dengan permasalahan yang akan diteliti. Tahap ini dilakukan untuk memperoleh informasi sehingga mempermudah dalam proses penelitian. Adapun referensi yang digunakan dalam tahap ini yaitu jurnal, buku, internet serta melakukan pengamatan komentar masyarakat pada masing-masing fanpage facebook calon kandidat presiden.
2. Crawling
Mengambil data dari source menggunakan Power Query. Data yang di crawling berupa komentar dari 2 fanpage kandidat presiden 2019-2024 yaitu fanpage Joko Widodo dan Ma’ruf Amin serta fanpage Prabowo Subianto dan Sandiaga Uno
3. Menyimpan data
Menyimpan data kedalam database. Data yang disimpan berupa data hasil crawling yang sudah dilabelisasi manual oleh penulis. Hasil data crawling yang sudah dilabelisasi akan disimpan dalam bentuk CSV file.
4. Preprocessing Text
Preprocessing Text digunakan untuk mempermudah sistem menganalisa sentimen. Tahap preprocessing text dalam penelitian ini antara lain punctuation, case folding, tokenizing, stopwords removal dan stemming.
5. Hasil Data Analisis Sentimen
Hasil data analisis sentimen berupa persentase nilai akurasi perhitungan sentimen positif, netral dan negatif.
1.7 Sistematika Penulisan
Bagian-bagian utama dalam sistematika penulisan skripsi adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi latar belakang pemilihan judul skripsi “Sistem Analisis Sentimen pada Fanpage Facebook Kandidat Presiden 2019-2024”, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini menjelaskan tentang Text Mining, Machine Learning, Analisis Sentimen, Algoritma Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN) secara umum, teori dan dasar-dasar perhitungan serta contoh implementasinya.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis terhadap masalah penelitian dan perancangan sistem yang akan dibangun sebagai solusi permasalahan tersebut.
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi implementasi Text Mining, Machine Learning, Analisis Sentimen, Algoritma Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN), dengan menguji sistem yang telah dibangun dengan menghitung klasifikasi komentar pada fanpage facebook kandidat presiden yang tergolong komentar positif, netral dan negatif, kemudian menampilkan hasil pengujian dan analisis.
BAB V KESIMPULAN DAN SARAN
Bab ini memuat kesimpulan dan saran berdasarkan penjelasan dan hasil pengujian dari beberapa bab sebelumnya. Penulis berharap penelitian ini dapat bermanfaat untuk penelitian selanjutnya.
BAB 2
LANDASAN TEORI
2.1. Text Mining
Text mining adalah proses menambang kata (text) oleh komputer untuk menemukan sesuatu yang baru dan belum pernah dilakukan dan ditemukan kembali informasi yang tersirat secara samar-samar, yang berasal dari informasi yang diekstrak secara otomatis dari sumber-sumber teks yang berbeda-beda. Text mining juga merupakan teknik yang digunakan untuk menangani masalah klasifikasi, clustering, information extraction dan information retrieval (Manalu, 2014).
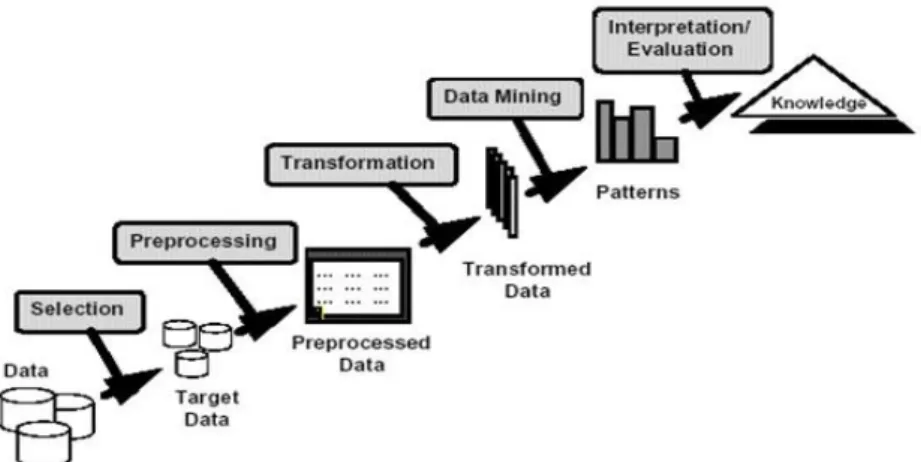
Text mining merupakan semacam cara dari data mining untuk mendapatkan pola yang unik dari beberapa teks yang berjumlah sangat besar. Pola pada text mining tidak terstruktur karena diambil dari kumpulan bahasa alami. Sedangkan data mining memiliki pola terstruktur karena didapatkan dari database terstruktur. Langkah- langkah untuk melakukan proses text mining antara lain mengumpulkan data, kemudian melakukan seleksi data (selection) untuk memilah data yang akan digunakan. Kemudian preprocessing untuk memproses data. Melakukan transformasi pada data (Transformation). Selanjutnya dilakukan data mining untuk menentukan pattern yang digunakan dan yang terakhir menampilkan perkembangan (Intepretation/Evolution) untuk menjadi data pengetahuan (Gusriani, 2016). Langkah melakukan proses text mining ditunjukkan pada gambar 2.1.
Gambar 2.1 Proses Text Mining (Sumber: Gusriani, 2016)
Perkembangan text mining telah mendapat banyak perhatian diberbagai bidang, antara lain:
1. Aplikasi Keamanan
Perangkat lunak yang menggunakan text mining untuk aplikasi keamanan seperti analisis plaintext pada berita internet yang menerapkan teks enkripsi.
2. Aplikasi Biomedis
Text mining digunakan pada aplikasi biomedis untuk memudahkan penyusunan data literatur pada perusahaan medis. Salah satu contoh aplikasi biomedis adalah PubGene.
3. Perangkat Lunak Otomatis
Dikembangkan program teknik text mining untuk lebih menyederhanakan proses analisis. Selain itu, perangkat lunak yang menggunakan sistem text mining akan diteliti lebih lanjut untuk meningkatkan performansinya.
4. Aplikasi Media Online
Text mining digunakan perusahaan besar agar dapat menghilangkan kebingungan informasi untuk memberikan sistem pencarian yang lebih baik pada pembaca. Selain itu, editor mampu berbagi properti paket berita secara signifikan untuk meningkatkan peluang bisnis dengan konten berita yang lebih menarik.
5. Aplikasi Pemasaran
Dalam bidang pemasaran, text mining digunakan dengan menganalisis kepuasan pelanggan terhadap suatu produk serta memanajemen hubungan pelanggan dengan menggunakan model analisis prediksi.
6. Sentiment Analysis
Analisis berdasarkan beberapa review dari berbagai media. Analisis ini membutuhkan data yang sudah diberi label sesuai dengan aktivitasnya. Sumber daya untuk label kata-kata contohnya adalah WordNet.
7. Aplikasi Akademik
Pembuatan aplikasi untuk akademik juga membutuhkan proses text mining dalam proses pencarian kata dan kalimat dari kumpulan data besar yang disimpan dalam database. Teks tertulis merupakan informasi yang paling spesifik dalam melakukan pencarian.
Pencarian pada website yang bebasis teks sudah sangat umum untuk digunakan untuk menemukan informasi sesuai dengan kata yang ditentukan. Namun dengan menggunakan text mining kita dapat menemukan informasi lebih sesuai dengan makna dan konteks yang diinginkan (Lidya S.K, 2014).
2.2. Machine Learning
Machine learning pertama kali diperkenal oleh Arthur Samuel seorang ahli komputer yang berasal dari Amerika Serikat pada tahun 1959. Pada saat itu Samuel masih bekerja di salah satu perusahaan teknologi yaitu IBM. Samuel mengartikan bahwa machine lerning merupakan suatu sistem yang dapat belajar tanpa harus diprogram kembali serta dapat memprediksi data dan mengambil keputusan dengan menggunakan beberapa algoritma.
Machine learning merupakan bagian dari kecerdasan buatan untuk mengembangkan suatu sistem yang diprogram oleh manusia kemudian diajarkan ke sistem agar sistem tersebut dapat belajar sendiri dan manusia tidak perlu memprogram sistem berulang kali. Untuk mengolah data menggunakan machine learning diperlukan data learning dan data testing. Data learning yaitu data yang digunakan sistem untuk belajar dan data testing untuk menguji kemampuan sistem yang telah belajar dari data learning. Semakin banyak data learning disiapkan maka sistem akan semakin banyak belajar sehingga akan menjadi lebih pintar.
Algoritma yang digunakan machine learning untuk klasifikasi teks antara lain:
K-Nearest Neighbours
Naive Bayes
Support Vector Machine
Decision Tree
Linear Regression
Neural Network
Dalam metode pembelajaran machine learning terhadap suatu ulasan, beberapa metode berikut merupakan metode terbaik untuk memprediksi sentimen yaitu Support Vector Machine (SVM), Naive Bayes Multinomial (NBM) dan Maximum Entropi (Maxent). Pada penelitian sebelumnya, fitur N-gram menggunakan bigrams juga dapat menentukan nilai akurasi terbaik (Troussas et al., 2013).
2.3. Facebook
Facebook merupakan sebuah platform sosial media yang saat ini sangat banyak digunakan. Dioperasikan oleh Facebook Inc dan diluncurkan pada tahun 2004.
Mark Zukerberg bersama 3 orang teman sekamarnya yang telah menciptakan Facebook. Selain teman sekamar mereka juga bersama-sama kuliah di jurusan ilmu komputer Harvard. Awalnya untuk penggunaan facebook dibatasi hanya mahasiswa Harvard saja, kemudian diserbarluaskan ke beberapa universitas lain seperti Stanford, Ivy League dan Boston karena semakin banyak orang yang tertarik menggunakan facebook. Pada awal tahun 2011, pengguna aktif Facebook lebih dari 600 juta. Data statistik pengguna menunjukkan bahwa AS berada di urutan teratas terdapat sebanyak 146 juta pengguna dan tingkat penetrasinya 47,25%. Studi Compete.com bulan Januari 2009 menempatkan Facebook sebagai layanan jejaringan sosial paling banyak digunakan menurut pengguna aktif bulanan diseluruh dunia, diikuti oleh MySpace (Patria, L., & Yulianto, K., 2011).
Facebook sebagai jejaring dan media sosial, mempresentasikan individu sebagai anggota jejaring sosial dengan penanda Akun dan Password. Syarat untuk mempunyai akun di facebook harus memiliki alamat email yang berguna sebagai ID untuk proses log-in serta untuk pengiriman notifikasi. Akun menjadi identitas untuk bisa menjadi anggota facebook dan mengenal pengguna facebook lainnya. Jika seorang pengguna sudah dapat berinteraksi dengan pengguna lain disebut sebagai friends. Sejauh ini berdasrkan informasi yang didapat jumlah friends yang bisa dimiliki oleh seorang pengguna Facebook maksimum sebanyak 5000 (Patria, L., &
Yulianto, K., 2011).
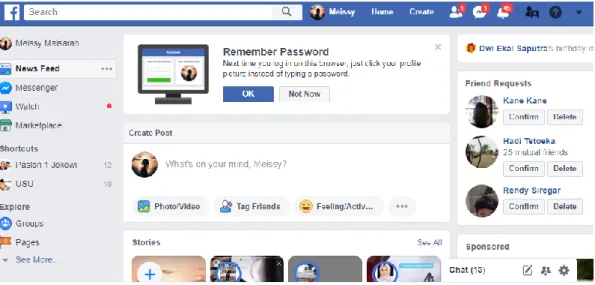
Setiap pengguna yang log-in ke Facebook akan mendapatkan tampilan seperti gambar 2.2 dibawah ini.
Gambar 2.2 Tampilan setelah log-in Facebook
1. Profil, berisi nama, lokasi tinggal, pendidikan dan lain-lain. Dilengkapi dengan gambar pengenal pengguna.
2. Tanda Notifikasi, merupakan catatan dan pemberitahuan atau notifikasi mengenai aktivitas yang baru saja dilakukan oleh teman facebook.
Pemberitahuan muncul dengan suara dan menampilkan berapa banyak jumlah aktifitas yang sudah dilakukan.
3. Pilihan Status, merupakan interaksi yang dilakukan oleh pengguna dengan teman. Status yang dapat pengguna bagikan kepada teman antara lain:
a. Text, berupa tulisan tentang perasaan yang sedang dialami oleh pengguna baik itu perasaan sedih maupun senang.
b. Photo, berupa pesan gambar yang diupload oleh pengguna.
c. Link, berupa teks link url untuk menuju ke halaman website lain.
d. Video, berupa rekaman tentang aktivitas atau peristiwa yang dianggap menarik untuk diupload oleh pengguna
e. Question, berupa pertanyaan untuk mengetahui reaksi atau pendapat mereka terhadap sesuatu.
4. Pengaturan akun, berisi pilihan menu untuk mengatur profil, keamanan seperti email dan password, aktifitas facebook dan lainnya.
5. Event, yaitu catatan waktu penting yang diagendakan, dibuat oleh pengguna ataupun teman yang menandai event dengan anda.
6. Chatting, merupakan interaksi bertukar pesan yang dapat dilakukan dengan teman sesama pengguna facebook. Proses bertukar pesan dilakukan secara real
time jika anda dan teman sedang menggunakan facebook pada waktu yang sama.
7. Wall, yaitu tempat untuk mengetahui aktifitas yang dilakukan teman berupa status dan gambar yang dibagikan.
8. Komentar, yaitu interaksi yang dilakukan teman pada status. Teman akan memberikan tanggapan tentang aktifitas yang dilakukan. dokumentasi komentar atas suatu status. Komentar akan ditata sesuai dengan urutan waktu komentar diberikan.
9. Foto friend, yaitu foto yang diunggah oleh teman dan menandai foto tersebut dengan anda. Foto akan tersimpan di galeri foto facebook.
10. Aplikasi dan Game, yaitu nama-nama aplikasi penunjang dan permainan yang dipergunakan oleh pengguna.
11. Daftar Group, yaitu para pengguna facebook yang bergabung dalam suatu grup. Pengguna maksimal dapat bergabung pada 200 grup dan masing-masing anggota grup maksimal berisi 5000 pengguna.
Sebagai sebuah aplikasi, Facebook adalah sebuah sistem yang mampu menarik perhatian secara visual dan sangat mudah untuk digunakan (Patria, L., & Yulianto, K., 2011).
2.4 Analisis Sentimen
Analisis sentimen merupakan langkah-langkah untuk mendapatkan informasi secara otomatis dengan melakukan analisis dan klasifikasi pendapat, mengevaluasi dan memberikan penilaian pada suatu produk, individu, jasa, organisasi dan peristiwa.
Secara umum, analisis sentimen terbagi 2 bagian besar, yaitu:
a) Coarse-grained sentiment analysis
Proses analisis dilakukan pada tingkat dokumen. Secara keseluruhan mencoba untuk mengklasifikasikan orientasi pada dokumen. Ada 3 jenis orientasi klasifikasi yaitu positif, netral, dan negatif. Nilai orientasi ini bersifat kontinu/tidak diskrit.
b) Fined-grained sentiment analysis
Analisis yang dilakukan terkait hal-hal yang sedang banyak dibicarakan.
Analisis ini tidak mengklasifikasikan pada tingkat dokumen tetapi yang di analisis adalah kalimat pada dokumen.
Dalam analisis sentimen, mengklasifikasikan jenis teks pada suatu dokumen merupakan tugas yang utama. Sentimen atau ekspresi merupakan fokus untuk topik tertentu. Pada suatu topik bisa saja ada 2 pernyataan sama namun memiliki perbedaan makna karena subjek yang berbeda. Contohnya seperti proses untuk pembuatan kamera digital sangat lama. Kata "lama" disini dinyatakan negatif namun jika kata
"lama" pada kalimat kamera ini memiliki usia baterai yang lama maka kata "lama"
dapat dinyatakan positif. Untuk itu, penelitian yang menggunakan proses opinion mining seperti review produk harus menentukan terlebih dahulu bagian apa yang sedang dibicarakan dari sebuah produk. Apakah produk tersebut perlu dilakukan analisis sentimen.
Langkah-langkah analisis sentimen pada sosial media Facebook antara lain:
2.4.1. Crawling
Crawling adalah proses untuk mendapatkan kemudian mengumpulkan informasi yang berasal dari halaman web. Cara kerja crawling yaitu dengan mendata beberapa link web kemudian nantinya link tersebut akan dikunjungi satu persatu. Pada tahap ini, sistem akan mengambil data berupa komentar dari source Facebook. Dalam melakukan pengambilan data, crawling untuk facebook menggunakan Power Query.
2.4.2. Pre-processing
Preprocessing merupakan proses mengolahan data untuk menyeragamkan setiap kata agar mempermudah pembacaan dan proses analisis sentimen selanjutnya.
Dalam penelitian ini beberapa tahap preprocessing yang dilakukan antara lain:
1. Cleaning, yaitu membersihkan komentar, seperti menghapus tanda baca, simbol tidak penting dan emoji. Tujuan data cleaning untuk mengurangi kebisingan kata pada proses analisis sentimen selanjutnya.
2. Case Folding, adalah proses mengubah huruf. Huruf dapat diubah menjadi kapital(besar) atau kecil.
3. Tokenizing adalah proses memecah teks menjadi kata tunggal. Proses tokenizing akan memecahkan teks yang terdiri dari satu kata.
4. Stopwords Removal merupakan proses untuk menhapus kata-kata yang sering muncul pada suatu dokumen. kata-kata tersebut merupakan kata yang tidak begitu penting karena terlalu banyak. Contohnya seperti kata saya, dan , ini,
atau dan lain-lain. Ada beberapa kamus atau library kumpulan kata Stopwords bahasa Indonesia yang dapat digunakan seperti Stopword Tala.
5. Stemming merupakan proses mengubah kata menjadi kata dasar. Setiap kata yang memiliki imbuhan diawal dan diakhir kata akan dihilangkan. Contoh seperti kata "perancangan" menjadi "rancang". Terdapat beberapa kamus dan library untuk daftar kata-kata stemming seperti Sastrawi untuk stemming bahasa Indonesia. Aturan morfologikal dari setiap bahasa menentukan proses pengaplikasian stemming karena proses stemming tergantung dari bahasa pada dokumen. Adapun algoritma stemming sama seperti yang diterapkan pada algoritma Nazief dan Andriani yaitu sebagai berikut:
Cari kata pada daftar kamus. Jika ada kata pada daftar kamus, maka kata tersebut merupakan kata dasar.
Jika kata seperti langkah pertama tidak ada pada kamus, periksa imbuhan pada kata belakang (sufiks) seperti kata “lah” dan “kah”. Jika ada hilangkan sufiks.
Periksa kata ganti milik seperti "-ku", "-mu" dan "nya" pada dokumen.
Jika terdapat kata tersebut maka dihilangkan.
Memeriksa akhiran (“-i”, “-an”), (“-lah”, “-kah”) dan kata ganti milik (“-ku”, “-mu”, “-nya”). Jika ada ditemukan, maka akhiran dihilangkan.
Sangat dibutuhkan ketelitian untuk sampai ke langkah 4.
Periksa awalan dokumen seperti kata “di-”, “se-”, “ke-”, “te-”, “be-”,
“pe-”, dan “me-”. Bila ditemukan, kata awalan dihapus. Adanya kemungkinan kata multi-prefiks diperlukan berulang kali pemeriksaan pada dokumen. Dibutuhkan ketelitian pada tahap ini karena harus memeriksa setiap awalan yang akan diluluhkan.
Setelah semua tahapan sudah selesai dilakukan dan berhasil, kata dasar yang ditemukan akan dikembalikan oleh algoritma.
2.4.3. Pembobotan Term
Pembobotan term yaitu setiap kata yang ada pada sebuah dokumen sudah melakukan tahap preprocessing kemudian akan diberikan sebuah nilai sesuai dengan tingkat kepentingan kata tersebut. Metode TF-IDF merupakan proses untuk
memberikan nilai pada kata dengan mencari gambaran nilai dari setiap komentar yang dikumpulkan pada dataset dan diolah dalam bentuk vektor (Lidya S.K, 2014).
Untuk metode menghitung bobot kata pada dokumen dapat dirumuskan sebagai berikut:
Wdt = tfdt * IDFt
Dimana
W = Bobot dokumen terhadap kata d = Dokumen
t = Token atau kata ke-
tf = Term Frequency atau jumlah kata dalam sebuah dokumen IDF = Invers Document Frequency
1. Term Frequency (TF)
TF (Term Frequency) adalah jumlah term (kata) yang muncul dari sebuah dokumen. Jika kata yang muncul pada dokumen berulang kali atau semakin banyak maka bobot kata yang akan diberikan juga akan semakin besar.
2. Inverse Document Frequency (IDF)
IDF (Inverse Document Frequency) merupakan proses melakukan pendistribusian pada term (kata) secara luas pada koleksi dokumen dengan melakukan suatu perhitungan. Nilai IDF akan semakin besar jika jumlah dokumen yang mengandung nilai termnya semakin sedikit.
Perhitungan untuk Inverse Document Frequency (IDF) menggunakan rumus sebagai berikut:
( )
Dimana D adalah banyaknya semua dokumen dalam sedangkan dfj adalah jumlah dokumen yang mengandung term (tj).
...(1)
...(2)
2.4.4. Analisis dan Validasi
Pada proses ini akan dilakukan analisis menggunakan algoritma SVM. Setelah komentar telah diberi pembobotan TF-IDF maka proses selanjutnya adalah menganalisis yaitu setiap komentar akan diberi tanda positif, netral atau negatif dan memvalidasi hasil labelisasi komentar untuk melihat akurasi/ketepatan suatu dokumen yang telah direpresentasikan (Lidya S.K, 2014).
Jika jumlah positif < jumlah negatif maka skor sentimen:
( )
Jika jumlah positif = jumlah negatif maka skor sentimen:
( )
Jika jumlah positif > jumlah negatif maka skor sentimen:
( )
Namun sebelum dilakukan proses validasi, akan dilakukan split data. Split data adalah pemisahan data menjadi dua bagian yaitu data training (data latih) dan data testing (data uji).
1. Data Training
Data training adalah data yang digunakan untuk pembelajaran sistem.
Data training diperlukan dalam machine learning agar mesin dapat belajar lebih pintar dan memahami informasi yang disampaikan. Ada 3 tipe pembelajaran yang digunakan pada data training yaitu Supervised, unsupervised dan Semi-unsupervised. Supervised merupakan pembelajaran dimana data training sudah dilabeli sehingga mesin dapat belajar dari contoh.
Unsupervised merupakan pembejaran hanya berdasarkan struktur data yang mana data training belum dilabeli. Semi-unsupervised merupakan gabungan ...(5)
...(4) ...(3)
dari pembelajaran Supervised dan Unsupervised yang mana mesin akan belajar dari contoh dan struktur data.
2. Data Testimg
Data testing merupakan tahap evaluasi untuk menguji bagaimana hasil dari pembejaran mesin serta bagaimana hasil dari penggunaan algoritma yang digunakan. Kinerja yang tinggi dari Algoritma akan dapat mengklasifikasikan data baru dengan benar dan lebih baik dari proses pembelajaran.
3. Confusion Matrix
Confusion matrix merupakan tabel matrix yang terdiri dari 2 kelas yaitu positif dan negatif untuk menghitung nilai akurasi dalam proses data mining dan proses Sistem Pendukung Keputusan. Ada 4 istilah untuk melakukan pengukuran kinerja dari proses algoritma klasifikasi yaitu:
True Positive (TP): Data Positif yang terprediksi benar
False Positive (FP): Data Negatif namun terprediksi Positif
True Negative (TN): Data Negatif yang terprediksi benar
False Negative (FN): Data Positif namun terprediksi Negatif Berikut tabel untuk Confusion Matrix pada gambar 2.3.
Gambar 2.3 Confusion Matrix
(Sumber: kuliahkomputer.com/pengujian-dengan-confusion-matrix)
Berdasarkan nilai dari TP, FP, TN, dan FN maka akan didapatkan nilai Precision, Recall dan Akurasi. Precision merupakan tingkat ketepatan nilai prediksi positif dengan sistem. Recall merupakan tingkat sebuah sistem berhasil dalam mendapatkan kembali informasi, dan akurasi adalah tingkat kedekatan nilai prediksi dengan nilai aktual atau total data yang diidentifikasi dengan data yang dinilai. Rumus perhitungan precision, recall dan akurasi adalah sebagai berikut:
2.5 Algoritma Support Vector Machine (SVM)
Algoritma klasifikasi yang pertama kali dipresentasikan pada tahun 1992 oleh Boser, Guyon dan Vapnik adalah Support Vector Machine (SVM). SVM merupakan penggabungan dari teori klasifikasi yang sudah ada sebelumnya seperti lagrange, kernel dan margin hyperplane. SVM memiliki fungsi pemisah dalam klasifikasi dua kelas secara linear tetapi karena kebutuhan klasifikasi yang semakin meningkat SVM dikembangkan tidak hanya untuk klasifikasi linear. Namun klasifikasi non-linear sudah dapat dilakukan oleh SVM dengan perpaduan kernel pada feature space (ruang yang berdimensi tinggi). Regresi yang outputnya bilangan ril juga dapat dilakukan oleh SVM atau algoritma ini disebut juga dengan Support Vector Regression (SVR).
Dengan menggunakan SVR, prediksi untuk klasifikasi antara beberapa kelas dapat dilakukan.
SVM merupakan himpunan metode supervised learning untuk classification, regression dan outliers detection. Keuntungan dari SVM adalah efektif pada ruang high dimensional dan menggunakan subnset dari titik training pada fungsi keputusan (support vector). Kekurangannya adalah jika jumlah fitur lebih besar dari jumlah sampel, metode memberikan performa yang kurang memuaskan, serta tidak menyediakan estimasi probabilitas. SVM merupakan supervised classifier yang sering digunakan untuk mengekstraksi statistic corpus untuk sentiment analysis (Chowdhury et al., 2018).
...(7) ...(6)
...(8)
Gambar 2.4 Hyperplane pada SVM (Sumber: Chowdhury et al., 2018)
Support vector machine membentuk hyperplane atau himpunan hyperplanes pada ruang dimensi infinite yang digunakan pada klasifikasi serta regresi. Keuntungan dari SVM adalah efektif pada high dimensional spaces serta kernel fungsi yang berbeda dapat ditentukan untuk fungsi keputusan.
Menurut (Trinh et al., 2016), SVM adalah sistem pembelajaran mesin yang prinsip kerjanya menggunakan Structural Risk Minimization (SRM). SRM bertujuan untuk mendapatkan garis pemisah terbaik (hyperplane) pada input space dalam klasifikasi dua kelas. Dengan mengukur margin pada garis pemisah dan mencari titik puncaknya maka akan dapat ditemukan garis pemisah terbaik antara duah buah kelas.
Jarak pada masing-masing duah buah kelas disebut dengan margin dan pola yang paling mendekati klasifikasi antara dua buah kelas disebut support vector.
Tahapan pembelajaran dalam SVM adalah:
1) Mencari Lagrance Multipliers( )
( ) ∑
∑
( )
Keterangan:
= kelas data latih (+1/-1).
= kelas data latih (+1/-1).
= vektor bobot kalimat komentar.
...(9)
= vektor bobot kalimat komentar.
2) Mencari Nilai Bobot (w)
∑(
)
Keterangan:
w = vektor bobot.
= kelas data latih (+1/-1)
= vektor bobot kalimat komentar yang menjadi vektor pendukung.
3) Mencari Nilai Bias (b)
∑(
)
Keterangan:
NSV = jumlah vektor pendukung.
W = vektor bobot.
= kelas data latih (+1/-1).
= vektor bobot kalimat komentar yang menjadi vektor pendukung.
Proses pengklasifikasian (pengujian) dalam SVM menggunakan persamaan berikut.
( ) ( ∑
)
Keterangan:
T = vektor bobot data uji = vektor pendukung = nilai bias
...(10)
...(11)
...(12)
= kelas atau label dari vektor pendukung (+1/-1)
2.5.1. Metode Kernel
Metode kernel merupakan cara untuk melakukan klasifikasi pada data yang tidak terklasifikasi secara linear. Metode kernel yang digunakan pada SVM adalah untuk mengimplementasikan model pada feature space (ruang yang lebih tinggi) agar model non linear dapat dipisahkan. Beberapa fungsi kernel memiliki jenis yang berbeda-beda. Perbedaan pada jenis kernel ini tergantung pada pengklasifikasiannya di feature space. Beberapa fungsi metode kernel yang paling banyak digunakan antara lain sebagai berikut (Lidya S.K, 2014) :
1. Kernel Linear
Kernel linear merupakan kernel yang paling sering digunakan untuk klasifikasi karena fungsi kernelnya paling sederhana. Kernel linear biasa digunakan untuk klasifikasi pada teks
2. Kernel Radial Basis Gaussian
Kernal yang paling umum digunakan. Kernel ini biasanya digunakan untuk mengklasifikasikan data yang sudah valid.
3. Kernel Polynominal
Kernel polynominal biasanya digunakan untuk mengklasifikasikan gambar.
4. Kernel Tangent Hyperbolic
Kernel ini biasanya digunakan untuk klasifikasi pada neural networks.
Untuk dapat menentukan feature space dalam mencari fungsi classifier yang akan dicari perlu dilakukan pemilihan metode kernel yang baik yaitu jika fungsi kernel yang dipilih cocok pada dataset yang akan diklasifikasi. Metode kernel lebih baik mengetahui bagaimana perkalian titik pada feature space dapat diganti oleh fungsi kernel. Dalam menentukan fungsi kernel biasanya menggunakan cross validation.
SVM sebenarnya dikembangkan untuk melakukan klasifikasi biner. Namun, klasifikasi biner sangat terbatas karena hanya melibatkan 2 kelas. Kemudian para peneliti mulai mengembangkan klasifikasi multi-kelas untuk memperluas jenis
klasifikasi. Klasifikasi multi-kelas diantaranya adalah SVC, NuSVC dan LinearSVC.
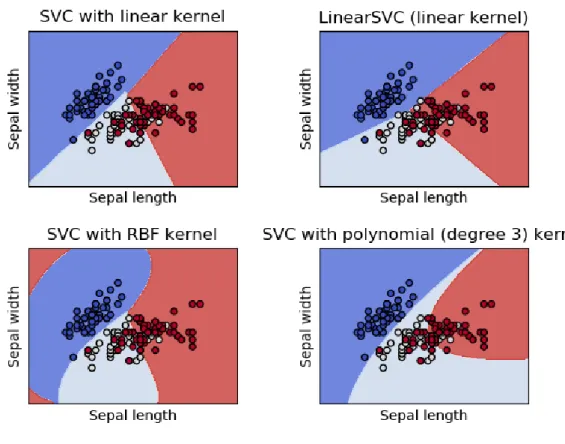
Pembagian klasifikasi multi-kelas ditunjukkan pada gambar 2.5 berikut.
Gambar 2.5 Klasifikasi Multi-kelas (Sumber: scikit-learn.org/sklearn.svm.SVC)
Pada gambar 2.5 dapat dilihat model klasifikasi data dengan menggunakan metode SVC dengan beberapa kernel yaitu linear kernel, RBF kernel dan polynomial kernel. SVC merupakan perintah dari algoritma SVM yang paling biasa digunakan.
Algoritma SVM pada SVC membagi garis tengah hyperplane menjadi linear 2 dimensi tanpa penambahan kernel lainnya. SVC menggunakan kernel linear dianggap sudah cukup baik untuk mendeteksi keakuratan suatu data.
2.5.2. Karakteristik SVM
Menurut (Nugroho, Witarto, & Handoko, 2003), ada beberapa karakteristik SVM yaitu sebagai berikut:
1. SVM secara prinsip merupakan linear classifier
2. SVM melakukan nilai optimasi di ruang hasil transformasi dengan dimensi yang lebih rendah dari dimensi input space
3. SVM menggunakan metode Structural Risk Minimization (SRM) 4. SVM pada prinsipnya menggunakan kernel linear yang unggul dalam
klasifikasi teks
2.5.3. Kelebihan dan Kekurangan SVM
Dalam menyelesaikan suatu permasalahan kelebihan dan kekurangan algoritma sangat penting untuk diperhatikan. Ada beberapa kelebihan dan kekurangan dari algoritma SVM. Kelebihan dari SVM adalah sebagai berikut (Chowdhury et al., 2018):
1. Efektif jika jumlah dimensi lebih besar daripada jumlah sample
2. Lebih hemat memori karena menggunakan vektor pendukung (support vector )
3. Banyak fungsi kernel yang berbeda yang dapat digunakan untuk klasifikasi Disamping kelebihan pasti ada kekurangan dari suatu algoritma.
Adapun kekurangan menggunakan algoritma SVM adalah sebagai berikut:
1. Menghindari pemasangan kernel yang berlebihan jika jumlah fitur lebih besar daripada umlah sample
2. Tidak langsung memberikan estimasi probabilitas
2.6 Algoritma K-Nearest Neighbours (K-NN)
Algoritma untuk mengklasifikasikan kumpulan data pembelajaran (data training) yang sudah diklasifikasikan sebelumnya. Algoritma ini merupakan salah satu dari supervised learning yang melakukan klasifikasi berdasarkan jarak terdekat. Contoh kasus penerapan algoritma K-NN yaitu dalam menghadiri suatu pertemuan, kita mengambil keputusan untuk datang atau tidak pada pertemuan tersebut (kelas). Kemudian perhatikan mayoritas keputusan yang diambil dari teman dan tetangga terdekat (instance). Teman dan tetangga dipilih berdasarkan kedekatannya dengan kita. Kedekatan dianggap sebagai invers (nilai yang berbanding terbalik dengan jarak). Antara 2 instance jika jarak antara 2 instance semakin kecil maka kedekatannya akan semakin besar. Kesimpulannya, K-NN dapat didefenisikan k instance yang memiliki jarak yang kecil dapat menghasilkan kedekatan (Nearest) yang besar.
Gambar 2.6 Algoritma K-Nearest Neighbours (Sumber: Lidya S.K, 2014)
Dalam metode pencarian jarak terdekat pada algoritma ini terdiri dari 2 jenis yaitu Euclidean Distance dan Cosine Similarity. Metode ini diperlukan untuk menentukan jumlah kemiripan dari kemunculan data teks. Adapaun satuan jarak yang digunakan Euclidean ada dua macam yaitu 1-NN dan k-NN.
1-NN merupakan klasifikasi pada 1 label data yang paling dekat sedangkan k- NN merupakan klasifikasi dengan menentukan nilai k pada label data yang paling dekat, dengan ketentuan k > 1. Dalam menentukan nilai k tergantung pada data yang digunakan. Jika nilai k tinggi maka efek noise tidak terlalu banyak pada proses klasifikasi, namun batasan dalam setiap pengklasifikasian menjadi semakin kabur. Dengan mengoptimasi parameter dapat ditentukan nilai k yang baik.
2.6.1. Algoritma Perhitungan K-NN
Cara kerja perhitungan algoritma K-Nearest Neighbours (K-NN) adalah sebagai berikut:
1. tentukan nilai parameter K untuk banyak jumlah tetangga terdekat dengan objek
2. hitung jarak antar objek baru dengan objek data training 3. hasil perhitungan diurutkan
4. berdasarkan jarak paling kecil ke K, tentukan tetangga paling dekat 5. berdasarkan tetangga yang terdekat pada objek, tentukan kategori 6. kategori yang paling banyak digunakan untuk klasifikasi pada objek
2.6.2. Kelebihan dan Kekurangan K-NN
Setiap algoritma pasti memiliki kelebihan dan kekurangan dalam setiap cara kerjanya begitu juga dengan algoritma ini. Adapun kelebihan dari algoritma K-NN adalah sebagai berikut:
1. Efektif digunakan pada data training yang besar 2. Data yang dihasilkan lebih akurat
3. Cocok digunakan pada data training yang mengandung noise 4. Dapat digunakan pada klasifikasi non-linear
Sedangkan kekurangan dari algoritma ini yaitu perlu ditentukan dahulu nilai k yang paling optimal sebelum melakukan klasifikasi.
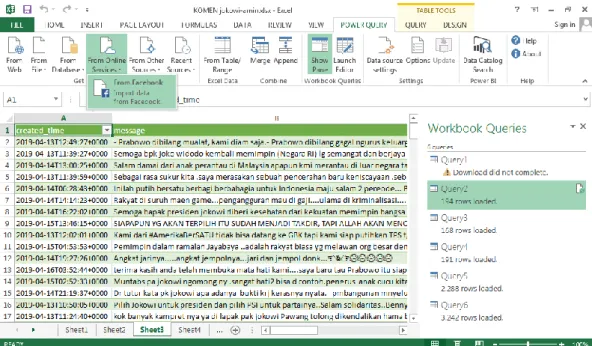
2.7 Power Query
Power query merupakan fitur analisis data yang tersedia untuk Excel yang memungkinkan pengguna menemukan, menggabungkan dan memperbaiki data.
Power query memungkinkan mentransformasikan data web dan menambahkan query ke model data ke worksheet yang ada (Gusriani et al., 2016).
Dengan power query dapat mempermudah proses mencari sumber data. Adapun langkah-langkah menggunakan power query untuk crawling komentar fanpage yaitu:
1. Buka Microsoft Excel yang sudah terinstall power query.
2. Klik power query kemudian pilih From Other Souce untuk memlilih proses pengambilan sumber data.
3. Kemudian pilih From Facebook untuk mengambil sumber data dari facebook.
4. Masukkan Id Object yang terdapat pada link fanpage facebook.
5. Pilih data yang akan diambil. Karena pada penelitian ini sumber data yang digunakan adalah komentar maka data yang dipilih untuk diambil adalah komentar. Kemudian klik ok.
6. Tunggu proses crawling. Sumber data secara otomatis akan tersusun dalam microsoft excel. Simpan file hasil crawling.
2.8 Penelitian yang Relevan
Berikut beberapa penelitian yang berkaitan dengan analisis sentimen dapat dilihat pada tabel 2.1.
Tabel 2.1 Rangkuman Penelitian Terdahulu
No Penulis Judul Tahun Metode Persamaan Perbedaan
1 Trinh, Son;
Nguyen, Luu; Vo, Minh; Do, Phuc
Lexicon- Based Sentiment Analysis of Facebook Comments in
Vietnamese Language
2016 Lexicon Based, Support Vector Machine (SVM)
Menggunakan Support Vector Machine (SVM) untuk
mengklasifikasikan kalimat.
Membuat kamus emosional berdasarkan opini masyarakat.Topik yang diambil dalam penelitian ini seperti olahraga, pendidikan dan film. Kalimat yang di input akan diberi nilai - 5 (negatif) sampai +5 (positif)
kemudian setiap kata dihitung untuk mendapatkan nilai dari kalimat tersebut apakah termasuk kalimat positif, negatif dan netral.
2 Dhaoui, Chedia;
Webster, Cynthia M.;
Tan, Lay Peng
Social media sentiment analysis:
lexicon versus machine learning
2017 membandingkan 2 metode yaitu lexicon-based dengan machine learning
Dataset yang digunakan adalah beberapa komentar facebook terhadap suatu produk.
Menggunakan pendekatan machine learning dalam pengujian data berupa fitur n- gram.
Dalam melakukan analisis sentimen, data diambil dari beberapa sosial media. Karena banyaknya data yang akan ditampung membuat proses analisis menjadi lebih lama dan tidak praktis.
Untuk itu dibandingkan dengan proses menggunakan machine learning yang lebih akurat dan praktis namun dalam proses pembuatan mesin masih
pelatihan.
3 Fang, Xing;
Zhan, Justin
Sentiment analysis using product review data
2015 Kategorisasi polaritas sentimen menentukan kalimat positif, negatif dan netral dengan level-document, level-sentence dan entiti and aspect level.
Menggunakan POS tagging untuk mengetahui besar jumlah sentimen pada kata.
Menggunakan metode Support Vector Machine, Random Forrest dan Naive Bayesian dalam label kalimat untuk
membandingkan metode mana yang terbaik dalam memprediksi kalimat.
menggunakan sckit learn
Mengunakan sentimen analisis dalam mengulas suatu produk dengan menetukan kalimat positif, negatif dan netral terhadap suatu produk. Penelitian ini juga
menerapkan peringkat/bintang dalam menentukan sentimen positif, netral dan negatif yang mana pada bintang 1 dan 2 merupakan sentimen negatif bintang 3 sentimen netral dan bintang 4 dan 5 sentimen positif. namun belum dapat diterapkan karena sulit dalam kategorisasi ulasan.
Penelitian ini membahas tentang analisis sentimen pada beberapa ulasan produk yang data nya diambil dari situs online Amazon.com.
Ulasan yang diambil dari ulasan bintang 1- 5.
4 Rachmat, Antonius;
Lukito, Yuan
Sentipol : Dataset Sentimen Komentar Pada Kampanye Pemilu Presiden Indonesia 2014 Dari Facebook Page
2016 Metode
Majority Voting dalam
pengumpulan dataset dan Crowdsourced Labelling untuk pemberian label sentimen pada data.
Dataset yang akan diambil berupa status dan komentar dari facebook page calon presiden 2014
Pada penelitian ini membahas tentang
bagaimana proses pengumpulan dataset dari facebook page.
Dataset dibangun pada penelitian ini untuk mendapatkan dataset yang valid dan dapat
digunakan datanya untuk bahan penelitian mengenai sentimen analisis dan supervised learning.
5 Chowdhury, Hemayet Ahmed;
Nibir, Tanvir Alam;
Islam, Md.
Saiful
Sentiment Analysis of Comments on
Rohingya Movement with Support Vector Machine
2018 Menggunakan metode Support Vector Machine (SVM) dan menggunakan library scikit- learn.
Menggunakan kernel non linear RBF untuk classifier sentimen agar mencapai akurasi yang lebih baik.
Dataset yang dikumpulkan diambil dari facebook yang berkaitan dengan gerakan rohingya.
Menggunakan metode yang sama yaitu Support Vector Machine (SVM).
Karena dataset rohingya tidak tersedia maka pengumpulan dataset ditentukan sendiri sebanyak 2500 positif dan 2500 negatif.
Pada penelitian ini sentimen yang dianalisis hanya sentimen positif dan negatif saja.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM 3.1. Analisis Sistem
Analisis sistem bertujuan untuk menjabarkan sistem informasi utuh menjadi beberapa bagian komponen agar dapat diidentifikasi dan dievaluasi masalah yang terdapat pada sistem sehingga permasalahan pada sistem dapat ditanggulangi dan dikembangkan menjadi lebih baik. Dalam penelitian ini terdapat 2 tahapan dalam proses analisis sistem yaitu analisis masalah dan analisis kebutuhan sistem.
3.1.1. Analisis Masalah
Analisis masalah merupakan proses untuk memahami suatu permasalahan dalam penelitian sehingga dapat dicari solusi dari permasalahan tersebut. Permasalahan pada penelitian ini adalah bagaimana dapat menghasilkan nilai akurasi terbaik dan akurat secara otomatis dalam analisis sentimen terhadap komentar dari fanpage facebook kandidat presiden 2019-2024 menggunakan metode Support Vector Machine (SVM) dan K-Nearest Neighbours (K-NN).
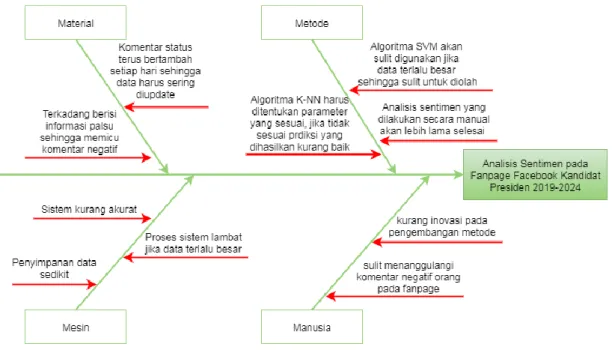
Permasalahan pada penelitian ini dapat dilihat pada gambar 3.1 Diagram Ishikawa.
Gambar 3.1 Diagram Ishikawa
Berdasarkan gambar 3.1, Pemasalahan pada penelitian ini terbagi menjadi 4 bagian yaitu material, metode, mesin dan manusia. Pada bagian material menjelaskan tentang hal-hal yang penting digunakan dalam penelitian. Bagian metode menjelaskan tentang bagimana permasalahan yang terjadi pada sistem yang akan dibangun menggunakan beberapa metode baru. Kemudian bagian mesin menjelaskan permasalahan yang terjadi jika mengalami overload dan berkurangnya kinerja pada sistem. Bagian manusia menjelaskan tentang permasalahan yang dialami oleh pembuat sistem dalam membangun dan menjalankan sistem.
Permasalahan ini merupakan kemungkinan yang terjadi pada sistem dan penulis berusaha untuk mengatasi permasalahan tersebut agar kesalahan dapat diminimalisir.
3.1.2. Analisis Kebutuhan
Analisis kebutuhan pada penelitian ini bertujuan untuk memenuhi hal-hal apa saja yang diperlukan untuk perkembangan penelitian dan sistem agar menjadi lebih baik. Pada penelitian ini analisis kebutuhan terbagi menjadi 2 yaitu analisis kebutuhan fungsional dan analisis kebutuhan nonfungsional.
a. Kebutuhan Fungsional
Analisis kebutuhan fungsional merupakan hal-hal yang harus disediakan dalam proses pembuatan sistem. Kebutuhan fungsional sistem dalam penelitian ini adalah sebagai berikut:
1. Dataset diambil dari 2 fanpage facebook yang sudah dikelompokkan secara manual menjadi sentimen positif, netral dan negatif untuk mendapatkan nilai akurasi terbaik.
2. Sistem dapat menampilkan nilai akurasi dari sentimen positif, netral dan negatif menggunakan metode Support Vector Machine (SVM) dan K- Nearest Neighbours (K-NN).
b. Kebutuhan non - fungsional
Analisis kebutuhan nonfungsional merupakan kebutuhan tambahan yang diperlukan dalam proses pembuatan sistem agar lebih optimal. Kebutuhan nonfungsional sistem dalam penelitian ini adalah sebagai berikut: