ANALISIS SENTIMEN TERHADAP FILM INDONESIA DENGAN PENDEKATAN BERT SKRIPSI DWI FIMOZA
Bebas
95
0
0
Teks penuh
(2) ANALISIS SENTIMEN TERHADAP FILM INDONESIA DENGAN PENDEKATAN BERT. SKRIPSI. Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Komputer. DWI FIMOZA 161401131. PROGRAM STUDI S-1 ILMU KOMPUTER FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA MEDAN 2021. UNIVERSITAS SUMATERA UTARA.
(3) UNIVERSITAS SUMATERA UTARA.
(4) PERNYATAAN. ANALISIS SENTIMEN TERHADAP FILM INDONESIA DENGAN PENDEKATAN BERT. SKRIPSI. Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya. Medan, 19 Januari 2021. Dwi Fimoza 161401131. UNIVERSITAS SUMATERA UTARA.
(5) UCAPAN TERIMA KASIH. Puji dan syukur penulis ucapkan ke hadirat Allah SWT, karena rahmat dan kuasa-Nya, penulis dapat menyelesaikan penyusunan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S-1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. Dengan kerendahan hati dan rasa bersyukur, penulis ingin menyampaikan rasa hormat dan ungkapan terima kasih yang sebesar-besarnya kepada semua pihak yang telah membantu penulis dalam proses pembuatan dan penyelesaian skripsi ini, baik dalam bentuk doa, bimbingan, kerjasama, dukungan dan kalimat-kalimat menenangkan. Penulis mengucapkan terima kasih kepada: 1. Prof. Dr. Runtung Sitepu, S.H., M.Hum. selaku Rektor Universitas Sumatera Utara 2. Prof. Dr. Opim Salim Sitompul, M.Sc. selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. 3. Bapak Dr. Poltak Sihombing, M. Kom. selaku Ketua Program Studi S1 Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara. 4. Ibu Amalia, S.T., M.T selaku dosen pembimbing I yang telah memberikan bimbingan, kritik, motivasi, dan saran kepada penulis dalam menyelesaikan skripsi ini. 5. Alm. Bapak Sajadin Sembiring, S.Si., M.Comp.Sc., selaku dosen pembimbing II yang telah memberikan saran, kritik, dan motivasi kepada penulis dalam menyelesaikan skripsi ini. 6. Ibu T. Henny Febriana Harumy, S.Kom., M.Kom. selaku dosen pembimbing II yang telah memberikan bimbingan, kritik, motivasi, dan saran kepada penulis dalam menyelesaikan skripsi ini. 7. Seluruh tenaga pengajar dan pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi USU yang telah membantu penulis dalam proses pembuatan skripsi.. UNIVERSITAS SUMATERA UTARA.
(6) 8. Kedua orangtua penulis, Mulyono Kaman dan Zulhijjah Tanjung, yang senantiasa menyayangi, mendoakan, dan mendukung penulis dalam tiap aspek kehidupan yang penulis lalui. 9. Saudara kandung penulis: Firola Muliza selaku kakak yang selalu sabar menjadi pendengar serta menyemangati penulis. Fadhil Maulana dan Faiz Muhammad selaku adik laki-laki yang dapat diandalkan. 10. Ananda Satria Sidharta yang selalu menemani, mendukung, dan memberi penulis semangat dan perhatian walau kadang jarak memisahkan. 11. Teman-teman yang berada ketika penulis merasa senang maupun lelah dan selalu percaya kepada penulis, Tengku Amadhea Irvida dan Mutiah Khairani Tanjung. 12. Teman-teman seperjuangan: Rizki Nofianty Tanjung, Annissa Kamila Mardhiyyah Nasution, Syarifah Kemala Putri, Selina Amelia Savittri, Indah Permata Syahnan, Nazli Alvira Siregar, Mega Ayuamartha Putri, Azizah Nur Lubis, Mirta Amalia, dan Rini Natalia Sinaga. 13. Teman-teman seperjuangan Angkatan 2016: Elsa Krismonti, Azis Fahri Tanjung, Rivaldo, Harry Nimrod Alexandro Sitorus, Adam Yosafat Noverico Damanik, dan teman-teman yang lain yang tidak dapat disebutkan satu-satu dan telah banyak membantu penulis dalam proses pengerjaan skripsi dan selama kuliah. 14. Keluarga XLFL Batch 6 Medan, khususnya Adrian Setiyadi, Cut Mutia Fahira, Syahnanda Putra, Rifa Alya, dan Putrie Rizki. 15. Seluruh wadah yang banyak memberikan penulis pengalaman dan membentuk karakter penulis: IKLC USU, PEMA Fasilkom-TI, IMILKOM USU, dan UKMI Al-Khuwarizmi. 16. Semua pihak yang terlibat baik secara langsung maupun tidak langsung yang telah banyak membantu, yang tidak dapat disebutkan namanya satu per satu. Last but not least, terima kasih kepada Dwi Fimoza yang akhirnya mampu mengalahkan segala rasa takut dan cemas. Semoga Allah SWT melimpahkan berkah kepada semua pihak yang telah memberikan bantuan,. UNIVERSITAS SUMATERA UTARA.
(7) semangat, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini. Semoga skripsi ini dapat memberika manfaat ke depannya. Medan, 19 Januari 2021. Penulis. UNIVERSITAS SUMATERA UTARA.
(8) ABSTRAK. Penelitian ini bertujuan untuk analisis sentimen Bahasa Indonesia terhadap review film Gundala di YouTube. Namun, analisis sentimen pada komentar YouTube yang bervariasi dari komentar positif, negatif, maupun netral membutuhkan. suatu. otomatisasi. dalam. mengklasifikasikan. komentar. berdasarkan polaritas sentimennya. Analisis sentimen dengan penggunaan algoritma machine learning tradisional seperti Naïve Bayes, SVM, dan lain-lain tidak dapat memahami konteks dari komentar secara mendalam tentang semantik kata yang ada karena hanya mempelajari pola-pola yang diberikan seperti frekuensi kemunculan kata. Untuk itu dibutuhkan sebuah pendekatan transfer learning seperti BERT (Bidirectional Encoder Representations from Transformers). yang. menghasilkan. sebuah. model. bahasa. dua. arah. (bidirectional). Dataset yang digunakan melalui tahap pre-processing yang terdiri dari case folding, data cleaning, tokenisasi, stopwords removal, stemming, dan normalisasi dengan library NLTK dan Sastrawi sebelum dilakukan analisis sentimen. Dalam penelitian ini hyperparameters yang digunakan adalah 10 epoch, learning rate 2e-5, dan batch size 16. Pengujian analisis sentimen menggunakan model BERTBASE multilingual-cased-model dan dilakukan dengan tiga kali percobaan. Nilai akurasi yang diperoleh pada percobaan pertama adalah 66%, sedangkan percobaan kedua adalah 68%, dan percobaan ketiga adalah 66%. Sehingga rata-rata nilai akurasi yang diperoleh adalah 66,7%. Kata Kunci: Analisis Sentimen, Film Indonesia, YouTube, Gundala, Bidirectional Encoder Representations from Transformers, Deep Learning, Transformers. UNIVERSITAS SUMATERA UTARA.
(9) SENTIMENT ANALYSIS OF INDONESIAN FILM USING BERT. ABSTRACT. This study aims to analyze the sentiment in Indonesia Language towards the Gundala movie reviews on YouTube. However, sentiment analysis on YouTube comments are varying from positive, negative, and neutral comments which requires some automation in terms of classifying comments based on the polarity of sentiment. Sentiment analysis using traditional machine learning algorithms such as Naïve Bayes, SVM, etc cannot understand the context of comments in depth about the semantic of words because it only learns the given patters such as the frequency of occurrence of words. We need a transfer learning approach such as BERT (Bidirectional Encoder Representations from Transformers) which produces a bidirectional language model. The dataset used to do sentiment analysis goes through a pre-processing step which consists of case folding, data cleaning, tokenization, stop words removal, stemming, and normalization, using libraries from NLTK and Sastrawi. In this study, the hyperparameters used were 10 epochs, learning rate of 2e-5, and a batch size 16. In sentiment analysis, we will be using a multilingual-cased-model BERTBASE model and it was carried out with three experiments. During this experiment, the accuracy gained in first experiment is 66%, while the second experiment was 68%, and the third experiment was 66%. So, the average accuracy obtained is 66,7%. Keywords: Sentiment Analysis, Indonesian Films, Gundala, YouTube, Bidirectional Encoder Representations from Transformers, Deep Learning, Transformers. UNIVERSITAS SUMATERA UTARA.
(10) DAFTAR ISI. PERSETUJUAN .............................................. Error! Bookmark not defined. PERNYATAAN ............................................................................................... iv UCAPAN TERIMA KASIH .............................................................................. v ABSTRAK ......................................................................................................viii ABSTRACT ...................................................................................................... ix DAFTAR ISI ..................................................................................................... x DAFTAR TABEL ............................................................................................ xii DAFTAR GAMBAR ......................................................................................xiii DAFTAR LAMPIRAN .................................................................................... xv BAB 1 PENDAHULUAN ................................................................................. 1 1.1. Latar Belakang .................................................................................... 1. 1.2. Rumusan Masalah ............................................................................... 3. 1.3. Batasan Masalah .................................................................................. 3. 1.4. Tujuan Penelitian................................................................................. 4. 1.5. Manfaat Penelitian............................................................................... 4. 1.6. Metodologi Penelitian ......................................................................... 4. 1.7. Sistematika Penyusunan ...................................................................... 5. BAB 2 LANDASAN TEORI............................................................................. 7 2.1. Perfilman ............................................................................................. 7. 2.2. Natural Language Processing (NLP) .................................................. 8. 2.3. Analisis Sentimen ................................................................................ 8. 2.4. Machine Learning ............................................................................... 9. 2.5. Neural Network ................................................................................. 10. 2.6. Deep Learning ................................................................................... 15. 2.7. Bidirectional Encoder Representations from Transformers (BERT) 15. 2.8. Penelitian yang Relevan .................................................................... 24. BAB 3 ANALISIS DAN PERANCANGAN .................................................. 26 3.1. Arsitektur Umum............................................................................... 26. 3.2. Scraping ............................................................................................ 27. 3.3. Labelisasi Dataset .............................................................................. 27. UNIVERSITAS SUMATERA UTARA.
(11) 3.4. Pre-processing Dataset ..................................................................... 28. 3.4.1. Case Folding .............................................................................. 29. 3.4.2. Data Cleaning ............................................................................ 29. 3.4.3. Tokenisasi .................................................................................. 30. 3.4.4. Stopwords Removal .................................................................... 30. 3.4.5. Stemming .................................................................................... 31. 3.4.6. Normalisasi ................................................................................ 31. 3.5. Implementasi BERT .......................................................................... 32. 3.5.1 3.6. Penjelasan BERT ....................................................................... 32. Evaluasi ............................................................................................. 44. BAB 4 IMPLEMENTASI DAN PENGUJIAN ............................................... 46 4.1. Implementasi Sistem ......................................................................... 46. 4.1.1. Spesifikasi Perangkat Keras ....................................................... 46. 4.1.2. Spesifikasi Perangkat Lunak ...................................................... 46. 4.2. Implementasi Web Scraping.............................................................. 47. 4.3. Labelisasi Dataset .............................................................................. 48. 4.4. Preprocessing Dataset ....................................................................... 50. 4.4.1. Case Folding .............................................................................. 50. 4.4.2. Data Cleaning ............................................................................ 51. 4.4.3. Tokenisasi .................................................................................. 51. 4.4.4. Stopwords Removal .................................................................... 51. 4.4.5. Stemming .................................................................................... 52. 4.4.6. Normalisasi ................................................................................ 52. 4.5. Split Dataset ...................................................................................... 53. 4.6. Implementasi BERT .......................................................................... 54. 4.7. Evaluasi ............................................................................................. 57. BAB 5 KESIMPULAN DAN SARAN ........................................................... 63 5.1 Kesimpulan ............................................................................................ 63 5.2 Saran ...................................................................................................... 63 DAFTAR PUSTAKA ...................................................................................... 65 LAMPIRAN ...................................................................................................A-1. UNIVERSITAS SUMATERA UTARA.
(12) DAFTAR TABEL. Tabel 3. 1 Contoh Dataset .................................................................................... 28 Tabel 3. 2 Perbandingan Hasil Case Folding ....................................................... 29 Tabel 3. 3 Perbandingan Hasil Data Cleaning ..................................................... 29 Tabel 3. 4 Perbandingan Hasil Tokenisasi ........................................................... 30 Tabel 3. 5 Contoh Stopwords pada Kamus Tala .................................................. 30 Tabel 3. 6 Perbandingan Hasil Stopwords Remioval............................................ 31 Tabel 3. 7 Perbandingan Hasil Stemming ............................................................. 31 Tabel 3. 8 Perbandingan Hasil Normalisasi ......................................................... 32 Tabel 3. 9 Input pada BERT ................................................................................. 42 Tabel 3. 10 Confusion Matrix............................................................................... 44. UNIVERSITAS SUMATERA UTARA.
(13) DAFTAR GAMBAR. Gambar 2. 1 Feed-forward neural network dan Recurrent neural network (Pekel & Kara, 2017)........................................................................................................ 11 Gambar 2. 2 Hubungan antara Kecerdasan Buatan, Machine Learning, dan Deep Learning (Chollet, 2018)....................................................................................... 15 Gambar 2. 3 Encoder (kiri) dan Decoder (kanan) (Vaswani et al., 2017) ........... 17 Gambar 2. 4 Proses pada Self-attention Layer (Alammar, 2018) ....................... 18 Gambar 2. 5 Proses pada Encoder (Alammar, 2018) .......................................... 18 Gambar 2. 6 Perbedaan Ukuran BERTBASE dan BERTLARGE .............................. 20 Gambar 2. 7 Arsitektur BERT ............................................................................. 20 Gambar 2. 8 Perbedaan Antara Arsitektur BERT Dengan OpenAI GPT dan ELMo (Devlin et al., 2019) ................................................................................... 21 Gambar 2. 9 Proses Masked Language Modelling .............................................. 22 Gambar 2. 10 Proses pre-training pada BERT .................................................... 22 Gambar 2. 11 Representasi Input pada BERT (Devlin et al., 2019) ................... 23 Gambar 2. 12 Prosedur Pre-training dan Fine-tuning (Devlin et al., 2019) ....... 24 Gambar 2. 13 Ilustrasi Fine-tuning pada Tugas dengan Single Sentence (Devlin et al., 2019)............................................................................................................ 24 Gambar 3. 1 Arsitektur Umum ............................................................................ 26 Gambar 3. 2 Proses Tokenisasi dengan WordPiece ............................................ 35 Gambar 3. 3 Proses Token Embeddings .............................................................. 35 Gambar 3. 4 Proses Pemberian Padding ............................................................. 36 Gambar 3. 5 Indeks pada Vocabulary ................................................................. 36 Gambar 3. 6 Tahap Substitusi Token dengan IDnya ........................................... 37 Gambar 3. 7 Tahap Sentence Embedding ............................................................ 37 Gambar 3. 8 Tahap Positional Embedding.......................................................... 37 Gambar 3. 9 Proses tokenisasi ............................................................................. 38 Gambar 3. 10 Representasi Input dan Output di BERT ...................................... 38 Gambar 3. 11 Input dan Output dalam BERT ..................................................... 39 Gambar 3. 12 Ilustrasi Layer untuk Analisis Sentimen ....................................... 40 Gambar 3. 13 Ilustrasi Proses Klasifikasi Menggunakan BERT......................... 41 Gambar 4. 1 Video yang Digunakan untuk Scraping ......................................... 47 Gambar 4. 2 Proses Scraping Menggunakan ChromeDriver .............................. 48 Gambar 4. 3 Dataset Hasil Scraping ................................................................... 48 Gambar 4. 4 Proses Sentence Splitting ................................................................ 49 Gambar 4. 5 Dataset Hasil Sentence Splitting ..................................................... 49 Gambar 4. 6 Dataset yang Sudah Dianotasi ........................................................ 50 Gambar 4. 7 Hasil Case Folding ......................................................................... 50 Gambar 4. 8 Hasil Data Cleaning ....................................................................... 51 Gambar 4. 9 Hasil Tokenisasi ............................................................................. 51. UNIVERSITAS SUMATERA UTARA.
(14) Gambar 4. 10 Hasil Stopwords Removal ............................................................. 51 Gambar 4. 11 Hasil Stemming ............................................................................. 52 Gambar 4. 12 Kamus Tidak Baku Tambahan ..................................................... 52 Gambar 4. 13 Kamus Alay (Aliyah Salsabila et al., 2019) ................................. 53 Gambar 4. 14 Hasil Normalisasi Menggunakan Kamus Alay yang Dibuat Penulis ............................................................................................................................... 53 Gambar 4. 15 Hasil Normalisasi Menggunakan Kamus Alay ............................ 53 Gambar 4. 16 Proses Splitting Dataset ................................................................ 54 Gambar 4. 17 Akurasi dengan Diperoleh dengan 4 Epoch ................................. 55 Gambar 4. 18 Akurasi yang Diperoleh dengan 10 Epoch ................................... 55 Gambar 4. 19 Akurasi yang Diperoleh dengan 16 Epoch ................................... 55 Gambar 4. 20 Proses Training dan Evaluasi Dataset pada Percobaan Pertama .. 56 Gambar 4. 21 Kurva Hasil Performa Training dan Evaluasi Pada Percobaan Pertama.................................................................................................................. 56 Gambar 4. 22 Kurva Hasil Performa Training dan Evaluasi Pada Percobaan Kedua .................................................................................................................... 57 Gambar 4. 23 Kurva Hasil Performa Model Training Dan Evaluasi Pada Percobaan Ketiga .................................................................................................. 57 Gambar 4. 24 Hasil Akurasi yang Diperoleh Multinomial Naive Bayes ............ 58 Gambar 4. 25 Akurasi Dari Percobaan Pertama .................................................. 58 Gambar 4. 26 Akurasi Dari Percobaan Kedua .................................................... 59 Gambar 4. 27 Akurasi Dari Percobaan Ketiga .................................................... 59 Gambar 4. 28 Diagram Confusion Matrix Percobaan Pertama ........................... 60 Gambar 4. 29 Diagram Confusion Matrix Percobaan Kedua .............................. 60 Gambar 4. 30 Diagram Confusion Matrix Percobaan Ketiga ............................. 61 Gambar 4. 31 Akurasi yang Diperoleh Dataset yang Seimbang ......................... 61 Gambar 4. 32 Hasil Akurasi yang Diperoleh IndoBERT (Koto et al., 2020) ..... 62. UNIVERSITAS SUMATERA UTARA.
(15) DAFTAR LAMPIRAN Lampiran 1. Listing Program .............................................................................. A-1 Lampiran 2. Curriculum Vitae ............................................................................ B-1. UNIVERSITAS SUMATERA UTARA.
(16) BAB 1. PENDAHULUAN. 1.1 Latar Belakang Saat ini industri film Indonesia sedang berkembang dengan sangat pesat. Perkembangan ini ditunjukkan dengan data dari Pusat Pengembangan Film Kemendikbud (Pusbang) yang menyebutkan bahwa jumlah film Indonesia tengah menunjukkan tren pertumbuhan dalam lima tahun terakhir. Pada tahun 2018 terdapat 201 film Indonesia yang diproduksi oleh para seniman. Sedangkan pada tahun 2014, hanya ada 109 film. Badan Ekonomi Kreatif mencatat jumlah penonton film Indonesia pada tahun 2018 mencapai lebih dari tiga kali lipat pencapaian pada tahun 2015, yaitu lebih dari 60 juta penonton. Lebih lanjut, Pusbang Film Kemendikbud juga menyebutkan bahwa jumlah film Indonesia yang mencapai penonton di atas 1 juta pun terus naik. Pada tahun 2018 saja terdapat 14 film yang berhasil mencapai penonton di atas 1 juta. Data tersebut menunjukkan bahwa minat masyarakat Indonesia terhadap film lokal semakin meningkat. Namun dengan segala pencapaian tersebut, film Indonesia belum menjadi tuan rumah di negaranya sendiri. Permasalahan tersebut dapat terjadi karena berbagai hal, salah satunya adalah anggapan bahwa film Indonesia tidak memiliki kualitas sebaik film asing. Berdasarkan survei yang dilakukan pada tahun 2019 oleh IDN Times, sebuah perusahaan media berita dan hiburan multiplatform, sebanyak 50,3% penonton mengkritisi jalan cerita yang mudah untuk ditebak. Teknis dalam film seperti sinematografi, scoring atau bahkan kecocokan peran dan pemain juga muncul sebagai alasan sebanyak 27,4%. Alasan membosankan juga menjadi pertimbangan sebesar 15% serta akting pemain yang tidak memuaskan muncul sebanyak 7,3%.. UNIVERSITAS SUMATERA UTARA.
(17) Permasalahan ini dapat diobservasi lebih lanjut. Salah satu cara untuk melakukan observasi adalah dengan melihat sentimen yang diberikan kepada film Indonesia. Berdasarkan hasil survey APJII (Asosiasi Penyelenggara Jasa Internet Indonesia pada tahun 2019, pengguna internet di Indonesia mengalami peningkatan menjadi 196,7 juta orang. YouTube menjadi sosial media yang paling banyak digunakan oleh 150 juta penduduk Indonesia yang aktif menggunakan media sosial pada tahun 2020 melalui survei yang dilakukan oleh HootSuite dan We Are Social (Kemp, 2020), sebuah situs layanan manajemen konten situs jejaring media. YouTube adalah sosial media berbagi video yang menjadi salah satu pilihan untuk melihat sentimen masyarakat terhadap suatu film. Pada umumnya, cuplikan film (trailer) diunggah pada platform ini oleh akun resmi dari rumah produksi film tersebut sehingga pengguna YouTube lainnya akan memberikan tanggapan dalam kolom komentar. Jumlah penonton video yang besar pada umumnya akan menarik perhatian pengguna. Pengguna kemudian akan menonton video tersebut dan memberi komentar. Dengan demikian, komentar pada YouTube dapat dimanfaatkan untuk mengetahui sentimen terhadap film Indonesia. Sentimensentimen yang diberikan kepada film Indonesia dapat diolah lebih lanjut agar menjadi catatan bagi para penggiat perfilman Indonesia. Sentimen-sentimen yang didasarkan pada perasaan dapat dianalisis dan diklasifikasikan ke dalam kategori sentimen atau kategori emosi. Analisis sentimen atau opinion mining mempelajari cara pandang, tingkah laku, dan perasaan atau emosi seseorang terhadap individu, masalah, aktivitas, produk, atau objek (Basari et al., 2013). Pada penelitian sebelumnya yang berkaitan dengan analisis sentimen adalah penelitian yang dilakukan oleh (Putri, 2020) menghasilkan hasil akurasi yang cukup baik yaitu sebesar 73.7%. Penelitian tersebut menggunakan dataset dari cornelledu dalam Bahasa Inggris. Namun pada penelitian tersebut, sentimen diklasifikasikan menjadi kategori positif dan negatif saja. Berdasarkan hasil dari penelitian, peneliti tersebut menyatakan hasilnya cukup baik jika dibandingkan dengan algoritmaalgoritma lain seperti Naïve Bayes. Berdasarkan latar belakang, maka pada penelitian yang akan dilakukan penulis menggunakan metode deep learning dengan language model yaitu BERT atau. UNIVERSITAS SUMATERA UTARA.
(18) Bidirectional Encoder Representations from Transformers untuk menganalisis sentimen pengguna YouTube melalui komentar yang diberikan di video trailer Gundala (2019). Sentimen-sentimen tersebut akan diklasifikasikan menjadi tiga kategori, yaitu negatif, netral, dan positif. 1.2 Rumusan Masalah YouTube sebagai salah satu sosial media berbasis sharing video dapat dimanfaatkan untuk analisis sentimen suatu produk atau jasa. Film Gundala yang rilis di tahun 2019 merupakan salah satu film Indonesia yang banyak memperoleh perhatian dari penonton. Untuk mengetahui komentar penonton tentang film Gundala dapat dilihat di komentar pada YouTube yang memutar trailer film tersebut. Namun, komentar pada YouTube bervariasi dari komentar positif, negatif, maupun netral. Untuk itu dibutuhkan suatu otomatisasi dalam mengklasifikasikan komentar berdasarkan polaritas sentimennya. Analisis sentimen dapat dilakukan dengan metode algoritma machine learning tradisional seperti Naïve Bayes, SVM, dan lain-lain. Namun, algoritma tersebut tidak dapat memahami tentang semantik kata yang ada karena hanya mempelajari pola-pola yang diberikan. Untuk mencapai hasil yang lebih baik, maka dibutuhkan sebuah pendekatan transfer learning seperti BERT (Bidirectional Encoder Representations from Transformers). Berdasarkan hal ini maka dilakukan penelitian ini membahas analisis sentimen terhadap komentar dalam Bahasa Indonesia pada film Gundala yang diperoleh dari kolom komentar YouTube dengan BERT. 1.3 Batasan Masalah 1. Data diperoleh dari komentar pada video YouTube trailer film bergenre action dan Sci-Fi yaitu Gundala dengan jumlah komentar sekitar 10.000 komentar dengan rentang waktu 20 Juli 2019 – 12 Agustus 2020. 2. Data hanya menggunakan bahasa Indonesia. 3. Hanya membagi opini ke dalam 3 jenis klasifikasi yaitu negatif, netral, dan positif. 4. Jumlah annotator yang melakukan labelisasi adalah 5 orang. 5. Tidak memisahkan data yang dibuat oleh robot ataupun haters. 6. Ukuran model BERT yang digunakan adalah BERTBASE.. UNIVERSITAS SUMATERA UTARA.
(19) 7. Bahasa pemrograman yang digunakan adalah bahasa pemrograman Python 3.6. 1.4 Tujuan Penelitian Tujuan penelitian adalah mendapatkan penilaian dari opini para pengguna sosial media YouTube mengenai film Indonesia berjudul “Gundala” dengan menggunakan BERT (Bidirectional Encoder Representations from Transformers). 1.5 Manfaat Penelitian Manfaat yang diperoleh dari penelitian ini adalah: 1. Mendapatkan informasi mengenai sentimen-sentimen yang diberikan kepada film Gundala yang ada pada opini sehingga dapat dijadikan kritik dan saran dari pengguna sosial media. 2. Mengetahui kinerja BERT dalam menganalisis sentimen dalam Bahasa Indonesia. 1.6 Metodologi Penelitian Metodologi penelitian yang dilakukan dalam penelitian ini adalah: 1. Studi Pustaka Pada tahap ini, dilakukan pengumpulan berbagai referensi dan sumber-sumber ilmu seperti jurnal, artikel, buku, makalah, paper, situs-situs internet dan seterusnya mengenai sentiment analysis, deep learning, BERT, dan lain-lain. 2. Identifikasi Masalah Pada tahap ini, dilakukan identifikasi masalah pada analisis sentimen. Masalah yang akan diidentifikasi adalah sebuah film Indonesia dengan genre Sci-Fi dengan judul Gundala. 3. Analisis Sistem Pada tahap ini, dilakukan pengumpulan data dengan menggunakan web scraping dari YouTube. 4. Perancangan dan Implementasi Sistem Pada tahap ini, dilakukan perancangan sesuai dengan hasil dari analisis sistem dan melakukan implementasi dari hasil analisis dan perancangan yang telah dibuat.. UNIVERSITAS SUMATERA UTARA.
(20) 5. Pengujian Sistem Pada tahap ini, dilakukan pengujian terhadap sistem dan percobaan terhadap sistem sesuai dengan kebutuhan yang ditentukan sebelumnya serta memastikan program yang dibuat berjalan seperti yang diharapkan. 6. Analisis Hasil Pada tahap ini, dilakukan analisis terhadap hasil penelitian yaitu berupa evaluasi hasil penelitian. 7. Dokumentasi Pada tahap ini dilakukan dokumentasi dan penulisan laporan mengenai analisis hasil penelitian. 1.7 Sistematika Penyusunan Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama untuk diketahui yaitu sebagai berikut: BAB 1: Pendahuluan Bab ini berisi tahapan awal penelitian yaitu dimulai dari latar belakang rumusan masalah, batasan masalah, tujuan penelitian, dan manfaat penelitian, metodologi penelitian, dan sistematika penulisan. BAB 2: Landasan Teori Bab ini berisi teori-teori yang berkaitan dengan permasalahan yang dibahas dalam penelitian ini yaitu teori Perfilman, Natural Language Processing, Analisis Sentimen, Machine Learning, Neural Network, Deep Learning, BERT (Bidirectional Encoder Representations from Transformers). BAB 3: Analisis dan Perancangan Bab ini berisi tentang analisis sentimen terhadap film Indonesia berjudul “Gundala” pada. YouTube. dengan. menggunakan. model. Bahasa. BERT. untuk. mengklasifikasikan sentimen menjadi tiga kategori yaitu negatif, netral, dan positif. Analisis sistem yang meliputi analisis masalah dan analisis kebutuhan dalam arsitektur umum sistem dan perancangan sistem.. UNIVERSITAS SUMATERA UTARA.
(21) BAB 4: Implementasi dan Pengujian Bab ini menjelaskan tentang hasil penelitian yang telah dilakukan dan penjelasan implementasi sistem berdasarkan analisis masalah dan kebutuhan sistem, skenario pengujian terhadap sistem yang telah dibangun dan pembahasan hasil pengujian sistem. BAB 5: Kesimpulan dan Saran Bab ini berisi tentang kesimpulan dari keseluruhan hasil penelitian beserta saransaran yang diajukan dan diharapkan dapat dikembangkan untuk penelitian selanjutnya.. UNIVERSITAS SUMATERA UTARA.
(22) BAB 2. LANDASAN TEORI. 2.1 Perfilman Menurut Kamus Besar Bahasa Indonesia, perfilman adalah pokok (hal) yang bersangkutan dengan film. Film sendiri memiliki definisi sebuah lakon (cerita) gambar hidup. Berdasarkan Undang-Undang Nomor 33 Tahun 2009 tentang Perfilman, film sebagai media komunikasi massa merupakan saran pencerdasan kehidupan bangsa, pengembangan potensi diri, pembinaan akhlak mulia, pemajuan kesejahteraan masyarakat, serta wahana promosi Indonesia di dunia Internasional sehingga film dan perfilman Indonesia perlu dikembangkan dan dilindungi. Pada perkembangannya, kualitas film Indonesia mulai diakui oleh tak hanya bangsa Indonesia tetapi juga dunia. Salah satunya adalah film Gundala. Gundala adalah karakter superhero yang diciptakan oleh Harya Suraminata pada tahun 1969. Pada tahun 2019, film Gundala pun dirilis dengan Joko Anwar sebagai sutradara. Sebagai film science-fiction, film ini memiliki popularitas yang besar. Ketika trailer dan teaser resminya diunggah di YouTube, Gundala berhasil menjadi salah satu video yang trending saat itu. Selain itu, film ini juga berhasil menembus jumlah penonton sebanyak satu juta hanya dalam 7 hari saja, dengan jumlah penonton akhir yaitu 1.699.433 juta penonton. Pada Festival Film Indonesia 2019, Gundala juga mendapatkan 9 nominasi dan berhasil pula memenangkan beberapa kategori seperti kategori Penata Suara Terbaik, Pengarah Sinematografi Terbaik, dan Penata Efek Visual Terbaik (Herfianto, 2020).. UNIVERSITAS SUMATERA UTARA.
(23) 2.2 Natural Language Processing (NLP) Natural Language Processing atau Pengolahan Bahasa Alami adalah salah satu cabang ilmu Kecerdasan Buatan yang mempelajari dan mengembangkan bagaimana komputer dapat mengerti, memahami, dan memproses bahasa alami dalam bentuk teks atau tuturan kata. NLP menganalisa bahasa manusia sedemikian rupa sehingga komputer dapat memahami bahasa alami seperti halnya manusia (Ghosh et al., 2012). NLP adalah salah satu bidang antar disiplin yang menggabungkan komputasi linguistik, ilmu komputasi, ilmu kognitif, dan kecerdasan buatan. Pada umumnya, NLP banyak diaplikasikan di berbagai hal seperti speech recognition, pemahaman bahasa lisan, sistem dialog, analisis leksikal, mesin penerjemah, knowledge graph, analisis sentimen, sistem pintar dan peringkasan bahasa alami. Sebuah sistem NLP dapat dimulai dari tingkat kata untuk menentukan struktur dan sifat morfologis (seperti part-of-speech atau makna) dari kata; kemudian dapat beralih ke tingkat kalimat untuk menentukan urutan kata, tata bahasa, dan arti dari seluruh kalimat. Kemudian ke konteks dan keseluruhan domain. Kata atau kalimat yang diberikan mungkin memiliki makna atau konotasi yang berbeda dalam konteks tertentu, yang terkait dengan banyak kata atau kalimat lain dalam konteks yang diberikan. 2.3 Analisis Sentimen Analisis sentimen merupakan salah satu bidang penelitian komputasi yang mempelajari opini-opini, sentimen-sentimen, dan emosi-emosi yang ada pada teks. Analisis sentimen yang juga dikenal dengan nama opinion mining, telah menjadi salah satu topik hangat di bidang NLP dan data mining (penambangan data). Tujuan utama dari analisis sentimen adalah untuk memproses, mengekstrak, merangkum, dan menganalisa informasi yang ada dalam teks melalui metode yang berbedabeda, sehingga dapat menyimpulkan emosi dan sudut pandang yang diberikan oleh penulis dari teks tersebut, dan membagi kecenderungan emosional di teks melalui informasi subjektif yang terkandung di dalamnya. Sentimen sendiri didefinisikan sebagai suatu sikap positif atau negatif seseorang atau sekelompok orang yang diarahkan kepada sesuatu. Opini atau sentimen dapat direpresentasikan sebagai. UNIVERSITAS SUMATERA UTARA.
(24) quintuple yang terdiri dari ei, aij, sijkl, hk, tℓ di mana ei adalah entiti atau target dari opini, aij adalah aspek dari target opini, sijkl adalah opini atau sentimen yang diberikan ke target, hk adalah opinion holder atau pemberi opini, dan tℓ adalah waktu ketika opini diberikan (Sun et al., 2017). Teks-teks opini termasuk ke dalam data yang tidak terstruktur (unstructured data), sehingga perlu dilakukan preprocessing untuk membuat data tersebut menjadi terstruktur dan dapat diproses untuk mengambil aspek yang ada melalui tokenisasi, word segmentation, Part-of-Speech Tagging, stemming, dan lain-lain. Secara umum, analisis sentimen dibagi menjadi tiga tingkatan yaitu tingkat dokumen (document level), tingkat kalimat (sentence level), dan tingkat berbutirhalus (fine-grained level). Document-level dan sentence-level dapat pula dikategorikan ke dalam coarse-grained level. Metode dalam analisis sentimen terbagi menjadi dua jenis, yaitu learning-based dan lexical-based. Learning-based menggunakan data. training. dan data. testing, sedangkan. lexical-based. menggunakan kamus (opinion lexicon). 2.4 Machine Learning Machine learning atau pembelajaran mesin adalah salah satu bidang ilmu di Kecerdasan Buatan. Machine learning, sesuai dengan namanya, bertujuan untuk membuat mesin dilatih dengan banyak contoh atau dataset yang berhubungan dengan tugas yang dibutuhkan. Mesin mempelajari pola-pola yang diberikan berdasarkan dataset dan menghasilkan sebuah rule sendiri. Sehingga ketika suatu data dimasukkan ke dalam mesin, mesin sudah dapat mengenali data tersebut. Secara umum, machine learning terbagi menjadi empat kategori besar yaitu supervised learning, unsupervised learning, self-supervised learning, dan reinforcement learning (Chollet, 2018). Supervised learning adalah pendekatan yang paling sering digunakan. Supervised learning membuat mesin belajar dari dataset yang sudah diberi label atau anotasi. Sedangkan unsupervised learning merupakan kebalikannya, dengan memberikan dataset yang tidak diberi label. Selfsupervised learning adalah sebuah supervised learning tetapi tanpa dataset yang dilabeli oleh annotator. Dataset yang digunakan tetap menggunakan label akan tetapi label diperoleh dari input data yang menggunakan algoritma heuristic. UNIVERSITAS SUMATERA UTARA.
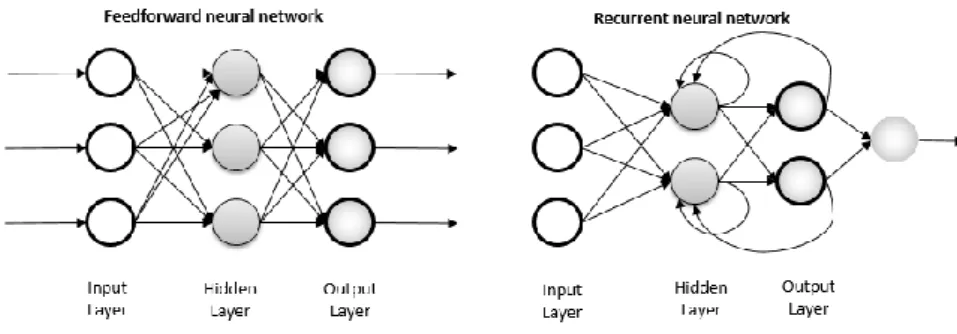
(25) (Chollet, 2018). Algoritma yang sering digunakan pada machine learning antara lain K-Nearest Neighbor, Naïve-Bayes, Support Vector Machine, K-Means, dan lain-lain. 2.5 Neural Network Neural Network atau jaringan syaraf tiruan adalah salah satu teknik machine learning yang populer dengan mensimulasikan mekanisme pembelajaran yang terinspirasi dari bagaimana cara sistem syaraf manusia atau makhluk biologis lainnya. Sistem saraf terdiri dari sel yang disebut dengan neuron. Neuron-neuron tersebut saling terhubung dengan satu sama lain menggunakan axon dan dendrites. Sinapsis adalah penghubung antara axon dan dendrites (Aggarwal, 2018). Network sendiri disebut sebagai arsitektur, di mana berbagai layers saling terhubung dengan satu sama lain. Layer yang ada di antara input layer dan output layer disebut dengan hidden layers dan output dari hidden layer disebut dengan hidden units (Osinga, 2018). Istilah hidden diberikan karena unit-unit tersebut tidak dapat langsung terlihat dari luar sebagai input atau output. Inti dari neural network adalah hidden layer yang dibentuk dari hidden units, yang masing-masing merupakan neural units, mengambil weighted sum dari input dan kemudian menerapkan non-linearity. Setiap unit pada tiap layer mengambil input dan output dari semua unit di layer sebelumnya dan hubungan antara setiap pasangan unit dari dua layer yang saling berdekatan sehingga setiap layer saling terhubung. Tiap hidden units akan menjumlahkan semua input unit (Jurafsky & Martin, 2019). Secara umum terdapat dua jenis arsitektur neural network, yaitu feed-forward network dan recurrent/recursive network. 1) Feed-forward Network atau Multi-Layer Perceptrons (MLP) Feed-forward Network atau Multi-Layer Perceptrons (MLP) adalah jaringan di mana unit-unit terhubung tanpa siklus dan outputnya dikembalikan ke lapisan bawah. Hal ini memungkinkan network untuk bekerja dengan input yang ukurannya tetap atau input dengan panjang variabel yang dapat diabaikan dari urutan elemen. Saat komponenkomponen input dimasukkan ke dalam jaringan, jaringan akan belajar untuk. UNIVERSITAS SUMATERA UTARA.
(26) menggabungkannya. Data hanya bergerak satu arah, dari input ke output. Jenis jaringan ini lebih mudah dan digunakan dalam pengenalan pola. Convolutional Neural Network (CNN atau ConvNet) adalah jenis feedforward network khusus dan sering digunakan dalam image recognition. 2) Recurrent Neural Network (RNN) Recurrent Neural Network sering diterapkan jika terdapat input yang berurutan. Input ini biasanya ditemukan ketika jaringan memproses teks atau suara. RNN menerima input sebuah urutan item dan menghasilkan vector dengan fixed size yang merangkum urutan. Dengan RNN, data dapat melewati jaringan dengan dua arah dan memungkinkan sebuah loop. Jaringan ini lebih powerful dan complex daripada CNN.. Gambar 2. 1 Feed-forward neural network dan Recurrent neural network (Pekel & Kara, 2017) Setiap layer diikuti dengan sebuah activation function, sebuah fungsi matematis yang digunakan untuk memetakan output dari satu layer ke input dari layer selanjutnya. Salah satu activation function adalah softmax function. Softmax activation function memastikan bahwa jumlah dari vector output adalah tepat 1. Output node dengan probabilitas tertinggi kemudian dipilih sebagai label prediksi untuk kalimat yang menjadi input (Munikar et al., 2019). Activation function ini cocok untuk jaringan yang membutuhkan output dengan label yang sudah ditentukan. Misalkan pada sebuah network yang dilatih untuk mengidentifikasi kucing dan tikus. Jika suatu input untuk identifikasi kucing memiliki output vector 0.65, jaringan melihat kucing dengan kepastian sebesar 65%. Softmax hanya berfungsi jika terdapat satu jawaban saja (Osinga, 2018). Output node dengan. UNIVERSITAS SUMATERA UTARA.
(27) probabilitas tertinggi kemudian dipilih sebagai label prediksi untuk kalimat yang menjadi input (Munikar et al., 2019). Rumus softmax function dirumuskan pada persamaan 2.1. 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑧)𝑖 =. 𝑒 𝑧𝑖 𝑧𝑗 ∑𝐾 𝑗=1 𝑒. ………………………………………………………(2.1). Dengan 𝑖 = 1, . . ., 𝐾 di mana: 1.. z = (𝑧1 , … , 𝑧𝑘 ) 𝜖 ℝ𝐾 adalah vektor input yang dimasukkan pada softmax function atau output dari layer terakhir yang disebut juga dengan logits. Inputan yang dapat diterima merupakan bilangan real.. 2.. 𝑒 𝑧𝑖 adalah eksponensial dari tiap elemen dari input vektor.. 3.. 𝑧𝑗 ∑𝐾 adalah proses normalisasi untuk memastikan semua nilai output dari 𝑗=1 𝑒. softmax akan berjumlah tepat 1 dan masing-masing nilai berada di antara kisaran (0,1) Saat proses training dilakukan, jaringan akan menampilkan loss. Jika nilai loss ini tidak menurun setelah beberapa iterasi, hal itu menandakan jaringan tidak mempelajari apapun dari proses yang sudah dilewati. Oleh karena itu, dibutuhkan sebuah loss function untuk mengatur output dari neural network agar sesuai dengan apa yang diinginkan (optimisasi). Loss function mengambil prediksi yang diberikan oleh neural network dan target (apa yang ingin dihasilkan oleh jaringan) dan menghitung distance score, sehingga dapat memperoleh seberapa baik jaringan (Chollet, 2018). Hasil dari loss function kemudian digunakan sebagai sinyal feedback untuk mengatur nilai weights sedikit sehingga dapat mengurangi loss score. Cross-entropy loss adalah salah satu loss function yang umumnya digunakan pada neural network dan pada umumnya sering dipasangkan dengan softmax (Aggarwal, 2018). Loss function ini merupakan hasil perhitungan antara dua distribusi probabilitas untuk variabel acak yang diberikan. Cross-entropy loss menghitung kemampuan model klasifikasi yang memberi output probabilitas dengan nilai di antara 0 sampai 1. Loss function ini cocok digunakan ketika output yang diberikan berupa probabilitas (Chollet, 2018).. UNIVERSITAS SUMATERA UTARA.
(28) 𝐿 = ∑𝑘𝑖=1 𝑦𝑖 log(𝑜𝑖 )…………………………………………………….(2.2) di mana: 1. 𝑦𝑖 adalah label dari klasifikasi 2. 𝑜𝑖 adalah probabilitas yang diprediksi oleh model terhadap label 3. log(𝑜𝑖 ) adalah nilai logaritma dari tiap probabilitas yang diprediksi oleh model Jaringan syarat tiruan memiliki beberapa parameter, seperti weights W, bias b yang dipelajari oleh gradient descent. Sedangkan hyperparameters adalah parameter yang dipilih oleh desainer algoritma seperti nilai optimal yang diatur pada sebuah devset, bukan dengan sebuah gradient descent di dataset training. Hyperparameters mencakup learning rate 𝜂, mini-batch size, arsitektur model (jumlah layer, jumlah hidden node tiap layer, fungsi aktivasi yang dipilih), dan lainlain (Jurafsky & Martin, 2019). Gradient descent (penurunan gradien) adalah sebuah algoritma optimasi yang digunakan ketika melatih sebuah model machine learning. Gradient descent hanya digunakan. untuk. menemukan. nilai. parameter. fungsi. (koefisien). yang. meminimalkan cost. Tujuan utama dari gradient descent adalah menemukan weight yang optimal dengan meminimalisasi loss function. Seberapa besar step yang dilakukan gradient descent ditentukan oleh learning rate yang menunjukkan seberapa cepat atau lambat bergeraknya fungsi ke weight yang optimal. Terdapat tiga jenis gradient descent yang sering digunakan, yaitu Batch Gradient Descent, Stochastic Gradient Descent, dan Mini-Batch Gradient Descent. 1. Batch gradient descent (BGD) atau vanilla gradient descent menghitung error dari tiap contoh yang ada pada dataset training. Proses ini seperti sebuah siklus yang disebut juga training epoch. Semua cost dari training pada dataset dihitung. Algoritma ini memiliki kelebihan yaitu dapat membuat jaringan syaraf tiruan bekerja lebih cepat, menghasilkan gradien kesalahan yang stabil, Akan tetapi gradien kesalahan yang stabil dapat pula membuat model tidak dapat menghasilkan kondisi konvergensi yang terbaik. Selain itu, seluruh training dataset harus berada dalam memori.. UNIVERSITAS SUMATERA UTARA.
(29) 2. Stochastic gradient descent (SGD) adalah algoritma yang meminimalkan loss function dengan menghitung gradiennya tiap kali training dilakukan (Jurafsky & Martin, 2019). Algoritma ini disebut stokastik karena hanya memiliki satu contoh acak dalam satu waktu, memindahkan weight-nya sehingga dapat meningkatkan performa dari contoh tersebut. Sehingga, SGD akan melakukan proses tersebut pada setiap contoh dataset satu per satu. Weight. yang. terus. diperbarui. memungkinkan. untuk. mendapatkan. peningkatan yang cukup detail. Akan tetapi pembaharuan yang terlalu sering dilakukan lebih mahal dan dapat menyebabkan gradient yang tidak rata karena error rate dapat naik turun. 3. Mini batch gradient descent menggabungkan konsep dari SGD dan BGD. Mini batch adalah proses training sekumpulan m contoh dataset (umumnya 512 atau 1024) yang lebih sedikit dari dataset asli. Algoritma ini akan membagi training dataset menjadi batch-batch yang kecil dan memperbarui weight dari masing-masing batch. Salah satu algoritma optimasi yang sering digunakan adalah Adam. Adam atau Adaptive Moment Estimation Algorithm (Kingma & Ba, 2015) menghitung estimasi momen dan menggunakannya untuk mengoptimasi fungsi. Adam merupakan kombinasi dari dua algoritma yaitu AdaGrad dan RMSProp. AdaGrad akan mempertahankan learning rate per parameter yang meningkatkan performa pada masalah dengan gradien yang renggan dan RMSProp juga mempertahankan learning rate per parameter yang diadaptasi berdasarkan rata-rata besaran gradien untuk weight (seberapa cepat berubah). Algoritma ini akan menghitung rata-rata eksponensial weighted bergerak kemudian mengkuadratkan gradien yang dihitung. Alih-alih mengadaptasi learning rate parameter berdasarkan rata-rata momen pertama seperti di RMS Prop, Adam juga menggunakan rata-rata momen kedua. Dengan menggunakan model dan dataset yang besar, Adam dapat secara efektif menyelesaikan masalah-masalah deep learning praktikal (Kingma & Ba, 2015). Hal ini membuat Adam optimizer menjadi metode yang efisien secara komputasi, membutuhkan sedikit memori, tidak berbeda dengan gradien dengan skala diagonal, cocok untuk masalah yang menggunakan data dan/atau parameter yang besar (Kingma & Ba, 2015).. UNIVERSITAS SUMATERA UTARA.
(30) 2.6 Deep Learning Deep Learning adalah cabang dari machine learning yang merupakan bagian dari Kecerdasan Buatan. Deep learning merupakan neural network yang lebih modern dan bersifat deep atau mendalam karena memiliki jauh lebih banyak layer dibandingkan dengan neural network pada biasanya (Jurafsky & Martin, 2010) (Chollet, 2018). Kata “deep” mengacu pada jumlah hidden layer yang ada, semakin banyak layernya, maka semakin “deep” pembelajaran yang dilakukan oleh jaringan. Deep learning bekerja untuk mempelajari sehingga tidak hanya dapat memprediksi tetapi juga merepresentasikan data dengan benar, sehingga cocok untuk melakukan prediksi (Goldberg, 2017). Deep learning dapat dibagi ke dalam tiga metode pendekatan yaitu supervised, semi-supervised, dan unsupervised learning. Deep learning didukung oleh banyak framework seperti Torch, Theano, TensorFlow, dan lain-lain.. Gambar 2. 2 Hubungan antara Kecerdasan Buatan, Machine Learning, dan Deep Learning (Chollet, 2018). 2.7 Bidirectional Encoder Representations from Transformers (BERT) Bidirectional Encoder Representations from Transformers (Devlin et al., 2019) atau disingkat BERT adalah model representasi bahasa terlatih yang dikembangkan oleh para peneliti di Google AI Language pada tahun 2018. BERT dikembangkan berdasarkan teknik-teknik deep learning dan berbagai metode seperti semisupervised learning, ELMo, ULMFiT, OpenAI Transformers, dan Transformers.. UNIVERSITAS SUMATERA UTARA.
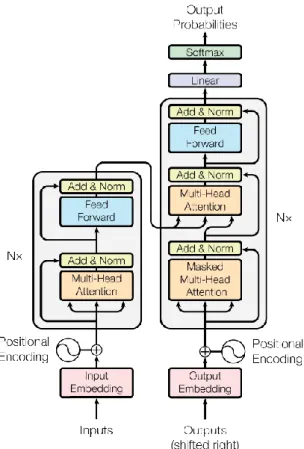
(31) Sesuai dengan namanya, BERT menggunakan Transformer. Transformer adalah sebuah mekanisme yang mempelajari hubungan kontekstual antara kata-kata dalam teks (Vaswani et al., 2017). Transformer dapat memahami dan mengkonversi pemahaman yang diperoleh dengan mekanisme yang bernama self-attention mechanism. Self-attention mechanism adalah cara Transformer untuk mengubah “pemahaman” kata terkait lainnya menjadi kata-kata yang akan diproses dengan mekanismenya. Pada Transformer terdapat dua mekanisme, yaitu: a. Encoder Encoder berfungsi untuk membaca seluruh input teks sekaligus. Encoder terdiri dari stack (tumpukan) dari N = 6 layers yang identik. Setiap layer memiliki dua sub-layer yaitu self-attention layer dan feed-forward neural network. Dengan self-attention layer, encoder dapat membantu node untuk tidak hanya fokus kepada kata yang sedang dilihat tetapi juga untuk mendapatkan konteks semantik dari kata tersebut. Setiap posisi di encoder dapat menangani semua posisi di layer sebelumnya di encoder. b. Decoder Decoder berfungsi untuk menghasikan urutan output yang berupa prediksi. Decoder juga terdiri dari stack (tumpukan) dari N = 6 layers yang identif. Setiap layer terdiri dari dua sub-layer seperti yang ada pada encoder, dengan tambahan attention layer di antara dua layers tersebut untuk membantu node saat ini mendapatkan key content yang membutuhkan attention (Vaswani et al., 2017) dengan melakukan multi-head attention pada output dari encoder. Sama dengan di encoder, self-attention layer di decoder membuat setiap posisi di decoder dapat menangani semua posisi sebelumnya dan posisi saat itu.. UNIVERSITAS SUMATERA UTARA.
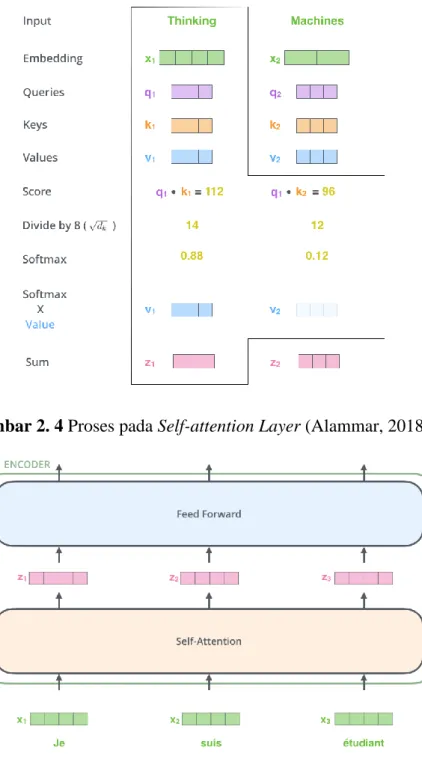
(32) Gambar 2. 3 Encoder (kiri) dan Decoder (kanan) (Vaswani et al., 2017) Langkah-langkah berikut menunjukkan proses yang terjadi pada encoder dan decoder (Alammar, 2018): 1. Setiap input kata yang memasuki encoder diubah menjadi sebuah list vector menggunakan embeddings. Karena self-attention layer tidak membedakan urutan kata-kata pada sebuah kalimat, positional encoding ditambahkan untuk menunjukkan posisi dari tiap kata. Tiap vektor dari input kata memiliki ukuran 512. Proses ini hanya terjadi di encoder yang berada paling bawah, sehingga encoder lainnya akan menerima output dari encoder yang pertama. 2. Input vektor melewati dua layer yang ada pada tiap encoder yaitu self-attention layer dan feed-forward neural network. Pada self-attention layer dibuat tiga vektor dari masing-masing input vektor yaitu Query, Key, dan Value vector. Ketiga vektor ini dibuat dengan mengalikan embedding. Dimensi dari tiap vektor adalah 64. Setelah itu, nilai self-attention dari tiap kata dihitung dengan mengalikan query vector dan key vector seperti yang ada pada Gambar 2.4.. UNIVERSITAS SUMATERA UTARA.
(33) Kemudian, nilai self-attention dibagi 8 karena 8 adalah akar kuadrat dari dimensi tiap vektor yaitu 64. Nilai self-attention juga dihitung dengan softmax sehingga tiap value vector akan dikali dengan nilai dari softmax. Akhirnya value vector dijumlahkan dan menjadi output dari self-attention layer. Output dari self-attention layer kemudian masuk ke feed-forward untuk tiap posisi seperti yang tertera pada Gambar 2.5.. Gambar 2. 4 Proses pada Self-attention Layer (Alammar, 2018). Gambar 2. 5 Proses pada Encoder (Alammar, 2018). UNIVERSITAS SUMATERA UTARA.
(34) 3. Setelah setiap proses pada encoder selesai, output dari encoder yaitu vector key dan vector value kemudian memasuki decoder. Tiap input dan output dari selfattention layer dan feed-forward neural network di encoder dan decoder diproses oleh layer add & norm yang berisi struktur residual dan normalisasi layer. Proses yang terjadi pada decoder sama dengan encoder akan tetapi di antara self-attention layer dan feed-forward neural network terdapat attention layer yang membantu decoder untuk fokus pada bagian-bagian dari kata yang relevan. Self-attention layer di decoder hanya boleh untuk menghadiri posisi sebelumnya dari output. Output dari tiap langkah dimasukkan ke dalam decoder terus menerus dan hasil dari decoder sama seperti hasil dari encoder. Akhirnya, output dari tumpukan decoder menghasilkan sebuah vector dengan nilai float. Untuk mengubahnya menjadi sebuah kata-kata, layer tambahan berupa fully connected layer dibutuhkan beserta softmax layer. Arsitektur model BERT berupa multi-layer bidirectional Transformer seperti yang dilakukan pada implementasi asli Transformer tetapi hanya menggunakan proses sampai encoder saja. Pada implementasinya, terdapat dua ukuran model yang ada pada BERT, yaitu BERTBASE dan BERTLARGE. Kedua ukuran model BERT ini memiliki banyak lapisan encoder atau Transformer Blocks. BERTBASE memiliki encoder dengan 12 layers, 12 self-attentions heads, hidden size sebesar 768, dan 110M parameters. Sedangkan BERTLARGE terdapat 24 layers, 16 selfattention heads, hidden size sebesar 1024, dan 340M parameters. BERTBASE dilatih selama 4 hari menggunakan 4 cloud TPUs sedangkan BERTLARGE membutuhkan 4 hari menggunakan 16 TPUs.. UNIVERSITAS SUMATERA UTARA.
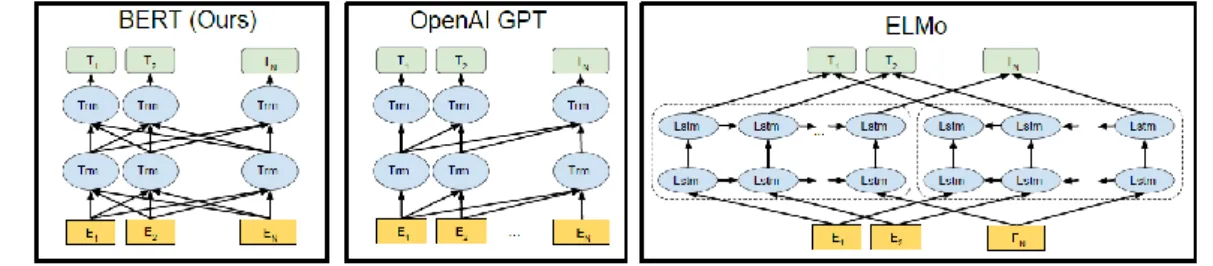
(35) Gambar 2. 6 Perbedaan Ukuran BERTBASE dan BERTLARGE Sesuai dengan namanya, BERT hanya menggunakan encoder. Sehingga arsitektur BERT terlihat seperti Gambar 2.7. BERT berbeda dengan model terarah (directional) yang melihat urutan teks dari kiri-ke-kanan, kanan-ke-kiri, atau gabungan dari kiri-ke-kanan dan kanan-ke-kiri. Model bahasa yang dilatih secara bidirectional dapat memiliki pemahaman yang lebih dalam tentang konteks daripada model bahasa satu arah. Gambar 2.8 menunjukkan perbandingan antara arsitektur BERT dengan OpenAI GPT dan ELMo. Di antara ketiga model arsitektur tersebut, hanya BERT yang secara bersamaan melihat kepada konteks kiri dan kanan di setiap layernya.. Gambar 2. 7 Arsitektur BERT. UNIVERSITAS SUMATERA UTARA.
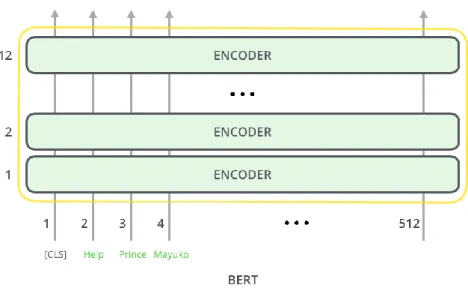
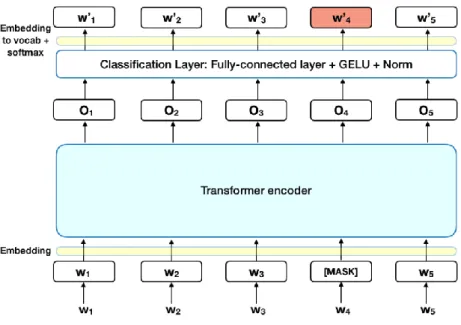
(36) Gambar 2. 8 Perbedaan Antara Arsitektur BERT Dengan OpenAI GPT dan ELMo (Devlin et al., 2019) BERT menggunakan WordPiece embeddings dengan 30,000 token vocabulary. Token pertama dari tiap urutan selalu berupa token klasifikasi khusus yaitu [CLS]. BERT dapat dilatih untuk memahami sebuah bahasa dan dapat pula disempurnakan (fine-tune) untuk mempelajari tugas-tugas tertentu. Training di BERT terdiri dari dua tahap, pre-training dan fine-tuning. Tahap pertama yaitu pre-training adalah tahap di mana BERT dibuat untuk memahami dan mempelajari bahasa dan konteksnya. BERT dapat memahami dengan training dengan dua tugas unsupervised yang dilakukan bersamaan yaitu Masked Language Model dan Next Sentence Prediction. 1.. Masked Language Modelling (Masked LM) Tujuan dari Masked Language Modelling adalah untuk memberi mask atau penutup ke kata secara acak pada kalimat dengan probabilitas yang kecil. Sebelum memasukkan urutan kata ke dalam BERT, 15% dari kata-kata di tiap urutan kata diganti dengan token [MASK]. Kemudian model akan mencoba untuk memprediksi nilai asli dari kata yang diberi [MASK] berdasarkan konteks yang diberikan oleh kata lain yang tidak ditutup dengan [MASK] di dalam urutan kata. Secara teknis, prediksi kata-kata output: i). Membutuhkan lapisan klasifikasi di atas output encoder.. ii). Mengalikan vector output dengan matriks embedding kemudian mengubahnya menjadi vocabulary dimension.. iii). Menghitung probabilitas dari setiap kata di vocabulary dengan softmax.. UNIVERSITAS SUMATERA UTARA.
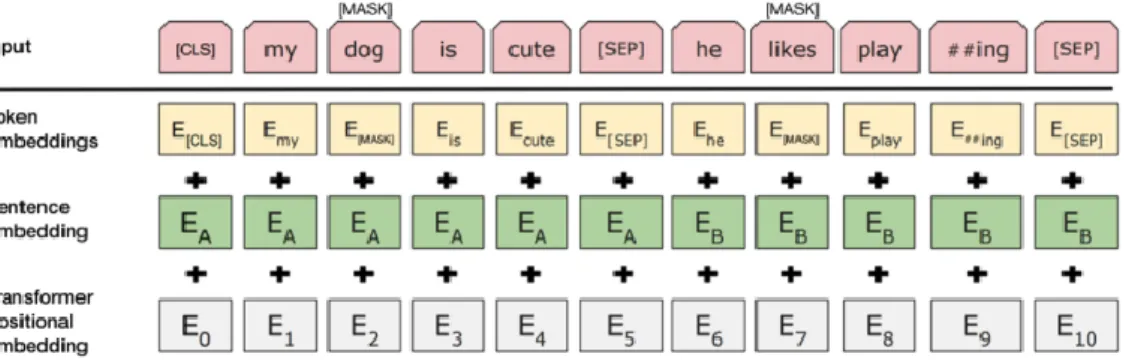
(37) Gambar 2. 9 Proses Masked Language Modelling 2.. Next Sentence Prediction Dalam proses training BERT, model dapat menerima pasangan kalimat sebagai input dan dilatih untuk memprediksi jika kalimat kedua pada pasangan tersebut adalah kalimat berikutnya pada dokumen aslinya atau hanya satu kalimat saja. Selama training, 50% dari input adalah pasangan kalimat di mana kalimat kedua adalah kalimat berikutnya pada dokumen asli. Sedangkan 50% lainnya adalah kalimat yang diambil secara acak dari corpus sebagai kalimat kedua.. Gambar 2. 10 Proses Pre-training pada BERT Sebagai representasi input pada BERT, terdapat tiga embedding layers yaitu: 1. Token embeddings adalah layer pertama yang token masuki, yaitu representasi vektor dari tiap token. Setiap token dalam input akan dipetakan ke representasi vektor berdimensi tinggi dari token yang diberikan. Tiap token diganti menjadi id yang didapatkan berdasarkan vocabulary.. UNIVERSITAS SUMATERA UTARA.
(38) 2. Sentence embeddings menunjukkan kalimat pertama atau kalimat kedua, ditambahkan ke setiap token dan digunakan untuk membedakan antar kalimat jika terdapat lebih dari dua kalimat. Lapisan ini hanya memiliki dua representasi: A untuk token yang termasuk dalam kalimat pertama, dan B untuk token yang termasuk dalam kalimat kedua. 3. Positional embedding ditambahkan ke setiap token untuk menyimpan informasi tentang posisi kata dalam urutan. Konsep dan implementasi dari positional embedding ditunjukkan dalam Transformer. BERT telah mempelajari posisi embedding layer selama pre-training.. Gambar 2. 11 Representasi Input pada BERT (Devlin et al., 2019) Untuk melatih sebuah model bahasa, classifier perlu dilatih dengan sedikit perubahan pada model BERT selama fase pelatihan (training) yang disebut finetuning. Seperti yang dipaparkan oleh Devlin dan rekan-rekannya, terdapat rekomendasi hyperparameters yang dapat di-fine-tuning untuk mencapai hasil yang maksimal. Fine-tuning sangat mudah dilakukan karena mekanisme self-attention di Transformer membuat BERT bisa membuat model untuk berbagai tugas, baik pada kalimat tunggal (single sentence) atau kalimat berpasangan, dengan menukar masukan dan keluaran yang sesuai.. UNIVERSITAS SUMATERA UTARA.
(39) Gambar 2. 12 Prosedur Pre-training dan Fine-tuning (Devlin et al., 2019). Gambar 2. 13 Ilustrasi Fine-tuning pada Tugas dengan Single Sentence (Devlin et al., 2019) 2.8 Penelitian yang Relevan Beberapa penelitian terdahulu yang relevan dengan penelitian yang akan dilakukan oleh penulis antara lain: 1. Pada penelitian yang dilakukan oleh (Putri, 2020), hasil akurasi yang diperoleh untuk analisis sentimen dengan Bidirectional Encoder Representations from Transformer (BERT) adalah 73%. Dataset yang digunakan adalah dataset yang telah disediakan oleh cornelledu dalam Bahasa Inggris dengan 2000 review di mana 1000 review dengan sentimen positif, dan 1000 review dengan sentimen negatif.. UNIVERSITAS SUMATERA UTARA.
(40) 2. Pada penelitian yang dilakukan (Abdul et al., 2019), peneliti menggunakan dataset yang diperoleh dari IMDB. Dataset tersebut menggunakan Bahasa Inggris. Peneliti menggunakan batch size sebanyak 32, learning rate 2e-5, dan 4 epoch. Penelitian ini memberikan hasil yang memuaskan. Hasil evaluation accuracy yang diperoleh mencapai 0.89 dengan loss 0.4856, precision 0.9174, dan recall 0.8812. 3. Pada penelitian dilakukan oleh (Munikar et al., 2019) menghasilkan sebuah analisis sentimen terhadap film. Dataset yang digunakan diperoleh dari Rotten Tomatoes, suatu situs untuk memberi ulasan dalam Bahasa Inggris. Akurasi yang diperoleh oleh penelitian ini adalah 94.0 pada model SST-2 dan 83.9 pada model SST-5 untuk BERTBASE. 4. Pada penelitian yang dilakukan (Maharani, 2020), peneliti melakukan analisis sentimen terhadap tweet apakah relevan atau tidak dengan tagar tentang banjir yang terjadi di Jakarta. Dataset menggunakan Bahasa Indonesia. Akurasi yang diperoleh saat training dataset adalah 90% dan test dataset adalah 79%. 5. Pada penelitian yang dilakukan oleh (Kurniawan et al., 2019), peneliti menggunakan dataset yang berasal dari forum KASKUS. Dataset yang digunakan menggunakan Bahasa Indonesia. Hasil dari analisis sentimen menggunakan Naïve-Bayes dan Lexicon-based akan mengklasifikasikan dataset menjadi dua kategori, yaitu positif dan negatif. Hasil pengujian menggunakan Naïve-Bayes dengan pembobotan lexicon-based features menghasilkan nilai akurasi 0.8, precision, recall 0.8, dan f-measure 0.8. Sedangkan hasil pengujian menggunakan Naïve-Bayes tanpa pembobotan lexicon-based features menghasilkan nilai akurasi 0.95, precision 1, recall 0.9, dan f-measure 0.9474.. UNIVERSITAS SUMATERA UTARA.
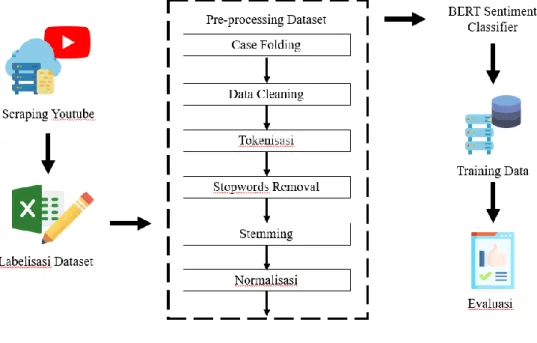
(41) BAB 3. ANALISIS DAN PERANCANGAN. Bab ini akan membahas tentang analisis dan perancangan sistem yang digunakan dalam proses analisis sentimen terhadap film Indonesia dengan metode aspect-based dan Bidirectional Encoder Representations from Transformers. 3.1 Arsitektur Umum Metode yang diajukan dalam analisis sentimen terhadap film Indonesia dengan metode Bidirectional Encoder Representations from Transformers terdiri dari beberapa langkah seperti yang tertera pada Gambar 3.1.. Gambar 3. 1 Arsitektur Umum. UNIVERSITAS SUMATERA UTARA.
(42) Arsitektur umum sistem di atas menunjukkan bahwa analisis sentimen dimulai dengan melakukan scraping atau ekstraksi data dari situs YouTube pada video trailer film Gundala yang akan dijadikan sebagai dataset. Hasil dari scraping kemudian dikumpulkan dan menjadi sebuah dataset. Dataset tersebut dipisah menjadi per kalimat. Setelah itu, dataset kemudian dianotasi dengan label negatif, netral, atau positif. Kemudian, dataset yang sudah dianotasi masuk ke dalam tahap preprocessing. Preprocessing dataset adalah tahap untuk mempersiapkan data yang awalnya tidak terstruktur menjadi data yang lebih terstruktur dengan melakukan beberapa tahapan, yaitu case folding, data cleaning, tokenisasi, stopwords removal, stemming, dan normalisasi Bahasa tidak baku. Dataset yang sudah melalui prosesproses tersebut dilatih untuk diklasifikasi menjadi tiga kategori, yaitu negatif, netral, dan positif menggunakan BERT. Hasil klasifikasi kemudian dievaluasi melihat hasilnya. 3.2 Scraping Penelitian ini menggunakan data yang diperoleh dari YouTube yang diambil dari komentar-komentar yang diberikan pengguna di video dengan judul Official Trailer GUNDALA (2019) yang diunggah pada 20 Juli 2019 pada akun resmi perusahaan produksinya yaitu Screenplay Films. Video tersebut dipilih karena merupakan video yang memilih jumlah penayangan dan komentar yang paling banyak. Scraping dilakukan dengan menggunakan Chrome Driver yang disediakan library Selenium. ChromeDriver berfungsi untuk mencari elemen yang menunjukkan komentar pada YouTube. Elemen yang dicari menggunakan XPATH. Dataset kemudian disimpan lalu melalui proses sentence splitting untuk memisahkan data dalam teks menjadi per kalimat. Kalimat dipisah menggunakan salah satu fungsi pada nltk, yaitu sent_tokenize. Sentence splitting dilakukan karena seringkali pada suatu komentar terdapat lebih dari dua kalimat dan memiliki sentimen yang berbeda pula. Dataset yang sudah melalui proses tersebut kemudian disimpan dalam bentuk excel worksheet (.xlsx). 3.3 Labelisasi Dataset Dalam analisis sentimen dengan metode supervised learning, diperlukan dataset yang sudah memiliki label atau dianotasi oleh annotator. Labelisasi ini perlu. UNIVERSITAS SUMATERA UTARA.
(43) dilakukan karena metode supervised learning membutuhkan contoh. Esensi dari supervised learning adalah membuat suatu mekanisme di mana model dapat melihat contoh dan menghasilkan generalisasi sehingga keluaran dari model adalah prediksi yang sesuai dengan label yang diinginkan (Goldberg, 2017). Model pun dapat melihat, memahami, dan mengerti bagaimana komentar yang memiliki sentimen negatif, netral, dan positif. Labelisasi yang dilakukan bertujuan untuk menentukan komentar ke dalam kategorinya yaitu negatif, netral, atau positif dengan memberi nilai sebagai penandanya. Komentar dengan sentimen positif diberi nilai 2. Sedangkan komentar dengan sentimen netral diberi nilai 1 dan sentimen negatif diberi nilai 0. Anotasi ini dilakukan oleh tim annotator sebanyak 5 orang. Contoh dataset yang sudah dilabelisasi sebagaimana terlihat pada Tabel 3.1. Tabel 3. 1 Contoh Dataset Komentar. Sentimen. Ini film paling keren yang pernah kutonton setelah the raid. 2. Keren abis neh harus nonton ini ni. 2. Cuma saran superhero biasanya badannya kekar2... ga kurus2. 0. NO coment .. krn blm lht film nya. 1. alur ceritanya gak jelas.... 0. Jadi tidak sabar untuk melihat sekuel dari Gundala 👍👍.. 2. Ini salah satu flm Indonesia yang sangat keren 👌. 2. Gatau lagi udh berapa kali gw nonton ini trailer, semoga menjadi. 2. langkah awal untuk kesuksesan industri film Indonesia BCU universe. 3.4 Pre-processing Dataset Pada penelitian ini, preprocessing dilakukan untuk mengubah dataset yang tidak terstruktur menjadi terstruktur sehingga mempermudah data untuk diproses dengan melakukan beberapa tahapan yaitu case folding, data cleaning, tokenisasi, stopwords removal, stemming, dan normalisasi Bahasa tidak baku. Selain itu,. UNIVERSITAS SUMATERA UTARA.
(44) dengan preprocessing maka hasil dari analisis sentimen akan lebih baik. Tahaptahap yang dilakukan meliputi: 3.4.1. Case Folding. Case folding dilakukan dengan membuat semua huruf besar (uppercase) pada dataset menjadi huruf kecil (lowercase). Tahap ini dilakukan agar semua karakter pada dataset menjadi sama, yaitu menggunakan huruf kecil. Dengan membuat semua kata menjadi huruf kecil akan sangat membantu untuk melakukan generalisasi (Jurafsky & Martin, 2019). Sehingga kata “Saya” dan “saya” akan dianggap sama. Fungsi yang digunakan untuk melakukan case folding adalah fungsi lower() yang sudah disediakan oleh library Python. Contoh dari case folding sebagaimana terlihat pada Tabel 3.2. Tabel 3. 2 Perbandingan Hasil Case Folding Komentar Film Indonesia TERBAGUS!!!. 3.4.2. Hasil Case Folding film indonesia terbagus!!!. Data Cleaning. Pada tahap ini, kalimat-kalimat pada dataset dibersihkan dari segala sesuatu yang dapat mempengaruhi hasil dari analisis seperti kata dengan karakter yang berulang dua atau lebih, link, username (@username), hashtag (#), angka, simbol-simbol, spasi berlebih, tanda baca, dan angka. Untuk melakukan data cleaning, penulis menggunakan regular expression untuk dicocokkan dengan yang akan dihapus. Contoh tahap data cleaning dapat dilihat pada Tabel 3.3. Tabel 3. 3 Perbandingan Hasil Data Cleaning Komentar. Hasil Data Cleaning. Gw ga nyangka bakal ada film indo gw ga nyangka bakal ada film indo sebagus ini... Pengen nangis gueeeee sebagus ini pengen nangis guee keren :"(((( keren abisss dah!. abiss dah. UNIVERSITAS SUMATERA UTARA.
(45) 3.4.3. Tokenisasi. Tokenisasi adalah suatu proses yang dilakukan untuk memecah kalimat-kalimat menjadi potongan kata-kata, tanda baca, dan ekspresi bermakna lainnya sesuai dengan ketentuan Bahasa yang digunakan. Pada proses ini, penulis menggunakan fungsi word_tokenize yang disediakan oleh library NLTK. Contoh tahap tokenisasi dapat dilihat pada Tabel 3.4. Tabel 3. 4 Perbandingan Hasil Tokenisasi Komentar. Hasil Tokenisasi. terima kasih teman-teman udah lihat ‘terima’ ‘kasih’ ‘teman-teman’ ‘udah’ trailer gundala dan ninggalin komen- ‘lihat’. ‘trailer’. komen yang bikin kami tambah ‘ninggalin’ semangat. dan. nggak. sabar. ‘dan’. ‘komen-komen’. ‘yang’. rilis ‘bikin ‘kami’ ‘tambah’ ‘semangat’ ‘dan’ ‘nggak’ ‘sabar’ ‘rilis’ ‘filmnya’. filmnya. 3.4.4. ‘gundala’. Stopwords Removal. Stopwords Removal adalah proses yang dilakukan untuk menghapus kata-kata yang tidak memiki arti. Tahap ini akan menggunakan library stopwords Bahasa Indonesia yang disediakan oleh NLTK dan ditambah dengan kamus yang dibuat oleh Tala1 sebanyak 758 kata. Contoh stopwords yang terdapat pada kamus Tala pada Tabel 3.5. Tabel 3. 5 Contoh Stopwords pada Kamus Tala Stopwords Tala. 1. ada. adalah. adanya. adapun. agak. agaknya. agar. akan. akankah. akhir. akhiri. akhirnya. aku. akulah. amat. amatlah. anda. andalah. antar. antara. antaranya. apa. apaan. apabila. https://github.com/masdevid/ID-Stopwords. UNIVERSITAS SUMATERA UTARA.
(46) Akan tetapi ada beberapa kata pada kamus Tala yang dihapus karena akan mempengaruhi dalam melakukan analisis sentimen seperti kata-kata sangat, terlalu, kurang, dan sekali yang merupakan booster words atau strong words. Selain itu, ada pula kata enggak dan tidak yang merupakan negasi. Kata negasi dapat mengubah polaritas dari suatu opini seperti pada kalimat “filmnya tidak bagus” memiliki sentimen negatif. Tetapi jika kata tidak dihapus, kalimat tersebut akan diklasifikasi sebagai kalimat dengan sentimen positif. Contoh tahap stopwords removal yang dapat dilihat pada Tabel 3.6. Tabel 3. 6 Perbandingan Hasil Stopwords Remioval Komentar. Hasil Stopwords Removal. film nya bagus udah saya nonton ada 'film', 'nya', 'bagus', 'udah', 'nonton', lucunya juga kwkwkw. 3.4.5. 'lucunya', 'kwkwkw'. Stemming. Stemming adalah proses yang dilakukan untuk mengubah kata yang memiliki imbuhan menjadi kata dasarnya (root form) dengan menghapus imbuhan seperti prefiks, sufiks, dan konfiks. Pada tahap ini, stemming dilakukan dengan menggunakan library Sastrawi. Contoh tahap stemming yang dapat dilihat pada Tabel 3.7. Tabel 3. 7 Perbandingan Hasil Stemming Komentar. Hasil Stemming. tapi setelah nonton film ini saya sangat 'nonton',. 'film',. 'sangat',. 'takjub',. takjub dan sangat mengapresiasi film 'sangat', 'apresiasi', 'film', 'cari', 'tau', ini. sampai. saya. cari. tau. siapa 'tulis', 'keren', 'makna', 'dedikasi', 'yg',. penulisnya.. Keren, banyak makna dan 'alami', 'indonesia' dedikasi yang bisa kita dapat yg sedang dialami di Indonesia sekarang. 3.4.6. Normalisasi. Tahap normalisasi adalah tahap di mana dataset yang memiliki kata-kata tidak baku diubah menjadi kata yang baku atau sesuai dengan ejaan. Hal ini dilakukan karena. UNIVERSITAS SUMATERA UTARA.
(47) pada umumnya banyak sekali yang menggunakan kata-kata gaul seperti: bgt, trus, slalu, pngn, aq, kereeen, kereenn, dan lain-lain. Jika kata-kata tersebut tidak melewati proses normalisasi, maka sistem akan menganggap kata kereeeen, kereenn, kereennn, kerenn adalah kata yang berbeda. Padahal seharusnya kata tersebut memiliki makna yang sama yaitu keren. Oleh karena itu, normalisasi dilakukan untuk mengubah kata tidak baku menjadi kata baku. Proses normalisasi ini menggunakan Kamus Alay2 (Aliyah Salsabila et al., 2019). Sebagai tambahan, kata tidak baku yang diperoleh saat menganotasi juga ditambahkan. Contoh tahap normalisasi yang dapat dilihat pada Tabel 3.8. Tabel 3. 8 Perbandingan Hasil Normalisasi Komentar. Hasil Normalisasi. sayang bgt yg nonton ke bioskop ga sayang banget yang nonton ke bioskop sebanyak yg nonton trailernya. enggak. sebanyak. yang. nonton. trailernya. 3.5 Implementasi BERT Pada penelitian ini, penulis menggunakan BERTBASE dan model bert-multilingualbase-cased. Model ini dipilih karena model tersebut mendukung 104 bahasa termasuk Bahasa Indonesia (Yanuar & Shiramatsu, 2020)(Maharani, 2020). Pada penelitian ini, penulis menggunakan library Transformers yang disediakan oleh HuggingFace3. Library ini menyediakan ribuan pre-trained model yang dapat digunakan untuk melakukan tugas-tugas klasifikasi, ekstraksi informasi, tanya jawab, summarization, translasi, text generation dan lain-lain dalam 100 bahasa. Transformers didukung oleh dua library deep learning yang terkemuka yaitu PyTorch dan TensorFlow. 3.5.1. Penjelasan BERT. Sebelum BERT di-training dengan dataset, dataset harus disesuaikan dengan representasi input yang dapat diterima oleh BERT. Oleh karena itu dibutuhkan. 2 3. https://github.com/nasalsabila/kamus-alay https://github.com/huggingface/transformers. UNIVERSITAS SUMATERA UTARA.
(48) sebuah tokenizer yang bertujuan untuk melakukan tokenisasi pada kalimat-kalimat dan menghasilkan input yang sesuai. Hal ini dilakukan karena BERT menggunakan vocabulary yang spesifik yang mana tergantung dengan model apa yang dipakai. Vocabulary dibuat dengan menggunakan sebuah model WordPiece. Vocabulary terdiri dari semua karakter dan tambahan sekitar 30.000 kata-kata yang sering digunakan serta sub kata yang sering muncul pada corpus yang model latih. Langkah-langkah membuat vocabulary antara lain: 1. Inisialisasi vocabulary dengan semua karakter yang digunakan pada bahasa yang ada di corpus atau bahasa yang dipilih (52 huruf untuk case-sensitive pada bahasa Inggris dan beberapa tanda baca). 2. Buat model bahasa dengan vocabulary yang telah dibuat. 3. Buat sebuah sub kata dengan menggabungkan pasangan sub kata dari suatu kata. Tambahkan sub kata ke dalam vocabulary untuk meningkatkan kemungkinan model bahasa saat training data, yaitu sub kata yang muncul paling sering muncul secara berurutan pada training data. 4. Lanjutkan ke langkah kedua sampai ukuran maksimum dari vocabulary telah tercapai. Pada penelitian ini, model yang digunakan adalah multilingual yang berarti data terdiri dari 100 bahasa dengan menggunakan dataset dari Wikipedia. Model bertmultilingual-base-cased sendiri memiliki sebanyak 119.547 kata. Vocabulary tersebut terdiri dari empat hal, yaitu: 1. Seluruh kata 2. Sub kata yang muncul di depan kata atau terpisah, seperti karakter “em” pada “embeddings” diberi vektor yang sama dengan karakter “em” yang ada pada “go get em” 3. Sub kata yang tidak berada di depan kata, yang diawali dengan ##. 4. Karakter individual seperti ‘a’, ‘b’, ‘c’, dan seterusnya. BERT menerima panjang yang tetap dan sama untuk setiap inputnya. BERT telah menentukan panjang urutan kalimat maksimumnya, yaitu 512 karena encoder pada Transformer hanya menghasilkan output dengan dimensi 512 saja. Jika panjang kalimat lebih dari panjang maksimum yang telah ditentukan, kalimat akan. UNIVERSITAS SUMATERA UTARA.
Gambar
+7


Garis besar
Dokumen terkait
Judul Skripsi : Sistem Rating Berdasarkan Komentar Dengan Analisis Sentimen Menggunakan Algoritma Naïve Bayes Pada Situs Tripadvisor Hasil Pengecekan Software iThenticate/Turnitin
para manajer di dalam suatu oragnisasi, dengan cara-cara aktivitas tertentu mereka mempengaruhi personil atau anggota organisasi. Humas adalah proses membangun relasi,
Sistem analisis komentar pada YouTube yang dibuat akan menghasilkan klasifikasi dari komentar-komentar pengguna YouTube dengan kategori positif dan negatif.. Sistem ini
Dalam penelitian ini, penulis akan melakukan analisis sentimen berdasarkan komentar yang terdapat dalam fanpage kandidat presiden dengan menerapkan proses text
Tujuan penelitian ini untuk melihat sentimen positif dan negatif pada komentar pengguna aplikasi youtube terdapat pada video channel sekretariat Presiden yang
Seksio sesarea ini direncanakan lebih dahulu karena sudah diketahui bahwa kehamilan harus diselesaikan dengan cara operasi, ibu hamil harus melakukan pemeriksaan selama
Tujuan dari penelitian ini adalah menganalisis faktor-faktor yang dapat mempengaruhi hasil performansi dari implementasi analisis sentimen komentar beracun pada media
Berdasarkan uraian diatas, tujuan dari penelitian ini adalah untuk melakukan analisis sentimen terhadap aplikasi dompet digital berdasarkan ulasan komentar yang ada
