32 BAB III PEMBAHASAN
Pada bab ini akan dijelaskan mengenai analisis regresi robust estimasi-S dengan pembobot Welsch dan Tukey bisquare. Kemudian akan ditunjukkan model regresi menggunakan regresi robust estimasi-S dengan pembobot Welsch dan Tukey bisquare. Selanjutnya, akan ditunjukan juga mengenai perbandingan hasil estimasi antara regresi robust estimasi-S dengan pembobot Welsch dan Tukey bisquare ditinjau dari nilai standard error dan adj R-square yang diperoleh pada masing-masing metode. Pada penelitian ini, contoh kasus yang digunakan untuk analisis regresi robust estimasi-S dengan pembobot Welsch dan Tukey bisquare adalah data Indeks Pembangunan Manusia berdasarkan provinsi di Indonesia tahun 2015 beserta faktor-faktor yang mempengaruhinya.
A. Regresi Robust Estimasi-S
Pada analisis regresi jika data terkontaminasi outlier pada variabel 𝑋, estimasi-M tidak dapat bekerja dengan baik. Estimasi-M tidak dapat mengidentifikasi bad observation yang berarti tidak dapat membedakan good laverage point dan bad laverage point. Untuk mengatasi hal tersebut, estimasi high breakdown point sangat diperlukan. Salah satu estimasi yang mempunyai nilai high breakdown point adalah estimasi-S. Estimasi-S merupakan estimasi robust yang dapat mencapai breakdown point hingga 50%. Karena estimasi-S dapat mencapai breakdown point hingga 50%, maka estimasi ini dapat mengatasi setengah dari outlier dan memberikan pengaruh yang baik bagi pengamatan lainnya. Pada metode kuadrat terkecil, estimator diperoleh dengan
33
meminimumkan jumlah kuadrat error pada persamaan umum regresi linier.
Estimasi-S didefinisikan 𝛽̂𝑠 = arg min
𝛽 𝜎̂𝑠 (𝜀1, 𝜀2, … , 𝜀𝑛) (3.1) dengan menentukan nilai estimator skala robust (𝜎̂) yang minimum dan memenuhi
𝑚𝑖𝑛 ∑ 𝜌 (𝑦𝑖− ∑𝑘𝑗=0𝑥𝑖𝑗𝛽𝑗
𝜎̂ )
𝑛
𝑖=1
(3.2)
dengan
𝜎̂ = √𝑛 ∑𝑛𝑖=0(𝜀𝑖2)− (∑𝑛𝑖=0𝜀𝑖)2 𝑛(𝑛 − 1)
Estimator 𝛽̂ pada metode regresi robust estimasi-S diperoleh dengan cara melakukan iterasi hingga diperoleh hasil yang konvergen. Cara tersebut dikenal sebagai metode kuadrat terkecil terboboti secara iteratif (Iteratively Reweighted Least Square) dengan prosedur (Fox, 2002):
1. Dipilih estimator awal yang diperoleh melalui metode kuadrat terkecil:
∑ 𝑌𝑖 − 𝑛𝛽0 − 𝛽1∑ 𝑋𝑖 = 0
∑ 𝑌𝑖𝑋𝑖− 𝛽0∑ 𝑋𝑖− 𝛽1∑ 𝑋𝑖2 = 0
2. Pada setiap iterasi ke-𝑡, dihitung residual 𝜀𝑖 = 𝑦𝑖− 𝑥𝑖𝛽̂(𝑡−1), skala 𝜎̂(𝑡−1), residual terstandarisasi 𝑢𝑖(𝑡−1) =𝜀𝑖(𝑡−1)
𝜎
̂(𝑡−1) , dan bobot 𝑤𝑖(𝑡−1) =(𝑢𝑖(𝑡−1))
𝑢𝑖(𝑡−1) dari iterasi sebelumnya.
3. Dihitung estimator kuadrat terkecil terboboti menggunakan bobot pada langkah ke-2
34 𝛽̂(𝑡) = (𝑋′𝑊(𝑡−1)𝑋)−1𝑋′𝑊(𝑡−1)𝑌
4. Langkah ke-2 dan ke-3 berulang hingga estimator yang diperoleh konvergen.
Dengan kata lain, jika |𝛽̂𝑗(𝑡)− 𝛽̂𝑗(𝑡−1)| cukup kecil atau samadengan 0 untuk 𝑗 = 0, 1, 2, … , 𝑘.
B. Fungsi Pembobot Metode Kuadrat Terkecil
Fungsi obyektif untuk metode kuadrat terkecil didefinisikan sebagai 𝜌(𝑢) =1
2𝑢2 (3.3)
dan fungsi pengaruh, , merupakan turunan dari 𝜌, sehingga dapat dituliskan = 𝜌′, sehingga fungsi metode kuadrat terkecil menjadi
(𝑢) = 𝑢
Untuk fungsi pembobot digunakan rumus sebagai berikut:
𝑤(𝑢) =(𝑢) 𝑢 sehingga diperoleh,
𝑤(𝑢) = 1 (3.4)
C. Fungsi Pembobot Welsch
Untuk melakukan analisis regresi robust terutama dalam menentukan estimasi koefisien dalam regresi robust harus menggunakan fungsi. Salah satu fungsi 𝜌 untuk estimator skala robust yaitu fungsi Welsch. Holland & Welsch (1977) mendefinisikan fungsi Welsh dalam persamaan berikut:
𝜌(𝑢) =𝐶2
2 [1 − 𝑒𝑥𝑝 (− (𝑢
𝑐)2)] (3.5) dengan 𝑢 = 𝜀
𝜎
̂,
35 𝜀 ∶ nilai residual
𝜎̂ ∶ skala estimasi robust
Kemudian untuk fungsi pengaruh yang merupakan turunan dari 𝜌 adalah sebagai berikut:
(𝑢) =𝜕𝜌(𝑢)
𝜕(𝑢)
(𝑢) = 𝑢 [𝑒𝑥𝑝 (− (𝑢
𝑐)2)] (3.6) dan untuk fungsi pembobot Welsch:
𝑤 = (𝑢) 𝑢 𝑤 = 𝑒𝑥𝑝 (− (𝑢
𝑐)2) (3.7) dengan nilai 𝑐 = 2,9846. Nilai 𝑐 adalah tuning constant yang telah ditetapkan untuk menentukan tingkat kerobustan suatu pembobot.
Sehingga fungsi pembobot menjadi seperti berikut 𝑤 = 𝑒𝑥𝑝 (− ( 𝑥
2,9846)2) D. Fungsi Pembobot Tukey bisquare
Fungsi 𝜌 yang lain untuk estimator skala robust yaitu fungsi Tukey bisquare. Fungsi Tukey bisquare secara umum didefinisikan sebagai berikut (Rousseeuw & Yohai, 1984: 260):
𝜌(𝑢) = { 𝑢2
2 − 𝑢4 2𝑏2− 𝑢6
6𝑏4 , |𝑢| ≤ 𝑏 𝑏2
6, |𝑢| > 𝑏
(3.8)
36
Fungsi pengaruh Tukey bisquare, , merupakan turunan dari 𝜌, sehingga dapat dituliskan = 𝜌′, sehingga fungsi Tukey bisquare menjadi
(𝑢) = 𝜌′(𝑢) = {𝑢 − 2𝑢3
𝑏2 −𝑢5
𝑏4 , |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏
(𝑢) = {𝑢 (1 −2𝑢2
𝑏2 −𝑢4
𝑏4) , |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏 (𝑢) = {𝑢 (1 −𝑢
2
𝑏2)2 , |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏
= {𝑢 (1 − (
𝑢 𝑏)2)
2
, |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏
(3.9)
Untuk fungsi pembobot digunakan rumus sebagai berikut:
𝑤(𝑢) =(𝑢)
𝑢 (3.10) sehingga diperoleh,
𝑤(𝑢) = {
𝑢 (1 − (𝑢 𝑏)2)
2
𝑢 , |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏
= {[1 − ( 𝑢 𝑏)
2
]
2
, |𝑢| ≤ 𝑏 0 , |𝑢| > 𝑏
(3.11)
dengan 𝑢 =𝑒𝑖
𝑠 , dipilih nilai 𝑏 = 4,685 (Rousseeuw & Yohai, 1984: 263).
Sehingga fungsi pembobot menjadi seperti berikut:
𝑤(𝑢) = {[1 − ( 𝑢 𝑏)
2
]
2
, |𝑢| ≤ 4,685 0 , |𝑢| > 4,685
37 E. Fungsi-fungsi Ukuran Robust
Secara ringkas fungsi obyektif dan fungsi pembobot dari metode kuadrat terkecil, Welsch dan Tukey bisquare dapat dilihat pada tabel 3.1.
Tabel 3.1 Fungsi Obyektif dan Fungsi Pembobot
Metode Fungsi obyektif Fungsi pembobot Interval
MKT 𝜌(𝑢) =1
2𝑢2 𝑤(𝑢) = 1 |𝑢| < ∞
Tukey
bisquare 𝜌(𝑢) =
{ 𝑢2
2 − 𝑢4 2𝑏2− 𝑢6
2𝑏4 𝑏2
6
𝑤(𝑢) = {[1 − ( 𝑢 𝑏)
2
]
2
0
|𝑢| ≤ 𝑏
|𝑢| > 𝑏
Welsch 𝜌(𝑢) =𝑐
2[1 − 𝑒𝑥𝑝 (− (𝑢 𝑐)
2
)] 𝑤(𝑢) = 𝑒𝑥𝑝 (− (𝑢 𝑐)
2
) |𝑢| < ∞
F. Penyelesaian untuk 𝜷̂
Fungsi tidak linier dan harus diselesaikan dengan iterasi, salah satunya dengan Iteratively Reweighted Least Square (IRLS). Dengan estimasi awal 𝛽̂𝑗0 dan estimasi skala 𝜎̂, maka bobot awal
𝑤𝑖0 = (𝜀𝑖
𝜎
̂)0 atau
𝑤𝑖0 =
(𝑦𝑖−∑ 𝑥𝑖𝑗𝛽̂𝑗0 𝑘𝑗=0
𝜎̂ )
𝑦𝑖−∑𝑘 𝑥𝑖𝑗𝛽̂𝑗0 𝑗=0
𝜎
̂
(3.12)
dengan 𝑥𝑖𝑗 adalah observasi ke-𝑖 pada regressor ke-𝑗 dan 𝑥𝑖0=1. Pada persamaan regresi linier sederhana, penyelesaian untuk 𝛽̂01 dan 𝛽̂11 (iterasi pertama terboboti) sebagai berikut:
38
∑ 𝑤𝑖0(𝑦𝑖 − 𝛽̂01− 𝛽̂11𝑥𝑖) = 0
𝑛
𝑖=1
(3.13)
∑ 𝑤𝑖0𝑦𝑖− 𝛽̂01∑ 𝑤𝑖0 − 𝛽̂11∑ 𝑤𝑖0𝑥𝑖
𝑛
𝑖=1 𝑛
𝑖=1
= 0
𝑛
𝑖=1
∑ 𝑤𝑖0𝑦𝑖 = 𝛽̂01∑ 𝑤𝑖0 + 𝛽̂11∑ 𝑤𝑖0𝑥𝑖
𝑛
𝑖=1 𝑛
𝑖=1 𝑛
𝑖=1
𝛽̂01∑ 𝑤𝑖0 = ∑ 𝑤𝑖0𝑦𝑖 −
𝑛
𝑖=1
𝛽̂11∑ 𝑤𝑖0𝑥𝑖
𝑛
𝑖=1 𝑛
𝑖=1
Sehingga diperoleh 𝛽̂01 :
𝛽̂01 = ∑𝑛𝑖=1𝑤𝑖0𝑦𝑖
∑𝑛𝑖=1𝑤𝑖0 −𝛽̂11∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0 (3.14) Sedangkan untuk mencari 𝛽̂11,
∑ 𝑤𝑖0𝑥𝑖(𝑦𝑖 − 𝛽̂01− 𝛽̂11𝑥𝑖) = 0
𝑛
𝑖=1
(3.15)
∑ 𝑤𝑖0𝑥𝑖𝑦𝑖 − 𝛽̂01∑ 𝑤𝑖0𝑥𝑖 − 𝛽̂11∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1 𝑛
𝑖=1
= 0
𝑛
𝑖=1
∑ 𝑤𝑖0𝑥𝑖𝑦𝑖 = 𝛽̂01∑ 𝑤𝑖0𝑥𝑖 + 𝛽̂11∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1 𝑛
𝑖=1 𝑛
𝑖=1
Dilakukan substitusi persamaan (3.14) ke persamaan (3.15)
∑ 𝑤𝑖0𝑥𝑖𝑦𝑖
𝑛
𝑖=1
= (∑𝑛𝑖=1𝑤𝑖0𝑦𝑖
∑𝑛𝑖=1𝑤𝑖0 −𝛽̂11∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0 ) ∑ 𝑤𝑖0𝑥𝑖
𝑛
𝑖=1
+ 𝛽̂11∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1
∑ 𝑤𝑖0𝑥𝑖𝑦𝑖
𝑛
𝑖=1
=∑𝑛𝑖=1𝑤𝑖0𝑦𝑖∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0 −𝛽̂11(∑𝑖=1𝑛 𝑤𝑖0𝑥𝑖)2
∑𝑛𝑖=1𝑤𝑖0 + 𝛽̂11∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1
39 𝛽̂11∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1
−𝛽̂11(∑𝑛𝑖=1𝑤𝑖0𝑥𝑖)2
∑𝑛𝑖=1𝑤𝑖0 = ∑ 𝑤𝑖0𝑥𝑖𝑦𝑖
𝑛
𝑖=1
−∑𝑛𝑖=1𝑤𝑖0𝑦𝑖∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0
𝛽̂11(∑ 𝑤𝑖0𝑥𝑖2
𝑛
𝑖=1
−(∑𝑛𝑖=1𝑤𝑖0𝑥𝑖)2
∑𝑛𝑖=1𝑤𝑖0 ) = ∑ 𝑤𝑖0𝑥𝑖𝑦𝑖
𝑛
𝑖=1
−∑𝑛𝑖=1𝑤𝑖0𝑦𝑖∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0 Didapat 𝛽̂11:
𝛽̂11 =
∑𝑛𝑖=1𝑤𝑖0𝑥𝑖𝑦𝑖 −∑𝑛𝑖=1𝑤𝑖0𝑦𝑖∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0
∑𝑛𝑖=1𝑤𝑖0𝑥𝑖2−(∑𝑖=1𝑛 𝑤𝑖0𝑥𝑖)2
∑𝑛𝑖=1𝑤𝑖0
(3.16)
Supaya lebih sederhana, persamaan (3.16) dikalikan ∑ 𝑤𝑖
0 𝑛 𝑖=1
∑𝑛𝑖=1𝑤𝑖0 sehingga diperoleh nilai 𝛽̂11 sebagai berikut:
𝛽̂11 = ∑𝑛𝑖=1𝑤𝑖0∑𝑛𝑖=1𝑤𝑖0𝑥𝑖𝑦𝑖 − ∑𝑛𝑖=1𝑤𝑖0𝑦𝑖∑𝑛𝑖=1𝑤𝑖0𝑥𝑖
∑𝑛𝑖=1𝑤𝑖0∑𝑛𝑖=1𝑤𝑖0𝑥𝑖2− (∑𝑖=1𝑛 𝑤𝑖0𝑥𝑖)2 (3.17) Untuk iterasi ke-𝑗 (dengan 𝑗 = 1, 2, …), maka penyelesaian untuk 𝛽̂0𝑗 dan 𝛽̂1𝑗 adalah
𝛽̂0𝑗 = ∑𝑛𝑖=1𝑤𝑖𝑗−1𝑦𝑖
∑𝑛𝑖=1𝑤𝑖𝑗−1 −𝛽̂11∑𝑛𝑖=1𝑤𝑖𝑗−1𝑥𝑖
∑𝑛𝑖=1𝑤𝑖𝑗−1 (3.18) dan
𝛽̂1𝑗 = ∑𝑛𝑖=1𝑤𝑖𝑗−1∑𝑛𝑖=1𝑤𝑖𝑗−1𝑥𝑖𝑦𝑖 − ∑𝑛𝑖=1𝑤𝑖𝑗−1𝑦𝑖∑𝑛𝑖=1𝑤𝑖𝑗−1𝑥𝑖
∑𝑛𝑖=1𝑤𝑖𝑗−1∑𝑛𝑖=1𝑤𝑖𝑗−1𝑥𝑖2 − (∑𝑛𝑖=1𝑤𝑖𝑗−1𝑥𝑖)2
(3.19)
dengan 𝑗 merupakan banyaknya iterasi, maka tercapai nilai 𝛽̂0 dan 𝛽̂1 yang konvergen apabila selisih antara 𝛽̂1𝑗 dengan 𝛽̂1𝑗−1 adalah 0.
Sedangkan pada persamaan regresi linier berganda, penyelesaian untul 𝛽̂1𝑗 sebagai berikut:
40 ∑ 𝑥𝑖𝑗𝑤𝑖0(𝑦𝑖 − ∑ 𝑥𝑖𝑗
𝑘
𝑗=0
𝛽̂𝑗1)
𝑛
𝑖=1
= 0 (3.20)
∑ ∑ 𝑤𝑖0𝑥𝑖𝑗𝑦𝑖 − ∑ ∑ 𝑤𝑖0𝑥𝑖𝑗2
𝑘
𝑗=0
𝛽̂𝑗1
𝑛
𝑖=1 𝑘
𝑗=0
= 0
𝑛
𝑖=1
∑ ∑ 𝑤𝑖0𝑥𝑖𝑗2
𝑘
𝑗=0
𝛽̂𝑗1
𝑛
𝑖=1
= ∑ ∑ 𝑤𝑖0𝑥𝑖𝑗𝑦𝑖
𝑘
𝑗=0 𝑛
𝑖=1
(3.21)
Persamaan (3.21) apabila ditulis dalam bentuk matriks, maka diperoleh 𝑊0𝑋′𝑋𝛽̂1 = 𝑊0𝑋′𝑌
𝛽̂1 = (𝑊0𝑋′𝑋)−1𝑊0𝑋′𝑌 (3.22) Untuk iterasi ke-𝑗 (dengan 𝑗 = 1, 2, … 𝑛), maka
𝛽̂𝑗 = (𝑊𝑗−1𝑋′𝑋)−1𝑊𝑗−1𝑋′ (3.23) dengan 𝑗 merupakan banyaknya iterasi, maka tercapai nilai 𝛽̂𝑗 yang konvergen apabila selisih antara 𝛽̂𝑗 dengan 𝛽̂𝑗−1 adalah 0.
G. Contoh Kasus 1. Deskripsi Data
Dalam skripsi ini, data yang digunakan merupakan data sekunder yang diperoleh dari publikasi Badan Pusat Statistik. Data yang digunakan adalah data Indeks Pembangunan Manusia menurut provinsi di Indonesia tahun 2015 beserta faktor-faktor yang mempengaruhinya dan dipilih data yang mengandung outlier.
Indek Pembangunan Manusia mempunyai pendekatan tiga dimensi dasar yaitu:
(1) umur panjang dan hidup sehat, (2) pengetahuan, dan (3) standar hidup layak.
Dari ketiga pendekatan dimensi dasar tersebut mempuyai komponen-komponen, beberapa diantaranya adalah rata-rata lama sekolah dan Upah Minimum Regional
41
(UMR). Sedangkan untuk konsep pembangunan manusia sendiri adalah pertumbuhan ekonomi yang menekankan pada Produk Domestik Regional Bruto (PDRB).
Berdasarkan uraian tersebut data yang digunakan dalam contoh kasus ini terdiri dari 4 variabel, yaitu satu variabel dependen yakni Indeks Pembangunan Manusia (IPM) dan 3 variabel independen yakni rata-rata lama sekolah, Upah Minimum Regional (UMR), dan Produk Domestik Regional Bruto (PDRB).
Sedangkan obyek yang digunakan terdiri dari 33 provinsi di Indonesia. Data dapat dilihat pada lampiran 1. Berikut penjelasan singkatnya mengenai variabel-variabel yang digunakan:
a. Variabel dependen
Parameter Indeks Pembangunan Manusia akan menjadi variabel dependen. Indeks Pembangunan Manusia menjelaskan bagaimana penduduk dapat mengakses hasil pembangunan dalam memperoleh pendapatan, kesehatan, pendidikan dan sebagainya. Indeks Pembangunan Manusia merupakan indikator penting untuk mengukur keberhasilan dalam upaya membangun kualitas hidup manusia (masyarakat/ penduduk). Angka Indeks Pembangunan Manusia disajikan pada tingkat nasional, provinsi, dan kabupaten/ kota. Penyajian Indeks Pembangunan Manusia menurut daerah memungkinkan setiap provinsi dan kabupaten/ kota mengetahui peta pembangunan manusia baik pencapaian, posisi, maupun disoparitas antar daearah. Dengan demikian, maka diharapkan setiap daearah dapat terpacu untuk berupaya meningkatkan kinerja pembangunan
42
melalui peningkatan kapasitas dasar penduduk. Data Indeks Pembangunan Manusia (IPM) dinyatakan dalam persen.
b. Variabel independen
Parameter-parameter yang akan menjadi variabel independen adalah sebagai berikut:
Rata-rata lama sekolah
Rata-rata lama sekolah merupakan rata-rata jumlah tahun belajar penduduk usia 15 tahun ke atas yang telah diselesaikan dalam pendidikan formal (tidak termasuk tahun yang mengulang) yang digunakan untuk melihat kualitas penduduk dalam hal mengenyam pendidikan formal. Tingginya angka rata-rata lama sekolah menunjukkan jenjang pendidikan yang pernah/sedang diduduki oleh seseorang. Semakin tinggi angka rata-rata lama sekolah maka semakin lama/tinggi jenjang pendidikan yang ditamatkannya. Kegunaan perhitungan angka rata-rata lama sekolah untuk melihat kualitas penduduk dalam mengenyam pendidikan formal.
Upah Minimum Regional
Upah Minimum Regional adalah suatu standar minimum yang digunakan oleh para pengusaha atau pelaku industri untuk memberikan upah kepada pekerja di dalam lingkungan usaha atau kerjanya. Komponen-komponen UMR merupakan harga barang konsumsi pokok sehari-hari. Hasil pembentukan harga tersebut kemudian akan menjadi bahan dasar penetapan UMR, selanjutnya modifikasi atas kepentingan pengusaha, pekerja pemerintah, dan juga masyarakat. Upah Minimum Regional juga sebagai pengukur tingkat kesejahteraan pada suatu
43
daerah, dimana pendapatan yang di dapat dari para pekerja yang ada di masing- masing provinsi.
Produk Domestik Regional Bruto (PDRB)
Produk Domestik Regional Bruto adalah nilai keseluruhan semua barang dan jasa yang diproduksi dalam suatu wilayah dalam suatu jangka waktu tertentu (biasanya satu tahun). Produk Domestik Regional Bruto digunakan sebagai indikator untuk mengetahui pertumbuhan ekonomi suatu daerah, bahan analisis tingkat kemakmuran masyarakat dan tingkat perubahan barang dan jasa, bahan analisis produktivitas secara sektoral, dan sebagai alat kontrol dalam menentukan kebijakan pembangunan.
Tabel 3.2 Deskripsi Data
Variabel Keterangan
Y Indeks Pembangunan Manusia (IPM) X1 Rata-rata lama sekolah
X2 Upah Minimum Regional (UMR)
X3 Produk Domestik Regional Bruto (PDRB)
Dari data dengan variabel-variabel diatas akan ditentukan model regresi menggunakan metode kuadrat terkecil (dengan dan tanpa outlier), regresi robust estimasi-S menggunakan pembobot Welsch dan Tukey bisquare, serta membandingkan keefektifan metode kuadrat terkecil dan regresi robust estimasi-S menggunakan pembobot Welsch dan Tukey bisquare dalam mengatasi outlier.
Proses analisis regresi dimulai dari pengujian asumsi klasik regresi terlebih dahulu, kemudian menentukan estimasi parameter menggunakan metode
44
kuadrat terkecil, selanjutnya pengidentifikasian outlier dan menetukan estimasi parameter dengan metode regresi robust estimasi-S menggunakan pembobot Welsch dan Tukey bisquare, kemudian dibandingan keefektifan antara regresi robust estimasi-S menggunakan pembobot Welsch dan pembobot Tukey bisquare dalam mengatasi outlier ditinjau dari nilai standard error dan nilai adj R-square yang diperoleh. Untuk pengolahan data menggunakan software bantuan yaitu:
Microsoft Excel, SPSS versi 20, dan SAS versi 3.2.3.
2. Uji Asumsi dalam Analisis Regresi
Pada model regresi, perlu dilakukan uji asumsi analisis regresi untuk mengetahui apakah model memenuhi asumsi atau tidak. Uji asumsi yang dilakukan pada model regresi adalah uji normalitas, homoskedastisitas, non autokorelasi dan non multikolineritas.
a. Uji normalitas
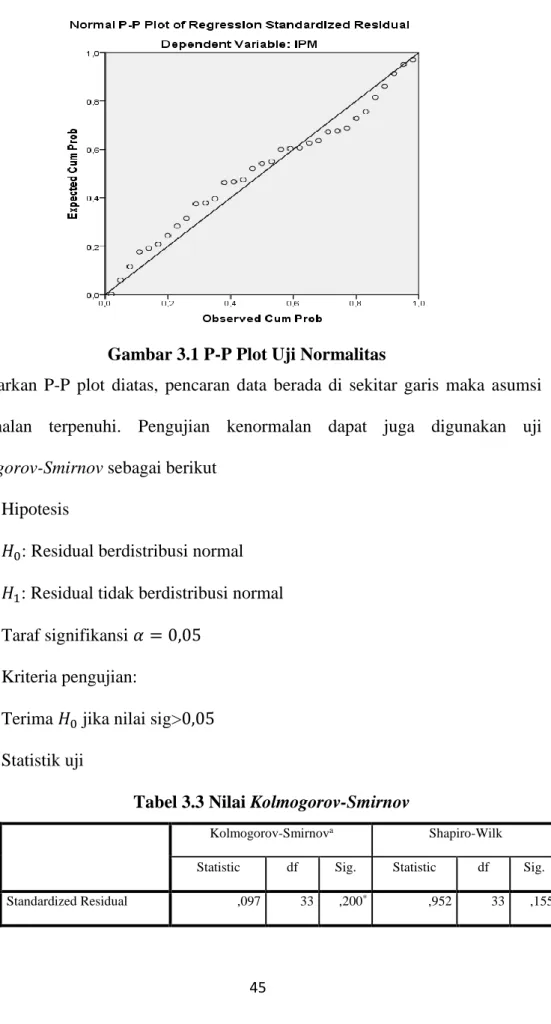
Uji normalitas digunakan untuk mengetahui apakah residual berdistribusi normal atau tidak. Dikatakan normal jika pada plot pencaran data berada di sekitar garis. Berdasarkan output SPSS, plot normalitas untuk residual dari model IPM menurut provinsi di Indonesia tahun 2015 beserta faktor-faktor yang mempengaruhinya dapat dilihat pada gambar 3.1.
45
Gambar 3.1 P-P Plot Uji Normalitas
Berdasarkan P-P plot diatas, pencaran data berada di sekitar garis maka asumsi kenormalan terpenuhi. Pengujian kenormalan dapat juga digunakan uji Kolmogorov-Smirnov sebagai berikut
1) Hipotesis
𝐻0: Residual berdistribusi normal 𝐻1: Residual tidak berdistribusi normal 2) Taraf signifikansi 𝛼 = 0,05
3) Kriteria pengujian:
Terima 𝐻0 jika nilai sig>0,05 4) Statistik uji
Tabel 3.3 Nilai Kolmogorov-Smirnov
Kolmogorov-Smirnova Shapiro-Wilk Statistic df Sig. Statistic df Sig.
Standardized Residual ,097 33 ,200* ,952 33 ,155
46
Berdasarkan hasil ouput SPSS pada tabel test of normality diperoleh nilai sig untuk uji Kolmogorov-Smirnov sebesar 0,2 > 0,05 maka 𝐻0 diterima.
5) Kesimpulan
𝐻0 diterima artinya residual berdistribusi normal.
b. Uji homoskedastisitas
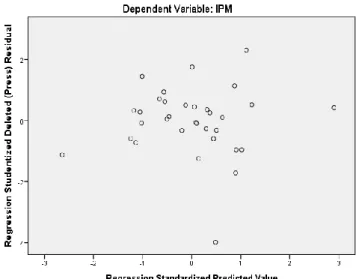
Pemeriksaan awal varians error bersifat homoskedastisitas atau tidak ada masalah heteroskedastisitas dapat dilihat dari scatterplot berikut:
Gambar 3.2 Scatterplot Uji Homoskedastisitas
Berdasarkan scatterplot diatas diketahui bahwa plot data menyebar secara normal dan tidak membentuk pola tertentu. Meskipun demikian perlu dilakukan uji statistik lain untuk meyakinkan bahwa plot data tersebut bersifat homoskedastisitas. Pengujian uji Glejser sebagai berikut:
1) Hipotesis
𝐻0: Tidak terjadi heteroskedastisitas 𝐻1: Terjadi heteroskedastisitas 2) Taraf signifikansi 𝛼 = 0,05
47 3) Kriteria pengujian:
Terima 𝐻0 jika 𝑡ℎ𝑖𝑡𝑢𝑛𝑔 < 𝑡(𝛼,𝑑𝑏) 4) Statistik uji
Tabel 3.4 Nilai t Pengujian Homoskedastisitas
Model Unstandardized Coefficients Standardized Coefficients
t Sig.
B Std. Error Beta
1
(Constant) -2,110 3,005 -,702 ,488
Rata-rata Lama Sekolah ,499 ,383 ,253 1,302 ,203
Upah Minimum Regional 9,112E-009 ,000 ,002 ,009 ,993
PDRB -,001 ,001 -,208 -1,151 ,259
Berdasarkan hasil output SPSS pada tabel diatas, diperoleh nilai 𝑡 dan signifikansi untuk variabel rata-rata lama sekolah (𝑋1), Upah Minimum Regional (𝑋2), dan Produk Domestik Regional Bruto (𝑋3), dengan 𝑡(𝛼,𝑑𝑏) = 𝑡(0,05;33) = 2,04, derajat bebas (𝑑𝑏)= 33 − 3 = 30 dan 𝛼 = 0,05, maka keputusannya sebagai berikut:
𝑡𝑥1 = 1,302 < 2,04 = 𝑡𝑡𝑎𝑏𝑒𝑙 𝑡𝑥2 = 0,009 < 2,04 = 𝑡𝑡𝑎𝑏𝑒𝑙 𝑡𝑥3 = −1,151 > −2,04 = 𝑡𝑡𝑎𝑏𝑒𝑙
dan dari hasil diperoleh nilai signifikansi ketiga variabel independen lebih dari 0,05. Dengan demikian dapat disimpulkan bahwa tidak terjadi masalah heteroskedastisitas pada regresi.
5) Kesimpulan
𝐻0 diterima artinya tidak terjadi heteroskedastisitas.
48 c. Uji non-autokorelasi
Pengujian hipotesis untuk uji non-autokorelasi adalah sebagai berikut 1) Hipotesis
𝐻0: Tidak terdapat autokorelasi 𝐻1: Terdapat autokorelasi 2) Taraf signifikansi 𝛼 = 0,05 3) Kriteria pengujian:
Terima 𝐻0 jika 𝑑𝑈 < 𝑑 < 4 − 𝑑𝑈 4) Statistik uji
Tabel 3.5 Nilai Durbin-Watson
Model R R Square Adjusted R Square Std. Error of the Estimate
Durbin-Watson
1 ,793a ,628 ,590 2,70801 2,380
Berdasarkan hasil output SPSS pada tabel Model Summary diatas diperoleh nilai Durbin-Watson hitung sebesar 2,38. Sementara, nilai Durbin-Watson tabel dengan banyaknya data 𝑛 = 33, 𝑘 = 3, 𝛼 = 0,05 diperoleh nilai 𝑑𝑈 pada tabel Durbin-Watson sebesar 1,65. Karena 𝑑 = 2,38 > 𝑑𝑈 = 1,65 dan 𝑑 = 2,38 > 4 − 𝑑𝑈 = 2,35 maka 𝐻0 diterima.
5) Kesimpulan
𝐻0 diterima artinya tidak terdapat autokorelasi.
d. Uji non-multikolinieritas
49
Pemeriksaan multikolinieritas dapat dilihat dari nilai VIF dan condition index. Nilai VIF lebih dari 10 menunjukkan adanya gejala multikolinieritas (Gujarati, 1995: 338). Nilai condition index melebihi 30 menunjukkan adanya gejala multikolinieritas. Berikut hasil output SPSS untuk nilai VIF:
Tabel 3.6 Nilai VIF
Model Unstandardized
Coefficients
Standardized Coefficients
t Sig. Collinearity Statistics
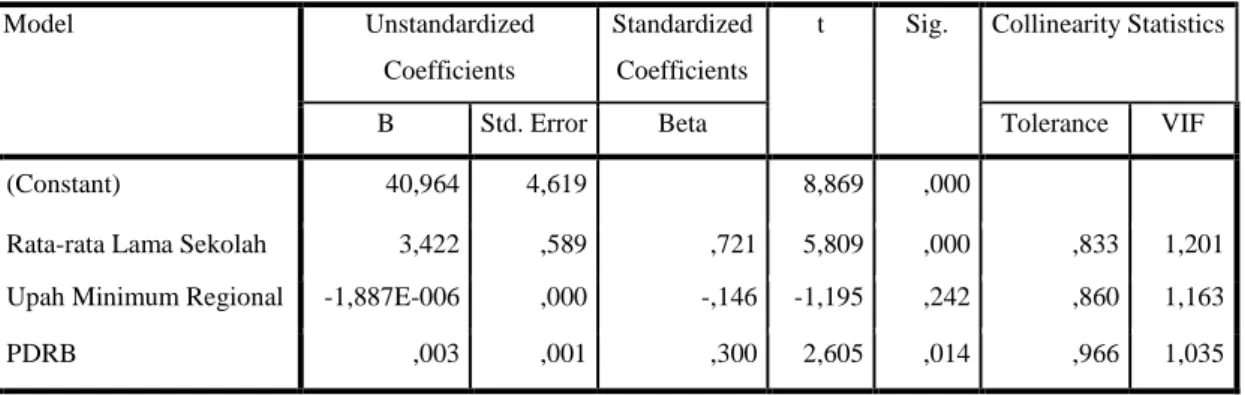
B Std. Error Beta Tolerance VIF
1
(Constant) 40,964 4,619 8,869 ,000
Rata-rata Lama Sekolah 3,422 ,589 ,721 5,809 ,000 ,833 1,201
Upah Minimum Regional -1,887E-006 ,000 -,146 -1,195 ,242 ,860 1,163
PDRB ,003 ,001 ,300 2,605 ,014 ,966 1,035
Berdasarkan hasil pada tabel 3.6, diketahui seluruh variabel independen yaitu rata- rata lama sekolah, Upah Minimum Regional, dan Produk Domestik Regional Bruto mempunyai nilai 𝑉𝐼𝐹 kurang dari batas maksimal 10 atau nilai tolerance lebih dari 0,1 sehingga 𝐻0 ditolak, yang artinya variabel independen tersebut tidak menunjukkan adanya gejala multikolinieritas.
Nilai condition index maksimum berdasarkan output SPSS dapat dilihat pada tabel dibawah ini:
Tabel 3.7 Nilai Condition Index
Mo del
Dimension Eigenvalue Condition Index Variance Proportions (Constant) Rata-rata Lama
Sekolah
Upah Minimum Regional
PDRB
1
1 3,404 1,000 ,00 ,00 ,00 ,03
2 ,565 2,454 ,00 ,00 ,00 ,94
3 ,026 11,394 ,09 ,04 ,96 ,00
4 ,005 25,842 ,91 ,96 ,03 ,02
50
Berdasarkan hasil pada tabel 3.7, nilai condition index maximum yang diporoleh adalah 25,842 kurang dari 30. Dengan demikian, dapat dikatakan bahwa tidak terdapat masalah multikolinieritas.
H. Estimasi Parameter 𝜷 dengan Metode Kuadrat Terkecil (dengan outlier) Estimasi parameter 𝛽 dengan metode kuadrat terkecil dilakukan sebagai estimasi awal untuk pembanding dengan estimasi lainnya. Estimasi dengan metode kuadrat terkecil memiliki pembobot 𝑤 = 1. Berdasarkan hasil output program R (lampiran 3, halaman: 69), diperoleh nilai koefisien variabel antara variabel dependen dan variabel independen pada data Indeks Pembangunan Manusia menurut provinsi di Indonesia tahun 2015 yang disajikan pada tabel 3.8.
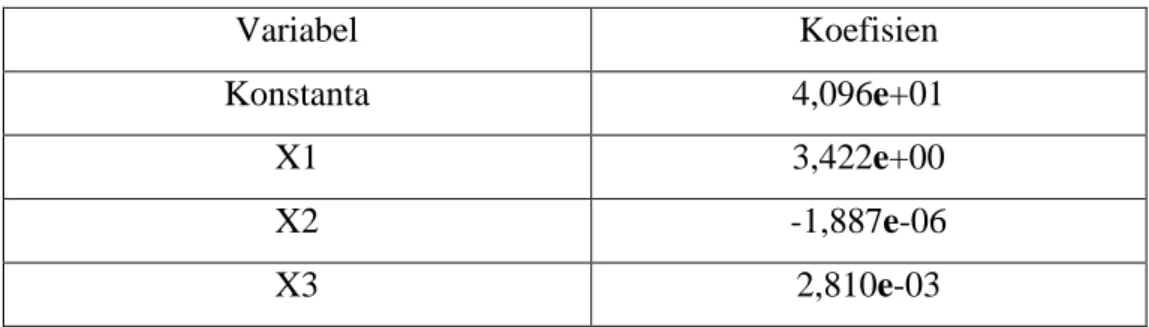
Tabel 3.8 Koefisien Variabel Metode Kuadrat Terkecil (dengan outlier)
Variabel Koefisien
Konstanta 4,096e+01
X1 3,422e+00
X2 -1,887e-06
X3 2,810e-03
Dari tabel diatas, model regresi yang dibentuk adalah sebagai berikut:
𝑌̂ = 40,096 + 3,422X1− 0,000002X2+ 0,00281X3
dan nilai standard error dan adj R-square untuk metode kuadrat terkecil dengan outlier adalah sebagai berikut:
Tabel 3.9 Nilai Standard Error dan Adj R-Square MKT (dengan outlier)
Standard Error 2,708
Adj R-square 0,59
51
Berdasarkan hasil tabel 3.9 diperoleh nilai standard error sebesar 2,708 artinya besarnya kesalahan dalam memprediksi variabel Indeks Pembangunan Manusia sebesar 2,708% dan nilai adj-R square sebesar 0,59 yang artinya 59% variasi pada variabel Indeks Pembangunan Manusia (𝑌) dapat dijelaskan oleh variabel independen, sedangkan sisanya dapat dijelaskan oleh variabel lain.
I. Deteksi Outlier
Suatu data diduga dan dinyatakan sebagai suatu outlier dapat dilakukan dengan berbagai metode. Dari data yang telah disediakan, akan dilakukan pendeteksian outlier dengan metode scatter plot, standarized residual dan Cook’s Distance. Pendektesian outlier dengan metode-metode tersebut dilakukan agar nantinya dilakukan metode kuadrat terkecil tanpa melibatkan outlier yang diaplikasikan pada data Indeks Pembangunan Manusia menurut provinsi di Indonesia tahun 2014 beserta faktor-faktor yang mempengaruhinya.
1. Scatter Plot
Dengan metode scatter plot, suatu data dikatakan outlier jika terdapat satu atau beberapa data yang terletak jauh dari pola kumpulan data. Hasil scatterplot dengan bantuan program R dapat dilihat pada gambar dibawah ini.
Gambar 3.3 Scatter Plot Data
52
Berdasarkan scatter plot pada gambar 3.3 terlihat bahwa data ke 14, 17, dan 32 mempunyai residual yang besar dan ketiga data tersebut jauh dari pola kumpulan data.
2. Standarized Residual
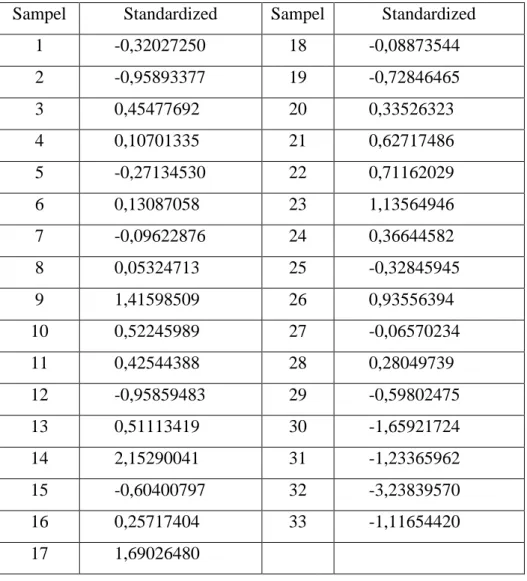
Jika nilai standard residual memiliki nilai yang lebih besar dari 3,5 atau kurang dari −3,5 maka data tersebut dikatakan sebagai data outlier. Hasil untuk nilai standard residual dapat dilihat pada tabel 3.10.
Tabel 3.10 Nilai Standarized Residual
Sampel Standardized Sampel Standardized
1 -0,32027250 18 -0,08873544 2 -0,95893377 19 -0,72846465 3 0,45477692 20 0,33526323 4 0,10701335 21 0,62717486 5 -0,27134530 22 0,71162029 6 0,13087058 23 1,13564946 7 -0,09622876 24 0,36644582 8 0,05324713 25 -0,32845945 9 1,41598509 26 0,93556394 10 0,52245989 27 -0,06570234 11 0,42544388 28 0,28049739 12 -0,95859483 29 -0,59802475 13 0,51113419 30 -1,65921724 14 2,15290041 31 -1,23365962 15 -0,60400797 32 -3,23839570 16 0,25717404 33 -1,11654420
17 1,69026480
Dari hasil diatas, tidak ada data yang merupakan data outlier.
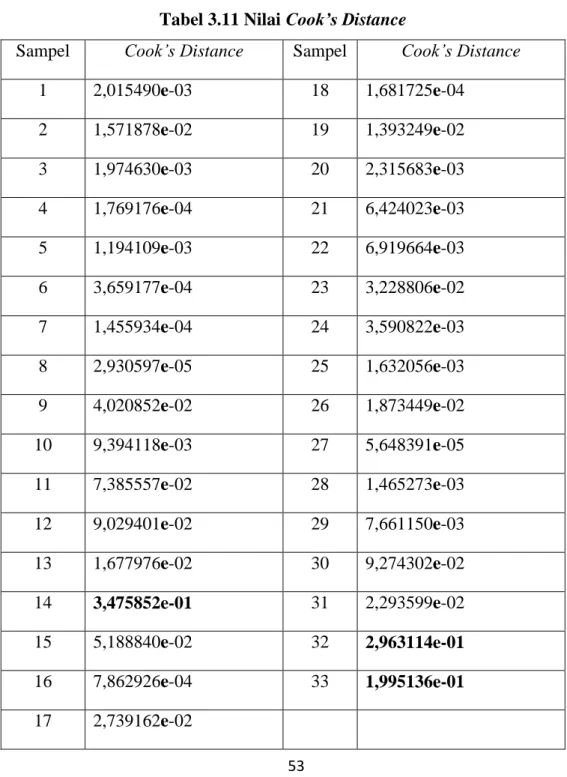
53 3. Metode Cook’s Distance
Metode ini digunakan untuk memastikan data yang merupakan outlier dengan melihat nilai Cook’s Distance. Suatu data diduga sebagai outlier jika nilai Cook’s Distance > 4/𝑛, dengan 𝑛 adalah banyaknya data. Pada data ini 𝑛 = 33 sehingga suatu data dikatakan outlier jika nilai Cook’s Distance > (4
𝑛) = 0,1212.
Tabel 3.11 Nilai Cook’s Distance
Sampel Cook’s Distance Sampel Cook’s Distance
1 2,015490e-03 18 1,681725e-04
2 1,571878e-02 19 1,393249e-02
3 1,974630e-03 20 2,315683e-03
4 1,769176e-04 21 6,424023e-03
5 1,194109e-03 22 6,919664e-03
6 3,659177e-04 23 3,228806e-02
7 1,455934e-04 24 3,590822e-03
8 2,930597e-05 25 1,632056e-03
9 4,020852e-02 26 1,873449e-02
10 9,394118e-03 27 5,648391e-05
11 7,385557e-02 28 1,465273e-03
12 9,029401e-02 29 7,661150e-03
13 1,677976e-02 30 9,274302e-02
14 3,475852e-01 31 2,293599e-02
15 5,188840e-02 32 2,963114e-01
16 7,862926e-04 33 1,995136e-01
17 2,739162e-02
54
Berdasarkan hasil yang diperoleh pada tabel 3.11, nilai Cook’s Distance pada data ke-14, 32, dan 33 berturut-turut (3,475852𝑒 − 01); (2,963114𝑒 − 01); dan (1,995136𝑒 − 01) yang ketiganya lebih dari 0,1212 maka dapat dikatakan bahwa data tersebut adalah outlier.
J. Estimasi Parameter 𝜷 dengan Metode Kuadrat Terkecil (tanpa outlier) Adanya outlier dalam data observasi mengakibatkan hasil estimasi parameter dengan metode kuadrat terkecil tidak tepat. Oleh karena itu, penulis menghilangkan outlier dari data observasi, kemudian menganalisis data tanpa outlier tersebut dengan metode kuadrat terkecil. Hal ini dilakukan untuk mendapatkan estimasi awal sebagai pembanding dengan estimasi lainnya. Dalam contoh kasus ini, terdapat beberapa data yang dihapus dari penelitian karena merupakan outlier. Data yang dihapus adalah data ke 14, 17, 32, dan 33, kemudian menganalisis data tanpa melibatkan outlier dengan metode kuadrat terkecil. Estimasi variabel dengan metode kuadrat terkecil memiliki pembobot 𝑤 = 1. Berdasarkan output program R (lampiran 3, halaman: 70) didapat koefisien variabel untuk metode kuadrat terkecil tanpa outlier sebagai berikut:
Tabel 3.12 Koefisien Variabel Metode Kuadrat Terkecil (tanpa outlier)
Variabel Koefisien
Konstanta 4,512e+01
Rata-rata Lama Sekolah 2,188e+00
Upah Minimum Regional (UMR) 2,319e-06
Produk Domestik Regional Bruto (PDRB) 3,004e-03 Dari tabel di atas, model regresi yang dapat dibentuk adalah sebagai berikut:
55
𝑌̂ = 45,1786 + 2,241086X1+ 0,0000002X2+ 0,002329X3
Berdasarkan hasil koefisien variabel pada tabel 3.12, didapatkan nilai standard error dan adj R-square dapat dilihat pada tabel 3.13.
Tabel 3.13 Nilai Standard Error dan Adj R-Square MKT (tanpa outlier)
Standard Error 1,551
Adj R-Square 0,777
Berdasarkan hasil diatas diperoleh nilai standard error sebesar 1,551 artinya besarnya kesalahan dalam memprediksi variabel Indeks Pembangunan Manusia sebesar 1,551% dan nilai adj-R square sebesar 0,777 yang artinya 77,7% variasi pada variabel Indeks Pembangunan Manusia (𝑌) dapat dijelaskan oleh variabel independen, sedangkan sisanya dapat dijelaskan oleh variabel lain.
K. Estimasi Parameter 𝜷 dengan Estimasi-S Pembobot Welsch
Estimasi variabel dengan pembobot Welsch memiliki pembobot 𝑤 sebagai berikut:
Tabel 3.14 Nilai Pembobot Welsch
Sampel Nilai Pembobot Sampel Nilai Pembobot
1 5.302553e-01 18 8.948495e-01
2 3.197310e-01 19 1.702723e-01
3 5.859562e-01 20 9.818268e-01
4 9.997456e-01 21 9.942053e-01
5 9.884628e-01 22 8.808055e-01
6 3.829137e-01 23 1.300242e-01
7 9.669116e-01 24 9.860149e-01
8 9.692238e-01 25 9.517556e-01
9 2.206572e-01 26 8.974722e-01
10 6.956263e-02 27 9.903807e-01
56
Sampel Nilai Pembobot Sampel Nilai Pembobot
11 9.942095e-01 28 9.995489e-01
12 9.872157e-01 29 4.909050e-02
13 6.583702e-02 30 2.794078e-02
14 4.783306e-12 31 2.891194e-02
15 9.956745e-01 32 2.674049e-15
16 4.397288e-01 33 4.015361e-09
17 8.158781e-04
Sedangkan untuk output nilai skala robust dan banyaknya iterasi dapat dilihat pada lampiran 3, dimana diperoleh nilai skala robust estimasi-S menggunakan pembobot Welsch sebesar 1,930279 yang didapat dari iterasi ke-41 hingga konvergen.
Berdasarkan output program R (lampiran 4, halaman: 71), didapatkan koefisien variabel untuk regresi robust estimasi-S menggunakan pembobot Welsch sebagai berikut:
Tabel 3.15 Koefisien Variabel Estimasi-S Pembobot Welsch
Variabel Koefisien
Konstanta 4,517860e+01
Rata-rata Lama Sekolah 2,241086e+00
Upah Minimum Regional (UMR) 2,214496e-06
Produk Domestik Regional Bruto (PDRB) 2,329118e-03 Dari tabel 3.15, diperoleh model regresi sebagai berikut:
𝑌̂ = 45,1786 + 2,241086X1+ 0,0000002X2+ 0,002329X3
Berdasarkan hasil koefisien variabel pada tabel 3.15, didapat nilai standard error dan adj R-square untuk regresi robust estimasi-S menggunakan pembobot Welsch dapat dilihat pada tabel 3.16.
57
Tabel 3.16 Nilai Standard Error dan Adj R-Square Estimasi-S Pembobot Welsch
Standard Error 0,575
Adj R-Square 0,937
Berdasarkan hasil diatas diperoleh nilai standard error sebesar 0,575 artinya besarnya kesalahan dalam memprediksi variabel Indeks Pembangunan Manusia sebesar 0,575% dan nilai adj-R square sebesar 0,937 yang artinya 93,7% variasi pada variabel Indeks Pembangunan Manusia (𝑌) dapat dijelaskan oleh variabel independen, sedangkan sisanya dapat dijelaskan oleh variabel lain.
L. Estimasi Parameter 𝜷 dengan Estimasi-S Pembobot Tukey bisquare Estimasi ini dilakukan sebagai estimasi awal untuk pembanding dengan estimasi lainnya. Estimasi variabel dengan pembobot Tukey bisquare memiliki pembobot 𝑤 sebagai berikut:
Tabel 3.17 Nilai Pembobot Tukey bisquare
Sampel Nilai Pembobot Sampel Nilai Pembobot
1 0.62356470 18 0.95166814
2 0.38527183 19 0.30436132
3 0.77212983 20 0.99829984
4 0.99992429 21 0.99350586
5 0.99998322 22 0.91674710
6 0.60554971 23 0.24034369
7 0.99631107 24 0.98376322
8 0.98543967 25 0.95570585
9 0.29465086 26 0.91289692
10 0.20419717 27 0.99992552
11 0.99122238 28 0.99800658
58
Sampel Nilai Pembobot Sampel Nilai Pembobot
12 0.98884948 29 0.06729511
13 0.06614638 30 0.00000000
14 0.00000000 31 0.00000000
15 0.99257710 32 0.00000000
16 0.66447211 33 0.00000000
17 0.00000000
Sedangkan untuk output nilai skala robust dan banyaknya iterasi dapat dilihat pada lampiran 4 (halaman: 72), dimana diperoleh nilai skala robust dengan estimasi-S menggunakan pembobot Tukey bisquare sebesar 1,967276 yang didapat dari iterasi ke-111 hingga konvergen.
Berdasarkan output program R (lampiran 5, halaman: 73), didapatkan koefisien variabel untuk regresi robust estimasi-S menggunakan pembobot Tukey bisquare sebagai berikut:
Tabel 3.18 Koefisien Variabel Estimasi-S Fungsi Tukey bisquare
Variabel Koefisien
Konstanta 4,397457e+01
Rata-rata Lama Sekolah 2,444729e+00
Upah Minimum Regional (UMR) 1,914014e-06
Produk Domestik Regional Bruto (PDRB) 2,246621e-03
Dari tabel 3.18, model regresi yang dapat dibentuk adalah sebagai berikut:
𝑌̂ = 43,97457 + 2,444729X1+ 0,000006X2+ 0,00224X3
Berdasarkan hasil koefisien variabel pada tabel 3.18, didapat nilai standard error dan adj R-square untuk regresi robust estimasi-S menggunakan pembobot Tukey bisquare dapat dilihat pada tabel 3.19.
59
Tabel 3.19 Nilai Standard Error dan Adj R-Square Estimasi-S Pembobot Tukey bisquare
Standard Error 0,749
Adj R-Square 0,920
Berdasarkan hasil diatas diperoleh nilai standard error sebesar 0,749 artinya besarnya kesalahan dalam memprediksi variabel Indeks Pembangunan Manusia sebesar 0,749% dan nilai adj-R square sebesar 0,92 yang artinya 92% variasi pada variabel Indeks Pembangunan Manusia (𝑌) dapat dijelaskan oleh variabel independen, sedangkan sisanya dapat dijelaskan oleh variabel lain.
Jika disajikan dalam tabel, metode pencarian koefisien 𝛽 dapat dibandingkan dalam tabel dibawah ini:
Tabel 3.20 Nilai Perbandingan Standard Error dan Adj-R Square
Metode Standard Error Adj-R2
Metode kuadrat terkecil (dengan outlier) 2,708 0,590 Metode kuadrat terkecil (tanpa outlier) 1,551 0,777
Estimasi S dengan pembobot Welsch 0,575 0,937
Estimasi S dengan pembobot Tukey bisquare 0,749 0,920 Dari tabel diatas, digunakan dua nilai pembanding untuk masing-masing metode yaitu standard error dan adj R-Square. Metode terbaik adalah metode yang memiliki nilai standard error paling kecil dan adj R-Square paling besar. Dari tabel diatas dapat ditarik kesimpulan bahwa analisis regresi robust dengan estimasi-S fungsi Welsch merupakan metode yang paling baik. Didapat model terbaik dari pembobot Welsch sebagai berikut:
𝑌̂ = 45,1786 + 2,241086X1+ 0,0000002X2 + 0,002329X3.
60
Model regresi tersebut dapat diartikan sebagai berikut:
a. Setiap peningkatan satu tahun rata-rata lama sekolah (𝑋1) maka akan meningkatkan Indeks Pembangunan Manusia (𝑌̂) sebesar 2,24%, apabila UMR (𝑋2) dan PDRB (𝑋3) tetap.
b. Setiap peningkatan satu rupiah UMR (𝑋2) maka akan meningkatkan Indeks Pembangunan Manusia (𝑌̂) sebesar 0,000002% apabila rata-rata lama sekolah (𝑋1) dan PDRB (𝑋3) tetap.
c. Setiap peningkatan satu rupiah PDRB (𝑋3), maka akan meningkatkan Indeks Pembangunan Manusia (𝑌̂) sebesar 0,0023% apabila rata-rata lama sekolah (𝑋1) dan UMR (𝑋2) tetap.
d. Jika rata-rata lama sekolah (𝑋1), UMR (𝑋2), dan PDRB (𝑋3) sama dengan 0, maka Indeks Pembangunan Manusia sebesar 45,2%.