BAB 4
Hasil Dan Pembahasan
4.1 Implementasi Sistem
Pada bagian ini, akan dibahas implementasi dari setiap perancangan yang sudah dibuat pada bab sebelumnya.
4.1.1 Proses Normalisasi Data Spasial
Seperti yang telah dijelaskan pada bagian perancangan sistem, sebelum melakukan clustering data user harus memasukkan data berupa data spasial. Data spasial tersebut akan dinormalisasi terlebih dahulu menggunakan rumus Min-Max Normalization. Pada bagian ini akan dibahas proses normalisasi
untuk salah satu objek dari data yang dimasukkan oleh user yaitu longitude = 129.879684 dan latitude = -0.444255 dengan nilai minimal untuk longitude adalah 129.879684 dan nilai minimal untuk latitude adalah -3.880696, sedangkan nilai maksimal untuk longitude adalah 134.870481 dan nilai maksimal untuk latitude adalah -0.046692. Berikut ini adalah proses normalisasi tersebut dengan nilai minimal baru yang diinginkan untuk longitude dan latitude adalah nol dan nilai maksimal baru untuk keduanya
adalah 100.
- Normalisasi longitude
Dari proses normalisasi di atas, dapat dilihat bahwa data longitude yang baru adalah 0.00000 dan data latitude yang baru
adalah 89.630605. Proses normalisasi tersebut dilakukan pada semua objek data yang dimasukkan oleh user. Data spasial yang menjadi kasus dalam penelitan ini dapat dilihat pada Lampiran 1 dan hasil normalisasi dapat dilihat pada Lampiran 2.
Implementasi proses normalisasi tersebut dalam program yang dibuat dituliskan dengan kode seperti pada Kode Program 4.1.
Kode Program 4.1 Proses Normalisasi Data
1. $setData = normalisasi($namadb, $kolom1, $kolom2); 2. $A = $setData[0];
8. $x = round(($A[$i][0]-$minA[0][0])/($maxA[0][0]-
$minA[0][0])*($D[0]-$C[0])+$C[0], 6);
9. $y = round(($A[$i][1]-$minA[0][1])/($maxA[0][1]-
$minA[0][1])*($D[1]-$C[1])+$C[1], 6);
10. .
11. .
12. .
Pada baris 1 dari Kode Program 4.1, dapat dilihat program memanggil fungsi normalisasi dengan parameter nama database yang digunakan serta kolom yang berisi data latitude dan longitude. Nilai yang dikembalikan dari fungsi tersebut adalah nilai terkecil dan terbesar data yang akan dinormalisasi serta range yang diinginkan untuk proses normalisasi tersebut.
Pengkodean untuk normalisasi data dengan rumus Min-Max Normalization terdapat pada baris 8 dan baris 9 dari Kode
Program 1.
4.1.2 Proses Clustering
Setelah data spasial dinormalisasi, data tersebut akan dikelompokkan melalui proses clustering. Proses clustering dilakukan menggunakan Algoritma K-Means. Berikut ini adalah proses clustering terhadap data yang sudah dinormalisasi sesuai dengan penjelasan mengenai Algoritma K-Means pada bab sebelumnya.
1. Menentukan nilai K atau jumlah cluster dan centroid
objek nomor satu (0.000000, 89.630605) yang dapat disimbolkan dengan C1 dan objek nomor dua (15.194267, 99.211999) yang
dapat disimbolkan dengan C2.
2. Mengelompokkan data ke dalam cluster
Data dikelompokkan berdasarkan jarak terdekat ke centroid yang dihitung menggunakan fungsi jarak yaitu Euclidean Distance. Berikut ini adalah contoh perhitungan jarak antara
objek dan centroid, untuk objek dengan longitude = 0.000000 dan latitude = 89.630605.
- Jarak objek ke C1
√
- Jarak objek ke C2
√ √
Perhitungan jarak dilakukan pada semua objek data seperti contoh di atas. Berdasarkan hasil perhitungan jarak maka anggota cluster satu berjumlah 10 dan anggota cluster dua berjumlah 69. Hasil perhitungan jarak dapat dilihat pada Lampiran 3. Implementasi perhitungan jarak pada program dituliskan dengan kode seperti pada Kode Program 4.2.
Kode Program 4.2 Perhitungan Jarak
1. function jarak($obj, $cent) {
2. $x = pow(($obj[0]-$cent[0]),2);
3. $y = pow(($obj[1]-$cent[1]),2);
4. return round(sqrt($x + $y), 2);
Pada Kode Program 4.2 terdapat fungsi jarak dengan parameter obj yaitu data objek yang akan dikelompokkan serta cent sebagai centroid yang akan digunakan untuk menghitung jarak. Fungsi jarak melakukan perhitungan jarak antara masing-masing objek data ke centroid yang sudah ditentukan. Sesuai dengan penjelasan mengenai Algoritma K-Means, maka langkah selanjutnya adalah mengelompokkan tiap data ke dalam cluster. Data dikelompokkan berdasarkan hasil perhitungan jarak
minimum. Implementasi pengelompokkan data pada sistem dapat dilihat pada Kode Program 4.3.
Kode Program 4.3 Pengelompokan Data
1. function clustering($data, $centroids, $k) {
2. foreach($data as $indexDataObj => $dataObj) {
3. foreach($centroids as $centroid) {
4. $arrJarak[$indexDataObj][] = jarak($dataObj,
$centroid);
5. }
6. }
7. foreach($arrJarak as $indexJarak => $jarak) {
8. $cluster = minCent($jarak);
9. $arrTempCluster[$cluster][] = $indexJarak;
10. $arrJarak_dari_clusters = array("$indexJarak" =>
$jarak);
11. }
12. if(count($arrTempCluster) < $k) {
13. $latLngCluster =
maxCent($arrJarak_dari_clusters);
14. foreach($arrTempCluster as $tempIndex =>
$tempCluster) {
15. foreach($tempCluster as $tempObj) {
16. if($tempObj == $latLngCluster) {
17. $clusters[$k+1][] = $tempObj;
18. } else {
19. $clusters[$tempIndex][] = $tempObj;
20. }
21. }
22. }
23. } else {
24. $clusters = $arrTempCluster;
25. }
26. return $clusters;
Pada Kode Program 4.3 terdapat fungsi clustering yang berfungsi untuk melakukan pengelompokan data. Secara garis besar, fungsi ini akan memanggil fungsi jarak untuk menghitung jarak dan hasilnya ditampung dalam variabel arrJarak. Setelah itu, akan diambil nilai minimum dari hasil perhitungan tersebut. Nilai minimum dari masing-masing objek kemudian dikelompokkan satu cluster yang sama.
3. Menghitung ulang K cluster
Setelah selesai mengelompokan objek ke dalam cluster, langkah selanjutnya adalah menghitung K cluster dengan centroid yang baru. Centroid baru ditentukan dengan cara sebagai
berikut :
- Centroid satu (C1)
( )
- Centroid dua (C2)
(
)
Berdasarkan hasil perhitungan centroid baru sesuai dengan cara di atas, maka centroid baru untuk C1 adalah (10.904094,
40.554836) dan untuk C2 adalah (59.051441, 67.729235). Setelah
Kode Program 4.4 Perhitungan Centroid Baru
Pada Kode Program 4.4 terdapat dua fungsi yaitu fungsi centroidBaru dan hitungCent. Secara garis besar, fungsi hitungCent akan memanggil fungsi centroidBaru seperti pada baris 19 untuk melakukan perhitungan centroid baru yang akan digunakan pada iterasi berikutnya dari algoritma K-Means.
Setiap kode program yang menerapkan proses algoritma K-Means akan dijalankan melalui fungsi kmeans seperti pada Kode
Program 4.5.
8. $center[0] = round($x / count($latLng), 6);
9. $center[1] = round($y / count($latLng), 6);
10. return $center;
11. }
12. function hitungCent($clusters, $data) {
13. foreach($clusters as $noCluster => $arrObjCluster) {
14. foreach($arrObjCluster as $objCluster) {
Kode Program 4.5 Eksekusi Algoritma K-Means
Pada Kode Program 4.5 terdapat fungsi kmeans yang akan dieksekusi untuk melakukan proses algoritma K-Means. Program akan menentukan nilai centroid awal dengan memanggil fungsi centroid pada baris 6. Baris 7 sampai baris 12 merupakan perulangan yang dilakukan untuk mendapatkan hasil clustering setelah tidak ada lagi data yang berpindah cluster. Hasil dari
proses clustering akan ditampilkan oleh program seperti pada Gambar 4.1.
Gambar 4.1 Hasil Clustering
1. function kmeans($data, $k) {
2. if($k <= 0) {
3. echo "Nilai K = ".$k.". K harus bilangan
positif!";
4. exit(0);
5. }
6. $centroidLama = centroid($data, $k);
7. while(true) {
8. $clusters = clustering($data, $centroidLama,
$k);
$centroidBaru = hitungCent($clusters, $data); if($centroidLama === $centroidBaru) {
9. return(array ($centroidBaru, $clusters));
10. }
11. $centroidLama = $centroidBaru;
12. }
Data yang dimasukkan oleh user adalah data mengenai potensi bahan tambang di Provinsi Papua Barat dengan jumlah titik sebanyak 79 titik. Berdasarkan hasil clustering pada Gambar 12, dapat dilihat bahwa nilai K yang dimasukkan oleh user adalah dua sehingga jumlah cluster yang dibuat juga sebanyak dua cluster. Selain itu, juga terdapat link Lihat Peta yang dapat digunakan untuk melihat peta dari hasil clustering yang sudah dilakukan.
4.1.3 Proses Konversi Data Ke Data Spasial
Setelah melakukan clustering data, data yang sudah dinormalisasi harus dikembalikan ke dalam bentuk spasial terlebih dahulu dan kemudian ditampilkan menggunakan Heatmap. Pengkodean untuk mengembalikan data ke dalam bentuk spasial dapat dilihat pada Kode Program 4.6.
Kode Program 4.6 Mengembalikan Data Spasial
1. $setData = normal($namadb, $kolom1, $kolom2);
Kode Program 4.6 merupakan pengkodean untuk mengembalikan data yang sudah dinormalisasi menjadi data spasial. Pada kode program tersebut dapat dilihat bahwa program memanggil fungsi normal yang berfungsi untuk mengambil data yang akan dikembalikan. Proses pengembalian data menjadi bentuk spasial terdapat pada baris 7 sampai baris 9 dari Kode Program 4.6. Setelah berhasil mengembalikan data dalam bentuk spasial, data akan ditampilkan menggunakan Heatmap.
4.1.4 Proses Menampilkan Data
Kode Program 4.7 Menampilkan Data Dengan Heatmap
Kode Program 4.7 merupakan potongan dari fungsi initialize dengan parameter nama database yang digunakan.
Fungsi tersebut dijalankan program untuk menampilkan data yang sudah dikelompokkan melalui clustering menggunakan Heatmap. Baris 1 dari Kode Program 4.7 memanggil data yang sudah dikembalikan ke dalam bentuk spasial sebelumnya. Data tersebut kemudian digunakan oleh fungsi initialize untuk ditampilkan dalam peta seperti yang terlihat pada baris 5 sampai baris 7 dari Kode Program 4.7 dan kemudian disimpan dalam
1. downloadUrl("../Skripsi/fungsi/map_xml.php?namadb="+
namadb, function(data) {
2. var xml = data.responseXML;
3. var markers = xml.documentElement.
getElementsByTagName("marker");
4. for (var i = 0; i < markers.length; i++) {
5. var nama = markers[i].getAttribute("nama");
6. var cluster = markers[i].getAttribute
("cluster");
7. var point = new google.maps.LatLng
(parseFloat(markers[i]. getAttribute("lat")), parseFloat(markers[i].
getAttribute("lng")));
8. disk_points.push(point);
9. var html = "<b>" + nama + "</b><br>Anggota <i>cluster</i> " + cluster;
10. var marker = new google.maps.Marker({
position: point});
13. pointArray = new google.maps.MVCArray(disk_points);
14. heatmap = new google.maps.visualization.
variabel pointArray pada baris 13. Pengkodean untuk menampilkan data dalam variabel pointArray dengan Heatmap terdapat pada baris 17 sampai baris 19 dari Kode Program 4.7. Data yang ditampilkan oleh Heatmap dapat dilihat pada Gambar 4.2.
Gambar 4.2 Peta Hasil Clustering
Gambar 4.2 menunjukkan hasil clustering dari data yang dimasukkan oleh user. Dari gambar tersebut dapat dilihat bahwa daerah yang berpotensi menghasilkan bahan tambang berwarna merah. Pada gambar tersebut juga terdapat form Tambah Objek Baru yang dapat digunakan jika user ingin menambah objek baru. Jika gambar tersebut diperbesar, maka akan ditampilkan detail
Gambar 4.3 Informasi Objek Tiap Titik
4.2 Pengujian
4.2.1 Black Box Testing
Setelah melakukan implementasi terhadap perancangan yang telah dibuat, maka tahap selanjutnya dalam penelitian ini adalah pengujian. Pengujian yang dilakukan yaitu Black Box Testing. Black Box Testing bisa juga disebut sebagai functional testing, sebab pengujian dilakukan pada tiap fungsi yang ada pada
program (Saleh, 2009).
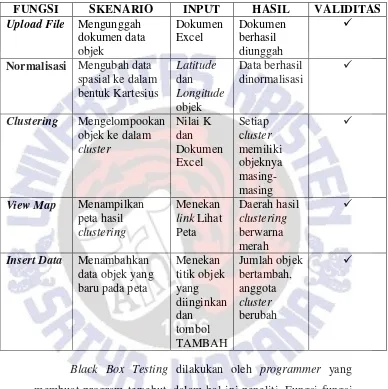
Tabel 4.1 Hasil Black Box Testing
FUNGSI SKENARIO INPUT HASIL VALIDITAS
Upload File Mengunggah
Black Box Testing dilakukan oleh programmer yang membuat program tersebut, dalam hal ini peneliti. Fungsi-fungsi yang digunakan untuk melakukan clustering diuji melalui Black Box Testing tersebut. Berdasarkan hasil pengujian pada Tabel 4.1,
4.2.2 Pengujian Penelitian
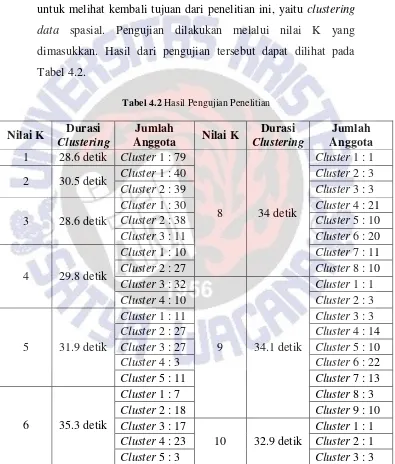
Selain Black Box Testing, juga dilakukan pengujian terhadap penelitian yang dilakukan. Pengujian ini dilakukan untuk melihat kembali tujuan dari penelitian ini, yaitu clustering data spasial. Pengujian dilakukan melalui nilai K yang
dimasukkan. Hasil dari pengujian tersebut dapat dilihat pada Tabel 4.2.
Tabel 4.2 Hasil Pengujian Penelitian
Cluster 6 : 11 Cluster 4 : 2
7 34.1 detik
Cluster 1 : 5 Cluster 5 : 14 Cluster 2 : 6 Cluster 6 : 10 Cluster 3 : 21 Cluster 7 : 22 Cluster 4 : 11 Cluster 8 : 13 Cluster 5 : 23 Cluster 9 : 3 Cluster 6 : 3 Cluster 10 : 10 Cluster 7 : 10
Pada Tabel 4.2 dapat dilihat bahwa semakin besar nilai K yang diberikan tidak mempengaruhi durasi clustering. Hal ini terlihat dari durasi clustering yang terus berubah-ubah untuk tiap nilai K. Berdasarkan hasil tersebut, dapat dikatakan bahwa durasi clustering tidak bergantung pada nilai K yang diberikan.
Gambar 4.4 Hasil Pengujian Penelitian
Gambar 4.4 menunjukkan hasil clustering dengan nilai K empat, sehingga ada empat cluster yang dibuat dari proses clustering tersebut. Pada Tabel 4.2 dapat dilihat bahwa cluster
terbaik untuk menghasilkan potensi tambang dengan nilai K empat adalah cluster tiga, sedangkan pada Gambar 4.4 dapat dilihat bahwa cluster terbaik untuk menghasilkan potensi tambang adalah cluster dua. Perbedaan ini disebabkan karena centroid yang digunakan dalam Algoritma K-Means ditentukan
secara acak.
Centroid 1 Centroid 2
Centroid 3