Implementasi Algoritma K-
Means
Dalam Keputusan Pemberian Beasiswa
(Studi Kasus SMA Santo Bernadus Pekalongan)
Artikel Ilmiah
Peneliti:
Valentino Giarto (672011005)
Magdalena A. Ineke Pakereng, M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
1. Pendahuluan
Setiap siswa yang berprestasi berhak mendapatkan beasiswa sebagaimana yang yang dituangkan dalam Undang-Undang Republik Indonesia Nomor 20 Tahun 2003 tentang Sistem Pendidikan Nasional, Bab V pasal 12 (1.c), menyebutkan bahwa setiap peserta didik pada setiap satuan pendidikan berhak mendapatkan beasiswa bagi yang berprestasi yang orang tuanya kurang mampu membiayai pendidikannya. Pasal 12 (1.d), menyebutkan bahwa setiap peserta didik pada setiap satuan pendidikan berhak mendapatkan biaya pendidikan bagi mereka yang orang tuanya kurang mampu membiayai pendidikannya.
SMA Santo Bernadus Pekalongan merupakan salah satu sekolah swasta yang turut serta membantu siswa kurang mampu dalam menempuh pendidikan di sekolah dengan cara pemberian beasiswa. Keputusan dalam memberikan beasiswa kepada siswa merupakan hak mutlak pihak sekolah. Keterbatasan beasiswa yang tersedia merupakan salah satu faktor betapa pentingnya alokasi beasiswa yang tersedia harus tepat diberikan kepada siswa yang sangat membutuhkan. Oleh sebab itu, dari sekian banyak pelamar beasiswa, sekolah harus melakukan seleksi dan menentukan siapa saja siswa yang layak mendapatkan beasiswa.
Masalah utama dalam membuat keputusan penerima beasiswa adalah dari semua siswa yang mengajukan permohonan beasiswa seluruh pelamar memenuhi kualifikasi penerima beasiswa namun beasiswa yang tersedia tidak dapat digunakan untuk seluruh pelamar beasiswa. Sekolah perlu menentukan siapa saja pelamar yang lebih pantas mendapatkan beasiswa.
Algoritma K-Means merupakan salah satu algoritma clustering yang paling sederhana dibandingkan dengan algoritma lainnya karena lebih muda diterapkan dan dijalankan, relatif cepat, mudah adaptasi, dan paling banyak digunakan dalam
data mining. K-Means membagi data kemudian mengelompokkannya ke dalam
berbagai cluster yang memiliki kemiripan dan memisahkan setiap cluster
berdasarkan perbedaan antar masing-masing cluster. Algoritma ini telah
dikemukakan oleh beberapa peneliti dari disiplin ilmu yang berbeda [1].
Algoritma K-Means dapat mengelompokkan data siswa yang mengajukan permohonan beasiswa ke dalam dua kelompok yakni kelompok prioritas dan tidak prioritas. Pengelompokan ini diharapkan dapat membantu pihak sekolah dalam mengambil keputusan pemberian beasiswa sehingga walaupun semua pelamar beasiswa memenuhi kualifikasi penerima beasiswa namun dengan adanya implementasi algoritma K-Means ini pihak sekolah dapat melihat siapa saja siswa-siswa yang berhak mendapatkan beasiswa.
Berdasarkan latar belakang tersebut, maka dilakukan penelitian yang
berjudul "Implementasi Algoritma K-Means dalam Keputusan Pemberian
Beasiswa (Studi Kasus SMA Santo Bernadus Pekalongan).
2. Tinjauan Pustaka
kepada siswa, baik yang berprestasi maupun yang kurang mampu. Beasiswa
ditujukan untuk membantu meringankan beban biaya siswa yang
mendapatkannya. Untuk memperoleh beasiswa tersebut harus sesuai dengan kriteria-kriteria yang telah ditetapkan, seperti jumlah penghasilan orang tua, jumlah tanggungan orang tua, jumlah saudara kandung, nilai rata-rata, dan persentase kehadiran siswa (kerajinan). Untuk membantu menentukan seorang siswa menerima beasiswa, maka dapat digunakan sebuah Sistem Penunjang Keputusan (SPK), dimana salah satu model keputusan yang dapat digunakan
adalah dengan model Fuzzy Multiple Attribute Decision Making (FMADM).
FMADM adalah suatu metode yang digunakan untuk mencari alternatif optimal dari sejumlah alternatif dengan kriteria tertentu. Hasil dari penelitian ini adalah sebuah aplikasi SPK yang dapat membantu pihak sekolah dalam menentukan siapa yang akan menerima beasiswa berdasarkan kriteria-kriteria serta bobot yang ditentukan [2].
Penelitian lainnya berjudul "Sistem Pendukung Keputusan Pemberian
Beasiswa Menggunakan Metode Simple Additive Weighting di Universitas Panca
Marga Probolinggo". Universitas Panca Marga Probolinggo sebagai tempat perkembangan belajar dan diri, menyediakan fasilitas untuk beasiswa prestasi siswa. Program beasiswa ini diharapkan dapat memacu minat siswa dalam belajar
untuk menjadi lebih sempurna. Dalam menentukan penerima beasiswa,
administrator memilih calon penerima beasiswa fakultas atas dasar kriteria yang ada. Dalam proses pemilihan, admin fakultas mengalami kesulitan memilih data calon penerima karena setiap jenis kriteria beasiswa dan bobot kriteria yang berbeda sehingga memerlukan ketelitian dalam melakukan perhitungan nilai
kriteria. Mengatasi masalah tersebut dikembangkanlah sistem pendukung
keputusan penentuan beasiswa dengan menggunakan metode Simple Additive
Weighting (SAW). Sistem ini dapat membantu admin untuk melakukan keputusan penerima beasiswa dan dapat meminimalkan terjadinya kehilangan data calon penerima beasiswa [3].
Penelitian lain yang menerapkan Algortima K-Means adalah "Implementasi Algoritma K-Means untuk Menentukan Kelompok Pengayaan Materi Mata Pelajaran Ujian Nasional (Studi Kasus: SMP Negeri 101 Jakarta)". Pengayaan materi merupakan salah satu persiapan peserta didik untuk menghadapi Ujian Nasional. Di SMP Negeri 101 Jakarta terdapat dua pengayaan materi, yaitu pengayaan materi wajib dan pengayaan materi khusus. Pengayaan materi khusus dilaksanakan dengan melihat hasil akhir rapor semester 5. Proses pengelompokan kemampuan siswa untuk melaksanakan pengayaan materi khusus masih belum maksimal karena kemampuan siswa tersebut tidak hanya diukur dari rapor terakhir saja, melainkan nilai rapor semester 1 hingga 5 berikut nilai tes terakhir untuk menambah keakuratan data. Untuk itu diperlukan solusi yang dapat
mengatasi kesulitan tersebut. Metode clustering dengan menggunakan algoritma
Berdasarkan penelitian-penelitian terdahulu terkait sistem informasi pendukung keputusan pemberian beasiswa, maka dilakukan penelitian yang membahas tentang implementasi algoritma K-Means dalam sistem keputusan pemberian beasiswa. Terdapat perbedaan metode dengan penelitian terdahulu dalam proses penentuan pemberian beasiswa. Penelitian terdahulu menggunakan metode yang diaplikasikan pada Sistem Pendukung Keputusan sedangkan metode yang digunakan pada penelitian ini adalah sistem clustering dalam pemberian keputusan penerima beasiswa. Sistem pendukung keputusan menghasilkan hasil perhitungan dalam bentuk ranking data mulai dari nilai tertinggi sampai dengan
nilai terendah sedangkan sistem clustering dengan menggunakan algoritma
K-Means menghasilkan informasi berupa kelompok siswa yang layak menerima beasiswa dan tidak layak menerima beasiswa.
Clustering adalah suatu alat untuk analisa data, yang memecahkan permasalahan pengelompokan. Obyeknya ialah untuk kasus pendistribusian (orang-orang, objek, peristiwa dan lainnya) ke dalam kelompok, sedemikian hingga derajat tingkat keterhubungan antar anggota cluster yang sama adalah kuat dan lemah antar anggota dari cluster yang berbeda. Berdasarkan cara ini masing-masing cluster menguraikan, dalam kaitan dengan kumpulan atau koleksi data,
class dimana milik anggota-anggotanya. Cluster disebut juga data item yang dikelompokkan menurut pilihan konsumen atau hubungan logis [5].
Clustering memegang peranan penting dalam aplikasi data mining, misalnya eksplorasi data ilmu pengetahuan, pengaksesan informasi dan text mining, aplikasi basis data spasial, dan analisis web. Clustering diterapkan dalam mesin pencari di Internet. Web mesin pencari akan mencari ratusan dokumen yang cocok dengan
kata kunci yang dimasukkan. Dokumen‐dokumen tersebut dikelompokkan dalam
cluster‐cluster sesuai dengan kata‐ kata yang digunakan
Algoritma clustering ke dalam kelompok besar seperti berikut [6]: Pertama
adalah Partitioning algorithms, algoritma dalam kelompok ini membentuk
bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa
kriteria. Kedua adalah Hierarchy algorithms, pembentukan dekomposisi hirarki
dari sekumpulan data menggunakan beberapa kriteria. Ketiga adalah
Density‐based, pembentukan cluster berdasarkan pada koneksi dan fungsi
densitas. Keempat adalah Grid‐based, pembentukan cluster berdasarkan pada
struktur multiple‐level granularity. Kelima adalah Model‐based, sebuah model dianggap sebagai hipotesa untuk masing‐ masing cluster dan model yang baik dipilih di antara model hipotesa tersebut.
K-means clustering merupakan salah satu metode data clustering non-hirarki yang mengelompokkan data dalam bentuk satu atau lebih cluster/kelompok. Data-data yang memiliki karakteristik yang sama dikelompokkan dalam satu
cluster/kelompok dan data yang memiliki karakteristik yang berbeda
dikelompokkan dengan cluster/kelompok yang lain sehingga data yang berada
dalam satu cluster/kelompok memiliki tingkat variasi yang kecil [7].
Langkah-langkah melakukan clustering dengan metode K-Means adalah
cluster diberi nilai awal dengan angka-angka random. Langkah ketiga adalah alokasikan semua data/ objek ke cluster terdekat. Kedekatan dua objek ditentukan berdasarkan jarak kedua objek tersebut, demikian juga kedekatan suatu data ke
cluster tertentu ditentukan jarak antara data dengan pusat cluster. Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster. Jarak paling dekat antara satu data dengan satu cluster tertentu akan menentukan suatu data masuk dalam cluster
mana. Untuk menghitung jarak semua data ke setiap titik pusat cluster dapat menggunakan teori jarak Euclidean yang dirumuskan seperti pada Rumus 1.
Rumus 1. Perumusan teori jarak Euclidean
Langkah keempat adalah hitung kembali pusat cluster dengan keanggotaan
cluster yang sekarang. Pusat cluster adalah rata-rata dari semua data/objek dalam
cluster tertentu. Jika dikehendaki dapat juga menggunakan median dari cluster
tersebut. Jadi rata-rata (mean) bukan satu-satunya ukuran yang dapat digunakan.
Langkah kelima adalah tugaskan lagi setiap objek menggunakan pusat cluster
yang baru. Jika pusat cluster tidak berubah lagi maka proses clustering selesai. Atau, kembali ke langkah nomor 3 sampai pusat cluster tidak berubah lagi.
Ada beberapa kelebihan pada algoritma k-means, yaitu [9]: Mudah untuk diimplementasikan dan dijalankan, waktu yang dibutuhkan untuk menjalankan pembelajaran ini relatif cepat, mudah untuk diadaptasi, dan umum digunakan.
Algoritma k-means memiliki beberapa kelebihan, namun ada kekurangannya
3. Metode dan Perancangan Sistem
Secara umum penelitian terbagi ke dalam empat tahap, yaitu: (1) tahap identifikasi masalah, (2) tahap perancangan sistem, (3) tahap implementasi sistem, (4) tahap pengujian sistem.
Gambar 1 Flowchart Tahapan Penelitian
Gambar 1 merupakan flowchart tahapan penelitian. Tahap pertama dalam proses penelitian adalah identifikasi masalah. Pada tahap ini dilakukan analisis terhadap permasalahan yang ada, yaitu mendapatkan data dan literatur yang terkait dengan algoritma K-Means. Tahap kedua pada proses penelitian adalah perancangan sistem. Pada tahap ini dilakukan proses perancangan sistem menggunakan UML untuk mengetahui setiap proses beserta semua aktifitas dari masing-masing user yang akan dibangun pada sistem. Selain itu dilakukan pula
perancangan pada user interface berupa prototype sistem. Pada Tahapan ini
dilakukan perancangan database yang akan di gunakan pada sistem serta
perancangan Algoritma K-Means yang dipakai sebagai acuan dalam keputusan pemberian beasiswa.
Tahap ketiga pada proses penelitian adalah implementasi sistem. Tahap ini merupakan pengembangan lebih lanjut dari tahap perancangan sistem. Sistem dibuat sesuai dengan kebutuhan yang telah didefinisikan pada tahap sebelumnya. Pada tahap ini dibangun aplikasi yang menggunakan algoritma K-Means dalam penentuan pemberian beasiswa. Tahap terakhir perancangan sistem adalah
pengujian sistem. Pada Tahap ini dilakukan pengujian sistem apakah sudah
berjalan sesuai dengan tujuan yang ditetapkan sebelumnya ataukah belum.
Perancangan UML sistem merupakan langkah yang harus dilakukan untuk menjelaskan kepada pemakai mengenai alur kerja secara garis besar dari sistem
yang akan dikembangkan. Perancangan UML dibuat dalam bentuk use case
diagram dan class diagram. Use case Diagram merupakan diagram yang
yang berada di luar sistem yang sedang dibangun (aktor). Jenis diagram ini dapat
digunakan untuk menangkap requirements sistem dan untuk memahami
bagaimana sistem seharusnya bekerja [10].
Gambar 2Use Case Diagram Sistem
Gambar 2 menunjukkan use case diagram pada aplikasi, dijelaskan sebagai berikut. Aplikasi memiliki 1 (satu) aktor yakni user. User adalah pihak sekolah yang diberi wewenang untuk menilai data calon penerima beasiswa. User mempunyai hak untuk mengolah data siswa, data semester, data beasiswa, data pelamar beasiswa, penilaian kriteria, dan laporan. Data siswa memuat informasi mengenai semua data siswa yang ada di lingkungan sekolah. Data semester memuat informasi mengenai semester berjalan di sekolah. Data beasiswa memuat informasi tentang semua informasi beasiswa yang tersedia di sekolah. Data pelamar beasiswa menyimpan informasi mengenai setiap pelamar beasiswa pada semester berjalan dan jenis beasiswa apa yang akan dia terima. Data kriteria merupakan data penilaian dari setiap calon penerima beasiswa yang dimasukan ke sistem.
Class diagram merupakan diagram yang membantu dalam visualisasi struktur kelas-kelas dari suatu sistem. Dalam diagram ini, diperlihatkan hubungan antar kelas dan penjelasan detail tiap-tiap kelas [10].
Data Beasiswa Penilaian Kriteria
Data Siswa Data Pelamar Beasiswa Data Semester
<<include>>
<<include>>
User Laporan
Gambar 3Class Digram Sistem
Gambar 3 merupakan diagram kelas yang digunakan oleh sistem. Pada gambar terlihat relasi antar kelas yang digunakan pada aplikasi. Hubungan antar kelas menggunakan derajat relasi one to one dan one to many yang mana derajat relasi ini akan digunakan sebagai acuan perancangan database yang digunakan pada aplikasi. Acuan ini juga nantinya akan memetakan setiap primary key dan
foreign key pada setiap tabel.
4. Pembahasan dan Hasil Pengujian
Perancangan K-Means dimulai dengan menentukan cluster yang akan
digunakan pada sistem. Cluster dibagi atas 3 bagian yakni prioritas pertama, prioritas kedua, dan prioritas ketiga untuk menerima beasiswa. Semua siswa yang
masuk ke cluster pertama akan digolongkan sebagai siswa yang layak untuk
mendapatkan beasiswa. Setelah menentukan cluster maka selanjutnya adalah
menentukan pusat cluster dari masing-masing cluster yang telah di tentukan seperti yang terlihat pada Tabel 1.
Tabel 1 Nilai CenterCentroid Awal
Centroid
Pusat Cluster Akademik Kemampuan
Keluarga
Wawancara
Centroid 1 72 65 70
Centroid 2 70 70 70
Centroid 3 65 70 70
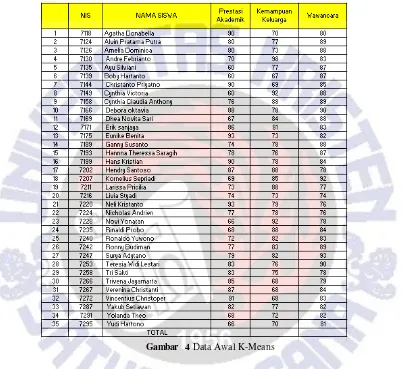
setiap siswa calon penerima beasiswa. Data awal yang dibutuhkan pada perancangan K-Means adalah data siswa yang mengajukan beasiswa dan telah dilakukan penilaian setiap siswa sesuai dengan kriteria penilaian dan aturan penilaian seperti yang telah dijelaskan pada Rumus 1. Data awal yang dibutuhkan dapat dilihat pada Gambar 4.
Gambar 4Data Awal K-Means
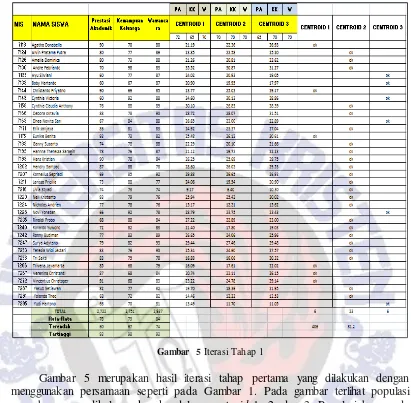
Gambar 5Iterasi Tahap 1
Gambar 5 merupakan hasil iterasi tahap pertama yang dilakukan dengan menggunakan persamaan seperti pada Gambar 1. Pada gambar terlihat populasi yang baru yang dikelompokan ke dalam centroid 1, 2, dan 3. Populasi baru pada masing-masing centroid kemudian akan dihitung nilai central centroidnya. Hasil dari nilai central centroid dapat dilihat pada Tabel 2.
Tabel 2 Nilai Center Centroid Iterasi 1
Centroid Pusat Cluster
Centroid 1 Centroid 2 Centroid 3
Akademik 89,33 78,57 63,17
Kemampuan Keluarga 69,33 80,57 80,33
Wawancara 82,17 84,13 84,83
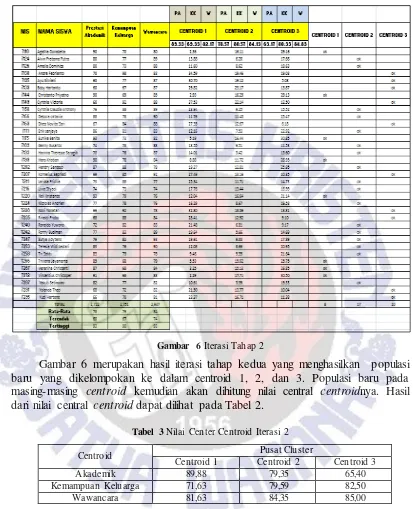
Gambar 6Iterasi Tahap 2
Gambar 6 merupakan hasil iterasi tahap kedua yang menghasilkan populasi baru yang dikelompokan ke dalam centroid 1, 2, dan 3. Populasi baru pada masing-masing centroid kemudian akan dihitung nilai central centroidnya. Hasil dari nilai central centroid dapat dilihat pada Tabel 2.
Tabel 3 Nilai Center Centroid Iterasi 2
Centroid Pusat Cluster
Centroid 1 Centroid 2 Centroid 3
Akademik 89,88 79,35 65,40
Kemampuan Keluarga 71,63 79,59 82,50
Wawancara 81,63 84,35 85,00
Tabel 3 merupakan nilai central centroid pada iterasi kedua. Proses iterasi akan terus dilakukan apabila nilai central centroid pada tahap sekarang sama dengan tahap sebelumnya. Pada tabel 3 terlihat bahwa proses iterasi masih terus dilakukan karena nilai central centroid pada iterasi kedua belum sama dengan nilai central centroid pada iterasi pertama.
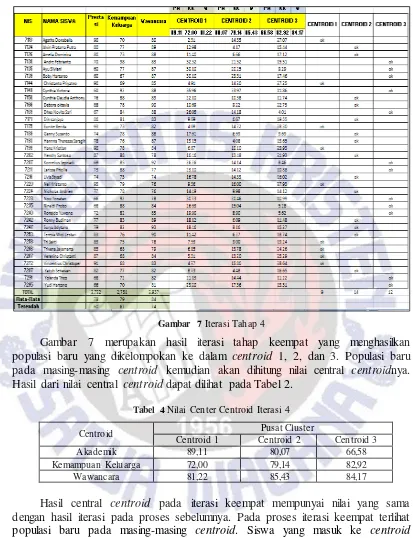
Gambar 7Iterasi Tahap 4
Gambar 7 merupakan hasil iterasi tahap keempat yang menghasilkan populasi baru yang dikelompokan ke dalam centroid 1, 2, dan 3. Populasi baru pada masing-masing centroid kemudian akan dihitung nilai central centroidnya. Hasil dari nilai central centroid dapat dilihat pada Tabel 2.
Tabel 4 Nilai Center Centroid Iterasi 4
Centroid Pusat Cluster
Centroid 1 Centroid 2 Centroid 3
Akademik 89,11 80,07 66,58
Kemampuan Keluarga 72,00 79,14 82,92
Wawancara 81,22 85,43 84,17
Hasil central centroid pada iterasi keempat mempunyai nilai yang sama dengan hasil iterasi pada proses sebelumnya. Pada proses iterasi keempat terlihat
populasi baru pada masing-masing centroid. Siswa yang masuk ke centroid
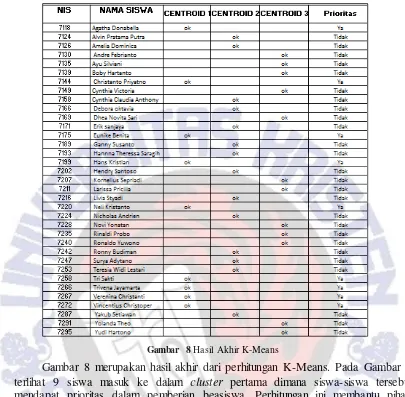
Gambar 8Hasil Akhir K-Means
Gambar 8 merupakan hasil akhir dari perhitungan K-Means. Pada Gambar 8 terlihat 9 siswa masuk ke dalam cluster pertama dimana siswa-siswa tersebut mendapat prioritas dalam pemberian beasiswa. Perhitungan ini membantu pihak sekolah membuat keputusan untuk memberikan beasiswa kepada siswa yang membutuhkan.
Pengujian Sistem menggunakan pengujian black box yaitu pengujian yang
akan menjelaskan status dari masing-masing proses dalam sistem, apakah sudah sesuai dengan yang diharapkan atau tidak. Hasil pengujian sistem yang telah dibuat, ditunjukkan pada Tabel 5.
yang terdaftar pada
Berdasarkan hasil pengujian dari masing-masing proses pada Tabel 5, maka dapat disimpulkan bahwa sistem yang dibuat telah berjalan dengan baik. Setelah masing-masing proses uji coba dijalankan secara berulang kali sesuai dengan keinginan user, maka sistem akan dievaluasi apakah telah sesuai dengan prosedur atau tidak. Selain menampilkan hasil perancangan sistem dalam bentuk black
box, juga dilakukan pengujian sistem melalui wawancara dengan user (Pihak
6. Simpulan
Berdasarkan pembahasan, pengujian, dan analisis sistem, maka dapat diambil kesimpulan bahwa pengelompokan (clustering) siswa calon penerima beasiswa dengan menggunakan metode K-Means sangat membantu pihak sekolah dalam mengolah data beasiswa serta membuat keputusan pemberian beasiswa kepada siswa yang layak diberikan beasiswa.
Saran pengembangan aplikasi ke depan adalah aplikasi dapat dibuat terintegrasi antara aplikasi web sekolah yang sudah ada sebelumnya serta dapat disatukan dengan sistem informasi beasiswa sekolah yang mana bukan hanya berupa sistem pendukung keputusan melainkan sistem informasi yang dapat
memantau perkembangan siswa yang telah diberikan beasiswa supaya
penggunaan beasiswa tersebut dapat dipantau dan digunakan sebaik-baiknya oleh siswa yang mendapatkan beasiswa.
7. Daftar Pustaka
[1] Wu, Xindong, 2009, The Top Ten Algorithms in Data Mining. Boca Raton:
Chapman & Hall/CRC.
[2] Gunawan, dkk., 2013, Pengembangan Sistem Penunjang Keputusan
Penetuan Pemberian Beasiswa Tingkat Sekolah, JSM STMIK Mikroskil
/Vol. 14/ No. 2/ ISNN 1412-0100.
[3] Fery, Eprilianto., dkk, 2013, Sistem Pendukung Keputusan Pemberian
Beasiswa Menggunakan Metode Simple Additive Weighting di Universitas
Panca Marga Probolinggo, Sekolah Tinggi Manajemen Informatika & Teknik Komputer Surabaya Jurusan Sistem Informasi.
[4] Fenty, Eka., 2015, Implementasi Algoritma K-Means untuk Menetukan
Kelompok Pengayaan Materi Mata Pelajaran Ujian Nasional Studi Kasus SMP Negeri 101 Jakarta, JURNAL TEKNIK INFORMATIKA VOL. 8/ NO. 1/ Tanggal APRIL 2015.
[5] Han, Jiawei. 2011. Data Mining Concept and Techniques Third Edition. San Francisco: Morgan Kaufmann Publishers.
[6] William, Graham. 200. Data Mining Cluster. Diakses melalui
http://datamining.anu.edu.au/student/math3346_2005/ 050809‐maths3346‐
clusters‐2x2.pdf tanggal 2 Juli 2016.
[7] Agusta, Y. 2007. K-means - Penerapan, Permasalahan dan Metode Terkait.
Jurnal Sistem dan Informatika/ Vol. 3 / Halaman 47-60/ Februari 2007.
[8] Santosa, B. 2007. Data Mining: Teknik Pemanfaatan Data untuk Keperluan
Bisnis. Yogyakarta: Graha Ilmu.
[9] Russell, S. 2010. 2- Artificial Intelligence A Modern Approach. Upper Saddle River, New Jersey 07458: Pearson Education, Inc., 3 ed.
[10] Nugroho, Adi., 2010, Mengembangkan Aplikasi Basis Data Menggunakan
[11] William, Graham. 200. Data Mining Cluster. Diakses melalui
http://datamining.anu.edu.au/student/math3346_2005/ 050809‐maths3346‐
clusters‐2x2.pdf tanggal 2 Juli 2016.