Jatisi, Vol. 1 No. 1 September 2014 1
Analisis Prediksi Tingkat Pengunduran Diri Mahasiswa
dengan Metode K-Nearest Neighbor
Ricky Imanuel Ndaumanu*1, Kusrini2, M. Rudyanto Arief3 3Magister Teknik Informatika STMIK AMIKOM Yogyakarta
E-mail: *1[email protected], 2[email protected], 3[email protected]
Abstrak
Kebutuhan akan analisis mengenai prediksi tingkat pengunduran diri mahasiswa di STIKOM UYELINDO Kupang, menjadi alasan dilakukannya penelitian terhadap prediksi tingkat pengunduran diri mahasiswa. Menentukan prediksi tingkat pengunduran diri mahasiswa dalam jumlah besar tidak mungkin dilakukan secara manual karena membutuhkan waktu yang cukup lama. Untuk itu dibutuhkan sebuah algoritma yang dapat mengkategorisasikan prediksi tingkat pengunduran diri mahasiswa secara otomatis menggunakan komputer. Dalam memprediksi digunakan sistem pendukung keputusan berupa prototype dan dalam menganalisis menggunakan Metode K-Nearest Neighbor karena memiliki prinsip kerja mencari jarak terpendek antara data yang akan dievaluasi dengan K terdekat dalam data pelatihannya. Berdasarkan dalam pengujian hasil prediksi dengan menggunakan Algoritma K-Nearest Neighbor yang pengujiannya dilakukan secara manual dan menggunakan sistem pendukung keputusan menghasilkan data yang baik. Hasil uji tersebut menyatakan sistem cukup layak untuk digunakan dalam prediksi calon mahasiswa meskipun sistem belum menghasilkan tingkat akurasi yang maksimal. Untuk menghasilkan nilai validasi yang maksimal membutuhkan data yang seimbang antara kasus keluar dan aktif. Hasil pengujian menggunakan prototype sistem pendukung keputusan dan dibandingkan secara manual yang menggunakan metode Algoritma K-Nearest Neighbor dengan 4 variabel yaitu IPK, Pekerjaan orang tua, jurusan dan semester adalah mendapatkan kesesuaian 79%.
Kata kunci—Sistem Pendukung Keputusan, Data Mining, K-Nearest Neighbor.
Abstract
The need for an analysis of the prediction of the level of resignation of a student at stikom uyelindo kupang, be the reason he did research on predictions the level of the resignation of a student. Determine the prediction of the level of the resignation of the students in large quantities could not be done manually because it requires time cukub a long time.For that required an algorithm that can be mengkategorisasikan predictions the level of the resignation of students automatically use the computer. In forecasting used the support system decision in the form of prototypes and in analyzing uses the method k-nearest neighbor because it has the working principle of looking for the shortest distance between the data will be evaluated with k nearest in the data his training. Based on in testing the outcome predicted by using algorithm k-nearest neighbor that its done manually and use the support system decision produces good data going back. The results of such tests said the system quite feasible for use in the prediction of a candidate student although the system has not generate a level of accuracy maximally.To produce the value of validation maximum requiring data that balanced between cases out and active. Results testing use prototype support system decision and compared manually that uses method algorithms k-nearest neighbor with 4 variable ipk, namely work parents, side and semester is get conformity 79 %.
1. PENDAHULUAN
Dari jumlah pendaftaran mahasiswa baru ini, banyak juga mahasiswa yang mengundurkan diri setiap tahunnya yang disebabkan berbagai masalah. Oleh karena adanya mahasiswa yang mengundurkan diri terutama di Sekolah Tinggi Manajemen Informatika Komputer (STIKOM) UYELINDO Kupang maka penulis ingin melakukan analisis pengunduran diri mahasiswa dengan mengangkat judul penelitian “Analisis Prediksi Tingkat Pengunduran Diri Mahasiswa Di STIKOM UYELINDO Kupang Dengan Metode K-Nearest Neighbor.
Penelitian ini mengangkat permasalahan bagaimana mengetahui prediksi pengunduran diri mahasiswa menggunakan Algoritma K-Nearest Neighbor (KNN) di STIKOM UYELINDO Kupang ?, Bagaimana keakuratan klasifikasi pengunduran diri mahasiswa dengan menggunakan Algoritma K-Nearest Neighbor (KNN) ?. Penelitian ini bertujuan untuk memprediksi seberapa tingkat akurasi pengunduran diri mahasiswa Sekolah Tinggi Manajemen Informatika Komputer (STIKOM) UYELINDO Kupang dengan metode Algoritma K-Nearest Neighbor (KNN). Manfaat penelitian ini bagi pihak Sekolah Tinggi Manajemen Informatika Komputer (STIKOM) UYELINDO Kupang yaitu bermanfaat untuk mempermudah perguruan tinggi mengambil keputusan secara baik, bijak dan benar dalam menentukan tujuan dan arah kedepan perguruan tinggi untuk mengurangi pengunduran mahasiswa dan dapat dijadikan sebagai dasar pembuatan kebijakan oleh pimpinan dalam hal sistem seleksi mahasiswa baru, sistem pembelajaran.
2. METODE PENELITIAN
2.1 Data Mining
Data Mining adalah suatu istilah yang di gunakan untuk menguraikan penemuan pengetahuan di dalam database [1]. Data mining adalah proses yang menggunakan teknik static. matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar [2].
Knowledge discovery data (KDD) adalah keseluruhan proses non-trivial untuk mencari dan mengidentifikasikan pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah, baru dapat bermanfaat dan dapat dimengerti [3].
Gambar 1. Proses KnowledgeDiscoveryin Database (KDD)[3]
Dimana tahapan proses KDD antara lain : 1. Data Selection
Jatisi, Vol. 1 No. 1 September 2014 3
2. Preprocesing / Cleaning
Pemprosesan pendahuluan dan pembersihan data merupakan operasi dasar seperti penghapusan noise dilakukan. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD.
3. Transformation
Proses ini merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Tahap ini merupakan bagian dari proses KDD yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
2.2 Algoritma
Algoritma dalam pengertian modern mempunyai kemiripan dengan istilah resep, proses, metode, teknik, prosedur, rutin. Algoritma adalah sekumpulan aturan-aturan berhingga yang memberikan sederetan operasi-operasi untuk menyelesaikan suatu jenis masalah yang khusus.
2.3 Algoritma K-Nearest Neighbor
K-Nearest Neighbor (KNN) termasuk kelompok instance-based learning. Algoritma ini juga merupakan salah satu teknik lazy learning. KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing[4]. Algoritma K-Nearest Neighbor adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Nearest Neighbor adalah pendekatan untuk mencari kasus dengan menghitung kedekatan antara kasus baru dan kasus lama yaitu berdasarkan pada pencocokan bobot dari akan diklasifikasi, dimana x=x1,x2,…,xi dan y=y1,y2,…,yi dan I merepresentasikan nilai atribut serta n merupakan dimensi atribut.
Pada fasetraining, algoritma ini hanya melakukan penyimpanan vektor-vektorfitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil.
Langkah-langkah untuk menghitung metode Algoritma K-Nearest Neighbor: a. Menentukan Parameter K (Jumlah tetangga paling dekat).
c. Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak Euclid terkecil.
d. Mengumpulkan kategori Y (KlasifikasiNearest Neighbor)
e. Dengan menggunakan kategori Nearest Neighbor yang paling mayoritas maka dapat diprediksi nilai queri instance yang telah dihitung.
2.4 Klasifikasi
Data classification memiliki dua tahap proses. Tahap pertama adalah membangun suatu model yang berdasarkan serangkaian data class, yang disebut learned model. Model tersebut dibangun dengan menganalisa database tuple. Setiap tuple diasumsikan menjadi predefined class yang ditentukan oleh satu atribut yang disebut class label attribute [5].
2.5 Metode Penelitian
Metode penelitian yang digunakan oleh penulis adalah Model Penelitian Tindakan (Action Research). Metode yang digunakan menggunakan metode tindakan kelas model
KurtLewin yang mengembangkan penelitian tindakan atas dasar konsep pokok bahwa penelitian tindakan terdiri dari empat komponen pokok yang juga menunjukkan langkah, yaitu [6]:
a. Perencanaan (planning), b. Tindakan (acting), c. Pengamatan (observing), d. Refleksi (reflecting).
Acting
Observing
Planning
Reflecting
Gambar 2. Metode Kurt Lewin 1990 [6]
1. Perencanaan
Rencana tindakan ini mencakup semua langkah tindakan secara rinci. 2. Tindakan
Tahap ini merupakan implementasidari semua rencana yang telah dibuat. 3. Pengamatan
Kegiatan pengamatan dilakukan bersamaan dengan pelaksanaan tindakan. 4. Refleksi
Tahapan ini merupakan tahapan untuk memproses data yang didapat saat dilakukan pengamatan dan data yang didapat kemudian dianalisis.
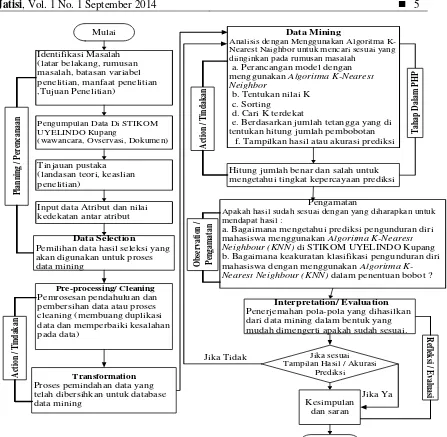
2.6 Alur Penelitian
Jatisi, Vol. 1 No. 1 September 2014 5
Input data Atribut dan nilai kedekatan antar atribut
Data Mining
Analisis dengan Menggunakan Algoritma K-Nearest Naighbor untuk mencari sesuai yang diinginkan pada rumusan masalah
e. Berdasarkan jumlah tetangga yang di tentukan hitung jumlah pembobotan
f. Tampilkan hasil atau akurasi prediksi
Tinjauan pustaka (landasan teori, keaslian penelitian)
Pengamatan
Apakah hasil sudah sesuai dengan yang diharapkan untuk mendapat hasil :
a. Bagaimana mengetahui prediksi pengunduran diri
mahasiswa menggunakan Algoritma K-Nearest
Neighbour (KNN) di STIKOM UYELINDO Kupang b. Bagaimana keakuratan klasifikasi pengunduran diri
mahasiswa dengan menggunakan Algoritma
K-Nearest Neighbour (KNN) dalam penentuan bobot ? Pre-processing/ Cleaning
Hitung jumlah benar dan salah untuk mengetahui tingkat kepercayaan prediksi
Pemilihan data hasil seleksi yang akan digunakan untuk proses dari data mining dalam bentuk yang mudah dimengerti apakah sudah sesuai.
2.7 Metode Pembobotan
Adapun rumus yang digunakan dapat dilihat pada persamaan (2) dan (3) [7]: a. Input nilai kriteria masing-masing model.
b. Input bobot masing-masing kriteria. c. Hitung normalisasi dari bobot.
3. HASIL DAN PEMBAHASAN
3.1 Pemberian Nilai Bobot
a. Memberi pembobotan pada IPK
Dalam model IPK ini diberikan nilai yang diurutkan berdasarkan pengaruh data pengunduran diri mahasiswa, yang nilainya diberikan berdasarkan pengaruhnya dari range 10 -100. Cara pembobotan ini dapat dilihat pada Table 1 [7].
Tabel 1 Pembobotan Pada IPK
NO Kriteria IPK Nilai Bobot
1 IPK < 2 100
80% menjadi 0,8 2 IPK >=2 and IPK<3 80
3 IPK>=3 and IPK<3,5 60
4 IPK >=3.5 40
Nilai Kriteria IPK Adalah:
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 =∑(100 × 0,8) + (80 × 0,8) + (60 × 0,8) + (40 × 0,8)4
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 =80 + 64 + 48 + 324
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 2244
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 56
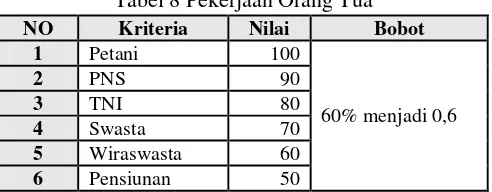
b. Memberi pembobotan pada Pekerjaan Orang Tua.
Tabel 2 adalah model pembobotan pada pekerjaan orang tua.
Tabel 2 Pembobotan Pekerjaan Orang Tua
NO Kriteria Nilai Bobot
1 Petani 100
60% menjadi 0,6
2 PNS 90
3 TNI 80
4 Swasta 70
5 Wiraswasta 60
6 Pensiunan 50
Dalam model Pekerjana Orang Tua ini diberikan nilai yang diurutkan berdasarkan pengaruh data pengunduran diri mahasiswa, yang nilainya diberikan berdasarkan pengaruhnya dari range 10-100. Cara pembobotan ini dapat dilihat pada Table 2 [7].
Nilai Kriteria Pekerjaan Orang Tua Adalah :
𝑁𝐾 =∑(100 × 0,6) + (90 × 0,6) + (80 × 0,6) + (70 × 0,6) + (60 × 0,6) + (50 × 0,6)6
Jatisi, Vol. 1 No. 1 September 2014 7
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 2706
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 4
c. Memberi Pembobotan pada Jurusan.
Berikut ini adalah model pembobotan pada jurusan :
Tabel 3 Pembobotan Jurusan
NO Kriteria Nilai Bobot
1 TI-S1 100
40% menjadi 0,4
2 SI-S1 70
3 TI-D3 40
Dalam model Jurusan ini diberikan nilai yang diurutkan berdasarkan pengaruh data pengunduran diri mahasiswa, yang nilainya diberikan berdasarkan pengaruhnya dari range 10-100. Cara pembobotan ini dapat dilihat pada Table 3 [7] .
Nilai Kriteria Jurusan Adalah:
𝑁𝐾 = ∑(100 × 0,4) + (70 × 0,4) + (40 × 0,4)3
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 40 + 28 + 163
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 843
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 28
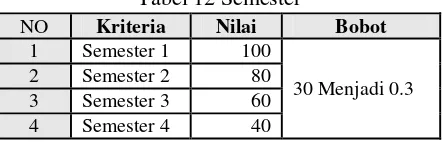
d. Memberi pembobotan pada Semester.
Berikut ini adalah model pembobotan pada Semester.
Tabel 4 Pembobotan Semester
NO Kriteria Nilai Bobot
1 Semester 1 100
30% menjadi 0,3 2 Semester 2 80
3 Semester 3 60 4 Semester 4 40
Dalam model semester ini diberikan nilai yang diurutkan berdasarkan pengaruh data pengunduran diri mahasiswa, yang nilainya diberikan berdasarkan pengaruhnya dari range 10-100. Cara pembobotan ini dapat dilihat pada Table 4 [7].
Nilai Kriteria semester Adalah :
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 =∑(100 × 0,3) + (80 × 0,3) + (60 × 0,3) + (40 × 0,3) 4
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 84 4
𝑁𝑖𝑙𝑎𝑖𝐾𝑟𝑖𝑡𝑒𝑟𝑖𝑎 = 21
e. Pembobotan Keseluruhan
Proses perhitungan keseluruhan model berdasarkan rumus dari pembobotan yang dijelaskan didepan adalah sebagai berikut :
Nilai akhir adalah:
𝑁𝑖𝑙𝑎𝑖𝐴𝑘ℎ𝑖𝑟 =∑56 + 45 + 28 + 214
𝑁𝑖𝑙𝑎𝑖𝐴𝑘ℎ𝑖𝑟 =150 4 𝑁𝑖𝑙𝑎𝑖𝐴𝑘ℎ𝑖𝑟 = 37,5
3.2 Mengklasifikasi pembobotan.
Dalam mengklasifikasi pembobotan ini adalah untuk mempermudah dalam penghitungan dalam proses di sistem Penunjang keputusan Analisis prediksi tingkat pengunduran diri mahasiswa sebagai berikut :
a. Pembobotan Variabel
Berikut ini adalah model pembobotan pada Variabel:
Tabel 5 Pembobotan Variabel No Variabel bobot
1 IPK 0.8
2 Pekerjaan Ortu 0.6
3 Jurusan 0.4
4 Semester 0.3
Dalam pembobotan variabel ini dilihat dari yang berpengaruh dalam studi di perguruan tinggi STIKOM UYELINDO Kupang, pembobotan tersebut dilihat dari data yang paling tinggi tingkat pengunduran diri disebabkan oleh variabel-variabel dilihat pada Tabel 5.
b. Kedekatan Nilai Variabel IPK
Berikut ini adalah model kedekatan nilai variable IPK:
Tabel 6Klasifikasi IPK
NO Kriteria IPK Nilai Bobot
1 IPK < 2 100
80% menjadi 0,8 2 IPK >=2 and IPK<3 80
3 IPK >=3 and IPK<3,5 60
4 IPK >=3.5 40
Jatisi, Vol. 1 No. 1 September 2014 9
Tabel 7 Kedekatan Nilai Variabel IPK
1 2 3 4
1 1 0.8 0.6 0.4
2 0.8 1 0.75 0.5
3 0.6 0.75 1 0.666667
4 0.4 0.5 0.666667 1
c. Kedekatan Nilai Variabel Pekerjaan Orang Tua.
Berikut ini adalah model kedekatan nilai variable pekerjaan orang tua:
Tabel 8 Pekerjaan Orang Tua
NO Kriteria Nilai Bobot
Nilai kedekatan variable pekerjaan orang tua di sajikan pada Tabel 9.
Tabel 9 Kedekatan Nilai Variabel Pekerjaan Orang Tua
PNS Swasta Wiraswasta TNI Pensiunan Petani
PNS 1 0.777778 0.666667 0.888889 0.555556 0.9
d. Kedekatan Nilai Variabel Jurusan.
Tabel 10 adalah model kedekatan nilai variabel jurusan.
Tabel 10 Kode Jurusan
Adapun nilai kedekatan variabel jurusan tersaji pada Tabel 11.
Tabel 11Kedekatan Nilai Variabel Jurusan
1 2 3
1 1 0.7 0.4
2 0.7 1 0.571429
3 0.4 0.571429 1
e. Kedekatan Nilai Variabel Semester.
Tabel 12 Semester
Tabel 13 adalah nilai kedekatan variabel semester.
Tabel 13 Kedekatan Nilai Variabel Semester
1 2 3 4
g Kedekatan pekerjaan orang tua 0.75 0.875 0.888888889
h Bobot pekerjaan orang tua 0.6 0.6 0.6
Jarak 0.8333333 0.77381 0.968253968
Berikut adalah contoh penghitungan tabel hasil perhitungan contoh kedekatan dengan kasus yang baru antara lain:
1. Menghitung kasus 1
a. Kedekatan semester kasus baru terhadap kasus 1 = 1 b. Bobot semester = 0.4
c. Kedekatan jurusan kasus baru terhadap kasus 1 = 1 d. Bobot jurusan = 0.3
e. Kedekatan IPK kasus baru terhadap kasus 1 = 0.75 f. Bobot IPK = 0.8
Jatisi, Vol. 1 No. 1 September 2014 11
2. Menghitung kasus 2
a. Kedekatan semester kasus baru terhadap kasus 2 = 0,8 b. Bobot semester = 0.4
c. Kedekatan jurusan kasus baru terhadap kasus 2 = 1 d. Bobot jurusan = 0.3
e. Kedekatan IPK kasus baru terhadap kasus 2 = 0.6 f. Bobot IPK = 0.8
g. Kedekatan Pekerjaan Orang Tua kasus baru terhadap kasus 2 = .75 h. Bobot Pekerjaan Orang Tua = 0.6
Menghitung:
Jarak = (𝑎∗𝑏)+𝑐∗𝑑)+(𝑒∗𝑓)+(𝑔∗ℎ)
𝑏+𝑑+𝑓+ℎ
Jarak = (0.8∗0.4)+1∗0.3)+(0.6∗0.8 )+(0.75∗0.6)
0.4+0.3+0.8+0.6
Jarak = 1.55
2.1
Jarak = 0.738
3. Menghitung kasus 3
a. Kedekatan semester kasus baru terhadap kasus 3 = 1 b. Bobot semester = 0.4
c. Kedekatan jurusan kasus baru terhadap kasus 3 = 1 d. Bobot jurusan = 0.3
e. Kedekatan IPK kasus baru terhadap kasus 3 = 1 f. Bobot IPK = 0.8
g. Kedekatan Pekerjaan Orang Tua kasus baru terhadap kasus 3 = 0.889 h. Bobot Pekerjaan Orang Tua = 0.6
Menghitung:
Jarak = (𝑎∗𝑏)+𝑐∗𝑑)+(𝑒∗𝑓)+(𝑔∗ℎ)
𝑏+𝑑+𝑓+ℎ
Jarak = (1∗0.4)+(1∗0.3)+(1∗0.8)+(0.889∗0.6)
0.4+0.3+0.8+0.6
Jarak = 0.968
3.3 Pengujian
3.3.1 Skenario Pengujian
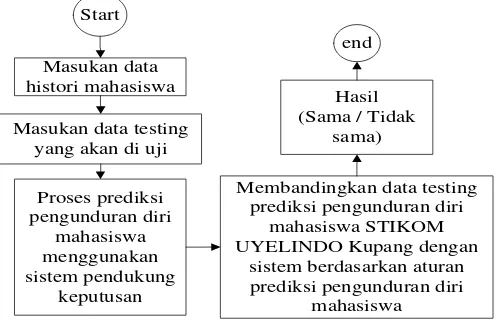
Gambar 4 adalah skenario pengujian aplikasi.Rencana pengujian yang dilakukan pada Aplikasi prediksi pengunduran diri mahasiswa di STIKOM UYELINDO Kupang, menggunakan pengujian data histori atau training untuk menghasilkan prediksi dan keakuratan klasifikasi dengan menggunakan Algoritma K-Nearest Neighbor. Adapun rencana pengujian tersebut dapat dilihat pada Gambar 4.
Start
Masukan data histori mahasiswa
Masukan data testing yang akan di uji
Proses prediksi pengunduran diri
mahasiswa menggunakan sistem pendukung
keputusan
Membandingkan data testing prediksi pengunduran diri
mahasiswa STIKOM UYELINDO Kupang dengan
sistem berdasarkan aturan prediksi pengunduran diri
mahasiswa Hasil (Sama / Tidak
sama) end
Gambar 4. Skenario Pengujian
3.3.2 Menu Utama
Menu utama ini merupakan tampak depan setelah memasukkan username dan password. Menu utama dapat di lihat pada Gambar 5.
Gambar 5. Menu utama
Jatisi, Vol. 1 No. 1 September 2014 13
3.3.3 Form Hasil Kasus Baru
Berikut ini adalah hasil dari proses tambah kasus baru pada SPK yang akan melakukan prediksi terhadap mahasiswa dan hasilnya mengeluarkan status aktif (a), keluar (k).
Gambar 6. Form Hasil Kasus Baru
Berdasarkan hasil pengujian (Gambar 6) prediksi secara manual (diperkirakan yang akan keluar) dan menggunakan sistem pendukung keputusan menunjukan hasil kesesuaian prediksi pengunduran diri mahasiswa STIKOM UYELINDO Kupang. Hasil kesesuaian di tunjukkan dengan cara menghitung secara manual dengan memasukkan data pada tabel (Tabel 15) untuk mendapatkan matriks seperti yang di sajikan pada Gambar 7.
Tabel 15 Perbandingan
HASIL JUMLAH
Sama 71
Tidak sama 19
Grand Total 90
Berikut uji Validitas yang ditunjukan pada Gambar7.
Uji Validitas = 71
90 100 %
= 78,89 % menjadi 79 %
3.4 Analisis Hasil
Berdasarkan pengujian hasil prediksi menggunakan algoritma k-nearest neighbor secara manual dan menggunakan sistem yang digunakan data training adalah mengunakan 90 data mahasiswa yaitu 42 orang data teknik informatika S1, 40 orang mahasiswa sistem informasi S1 dan 8 orang mahasiswa teknik informatika D3.
Berdasarkan hasil uji coba menggunakan secara manual dan menggunakan sistem didapatkan kesamaan hasil prediksi yaitu 79% dan melihat dari presentasi mungkin saja ini kurang akurat.
4. KESIMPULAN
Berdasarkan hasil dan pembahasan maka didapatkan kesimpulan sebagai berikut: 1. Bagaimana mengetahui prediksi pengunduran diri mahasiswa menggunakan algoritma
K-Nearest Neighbor di STIKOM UYELINDO Kupang dengan cara Langkah awal implementasi metode K-Nearest Neighbor adalah dengan menghitung nilai kemiripan atau jarak vektor data pada testing terhadap data yang akan digunakan sebagai data training. Selanjutnya akan diambil sejumlah k tetangga terdekat sesuai hasil penghitungan kemiripan atau jarak. Kemudian dilakukan penghitungan apakah cocok dengan data manual pada data testing. Data testing diklasifikasi kedalam kelas kategori yang memiliki nilai kesamaan kelas untuk data testing yang paling tinggi.
2. Hasil pengujian menggunakan prototype sistem pendukung keputusan dan dibandingkan secara manual yang menggunakan metode Alogaritma K-Nearest Neighbor dengan 4 variabel yaitu IPK, Pekerjaan orang tua, jurusan dan semester adalah mendapatkan kesesuaian 79% . 3. Sistem pendukung keputusan yang dibangun untuk memprediksi tingkat pengunduran diri
mahasiswa STIKOM UYELINDO Kupang dapat menjadi acuan atau pedoman dalam penyeleksian penerimaan mahasiswa.
4. Dalam mendapatkan hasil dari proses prototype pada data training mempunyai data yang masih aktif, nonaktif dan keluar datanya kurang berimbang menyebabkan dalam memprediksi. Oleh sebab itu status aktif lebih sering muncul karena kurang berimbang antara kasus tersebut.
5.SARAN
Berikut adalah saran agar penelitian berikutnya yang akan melakukan penelitian yang sama, agar mendapatkan hasil yang lebih baik lagi.
1. Data yang digunakan dalam penelitian ini kurang berimbang antara data yang mengundurkan diri dengan yang masih aktif, sehingga data yang masih aktif lebih dominan hal ini berimbas pada sistem, justru menganalisis data yang aktif lebih sering muncul, untuk kedepannya lebih diselaraskan dan lebih seimbang antara data mahasiswa yang aktif dan sudah keluar ucapan terima kasih.
Jatisi, Vol. 1 No. 1 September 2014 15
DAFTAR PUSTAKA
[1] Kusrini, Emha T. Luthfi, 2009, Algoritma Data Mining. Andi, Yogyakarta
[2] Turban, 2005,Decision Support System and Intelligent System(Terjemahan: Sistem Pendukung Keputusan dan Sistem Cerdas)Jilid 1, Andi Offset, Yogyakarta
[3] Fayyad, Usama. 1996.Advances in Knowledge Discovery and Data Mining.MIT Press.
[4] Chang, C, Wu, Y., Hou, S. (2009) Preparation and Characterization of Superparamagnetic Nanocomposites of Aluminosilicate/Silica/Magnetite, Coll. Surf. A336: 159,166.
[5] Han, J. Kamber, M. 2001. Data Mining: Concepts and Techniue.Morgan Kaufmann Publishers: San Fransisco.
[6] Kurt Lewin, 1990, Action Research Minority Problems, 3rd ed. Victoria : DeaklinUniversity.
![Gambar 1. Proses KnowledgeDiscoveryin Database (KDD)[3]](https://thumb-ap.123doks.com/thumbv2/123dok/2702112.1673768/2.595.174.447.502.674/gambar-proses-knowledgediscoveryin-database-kdd.webp)