Fakultas Ilmu Komputer
1443
Prediksi Waktu Panen Tebu Menggunakan Gabungan Metode
Backpropagation dan Algoritma Genetika
Dwi Ari Suryaningrum1, Dian Eka Ratnawati2, Budi Darma Setiawan3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Sebelum tebu digiling oleh pabrik, dilakukan analisis kemasakan tebu terlebih dulu. Tebu yang baik untuk digiling adalah tebu yang sudah dikatakan matang yang dapat dilihat dari beberapa faktor seperti luas kebun, umur, diameter batang, rata ruas per batang dan rata panjang per batang. Faktor – faktor tersebut digunakan sebagai atribut dalam penelitian yang dilakukan. Untuk mempermudah proses tersebut maka dilakukan penelitian mengenai prediksi waktu panen tebu. Dengan banyaknya data yang digunakan dan proses yang dilakukan berulang kali, maka akan sulit diolah secara manual dan membutuhkan waktu yang cukup lama. Selain itu tidak menutup kemungkinan terjadi kesalahan. Penelitian ini menggunakan gabungan algoritma genetika dan backpropagation dalam proses prediksi waktu panen. Algoritma genetika digunakan untuk mengoptimalkan hasil prediksi dengan pemilihan bobot dan bias yang merupakan solusi terbaik. Sedangkan metode backpropagation digunakan untuk menghitung nilai Mean Square Error (MSE) yang digunakan dalam perhitungan fitness dan juga pada proses prediksi data uji. Pada penelitian ini akan dilakukan lima macam pengujian yaitu banyaknya generasi, ukuran populasi, pengujian kombinasi nilai crossover rate dan mutation rate, pengujian
learning rate dan pengujian nilai Average Forecasting Error Rate (AFER). Hasil yang didapat dari penelitian ini adalah prediksi waktu panen dan AFER. Hasil pengujian terbaik yaitu dengan hasil AFER sebesar 0,0205%.
Kata kunci: prediksi, algoritma genetika, backpropagation, MSE, AFER
Abstract
Before sugar cane was milled by the factory, the first process is analysis of sugar cane maturity. The best sugar cane condition to be ground is mature cane that can be seen from several factors such as garden area, age, stem diameter, the average segment per stem and the average length per stem. These factors are used as attributes in the research conducted. To simplify the process, then we proposed this research on the prediction of sugar cane harvest time. With so much data being used and repeated processes, it will be difficult to process manually and takes a long time. In addition, the manual process does not close the possibility of an increasing error. This research uses a combination of genetic algorithm and backpropagation in the process of predicting the harvest time. Genetic algorithms are the best solution used to optimize prediction results by weight selection and bias. Backpropagation method is used to calculate Mean Square Error (MSE) value, which will be used in calculation of fitness value and also on prediction of data test. In this research will be done five kinds of testing, as follows generation test, population size test, test combination of crossover rate and mutation rate, testing of learning rate and testing of Average Forecasting Error Rate (AFER). The result of this research are predictions of harvest time, the value of fitness and AFER. The best result is result of AFER value is 0,0205%.
Keywords: prediction, genetic algorithm, backpropagation, MSE, AFER
1. PENDAHULUAN
Sebelum tebu digiling oleh pabrik, dilakukan analisis kemasakan tebu terlebih dahulu. Tebu yang baik untuk digiling adalah
atribut dalam penelitian yang dilakukan. Analisis kemasakan tebu dilakukan beberapa kali untuk menentukan bahwa tebu tersebut sudah matang atau belum.
Untuk mempermudah proses analisis maka dilakukan cara prediksi waktu panen tebu dari data tebu. Data yang digunakan sangat banyak, karena data dalam 1 perode biasanya terdapat ± 10 ronde dari banyak wilayah. Dan jika data yang dikelola atau dianalisis berjumlah cukup banyak, maka akan sulit diolah secara manual dan membutuhkan waktu yang cukup lama. Selain itu, jika proses dilakukan secara manual, tidak menutup kemungkinan peluang terjadi kesalahan akan semakin besar. Alasan lainnya yaitu masalah jumlah pengambilan contoh tebu yang akan dianalisis dimana dalam 1 ronde petani harus mengirim minimal 3 kali. Hal ini juga akan berdampak kepada petani yang jumlah tebunya akan berkurang untuk dianalisis. Karena hal di atas, maka dilakukan penelitian tentang prediksi waktu panen tebu dengan bantuan komputer. Sehingga penelitian ini bertujuan untuk memprediksikan waktu tebu yang siap untuk dipanen dan mengurangi jumlah tebu yang diperlukan untuk proses analisis.
Penelitian ini menggunakan penggabungan dua metode yaitu algoritma genetika dan
backpropagation. Dimana proses awal yaitu untuk proses inisalisasi bobot dan bias awal menggunakan algoritma genetika. Sedangkan untuk proses selanjutnya yaitu untuk proses prediksi digunakan metode backpropagation. Metode backpropagation juga digunakan untuk menghitung nilai MSE yang akan digunakan dalam perhitungan nilai fitness. Alasan penggunaan dua metode tersebut yaitu untuk mengoptimasi nilai bobot awal dan bias awal dengan memilih nilai fitness terkecil untuk proses prediksi waktu panen tebu. Algoritma genetika sangat cocok digunakan untuk permasalahan optimasi. Sedangkan untuk metode backpropagation merupakan salah satu model jaringan syaraf tiruan yang digunakan pada penyelesaian suatu masalah berkaitan dengan prediksi, identifikasi dan sebagainya.
2. METODOLOGI
2.1. Algoritma Genetika
Salah satu tipe dari algoritma evolusi adalah algoritma genetika. Algoritma genetika merupakan algoritma pencarian heuristik yang berdasarkan atas mekanisme evolusi biologis (Kusumadewi & Purnomo, 2005). Algoritma
genetika pertama kali dirintis oleh John Holland dari Universitas Michigan pada tahun 1960. Algorima genetika banyak digunakan dalam permasalahan optimasi (Haupt & Haupt, 2004). Pada algoritma genetika, tenik pencarian dilakukan dari sejumlah solusi yang mungkin didapatkan dengan istilah populasi. Kromosom adalah individu yang terdapat dalam satu populasi. Kromosom ini merupakan suatu solusi. Pada saat inisialisasi awal populasi dilakukan dengan cara random (acak), sedangkan untu populasi berikutnya merupakan hasil evolusi dari kromosom-kromosom yang sudah melalui iterasi yang disebut dengan generasi. Kromosom akan melalui tahap evaluasi pada setiap generasi. Proses evaluasi ini menggunakan alat ukur yang disebut dengan fungsi fitness. Nilai fitness akan menunjukkan kualitas kromosom dalam populasi tersebut.
Generasi yang terbentuk berikutnya disebut sebagai anak (offspring) yang terbentuk dari gabungan 2 kromosom sebelumnya yang dianggap sebagai induk (parent) dengan menggunakan operator crossover (Kusumadewi & Purnomo, 2005). Operator crossover
dilakukan dengan cara melakukan pertukaran gen dari dua induk yang terpilih secara acak. Selain operator crossover, terdapat juga operator mutasi. Operator mutasi merupakan operator yang menukar nilai gen kromosom dengan nilai
invers-nya. Misalkan nilai 0 menjadi 1 atau sebaliknya (Zamani et al., 2012). Pada pembentukan populasi generasi yang baru didapatkan dengan cara menyeleksi nilai fitness. Dalam siklus perkembangan algoritma genetika untuk mencari solusi (kromosom) terbaik terdapat beberapa proses sebagai berikut:
a. Representasi kromosom
Chromosome merupakan kode atau representasi dari suatu solusi permasalahan.
Chromosome dibentuk dari beberapa gen yang mewakili variabel keputusan yang digunakan. Panjang chromosome didapatkan dari banyaknya bobot dan bias awal yang akan digunakan.Dalam penelitian banyaknya bobot dan bias awal pada neuron antara hidden layer
dan output layer yang digunakan berjumlah 4 dan banyaknya bobot dan bias awal pada
neuron antara input layer dan hidden layer
yang digunakan berjumlah 18, sehingga total
chromosome yaitu sebanyak 22 gen. Representasi chromosome yang digunakan yaitu representasi dalam bentuk bilang real
b. Inisialisasi
Inisialisasi populasi awal ditentukan oleh banyaknya ukuran populasi atau popsize yang menunjukkan individu. Suatu nilai dibangkitkan untuk dijadikan panjang
chromosome. Chromosome berisi gen yang nilai – nilainya dipilih secara acak dengan range 0-1. Setiap individu akan dilakukan tahap reproduksi yang terdiri dari crossover
dan mutasi untuk mendapatkan nilai fitness. c. Reproduksi
• Crossover (Extended Intermediate Crossover)
Untuk mendapatkan nilai offspring (child) menggunakan Persamaan (1) dan (2).
𝐶1= 𝑃1+ 𝛼 (𝑃2− 𝑃1) (1)
𝐶2= 𝑃2+ 𝛼 (𝑃1− 𝑃2) (2)
P1 merupakan induk pertama dan P2
merupakan induk kedua yang terpilih secara
acak. Nilai α adalah konstanta yang dipilih
secara acak pada interval [-0,25, 1,25].
• Mutasi (Random Mutation)
Metode random mutation adalah metode mutasi yang dilakukan dengan cara memilih satu induk secara acak dan melakukan penambahan atau pengurangan terhadap nilai gen yang terpilih dengan bilangan random
yang kecil. Dalam penelitian ini metode mutasi yang digunakan adalah random mutation. Misalkan domain variabel xi adalah [mini , maxi] dan offspring yang dihasilkan adalah C = [x’1, …., x’n], maka nilai gen offspring bisa didapatkan dengan Persamaan (3) sebagai berikut (Mahmudy, 2013) :
𝑥′𝑖= 𝑥𝑖+ 𝑟 (𝑚𝑎𝑥𝑖− 𝑚𝑖𝑛𝑖) (3)
Nilai konstanta r dipilih secara acak misalkan dengan range [-0,1, 0,1].
d. Evaluasi
Proses evaluasi ini bertujuan untuk menghitung nilai fitness dari masing-masing individu dalam populasi yaitu induk (parent) dan offspring (child). Dimana nilai fitness yang didapatkan akan digunakan pada proses seleksi. Nilai fitness dapat dihitung dengan Persamaan (4) sebagai berikut :
𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = 𝑀𝑆𝐸1 (4)
Dengan nilai MSE yang didapatkan dari
proses perhitungan menggunakan
backpropagation.
e. Seleksi
Metode seleksi yang digunakan pada
penelitian adalah metode binary tournament selection. Metode binary tournament selection
adalah metode seleksi yang digunakan dalam sistem. Metode ini bekerja dengan cara mengambil 2 individu secara acak dari populasi dan offspring. Masing – masing individu akan dibandingkan nilai fitness-nya. Individu yang memiliki nilai fitness terbesar, maka akan lolos pada generasi berikutnya.
2.2. Metode Backpropagation
Jaringan yang berasal dari kumpulan pemrosesan kecil yang dimodelkan berdasarkan jaringan saraf manusia disebut jaringan saraf tiruan (JST). JST dapat digunakan untuk memodelkan hubungan yang kompleks antara
input dan output untuk menemukan pola-pola pada data yang digunakan. Jaringan saraf tiruan memiliki kemampuan dalam hal emulasi, analisis, prediksi dan asosiasi. Salah satu yang sering digunakan dalam jaringan saraf tiruan adalah backpropagation. Terdapat dua proses
dalam metode backpropagation yaitu
feedforward dan proses backward. Berikut merupakan langkah-langkah algoritma
backpropagation secara rinci (Zamani et al., 2012):
1. Inisialisasi bobot awal, bias awal dan konstanta laju pelatihan (α)
2. Tahap 1 merupakan umpan maju (feedforward). Dimana tiap unit masukan menerima sinyal dan meneruskannya ke unit tersembunyi diatasnya.
3. Mengalikan masing-masing unit di lapisan tersembunyi dengan bobotnya dan dijumlahkan serta ditambahkan dengan biasnya seperti pada Persamaan (5)
hidden layer. Kemudian dilakukan fungsi aktivasi pada hasil tersebut dengan Persamaan (6).
𝑧𝑗= 𝑓(𝑧_𝑛𝑒𝑡𝑗) =1+𝑒−𝑧_𝑛𝑒𝑡𝑗1 (6)
4. Mengalikan masing-masing unit output
dengan bobot dan dijumlahkan serta ditambahkan dengan biasnya seperti pada Persamaan (7) dan (8).
𝑦_𝑛𝑒𝑡𝑘= 𝑤𝑘0+ ∑𝑝𝑖=1𝑧𝑖𝑤𝑘𝑖 (7)
Dimana y_netk adalah unit keluaran. Wk0
adalah bobot bias hidden layer ke output layer. Wki adalah bobot hidden layer ke output layer. Yk adalah fungsi aktivasi untuk unit keluaran.
5. Tahap 2 merupakan umpan mundur (backward propagation). Dimana masing-masing unit output menerima pola target tk sesuai dengan pola masukan saat pelatihan dan kemudian informasi error
lapisan output (δk) dihitung. δk dikirim ke
lapisan dibawahnya dan digunakan untuk menghitung besarnya koreksi bobot dan
bias (∆Vjk dan ∆Vko) antara lapisan tersembunyi dengan lapisan output
dengan Persamaan (9) sebagai berikut : 𝛿𝑘 = (𝑡𝑘− 𝑦𝑘)(𝑦𝑘)(1 − 𝑦𝑘) (9)
Menghitung koreksi bobot yang kemudian akan digunakan untuk memperbaiki nilai
Vkj dan Vk0 dengan Persamaan (10) dan (11) sebagai berikut :
∆𝑉𝑘𝑗= 𝛼𝛿𝑘𝑥𝑖 (10)
∆𝑉𝑘0= 𝛼𝛿𝑘 (11)
6. Pada setiap unit lapisan tersembunyi dilakukan perhitungan kesalahan lapisan tersembunyi (δj). δj digunakan untuk
menghitung besar koreksi bobot dan bias
(∆Wji dan ∆Wjo) antara lapisan input dan lapisan tersembunyi. Perhitungan kesalahan lapisan tersembunyi dapat dilakukan dengan Persamaan (12) dan
7. Tahap 3 merupakan peng-updatean bobot dan bias. Perubahan nilai bobot dan bias menggunakan Persamaan (16) dan (17) sebagai berikut :
𝑣𝑘𝑗(𝑏𝑎𝑟𝑢) = 𝑣𝑘𝑗(𝑙𝑎𝑚𝑎) + ∆𝑣𝑘𝑗 (16)
𝑤𝑗𝑖(𝑏𝑎𝑟𝑢) = 𝑤𝑗𝑖(𝑙𝑎𝑚𝑎) + ∆𝑤𝑗𝑖 (17)
8. Menghitung nilai error untuk digunakan pada perhitungan MSE dengan Persamaan (18).
𝐸 = 𝑡 − 𝑦𝑘 (18)
9. Uji kondisi berhenti
10. Menghitung nilai MSE (Mean Square Error) untuk mengetahui tingkat akurasi pada proses prediksi. Nilai MSE akan digunakan untuk menghitung nilai fitness
pada proses algoritma genetika. Berikut Persamaan (19) untuk mendapatkan nilai MSE :
𝑀𝑆𝐸 = ∑ 𝐸𝑛2 (19)
2.3. Metode Error AFER
Sebuah sistem dapat ditentukan sudah sesuai atau belum dengan hasil kenyataanya dari tingkat akurasi yang didapat. Penelitian ini
menggunakan metode error Average
Forecasting Error Rate (AFER). AFER digunakan untuk mengetahui nilai kesalahan yang terjadi pada sistem peramalan (Jilani et al., 2017). Untuk mendapatkan nilai AFER dapat dilihat pada Persamaan (20) berikut (Lee et al., 2006):
𝐴𝐹𝐸𝑅 = (1𝑛∑ (|𝐴𝑛𝑖=1 𝑖− 𝐹𝑖| /𝐴𝑖))×100% (20)
AFER merupakan nilai yang menyatakan persentase selisih antara data prediksi dengan data aktual atau kenyataan. Tingkat keakuratan dapat dikatakan baik jika nilai error yang dihasilkan semakin kecil (Rahmadiani, 2012). Terdapat aturan untuk menentukan sebuah sistem peramalan dapat dikatakan baik atau buruk. Aturan tersebut yaitu jika nilai error
AFER mendekati 0%, maka sistem peramalan tersebut dapat dikatakan baik. Namun dalam kenyataannya jarang sekali kasus prediksi yang nilai error AFER benar – benar 0% (Stevenson, 2009).
2.4. Gabungan Algoritma Genetika dan Backpropagation
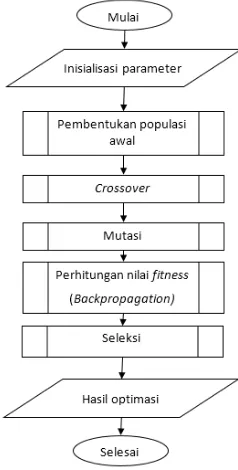
Algoritma genetika memiliki beberapa tahap. Tahap pertama adalah melakukan Inisialisasi parameter berupa inputan yang meliputi pengkodean gen dan chromosome. Setelah menginputkan parameter, proses yang harus dilakukan adalah membangkitkan populasi awal, menghitung nilai fitness, melakukan
crossover, melakukan mutase dan menyeleksi
chromosome sehingga menghasilkan solusi akhir berupa chromosome atau individu dengan nilai fitness tertinggi yang merupakan solusi terbaik. Pada penelitian ini algoritma
backpropagation digunakan saat proses evaluasi pada algoritma genetika untuk mendapatkan nilai fitness. Berikut merupakan gambar
flowchart siklus sistem gabungan metode
Gambar 1. Flowchart GA-BP
3. PENGUJIAN
Proses pengujian meliputi pengujian banyaknya generasi, ukuran populasi (popsize), pengujian kombinasi nilai crossover rate dan
mutation rate untuk proses algoritma genetika. Sedangkan untuk algoritma backpropagation
pengujian dilakukan terhadap nilai learning rate
(α). Proses pengujian ini dilakukan sebanyak 5 kali untuk setiap variasi nilai yang digunakan. Kemudian dihitung rata – rata nilai fitness yang didapat dan akan dipilih kombinasi dengan hasil paling optimal. Selain itu pengujian juga dilakukan pada prediksi terhadap data uji dengan penilaian nilai error AFER.
3.1. Uji Coba Generasi
Uji coba pertama yang dilakukan yaitu terhadap ukuran populasi. Pada proses pengujian ini dilakukan input beberapa ukuran populasi. Ukuran populasi yang digunakan yaitu 20, 50, 100, 150, 200, 250, 300, 350, 400, 450 dan 500. Nilai parameter yang digunakan yaitu learning rate adalah 0.1, popsize (ukuran populasi) adalah 20, cr adalah 0.2 dan mr adalah 0.1. Hasil pengujian dapat dilihat pada grafik Gambar 2.
Gambar 2. Grafik Pengujian Generasi
Berdasarkan Gambar 2 dapat diketahui bahwa garis grafik yang ditampilkan mengalami kondisi naik dan turun. Titik terendah terdapat pada generasi sebanyak 400 dengan nilai rata – rata fitness sebesar 9,26162. Sedangkan nilai rata
– rata tertinggi terdapat pada generasi sebanyak 20 dengan nilai rata – rata fitness sebesar 11,47432. Parameter banyaknya generasi mempengatuhi rata – rata nilai fitness. Semakin besar nilai generasi, maka rata – rata nilai fitness
akan semakin kecil. Hal ini disebabkan oleh pembangkitan nilai awal pada setiap individu secara acak. Selain itu, dapat juga disebabkan oleh penggunaan binary tournament selection
dalam proses seleksi.
3.2. Uji Coba Ukuran Populasi
Uji coba pertama yang dilakukan yaitu terhadap ukuran populasi. Pada proses pengujian ini dilakukan input beberapa ukuran populasi. Ukuran populasi yang digunakan yaitu 5, 10, 15, 20, 25, 30, 35, 40, 45 dan 50. Nilai parameter yang digunakan yaitu generasi sebanyak 20,
learning rate adalah 0.1, cr adalah 0.2 dan mr
adalah 0.1. Hasil pengujian dapat dilihat pada grafik Gambar 3.
Gambar 3. Grafik Pengujian Ukuran Populasi
fitness sebesar 9,43468. Sedangkan nilai rata – rata tertinggi terdapat pada ukuran populasi 10 dengan nilai rata – rata fitness sebesar11,85884. Hal ini disebabkan oleh pembangkitan nilai awal pada setiap individu secara acak. Selain itu, dapat juga disebabkan oleh penggunaan binary tournament selection dalam proses seleksi. Dimana metode seleksi ini memang dapat mengakibatkan konvergensi dini.
3.3. Uji Coba Kombinasi Cr dan Mr
Uji coba kedua yang dilakukan yaitu terhadap kombinasi nilai cr dan mr. Pada proses pengujian ini dilakukan input beberapa kombinasi cr dan mr. Kombinasi cr dan mr yang diujikan bernilai 1. Nilai parameter yang digunakan yaitu generasi sebanyak 20, learning rate adalah 0.1, popsize adalah 20, cr antara 0.9 sampai 0.1 dan mr antara 0.1 sampai 0.9. Hasil pengujian dapat dilihat pada grafik gambar 4.
Gambar 4. Grafik Pengujian Kombinasi Cr dan Mr
Berdasarkan Gambar 4 dapat diketahui bahwa grafik mengalami kondisi naik turun. Titik terendah terdapat pada kombinasi 0,4 untuk
cr dan 0,6 untuk mr dengan nilai rata – rata
fitness 9,66708. Sedangkan nilai rata – rata tertinggi terdapat pada kombinasi 0,1 untuk cr
dan 0,9 untuk mr dengan nilai rata – rata fitness
sebesar 11,8865. Dari hasil rata – rata nilai fitness yang didapatkan dengan nilai cr yang lebih besar dari nilai mr rata – rata menghasilkan solusi yang kurang baik dibandingkan dengan nilai cr yang lebih kecil dari nilai mr. Semakin besar perbedaan nilai cr dengan mr dengan nilai
cr yang lebih besar dapat menghasilkan solusi yang lebih baik. Namun tidak menutup kemungkinan jika nilai cr yang digunakan lebih kecil dari nilai mr dapat menghasilkan solusi yang lebih baik.
3.4. Uji Coba Learning Rate
Uji coba ketiga yang dilakukan yaitu terhadap variasi nilai learning rate. Pada proses pengujian ini dilakukan input beberapa nilai dengan range 0-0,9. Nilai parameter yang digunakan yaitu generasi sebanyak 20, popsize
adalah 20, cr adalah 0.2 dan mr adalah 0.1. Hasil pengujian dapat dilihat pada grafik gambar 5.
Gambar 5. Grafik Pengujian Learning Rate
Berdasarkan Gambar 5 dapat diketahui bahwa grafik mengalami titik tertinggi berada pada nilai learning rate sebesar 0,5. Titik terendah terdapat pada nilai learning rate
sebesar 0,1 dengan nilai rata – rata fitness
12.6211. Sedangkan nilai rata – rata terendah terdapat pada nilai learning rate sebesar 0,1 dengan rata – rata fitness sebesar 11,39826. Untuk nilai learning rate 0,1 – 0,5 selalu mengalami kenaikan. Akan tetapi setelah itu mengalami penurunan secara terus menerus hingga nilai learning rate sebesar 0,9. Hal ini disebabkan nilai learning rate digunakan untuk menghitung koreksi bobot dan bias pada hidden layer dan output layer pada proses
backpropagation.
3.5. Uji Coba AFER
Uji coba keempat yang dilakukan yaitu menghitung nilai AFER pada setiap data uji. Pengujian ini dilakukan untuk mengetahui tingkat akurasi setiap hasil prediksi terhadap target sesungguhnya. Pengujian dilakukan dengan dua parameter berbeda. Parameter pertama didapatkan dari pengujian – pengujian sebelumnya yang menghasilkan nilai fitness
terbaik.
Parameter yang digunakan pada pengujian AFER pertama yaitu generasi sebanyak 50,
learning rate adalah 0.5, popsize adalah 20, cr
adalah 0.2 dan mr adalah 0.1. Dengan parameter yang dipilih dari pengujian sebelumnya maka didapatkan nilai AFER sebesar 2,4382%. Kemudian pengujian berikutnya dilakukan dengan pemilihan nilai parameter secara acak.
Parameter yang digunakan pada pengujian AFER kedua yaitu generasi sebanyak 20,
learning rate adalah 0.1, popsize adalah 20, cr
Nilai AFER yang didapatkan dengan pengujian kedua menghasilkan nilai yang lebih baik dibandingkan pengujian pertama yaitu 0,0205%, maka digunakan sebagai hasil pengujian terbaik. Karena nilai yang didapatkan mendekati 0%. Dimana sistem yang dibuat dapat dikatakan baik sesuai dengan penjelasan yang ada pada Sub bab 2.3 bahwa sebuah sistem prediksi atau peramalan yang baik adalah yang memiliki nilai AFER mendekati 0%. Dengan nilai bobot dan bias yang digunakan dari proses
gabungan algoritma genetika dan
backpropagation, maka didapatkan nilai - nilai yang belum didenormalisasi adalah y (output) sebesar 0,483 dan nilai target 0,5. Sehingga selisih antara target seharusnya dengan hasil prediksi sistem adalah 0,017.
4. KESIMPULAN
Kesimpulan yang didapatkan dari hasil penelitian mengenai prediksi waktu panen tebu dengan gabungan algoritma backpropagation
dan algoritma genetika adalah sebagai berikut: a. Dengan mengimplementasikan algoritma
genetika dalam proses inisialisasi bobot dan bias awal dapat menghasilkan prediksi yang lebih optimal. Panjang kromosom yang digunakan sebanyak 22 gen. 4 gen pertama merupakan representasi dari bobot dan bias pada neuron antara hidden layer dan output layer. 18 gen sisanya merupakan representasi dari bobot dan bias pada
neuron antara input layer dan hidden layer. Hal ini dapat dilihat dari nilai APER dan
fitness yang didapatkan. Algoritma genetika diimplementasikan dengan memasukkan beberapa parameter untuk proses optimasi yatu banyaknya generasi, popsize,
crossover rate dan mutation rate. Penelitian yang dilakukan menggunakan model
extended intermediate crossover dan
random mutation untuk proses reproduksi. Sedangkan untuk proses seleksi menggunakan binary tournament selection. b. Parameter terbaik yang dihasilkan dari
beberapa proses pengujian. Hasil pengujian terbaik yaitu dengan hasil nilai AFER sebesar 0,0205%. Karena hasil AFER pada prediksi data uji yang digunakan mendekati 0%, maka sistem dapat dikatakan baik. Parameter terbaik yang terpilih yaitu generasi sebanyak 20, learing rate adalah 0.1, ukuran populasi adalah 20, cr adalah 0.2 dan mr adalah 0.1.
5. DAFTAR PUSTAKA
Esfandani, Muhammad Asghari, Nematzadeh.
(2016). “Prediction air pollution in Tehran : Genetic algorithm and back propagation neural network”. Journal of AI and Data Mining. Volume 4, No. 1. 49-54
Gao Pengyu, dkk. (2016). “Fluvial facies
reservoir productivity prediction method based on principal component analysis and
artificial neural network”. Advancing
Research Evolving Science. No. 2. 49-53
Haviluddin, Alfred Rayner. (2015). “A Genetic -Based Backpropagation Neural Network for Forecasting in Time-Series Data”. International Conference on Science in Information Technology. 158-163
Kusmadewi S, Purnomo H. (2005).
“Penyelesaian Masalah Optimasi dengan
Teknik-Teknik Heuristik”. Yogyakarta : Graha Ilmu
Lee Li-Wei, dkk. (2006). “Handling Forecasting Problems Based on Two-Factors
High-Order Fuzzy Time Series”. IEEE
Transactions On Fuzzy Systems. Volume 14, No. 3. 468-477
Mahmudy, Wayan Firdaus. (2013). “Algoritma Evolusi”. Program Teknologi Informasi
dan Ilmu Komputer. Universitas Brawijaya. Malang
Rabiha Sucianna Ghadati, Santoso Stefanus.
(2013). “Prediksi data arus lalu lintas
jangka pendek menggunakan optimasi
neural network berbasis gentic algorithm”.
Jurnal Teknologi Informasi. Volume 9, No. 2. 54-61
Rahmadiani Ani, Anggraeni Wiwik. (2012).
“Implementasi Fuzzy Neural Network
untuk Memperkirakan Jumlah Kunjungan Pasien Poli Bedah di Rumah Sakit
Onkologi Surabaya”. Jurnal Teknik
Institut Teknologi Sepuluh Nopember. Surabaya. Volume 1. 403-407
Singh Shaminder, Gill Jasmeen. (2014).
“Temporal Weather Prediction using Back Propagation based Genetic Algorithm
Technique”. I.J. Intelligent Systems and
Applications. Volume 12. 55-61
Vakili Masoud, dkk. (2015). “Using Artificial
Neural Networks for Prediction of Global Solar Radiation in Tehran Considering
International Conference on Technologies and Materials for Renewable Energy, Environment and Sustainability. 1205-1212
Wiguna Anggri Sartika, dkk. (2014). “Analisis
dan Peramalan Kepadatan Jalan Raya Kodya Malang dengan FTS Average
Based”. Jurnal EECCIS. Volume 8. No. 2.
157-162
Zamani, Adam Mizza, dkk. (2012).
“Implementasi Algoritma Genetika pada
Struktue Backpropagation Neural Network
untuk Klasifikasi Kanker Payudara”.