commit to user
PEMODELAN INDEKS HARGA SAHAM GABUNGAN (IHSG)
DENGAN RADIAL BASIS FUNCTION NETWORK
Oleh:
NIKEN RETNOWATI
M0107012
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan
memperoleh gelar Sarjana Sains Matematika
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET SURAKARTA
commit to user
ABSTRAK
Niken Retnowati, 2012. PEMODELAN INDEKS HARGA SAHAM GABUNGAN (IHSG) DENGAN RADIAL BASIS FUNCTION NETWORK. Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sebelas Maret.
Indeks harga saham merupakan suatu indikator yang menunjukkan pergerakan perubahan harga saham. Indeks inilah yang paling banyak digunakan dan dipakai sebagai acuan tentang perkembangan kegiatan di pasar modal. Indeks Harga Saham Gabungan (IHSG) dapat digunakan untuk menilai situasi pasar secara umum. Berdasarkan kondisi ini, perlu dilakukan penelitian untuk memodelkan IHSG guna mempermudah para investor untuk mengetahui pergerakan pasar modal. Model terpilih yang digunakan peneliti adalah Radial Basis function Network (RBFN), selain bersifat nonparametrik juga cocok untuk data nonlinear.
Data yang digunakan dalam penelitian ini adalah data sekunder yang diperoleh dari www.finance.yahoo.com dengan periode Januari sampai November 2011 untuk semua hari kerja. Tujuan dari penelitian ini adalah menentukan model matematik yang sesuai dalam menjelaskan IHSG pemerintah dengan menggunakan teknik RBFN. Berdasarkan hasil penelitian diperoleh kesimpulan bahwa dengan menggunakan 3 variabel sebagai input yaitu Nikkei, ASX dan FTSE, dan 1 variabel sebagai output yaitu IHSG maka diperoleh model yang terbaik, jika digunakan 5 center pada lapisan tersembunyi dengan spread 8.
commit to user
ABSTRACT
Niken Retnowati, 2012. MODELING OF INDEKS HARGA SAHAM
GABUNGAN (IHSG) WITH RADIAL BASIS FUNCTION NETWORK.
Faculty of Mathematics and Natural Sciences, Sebelas Maret University.
Stock price index is an indicator that shows the movement of stock price changes. Index is the most widely used as a reference of capital market activities delevopment. Indeks Harga Saham Gabungan (IHSG) can be used to assess the market situation in generally. Under these conditions, research is needed to model the composite index in order to facilitate the investors to know the movement of capital markets. The selected model which is used by the researcher is Radial Basis Function Network (RBFN), which is nonparametric, and also suitable for the nonlinear data.
The used data in this study is secondary data which taken from www.finance.yahoo.com issued from January to November 2011 for all working days. The purpose of this study is to determinine the appropriate mathematical models in explaining the government's stock index using RBFN. Based on research result it can be concluded that by using three variables input Nikkei, ASX and FTSE, and a variable IHSG as the output. The best model can be obtained when the selection of five centers in the hidden layer with spread 8 is used.
commit to user
MOTO
commit to user
PERSEMBAHAN
Karya ini aku persembahkan untuk
Ibu, Bapak, Kakak dan Adikku tercinta, serta Rolies Erfan Hermawan,
commit to user
KATA PENGANTAR
Puji syukur kepada Allah SWT yang senantiasa memberikan rahmat dan
hidayahNya, sehingga penulis dapat menyelesaikan skripsi ini. Selain itu, penulis
juga mengucapkan terimakasih kepada semua pihak yang telah membantu dalam
penyusunan skripsi ini, khususnya kepada
1. Ibu Winita Sulandari, M.Si selaku dosen pembimbing I atas kesediaan dan
kesabaran yang diberikan dalam membimbing penulis,
2. Bapak Dr. Sutanto, DEA, selaku pembimbing II atas kesediaan waktu dan
tenaga guna kesempurnaan penulisan,
3. Ibu Titin Sri Martini, S.Si, M.Kom dan Ibu Dra. Mania Roswitha, M.Si
selaku tim penguji,
4. Septi, Prita, Atik, Nanthi, Lissa, dan segenap teman math 07 atas segala
dukungannya,
5. Mas Dika (Alumnus ITS) terimakasih atas ilmu dan bantuan selama
penulis menyusun skripsi,
6. Semua pihak yang membantu dalam penulisan skripsi ini yang tidak dapat
penulis sebut satu per satu.
Semoga skripsi ini dapat bermanfaat bagi semua pihak yang memerlukan.
Surakarta, Februari 2012
commit to user
1.1 Latar Belakang Masalah ...
1.2 Perumusan Masalah ...
2.1.1 Indeks Saham Gabungan ...
2.1.2 Linearitas ...
2.1.3 Neural Network ...
2.1.4 Radial Basis Function Network ...
commit to user
3.3 Analisis Data ... 16
BAB IV PEMBAHASAN ...
4.1 Diskripsi Data ...
4.2 Rancangan dalam RBFN ...
4.3 Pemodelan RBFN ...
4.3.1 Prepocessing ...
4.3.2 Penentuan Banyaknya Neuron pada Lapisan Tersembunyi ...
4.3.3 Penentuan Spread ...
4.3.4 Menentukan Jarak ...
4.3.5 Mencari Nilai dari Fungsi Gaussian ...
commit to user
DAFTAR TABEL
Tabel 1.1 Saham Bluechip ... 1
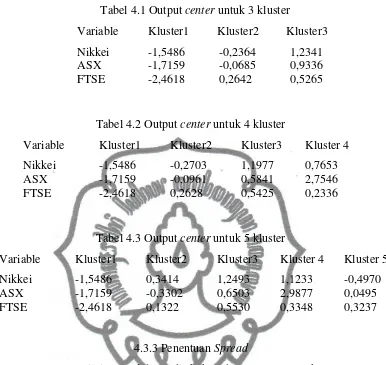
Tabel 4.1 Output center untuk 3 kluster ... 21
Tabel 4.2 Output center untuk 4 kluster ... 21
Tabel 4.3 Output center untuk 5 kluster ... 21
Tabel 4.4 Jarak center untuk 3 kluster ... 22
Tabel 4.5 Nilai spread untuk tiap kluster ... 22
commit to user
DAFTAR GAMBAR
Gambar 2.1 Arsitektur Jaringan NN Satu Lapisan Tersembunyi ... 9
Gambar 2.2 Arsitektur Jaringan RBFN secara umum ... 10
Gambar 3.1 Alur Penelitian ... 17
Gambar 4.1 Plot IHSG vs Nikkei ... 18
Gambar 4.2 Plot IHSG vs ASX ... 18
Gambar 4.3 Plot IHSG vs FTSE ... 19
Gambar 4.4 Arsitektur RBFN dengan 3 unit input, Nilai Gaussian dan Bobot belum diketahui ... 19
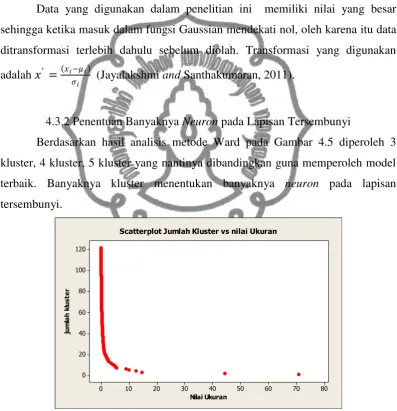
Gambar 4.5 Plot Antara Jumlah Kluster vs Nilai Ukuran ... 20
Gambar 4.6 Arsitektur RBFN Terpilih ... 27
commit to user
DAFTAR ISTILAH
Bluechip : Saham unggulan berkapitalisasi besar, memiliki likuiditas
tinggi dan pergerakan pasar. Pergerakan harganya biasanya
relatif mudah diramalkan.
Bursa efek : Pihak yang menyelenggarakan dan menyediakan sistem dan
atau sarana untuk mempertemukan penawaran jual dan beli
efek pihak-pihak lain dengan tujuan memperdagangkan efek
di antara mereka
Deviden : Pembagian laba kepada pemegang saham berdasarkan
banyaknya saham yang dimiliki.
Efek : Surat berharga (dapat berupa surat pengakuan utang, surat
berharga komersial saham dan lain-lain)
Emiten : Perusahaan yang menjual pemilikannya kepada masyarakat
dengan tujuan memperoleh tambahan dana yang digunakan
dalam perluasan usaha, mengubah atau memperbaiki
komposisi modal, melakukan pengalihan pemegang saham
Indeks : Nilai sekelompok saham digabungkan dengan rasio tertentu.
Investasi : Kegiatan menanam dana atau modal dengan tujuan untuk
mendapatkan keuntungan dimasa mendatang.
Investor : Orang perorangan atau lembaga baik domestik atau non
domestik yang melakukan suatu investasi (bentuk penanaman
modal sesuai dengan jenis investasi yang dipilihnya) baik
dalam jangka pendek atau jangka panjang.
Kapitalisasi pasar : Nilai seluruh saham emiten, dihitung dengan harga saham
perusahaan sekarang dikalikan dengan jumlah saham yang
beredar.
Konstituen : Seseorang yang secara aktif mengambil bagian dalam proses
menjalankan organisasi dan yang memberikan otoritas
kepada orang lain untuk bertindak mewakili dirinya
Kriling : Proses penentuan hak dan kewajiban anggota kriling yang
commit to user
Likuiditas : Karakteristik suatu saham yang jumlahnya cukup banyak di
dalam peredarannya sehingga memungkinkan kemudihan
transaksi
Nilai pasar : Harga terakhir yang tercatat di bursa.
Obligasi : Suatu istilah yang digunakan dalam dunia keuangan
merupakan suatu penyertaan utang dari penerbit obligasi
kepada pemegang saham obligasi serta berjanji membayar
pada jatuh tempo pembayaran.
Pasar modal : Kegiatan yang bersangkutan dengan Penawaran Umum dan
perdagangan Efek, Perusahaan Publik yang berkaitan dengan
Efek yang diterbitkannya, serta lembaga dan profesi yang
berkaitan dengan Efek.
Pasar reguler : Pasar dengan sistem lelang berkesinambungan
Retroaktif : Bersifat atau berlaku surut
Ritel : Penjualan barang atau jasa kepada masyarakat.
Saham : Bukti penyertaan modal di suatu perusahaan ,atau merupakan
bukti kepemilikan atas suatu perusahaan yang dapat
diperdagangkan di bursa efek indonesia.
Saham biasa : Surat berharga dalam bentuk piagam atau sertifikat yang
memberikan pemegangnya bukti atas hak-hak dan kewajiban
menyangkut andil kepemilikan dalam suatu perusahaan.
Saham biasa mempunyai sifat kebalikan dari Saham Preferen
dalam hal pengambilan suara, pembagian deviden dan
hak-hak yang lain.
Saham preferen : Bagian saham yang memiliki tambahan hak melebihi saham
biasa
Waran : Hak untuk membeli saham kepada pemegang saham
sebelumperusahaan/emiten menerbitkannya dengan harga
commit to user
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Indeks harga saham merupakan suatu indikator yang menunjukkan
pergerakan perubahan harga saham. Indeks Harga Saham Gabungan (IHSG)
menunjukkan pergerakan harga saham yang tercatat di Bursa Efek Indonesia
(BEI). Indeks inilah yang paling banyak digunakan dan dipakai sebagai acuan
tentang perkembangan kegiatan di pasar modal, selain itu IHSG juga dapat
dipakai untuk menilai situasi pasar secara umum. Indeks Harga Saham Gabungan
melibatkan seluruh harga saham yang tercatat di bursa, mencakup pergerakan
harga seluruh saham biasa dan saham preferen yang tercatat di BEI. Dengan
memodelkan IHSG, para investor lebih mudah untuk mengetahui pergerakan
pasar modal.
Indeks Harga Saham Gabungan dapat dikatakan sebagai gambaran umum
dari BEI. Dilihat dari formula perhitungan IHSG beberapa saham perusahaan
yang berkapitalisasi besar atau biasa disebut juga bluechip jelas sekali terlihat jika
bergerak akan mempengaruhi indeks, yang perlu ditanyakan adalah ketika indeks
saham luar negeri yang bergerak. Beberapa saham bluechip yang sangat
berpengaruh antara lain dapat dilihat pada Tabel 1.1
Tabel 1.1 Saham Bluechip
TLKM Telekomunikasi Indonesia (Persero) Tbk
BUMI PT. Bumi Resources Tbk (Migas)
INCO PT INCO INDONESIA (nikel)
BBCA Bank Central Asia Tbk
MEDC Medco Energi International Tbk
ANTM PT Aneka Tambang Tbk
SGRO Sampoerna Agro Tbk
TKIM Pabrik Kertas Tjiwi Kimia Tbk
commit to user
Beberapa penelitian terkait pemodelan IHSG pernah dilakukan oleh
Mansur (2005), Pasaribu dkk (2008), dan Mauliano (2009). Mansur (2005)
meneliti pengaruh bursa global yaitu Nikkei, Dow Jones, Kospi, TAIEX, Hang
seng, FTSE dan ASX terhadap IHSG pada tahun 2000- 2002 dengan metode path
analysis dan menyimpulkan bahwa ketujuh bursa saham global bersama-sama
signifikan tetapi secara individual hanya indeks bursa Kospi, Nikkei, TAIEX dan
ASX saja yang mempengaruhi IHSG.
Pasaribu dkk (2008) menganalisis tentang pengaruh variabel
makroekonomi terhadap IHSG menggunakan metode regresi berganda dengan
faktor dari luar adalah indeks Dow Jones dan indeks Hang Seng, dan
menyimpulkan hanya Indeks Hang Seng yang memberikan pengaruh signifikan
terhadap IHSG. Penelitian lain yang juga menggunakan metode analisis regresi
berganda adalah Mauliano (2009) dengan periode pengamatan Januari 2004- Mei
2009 menyimpulkan bahwa dari delapan indeks global yang diamati yaitu Dow
Jones, NYSE, FTSE, STI, Nikkei, Hang Seng, Kospi, dan KLSE hanya Dow
Jones, Hang Seng dan KLSE yang mempengaruhi pergerakan IHSG.
Penulis memodelkan menggunakan faktor yang sama dengan Mansur
(2005), karena dari beberapa penelitian di atas pada penelitian Mansur variabel
saham global yang digunakan dirasa dapat mewakili saham global secara umum.
Penulis menggunakan data Januari-November 2011, dengan menggunakan
metode analisis regresi ternyata hanya Indeks Nikkei, ASX dan FTSE yang
berpengaruh signifikan terhadap IHSG. Hasil dari analisis regresi juga
menunjukkan adanya hubungan nonlinear antara IHSG dengan ketiga saham
global tersebut di atas. Menurut Chen et al. (1991) Radial Basis Function
Networks (RBFN) sangat cocok untuk data nonlinear, selain itu model RBFN
adalah model nonparametrik sehingga tidak diperlukan adanya asumsi tertentu.
Radial Basis Function Networks merupakan suatu jaringan yang terdiri atas 3
lapisan, yaitu lapisan input, lapisan tersembunyi dan lapisan output. Performa dari
RBFN sangat dipengaruhi oleh penentuan center, spread, dan bobot koneksi.
Penelitian tentang RBFN untuk model regresi juga pernah dilakukan oleh
commit to user
to Maturity dengan center dipilih secara acak dari data pelatihan. Penelitian yang
pernah dilakukan terkait pemilihan center yaitu oleh Sutijo (2006) dengan
menggunakan K-mean kluster sebagai metode pemilihan banyaknya unit center
pada lapisan tersembunyi, Lin & Chen (2005) menggunakan SOM sebagai
metode pemilihan banyaknya center dan nilai center pada lapisan tersembunyi,
hanya pada penelitian-penelitian sebelumnya diaplikasikan pada data time series.
Pada penelitian ini penulis menggunakan metode yang sama dengan sutijo (2006)
yaitu RBFN dengan metode pemilihan center menggunakan K-mean kluster
tetapi yang berbeda pada penelitian ini adalah penulis mengaplikasikan untuk data
regresi.
1.2 Perumusan Masalah
Berdasarkan latar belakang di atas, permasalahan yang akan dibahas pada
penelitian ini adalah
1. Bagaimana memodelkan IHSG dengan RBFN?
2. Bagaimana model terbaik yang didapat dari metode RBFN untuk
memodelkan IHSG?
1.3 Batasan Masalah
1. Penentuan center pada model RBFN dengan menggunakan K-mean
kluster.
2. Data yang digunakan adalah data IHSG, Nikkei, ASX, dan FTSE pada
bulan Januari 2011 sampai November 2011.
3. Data yang digunakan adalah data untuk semua hari kerja.
1.4 Tujuan Penelitian
Tujuan penelitian ini adalah menentukan model matematik yang sesuai
commit to user
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan memberikan manfaat bagi beberapa
kalangan yang meliputi :
1. Akademisi, yaitu memberikan referensi kajian ilmiah tentang
pemodelan IHSG dengan menggunakan metode RBFN
2. Pemerintah, yaitu mempermudah pengontrolan kinerja pasar saham
yang nantinya berhubungan dengan penentuan kebijakan ekonomi
makro.
3. Investor, yaitu dapat memberikan informasi mengenai nilai IHSG
commit to user
BAB II
LANDASAN TEORI
2.1 Tinjauan Pustaka
Pada penelitian ini diperlukan teori yang mendukung tercapainya tujuan
penelitian. Berikut ini diberikan gambaran singkat mengenai Indeks Harga Saham
Gabungan (IHSG), Neural Network (NN), Radial Basis Function Network
(RBFN), K-mean kluster, dan metode Ward. Oleh karena itu, sebelumnya berapa
penelitian terdahulu pernah dilakukan oleh Mansur (2005), Pasaribu dkk (2008)
dan Mauliano (2009), dimana ketiganya membahas pengaruh saham global
terhadap IHSG dengan metode regresi dan memberikan kesimpulan bahwa saham
global yang diteliti signifikan terhadap IHSG, untuk masing-masing penelitian.
Dewasa ini penelitian tentang RBFN sudah banyak dikembangkan,
terutama untuk data timeseries, sedangkan untuk data regresi sendiri masih jarang.
Asmara (2009) berhasil mengaplikasikan model RBFN untuk data regresi. Selain
itu untuk pemilihan center dalam RBFN sendiri juga mengalami perkembangan,
dibuktikan dengan penelitian sutijo (2006) dengan K-mean kluster sebagai metode
pemilihan center dan Lin & Chen (2005) menggunakan SOM.
Perbedaan penelitian terdahulu dengan penelitian penulis adalah pada
variabel yang digunakan yaitu HSG, Nikkei, ASX dan FTSE terhadap IHSG,
dengan periode Januari sampai November 2011. Metode yang digunakan adalah
RBFN dengan K-mean kluster sebagai pemilihan center.
2.1.1. Indeks Saham Gabungan
Beberapa Indeks Harga Saham yang digunakan dalam penelitian ini adalah
1. IHSG
Menurut Robert (1997) Indeks Harga Saham Gabungan (IHSG)
merupakan suatu nilai yang digunakan untuk mengukur kinerja saham
yang tercatat dalam suatu bursa efek. IHSG ini ada yang dikeluarkan oleh
commit to user
institusi swasta tertentu seperti media massa keuangan, institusi keuangan,
dan lain-lain. Formula perhitungan IHSG adalah sebagai berikut
IHSG = P
d x 100
dimana P adalah close price, x adalah jumlah Saham, dan d adalah nilai
dasar.
Rata−rata IHSG = jumlah IHSG periode selama 1 bulan jumlah periode waktu selama satu bulan
Perhitungan Indeks merepresentasikan pergerakan harga saham di
pasar/bursa yang terjadi melalui sistem perdagangan lelang. Nilai dasar
akan disesuaikan secara cepat bila terjadi perubahan modal emiten atau
terdapat faktor lain yang tidak terkait dengan harga saham. Penyesuaian
akan dilakukan bila ada tambahan emiten baru, harga saham yang
digunakan dalam menghitung IHSG adalah harga saham di pasar reguler
yang didasarkan pada harga yang terjadi berdasarkan sistem lelang.
Perhitungan IHSG dilakukan setiap hari, yaitu setelah penutupan
perdagangan setiap harinya
2. Kospi
Korea Indeks Harga Saham Gabungan atau Kospi adalah indeks
dari semua saham biasa yang berasal dari Korea Selatan yang
diperdagangkan di Bursa Efek Korea. Kospi diperkenalkan pada tahun
1983 menggantikan KCSPI (Korea Indeks Harga Saham Gabungan).
Indeks ini merupakan indeks nilai pasar tertimbang yang terdiri dari 200
saham terpilih berdasar status dan likuiditasnya dalam industri.
(Setyawardhana, 2005)
3. Hang Seng
Hang Seng Index atau dikenal dengan HSI adalah indeks pasar
saham di Hong Kong. Indeks ini merupakan nilai gabungan dari 33 saham
perusahaan yang tercatat di Bursa Saham Hongkong, yang termasuk
golongan aktif dalam transaksi sahamnya dan merupakan 70% dari
commit to user
4. Nikkei
Nikkei 225 lebih sering disebut Nikkei, indeks Nikkei, atau Nikkei
Stock Average adalah sebuah indeks pasar saham untuk Bursa Saham
Tokyo. Nikkei 225 merupakan komponen dari Nikkei Stock Average yang
paling aktif diperdagangkan, yang utama dalam bursa saham Tokyo.
Terdapat 225 saham didalamnya yang dapat mencerminkan kondisi
ekonomi Jepang. (Setyawardhana, 2005)
5. TAIEX
Taiwan Weighted Kapitalisasi Indeks Saham adalah sebuah indeks
pasar saham untuk perusahaan di Taiwan Stock Exchange. TAIEX mencakup
semua saham yang tercatat tidak termasuk saham preferen dan saham yang
baru terdaftar. Ini pertama kali diterbitkan pada tahun 1967. (www.
bapepam. go.id).
6. Dow Jones
Indeks Dow Jones Industrial Average didirikan oleh Charles Dow
pada tanggal 26 Mei 1896, dan mewakili rata-rata 12 saham dari industri
Amerika terkemuka. Sebelumnya pada tahun 1884, Dow telah menyusun
rata-rata saham awal yang disebut Dow Jones Average. Dari 12 saham asli
yang membentuk Dow Jones Industrial Average disusun kemudian di
tahun 1896. (www. bapepam. go. id)
7. FTSE
FTSE 100 juga dikenal sebagai FTSE atau lebih akrab “Footsie”
adalah indeks saham dari 100 perusahaan terbaik dikapitalisasi Inggris
terdaftar di London Stock Exchange. Sarana perdagangan elektroni
dilaksanakan oleh The London International Financial Futures and Option
Exchange (LIFFE). (www.bapepam.go.id)
8. ASX
Bursa Efek Australia (ASX) diciptakan oleh penggabungan dari
Bursa Efek Australia dan Sydney Futures Exchange pada bulan Juli 2006.
commit to user
sebagai operator pasar, rumah kliring dan fasilitator sistem pembayaran.
Tugasnya mengawasi sesuai dengan aturan operasi, mempromosikan
standar tata kelola perusahaan antara perusahaan Australia terdaftar,
memiliki peran dalam pendidikan investor ritel, menyediakan bahan-bahan
pendidikan yang berkaitan dengan produk termasuk kursus online gratis.
ASX menawarkan produk dan jasa termasuk saham berjangka dan waran,
(www.bapepam.go.id)
2.1.2 Linearitas
Regresi linear dibangun berdasarkan asumsi bahwa variabel-variabel yang
dianalisis memiliki hubungan linear. Prosedur uji linearitas terbagi menjadi dua
jenis, yaitu prosedur analisis melalui grafik dan melalui uji statistik (Widhiarso,
2010).
Salah satu prosedur analisis melalui grafik adalah scatterplot dengan
menunjukkan hubungan antara variabel dalam bentuk titik-titik pertemuan nilai
kuantitatif antara satu variabel dengan variabel lainnya. Plot yang bersifat acak
menunjukkan bahwa hubungan antar variabel yang dianalisis bersifat nonlinear.
Analisis melalui uji statistik dapat dilakukan dengan uji ANOVA yaitu
dengan membandingkan nilai F hitung dengan F tabel atau p-value dengan
𝛼=0.05. Hipotesis yang menyatakan koefisien garis regresi nonlinear akan ditolak ketika p-value < 0.05 atau F hitung < F tabel.
2.1.3 Neural Network
Artificial Neural Network (ANN) atau disebut Jaringan Syaraf Tiruan
(JST) dan yang selanjutnya disebut Neural Network (NN) adalah sistem
pemproses informasi yang memiliki karakteristik menyerupai dengan jaringan
syaraf biologi pada manusia. ( Astuti, D,E. 2009)
Komponen terkecil dari jaringan saraf tiruan adalah unit atau disebut juga
neuron dimana akan menstransformasikan informasi yang diterima menuju
commit to user
dikenal dengan nama bobot yang akan menyimpan informasi pada suatu nilai
tertentu pada bobot tersebut.
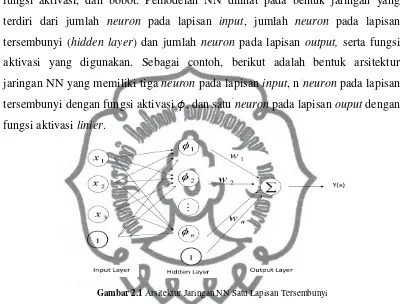
Secara umum NN memiliki beberapa komponen, yaitu neuron, lapisan,
fungsi aktivasi, dan bobot. Pemodelan NN dilihat pada bentuk jaringan yang
terdiri dari jumlah neuron pada lapisan input, jumlah neuron pada lapisan
tersembunyi (hidden layer) dan jumlah neuron pada lapisan output, serta fungsi
aktivasi yang digunakan. Sebagai contoh, berikut adalah bentuk arsitektur
jaringan NN yang memiliki tiga neuron pada lapisan input, n neuron pada lapisan
tersembunyi dengan fungsi aktivasi 𝜙, dan satu neuron pada lapisan ouput dengan
fungsi aktivasi linier.
Gambar 2.1 Arsitektur Jaringan NN Satu Lapisan Tersembunyi .
Menurut Trapletti (2000) arsitektur jaringan pada Gambar 2.1 akan menghasilkan
suatu model Y(X) untuk memprediksi output, sebagai berikut
𝑌 𝑋 =𝑊0+ 𝑊𝑗∆𝑗(𝜙0𝑗 + 𝜙𝑖𝑗𝑥𝑖 3
𝑖=1
) 𝑛
𝑗=1
dengan 𝑊𝑗 dan ∅𝑖𝑗 adalah besaran bobot, dimana 𝑊0 adalah bobot bias input dan
∅0𝑗 adalah bobot bias lapisan. Bias adalah sebuah parameter saraf yang
ditambahkan ke masukan yang sudah terbobot dan melewati fungsi aktivasi untuk
mengaktifkan keluaran sel.
2.1.4 Radial Basis Function Network
RBFN merupakan suatu jaringan yang terdiri atas 3 lapisan, yaitu lapisan
commit to user
dipengaruhi oleh penentuan center, spread, dan bobot koneksi. Apabila
banyaknya neuron pada lapisan tersembunyi sama dengan banyaknya data
pelatihan maka setiap input dapat dipilih sebagai center. Penelitian yang pernah
dilakukan terkait pemilihan center yaitu oleh Sutijo (2006) dengan menggunakan
K-mean kluster sebagai metode pemilihan banyaknya center pada lapisan
tersembunyi, Lin & Chen (2005) menggunakan SOM sebagai metode pemilihan
banyaknya neuron dan center pada lapisan tersembunyi. Metode SOM adalah alat
yang digunakan dalam analisis pengelompokan, dimana algoritmanya tidak jauh
berbeda dengan K-mean kluster. Sementara disini penulis menentukan banyaknya
neuron dan center pada lapisan tersembunyi menggunakan metode K-mean
kluster.
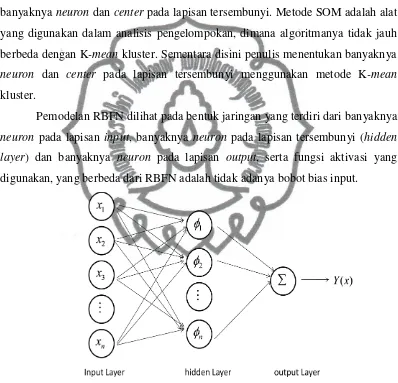
Pemodelan RBFN dilihat pada bentuk jaringan yang terdiri dari banyaknya
neuron pada lapisan input, banyaknya neuron pada lapisan tersembunyi (hidden
layer) dan banyaknya neuron pada lapisan output, serta fungsi aktivasi yang
digunakan, yang berbeda dari RBFN adalah tidak adanya bobot bias input.
Gambar 2.2 Arsitektur Jaringan RBFN secara umum
Arsitektur jaringan pada Gambar 2.2 akan menghasilkan suatu model y(x) untuk
memprediksi output, sebagai berikut
commit to user
dan jika dirubah dalam bentuk matriks adalah sebagai berikut
Y = w𝜙
dengan n sebanyak jumlah input, (𝑤𝑘) adalah besaran bobot dari hidden layer ke
output, ck adalah center, k hidden neuron, dan menunjukkan aturan
Eucledian, dan 𝜙 dipilih sebagai fungsi Gaussian.
Algoritma proses pembentukan jaringan arsitektur RBFN adalah sebagai
berikut
1. Semua variabel independent (x) diatur sebagai nilai input (P) dan variabel
dependent (y) sebagai nilai target atau output (T)
2. Penentuan banyaknya neuron pada lapisan tersembunyi
a. Inisialisasi pembelajaran untuk RBFN center secara acak atau
pengelompokan dari training set.
b. Penentuan spread yang selanjutnya akan disimbolkan dengan 𝜎
menurut Haykin (1994) dapat ditentukan dengan
𝜎=𝑑𝑚𝑎𝑥
2𝑚 (𝟐.𝟐)
dimanadmax adalah jarak maksimum antara RBFN center yang dipilih,
max maxi k, 1, m k i; i j
d c c . Dan m adalah banyaknya center.
3. Penentuan fungsi basis dan operasi hitung pada lapisan tersembunyi.
a. Menghitung jarak (r) setiap data dengan RBFN center menggunakan
persamaan
𝑟= 𝑥𝑖𝑘 − 𝑐𝑗 (𝟐.𝟑)
dimana 𝑥𝑖𝑘 merupakan nilai data ke-i pada variabel ke-k, dan 𝑐𝑗𝑘
merupakan center ke-j, untuk i=1,...,m dan k=1,....n
b. Menghitung hasil fungsi aktivasi dari jarak pada langkah a.
4. Menghitung nilai estimasi w menggunakan persamaan (2.1)
5. Menghitung nilai bobot menggunakan persamaan
W = 𝜙T𝜙 −1𝜙Ty (𝟐.𝟒)
commit to user
Berikut adalah beberapa fungsi aktivasi yang dapat digunakan pada RBFN
(Sutijo, 2006). Fungsi aktivasi adalah fungsi yang digunakan untuk membawa dan
mentransfer nilai input sampai menghasilkan output yang diharapkan.
𝐺𝑎𝑢𝑠𝑠𝑖𝑎𝑛 𝜙 𝑟 =𝑒−𝑟
merupakan spread, dan θ adalah bias yang telah disesuaikan.
Ada dua cara mendapatkan nilai center untuk RBFN, yaitu
1. Secara acak dari training set
2. Secara pengelompokan dari training set
Cara sederhana untuk mendapatkan RBFN center adalah memilih secara
acak himpunan bagian dari input berpola yang berasal dari training set.
Masing-masing RBFN center secara tepat menunjuk pada satu input berpola.
2.1.5 K-mean kluster
Pada metode K-mean, data dipartisi ke dalam kluster, dimana setiap
kluster mempunyai sifat homogen serta antar kluster mempunyai ciri yang
berbeda.
Alogoritma dari metode K-mean dengan menggunakan metode non-hirarki
secara garis besar adalah sebagai berikut :
1. Menentukan pendekatan banyaknya kluster.
2. Menentukan pusat kluster secara acak.
3. Menghitung jarak setiap data yang ada terhadap setiap pusat kluster dengan
𝑑𝑖𝑗 = (𝑥𝑖𝑘 − 𝑐𝑗𝑘)2 𝑛
𝑘=1
dij : jarak kuadrat Euclid antara obyek ke-i dengan center ke-j
commit to user Xik : nilai atau data obyek ke-i pada variabel ke-k.
Cjk : center ke-j dari variabel ke-k
4. Selanjutnya menghitung kembali pusat kluster yang baru yang merupakan
rataan semua variabel pada tiap kluster.
5. Ulangi langkah ke 3 sampai tidak ada perubahan.
2.1.6 Metode Ward
Menurut Khattree & Naik (2000), metode Ward dapat digunakan untuk
menentukan jumlah kluster pada analisis K-mean kluster, dengan membuat plot
antara jumlah kluster dengan ukuran jarak. Secara umum algoritma metode Ward
menurut Kariyam dan Subanar (2004) adalah
a. Dimulai dengan n kluster, kemudian menghitung matriks jarak antar D =
𝑑𝑖ℎ, i = d = 1,2,3,....n yang berukuran nxn
b. Menentukan 2 kluster U dan V yang mempunyai jarak terdekat
c. Menggabungkan dua kelompok terdekat U dan V menjadi satu kelompok
baru, misalkan diberi label (UV), sedemikian hingga ukuran baris dan
kolom menjadi berukuran sama, dan menentukan kembali matriks jarak.
d. Melakukan langkah b dan c sebanyak (n-1) kali, sampai semua data masuk
dalam satu kelompok.
2.2 Kerangka Pemikiran
Data indeks saham yang digunakan dalam penelitian ini cenderung
memiliki pola hubungan yang nonlinear. Dalam analisis data regresi telah banyak
dikembangkan model yang dapat digunakan untuk data nonlinear maupun linear.
Namun pada kenyataannya model tersebut dikembangkan dengan beberapa syarat
asumsi awal yaitu normalitas, multikolinearitas, autokorelasi dan homosedastik.
Oleh karena itu diperlukan pemodelan yang lebih fleksibel salah satunya model
Neural Network (NN).
Berdasarkan tinjauan pustaka yang sudah dijelaskan di atas, analisis data
yang digunakan dalam penelitian ini adalah Radial Basis Function Networks
commit to user
saham dimana input adalah tiga indeks saham luar negeri dan output adalah
IHSG.
Arsitektur RBFN terdiri dari tiga lapisan yaitu lapisan input, lapisan
tersembunyi dan lapisan output. Selain itu dalam RBFN penentuan center, dan
spread sangat mempengaruhi dalam penentuan banyaknya neuron pada lapisan
tersembunyi dan nilai bobot yang didapat. Dalam penelitian ini, peneliti
menggunakan metode K-mean kluster dalam penentuan center dan banyaknya
commit to user
BAB III
METODE PENELITIAN
3.1 Sumber Data
Dalam penulisan skripsi ini, data yang digunakan adalah data sekunder yang
diambil dari www.finance.yahoo.com pada bulan Januari 2011 sampai November
2011.
3.2 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini meliputi variabel dependent
(y) yaitu IHSG dan variabel independent (x) yang merupakan tiga indeks harga
saham luar negeri yaitu Nikkei, ASX, dan FTSE. Pengolahan data dilakukan
dengan bantuan Software MinitabRelease 16.
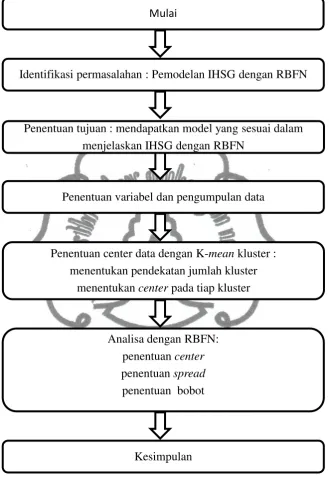
3.3 Analisis Data
Data yang digunakan dalam langkah-langkah analisis adalah data harian
selama periode Januari 2011 -November 2011. Metodologi penelitian ini terdiri
dari beberapa tahap, yaitu :
1. Identifikasi permasalahan tentang pemodelan IHSG.
2. Penentuan tujuan dari penelitian yaitu mendapatkan model yang sesuai
dalam menjelaskan IHSG dengan menggunakan RBFN.
3. Pengumpulan literatur yang berasal dari buku, jurnal serta homepage
yang menunjang sumber ilmiah untuk penelitian.
4. Pemilihan banyaknya center dengan K-mean kluster.
a. Menentukan pendekatan jumlah kluster
b. Menentukan center secara acak
c. Menghitung jarak antara data dengan pusat kluster
d. Selanjutnya menghitung kembali pusat kluster yang baru yang
merupakan rataan semua variabel pada tiap kluster.
commit to user
f. Pendekatan jumlah kluster yang mempunyai error terkecil akan
digunakan sebagai penentuan banyaknya center dalam RBFN
5. Analisis data dengan metode RBFN
a. Banyaknya Center yang didapat dari K-mean kluster merupakan
banyaknya neuron pada lapisan tersembunyi.
b. Menentukan spread.
c. Menentukan jarak data dengan center.
d. Menghitung hasil fungsi aktivasi.
e. Mencari bobot.
f. Menghitung error
6. Tahapan terakhir adalah memberikan kesimpulan yang menjawab
permasalahan. Metodologi ini secara lengkap dapat dilihat pada
commit to user
Gambar 3.1 Alur Penelitian
Mulai
Identifikasi permasalahan : Pemodelan IHSG dengan RBFN
Penentuan tujuan : mendapatkan model yang sesuai dalam menjelaskan IHSG dengan RBFN
Penentuan variabel dan pengumpulan data
Penentuan center data dengan K-meankluster : menentukan pendekatan jumlah kluster
menentukan centerpada tiap kluster
Analisa dengan RBFN: penentuan center
penentuan spread
penentuan bobot
commit to user
dan tiga indeks saham luar negeri sebagai variabel independent (x) yaitu Nikkei,
ASX, dan FTSE. Data diperoleh dari www.finance.yahoo.com periode Januari
2011 sampai November 2011. Data yang diambil adalah untuk semua hari kerja.
Data pada bulan Januari sampai Agustus digunakan sebagai data pelatihan yaitu
sebanyak 122 data, sisanya 53 data yaitu bulan September sampai November
digunakan sebagai data uji.
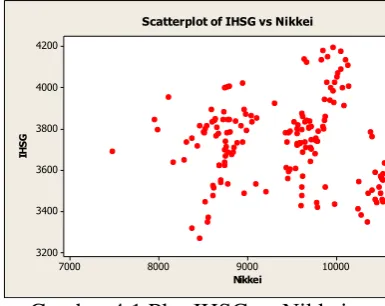
Hubungan antara variabel independet dan dependent bersifat nonlinear,
dapat dilihat pada Gambar 4.1, Gambar 4.2, dan Gambar 4.3 dimana plot yang
dihasilkan bersifat acak. Hal ini juga diperkuat dengan uji hipotesis berikut
𝐻0 : Koefisien garis regresi tidak linear 𝐻1 : Koefisien garis regresi linear
Hasil output kelinieran garis regresi dapat dilihat dari nilai p-value. 𝐻0 akan
ditolak ketika nilai p-value < 0.05, dari output ANOVA dengan sofware Minitab
Release 16 diperoleh nilai p-value 0.057 yang artinya 𝐻0 tidak ditolak sehingga
koefisien garis regresi tidak linear.
10000
Gambar 4.1 Plot IHSG vs Nikkei
7
commit to user
Gambar 4.3 Plot IHSG vs FTSE
4.2 Rancangan dalam RBFN
Sebagaimana telah dijelaskan sebelumnya arsitektur yang digunakan
adalah arsitektur RBFN yang terdiri dari tiga lapisan yang berupa neuron-neuron
yaitu lapisan input, lapisan tersembunyi, dan lapisan output, dengan arah
feedforward. Pada lapisan input digunakan 3 neuron, hal ini karena jumlah
variabel independet yang digunakan sebanyak 3. Pada lapisan tersembunyi
digunakan metode K-mean kluster sebagai penentu banyaknya neuron, sedangkan
dalam lapisan output digunakan satu neuron yaitu nilai variabel dependent y atau
target.
Arsitektur RBFN dapat dilihat pada Gambar 4.4. Nilai
𝑥1,𝑥2,𝑥3merupakan 3 indeks saham global yang berlaku sebagai input. Nilai
Gaussian 𝜙 dan nilai bobot W dalam rancangan belum diketahui.
commit to user
4.3 Pemodelan RBFN
Sebanyak 122 data pelatihan dilakukan perancangan pasangan input dan
output. Hasil rancangan dapat dilihat pada Lampiran 1. Langkah – langkah dalam
menentukan model RBFN adalah sebagai berikut
4.3.1 Preprocessing
Data yang digunakan dalam penelitian ini memiliki nilai yang besar
sehingga ketika masuk dalam fungsi Gaussian mendekati nol, oleh karena itu data
ditransformasi terlebih dahulu sebelum diolah. Transformasi yang digunakan
adalah 𝑥′ = 𝑥𝑖−𝜇𝑖
𝜎𝑖 (Jayalakshmi and Santhakumaran, 2011).
4.3.2 Penentuan Banyaknya Neuron pada Lapisan Tersembunyi
Berdasarkan hasil analisis metode Ward pada Gambar 4.5 diperoleh 3
kluster, 4 kluster, 5 kluster yang nantinya dibandingkan guna memperoleh model
terbaik. Banyaknya kluster menentukan banyaknya neuron pada lapisan
tersembunyi.
Scatterplot Jumlah Kluster vs nilai Ukuran
Gambar 4.5 Plot antara jumlah kluster vs nilai ukuran
Langkah selanjutnya menentukan center dari K-mean kluster. Berikut
commit to user
Tabel 4.1 Output center untuk 3 kluster
Variable Kluster1 Kluster2 Kluster3
Nikkei -1,5486 -0,2364 1,2341 ASX -1,7159 -0,0685 0,9336
FTSE -2,4618 0,2642 0,5265
Tabel 4.2 Output center untuk 4 kluster
Variable Kluster1 Kluster2 Kluster3 Kluster 4
Nikkei -1,5486 -0,2703 1,1977 0,7653
ASX -1,7159 -0,0961 0,5841 2,7546
FTSE -2,4618 0,2628 0,5425 0,2336
Tabel 4.3 Output center untuk 5 kluster
Variable Kluster1 Kluster2 Kluster3 Kluster 4 Kluster 5
Nikkei -1,5486 0,3414 1,2493 1,1233 -0,4970
ASX -1,7159 -0,3302 0,6503 2,9877 0,0495
FTSE -2,4618 0,1322 0,5530 0,3348 0,3237
4.3.3 Penentuan Spread
Penentuan nilai spread dapat dilakukan dengan menggunakan rumus (2.2)
atau dengan mengambil sembarang nilai Standar Deviasi (𝑆2) yang merupakan
penduga dari 𝜎2. Penulis mencoba untuk menggunakan kedua metode di atas,
kemudian dibandingkan untuk memperoleh model terbaik.
Menggunakan rumus (2.3) untuk menentukan nilai spread maka terlebih
dahulu harus mengetahui nilai jarak maksimal dari setiap center pada tiap kluster.
Semisal diambil contoh untuk 3 kluster. Jarak antara center 1 dan 2 adalah
sebagai berikut
𝑐12 = −1,5486−(−0,2364 )2+⋯+ −2,4618−(0,2642) 2
= 3,4448
commit to user
Tabel 4.4 Jarak center untuk 3 kluster
Kluster1 Kluster2 Kluster3
Kluster1 0,0000 3,4448 4,8675
Kluster2 3,4448 0,0000 1,7987
Kluster3 4,8675 1,7987 0,0000
Tabel 4.4 menunjukkan bahwa jarak maksimal terdapat antara kluster ke 1
dan kluster ke 3 yaitu 4,8675, sehingga nilai spread adalah 1,9871. Selanjutnya
adalah menentukan pula nilai spread untuk 4 kluster, dan 5 kluster, dengan
langkah yang sama diperoleh hasil seperti pada Tabel 4.5.
Tabel 4.5 Nilai spread untuk tiap kluster
Jumlah Kluster Nilai Spread
3 kluster 1,9871
4 kluster 2,0187
5 kluster 1.9257
Selain dengan rumus (2.2) penentuan spread dapat pula dilakukan dengan
mengambil sembarang nilai spread sebagai pembanding. Pemilihan nilai spread
dari 1 sampai 10 berdasarkan pada percobaan yang dilakukan dimana ketika nilai
spread semakin besar maka error akan semakin kecil, tetapi untuk 4 kluster dan 5
kluster nilai error mengalami kenaikan saat pemilihan nilai spread 3.
4.3.4 Menentukan Jarak
Bobot diperoleh dengan menentukan jarak dan nilai fungsi aktivasi
terlebih dahulu. Jarak diperoleh dengan menggunakan persamaan (2.3). Semisal
diambil untuk 3 kluster.
𝑟1.1 = 0,740613− −1,5486 + 0.740613−(−1,7159 +⋯
+ 0,074056− −2,4618
commit to user
4.3.5 Mencari Nilai dari Fungsi Gaussian
Seperti yang telah diterangkan di atas selain jarak, nilai fungsi aktivasi
juga harus dicari untuk memperoleh bobot. Penulis menggunakan fungsi aktivasi
Gaussian yaitu 𝜙 𝑟 =𝑒−𝑟 2
2𝜎2 dalam perhitungan. Nilai 𝜎 merupakan nilai spread
yang telah dicari pada langkah 4.3.3, dan r adalah jarak yang diperoleh dari
langkah 4.3.4. Berikut adalah nilai Gaussian untuk 3 kluster.
𝜙 𝑟1.1 =𝑒−
pada data pertama dan center kedua, demikian seterusnya sampai pada 𝜙 𝑟122.3
yaitu nilai Gaussian untuk jarak data ke 122 dengan center ketiga. Nilai Gaussian
commit to user
Hasil dari nilai Gaussian untuk tiap kluster dapat dilihat pada lampiran 3. Sebagai
pembanding dihitung pula untuk nilai spread yang lain.
4.3.6 Mencari Nilai Bobot
Estimasi parameter dengan metode Least Square dilakukan untuk
menentukan fungsi dari bobot. Persamaan (2.1) dapat dijabarkan dalam bentuk
matriks menjadi
Diperoleh nilai pendekatan untuk target yaitu
commit to user
kemudian diturunkan terhadap 𝑤0 dan disama dengankan 0
𝜕𝐽
Dapat disederhanakan ke dalam bentuk matriks menjadi
commit to user
Setelah ditemukan fungsi dari bobot dan didapat nilai Gaussian pada
langkah 4.3.5 , maka selanjutnya nilai bobot dapat dicari. Hasil dari nilai bobot
dapat dilihat pada lampiran 4.
Berikut adalah bagian dari percobaan yang telah dilakukan peneliti. Tabel
4.6 menjelaskan nilai MSE sebagian dari model RBFN yang didapat, dimana c
menyatakan jumlah neuron pada lapisan tersembunyi, dan 𝜎adalah nilai spread.
Berdasarkan Tabel 4.6 diperoleh kesimpulan bahwa nilai MSE terkecil pada data
uji adalah 5 kluster dengan spread 8. Pada data pelatihan MSE terkecil pada 5
kluster dengan spread 1. Menurut Suhartono (2007) model yang memberikan
hasil data uji terbaik yang dipilih, dan kemudian dilakukan estimasi kembali pada
semua data yang ada, sehingga model yang terpilih adalah 5 neuron pada lapisan
tersembunyi dengan spread 8. Arsitektur RBFN terpilih dapat dilihat pada
Gambar 4.6.
Tabel 4.6 Nilai MSE dari Hasil Percobaan yang Dilakukan
Model
(5,7.41) 0,602185 0,601363
(5,1.0) 0,598944 0,740674
(5,6.0) 0,669834 0,558515
commit to user
Gambar 4.6 Arsitektur RBFN Terpilih
4.3.7 Uji Linearitas
Dilakukan uji linearitas antara target dengan nilai prediksi dari hasil
pengujian terhadap semua data yaitu Januari 2011 – November 2011
menggunakan model terpilih. Gambar 4.6 menunjukkan plot hubungan antara
nilai prediksi dengan target. Hal ini diperkuat juga dengan uji hipotesis sebagai
berikut
𝐻0 : Koefisien garis regresi tidak linear 𝐻1 : Koefisien garis regresi linear
Hasil output kelinieran garis regresi dapat dilihat dari nilai p-value. 𝐻0 akan
ditolak ketika nilai p-value < 0.05, dari output ANOVA dengan sofware Minitab
Release 16 diperoleh nilai P-value 0.000 yang artinya 𝐻0ditolak sehingga
koefisien garis regresi linear.
3
commit to user
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
1. Prosedur pemodelan RBFN dimulai dari diskripsi data, uji nonlinearitas
data, penentuan bobot dengan menentukan jarak dan nilai fungsi aktivasi
terlebih dahulu. Model terbaik adalah model dengan MSE terkecil. Hasil
analisis data indeks harga saham pada data uji bulan September –
November 2011 dengan Radial Basis Function Network diperoleh bahwa
untuk data pelatihan model terbaik diperoleh pada pemilihan 5 neuron
pada lapisan tersembunyi dengan spread 1 dengan MSE 0.59844. Pada
data uji pemilihan 5 neuron pada lapisan tersembunyi dengan spread 8
menghasilkan model terbaik dengan MSE 0.557535.
2. Model terbaik dapat dinotasikan 𝑦 𝑥 = 5𝑖=1𝑤𝑖𝜙𝑖(𝑥) dengan bobot
𝑤 =
893,4 10255,9
−11033,8
4891,7
−4740,9
5.2 Saran
Saran yang dapat diberikan dari penulis bagi para pembaca antara lain
adalah pembaca dapat melakukan analisis dengan metode neural network yang
lain yang lain. Selain itu pembaca dapat menggunakan metode pemilihan center
commit to user
LAMPIRAN
Lampiran 1 : Nilai Target dan Input data pelatihan yaitu bulan Januari –
Agustus 2011
Lampiran 2 : Nilai Jarak untuk bulan Januari – Agustus 2011
Lampiran 3 : Hasil nilai Gaussian untuk tiap kluster pada bulan Januari
-Agustus 2011
Lampiran 4 : Hasil nilai Bobot untuk tiap kluster pada bulan Januari -Agustus
commit to user
Lampiran 1 : Nilai Target dan Input data pelatihan yaitu bulan Januari – Agustus 2011
0,074056 0,141736 0,44795 0,46294 … -0,249714 0,740613 0,959074 1,17022 1,03324 … 0,253598 0,789474 0,758183 1,30578 1,29013 … -0,227486
commit to user
1. Lampiran 2 : Nilai Jarak untuk bulan Januari – Agustus 2011
commit to user
3. 5 kluster
jarak 1 2 3 4 5
1 7,49081 1,94959 1,59107 4,49100 2,23421 2 7,74877 2,17722 1,51455 4,34920 2,46318 3 8,80460 3,11705 1,53336 3,83765 3,40765 4 8,65785 2,96126 1,42827 3,86846 3,25448 5 7,44109 1,92516 1,64063 4,53313 2,20625
. . . . . .
. . . . . .
. . . . . .
commit to user
Lampiran 3 : Hasil nilai Gaussian untuk tiap kluster pada bulan Januari -Agustus 2011
118 0,527869 0,051402 0,000814 119 0,231172 0,219750 0,010412 120 0,123083 0,569365 0,057749 121 0,041400 0,809191 0,164156 122 0,016990 0,891368 0,290756
2. 4 Kluater
𝜙 1 2 3 4
1 0,0010240 0,588734 0,755563 0,137482 2 0,0006322 0,516606 0,771697 0,153545 3 0,0000741 0,263037 0,741025 0,214197 4 0,0001014 0,297916 0,773212 0,212969 5 0,0011216 0,597607 0,742149 0,132453
. . . . .
. . . . .
. . . . .
commit to user
3. 5 Kluater
𝜙 1 2 3 4 5
1 0,0005179 0,599005 0,710826 0,065911 0,510154 2 0,0003048 0,527743 0,733968 0,078048 0,441284 3 0,0000289 0,269811 0,728318 0,137277 0,208944 4 0,0000408 0,306555 0,759533 0,132952 0,239765 5 0,0005724 0,606699 0,695639 0,062617 0,518766
. . . . . .
. . . . . .
. . . . . .
commit to user
commit to user
.