LECTURE 9
REGRESI LOGISTIK &
DISKRIMINAN
DR. MUDRAJAD KUNCORO, M.Soc.Sc
Fakultas Ekonomi & Pascasarjana UGM Outline: Outline:
•
• Multinomial Multinomial RegresiRegresi •
• Binary Binary LogistikLogistik •
• AnalisisAnalisis DiskriminanDiskriminan •
• PerbandinganPerbandingan
multinomial, binary,
multinomial, binary, dandan diskriminan
ANALISIS REGRESI LOGISTIK
ANALISIS REGRESI LOGISTIK
–
Tidak memiliki asumsi normalitas atas
variabel bebas yang digunakan dalam
model
–
Variabel bebas bisa variabel kontinyu,
diskrit, dan dikotomis
–
Distribusi respon atas variabel terikat
diharapkan nonlinear
–
Jenis:
• binary logistic regression
STUDI KASUS WANITA KARIR VS IBU RT
STUDI KASUS WANITA KARIR VS IBU RT
• Studi kasus mengenai
probabilitas wanita karir dan
ibu rumah tangga
(Tabachnick, 1996: bab 12)
• Pertanyaan yang hendak
dijawab adalah: apakah
status pekerjaan (wanita
karir versus ibu rumah
tangga) dapat dijelaskan
oleh empat variabel perilaku
(ATTHOUSE, ATTMAR,
ATTROLE, dan CONTROL)
• Keempat variabel penjelas
tersebut adalah:
– ATTHOUSE= perilaku terhadap pekerjaan di dalam rumah. – ATTMAR=perilaku terhadap status pernikahan. – ATTROLE= perilaku terhadap perannan/hak wanita. – CONTROL= kemampuan mengendalikan diri (locus of control).Tahapan
Tahapan
Estimasi
Estimasi
Regresi
Regresi
Logistik
Logistik
Multinomial (1)
Tahapan
Hasil
Hasil
Output SPSS
Output SPSS
Model Fitting Information
884.175 836.411 47.764 8 .000 Model Intercept Only Final -2 Log
Likelihood Chi-Square df Sig.
• Chi square signifikan pada derajat 1% dengan nilai 47,8. artinya model dengan hanya intercept berbeda secara statistik dibandingkan dengan model yang memasukkan semua variabel prediktor.
Classification 213 25 2 88.8% 98 30 2 23.1% 63 10 3 3.9% 83.9% 14.6% 1.6% 55.2% Observed wanita karir ibu RT bahagia ibu RT tidak bahagia Overall Percentage wanita karir ibu RT bahagia ibu RT tidak bahagia Percent Correct Predicted
• Dari hasil overall classification result untuk regresi logistik multinomial ternyata kurang baik. Persentase kebenaran klasifikasi untuk ibu RT bahagia dan ibu RT tidak bahagia yang di bawah 50 %, yaitu 23.1% dan 3.9%, menunjukkan banyak salah klasifikasi untuk ibu RT bahagia dan tidak bahagia. Oleh karenanya, kita perlu melakukan klasifikasi ulang dan menggunakan regresi logistik binari.
Tahapan
Tahapan
Estimasi
Estimasi
Binary Logistic Regression
Binary Logistic Regression
Klasifikasi
Klasifikasi
ulang
ulang
:
:
MengubahMengubah values values padapada workstatworkstatÆ
Æ
11””wanita wanita karirkarir””, 2, 2””Ibu RT Ibu RT bahagiabahagia””, 3 , 3 ““IbuIbu RT RT tidaktidak bahagiabahagia””, , dandan values values padapada status
Tahapan
Tahapan
Tahapan
Output
Output
Estimasi
Estimasi
Regresi
Regresi
Logistik
Logistik
Binari
Binari
• Pengujian dengan model penuh dengan 4 variabel bebas dibanding model hanya dengan konstanta terbukti secara statistik dapat dipercaya. Ini terlihat dari Chi-Square(4,
N=440)=22.78 yang
signifikan dengan p<,001 artinya model dengan hanya intercept berbeda secara statistik dibandingkan dengan model yang memasukkan semua variabel prediktor.
• Kemampuan prediksi model ini lumayan bagus. Tingkat sukses total 60%, dengan 46.6% ibu RT dan 71.3% wanita karir telah mampu diprediksi secara benar
Omnibus Tests of Model Coefficients
22.781 4 .000 22.781 4 .000 22.781 4 .000 Step Block Model Step 1 Chi-square df Sig. Classification Tablea 96 110 46.6 69 171 71.3 59.9 Observed Ibu RT wanita karir work status Overall Percentage Step 1
Ibu RT wanita karir
work status Percentage Correct Predicted
The cut value is .500 a.
Output
Output
Estimasi
Estimasi
Binary
Binary
Regresi
Regresi
Variables in the Equation
-.032 .023 1.826 1 .177 .969 .925 1.014 -.070 .016 19.851 1 .000 .932 .904 .962 .014 .012 1.345 1 .246 1.014 .991 1.038 -.055 .077 .506 1 .477 .947 .814 1.101 3.423 .978 12.255 1 .000 30.656 ATTHOUS ATTROLE ATTMAR CONTRO Constant Step 1a
B S.E. Wald df Sig. Exp(B) Lower Upper 5.0% C.I.for EXP(B
Variable(s) entered on step 1: ATTHOUSE, ATTROLE, ATTMAR, CONTROL. a. Correlation Matrix 1.000 -.618 -.726 -.036 -.414 -.618 1.000 .313 -.230 -.113 -.726 .313 1.000 -.036 -.016 -.036 -.230 -.036 1.000 -.165 -.414 -.113 -.016 -.165 1.000 Constant ATTHOUSE ATTROLE ATTMAR CONTROL Step 1
Output
Output
Estimasi
Estimasi
Binary
Binary
Logistik
Logistik
• Matriks korelasi menunjukkan tidak adanya
multikolinearitas yang serius antarvariabel bebas,
sebagaimana terlihat dari nilai korelasi antarvariabel
bebas yang di bawah 0,8.
• Hasil di atas juga menyajikan koefisien regresi, statistik
Wald, odds ratio, serta interval dengan keyakinan 95%
atas odds ratio untuk masing-masing variabel bebas.
Menurut kriteria Wald, hanya variabel perilaku terhadap
peranan wanita yang dapat diandalkan untuk
memprediksi status pekerjaan wanita. Ini terlihat dari
nilai z sebesar –19.8 dengan p<0,01. Odds ratio 0,93
menunjukkan adanya sedikit perubahan dalam
kemungkinan bekerja atas dasar satu unit perubahan
perilaku terhadap peranan wanita.
ANALISIS DISKRIMINAN
ANALISIS DISKRIMINAN
-
Semua variabel independen merupakan
variabel yang kontinyu dan berdistribusi
normal
-
Tujuan utama:
• diskriminasi
: Pembedaan grup
dicapai dengan fungsi diskriminan
• klasifikas
i: mengklasifikan
individu/obyek ke dalam grup
terpisah berdasarkan sejumlah
variabel bebas
Studi tentang Kluster Industri
Michael E. Porter
• Innovation: Location Matters (2001) •Competing Across Locations (1998) • On Competition (1998)
• The Role of Geography in the Process of Innovation and the Sustainable (1998)
• Competitive Advantage of Firms (1998)
• Clusters and the New Economics of Competition (1998)
Mudrajad Kuncoro
• Analisis Spasial & Regional: Studi Aglomerasi dan Kluster Industri Indonesia (2002)
• Why Manufacturing Industry Persisted to Cluster Spatially in Java ?, Gadjah Mada International Journal of Business (2003), 5(2)
• “Regional Clustering Of Indonesia’s Manufacturing Industry: A Spatial Analysis with Geographic Information System (GIS)”, Gadjah Mada
Kasus
Kasus
IKRT
IKRT
di
di
Jawa
Jawa
• Sebagai contoh aplikasi analisis diskriminan akan disajikan studi empiris mengenai industri kecil dan rumah tangga (IKRT) di Jawa
(Kuncoro, 2000)
• Pertanyaan penelitian yang
hendak dijawab adalah: Apakah sentra-sentra IKRT di Jawa
merupakan industrial district
dengan ciri-ciri yang menonjol?
• Untuk memudahkan analisis, kita
mengklasifikasikan sentra-sentra industri dan non-sentra industri
• Di = di1 RURAL + di2 WAGES +
di3 SKILL + di4 STEP + di5AGE + di6 POP + di7 UNPAIDW + di8 PRODUCTIVITY
Variabel:
• proporsi daerah perdesaan
(RURAL)
• upah rata-rata (WAGES)
• jumlah tenaga terdidik dengan
pendidikan minimum SMU (SKILL)
• proporsi perusahaan yang
terlibat dalam program Bapak Angkat (STEP)
• rata-rata umur perusahaan
(AGE)
• jumlah penduduk (POP)
• proporsi pekerja keluarga (UNPAIDW)
• produktivitas tenaga kerjada (PRODUCTIVITY)
Tahapan
Tahapan
Tahapan
Estimasi
Estimasi
Diskriminan
Diskriminan
define range
Tahapan
Tahapan
Estimasi
Estimasi
Diskriminan
Diskriminan
Æ
Tahapan
Tahapan
Estimasi
Estimasi
Diskriminan
Diskriminan
Æ
Output
Output
Estimasi
Estimasi
Diskriminan
Diskriminan
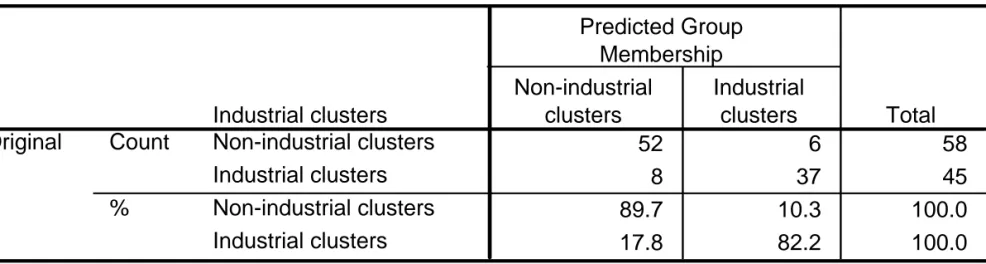
Classification Results a 52 6 58 8 37 45 89.7 10.3 100.0 17.8 82.2 100.0 Industrial clusters Non-industrial clusters Industrial clusters Non-industrial clusters Industrial clusters Count % Original Non-industrial clusters Industrial clusters Predicted Group Membership Total
86.4% of original grouped cases correctly classified. a.
Secara umum model diskriminan ini mampu
mengalokasikan secara benar lebih dari 86% kasus.
Tabel diatas menyajikan ringkasan klasifikasi dari model
tsb, yang hanya gagal mengalokasikan 6 kabupaten ke
dalam non-sentra industri dan 8 kasus untuk sentra
industri. Akibatnya, keanggotan grup secara benar telah
diprediksi sebesar 89.7% untuk non-sentra industri dan
82.2% untuk sentra industri.
Output
Output
Estimasi
Estimasi
Diskriminan
Diskriminan
Wilks' Lambda
.407 87.312 8 .000 Test of Function(
1
Wilks'
Lambda Chi-square df Sig.
Tabel diatas memperlihatkan chi-square yang tinggi
dan signifikan pada derajat kepercayaan 1% yaitu
sebesar 87.312. Artinya model dengan hanya
intercept berbeda secara statistik dibandingkan
dengan model yang memasukkan semua variabel
prediktor
Output
Output
Estimasi
Estimasi
Diskriminan
Diskriminan
• upah merupakan variabel terbaik untuk memprediksi lokasi IKRT di sentra industri dan non-sentra industri.
• Koefsien untuk upah yang positif menunjukkan bahwa semakin tinggi
upah semakin besar kemungkinan IKRT mengelompok di sekitar sentra industri
• Proporsi tenaga kerja keluarga dan proporsi yang tinggal di perdesaan memiliki daya prediksi yang kurang lebih sama dengan tanda negatif. Tanda koefisien yang negatif menunjukkan bahwa semakin rendah
proporsi pekerja keluarga dan proporsi pedesaan dalam suatu kabupaten maka akan mendorong IKRT untuk mengelompok di seputar sentra
industri. Structure Matrix .667 -.659 -.656 .558 -.319 .232 .054 .041 Average wages
Family workers proportion Rural proportion
Productivity of labour Age of firm
Step father proportion Number of skilled workers
Population
1 Function
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function.
HOMEWORK
1.Untuk kasus studi wanita:
a. coba anda lakukan estimasi dengan model diskriminan, baik dengan 3 klasifikasi (workstat) dan 2 klasifikasi (STATUS), dengan menggunakan prediktor yang sama.
b. Bandingkan hasil estimasi dengan diskriminan dan regresi logistik.
c. Interpretasikan hasil berdasarkan model yang menurut anda paling baik.
2.Untuk kasus IKRT di Jawa:
a. Bandingkan hasil estimasi model diskriminan dengan 2 klasifikasi daerah (D) dan 3 klasifikasi (GROUP3).
b. Bandingkan hasil estimasi dengan diskriminan dan regresi logistik.