i
TUGAS AKHIR
Penerapan Fitur Seleksi Forward Selection Menggunakan
Algoritma Naive Bayes Untuk
Menetukan Atribut Yang Berpengaruh Pada Klasifikasi
Kelulusan Mahasiswa
Oleh:
Bondhan Arya Purnanditya
A11.2011.05957
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2015
ii UNIVERSITAS DIAN NUSWANTORO
PERSETUJUANTUGAS AKHIR
JUDUL : Penerapan Fitur Seleksi Forward Selection Menggunakan Algoritma Naive Bayes Untuk Menetukan Atribut Yang Berpengaruh Pada Klasifikasi Kelulusan Mahasiswa
NAMA : Bondhan Arya Purnanditya NIM : A11.2011.05957
Proposal ini telah disetujui untuk diseminarkan dihadapan Komite Seminar. Semarang, Oktober 2015
Ahmad Zainul Fanani, SSi, M.Kom Pembimbing
iii
DAFTAR ISI
HALAMAN JUDUL ………i
PERSETUJUAN PROPOSAL TUGAS AKHIR .………...ii
DAFTAR ISI ... iii
DAFTAR GAMBAR ... v DAFTAR TABEL ... vi BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 4 1.3 Batasan Masalah ... 4 1.4 Tujuan Penelitian ... 4 1.5 Manfaat Penelitian ... 5 1.6 Sistematika Penelitian ... 5
BAB II TINJAUAN PUSTAKA ... 6
2.1 Tinjauan Studi ... 6
2.2 Landasan Teori ... 8
2.2.1 Klasifikasi ... 8
2.2.2 Naïve Bayes ... 8
2.2.3 Forward Selection ... 11
2.3 Evaluasi dan Validasi Hasil Klasifikasi Data Mining ... 13
2.3.1 Confusion Matrix ... 13
2.3.2 Kappa ... 14
2.4 Dataset IAsol ... 15
2.4.1 Fakultas Ilmu Komputer ... 16
2.4.1.1 Teknik Informatika ... 16
2.4.1.2 Sistem Informasi ... 16
2.5 Kerangka Pemikiran ... 17
BAB III METODE PENELITIAN... 18
3.1 DesainPenelitian ... Error! Bookmark not defined. 3.2 Pengumpulan Data ... 18 3.3 Pengolahan Awal Data ... Error! Bookmark not defined.
iv 3.4 Metode Yang Diusulkan ... Error! Bookmark not defined.
3.5 Pengujian Model/Metode ... 22
3.6 Evaluasi Dan Validasi Hasil ... 23
3.7 Jadwal Penelitian ... 23
BAB IV HASIL DAN PEMBAHASAN ... 24
4.1 Hasil ... 24
4.1.1 Algoritma Naïve Bayes ... 24
4.1.1.1 Evaluasi Naïve Bayes dengan data sampel ... 25
4.1.1.2 Evaluasi Naïve Bayes dengan data lengkap ... 26
4.1.2 Naïve Bayes dengan Forward Selection sebagai fitur seleksi ... 27
4.1.2.1 Evaluasi Naïve Bayes dengan Forward Selection sebagai fitur seleksi dengan data sampel ... 28
4.1.2.2 Evaluasi Naïve Bayes dengan Forward Selection sebagai fitur seleksi dengan data lengkap ... 41
4.2 Pembahasan ... 43
BAB V ... 45
5.1 Kesimpulan ... 45
5.2 Saran ... 45
v
DAFTAR GAMBAR
Gambar 2.1: Relasi Variabel Pada Naive Bayes ... 10
Gambar 2.2: Tahapan Feature Selection ... 12
Gambar 2.3: Kerangka Pemikiran ... 17
Gambar 4.1: Validasi Naïve Bayes Data Sampel... 26
Gambar 4.2: Validasi Naïve Bayes Data Lengkap... 27
Gambar 4.3: Kappa Naïve Bayes Data Lengkap ... 27
Gambar 4.4: Validasi Forward Selection-Naïve Bayes Data Sampel ... 41
Gambar 4.5: Validasi Forward Selection-Naïve Bayes Data Lengkap ... 42
vi
DAFTAR TABEL
Tabel 2.1: Tinjauan Studi ... 7
Tabel 2.2: Confusion Matrix ... 13
Tabel 3.1: Tipe Atribut Data ... 19
Tabel 4.1: Data Training Cross Validation Naïve Bayes ... 25
Tabel 4.2: Data Training 1 ... 29
Tabel 4.3: Data Training 2 ... 30
Tabel 4.4: Data Training 3 ... 30
Tabel 4.5: Data Training 4 ... 31
Tabel 4.6: Data Training 5 ... 32
Tabel 4.7: Data Training 6 ... 33
Tabel 4.8: Data Training 7 ... 34
Tabel 4.9: Data Training 8 ... 35
Tabel 4.10: Data Training 9 ... 36
Tabel 4.11: Data Training 10 ... 37
Tabel 4.12: Validasi Atribut Kelompok ... 38
Tabel 4.13: Tahapan Generation Forward Selection... 39
Tabel 4.14: Model Subset Forward Selection ... 40
Tabel 4.15: Model Atribut Forward Selection-Naïve Bayes Data Sampel ... 40
Tabel 4.16: Model Atribut Forward Selection-Naïve Bayes Data Lengkap ... 41
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Universitas dalam pendidikan di Indonesia merupakan salah satu bentuk perguruan tinggi selain akademi, institut, politeknik, dan sekolah tinggi [1]. Universitas terdiri atas sejumlah fakultas yang menyelenggarakan pendidikan akademik dan pendidikan vokasi pada sejumlah ilmu pengetahuan, teknologi, seni dan jika memenuhi syarat dapat menyelenggarakan pendidikan profesi. Universitas adalah suatu institusi pendidikan tinggi dan penelitian, yang memberikan gelar akademik dalam berbagai bidang. Universitas didirikan untuk mengarahkan lulusannya menjadi tenaga profesional, siap kerja, tenaga pendidikan, atau bahkan peneliti. Pada umumnya program yang ditawarkan di salah satu Universitas adalah program pendidikan sarjana dan pascasarjana [2]. Didalam suatu universitas terdapat beberapa fakultas-fakultas diantaranya fakultas-fakultas ilmu komputer, fakultas-fakultas ekonomi, fakultas-fakultas bahasa dan fakultas lainnya.
Fakultas ilmu komputer adalah salah satu fakultas yang ada di sebuah perguruan tinggi yang mempelajari tentang komputasi, pemrograman, dan perhitungan dalam korespondensi dengan sistem komputer. Bidang studi ini menggunakan teori tentang bagaimana komputer bekerja untuk merancang, menguji, dan menganalisis konsep agar dapat berfungsi dengan baik[3].
Teknik informatika adalah suatu program studi di fakultas ilmu komputer yang didalamnya mempelajari tentang pemrosesan, pengarsipan, dan penyebaran informasi dengan menggunakan teknologi informasi dan pemrograman yang berbasis komputer[4]. Di program studi ini diharapkan mahasiswa dapat menentukan satu diantara dua bidang konsentrasi yaitu web developing dan mobile developing.Sistem informasi adalah program studi ilmu komputer yang membahas tentang sekumpulan
2 perangkat keras dan perangkat lunak yang dirancang untuk mentransformasikan data dalam bentuk informasi yang berguna dan juga untuk cara di mana orang berinteraksi dengan teknologi ini dalam mendukung proses bisnis [4]. Pada sistem informasi juga diharapkan mahasiswa dapat menentukandiantara dua konsentrasi yaitu sistem enterprise dan audit sistem, sesuai dengan minat bakat mahasiwa itu sendiri.
Berdasarkan berlimpahnya data mahasiswa dan data jumlah kelulusan mahasiswa, informasi yang tersembunyi dapat diketahui dengan cara melakukan pengolahan terhadap data mahasiswa sehingga berguna bagi pihakuniversitas [5].Pengolahan data mahasiswa perlu dilakukan untuk mengetahui informasi penting berupa pengetahuan baru (knowledge Discovery), misalnya informasi mengenai pengklasifikasian data mahasiswa berdasarkan profil dan data akademik. Pengetahuan baru tersebut dapat membantu pihak universitas untuk melakukan klasifikasi mengenai tingkat kelulusan mahasiswa guna menetukan strategi untuk meningkatkan kelulusan pada tahun-tahun berikutnya.
Berdasarkan data yang diperoleh dari IAsol yaitu sebuah sistem informasi akademik Universitas Abadi Karya Indonesia atau UNAKI [6] yang didalamnya terdapat beberapa informasi akademik diantaranya status dan indeks prestasi mahasiswa, kartu rencana studi, matakuliah syarat dan prasyarat yang menjadi penunjang prestasi. Pada penelitian kali ini dataset yang akan digunakan yaitu dataset yang diambil dari IAsolkhususnya pada fakultas ilmu komputer[7]. Berdasar data yang ada, total jumlah kelulusan mahasiswa fakultas ilmu komputer pada tahun 2008 sampai dengan tahun ajaran 2011 yang jumlah kelulusannya fluktuatif dijadikan sebagai dasar acuan dilakukannya proses klasifikasi, maka penulis akan melakukan penelitian mengenai klasifikasi kelulusan mahasiswa yaitu dengan menggunakan data mahasiswa Fakultas Ilmu Komputer tahun ajaran 2008 sampai dengan tahun ajaran 2011.
Penelitian ini akan melakukan analisis data secara ilmiah dengan menggunakan metode klasifikasi Data Mining kelulusan mahasiswa Fakultas Ilmu Komputer tahun 2008 sampai dengan tahun ajaran 2011. Jika hasil klasifikasi kelulusan mahasiswa menunjukkan tingkat peningkatan maupun penurunan, maka hasil klasifikasi tersebut
3 dapat dijadikan sebagai salah satu bahan evaluasi dalam menentukan kebijakan pihak fakultas ilmu komputer dengan menggunakan teknik data mining.
Penelitian ini akan melakukan pengklasifikasian berdasarkan dataset IAsol yang didapat dari Universitas Abadi Karya Indonesia khususnya di Fakultas Ilmu Komputer pada tahun ajaran 2008 sampai 2011. Atribut yang akan digunakan dalam melakukan klasifikasi kelulusan adalah Nomor Induk Mahasiswa (NIM), nama, jurusan, umur, jenis kelamin, daerah asal, status pernikahan, status pekerjaan, kelompok atau jenis beasiswa, indeks prestasi dari semester 1 sampai dengan semester 9, IPK, jumlah sks yang ditempuh dan jenis konsentrasi jalur peminatan. Berbagai algoritma klasifikasi Data Mining telah banyak diterapkan untuk membantu mengklasifikasikan penentuan status kelulusan salah satunya menggunakanNaïve
bayes. Naïve bayes diketahui memiliki kecepatan komputasi yang sangat tinggi,
mampu menangani masalah data dataset yang berdimensi besar dan dataset yang bersifat Class Imbalance[8][9][10][11][12]. Pada penelitian kali ini selain mendapatkan nilai akurasi yang baik juga bertujuanmendapatkan model atribut yang berpengaruh dengan cara menerapkan Feature Selection.
Feature Selectionadalah salah satu cara untuk menentukan atribut yang paling
berpengaruh di dalam dataset. Feature Selection berperan memilih subset yang tepat dari set fitur asli, karena tidak semua fitur/atribut relevan dengan masalah [13]. Bahkan beberapa dari fitur atau atribut tersebut mengganggu dan dapat mengurangi akurasi. Noisy Features atau fitur yang tidak terpakai tersebut harus dihapus untuk meningkatkan akurasi. Selain itu dengan fitur atau atribut yang banyak akan memperlambat proses komputasi.
Wraper Feature Selection terdiri dari Forward Selection, Backward Elimination dan Stepwise Selection. Forward Selection dan Stepwise Selection memiliki hasil yang
lebih memuaskan dibandingkan dengan proses Backward Elimination. Forward
Selection juga memerlukan waktu komputasi yang relatif lebih pendek dibandingkan
dengan Backward Elimination maupun dengan Stepwise Selection.
Pada penelitian ini akan menggunakan Forward Selection. Forward Selection atau seleksi kedepan dalam analisisnya pemilihan ke depan di mulai dengan tidak ada
4 prediktor dalam model untuk membantu meningkatkan hasil akurasi dan menentukan atribut yang berpengaruh.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan di atas, rumusan masalah pada penelitian ini adalah:
1. Bagaimana mendapatkan hasil akurasi yang maksimal dengan menggunakan algoritma klasifikasi Naive Bayes.
2. Bagaimana fitur seleksi Forward Selection dapat menentukan atribut yang
paling berpengaruh dan dapat membantu meningkatkan hasil akurasi klasifikasi Naïve Bayes dari dataset dengan data yang besar.
1.3 Batasan Masalah
Untuk menghindari penyimpangan dari judul yang sebenarnya serta keterbatasan pengetahuan yang dimiliki oleh penulis, adapun batasan masalah pada tugas akhir ini sebagai berikut:
1. Dataset didapat dari sistem informasi akademik Universitas Aki Semarang [7] 2. Berisi 240 record dan 21 atribut.
1.4 Tujuan Penelitian Tujuan penelitian ini adalah
1. Mendapatkan hasil akurasi menggunakan algoritma klasifikasi Naive Bayes. 2. Menerapkan fitur seleksi Forward Selection untuk menentukan model atribut
yang berpengaruh dan dapat membantu meningkatkan hasil akurasi klasifikasi algoritma Naïve Bayes.
5 1.5 Manfaat Penelitian
Manfaat dari penelitian ini diharapkan membantu administrasi perguruan tinggi untuk memberikan peringatan dini dan pembimbingan awal bagi mahasiswa yang kemungkinan tidak lulus tepat waktu dan membantu perguruan tinggi dalam membuat kebijakan untuk bisa meningkatkan kelulusan mahasiswa.
1.6 Sistematika Penelitian
Penulisan pada penelitian ini akan dibagi menjadi lima bagian, yaitu:
BAB I Pendahuluan
Bab ini membahas tentang latar belakang penelitian tentang klasifikasi status kelulusan mahasiswa, rumusan permasalahan yang ditemukan, tujuan serta manfaat dari penelitian, dan sistematika penulisan.
BAB II Tinjauan Pustaka
Bab ini berisi tentang penelitian-penelitian terkait khususnya mengenani
State-of-The-Art dari penelitian tentang klasifikasi kelulusan mahasiswa dan tinjauan pustaka
untuk teori-teori yang digunakan, serta kerangka pemikiran. BAB III Metode Penelitian
Bab ini akan menjelaskan metode penelitian yang digunakan, secara umum terdiri dari teknik pengumpulan data yang digunakan, proses pengolahan awal data, eksperimen dan pengujian metode, serta evaluasi dan validasi hasil.
BAB IV Hasil dan Pembahasan
Bab ini akan berisi pembahasan dari hasil eksperimen yang dilakukan. Bagian ini akan berisi data yang disajikan dalam bentuk tabel-tabel dan hasil analisa tingkat akurasi dari metode yang digunakan.
BAB V Penutup
Bab ini berisi kesimpulan dari hasil penelitian dan saran dari penelitian yang telah dilakukan.
6
BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Studi
Berikut ini beberapa penelitian terkait yang tentang klasifikasi yang menggunakan algoritma Naive Bayes dan Forward Selection:
Alfa Saleh [10] dalam penelitiannya yang berjudul Penerapan Data Mining Dengan
Metode Klasifikasi Naïve Bayes Untuk Memprediksi Kelulusan Mahasiswa Dalam Mengikuti English Proficiency Test. Metode Naive Bayes memanfaatkan data
training untuk menghasilkan probabilitas setiap kriteria untuk class yang berbeda, sehingga nilai-nilai probabilitas dari kriteria tersebut dapat dioptimalkan untuk memprediksi kelulusan mahasiswa berdasarkan proses klasifikasi yang dilakukan oleh metode Naive Bayes itu sendiri. Dan metode tersebut berhasil mengklasifikasikan 49 data dari 50 data yang diuji. Sehingga dengan demikian metode Naive Bayes ini berhasil memprediksi kelulusan mahasiswa dengan persentase keakuratan sebesar 98 %.
Mujib Ridwan, Hadi Suyono dan M. Sarosa [11] dalam penelitiannya yang berjudul
Penerapan Data Mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier. Algoritma Naïve Bayes
menghasilkan nilai precision83%, recall50%, dan accuracy70%.
Carlos N. Silla Jr [14] menerapkan Feature Selection dengan pendekatan Wrapper
Feature Selection yaitu Genetic Algorithm(GA) diterapkan pada beberapa algoritma
yaitu Naive-Bayes, Decision Tree (J48), Neural Nets, Support Vector Machines and
Multi-Layer Perceptron.Carlos N. Silla Jr menjelaskan bahwa hasil yang dicapai
dengan cara pemilihan fitur yang ini berlaku efektif untuk J48, Neural Nets dan
7 L.Ladha dan T.Deepa[15] dalam penelitiannya yang berjudul Feature Selection
Methods And Algorithms. Bayesian classifier adalah statistik, algoritma klasifikasi Naive Bayes didasarkan pada aturan Bayes dan mengasumsikan bahwa kelas yang
diberikan adalah fitur yang independen. Secara teori pengklasifikasian Bayesian memiliki tingkat kesalahan minimal dibandingkan dengan algoritma lainnya. Tetapi hal ini tidak selalu terjadi dalam prakteknya, karena asumsi yang disebutkan sebelumnya. Meski begitu Feature Selection pada Naïve Bayes classifier menunjukkan akurasi dan kecepatan tinggi bila diterapkan pada database yang besar. Mark A. Hall dan Geoffrey Holmes[16] dalam penelitiannya menyajikan perbandingan patokan metode Feature Selection dari beberapa algoritma klasifikasi. Dan meyimpulkan bahwa metode Forward Selection sangat cocok untuk Naïve
Bayes.
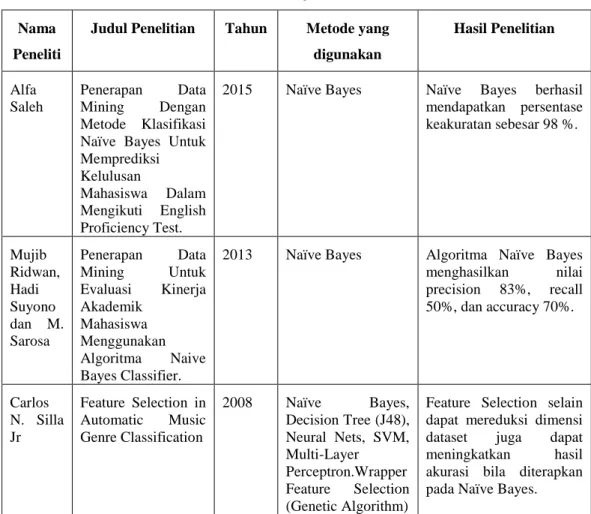
Tabel 2.1: Tinjauan Studi Nama
Peneliti
Judul Penelitian Tahun Metode yang digunakan Hasil Penelitian Alfa Saleh Penerapan Data Mining Dengan Metode Klasifikasi Naïve Bayes Untuk Memprediksi Kelulusan
Mahasiswa Dalam Mengikuti English Proficiency Test.
2015 Naïve Bayes Naïve Bayes berhasil
mendapatkan persentase keakuratan sebesar 98 %. Mujib Ridwan, Hadi Suyono dan M. Sarosa Penerapan Data Mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier.
2013 Naïve Bayes Algoritma Naïve Bayes menghasilkan nilai precision 83%, recall 50%, dan accuracy 70%. Carlos N. Silla Jr Feature Selection in Automatic Music Genre Classification 2008 Naïve Bayes, Decision Tree (J48), Neural Nets, SVM, Multi-Layer Perceptron.Wrapper Feature Selection (Genetic Algorithm)
Feature Selection selain dapat mereduksi dimensi dataset juga dapat meningkatkan hasil akurasi bila diterapkan pada Naïve Bayes.
8 L. Ladha dan T. Deepa Feature Selection Methods And Algorithms
2011 ID3, Naïve Bayes, SVM
Feature Selection pada Naïve Bayes classifier menunjukkan hasil akurasi dan kecepatan yang tinggi. Mark A. Hall dan Geoffrey Holmes Benchmarking Attribute Selection Techniques for Discrete Class Data Mining
2003 Decision Tree C4.5, Naïve bayes
Forward Selection sangat cocok untuk Naïve Bayes.
Berdasar tinjauan studi diatas maka pada penelitian kali ini akan menerapkan metode
Forward Selection untuk fitur seleksi pada klasifikasi status kelulusan mahasiswa
menggunakan algoritma Naïve Bayesdari dataset yang diambil dari sistem informasi akademik Universitas Abadi Karya Indonesia.
2.2 Landasan Teori
Data Mining adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam data berukuran besar. Data mining memiliki hubungan dari bidang ilmu seperti artificial intelligent, machine learning, statistik dan database[17]. Beberapa teknik data mining antara lain: clustering, classification, association rule mining, neural network, genetic algorithm dan lain-lain[18].
2.2.1 Klasifikasi
Proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui[18][19].
2.2.2 Naïve Bayes
Naïve Bayes merupakan salah satu penerapan teorema Bayes. Naïve Bayes
didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisional saling bebas jika diberikan nilai output [20]. Bayes merupakan pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class [21]. Bayes memiliki akurasi dan kecepatan yang sangat tinggi saat diaplikasi ke dalam database dengan data yang besar.
9
Naïve Bayes adalah metode yang baik karena mudah dibuat, tidak membutuhkan
skema estimasi parameter perulangan yang rumit, ini berarti bisa diaplikasikan untuk dataset berukuran besar [19]. Mudah diinteprestasikan sehingga pengguna yang tidak punya keahlian dalam bidang teknologi klasifikasi pun bisa mengerti. Naive Bayes merupakan algoritma yang dapat meminimalkan tingkat kesalahan dibandingkan dengan semua pengklasifikasi lainnya. Namun, dalam praktek ini tidakselalu terjadi, karenauntuk ketidakakuratan dalam asumsi yang dibuat untukpenggunaannya class yang tidak utuh dan kurangnya data probabilitas yang tersedia.
Pengklasifikasi Bayesian juga berguna dalam pembenaran teoritis untukpengklasifikasi lain yang tidak secara eksplisit menggunakan teoremaBayes[21].Untuk mendapatkan nilai probabilitas pada sebuah sampel diberikan sebuah teorema Bayes:
𝑃(𝑋|𝐻) =𝑃(𝐻|𝑋)𝑃(𝐻) 𝑃(𝑋)
(1)
Naive bayes adalah penyederhanaan dari teorema Bayes, berikut rumusnya:
𝑃(𝑋|𝐻) = 𝑃(𝐻|𝑋)𝑃(𝐻)
(2)Keterangan :
X : Data dengan class yang belum diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (posteriori probability)
P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasar kondisi pada hipotesis H
P(X) : Probabilitas dari X
Beberapa keuntungan dari algoritma klasifikasi Naive Bayes adalah [18]: 1) Kuat terhadap pengisolasi gangguan pada data
2) Jika terjadi kasus missing value ketika proses komputasi sedang berlangsung, maka objek tersebut akan diabaikan
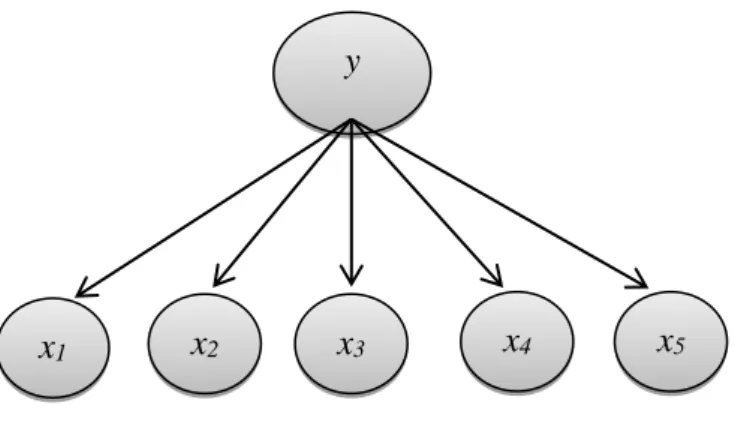
10 Gambar 2.1: Relasi Variabel Pada Naive Bayes
Diberikan sebuah sampel x dengan nilai probabilitas prior terbesar. Dimana sampel x dapat dihitung berdasarkan teorema Bayes sebagai berikut:
𝑃(𝐶𝑖|𝑥) =
𝑃(𝑥|𝐶𝑖)𝑃(𝐶𝑖) 𝑃(𝑥)
(3)
Dimana P(x) adalah konstan untuk semua kelas, hanya saja P(Ci|x)=P(x|Ci)P(Ci) membutuhkan nilai maksimum. Asumsi sederhana yang di ambil dari atribut, dimana
k adalah kondisi yang independen.
𝑃(𝑥|𝐶𝑖) = ∑ 𝑃(𝑥𝑘|𝐶𝑖) 𝑛
𝑘=1
= 𝑃(𝑥1|𝐶𝑖) × 𝑃(𝑥2|𝐶𝑖) × … × 𝑃(𝑥𝑛|𝐶𝑖)
(4)
Jika banyak atribut memiliki kondisi probabilitas 0, maka klasifikasi Naive Bayes menjadi
𝑃(𝐶𝑖|𝑥) = ∑ 𝑃(𝑥𝑘|𝐶𝑖) ∗𝑃(𝐶𝑖) 𝑛
𝑘=1 (5)
Gunakan sebuah estimator dengan menambahkan 1 pada kasus yang lain:
𝑝𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 = 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑 × 𝑝𝑟𝑖𝑜𝑟 𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒 (6) y x4 x3 x2 x1 x5
11 Selanjutnya gunakan probabilitas estimasi M:
𝑛𝑐+ 𝑚𝑝 𝑛 + 𝑚
(7)
Dimana nc adalah total nilai dari contoh sampel pada atribut yang dimiliki kelas C, n merupakan total nilai pada keseluruhan sampel yang berada pada kelas C dan m adalah sebuah nilai ekivalen yang konstan dari ukuran sampel yang diberikan. Sedangkan p adalah probabilitas prior yang menggunakan set 1/k sebagai informasi tambahan dimana k adalah nilai dari kemungkinan yang muncul pada atribut-atribut pada sampel yang akan diklasifikasikan.
2.2.3 Forward Selection
Forward Selection adalah bagian dari Feature Selection. Feature Selection adalah sebuah proses yang biasa digunakan pada Machine Learningdimana sekumpulan dari fitur yang dimiliki oleh data digunakan untuk pembelajaran algoritma. Feature selection menurut Oded Maimon [13] telah menjadi bidang penelitian aktif dalam pengenalan pola, statistik, dan data mining. Ide utama dari feature selection adalah memilih subset dari fitur yang ada tanpa transformasi karena tidak semua fitur / atribut relevan dengan masalah. Bahkan beberapa dari fitur atau atribut tersebut mengganggu dan mengurangi akurasi. Noisy Features atau fitur yang tidak terpakai tersebut harus dihapus untuk meningkatkan akurasi. Selain itu dengan fitur atau atribut yang banyak akan memperlambat proses komputasi. Metode yang digunakan untuk memilih fitur yang optimal antara lain, Forward Selection, Backward
12 Berikut gambar tahapan Feature Selection
Gambar 2.2: Tahapan Feature Selection
Generation= memilih Subset
Evaluation= menghitung relevansi nilai dari subset Stoppingcriterion= menentukan bagian yang relevan Validation= memverifikasi validitas subset
Metode ForwardSelectionadalah pemodelan dimulai dari nol peubah (empty model), kemudian satu persatu peubah dimasukan sampai kriteria tertentu dipenuhi. Langkah-langkah metode forward adalah sebagai berikut :
1. Membuat model dengan meregresikan variabel respon Y dengan setiap variabel prediktor. Kemudian dipilih model yang mempunyai nilai R2 tertinggi. Misal model tersebut adalah yang memuat prediktor Xa, yaitu Yˆ b0 baXa.
2. Meregresikan variabel respon Y, dengan prediktor Xa, ditambah dengan setiap
pre-diktor selain Xa dan prediktor lain. Kemudian dipilih model yang nilai R2
nya ter-tinggi, misal mengandung tambahan prediktor Xb, yaitu model b b a aX b X b b
Yˆ 0 . Prediktor terpilih Xb berarti mempunyai Fsequensial
tertinggi. Formula Fsequensial untuk Xb adalah Fseq R(b |0,a)/MSE/db.
Nilai Fsequensial untuk Xb juga dapat diperoleh dengan cara mengkuadratkan nilai
statistik uji T pre-diktor Xb.
3. Proses diulang sampai didapatkan Fsequensial> Fin. Nilai Fin = F(1,v,in),
sehingga model terbaik yang dipilih adalah model yang tidak mempunyai prediktor dengan Fsequensial< Fin.
13 2.3 Evaluasi dan Validasi Hasil Klasifikasi Data Mining
Diperlukan cara yang sistematis untuk mengevaluasi kinerja suatu metode. Evaluasi klasifikasi didasarkan pada pengujian pada obyek benar dan salah [18]. Dalam penelitian ini menggunakan metode Confusion Matrix dan Kappa untuk mengukur hasil proses klasifikasi.
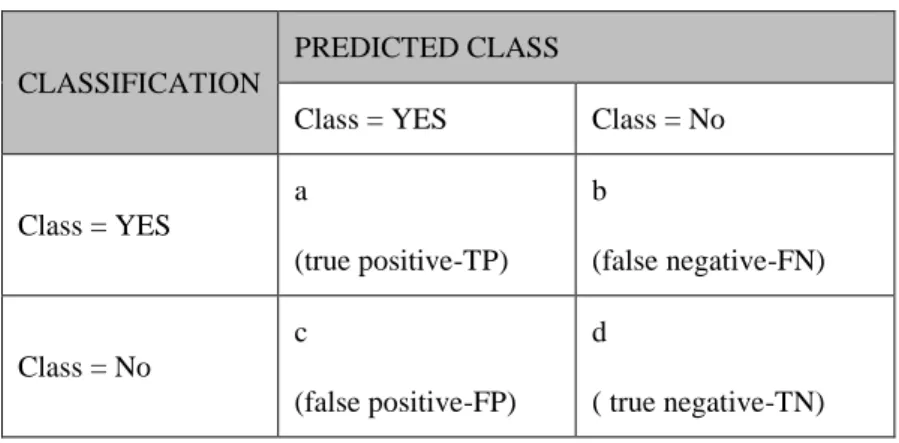
2.3.1 Confusion Matrix
Confusion matrixmerupakan metode yang digunakan untuk mengetahui performansi
algoritma [18]. Dalam confusion matrix terdapat 4 sel yang harus ditentukan isinya. Kelas yang diprediksi ditampilkan dibagian atas matriks dan kelas yang diamati disisi kiri. Setiap sel berisi angka yang menunjukkan berapa banyak kasus yang sebenarnya dari kelas yang diamati untuk diprediksi.
Tabel 2.2: Confusion Matrix
CLASSIFICATION
PREDICTED CLASS
Class = YES Class = No
Class = YES a (true positive-TP) b (false negative-FN) Class = No c (false positive-FP) d ( true negative-TN)
Hasil klasifikasi dapat dihitung tingkat akurasinya berdasarkan kinerja matriks. Tingkat true positive (TP) adalah jumlah dari klasifikasi abnormal yang benar, TP juga disebut sensitivitas. Untuk menghitung TP digunakan rumus:
𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑅𝑎𝑡𝑒 (𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦) = 𝑇𝑃 𝑇𝑃 + 𝐹𝑁
(2)
TN dikatakan sebagai spesifisitas karena mengukur proporsi benar “negatif”.
𝑇𝑟𝑢𝑒𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒𝑅𝑎𝑡𝑒(𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦) = 𝑇𝑁 𝑇𝑁 + 𝐹𝑃
14 Sensitivitas dan spesifisitas tidak memberikan informasi untuk nilai diagnosa yang benar.Maka perlu adanya PPV (positive predictive value) dimana proporsi kasus dengan hasil tes “positif”
𝑃𝑃𝑉 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑃
(4)
dan membutuhkan negative predictive value (NPV) dengan proporsi kasus dengan hasil tes “negatif”.
𝑁𝑃𝑉 = 𝑇𝑁
𝑇𝑁 + 𝐹𝑁
(5)
Tingkat false positive (FP) adalah jumlah normal kasus yang kesalahannya diklasifikasikan sebagai kelas abnormal.
𝐹𝑎𝑙𝑠𝑒𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑅𝑎𝑡𝑒 = 𝐹𝑃 𝐹𝑃 + 𝑇𝑁
(6)
Tingkat false negative (FN) adalah jumlah kasus normal yang kesalahannya diklasifikasikan sebagai kelas normal.
𝐹𝑎𝑙𝑠𝑒𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒𝑅𝑎𝑡𝑒 = 𝐹𝑁 𝐹𝑁 + 𝑇𝑃
(7)
Akurasi paling banyak digunakan dalam klasifikasi yang menggunakan kinerja matriks. Dan untuk menghitung tingkat akurasi pada matriks digunakan:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁
(8)
2.3.2 Kappa
Kappa merupakan metode statistik yang menilai kesepakatan interjudge (rater) untuk
data nominal dikodekan. Kappa dapat diterapkan pada sistem pengkodean secara keseluruhan dan untuk kategori individu[22][23].
Kappa (kesepakatan antar rater), relibilitas antar rater ini dipakai untuk menilai dua
15 semakin banyak kemiripan hasil penilai antar satu rater dengan lainnya maka koefisien relibilitas yang dihasilkan akan semakin tinggi.
Hasil klasifikasi dapat dihitung tingkat akurasinya berdasarkan kinerja Kappa, dengan rumus:
𝐾𝑎𝑝𝑝𝑎 = 𝑃𝑟 (𝑎) − 𝑃𝑟 (𝑒) 1 − 𝑃𝑟 (𝑒)
(1)
Dimana Pr(a) adalah proporsi unit yang dua Rater yang sama. Dan Pr(e) adalah proporsi yang diharapkan secara kebetulan.
Sebuah rumus setara, bila menggunakan frekuensi adalah:
𝐾𝑎𝑝𝑝𝑎 = 𝐹𝑜 − 𝐹𝑐 𝑁 − 𝐹𝑐
(2)
Dimana Fo menunjukkan jumlah (bukan proporsi) dari unit kode yang sama, dan Fc mewakili jumlah unit yang akan diharapkan dikodekan dengan cara yang sama secara kebetulan, dan N adalah jumlah unit yang dikodekan dengan baik. Joseph L. Fleiss [23]mengkategorikan tingkat reliabilitas antar rater/nilai Kappa menjadi:
<0,4 = buruk (bad)
0,40 –0,60 = cukup (fair)
0,60 – 0,75 = memuaskan (good)
> 0,75 = istimewa (excellent)
2.4 Dataset IAsol
IAsol adalah sebuah sistem informasi akademik pada Universitas Abadi Karya Indonesia atau UNAKI yang didalamnya terdapat beberapa informasi akademik diantaranya status dan indeks prestasi mahasiswa, kartu rencana studi, matakuliah syarat dan prasyarat yang menjadi penunjangprestasi. Pada penelitian kali ini dataset yang akan digunakan yaitu dataset yang diambil dari IAsolkhusus nya pada fakultas ilmu komputer.
16 2.4.1 Fakultas Ilmu Komputer
Sebuah fakultas yang mempelajari tentang ilmu komputasi, pemrograman, dan perhitungan dalam korespondensi dengan sistem komputer. Bidang studi ini menggunakan teori tentang bagaimana komputer bekerja untuk merancang, menguji, dan menganalisis konsep agar dapat berfungsi bagi pemakainya.
2.4.1.1 Teknik Informatika
Program studi yang mempelajari tentang pemrosesan, pengarsipan, dan penyebaran informasi dengan menggunakan teknologi informasi dan pemrograman yang berbasis komputer.
1. Web Developing
Pada jalur ini mempersiapkan mahasiswa untuk menjadi Webmaster, yaitu gabungan dari web developer dan web desain.
2. Mobile Developing
Pada jalur ini mempersiapkan mahasiwa menjadi seorang yang mampu mengembangkan dan menciptakan programdi perangkat mobile. 2.4.1.2 Sistem Informasi
Program studi yang membahas tentang sekumpulan perangkat keras dan perangkat lunak yang dirancang untuk mentransformasikan data dalam bentuk informasi yang berguna.
1. AuditSistem Informasi
Pada jalur ini mempersiapkan mahasiswa untuk menjadi Auditor Sistem yang handal dan sangat dibutuhkan.
2. Sistem Enterprise
Pada jalur ini mempersiapkan mahasiswa menjadi Analis Sistem bidang sistem informasi yang mampu memenuhi kebutuhan manajemen di segala bidang.
17 2.5 Kerangka Pemikiran
Kerangka pemikiran pada penelitian ini berdasarkan karena dataset dari dataset IAsol
UNAKI. Algoritma klasifikasi Naïve Bayes diketahui bisa menangani masalah
dataset yang besar, Sedangkan proses fitur seleksi yaitu Forward Selection digunakan untuk menentukan atribut yang paling berpengaruh dan dapat membantu meningkatkan hasil akurasi klasifikasi Naïve Bayes.
Adapun kerangka pemikiran dari penelitian ini dapat dilihat sebagai berikut:
Naïve Bayes berbasis Forward Selection
PROPOSED METHOD OBJECTIVES
Model & Accuracy MEASUREMENT Kappa Dataset IAsol Feature Selection Forward Selection Naïve Bayes Confusion Matrix 10-Fold Cross Validation VALIDATION
18
BAB III
METODE PENELITIAN
Jenis penelitian yang dilaksanakan ini merupakan penelitian eksperimen. Selain itu data yang digunakan adalah data kualitatif. Data kualitatif adalah data yang berupa kalimat. 3.1 Instrumen Penelitian
Instrumen yang digunakan untuk mendukung dalam penelitian ini antara lain: 3.1.1 Software
PC atau laptop yang digunakan penulis dengan spesifikasi sebagai berikut: Operating System : Windows 7 64-bit
Processor : Intel Core i5-4210U,up to 2.7 GHz
Memory : 4096MB RAM
3.1.2 Software
Software yang digunakan penulis sebagai berikut: Software developer : Rapid Miner Studio
Software penunjang : Microsoft Office Word 2013, Microsoft Excel 2013 3.2 Pengumpulan Data
Pengumpulan data pada penelitian ini meliputi: studi literatur yang digunakan sebagai referensi dalam penelitian bias berupa buku, jurnal dan karya ilmiah yang relevan dengan algoritma klasifikasi data mining. Tahap ini dilakukan sebagai langkah awal dari suatu penelitian. Untuk memperoleh data yang benar-benar akurat, maka penentuan jenis dan sumber data sangatlah penting. Sumber data pada penelitian ini adalah dataset yang didapat dari IAsol UNAKI [7] khususnya di Fakultas Ilmu Komputer pada tahun ajaran 2008 sampai 2011. Atribut yang akan digunakan dalam melakukan klasifikasi kelulusan adalah Nomor Induk Mahasiswa (NIM), nama, jurusan, umur, jenis kelamin, daerah asal, status pernikahan, status pekerjaan, kelompok atau jenis beasiswa, indeks prestasi dari semester 1sampai dengan semester 9, IPK, jumlah sks yang ditempuh dan jenis konsentrasi jalur peminatan.
19 3.3 Teknik Analisis Data
Tahap pengolahan awal data dilakukan untuk mempersiapkan data yang benar-benar valid sebelum diproses pada tahap berikutnya namun tidak semua data dapat digunakan dan tidak semua atribut digunakan karena harus melalui beberapa tahap pengolahan awal data (preparation data). Jumlah data awal yang diperoleh dari pengumpulan data, namun tidak semua data dapat digunakan dan tidak semua atribut digunakan karena harus melalui beberapa tahap pengolahan awal data (preparation data). Untuk mendapatkan data yang berkualitas, menurut Vercellis [26] dilakukan beberapa teknik:
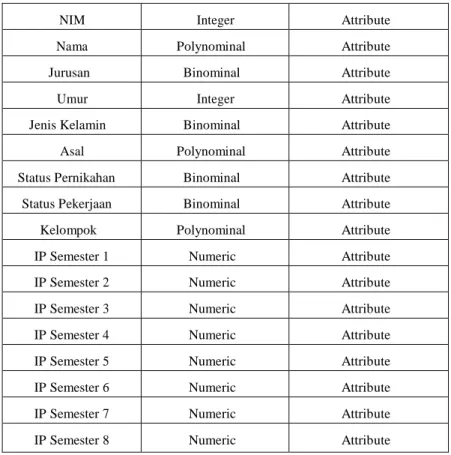
1. Data integration and transformation, untuk meningkatkan akurasi dan efisiensi algoritma. Data yang digunakan dalam penulisan ini bernilai kategorikal. Data ditransformasikan kedalam software RapidMiner. Tabel kategorikal atribut terlihat pada tabel 3-1.
2. Data size reduction, untuk memperoleh data set dengan jumlah atribut dan record yang lebih sedikit tetapi tetap bersifat informatif.
Pada penelitian kali ini tahapan yang dilakukan hanya transformasi data yaitu merubah beberapa tipe atribut data agar dikenali oleh RapidMiner.
Tabel 3.1: Tipe Atribut Data
NIM Integer Attribute
Nama Polynominal Attribute
Jurusan Binominal Attribute
Umur Integer Attribute
Jenis Kelamin Binominal Attribute
Asal Polynominal Attribute
Status Pernikahan Binominal Attribute
Status Pekerjaan Binominal Attribute
Kelompok Polynominal Attribute
IP Semester 1 Numeric Attribute
IP Semester 2 Numeric Attribute
IP Semester 3 Numeric Attribute
IP Semester 4 Numeric Attribute
IP Semester 5 Numeric Attribute
IP Semester 6 Numeric Attribute
IP Semester 7 Numeric Attribute
20
IP Semester 9 Numeric Attribute
IPK Numeric Attribute
SKS Integer Attribute
Konsentrasi Polynominal Attribute
Status Polynominal Label
3.4 Metode Penelitian
Penelitian adalah mencari melalui proses yang bermetode untuk menambahkan pengetahuan itu sendiri dan dengan yang lainnya, oleh penemuan fakta dan wawasan tidak biasa. Pengertian penelitian berarti kegiatan pemecahan masalah yang sistematis, yang dilakukan dengan perhatian dan kepedulian dalam konteks situasi yang dihadapi [24]. Penelitian dalam akademik yaitu digunakan untuk mengacu pada aktivitas yang rajin dan penyelidikan sistematis atau investigasi disuatu daerah, dengan tujuan menemukan atau merevisi fakta, teori, aplikasi dan tujuannya adalah untuk menemukan dan menyebarkan pengetahuan baru.
Dalam konteks penelitian, metode yang dilakukan mengacu kepada pemecahan masalah yang meliputi mengumpulkan data, merumuskan hipotesis atau proposisi, pengujian hipotesis, menafsirkan hasil, dan kesimpulan [24]. Menurut Dawson [25] ada empat metode penelitian yang umum digunakan yaitu: Action Research,
Experiment, Case Study, dan Survey.
Pada penelitian kali ini menggunakan metode penelitian eksperimen. Penelitian eksperimen melibatkan penyelidikan perlakuan pada atribut parameter atau variabel tergantung dari penelitinya dan menggunakan tes yang dikendalikan oleh si peneliti itu sendiri dengan bagan penelitian/blok diagram sebagai berikut:
21 IAsoldataset PemilihanFituratribut TrainingNaiveBayesModel ForwardSelection NO Performance&Weight Stoppingcriterion YES Atribut/Modeloptimal klasifikasiNaïve Bayes AkurasiKlasifikasi NaïveBayes Gambar 3.1:TahapanProposedModel/Method
Tahap ini akan membahas metode yang akan digunakan untuk penelitian. Berikut ini adalah tahap yang akan dilakukan dalam penelitian. Tahapan dilakukan mengikuti langkah-langkah metode Forward Selection dengan algoritma NaïveBayes yaitu:
1. Dataset dari Iasol UNAKI diseleksi fitur menggunakan Forward Selection, Metode Forward Selection adalah pemodelan dimulai dari nol peubah (empty
model).
2. Pemilihan fitur seleksi forward selection diuji menggunakan training atau metode NaiveBayes.
3. Dari training Naive Bayes yang diujikan mendapatkan hasil dan pembobotan. 4. Apabila proses tersebut lolos maka akan mendapatkan suatu atribut/model yang
22 5. Sedangkan bila proses tersebut berhenti pada stopping criterion maka proses
tersebut diulang dari awal (pemilihan fitur seleksi forward selection) sampai mendapatkan atribut/model optimal.
6. Setelah mendapatkan atribut/model yang optimal pada klasifikasi Naive Bayes maka akan muncul hasil akurasi dari klasifikasi Naive Bayes yang sudah di fitur seleksi.
Tahap ini akan membahas metode yang akan digunakan untuk penelitian nanti. Berikut ini adalah tahap yang akan dilakukan dalam penelitian. Seleksi fitur digunakan sebagai input untuk proses klasifikasi. Seleksi fitur dilakukan dengan mengambil sebagian variabel pada seluruh atribut yang ada pada data untuk dijadikan atribut penentu dalam melakukan pemberian keputusan. Dataset diseleksi fitur menggunakan Forward Selection, proses selanjutnya adalah melakukan klasifikasi menggunakan algoritma Naïve Bayes, hasil proses klasifikasi dievaluasi dengan menggunakan Confussion Matrix dan Kappa untuk mengukur performan atau tingkat akurasi.
3.5 Pengujian Model/Metode
Pada tahapan ini menjelaskan tentang teknik pengujian yang digunakan. Tahap modeling untuk mengklasifikasikan status kelulusan dengan menggunakan dua metode yaitu algoritma Naïve Bayes dan Forward Selection-NaïveBayes. Proses eksperimen dan pengujian model menggunakan dataset IAsol [7]. Metode eksperimen dan pengujian ini mengikuti cara pengklasifikasian menggunakan
RapidMiner.
Dalam melakukan penelitian ini diperlukan eksperimen dan proses pengujian model yang diusulkan. Proses eksperimen dan pengujian model menggunakan bagian dari dataset yang ada. Semua dataset kemudian diuji dengan metode yang diusulkan pada tools RapidMiner. Pengujian model berdasarkan perhitungan metode X-Validation, proses ini diulang sebanyak 10 kali dan hasil pengujian model berupa nilai akurasi dan nilai kappa.
23 3.6 Evaluasi Dan Validasi Hasil
Pada tahap ini akan dibahas tentang hasil evaluasi dari eksperimen yang telah dilakukan. Model yang terbentuk akan diuji dengan menggunakan Confusion Matrix untuk mengetahui tingkat akurasi. Confusion Matrix akan menggambarkan hasil akurasi mulai dari prediksi positif yang benar, prediksi positif yang salah, prediksi negative yang benar, dan prediksi negative yang salah. Akurasi akan dihitung dari seluruh prediksi yang benar (baik prediksi positif dan negatif). Semakin tinggi nilai akurasi, semakin baik pula model yang dihasilkan.
Pengujian juga diukur dengan menggunakan Kappa, semakin tinggi nilai Kappa, maka semakin baik pula model klasifikasiyang terbentuk.
Dataset IAsol Unaki [7] diuji hanya menggunakan algoritma Naïve Bayes saja, setelah itu dengan dataset yang sama menggunakan metode Forward Selection dengan algoritma NaïveBayes.
Dari hasil yang diperoleh kemudian dibandingkan untuk mengetahui ada perubahan atau tidak. Diharapkan dalam penelitian ini optimasi fitur seleksi Forward Selection dapat bekerja dengan baik.
3.7 Jadwal Penelitian
NO KEGIATAN
BULANI BULANII BULANIII
1 2 3 4 1 2 3 4 1 2 3 4
1 Pengumpulan Data 2 Pengolahan Awal data 3 Metode Yang Diusulkan
4
Eksperimen dan Pengujian Model/Metode
24
4
HASIL DAN PEMBAHASAN
4.1 Hasil
Pada penelitian ini menguji keakuratanklasifikasi kelulusan mahasiswa dengan menggunakan algoritmaNaïve Bayes, setelah ituNaïve Bayes dengan Forward
Selection sebagai fitur seleksi. Penelitian ini menggunakan dataset yang diambil
dariIAsol Dataset yaitu dataset kelulusan mahasiwa yang memiliki 3classatau 3 kategori kelulusan, dengan data yang besar (memiliki 240 record dan 21 attribute) serta bersifat class imbalance.
3.1.1 Algoritma Naïve Bayes
Algoritma Naïve Bayes merupakan pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class [21]. Naive Bayes dapat memprediksikan kemungkinan-kemungkinan kelas anggota, seperti kemungkinan yang menempatkan sampel baru pada kelas khususnya. Asumsi dari algoritma Naïve Bayes adalah bahwa setiap variabel bersifat independen dan keberadaan sebuah variabel tidak ada kaitannya dengan keberadaan variabel yang lain. Naïve Bayes adalah metode yang baik karena mudah dibuat, tidak membutuhkan skema estimasi parameter perulangan yang rumit, ini berarti bisa diaplikasikan untuk dataset berukuran besar [19].
Berikut teorema bayes :
𝑃(𝑋|𝐻) =
𝑃(𝐻
|𝑋
)𝑃(𝐻)𝑃(𝑋) (1)
Berikut rumus Naive Bayes :
25 Keterangan :
X : Data dengan class yang belum diketahui
H : Hipotesis data x merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (posteriori probability)
P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasar kondisi pada hipotesis H
P(X) : Probabilitas dari X
3.1.1.1 Evaluasi Naïve Bayes dengan data sampel
Pengujian menggunakan data sampel yang diambil dari IAsol dataset dengan: 2 label
class (tepat dan terlambat), 10 record (7 class tepatdan 3 class terlambat) dan 21 attribute seperti yang dapat dilihat pada halaman lampiran.
Berikut ini adalah contoh perhitungan mencari nilai akurasi dari atribut kelompok dengan menggunakan metode Cross-Validation (X-Validation).
Training 1:
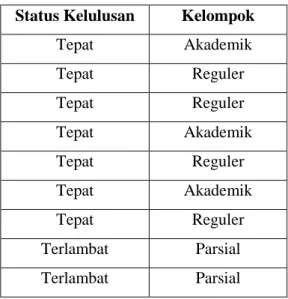
Tabel 4.1: Data Training Cross Validation Naïve Bayes
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) = 7/9 = 0.777777777
P(Terlambat) = 2/9 = 0.222222222
26 P(Akademik|Tepat) = 3/7 = 0.428571429 P(Reguler|Tepat) = 4/7 = 0.571428572 P(Parsial|Tepat) = 0/7 = 0 P(Akademik|Terlambat) = 0/2 = 0 P(Reguler|Terlambat) = 0/2 = 0 P(Parsial|Terlambat) = 2/2 =1 Testing 1:
Data testing dari status kelulusan dengan kelompokparsial: Prediction parsial: P(X|Tepat) = 0/7 = 0
P(X|Terlambat) = 2/2 = 1
Perhitungan dilakukan 10 kali sampai training 10 dan testing 10 sesuai metode
Cross-Validation (X-Validation).
Dari hasil klasifikasi menggunakan data sample (2 label class. 10 record dan 21
attribute) dengan metode Naïve Bayesdiperoleh hasil nilai akurasi sebesar 70.00%,
berikut ini hasil perhitungannya seperti dapat dilihat pada gambar 4.1.
Gambar 4.1: Validasi Naïve Bayes Data Sampel
= 5+2
5+1+2+2
= 0.7 = 70%
3.1.1.2 Evaluasi Naïve Bayes dengan data lengkap
Hasil klasifikasi menggunakan data lengkap (Iasol dataset)dengan metode Naïve
27 Gambar 4.2: Validasi Naïve Bayes Data Lengkap
=230
240
= 0.9583 = 95.83%
Evaluasi dan validasi pada penelitian ini mengikuti aturan Kappa, dengan perhitungan nilai Kappa:
Gambar 4.3: Kappa Naïve Bayes Data Lengkap
𝐾𝑎𝑝𝑝𝑎 = 𝑃𝑟 (𝑎) − 𝑃𝑟 (𝑒)
1 − 𝑃𝑟 (𝑒) (1)
Pr(a) adalah proporsi unit yang dua Rater yang sama. Pr(e) adalah proporsi yang diharapkan secara kebetulan.
𝐾𝑎𝑝𝑝𝑎 = 0.914 − 0.00000000202 1 − 0.00000000202
(2)
𝐾𝑎𝑝𝑝𝑎 = 0.914
Kappa = 0.914 termasuk kategori Kappa excellent.
3.1.2 Naïve Bayes dengan Forward Selection sebagai fitur seleksi
Metode Forward Selection berdasarkan pada model Wrapper Feature Selection yaitu metode yang mengadopsi dari algoritma pembelajaran yang utama. Pada penelitian
28 kali ini berdasar dari algoritma Naïve Bayesuntuk mengevaluasi kinerja dari subset fitur yang optimal sesuai dengan kriteria akhir.
Metode Forward Selection adalah pemodelan dimulai dari nol peubah (empty
model), kemudian satu persatu peubah dimasukan sampai kriteria tertentu dipenuhi.
Tahapan metode Forward Selection adalah sebagai berikut:
1. Tahapan metode Forward Selection berdasarkan perhitungan metode
X-Validation Naïve Bayes. Seperti cara penghitungan pada eksperimen diatas,
nilai akurasi tersebut dijadikan nilai subset atau nilai prediktor pada masing masing atribut. Untuk variabel pertama untuk memasukkan model, pilih prediktor (nilai subset) yang paling berkorelasi dengan target atau yang memiliki nilai subset terbesar. Jika menghasilkan model yang tidak signifikan, berhenti dan melaporkan bahwa tidak ada variabel adalah prediktor penting. Nilai subset yang kecil diabaikan, hanya menggunakan nilai subset terbesar, lanjutkan ke langkah 2.
2. Untuk setiap variabel atau nilai subset yang terbesar, dihitung dengan menjumlah nilai subset yang terbesar dengan berurutan untuk variabel yang diberikan variabel sudah dalam model. Pilih variabel nilai subset dengan F-statistic berurutan terbesar.
3. Untuk variabel nilai subset yang dipilih pada langkah 2, uji untuk F-statistic berurutan. Jika menghasilkan model yang tidak signifikan, berhenti, dan melaporkan model saat ini tanpa menambahkan variabelnilai subset di langkah 2. Jika tidak, menambahkan variabel dari langkah 2 ke dalam model dan kembali ke langkah 2, sampai mendapatkan nilai subset terbesar.
3.1.2.1 Evaluasi Naïve Bayes dengan Forward Selection sebagai fitur seleksidengan data sampel
Pengujian menggunakan data sampel yang diambil dari IAsol dataset dengan: 2 label
class (tepatdan terlambat), 10 record (7 class tepatdan 3 class terlambat) dan 21 attribute seperti yang dapat dilihat pada halaman lampiran.
29 Tahap Generation Forward Selection-Naïve Bayesdimulai darimemilih prediktor (nilai subset) yang paling berkorelasi dengan target dengan nilai akurasi tertinggi.Tahapan ini dilakukan berdasarkan perhitungan metodeX-Validation.
Training 1:
Tabel 4.2: Data Training 1
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) = 7/9 = 0.777777777
P(Terlambat) = 2/9 = 0.222222222
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) = 3/7 = 0.428571429 P(Reguler|Tepat) = 4/7 = 0.571428571429 P(Parsial|Tepat) = 0/7 = 0 P(Akademik|Terlambat) = 0/2 = 0 P(Reguler|Terlambat) = 0/2 = 0 P(Parsial|Terlambat) = 2/2 =1 Testing 1:
Data testing dari status kelulusan terlambat dengan kelompok parsial: Prediction terlambat: P(X|Tepat) = 0/7 = 0
P(X|Terlambat) = 2/2 = 1
30 Tabel 4.3: Data Training 2
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) = 7/9 = 0.777777778
P(Terlambat) = 2/9 = 0.222222222
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/7 = 0.428571429 P(Reguler|Tepat) = 4/7 = 0.571428571429 P(Parsial|Tepat) = 0/7 = 0 P(Akademik|Terlambat) = 0/2 = 0 P(Reguler|Terlambat) = 0/2 = 0 P(Parsial|Terlambat) = 2/2 = 1 Testing 2:
Data testing dari status kelulusan terlambat dengan kelompok parsial: Prediction terlambat: P(X|Tepat) = 0/7 = 0
P(X|Parsial) = 2/2 = 1
Training 3:
31
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) = 7/9 = 0.777777777
P(Terlambat) = 2/9 = 0.222222222
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/7 = 0.428571429 P(Reguler|Tepat) =4/7 = 0.571428571429 P(Parsial|Tepat) =0/7 = 0 P(Akademik|Terlambat)=0/2 = 0 P(Reguler|Terlambat) =0/2 = 0 P(Parsial|Terlambat) =2/2 = 1 Testing 3:
Data testing dari status kelulusan terlambat dengan kelompok parsial: Prediction terlambat P(X|Tepat) =0/7 = 0
P(X|Terlambat)=2/2 = 1
Training 4:
32
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666666
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/6 = 0.5 P(Reguler|Tepat)=3/6 = 0.5 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/6 = 0 P(Reguler|Terlambat) =0/6 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 4:
Data testing dari status kelulusan tepat dengan kelompok reguler: Prediction tepat P(X|Tepat) =3/6 = 0.5
P(X|Terlambat)=0/3 = 0
Training 5:
33
Status Kelulusan Kelompok
Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666667
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =2/6 = 0.333333333 P(Reguler|Tepat) =4/6 = 0.666666666 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 5:
Data testing dari status kelulusan tepat dengan kelompok Akademik: Prediction tepat P(X|Tepat) =2/6 = 0.333333333
P(X|Terlambat) =0/3 = 0
Training 6:
Tabel 4.7: Data Training 6
34 Tepat Akademik Tepat Reguler Tepat Reguler Tepat Akademik Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666667
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/6 = 0.5 P(Reguler|Tepat) =3/6 = 0.5 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 6:
Data testing dari status kelulusan tepat dengan kelompok Reguler: Prediction tepat P(X|Tepat) =3/6 = 0.5
P(X|Terlambat)=0/3 = 0
Training 7:
Tabel 4.8: Data Training 7
35 Tepat Akademik Tepat Reguler Tepat Reguler Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666667
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =2/6 = 0.333333333 P(Reguler|Tepat) =4/6 = 0.666666666 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 7:
Data testing dari status kelulusan tepat dengan kelompok Akademik: Prediction tepat P(X|Tepat) =2/6 = 0.333333333
P(X|Terlambat) =0/3 = 0
Training 8:
Tabel 4.9: Data Training 8
36 Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666666
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/6 = 0.5 P(Reguler|Tepat) =3/6 = 0.5 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 8:
Data testing dari status kelulusan tepat dengan kelompok reguler: Prediction tepat P(X|Tepat) =3/6 = 0.5
P(X|Terlambat)=0/3 = 0
Training 9:
Tabel 4.10: Data Training 9
Status Kelulusan Kelompok
37 Tepat Reguler Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666667
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =3/6 = 0.5 P(Reguler|Tepat) =3/6 = 0.5 P(Parsial|Tepat)=0/6 = 0.333333333 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 9:
Data testing dari status kelulusan tepat dengan kelompok reguler: Prediction tepat P(X|Tepat) =3/6 = 0.5
P(X|Terlambat)=0/3 = 0
Training 10:
Tabel 4.11: Data Training 10
Status Kelulusan Kelompok
Tepat Reguler
38 Tepat Akademik Tepat Reguler Tepat Akademik Tepat Reguler Terlambat Parsial Terlambat Parsial Terlambat Parsial
Dari data diatas didapatkan Probabilitas kelas: P(Tepat) =6/9 = 0.666666667
P(Terlambat) =3/9 = 0.333333333
Dari data diatas didapatkan Probabilitas kelompok terhadap masing masing kelas: P(Akademik|Tepat) =2/6 = 0.333333333 P(Reguler|Tepat) =4/6 = 0.66666666 P(Parsial|Tepat) =0/6 = 0 P(Akademik|Terlambat) =0/3 = 0 P(Reguler|Terlambat) =0/3 = 0 P(Parsial|Terlambat) =3/3 = 1 Testing 10:
Data testing dari status kelulusan tepat dengan kelompok Akademik: Prediction tepat P(X|Tepat) =2/6 = 0.333333333
P(X|Terlambat) =0/3 = 0
Dari eksperimen diatas berdasarkan metode Cross-Validation, didapat nilai akurasi dari satu atribut, yaitu atribut Kelompok.
Tabel 4.12: Validasi Atribut Kelompok
Cross-validation Prediction
Tepat Terlambat
39
Terlambat 0 3
= 7+3
7+0+0+3
= 1
= 100% (nilai akurasi atribut kelompok)
Nilai akurasi tersebut dijadikan nilai subsetpada atribut kelompok atau dijadikan nilai prediktor untuk perhitungan yang digunakan dalam metode Forward Selection-Naïve
Bayes.
Seperti cara penghitungan eksperimen diatas, mencari nilai akurasi atau nilai subset pada masing masing atribut. Yang kemudian didapatkan hasil nilai subset dari masing-masing atribut, seperti yang dapat dilihat pada tabel 4.12.
Tabel 4.13: Tahapan Generation Forward Selection Nama Atribut Nilai Subset
NIM 80 Nama 70 Jurusan 50 Jenis Kelamin 70 Umur 30 Daerah Asal 60 Status Pernikahan 70 Status Pekerjaan 60 Kelompok 100 IPS 1 60 IPS 2 80 IPS 3 60 IPS 4 60 IPS 5 60 IPS 6 50
40 IPS 7 60 IPS 8 50 IPS 9 90 IPK 70 SKS 80 Konsentrasi 90
Dari data tabel diatas dipilih atau didapatkan model atribut dengan nilai subset yang paling tinggi atau paling berkorelasi dengan target, seperti yang dapat dilihat pada tabel 4.13.
Tabel 4.14: Model Subset Forward Selection Nama Atribut Nilai Subset
Kelompok 100
Tahapan terakhir pada Forward Selection yaitu memverifikasi validitas dari subset. Seperti dapat dilihat pada tabel 4.14 diatas didapatkan model atribut terbaik yaitu:
Kelompok
Tabel 4.15: Model Atribut Forward Selection-Naïve Bayes Data Sampel Nama Atribut
Kelompok
Berdasarkan dari pemodelan seleksi atribut dengan menggunakan metode Forward
Selection, eksperimen algoritma Naïve Bayes dengan Forward Selection sebagai fitur
41 Gambar 4.4: Validasi Forward Selection-Naïve Bayes Data Sampel
= 7+3
7+0+0+3
= 1 = 100%
3.1.2.2 Evaluasi Naïve Bayes dengan Forward Selection sebagai fitur seleksidengan data lengkap
Berdasarkan dari eksperimen algoritma Naïve Bayes dengan Forward Selection sebagai fitur seleksi menggunakan data lengkap (IAsol dataset), pemodelan seleksi atribut Forward Selection diperoleh 4model atribut yaitu atribut kelompok, IPS 1, IPS 3, IPS 9.
Tabel 4.16: Model Atribut Forward Selection-Naïve Bayes Data Lengkap Nama Atribut
Kelompok IPS 1 IPS 3 IPS 9
42 Dengan hasil nilai akurasi sebesar 99.17%.
Gambar 4.5: Validasi Forward Selection-Naïve Bayes Data Lengkap =238
240
= 0.9917 = 99.17%
Evaluasi dan validasi pada penelitian ini mengikuti aturan Kappa, dengan perhitungan nilai Kappa:
Gambar 4.6: Kappa Forward Selection-Naïve Bayes Data Lengkap
𝐾𝑎𝑝𝑝𝑎 = 𝑃𝑟 (𝑎) − 𝑃𝑟 (𝑒) 1 − 𝑃𝑟 (𝑒) (1) 𝐾𝑎𝑝𝑝𝑎 = 0.976 − 0.00000002698 1 − 0.00000002698 (2) 𝐾𝑎𝑝𝑝𝑎 = 0.976
Kappa= 0.976 termasuk kategori Kappa excellent.
Evaluasi dan validasi dari eksperimen Naïve Bayes dengan Forward Selection sebagai fitur seleksimenggunakan data lengkap (IAsol dataset) berdasarkan aturan
43 3.2 Pembahasan
Pada penelitian ini menguji keakuratan klasifikasi kelulusan mahasiswa dengan menggunakan algoritmaNaïve Bayes dengan Forward Selection sebagai fitur seleksidari dataset yang diambil dari IAsol Dataset, yaitu dataset mahasiswa yang memiliki 3classatau 3 kategori kelulusan mahasiswa, dengan data yang besar (memiliki 240record dan 21attribute) serta bersifat class imbalance.
Seperti diketahui sebelumnya bahwa Naïve Bayes bisa memecahkan masalah data
class imbalancedan fitur seleksi dari Forward Selectionadalah salah satu cara untuk
mereduksi dimensi dataset yang besar, Forward Selection berperan memilih subset yang tepat dari set fitur asli, karena tidak semua fitur/atribut relevan dengan masalah karena beberapa dari fitur atau atribut tersebut mengganggu dan dapat mengurangi akurasi.
Tujuan dari penelitian ini adalah mendapatkan model fitur/atribut parameter yang relevan dengan algoritma Naïve Bayes. Data dianalisa dengan melakukan dua perbandingan yaitu menggunakan algoritma Naïve Bayes saja dan algoritma Naïve
Bayes dengan Forward Selection sebagai fitur seleksi.
Pada eksperimen tahap awal, dilakukan mencari nilai akurasi dari masing-masing atribut yang dimiliki oleh dataset berdasar metode X-Validation yang akandigunakan sebagai nilai subset Forward Selection.
Eksperimen algoritma Naïve Bayes memperoleh hasil akurasi sebesar 95.83%dengan nilai Kappa0.914 dan termasuk kategori Kappaexcellent.
Eksperimen algoritma Naïve Bayes dengan Forward Selection sebagai fitur seleksi memperoleh hasil akurasi sebesar 99.17%dengan dengan nilai Kappa0.976 dan termasuk kategori Kappaexcellent.Berdasarkan pemodelan seleksi atribut dengan
Forward Selection diperoleh hasil dengan model atribut Kelompok, IPS 1, IPS 3, IPS 9.
Dari hasil ekperimen dapat disimpulkan ke dalam tabel berikut: Tabel 4.17: Hasil Eksperimen IAsol Dataset
44
Algoritma Naive Bayes Forward Selection berbasis Naive Bayes Akurasi 95.83% 99.17% Kappa 0.914 0.976 Waktu Komputasi Sangat Cepat (1 detik) Cepat (3 detik) Model Atributterpilih 21 atribut (semua atribut terpakai) 4 atribut:
45
BAB IV
PENUTUP
4.1 Kesimpulan
Algoritma Naive Bayes terbukti efektif dalam mengklasifikasikan status kelulusan mahasiswa dari dataset dengan dimensi data yang besar dan memiliki keadaan kelas yang tidak seimbang antara kelas yang satu dengan kelas yang lain atau bersifat class
imbalance dengan memperoleh hasil akurasi 95.83%.
Metode Forward Selection dapat mereduksi dimensi dataset yang besar dan dapat membantu meningkatkan hasil akurasi klasifikasi Naïve Bayes.
Dalam hal ini Naive Bayes memanfaatkan fungsi seleksi fitur dari Forward Selection untuk pemilihan atribut data dengan karakteristik data itu sendiri, dan meningkatkan ketepatan klasifikasi Naïve Bayes.
Forward Selection berbasis Naive Bayes lebih akurat dan efektif dalam
mengklasifikasikan status kelulusan mahasiswa dari dataset yang bersifat class
imbalance dengan data yang besar dengan hasil akurasi 99.17% dan termasuk dalam
kategori “Kappa excellent”, dengan memperoleh atribut yang berpengaruh yaitu: Kelompok, IP Semester 1, IP Semester 3, IP Semester 9.
4.2 Saran
Metode Forward Selection berbasis Naive Bayes terbukti akurat dalam klasifikasi status kelulusan mahasiswa dari dataset yang bersifat class imbalance dengan dimensi data yang besar, tetapi dalam penelitian ini terdapat beberapa saran dalam pengembangannya antara lain prosedur ini tidak selalu mengarahkan ke model pemilihan atribut yang terbaik. Forward Selection berbasis Naive Bayes hanya mempertimbangkan sebuah subset kecil dari semua model-model yang mungkin, sehingga resiko melewatkan atau kehilangan model terbaik akan bertambah, seiring dengan penambahan jumlah variabel bebas.
46 1. Membantu administrasi perguruan tinggi untuk memberikan peringatan dini dan pembimbingan awal bagi mahasiswa yang kemungkinan tidak lulus tepat waktu dan membantu perguruan tinggi dalam membuat kebijakan untuk bisa meningkatkan kelulusan mahasiswa
2. Penelitian ini dapat dikembangkan dengan metode klasifikasi data mining lainnya, penggunaan metode fitur seleksi atau metode optimasi lainnya yang dapat mengatasi masalah dimensi data yang besar, class imbalance dan
47
REFERENSI
[1] Undang-Undang Republik Indonesia Nomor 2 Tahun 1989 tentang Sistem
Pendidikan Nasional.
[2] Romi Satria Wahono, Dapat Apa Sih Dari Universitas? Bandung: Zip Book, 2009.
[3] Jennifer Streubel , "What Is Computer Science," Department of Computer Science, Boston, 2003.
[4] David M Kroenke, Experiencing MIS.: Prentice Hall, Upper Saddle River, NJ, 2008.
[5] Johan Oscar Ong, "Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing President University," Jurnal Ilmiah Teknik
Industri, Juni 2013.
[6] http://www.unaki.ac.id/.
[7] http://iasol.unaki.ac.id:9090/IasolWeb/Login.aspx?ReturnUrl=%2fIasolWeb%2f default.aspx.
[8] Yi Liu , Lei Wei , and Peng Wang, "Regional Style Automatic Identification for Chinese folk Songs," 2009.
[9] Christopher DeCoro, Zafer Barutcuoglu, and Rebecca Fiebrink, "Bayesian Aggregation For Hierarchical Genre Classification," in Austrian Computer
Society (OCG), 2007.
[10 ]
Alfa Saleh , "Penerapan Data Mining Dengan Metode Klasifikasi Naive Bayes Untuk Memprediksi Kelulusan Mahasiswa Dalam Mengikuti Test English Proficiency Test".
[11 ]
Mujib Ridwan , Hadi Suyono , and M. Sarosa , "Penerapan Data Mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier," Juni 2013.