(52-kol-10-220)
PROGRAM PENELITIAN PENDIDIKAN DAN KELEMBAGAAN ISLAM 2010
Pengembangan Software Computerized Adaptive Testing (CAT) Berbasis Tingkat Kesukaran, Daya Beda Dan Tingkat Menebak (Guessing) Menggunakan Bahasa
Pemogramaan PHP dan My SQL
Oleh:
1. Winarno, S. Si, M. Pd. (Ketua Tim) 2. Haryo Aji Nugroho, M. Hum (Anggota) 3. Muh. Muqtafin, A. Md Komp (Anggota)
Sekolah Tinggi Agama Islam Negeri (STAIN)
S A L A T I G A
BAB I PENDAHULUAN
A. Latar Belakang Masalah
Salah satu cara dalam melaksanakan evaluasi dalam proses belajar mengajar adalah dengan menggunakan tes. Selama ini, sebagian besar alat untuk mengukur tes menggunakan kertas dan pencil (papper and pencils). Perkembangan terkini dalam usaha peningkatan pelaksanaan tes dengan kehadiran teknologi komputer telah mulai dipergunakan untuk kemajuan pengujian (Hambleton, R.K., Swaminathan, H., dan Rogers, H.: 1991). Komputerisasi penilaian individu lebih efisien dan akurat daripada penilaian menggunakan kertas dan pensil (pencil and paper test) (Wainer, 1990: 273). Salah satu prototype komputerisasi penilaian individu yang berkembang saat ini adalah Computerized
Adaptive Testing (CAT). CAT adalah suatu metode pengujian atau evaluasi dengan
menggunakan teknologi informasi yang bersifat adaptif. Adaptif berarti bahwa pemberian soal ujian berikutnya tergantung pada perilaku peserta ujian dalam menjawab soal sebelumnya sehingga ujian yang diberikan untuk setiap peserta dapat bersifat unik berdasarkan tingkat kemampuan masing-masing peserta
tersebut yang dapat mengupdatenya; 6). Ujian dapat dipresentasikan melalui teks, grafik,audio, dan bahkan video klip.
Dalam Computerized Adaptive Testing (CAT) memerlukan : (a) Bank soal, (b) Prosedur pemilihan item awal, (c) Prosedur pemilihan item selama pelaksanaan tes, (d) Metode untuk penskoran tes, (e) Prosedur untuk mengakhiri tes, dan (f) Estimasi kemampuan peserta tes (Weiss & Schleisman dalam Masters & Keeves, 1999: 130). Elemen penting dalam CAT adalah bank soal (item bank), bank soal terdiri dari koleksi item tes, jawaban, tingkat kesukaran tes, daya beda dan tingkat kesukaran (Reckase, 2003). Dalam prosedur pemilihan item awal diberikan item tes dengan tingkat kesukaran yang sedang. Prosedur mengakhiri tes diberikan agar tes tidak terlalu panjang.
Saat ini bidang pengukuran di Indonesia mengalami kemajuan yang pesat. Penggunaan software komputer untuk analisis item soal telah mengalami kemajuan yang luar biasa.
Analisis item soal terkini yang sering digunakan adalah menggunakan pendekatan IRT (Item Response Theory). Dalam IRT bisa dilakukan estimasi kemampuan peserta tes dan mengetahui karakteristik item soal mengenai daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c). Dalam pelaksanaannya, analisis secara IRT sangat mudah karena dalam analisis dapat digunakan program komputer, seperti program RASCAL, PASCAL, BIGSTEPS, QUEST atau BILOG MG
B. Identifikasi Masalah
Berdasarkan latar belakang masalah di atas, dapat diidentifikasi permasalahan sebagai berikut:
1. Tes merupakan salah satu cara dalam melakukan evaluasi dalam proses belajar mengajar.
2. Komputerisasi penilaian individu lebih efisien dan akurat daripada penilaian menggunakan kertas dan pensil (pencil and paper test)
3. Dalam mengembangkan Computerized Adaptive Testing (CAT) keberadaan bank soal (item bank) sangat penting.
4. Bagaimana prosedur pemilihan item awal dalam CAT dilakukan?
6. Prosedur pemilihan item selama pelaksanaan tes dalam mengembangkan software CAT yang berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes.
7. Prosedur untuk mengakhiri tes (stopping rule) dalam CAT dilakukan.
8. Berapa lama setiap item soal akan ditampilkan oleh komputer sebelum computer menampilkan soal berikutnya.
9. Metode untuk penskoran dalan CAT
10.Estimasi Kemampuan Peserta tes dalam CAT menggunakan metode Maximum Likelihood (MLE)
C. Pembatasan Masalah
Untuk mengarahkan agar penelitian lebih terfokus pada permasalahan, maka penelitian ini dibatasi pada:
1. Bank soal yang diambil dari soal Ujian Plecement Tes Program Studi Intensif Bahasa Arab (SIBA) Masuk STAIN Salatiga tahun akademik 2009/2010
2. Pembuatan CAT (Computerized Adaptive Testing) berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes
3. Estimasi kemampuan peserta tes menggunakan metode Maximum Likelihood (MLE)
D. Rumusan Masalah
Mengacu pada identifikasi dan pembatasan masalah di atas maka rumusan masalah dalam rancangan penelitian ini antara lain:
1. Bagaimana mengembangkan bank soal dalam membuat software CAT?
2. Bagaimana mengembangkan software CAT berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes?
E. Tujuan Penelitian
Penelitian ini bertujuan untuk:
1. Mengembangkan bank soal dalam membuat softwrae CAT.
2. Membuat, mengembangkan dan menghasilkan software CAT berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes
3. Membuat, mengembangkan dan menghasilkan software CAT yang mampu mengukur kemampuan peserta tes dengan tepat dan akurat menggunakan metode Maximum Likelihood (MLE)
F. Manfaat Penelitan
Dari penelitian ini diharapkan dapat memperoleh manfaat 1. Secara teoritis
Hasil software Computerized Adaptive Testing (CAT) yang dihasilkan dalam penelitian ini dìharapkan dapat membantu dalam menemukan solusi untuk mengetahui kemampuan seseorang yang lebih akurat dan mengurangi kecurangan dalam sistem pengujian
2. Secara praktis
Hasil software Computerized Adaptive Testing (CAT) dalam penelitian ini diharapkan dapat berguna bagi pengukuran kemampuan peserta tes di dalam bidang pendidikan
3. Bagi STAIN Salatiga dan Perguruan Tinggi Islam (PTI)
BAB II
TINJAUAN PUSTAKA
A. Computeriized Adaptive Testing (CAT)
Adaptive testing juga disebut sebagai tailored test, yaitu suatu tes yang
menyesuaikan kemampuan peserta (Lord, 1980). Menurut Wainer (1990) Adaptive testing merupakan tes yang diselenggarakan bagi peserta tes dengan pertanyaan-pertanyaan / item-itemnya ditentukan berdasarkan jawaban (respon) awal peserta.
Penyelenggaraan tes adaptif berbeda dengan paper and pencil test (PP test). Pada PP tes seluruh peserta tes akan diberikan soal yang sama dan dengan jumlah soal yang tetap/sama, sedangkan pada tes adaptif setiap peserta akan diberikan soal yang berbeda-beda. Pertanyaan-pertanyaan pada tes adaptif menyesuaikan dengan kemampuan masing-masing peserta tes.
Adaptive tes memerlukan : (a) bank soal, (b) prosedur pemilihan item awal, (c) prosedur pemilihan item selama pelaksanaan tes, (d) metode untuk penskoran tes, dan (e) prosedur untuk mengakhiri tes (Weiss & Schleisman dalam Masters & Keeves, 1999: 130).
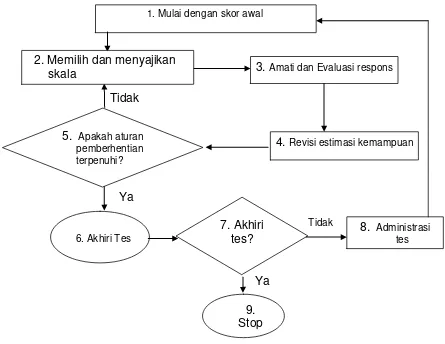
Diagram berikut adalah algoritma adaptive test.
Gambar 1. Diagram alur Adaptive Test (Sumber : Wainer, 1990. :108)
Berdasarkan Gambar 1. Pertama-tama kemampuan sementara peserta diestimasi. Apabila tidak ada informasi kemampuan awal peserta tes maka diambil soal tes dengan tingkat kesukaran yang sedang. Kemudian estimasi kemampuan peserta tes dari respon jawaban yang diberikan sebagai dasar pertimbangan dalam mengambil soal berikutnya. Berikutnya diberikan/disajikan butir soal yang optimal sesuai dengan kemampuan awal, amati dan evaluasi respon peserta, setelah itu perbaiki estimasi kemampuan peserta, kemudian berdasarkan aturan pemberhentian tes, dilakukan uji apakah kriteria pemberhentian tes telah dipenuhi ataukah tidak. Jika telah dipenuhi maka tes berhenti, sebaliknya jika belum dipenuhi peserta diberikan butir soal yang optimal lainnya, hal ini terus berlangsung sampai terpenuhinya kriteria pemberhentian tes.
1. Mulai dengan skor awal
3. Amati dan Evaluasi respons
4. Revisi estimasi kemampuan
8. Administrasi tes berikutnya
7. Akhiri tes?
6. Akhiri Tes
Tidak
Ya
Tidak
Ya 2. Memilih dan menyajikan
skala
Item yang optimal
9. Stop 5. Apakah aturan
Dalam merancang CAT, pengembang tes harus menentukan bagaimana dan estimasi kemampuan dihitung sementara, bagaimana item tes dipilih pada estimasi tersebut dan bagaimana estimasi kemampuan akhir diperoleh (Linden, 2002:3)
1. Sejarah CAT
Gagasan awal dari adaptive test berasal dari seorang psikolog kebangsaan Perancis bernama Alfred Binet (1859-1911). Computerized adaptive testing (CAT) dirancang untuk setiap individu peserta tes (Wiener, 1990). Peserta tes akan diberi satu set soal yang memenuhi spesifikasi rancangan tes (kisi-kisi) dan biasanya sesuai dengan tingkat kemampuan setiap individu. Tes dimulai dengan soal-soal yang tidak terlalu sukar (katagori sedang). Setiap peserta tes menjawab soal dan komputer akan memberikan skor. Jawaban terhadap soal tersebut akan menentukan soal yang akan ditampilkan oleh komputer selanjutnya. Setiap menjawab soal dengan benar, peserta tes akan diberi soal yang lebih sukar. Sebaliknya, bila menjawab salah, komputer akan memilihkan soal yang lebih mudah. Urutan soal disajikan tergantung pada jawaban terhadap soal-soal sebetutnnya dan pada kisi-kisi tes. Dengan kata lain, komputer diprogram untuk memberikan soal yang sesuai dengan kisi-kisi tes, sekaligus secara terus menerus mencari soal-soal yang tingkat kesulitannya sesuai dengan tingkat kemampuan peserta ujian. Dalam hal ini peserta ujian harus menjawab semua soal. Keuntungannya, pada setiap layar hanya ditampilkan satu butir soal, sehingga peserta tes dapat berkonsentrasi untuk menjawab soal tersebut. Setelah menjawab soal, peserta ujian tidak akan dapat mengulang soal-soal sebelumnya dan mengganti jawabannya.
2. Prinsip Computerized Adaptive Testing (CAT) a. Membangun Item bank
Item bank dalam CAT umumnya menggunakan Item Response Theory (IRT) (Lord and Novick, 1968; Lord, 1980). Asal mula IRT adalah kombinasi suatu versi hukum phi-gamma dengan suatu analisis faktor butir soal (item factor analisis) kemudian bernama
Teori Trait Latent (Latent Trait Theory), kemudian sekarang secara umum dikenal menjadi teori jawaban butir soal (Item Response Theory) (McDonald, 1999: 8).
perkiraan tingkat kemampuan peserta didik adalah independen; (7) Asumsi pada populasi tingkat kesukaran, daya pembeda merupakan independen sampel yang menggambarkan untuk tujuan kalibrasi soal; (8) Statistik yang digunakan untuk menghitung tingkat kemampuan siswa diperkirakan dapat terlaksana, (Hambleton dan Swaminathan, 1985: 11). Jadi IRT merupakan hubungan antara probabilitas jawaban suatu butir soal yang benar dan kemampuan siswa atau tingkatan/level prestasi siswa.
Dalam pembuatan item bank, akan dilakukan kegiatan menganalisis butir soal yang merupakan suatu kegiatan yang harus dilakukan untuk meningkatkan mutu soal yang telah ditulis. Kegiatan ini merupakan proses pengumpulan, peringkasan, dan penggunaan informasi dari jawaban siswa untuk membuat keputusan tentang setiap penilaian (Nitko, 1996: 308). Tujuan penelaahan adalah untuk mengkaji dan menelaah setiap butir soal agar diperoleh soal yang bermutu sebelum soal digunakan. Di samping itu, tujuan analisis butir soal juga untuk membantu meningkatkan tes melalui revisi atau membuang soal yang tidak efektif, serta untuk mengetahui informasi diagnostik pada siswa apakah mereka sudah/belum memahami materi yang telah diajarkan (Aiken, 1994: 63). Soal yang bermutu adalah soal yang dapat memberikan informasi setepat-tepatnya sesuai dengan tujuannya di antaranya dapat menentukan peserta didik mana yang sudah atau belum menguasai materi yang diajarkan pengajar.
Dalam melaksanakan analisis butir soal, para penulis soal dapat menganalisis secara kualitatif, dalam kaitan dengan isi dan bentuknya, dan kuantitatif dalam kaitan dengan ciri-ciri statistiknya (Anastasi dan Urbina, 1997: 172) atau prosedur peningkatan secara judgment dan prosedur peningkatan secara empirik (Popham, 1995: 195). Analisis kualitatif mencakup pertimbangan validitas isi dan konstruk, sedangkan analisis kuantitatif mencakup pengukuran kesulitan butir soal dan diskriminasi soal yang termasuk validitas soal dan reliabilitasnya
1). Asumsi-asumsi Pendekatan IRT
Hambleton dan Swaminathan (1985: 16) dan Hambleton, Swaminathan, dan Rogers (1991: 9) menyatakan bahwa ada tiga asumsi yang mendasari teori respon butir, yaitu unidimensi, independensi lokal dan invariansi parameter. Ketiga asumsi dapat dijelaskan sebagai berikut. Unidimensi, artinya setiap butir tes hanya mengukur satu kemampuan. Contohnya, pada tes prestasi belajar bidang studi matematika, butir-butir yang termuat di dalamnya hanya mengukur kemampuan siswa bidang studi matematika saja, bukan bidang yang lainnya. Pada praktiknya, asumsi unidimensi tidak dapat dipenuhi secara ketat karena adanya faktor-faktor kognitif, kepribadian dan faktor-faktor administratif dalam tes, seperti kecemasan, motivasi, dan tendensi untuk menebak. Memperhatikan hal ini, asumsi unidimensi dapat ditunjukkan hanya jika tes mengandung hanya satu komponen dominan yang mengukur prestasi suatu subjek.
Independensi lokal terjadi jika faktor-faktor yang mempengaruhi prestasi menjadi konstan, maka respons subjek terhadap pasangan butir yang manapun akan independen secara statistik satu sama lain. Asumsi ini akan terpenuhi apabila jawaban peserta terhadap sebuah butir soal tidak mempengaruhi jawaban peserta terhadap terhadap butir soal yang lain. Tes untuk memenuhi asumsi independensi lokal dapat dilakukan dengan membuktikan bahwa peluang dari pola jawaban setiap peserta tes sama dengan hasil kali peluang jawaban peserta tes pada setiap butir soal.
Menurut Hambleton, Swaminathan, dan Rogers (1991: 10), independensi lokal secara matematis dinyatakan sebagai berikut :
u u un
p u pu p
unberubah hanya karena diujikan pada kelompok peserta tes yang berbeda tingkat kemampuannya.
Menunurut Hambleton, Swaminathan, dan Rogers (1991: 18), invarian parameter kemampuan dapat diselidiki dengan mengajukan dua seperangkat tes atau lebih yang memiliki tingkat kesukaran yang berbeda pada sekelompok peserta tes. Invarians parameter kemampuan akan terbukti jika estimasi kemampuan peserta tes tidak berbeda walaupun tes yang dikerjakan berbeda tingkat kesulitannya. Invarians parameter butir dapat diselidiki dengan mengujikan tes pada kelompok peserta yang berbeda. Invarians parameter butir terbukti jika estimasi parameter butir tidak berbeda walaupun diujikan pada kelompok peserta yang berbeda tingkat kemampuannya.
Dalam teori respons butir, selain asumsi-asumsi yang telah diuraikan sebelumnya di atas adala ada hal penting yang perlu diperhatikan adalah pemilihan model yang tepat. Pemilihan model yang tepat akan mengungkap keadaan yang sesungguhnya dari data tes sebagai hasil pengukuran.
Selain ketiga asumsi yang dikemukakan Hambleton dkk di atas, Wainer dan Mislevy mengajukan empat asumsi lain dari pendekatan IRT. Asumsi pendekatan IRT menurut Wainer dan Mislevy (1990) adalah:
a). Urutan dari pemberian butir tes tidak relevan. Berbeda dengan pendekatan klasik yang memberikan butir soal yang mudah di awal tes kemudian dilanjutkan dengan butir soal yang lebih sukar, pemberian butir soal pada pendekatan IRT tidak perlu melihat urutan dari kesukaran butir soal. Dengan demikian, butir soal dapat diadministrasikan sesuai dengan kemampuan butir soal.
b). Parameter butir soal yang sama digunakan untuk semua peserta tes. Apabila sekelompok peserta tes akan diperkirakan kemampuannya dengan seperangkat butir tes, maka model IRT yang digunakan pada butir-butir soal tersebut harus sama. Tujuannya agar skor yang diperoleh dapat diperbandingkan satu sama lain.
c). Semua parameter butir soal diketahui. Untuk dapat memperkirakan kemampuan (proficiency) peserta tes, maka parameter dari setiap butir soal perlu diketahui. Untuk mengetahui parameter dari setiap butir soal perlu dilakukan kalibrasi atau pendugaan (estimations).
2). Model Pendekatan Item Response Theory
Model yang digunakan pada pendekatan IRT adalah falsifiable model (Hambleton, Swaminathan dan Rogers, 1991: 7). Artinya, model IRT yang digunakan dapat cocok ataupun tidak cocok dengan data tes yang dianalisis. Dengan kata lain dapat saja model IRT yang digunakan tidak dapat menjelaskan data tes tersebut. Dengan demikian, perlu dilakukan analisis kecocokkan model (goodness of fit) terhadap data tes. Sehingga apabila ditemukan ketidakcocokkan antara data dengan model, artinya model IRT yang digunakan tidak dapat diterapkan pada data tes yang dianalisis. Hal demikian tidak ditemui pada pendekatan teori klasik, dimana apabila dari analisis butir soal diperoleh hasil yang tidak mencapai standard yang ditentukan, maka butir soal tersebut dianggap tidak biak sehingga didrop dari tes.
Item characteristic function atau item characteristic curve (ICC) merupakan
ekpresi matematika yang menggambarkan peluang menjawab benar pada kemampuan dan karakteristik item tertentu. Dalam IRT, ada tiga model yang paling banyak digunakan (Hambleton, Swaminathan dan Rogers, 1991:12), yaitu model satu parameter logistik (1 PL), dua parameter logistik (2 PL), dan tiga parameter logistik (3 PL). Ketiga model ini digunakan pada asumsi unidimensi dan data butir soal yang diskor dikotomous.
a). Model Logistik Tiga Parameter (3P)
Sesuai dengan namanya, model logistik tiga parameter ditentukan oleh tiga karakteristik butir yaitu indeks kesukaran butir soal, indeks daya beda butir, dan parameter pseudoguessing (tingkat menebak). Dengan adanya tingkat menebak pada model logistik
tiga parameter, memungkinkan subyek yang memiliki kemampuan rendah mempunyai peluang untuk menjawab butir soal dengan benar. Secara matematis, model logistik tiga parameter dapat dinyatakan sebagai berikut (Hambleton, Swaminathan, dan Rogers, 1991: 17, Hambleton, dan Swaminathan, 1985 : 49).
) secara acak dapat menjawab butir i dengan benar
: tingkat kemampuan subjek D : faktor skala = 1,7
ai : indeks daya beda dari butir ke-i
ci : indeks tingkat menebak butir ke-i
e : 2,718
n : banyaknya item dalam tes.
Nilai kemampuan peserta () terletak di antara –4 dan +4, sesuai dengan daerah asal sebaran normal. Pernyataan ini merupakan asumsi yang mendasari besar nilai bi.
Secara teoretis, nilai bi terletak di antara - dan + . Suatu butir dikatakan baik jika nilai
ini berkisar antara –2 dan +2 (Hambleton dan Swaminathan, 1985: 107). Jika nilai bi
mendekati –2, maka indeks kesukaran butir sangat rendah, sedangkan jika nilai bi
mendekati +2 maka indeks kesukaran butir sangat tinggi untuk suatu kelompok peserta tes. Parameter ai merupakan daya beda yang dimiliki butir ke-i. Parameter ini
menggambarkan seberapa baik sebuah butir dapat membedakan peserta yang berkemampuan tinggi dengan yang berkemampuan rendah. Pada kurva karakteristik, ai
merupakan kemiringan (slope) dari kurva di titik bi pada skala kemampuan tertentu.
Karena merupakan kemiringan, diperoleh semakin besar kemiringannya, maka semakin besar daya beda butir tersebut. Secara teoretis, nilai ai ini terletak antara 0 dan +. Pada
pada butir yang baik nilai ini mempunyai hubungan positif dengan performen pada butir dengan kemampuan yang diukur, dan ai terletak antara 0 dan 2 (Hambleton dan
Swaminathan, 1985: 37 ).
Peluang menjawab benar dengan memberikan jawaban tingkat menebak dilambangkan dengan ci, yang disebut dengan tingkat menebak. Parameter ini memberikan
suatu kemungkinan asimtot bawah yang tidak nol (nonzero lower asymtote) pada kurva karakteristik butir (ICC). Parameter ini menggambarkan peluang peserta dengan kemampuan rendah menjawab dengan benar pada suatu butir yang mempunyai indeks kesukaran yang tidak sesuai dengan kemampuan peserta tersebut. Besarnya harga ci
diasumsikan lebih kecil daripada nilai yang akan dihasilkan jika peserta tes menebak secara acak jawaban pada suatu butir. Pada suatu butir tes, nilai ci ini berkisar antara 0 dan
1. Suatu butir dikatakan baik jika nilai ci tidak lebih dari 1/k, dengan k banyaknya pilihan
(Hullin, 1983: 36). Jadi misalnya pada suatu perangkat tes pilihan ganda, ada 4 pilihan untuk setiap butir tesnya, butir ini dikatakan baik jika nilai ci tidak lebih dari 0,25.
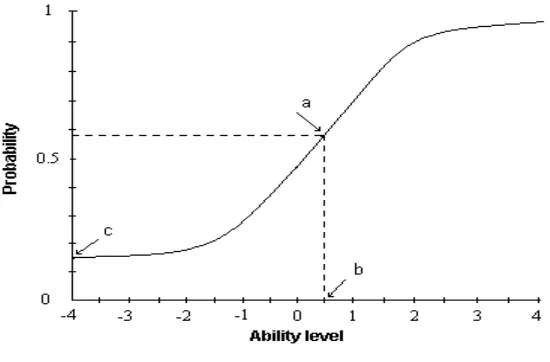
Gambar 1 memperlihatkan contoh plot ICC untuk model 3 PL (Hambleton dan Swaminathan, 1985:39) dengan kemampuan pada absis dan peluang menjawab benar pada ordinat. ICC pada gambar 1, menunjukkan parameter tingkat kesulitan, b sebesar 0,50. Parameter daya beda, a sebesar 1,5. Dan parameter tingkat menebak, c sebesar 0,15.
Gambar 2. ICC model 3 PL
Parameter tingkat kesulitan memiliki skala sama dengan tingkat kemampuan ( ), dengan nilai berkisar antara -4 sampai +4. Dalam ICC, parameter tingkat kesulitan merupakan titik pada skala kemampuan yang menunjukkan nilai maksimum dari kemiringan ICC (Hambleton dan Swaminathan, 1985:38). Pada model IRT 3 PL, maksimum kemiringan berada pada p = (1 + c)/2. Sedangkan pada 2 PL dan 1 PL maksimum kemiringan berada pada p = 0,5, karena c sama dengan nol.
b). Daya beda (b), Tingkat kesukaran (a) dan Tingkat Menebak (c)
Dalam Item Response Theory (IRT) keberadaan Daya beda (b), Tingkat kesukaran (a) dan Tingkat Menebak (c) dinamakan Fungsi Informasi Butir. Fungsi informasi butir (item information functions) merupakan suatu metode untuk menjelaskan kekuatan suatu butir pada perangkat soal dan menyatakan kekuatan atau sumbangan butir soal dalam mengungkap kemampuan laten (latent trail) yang diukur dengan tes tersebut. Dengan fungsi informasi butir diketahui butir mana yang cocok dengan model sehingga membantu dalam seleksi butir soal. Secara matematis, fungsi informasi butir didefinisikan sebagai berikut.
i i
i i
Q P
P I
2
keterangan : Birnbaum (Hambleton & Swaminathan, 1985: 107) dalam persamaan berikut.
c : indeks tebakan semu (pseudoguessing) butir ke-i
e : bilangan natural yang nilainya mendekati 2,718
Berdasarkan persamaan fungsi informasi di atas, maka fungsi informasi memenuhi sifat: (1) pada respons butir model logistik, fungsi informasi butir mendekati maksimal ketika nilai bi mendekati 0. Pada model logistik tiga parameter nilai maksimal dicapai ketika 0 terletak sedikit di atas bi dan indeks tebakan semu butir menurun; (2) fungsi informasi secara keseluruhan meningkat jika parameter daya beda meningkat.
n
i i
I I
1
... (7)
Nilai-nilai indeks parameter butir dan kemampuan peserta merupakan hasil estimasi. Karena merupakan hasil estimasi, maka kebenarannya bersifat probabilistik dan tidak terlepaskan dengan kesalahan pengukuran. Dalam teori respons butir, kesalahan pengukuran standar (Standard Error of Measurement, SEM) berkaitan erat dengan fungsi informasi. Fungsi informasi dengan SEM mempunyai hubungan yang berbanding terbalik kuadratik, semakin besar fungsi informasi maka SEM semakin kecil atau sebaliknya (Hambleton, Swaminathan, & Rogers, 1 991, 94). Jika nilai fungsi informasi dinyatakan dengan I(θ) dan nilai estimasi hubungan keduanya, menurut (199.l :94) dinyatakan dengan SEM, maka Hambleton, Swaminathan, & Rogers disajikan grafik nilai fungsi informasi standar suatu butir dengan parameter
I
SEM ˆ 1 ……….. (8)
b. Prosedur Pemilihan Item Awal (Starting Rule)
Computerized adaptive testing (CAT) dirancang untuk setiap individu peserta tes
(Wiener, 1990). Dalam prosedur pemilihan item awal, peserta tes akan diberi satu set soal yang memenuhi spesifikasi rancangan tes (kisi-kisi) dan biasanya sesuai dengan tingkat kemampuan setiap individu. Tes dimulai dengan soal-soal yang tidak terlalu sukar atau tidak terlalu mudah. Jika tidak ada performance awal mengenai kemampuan awal peserta tes maka CAT dapat dimulai dengan memilih butir soal dengan tingkat kesukaran yang sedang (Mills, 1999: 123).
Setiap peserta tes menjawab soal dan komputer akan memberikan skor. Jawaban terhadap soal tersebut dan akan menentukan soal yang akan ditampilkan oleh komputer selanjutnya. Setiap menjawab soal dengan benar, peserta tes akan diberi soal yang lebih sukar. Sebaliknya, bila menjawab salah, komputer akan memilihkan soal yang lebih mudah.
menjawab soal, peserta ujian tidak akan dapat mengulang soal-soal sebelumnya dan mengganti jawabannya.
c. Prosedur Pemilihan Item Selama Pelaksanaan Tes
Salah satu prosedur penting dalam CAT adalah pemilihan utem selama pelaksanaan tes. Prosedur seleksi atau pemilihan item menyangkut beberapa tahap kerja. Prosedur yang paling sederhana meliputi dua tahap (Azwar, 2003:55), yang akan dijelaskan berikut ini. 1) Tahap pertama, analisis dan seleksi item berdasarkan evaluasi kualitatif. Evaluasi ini melihat a) apakah item yang ditulis sesuai dengan blue-print dan indikator perilaku yang hendak diungkapnya? b) apakah item telah ditulis sesuai dengan kaidah penulisan yang benar? c) melihat apakah item-item yang ditulis masih mengandung sosial desirability yang tinggi? 2) Tahap kedua, adalah prosedur seleksi item berdasarkan data empiris (data hasil uji coba item pada kelompok subjek yang karakteristiknya setara dengan subjek yang hendak dikenai pengukuran) dengan melakukan analisis kuantitatif terhadap parameter-parameter item. Pada tahap ini paling tidak dilakukan seleksi item berdasarkan daya pembeda, tingkat kesulitan item dan tingkat menebak (guessing).
Salah satu metode untuk melakukan prosedur pemilihan item selama pelaksanaan tes dalam software CAT yang berdasar pada daya pembeda, tingkat kesulitan item dan tingkat menebak (guessing) adalah sebuah segitiga pohon keputusan (a triangle decision tree / TDT) (Phankokkruad. 2008: 656). Segitiga pohon keputusan adalah model keputusan yang berbentuk grafik. Sebuah titik menunjukkan parameter tes sebaliknya ranting manunjukkan target paramater tes berikunya. Setiap titik hanya ada dua ranting untuk anak titik dan berisi tiga parameter IRT yaitu tingkat kesulitan, daya beda dan tingkat menebak. Ranting yang keluar dari titik ada dua yaitu ranting ke arah kiri dan ranting kearah kanan. Arah ranting ke kanan bila peserta tes menjawab pertanyaan dengan benar dan arah ranting ke ke kiri bila peserta tes menjawab pertanyaan item yang salah. Gambar dari Segitiga pohon keputusan
1
2 3
Dengan bi1,j bi,j bi1,j1 dan bi,1bi,2 ...bi,j
w = bobot dari tingkat kesukaran (a) b
d. Prosedur Untuk Mengakhiri Tes (Stopping Rule)
Keputusan mengenai kapan harus menghentikan tes CAT adalah elemen yang paling penting. Jika tes ini terlalu pendek, maka perkiraan kemampuan peserta tes tidak akurat. Jika tes ini terlalu panjang, maka banyak waktu dan beaya yang terbuang dan menyebabkan hasil tes tidak valid. Tes CAT berhenti bila: (1) item bank telah habis. Ini terjadi biasanya dengan bank item kecil ketika setiap item telah diberikan kepada pengambil tes; (2) seluruh item tes telah diberikan. Jumlah item tes maksimum yang diperbolehkan untuk diberikan kepada pengambil tes biasanya jumlah item yang sama seperti pada paper pencils tet; (3) Kemampuan mengukur diperkirakan dengan ketepatan yang cukup. Setiap respons menyediakan lebih banyak informasi statistik tentang kemampuan mengukur, meningkatkan presisi dengan menurunkan standar error dengan pengukuran. Bila ukuran cukup tepat, pengujian berhenti. Error standar yang digunakan adalah 0,2; (4) Sebuah jumlah minimal item telah diberikan; (5) Setiap kompetensi tes telah dikerjakan dengan benar; (6) waktu telah habis.
e. Estimasi Kemampuan Peserta tes
1). Maximum Likelihood
Bila seorang peserta tes dengan tingkat kemampuan θ menjawab tes yang berisi sebanyak n butir soal pilihan ganda dengan parameter butir (tingkat kesukaran, daya beda dan guessing) yang sudah diketahui dan sudah diestimasi sebelumnya maka peluang bersama dari peserta tes sebagai p
U1,U2,U3....Un
. Dalam praktik pengukuran makaJika asumsi independensi local dipenuhi maka fungsi kemungkinan maximum likelihood adalah
Item pilihan ganda (multiple choice) merupakan salah satu bentuk item dari metode selected response yang paling sering digunakan dan dipilih untuk berbagai keperluan
pengujian. Secara umum item pilihan ganda terdiri dari dua bagian, bagian pertama disebut stem adalah bagian pokok yang berisi informasi dan permasalahan atau pertanyaan. Bagian
kedua, berupa sejumlah pilihan jawaban (option) yang disediakan untuk menjawab permasalahan atau pertanyaan stem.
Item pilihan ganda menyediakan sejumlah pilihan tetapi hanya satu jawaban pilihan jawaban yang benar. Sedangkan yang lain berfungsi sebagai pengecoh (distractors). Model item pilihan ganda dengan format semacam ini dikategorikan sebagai model konvensional (Haladyna dkk. 2002; oosterhof: 200)
Pedoman utama dalam pembuatan butir soal bentuk pilihan ganda adalah: 1). Pokok soal harus jelas
2). Pilihan jawaban homogen dalam arti isi. 3). Panjang kalimat pilihan jawaban relatif sama. 4). Tidak ada petunjuk jawaban benar
5). Hindari mengggunakan pilhan jawaban: semua benar atau semua salah. 6). Pilihan jawaban angka diurutkan.
7). Semua pilihan jawaban logis
8). Jangan menggunakan negatif ganda.
9). Kalimat yang digunakan sesuai dengan tingkat perkembangan peserta tes 10). Bahasa Indonesia yang digunakan baku.
11). Letak pilihan jawaban benar ditentukan secara acak.
Dalam soal pilihan ganda, peserta tes hanya memilih jawabannya tanpa memberikan alasan mengapa jawaban tersebut dipilih. Butir tes berbentuk pilihan ganda biasanya diberi skor 1 bila jawaban benar dan diberi skor 0 bila jawaban salah sehingga butir tes berbentuk pilihan ganda termasuk butir tes dikotomus.
B. Computerized Adaptive Test (CAT) sebagai Sistem Informasi
Sistem informasi yang terkomputerisasi akan melalui siklus-siklus: 1). Identifikasi Masalah; 2). Penentuan syarat; 3). Analisis kebutuhan sistem; 4). Perancangan sistem; 5). Implementasi dan mendokumentasikan; 6). Testing dan perbaikan sistem; 7). Evaluasi sistem (Kendal & Kendal, 2002: 11). CAT sebagai sebuah program adalah termasuk sebagai software sistem informasi sehingga perlu dipilih dan dilakukan uji kelayakannya.
Program dapat dipilih dengan pertimbangan: 1). Mendapat banyak dukungan dari lembaga atau pemakai; 2). Mampu meningkatkan kualitas layanan; 3). Basis data yang dibuat dapat dipergunakan untuk berbagai keperluan yang banyak; 4). Meningkatkan proses layanan, dan 5). Mengurangi kesalahan. (Kendal & Kendal, 2002:62). Program bernilai layak adalah jika dipakai memenuhi kriteria: 1). Kelayakan teknis; 2). Kelayakan ekonomis dan 3). Kelayakan operasionalitas
kemanfaatan yang diperoleh. Di samping itu, biaya operasional juga merupakan faktor penting yang harus dipertimbangkan. Kelayakan operasional, sangat bergantung pada sumber daya manusia yang tersedia dan kelangsungan program setelah diinstal. Kriteria penerimaan adalah adanya permintaan sistem, efektif dan kemudahan operasional.
Dalam penelitian ini hasil software berupa produk CAT memenuhi kriteria-kriteria yang telah disebutkan di atas. Data untuk menguji pemilihan dan kelayakan dapat dilakukan melalui wawancara mendetail dan angket terhadap sejumlah pengguna. Grafik dan diagram dapat digunakan untuk membantu memperkirakan waktu dan beban pekerjaan yang dilakukan. Untuk penggambaran program yang dihasilkan dapat dilakukan melalui pembuatan dengan bantuan grafis diagram aliran data atau prototyping (pemodelan) yang memuat unit antarmuka sistem dengan pengguna.
CAT sebagai sebuah software sistem informasi dalam penelitian ini tak lepas dari ketentuan-ketentuan tersebut di atas. Untuk membangun produk software yang efektif dan berkualitas diperlukan perancangan yang baik mengenai basis data, tampilan output, input, antarmuka pengguna, dan prosedur masukan data yang akurat
C. Layout Antarmuka Pemakai
Layout antarmuka adalah halaman informasi yang dikirimkan kepada para
pengguna melalui sistem informasi yang dihasilkan oleh peralatan (komputer) (Santoso, I. 2004). Wujud layout dapat berupa data gratis, teks maupun bilangan yang tersimpan dalam bentuk hard copy laporan tercetak, dan soft copy berupa besaran elektrik pada monitor, penyimpan elektronik, media magnetik maupun optik.
Pengembangan CAT dalam penelitian ini lebih mengutamakan penampilan output di layar display. Disain layar yang disarankan oleh Kendal & Kendal, (2002: 28) adalah sebagai berikut: 1). Buat layar yang sederhana (layout dan pewarnaan); 2). Buatlah presentasi layar yang tetap konsisten; 3). Tentukan navigasi untuk pengguna se-efektif mungkin; 4). Ciptakan layar yang menarik.
Produk software tidak hanya dilihat dari segi tampilan, tetapi terkait juga dengan isi tampilan yang meliputi: Isi, Teks, Grafik, Presentasi dan (Kendal & Kendal, 2002:40).
gambar-gambar metafora dan hindari gambar-gambar kartun; 7). Sesuaikan dengan pengguna yang dituju; 8). Gunakan bahasa yang tepat.
Teks perlu mempertimbangkan: 1). Memiliki sebuah judul; 2). Gunakan kata-kata yang berarti pada kalimat pertama yang muncul; 3). Gunakan kata-kata sedemikian rupa untuk kemudahan browser; 4). Gunakan model tulisan yang jelas untuk heading, sub-heading, dan paragraf pertama.
Dalam Grafik, perlu pembuatan grafik yang efektif yaitu: 1). Gunakan format garnbar yang umum, GIF, JPEG atau BMP, namun dengan ukuran masuk akal; 2). Buat grafik yang profesional; 3). Buat latar belakang yang sederhana; 4). Gunakan garis horisontal sebagai penanda batas halaman; 5). Gunakan bullet, tombol navigasi berwarna, dan bentuk kursor yang berbeda untuk menuju halaman yang lain; 6). Gunakan tiga aturan klik pada mouse.
Presentasi adalah cara merancang layar tampilan antarmuka agar menarik. Presentasi yang menarik mempunyai beberapa kriteria diantaranya: 1). Buat desain tampilan yang menarik; 2). Dapat diakses (down load) dengan cepat; 3). Gunakan ukuran huruf yang sesuai dan pewarnaan yang serasi; 4). Gunakan garnbar-gambar dan tombol-tombol yang menarik untuk jalur-jalur akses yang diinginkan; 5). Gunakan gambar grafts yang sarna dan konsisten dari sejumlah halaman; 6). Hindari penggunaan animasi yang berlebihan, karena dapat melelahkan penglihatan, dan 7). Sediakan area di sisi halarnan utama untuk tombol-tombol menuju (hyperlink) ke halarnan yang lain.
Navigasi adalah arah kontrol untuk akses informasi yang diinginkan. Hal-hal yang
perlu diperhatikan dalam pembuatan navigasi diantaranya: 1). Buat perbedaan penunjuk manakala melintas pada tombol navigasi yang disediakan; 2). Munculkan juga keterangan singkat target yang dituju saat penunjuk melintas di tombol navigasi; 3) Buat navigasi yang memungkinkan agar pemakai dapat kembali dengan nyaman jika terjebak pada halaman yang tidak diinginkan.
D. Pengelolaan Sistem Basis Data.
mengenai data yang terstruktur atas hubungan data alami yang menyediakan semua keperluan akses masing-masing unit data yang diperlukan pemakai yang berbeda-beda. Basis data adalah sekumpulan data yang saling berhubungan dan disimpan bersama dengan menghindarkan redundansi namun bersifat independent dan dapat diakses oleh pengguna untuk memenuhi keperluan berbagai aplikasi.
Dalam penelitian ini yang dimaksud dengan basis data adalah sekumpulan data materi testing yang saling berhubungan dan disimpan bersama dengan menghindarkan redundansi namun bersifat independent dan dapat diakses oleh pengguna yaitu administrator, guru dan siswa untuk memenuhi berbagai keperluan aplikasi pengukuran.
Pengolahan model evaluai pada sistem basis data dengan menggunakan bantuan komputer memiliki berbagai kelebihan dibanding jika dilakukan secara manual. Kroenke (1995) menyebutkan bahwa operasi-operasi dasar basis data me1iputi: 1. Pembuatan basis data baru (create data base), 2. Penghapusan basis data (drop data base), 3. Pembuatan tabel basis data (create table), 4. Penghapusan tabel basis data (drop table), 5. Penambahan/pengisian basis data (insert data), 6. Pengambilan/ pencarian data (retrieve/search), 7. pengubahan data (update), 8. Penghapusan data (delete).
Pengelolaan dan pemanfaatan dengan model sistem basis data secara komputer memiliki keuntungan (Kendak & Kendal, 2002), sebagai berikut: 1. Kecepatan dan kemudahan (speed), 2. Efisiensi ruang penyimpan (space), 3. Keakurasian (acuracy), 4. Ketersediaan (availability), 5. Kelengkapan (completeness), 6. Keamanan (security), 7. Kebersamaan pemakaian (sharability).
Bangunan model evaluasi dengan sistem basis data secara lengkap diperlukan adanya komponen-komponen pembangun. Setiap komponen merupakan satu kesatuan yang tidak dapat dipisahkan. Menurut Kroenke (1995), komponen utama pembangun sistem tersebut adalah: 1. Perangkat keras (hardware), 2. Sistem operasi (operating system), 3. Basis data (data base), 4. Sistem pengelolaan basis data (data base
management system), 5. Pemakai (user), 6. Program aplikasi (aplication program).
E. Kerangka Pikir
Berdasar kajian teori tersebut di atas, maka kerangka pikir penelitian ini adalah sebagai berikut:
Perkembangan terkini, bentuk tes yang menggunakan bantuan teknologi komputer yang disebut Computerized Adaptive Testing (CAT). Penggunaan CAT dalam tes memiliki banyak kelebihan dibanding metode papper and pencils. Dalam pembuatan program CAT, bank soal yang disiapkan telah dilakukan kalibrasi untuk mengetahui tingkat kesukaran, daya beda dari butir soal dan tingkat menebak (guessing). Butir soal yang baik adalah yang memiliki tingkat kesukaran antara 0.0 – 2.0, memiliki daya beda antara -2.0 – 2.0 dan tingkat menebak =
k
1
, dengan k = banyak opsi jawaban.
Bank soal yang terdiri dari butir-butir soal yang baik akan menjadi pertimbangan untuk melakukan prosedur pemilihan item awal, biasanya item tes awal memiliki tingkat kesukaran, daya beda dan tingkat menebak yang sedang. Hal ini dilakukan bila peserta tes yang memiliki kemampuan ektrim tinggi apabila diberi item tes awal yang rendah maka akan memerlukan waktu yang lama untuk mencari soal yang sesuai denga kemampuannya. Dari respon peserta dalam menjawab benar atau salah dilakukan estimasi kemampuan menggunakan metode Maximum Likelihood. Dari hasil estimasi kemampuan ini maka software CAT yang berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c)
dalam prosedur pemilihan item selama pelaksanaan tes akan mengambil soal berikutnya dengan pertimbangan kemampuan yang dimilikinya. Kemudian dilakukan metode untuk penskoran tes.
Langkah berikutnya dilakukan prosedur untuk mengakhiri tes agar tes bisa lebih efisien. Langkah terakhir dalam pembuatan program CAT adalah Estimasi Kemampuan Peserta tes, estimasi kemampuan peserta tes juga menggunakan metode Maximum Likelihood. Program Software CAT dibuat menggunakan bahasa pemograman Delphi.
Software basis data menggunakan My SQL
C. Pertanyaan Penelitian
Berdasar uraian di atas maka pertanyaan penelitiannya sebagai berikut:
1. Bagaimana kualitas butir-butir test pada bank soal dalam pengembangan software CAT?
2. Bagaimana software CAT yang berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes.? 3. Bagaimana mencari estimasi kemampuan peserta tes menggunakan metode
BAB III
METODE PENELITIAN
A. Model Pengembangan
Dalam penelitian mengembangkan program software CAT yang berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes menggunakan pendekatan penelitian Research and Development (R&D). Ada dua tahapan dalam pelaksanaan yaitu: tahap pengembangan produk dan tahap implementasi produk.
Pada tahap pertama dalam pengembangan produk, langkah yang diambil mengikuti yang dikemukakan oleh Kendal dan Kendal serta Pressman dan telah dilengkapi oleh Rolston (1988: 138) dengan langkah-langkah seperti gambar berikut ini:
Dalam tahap 1 pemilihan dan analisis kebutuhan system yang akan dilakukan adalah pengumpulan informasi yang berfungsi untuk need assessment sebagai desain penyusunan model. Berdasarkan informasi yang terkumpul dibuat prototipe perangkat lunak. Proses kembali ke pemilihan dan analisis kebutuhan jika dalam pengembangan prototipe ada kekurangan informasi. Langkah ini dinamakan PROBLEM REVISION.
Pada langkah ini dilakukan terus menerus untuk memperoleh langkah yang representative. Langkah akan berlanjut ke langkah berikutnya apabila ruang lingkup permasalahan yang diselesaikan telah terpenuhi.
Langkah kedua dalam perancangan logaritma dilakukan pembuatan sistematika kerja program perangkat lunak (software) yang berdasarkan langkah pertama. Dengan langkah pada algoritma kemudian menerjemahkan algoritma ke dalam kode program. Pada langkah kedua ini akan kembali ke langkah perancangan algoritma apabila terdapat kode program yang tidak sesuai dengan algoritma. Langkah kedua ini dinamakan FORMALISM REVISION.
Proses ini juga bisa menuju ke langkah pertama bila terdapat informasi yang belum lengkap dan kurang sesuai dengan langkah pada langkah pertama. Proses pada langkah kedua ini akan menuju ke langkah ketiga bila target telah terpenuhi yaitu mendapatkan sebuah program yang mampu digunakan untuk menyelesaikan masalah.
yaitu: 1) Syntax error (kesalahan kalimat), 2). Run time error (kesalahan saat dijalankan), dan 3). Logic error (kesalahan fungsi dan hasil dari penalaran logika). Dari langkah ini dijadikan dasar proses perbaikan dan penyempurnaan program. Proses ini akan kembali ke pengujian program jika masih ada kesalahan yang menyebabkan program belum berfungsi seperti yang diharapkan. Langkah ketiga ini dinamakan EVOLUTIONARI REVISION.
Proses akan kembali ke langkah kedua (Formalism revision) jika ada kesalahan yang disebabkan oleh algoritma dan penulisan kode program yang belum sesuai dengan langkah ke dua. Atau bahkan akan ke langkah pertama (problem revision) apabila ada kesalahan algoritma dank ode program yang kurang sesuai yang disebabkan oleh adanya algoritma dan kode program yang belum sesuai pada langkah pertama.
Langkah-langkah ini adalah berbentuk siklus hidup untuk mengembangkan software CAT . Dalam siklus-siklus ini mengalami proses berulang jika pada langkah
tertentu ada kesalahan. Proses akan berulang pada bagian yang ditemukan kesalahan. Siklus akan bergerak terus menerus sehingga diperoleh perangkat lunak yang secara operasional dapat berfungsi sesuai dengan tujuan yang telah ditentukan.
Tahap kedua adalah tahap pengembangan, dalam tahap proses pengembangan menerapkan produk dalam situasi kelas yang sesungguhnya. Proses ini mengikuti langkah dari Borg & Gall (1983: 774-776)
1. Research and information collecting yaitu melukan review literatur, observasi kelas yang akan dijadikan implementasi dan mempersiapkan pelaksanaan.
2. Planning yaitu mendefinisikan skill yang akan diamati, menentukan urutan-urutan tujuan yang hendak dicapai dan menguji
3. Devolop preliminary from product yaitu mempersiapkan materi, instruksional yang akan diberikan (memilih, mengorganisasi, mengemas materi, buku pegangan, peralatan evaluasi untuk mengukur keberhasilan tujuan.
4. Preliminary field testing yaitu menggunakan produk dalam situasi kelas yang sebenarnya
5. Main product revision yaitu perbaikan product berdasarkan informasi hasil analisis data
6. Main field testing yaitu menggunakan product hasil percobaan di kelas
8. Operational field testing yaitu menggukan kembali hasil product yang telah diperbaiki
9. Final product revision yaitu memperbaiki product akhir dengan diperoleh product yang lebih sempurna
10.Desimination and implementation yaitu melaporkan hasil product akhir yang telah disempurnakan dan disebarluaskan untuk lingkup yang leih luas.
B. Uji Coba Produk
Uji coba produk software CAT yang berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes akan dilakukan beberapa kegiatan sebagai berikut:
1. Desain Uji Coba
Uji coba dilakukan setelah software CAT jadi kemudian dilakukan uji coba kepada mahasiswa baru STAIN Salatiga tahun akademik 2010/2011 dalam rangka uji coba dalam plecement tes SIBA (Studi Intensif Bahasa Arab)
2. Subyek Coba
Subyek coba adalah mahasiswa baru STAIN Salatiga tahun akademik 2010/2011 dalam rangka uji coba dalam plecement tes SIBA (Studi Intensif Bahasa Arab)
C. Tempat dan Waktu Penelitian
Penelitian ini adalah pengembangan perangkat lunak software CAT berbasis daya beda (b), tingkat kesukaran (a) dan tingkat menebak (c) dalam prosedur pemilihan item selama pelaksanaan tes dilakukan di:
1. Tempat penelitian (pengembangan software): Laboratorium Komputer Sekolah Tinggi Agama Islam Negeri (STAIN) Salatiga
2. Tempat penelitian (implementasi software): STAIN Salatiga. 3. Waktu penelitian: 6 bulan (Juli – Desember 2010).
D. Sumber Data Penelitian
Sumber data yang dilibatkan dalam penelitian ini meliputi: 1. Bank soal ujian plecemen test SIBA STAIN Salatiga; 2. Uji kelayakan, dan evaluasi produk yaitu: ahli
E. Instrumen Pengumpulan Data Penelitian
Instrument yang digunakan untuk mengumpulkan data dalam penelitian meliputi: 1. Lembar observasi identifikasi kebutuhan
2. Lembar observasi kelayakan produk (pengujian Internal) 3. Lembar evaluasi produk (pengujian eksternal)
Lembar evaluasi produk (pengujian eksternal) meliputi: a. Validasi produk
b. Verifikasi kriteria produk standar c. Validasi standar produk
Keterangan: beri nomor dengan ketentuan 1=kurang, 2=cukup, 3=baik, 4=amat baik
Alat dan bahan yang digunakan dalam penelitian dan pengembangan CAT ini meliputi: 1). Satu unit komputer, untuk membuat software CAT; 2). Scanner, untuk pengambilan data gambar dan hasil respon peserta tes; 3). Camera digital Handycam untuk pengambilan gambar hidup yang diperlukan bagi program; 4). Printer, untuk mencetak hasil-hasil kerja; 5). Perangkat lunak Delphi untuk membuat kode program; 6). Perangkat keras pendukung: flash disk dan CD.
F. Teknik Analisis Data
Teknik analisis data yang digunakan pengembangan software CAT ini menggunakan teknik analisis deskriptif evaluatif. Penelitian ini akan menguji kelayakan produk software yang digunakan untuk mengevaluasi kemampuan peserta menggunakan software CAT software CAT berbasis daya beda (b), tingkat kesukaran (a) dan tingkat
DAFTAR PUSTAKA
Aiken, Lewis R. (1994). Psychological Testing and Assessment,(Eight Edition), Boston: Allyn and Bacon.
Allen, M.J. & Yen, W.M. (1979). Introductions to measurement theory, Belmont, CA: Wadsworth, Inc.
Ariel, A., Linden, W.J., & Veldkamp, B.P. (2006). A Strategi for Optimizing Item-Pool Management. Journal of Educational Measurement. Vol. 43, No. 2, p. 85–96.
Crocker, L. & Algina, J. (1986). Introduction to Classical and Modern Test, Theory_. New York: Holt, Rinehart and Winston, Inc.
Drasgow, F., & Buchanan, J.B. (1999). Innovations in Computerized Assesment. Lewrence Erlbaum Associates, Publishers. New Jersey, London.
Flaugher, R. (2000). Item Pool. Dalam Wainer, H. (Ed), Computerized adaptive testing: A Primer (2 nd ed.) hal. 37 - 59). Mahwah, NH: Lawrence Erlbaum Associates.
Forsyth, I. (1998). Teaching and Learning Material dan the Internet. Second Edition. London: Bidles Ltd.
Haladyna, T.M., Downing, S. M., & Rodrigues, C. (2002). A Review of Multiple Choice Item-Writing guidelines for Classroom Assesment. Aplied Measurement in Education, 15(3) 309-334.
Hambleton, R.K. & Swaminathan, H. & Rogers, H.J. (1991). Fundamental of Item response theory, Newbury Park, CA: Sage Publication Inc.
Hambleton, R.K. & Swaminathan, H. (1995). Item response theory, Boston, MA: Kluwer Inc.
Hambleton, R.K. & Linden, W.J. (1997). Handbook of modern item response theory, Springer, New York: Edwards Brothers Inc.
Hopkins, K.D., Stanley, J.C., & Hopkins, B.R. (1990). Educational and Psychological Measurement and Evaluation. Sevent Edition. Prentice Hall. Ney Jersey.
Hullin, C.L., et.al. (1983). Item response theory: Application to psichologycal measurement. Homewood, IL : Dow Jones-Irwin.
Keung, C., Chang, H.H., & Hua. (2003). Computerized Adaptive Testing : Comparison of Three Content Balancing Methods. Journal of Technology, Learning, and Assesment. Vol. 2, No. 5.
Kit, T.H., & Chang, H.H. (2001). Item Selection in Computerized Adaptive Testing : Should More Discriminating Item be Used First? Journal of Education Measurement. Vol. 38. No. 3. p:249 – 266.
Kroenke. J.M. (1975). Computer Database Organization. NJ: Prentice Hall International. Inc.
Linden, W.J., & Veldkamp, B.P. (2004). Contraining Item Exposure in Computerized Adaptive Testing. Journal of Educational and Behavioral Statistics. Vol. 29, No. 3 p. 273. Washington.
Linden, W.J. (2006). Optimal Assembly of Test With Item Sets. Computer Testing Report 99 - 04.
Mardapi, Djemari (2004). Penyusunan Tes Hasil Belajar. Yogyakarta: PPs UNY Yogyakarta.
Masters, N.G. & Keeves, P.J. (1999). Advances in Measurement in Educational Research and Assesment. Pergamon, An Imprint of Elsevier Science, New York.
Mehrens, W.A. & Lehmann, I.J. (1973). Measurement and evaluation in education and psychology. New York : Hold, Rinehart and Wiston, Inc.
Mislevy, R.J. & Bock, R.D. (1990). BILOG 3 : Item analysis & test scoring with binary logistic models. Moorseville: Scientific Software Inc.
Murshel, J.L. (1954). Successfull Teaching, Its Psychological Principles. USA: Mc. Graw Hill Book Company Inc.
Lord, F.M. (1980). Applications of item response theory to practical testing problems, Hillsdale, NJ : Erlbaum.
Nitko, Anthony J. (1996). Educational Assessment of Students, Second Edition. Ohio: Merrill an imprint of Prentice Hall Englewood Cliffs.
Nunally, Jum C. (1978). Psychometric Theory, Second Edition. New Delhi: Tata McGrawHill Publishing Company Limited.
Oosterhof, A. (2003). Developing and Using Classroom Assesment (3th ed). Upper Saddle River: Merrill Prentice Hall
Popham, W. J. (1995). Classroom Assesment: what Teachers need to know. Boston: Allyn and Bacon.
Reckase, M. D. (2003). Item pool design for computerized adaptive testing. Annual meeting of the national council of measurement in education, Chicago, IL, April 2003.
Sutanta, E. (1996). Sistem Basis Data; Konsep Dan Peranannya Dalam Sistem Informasi Manajemen. Yogyakarta: Andi Offset
Syaifudin Azwar. (2004). Reliabilitas dan validitas (Edisi 3). Yogyakarta: Pustaka Pelajar. Wainer, H. (1990). Computerized Adaptive Testing : A Primer. New Jersey: Lawrence
Erlbaum Associates, Publisher
Weiss, D.J. (2004). Computerized Adaptive Testing for Effective and Efficient Measurement in Counseling and Education. Measurement and Evaluation in Counseling and Development. Vol. 37, pg. 70.
Yan, D., Lewis, C., & Stocking, M. (2004). Adaptive Testing With Regression Trees in Presence of Multidimensionality. Journal of Educational and Behavioral Statistics, Vol 29, No. 3. p.293 -316.