PART OF SPEECH TAGGER UNTUK BAHASA INDONESIA
DENGAN MENGGUNAKAN MODIFIKASI BRILL
Eka Rahayu Setyaningsih
Teknik Informatika, Sekolah Tinggi Teknik Surabaya (1) e-mail: [email protected]
ABSTRAK
Dalam penelitian ini disajikan informasi mengenai pembentukan Part of Speech Tagging untuk Bahasa Indonesia dengan menggunakan pendekatan berbasis rule (rule-based). Algoritma yang digunakan dalam proses ini adalah Brill Tagger yang telah mengalami sedikit modifikasi dan ditulis ulang dalam bahasa C#. Tagset yang disusun mereferensi pada tagset bahasa Inggris milik Penn Trebank dan CLAWS, juga mereferensi tagset bahasa Indonesia yang telah ada, yang dikeluarkan oleh UI dan ITB. Jumlah tagset yang dihasilkan berjumlah 39 tag untuk bahasa Indonesia. Dalam proses ujicobanya, digunakan corpus yang bersumber dari artkel berita seperti viva.co.id dan cerita-cerita anak.
Kata kunci: POS Tagging, Brill Tagger, Lexical Rule, Contextual Rule, Tagset Bahasa Indonesia
PENDAHULUAN
Part of Speech (POS) Tagging, juga dikenal dengan istilah grammatical tagging merupakan proses pemberian informasi mengenai kelas kata kepada sebuah kata dalam kalimat.1 Secara umum kelas kata dapat dibedakan menjadi kelas Kata Benda (Noun), Kata Kerja (Verb), Kata Sifat (Adjective), Kata Keterangan (Adverb), Kata Penghubung (Conjunction Word), Kata Ganti Orang (Personal Pronoun), Kata Bilangan (Numeral), dan Lainnya (Other) termasuk didalamnya berupa tanda baca.
Informasi kelas kata yang diperoleh dari proses part of speech tagging sangat membantu dalam berbagai aplikasi komputasional linguistik yang ada, seperti membantu dalam word sense disambiguation, meningkatkan akurasi dalam pelafalan kata (text to speech), membantu proses stemming dalam Information Retrieval, membantu dalam linguistik forensik dan berbagai aplikasi-aplikasi lainnya.
Pemberian label atau kelas kata secara manual akan memakan waktu yang lama dan membutuhkan tenaga kerja yang tidak sedikit. Mengingat pentingnya keberadaan part of speech tagging, maka diperlukan adanya sebuah pendekatan yang
1Part of Speech Tagging:University of Maryland,
dapat melakukan proses tagging secara otomatis. Berbagai pendekatan untuk proses tagging telah banyak dikembangkan. Beberapa diantaranya menggunakan perhitungan probabilistik, statistika, dan berbasis rule.
Salah satu pendekatan yang digunakan dalam penelitian ini adalah pendekatan berbasis rule dengn menggunakan algoritma Brill Tagger. Proses tagging yang dilakukan secara garis besar dibedakan menjadi 2, yaitu dengan melihat sebuah kata dari perubahan bentuknya akibat awalan atau akhiran (lexical rule) dan melihat keberadaan kata-kata yang ada disekitar sebuah kata-kata yang hendak dilabeli (contextual rule). Pendekatan berbasis rule dipilih dengan pertimbangan tingginya tingkat akurasi yang berhasil dicapai dengan menggunakan pendekatan berbasis rule pada proses tagging beberapa bahasa negara tetangga, seperti bahasa Inggris.
TAGSET
Tagset adalah daftar tag atau kelas kata yang digunakan untuk melabeli setiap kata (unannotated – tidak berlabel) yang menjadi input dari proses Part of Speech Tagging. Pada bahasa Inggris, penelitian Part of Speech Tagging sudah banyak
dikembangkan oleh beberapa universitas seperti Stanford University dan University of Pennsylvania. Perkembangan penelitian Part of Speech Tagging untuk bahasa Inggris membawa dampak pada perkembangan Tagset itu sendiri.
Pembahasan mengenai pembentukan tagset untuk bahasa Indonesia akan dibagi menjadi 8 bagian besar, yaitu Kata Benda (Noun), Kata Kerja (Verb), Kata Sifat (Adjective), Kata Keterangan (Adverb), Kata Penghubung (Conjunction Word), Kata Ganti Orang (Personal Pronoun), Kata Bilangan (Numeral), dan Lainnya (Other). Dalam setiap kategori tersebut akan dibahas tag-tag apa yang sebaiknya ada dan tag-tag apa sajakah yang sebaiknya dihilangkan. Pertimbangan yang digunakan juga merujuk pada beberapa tagset yang telah dikembangkan untuk bahasa Inggris, seperti Penn Treebank dan CLAWS. Selain itu juga merujuk pada tagset bahasa Indonesia yang telah dikembangkan oleh UI dan ITB.
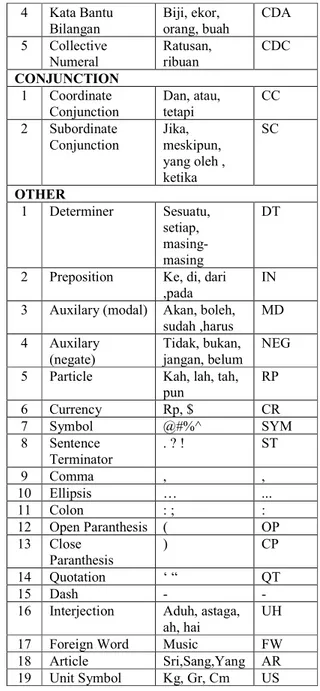
Tabel 1. Daftar Tagset Bahasa Indonesia
No Tagset Contoh Simbol
NOUN
1 Noun Martabat N
2 Singular Noun Orang NS
3 Plural Noun Orang-orang NP
4 Proper Common Noun Jakarta, Raffles, Surabaya NNP 5 Generative Common Noun Keduanya, satunya NNG VERB
1 Transitive Verb Membeli, menyiram
VBT 2 Intransitive Verb Pergi, pulang VBI PERSONAL PRONOUN 1 Personal Pronoun aku, kami, kamu, kalian PRP
2 WH Pronoun Siapa, apa WDT
3 Locative Pronoun
Sana, sini, situ PRL ADJECTIVE
1 Adjective Mahal, besar,
cantik
JJ ADVERB
1 Adverb Paling, akan,
sementara, sekarang RB 2 WH Adverb Bagaimana, mengapa WPRB NUMERAL
1 Primary Numeral Satu, dua CDP
2 Ordinal Numeral Kesatu, kedua CDO 3 Irregular Numeral Beberapa, segala, semua CDI 4 Kata Bantu Bilangan Biji, ekor, orang, buah CDA 5 Collective Numeral Ratusan, ribuan CDC CONJUNCTION 1 Coordinate Conjunction Dan, atau, tetapi CC 2 Subordinate Conjunction Jika, meskipun, yang oleh , ketika SC OTHER 1 Determiner Sesuatu, setiap, masing-masing DT
2 Preposition Ke, di, dari ,pada
IN 3 Auxilary (modal) Akan, boleh,
sudah ,harus MD 4 Auxilary (negate) Tidak, bukan, jangan, belum NEG
5 Particle Kah, lah, tah,
pun RP 6 Currency Rp, $ CR 7 Symbol @#%^ SYM 8 Sentence Terminator . ? ! ST 9 Comma , , 10 Ellipsis … ... 11 Colon : ; : 12 Open Paranthesis ( OP 13 Close Paranthesis ) CP 14 Quotation ‘ “ QT 15 Dash - -
16 Interjection Aduh, astaga, ah, hai
UH
17 Foreign Word Music FW
18 Article Sri,Sang,Yang AR
19 Unit Symbol Kg, Gr, Cm US
BRILL TAGGER
Brill Tagger merupakan salah satu dari algoritma yang berbasis rule, yang dapat digunakan dalam proses Part-of Speech Tagging. Nama Brill diambil dari nama penemunya yaitu Eric Brill, 1992 yang diulas dalam topik disertasinya. Sekalipun termasuk dalam kategori Rule Based Learning, Brill Tagger juga sering disebut sebagai Transformation-Based Error-Driven Learning yang biasa disingkat TEL. Istilah TEL menggambarkan kenyataan bahwa Brill Tagger tersebut bekerja berdasarkan transformasi rule dimana proses transformasinya belajar dari kesalahan-kesalahan yang dideteksi selama proses learning.
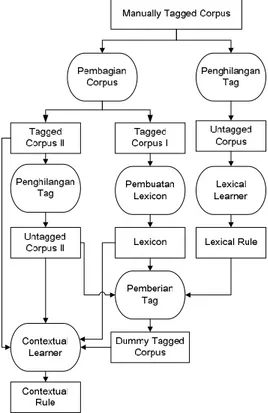
Gambar 1. Proses Kerja Brill Tagger2
Secara umum, POS Tagging dengan memanfaatkan Brill Tagger dapat menjadi 2 fase utama, yaitu learning dan application.3
Fase learning hanya dilakukan satu kali (sekalipun didalamnya sangat mungkin terjadi banyak iterasi khususnya dalam modifikasi atau transformasi rulenya). Proses learning ini membutuhkan waktu yang relatif lama karena proses yang terjadi didalamnya cukup kompleks. Nantinya, rule yang dibentuk dari proses learning dapat digunakan berulang kali dalam fase application. Berbeda dengan fase learning, fase application (pengaplikasian rule) relatif lebih cepat dibandingkan dengan fase learningnya. Hal itu dikarenakan proses yang terjadi dalam fase application lebih sederhana dibandingkan proses yang terjadi dalam fase learning.
Pada Gambar 1 dapat dilihat bahwa sebagai input, diberikan sejumlah teks yang belum dilabeli atau belum diberi tag atau dalam gambar diatas disebut sebagai unannotated text. Unannotated text tersebut dipassingkan ke initial state annotator. Dalam initial state annotator, semua kata atau token dalam unannotated text tersebut diberi initial tag. Output dari initial state ini disebut sebagai temporary corpus, yang berisikan unannotated text dengan initial tag pada masing-masing katanya.
Temporary corpus ini nantinya akan dibandingkan dengan goal corpus yang berisikan daftar kata atau token yang telah dilabeli secara manual. Dalam setiap iterasinya, temporary corpus yang dipassingkan ke dalam lexical learner atau contextual learner (yang berupa perhitungan statistical sederhana) akan mengembalikan sebuah
2 Beáta Megyesi, Brill’s Rule-Based PoS Tagger, Department of
Linguistics University of Stockholm. p 1.
rule dengan tingkat akurasi paling tinggi (yang memberikan selisih terkecil antara temporary corpus dengan goal corpus).
TRAINING
Dalam proses pelabelan dengan menggunakan algoritma Brill Tagger diperlukan Lexical Rule dan Contextual Rule yang memuat sejumlah rule yang nantinya akan diaplikasikan pada setiap kata dalam corpus input, sehingga diperoleh tag yang sesuai dengan rule tersebut. Oleh karena itu, pada proses training ini dilakukan pembentukan rule lexical dan contextual melalui Lexical Learner dan Contextual Learner.
Gambar 2. Proses Training Brill Tagger
Lexical Learner akan menghasilkan Lexical Rule, yaitu rule yang melihat perubahan bentuk dari kata itu sendiri, baik awalan ataupun akhiran. Sedangkan Contextual Learner akan menghasilkan Contextual Rule, yaitu rule yang memperhitungkan keberadaan kata atau tag yang berada disekitar kata yang bersangkutan. Aturan yang dipelajari dari Lexical Rule dapat digunakan untuk memprediksi tag yang memiliki probabilitas paling tinggi untuk melabeli suatu kata. Contoh dalam bahasa Inggris, jika diketahui sebuah kata berakhiran –ed, maka 3Martin Rajiman, Jean-Cedric Chappelier, Part of Speech Tagging,
kemungkinan kata tersebut merupakan bentuk dari Past Tense Verb (kata kerja bentuk lampau). Sedangkan aturan yang dipelajari dari Contextual Rule digunakan untuk meningkatkan akurasi. Contoh sederhana dalam bahasa Inggris, jika diketahui dalam corpus bahwa sering kali sebuah kata yang mengikuti kata kerja adalah NN, maka jika ditemukan sebuah kata kerja dan kata yang mengikutinya bukan sebuah NN, maka tag kata tersebut akan diganti dengan NN.
Proses training, untuk memperoleh Lexical Rule dan Contextual Rule dapat dilihat pada gambar berikut ini. Pada proses training dibutuhkan Manually Tagged Corpus (corpus yang secara manual telah diberi tag sebelumnya) yang cukup besar. Manually Tagged corpus ini selanjutnya dibagi menjadi 2 bagian sama besar yang masing-masing akan digunakan untuk pembentukan contextual rule dalam Contextual Learner dan digunakan dalam pembentukan lexicon (yang akan digunakan bagik dalam Contextual Learner ataupun Lexical Learner).
UJI COBA
Terdapat 2 tahap yang dilakukan dalam proses training Brill Tagger. Tahap pertamanya yaitu Lexical Learner, sebuah pembelajaran untuk memperoleh Lexical Rule dengan melihat perubahan bentuk kata akibat adanya imbuhan, baik awalan maupun akhiran. Tahap keduanya disebut dengan istilah Contextual Learner, yaitu sebuah pembelajaran untuk memperoleh Contextual Rule dengan melihat kemunculan tag-tag dari kata-kata yang berada di sekitar kata yang sedang diproses saat itu.
Dalam Lexical Learner dan Contextual Learner, terdapat sebuah parameter yang diberi nama threshold. Variable threshold untuk Lexical Learner dan Contextual Learner dapat berbeda nilainya. Pada subbab berikut ini akan ditunjukkan peran dari nilai parameter threshold tersebut terhadap pembentukan rule, baik dalam proses Lexical Learner ataupun Contextual Learner.
LEXICAL LEARNER
Dalam Lexical Learner, nilai threshold digunakan untuk membatasi nilai rule yang akan didaftarkan sebagai Lexical Rule. Sebagai contoh, untuk threshold dengan nilai 5 memiliki arti bahwa rule dengan nilai 5 atau lebih sajalah yang dapat didaftarkan sebagai Lexical Rule. Sedangkan
nilai-nilai rule yang berada dibawah 5, tidak boleh didaftarkan dalam Lexical Rule.
Dalam uji coba dengan menggunakan 5 buah artikel pertama yang terdiri atas 1.177 kata, akan dilakukan perubahan nilai threshold antara 1 sampai 5. Berikut ini adalah hasil perolehan rule dengan menggunakan kombinasi nilai threshold tersebut.
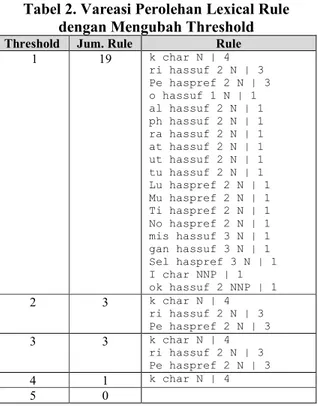
Tabel 2. Vareasi Perolehan Lexical Rule dengan Mengubah Threshold
Threshold Jum. Rule Rule
1 19 k char N | 4 ri hassuf 2 N | 3 Pe haspref 2 N | 3 o hassuf 1 N | 1 al hassuf 2 N | 1 ph hassuf 2 N | 1 ra hassuf 2 N | 1 at hassuf 2 N | 1 ut hassuf 2 N | 1 tu hassuf 2 N | 1 Lu haspref 2 N | 1 Mu haspref 2 N | 1 Ti haspref 2 N | 1 No haspref 2 N | 1 mis hassuf 3 N | 1 gan hassuf 3 N | 1 Sel haspref 3 N | 1 I char NNP | 1 ok hassuf 2 NNP | 1 2 3 k char N | 4 ri hassuf 2 N | 3 Pe haspref 2 N | 3 3 3 k char N | 4 ri hassuf 2 N | 3 Pe haspref 2 N | 3 4 1 k char N | 4 5 0
Dari tabel di atas dapat dilihat bahwa nilai threshold untuk Lexical Rule mempengaruhi jumlah rule yang didaftarkan ke dalam Lexical Rule. Semakin kecil nilai threshold, semakin besar jumlah rule yang terdaftar. Semakin tinggi nilai threshold, semakin sedikit jumlah rule yang terdaftar. Akan tetapi, semakin tinggi nilai threshold, maka semakin tinggi peran rule-rule yang terdaftar karena probabilitas kemunculannya lebih tinggi dibanding dengan rule dengan nilai 1.
CONTEXTUAL LEARNER
Sama halnya dengan Lexical Learner, dalam Contextual Learner juga terdapat sebuah parameter threshold yang mempengaruhi proses perolehan rule. Yang berbeda pada Contextual Rule, nilai threshold ini memiliki arti sebagai nilai toleransi error. Perlu diingat bahwa input Contextual Rule adalah sebuah dummy tagged corpus yang merupakan corpus yang telah dilabeli dari proses Lexical Learner. Dummy tagged corpus ini selanjutnya dicocokan dengan manually tagged
corpus dan dihitung jumlah tag yang tidak sesuai dengan merujuk pada manually tagged corpus sebagai corpus goal. Jumlah kesalahan tagging dari Lexical Learner inilah yang dibatasi dengan threshold pada Contextual Learner. Sehingga jika ditemukan sebuah threshold bernilai 3, berarti jika kesalahan tag pada suatu kata ditemukan jumlahnya mencapai nilai threshold (dalam hal ini adalah 3) atau lebih, maka akan dibuatkan contextual rulenya. Berikut adalah hasil ujicoba pengaruh threshold terhadap jumlah perolehan contextual rule:
Tabel 3. Vareasi Perolehan Contextuall Rule dengan Mengubah Threshold
Threshold Jum. Rule Rule
1 21 N VBT SURROUNDTAG NNP N N VBT PREVTAG CC N VBT PREVWD seperti N CDP PREVBIGRAM N , N CDP NEXT2TAG CDP N CC CURWD seperti NNP SC PREVTAG ST N CDP PREVTAG NNP N VBT PREVTAG DT N VBT PREVTAG MD N VBT NEXT1OR2TAG QT N CDP NEXT1OR2TAG CP N RB PREVBIGRAM CDP QT N VBT PREVTAG RB NNP N CURWD Selasa N CC CURWD atau N FW PREV1OR2WD 3 N SC WDNEXTTAG oleh N NNP FW NEXT1OR2TAG QT N CR NEXTWD 1 N VBT PREVTAG NEG 2 9 N VBT SURROUNDTAG NNP N N VBT PREVTAG CC N VBT PREVWD seperti N CDP PREVBIGRAM N , N CDP NEXT2TAG CDP N CC CURWD seperti NNP SC PREVTAG ST N CDP PREVTAG NNP N VBT PREVTAG DT 3 3 N VBT SURROUNDTAG NNP N N VBT PREVTAG CC N VBT PREVWD seperti 4 2 N VBT SURROUNDTAG NNP N N VBT PREVTAG CC 5 2 N VBT SURROUNDTAG NNP N N VBT PREVTAG CC
Dari tabel di atas dapat dilihat bahwa nilai threshold untuk Contextual Rule mempengaruhi jumlah rule yang didaftarkan ke dalam Contextual Rule. Semakin kecil nilai threshold, semakin besar jumlah rule yang terdaftar. Semakin tinggi nilai threshold, semakin sedikit jumlah rule yang terdaftar. Hal itu dikarenakan, semakin besar nilai threshold maka semakin tinggi tingkat toleransi terhadap error. Sehingga jika dalam dummy corpus ditemukan jumlah kesalahan yang berada dibawah threshold, maka akan diabaikan (dengan kata lain tidak dibuatkan contextual rule untuk memperbaikinya).
UJICOBA DENGAN DATA SEJENIS Dengan menggunakan 5 buah artikel yang terdiri atas 1.177 kata yang telah digunakan dalam proses training, maka akan dilakukan proses testing dengan ke-5 artikel tersebut. Berikut ini adalah hasil dari proses tagging yang diperoleh:
Tabel 4. Tingkat Akurasi untuk Data Sejenis
Vareasi Threshold Akurasi Lexical Contextual 1 2 100% 2 2 100% 3 1 100% 3 2 100% 3 3 100%
Dari tabel di atas dapat dilihat bahwa dengan menggunakan data sejenis, dimana data testing merupakan salah satu dari data testing, maka akan diperoleh tingkat akurasi 100% dengan berbagai kombinasi nilai parameter threshold. Hal ini dikarenakan hampir keseluruhan kata yang ada telah dicatat dalam file Lexicon. Sehingga jika data testing merupakan salah satu dari data training, maka berapapun parameternya tidak akan mempengaruhi tingkat akurasinya. Karena proses tagging telah dilakukan secara akurat dengan memanfaatkan isi file Lexicon.
UJICOBA DENGAN DATA BARU Dengan menggunakan kelima buah artikel yang sama seperti yang telah digunakan dalam proses sebelumnya, maka akan dilakukan uji coba untuk kalimat baru yang tidak berasal dari kelimat artikel tersebut. Berikut ini adalah contoh-contoh sederhana penggunaan Brill tagger untuk proses tagging setelah melakukan pembelajaran dengan menggunakan 5 buah artikel tersebut:
Input : Saya memberitakan kabar baik.
Output : Saya/PRP memberitakan/VBT kabar/N baik/N ./ST Input : Budi membawa makan siang.
Output : Budi/NNP membawa/VBT makan/N siang/N ./ST Input : Pangeran William bersama Putri Diana pergi ke
istana.
Output : Pangeran/AR William/NNP bersama/VBT Putri/N
Diana/NNP pergi/CDP ke/IN istana/N ./ST Dari contoh-contoh di atas dapat dilihat bahwa terdapat beberapa kata yang tidak sesuai tag-nya (ditandai dengan cetak tebal dan garis bawah). Beberapa kata tersebut mendapatkan tag yang tidak sesuai karena kata-kata yang bersangkutan tidak pernah ditemukan muncul dalam data training.
Sehingga dalam proses tagging, kata-kata tersebut memperoleh label atau tag yang didasari oleh rule yang biasa terbentuk dengan kondisi seperti kalimat di atas.
Uji coba berikutnya dilakukan dengan menggunakan 54 artikel, menghilangkan salah satu artikel, dan menggunakannya sebagai data training sehingga terbentuk Lexical Rule dan Contextual Rule. Selanjutnya dilakukan proses tagging dengan menggunakan sebuah artikel yang tidak termasuk sebagai data training. Hasil yang diperoleh adalah dari 272 kata yang ada dalam artikel testing, peroleh 244 kata yang sesuai dengan tag dari manually tagged corpus. Sehingga dapat diseimpulkan bahwa prosentasi akurasi dari program Brill Tagger ini adalah:
ℎ ×100%
244
272×100% = 89.70%
KESIMPULAN DAN SARAN
Berikut ini adalah beberapa hal yang dapat disimpulkan dari penelitian Penetapan Tagset dan Modifikasi Brill Tagger untuk Part-of Speech Bahasa Indonesia:
Nilai threshold untuk Lexical Learner berperan dalam menentukan score rule yang akan didaftarkan dalam Lexical Rule.
Nilai threshold untuk Contextual Learner berperan dalam menunjukkan tingkat toleransi proses pembelajaran terhadap error yang ditemukan.
Brill Tagger dapat digunakan untuk berbagai bahasa dengan mengganti Manually Tagged Corpus-nya saja.
Proses kerja Brill Tagger tidak dipengaruhi jenis atau vareasi tagset yang digunakan.
Semakin banyak jumlah tagset yang digunakan, semakin tinggi jumlah ambigu yang ditemui.
Semakin tinggi jumlah corpus yang digunakan dalam proses training, semakin tinggi pula tingkat akurasi yang diperoleh. Berikut ini adalah beberapa saran yang dapat digunakan sebagai pertimbangan dalam penggunaan Brill Tagger untuk penelitian selanjutnya atau pemanfaatan hasil Brill Tagger untuk berbagai aplikasi komputasional linguistik lanjutnya:
Untuk meningkatkan akurasi sebaiknya jumlah corpus ditingkatkan
Ada baiknya untuk mempertimbangkan membuat tag MD (Modal) untuk digabungkan dengan tag RB (Adverb). Saran ini diberikan dengan mempertimbangkan hasil dari KBBI yang sering kali menyebutkan kelas kata beberapa buah kata yang diangap MD sebagai RB. Sebagai contoh, kata “akan”, “sudah”, dan “harus”. Dalam sebuah kalimat, kata-kata tersebut dapat digolongkan sebagai kata kerja bantu (modal). Disebut sebagai kata kerja bantu karena posisinya yang biasa muncul sebelum kata kerja. Namun oleh KBBI, kata-kata tersebut digolongkan dalam kata keterangan (adverb).
Untuk pembentukan corpus, sebaiknya dihindari keberadaan kata-kata takbaku yang dapat merusak makna kata.
DAFTAR PUSTAKA [1] Adriani, Mirna, Probabilistic Part-of
Speech Tagging untuk Bahasa Indonesia, Universitas Indonesia.
[2] Angelina, Novita, Studi Pengkajian Part of Speech Tagging, Tugas Akhir STTS 2008. [3] Bahasa Baku,
http://id.wikipedia.org/wiki/Bahasa_baku
(diakses 15 Juni 2014) [4] Brill Tagger,
http://en.wikipedia.org/wiki/Brill_tagger.
Diakses tanggal 10 Mei 2012.
[5] Brill, Eric, A Simple Rule-Based Part Of Speech Tagger, Department of Computer Science University of Pennsylvania. [6] Claws Tagset C8,
http://research.ncl.ac.uk/necte/clawstags_c
8.pdf. Diakses tanggal 10 Mei 2012
[7] Daftar Tagset KEBI,
nlp.aia.bppt.go.id/kebi/. Diakses tahun
2009.
[8] Farizki, Alfan dan Ayu Purwarianti, HMM Based Part-ofSpeech Tagger for Bahasa Indonesia, Institute Teknik Bandung [9] Hasan, Fahim Muhammad, Comparison of
Different POS Tagging Techniques for Some South Asian Language, Desember 2006.
[10]G., Keraf, Tata Bahasa Indonesia, Flores: Nusa Indah, 1980
[11]Leonard, Part Of Speech Tagging Dan Probabilistic Parsing dengan Menggunakan Algoritma Hidden Markov Model. Tugas Akhir STTS 2010.