1
PEMODELAN STATISTIKA
(Dari Data ke Model dan Analisanya untuk Data Pertanian)
Dr. Hanna Arini Parhusip
Abstrak
Pada makalah ini ditunjukkan bagaimana melakukan pemodelan dengan statistika dimula i dari data khususnya pada bidang pertanian. Pemodelan yang dimaksud khususnya dengan regresi linear. Secara sederhana regresi linear dijelaskan untuk regresi klasik dan data time series (autoregresi) dan regresi dalam GSTAR (Generalized Space Time Autoregressive). GSTAR sendiri dibedakan menjadi 2 ya itu GSTAR standar (hanya autoregresi dan memperhatikan lokasi) dan GSTAR termodifikasi yaitu GSTAR yang menggabungkan regresi klasik dan GSTAR klasik.
Beberapa contoh juga ditunjukkan agar dapat membantu pembaca dalam melakukan pemodelan dengan statistika khususnya regresi. Data yang digunakan khususnya data iklim dan pertanian Boyola li pada tahun 2009-2013.
Kata kunci : regresi, GSTAR, GSTAR Termodifikasi
1. LATAR BELAKANG
Pada kehidupan sehari-hari yang kita jumpai seringkali merupakan data atau tabel dimana kita harus menterjemahkan data tersebut secara kualitatif dan mengambil keputusan berdasarkan data yang diperoleh. Untuk itu maka diperlukan penyusunan data dalam bentuk yang lebih kontinu dan obyektif sehingga jika diperoleh data baru yang berada pada sekitar data yang ada tetapi data baru bukan sebagai data observasi maka kita dapat menginterpretasikan data baru berdasarkan data yang lama. Untuk itulah maka kita perlu menyatakan data observasi dalam bentuk model. Jika model yang dipilih lebih diinterpretasikan secara statistik, maka teknik-teknik dan tata bahasa statistika (dimana variabel sebagai variabel random. Sebaliknya jika data yang diobservasi sebagai data deterministik, maka kita lebih banyak menggunakan kosa kata matematika . Pada bagian ini kita akan menggabungkan keduanya.
Pada tulisan ini beberapa contoh kasus khususnya tentang pertanian akan disajikan di sini. Pemodelan Statistika pada bagian ini hanya dibatasi pada untuk regresi khususnya regresi multivariat. Esensi regresi adalah menyatakan variabel dependent (biasa disebut variabel respon) sebagai fungsi variabel independent (biasa disebut variabel prediktor).
Sebelum melakukan pemodelan, maka perlu pula diketahui bagaimana data dalam bentuk tak berdimensi agar kita dapat menginterpretasikan dengan mudah karena bebas dimensi. Beberapa transformasi dapat digunakan (logaritma, membagi data dengan maksimum data, atau membagi data dengan rata-rata data untuk tiap variabel). Pada diskusi berikut ini data telah tak berdimensi.
Selain itu, data seringkali merupakan data time series. Beberapa teknik memerlukan agar data distationerkan terhadap mean dan variansinya. Beberapa teknik klasik untuk itu tidak dibicarakan disini, sehingga diasumsikan data sudah stationer.
2. PEMODELAN REGRESI LINEAR
Materi ini telah ditulis secara detail dalam buku (Parhusip ,dkk, 2014) dengan berbagai kasus yang sudah dipelajari.
2 Pada regresi linear sederhana berarti bahwa model hanya menjelaskan hubungan 1 variabel tak bebas(variabel respon) terhadap 1 variabel bebas (juga disebut variabel prediktor) dimana setiap pasangan memenuhi i i i
x
y
0
1
. i=1,…,n (1) 1 0,
dicari berdasarkan data. Secara geometri, jika ada 2 titik maka kita dapat mengilustrasikan garis lurus melalui kedua titik itu dengan
0 disebut intercept sedangkan
1 sebagai gradient. Karena banyaknya data n (lebih dari 2 titik) maka perlu dicari yang terbaik sehingga kita masih dapat membuat garis yang dianggap mengilustrasikan hubungan linear antara tiap pasangan data
x
i,
y
i
, i=1,...,n.Untuk mendapatkan parameter terbaik digunakan ‘goodness of fit’ yaitu meminimalkan deviasi kuadrat antara data yang diobservasi dengan model, yaitudeviasi =
y
i,data-
y
i,model
2. (2) Ada berbagai selisih/deviasi karena hal ini. Misal dengan SST(total sum square) adalah jumlah total antara selisih data observasi (Y) dengan rata-rata dari hasil model. Sekalipun nantinya parameter sudah diperoleh terbaik yaitu
0,
1 telah diperoleh sehinggai
x
y
model,i
0
1
maka selisih antara
y
i,datadany
i,modeltidak bisa selalu 0. Oleh karena itu selisih ini disebut residual sum square yang disimbolkan SSR. Selain itu dapat pula dipelajari selisih antara nilai rata-rata data observasi (Y) dengan garis regresi. Jumlah kuadrat selisih ini dikenal dengan model sum squares(SSM ).Catatan : Ingat, kita dapat menggambarkan hubungan
x
i,
y
i
sebelum menetapkan persamaan (1) sebagai model yang kita pilih. Jika data
x
i,
y
i
tidak berpola linear, maka kita perlu memilih model yang lain dan kemungkinan besar tak linear.2.2 Regresi linear Multivariat (klasik)
Misalkan kita mempunyai variabel tak bebas
Y
[
y
1,...,
y
n]
T dan p variabel bebas dengan mengasumsikan bahwa data disimpan dalam sebuah matriks random X dimana elemen baris menyatakan n observasi X= [X1...Xp] dan banyaknya kolom menyatakan p variabel X1, . . . , Xp.Perhatikan bahwa setiap vektor Xj mempunyai n observasi yang ditulis sebagai vektor kolom sehingga
jika matriks X ditulis perkomponennya sebagai adalah
p np n n p p X X X x x x x x x x x x 2 1 2 1 2 22 21 1 12 11 . X
Model regresi linear dengan variabel tak bebas tunggal Y dalam bentuk
X
X
pX
py
0 1 1 2 2...
. (3)3
y
1
0
1x
11
2x
12
3x
13
...
px
p1
1y
2
0
1x
21
2x
22
3x
23
...
px
2p
n n p p n n nx
x
x
xn
y
0
1 1
2 2
3 23
...
2
dimana suku-suku error diasumsikan mempunyai sifat-sifat
1.
E
(
j)
0
;
(4.a)2.
Var
(
j)
2 (konstan) dan (4.b)3.
Cov
(
j,
k)
0
,
j k. (4.c)Dalam notasi matriks –vektor, persamaan (3) menjadi
n p np n n p p n x x x x x x x x x y y y
2 1 1 0 2 1 2 22 21 1 12 11 2 1 1 1 1 . Ditulis ) 1 ( ) 1 ) 1 (( )) 1 ( ( 1 nx p p x nx nxZ
Y
(5)Perhatikan bahwa kolom pertama matriks
Z
(nx(p1)) hanya mempunyai komponen bernilai 1 dan kolom ke-2 hingga ke p+1 adalah vektor-vektor X1, . . . , Xp.Parameter regresi yaitu vektor
((p1)x1)
=
T p
0 1
diperoleh dengan least square yaitu meminimumkan
2 1 1 0
n i p j ij j i x y R
. (6)Dalam notasi vektor matriks ditulis (lihat untuk regresi univariat)
=
y
Z
2
y
Z
y
Z
=
y
y
2
y
Z
Z
Z
.Oleh karena itu turunan pertama R terhadap masing-masing variabel (yaitu
0,
1,...
p ditulis sebagai vektor (ingat kalkulus pebuah banyak) yang harus sama dengan 0 yaituT p R R R 0,..., =
yy2yZZZ
=2
2
0
Z
Ty
Z
TZ
. Diperoleh
2
Z
Ty
2
Z
TZ
0
atau
Z
Z
y
Z
T
T . Jadi untuk mendapatkan
kita harus menyelesaikan
Z
Z
y
Z
T
T yaitu
Z
TZ
Z
Ty
1
. (7)Paragraf ini lebih matematis. Menurut aljabar linear tidak selamanya invers matriks ada. Untuk itu perlu disyaratkan bahwa
dapat diperoleh jika
Z
TZ
1ada. Perlu diketahui pula bahwa hasil yang diperoleh pada persamaan (7) menjamin peminimum R asalkan matriks ZTZ positive4 definite (nilai eigen semua positif). Ekspresi ZTZ diperoleh dari (R)R=ZTZ yang merupakan matriks Hessian R.
Ternyata pemilihan variabel yang dapat dilibatkan dalam model menjadi diskusi berbagai peneliti. Salah satunya pada literatur (Kutner, dkk. 2008.) Ada berbagai metode yang digunakan dalam literatur tersebut tetapi tetap mensyaratkan n > p.
2.3 Regresi GSTAR (Generalized Space Time Auto Regressive)
Model Generalized Space Time Auto Regressive (GSTAR) pertama kali diperkenalkan oleh Borovkova, Lopuhaa, dan Ruchjana (2002) (Parhusip,dkk,2014) sebagai generalisasi dari model Space Time Autoregressive (STAR). Mengingat bahwa model ini masih baru dalam dunia statistika maka dalam makalah ini akan ditunjukkan mengenai simulasi penyusunan model GSTAR untuk memperoleh model yang tepat dan apabila model tidak tepat akan ditunjukkan mengapa model tersebut dikatakan tidak tepat.
2.3.1 Model GSTAR klasik
Secara matematis, notasi dari model GSTAR(p1) sama dengan notasi model STAR(p1). Perbedaan
utamanya terletak pada nilai-nilai parameter pada lag spasial yang sama diperbolehkan tidak sama (Suhartono, Subanar, 2006).
Persamaan model GSTAR untuk orde waktu dan orde spasial 1 dengan menggunakan 3 lokasi yang berbeda dalam bentuk matriks sebagai berikut,
) ( ) ( ) ( ) 1 ( ) 1 ( ) 1 ( 0 0 0 0 0 0 0 0 0 ) 1 ( ) 1 ( ) 1 ( 0 0 0 0 0 0 ) ( ) ( ) ( 3 2 1 3 2 1 32 31 23 21 13 12 33 22 11 3 2 1 30 20 10 3 2 1 t e t e t e t Z t Z t Z w w w w w w t Z t Z t Z t Z t Z t Z (8.a) Ada berbagai macam metode penentuan bobot lokasi pada model GSTAR tetapi metode
yang paling umum digunakan adalah bobot lokasi seragam karena bersifat sederhana dan mudah untuk ditentukan (Ruchjana, 2002). Salah satu penentuan nilai bobot seragam adalah sebagai berikut :
i ij
n
w
1
dengan
n
i merupakan banyaknya lokasi yang berdekatan dengan lokasi ke-i. Estimasi parameter model GSTAR yaitu)' (
10
20
30
11
21
31
dapat diselesaikan dengan menggunakan metode kuadrat terkecil yang dapat diperoleh dengan cara ynag sama pada regresi klasik sebagaimana ditunjukkan pada persamaan (7).
2.3.2 GSTAR Termodifikasi
Model (8.a) dimodifikasi untuk
Z
1(
t
)
dalam bentuk untuk) ( ) ( ) ( ) ( 0 1 1t Z t Z t Z t Z 1 1 2 2 2 3 . (8.b)
Persamaan (8.b) dapat disusun secara sama untuk
Z
2(
t
)
dan Z3(t). Anggaplah bahwa semua parameter harus ditentukan, dimana wij juga ditentukan sebagaimana pada regresi klasik. Untuk selanjutnya beberapa modifikasi juga dilakukan yang ditunjukkan pada Bab 3.Persamaan (8.a) menjelaskan bahwa kuantitas
Z
1(
t
)
tergantung dariZ
2(
t
1
)
danZ
3(
t
1
)
. Artinya kuantitas ini regresi terhadap dirinya sendiri (autoregressive) pada waktu sebelumnya. Akan tetapi5 pendekatan ini tidak selalu tepat. Pada Bab ini penulis menunjukkan beberapa contoh modifikasi untuk data yang sama yang digunakan pada Bab 3 atau diambil dari Parhusip dan Edi (2014).
2.4 Pemodelan Tak Linear
Pemodelan tak linear digunakan ketika pemodelan linear mungkin tidak cukup bagus, atau untuk mengurangi banyaknya parameter yang harus ditentukan, maka dipilih model tak linear artinya variabel tak bebas sebagai fungsi dari variabel bebas. Pada makalah pemodelan tak linear tidak ditunjukkan secara detail .
3. CONTOH-CONTOH HASIL PEMODELAN
3.1 Regresi klasik dan autoregresi
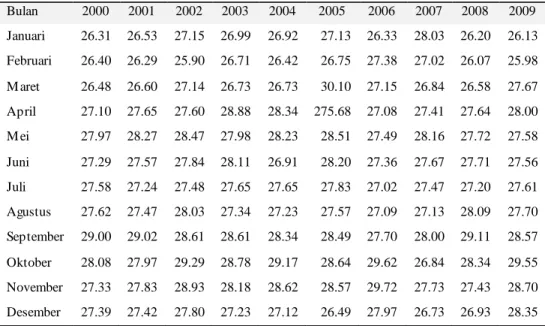
Data rata-rata temperatur, kelembaban udara, dan curah hujan yang diperoleh dari data iklim oleh Komando Pendidikan TNI Angkatan Udara Pangkalan TNI AU Adi Soemarmo tahun 2000-2009 digunakan pada Penelitian ini. Adapun contoh data ditunjukkan pada Tabel 1.
Tabel 1. Rata-rata Suhu Udara tahun 2000-2009
Bulan 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 Januari 26.31 26.53 27.15 26.99 26.92 27.13 26.33 28.03 26.20 26.13 Februari 26.40 26.29 25.90 26.71 26.42 26.75 27.38 27.02 26.07 25.98 M aret 26.48 26.60 27.14 26.73 26.73 30.10 27.15 26.84 26.58 27.67 April 27.10 27.65 27.60 28.88 28.34 275.68 27.08 27.41 27.64 28.00 M ei 27.97 28.27 28.47 27.98 28.23 28.51 27.49 28.16 27.72 27.58 Juni 27.29 27.57 27.84 28.11 26.91 28.20 27.36 27.67 27.71 27.56 Juli 27.58 27.24 27.48 27.65 27.65 27.83 27.02 27.47 27.20 27.61 Agustus 27.62 27.47 28.03 27.34 27.23 27.57 27.09 27.13 28.09 27.70 September 29.00 29.02 28.61 28.61 28.34 28.49 27.70 28.00 29.11 28.57 Oktober 28.08 27.97 29.29 28.78 29.17 28.64 29.62 26.84 28.34 29.55 November 27.33 27.83 28.93 28.18 28.62 28.57 29.72 27.73 27.43 28.70 Desember 27.39 27.42 27.80 27.23 27.12 26.49 27.97 26.73 26.93 28.35
Kasus 1 : Regresi Klasik
Diasumsikan bahwa model regresi linier dari data dengan curah hujan sebagai variabel tak bebas𝑌adalah
𝑦 = 𝛽0+ 𝛽1𝑋1 + 𝛽2𝑋2+ 𝜀 (i) Dalam notasi matriks -vektor, persamaan (i) menjadi
𝑦1 𝑦2 ⋮ 𝑦𝑛 = 1 1 ⋮ 1 𝑥11 𝑥21 ⋮ 𝑥𝑛1 𝑥12 𝑥22 ⋮ 𝑥𝑛2 𝛽𝛽10 𝛽2 + 𝜀1 𝜀2 ⋮ 𝜀𝑛
6 ditulis
((21) 1) 1 )) 1 2 ( ( 1 nx x nx nx Z Y (ii) MatriksZ
(nx(21))pada kolom pertama adalah 1 dan kolom ke-2 dan ke-3 adalah vektor-vektor𝑥1,𝑥2. Parameter regresi yaitu vektor
((21)x1)= 𝛽0 𝛽1 𝛽2 𝑇diperoleh dengan least square yaitu meminimumkan
2 1 2 1 0
n i j ij j ix
y
R
.Dengan mengikuti prosedur pada persamaan Bab 2 dapat diperoleh
A
Z
Ty
1
;A(ZTZ) (iii) dan 𝑍 = 1 1 ⋮ 1 𝑥11 𝑥21 ⋮ 𝑥𝑛1 𝑥12 𝑥22 ⋮ 𝑥𝑛2Kita dapat menggembangkan ide regresi dengan melakukan autoregresi (regresi terhadap dirinya sendiri dimana data merupakan data yang tergantung waktu). Ide ini diperkenalkan agar pembaca dapat memahami ide GSTAR (Generalized Spasial Time Autoregressive Regression: regresi yang datanya tergantung pada waktu dan lokasi) yang akan dibicarakan lebih lanjut.
Kasus 2 : Autoregresi
Diasumsikan model autoregresi dari data curah hujan sebagai variabel tak bebas pada saat t
𝑌𝑡= 𝛼0+ 𝛼1𝑌(𝑡−1)+ 𝛼2𝑋(𝑡−1)+ 𝛼2𝑋𝑡+ 𝜀 (iv) Dapat ditulis
1 ) 1 ( ) 1 ) 1 3 (( )) 1 3 ( ) 1 (( 1 ) 1 (n xW
n x x n xY
(v)Untuk mencari estimasi parameter 𝛼 adalah𝑌 = 𝑊 𝛼 dengan mengalikan ruas kiri dan ruas kanan dengan 𝑊𝑇 maka diperoleh
𝑊𝑇𝑌 = 𝑊𝑇𝑊 𝛼
Sehingga dapat diperoleh parameter 𝛼 yaitu
𝛼 = 𝑊𝑇𝑊 −1𝑊𝑇𝑌 (vi) 𝛼 = 𝐴 −1𝑊𝑇𝑌 (vii) dengan 𝐴 = 𝑊𝑇𝑊 𝑊 = 1 𝑦1 𝑥1 𝑥2 1 𝑦2 𝑥2 𝑥3 ⋮ 1 ⋮ 𝑦𝑛−1 𝑥𝑛⋮ ⋮𝑥𝑛−1
Akan dibuktikan bahwa pada persamaan (vii) dan 𝛼 pada persamaan (vii)ada dan terbaik yaitu dengan:
1. Matriks
A
pada kedua persamaan dikatakaninvertible jika determinan dari matriks A tersebut ≠0. A invertibel artinya penyelesaian dari matriks A tunggal (Peressini, dkk 1998).2. Error/residu merupakan jarak/beda antara data aktual dengan data pendekatan (dari model hasil fungsi tujuan) yaitu
E= 𝑆 𝑝𝑒𝑛𝑑𝑒𝑘𝑎𝑡𝑎𝑛 𝑆 −𝑆 𝑑𝑎𝑡𝑎
7 3. Jika 𝐴−1 adalah invers A yang eksak maka secara komputasi ditulis (𝐴 + 𝐸)−1, dimana E matriks error komponen-komponennya merupakan bilangan yang cukup kecil sehingga A+E invertible. Kemudian errornya adalah (Horn dan Johnson,1985)
𝐴−1− 𝐴 + 𝐸 −1= 𝐴−1− (𝐼 + 𝐴−1𝐸)−1𝐴−1
Akan dicari 𝐴−1− (𝐼 + 𝐴−1𝐸)−1𝐴−1 maka perlu menyatakan bentuk (𝐼 + 𝐴−1𝐸)−1 dalam bentuk lain.
Analog dengan deret (1 + 𝑥)−1akan diperoleh
(𝐼 + 𝐴−1𝐸)−1 = 𝐴−1− ∞ −1 𝑘+1(𝐴−1𝐸)𝑘𝐴−1, 𝑘=0
= ∞𝑘=1 −1 𝑘+1(𝐴−1𝐸)𝑘𝐴−1, jika 𝜌 𝐴−1𝐸 < 1 Dengan 𝜌 𝐴−1𝐸 adalah spektral radius (nilai eigen) dari matriks 𝐴−1𝐸.
Terdapat banyak definisi ||.|| dalam matriks, diantaranya yaitu norm Euclid, norm maksimum, dan norm Frobenius. Dalam kasus ini yang digunakan dalam perhitungan adalah norm euclid. Contoh menghitung norm Euclid:
Misalkan dipunyai matriks 𝐴 = 1 2
3 4 , perlu disusun matriks 𝐴′ yaitu 𝐴′ = 1 32 4 untuk mencari norm euclid = max 𝜆(𝐴𝐴′) dengan 𝜆 adalah nilai eigen. Nilai eigen dari 𝐴𝐴′ adalah 0.1 dan 29.9. Jadi norm euclid dari A adalah 29.9 = 5.47 (web 3).
Diasumsikan ||𝐴−1𝐸||<1, batas atas kesalahan relatif dengan menghitung invers adalah
𝐴−1− 𝐴+𝐸 −1
𝐴−1 ≤
𝐴−1𝐸
1− 𝐴−1𝐸 jika 𝐴−1𝐸 < 1. (*) Ruas kanan dikalikan 𝐴
𝐴 sehingga 𝐴−1 𝐸 (1− 𝐴−1 𝐸 ) 𝐴 𝐴 = 𝐴−1 𝐴 𝐴 − 𝐴−1 𝐸 𝐸 𝐴 = 𝐴−1 𝐴 ( 𝐴 − 𝐴−1 𝐴 𝐸 ) 𝐸 𝐴 𝐴 (**) Didefinisikan κ 𝐴 ≡ 𝐴−1 𝐴 jika 𝐴 nonsinguler
∞jika 𝐴 singuler (viii)
Persamaan (xiv) disebut conditional number dari invers matriks dengan melihat norm matriks . . Persamaan (*) dengan (**) menjadi
𝐴−1 𝐸 1− 𝐴−1 𝐸 𝐴 𝐴 = 𝐴−1 𝐴 𝐴 − 𝐴−1 𝐸 𝐸 𝐴 = κ 𝐴 𝐸 1−κ 𝐴 𝐸 𝐴 𝐴 .
Jadi error relatif untuk invers matriks terbatas tergantung dari nilai κ(𝐴) sehingga κ(𝐴) tidak boleh terlalu besar.
Conditional numbermatriks pada MATLAB juga menggunakan persamaan (xiv). Menurut Anderson, dkk (1999) jika conditional number dibawah 67108864 maka nilai i dinyatakan
terbaik karena error invers terbatas ke atas. Untuk menghitung conditional number digunakan perintah cond() pada MATLAB.
4. Sifat titik kritis (minimum) ditunjukkan dengan tipe matriks Hessian 𝐻𝑓 (matriks yang disusun turunan kedua dari fungsi terhadap masing-masing variabel bebas).
𝐻𝑓= ∇ ∇𝑅 = ∇ −2𝐴𝑇𝑤 + 2𝐴𝑇𝐴𝑣 = 2𝐴𝑇𝐴 (ix)
Analog pada kalkulus, titik kritis va sebagai peminimum lokal jika nilai eigen dari mariks Hessiannya bersifat positive semi definite yang artinya nilai eigen 𝐻𝑓 ≥ 0
Kita akan membahas Kegiatan penelitian yang berkaitan dengan metode tersebut.
8
Variabel yang digunakan
Y : Rata-rata curah hujan tahun 2000-2009
𝑋1 : Rata-rata suhu udara tahun 2000-2009
𝑋2 : Rata-rata kelembaban udara tahun 2000-2009
Pada kasus ini akan dibahas hubungan linier antara suhu dan kelembaban udara terhadap curah hujan sebagai variable tak bebas.
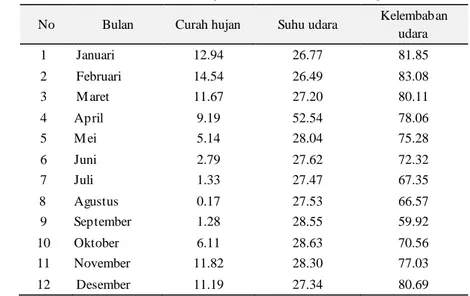
Dari data yang diperoleh olehKomando Pendidikan TNI Angkatan Udara Pangkalan TNI AU Adi Soemarmo yaitu data iklim daerah Surakarta-Boyolali tahun 2000-2009, diolah kembali dengan merata-rata sehingga diperoleh data pada Tabel 2.
Tabel.2 Rata-rata suhu udara, curah hujan, dan kelembaban udara tiap bulan ditahun 2000-2009
No Bulan Curah hujan Suhu udara Kelembaban
udara 1 Januari 12.94 26.77 81.85 2 Februari 14.54 26.49 83.08 3 M aret 11.67 27.20 80.11 4 April 9.19 52.54 78.06 5 M ei 5.14 28.04 75.28 6 Juni 2.79 27.62 72.32 7 Juli 1.33 27.47 67.35 8 Agustus 0.17 27.53 66.57 9 September 1.28 28.55 59.92 10 Oktober 6.11 28.63 70.56 11 November 11.82 28.30 77.03 12 Desember 11.19 27.34 80.69 Kasus .4
Variabel yang digunakan
𝑌𝑡 : Rata-rata curah hujan tahun 2000-2009 pada saat t
𝑋𝑡 : Rata-rata kelembaban udara tahun 2000-2009 pada saat t dengan t = 2,3,4…12
Pada kasus ini akan dibahas apakah ada hubungan linier variabel 𝑌𝑡−1 (curah hujan pada saat t-1),𝑋𝑡 dan 𝑋𝑡−1(kelembaban udara pada saat t dan t-1)terhadap variable 𝑌𝑡 (curah hujan pada saat t)
Tabel 3. Rata-rata curah hujan dan kelembaban udara (Parhusip, dkk,2014)
t Bulan 𝑌𝑡 𝑋𝑡 1 Januari 12.94 81.85 2 Februari 14.54 83.08 3 M aret 11.67 80.11 4 April 9.19 78.06 5 M ei 5.14 75.28 6 Juni 2.79 72.32 7 Juli 1.33 67.35 8 Agustus 0.17 66.57 9 September 1.28 59.92 10 Oktober 6.11 70.56 11 November 11.82 77.03 12 Desember 11.19 80.69
Tabel. 4 Data curah hujan dan kelembaban udara tiap bulan (lanjutan ,sesuai dengan nama variabel) (Parhusip, dkk,2014)
9 14.54 12.94 83.08 81.85 11.67 14.54 80.11 83.08 9.19 11.67 78.06 80.11 5.14 9.19 75.28 78.06 2.79 5.14 72.32 75.28 1.33 2.79 67.35 72.32 0.17 1.33 66.57 67.35 1.28 0.17 59.92 66.57 6.11 1.28 70.56 59.92 11.82 6.11 77.03 70.56 11.19 11.82 80.69 77.03
Menguji Normalitas data
Data yang ada diuji normalitasnya dengan teknik chi-kuadrat. Pengujian normalitas data dilakukan dengan menggunakan alat bantu MATLAB. Untuk data yang akan dianalisa diperoleh bahwa perhitungan uji normal data mempunyai persentase normal pada kasus 1 adalah 83.333% dan pada kasus 2 adalah 81.8182% sebagaimana ditunjukkan pada Gambar 1.Dapat disimpulkan kedua data sudah cukup normal untuk dapat dianalisis lebih lanjut.
Gambar.1 Uji normalitas data multivariat Melakukan Analisis Regresi Multivariat dan Autoregresi
Mencari model regresi linier serta mencari hubungan atau pengaruh variabel tak bebas (curah hujan) dengan masing-masing variabel bebasnya yaitu kelembaban serta suhu udara.
Kasus 5.
Dengan menggunakan 𝑦 = 𝛽0+ 𝛽1𝑋1 + 𝛽2𝑋2+ 𝜀 maka dilakukan perhitungan untuk memperoleh parameter . Dengan bantuan program R maka didapatlah model regresi pengaruh kelembaban dan suhu terhadap curah hujan adalah sebagai berikut:
𝑌 = −41.08298 − 0.01903𝑋1+ 0.65853𝑋2
denganY: rata-rata curah hujan; 𝑋1: rata-rata suhu udara; 𝑋2:rata-rata kelembaban udara.
Hasil yang diperoleh dengan program R didapat bahwa p-value untuk variable 𝑌 dan 𝑋2 dibawah 0.05 sehingga dapat dikatakan signifikan.Namun tidak pada variable 𝑋1 dengan nilai p-value adalah 0.849161 dan lebih besar dari 0.05.Artinya kontribusi 𝑋1 tidak signifikan terhadap persamaan 𝑦 = 𝛽0+ 𝛽1𝑋1+ 𝛽2𝑋2+ 𝜀. Nilai F statistik adalah 22.68, sedangkan
F
3,np1,0.95= 4.066181.Sehingga nilai F statistik lebih besar daripadaF
3,np1,0.95.Oleh karena itu
j
0
ditolak.Sehingga persamaan model regresi liniernya menjadi 𝑦 = 𝛽0+ 𝛽2𝑋2+ 𝜀. Dengan menggunakan program SPSS juga didapati hasil yang sama sebagaimana ditunjukkan pada Tabel 6.
Hasil keluaran di atas sama dengan hasil yang diperoleh dengan program R yang sebelumnya telah dijalankan. Yaitu nilai parameter pada kolom B yang menunjukkan nilai 0,1,2 serta nilai Sig. adalah nilai p-value.
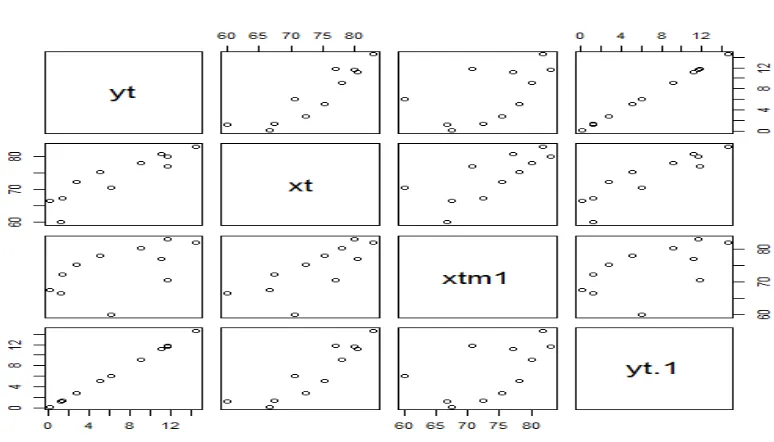
10 Hubungan tiap variabel
Dari hasil Gambar 2 oleh program R kita juga dapat melihat hubungan variabel tak bebas𝑌 (curah hujan) dengan masing-masing variabel intak bebas𝑋1 dan 𝑋2 (suhu dan kelembaban udara). Dari gambar tersebut dapat disimpulkan ada hubungan linier variabel 𝑌dengan 𝑋2 ,namun tidak pada variabel 𝑌 dan 𝑋1.
Gambar 2. Ga mba r Hasil analisis regresi dengan program R
Tabel.5 Hasil ke luaran reg resi progra m R
Es timate Std. Error t value Pr(> 𝒕 )
(Intercept) - 41.08298 7.59873 - 5.407 0.000429 ***
𝑋1 - 0.01903 0.09721 -0.196 0.849161
𝑋2 0.65853 0.09804 6.717 8.69e -05 ***
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Tabel 6.. Hasil keluarandengan program SPSS
Demikian pula hubungan antar variable dapat dilihat dari korelasi antar 2 variabel yang berbeda. Hasil uji korelasi menunjukkan bahwa 𝑌 berkorelasi dengan 𝑋2 sedangkan 𝑌 tidak berkorelasi dengan 𝑋1. Variabel 𝑋1 dan 𝑋2 juga tidak berkorelasi.
Perlu ditunjukkan dengan yang diperoleh adalah yang terbaik yang artinya meminimumkan R. Hal ini dilakukan dengan menghitung determinan A, error fungsi, menghitung Conditional Number Ayang dapat dilihat pada Tabel 7
Tabel 7. Sifat dari yang diperoleh Kondisi yang dia mati Hasil Determinan Matriks ) (Z Z A T 3.8413x 106 x1 60 65 70 75 80 30 35 40 45 50 60 65 70 75 80 x2 30 35 40 45 50 0 2 4 6 810 14 0 2 4 6 8 10 14 y Coefficientsa
M odel Unstandardized Coefficients
Standardized Coefficients
T Sig.
95% Confidence Interval for B
B Std. Error Beta Lower
Bound Upper Bound 1 (Constant) -41.095 7.595 -5.411 .000 -58.276 -23.914 Temperature (Celcius) -.019 .097 -.027 -.197 .849 -.239 .201 Kelembaban Nisbi .659 .098 .916 6.722 .000 .437 .880
11
Error 7.69 %
Conditional number 8.3572x 105
Sifat Hf positive semi definite
Diperoleh determinan matriks A≠0, sehingga sistem persamaan liniernya mempunyai penyelesaian tunggal . Error cukup kecil yaitu 7.69% Dari conditional number yang diperoleh masih lebih kecil dari batas maksimumnya atau Conditional number < 67108864. Kemudian diperoleh juga nilai eigen =[0 ; 533 ; 77634] yang artinya sifat 𝐻𝑓 adalah positive semi definitesehingga parameter yang diperoleh dinyatakan sebagai yang terbaik karena meminimumkan R.
Kasus 6.
Diasumsikan
𝑌𝑡= 𝛼0+ 𝛼1𝑦(𝑡−1)+ 𝛼2𝑥(𝑡−1)+ 𝛼2𝑥𝑡+ 𝜀
maka dilakukan perhitungan untuk memperoleh parameter
. Dengan bantuan program R maka didapatlah model sebagai berikut:𝑌𝑡= 4.0249 + 0.8432 𝑦(𝑡−1)+ 0.4239 𝑥(𝑡−1)− 0.4651 𝑥𝑡
Gambar 3. Gambar hasil analisis regresi pada tabel 3 dengan program R (Parhusip, dkk,2014)
Hasil yang diperoleh dengan program R didapat bahwa p-value untuk semua variable lebih besar dari 0.05 sehingga dapat dikatakan tidak signifikan. Nilai F statistic/F hitung adalah 15.46, sedangkan
F
3,np1,0.95= 4.533677 (F tabel) .Sehingga nilai F statistik lebih besar daripada95 . 0 , 1 , 3np
F
.Oleh karena itu
j
0
diterima. Dengan kata lain hipotesis nul diterima. Artinya model linear diatas tidak dapat diterima karena paling tidak ada 1 parameter yang tidak signifikan.Dari hasil yang diperoleh determinan matrik A≠0, kemudian Conditional number yang masih lebih kecil dari batas maksimumnya. Conditional number< 67108864, serta sifat Hf positive definite
dapat dikatakan bahwa parameter yang diperoleh ada hanya saja belum yang terbaik dilihat dari error yang masih cukup besar yaitu 20.9380%.
Tabel 8. Sifat sifat dari
Kondisi yang dia mati Hasil Determinan Matriks A(WTW) 3.4553 x 109Error 20.9380
Conditional number 902.0237
12
Berdasarkan uraian pembahasan di atas dapat disimpulkan
Data yang diolah yaitu rata-rata curah hujan, suhu serta kelembaban udara didaerah Boyolali tahun 2000-2009 berdistribusi normal.
Terdapat hubungan linier yang signifikan antara variabel tak bebas𝑌 (curah hujan) dengan variabel intak bebas 𝑋2 (kelembaban udara), namun tidak dengan variabel 𝑋1(suhu udara). Model regresi linier yang diperoleh adalah
𝑦 = 𝛽0+ 𝛽2𝑋2+ 𝜀
𝑦 = −41.08298 + 0.65853𝑋2+ 𝜀
Hasil analisis autoregresi yang memperlihatkan curah hujan pada saat t (dimulai bulan ke-2 yaitu Februari) dipengaruhi tidaknya oleh curah hujan pada saat t-1, kelembaban udara pada saat t dan t-1 mendapatkan model adalah
𝑌𝑡= 𝛼0+ 𝛼1𝑦(𝑡−1)+ 𝛼2𝑥(𝑡−1)+ 𝛼2𝑥𝑡 𝑌𝑡= 4.0249 + 0.8432 𝑦(𝑡−1)+ 0.4239 𝑥(𝑡−1)− 0.4651 𝑥𝑡
Hanya saja model yang didapat itu tidak menjadi model yang terbaik dilihat dari hasil setiap variabel yang tidak signifikan dan juga error yang masih terlalu besar pada sifat
.3.2 Beberapa Hasil Model GSTAR Termodifikasi Kasus 7.
Gunakan model (8.b) untuk data curah hujan dari kecamatan Selo, Ampel dan Cepogo. Hasil ini memberikan kesalahan yang lebih kecil sebagaimana ditunjukkan pada Gambar 4. Jika mengganti model (8.b) pada ruas kanan dengan
Z
2(
t
1
),
Z
3(
t
1
)
ternyata memberikan kesalahan/error lebih besar yaitu sekitar 80%. Sebaliknya dengan model (9) maka error terjadi pada sekitar103%. Demikian pula jika hal ini juga dilakukan untukZ
2(
t
)
andZ
3(
t
)
, maka diperoleh error yang serupa.Perhatikan pula bahwa Zk(t) dan
Z
k(
t
1
)
tidak beritnteraksi secara linear secara signifikan karena
1 mendekati 0 untuk semua lokasi. Jadi kita dapat menyimpulkan bahwa ketiga variabel berinteraksi pada waktu yang bersamaan. Oleh karena itu kita dapat meringkas model persamaan (8.b) baris pertama menjadi)
(
)
(
)
(
t
Z
t
Z
t
Z
1
0
2 2
2 3 . (9)Demikian pula model ini juga dapat diimplementasikan pada data yang memuat luas lahan dengn kekritisan di Boyolali sebagaimana akan ditunjukkan selanjutnya. Proses ini telah ditunjukkan secara detail (Parhusip dan Edi, 2015) dengan beberapa modifikasi yang lain.
Kasus 8.
Gunakan data lahan kritis tiap kritis untuk 3 lokasi di atas (Selo, Ampel Cepogo) dalam memodelkan besarnya lahan kritis tiap lokasi.
13 Gambar 4. Pendekatan curah hujan dengan persamaan (9) pada Selo Horizontal : indeks, Ve rtikal:
banyaknya curah (tak berdimensi, karena data sudah distasionerisasi) (Parhusip dan Edi, 2014) Lahan kritis pada ketiga lokasi juga dimodelkan dengan persamaan (8.b). Ternyata berturut =turut error adalah hanya 0.4178% , 0.4023 %, 0.9230% untuk Selo, Ampel dan Cepogo. Gambar 5 mengilustrasikan contoh pendekatan GSTAR untuk banyaknya curah hujan di Selo.
Gambar 5. Regresi GSTAR untuk curah hujan di Selo. Data (*,o,dan model (*) ditunjukkan dengan garis (Parhusip,dkk, 2014).
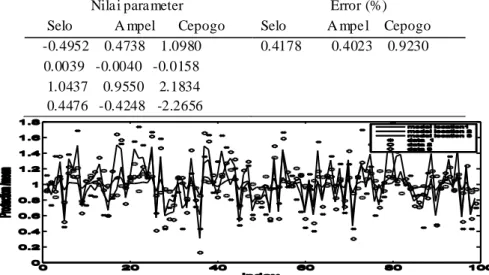
Koefisien bobot untuk setiap persamaan linear pada persamaan (8.b) ditunjukkan pada Tabel 9. Untuk produktivitas padi, model yang sudah dimodifikasi tidak dapat digunakan karena error yang cukup besar berturut-turut untuk 25.5821%, 11.5124%, 21.7046% untuk Selo, Ampel dan Cepogo. Salah satu hasil ditunjukkan pada Gambar 6. Oleh karena itu GSTAR harus dimodifikasi lagi.
Tabel 9. Para meter pada model modifikasi GSTA R untuk data luas lahan krit is pada Selo, A mpe l dan Cepogo Nila i para meter
Selo A mpel Cepogo
Error (%) Selo A mpe l Cepogo -0.4952 0.4738 1.0980
0.0039 -0.0040 -0.0158 1.0437 0.9550 2.1834 0.4476 -0.4248 -2.2656
0.4178 0.4023 0.9230
Gambar 6. Pendekatan dan data hasil produksi padi di Selo sebagai model produksi padi yang tergantung produksi padi di Selo pada waktu sebelumnya, dan produksi padi dari Ampel dan Cepogo (Parhusip dan Edi, 2015)
Kasus 10
Area lahan kritis dianggap bergantung pada banyaknya curah hujan disekitarnya juga area lahan kritis sekitarnya.
)
(
)
(
)
(
)
(
)
(
)
(
t
Z
t
Z
t
Y
t
Y
t
Y
t
Z
1
0
2 2
2 3
3 1
4 2
5 3 (10) dimana14
:
)
(
t
Z
1 area lahan kritis lokasi ke-1 pada waktu t,Z
2(
t
)
:
area lahan kritis lokasi ke-2 pada waktu t,Z
3(
t
)
:
area lahan kritis dari lokasi ke-3 pada waktu t,Y
1(
t
)
:
banyaknya curah hujan padalokasi ke-1 pada waktu t,
Y
2(
t
)
:
banyaknya curah hujan pada lokasi ke-2 pada waktu t,Y
3(
t
)
:
banyaknya curah hujan pada lokasi ke-3 pada waktu t.
Model (10) memberikan error 0.4064 % dengan nilai parameter adalah
T 124.0760 613.7395 283.9430 0.4484 1.0435 205.2286 .
Dari sisi aljabar linear, det
X
'
X
mendekati 0 yang artinya matriks mendekati singular. Karena error cukup kecil, kita dapat membuat pendekatan model persamaan (11) untuk lokasi yang lain (Ampel dan Cepogo). Jadi model persamaan (10) dapat ditulis dalam bentuk umum: ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( t e t e t e t Y t Y t Y t Z t Z t Z t Z t Z t Z 3 2 1 3 2 1 33 32 31 23 22 21 13 12 11 3 2 1 32 31 23 21 13 12 30 20 10 3 2 1 0 0 0 1 1 1 0 0 0 0 0 0 . (11)
Vektor pertama pada ruas kanan menyatakan parameter konstan pada regresi. Vektor kedua mengilustrasikan kuantitas yang sama (misal lahan kritis) dari 2 lokasi sekitarnya. Sedangkan vektor ketiga menyatakan kuantitas yang lain (misal curah hujan). Jika dibandingkan dengan GTAR yang standard, model GSTAR dari persamaan (11) lebih valid.
3.3 Modifikasi GSTAR untuk produksi padi 3.3.1 Bobot dengan regresi klasik
Pada paragraph ini akan ditunjukkan bagai-mana model GSTAR kembali dimodifikasi. Misalkan luas lahan kritis dan curah hujan untuk masig-masing lokasi dimodelkan dalam bentuk
)
(
)
(
)
(
t
Z
t
Z
t
Z
1
0
2 2
2 3 .Kemudian banyaknya padi yang dipanen merupakan fungsi linear lahan kritis dan curah hujan. Jadi model GSTAR menjadi
)
(
)
(
)
(
t
Z
t
Z
t
Z
1
0
2 2
2 3 (model lahan kritis pada lokasi ke-1) (P.1)Y1(t)
0
1Y2(t)
2Y3(t)(model banyaknya curah hujan untuk pada ke-1) (P.2) ) ( ) ( ) ( ) ( ) (t P t P t Z t wY t P1
0
1 2
2 3
3 1 1 1(model banyaknya padi pada lokasi ke-1 ) (P.3) Jadi untuk 3 lokasi model modifikasi GSTAR untuk panen padi memuat 3 sistem persamaan linear yaitu (Parhusip dan Edi, 2015)
) ( ) ( ) ( ) ( ) ( ) ( t Z t Z t Z t Z t Z t Z 3 2 1 32 31 23 21 13 12 30 20 10 3 2 1 0 0 0 1 1 1 0 0 0 0 0 0 (P.4) ) ( ) ( ) ( ) ( ) ( ) ( t Y t Y t Y t Y t Y t Y 3 2 1 32 31 23 21 13 12 30 20 10 3 2 1 0 0 0 1 1 1 0 0 0 0 0 0 (P.5)
15 ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( t Y t Y t Y w w w t Z t Z t Z t P t P t P t P t P t P 3 2 1 33 22 11 3 2 1 33 22 11 3 2 1 32 31 23 21 13 12 30 20 10 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 (P.6)
Dibandingkan dengan model-model sebelumnya, model (P.6) memuat lebih sedikit variabel. Demikian pula untuk optimasi, model ini lebih menguntungkan. Model ini digunakan untuk menyusun fungsi tujuan produksi padi pada Selo, Ampel dan Cepogo (Parhusip dan Edi, 2015).
Pemilihan variabel prediktor lebih lanjut
Pada penelitian terdahulu (Parhusip dan Edi, 2014) curah hujan dan luas area lahan kritis sebagai variabel prediktor selain banyaknya padi pada waktu sebelumnya sebagai variabel autoregresi. Akan tetapi untuk mengetahui produksi padi pada tiap kecamatan, lahan kritis tidak dapat menjadi faktor dalam menentukan optimal produksi padi (sebagaimana pada awal penelitian) karena beberapa lokasi mempunyai luas lahan kritis 0. Sebenarnya tidak adanya lahan kr itis pada lokasi tersebut menunjukkan bahwa lokasi tersebut cukup subur dibandingkan lokasi yang memiliki area kritis. Akan tetapi karena beberapa tidak mempunyai lahan kritis, kita tidak dapat membuat model dengan variabel prediktor yang sama. Oleh karena itu variabel prediktor yang dipilih adalah variabel prediktor natural yang memungkinkan pertumbuhan padi yaitu curah hujan dan luas lahan dimana luas lahan merupakan area yang dapat dipanen. Hasil optimal curah hujan dan luas lahan hanya akan menunjukkan kemampuan lokasi tersebut untuk produksi optimal pada berdasarkan data curah hujan dan luas lahan panen.
3.3.3 GSTAR Termodifikasi dengan bobot seragam
GSTAR Termodifikasi disusun berdasarkan regresi dari 3 lokasi yang dikerjakan secara simultan dimana model tersebut berbentuk : (Apriyanti, dkk, 2014), yaitu
() ()
() ) 1 ( ) ( 10 1 11 111 12 1 1 1t Z t w Y t w R t e t Z ; (12.a)
() ()
() ) 1 ( ) ( 20 2 21 21 2 23 2 2 2 t Z t w Y t w R t e t Z ; (12.b)
() ()
() ) 1 ( ) ( 30 3 31 31 3 32 3 2 3 t Z t w Y t w R t e t Z . (12.c) denganZi(t) = variabel data produksi padi pada waktu t di lokasi i, i = 1,2,3.
Yi(t) = variabel luas lahan panen pada waktu t di lokasi i, i = 1,2,3 .
Ri(t) = variabel curah hujan padi pada waktu t di lokasi i, i = 1,2,3 .
0
k
= diag(
k10,...,
kn0)
dan
k1 = diag(
,...,
1)
11
N k k
merupakan parameter modelw = bobot (weigth) yang dipilih untuk memenuhi wii 0 dan
1
1
jw
ijModel (12.a)-(12.c) telah digunakan untuk menyatakan produksi padi dan juga jagung (Apriyanti, dkk, 2014) untuk tiap kecamatan di Boyolali. Model ini lebih sederhana dan dapat diimplementasikan pada excel. Model (12.a)-(12.c) menjadi fungsi tujuan dalam proses optimasi agar dapat diprediksi produksi optimal berdasarkan data yang ada. Teknik-teknik optimasi dijelaskan secara rinci (Parhusip, 2014).
16
KESIMPULAN
Pada makalah ini telah ditunjukkan proses regresi sederhana dari regresi klasik, autoregresi dan regresi GSTAR standar maupun GSTAR termodifikasi. Proses penyusunan model ditunjukkan dengan beberapa contoh khususnya yang terkait dengan curah hujan, lahan krit is dan produksi padi di Boyolali.
Ucapan Terima kasih : Makalah ini sebagai hasil kegiatan dengan pendanaan United Board , tahun 2015.
DAFTAR PUSTAKA
Anderson E, Z Bai, C Bischof, S Blackford, J Demmel, J Dongarra, J Du Croz, A Greenbaum, S Hammarling, A McKenney & D Sorensen.(1999). LAPACK User's Guide Third Edition, SIAM, Philadelphia. (http://www.netlib.org/lapack/lug/lapack_lug.html)
Apriyanti, P.D, Parhusip, H.A, Linawati.(2014). Model GSTAR Termodifikasi untuk Produktivitas Jagung di Boyolali, Prosiding Seminar Nasional UNNES,8 Nov 2014, ISBN 978-602-1034-06-4;hal.314-325 (https://www.researchgate.net/profile/Hanna_Parhusip/publications :
doi 10.13140/2.1.4197.4084)
Parhusip, H.A.(2014). Optimasi Taklinear, ISBN 978-602-9493-14-6, Tisara Grafika Salatiga,221 hlm.
Parhusip, H.A & Edi, W.M.(2014). Analisa Data Iklim Boyolali dengan Regresi Klasik dan Metode GSTAR, Prosiding Seminar Nasional Matematika dan Pendidikan Matematika, ISBN 978-602-70609-0-6, hal.319-331,24 Mei 2014, Universitas PGRI Ronggolawe,Tuban.
Parhusip,H.A, Edi, S.W.M., Prasetyo, S.Y.J.( 2014). Analisa Data PemodelanUntuk Ilmu Sosial dan Sains, ISBN 978-602-9493-16-0, Tisara Grafika Salatiga,398 hlm,25 cm.
Parhusip, H.A & Edi, S.W.M, (2015). Optimal Production of Paddy Fields Using Modified GSTAR Models, International Journal of Agricultural Science and Technology (IJAST) , Vol. 3, Issue 1, February 2015 www.seipub.org/ijast; ISSN(online) : 2327-7645; ISSN print: 2327-7246 doi: 10.14355/ijast.2015.0301.01.
Ruchjana. B. N, 2002. Pemodelan Kurva Produksi Minyak Bumi Menggunakan Model Generalisasi STAR. Forum Statistika dan Komputasi. IPB : Bogor.