BAB II
LANDASAN TEORI
2.1 Data Mining
2.1.1 Pengertian Data Mining
Secara singkat, data mining berarti menggali atau menemukan informasi dari sejumlah besar data (Han & Kamber, 2006). Dan secara luasnya, data mining adalah proses menemukan interesting knowledge dari sejumlah besar data yang tersimpan dalam database, data warehouse, atau media penyimpanan lainnya (Han & Kamber, 2006). Sedangkan berdasarkan Gartner Group (Larose, 2005), data mining adalah sebuah proses untuk menemukan hubungan, pola, dan tren dengan memilah-milah sejumlah besar data yang tersimpan dalam media penyimpanan, menggunakan teknologi pengenalan pola serta statistika dan matematika.
Dengan berdasarkan pengertian diatas, maka dapat dikatakan jika data mining adalah sebuah proses mencari informasi dari data yang berjumlah besar dan tersimpan dalam media penyimpanan. Data mining bisa tercipta dikarenakan adanya keinginan untuk mencari pengetahuan atau informasi dari data yang tersimpan dalam jumlah yang banyak. Selain hal tersebut, dalam penerapannya terdapat beberapa faktor yang mendukung pengembangan data mining, yaitu:
Data mining, dalam penerapannya akan mengakses file yang
besar. Hal ini dikarenakan hasil dari data mining akan menjadi dasar dalam pengambilan keputusan untuk melakukan tindakan tertentu, sehingga tingkat kebeneran informasi yang dihasilkan sangat diperlukan.untuk mencapai tingkat kebenaran informasi yang tinggi, maka diperlukan data yang sangat besar untuk diolah. Seiring dengan perkembangan media penyimpanan, maka perkembangan jumlah data yang disimpan bergerak naik sangat cepat. Akan tetapi, jika terjadinya minim pengetahuan untuk mengolah data tersebut maka akan tercipta kondisi “data rich but information poor” (Han & Kamber, 2006), dimana tidak diketahuinya informasi dari data yang tersimpan tersebut.
- Pertumbuhan yang luar biasa dalam daya komputasi dan kapasitas penyimpanan oleh perangkat keras
Penerapan data mining pada dasarnya akan membutuhkan kebutuhan sumber daya dan kemampuan komputasi yang sangat besar. Dengan perkembangan teknologi yang terjadi, mengakibatkan perkembangan yang sangat pesat bagi kemampuan komputasi dan kapasitas penyimpanan oleh perangkat keras. Sehingga dengan ketersediaan perangkat yang memiliki kemampuan tersebut, dapat menjadikan proses data mining menjadi cukup layak untuk dilakukan secara komersial.
- Peningkatan persaingan untuk meningkatkan pasar dalam ekonomi global
Seiring dengan persaingan bisnis yang semakin ketat, maka akan mendorong setiap perusahaan untuk selalu dapat berinovasi dan memberikan pelayanan-pelayanan atau promosi agar dapat bersaing dengan perusahaan lain. Data mining dalam peranannya dapat memberikan pengolahan informasi yang dapat menjadi pertimbangan bagi perusahaan dalam melakukan sebuah tindakan, seperti dalam memilih promosi, produk, dan pelayanan yang akan dipasarkan. - Peningkatan terhadap akses ke data dengan melalui navigasi Web atau
intranet
Perkembangan teknologi jaringan sampai sekarang, mengakibatkan kemudahan akses oleh data baik itu melalui jaringan internet atau intranet. Dengan kemudahan akses tersebut, maka mengakibatkan data transaksi mengenai akses data yang sangat besar. Sehingga dengan data mining, diharapkan dapat membantu dalam mengolah data transaksi tersebut agar dapat menjadi informasi yang berguna bagi perusahaan.
- Pengembangan terhadap perangkat lunak untuk data mining
Seiring dengan perkembangan dan kebutuhan akan data mining, mengakibatkan pertumbuhan perangkat lunak yang dapat mendukung
data mining tersebut. Perangkat lunak yang dapat membantu dalam data mining, antara lain Orange, RapidMiner, Weka, JhepWork,
KNIME, dan lain sebagainya. Dimana pada masing-masing perangkat lunak memiliki perbedaan masing-masing seperti bahasa pemrograman yang digunakan, bentuk tampilan, dan lain sebagainya.
Dalam penerapannya, data mining dapat diterapkan dalam berbagai penyimpanan data (Han & Kamber, 2006). Media penyimpanan yang disebut antara lain realational database, data warehouses, transactional
database, advanced database system, flat files, data streams, dan World Wide Web. Dan dalam penerapannya pun, teknik dan algoritma yang
digunakan untuk data mining pun berbeda satu sama lain antar setiap media penyimpana dan fungsi dari data mining tersebut. Algoritma data mining yang ada sekarang bermacam-macam, namun berdasarkan jurnal (Wu, et al., 2008) disebutkan 10 algoritma terbaik untuk data mining, antar lain C4.5, algoritma k-means, support vector machine, algoritma apriori, algoritma EM, PageRank, AdaBoost, kNN(k-nearest neighbor), Naive Bayes, CART(Classification and Regression Tree). Sedangkan untuk setiap algoritma menyesuaikan dengan fungsi dari data mining, yaitu fungsi karakterisasi, fungsi diskriminasi, fungsi asosiasi, fungsi prediksi, fungsi klasifikasi, dan fungsi cluster (Han & Kamber, 2006).
2.1.2 Data Stream
Data mining dapat diterapkan dalam berbagai data salah satunya
adalah data stream. Data stream adalah data dengan karakteristik dimana aliran data masuk dan keluar terjadi secara dinamis dari sebuah platform observasi (Han & Kamber, 2006). Data stream memiliki beberapa karakteristik unik lainnya antara lain volume data yang besar dan tidak terbatas, berubah secara dinamis, mengalir masuk dan keluar, dan memungkinkan hanya satu atau sebagian pemeriksaan, dan bersifat cepat dalam waktu respon.
Data stream pada penerapannya akan menjadi 2 kategori (Liu, Lin, &
Han, 2009), yaitu:
- Transactional Data Stream
Data stream yang mencatat kegiatan interaksi antara dua
entitas. Contoh dari transactional data stream adalah transaksi retail, tellecommunications record, web access logs, dan operasi ATM.
- Measurement Data Stream
Data stream yang mencatat hasil pengukuran pada sebuah
entitas. Contoh dari measurement data stream adalah data sensor jaringan, sinyal peralatan mobile, IP packets, dan pembacaan instrumen sains.
2.1.3 Metodologi Data Mining
Pada pengembangannya hingga sekarang ini, terjadi beberapa perkembangan terhadap metodologi dalam penerapan data mining. Metodologi atau model proses merupakan suatu rangkaian tugas yang harus dilakukan untuk mengembangkan elemen tertentu, serta unsur-unsur yang diproduksi dalam setiap tugas(output) dan dan unsur-unsur yang diperlukan untuk melakukan tugas(input). Dengan tujuan untuk membuat proses agar dapat berulang, dikendalikan, dan terukur (Marbán, Mariscal, & Segovia, 2009).
Perkembangan metodologi pada data mining terjadi mulai pada metodologi KDD(Knowledge Discovery from Data) pada awal tahun
1990-an. Setelah itu terjadi perkembangan metodologi yang menyusul setelahnya. Berikut merupakan gambaran perkembangan metodologi data mining.
Gambar 2.1 Perkembangan Metodologi Data Mining (Marbán, Mariscal, & Segovia, 2009)
Pada gambaran diatas, diketahui perkembangan metodologi dimulai pada metodologi KDD. Selanjutnya dengan berdasar KDD dikembangkan beberapa metodologi dengan melakukan beberapa perubahan namun secara garis besar memiliki fitur serupa, yaitu Human-centered, SEMMA, Two Crows, Anand & Buchner dan Cabena.
Di lain sisi, metodologi 5 A’s merupakan metodologi yang menjadi pelopor dari CRISP-DM, dimana siklus yang dikerjakan memiliki kemiripan dengan siklus pada CRISP-DM. Selanjutnya CRISP-DM menjadi dasar pengembangan CIOS yang lebih fokus pada kebutuhan riset akademik, RAMSYS (RApid collaborative data Mining SYStem) dan DMIE (Data
Mining for Industrial Engineering). Metodologi tersebut tetap didasarkan pada CRISP-DM dan mempertahankan fase yang sama secara generik. Pada tabel berikut ini akan dijelaskan mengenai tahapan pada beberapa metodologi.
Tabel 2.1 Perbandingan Metodologi (Marbán, Mariscal, & Segovia, 2009)
Walau jumlah tahapan dan tahapan yang dilakukan berbeda-beda, namun secara garis besar tahapan pada setiap metodologi data mining adalah sebagai berikut:
- Pre-processing
Pada tahapan ini dilakukan persiapan mengenai data
mining yang akan dilakukan. Seperti pengenalan bisnis,
- Data Mining
Pada tahap ini dilakukan kegiatan data mining dengan berdasarkan metode dan algoritma yang ditentukan.
- Post-processing
Tahapan ini adalah tahapan setelah melakukan proses data
mining.
Berikut merupakan penjelasan mengenai beberapa metodologi:
2.1.3.1 KDD
KDD merupakan singkatan dari Knowledge Discovery from
Data. KDD mulai dikembangkan pada era awal 1990-an. Fayyad pada
1996 menggagas proses model KDD dan menetapkan langkah untuk proyek DM. Pada metodologi KDD terdapat 9 tahap (Han & Kamber, 2006) sesuai dengan gambar di bawah.
Gambar 2.2 Tahapan Metodologi KDD (Han & Kamber, 2006)
- Data Cleaning
Pada tahapan ini melakukan pemilihan data yang relevan dari database dengan melakukan pemisahan terhadap data yang tidak konsisten dan data yang tidak relevan.
Pada tahapan ini dilakukan integrasi terhadap data yang ada dengan cara menggabungkan berbagai sumber data menjadi satu sumber.
- Data Selection
Pada tahapan ini melakukan pemilihan terhadap data yang relevan dengan analisa yang akan dilakukan pada database. - Data Transformation
Pada tahapan ini dilakukan pengubahan terhadap format data yang ada menjadi format data yang sesuai untuk diproses dalam data mining.
- Data Mining
Pada tahapan ini dilakukan proses data mining, dengan menerapkan metode tertentu untuk mendapatkan informasi yang tersembunyi dari data yang ada.
- Pattern Evaluation
Pada tahapan ini dilakukan identifikasi terhadap pola-pola yang menarik yang didapat dari hasil data mining, untuk kemudian direpresentasikan.
- Knowledge Presentation
Pada tahapan ini dilakukan visualisasi dan penyajian terhadap pengetahuan mengenai teknik yang digunakan untuk memperoleh pengetahuan yang diperoleh user.
2.1.3.2 SEMMA
SEMMA merupakan singakatan dari Sample Explore Modify
Model Assess, singkatan tersebut mengacu pada proses dalam
melakukan sebuah proyek data mining. Pada penerapannya, SAS Institute membagi siklus SEMMA menjagi 5 tahapan untuk proses data mining (Azevedo & Santos, 2008), berikut tahapannya:
- Sample
Tahap ini melakukan sampling data dengan cara mengekstraksi sebagian besar data dan menetapkan besar data yang cukup untuk menampung informasi yang signifikan. - Explore
Tahap ini melakukan eksplorasi terhadap data dengan cara mencari tren yang tak terduga dan anomali dalam rangka untuk mendapatkan pemahaman dan ide-ide.
- Modify
Tahap ini melakukan modifikasi terhadap data dengan menciptakan, memilih, dan mengubah variabel untuk fokus pada proses pemilihan model.
- Model
Pada tahap ini terdiri pada pemodelan data dengan suatu perangkat lunak untuk mencari kombinasi data yang dapat memprediksi hasil yang diinginkan.
Pada tahap ini terdiri dari penilaian data dengan mengevaluasi kegunaan dan keandalan dari temuan pada proses data mining.
Gambar 2.3 Tahapan Metodologi SEMMA (Mariscal, Marban, & Fernandez, 2010)
2.1.3.3 CRISP-DM
CRISP-DM merupakan singkatan dari Cross Industry
Standard Process for Data Mining. CRISP-DM merupakan
standarisasi data mining yang disusun oleh tiga penggagas data mining market. Yaitu Daimler Chrysler (Daimler-Benz), SPSS (ISL), NCR (Larose, 2005). Pada metodologi ini dilakukan pembagian siklus untuk proses data mining menjadi 6 tahap, dimana ketergantungan antara setiap tahap digambarkan dengan panah. Berikut merupakan gambaran dari metodologi CRISP-DM.
Gambar 2.4 Tahapan Metodologi CRISP-DM (Larose, 2005)
Berdasarkan pada gambar di atas, lingkaran siklus paling luar menggambarkan bahwa data mining dengan metodologi CRISP-DM dapat mengambil pengalaman dari proyek masa lalu untuk menjadi masukan dalam proyek-proyek baru. Pada beberapa literatur digambarkan bahwa dari tahapan evaluasi dapat mengirim analisis kembali ke salah satu tahapan sebelumnya, namun untuk kesederhanaan maka pada literatur ini digambarkan proses yang paling umum dimana dari tahapan evaluasi dapat kembali ke tahap
modeling. Berikut adalah penjelasan dari setiap tahap:
Pada tahap ini berfokus pada pemahaman mengenai tujuan dari proyek dan kebutuhan secara persepktif bisnis, kemudian mengubah hal tersebut menjadi sebuah permasalahan data
mining dan rencana awal untuk mencapai tujuan tersebut.
Kegiatan yang dilakukan antara lain: menentukan tujuan dan persyaratan dengan jelas secara keseluruhan, menerjemahkan tujuan tersebut serta menentukan pembatasan dalam perumusan masalah data mining, dan selanjutnya mempersiapkan strategi awal untuk mencapai tujuan tersebut.
- Data Understanding
Pada tahap ini dilakukan pengumpulan terhadap data, lalu kemudian mempelajari data tersebut dengan tujuan untuk mengenal data, melakukan identifikasi dan mengetahui kualitas dari data, serta mendeteksi subset yang menarik dari data yang dapat dijadikan hipotesa bagi informasi yang tersembunyi. - Data Preparation
Pada tahap ini dilakukan persiapan mengenai data yang akan digunakan pada tahap berikutnya. Kegiatan yang dilakukan antara lain: memilih kasus dan parameter yang akan dianalisis(Select Data), melakukan transformasi terhadap parameter tertentu(Transformation), dan melakukan pembersihan data agar data siap untuk tahap
modeling(Cleaning).
Pada tahap ini dilakukan penentuan terhadap teknik data
mining, alat bantu data mining, dan algoritma data mining yang
akan diterapkan. Lalu selanjutnya adalah melakukan penerapan teknik dan algoritma data mining tersebut kepada data dengan bantuan alat bantu. Jika diperlukan penyesuaian data terhadap teknik data mining tertentu, dapat kembali ke tahap persiapan data.
- Evaluation
Melakukan interpretasi terhadap hasil dari data mining yang dihasilkan dalam proses pemodelan pada tahap sebelumnya. Evaluasi dilakukan terhadap model yang diterapkan pada tahap sebelumnya dengan tujuan agar model yang ditentukan dapat sesuai dengan tujuan yang ingin dicapai dalam tahap pertama.
- Deployment
Melakukan penyusunan laporan terhadap hasil yang didapat dari evaluasi pada tahap sebelumnya atau dari proses
data mining yang dilakukan secara keseluruhan.
2.1.3.4 Perbandingan KDD, SEMMA, dan CRISP-DM
Dengan berdasarkan pada penjelasan ketiga metodologi diatas, dapat dinyatakan jika pendekatan KDD and SEMMA adalah ekuivalen atau memiliki kesamaan. Sample dapat diidentifikasikan dengan Selection. Explore dapat diidentifikasikan sebagai Pre
Mining. Assess dapat berarti Interpretation/Evaluation. Sehingga
dapat dikatakan proses SEMMA terlihat mirip dengan lima tahapan pada KDD. Pada tabel berikut akan dijelaskan mengenai tahapan pada masing-masing metodologi:
Tabel 2.2 Perbandingan Tahapan KDD, SEMMA, dan CRISP-DM (Azevedo & Santos, 2008)
Pada tabel di atas diketahui jika penggunaan CRISP-DM, menambahkan sebuah tahapan yaitu business undertanding, dimana pada penerapannya tahapan ini dilakukan untuk mengetahui pemahaman mengenai tujuan dari proyek data mining yang akan dilakukan. Sedangkan tahap lainnya dapat diidentifikasikan dengan tahapan pada KDD, atau merupakan kombinasi dari tahapan pada KDD sesuai dengan gambaran pada tabel di atas.
Setiap metodologi memiliki kelebihan masing-masing, akan tetapi untuk mengetahui metodologi yang sering digunakan maka dilakukan survey mengenai penggunaan metodologi tersebut. Berikut merupakan gambar mengenai survey yang dilakukan terhadap penggunaan metodologi dalam data mining.
Gambar 2.5 Survey Penggunaan Metodologi Data Mining (Mariscal, Marban, & Fernandez, 2010)
Dari hasil survey diatas diketahui bahwa metodologi CRISP-DM menjadi metodologi yang paling sering digunakan. Dimana pada tahun 2002 jumlah pemilih CRISP-DM mencapai 51%, sedangkan pada tahun 2004 dan 2007 menurun menjadi 41%. Walau menurun, CRISP-DM tetap menjadi metodologi yang sering digunakan sesuai dengan survey tersebut.
2.1.4 Fungsional Data Mining
Selanjutnya, terdapat beberapa fungsi atau tugas dari data mining yang biasanya dikerjakan dalam proyek data mining. Fungsi tersebut antara lain (Larose, 2005):
Data mining dapat berfungsi untuk melakukan deskripsi pola dan trend pada kumpulan data, dengan melakukan deskripsi akan didapat penjelasan yang mungkin untuk tren atau pola tersebut. Data mining harus bersifat se-transparan mungkin, karena hasil dari data mining harus menjelaskan pola yang jelas. - Estimation
Fungsi estimation memiliki kemiripan dengan fungsi
classification, yaitu bertujuan untuk menentukan nilai dari
atribut output yang belum diketahui. Namun berbeda dengan
classification, atribut output pada estimation lebih bersifat
numerik daripada kategori.
Contoh kasus yang menerapkan estimation antara lain: o Memperkirakan rata-rata nilai(IPK) dari seorang mahasiswa pasca sarjana dengan didasarkan pada IPK ketika sarjana.
o Memperkirakan jumlah uang yang dikeluarkan untuk berbelanja keperluan sekolah ketika tahun ajaran baru dimulai oleh sebuah keluarga.
- Prediction
Tujuan dari fungsi ini adalah untuk menemukan kemungkinan hasil di masa depan dengan berdasarkan tindakan sekarang. Dimana atribut output yang dihasilkan bisa berupa kategori atau numerik. Berikut merupakan contoh kasus yang menerapkan fungsi prediction:
o Memprediksi pemenang dari kejuaraan dengna berdasarkan perbandingan statistik tim.
o Memprediksi persentase kenaikan tingkat kecelakaan lalu lintas pada tahun depan jika batasan kecepatan meningkat.
o Memprediksi harga saham 3 bulan ke depan.
Gambar 2.6 Prediksi Harga Saham 3 Bulan Kedepan (Han & Kamber, 2006)
- Classification
Klasifikasi merupakan sebuah proses untuk mencari model atau fungsi yang menjelaskan dan membedakan kelas atau konsep dari data, dengan tujuan untuk menggunakan model dan melakukan prediksi dari kelas suatu objek dimana tidak diketahui label dari kelas tersebut (Han & Kamber, 2006).
Berikut merupakan contoh dari penerapan fungsi klasifikasi:
o Menentukan apakah transaksi dengan kartu kredit tersebut adalah penipuan.
o Menilai apakah pengajuan kredit yang diajukan memiliki resiko kredit yang baik atau buruk.
o Mendiagnosis apakah terdapat penyakit tertentu.
Dalam melakukan representasi terhadap klasifikasi, terdapat beberapa model yang dapat digunakan. Representasi tersebut bisa dengan menggunakan classification (IF-THEN)
rules, decision trees, mathematical formulae, atau neural networks.
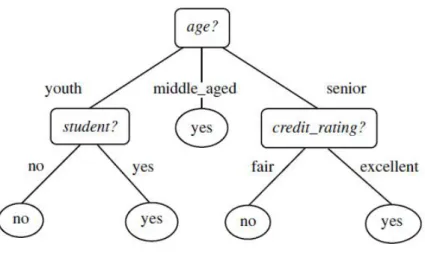
Decision tree merupakan sebuah diagram alur yang
berbentuk seperti pohon, dimana setiap cabang merepresentasikan output dari pengujian dan daun pohon merepresentasikan kelas atau distribusi dari kelas.
Gambar 2.7 Contoh Decision Tree (Han & Kamber, 2006)
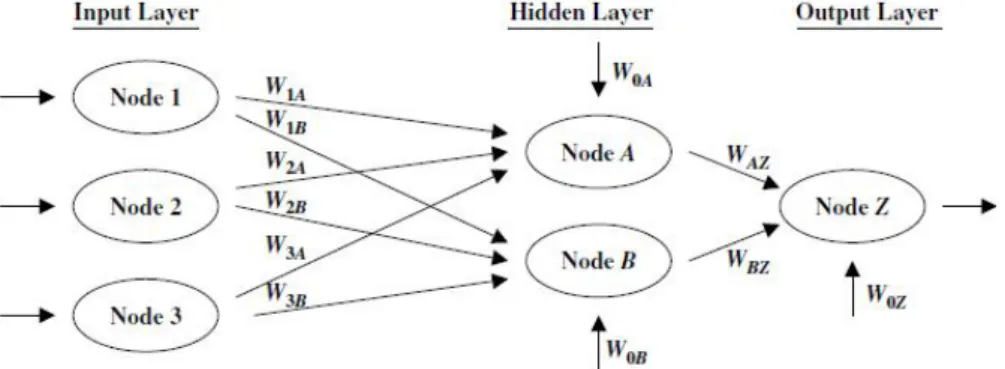
Neural network berbentuk seperti sebuah koleksi unit
proses yang berbentuk neuron dengan weighted connections diantara setiap unit.
Gambar 2.8 Contoh Neural Network (Han & Kamber, 2006)
Dalam pemanfaatannya terdapat banyak metode yang dapat digunakan untuk melakukan model klasifikasi, seperti
support vector machine, naive Bayesian classification, dan k-nearest neighbor classification.
- Clustering
Clustering berkaitan dengan pengelompokan dari records,
penelitian, atau kasus ke dalam kelas yang memiliki kesamaan objek. Clustering berbeda dengan classification, dikarenakan pada clustering tidak ada target parameter yang digunakan untuk
clustering. Algoritma pada clustering akan melakukan
segmentasi data pada seluruh data menjadi sub-kelompok yang relatif memiliki kesamaan.
Berikut merupakan contoh dari penerapan fungsi
clustering:
o Menentukan target pemasaran produk untuk bisnis kecil yang tidak memiliki anggaran pemasaran yang besar.
o Sebagai alat pengurangan dimensi data ketika set data memiliki ratusan atribut
o Mengelompokkan pelanggan dengan berdasarkan karakterisasi pola pembeliannya, sehingga dapat membantu pemasaran untuk strategi pemasaran.
Gambar 2.9 Contoh Penerapan Clustering terhadap lokasi pelanggan dalam sebuah kota (Han & Kamber, 2006)
Dalam penerapannya, banyak algoritma yang dapat digunakan untuk melakukan clustering, seperti k-means
algorithm, dan self-organizing maps(SOM).
- Association
Asosiasi dalam penerapan data mining memiliki tugas untuk menemukan atribut yang memiliki keterkaitan atau mencari hubungan atau suatu item. Sebagai contohnya dalam himpunan transaksi, dimana dari himpunan transaksi tersebut mungkin akan ditemukan suatu hubungan seperti berikut, pada sebuah supermarket ditemukan bahwa terdapat 1000 pelanggan
yang melakukan transaksi pembelian dimana 200 pelanggan membeli popok, dan dari 200 pelanggan tersebut diketahui 50 pelanggannya membeli bir. Dalam bahasa asosiasi hal tersebut dibaca menjadi “Jika membeli popok, maka membeli bir” dengan support 200/1000 = 20% dan confidence 50/200 = 25%.
Support dalam hal ini berarti persentase jumlah transaksi
dalam analisis yang menggambarkan bahwa kedua produk telah dipesan dalam satu transaksi yang sama. Sedangkan confidence berarti persentase jumlah pelanggan yang akan membeli produk ke-2 jika membeli produk pertama, dalam hal ini berarti jika pembeli membeli popok, maka ada peluang 25% pembeli tersebut juga akan membeli bir.
Dengan demikian, untuk dapat menemukan hubungan antar item tersebut mungkin diperlukan pembacaan terhadap data transaksi secara berulang terhadap data transaksi tersebut. Dikarenakan data transaksi tersebut berjumlah sangat besar maka diperlukan algoritma yang efisien untuk dapat mengerjakannya.
Selain itu terdapat beberapa contoh penerapan fungsi asosiasi, antara lain:
o Menginvestigasi proporsi pelanggan yang akan merespon positif terhadap tawaran dari perusahaan ponsel. o Memprediksi degradasi dari jaringan telekomunikasi.
o Mendapatkan keterkaitan antar parameter yang berpengaruh pada peluang berhasilnya lulus ujian dari seorang pelajar ketika menghadapi ujian akhir.
Untuk menerapkan asosiasi terdapat beberapa algoritma yang dapat digunakan, yaitu apriori algorithm, dan
GRI(generalized rule induction) algorithm.
2.1.5 Clustering
Clustering merupakan proses pengelompokan sekumpulan objek fisik
atau abstrak kedalam kelas dengan objek yang serupa (Han & Kamber, 2006). Sedangkan cluster merupakan koleksi objek data yang memiliki kesamaan satu sama lain dalam kelompok yang sama dan berbeda dengan objek di kelompok lain. Cluster analisis dapat diterapkan secara luas pada berbagai penggunaan, termasuk dalam market research, pattern recognition,
data analysis, dan image processing. Salah satunya dalam bisnis, clustering
dapat membantu pemasaran dalam mengetahui pengelompokan bagi pelanggannya dan mengkarakterisasi kelompok pelanggannya berdasarkan pola belanjanya.
Clustering dapat juga dikatakan sebagai data segmentation pada
beberapa penerapan, karena clustering akan membagi sekumpulan data yang besar ke dalam kelompok-kelompok dengan berdasarkan pada kesamaannya. Han & Kamber (2006) juga menyebutkan bahwa clustering merupakan sebuah contoh dari unsupervised learning. Karena tidak seperti klasifikasi, clustering tidak berdasarkan pada parameter atau kelas yang
ditentukan sebelumnya. Sehingga clustering merupakan bentuk “learning by
observation”, bukan “learning by examples”.
Clustering pada penerapannya di data mining memiliki beberapa
kebutuhan, yaitu (Han & Kamber, 2006): - Scalability
Skalabilitas dari clustering, baik dalam sampel kecil atau database yang besar untuk menghindari hasil yang bias.
- Ability to deal with different types of attributes
Clustering dapat memiliki kemampuan untuk mengolah
berbagai macam jenis atribut, yang dapat berupa data biner, nominal, ordinal, atau kombinasi dari tipe data tersebut.
- Discovery of clusters with arbitrary shape
Algoritma clustering dengan berdasarkan ukuran jarak cenderung akan menemukan cluster dengan bentuk lingkaran, akan tetapi clustering sebaiknya dapat mendeteksi cluster dengan bentuk apapun, karena tidak semua cluster akan berbentuk bulat.
- Minimal requirements for domain knowledge to determine input parameters
Algoritma pada clustering terkadang mengharuskan pengguna untuk memasukkan parameter tertentu dalam analisis cluster (seperti jumlah cluster yang diinginkan), dimana hasil dari clustering sangat sensitif terhadap parameter yang dimasukkan. Akan tetapi parameter seringkali sulit untuk ditentukan sehingga menjadi kesulitan bagi
pengguna. Untuk itu diperlukan kebutuhan yang minimal untuk menentukan parameter masukan.
- Ability to deal with noisy data
Database yang ada cenderung akan memiliki data yang salah, sedangkan pada beberapa algoritma clustering yang sensitif terhadap data tersebut dapat mengakibatkan kualitas hasil yang buruk.
- Incremental clustering and insensitivity to the order of input records
Beberapa algoritma clustering sensitif terhadap urutan data masukan. Artinya, ketika diberi satu set objek data, algoritma dapat memberikan hasil clustering yang berbeda tergantung pada urutan penyajian data masukan. Hal ini berkaitan dengan pengembangan terhadap algoritma clustering dan algoritma tambahan yang sensitif terhadap urutan data masukan.
- High dimensionality
Database atau data warehouse cenderung memiliki beberapa dimensi atau atribut, dan banyak algoritma clustering yang dapat menangani dimensi data yang kecil seperti dengan dua atau tiga dimensi. Sehingga dapat mengurangi penanganan berdimensi tinggi, karena manusia normal dapat belajar setidaknya sampai 3 dimensi. - Constraint-based clustering
Pada penerapannya mungkin diperlukan pengelompokkan dengan berdasarkan pada berbagai macam batasan, sehingga hal ini
akan menjadi tantangan untuk menemukan hasil clustering data yang baik dengan memenuhi terhadap batasan tersebut.
- Interpretability and usability
Dalam penerapan clustering, pengguna mengharapkan hasil dari penerapannya dapat dipahami, serta dapat digunakan. Sehingga dengan kata lain, diperlukan pertimbangan terhadap tujuan dari aplikasi tersebut ketika melakukan pemilihan fitur dan metode clustering.
Untuk kebutuhan penggunaan clustering, biasanya penerapan dilakukan pada (Jain, 2009):
- Underlying structure, untuk mendapatkan informasi tentang
data, menghasilkan hipotesis, mendeteksi anomali, dan mengidentifikasi fitur yang penting.
- Natural classification,untuk mengidentifikasi tingkat kesamaan antara bentuk-bentuk (phylogenetic relationship).
- Compression, sebagai metode untuk mengatur dan meringkas
data dengan melalui prototipe cluster.
2.1.5.1 K-Means
Kegiatan clustering merupakan proses pengelompokan sekumpulan objek fisik atau abstrak kedalam kelas dengan objek yang serupa. Dalam melakukan clustering tersebut, pada jurnal “Data
Clustering: 50 Years Beyond K-Means” (Jain, 2009) diungkapkan
yang cukup handal digunakan untuk proses clustering. K-means yang disebutkan merupakan salah satu algoritma yang digunakan ketika akan melakukan proses clustering.
Pada jurnal “Top 10 algorithms in data mining” (Wu, et al., 2008), disebutkan bahwa algoritma K-means merupakan algoritma yang paling banyak digunakan dalam data mining dan menempati peringkat ke-2(dua), selanjutnya K-means menjadi posisi pertama untuk algoritma clustering. Berikut urutan algoritma yang menjadi terbaik (Wu, et al., 2008):
- C4.5 - K-means
- SVM (Support Vector machines) - Algoritma Apriori - EM (Expectation Maximazation) - Algoritma PageRank - Algoritma AdaBoost - K-Nearst Neighbor - Naive Bayes
- Classification and Regression Trees.
Algoritma K-means adalah metode iteratif sederhana untuk melakukan partisi terhadap data yang diberikan ke dalam sejumlah penggunaan cluster tertentu (Wu, et al., 2008). Algoritma K-means ditemukan oleh beberapa peneliti di seluruh disiplin ilmu yang
berbeda, terutama Lloyd (1957, 1982), Forgey (1965), Friedman dan Rubin (1967), dan McQueen (1967).
Anggap X = {xi}, dimana i = 1,. . . ,n, merupakan himpunan
pada n d-dimensi yang akan dikelompokkan pada K cluster, yang digambarkan C = {
c
k, k=1,...,K}. Selanjutnya k-means akanmenemukan partisi secara sedemikian rupa sehingga kesalahan kuadrat antara rata-rata empiris cluster dan poin di cluster dapat diminimalkan. Anggap
k menjadi rata-rata dari clusterc
k, makahubungan antara keduanya dirumuskan menjadi:
Selanjutnya tujuan dari k-means akan meminimalkan nilai
J(ck) terhadap keseluruhan K cluster, sehingga dirumuskan menjadi:
Secara umum, langkah-langkah utama dari algoritma K-means adalah sebagai berikut:
- Pilih partisi awal pada cluster K, ulangi langkah 2 dan 3 sampai keanggotaan cluster telah stabil.
- Menghasilkan sebuah partisi baru dengan menetapkan kepada masing-masing pola terhadap pusat cluster terdekatnya.
Berikut merupakan gambaran dari algoritma k-means pada sebuah data dua dimensi dengan tiga cluster:
Gambar 2.10 Ilustrasi K-means (Jain, 2009)
Berdasarkan pada gambar di atas, maka pada tahap pertama masukan data diberikan dengan tiga cluster(a), selanjutnya tiga titik utama dipilih sebagai pusat cluster dan nilai awal untuk melakukan cluster(b), lalu pada (c) dan (d) dilakukan iterasi langkah-langkahnya untuk memperbaharui cluster dan pusat pada masing-masing cluster, dan pada akhir clustering diperoleh pengelompokkan terakhir(e).
2.2 CDR(Call Details Records)
Perusahaan telekomunikasi mendapatkan keuntungan dari penjualan jasa komunikasi untuk pelanggannya. Dari jasa komunikasi yang disediakan, panggilan melalui telepon selular merupakan salah satu pelayanan dari perusahaan telekomunikasi, dimana dengan menggunakan layanan tersebut maka
memungkinkan komunikasi langsung antara pelaku dan penerima panggilan. Dalam penggunaan layanan panggilan tersebut, maka transaksi mengenai panggilan akan disimpan dalam sebuah penyimpanan yang kemudian hasil penyimpanan akan disebut sebagai Call Details Records(CDR).
Call Details Records(CDR) menyimpan informasi yang memadai dan
menggambarkan kegiatan panggilan dari setiap kegiatan panggilan yang terjadi (Folasade, 2011). Call Details Records(CDR) pada umumnya akan terdiri dari hal berikut (Ofrane & Lawrence, 2003):
- Nomor telepon asal dan tujuan panggilan (who)
Berisikan informasi mengenai nomor telepon dari pengguna yang melakukan panggilan, dan nomor telepon tujuan dari panggilan yang dilakukan.
- Tanggal dan waktu panggilan, serta durasi panggilan (when)
Berisikan informasi mengenai tanggal dan waktu pada saat melakukan panggilan serta lama waktu yang terjadi pada saat melakukan panggilan. - Jenis panggilan dan perinciannya (what)
Berisikan informasi mengenai tanggal dan waktu pada saat melakukan panggilan.
- Lokasi panggilan (where)
Berisikan informasi mengenai lokasi terjadinya panggilan. - Alasan kejadian perekaman (why)
Berisikan alasan terhadap perekaman panggilan.
Call Details Records(CDR) dihasilkan dari mediation devices. Mediation devices adalah perangkat yang akan menerima, mengolah, dan mengubah format
informasi dari jaringan telekomunikasi menjadi format yang sesuai dengan satu atau lebih billing dan customer care system (Ofrane & Lawrence, 2003). Berikut merupakan gambaran dari proses kerja mediation devices.
Gambar 2.11 Proses Kerja Mediation Devices (Ofrane & Lawrence, 2003)
Sesuai dengan gambar di atas, maka mediation device mampu untuk menerima, dan melakukan decoding format data yang diterima dari switch yang berbeda. Dan mengubahnya menjadi standar Call Details
Records(CDR) yang dapat digunakan oleh billing system.
Selanjutnya pada gambar di bawah ini, terdapat gambaran mengenai struktur dasar dari Call Details Records(CDR). Diagram ini melakukan referensi terhadap, Usage Detail Record(UDR). Hal ini dikarenakan tidak semua kejadian merupakan suara atau panggilan data, sehingga terdapat catatan yang dihasilkan pada jaringan yang disebut Usage Detail
nomor identifikasi yang unik, pelaku panggilan, nomor tujuan panggilan, serta waktu awal dan waktu akhir dari panggilan.
Gambar 2.12 Usage Detail Record(UDR) (Ofrane & Lawrence, 2003)
Selanjutnya dari Call Details Records(CDR) setiap pelanggan, dapat dilakukan pengolahan sehingga menghasilkan informasi berupa catatan yang menggambarkan perilaku pelanggan menelepon. Pada umumnya, selain dengan
Call Details Records(CDR), perusahaan telekomonukasi dapat melakukan
pengelompokkan pelanggan mereka dengan menggunakan billing system. Akan tetapi dari data yang tersimpan pada billing system, hanya menggambarkan mengenai perilaku pelanggan dalam berlangganan, berbelanja, dan melakukan pembayaran. Sedangkan pada Call Details Records(CDR), dapat menggambarkan perilaku dari pelanggan dalam memanfaatkan layanan panggilan. Dari hal tersebut, dapat diketahui jika Call Details Records(CDR) memiliki data yang lebih tepat untuk menggambarkan mengenai perilaku pelanggan daripada data di
billing system (Lin, 2007).
Dengan berdasarkan pada Call Details Records(CDR) yang mengandung data mengenai perilaku pelanggan, maka hal ini dapat membantu untuk mendapatkan informasi pelanggan yang dapat diperoleh untuk tujuan pemasaran.
Salah satu informasi tersebut adalah mengenai perilaku komunikasi dari pelanggan, dimana perilaku komunikasi pelanggan tersebut akan mewakili perilaku panggilan dari para pelanggan selama periode yang cukup lama. Dengan mendapatkan informasi pelanggan tersebut maka perusahaan dapat memahami kebutuhan pelanggan, sehingga penawaran khusus mengenai penggunaan panggilan dapat dibuat dan tarif dapat disesuaikan dengan perilaku pelanggan tersebut (Maedche, Hotho, & Wiese). Jika berdasarkan data yang tersedia pada
Call Details Records(CDR), maka perilaku komunikasi dari pelanggan dapat
digambarkan dengan ketertarikan pelanggan (profile interest) dalam panggilan melalui pengelompokan berdasarkan lama panggilan yang dilakukan, ketertarikan panggilan dari dan ke mana panggilan terjadi, serta dari penyebaran data panggilan berdasarkan jam. Yang kemudian dari hal tersebut bisa diketahui mengenai pola kemana panggilan yang dilakukan, darimana panggilan berasal, serta kapan dan berapa lama panggilan terjadi.