Klasifikasi Citra Daun Tanaman Menggunakan
Metode Extreme Learning Machine
Murdoko
Program Studi Teknik Informatika, Fakultas Ilmu Komputer,Universitas Sriwijaya
Palembang, Indonesia e-mail: [email protected],
Saparudin*)
Program Studi Teknik Informatika, Fakultas Ilmu Komputer,Universitas Sriwijaya
Palembang, Indonesia
*)
Corresponding author e-mail: [email protected]
Abstrak –Klasifikasi citra daun tanaman digunakan untuk pengelompokan spesies tanaman yang bermanfaat untuk mengidentifikasi jenis tanaman dalam kegiatan industri pertanian, perkebunan, kehutanan dan lain-lain. Tanaman yang memiliki daun dapat dikenali dari tekstur daunnya. Tetapi, tekstur daun pada beberapa tanaman memiliki kemiripan bentuk, warna dan ukuran sehingga tidak mudah diklasifikasi. Penelitian ini mengusulkan metode Jaringan Saraf Tiruan-Extreme Learning Machine (JST-ELM) dengan ekstraksi fitur Gabor Filter dan Gray Level Co-occurrence Matrix (GLCM) untuk mengklasifikasi kelas tanaman melalui fitur citra daun. Terdapat tiga langkah yang dilakukan: pertama, pra-pemrosesan dan filterisasi. Kedua, ekstraksi fitur. Terakhir, klasifikasi daun. Hasil pengujian terhadap 1.797 citra daun dalam 32 kelas tanaman menunjukkan nilai akurasi pembelajaran 92,9% dan pengujian 88,9%. Hasil tersebut lebih baik dari penelitian sebelumnya.
Kata kunci: Klasifikasi Citra Daun, Jaringan Saraf Tiruan, Extreme Learning Machine, Gabor Filter, Gray Level Co-occurrence Matrix.
I. PENDAHULUAN
Klasifikasi citra daun tanaman merupakan bagian penting dalam identifikasi tanaman karena pencarian kembali jenis tanaman di dalam sejumlah besar basis data jenis tanaman sangat sulit dan memerlukan waktu yang lama. Pada dasarnya klasifikasi citra daun tanaman memberikan penandaan gambar ke dalam salah satu dari sejumlah kategori atau kelas daun tanaman. Secara umum suatu sistem klasifikasi citra digital terdiri dari sensor gambar yang digunakan untuk mengambil gambar, pra-pemrosesan gambar, deteksi gambar, segmentasi gambar, ekstraksi fitur dan klasifikasi gambar [1].
Pada proses klasifikasi citra daun tanaman tidak mudah mengenali tekstur daun sebagai salah satu jenis tanaman dari beberapa kelas tekstur. Pemilihan fitur tekstur harus tepat sehingga dapat
membedakan antara suatu citra dengan citra yang lain. Secara umum fitur tekstur dapat diperoleh dari penerapan operator lokal, analisis statistik dan perhitungan transformasi asal(domain). Tetapi, penggunaan banyak parameter dalam klasifikasi dapat menurunkan akurasinya, sehingga sangat penting untuk memilih fitur yang tepat [2].
Terdapat banyak teknik klasifikasi citra yang telah dikembangkan, seperti teknik statistik, pohon keputusan, klasifikasi fuzzy dan jaringan saraf tiruan. Masalah pada jaringan saraf tiruan terletak pada kecepatan pembelajaran yang sangat lambat dari yang diharapkan karena semua fitur pada jaringan dimasukkan secara berulang-ulang [3]. Pengulangan diperlukan untuk meningkatkan akurasi klasifikasi tapi akan meningkatkan waktu pembelajaran. Extreme Learning Machine (ELM) adalah jaringan saraf tiruan feedforward dengan satu hidden-layer atau yang sering disebut
single-hidden layer feedforward netwoks (SLFNs). ELM
mempunyai kelebihan dalam kecepatan pembelajaran yang cepat dan keakuratan klasifikasi yang tinggi [4].
Penelitian ini menggunakan metode Jaringan Saraf Tiruan JST-ELM untuk mengklasifikasi kelas tanaman. Tulisan dimulai dengan pendahuluan, kajian pustaka yang menyajikan berbagai penelitian sebelumnya dengan menggunakan metode JST. Selanjutnya, deskripsi metode yang diusulkan. Kemudian, hasil eksperimen, analisis, dan pembahasan. Bagian akhir adalah kesimpulan.
II. KAJIAN PUSTAKA
Berdasarkan metode taksonomi, tanaman dapat diklasifikasikan berdasarkan bentuk daun, serat batang, biji dan bunganya [4]. Pengklasifikasian tanaman berdasarkan citra daun merupakan cara yang paling baik dan murah karena dapat dengan mudah mentransfer citra daun ke komputer untuk diektraksi fiturnya menggunakan teknik pengolahan citra [5]. Bentuk daun adalah fitur yang sering digunakan untuk mengenali dan mengklasifikasikan tanaman [12].
Terdapat 5 fitur dasar geometris yang dapat digunakan untuk pengenalan pada daun yaitu
diameter: jarak terpanjang dari dua titik pada
margin daun, physiological length: jarak antara dua terminal pada daun, physiological width: lebar antara dua terminal pada daun, leaf area dan leaf
perimeter[5].
Menurut Shabanzade, Zahedi dan Aghvani terdapat dua kategori fitur daun tanaman yang dapat digunakan, yaitu: fitur global yang terdiri dari panjang dan lebar area daun atau fitur-fitur lain yang menentukan bentuk daun secara keseluruhan; deskripsi lokal yang menjelaskan rincian fitur daun berbasis tekstur seperti energi, kontras, korelasi dan homogenitas [6].
Zhai dan Du menggunakan metode jaringan saraf tiruan Extreme Learning Machine (ELM) untuk klasifikasi spesies tanaman. Pada penelitiannya dilakukan perbandingan antara metode ELM dan Backpropagation Neural Networks (BPNN). Sampel citra daun dari 50
spesies tanaman yang berbeda. Setiap spesies terdapat 10 citra daun, 6 diantaranya digunakan untuk sampel pelatihan. Totalnya terdapat 600 citra daun. Hasil percobaan menunjukkan bahwa performa rata-rata generalisasi oleh ELM dengan
sigmoid dan RBF kernel adalah 75,12 % dan 75,68
% sedangkan performa rata-rata generalisasi BPNN adalah 74,82 %. Selain itu waktu yang diperlukan dalam proses pembelajaran ELM dengan sigmoid dan RBF kernel adalah 1.065 detik dan 10.294 detik sedangkan waktu yang diperlukan dalam proses pembelajaran BPNN adalah 956.63 detik [4].
Sangeetha dan Radha membandingkan metode
Support Vector Machine (SVM) dan metode ELM
untuk pengenalan iris mata. Hasilnya bahwa tingkat performa waktu pada metode ELM lebih baik dari metode SVM [13]. Pengenalan bahasa isyarat menggunakan ELM yang dilakukan oleh Sole dan Tsoeu dengan tingkat akurasi 95 % [14].
III. METODE YANG DIUSULKAN Proses klasifikasi daun tanaman menggunakan JST-ELM dimulai dengan menerima masukan berupa citra berwarna daun tanaman, kemudian dilakukan proses konversi citra warna ke citra keabuan dan dilanjutkan dengan proses perataan histogram menggunakan metode histogram equalization. Proses selanjutnya adalah filterisasi
menggunakan gabor filter dan pencarian nilai-nilai fitur menggunakan GLCM. Kemudian, didapatkan nilai-nilai fitur berupa energy yang akan digunakan sebagai masukan pada proses pembelajaran dan pengujian ELM. Dari proses pembelajaran dan pengujian akan diperoleh nilai akurasi dan kecepatan dari proses pembelajaran dan pengujian. Skema proses klasifikasi citra daun tanaman secara keseluruhan ditunjukkan pada gambar 1.
Gambar 1. Skema Klasifikasi Citra Daun Tanaman 3.1 Pra-pengolahan Citra
3.1.1 Citra Skala Keabuan
Citra skala keabuan adalah citra yang memiliki intensitas warna abu-abu (0-255). Penggunaan citra dengan skala keabuan untuk memperoleh algoritma yang sederhana dan menurunkan kebutuhan perhitungan citra berwarna yang kompleks [7]. Dalam prosesnya, Citra berwarna yang terdiri dari 3 kanal, red (R), green (G) dan blue (B) dihitung dengan persamaan 1 menjadi satu kanal yaitu citra keabuan.
𝐾 = (0.2989 ∗ 𝑅) + (0.587 ∗ 𝐺) + (0.114 ∗ 𝐵) (1) 3.1.2 Perataan Histogram
Citra yang diperoleh dari kamera dengan kondisi kontras yang rendah akan bermasalah dalam ekstrasi fitur. Untuk itu, diperlukan perataan histogram untuk memperoleh citra dengan kontras yang lebih baik. Terdapat beberapa algoritma perbaikan kontras citra, salah satunya adalah Perataan Histogram (Histogram Equalization=HE). Histogram adalah distribusi nilai intensitas piksel pada citra. Nilai intensitas citra yang sama akan dijumlahkan sehingga membentuk satu bin pada histogram. Sekumpulan nilai bin dari setiap intensitas citra akan membentuk histogram dari suatu citra. Langkah selanjutnya yaitu memperlebar puncak dan memperkecil titik minimum dari histogram citra supaya penyebaran nilai piksel setiap citra merata. Nilai histogram dari suatu citra dapat dihitung dengan persamaan 2.
ℎ(𝑖) = ∑𝐿−1𝑛;
𝑖=0 (2)
Nilai n ditentukan oleh aturan berikut, 𝑛 = {1, jika f(x, y) = 𝑖0, jika f(x, y) ≠ 𝑖
dimana:
ℎ(𝑖) = nilai histogram citra; Citra Daun Grayscale GLCM Histogram Equalization Gabor Filter Akurasi Pembelajaran
Pembelajaran ELM Pengujian ELM
𝑓(𝑥, 𝑦) = nilai piksel citra koordinat x,y; 𝑖 = intensitas piksel (0,1,2,…,255).
Perataan histogram merupakan proses normalisasi untuk melakukan pemerataan intensitas piksel suatu citra. Sebelum proses normalisasi terlebih dahulu harus diketahui jumlah histogram dari keseluruhan intensitas piksel gambar. Persamaan 3 digunakan untuk menghitung nilai jumlah histogram.
𝑆(𝑗) = ∑𝑙−1 ℎ(𝑗)
𝑘=0 (3)
dimana:
𝑆(𝑗) = jumlah nilai histogram ke-j;
ℎ(𝑗) = nilai histogram ke-j; 𝑗= 0,1,2,3,…,255; Dengan demikian nilai perataan histogram citra dapat dihitung dengan persamaan 4.
𝑛𝑜𝑟𝑚(𝑖) =𝑆(𝑖) ∗ (𝐿−1)∑𝑙−1ℎ(𝑖)
𝑖=0 (4)
dimana:
𝑛𝑜𝑟𝑚(𝑖) = nilai histogram hasil normalisasi; 𝑆(𝑖) = jumlah nilai histogram;
𝐻(𝑖) = nilai histogram ke-i;
𝐿 = nilai maksimum intensitas piksel citra. 3.2 Ekstraksi Fitur
3.2.1 Gabor Filter
Gabor filter telah digunakan secara luas untuk
melakukan filter suatu citra dan telah terbukti sangat efisien [4]. Nilai-nilai fitur dari setiap daun tanaman dapat diekstraksi dengan metode Gabor
filter. Gabor filter merupakan sekumpulan wavelet
dimana setiap wavelet menangkap energi pada frekuensi tertentu dan arah tertentu. Perluasan sinyal menggunakan dasar ini menyediakan gambaran frekuensi lokal, sehingga bisa menangkap fitur lokal dan sinyal energi pada citra daun.
Untuk melakukan filtering pada citra terlebih dahulu dibuat kernel gabor filter dengan skala yang bervariasi. Dengan demikian akan tercipta beberapa filter yang berbeda sehingga akan digunakan sebagai filter. Adapun model matematika dari gabor filter adalah sebagai berikut:
g(x,y) = (2𝜋𝜎1 𝑥𝜎𝑦) 𝑒𝑥𝑝 [−0.5 ( 𝑥2 𝜎𝑥2+ 𝑦2 𝜎𝑦2) + 𝜋𝑗𝑤𝑥] (5) Dari model matematika diatas dilakukan perluasan menjadi gabor wavelet sebagai berikut: 𝑔𝑚𝑛(𝑥, 𝑦) = 𝑎−𝑚𝑔(𝑥′, 𝑦′), 𝑎 > 1 (6) dimana : 𝑚 = 0,1,2, … , 𝑠 − 1 𝑥′= 𝑎−𝑚(𝑥 cos 𝜃 + 𝑦 sin 𝜃) 𝑦′= 𝑎−𝑛(𝑦 cos 𝜃 − 𝑥 sin 𝜃) 𝜃 =𝑛𝜋 𝑁 (𝑚 = 0,1,2, … , 𝑀, 𝑛 = 0,1,2, … , 𝑁) 𝑔𝑚𝑛(𝑥, 𝑦) = kernel gabor filter dengan skala panjang = x dan lebar =y;
w =frekuensi sinusoid
𝜎𝑥 , 𝜎𝑦 = standard deviasi Gaussian 𝜃 = orientasi
M = jumlah skala N = jumlah orientasi
Setelah filter dibuat dengan skala dan orientasi yang berbeda-beda maka akan dikonvolusikan dengan citra daun hasil pra-pemrosesan. Hasilnya berupa sejumlah citra baru sebanyak jumlah skala dan orientasi yang telah ditentukan. Citra hasil pra-pengolahan 𝐼(𝑥, 𝑦) dilakukan konvolusi dengan kernel gabor filter 𝑔𝑚𝑛(𝑥, 𝑦) menggunakan persamaan 7, sehingga menghasilkan citra baru 𝑣𝑙,𝑘(x,y).
𝑉𝑙,𝑘(𝑥, 𝑦) = 𝐼(𝑥, 𝑦) ∗ 𝑔𝑚𝑛(𝑥, 𝑦) (7) dimana:
𝑚 = 0,1,2, … , 𝑀, 𝑛 = 0,1,2, … , 𝑁
3.2.2 Gray Level Co-occurrence Matrix
Gray Level Co-occurrence Matrix (GLCM)
adalah matriks yang mendeskripsikan frekuensi suatu level keabuan yang muncul pada hubungan linier spasial tertentu dengan level keabuan terhadap piksel yang lain. Terdapat dua parameter dalam perhitungan matriks co-occurrence yaitu, jarak relatif antara pasangan piksel diukur pada jumlah piksel dan orientasi relatifnya.
Menurut Mokji dan Abu terdapat enam fitur tekstur yang dapat digunakan yaitu energy, entropy,
contrast, variance, correlation dan homogenity [8].
Penelitian ini hanya mengambil 4 fitur yang digunakan untuk membedakan dengan citra kelas lainnya yaitu energy, contrast, homogenity, dan
correlation. Persamaan fitur-fitur tersebut adalah:
1. Energi (Energy) ∑𝑖,𝑗𝑝(𝑖, 𝑗)2 (8) 2. Kontras (Contrast) ∑ |𝑖 − 𝑗|2 𝑖,𝑗 p(i,j) (9) 3. Homogenitas (Homogenity) ∑ 𝑝(𝑖,𝑗) 1+|𝑖−𝑗| 𝑖,𝑗 (10) 4. Korelasi (Correlation) ∑ (𝑖−𝜇𝑖)(𝑗−𝜇𝑗)𝑝(𝑖,𝑗) 𝜎𝑖𝜎𝑗 𝑖,𝑗 (11)
3.3 JST-ELM
Jaringan Saraf Tiruan (JST) adalah model komputasi untuk pemrosesan informasi dan identifikasi pola yang dikembangkan berdasarkan permodelan sistem saraf biologis dari otak manusia [9]. Model JST pertama kali diperkenalkan pada tahun 1943 oleh McCulloch dan Pitts [10].
JST merupakan jaringan dengan banyak unit komputasi yang disebut dengan neuron atau sel yang saling berhubungan dan terorganisasi dalam
layers [9]. Setiap neuron yang terdapat pada lapisan
JST bertugas untuk melakukan pengolahan informasi dengan memproses input yang diterima menjadi output. Setiap neuron saling berhubungan dan memiliki bobot masing-masing yang akan mengalikan sinyal yang ditransmisikan. Terdapat fungsi aktivasi pada setiap neuron yang akan menentukan besarnya keluaran. Susunan dari JST sering ditentukan berdasarkan jumlah layer dan banyaknya neuron pada setiap layer. Tipe dari layer tersebut adalah:
a. Input layer: Neuron pada lapisan ini disebut sebagai unit masukan yang diberikan untuk pemrosesan jaringan.
b. Hidden layer: Neuron pada lapisan ini disebut sebagai unit tersembunyi, yang tidak dapat diamati karena tersembunyi.
c. Output layer: Neuron pada lapisan ini disebut sebagai unit keluaran yang menghasilkan nilai yang ditetapkan sesuai perhitungan [10]. ELM adalah jaringan saraf tiruan feedforward
single layer atau yang biasanya disingkat dengan
SLFNs. ELM pertama kali dikenalkan oleh Huang, Zhu dan Siew [3]. Terdapat banyak jenis dari jaringan saraf tiruan feedforward yang populer yang terdiri dari single atau multi hidden layer seperti pembelajaran basis gradient, contohnya metode
backpropagation untuk multi-layer feedforward neural network. Namun, pembelajarannya sangat
lambat dari yang diharapkan hal ini disebabkan karena semua parameter yang diberikan harus ditentukan secara manual dan diperlukan iterative
tuning pada setiap parameternya. Pada metode
ELM setiap pameter diberikan secara acak tanpa
iterative tuning sehingga menghasilkan learning speed yang cepat [11].
Metode ELM memiliki struktur yang hampir sama dengan SLFNs, namun memiliki model komputasi yang berbeda. Secara matematis, ELM dimodelkan seperti berikut :
Diketahui :
1. Himpunan latih X dan target sampel T, dimana: T= {(𝑥𝑖, 𝑡𝑖) |𝑥𝑖 𝜖 𝑅𝑛, 𝑡𝑖∈ 𝑅𝑚, i=1, … , N}; 2. Jumlah fitur dari sampel disimbolkan dengan n;
Fungsi aktifasi disimbolkan dengan g(x); 3. Jumlah node pada hidden layer disimbolkan
dengan L;
4. Nilai vektor bobot input (W) dan hidden node bias (b) yang ditentukan secara acak.
Dari penjelasan sebelumnya maka perhitungan matematisnya adalah sebagai berikut:
1. Hitung keluaran dari lapisan tersembunyi H= H(g(w.x+b)
2. Hitung bobot output (β) β= 𝐻ϯ T 3. Hitung nilai output Y
Y= 𝐻𝑇 β dimana :
𝐻ϯ adalah generalisasi invers Moore-Penrose dari
output hidden layer (matrik H). Aturan dari Moore-
Penrose yaitu : H ●𝐻ϯ ●H= H
IV. HASIL EKSPERIMEN
4.1 DataSet
Jenis data yang digunakan pada penelitian ini yaitu citra digital daun tanaman yang diperoleh dari
public database http://flavia.sourceforge.net. Data citra daun tanaman memiliki ukuran 500 x 375 piksel dengan format RGB (red, green, blue) sebanyak 32 kelas tanaman dengan jumlah data setiap kelasnya bervariasi. Total keseluruhan data yaitu 1798 citra daun tanaman. Citra daun tanaman yang digunakan dalam penelitian ini merupakan citra asli (original) tanpa pre-proses. Format citra yang digunakan berupa *.jpg. Gambar 2 merupakan contoh data citra daun tanaman yang digunakan dalam penelitian ini.
Gambar 2. Citra Daun Tanaman
4.2 Hasil
Eksperimen menggunakan data sekunder sebanyak 1.797 citra daun tanaman dari 32 kelas yang berbeda. Keseluruhan data dibagi menjadi dua kelompok yakni data latih dan data uji. Pembagian data latih dan data uji dibagi secara bervariasi. 10 % data latih dan 90% data uji, 30% data latih dan 70% data uji, 50% data latih dan 50% data uji, 70% data latih dan 30% data uji dan 90% data latih dan 10% data uji, masing-masing untuk eksperimen I, II, III, IV, dan V secara berurutan. Selain itu juga dilakukan eksperimen dengan menggunakan 100% data latih dan mengambil 10 citra daun dari masing-masing kelas yang digunakan untuk data uji.
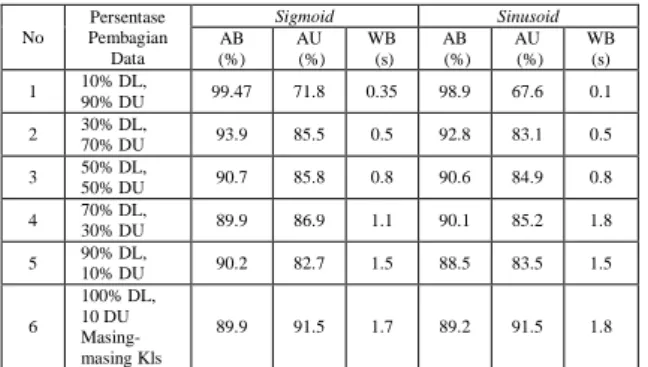
Tabel 1. Hasil eksperimen dengan data latih dan data uji yang bervariasi
No Persentase Pembagian Data Sigmoid Sinusoid AB (%) AU (%) WB (s) AB (%) AU (%) WB (s) 1 10% DL, 90% DU 99.47 71.8 0.35 98.9 67.6 0.1 2 30% DL, 70% DU 93.9 85.5 0.5 92.8 83.1 0.5 3 50% DL, 50% DU 90.7 85.8 0.8 90.6 84.9 0.8 4 70% DL, 30% DU 89.9 86.9 1.1 90.1 85.2 1.8 5 90% DL, 10% DU 90.2 82.7 1.5 88.5 83.5 1.5 6 100% DL, 10 DU Masing-masing Kls 89.9 91.5 1.7 89.2 91.5 1.8 Keterangan:
DL: Data Latih, DU: Data Uji, AB: Akurasi Pembelajaran, AU: Akurasi Pengujian, WB: Waktu Pelatihan.
Pembagian data dilakukan untuk melihat tingkat akurasi dari setiap jumlah data yang berbeda dengan fungsi aktivasi sigmoid dan sinusoid. Persentase akurasi dalam pembelajaran dan pengujian ditunjukkan dengan hasil klasifikasi yang benar untuk setiap data citra yang dilatih atau diuji ke dalam kelas tanaman yang sesuai, berbanding dengan jumlah data latih atau data uji yang ditetapkan. Tabel 1 menunjukkan hasil akurasi pembelajaran dan pengujian data citra daun tanaman dengan nilai hidden node 95.
Salah satu atribut yang memengaruhi akurasi pembelajaran dan pengujian JST adalah jumlah
hidden node yang ditetapkan. Tabel 2 menunjukkan
hasil percobaan dengan jumlah hidden node yang bervariasi.
Tabel 2. Eksperimen dengan pada hidden node
4.3 Analisis dan Pembahasan
Pada percobaan yang dilakukan terdapat beberapa mekanisme pengujian klasifikasi citra daun tanaman menggunakan metode JST-ELM. Untuk mekanisme yang pertama dilakukan percobaan dengan menggunakan pembagian data
latih dan data uji yang berbeda serta menggunakan fungsi aktivasi yang berbeda. Fungsi aktivasi yang digunakan adalah sigmoid dan sinusoid. Dari percobaan yang telah dilakukan didapat nilai akurasi dan waktu pembelajaran. Gambar 3 memperlihatkan grafik hasil dari percobaan yang telah dilakukan.
Gambar 3. Grafik hasil eksperimen dengan variasi jumlah data
Gambar 3 menunjukkan hasil berupa nilai akurasi yang didapatkan sesuai dengan jumlah pembagian data yang telah dilakukan. Pada percobaan menggunakan fungsi aktivasi sigmoid biner dengan pembagian data latih dan data uji 10% dan 90% didapatkan nilai akurasi pembelajaran sebesar 99.4% dan nilai akurasi pengujian sebesar 71.75%. Pada pembagian data 30% dan 70% mengalami penurunan nilai akurasi pembelajaran sebesar 93.9 % namun mengalami kenaikan nilai akurasi pengujian sebesar 85.5%. Pada percobaan selanjutnya pada pembagian data 50% - 50% , 70% - 30% dan 90 % - 10 % mengalami penurunan akurasi pembelajaran 90.7% dan 89.9% serta mengalami kenaikan pada nilai akurasi pengujian data uji sebesar 85.8 % dan 86.9 %, namun sedikit penurunan pada pelatihan 90% - 10% yaitu 90.2% dan pengujian 82.7 %. Selain semua hasil yang telah dijelaskan terdapat eksperimen tambahan yang menggunakan 100 % data untuk pelatihan dan mengambil 10 data dari masing-masing 32 kelas. Hasil akurasi pembelajaran dari eksperimen ini yaitu 89.9% dan akurasi pengujian sebesar 91.5 %. Berbeda pada mekanisme percobaan menggunakan fungsi aktivasi sinusoid mendapatkan nilai akurasi yang lebih tinggi dari fungsi aktivasi
sigmoid biner. Dari beberapa percobaan menggunakan persentase data latih dan data uji yang berbeda didapatkan nilai akurasi pembelajaran secara berurutan sebesar 98.9%, 92.8%, 90.6%, 90.1%, 88.5% dan 91.5 % serta nilai akurasi pengujian sebesar 67.6%, 83.1%, 84.9%, 85.2%, 83.5% dan 91.5%. Dari nilai yang didapat menunjukkan bahwa semakin banyak jumlah sampel data latih akan meningkatkan nilai akurasi pembelajarannya. Selain jumlah sampel data masukan yang memengaruhi nilai akurasi pembelajaran pemilihan fungsi aktivasi juga memengaruhi nilai akurasinya.
Gambar 4. Grafik eksperimen dengan variasi
hidden node
Pada mekanisme percobaan selanjutnya menggunakan pembagian data latih dan data uji 30% - 70% dengan menggunakan fungsi aktivasi sinusoid sebesar 90 dan nilai hidden node yang bervariasi (lihat Tabel 2). Penggunaan nilai hidden
node yang bervariasi bertujuan untuk melihat
pengaruh jumlah nilai hidden node pada tingkat akurasi pembelajaran dan pengujian dari metode JST ELM.
Gambar 4 menunjukkan grafik hasil percobaan menggunakan nilai hidden node yang bervariasi. Akurasi pembelajaran mengalami kenaikan saat ditingkatkan nilai hidden node mulai dari 30, 35, 40, 45 dan 50 namun mengalami penurunan pada nilai hidden node 55 dan mengalami kenaikan pada nilai hidden node selanjutnya. Hal yang serupa juga terjadi pada akurasi pengujian. Nilai akurasi tertinggi didapat saat nilai hidden node 130 sebesar 92.9% untuk akurasi pembelajaran dan 88,9% untuk akurasi pengujian. Semakin tinggi nilai
hidden node maka akan meningkatkan nilai akurasi.
V. KESIMPULAN
Berdasarkan hasil pengujian terhadap data uji citra daun tanaman dapat disimpulkan bahwa klasifikasi citra daun tanaman menggunakan metode JST-ELM berhasil dilakukan dengan nilai akurasi pembelajaran 92,9 % dan akurasi pengujian sebesar 88,9%.
Hasil pengujian ditentukan oleh banyaknya data latih yang digunakan. Semakin banyak data latih maka akan meningkatkan nilai akurasi pengujiannya.
Penentuan jumlah hidden node berpengaruh besar dalam menghasilkan nilai akurasi. Hasil eksperimen menunjukkan bahwa nilai hidden node sebesar 130 menghasilkan nilai akurasi terbaik. Referensi
[1] Kamavisdar, P., Saluja, S., & Agrawal, S. “A Survey on Image Classification Approaches and Techniques”. International Journal of
Advanced Research in Computer and Communication Engineering, 2(1), 2013.
[2] Lu, D., & Weng, Q. “A Survey Of Image Classification Methods And Techniques For Improving Classification Performance”.
International journal of Remote sensing, 28(5), 823-870, 2007.
[3] Huang, G. B., Zhu, Q. Y., & Siew, C. K. “Extreme Learning Machine: Theory and Applications”. Neurocomputing, 70(1), 489-501, 2006.
[4] Zhai, C. M., & Du, J. X. “Applying Extreme Learning Machine to Plant Species Identification”. In Information and Automation. ICIA 2008. International Conference on (pp. 879-884), IEEE, 2008. [5] Wu, S. G., Bao, F. S., Xu, E. Y., Wang, Y. X.,
Chang, Y. F., & Xiang, Q. L. “A Leaf Recognition Algorithm for Plant Classification Using Probabilistic Neural Network”. In Signal Processing and Information Technology, IEEE International Symposium on (pp. 11-16), 2007.
[6] Shabanzade, M., Zahedi, M., & Aghvami, S. A. “Combination of Local Descriptors and Global Features for Leaf Recognition”. Signal and Image Processing: An International Journal (SIPIJ). v2 i3, 23-31, 2011.
[7] Kanan C, Cottrell GW. “Color-to-Grayscale: Does the Method Matter in Image Recognition?”. PLoS ONE 7(1): e29740. doi:10.1371/journal.pone.0029740, 2012. [8] Mokji, M. M., & Abu Bakar, S. A. R. “Gray
Level Co-Occurrence Matrix Computation Based On Haar Wavelet”. In Computer
Graphics, Imaging and Visualisation, 2007. CGIV'07 (pp. 273-279). IEEE.
[9] Zhang, G. P. (Ed.). “Neural Networks In Business Forecasting”. IGI Global, 2004. [10] Fu, L. M. “Neural Networks In Computer
Intelligence”. Tata McGraw-Hill Education, 1994.
[11] Huang, G. B., Wang, D. H., & Lan, Y. “Extreme Learning Machines: a survey”. International Journal of Machine Learning and Cybernetics, 2(2), 107-122, 2011.
[12] Jabal, M.F., Hamid, S., Shuib, S., & Ahmad, I. “Leaf Features Extraction and Recognition Approaches To Classify Plant”. Journal of Computer Science, 9(10), 1295, 2013.
[13] Sangeetha, S., & Radha, N. “A New Frame-work for IRIS and Fingerprint Recognition using SVM Classification and Extreme Learning Machine based on Score Level Fusion”. Intelligent System and Control (ISCO), 2013 7th International Conference (pp. 183-188) IEEE, 2013.
[14] Sole, M.M., & Tsoeu, M.S. “Sign Language Recognition using the Extreme Learning Machine”. In AFRICON, (pp. 1- 6) IEEE, 2011.