PENGELOMPOKAN MAHASISWA BERDASARKAN NILAI UJIAN
NASIONAL DAN IPK MENGGUNAKAN METODE K-MEANS
Hartatik
STMIK Amikom
Manajemen Informatika STMIK AMIKOM Yogyakarta Jl. Ringroad Utara, Condong Catur, Depok, Sleman, Yogyakarta
E-mail : [email protected]
Abstrak
Seleksi mahasiswa baru di STMIK AMIKOM Yogyakarta dilakukan lewat 2 cara yaitu seleksi penerimaan mahasiswa baru dengan ujian tertulis dan seleksi penerimaan mahasiswa baru berprestasi (PJ2AB). Pembeda antara tes tertulis dan tes PJ2AB adalah nilai UN calon mahasiswa. Mahasiswa yang memiliki nilai ujian nasional (UN) lebih dari 7,5 akan mengikuti tes PJ2AB yang berupa wawancara langsung. Namun bagi calon mahasiswa yang memiliki nilai ujian nasional kurang dari 7,5 wajib mengikuti tes tertulis. Diharapkan calon mahasiswa yang mengikuti seleksi PJ2AB akan memiliki prestasi dan nilai akademik yang lebih baik dibandingkan mahasiswa yang mengikuti ujian tertulis. Namun pada kenyataannya, didapatkan beberapa mahasiswa yang mengikuti tes seleksi masuk melalui jalur PJ2AB tidak memiliki IPK yang lebih baik dibandingkan dengan mahasiswa yang mengikuti tes seleksi masuk melalui tes tertulis. K-Means merupakan salah satu algoritma dalam data mining yang bisa digunakan untuk melakukan pengelompokan/clustering suatu data. Parameter yang digunakan sebagai inputan pada kasus ini ada 2 yaitu tes seleksi masuk dan nilai ujian nasional mahasiswa. Metode K-Means akan membagi mahasiswa STMIK AMIKOM Yogyakarta kedalam n cluster sehingga akan didapatkan pola pengelompokan yang diharapkan dapat memperlihatkan asosiasi antara tes masuk dan IPK mahasiswa STMIK AMIKOM Yogyakarta.
Kata Kunci : Tes seleksi masuk, IPK, clustering, K-Means
1. Pendahuluan
STMIK AMIKOM Yogyakarta adalah salah satu perguruan tinggi swasta di kota Yogyakarta. Setiap tahunnya, STMIK AMIKOM Yogyakarta menerima kurang lebih 2500 mahasiswa. Seleksi yang diterapkan oleh STMIK AMIKOM Yogyakarta untuk dapat menyeleksi kandidat mahasiswa baru yang potensial dilakukan lewat 2 cara yaitu tes tertulis dan tes seleksi penerimaan mahasiswa baru lewat wawancara yang sering disebut jalur PJ2AB (Jalur Penelusuran Prestasi Akademik dan Bakat). Tes tertulis adalah seleksi masuk yang diikuti oleh calon mahasiswa yang memiliki nilai UN (Ujian Nasional) kurang dari 2,75. Tes ini terdiri dari pertanyaan-pertanyaan umum (psikotes dan tes akademik) yang harus dijawab oleh peserta atau calon mahasiswa dengan waktu maksimal 100 menit. Peserta tes akan dinyatakan lulus jika mampu menjawab pertanyaan dengan benar lebih dari 50% dari jumlah soal yang tersedia.
JP2AB (Jalur Penelusuran Prestasi Akademik dan Bakat) adalah ujian masuk yang diselenggarakan untuk menyaring calon mahasiswa yang memiliki prestasi akademik (dibuktikan dengan nilai UN lebih dari 2,75) dan bakat (seni, olahraga dan IPTEK). Mahasiswa
yang mengikuti jalur ini akan mengikuti tes berupa wawancara langsung.
Secara sekilas, yang menjadi pembeda antara tes tertulis dan tes jalur PJ2AB adalah nilai UN. Diharapkan calon mahasiswa yang mengikuti seleksi PJ2AB akan memiliki prestasi dan nilai akademik yang lebih baik dibandingkan mahasiswa yang mengikuti ujian tertulis.
Menurut penelitian yang dilakukan oleh Suparyoko (1997), dilihat dari dimensi prediksi, proses seleksi masuk menggunakan nilai UN agak sullit dipertanggungjawabkan. Alasannya, nilai UN lebih mengacu pada kurikulum SMU, bukan mengacu pada kurikulum perguruan tinggi. Ada kesangsian pada dimensi efektivitas prediksi yang menjadikan nilai UN sebagai penentu utama kelulusan tes masuk perguruan tinggi. Untuk melihat asosiasi antara nilai UN (Ujian Nasional) dan IPK (indeks prestasi kumulatif) mahasiswa digunakanlah algoritma K-Means. Dengan algoritma K-Means diharapkan dapat diketahui pola pengelompokan mahasiswa STMIK AMIKOM Yogyakarta berdasarkan kedua parameter tersebut.
Data, informasi dan pengetahuan memiliki peranan dan nilai yang penting dalam berbagai aktivitas manusia. Data mining adalah proses penemuan suatu pengetahuan dengan menganalisis sejumlah besar data dari berbagai
perspektif dan meringkasnya menjadi suatu informasi. Pentingnya pencarian pengetahuan/informasi dari suatu data yang berukuran besar membuat data mining menjadi komponen yang penting dalam mengekstrak suatu pengetahuan yang dapat berguna dalam suatu sistem. Pada penelitian yang dilakukan oleh Chuchra (2012), disebutkan bahwa data mining dapat digunakan untuk mengevaluasi kinerja siswa. Dengan menggunakan algoritma yang ada dalam data mining, dicoba untuk mengekstrak pengetahuan yang bisa menggambarkan kinerja siswa pada akhir semester. Hasil ekstraksi ini dapat digunakan untuk membantu dalam mengidentifikasi siswa yang mungkin akan putus sekolah dan membantu siswa yang membutuhkan perhatian khusus serta mengantisipasi keadaan tersebut dengan memberikan seorang profesor yang tepat untuk membantu menasehati dan membimbing para siswa.
Penelitian yang dilakukan oleh Tiwari, Singh dan Vimal (2013), menyebutkan bahwa institusi pendidikan adalah bagian penting dalam masyarakat dan memainkan peranan yang penting dalam pertumbuhan dan pembangunan suatu bangsa. Selain itu institusi pendidikan juga berperan untuk mengontrol dan melakukan evaluasi serta prediksi prestasi akademik siswanya. Prestasi akademik siswa dapat didasarkan pada berbagai faktor seperti kepribadian, lingkungan sosial serta psikologi dari siswa tersebut. Educational data mining mengimplementasikan algoritma data mining untuk menemukan pengetahuan dari data yang berasal dari domain pendidikan. Hasil penelitian ini menyebutkan bahwa data mining dapat digunakan sebagai tool pengambilan suatu keputusan yang dapat menemukan suatu pengetahuan dari sejumlah besar data yang bisa digunakan dalam menilai prestasi siswa.
2. Metode Penelitian
Penelitian yang diusulkan ini menggunakan data primer, dengan respondennya adalah mahasiswa jurusan S1. Teknik Informatika STMIK AMIKOM Yogyakarta angkatan 2011 dan 2012. Pengumpulan data dilakukan melalui kuisioner yang dibagikan langsung kepada mahasiswa. Dalam kuisioner ini, mahasiswa diminta untuk mengisikan nim, nama, asal SLTA/sederajat, tes seleksi yang pernah diikuti ketika hendak mendaftar menjadi calon mahasiswa STMIK AMIKOM Yogyakarta dan IPK terakhir yang diperoleh.
Parameter yang digunakan untuk melakukan pengelompokan mahasiswa terdiri dari 2 yaitu :
1. IPK
IPK dihitung dengan menjumlahkan indeks prestasi (IP) yang didapat pada tiap semester dibagi dengan jumlah semester yang telah dilewati.
2. Tes seleksi masuk
Setelah data dikumpulkan, tahapan selanjutnya adalah studi literatur. Pada tahap ini dipelajari berbagai macam referensi tentang data mining dan metode K-Means baik melalui jurnal penelitian, buku-buku teori, tutorial, dan sumber-sumber lain termasuk internet. Berdasarkan beberapa literatur, untuk melakukan clustering menggunakan metode k-means ada beberapa langkah yang harus dilakukan :
Berdasarkan beberapa buku Witten, Ian dan Frank (2005), untuk melakukan clustering menggunakan metode k-means ada beberapa langkah yang harus dilakukan :
1. Langkah pertama yang dilakukan adalah menentukan jumlah k cluster yang diinginkan sebagai centroid awal. Algoritma k-means membutuhkan parameter input sebanyak k dan membagi sekumpulan n objek kedalam k cluster sehingga tingkat kemiripan antar anggota dalam satu cluster tinggi sedangkan tingkat kemiripan dengan anggota pada cluster lain sangat rendah. Kemiripan anggota terhadap cluster diukur dengan kedekatan objek terhadap nilai mean pada cluster atau dapat disebut sebagai centroid cluster atau pusat massa. Rumus pengukuran jarak dapat dihitung menggunakan rumus 1 (Santosa, 2007) :
2. Langkah yang kedua adalah melakukan clustering obyek dengan memasukkan setiap obyek ke dalam cluster (grup) berdasarkan jarak minimumnya. Suatu data akan menjadi anggota dari suatu cluster (C1, C2 maupun C3) bila memiliki jarak terkecil dari pusat cluster-nya.
3. Langkah ketiga adalah menghitung pusat cluster baru. Pusat cluster yang baru ditentukan berdasarkan pengelompokan anggota masing-masing cluster. Pusat cluster baru diperoleh dari rata – rata semua data/objek dalam cluster.
4. Langkah yang keempat dilakukan dengan mengulangi iterasi yang dimulai dari langkah 1, sehingga cluster yang baru memiliki angka yang tetap (tidak mengalami perubahan).
3. Hasil Dan Pembahasan
Sample yang digunakan berjumlah 40 orang dari berbagai angkatan. Tabel 1
menunjukkan data mahasiswa yang dijadikan sample data.
Tabel 1. Data sampling
NIM IP UN 06.11.1009 3 7.6 11.11.5115 3.83 7 11.11.5076 3.75 6.5 11.11.5100 3 6.25 11.11.5101 1.92 7 11.11.5099 3.6 7.05 11.11.5081 1.5 6.75 11.11.5121 2.98 6.8 11.11.5090 3.33 7 11.11.5113 3.75 7.1 11.11.5108 3.75 7.5 11.11.5126 3 8 12.11.6403 2 8.5 06.11.1010 3 7 11.11.5093 3.54 6.5 11.11.5085 3.67 6.4 11.11.5117 3.45 6 11.11.5080 3 6.8 11.11.5131 2.48 6.9 11.11.5071 3.71 5.5 12.11.5749 2 6 12.11.5851 2 6.5 11.11.5079 3.25 6.7 11.11.5256 3.54 6.4 11.11.5266 3.75 7.8 11.11.5213 3.58 7.9 11.11.5129 3 7.5 11.11.5114 3.75 7 12.02.8188 4 6.5 11.11.5123 3.5 6.8 11.11.5126 3.5 6.4 11.11.5130 3.3 6.2 11.11.5112 3.67 7.9 11.11.5180 3.5 8 11.11.5065 2.75 6.7 11.11.5072 3.67 6.6 11.11.5092 3.46 7.5 11.11.5110 3.6 7 11.11.5125 3.55 6.6 11.11.5270 3.79 6.5
Data sampling pada tabel 1 dilakukan pengelompokan menggunakan algoritma K-Means. Langkah-langkah yang dilakukan untuk melakukan pengelompokan adalah :
Iterasi pertama
Menentukan jumlah k kluster yang diinginkan sebagai centroid awal. Pada penelitian ini kluster yang dibuat sebanyak 3 buah seperti yang ditunjukkan pada tabel 2.
Tabel 2. Centroid Awal
Pusat Kluster
1.5 5
2.5 6
3.5 7
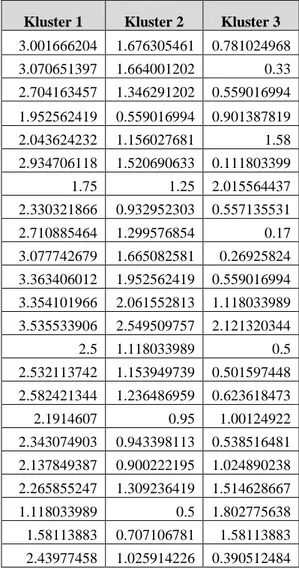
Mengukur kedekatan objek terhadap nilai mean pada kluster atau dapat disebut sebagai centroid kluster atau pusat massa dengan menggunakan rumus 1. Hasil pengukuran ini dapat dilihat pada tabel 3.
Tabel 3. Centroid Kluster pada iterasi yang pertama
Kluster 1 Kluster 2 Kluster 3
3.001666204 1.676305461 0.781024968 3.070651397 1.664001202 0.33 2.704163457 1.346291202 0.559016994 1.952562419 0.559016994 0.901387819 2.043624232 1.156027681 1.58 2.934706118 1.520690633 0.111803399 1.75 1.25 2.015564437 2.330321866 0.932952303 0.557135531 2.710885464 1.299576854 0.17 3.077742679 1.665082581 0.26925824 3.363406012 1.952562419 0.559016994 3.354101966 2.061552813 1.118033989 3.535533906 2.549509757 2.121320344 2.5 1.118033989 0.5 2.532113742 1.153949739 0.501597448 2.582421344 1.236486959 0.623618473 2.1914607 0.95 1.00124922 2.343074903 0.943398113 0.538516481 2.137849387 0.900222195 1.024890238 2.265855247 1.309236419 1.514628667 1.118033989 0.5 1.802775638 1.58113883 0.707106781 1.58113883 2.43977458 1.025914226 0.390512484
2.474186735 1.114271062 0.601331855 3.592005011 2.1914607 0.838152731 3.568809325 2.185497655 0.90354856 2.915475947 1.58113883 0.707106781 3.010398645 1.600781059 0.25 2.915475947 1.58113883 0.707106781 2.690724809 1.280624847 0.2 2.441311123 1.077032961 0.6 2.163330765 0.824621125 0.824621125 3.622002209 2.231344886 0.915914843 3.605551275 2.236067977 1 2.110094785 0.743303437 0.807774721 2.696089761 1.31487642 0.434626276 3.176727876 1.78089865 0.501597448 2.9 1.486606875 0.1 2.600480725 1.209338662 0.403112887 2.737535388 1.383510029 0.578013841 Langkah selanjutnya adalah melakukan clustering objek sehingga didapatkan data clustering yang baru. Hasil clustering pada iterasi yang pertama dapat dilihat dengan tabel 4.
Tabel 4. Data clustering baru pada iterasi yang pertama
Pusat Cluster Baru
0 0
2.611 6.38 3.439032 7.066129
Langkah selanjutnya adalah mengulangi iterasi yang dimulai dari langkah 1, sehingga cluster yang baru memiliki angka yang tetap (tidak mengalami perubahan).
Iterasi Kedua
Langkah pertama pada iterasi kedua adalah menentukan jumlah k cluster berdasarkan hasil pada iterasi yang pertama. Cluster awal pada iterasi yang kedua sama dengan tabel 4.
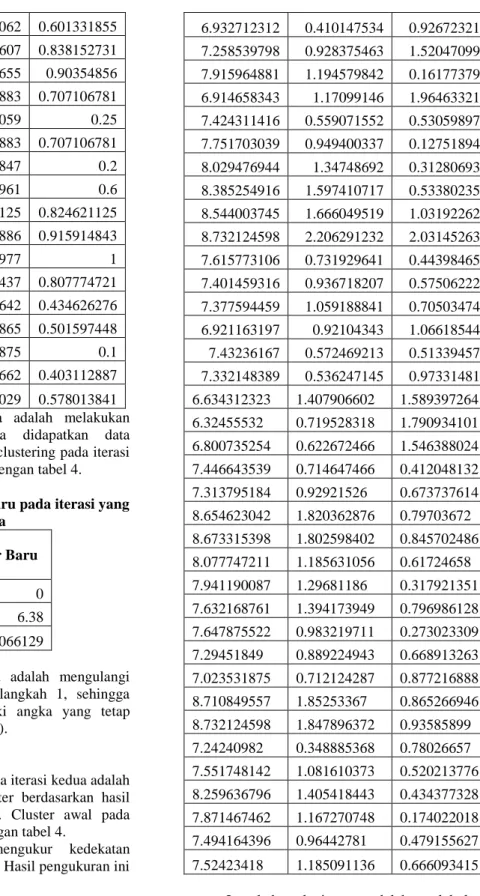
Langkah kedua mengukur kedekatan objek terhadap nilai mean. Hasil pengukuran ini dapat dilihat pada tabel 5.
Tabel 5. Centroid Cluster pada iterasi yang kedua
Cluster 1 Cluster 2 Cluster 3
8.170679286 1.280515912 0.691207302 7.979279416 1.367611421 0.3965209 7.50416551 1.14530389 0.645912546 6.932712312 0.410147534 0.926723217 7.258539798 0.928375463 1.520470996 7.915964881 1.194579842 0.161773792 6.914658343 1.17099146 1.964633213 7.424311416 0.559071552 0.530598978 7.751703039 0.949400337 0.127518948 8.029476944 1.34748692 0.312806936 8.385254916 1.597410717 0.533802354 8.544003745 1.666049519 1.031922627 8.732124598 2.206291232 2.031452631 7.615773106 0.731929641 0.443984653 7.401459316 0.936718207 0.575062228 7.377594459 1.059188841 0.705034741 6.921163197 0.92104343 1.066185446 7.43236167 0.572469213 0.513394571 7.332148389 0.536247145 0.973314814 6.634312323 1.407906602 1.589397264 6.32455532 0.719528318 1.790934101 6.800735254 0.622672466 1.546388024 7.446643539 0.714647466 0.412048132 7.313795184 0.92921526 0.673737614 8.654623042 1.820362876 0.79703672 8.673315398 1.802598402 0.845702486 8.077747211 1.185631056 0.61724658 7.941190087 1.29681186 0.317921351 7.632168761 1.394173949 0.796986128 7.647875522 0.983219711 0.273023309 7.29451849 0.889224943 0.668913263 7.023531875 0.712124287 0.877216888 8.710849557 1.85253367 0.865266946 8.732124598 1.847896372 0.93585899 7.24240982 0.348885368 0.78026657 7.551748142 1.081610373 0.520213776 8.259636796 1.405418443 0.434377328 7.871467462 1.167270748 0.174022018 7.494164396 0.96442781 0.479155627 7.52423418 1.185091136 0.666093415
Langkah selanjutnya adalah melakukan clustering objek sehingga didapatkan data clustering yang baru. Hasil clustering pada iterasi yang pertama dapat dilihat dengan tabel 6.
Tabel 6. Data clustering baru pada iterasi yang kedua
Pusat Cluster Baru
0 0
2.611 6.38 3.443667 7.095
Langkah keempat adalah membandingkan hasil pengelompokan/cluster pada iterasi yang pertama dan iterasi yang kedua. Jika hasil clustering sama maka kita sudah mendapatkan cluster yang benar. Jika tidak dilanjutkan ke iterasi yang ketiga.
Iterasi ketiga
Langkah pertama pada iterasi ketiga adalah menentukan jumlah k cluster berdasarkan hasil pada iterasi yang kedua. Cluster awal pada iterasi yang tiga sama dengan tabel 6.
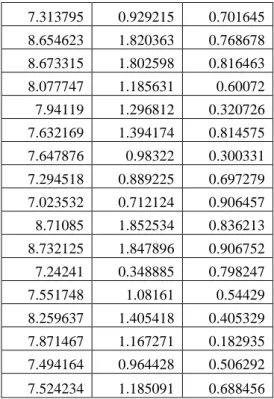
Langkah kedua mengukur kedekatan objek terhadap nilai mean. Hasil pengukuran ini dapat dilihat pada tabel 7.
Tabel 7. Centroid Cluster pada iterasi yang ketiga
Cluster 1 Cluster 2 Cluster 3
8.170679 1.280516 0.672209 7.979279 1.367611 0.397842 7.504166 1.145304 0.669227 6.932712 0.410148 0.954393 7.25854 0.928375 1.526625 7.915965 1.19458 0.162681 6.914658 1.170991 1.974048 7.424311 0.559072 0.549556 7.751703 0.9494 0.148139 8.029477 1.347487 0.306374 8.385255 1.597411 0.507804 8.544004 1.66605 1.007901 8.732125 2.206291 2.014497 7.615773 0.73193 0.453724 7.401459 0.936718 0.602748 7.377594 1.059189 0.730925 6.921163 0.921043 1.095018 7.432362 0.572469 0.53279 7.332148 0.536247 0.983198 6.634312 1.407907 1.617083 6.324555 0.719528 1.81196 6.800735 0.622672 1.561473 7.446644 0.714647 0.439922 7.313795 0.929215 0.701645 8.654623 1.820363 0.768678 8.673315 1.802598 0.816463 8.077747 1.185631 0.60072 7.94119 1.296812 0.320726 7.632169 1.394174 0.814575 7.647876 0.98322 0.300331 7.294518 0.889225 0.697279 7.023532 0.712124 0.906457 8.71085 1.852534 0.836213 8.732125 1.847896 0.906752 7.24241 0.348885 0.798247 7.551748 1.08161 0.54429 8.259637 1.405418 0.405329 7.871467 1.167271 0.182935 7.494164 0.964428 0.506292 7.524234 1.185091 0.688456
Langkah selanjutnya adalah melakukan clustering objek sehingga didapatkan data clustering yang baru. Hasil clustering pada iterasi yang pertama dapat dilihat dengan tabel 8.
Tabel 8. Data clustering baru pada iterasi yang ketiga
Pusat Cluster
0 0
2.611 6.38 3.443667 7.095
Langkah keempat adalah
membandingkan hasil pengelompokan/cluster pada iterasi yang pertama dan iterasi yang kedua. Hasil cluster kedua dan ketiga sama, sehingga kita sudah mendapat nilai cluster yang tetap/stabil.
Kebutuhan Fungsional
Perangkat lunak yang dibangun memiliki kebutuhan fungsional sebagai berikut :
1. Sistem dapat memasukkan data mahasiswa yang akan di cluster
2. Sistem dapat memasukkan parameter-parameter
3. Sistem dapat memasukkan nilai IPK dan UN untuk masing-masing mahasiswa
4. Sistem dapat melakukan pengelompokan data mahasiswa yang telah diinputkan.
Use Case Diagram
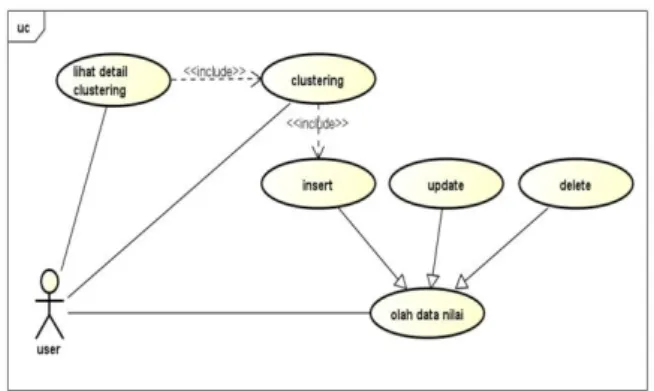
Kebutuhan fungsional tersebut lalu dituangkan ke dalam diagram use case. Diagram use case dapat dilihat pada gambar 1.
Gambar 1. Diagram use case clustering
4. Kesimpulan
Kesimpulan dari penelitian ini adalah bahwa metode K-Means dapat digunakan untuk melakukan pengelompokan atau peng-cluster-an mahasiswa berdasarkan dua parameter yaitu IPK dan nilai UN mahasiswa tersebut ketika lulus SMU. Namun berdasarkan hasil yang didapatkan dengan sample 40 orang mahasiswa belum didapatkan nilai cluster yang bisa mewakili pengelompokan mahasiswa STMIK Amikom Yogyakarta secara keseluruhan. Hasil cluster sementara yang didapatkan adalah {0 ; 0} untuk cluster yang pertama, {2,611 ; 6,38} untuk cluster yang kedua dan {3,44 ; 7,095} untuk cluster yang ketiga. Jarak antara cluster yang pertama dan kedua terlalu jauh sedangkan jarak antara cluster yang kedua dan ketiga relatif terlalu dekat. Dari nilai cluster yang didapatkan, bisa disimpulkan bahwa nilai UN tidak menjamin seseorang akan mempunyai nilai IPK yang relatif tinggi.
5. Saran
Untuk mendapatkan hasil yang lebih akurat, sample yang digunakan perlu ditambahkan setidaknya 10% dari jumlah mahasiswa STMIK Amikom Yogyakarta agar didapatkan nilai cluster yang benar-benar bisa mewakili kondisi sebenarnya.
Daftar Pustaka
[1]. Chuchra, Rimmy., 2012, Use of Data Mining Techniques for The Evaluation of Student Performance : A Case Study, International Journal of Computer Science and Management Research, Vol 1.
[2]. Santosa, Budi., 2007, Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis, Graha Ilmu.
[3]. Supriyoko, Ki., 23 Juni 1997, Sistem Seleksi Masuk Perguruan Tinggi 1 dan 2, Surat Kabar Pikiran Rakyat.
[4]. Tiwari, M., Singh, R., Vimal, N., 2013, An Empirical Study of Data Mining Techniques for Predicting Student Performance in Higher Education, IJCSMC, Vol. 2, Issue 2. [5]. Witten, Ian H., Frank, Eibe., 2005, Data
Mining Practical Machine Learning Tools and Techniques, Second Edition, Morgan Kaufmann, San Francisco.