BAB 3
METODOLOGI PENELITIAN
3.1. Pendahuluan
Metodologi penelitian ini digunakan untuk mendapatkan hasil sesuai dengan yang diharapkan. Penelitian ini berdasarkan referensi dari penelitain yang telah dilakukan oleh Mardiani yang membahas mengenai perbandingan algoritma K-Means dan EM untuk clusterisasi nilai mahasiswa berdasrkan asal sekolah dan penelitian yang telah dilakukan oleh Ni Made et al mengenai clustering DBSCAN dalam proses sistem pengambilan keputusan. Oleh karena itu, dalam penelitian ini peneliti akan melakukan pengujian kinerja metode DBSCAN dan K-Means dalam sistem pendukung keputusan, serta sebagai metode kalsifikasi yaitu rule-based classification dalam pengelompokan data yang berbeda dengan menggunakan metode yang berbeda pula untuk mengelompokan data siswa dalam penentuan jurusan pada sekolah menengah kejuruan.
kedua metode tersebut yang akan menunjukan metode tersebut optimal dalam pengelompokannya, yaitu dengan menggunakan pengujian statistik nonparametrik.
Berdasarkan hal tersebut, peneliti akan melakukan penelitian pada salah satu sekolah menengah kejuruan. Objek penelitian ini adalah seluruh SMK yang berada di kota Medan provinsi Sumatera Utara. Dari seluruh sekolah menengah kejuruan, peneliti akan mengambil sample penelitian yaitu sekolah menengah kejuruan swasta medan area-1. Penelitian ini akan dilakukan dengan menggunakan metode yang telah dipaparkan sebelumnya berupa metode DBSCAN dan K-Means.
3.2.Lingkungan penelitian
Cluster merupakan metodologi untuk klasifikasi data secara otomatis menjadi beberapa kelompok dengan menggunakan ukuran asosiasi, sehingga data yang sama berada dalam satu kelompok yang sama dan data yang berbeda berada dalam kelompok data yang tidak sama. Dalam cluster terdapat dua metode berdasarkan partisinya yaitu DBSCAN (Density-Based Spatial Clustering Of Applications with Noise) dan K-Means. Pada metode DBSCAN data akan dikelompokan sesuai tingkat kepadatan data yang memiliki noise dalam setiap data. Sedangkan pada K-Means data akan dikelompokan sesuai rata-rata data ke dalam suatu kelompok yang sama apabila data yang ada adalah data yang sama dan data yang berbeda akan dikelompokan di kelompok lain.
3.3.Teknik Pengembangan
komputasi tambahan. Untuk itu pada penelitian ini, penulis akan menggunakan dua metode tersebut untuk diterapkan pada data yang sama, sehingga data tersebut akan dapat diketahui keefektifan data yang lebih baik.
3.4.Rancangan Penelitian
Untuk rancangan kerja penelitian ini akan dilakukan analisis terhadap data yang akan diinputkan ke dalam metode yang digunakan pada penelitian ini. Dimana untuk tahap pertama adalah mengambil data yang akan diteliti dan kemudian data tersebut diuji dengan mengolah data untuk dikelompokan sesuai karakteristiknya dengan menggunakan metode K-Means. Setelah mendapat kelompok data dengan K-Means, kemudian pengelompokkan data akan diuji dengan menggunakan metode DBSCAN dengan proses yang berbeda, kemudian pengujian data dengan kedua metode tersebut K-Means dan DBSCAN. Untuk data yang tidak besar, penyelesaiannya dapat menggunakan rule-based classification untuk pengujiannya. Untuk lebih jelas dapat dilihat pada gambar 3.1 berikut.
Analisis data Pengambilan data Pengelompokan data sesuai kriteria
3.5.1. Analisis dan Pengambilan Data
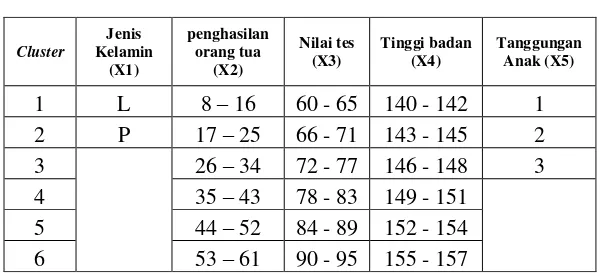
telah mendaftar di sekolah menengah kejuruan. Data sampel tersebut berisi nomor pendaftaran siswa, nama, usia, jenis kelamin, pekerjaan orang tua, penghasilan orang tua, hasil nilai tes, tinggi badan calon siswa dan tanggungan anak orang tua. Dalam hal ini, peneliti akan mengambil beberapa kriteria dari data sampel tersebut untuk dilakukan pengelompokan data berikutnya yaitu jenis kelamin, pekerjaan orang tua, penghasilan orang tua, hasil nilai tes, tinggi badan calon siswa dan tanggungan anak orang tua.
Sebelum data sampel dikelompokan maka data awal akan diubah menjadi data interval agar data mudah digunakan dalam pengelompokan. Setelah data diintervalkan maka selanjutnya dilakukan penginisialisasian pada setiap data.
Tabel 3.1 Inisialisasi Data
3.5.2. Pengelompokan Data Sesuai Kriteria
R1: IF X1=1 OR 2 AND X2=1 AND X3=1 AND X4=1 AND X5=1 THEN tidak lulus
Algoritma DBSCAN digunakan pada spatial database yang memuat noise. Density dari objek Ɵdapat diukur dari banyaknya objek yang dekat ke Ɵ. DBSCAN
menghubungkan objek inti dan daerah sekitarnya untuk membentuk daerah padat sebagai cluster (Nurjayanti, 2016).
Input: sebuah set titik = { , , … . . , }, jarak threshold ԑ, dan jumlah minimum
titik yang dibutuhkan untuk cluster MinPts.
Output: sebuah titik set berlabel = { , , … . . , }, dimana masing-masing titik
mempunyai lambang yang sesuai dengan salah satu dari cor, border atau noise dan dalam kasus lambang menjadi core atau border sesuai pengidentifikasian cluster.
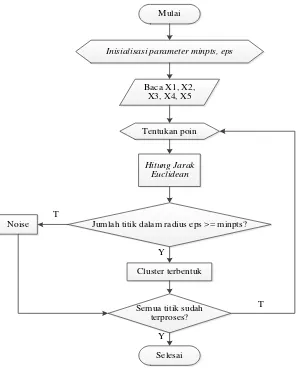
Berikut Algoritma DBSCAN (Ni Made et al, 2015): 1. Menginisialisasi parameter minpts, eps
2. Menentukan titik awal atau p secara acak 3. Mengulangi langkah 3 – 5 hingga titik diproses
4. Menghitung eps atau semua jarak titik yang density reachable terhadap p menggunakan persamaan 3.1
,
= √∑
=−
... (3.1) Jika titik yang memenuhi eps lebih dari minpts maka titik p adalah core point dan cluster terbentukBerikut adalah langkah – langkah persamaan 3.1 dengan menggunakan flowchart:
Jumlah titik dalam radius eps >= minpts?
Cluster terbentuk
Gambar 3.2 Flowchart DBSCAN Sumber: Ni Made et al (2015)
3.5.3.2. Clustering dengan DBSCAN
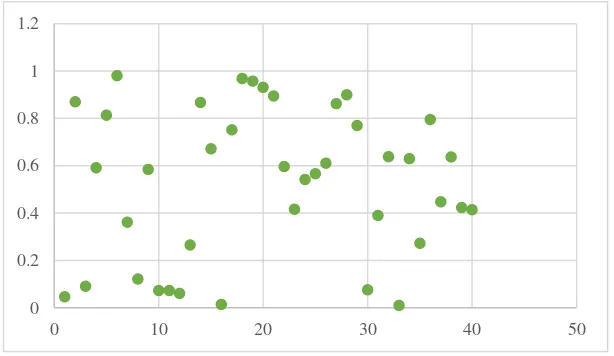
0 Setelah dilakukan perhitungan jarak euclidean terhadap r, akan digambarkan ke dalam bentuk grafik. Seperti pada gambar 3.2 berikut:
Gambar 3.3 Jarak Euclidean pada DBSCAN
Pada gambar di atas menjelaskan bahwa penyebaran data berdasarkan jarak euclidean pada metode DBSCAN secara acak (random) terhadap radius epsilon.
3.5.3.3. Algoritma K-Means
Secara umum pengelompokan data dengan metode K-Means dapat dilakukan dengan algoritma (Eko P., 2012), diantaranya:
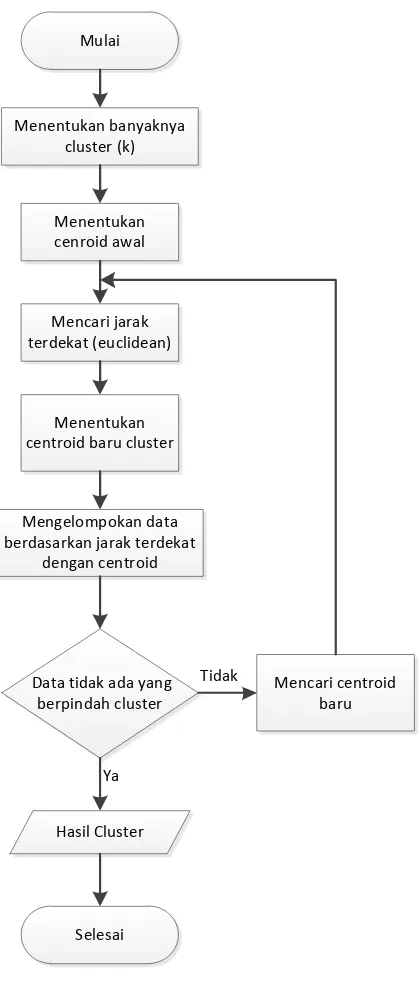
1. Menentukan jumlah k sebagai cluster yang akan dibentuk
2. Membangkitkan k centroid (titik pusat cluster) awal secara random (acak)
3. Menghitung jarak setiap data ke masing – masing centroid dari masing – masing cluster
4. Mengalokasikan masing-masing data ke dalam centroid yang paling terdekat
5. Melakukan iterasi, kemudian menentukan posisi centroid baru dengan cara menghitung rata – rata dari data yang berada pada centroid yang sama
Mulai
Menentukan banyaknya cluster (k)
Menentukan cenroid awal
Mencari jarak terdekat (euclidean)
Menentukan centroid baru cluster
Mengelompokan data berdasarkan jarak terdekat
dengan centroid
Data tidak ada yang berpindah cluster
Hasil Cluster
Selesai
Mencari centroid baru
Ya
Tidak
Gambar 3.4 Flowchart K-Means Sumber: Ernie et al (2017)
3.5.3.4. Clustering dengan K-Means
metode K-Means. Agar data tersebut dapat dikelompokan harus menggunakan tahapan langkah – langkah cluster untuk mengelompokkan data tersebut, yaitu sebagai berikut: 1. Terlebih dahulu menentukan jumlah kelompoknya. Dalam penelitian ini pengelompokan data akan dikelompokan menjadi 6 cluster, untuk menentukan jumlah cluster menggunakan rumus:
� = √ / ... (3.2) menentukan target awal k-means, rumus tersebut digunakan untuk mendapatkan target data atau jarak antara kelompok, yaitu titik pusat awal untuk menghitung algoritma k-means iterasi 0. Rumus tersebut seperti pada persamaan 3.3 berikut:
� ℎ
� ℎ + ... (3.3) Keterangan :
Jumlah data = jumlah data yang akan digunakan
Jumlah class = jumlah kelompok (cluster) yang telah ditentukan sebelumnya Sehingga,
+ =
Tabel 3.2 Penentuan Range untuk Cluster Cluster Ʃmin Ʃmax Cluster
1 0 7 Tidak Lulus
2 8 11 Rekayasa Perangkat Lunak (RPL)
3 12 15 Teknik Komputer dan Jaringan (TKJ)
4 16 18 Administrasi Perkantoran (AP)
5 19 20 Akuntansi (AK)
6 21 22 Multimedia (MM)
3. Menghitung jarak terdekat (euclidean) dengan centroid (titik pusat) pada setiap record data dengan menggunakan rumus euclidean pada persamaan 2.3.
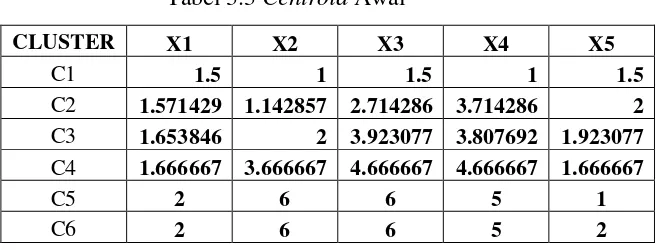
Tabel 3.3 Centroid Awal
CLUSTER X1 X2 X3 X4 X5
C1 1.5 1 1.5 1 1.5
C2 1.571429 1.142857 2.714286 3.714286 2
C3 1.653846 2 3.923077 3.807692 1.923077
C4 1.666667 3.666667 4.666667 4.666667 1.666667
C5 2 6 6 5 1
C6 2 6 6 5 2
Untuk menentukan jarak terdekat tersebut akan dihitung jarak Euclidean dari data calon siswa pertama ke pusat cluster pada iterasi-1.
Jarak data calon siswa pertama ke pusat cluster pertama:
D(1,1)= √ − . + − + − . + − + − . = 3.4278
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster pertama adalah 3.4278.
Jarak data calon siswa pertama ke pusat cluster kedua:
D(1,2)=√ − . + − . + − . + − . + − =1.7554
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster kedua adalah 1.7554.
Jarak data calon siswa pertama ke pusat cluster ketiga:
D(1,3)= √ − . + − . + − . + − . + − . = 0.8854
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster ketiga adalah 0.8854.
Jarak data calon siswa pertama ke pusat cluster keempat:
D(1,4)= √ − . + − . + − . + − . + − . = 2.4944
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster keempat adalah 2.4944.
Jarak data calon siswa pertama ke pusat cluster kelima:
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster kelima adalah 5.
Jarak data calon siswa pertama ke pusat cluster keenam:
D(1,6)= √ − + − + − + − + − = 4.898
Dari hasil perhitungan di atas didapatkan bahwa jarak data calon siswa pertama dengan pusat cluster keenam adalah 4.898. Berdasarkan perhitungan jarak terdekat pada setiap data ke titik pusat, bahwa pada data siswa pertama dapat dikelompokan ke dalam kelompok ketiga dengan jarak terdekat 0.885.
3.5.4. Pengujian Metode
Pengujian metode merupakan tahapan akhir penelitian ini, yaitu pengujian dilakukan dengan pengujian statistik nonparametrik. Dalam pengujian tersebut agar menunjukkan hasil yang diharapkan adalah pengujian dilakukan dengan menggunakan uji tanda (sign test). Pada penelitian ini digunakan uji tanda dalam uji statistik nonparametrik dengan menggunakan tabel Z. Uji tanda digunakan pada situasi dimana data tidak dianggap normal atau datanya bersifat ordinal. Terlebih dahulu menentukan nilai tabel Z yang bernilai � = . dengan menggunakan formula:
= − �� ... (3.4)
� = √� ∗ ∗ ... (3.5)
Gambar 3.5 Penggunaan Notasi Uji Nonparametrik
Berdasarkan penetapan H0 dan H1, maka data sampel akan diuji menggunakan uji satu arah. Uji tersebut akan memperlihatakan pengoptimalan kinerja dari metode yang telah digunakan.
BAB 4
HASIL DAN PEMBAHASAN
4.1. Pengantar
Pada bab ini akan dibahas mengenai hasil – hasil yang diperoleh dalam penelitian ini terhadap analisis yang telah dilakukan. Pada selanjutnya akan ditarik kesimpulan dari hasil penelitian ini, apakah dengan menggunakan metode K-Means dan DBSCAN dapat menghasilkan pengelompokan yang optimal sesuai kriteria yang telah ditentukan dalam penelitian ini.
Pada penelitian ini untuk pengelompokan data menggunakan ms.excel dan RapidMiner yang bertujuan untuk mengelompokan data siswa pada metode DBSCAN (Density-Based Spatial of Applications with Noise) dan K-Means dalam sistem pendukung keputusan untuk menentukan pengelompokan jurusan pada tingkat sekolah menengah kejuruan. Pada penelitian ini akan menggunakan beberapa kriteria dalam menentukan pengelompokan jurusan tersebut. Selain menggunakan metode DBSCAN dan K-Means dalam penelitian ini dapat didukung dengan rule-based untuk menentukan mengklasifikasi data dalam bentuk kelompok. Setelah data – data siswa telah terkelompok, maka akan dilakukan pengujian kinerja metode menggunakan uji statistik nonparametrik. Sehingga akan menghasilkan pengoptimalan kinerja dari salah satu metode tersebut.
4.2. Hasil Uji Coba
4.2.1. Clustering Metode DBSCAN
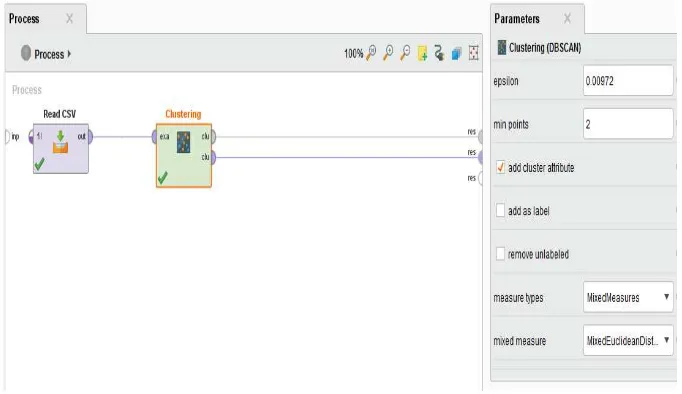
Pengujian metode DBSCAN ini akan dilakukan untuk mengetahui bagaimana metode ini mampu menentukan jurusan siswa dalam sistem pengambilan keputusan. Setiap data adalah objek yang akan diuji kedekatannya menggunakan metode DBSCAN dalam proses clustering. DBSCAN diawali dengan menetapkan nilai dari parameter yang akan diinputkan. Dalam hal ini nilai parameter Eps ditetapkan 0.00972 sedangkan parameter MinPts ditetapkan 2. Pada tahap pertama, DBSCAN akan menandai semua objek dan kemudian memilih secara random satu objek untuk diuji kedekatannya dengan menggunakan fungsi pengukuran jarak yaitu Euclidean Distance. Berikut hasil clustering untuk epsilon= 0.00972 dan minpts = 2 untuk 40 calon siswa yang diuji. Data tersebut akan diuji menggunakan aplikasi RapidMiner sehingga akan menghasilkan pengelompokan data sesuai kriteria data siswa.
Berdasarkan parameter tersebut, data yang berjumlah 40 data akan diuji menggunakan RapidMiner seperti di bawah ini:
Gambar 4.1 Proses Pengujian pada DBSCAN
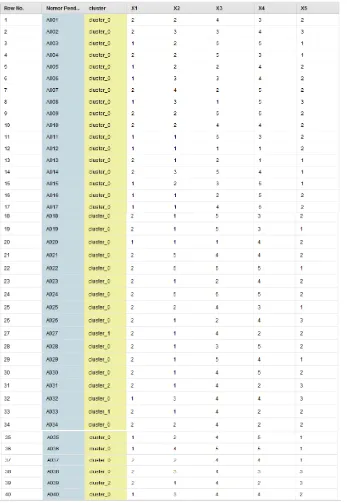
diinputkan terlebih dahulu sebagai penentuan pengelompokan data, sehingga memiliki hasil seperti di bawah ini pengelompokan untuk 40 data record.
Berdasarkan hasil uji 40 sampel data terdapat 3 kelompok dalam pengelompokan tersebut yaitu cluster_0 sebanyak 36 data, cluster_1 sebanyak 2 data dan cluster_2 sebanyak 2 data.
Gambar 4.3 Pengelompokan Data dengan DBSCAN
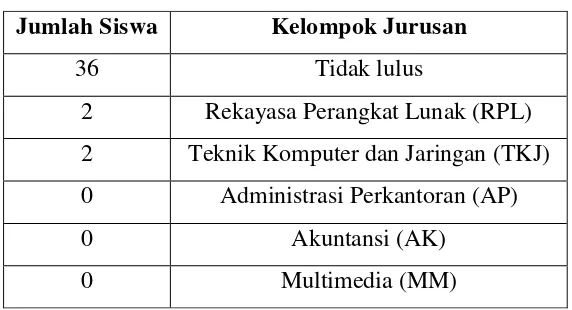
Berdasarkan gambar di atas tersebut adalah hasil clustering yang digambarkan dalam sebuah grafik tiga dimensi. Titik – titik yang terbentuk tersebut terdiri dari core point, border point dan noise. Berikut adalah hasil akhir pengelompokan data siswa menggunakan DBSCAN:
Tabel 4.1 Hasil Cluster dengan DBSCAN
Jumlah Siswa Kelompok Jurusan
36 Tidak lulus
2 Rekayasa Perangkat Lunak (RPL) 2 Teknik Komputer dan Jaringan (TKJ) 0 Administrasi Perkantoran (AP)
0 Akuntansi (AK)
0
4.2.2. Clustering Metode K-Means
Pada K-Means semua data dikelompokkan ke dalam cluster yang terdekat. Selanjutnya hitung kembali pusat cluster baru berdasarkan nilai rata – rata anggota dari cluster sebelumnya. Dalam hal ini, jika centroid yang baru konvergen dengan centroid yang sebelumnya, maka iterasi akan dihentikan. Jika tidak maka iterasi berikutnya dilanjutkan. Penghentian iterasi akan dilakukan karena ketika centroid baru yang dibangkitkan dengan centroid yang lama akan menyebabkan konvergensi pada kelompok sehingga tidak perlu menghitung jarak data terhadap centroid tersebut. Clustering digambarkan dalam sebuah grafik di bawah ini yang menunjukkan data siswa yang terkelompok pada iterasi pertama.
Gambar 4.4 Cluster Awal pada K-Means
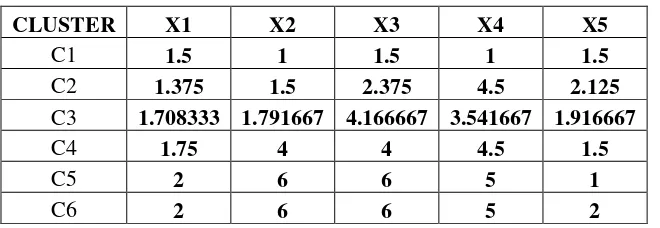
Pada pengelompokkan cluster hasil pertama tersebut belum konvergen, maka akan dilakukan perhitungan kembali centroid cluster pada setiap data. Dalam hal ini akan dibangkitkan kembali centroid baru dengan menggunakan formula euclidean. Maka akan didapat hasil centroid baru pertama, seperti pada tabel 4.1 berikut:
Tabel 4.2 Centroid Baru Pertama
CLUSTER X1 X2 X3 X4 X5
C1 1.5 1 1.5 1 1.5
C2 1.375 1.5 2.375 4.5 2.125
C3 1.708333 1.791667 4.166667 3.541667 1.916667
C4 1.75 4 4 4.5 1.5
C5 2 6 6 5 1
Berdasarkan perhitungan euclidean tersebut centroid baru untuk iterasi-1 yang dibangkitkan tersebut ternyata belum konvergen, sehingga harus dilanjutkan ke iterasi-2. Sebelum melakukan perhitungan untuk iterasi-2, maka ditentutakan terlebih dahulu titik pusat baru berikutnya. Sehingga menghasilkan titik pusat kedua dengan menggunakan perhitungan euclidean.
Tabel 4.3 Centroid Baru Kedua
CLUSTER X1 X2 X3 X4 X5
C1 1.5 1 1.5 1 1.5
C2 1.3 1.6 2.3 4.6 2.1
C3 1.809524 1.714286 4.380952 3.3809524 1.904762
C4 1.6 3.8 4 4.4 1.6
C5 2 6 6 5 1
C6 2 6 6 5 2
Setelah data dihitung dengan titik pusat baru kedua ternyata hasil pengelompokan data tersebut belum konvergen pada iterasi-3, sehingga akan dilakukan perhitungan kembali titik pusat baru ketiga untuk iterasi-4. Centroid dari setiap data tersebut berubah dan terdapat data yang berpindah cluster-nya dari satu cluster ke cluster lainnya sehingga centroid harus dibangkitkan kembali.
Tabel 4.4 Centroid Baru Ketiga
CLUSTER X1 X2 X3 X4 X5
C1 1.5 1 1.5 1 1.5
C2 1.333333 1.444444 2.222222 4.6666667 2.111111
C3 1.894737 1.631579 4.526316 3.2631579 1.789474
C4 1.375 3.375 3.625 4.375 2
C5 2 6 6 5 1
C6 2 6 6 5 2
0 1 2 3 4 5 6 7 8 9
0 5 10 15 20 25 30 35 40 45
Gambar 4.5 Cluster Akhir pada K-Means
Berdasarkan gambar penyebaran kelompok tersebut menyatakan bahwa data telah terkelompok sesuai dengan kriteria – kriteria dari data siswa yang digambarkan dalam sebuah grafik. Berdasarkan perhitungan jarak terdekat (euclidean) dari data calon siswa yang mendaftar di sekolah menengah kejuruan medan area-1, maka didapat pengelompokan data sesuai kriteria yang telah ditentukan dengan hasil sebagai berikut:
Tabel 4.5 Hasil Cluster dengan K-Means
Jumlah Siswa Kelompok Jurusan
2 Tidak lulus
9 Rekayasa Perangkat Lunak (RPL) 19 Teknik Komputer dan Jaringan (TKJ)
8 Administrasi Perkantoran (AP)
1 Akuntansi (AK)
4.2.3. Kinerja Metode
Dalam hal ini statistik nonparametrik digunakaan menjadi tolak ukur pada kinerja metode DBSCAN dan K-Means. Untuk mengetahui hasil uji tersebut maka dilakukan perhitungan menggunakan uji nonparametrik yaitu uji tanda seperti tabel 4.6. Pada tabel tersebut didapat hasil clustering dari metode DBSCAN dan K-Means. Hasil penelitian tersebut menggunakan perlakuan dari masing – masing metode yang menghasilkan didapat dari selisih nilai antara metode tersebut. Hasil dari selisih tersebut berupa tanda (+) yang berarti jika nilai K-Means > DBSCAN, tanda (-) yang berarti jika nilai K-Means < DBSCAN, dan tanda keluar ketika nilai K-Means = DBSCAN sehingga pasangan tersebut dapat diabaikan.
Tabel 4.6 Uji Tanda Data No.
Pendaftaran K-Means DBSCAN Selisih Tanda
A025 3 1 2 +
jika diasumsikan K-Means lebih optimal dibanding DBSCAN maka SUKSES dalam sampel adalah: 2) Menggunakan statistik uji Z
3) Menggunakan uji 1 arah 4) Taraf pengujian α 0.05
ℎ � = �̅− �0 √ 0 � 0� =
. − . √0. 0 � 0. 0 =
. √0. =
.
√ . =
.
. = 4.76 ≈ 4.8 Hasil, Zhitung = 4.8 sehingga didapat menolak H0 dan menerima H1 Jadi, K-Means lebih optimal dari DBSCAN
4.3. Kontribusi Penelitian
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Berdasarkan pembahasan dan pengujian dari bab – bab sebelumnya, maka dapat diambil kesimpulan sebagai berikut:
1. Dari pengujian yang dilakukan, hasil pengelompokan dengan metode K-Means berjumlah sebanyak 6 cluster yang terdapat 2 noise, sedangkanpengelompokan menggunakan metode DBSCAN berjumlah sebanyak 3 cluster.
2. Pada penelitian ini, uji tanda digunakan untuk melihat hasil pengaruh dari dua perlakuan metode yang didapat dari selisih antara kedua metode clustering. 3. Dari pengujian yang telah dilakukan menggunakan uji statistik nonparametrik
menghasilkan bahwa kinerja metode K-Means lebih optimal dari metode DBSCAN dalam penelitian ini.
5.2. Saran
Adapun saran – saran untuk kesempurnaan dari penelitian sebagai berikut:
1. Dalam penelitian ini, peneliti masih menggunakan sampel data yang berjumlah sedikit sehingga untuk metode pengelompokan tertentu pengelompokan akan dapat menjadi tidak optimal untuk pengujian.