BAB 2
TINJAUAN PUSTAKA
2.1. Penelitian Terkait
Pada penelitian ini, peneliti melakukan penelitian yang didasarkan pada penelitian terdahulu yang terkait dengan penelitian yang akan dilakukan peneliti. Penelitian terdahulu yang telah dilakukan berguna sebagai referensi untuk melengkapi penelitian yang akan dilakukan. Penelitian terkait yang menggunakan metode K-Means untuk menyelesaikan pengelompokan telah banyak dilakukan. Mardiani (2014) melakukan penelitian mengenai perbandingan algoritma K-Means dan EM untuk clusterisasi nilai mahasiswa berdasarkan asal sekolah. Dari hasil clustering algoritma K-Means dan EM dibagi menjadi beberapa kelompok. Dari sekolah-sekolah tersebut, nilai IPK dikelompokkan menjadi 3 cluster dengan ketentuan tinggi, sedang dan rendah dengan
jumlah sekolah. Dari hasil yang didapat bahwa algoritma K-Means lebih banyak mengelompokan sekolah-sekolah ke kategori tinggi dibanding EM, sedangkan untuk EM lebih banyak mengelompokan sekolah-sekolah ke kategori sedang.
Ni Made, et al (2015), melakukan penelitian mengenai clustering metode DBSCAN pada proses pengambilan keputusan. Dalam penelitian tersebut pengujian sistem pada metode DBSCAN dilakukan untuk mengetahui bagaimana metode tersebut mampu menentukan pelanggan potensial untuk membantu proses pengambilan keputusan. Langkah awal pada penelitian tersebut adalah memilih field – field yang digunakan dalam proses clustering. Field – field tersebut nantinya dapat mempresentasikan nilai – nilai pada proses transformasi data dan kemudian disimpan pada sebuah tabel statis atau tabel standar. Proses uji coba clustering metode DBSCAN tersebut menggunakan data selama satu tahun yang dibentuk menjadi beberapa cluster.
kriteria di dalamnya dan menghasilkan kinerja metode yang efektif dan optimal dengan penggunaan uji statistik dalam pengujiannya.
2.2. Sistem Pendukung Keputusan (SPK)
Konsep Sistem Pendukung Keputusan (SPK) atau disebut dengan Decision Support Sistem (DSS) pertama kali diungkapkan pada awal tahun 1970-an oleh Michael S. Scott Morton dengan istilah Management Decision Sistem. Sistem tersebut adalah suatu sistem yang berbasis komputer yang ditujukan untuk membantu pengambil keputusan dengan memanfaatkan data dan model tertentu untuk memecahkan berbagai persoalan yang tidak terstruktur. Menurut Hick (1993), Sistem Pendukung Keputusan sebagai sekumpulan tools komputer yang terintegrasi yang mengijinkan seorang decision maker untuk berinteraksi langsung dengan komputer untuk menciptakan informasi yang bergunaka dalam membuat keputusan semi terstruktur dan keputusan tak terstruktur yang tidak terantisipasi. Sedangakn menurut Bonczek (1980), Sistem Pendukung Keputusan sebagai sebuah sistem berbasis komputer yang terdiri atas
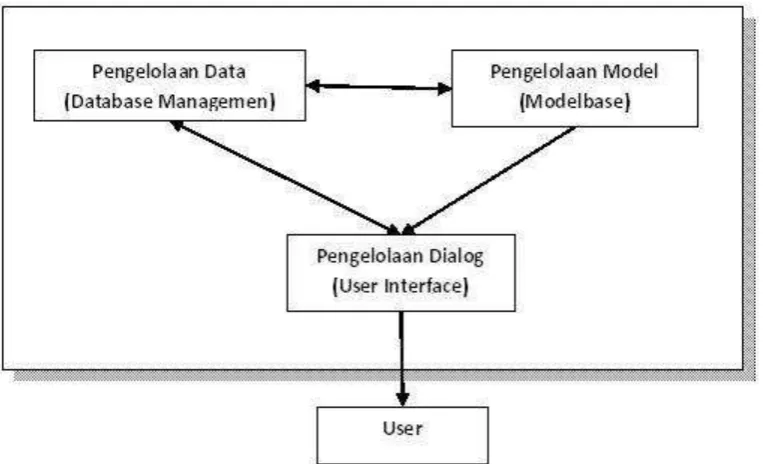
komponen-komponen antara lain komponen-komponen sistem bahasa (languange), komponen-komponen sistem pengetahuan (knowledge), dan komponen sistem pemrosesan masalah (problem processing) yang saling berinteraksi satau dengan yang lainnya.
Gambar 2.1 Komponen Sistem Pendukung Keputusan (SPK) Sumber: Abdan S. (2016)
2.3. Data Mining
Dari kedua istilah tersebut, data mining sebagai disiplin ilmu memiliki tujuan utama yaitu untuk menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang dimilki. Sesuai dengan tujuan utama data mining , terdapat enam fungsi dalam data mining (Prabowo, 2013), diantaranya: (1) fungsi deskripsi (description), (2) fungsi estimasi (estimation), (3) fungsi prediksi (prediction), (4) fungsi klasifikasi (classification), (5) fungsi pengelompokan (clustering), dan (6) fungsi asosiasi (association). Kegiatan data mining dapat dibagi kedalam dua inti penyelidikan utama, sesuai dengan tujuan utama analisis, yaitu: interpretasi dan prediksi (Vercilles, 2009).
1. Interpretasi
Dalam hal ini, tujuan dari interpretasi adalah untuk mengidentifikasi pola yang teratur dalam data dan untuk mengekspresikan data melalui peraturan dan kriteria yang dapat dengan mudah dipahami oleh para ahli dalam domain aplikasi, sebagai contoh: clustering, association rules.
2. Prediksi
Dalam hal ini, tujuan dari prediksi adalah untuk mengantisipasi atau
memprediksi nilai suatu variabel random (acak) yang akan menggambarkan kondisi dimasa mendatang atau memperkirakan kemungkinan peristiwa masa depan, sebagai contoh: classification regression, time series analysis.
2.3.1. Proses Data Mining
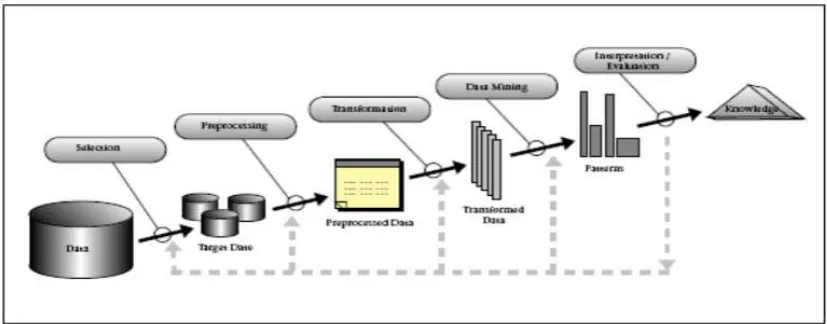
Secara sistematis, ada tiga langkah utama dalam data mining (Gonunescu, 2011) 1. Eksplorasi/pemrosesan awal data
Eksplorasi atau pemrosesan awal data terdiri dari pembersihan data, normalisasi data, transformasi data, penanganan data yang salah, reduksi dimensi, pemilihan subset.
2. Membangun model dan melakukan validasi terhadapnya
deteksi anomali juga masuk dalam langkah eksplorasi, akan tetapi deteksi anomali juga dapat digunakan sebagai algoritma utama, terutama untuk mencari data yang spesial.
3. Penerapan
Penerapan berarti menerapkan model pada data yang baru untuk menghasilkan perkiraan/prediksi masalah yang diinvestigasi.
Gambar 2.2 Proses Data Mining Sumber: Berka (2009)
2.3.2. Data Mining dalam Berbagai Disiplin Ilmu
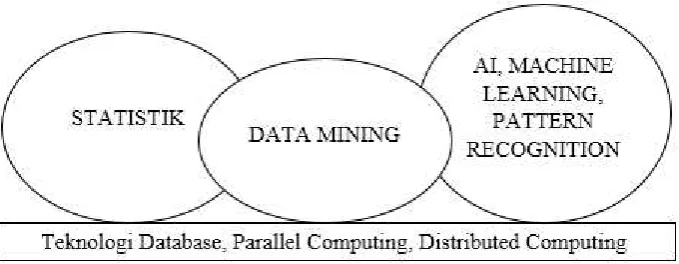
Gambar 2.3 Posisi Data Mining di antara Beberapa Bidang Ilmu
Sumber: Eko P. (2012)
2.4. Clustering
Analisis kelompok (cluster analysis) adalah mengelompokkan data (objek) yang didasarkan hanya pada informasi yang ditemukan dalam data yang menggambarkan objek tersebut dan hubungan diantaranya (Tan, dalam Eko Prasetyo, 2012). Analisis kelompok tersebut bertujuan objek-objek yang bergabung dalam sebuah kelompok merupakan objek-objek yang mirip satu sama lain dan berbeda dalam kelompok dan lebih besar perbedaannya diantara kelompok lain.
Analisis Cluster sebagai metodologi untuk klasifikasi data secara otomatis menjadi beberapa kelompok dengan menggunakan ukuran asosiasi, sehingga data yang sama berada dalam satu kelompok yang sama dan data yang berbeda berada dalam kelompok data yang tidak sama. Masukan (input) untuk sistem analisis cluster adalah seperangkat data dan kesamaan ukuran (atau perbedaan) antara dua data. Sedangkan keluaran (output) dari analisis cluster adalah sejumlah kelompok yang membentuk sebuah partisi atau struktur partisi dari kumpulan data. Salah satu hasil tambahan dari analisis cluster adalah deskripsi umum dari setiap cluster dan hal itu sangat penting untuk analisis lebih dalam dari karakteristik data set tersebut (Ni Putu et al, 2014).
kriteria yang berbeda untuk membentuk cluster dari data. Diantara algoritma yang paling banyak digunakan untuk clustering adalah K-Means dan DBSCAN (Eko P, 2014).
2.4.1. Konsep Clustering
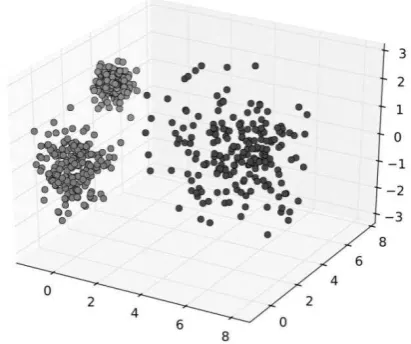
Menurut Eko P. (2014), Ada saatnya di mana set data yang akan diproses dalam data mining belum diketahui label kelasnya. Pengelompokan data dilakukan dengan menggunakan algoritma yang sudah ditentukan dan selanjutnya data akan diproses oleh algoritma untuk dikelompokkan menurut karakteristik alaminya. Tidak unsur pembimbingan (dengan pemberian label kelas), melainkan algoritma akan berjalan dengan sendirinya untuk mengelompokkan data tersebut. Data yang lebih dekat (mirip) dengan data yang lain akan berkelompok dalam satu cluster, sedangkan data yang lebih jauh (berbeda) dari data yang lain akan berpisah dalam kelompok yang berbeda.
Gambar 2.4 Pengelompokan dengan Cluster Sumber: Eko P. (2014)
terbimbing (unsupervised learning). Dalam konteks lain pembelajaran tidak terbimbing disebut juga dengan pengelompokan (clustering). Banyak metode clustering yang telah dikembangkan oleh para ahli, masing-masing metode memilki karakterk, kelebihan, dan kekurangan. Clustering dapat dibedakan menurut struktur cluster, keanggotaan data dalam cluster, dan kekompakan data dalam cluster.
Menurut kategori kekompakan, clustering terbagi menjadi dua, yaitu komplet dan parsial. Jika semua data dapat bergabung menjadi satu (dalam konteks partisi) maka dapat dikatakan semua data kompak menjadi satu cluster, tetapi jika ada satu atau dua data yang tidak ikut bergabung dalam cluster mayoritas maka data tersebut dikatakan data yang mempunyai perilaku yang menyimpang. Data yang menyimpang ini disebut outlier, noise atau uninterested background. Maka dari itu, metode yang tangguh untuk melakukan deteksi outlier adalah DBSCAN. Akan tetapi metode lain seperti K-Means juga dapat melakukan deteksi outlier dengan sejumlah komputasi tambahan.
2.4.2. Ciri – Ciri Cluster
Clustering melakukan pengelompokan data tanpa berdasarkan pada kelas data tertentu yang sudah ditetapkan dari awal. Proses ini sangat berbeda dengan proses yang terdapat pada classification yang pada awal proses harus memberikan kelas – kelas data. Sehingga clustering sering disebut dengan pengelompokan data yang tidak terstruktur. Tugas clustering tidak untuk mengklasifikasikan, mengestimasi, atau memprediksi nilai variabel target (Larose, 2005). Algoritma clustering berusaha mensegmentasikan seluruh kumpulan data ke dalam subkelompok – subkelompok atau cluster – cluster homogen secara relatif. Adapun ciri – ciri pada cluster adalah (Santoso, 2002):
1. Homogenitas (kesamaan) yang tinggi antar anggota dalam satu cluster.
2. Heterogenitas (perbedaan) yang tinggi antar cluster yang satu dengan cluster yang lain.
1. Skedul Algomerasi (Algomeration Schedule), merupakan jadwal yang memberikan informasi tentang objek atau kasus yang akan dikelompokan pada setiap tahap suatu proses analisis cluster dengan metode hierarki.
2. Rata – rata Cluster (Cluster Centroid), merupakan nilai rata – rata variabrl dari semua objek atau observasi dalam cluster tertentu.
3. Pusat Cluster (Cluster Centers), merupakan titik awal dimulainya pengelompokan di dalam cluster nonhierarki.
4. Keanggotaan Cluster (Cluster Memberships), merupakan keanggotaan yang menunjukkan cluster untuk setiap objek yang menjadi anggotanya.
5. Dendogram atau disebut dengan grafik pohon, merupakan output SPSS yang menggambarkan hasil analisis cluster yang dilakukan.
6. Distance between cluster centers, merupakan jarak yang menunjukkan bagaimana terpisahnya pasangan individu cluster (Supranto, 2004).
2.4.3. Hierarchical dan Non Hierarchical Clustering
Hierarchical dan Non Hierarchical Clustering termasuk merupakan metode pada clustering. Menurut Santoso (2010), hierarchical clustering yaitu suatu metode pengelompokan dua atau lebih objek yang memiliki kesamaan paling dekat. Kemudian proses dilanjutkan ke objek lain yang memiliki kedekatan kedua. Demikian seterusnya sehingga cluster akan membentuk semacam pohon dimana ada hierarki (tingkatan) yang jelas antar objek, dari yang paling mirip hingga yang paling tidak mirip. Secara logika semua objek pada kahirnya akan hanya membentuk sebuah cluster.
2.5. Rule-Based Classification
Rule-based classification dalam penelitian ini merupakan metode tambahan sebagai perbandingan antara clustering dan classification. Pada rule-based classification ini, terdapat aturan model IF - THEN yang ditunjukkan sebagai satu set aturan. Rules adalah sebuah cara yang baik untuk menggambarkan informasi atau pengetahuan. Sebuah aturan menggunakan seperangkat peraturan IF –THEN untuk klasifikasi data. Sebuah aturan IF – THEN merupakan ekspresi dari bentuk berikut:
IF condition THEN conclusion
Sebagai contoh adalah rule R1,
R1: IF age = youth AND student = yes THEN buys_computer = yes.
Pada “IF” dari rule tersebut disebut sebagai aturan pendahulu atau prasyarat. Sedangkan
pada “THEN” adalah aturan sebagai akibat. Dalam aturan pendahulu, kondisi (condition) terdiri dari satu atau lebih atribut, sebagai contoh: age = youth and student = yes (Jiawei Han et al, 2012). Dalam penelitian ini, peneliti akan menerapkan rule-based classification untuk mengklasifikasi data dalam jumlah sedikit.
2.6. Metode DBSCAN
Menurut Eko P. (2012), Density-Based Spatial Clustering of Applications with Noise (DBSCAN) merupakan algoritma pengelompokan yang didasarkan pada kepadatan (density) data. Konsep kepadatan yang dimaksud dalam DBSCAN adalah jumlah data yang berada dalam radius Eps (ԑ) dari setiap data. Jika jumlah data tersebut dalam radius ԑ lebih dari atau sama dengan MinPts (jumlah minimal data dalam radius ԑ), data
tersebut masuk ke dalam kategori kepadatan yang diinginkan, jumlah data radius tersebut termasuk data itu sendiri. Konsep kepadatan tersebut akan memunculkan tiga macam status dari setiap data, diantaranya inti (core), batas (border), dan noise (noise).
Sebuah data akan dimasukkan sebagai inti apabila jumlah data tetangga dan
radius ԑ < MinPts, tetapi tetangganya menjadi inti karena keberadaannya, data tersebut
dikategorikan sebagai batas. Sementara, jika tidak memenuhi kondisi jumlah tetangga dan dirinya sendiri dalam radius ԑ < MinPts dan tidak ada tetangga yang menjadi inti
karena keberadaannya, maka data tesebut dikategorikan sebagai noise.metode ini melakukan pengelompokan dengan baik pada data berkepadatan tinggi, dan dapat menemukan sembarang kelompok dengan baik. Karena basisnya dari kepadatan data, DBSCAN dapat memisahkan data berkepadatan tinggi dan data berkepadatan rendah.
DBSCAN bekerja dengan cara melakukan pengumpulan data jarak secara iterasi dimulai titik pertama sampai titik terakhir, mengumpulkan jumlah titik – titik yang menjadi tetangga dengan batas jarak antar titik tetangga dengan titik acuan tidak boleh lebih dari Eps. Kemudian membandingkan jumlah titik tetangga tersebut dengan parameter MinPts. Perbandingan ini dilakukan untuk menentukan tipe titik (core, border, noise) dan membentuk cluster baru. Cluster yang terbentuk akan memiliki tingkat kesamaan yang tinggi di dalam cluster itu sendiri, dan tingkat kesamaan yang rendah antar cluster yang berbeda (Kantarzzic,dalam Yuwono, 2009).
Ada beberapa konsep kunci dari definisi DBSCAN (Irving et al, 2015), di bawah ini penjelasannya sebagai berikut:
a. � : untuk titik ∈ , lingkungan ϵ yang didefinisikan sebagai � =
{ ∈ | � , �} dimana dist adalah fungsi jarak.
b. Core point: sebuah titik ∈ adalah sebuah titik inti jika | � | ��� .
c. Directly density reachable: sebuah titik ∈ adalah kepadatan yang dicapai langsung dari ∈ jika ∈ � dan adalah sebuah titik inti.
e. Density connected: sebuah titik ∈ adalah kepadatan yang terhubung ke
∈ jika ada sebuah titik ∈ sehingga , adalah kepadatan yang dicapai dari .
f. Cluster: C adalah sebuah cluster jika ʗ dan untuk setiap , ∈
∁ , � adalah density connected.
g. Border point: p adalah titik perbatsan, jika ∈ � ∁ � bukan titik inti.
h. Noise point: p adalah titik perbatasan jika bukan milik bagian cluster.
Adapun Menurut Mumtaz (Eko Prasetyo, 2012) terdapat beberapa karakteristik, diantaranya:
1. DBSCAN tidak perlu mengetahui jumlah kelompok dalam data secara sesukanya seperti pada K-Means. Hal ini memberikan keuntungan karena umumnya bentuk dan jumlah kelompok yang sebaiknya diberikan pada data berdimensi tinggi tidak dapat diketahui dengan cara analisis visual data.
2. DBSCAN dapat menemukan bentuk kelompok sembarang, bahkan kelompok berbentuk melingkar yang tidak dapat ditangani K-Means. Untuk hal ini dapat disesuaikan dengan menentukan nilai MinPts.
3. Dapat mengenali noise dengan baik.
4. Hanya membutuhkan dua parameter yang kebanyakan tidak sensitif terhadap urutan
data dalam basis data. Tetapi penentuan parameter Eps (ԑ) hanya mudah diberikan
ketika melihat data spasial dua dimensi. Untuk data berdimensi tinggi, nilai Eps (ԑ)
yang tepat sangat sulit ditentukan.
6. Tidak dapat memberikan hasil yang baik untuk data yang mempunyai kelompok kepadatan yang berbeda. Hal ini karena DBSCAN hanya melihat proses pengelompokan berdasarkan radius Eps (ԑ), sehingga ketika ada dua kelompok atau
lebih yang mempunyai kepadatan yang berbeda, DBSCAN tidak dapat memberi hasil yang baik.
2.7.Metode K-Means
Pengelompokan K-Means merupakan metode analisis kelompok yang mengarah pada pemartisian N objek pengamatan ke dalam K kelompok (cluster), dimana setiap objek pengamatan dimiliki oleh sebuah kelompok dengan rata-rata terdekat. K-Means merupakan salah satu metode pengelompokan nonhierarki yang berusaha mempartisi data yang ada ke dalam bentuk dua atau lebih kelompok. Metode ini mempartisi data ke dalam kelompok sehingga data berkarakteristik sama dikelompokan ke dalam satu kelompok yang sama data yang berkarakteristik berbeda dikelompokan ke dalam kelompok yang lain. Tujuan pengelompokan ini adalah untuk meminimalkan fungsi objek yang diset dalam proses pengelompokan, yang pada umumnya berusaha
meminimalkan variasi di dalam suatu kelompok dan memaksimalkan variasi antarkelompok (Eko P., 2012).
Lokasi sentroid setiap kelompok yang diambil dari rata-rata (mean) semua nilai data pada setiap fiturnya harus dihitung kembali. Jika M menyatakan jumlah data dalam sebuah kelompok, i menyatakan fitur ke-i dalam sebuah kelompok, dan p menyatakan dimensi data (Eko Prasetyo, 2012).
Untuk menghitung sentroid fitur ke-i digunakan formula:
=
�∑
�= ... (2.2)
Formula tersebut dilakukan sebanyak p dimensi sehingga i mulai dari 1 sampai p. Pengukuran jarak pada ruang jarak Euclidean menggunakan formula:
(
,) = ‖ − ‖
2=
√∑ |
�=−
|
2 ... (2.3)Pengukuran jarak pada ruang jarak Manhattan menggunakan formula:
(
,) = ‖ − ‖
1=
∑ |
�=−
|
... (2.4)Pengukuran jarak pada ruang jarak Minkowsky menggunakan formula:
(
,) = ‖ − ‖
λ=
�√∑ |
�=−
|
λ ... (2.5)Adapun karakteristik dari K-Means (Eko P., 2012) adalah sebagai berikut:
1. K-Means merupakan metode pengelompokan yang sederhana dan dapat digunakan dengan mudah.
2. Pada jenis set data tertentu, K-Means tidak dapat melakukan segmentasi data dengan baik dimana hasil segmentasinya tidak dapat memberikan pola kelompok yang mewakili karakteristik bentuk alami data.
3. K-Means dapat mengalami masalah ketika mengelompokan data yang mengandung outlier.
2.8. Konvergen
Apabila clustering pada metode K-Means telah diimplementasikan dengan benar, maka akan membentuk kelompok sesuai subkelompok berdasarkan kriteria data, sehingga menghasilkan cluster yang optimal. Dalam hal ini, pengelompokan data dimulai dari menyusun k buah rata – rata, yang dapat membentuk centroid dari sekumpulan data berdimensi n. Kemudian data tersebut akan membentuk cluster – cluster. Setelah cluster telah terbentuk, maka akan dihitung rata – rata dari setiap cluster untuk membentuk centroid pada cluster – cluster tersebut. Tahap tersebut akan terus berulang dan akan berhenti hingga membentuk cluster yang tidak mengubah nilai pusat cluster .
Konvergen merupakan pembentukan kelompok yang tidak terjadi perubahan yang signifikan pada pusat cluster. Perubahan tersebut pada umumnya dapat diukur menggunakan jumlah atau rata – rata jarak terdekat pada setiap data dengan pusat
2.9. Statistik Nonparametrik
Metode statistik nonparametrik merupakan metode statistik yang dapat digunakan dengan mengabaikan asumsi – asumsi yang melandasi penggunaan metode statistik parametrik, terutama yang berkaitan dengan distribusi normal atau dengan istilah lain disebut statistik bebas (distribution free statistics) distribusi dan uji bebas asumsi (assumption-free test). Istilah nonparametrik pertama kali digunakan oleh Wolfwofiz, pada tahun 1942. Uji statistik nonparametrik adalah suatu uji statistik yang tidak memerlukan adanya asumsi – asumsi mengenai sebaran data populasi. Statistik nonparametrik dapat digunakan untuk menganalisis data yang berskala nominal atau ordinal, karena pada umumnya data berjenis nominal dan ordinal tidak menyebar normal. Statistik nonparametrik merupakan suatu analisis data statistik yang cocok digunakan untuk menguji data ilmu – ilmu sosial karena asumsi – asumsi yang digunakan dalam uji nonparametrik adalah pengamatan – pengamatannya yang bebas, tidak mengikat, dan lebih longgar dibanding uji parametrik (Mutijah, 2007).
Adapun beberapa macam yang terdapat pada uji nonparametrik, diantaranya: a. Uji Tanda (Sign Test)
b. Uji Peringkat 2 Sampel Wilcoxon
c. Uji Korelasi Peringkat Spearman (Rank-Correlation Method) d. Uji Konkordansi Kendall
e. Uji Run(S)
f. Uji Median (Median Test) g. Uji Chi-Square
Dalam penelitian ini berdasarkan beberapa macam uji nonparametrik, peneliti hanya membahas mengenai uji tanda (sign test.
2.10. Uji Tanda (Sign Test)
dapat digunakan untuk mengevaluasi efek dari suatu treatment tertentu. Efek dari variabel eksperimen atau treatment tidak dapat diukur hanya dapat diberi tanda positif (+) atau negatif (-) saja. Dalam hal ini, pengaruh diukur oleh rata – rata, sehingga uji tanda tersebut dapat digunakan untuk menguji kesamaan dua rata – rata populasi (samsudin). Uji tanda (sign test) dapat digunakan untuk menguji hipotesis dengan dua komparatif dan datanya berbentuk data ordinal dan dilakukan berdasarkan tanda (+) dan (-) yang didapat dari selisih nilai pengamatan. Adapun syarat – syarat untuk menggunakan uji tanda sebagai berikut (Nur Fadlilah, 2012):
1. Pasangan hasil pengamatan yang sedang dibandingkan bersifat independen
2. Masing – masing pengamatan dari tiap pasang terjadi karena pengaruh kondisi yang sama
3. Pasangan yang berlainan terjadi karena kondisi berbeda
Uji tanda ini hanya memerhatikan arah perbedaan dan tidak besarnya perbedaan tersebut. Berdasarkan hal tersebut, terdapat 2 macam uji tanda (Harry K., 2010) diantaranya: