BAB II
LANDASAN TEORI
2.1 Algoritma
Istilah algoritma berasal dari nama seorang pengarang berkebangsaan Arab bernama Ja’fat Mohammed bin Musa al Khowarizmi (tahun 790 – 840), yang sangat terkenal dengan sebutan bapak Aljabar. Algoritma merupakan alur pemikiran yang logis yang
dapat dituangkan ke dalam bentuk tulisan (Antonius Rachmat C, 2010, 4).
Dalam matematika dan komputasi, algoritma atau algoritme merupakan
kumpulan perintah untuk menyelesaikan suatu masalah. Kompleksitas dari suatu
algoritma merupakan ukuran seberapa banyak komputasi yang dibutuhkan algoritma
tersebut untuk menyelesaikan masalah. Secara informal, algoritma yang dapat
menyelesaikan suatu permasalahan dalam waktu yang singkat memiliki kompleksitas
yang rendah, sementara algoritma yang membutuhkan waktu lama untuk
menyelesaikan masalahnya mempunyai kompleksitas yang tinggi (Simanullang,
2011).
2.2 Android
Android adalah sebuah sistem operasi untuk perangkat mobile berbasis linux yang
mencakup sistem operasi, middleware dan aplikasi (Nazruddin Safaat H, 2012, 1).
Android adalah kumpulan perangkat lunak yang di tujukan bagi perangkat bergerak
mencakup sistem operasi, middleware, dan aplikasi kunci, Android Software
Development Kid (SDK) menyediakan perlengkapan dan Application Programming
Interface (API) yang diperlukan untuk mengembangkan aplikasi pada platform
Android menggunakan bahasa pemprograman Java. (Holla et al, 2012).
Awalnya Google Inc. membeli Android Inc pendatang baru yang membuat
Handset Alliance (OHA) yaitu aliansi perangkat selular terbuka yang terdiri dari 47
perusahaan Hardware, Software dan perusahaan telekomunikasi di tujukan untuk
mengembangkan standar terbuka bagi perangkat selular. (Gargenta, 2011).
2.3 Pencocokan String (String Matching)
Algoritma pencarian string, juga disebut algoritma pencocokan string.
Pencocokan string adalah kelas algoritma string yang mencoba menemukan
tempat di mana satu atau beberapa string (juga disebut pola) ditemukan dalam
teks yang lebih besar. (Krishna et al. 2012)
Untuk melakukan proses pencocokan string dibutuhkan 2 jenis data:
1. Teks, yaitu string sepanjang n karakter sebagai sumber pencarian
2. Pattern, yaitu string sepanjang m dengan m < n yang akan dicari di dalam teks.
(Tanjung, 2015).
Pencocokan string (string matching) secara garis besar dapat dibedakan
menjadi dua yaitu :
1. Inexact string matching atau Fuzzy string matching, adalah pencocokan string
secara samar, yaitu pencocokan string dimana string yang dicocokkan
memiliki kemiripan namun keduanya memiliki susunan karakter yang berbeda
(mungkin jumlah atau urutannya) tetapi string tersebut memiliki kemiripan,
baik kemiripan tekstual/penulisan atau kemiripan ucapan (Rochmawati, 2015).
2. Exact string matching, merupakan pencocokan string secara tepat dengan
susunan karakter dalam string yang dicocokkan memiliki jumlah maupun
urutan karakter dalam string yang sama (Syaroni, 2005).
Exact string matching bermanfaat jika pengguna ingin mencari string dalam
dokumen yang sama persis dengan string masukan. Tetapi jika pengguna
menginginkan pencarian string yang mendekati dengan string masukan atau terjadi
kesalahan penulisan string masukan maupun dokumen objek pencarian, maka inexact
string matching yang bermanfaat. Beberapa algoritma exact string matching antara
lain: algoritma Knuth Morris-Pratt, Boyer-Moore, dll. Beberapa algoritma phonetic
string matching antara lain: soundex, metaphone, caverphone, phonex, NYSIIS, Jaro
2.4 Algoritma Morris-Pratt
Algoritma Morris - Pratt dicetuskan oleh James H. Morris – bersama Vaughan R.
Pratt pada (1966). Algoritma Morris - Pratt terdiri dari dua fase, yaitu fase
preprocessing dan fase pencarian string.
Pada fase preprocessing dilakukan fungsi pinggiran untuk menentukan
jumlah langkah pergeseran pattern terbesar dengan menggunakan perbandingan
sebelum pencarian string. Fungsi pinggiran ini bergantung pada karakter-karakter
yang terdapat dalam pattern, bukan dalam teks. Perbandingan karakter dilakukan
dengan mencocokkan pattern ke dalam teks yang dicari dari kiri ke kanan
(Hussain, 2010).
2.4.1 Fase Preprocessing
Pada fase preprocessing dilakukan perhitungan jumlah langkah pergeseran
pattern terbesar yang mungkin terjadi dengan menggunakan perbandingan
yang dibentuk sebelum fase pencarian string. Fase ini menggunakan tabel
pergeseran mpNext.
Untuk mendapatkan nilai pergeseran, mpNext[i] untuk indeks 0 diberi
nilai -1 sebagai inisialisasi. Kemudian, bandingkan karakter pada indeks 0
dengan karakter pada indeks 1. Apabila karakternya sama, maka mpNext[i]
bernilai 1. Namun apabila karakternya berbeda, maka mpNext[i] bernilai
sesuai index . (Charras, 2004).
2.4.2 Fase Pencarian
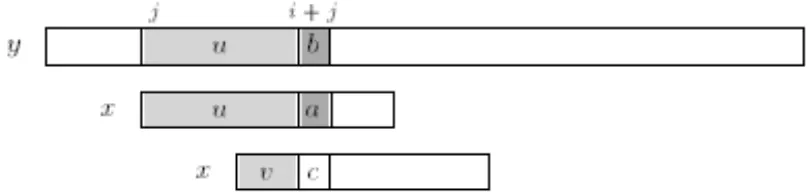
Selama fase pencarian, dimulai dari posisi j didalam y, ditentukan dimana :
Jendela karakter diposisikan pada teks y[j..j + m– 1]
x[i] = y[i + j] dan 0 ≤ i ≤ m
x[0..i-j] = y[j..i + j-1] = u dan a = x[i] ≠y[i + j]
Gambar 2.1 Pergeseran pada algoritma Morris - Pratt : v adalah batasan dari u
2.5 Algoritma Horspool
Algoritma Horspool dibuat oleh R. Nigel Horspool. Algoritma Horspool hampir
mirip dengan Algoritma Quick Search dan Algoritma Boyer – Moore tetapi
sebenarnya memiliki metode yang berbeda yaitu tidak melakukan lompatan
berdasarkan karakter pada pattern yang tidak cocok pada teks. Algoritma
Horspool bekerja dalam berbagai perintah, dan nilai rata-rata dari perbandingan
untuk satu karakter antara 1/σ dan 2/ (σ +1) (Hnaif et al. 2009 ).
Menurut Horspool, R.N. (1980), masalah dalam pencarian teks ini adalah
menemukan pattern pertama dalam teks yang besar. Karena teks yang dicari bisa
sangat besar (memungkinkan ratusan ribu karakter) maka diperlukan penyelesaian
yang efektif.
Algoritma Horspool memiliki nilai pergeseran karakter yang paling kanan
dari window. Pada tahap observasi awal (preprocessing), nilai shift akan dihitung
untuk semua karakter. Pada tahap ini, dibandingkan pattern dari kanan ke kiri
hingga kecocokan atau ketidakcocokan pattern terjadi. Karakter yang paling
kanan pada window digunakan sebagai indeks dalam melakukan nilai shift. Dalam
kasus ketidakcocokan (karakter tidak terdapat pada pattern) terjadi, window
digeser oleh panjang dari sebuah pattern. Jika tidak, window digeser menurut
karakter yang paling kanan pada pattern (Baeza-Yates, R.A. & Regnier, M.
1992).
2.5.1 Pencarian Dengan Algoritma Horspool
Terdapat dua tahap pada pencocokan string menggunakan algoritma Horspool (Singh,
1. Tahap praproses
Pada tahap ini, dilakukan observasi pattern terhadap teks untuk membangun
sebuah tabel bad-match yang berisi nilai shift ketika ketidakcocokan antara pattern
dan teks terjadi. Secara sistematis, langkah-langkah yang dilakukan algoritma
Horspool pada tahap praproses adalah:
a. Algortima Horspool melakukan pencocokan karakter ter-kanan pada pattern.
b. Setiap karakter pada pattern ditambah ke dalam tabel bad-match dan dihitung
nilai shift-nya.
c. Karakter yang berada pada ujung pattern tidak dihitung dan tidak dijadikan
karakter ter-kanan dari karakter yang sama dengannya.
d. Apabila terdapat dua karakter yang sama dan salah satunya bukan karakter
ter-kanan, maka karakter dengan indeks terbesar yang dihitung nilai shift-nya.
e. Algoritma Horspool menyimpan panjang dari pattern sebagai panjang nilai shift
secara default apabila karakter pada teks tidak ditemukan dalam pattern.
f. Nilai (value) shift yang akan digunakan dapat dicari dengan perhitungan panjang
dari pattern dikurang indeks terakhir karakter dikurang 1, untuk masing-masing
karakter, = − − 1.
2. Tahap pencarian
Secara sistematis, langkah-langkah yang dilakukan algoritma Horspool pada tahap
praproses adalah:
a. Dilakukan perbandingan karakter paling kanan pattern terhadap window.
b. Tabel bad-match digunakan untuk melewati karakter ketika ketidakcocokan
terjadi.
c. Ketika ada ketidakcocokan, maka karakter paling kanan pada window berfungsi
sebagai landasan untuk menentukan jarak shift yang akan dilakukan.
d. Setelah melakukan pencocokan (baik hasilnya cocok atau tidak cocok)
dilakukan pergeseran ke kanan pada window.
e. Prosedur ini dilakukan berulang-ulang sampai window berada pada akhir teks
2.6 Notasi Asimptotik
Ilmuwan komputer menggunakan notasi Asimptotik yang terdiri dari tiga notasi :
O (big oh), Ω (big omega), dan Ө (big theta).
2.6.1 Notasi O
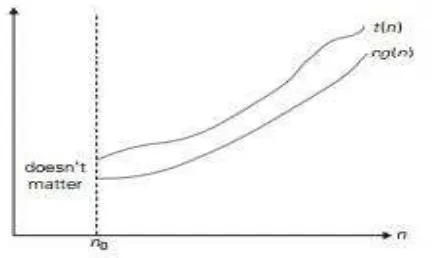
Fungsi t(n) disebutkan berada dalam O(g(n)), dan dilambangkan dengan t(n) ϵ
O(g(n)), jika t(n) diberi batas atas oleh beberapa pengali konstan dari g(n) untuk
semua n bernilai besar, seperti beberapa konstan c bernilai positif dan n0 integer
bukannegatif seperti t(n) ≤ cg(n) untuk semua n ≥ n0 (Levitin, 2012).
Gambar 2.2 Notasi Big-Oh (Levitin 2012)
2.6.2 Notasi Ω
Fungsi t(n) didefinisikan berada dalam Ω(g(n)), dan t(n) ϵ Ω(g(n)) merupakan
lambangnya, jika t(n) diberi batas bawah oleh beberapa pengali konstan dari
g(n) untuk semua n bernilai besar, seperti, beberapa konstan c bernilai positif
dan n0 integer bukan negatif seperti t(n) ≥ cg(n) untuk semua n ≥ n0 (Levitin,
2012).
2.6.3 Notasi Ө
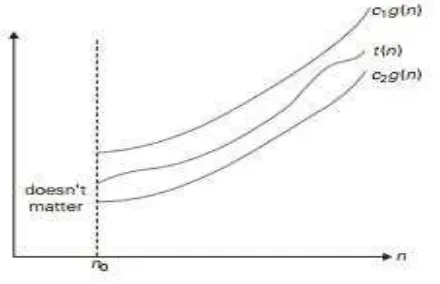
Fungsi t(n) dimaksudkan berada dalam Ө(g(n)), dan dilambangkan dengan t(n) ϵ
Ө(g(n)), jika t(n) diberi batas atas dan batas bawah oleh beberapa pengali
konstan dari g(n) untuk semua n bernilai besar, seperti, beberapa konstan c1 dan
c2 bernilai positif dan n0 integer bukan negatif seperti c2g(n) ≤ t(n) ≤ c2g(n)
untuk semua n ≥ n0 (Levitin, 2012).
Gambar 2.4 Notasi Big-theta (Levitin 2012)
2.7 Penelitian yang Relevan
Berikut ini beberapa penelitian yang terkait dengan algoritma Morris - Pratt dan
algoritma Horspool :
1. Penelitian Evelyn Dwi Tambun (2010) mengangkat penelitian dengan judul “Penggunaan Algoritma BM dan Algoritma Horspool pada Pencarian String dalam Bahasa Medis”. Hasil penelitian menunjukkan bahwa pencarian string pada teks bahasa medis dengan menggunakan algoritma Boyer-Moore lebih
baik dibandingkan dengan algoritma Horspool. Bahasa medis banyak
menggunakan kosakata yang panjang dengan varian karakter yang beragam.
Karakter teks seperti bahasa medis ini sangat cocok dengan algoritma
Boyer-Moore sehingga algoritma ini dapat bekerja dengan maksimal pada pencarian
2. Penelitian oleh Agustin Sri Intan Sinaga (2017) mengangkat penelitian dengan judul “Studi Perbandingan Kinerja Teoritis dan Riil Algoritma Exact
String Matching Shift-And dan Morris-Pratt”. Hasil penelitian ini didapat
bahwa algoritma Morris-Pratt lebih efisien dibandingkan dengan algoritma
Shift-And karena dalam percobaan pada sampel pattern sebanyak 10 buah
diperoleh hasil rata – rata waktu pencarian sebesar 110.1 ms untuk algoritma
Shift-And dan 59 ms untuk algoritma Morris-Pratt.
3. Penelitian oleh Ade Mutiara Kartika Dewi Nasution (2016) yang mengangkat
penelitian yang berjudul “Implementasi algoritma Horspool dalam Pembuatan Kamus Istilah Psikologi pada Platform Android”. Hasil dari implementasi tersebut adalah Algoritma Horspool menerapkan informasi pencarian yang
disimpan untuk melakukan pergeseran yang lebih jauh karena pencocokan
string dilakukan dari kanan ke kiri, sehingga waktu pencarian string lebih
singkat.
4. Penelitian oleh Mirabella, F.M (2012) yang membandingkan algoritma Boyer
– Moore dan variasi – variasinya dalam pencarian string telah dihasilkan
bahwa algoritma Horspool jauh lebih sederhana penggunaanya dibandingkan
dengan algoritma Boyer – Moore tetapi kompleksitas waktu yang dibutuhkan
algoritma menyatakan algoritma Horspool masih kalah cepat dalam
melakukan pencocokan string dibandingkan dengan beberapa variasi turunan
algoritma Boyer – Moore.
5. Penelitian oleh Nababan (2015) mengangkat penelitian dengan judul “Implementasi Algoritma Brute Force dan Algoritma Knuth - Morris –Pratt (KMP) dalam Pencarian Word Suggestion”. Hasil penelitian ini didapat
bahwa Algoritma Knuth-Morris - Pratt (KMP) menyimpan sebuah informasi
yang digunakan untuk melakukan jumlah pergeseran. Dengan ini penggunaan
algoritma Knuth-Morris-Pratt (KMP) dapat mempersingkat waktu dengan
hasil rata-rata runtime 0,42717 ms dibandingkan dengan algoritma Brute
Force yang memiliki hasil rata-rata runtime 0,44683 ms dalam pencocokan