fl
lrs
Jrl
zo."']7-KNMru
Koffierems0
Nosnomd
Mdernffio
DAFTAR ISI
lnformasi
1.1 Susunan Panitia Konferensi Nasional Matematika XV11,2Ot4...1
1.2 Laporan Ketua Panitia KNM
)(Vll...
...71.3 Sambutan Presiden lndoMS
2OL2-20L4
...91.4 Sambutan Rektor lnstitut Teknologi Sepuluh
Nopember.
...131.5 Sambutan Dekan FMIPA lnstitut Teknologi Sepuluh Nopember...15
1.6 Susunan
Acara...
...L7 Abstrak lnvitedSpeaker...
...-...o.... 23Jadwat Presentasi Sesi Paralel 3.1Jaowm Prnserurnsr Maxnum Sesr PRRRUI-
1...
...333.2 Jnowar PEnsErurlsr Mnrlus Sesr Pmalrr
2...
....-...473.3 Jnowm PeRsEurns Mernux Srsr
PRmrE13...
...604.
Denah LokasiRuangan
...755.
lnformasiSingkatEkskursi
...-....-...775.
lklan danSponsor...
...817.
Ucapqn TerimaKasih...
...83 2.Konferensi Nosional Motemotiko (KNM)XVll- ITS Suraboya
MENGG UNAKAN PEN DE KATAN BAYESIAN
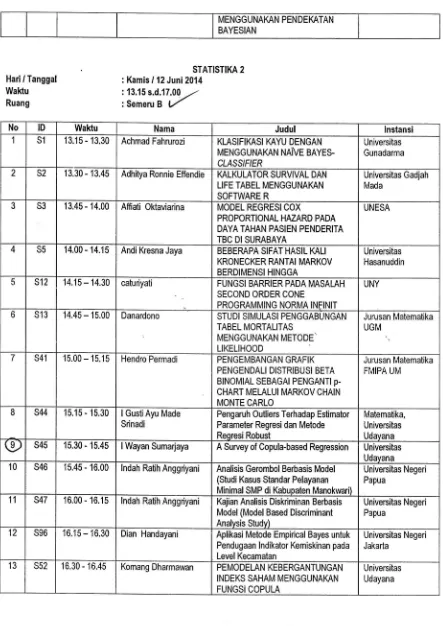
Hari/
Tanggat
r Kamis / 12 Juni 2osTATlsTlKA2
Wahu
:13.'15s.d.17.00-,-Ruang
:SemeruB/
No ID Waktu Nama Judul lnstansi
1 S1 13.15 - 13.30 Achmad Fahrurozi KLASIFIKASI KAYU DENGAN MENGGUNAKAN NAiVE BAYES. CLASS/F/ER
Universitas Gunadarma
2 S2 1 3.30 - 13.45 Adhitya Ronnie Effendie KqLKULATOR SURVIVAL DAN LIFE TABEL MENGGUNAKAN SOFTWARE R
Universitas Gadjah Mada
3 S3 13.45 - 14.00 Affiati Oktaviarina MODEL REGRESI COX
PROPORTIONAL HAZARD PADA DAYA TAHAN PASIEN PENDERITA TBC DI SURABAYA
UNESA
4 S5 14.00 - 14.15 Andi Kresna Jaya BEBEMPA SIFAT HASIL KALI KRONECKER MNTAI MARKOV BERDIMENSI HINGGA
Universitas Hasanuddin
5 s12 14.15 - 14.30 caturiyati FUNGSI BARRIER PADA MASALAH SECOND ORDER CONE
PROGRAMMING NORMA INFINIT
UNY
o s13 14.45 - 'l 5.00 Danardono
STUDI SIMULASI PENGGABUNGAN TABEL MORTALITAS
MENGGUNAKAN METODE. LIKELIHOOD
Jurusan Matematika UGM
7 s41 15.00 - 15.15 Hendro Permadi PENGEMBANGAN GRAFIK PENGENDALI DISTRIBUSI BETA BINOMIAL SEBAGAI PENGANTI p-CHART MELALUI MARKOV CHAIN MONTE CARLO
Jurusan Matematika FMIPA UM
8 s44 15.15 - 15.30 lGustiAyu Made Srinadi
Pengaruh Outliers Terhadap Estimator Parameter Regresi dan Metode Reqresi Robust
Matematika, Universitas Udavana
(9
s45 15.30 - 15.45 lWayan Sumarjaya A Survey of Copula-based Regression Universitas Udayana 10 s46 1s.45 - 16.00 lndah Ratih Anggriyani Analisis Gerombol Berbasis Model(Studi Kasus Standar Pelayanan Minimal SMP di Kabupaten Manokwari)
Universitas Negeri Papua
11 s47 16.00 - 16.15 lndah Ratih Anggriyani Kajian Analisis Diskriminan Berbasis Model (Model Based Discriminant Analvsis Studv)
Universitas Negeri Papua
12 s96 16.1 5 - 16.30 Dian Handayani Aplikasi Metode Empirical Bayes untuk Pendugaan lndikator Kemiskinan pada Level Kecamatan
Universitas Negeri Jakarta
13 s52 16.30 - 16,45 Komang Dharmawan PEMODELAN KEBERGANTUNGAN INDEKS SAHAM MENGGUNAKAN FUNGSI COPULA
[image:3.552.36.479.76.702.2]SUATU SURVEI TENTANG
REGRESI BERBASIS KOPUL
I WAYAN SUMARJAYA'
' Jurusan Matematika Universitas Udayana, sumarj [email protected]. id
Extended abstract
Analisis regresi merupakan salah satu metode statistika yang paling sering digunakan. Pengembangan analisis regresi dalam bentuk model linear rampat (generalized linear model) telah sukses dalam memodelkan datayang melibatkan
peubah respons kontinu ataupun disket. Model linear rampat ini mengasumsikan
bahwa peubah respons termasuk dalam keluarga eksponensial. Namun, dalam
banyak aplikasi seperti dalam bidang asuransi dan manajemen risiko struktur kebergantungan yang diberikan keluarga eksponensial menjadi tidak fleksibel. Klugman et al.
|5)
memperluas konsep model linear rampat untuk distribusi selain anggota keluarga eksponensial. Perluasan lebih lanjut dilakukan oleh Venter [30] dengan aplikasi pada /oss reserve.Mengingat analisis regresi melibatkan hubungan antara dua peubah atau lebih, konsep kebergantungan (dependence) memegang peranan penting. Pada analisis regresi linear hubungan kebergantungan antarpeubah dinyatakan oleh korelasi. Namun, Embrechts et
al.
ll2l
dan [13] mengatakan bahwa pada dunia non-normal, korelasi bukanlah merupakan ukuran kebergantungan yang berguna.Kelemahan lain adalah korelasi tidaklah invarian dalam transformasi, yang mana
hal ini tidak terjadi pada kebergantungan berbasis kopula. Dalam konteks analisis regresi peranan penting kopula antara lain dalam memodelkan kebergantungan
nonlinear dan memisahkan pengaruh margin univariat.
Kolev and Paiva
[9]
telah mensurvei beberapa model regresi berbasis kopula. Namun, setelah tahun 2009 terdapat beberapa model atau ide baru tentang regresiberbasis kopula yang layak dibahas. Beberapa hasil tersebut antara lain regresi
kuantil-kopula, model berbasis kopula bersama, regresi kuadrat terkecil biasa
rampat dengan kopula normal, analisis regresi marginal kopula Gauss, dan regresi
berbasis kopula untuk data cacah. Mengingat regresi berbasis kopula termasuk
area riset yang aktif dan masih belum banyak diketahui dan diaplikasikan, maka survei ini dititikberatkan pada model-model tersebut dan aplikasinya.
1. Latar Belakang
Analisis regresi melibatkan hubungan antara dua peubah atau lebih. Hal ini berarti konsep kebergantungan (dependence) memegang peranan penting. Pada analisis regresi linear hubungan antarpeubah dinyatakan oleh korelasi. Namun, Embrechts
et al. [12] dan [13] mengatakan bahwa pada dunia/aplikasi nonnormal (noneliptik), korelasi bukanlah ukuran kebergantungan yang berguna. Lebih lanjut dalam [12] dan [13] setidaknya ada enam masalah penggunaan korelasi sebagai ukuran kebergantungan.
Ada tiga masalah penyalahgunaan korelasi yang sering ditemukan lihat [12], [13]. Pertama, distribusi marginal dan korelasi menentukan distribusi bersama. Hal ini tentu saja hanya berlaku untuk distribusi eliptik. Distribusi eliptik adalah distribusi yang densitasnya konstan pada ellipsoid dan pada dimensi dua gari kontur permukaan densitas adalah elips [12]. Penyalahgunaan selanjutnya adalah sebagai berikut: diberikan distribusi marginal F1 dan F2 untuk X dan Y, semua korelasi linear antara −1 dan 1 dapat diperoleh dengan spesifikasi yang sesuai dari distribusi bersama. Hal ini juga tidaklah benar. Embrechts et al. [12] mencontohkan jika X ~LOGN(0,1) dan Y ~LOGN(0,
σ
2) dengan σ2 >0, maka nilai) 1 ) )(exp( 1 ) 1 (exp(
1 ) exp(
2 min
− −
− − =
σ
σ
ρ
dan
) 1 ) )(exp( 1 ) 1 (exp(
1 ) exp(
2 max
− −
− =
σ
σ
ρ
yang tidak berada pada selang [−1,1]. Penyalahgunaan ketiga adalah pada saat kuantil untuk portofolio linear X +Y terjadi pada saat
ρ
(X +Y) maksimal. Embrechts [12] menegaskan bahwa ini juga hanya terjadi pada dunia eliptik. Berdasarkan kelemahan-kelemahan tersebut di atas diperlukan ukuran kebergantungan lain yang mampu memodelkan hubungan nonlinear. Salah satu cara untuk memodelkan struktur kebergantungan ini adalah dengan kopula. Kopula merupakan fungsi yang menggabungkan atau memasangkan fungsi distribusi multivariat dengan fungsi distribusi marginal satu dimensi.Artikel ini diatur sebagai berikut. Bagian pertama berisi motivasi kelemahan korelasi dalam memodelkan hubungan antarpeubah. Selanjutnya, bagian kedua berisi pengantar kopula dan ukuran Kendall
τ
dan Spearman ρ. Model-model regresi berbasis kopula dibahas pada bagian ketiga. Bagian keempat membahas teknik umum pendugaan parameter model. Bagian terakhir dari artikel adalah diskusi.2. Pengantar Kopula
Pada bagian ini akan dibicarakan konsep kopula. Pembahasan diawali dengan konsep kopula bivariat, kemudian dilanjutkan dengan kasus multivariat. Literatur standar tentang kopula dapat dibaca pada monograf [23] dan [5].
3
) Pr( )
(x X x
F = ≤ dan G(y)=Pr(Y ≤y) serta distribusi bersama
) , Pr( ) ,
(x y X xY y
H = ≤ ≤ . Untuk masing-masing bilangan real (x,y) dapat diasosiasikan tiga bilangan F(x), G(y), dan H(x,y). Sebagai catatan ketiga bilangan tersebut berada pada selang [0,1]. Hubungan antara F(x), G(y), dan
) , (x y
H dapat dijelaskan oleh Teorema Sklar untuk kasus bivariat berikut (lihat misalnya [23] dan [5]).
Teorema Sklar [23] Misalkan H(x,y) adalah fungsi distribusi bersama dengan margin F(x) dan G(y), maka terdapat suatu kopula C, sedemikian hingga untuk semua x, y di dalam garis real diperluas R=[−∞,∞]
)) ( ), ( ( ) ,
(x y C F x G y
H = . (1) Jika F(x) dan G(y) kontinu, maka Ctunggal (unique); jika tidak, C secara tunggal ditentukan pada ran F dan ran G. Sebaliknya, jika C adalah kopula dan
) (x
F serta G(y) adalah fungsi distribusi, maka fungsi H(x,y) adalah distribusi bersama dengan margin F(x) dan G(y).
Berdasarkan Teorema Sklar di atas dapat dilihat bahwa fungsi densitas peluang bersama dipisahkan menjadi marginal dan kopula, sehingga dalam hal ini kopula hanya menyatakan ”asosiasi” antara X dan Y [5]. Dengan demikian kopula memisahkan tingkah laku marginal yang diwakili oleh Fdan G dari asosiasi. Hal inilah yang menyebabkan kopula juga dikatakan fungsi kebergantungan (dependence function).
Contoh 1. Kopula Gauss C(u,v) didefinisikan oleh
, d d ) 1 ( 2 2 exp 1
2 1
)) ( ), ( ( ) , (
)
( ( )
2 2 2
2 1 1
1 1
t s t s st v
u N
v u C
u v
∫ ∫
− −
Φ
∞ −
Φ
∞ − − −
− − − − −
=
Φ Φ
=
ρ
ρ
ρ
π
ρdengan ρ adalah koefisien korelasi.
Contoh 2. Kelas kopula Archimedes (Archimedean copula) yang didefinisikan oleh
)) ( ) ( ( )
,
(u v [ 1] u v C =
ϕ
−ϕ
+ϕ
dengan
ϕ
[−1] adalah pseudo-invers dari pembangkit (generator)ϕ
. Contoh anggota kopula Archimedes adalah kopula Gumbel(
[( ln ) ( ln ) ])
, [1, ) exp) ,
(u v = − − u θ + − v θ 1/θ
θ
∈ ∞ Cdan kopula Frank
) [1, , ] ) 1 ( ) 1 ( ) 1 ( ) 1 [( 1 ) ,
(u v = − −u θ + −v θ − −u θ −v θ 1/θ
θ
∈ ∞C .
Kopula Gumbel merupakan salah satu kopula yang mampu menangkap kebergantungan ekor atas [11].
Definisi [5]. Densitas c(u,v) yang berasosiasi dengan kopula C(u,v) adalah . ) , ( ) , ( 2 v u v u C v u c ∂ ∂ ∂ =
Contoh 3. Fungsi densitas kopula Gauss adalah
− − − + + − = ) 1 ( 2 2 2 exp 1 1 ) , ( 2 2 2 2 1 2 1 2 2 2 1 2
ρ
ν
ν
ν
ρν
ν
ν
ρ
v u cdengan
ν
1=Φ−1(u) danν
2 =Φ−1(v).Pada vektor acak kontinu, densitas kopula c berhubungan dengan densitas f
dan fungsi distribusi F; lebih jelasnya hal ini sama dengan rasio densitas bersama
f yang merupakan produk dari densitas marginal fi,i=1 ,2, yakni
. ) ( ) ( ) , ( )) ( ), ( ( 2 1 2 1 y f x f y x f y F x F c =
Berdasarkan Teorema Sklar pada persamaan (1), hubungan di atas memunculkan representasi kanonik berikut
). ( ) ( )) ( ), ( ( ) ,
(x y c F1 x F2 y f1 x f2 y
f =
Selanjutnya perluasan Teorema Sklar untuk dimensi d dapat dilihat pada [23] dan [5]. Misalkan H adalah fungsi distribusi berdimensi d dengan margin
) ( , ), ( ), ( 2
1 x F x F x
F K d , maka terdapat kopula C berdimensi d sedemikian hingga
untuk semua x=(x1,x2,K,xd)∈Rd
)). ( , ), ( ), ( ( ) , , ,
(x1 x2 xd C F1 x1 F2 x1 Fd xd
H K = K
Jika F1(x1),F2(x1),K,Fd(xd) semuanya kontinu, maka C tunggal. Jika tidak C secara tunggal ditentukan pada ran F1×ran F2×Lran Fd. Sebaliknya, jika C adalah kopula berdimensi d dan F1(x1),F2(x1),K,Fd(xd) adalah fungsi distribusi, maka H adalah fungsi distribusi berdimensi d dengan margin
) ( , ), ( ), ( 1 2 1
1 x F x Fd xd
F K .
Contoh 4. Kopula Gauss C(u) multivariat didefinisikan oleh
d 1 ) ( ( ) 1 2 / 1 2
/ d d
2 1 exp | | ) 2 ( 1 ) ( 1 1 1 x x R R C u u T d d L L
∫
∫
− − Φ ∞ − Φ ∞ − − −= x x
u
π
dengan |R|1/2 adalah determinan.
Seperti halnya pada kasus bivariat densitas kopula dan representasi kanonik dapat dikembangkan sebagai berikut.
Definisi [5]. Densitas c(u1,K,ud) yang berasosiasi dengan kopula )
, , ,
(u1 u2 ud
5 . ) , , , ( ) , , ( 2 1 2 1 1 d d d d u u u u u C u u c ∂ ∂ ∂ ∂ = L K K
Demikian pula fungsi densitas f yang bersesuaian dengan densitas kopula diberikan oleh representasi kanonik
∏
= = d i i i d dd c F x F x F x f x x x x f 1 2 2 1 1 2
1, , , ) ( ( ), ( ), , ( )) ( )
( K K (2)
dengan . ) ( ) ( ) ( )) ( , ), ( ), ( ( )) ( , ), ( ), ( ( 2 2 1 1 2 2 1 1 2 2 1 1 d d d d d d d x F x F x F x F x F x F C x F x F x F c ∂ ∂ ∂ ∂ = K K K
Contoh 5. Representasi densitas kopula Gauss CGa(u) multivariat dapat dinyatakan sebagai − − = − ξ ξ
u ( )
2 1 exp | | 1 )
( 1/2 1
Ga
I R R
cR T
dengan ξ=(Φ−1(u1),Φ−1(u2),L,Φ−1(ud)).
Pada bagian sebelumnya salah satu kelemahan korelasi adalah tidak invarian dalam transformasi, sehingga diperlukan ukuran kebergantungan lain yang invarian seperti Kendall
τ
dan Spearman ρ.Definisi [5] Kendall
τ
untuk peubah acak X dan Y dengan kopula Cdidefinisikan sebagai
∫∫
× − = ] 1 , 0 [ ] 1 , 0[ ( , )d ( , ) 1.
4 C u v C u v
τ
Versi sampel Kendall
τ
dapat dihitung sebagai berikut (lihat [5]). ) )( sgn( ) 1 ( 2 1
∑∑
= > − − − ni j i
j i j
i X Y Y
X n
n
Definisi [5] Spearman
ρ
untuk peubah acak X dan Y dengan kopula Cdidefinisikan sebagai
∫∫
× − = ] 1 , 0 [ ] 1 , 0[ d ( , ) 3.
12 uv C u v
ρ
Untuk Spearman
ρ
versi sampel dihitung sebagai berikut (lihat [5])∑
∑
= = − − − − ni i i n
i i i
S S R R S S R R 1 2 2 1 ) ( ) ( ) )( (
dengan Ri =rank(Xi) dan Si =rank(Yi).
3. Model-model Regresi Berbasis Kopula
linear model, disingkat GLM). Namun, GLM memiliki keterbatasan yakni peubah takbebas harus berasal dari keluarga eksponensial. Pengembangan lebih lanjut GLM untuk distribusi selain keluarga eksponensial telah diusulkan oleh [15] dan dikembangkan lebih lanjut oleh [30]. Pada subbagian ini akan dibahas beberapa model regresi berbasis kopula. Dalam konteks analisis regresi peranan penting kopula antara lain dalam memodelkan kebergantungan nonlinear [26] dan memisahkan pengaruh margin univariat [28]. Selain itu, kopula invarian dalam transformasi [7].
Pembahasan model regresi pada subbagian berikut meliputi model regresi kuadrat terkecil biasa rampat dengan kopula Gauss [26], model regresi marginal kopula Gauss [22], Regresi berbasis kopula bersama [20], regresi kopula data cacah [24], dan regresi kuantil kopula [2].
3.1Model Regresi Kuadrat Terkecil Biasa Rampat dengan Kopula Gauss
Parsa dan Klugman [26] mengusulkan perluasan regresi kuadrat terkecil dengan kopula. Proses perluasan ini meliputi tiga langkah. Pertama, asumsikan suatu model untuk distribusi bersama untuk semua peubah, baik respons maupun kovariat. Kemudian, estimasi parameter model baik parameter pada distribusi marginal ataupun parameter kopula. Langkah terakhir, hitung nilai prediksi Y
bersyarat suatu himpunan kovariat dengan menggunakan nilai tengah bersyarat Y
diketahui kovariat yakni E(Y|X1=x1,K,Xk =xk).
Parsa dan Klugman [26] menggunakan fungsi kopula Gauss dengan mengasumsikan distribusi normal multivariat dengan nilai tengah nol, varians satu, dan matriks korelasi R. Menggunakan representasi kanonik kopula pada persamaan (2) diperoleh
. ) ( 2 1 exp | | 1 ) ( ) ( ) , , ,
( 1 2 = 1 1 1/2 − ξ R−1−I ξ
R x f x f x x x
f K d L d d T
Selanjutnya dihitung distribusi bersyarat xd diketahui x1,x2,K,xd−1 yakni
(
)
, ) 1 ( )) ( ( ( 1 ) ) ( ( 2 1 exp ) ( ) , , , | ( 2 / 1 1 1 2 1 1 1 2 * 1 1 1 1 2 1 − − − − − − − − − − − × Φ − − − Φ − = r R r x F r R r R r x F x f x x x x f n T d d n T n T d d d d d d ξ Kdengan ξ=(Φ−1(u1),Φ−1(u2),K,Φ−1(ud−1)) ,
= − 1 1 T d r r R
R , dan r adalah vektor
1 ) 1
(d− × adalah kolom paling kanan dari R dengan elemen terakhir dari elemen terakhir dihilangkan. Selanjutnya, dalam konteks regresi apabila xd diganti dengan y akan diperoleh
(
)
. ) 1 ( )) ( ( ( 1 ) ) ( ( 2 1 exp ) ( ) , , , | ( 2 / 1 1 1 2 1 1 1 2 * 1 1 1 1 2 1 − − − − − − − − − − − × Φ − − − Φ − = r R r y F r R r R r y F y f x x x y f n T n T n T d ξ K7 3.2Regresi Marginal Kopula Gauss
Masarotto dan Varin [22] mengusulkan kelas model kopula Gauss untuk analisis regresi marginal untuk data nonnormal berkorelasi. Kelas model ini memberikan perluasan alamiah dari model regresi linear tradisional dengan galat berkorelasi normal dengan respons kontinu, diskret, dan kategorik diperbolehkan. Misalkan
T n Y Y, , ) ( 1 K
=
Y adalah vektor peubah respons kontinu, diskret, ataupun kovariat
dan y=(y1,K,yn)T adalah realisasinya serta
T ip i
i =(x1,K,x )
x adalah vektor p
kovariat. Masarotto dan Varin [22] mengusulkan model regresi berbentuk ,
, , 1 ), , ,
( i n
g
Yi = xi εi λ = K
dengan (.)g adalah fungsi yang sesuai dari peubah bebas xi dan peubah stokastik yang tidak teramati εi. Diasumsikan bahwa model regresi di atas diketahui sampai dengan vektor parameter λ. Selanjutnya, salah satu spesifikasi yang mungkin untuk fungsi (.)g adalah
, , , 1 ), ); ( ( 1
n i
F
Yi = i− Φ εi λ = K (3)
dengan Fi(,;
λ
)=F(.|xi;λ
) adalah fungsi distribusi kumulatif normal Yi |xi, dan (.)Φ adalah fungsi distribusi normal. Dalam memodelkan kebergantungan diasumsikan ε=(ε1,K,εn)T adalah normal multivariat dengan nilai tengah nol dan matriks korelasi Ω yakni
) , 0 MVN(
~ Ω
ε . (4) Persamaan (3) di atas menspesifikasikan komponen marginal dan komponen kebergantungan dinyatakan oleh persamaan (4). Keluarga model yang melibatkan persamaan (3) dan (4) disebut regresi marginal kopula Gauss. Pada kasus kontinu pemetaan antara εi dan Yi pada (3) adalah satu-satu. Sebagai contoh pada kasus bivariat
), ; , ( ) ; ( ) ; ( ) ; ,
( i j θ i i λ j j λ i j θ
ij y y f y f y h
f = ε ε
dengan fi(yi;λ)= f(yi|xi;λ) , fj(yj;λ)= fj(yj|xj;λ), dan
) , ( ) , (
) ; , ( )
; , (
λ
ε
λ
ε
ε
ε
ε
ε
j i
j i j
i
f f
f
h θ = θ
adalah densitas kopula Gauss bivariat, f(
ε
i,λ
) adalah densitas normal baku bivariat, f(ε
i,ε
j;θ) adalah densitas normal bivariat dengan nilai tengah nol, varians satu, dan korelasi yang diberikan oleh elemen pada posisi (i, j) dalam matriks Ω. Untuk kasus diskret dan kategorik, pemetaan (3) tidaklah satu-satu melainkan banyak-satu (many-to-one) sehingga, d d ) , ( )
; , (
) ,
( ( , )
∫
∫
=
λ λ
θ
i i y j j D D y
j i j i j
i
ij y y f
f ε ε ε ε
dengan domain hasil kali Cartesius Di(yi,λ)=[Φ−1(Fi(yi−;λ)),Φ−1(Fi(yi;λ))], )
; ( i− λ i y
F adalah limit dari Fi(.;λ) pada yi dan = −1
−
i i y
y apabila support Yi
3.3Regresi Berbasis Kopula Bersama
Kramer et al. [20] mengusulkan model regresi berbasis kopula bersama dalam memodelkan kebergantungan antara ukuran klaim dan jumlah klaim dengan mengombinasikan distribusi marginal dari frekuensi klaim dan keparahan (severity) dengan kopula bivariat. Model yang diusulkan [20] merupakan pengembangan dari model [21] dan [8].
Konsep pemodelan kopula berdasarkan distribusi bersama adalah sebagai berikut. Misalkan X menyatakan peubah acak kontinu dan Y adalah peubah acak diskret. Diasumsikan Y bernilai 1,2,K. Distribusi bersama X dan Y
didefinisikan oleh kopula parametrik C(⋅,⋅|θ) yang tergantung pada parameter θ, yakni
). | ) ( ), ( ( ) | (
|
, θ x y C F x F y θ
FXY = X Y
Selanjutnya didefinisikan turunan parsial kopula terhadap peubah pertama yakni
). | , ( )
| , (
1 θ C u v θ
u v
u D
∂ ∂ =
Kemudian fungsi densitas peluang bersama fX,Y|θ(x,y|θ) dari peubah acak kontinu X dan diskret Y diberikan oleh
)]. | ) 1 ( ), ( ( ) | ) ( ), ( ( )[ ( ) | ,
( 1 1
|
, θ x y θ = f x D F x F y θ −D F x F y− θ
fXY X X Y X Y
Distribusi bersyarat Y |X =x dapat diperoleh dari model di atas dengan menerapkan aturan peluang bersyarat.
Dalam pemodelan polis kerugian (policy loss) didefinisikan kerugian L
sebagai perkalian antara rata-rata ukuran klaim X dan jumlah klaim Y sebagai
XY
L= dan fungsi densitas distribusi kerugian ini diberikan oleh
) | ( 1 )] | ) 1 ( ), ( ( ) | ) ( ), ( ( [ ) (
1
1
1
θ
θ
yθ
l X y
Y y l X Y
y l X
L f
y y
F F D y
F F D l
f
∑
∞ =
− −
=
untuk l>0. Persamaan ini diperoleh dengan memarginalkan sepanjang vektor peubah acak diskret l>0.
Dalam formulasi model, [20] menggunakan GLM untuk model regresi marginal dan mengombinasikannya dengan keluarga kopula bivariat.
3.4Regresi Kopula Data Cacah
Nikoloulopoulos dan Karlis [24] mengusulkan model regresi berbasis kopula dengan kovariat yang digunakan tidak saja untuk marginal tetapi juga parameter kopula. Biasanya kopula digunakan untuk analisis data kontinu karena kemampuannya memisahkan marginal dari sifat kebergantungan. Namun, hal ini tidaklah berlaku untuk data cacah karena terdapat perancu (confounding) antara margin univariat dan ukuran asosiasi [24]. Lebih lanjut, menurut [24] informasi kovariat yang berhubungan dengan kebergantungan ada tiga yaitu dengan menempatkan kovariat pada parameter-parameter marginal, pada parameter kopula, dan pada keduanya (marginal maupun kopula).
Misalkan model parametrik berbasis kopula bivariat untuk respons cacah Y1 dan Y2 dengan fungsi distribusi H yang diberikan oleh representasi
) ); , ( ); , ( ( ) ; , , ,
(y1 y2
α
1α
2θ
C F1 y1α
1 F2 y2α
2θ
9
dengan F1 dan F2 adalah distribusi marginal dengan vektor parameter
α
1danα
2 serta θ adalah parameter kopula. Misalkan akan diselidiki efek informasi kovariat pada struktur kebergantungan. Misalkan pula data (yij,xij),i=1,K,n;j=1,2, dengan i adalah indeks untuk individu, j adalah indeks untuk respons cacah, danij
x adalah vektor kovariat untuk individu ke-i yang berasosiasi dengan respons cacah ke-j. Kovariat xij dimasukkan pada model parametrik berbasis kopula dengan mengasumsikan model marginal univariat
) (.; ~ j ij ij F
y α
dengan
α
ij =(µ
ij =g(β
Tj xij,γ
j)), µijmenyatakan nilai tengah yang diparameterisasi oleh fungsi tautan (link function) yang sesuai g(.) untuk mengakomodasi kovariat, βj adalah vektor koefisien regresi, dan γj adalah vektor parameter marginal yang tidak tergantung pada kovariat. Selanjutnya bagian regresi untuk parameter kopula θ menggunakan fungsi kovariat (.)s pada θ, yakni s(θ)=bTxi.3.5Regresi Kuantil Kopula
Regresi klasik menitikberatkan pada nilai harapan peubah takbebas Y bersyarat pada nilai peubah X yang disebut fungsi regresi. Regresi kuantil tidak membatasi perhatian pada harapan bersyarat sehingga memungkinkan untuk mendekati distribusi bersyarat secara keseluruhan dari peubah respons [9]. Regresi kuantil muncul sebagai solusi dari peminimuman (minimization)
∑
=
∈ −
n
i
T i i x y p
1
) (
min ρτ β
β R
(lihat [17],[16], dan [18]).
Bouyé dan Salmon [2] mengusulkan pendekatan untuk memodelkan regresi kuantil nonlinear berdasarkan fungsi kopula yang mendefinisikan struktur kebergantungan antarpeubah yang diteliti. Lebih lanjut Bouyé dan Salmon [2] memperluas konsep regresi kuantil yang diusulkan oleh [17]. Perluasan ini dilakukan dengan menentukan distribusi untuk peubah acak respons Y bersyarat pada peubah bebas X dengan demikian menspesifikasikan fungsi regresi kuantil. Sebelum membahas model regresi kuantil terlebih dahulu didefinisikan kurva kuantil kopula ke-p.
Definisi [2]. Untuk suatu kopula parametrikC(⋅,⋅;θ) kurva kuantil kopula ke-p
dari y bersyarat pada x didefinisikan oleh persamaan berikut
), ); ( ), ( (
1 F x F y
δ
C
p= X Y (5) dengan θ∈Ω himpunan parameter dan C(u,v;θ)=∂C(u,v;θ)/∂u. Pada beberapa kondisi tertentu, seperti C1 harus terbalikkan sebagian (partially invertible), maka persamaan di atas dapat dinyatakan sebagai
), ; , ( p δ y=q x
dengan q(x,p;
δ
)=FY[−1](D(FX(x),p;δ
)).θ θ
θ
θ
1/) 1 ( ) ; ,
(u v = u− +v− − −
C memiliki kuantil kopula bersyarat Y|X (lihat [4])
(
θ/(1θ) θ 1/θ)
1 ) 1 ) ( ) 1 (( − + − − − − +
=F p F x
y Y X .
Selanjutnya regresi kuantil kopula didefinisikan sebagai berikut.
Definisi [2]. Regresi kuantil kopula ke-p q(xt,p;
δ
) adalah solusi dari masalah berikut: − − + −∑
∑
Τ∈ p ∈Τ−p
t t
t t t
t p p y p
y p 1 | ) ; , ( | ) 1 ( | ) ; , ( |
min
δ
δ
δ q x q x
dengan Τp ={t:yt ≥q(xt,p;δ} dan Τ1−p adalah komplemennya. Bentuk ini juga dapat dinyatakan sebagai
− −
∑
= ≤ ) ; , ( ( ) ( min 1 )} ; , ( { δ δδ p yt t p
T
t
p
yt t q x
1 qx .
Allen et al. [1] melakukan studi empiris terhadap enam pasangan data volatilitas-return dan menyimpulkan bahwa regresi kuantil berbasis kopula memberikan hasil yang lebih baik dibandingkan regresi kuantil biasa dalam hal menangkap ketidaklinearan hubungan volatilitas-return.
4. Estimasi Parameter
Secara umum metode pendugaan parameter dapat dilakukan secara parametrik, nonparametrik, dan semiparametrik.
4.1Metode Parametrik
Pada pendugaan parameter secara parametrik dapat dilakukan dengan menggunakan metode kemungkinan maksimum penuh (full maximum likelihood, disingkat FML), metode kemungkinan maksimum dua-tahap (two-step maximum likelihood, disingkat TSML), dan metode momen rampat (generalized method of moments, disingkat GMM). Subbagian hanya membahas metode FML dan TSML. Lihat kembali representasi kanonik pada persamaan (2) yakni
∏
= = d i i i d dd c F x F x F x f x x x x f 1 2 2 1 1 2
1, , , ) ( ( ), ( ), , ( )) ( )
( K K (6)
dengan . ) ( ) ( ) ( )) ( , ), ( ), ( ( )) ( , ), ( ), ( ( 2 2 1 1 2 2 1 1 2 2 1 1 d d d d d d d x F x F x F x F x F x F C x F x F x F c ∂ ∂ ∂ ∂ = K K K
Apabila diambil sampel acak berdistribusi saling bebas dan identik dari vektor )
, , ,
( 1( ) 2( ) ( )
) ( j d j j j x x x K =
x , j=1,2,K,n, maka likelihood dari bentuk kanonik di
pada (6) adalah
∏
∏
∏
= = = = n j d i i i d d n j j d j j x f x F x F x F c x x x f 1 1 2 2 1 1 1 ) ( ) ( 2 ) (1 , , , ) ( ( ), ( ), , ( )) ( )
( K K
11 . ) ( log )) ( , ), ( ), ( ( log ) , , , ( log 1 1 ) ( ) ( ) ( 1 2 ) ( 1 1 1 ) ( ) ( 2 ) ( 1 1
∑∑
∑
∑
= = = = + = d i n j j i i j d d j j n j j d j j n j x f x F x F x F c x x xf K K
(7)
Kemudian tuliskan likelihood =
∑
n=j j d j j x x x f L 1 ) ( ) ( 2 ) (
1 , , , )
(
log K , likelihood dari
struktur kebergantungan =
∑
n=j j d d j j
C c F x F x F x
L 1 ) ( ) ( 1 2 ) ( 1
1( ), ( ), , ( ))
(
log K , dan
likelihood dari masing-masing margin =
∑
n=j
j i i i f x
L 1 ) ( ) (
log . Dengan demikian
representasi bentuk kanonik di atas dapat dituliskan sebagai
∑
= + = d i i C L L L 1 .Misalkan kopula C adalah anggota dari keluarga kopula yang diindeks oleh parameter θ yakni C(u1,u2,K,ud;
θ
) dan margini
F serta densitas univariat fi
diindeks oleh parameter
β
i yakni Fi =Fi(xi;β
i) dan fi = fi(xi;β
i). Penduga kemungkinan maksimum parameter model (β
1,K,β
d) adalah∑∑
∑
= = = + = = d i n j i j i i d j d d j n j d d x f x F x F c L d d 1 1 ) ( ) ( 1 ) ( 1 1 1 , , 1 , , MLE MLE MLE 2 MLE 1 ). , ( log ) ); , ( , ), , ( ( log max arg ) ; , , ( max arg ) ˆ ; ˆ , , ˆ , ˆ ( 1 1β
θ
β
β
θ
β
β
θ
β
β
β
β β β β K K K K KMetode alternatif untuk mengestimasi likelihood (7) adalah metode inference function for margin (IFM) (lihat [29] atau [6]). IFM meliputi dua tahap. Pada tahap pertama, penduga
β
ˆiIFM diestimasi dari log-likelihood Li pada masing-masing margin ) ( max arg ˆIFM i i i L i β β β =dengan demikian
β
ˆ1IFM,β
ˆ2IFM,K,β
ˆdIFM didefinisikan sebagai MLE dari parametermodel dalam asumsi kebebasan. Pada tahap kedua penduga θˆIFM dari persamaan
kopula θIFM dihitung dengan memaksimumkan kontribusi likelihood LC dengan
parameter marginal βi diganti dengan penduga tahap pertama
). ; ˆ , , ˆ , ˆ ( max arg
ˆ IFM IFM
2 IFM 1
IFM β β β θ
β
θ C d
i L
i
K
=
Pada kondisi regularitas tertentu penduga MLE 2MLE MLE MLE MLE
1 , ˆ , , ˆ ,ˆ
ˆ
β
β
θ
β
K d adalahsolusi dari . 0 , , , , 2 1 = ∂ ∂ ∂ ∂ ∂ ∂ ∂ ∂
θ
β
β
β
L L L L d Kpenyelesaian
. 0 ,
, , ,
2 2
1
1 =
∂ ∂ ∂ ∂ ∂
∂ ∂ ∂
θ
β
β
β
L L L
L
d d L
Strategi alternatif penghitungan likelihood adalah algoritma maximation by parts
(MBP) yang diusulkan Song [27] (lihat juga [29]). Langkah pertama adalah
mendapatkan estimasi awal (
β
1,K,β
d) dengan memaksimumkan∑
=
d
i 1Li dengan kata lain mengabaikan kebergantungan. Langkah selanjutnya adalah mencari solusi untuk θ. Estimasi awal mengabaikan kebergantungan jadi tidak efisien. Solusi iteratif (β1MBP,β2MBP,K,βdMBP) memberikan suatu estimasi θ. Kemudian θ diberikan estimasi (β1,K,βd) menghasilkan estimasi efisien karena prosedur ini mempertimbangkan kebergantungan. Lebih lanjut jika tidak terdapat kebergantungan, langkah pertama penduga adalah efisien.
4.2Metode Semiparametrik
Metode pendugaan semiparametrik meliputi dua tahap. Pada tahap pertama margin univariat Fi diestimasi secara nonparametrik, yakni dengan distribusi
empiris Fˆi atau versi skalanya. Pada tahap kedua, parameter kopula diestimasi dari fungsi likelihood LC yakni
) ); ( , ), ( ), ( ( log max arg
) ( max arg ˆ
) ( )
( 1 2 ) ( 1 1 1
θ
θ
θ
θ θ
j d d j
j n
j C
x F x
F x F c L
K
∑
=
= =
dengan Fˆi adalah penduga nonparametrik margin univariat Fˆi .
Noh et al. [25] mengusulkan pendekatan semiparametrik dalam menduga regresi berbasis kopula; kopula dimodelkan secara parametrik tetapi distribusi marginal dimodelkan secara parametrik. Kelebihan metode ini adalah keluwesannya dan juga tidak terlalu dipengaruhi oleh curse of dimensionality. Dette et al.[10] memperingatkan pentingnya spesifikasi model. Lebih lanjut, jika salah dalam menspesifikasikan struktur kopula sebenarnya, seringkali pendekatan ini tidak menghasilkan estimasi yang dapat dipercaya.
4.3Metode Nonparametrik
Prosedur estimasi nonparametrik untuk kopula berdasarkan formula invers dari kopula empiris
)) ( ˆ , ), ( ˆ ), ( ˆ ( ˆ ) , , , (
ˆ 1
2 1 2 1 1 1 2
1 u ud F F u F u Fd ud
u
C K = − − K −
dengan Fˆ adalah penduga nonparametric dari fungsi distribusi F berdimensi d
dan Fˆ1−1(u1),Fˆ2−1(u2),K,Fˆd−1(ud) adalah penduga nonparametrik dari
pseudo-invers Fi 1(s)={t:Fi(t)≥s}
−
dari margin univariat F1,F2,K,Fd. Biasanya fungsi
13
∑
=
≤ ≤
≤
= T
t
d d d I X x X x X x
T x x x F
1
2 2 1 1 2
1 ( , , , )
1 ) , , , (
ˆ K K
estimasi pseudo-invers Fˆi−1(s)={t:Fˆi(t)≥s} dan distribusi univariat empiris
∑
= ≤ = Tt i i T I X x
F
1
1 ( )
ˆ . Pendugaan kopula dengan metode nonparametrik dapat
dilihat pada [3].
5. Diskusi
Pada bagian ini dibahas hal-hal yang layak menjadi bahan diskusi. Hal pertama adalah penerapan kopula pada kasus diskret. Genest dan Nešlehová [14]
menegaskan bahwa bahaya dan keterbatasan dalam memodelkan dan inferensi dari kasus kontinu ke kasus diskret.
Hal berikutnya, meskipun konsep kopula dipahami dengan baik, estimasi empirisnya lebih susah dan banyak perangkap dan kesulitan teknis dan biasanya hal ini diabaikan atau dianggap remeh oleh praktisi (lihat [3]).
Daftar Pustaka
[1] Allen, D. E., Singh, A. K., Powell, R. J., McAleer, M., Taylor, J. and Thomas, L.The Volatility-Return Relationship: Insights from Linear and Non-linear Quantile Regression, Working Paper 1201, School of Accounting, Finance and Economics & FEMARC Working Paper Series, Edith Cowan University, 2012.
[2] Bouyé, E. and Salmon, M. Dynamic Copula Quantile Regressions and Tail Area Dynamic Dependence in Forex Markets, The European Journal of Finance, 15, 721—750, 2009.
[3] Charpentier, A., Fermanian, J-D. and Scaillet. The Estimation of Copulas: Theory and Practice. In Copulas: From Theory to Application in Finance, Jörn Rank (eds), Wiley, 2006.
[4] Cherubini, U., Gobbi, F., Mulinacci, S. and Romagnoli, S. Dynamic Copula Methods in Finance, John Wiley & Sons, 2012.
[5] Cherubini, U., Luciano, E., and Vecchiato, W. Copula Methods in Finance, John Wiley and Sons, 2004.
[6] Choroś, B., Ibragimov, R. and Permiakova, E. Copula Estimation.
in: Workshop on Copula Theory and its Applications, Durante, F., Härdle, W., Jaworski, P. , Rychlik, T., (eds.), Springer, Dortrecht (NL), 2010.
[7] Crane, G. J. and van der Hoek, J., Conditional Expectation Formulae for Copulas,
Aust. N. Z. J. Stat., 50, 53—67, 2008.
[8] Czado, C., Kastenmeier, R., Brechmann, E., Min, A. A Mixed Copula Model for Insurance Claims and Claim Sizes, Scandinavian Actuarial Journal, 4, 278—305, 2012.
[9] Davino, C., Furno, M., and Vistocco, D. Quantile Regression: Theory and Applications, John Wiley and Sons, 2014.
[10] Dette, H., Van Hecke, R. and Volgushev, S. Misspecification in Copula-based Regression, arXiv: 1310.8037v1[stat.ME], 30 October, 2013.
[11] Embrechts, P. and Hofert, M., Statistics and Quantitative Risk Management for Banking and Insurance, Annual Review of Statistics and Its Application, 1, 493— 513, 2014.
at Risk and Beyond, ed. M. Dempster, 176—223, New York, Cambridge University Press, 1999.
[13] Embrechts, P., McNeil, A. and Straumann, D. Correlation and Dependence in Risk Management: Properties and Pitfalls, Risk Management: Value at Risk and Beyond, ed. M. Dempster, 176—223, New York, Cambridge University Press, 2002. [14] Genest, C. and Nešlehová, A Primer on Copulas for Count, Astin Bulletin, 37,
475—515, 2007.
[15] Klugman, S., Panjer, H. and Willmot, G. Loss Models: From Data to Decisions, Second Edition, New York, Wiley, 2004.
[16] Koenker, R. Quantile Regression, Cambridge, Cambridge University Press, 2005. [17] Koenker, R. and Bassett, G., Regression Quantiles, Econometrica, 46,33—50,
1979.
[18] Koenker, R. and Hallock, K. F., Quantile Regression, EJournal of Economic Perspectives, 15,143—156, 2001.
[19] Kolev, N. and Paiva, D., Copula-based Regression Models: a Survey, Journal of Statistical Planning and Inference, 139,3847—3856, 2009.
[20] Krämer, N., Brechmann, E. C., Silvestrini, D. and Czado, C.,Total Loss Estimation Using Copula-based Regression Models, Insurance: Mathematics and Economics,
53, 829—839,2013.
[21] de Leon, A. R. and Wu, B., Copula-based Regression Models for a Bivariate Mixed Discrete and Continuous Outcome, Statistics in Medicine, 30, 175—185,2010. [22] Masarotto, G. and Varin, C., Gaussian Copula Marginal Regression. Electronic
Journal of Statistics, 6,1517—1549, 2012.
[23] Nelsen, R. B., An Introduction to Copulas, Second Edition, New York, Springer, 2006.
[24] Nikoloulopoulos, A. K. and Karlis, D., Regression in a Copula Model for Bivariate Count Data. Journal of Applied Statistics, 37, 1555—1568, 2010.
[25] Noh, H., El Ghouch, A. and Bouezmarni, T., Copula-based Regression Estimation and Inference, Journal of the American Statistical Association, 108, 676—688, 2013.
[26] Parsa, R. A., and Klugman, S. A., Copula Regression, Variance: Advancing the Science of Risk, 5, 45—54, 2011.
[27] Song, P. X. K., Fan, Y. and Kalbfleisch, J. D, Maximation by Parts in Likelihood Inference, Journal of the American Statistical Association, 100, 1145—1158, 2005. [28] Sungur, E. A., Some Observations on Copula Regression Functions,
Communication in Statistics—Theory and Methods, 34, 1967—1978, 2006. [29] Trivedi, P. K. and Zimmer, D. M. Copula Modelling: An Introduction for
Practitioners, Foundation and Trends in Econometrics, 1, 1—111, 2005. [30] Venter, G. G., Generalized Linear Models Beyond the Exponential Family with
Sertfut
#"'
**
ils
lr L
.o.
L*.
.-I
Wayan
Sumariaya
Sebagai :
PENYAJI
MAKAIAH
Dengan
Judul
Suatu Survei
Tentang
Regresi
Berhasis Kopula
l3Juni?{J.14
M.Sa
IrrY'
tr.Eftdi NuraniR.1223 198803 2 001