Transformasi data, mengubah data ke bentuk yang dapat di-mine sesuai dengan perangkat lunak yang digunakan pada penelitian.
Penentuan Data Latih dan Data Uji
Dalam penelitian ini data terdapat dua metode uji yang digunakan yaitu pembagian data latih dan data uji dengan proporsi 70% data latih dan 30% data uji dan metode uji 10-fold cross validation.
Aplikasi Teknik Klasifikasi
Tahapan ini merupakan tahap yang penting karena pada tahap ini teknik klasifikasi diaplikasikan terhadap data. Teknik klasifikasi yang digunakan adalah k-Nearest Neighbor.
Langkah-langkah pada metode tersebut yaitu:
Hitung jarak Euclidean: Pada tahap ini setiap data uji akan dihitung jaraknya ke setiap data latih untuk mengetahui ukuran kedekatan atau ukuran kesamaan antara data uji dengan data latih.
Penentuan nilai k: Hal terpenting pada k- Nearest Neighbor adalah menentukan nilai yang tepat untuk k yang menunjukan jumlah tetangga terdekat.
Majority voting: Penentuan kelas target untuk data uji berdasarkan kelas yang utama pada tetangga terdekat.
Jenis Percobaan dan Evaluasi Keluaran Dalam penelitian ini dilakukan beberapa bentuk percobaan yang dibedakan berdasarkan jenis dataset dan metode pembagian data latih dan data uji. Jenis-jenis percobaan tersebut adalah:
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target tidak sama dengan metode uji 70% data latih dan 30% data uji.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target tidak sama dengan metode uji 10-fold cross validation.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target sama dengan metode uji 70% data latih dan 30% data uji.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target sama dengan metode uji 10-fold cross validation.
Selanjutnya akan dibentuk tabel confusion matrix dari setiap classifier untuk mengevaluasi
klasifikasi yang dihasilkan metode k-Nearest Neighbor.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
a Perangkat keras berupa komputer personal dengan spesifikasi:
Prosesor Intel(R) Pentium(R) D CPU 2.80 GHz (2 CPUs)
Memori DDR2 512 MB Harddisk 80 GB Keyboard dan mouse Monitor
b Perangkat Lunak
Sistem operasi Windows XP Professional
Microsoft Excel 2007 sebagai media merapihkan data
Microsoft Access 2007 sebagai media penggabungan data, pembersihan data, transformasi data
QtOctave 0.7.2 untuk menjalankan metode k-Nearest neighbor
HASIL DAN PEMBAHASAN Data
Data IPK dengan format spreadsheet Excel terdiri dari 2989 record dan 4 atribut (Nama, NRP, IPK, dan Status Studi). Sedangkan data Biodata dengan format spreadsheet Excel terdiri dari 3010 record dan 41 atribut (NRP, jalur masuk, jenis kelamin, tempat lahir, tanggal lahir, status kawin, warganegara, agama, nama ayah, tahun lahir ayah, pendidikan ayah, pekerjaan ayah, pendapatan orang tua, nama ibu, tahun lahir ibu, pendidikan ibu, pendidikan orang tua, pekerjaan ibu, alamat orang tua, kode pos, wilayah telp orang tua, nomor telp orang tua, nama wali, alamat wali, nama darurat, alamat darurat, nomor telp darurat, nomor SMA, nama SMA, nomor induk, status SMA, tahun ijazah, jumlah mata pelajaran UAN, nilai UAN, prestasi, minat/hobi, listrik, golongan darah, tinggi badan, berat badan, dan riwayat kesehatan).
Penggabungan dan Pembersihan Data Data IPK dan Biodata digabung menggunakan Microsoft Access berdasarkan kesamaan NRP pada kedua data. Pada data hasil gabungan data IPK dan Biodata ditambahkan
atribut baru yaitu atribut jurusan dengan ketentuan berdasarkan tabel kode jurusan mayor IPB tahun akademik 2007/2008 (Lampiran 1), penambahan atribut asal daerah berdasarkan asal SMA. Penentuan asal daerah sesuai dengan ketentuan pada Lampiran 2. Selain itu ditambahkan juga kolom kelas target yang ditentukan berdasarkan IPK dengan ketentuan:
resiko rendah (IPK≥2.76), resiko sedang (2≤IPK<2.76), dan resiko tinggi (IPK<2).
Selanjutnya dilakukan pemilihan atribut.
Atribut yang tidak relevan dan atribut yang banyak mengandung missing value akan dihilangkan. Semua atribut terpilih yang bertipe nominal dan kelas target dikategorikan sesuai dengan ketentuan pada pada Lampiran 3.
Record yang mengandung nilai kosong dan atau duplikat dihapus. Hasil akhir dari proses penggabungan data IPK dan Biodata terdiri dari 2785 record serta 9 atribut (jurusan, asal daerah, jalur masuk, jenis kelamin, pendapatan orang tua, pendidikan orang tua, nilai uan SMA, hobi, dan riwayat kesehatan) serta kolom kelas target.
Pemilihan Data
Dari 9 atribut yang ada akan dilakukan pemilihan atribut lagi menggunakan uji hipotesis statistika yaitu uji kebebasan chi- square dan uji korelasi peringkat Spearman. Uji kebebasan diterapkan untuk atribut yang bertipe nominal (jurusan, asal daerah, jalur masuk, jenis kelamin, pendapatan orang tua, pendidikan orang tua, hobi, dan riwayat kesehatan) sedangkan uji Spearman diterapkan untuk atribut yang bertipe numerik (nilai uan SMA).
Uji kebebasan dan uji Spearman dilakukan untuk melihat hubungan antara setiap atribut dengan kelas target, apakah berpengaruh atau tidak. Jika berdasarkan uji yang dilakukan suatu atribut dinyatakan tidak berpengaruh, maka atribut tersebut dihilangkan, dan sebaliknya.
Dalam hal ini, kelas target menunjukkan tingkat keberhasilan mahasiswa.
Berikut merupakan salah satu contoh penerapan uji kebebasan pada atribut jenis kelamin. Penentuan hipotesis:
H0 : jenis kelamin tidak berhubungan dengan kelas target
H1 : jenis kelamin berhubungan dengan kelas target
Sebelum dilakukan uji kebebasan, dibuat tabel kontingensi terlebih dahulu antara setiap atribut dengan kelas target. Tabel kontingensi antara atribut jenis kelamin dan kelas target
dapat dilihat pada Tabel 2, sedangkan tabel kontingensi atribut lainnya dapat dilihat pada Lampiran 4.
Tabel 2 Tabel kontingensi antara jenis kelamin dan kelas target
Jenis kelamin
Kelas target Total Resiko
rendah
Resiko sedang
Resiko tinggi
Perempuan 978 569 139 1686
Laki-laki 517 418 164 1099
Total 1495 987 303 2785
Selanjutnya, dihitung nilai frekuensi harapan (Eij) dan nilai chi-square ( 2) dari setiap tabel kontingensi. Hasil perhitungan Eij dan 2hitung untuk atribut jenis kelamin diperlihatkan pada Tabel 3.
Tabel 3 Nilai frekuensi harapan dan chi-square atribut jenis kelamin
Ei1 Ei2 Ei3 i12
i22 i32
905.052 597.516 183.432 5.879 1.360 10.762 589.947 389.484 119.568 9.020 2.087 16.511
2hitung 45.622
2 (db, α) = 2 (2, 0.05)
5.99
Jenis kelamin memiliki 2 level (perempuan dan laki-laki) dan kelas target memiliki 3 level (resiko rendah, resiko sedang, resiko tinggi) maka besarnya derajat bebas=(2-1) (3-1)=2.
Nilai α yang digunakan yaitu sebesar 0.05.
Berdasarkan Tabel 3, nilai 2hitung> 2(2, α).
Oleh karena itu, dapat disimpulkan bahwa pada taraf nyata α = 0.05, peubah jenis kelamin berpengaruh terhadap atribut kelas target. Untuk nilai frekuensi harapan dan chi-square atribut lainnya dapat dilihat pada Lampiran 5.
Berdasarkan uji hipotesis yang telah dilakukan terhadap seluruh atribut, diperoleh hasil yang diperlihatkan pada Tabel 4.
Tabel 4 Hasil uji hipotesis
Atribut Keterangan terhadap kelas target
Jurusan Berpengaruh
Asal daerah Berpengaruh
Jalur masuk Berpengaruh
Jenis kelamin Berpengaruh
Pendapatan Tidak Berpengaruh Pendidikan orang tua Tidak Berpengaruh
Hobi Berpengaruh
Riwayat kesehatan Tidak Berpengaruh Nilai uan sma Berpengaruh
Data akhir yang dihasilkan terdiri dari 2785 record dan 6 atribut yang berdasarkan uji hipotesis berpengaruh, yaitu: jurusan, asal daerah, jalur masuk, jenis kelamin, hobi, dan nilai uan SMA serta satu kolom kelas target.
Dari 6 atribut yang digunakan pada penelitian ini 5 diantaranya merupakan data nominal yaitu:
jurusan, asal daerah, jalur masuk, jenis kelamin, dan hobi. Sedangkan atribut nilai uan SMA merupakan data numerik. Pada atribut nilai uan SMA terdapat 10 record yang tidak relevan sehingga data yang digunakan dalam proses data mining terdiri dari 2775 record dan 6 atribut.
Transformasi Data
Karena adanya perbedaan range antar atribut maka perlu dilakukan normalisasi.
Normalisasi yang dilakukan bergantung jenis datanya.
Untuk atribut nilai uan SMA yang bertipe numerik, normalisasi menggunakan min-max normalization. Nilai maksimum atribut nilai uan SMA sebesar 29,67 sedangkan nilai minimum sebesar 17.13. Contoh normalisasi untuk record pertama berdasarkan rumus normalisasi (persamaan 3) adalah:
Meskipun atribut nilai uan SMA bertipe numerik tetapi bisa dinormalisasi dengan rumus tersebut karena atribut numerik termasuk dalam atribut kontinu.
Pada penelitian ini perangkat lunak yang digunakan adalah QtOctave sehingga data yang digunakan disimpan dalam format yang dapat diolah dalam QtOctave yaitu format txt atau .m.
Octave merupakan suatu perangkat lunak tiruan dari Matlab untuk komputasi numerik dan visualisasi data sedangkan QtOctave merupakan sebuah antar muka grafis yang dikembangkan untuk program Octave. Antar muka grafis ini dikembangkan untuk menambahkan beberapa fasilitas yang tidak terdapat pada program Octave yang langsung dijalankan dari shell command sehingga program Octave lebih mudah digunakan. Pada QtOctave, perintah- perintah yang diberikan tidak dimasukkan secara langsung pada baris perintah, melainkan pada kotak teks masukkan yang terdapat pada bagian bawah dari jendela QtOctave.
Aplikasi Teknik Klasifikasi
Dari total data sebanyak 2775 record, diambil 1% data dari setiap kelas target yang akan dihilangkan kelas targetnya sebagai data
tanpa label kelas yang akan diterapkan pada classifier terbaik. Jadi dataset untuk pembagian data latih dan data uji sebanyak 2747 record.
Pada percobaan pertama, menggunakan seluruh dataset sebanyak 2747 record yang proporsi record pada setiap kelas target tidak sama dan metode uji yang digunakan 70%
sebagai data latih sedangkan sisanya sebanyak 30% sebagai data uji. Jumlah record untuk data latih dan data uji dari setiap kelas diperlihatkan Tabel 5.
Tabel 5 Jumlah record data latih dan data uji percobaan 1
Data latih Data uji Kelas 1 1033 record 443 record Kelas 2 682 record 292 record Kelas 3 208 record 89 record
Total 1923 record 824 record
Data tersebut kemudian diterapkan dalam metode k-Nearest Neighbor melalui tahap-tahap berikut ini:
1 Setiap record data uji dihitung jaraknya ke setiap record data latih untuk mengetahui ukuran kedekatan antara data uji dengan data latih. Untuk data bertipe nominal, selisih antara data uji dengan data latih dilihat dari kesamaan nilai kedua data. Jika nilai data uji sama dengan nilai data latih maka selisihnya 0, tetapi jika nilai data uji berbeda dengan nilai data latih maka selisihnya adalah 1. Untuk data bertipe numerik, selisih antara data uji dengan data latih adalah pengurangan nilai data uji dengan nilai data latih.
2 Penentuan nilai k tetangga terdekat pada percobaan 1 dilakukan dengan mencoba nilai k mulai dari 5 sampai 70 dengan selang 5 angka dalam metode k-Nearest Neighbor.
Pada setiap percobaan dengan suatu nilai k dihitung akurasi classifier dan sebaran kelas target ditampilkan dalam histogram.
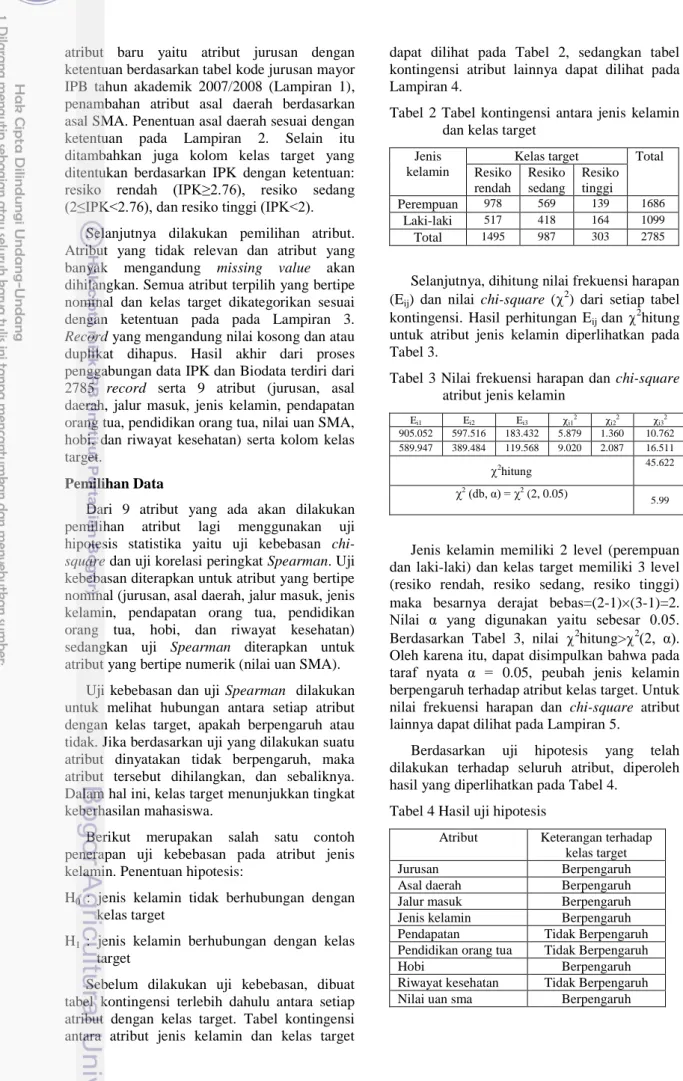
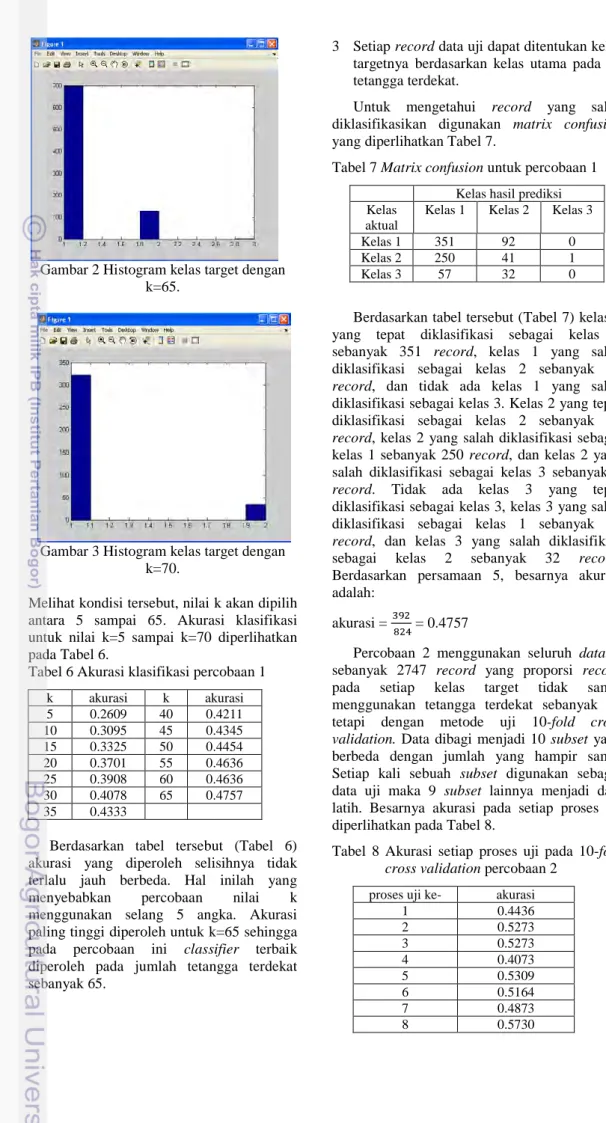
Berdasarkan percobaan sampai nilai k=65, diperoleh bahwa sebaran kelas target mencakup ketiga kelas yaitu resiko rendah, sedang, dan tinggi. Jika nilai k dinaikkan menjadi 70, maka sebaran kelas target untuk kelas 3 (resiko tinggi) tidak tercakup seperti diperlihatkan Gambar 2 dan Gambar 3
Gambar 2 Histogram kelas target dengan k=65.
Gambar 3 Histogram kelas target dengan k=70.
Melihat kondisi tersebut, nilai k akan dipilih antara 5 sampai 65. Akurasi klasifikasi untuk nilai k=5 sampai k=70 diperlihatkan pada Tabel 6.
Tabel 6 Akurasi klasifikasi percobaan 1
k akurasi k akurasi
5 0.2609 40 0.4211
10 0.3095 45 0.4345
15 0.3325 50 0.4454
20 0.3701 55 0.4636
25 0.3908 60 0.4636
30 0.4078 65 0.4757
35 0.4333
Berdasarkan tabel tersebut (Tabel 6) akurasi yang diperoleh selisihnya tidak terlalu jauh berbeda. Hal inilah yang menyebabkan percobaan nilai k menggunakan selang 5 angka. Akurasi paling tinggi diperoleh untuk k=65 sehingga pada percobaan ini classifier terbaik diperoleh pada jumlah tetangga terdekat sebanyak 65.
3 Setiap record data uji dapat ditentukan kelas targetnya berdasarkan kelas utama pada 65 tetangga terdekat.
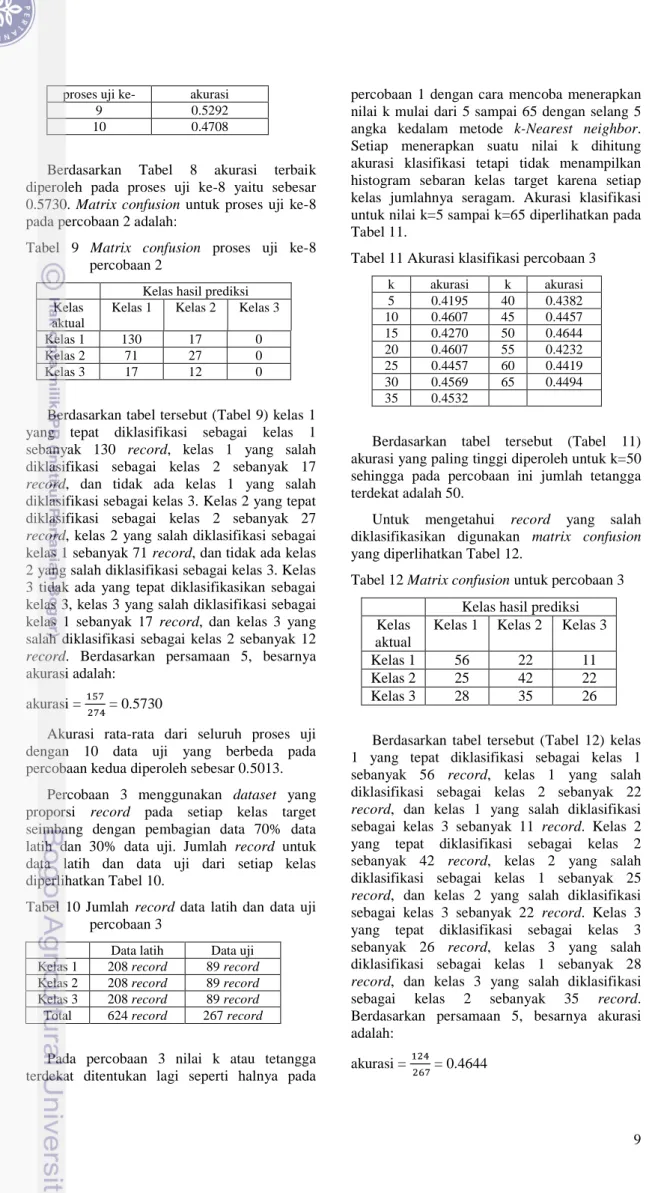
Untuk mengetahui record yang salah diklasifikasikan digunakan matrix confusion yang diperlihatkan Tabel 7.
Tabel 7 Matrix confusion untuk percobaan 1 Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 351 92 0
Kelas 2 250 41 1
Kelas 3 57 32 0
Berdasarkan tabel tersebut (Tabel 7) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 351 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 92 record, dan tidak ada kelas 1 yang salah diklasifikasi sebagai kelas 3. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 41 record, kelas 2 yang salah diklasifikasi sebagai kelas 1 sebanyak 250 record, dan kelas 2 yang salah diklasifikasi sebagai kelas 3 sebanyak 1 record. Tidak ada kelas 3 yang tepat diklasifikasi sebagai kelas 3, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 57 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 32 record.
Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.4757
Percobaan 2 menggunakan seluruh dataset sebanyak 2747 record yang proporsi record pada setiap kelas target tidak sama, menggunakan tetangga terdekat sebanyak 65 tetapi dengan metode uji 10-fold cross validation. Data dibagi menjadi 10 subset yang berbeda dengan jumlah yang hampir sama.
Setiap kali sebuah subset digunakan sebagai data uji maka 9 subset lainnya menjadi data latih. Besarnya akurasi pada setiap proses uji diperlihatkan pada Tabel 8.
Tabel 8 Akurasi setiap proses uji pada 10-fold cross validation percobaan 2
proses uji ke- akurasi
1 0.4436
2 0.5273
3 0.5273
4 0.4073
5 0.5309
6 0.5164
7 0.4873
8 0.5730
proses uji ke- akurasi
9 0.5292
10 0.4708
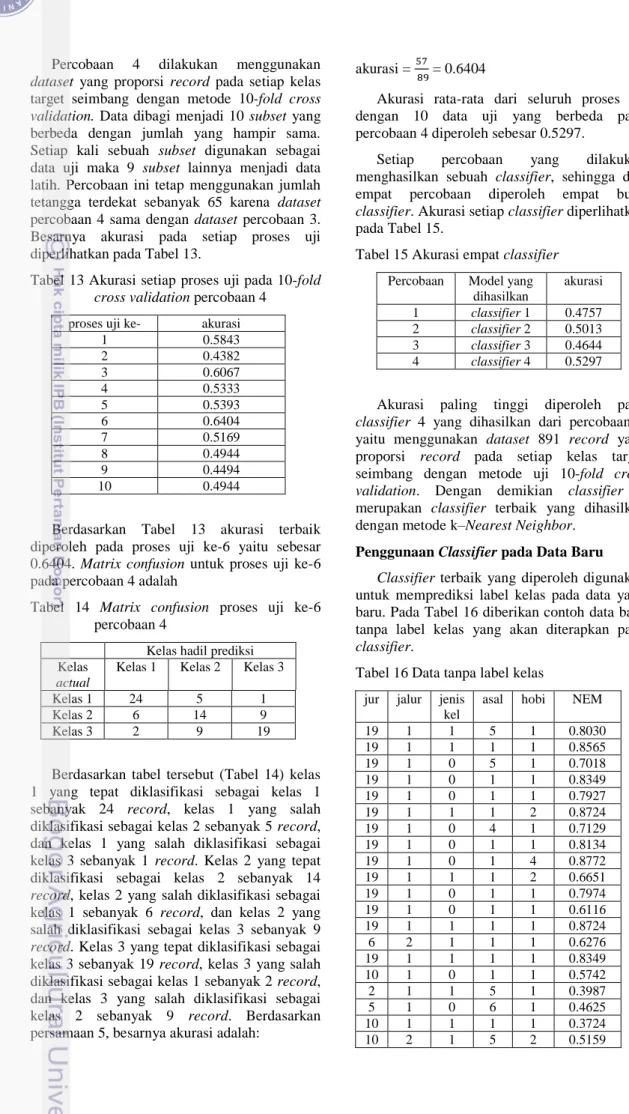
Berdasarkan Tabel 8 akurasi terbaik diperoleh pada proses uji ke-8 yaitu sebesar 0.5730. Matrix confusion untuk proses uji ke-8 pada percobaan 2 adalah:
Tabel 9 Matrix confusion proses uji ke-8 percobaan 2
Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 130 17 0
Kelas 2 71 27 0
Kelas 3 17 12 0
Berdasarkan tabel tersebut (Tabel 9) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 130 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 17 record, dan tidak ada kelas 1 yang salah diklasifikasi sebagai kelas 3. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 27 record, kelas 2 yang salah diklasifikasi sebagai kelas 1 sebanyak 71 record, dan tidak ada kelas 2 yang salah diklasifikasi sebagai kelas 3. Kelas 3 tidak ada yang tepat diklasifikasikan sebagai kelas 3, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 17 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 12 record. Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.5730
Akurasi rata-rata dari seluruh proses uji dengan 10 data uji yang berbeda pada percobaan kedua diperoleh sebesar 0.5013.
Percobaan 3 menggunakan dataset yang proporsi record pada setiap kelas target seimbang dengan pembagian data 70% data latih dan 30% data uji. Jumlah record untuk data latih dan data uji dari setiap kelas diperlihatkan Tabel 10.
Tabel 10 Jumlah record data latih dan data uji percobaan 3
Data latih Data uji Kelas 1 208 record 89 record Kelas 2 208 record 89 record Kelas 3 208 record 89 record Total 624 record 267 record
Pada percobaan 3 nilai k atau tetangga terdekat ditentukan lagi seperti halnya pada
percobaan 1 dengan cara mencoba menerapkan nilai k mulai dari 5 sampai 65 dengan selang 5 angka kedalam metode k-Nearest neighbor.
Setiap menerapkan suatu nilai k dihitung akurasi klasifikasi tetapi tidak menampilkan histogram sebaran kelas target karena setiap kelas jumlahnya seragam. Akurasi klasifikasi untuk nilai k=5 sampai k=65 diperlihatkan pada Tabel 11.
Tabel 11 Akurasi klasifikasi percobaan 3
k akurasi k akurasi
5 0.4195 40 0.4382
10 0.4607 45 0.4457
15 0.4270 50 0.4644
20 0.4607 55 0.4232
25 0.4457 60 0.4419
30 0.4569 65 0.4494
35 0.4532
Berdasarkan tabel tersebut (Tabel 11) akurasi yang paling tinggi diperoleh untuk k=50 sehingga pada percobaan ini jumlah tetangga terdekat adalah 50.
Untuk mengetahui record yang salah diklasifikasikan digunakan matrix confusion yang diperlihatkan Tabel 12.
Tabel 12 Matrix confusion untuk percobaan 3 Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 56 22 11
Kelas 2 25 42 22
Kelas 3 28 35 26
Berdasarkan tabel tersebut (Tabel 12) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 56 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 22 record, dan kelas 1 yang salah diklasifikasi sebagai kelas 3 sebanyak 11 record. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 42 record, kelas 2 yang salah diklasifikasi sebagai kelas 1 sebanyak 25 record, dan kelas 2 yang salah diklasifikasi sebagai kelas 3 sebanyak 22 record. Kelas 3 yang tepat diklasifikasi sebagai kelas 3 sebanyak 26 record, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 28 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 35 record.
Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.4644
Percobaan 4 dilakukan menggunakan dataset yang proporsi record pada setiap kelas target seimbang dengan metode 10-fold cross validation. Data dibagi menjadi 10 subset yang berbeda dengan jumlah yang hampir sama.
Setiap kali sebuah subset digunakan sebagai data uji maka 9 subset lainnya menjadi data latih. Percobaan ini tetap menggunakan jumlah tetangga terdekat sebanyak 65 karena dataset percobaan 4 sama dengan dataset percobaan 3.
Besarnya akurasi pada setiap proses uji diperlihatkan pada Tabel 13.
Tabel 13 Akurasi setiap proses uji pada 10-fold cross validation percobaan 4
proses uji ke- akurasi
1 0.5843
2 0.4382
3 0.6067
4 0.5333
5 0.5393
6 0.6404
7 0.5169
8 0.4944
9 0.4494
10 0.4944
Berdasarkan Tabel 13 akurasi terbaik diperoleh pada proses uji ke-6 yaitu sebesar 0.6404. Matrix confusion untuk proses uji ke-6 pada percobaan 4 adalah
Tabel 14 Matrix confusion proses uji ke-6 percobaan 4
Kelas hadil prediksi Kelas
actual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 24 5 1
Kelas 2 6 14 9
Kelas 3 2 9 19
Berdasarkan tabel tersebut (Tabel 14) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 24 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 5 record, dan kelas 1 yang salah diklasifikasi sebagai kelas 3 sebanyak 1 record. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 14 record, kelas 2 yang salah diklasifikasi sebagai kelas 1 sebanyak 6 record, dan kelas 2 yang salah diklasifikasi sebagai kelas 3 sebanyak 9 record. Kelas 3 yang tepat diklasifikasi sebagai kelas 3 sebanyak 19 record, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 2 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 9 record. Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.6404
Akurasi rata-rata dari seluruh proses uji dengan 10 data uji yang berbeda pada percobaan 4 diperoleh sebesar 0.5297.
Setiap percobaan yang dilakukan menghasilkan sebuah classifier, sehingga dari empat percobaan diperoleh empat buah classifier. Akurasi setiap classifier diperlihatkan pada Tabel 15.
Tabel 15 Akurasi empat classifier Percobaan Model yang
dihasilkan
akurasi
1 classifier 1 0.4757
2 classifier 2 0.5013
3 classifier 3 0.4644
4 classifier 4 0.5297
Akurasi paling tinggi diperoleh pada classifier 4 yang dihasilkan dari percobaan 4 yaitu menggunakan dataset 891 record yang proporsi record pada setiap kelas target seimbang dengan metode uji 10-fold cross validation. Dengan demikian classifier 4 merupakan classifier terbaik yang dihasilkan dengan metode k–Nearest Neighbor.
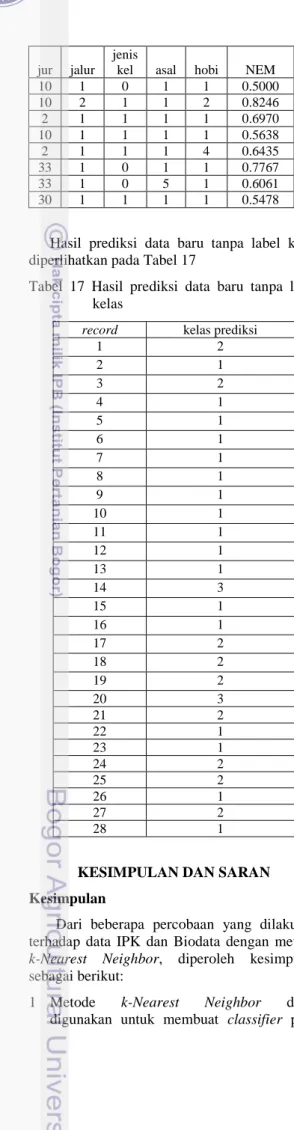
Penggunaan Classifier pada Data Baru Classifier terbaik yang diperoleh digunakan untuk memprediksi label kelas pada data yang baru. Pada Tabel 16 diberikan contoh data baru tanpa label kelas yang akan diterapkan pada classifier.
Tabel 16 Data tanpa label kelas jur jalur jenis
kel
asal hobi NEM
19 1 1 5 1 0.8030
19 1 1 1 1 0.8565
19 1 0 5 1 0.7018
19 1 0 1 1 0.8349
19 1 0 1 1 0.7927
19 1 1 1 2 0.8724
19 1 0 4 1 0.7129
19 1 0 1 1 0.8134
19 1 0 1 4 0.8772
19 1 1 1 2 0.6651
19 1 0 1 1 0.7974
19 1 0 1 1 0.6116
19 1 1 1 1 0.8724
6 2 1 1 1 0.6276
19 1 1 1 1 0.8349
10 1 0 1 1 0.5742
2 1 1 5 1 0.3987
5 1 0 6 1 0.4625
10 1 1 1 1 0.3724
10 2 1 5 2 0.5159
jur jalur jenis
kel asal hobi NEM
10 1 0 1 1 0.5000
10 2 1 1 2 0.8246
2 1 1 1 1 0.6970
10 1 1 1 1 0.5638
2 1 1 1 4 0.6435
33 1 0 1 1 0.7767
33 1 0 5 1 0.6061
30 1 1 1 1 0.5478
Hasil prediksi data baru tanpa label kelas diperlihatkan pada Tabel 17
Tabel 17 Hasil prediksi data baru tanpa label kelas
record kelas prediksi
1 2
2 1
3 2
4 1
5 1
6 1
7 1
8 1
9 1
10 1
11 1
12 1
13 1
14 3
15 1
16 1
17 2
18 2
19 2
20 3
21 2
22 1
23 1
24 2
25 2
26 1
27 2
28 1
KESIMPULAN DAN SARAN Kesimpulan
Dari beberapa percobaan yang dilakukan terhadap data IPK dan Biodata dengan metode k-Nearest Neighbor, diperoleh kesimpulan sebagai berikut:
1 Metode k-Nearest Neighbor dapat digunakan untuk membuat classifier pada
data akademik dan biodata mahasiswa tingkat I IPB.
2 Classifier terbaik dihasilkan dari percobaan 4 yaitu menggunakan dataset 891 record yang proporsi record pada setiap kelas target seimbang dengan metode uji 10-fold cross validation.
3 Akurasi yang diperoleh pada classifier terbaik hanya sebesar 52.97%.
4 Classifier terbaik yang dihasilkan dapat digunakan untuk memprediksi keberhasilan mahasiswa baru IPB.
5 Atribut yang mempengaruhi tingkat keberhasilan mahasiswa tingkat I IPB berdasarkan uji hipotesis adalah jurusan, jalur masuk, jenis kelamin, asal daerah, hobi, dan nilai uan (NEM).
Saran
Pada penelitian ini masih terdapat beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran yang dapat dilakukan antara lain:
1. Penggunaan metode lain untuk memperoleh classifier yang lebih baik, karena akurasi classifier dari k-Nearest Neighbor hanya sebesar 52.97% .
2. Dibangun aplikasi sederhana yang dapat memprediksi keberhasilan mahasiswa baru dengan menerapkan model terbaik.