Pendiskritan Kelas Kontinyu dengan Algoritma K-Mean Cluster Kusrini
Dosen STMIK AMIKOM YOGYAKARTA [email protected]
Abstract
Dalam proses pembentukan pengetahuan sering ditemui algoritma yang menyaratkan data dalam bentuk kelas diskrit, padahal dalam dunia nyata sering ditemui data dalam bentuk kelas kontinyu. Proses pengubahan data dalam kelas kontinyu menjadi data dalam kelas diskrit dapat dilakukan dengan cara manual,yaitu analis mendefinisikan interval nilai data kelas kontinyu yang akan dimasukkan dalam suatu kelas diskrit.
Kelemahan dari pengubahan data dalam kelas kontinyu menjadi data dalam kelas diskrit diantaranya:1. tingkat akurasi tidak pasti, tergantung pada kepiawaian analis dalam menentukan kelas diskrit. 2. adanya data dalam kelas kontinyu yang memiliki kelas diskrit ganda. 3. adanya data dalam kelas kontinyu yang tidak memiliki kelas dalam kelas diskrit.
4. diperlukan usaha dari analis
Dalam makalah ini, penulis memaparkan suatu metode pengubahan data kelas kontinyu menjadi data dalam kelas diskrit dengan menggunakan algoritma k-mean cluster. Metode ini berhasil diimplementasikan dengan script PHP dan DBMS My Sql. Hasil implementasi mampu mengubah tabel berisi data kelas kontinyu menjadi tabel berisi data kelas diskrit.
Kata kunci : diskrit, kontinyu, k-mean cluster Pendahuluan
Dalam proses pembentukan pengetahuan seringkali para peneliti dihadapkan pada
algoritma yang hanya manangani data kelas diskrit, sementara data yang tersedia
merupakan data kelas kontinyu(Quinlan, J.R, 1993). Yang dimaksud dengan data diskrit
adalah data yang sifatnya terputus-putus, nilainya utuh (bukan pecahan), misalnya data
jumlah penduduk dan jumlah kendaraan. Sedangkan data kontinyu adalah data yang
sifatnya sinambung atau kontinyu, nilainya bisa berupa pecahan. Contoh data kontinyu
yaitu data tentang panjang jalan dan data berat badan seorang anak(Kuswadi dan
Mutiara, E., 2004).
Proses pendiskritan kelas kontinyu akan mengubah data kelas kontinyu menjadi data kelas diskrit. Misalnya temperatur nilainya tidak lagi 30,7
oC atau 36
oC tetapi teperatur rendah, sedang dan tinggi. Pengkonversian data kelas kontinyu kedalam kelas diskrit memerlukan pendefinisian interval nilai data kelas kontinyu untuk masing-masing kelas diskrit. Misalnya kelas diskrit temperatur rendah adalah konversi dari kelas kontinyu temperatur dengan nilai data antara 30
oC sampai dengan 34
oC.
Pembentukan kelas diskrit dapat dilakukan secara manual. Pembuat sistem akan mendefinisikan terlebih dahulu interval-interval kelas kontinyu yang masuk dalam suatu kelas diskrit. Tetapi hal ini dapat menyebabkan pembagian kelas yang tidak seimbang, suatu nilai dalam kelas kontinyu masuk ke beberapa kelas diskrit atau suatu nilai dalam kelas kontinyu tidak masuk dalam salah satu kelas diskrit. Selain itu, proses pembentukan kelas diskrit secara manual memerlukan usaha dari analis. Tentu saja hal ini tidak efektif dan tidak efisien.
Penulis pernah melakukan proses pembentukan kelas diskrit secara manual dalam pra proses pembentukan pengetahuan dengan menggunakan pohon keputusan. Algoritma yang penulis gunakan dalam pembentukan pohon keputusan adalah algoritma C4.5 dan algoritma nearest neighbor. Dengan proses pembentukan kelas diskrit secara manual ini ternyata menyulitkan untuk mendapatkan performa algoritma pembentukan pohon keputusan. Hal ini disebabkan nilai akurasi dari pengetahuan yang terbentuk sangat tergantung pada proses pembentukan kelas diskritnya(Kusrini dan Harjoko, A., 2008)(Kusrini dah Hartati, S, 2007).
Berdasarkan pengalaman penulis tersebut, penulis menganggap perlu dibuat sebuah algoritma pembentukan kelas diskrit secara otomatis.
Pada makalah ini, penulis ingin memaparkan hasil penelitian untuk melakukan proses pembentukan kelas diskrit secara otomatis. Proses ini memanfaatkan algoritma clustering k-mean cluster.
Algoritma K-Mean Cluster
K-Means merupakan salah satu metode data clustering non hirarki yang berusaha
mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Metode ini
mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik
yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai
karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain.
Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi antar cluster.
Data clustering menggunakan metode K-Means ini secara umum dilakukan dengan algoritma dasar sebagai berikut(Agusta, Y., 2007):
1. Tentukan jumlah cluster
2. Alokasikan data ke dalam cluster secara random
3. Hitung centroid/rata-rata dari data yang ada di masing-masing cluster 4. Alokasikan masing-masing data ke centroid/rata-rata terdekat
5. Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan
Rancangan Sistem
Dalam makalah ini akan ditunjukkan proses pengubahan tabel dengan data berisi kelas kontinyu menjadi tabel dengan data berisi kelas diskrit. Skema pengubahan tabel akan ditunjukkan pada Gambar 1.
Gambar 1. Skema pengubahan tabel dengan kelas kontinyu menjadi tabel dengan kelas diskrit
Pada algoritma k-mean asli, nilai centroid awal ditentukan secara acak. Namun dengan
pertimbangan kecepatan, peneliti menetapkan nilai awal centroid kelas dengan suatu
nilai dengan menggunakan rumus 1:
xn n
x c
ii
2 min max min)
(max ) 1 (
min −
− +
−
= + [1]
dimana
c
i :centroid dari kelas ke i
min : nilai terkecil dari data kelas kontinyu max : nilai terbesar dari data kelas diskrit n : jumlah kelas diskrit
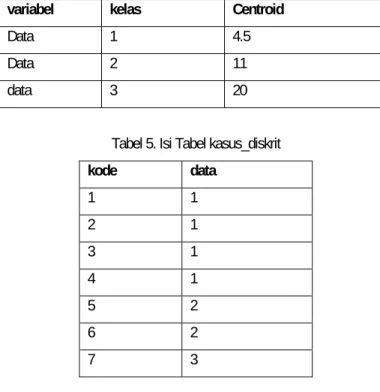
Misalnya dimiliki data dalam kelas kontinyu dengan nilai : 2, 4, 5, 7, 10, 12, 20. Akan dibuat 2 kelas diskrit. Besarnya centroid kelas diskrit pertama adalah:
33 , 3
6 18 3 2
3 2
2 20 3
) 2 20 ( ) 1 1 ( 2
1 1 1
= +
=
+ −
−
−
= +
c c
x c x
6 . 12
6 18 3 20
3 2
2 20 3
) 2 20 ( ) 1 2 ( 2
2 2 2
= +
=
+ −
−
−
= +
c c
x c x
67 . 18
6 18 3 38
3 2
2 20 3
) 2 20 ( ) 1 3 ( 2
3 3 3