ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING
TESIS
MHD. DICKY SYAHPUTRA LUBIS 147038050
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2017
ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
MHD. DICKY SYAHPUTRA LUBIS 147038050
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2017
PERSETUJUAN
Judul : ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING
Kategori : DATA MINING, CLUSTERING
Nama : MHD. DICKY SYAHPUTRA LUBIS
Nim : 147038050
Program Studi : MAGISTER (S2) TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Prof. Dr. Saib Suwilo, M.Sc Prof. Dr. Herman Mawengkang
Diketahui/disetujui oleh
Program Studi S2 Teknik Informatika Ketua,
Prof. Dr. Muhammad Zarlis NIP. 19570701 198601 1 003
PERNYATAAN
ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 03 Agustus 2017
Mhd. Dicky Syahputra Lubis NIM. 147038050
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertandatangan dibawah ini :
Nama : Mhd. Dicky Syahputra Lubis
NIM : 147038050
Program Studi : Magister Teknik Informatika Jenis Karya Ilmiah : Teknik Informatika
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul :
ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Dengan pernyataan ini dibuat dengan sebenarnya.
Medan, 03 Agustus 2017
Mhd. Dicky Syahputra Lubis 147038050
Telah diuji pada
Tanggal : 03 Agustus 2017
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis Anggota : 1. Prof. Dr. Herman Mawengkang
2. Prof. Dr. Saib Suwilo, M.Sc
3. Prof. Dr. Tulus, Vor.Dipl, Math, M.Si 4. Prof. Dr. Muhammad Zarlis
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Mhd. Dicky Syahputra Lubis Tempat danTanggal Lahir : Pasar Bengkel, 01 Mei 1991
Alamat Rumah : Jln. Lokasi Komp. TMI II B. 37 Tanjung Morawa, Deli Serdang
Telepon/Fax/HP : -/-/+6285270952099
Email : [email protected]
Instansi : -
Alamat Kantor : -
DATA PENDIDIKAN
SD : SD Swasta Taman Pendidikan Islam Medan TAMAT : 2003
SMP : MTsN 1 Model Medan TAMAT : 2006
SMA : MAN 3 Medan TAMAT : 2009
S1 : Teknik Informatika STT Harapan TAMAT : 2013 S2 : Teknik Informatika Universitas Sumatera Utara TAMAT : 2017
UCAPAN TERIMA KASIH
Puji dan syukur penulis panjatkan kehadirat Allah Azza wa Jalla, karena rahmat karunianyalah diberi berupa pengetahuan, kesehatan dan kesempatan yang diberikan kepada penulis sehingga dapat menyelesaikan tesis ini dengan judul “ANALISIS KINERJA METODE ENTROPY PADA K-MEANS DALAM PROSES CLUSTERING”.
Dalam penyusunan untuk menyelesaikan tesis ini, penulis banyak mendapatkan pelajaran yang besar, baik berupa saran maupun nasehat dari berbagai pihak terutama dari dosen pembimbing serta dosen pembanding, sehingga pengerjaan tesis ini dapat diselesaikan dengan baik. Tidak lepas dari dukungan orang tua beserta keluarga juga sahabat yang telah banyak memberikan banyak bantuan dan dukungan, sehingga penulis dapat sampai pada tahap penyelesaian tesis ini.
Untuk itu penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya kepada:
1. Bapak Prof. Dr. Runtung Sitepu, S.H., M.Hum., selaku rektor Universitas Sumatera Utara atas kesempatan yang telah diberikan kepada penulis, sehingga bisa mengikuti dan menyelesaikan pendidikan Magister Teknik Informatika.
2. Bapak Prof. Dr. Opim Salim Sitompul, selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Medan.
3. Bapak Prof. Dr. Muhammad Zarlis, M.Si., selaku Ketua Program Studi Pascasarjana Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara Medan.
4. Bapak Dr. Syahril Efendi, M,IT, selaku Sekretaris Program Studi Magister Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
5. Bapak Prof. Dr. Herman Mawengkang, selaku Dosen Pembimbing I yang telah bersedia memberikan bimbingan serta pengarahan hingga selesainya penulisan tesis ini.
6. Bapak Prof. Dr. Saib Suwilo, M.Sc, selaku Dosen Pembimbing II yang telah bersedia memberikan bimbingan serta pengarahan hingga selesainya penulisan tesis ini.
7. Bapak Prof. Dr. Tulus, Vor.Dipl, Math, M.Si, selaku dosen Pembanding/Penguji yang telah memberikan saran untuk perbaikan dan penyelesaian tesis ini.
8. Bapak Prof. Dr. Muhammad Zarlis, M.Si., selaku dosen Pembanding/Penguji yang telah memberikan saran untuk perbaikan dan penyelesaian tesis ini.
9. Bapak dan Ibu dosen yang telah memberikan materi perkuliahan dan ilmu pengetahuan selama penulis menyelesaikan Program Studi Magister Teknik Informatika.
10. Seluruh staf atau pegawai pada Program Studi Magister Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
11. Buat Ayahanda Sahrul Saragih dan Ibunda Rahmawita Chaniago, yang selalu memberi semangat dan doa yang tiada putus dan dorongan moril maupun materil kepada saya sehingga dapat menyelesaikan tesis ini dengan baik.
12. Buat Istri Fani Ariana Siregar, SH yang selalu memberikan semangat dan doa yang tiada putus dan dorongan moril maupun materil kepada saya, sehingga dapat menyelesaikan tesis ini dengan baik.
13. Senior-senior saya Anggi Syahadat Harahap, Muhammad Zulfansyuri, Robbi Rahim, Sudirman, Risky Muliono, yang telah memberikan dukungan dalam penyelesaian tesis ini.
14. Sahabat-sahabat saya Roy Nuary Singarimbun, Eka Hayana Hasibuan, Tarida Yanti Nasution, beserta teman-teman seperjuangan angkatan 2015 Kom-A
Akhir kata penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi semua pihak, khususnya dalam bidang pendidikan. Penulis menyadari bahwa masih ada kekurangan dalam penulisan tesis ini, untuk itu penulis mengharapkan kritik dan saran dari pembaca demi kesempurnaan penelitian selanjutnya.
Medan, 03 Agustus 2017 Penulis
Mhd. Dicky Syahputra Lubis 147038050
ABSTRAK
K-means adalah metode pengelompokan data non-hirarki yang mencoba memecah data yang ada menjadi satu atau beberapa kelompok/cluster. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam cluster dan data yang sama yang memiliki karakteristik berbeda dikelompokkan ke dalam kelompok lain. Tujuan dari pengelompokan data ini adalah untuk meminimalkan fungsi tujuan yang ditetapkan dalam proses pengelompokan, yang umumnya mencoba untuk meminimalkan variasi dalam cluster dan memaksimalkan variasi antar kelompok. Namun, kelemahan utama dari metode ini adalah bahwa jumlah k sering tidak diketahui sebelumnya. Selanjutnya, titik awal yang dipilih secara acak dapat menyebabkan dua titik mendekati jarak yang akan ditentukan sebagai dua centroid. Oleh karena itu, untuk penentuan titik awal pada K- means digunakan metode entropy dimana metode ini merupakan metode yang dapat digunakan untuk menentukan bobot dan mengambil keputusan dari satu set alternatif.
Entropy mampu menyelidiki harmoni dalam diskriminasi di antara sejumlah kumpulan data. Dengan menggunakan kriteria entropy dengan variasi nilai tertinggi akan mendapatkan bobot tertinggi. Dengan metode entropy ini dapat membantu proses kerja K-means dalam menentukan pusat centroid awal yang biasanya ditentukan secara acak. Dengan demikian proses pengelompokan pada proses K- means Standar dimana dataset pasien pasca operasi yang digunakan dari UCI Repository Machine Learning sebagai contoh perhitungannya diperoleh dengan metode entropy hanya dengan 3 kali iterasi bisa mendapatkan hasil akhir yang diinginkan.
Kata Kunci : K-Means, Metode Entropy, Centroid Awal, Clustering
PERFORMANCE ANALYSIS OF ENTROPY METHOD ON
K-MEANS IN CLUSTERING PROCESS
ABSTRACT
K-means is a non-hierarchical data clustering method that attempts to partition existing data into one or more clusters / groups. This method partitions the data into clusters / groups so that data that have the same characteristics are grouped into the same cluster and data that have different characteristics are grouped into other groups. The purpose of this data clustering is to minimize the objective function set in the clustering process, which generally attempts to minimize variation within a cluster and maximize the variation between clusters. However, the main disadvantage of this method is that the number k is often not known before. Furthermore, a randomly chosen starting point may cause two points to approach the distance to be determined as two centroids. Therefore, for the determination of the starting point in K-means used entropy method where this method is a method that can be used to determine a weight and take a decision from a set of alternatives. Entropy is able to investigate the harmony in discrimination among a multitude of data sets. Using Entropy criteria with the highest value variations will get the highest weight. Given this entropy method can help K-means work process in determining the starting point which is usually determined at random. Thus the process of clustering on K-means can be more quickly known by helping the entropy method where the iteration process is faster than the K-means Standard process. Where the postoperative patient dataset of the UCI Repository Machine Learning used as an example of its calculations is obtained by entropy method only with 3 times iteration can get the desired end result.
Keywords : K-Means, Entropy Methods, Centre Centroid, Clustering
DAFTAR ISI
ANALISIS ... I PESETUJUAN ... III PERNYATAAN ... IV PANITIA PENGUJI TESIS ... VI RIWAYAT HIDUP ... VII UCAPAN TERIMAKASIH ... VIII ABSTRAK ... X ABSTRACT ... XI
DAFTAR ISI ... 12
DAFTAR TABEL ... 3
DAFTAR GAMBAR ... 5
BAB 1 PENDAHULUAN ... ERROR! BOOKMARK NOT DEFINED. 1.1. Latar Belakang ... Error! Bookmark not defined. 1.2.Rumusan Masalah ... 3
1.3.Batasan Masalah ... Error! Bookmark not defined. 1.4.Tujuan Penelitian ... Error! Bookmark not defined. BAB 2 TINJAUAN PUSTAKA ... ERROR! BOOKMARK NOT DEFINED. 2.1.Analisis ... Error! Bookmark not defined. 2.2.K-Means ... 4
2.2.1. Perkembangan Penerapan K-Means ... 5
2.2.2. Distance Space Untuk Menghitung Jarak Antara Data dan Centroid ... 5
2.3.Metode Entropy ... 6
BAB 3 METODOLOGI PENELITIAN ... 8
3.1.Tahapan Penelitian ... 8
3.2.Dataset yang Digunakan ... 9
3.3.Penentuan Bobot Awal Menggunakan Metode Entropy ... 9
3.4.K-Means Clustering ... 14
3.4.1.Penentuan Nilai Centroid ... 14
BAB 4 HASIL DAN PEMBAHASAN ... 1813
4.1.Pendahuluan ... 1813
4.2.Nilai bobot yang Dihasilkan ... 118
4.2.1.Perhitungan Bobot dengan Metode Entropy ... 118
4.2.2.K- Means Standar... 21
4.3.Hasil Penelitian ... 22
4.4.Pembahasan (Perbandingan) ... 23
BAB 5 KESIMPULAN DAN SARAN ... 25
5.1.Kesimpulan ... 25
5.2.Saran ... 25
DAFTAR PUSTAKA ... 26
LAMPIRAN ... 27
DAFTAR TABEL
Tabel 3.1 Contoh Data Set Yang Digunakan ... 9
Tabel 4.1 Hasil Normalisasi Menggunakan Entropy ... ERROR! BOOKMARK NOT DEFINED.4 Tabel 4.2 Hasil Data Dikalikan dengan Bobot Entropy Akhir ... ERROR! BOOKMARK NOT DEFINED.5 Tabel 4.3 Nilai Berdasarkan Range (Pusat Centroid Awal) ... ERROR! BOOKMARK NOT DEFINED.6 Tabel 4.4 Hasil Iterasi ke-1 ... ERROR! BOOKMARK NOT DEFINED.7 Tabel 4.5 Pengelompokkan Berdasarkan Cluster ... ERROR! BOOKMARK NOT DEFINED. Tabel 4.6 Pengelompokkan Berdasarkan Cluster Lanjutan .... ERROR! BOOKMARK NOT DEFINED.8 Tabel 4.7 Penentuan Pusat Centroid Baru ... ERROR! BOOKMARK NOT DEFINED. Tabel 4.8 Hasil Perhitungan Pada Iterasi Ke-2 ... ERROR! BOOKMARK NOT DEFINED.8 Tabel 4.9 Hasil Perhitungan Pada Iterasi Ke-2 (Lanjutan) ... 19
Tabel 4.10 Pengalokasian Berdasarkan Cluster ... 19
Tabel 4.11 Hasil Iterasi Ke-5 ... ERROR! BOOKMARK NOT DEFINED.0 Tabel 4.12 Pengalokasian Ke Dalam Cluster ... ERROR! BOOKMARK NOT DEFINED. Tabel 4.13 Penentuan Pusat Awal Centroid ... ERROR! BOOKMARK NOT DEFINED. Tabel 4.14 Hasil Akhir Iterasi K-Means Standar ... ERROR! BOOKMARK NOT DEFINED. Tabel 4.15 Hasil Clustering Dengan K-Means Standar ... 22
Tabel 4.16 Hasil Perbandingan ... ERROR! BOOKMARK NOT DEFINED. Tabel Lampiran.1 Dataset Pasien Pasca Operasi ... 27
Tabel Lampiran.2 Titik Awal Centroid ... 28
Tabel Lampiran.3 Iterasi Ke 1 ... 28
Tabel Lampiran.4 Pengalokasian Ke Dalam Cluster... 31
Tabel Lampiran.5 Penentuan Centroid Baru ... 32
Tabel Lampiran.6 Iterasi Ke 2 ... 32
Tabel Lampiran.7 Pengalokasian Ke Dalam Cluster... 35
Tabel Lampiran.8 Penentuan Centroid Baru ... 36
Tabel Lampiran.9 Iterasi Ke 3 ... 36
Tabel Lampiran.10 Pengalokasian Ke Dalam Cluster ... 39
Tabel Lampiran.11 Penentuan Centroid Baru ... ERROR! BOOKMARK NOT DEFINED.
Tabel Lampiran.12 Iterasi Ke 4 ... 40
Tabel Lampiran.13 Pengalokasian Ke Dalam Cluster ... 43
Tabel Lampiran.14 Penentuan Centroid Awal K-Means ... 44
Tabel Lampiran.15 Iterasi Ke-1 K-Means ... 44
Tabel Lampiran.16 Pengalokasian Kedalam Cluster ... 47
Tabel Lampiran.17 Penentuan Centroid Baru ... 48
Tabel Lampiran.18 Iterasi Ke-2 K-Means ... 48
Tabel Lampiran. 19 Pengalokasian Kedalam Cluster ... 51
Tabel Lampiran.20 Penentuan Centroid Baru ... 52
Tabel Lampiran. 21 Iterasi Ke-3 K-Means ... 52
Tabel Lampiran. 22 Pengalokasian Kedalam Cluster ... ERROR! BOOKMARK NOT DEFINED. Tabel Lampiran. 23 Penentuan Centroid Baru ... ERROR! BOOKMARK NOT DEFINED. Tabel Lampiran. 24 Iterasi Ke-4 K-Means ... 56
Tabel Lampiran. 25 Pengalokasian Ke Dalam Cluster ... 59
DAFTAR GAMBAR
Gambar 3.1 Diagram Metodologi Penelitian ... 8 Gambar 3.2 Penentuan Nilai Bobot Centroid Terbaik ... ERROR! BOOKMARK NOT DEFINED.
Gambar 3.3 Flowchart K-Means ... 15
BAB I PENDAHULUAN
1.1 Latar Belakang
Data clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised). Ada dua jenis data clustering yang sering dipergunakan dalam proses pengelompokan data yaitu hierarchical (hirarki) data clustering dan non-hierarchical (non hirarki) data clustering. K-Means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok.
Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain.
Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi antar cluster. (Yudi Agusta 2007).
Dalam beberapa tahun terakhir, penelitian pada data dimensi tinggi telah sangat berkembang dengan peningkatan aplikasi data mining dalam bidang terkait. Biasanya, aplikasi data mining dapat menanganani sejumlah dimensi data yang besar. Teknik utama yang digunakan dalam data mining adalah dengan menentukan euclidean distance untuk mendapatkan nilai antara jarak dan obyek.
Namun, banyak penelitian menunjukkan bahwa sebagian teknik yang ada tidak cocok untuk dimensi data yang besar karena fenomena yang dikenal sebagai
“curse of dimensionality”.
Dimensi data yang besar muncul ketika beberapa keadaan terjadi seperti proximity, distance, atau the nearest neighbor yang tidak diketahui dengan besarnya
dimensi dari data set. Penelitian-penelitian terdahulu menunjukkan bahwa jarak relatif antara titik terjauh dan titik terdekat sama dengan 0 dengan pertambahan dimensi d: 1 Dimana, perbedaan antara titik terdekat dan titik terjauh dalam jumlah data yang besar menjadi agak lemah.
Dalam, metode yang didasarkan pada sudut vektor disarankan untuk mengetahui sudut antara kedua vektor dari objek data. Langkah ini tampaknya jauh lebih sensitif terhadap kumpulan data high dimension berdasarkan jarak. (Shu-yin Xia 2015).
Algoritma k-means adalah metode yang paling banyak digunakan dalam kategori partisi karena kecepatannya yang cepat dan mudah dimengerti. Namun, kelemahan utama metode ini adalah bahwa jumlah k sering tidak diketahui sebelumnya. Selanjutnya, titik awal yang dipilih secara acak dapat menyebabkan dua titik yang mendekati jarak yang akan ditentukan sebagai dua centroid. Juga sensitif terhadap outlier. Pengelompokan k-means adalah pendekatan yang sama sekali tidak terstruktur, yang berjalan dengan cara yang sama sekali lokal dan menghasilkan kumpulan cluster yang tidak terorganisir yang tidak konduktif terhadap interpretasi.
Dalam dua dimensi, panjang sambungan garis lurus menjadi dua titik x dan y. Dalam n dimensi, satu masalah dengan metode ini adalah jarak euclidean sensitif terhadap nilai besar; Dengan kata lain, sensitif terhadap outlier. Selain itu, akan kehilangan korelasi negatif karena mereka akan memberikan jarak yang jauh.
(Bernard Chen et al 2005).
Metode entropy merupakan metode yang dapat digunakan untuk menentukan suatu bobot dan mengambil keputusan dari sekumpulan altenatif. entropy mampu menyelidiki keserasian dalam diskriminasi diantara sekumpulan data yang beratirbut banyak. Dengan menggunakan entropy kriteria dengan variasi nilai tertinggi akan mendapatkan bobot tertinggi (Abbas, 2004). Penelitian lain menyebutkan bahwa entropy dapat mengambil keputusan dalam pemilihan subkontrak produksi sarung tangan (Jamila, 2012). Pada penelitian tersebut, dilakukan pembobotan setiap kriteria dan penentuan subkontrak mana yang menjadi pilihan terbaik.
Untuk itu penulis tertarik untuk melakukan penelitian tentang sejauh mana kinerja metode entropy dalam menentukan nilai centroid awal pada k-means clustering. Metode entropy akan mencari nilai bobot awal dari dataset, kemudian nilai bobot awal tersebut akan digunakan dalam pelatihan dan pengujian pada . Maka dengan metode entropy tersebut dapat menghasilkan suatu nilai bobot awal yang dapat memberikan bobot nilai awal centroid sehingga mempercepat proses pembelajaran dan memilki tingkat akurasi yang baik bila dibandingkan dengan k-means standar.
Oleh karena itu judul penelitian tesis yang diusulkan adalah “Analisis Kinerja Metode Entropy pada K Means dalam Proses Clustering”. Untuk melakukan proses pelatihan dan pengujian pada k-means diaplikasikan pada dataset pasien pasca operasi.
1.2 Rumusan Masalah
Menganalisa apakah metode entropy mampu mendapatkan bobot nilai awal untuk centroid dalam membuat clustering pada algoritma k-means.
1.3 Batasan Masalah
Dalam penelitian ini telah ditentukan batasan-batasan dari topik yang dibahas sehingga cakupan pembahasan tidak terlalu luas dan fokus utama penelitian tidak menjadi kabur. Beberapa batasan masalah yang ditentukan pada penelitian ini dijabarkan sebagai berikut:
1. Dalam menormalisasi data dan penentuan bobot awal dilakukan dengan metode entropy.
2. Menggunakan euclidian distance pada k-means clustering sebagai persamaan dasar.
3. Menggunakan dataset pasien pasca operasi dari UCI Repository Machine Learning.
1.4 Tujuan Penelitian
Adapun tujuan penelitian ini adalah ingin mengetahui apakah penerapan metode entropy pada algoritma K-Means dapat lebih optimal atau tidak dalam mendapat kan nilai pusat Centroid untuk clustering.
BAB 2
TINJAUAN PUSTAKA
2.1 Analisis
Analisis adalah sebuah aktifitas atau kegiatan yang menguraikan, mengelompokkan, memilah suatu kondisi untuk memperoleh informasi pada kriteria tertentu yang memungkinkan adanya kesalahan yang mungkin terjadi dan ada kemungkinan untuk dikembangkan.
2.2 K-Means
K-Means merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok. Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain. Adapun tujuan dari data clustering ini adalah untuk meminimalisasikan objective function yang diset dalam proses clustering, yang pada umumnya berusaha meminimalisasikan variasi di dalam suatu cluster dan memaksimalisasikan variasi antar cluster. (Yudi Agusta 2007)
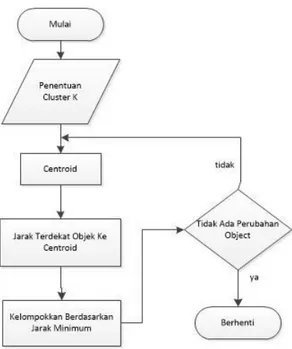
Data clustering menggunakan metode k-means ini secara umum dilakukan dengan algoritma dasar sebagai berikut:
1. Tentukan jumlah cluster
2. Alokasikan data ke dalam cluster secara random
3. Hitung centroid/rata-rata dari data yang ada di masing-masing cluster 4. Alokasikan masing-masing data ke centroid/rata-rata terdekat
5. Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan
2.2.1 Perkembangan Penerapan K Means
1
Beberapa alternatif penerapan k-means dengan beberapa pengembangan teori-teori penghitungan terkait telah diusulkan. Hal ini termasuk pemilihan:
1. Distance space untuk menghitung jarak di antara suatu data dan centroid
2. Metode pengalokasian data kembali ke dalam setiap cluster 3. Objective function yang digunakan
2.2.2 Distance Space Untuk Menghitung Jarak Antara Data dan Centroid
Beberapa teori distance space telah diimplementasikan dalam menghitung jarak (distance) antara data dan centroid termasuk di antaranya L1 (Manhattan/City Block) distance space, L2 (Euclidean) distance space, dan Lp (Minkowski) distance space. Jarak antara dua titik x1 dan x2 pada Manhattan/City Block distance space dihitung dengan menggunakan rumus sebagai berikut:
dimana:
p : Dimensi data
| . | : Nilai absolut
Sedangkan untuk L2 (Euclidean) distance space, jarak antara dua titik dihitung menggunakan rumus sebagai berikut:
Dimana p = Dimensi data
Lp (Minkowski) distance space yang merupakan generalisasi dari beberapa distance space yang ada seperti L1 (Manhattan/City Block) dan L2
(Euclidean), juga telah di implementasikan. Tetapi secara umum distance space yang sering digunakan adalah Manhattan dan Euclidean. Euclidean sering digunakan karena penghitungan jarak dalam distance space ini merupakan jarak terpendek yang bisa didapatkan antara dua titik yang diperhitungkan, sedangkan Manhattan sering digunakan karena kemampuannya dalam mendeteksi keadaan khusus seperti keberadaaan outliers dengan lebih baik. (Yudi Agusta 2007)
2.3 Metode Entropy
Metode entropy merupakan metode yang dapat digunakan untuk menentukan suatu bobot. entropy mampu menyelidiki keserasian dalam diskriminasi diantara sekumpulan data. Sekumpulan data nilai alternatif pada kriteria tertentu digambarkan dalam decision matrix (DM). Menggunakan metode entropy, kriteria dengan variasi nilai tertinggi akan mendapatkan bobot tertinggi. Dengan demikian, metode entropy dapat menghitung kemungkinan maksimum (maximum entropy) untuk setiap data tunggal dalam suatu kumpulan (entitas) yang memiliki kemungkinan berbeda-beda.
Secara spesifik, entropy juga mampu beradaptasi dengan sekumpulan data beratribut jamak yang meiliki variasi berbeda-beda antar satu kriteria dengan kriteria lainnya.
Adapun langkah-langkah pembobotan dengan menggunakan metode entropy adalah sebagai berikut (Tiyaswiyoso, 2012)
1. Normalisasi Data Kriteria
Rumus normalisasi adalah sebagai berikut :
i = 1, 2, ... , n Dimana :
= nilai data yang telah dinormalisasi
= nilai data yang belum dinormalisasi
= nilai datang yang belum dinormalisasi yang mempunyai nilai paling tinggi
= jumlah nilai data yang telah dinromalisasi
= jumlah alternatif 2. Perhitungan Entropy
Langkah selanjutnya adalah pengukuran entropy untuk setiap kriteria ke-i.
Rumusnya adalah :
Dimana :
= Entropy maksimum K = konstanta entropy
= Entropy untuk setiap atribut/ kriteria ke-i
Setelah mendapatkan untuk masing-masing kriteria, maka dapat ditentukan total entropy untuk masing-masing kriteria, rumusnya adalah :
n adalah jumlah kriteria 3. Perhitungan Bobot Entropy
Langkah berikutnya adalah menghitung bobot dengan menggunakan rumus sebagai berikut :
Dimana :
= bobot entropy sementara n = jumlah atribut/kriteria
E = total entropy untuk masing-masing kriteria
BAB 3
METODOLOGI PENELITIAN
Bab ini menjelaskan tahapan-tahapan yang dilakukan dalam penelitian, mulai dari dataset yang digunakan dalam melatih dan menguji k-means, arsitektur jaringan pada k-means dengan menggunakan entropy sebagai penentuan nilai bobot awalnya, dan contoh dari perhitungan penelitian.
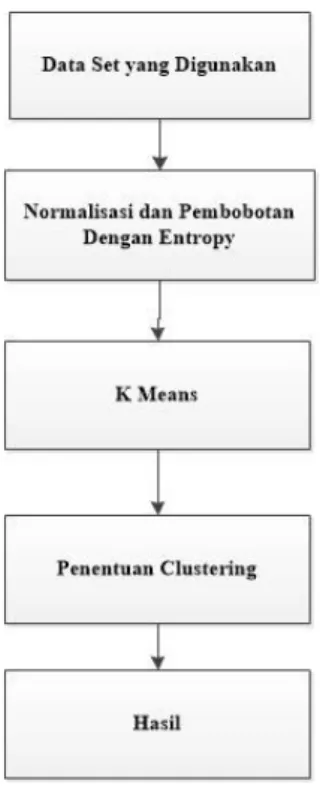
3.1 Tahapan Penelitian
Tahapan penelitian ditunjukkan pada Gambar 3.1 di bawah ini :
Gambar 3.1 Diagram Metodologi Penelitian 3.2 Dataset yang Digunakan
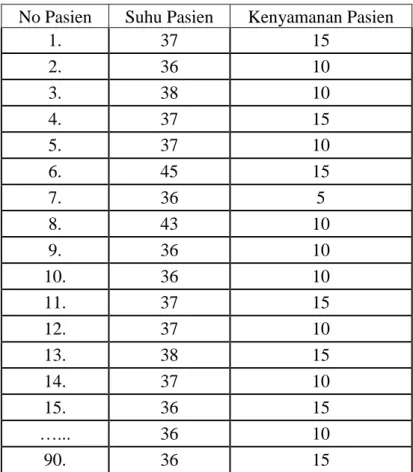
Pada penelitian ini digunakan dataset (kumpulan data) yang berasal dari UCI Repository Machine Learning mengenai data pasien pasca operasi. Dataset ini terdiri dari 90 jumlah data, dengan klasifikasi suhu pasien dan kenyamanan. Namun dataset ini memiliki masing-masing nilai yang berbeda dan akan diganti dengan metode
14
median yaitu dengan mencari nilai tengah, metode ini adalah metode yang paling baik untuk kasus dataset tersebut (Nurul et al, 2012). Adapun atribut/kriteria dan nilai dari dataset dapat dilihat pada Tabel 3.1
Tabel 3.1 Contoh Data Set Yang Digunakan No Pasien Suhu Pasien Kenyamanan Pasien
1. 37 15
2. 36 10
3. 38 10
4. 37 15
5. 37 10
6. 45 15
7. 36 5
8. 43 10
9. 36 10
10. 36 10
11. 37 15
12. 37 10
13. 38 15
14. 37 10
15. 36 15
…... 36 10
90. 36 15
3.3 Penentuan Bobot Awal Menggunakan Metode Entropy
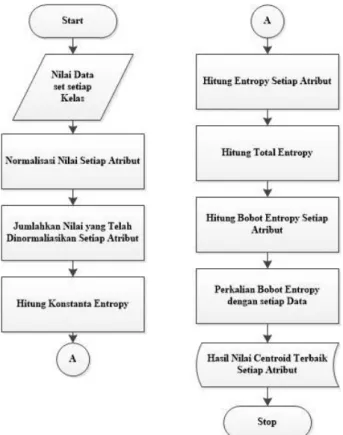
Pada proses penentuan nilai bobot awal untuk pusat centroid dengan metode entropy dilakukan dengan dua cara yaitu :
1. Penentunan bobot langsung dihasilkan dari perhitungan menggunakan entropy dari dataset dalam setiap kelasnya. Alur yang dilakukan dalam penentuan bobot dapat dilihat pada Gambar.3.2.
15
Gambar 3.2 Penentuan Nilai Bobot Centroid Terbaik
Cara penentuan bobot metode entropy
a. Perhitungan Entropy untuk setiap kriteria ke-i
Dengan :
b. Perhitungan Bobot Entropy untuk setiap kriteria ke-i
16
c. Nilai data dikalikan dengan bobot entropy akhir. Kemudian nilai tersebut dicari nilai tertinggi, tengah dan nilai terendahnya untuk dijadikan sebagai pusat centroid awal.
3.4 K-Means Clustering
Setelah menentukan arsitektur dan penentuan nilai bobot C pada k-means maka langkah selanjutnya adalah melakukan proses clustering dataset. Proses clustering dimaksudkan agar data pasien yang dikelompokkan bisa sesuai dengan kelasnya.
Dalam tulisan ini beberapa hal terkait dengan metode k-means ini penulis berusaha untuk menjelaskan, mengenai metode k-means untuk dataset yang mempunyai bentuk khusus, serta algoritma dari metode-metode pengelompokan k-means. Gambar 3.3 menerangkan cara kerja dari K-Means Clustering
Gambar 3.3 Flowchart K-means
3.4.1 Penentuan Nilai Centroid
Dalam contoh ini jumlah data uji coba hanya sebanyak 15 data dan dibagi menjadi 2 atribut data dimana dengan euclidean distance yang dipakai untuk mencari nilai C nya
17
dengan persamaan:
dij = Jarak objek antara objek i dan j P = Dimensi data
Xik = Koordinat dari obyek i pada dimensi k Xjk = Koordinat dari obyek j pada dimensi k
Dengan mengacu pada persamaan diatas maka untuk menentukan clustering pada data set ini dengan menggunakan metode entropy dimana untuk mendapatkan nilai awal centroid sudah didapatkan yang akan dijelaskan pada bab 4.
18
BAB 4
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Pada bab ini menjelaskan bagaimana hasil penelitian dan pembahasan dari kinerja metode entropy untuk menentukan nilai bobot awal centroid pada k-means untuk mendapatkan clustering. Nilai bobot yang dihasilkan oleh metode entropy diharapkan mendapatkan tingkat akurasi yang lebih baik pada proses clustering jika dibandingkan dengan cara K-means standar.
Penelitian dilakukan dengan menggunakan dataset pasien pasca operasi yang didapat dari UCI Repository Machine Learning. Dataset yang digunakan sebanyak 12 data pasien yang terdiri dua kelas yaitu berdasarkan suhu pasien dan kenyamanan pasien. Kemudian dataset tersebut dilakukan proses normalisasi oleh entropy untuk mendapatkan nilai centroid data agar dapat diuji pada proses testing.
4.2. Nilai Bobot yang Dihasilkan
Penentuan nilai bobot pada penelitian ini dilakukan dengan tiga cara yaitu hasil perhitungan bobot dengan metode entropy, data terbaik dari perhitungan metode entropy dan nilai bobot yang diambil dari data pada setiap kelasnya.
4.2.1. Perhitungan Bobot dengan Metode Entropy
Penentuan nilai bobot dilakukan dengan menggunakan metode entropy dari dataset yang telah terbagi atas dua kelas yang berbeda, yaitu data suhu pasien dan kenyamanan pasien. Dataset kedua kelas tersebut dipisah dan kemudian diolah sehingga menghasilkan nilai bobot entropy. Dalam mencari bobot entropy nilai dari masing-masing data dibagi dengan nilai maksimum dari atribut tersebut.
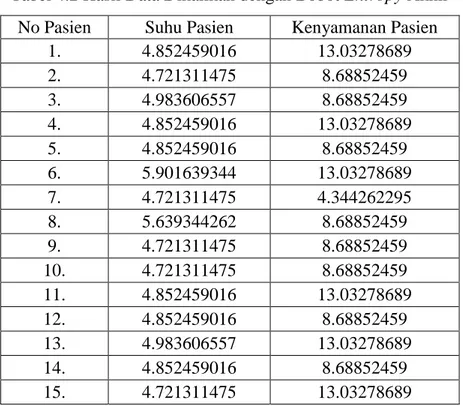
Berikut hasil normalisasi perhitungan penentuan nilai bobot untuk pusat cluster menggunakan entropy dengan dataset yang digunakan pada Tabel 4.1.
19
Tabel 4.1 Hasil Normalisasi Menggunakan Entropy No
Pasien Suhu Pasien Kenyamanan Pasien
1. 0.822222222 1
2. 0.8 0.666666667
3. 0.844444444 0.666666667
4. 0.822222222 1
5. 0.822222222 0.666666667
6. 1 1
7. 0.8 0.333333333
8. 0.955555556 0.666666667
9. 0.8 0.666666667
10. 0.8 0.666666667
11. 0.822222222 1
12. 0.822222222 0.666666667
13. 0.844444444 1
14. 0.822222222 0.666666667
15. 0.8 1
………
89. 0.822222222 0.666666667
90. 0.8 1
Jumlah 72.26666667 64.86666667
a. Perhitungan Entropy Untuk Setiap Kriteria ke-i
= =
20
Dengan :
, maka :
b. Perhitungan Bobot Entropy untuk setiap kriteria ke-i
maka didapatkan :
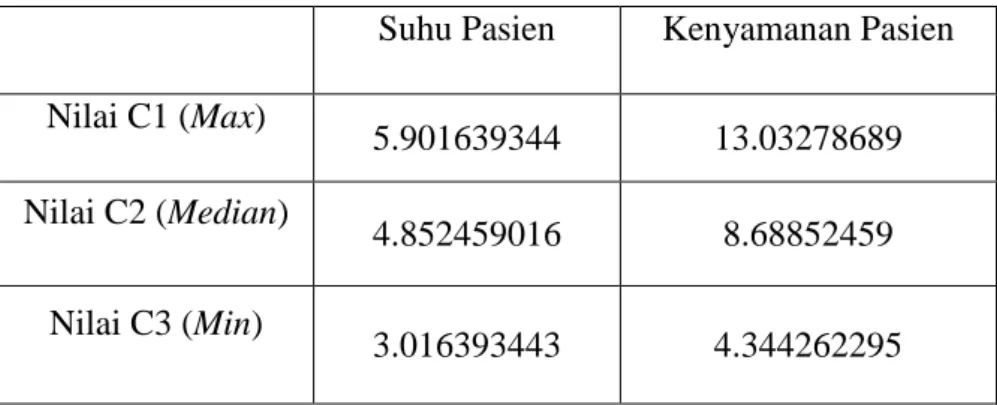
c. Nilai data dikalikan dengan bobot entropy akhir. Kemudian nilai tersebut dicari nilai tertinggi, tengah dan nilai terendahnya untuk dijadikan sebagai pusat centroid awal. Dimana nilai tersebut ditulis pada tabel 4.2 dan 4.3:
Tabel 4.2 Hasil Data Dikalikan dengan Bobot Entropy Akhir No Pasien Suhu Pasien Kenyamanan Pasien
1. 4.852459016 13.03278689
2. 4.721311475 8.68852459
3. 4.983606557 8.68852459
4. 4.852459016 13.03278689
5. 4.852459016 8.68852459
6. 5.901639344 13.03278689
7. 4.721311475 4.344262295
8. 5.639344262 8.68852459
9. 4.721311475 8.68852459
10. 4.721311475 8.68852459
11. 4.852459016 13.03278689
12. 4.852459016 8.68852459
13. 4.983606557 13.03278689
14. 4.852459016 8.68852459
15. 4.721311475 13.03278689
21
Tabel 4.3 Nilai Berdasarkan Range (Pusat Centroid Awal) Suhu Pasien Kenyamanan Pasien Nilai C1 (Max)
5.901639344 13.03278689 Nilai C2 (Median)
4.852459016 8.68852459 Nilai C3 (Min)
3.016393443 4.344262295
maka berikut perhitungan pada iterasi nya:
Dimana pada iterasi 1
Data inputan ke-1 : (4.8524, 13.0327) Pusat centroid 1: (5.9016, 13.0327) Pusat centroid 2: (4.8524, 8.6885) Pusat centroid 3: (3.0163, 4.3442) Jarak pada:
C1=
= = =
= 1,0492
C2=
= = =
= 4,3442
22
C3=
= = = = 8,8803
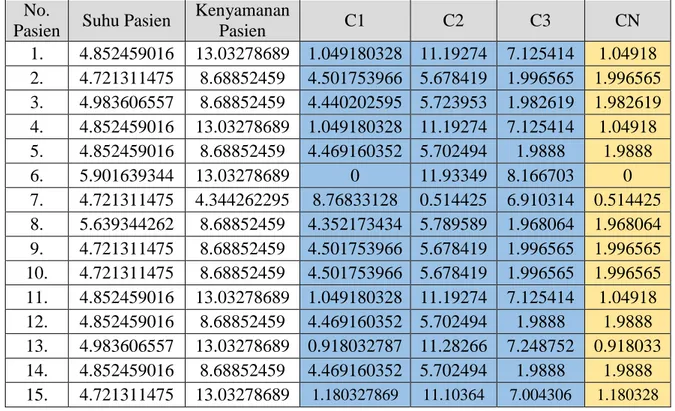
Dan seterus nya sehingga didapatkan hasil nya yang ditunjukkan pada tabel 4.4 Tabel 4.4 Hasil Iterasi ke-1
No.
Pasien Suhu Pasien Kenyamanan
Pasien C1 C2 C3 CN
1. 4.852459016 13.03278689 1.049180328 11.19274 7.125414 1.04918 2. 4.721311475 8.68852459 4.501753966 5.678419 1.996565 1.996565 3. 4.983606557 8.68852459 4.440202595 5.723953 1.982619 1.982619 4. 4.852459016 13.03278689 1.049180328 11.19274 7.125414 1.04918 5. 4.852459016 8.68852459 4.469160352 5.702494 1.9888 1.9888 6. 5.901639344 13.03278689 0 11.93349 8.166703 0 7. 4.721311475 4.344262295 8.76833128 0.514425 6.910314 0.514425 8. 5.639344262 8.68852459 4.352173434 5.789589 1.968064 1.968064 9. 4.721311475 8.68852459 4.501753966 5.678419 1.996565 1.996565 10. 4.721311475 8.68852459 4.501753966 5.678419 1.996565 1.996565 11. 4.852459016 13.03278689 1.049180328 11.19274 7.125414 1.04918 12. 4.852459016 8.68852459 4.469160352 5.702494 1.9888 1.9888 13. 4.983606557 13.03278689 0.918032787 11.28266 7.248752 0.918033 14. 4.852459016 8.68852459 4.469160352 5.702494 1.9888 1.9888 15. 4.721311475 13.03278689 1.180327869 11.10364 7.004306 1.180328 Berdasarkan jarak terpendek diatas maka clusterisasi data ini adalah sebagai berikut:
Tabel 4.5 Pengelompokkan Berdasarkan Cluster
No Pasien C1 C2 C3
1. 1
2. 1
3. 1
4. 1
5. 1
23
Tabel 4.6 Pengelompokkan Berdasarkan Cluster (Lanjutan)
6. 1
7. 1
8. 1
9. 1
10. 1
11. 1
12. 1
13. 1
14. 1
15. 1
Berdasarkan pengelompokkan diatas didapatkan clusterisasi yang didapat maka dilanjutkan kembali pada proses iterasi ke-2 yang cara nya hampir sama dengan iterasi ke-1 yang hanya membedakan nya ialah pada penentukan pusat C nya dimana pada iterasi ke-2 ini pusat C nya ditentukan dengan mencari rata-rata dari setiap cluster sebelumnya, Pada iterasi ke 2 pusat cluster baru ditentukan berdasarkan rata-rata masing-masing nilai pada setiap cluster baru yaitu:
Tabel 4.7 Penentuan Pusat Centroid Baru Centroid Baru
C1 C2 C3
4.866264 4.485246 4.721311475 13.03279 5.213115 8.662195728
Setelah ditentukan pusat centroid baru nya dapat dilanjutkan ke proses iterasi ke 2 sehingga didapatkan hasilnya yang ditunjukkan pada tabel 4.8
Tabel 4.8 Hasil Perhitungan Pada Iterasi Ke 2 No
Pasien
Suhu Pasien
Kenyamanan
Pasien C1 C2 C3 Cn
1. 4.852459 13.03278689 0.013805 7.82829 4.372558375 0.013805 2. 4.7213115 8.68852459 4.34668 3.483418 0.026328862 0.026329
24
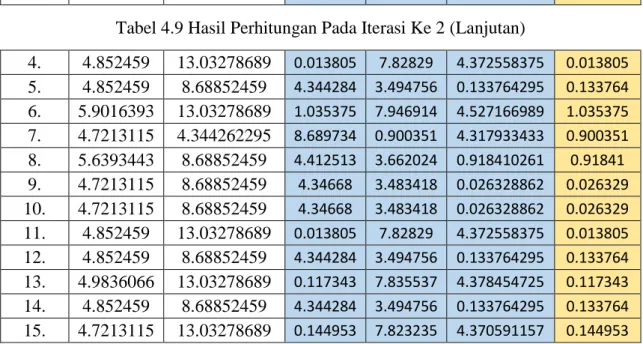
3. 4.9836066 8.68852459 4.345847 3.51096 0.2636132 0.263613 Tabel 4.9 Hasil Perhitungan Pada Iterasi Ke 2 (Lanjutan)
4. 4.852459 13.03278689 0.013805 7.82829 4.372558375 0.013805 5. 4.852459 8.68852459 4.344284 3.494756 0.133764295 0.133764 6. 5.9016393 13.03278689 1.035375 7.946914 4.527166989 1.035375 7. 4.7213115 4.344262295 8.689734 0.900351 4.317933433 0.900351 8. 5.6393443 8.68852459 4.412513 3.662024 0.918410261 0.91841 9. 4.7213115 8.68852459 4.34668 3.483418 0.026328862 0.026329 10. 4.7213115 8.68852459 4.34668 3.483418 0.026328862 0.026329 11. 4.852459 13.03278689 0.013805 7.82829 4.372558375 0.013805 12. 4.852459 8.68852459 4.344284 3.494756 0.133764295 0.133764 13. 4.9836066 13.03278689 0.117343 7.835537 4.378454725 0.117343 14. 4.852459 8.68852459 4.344284 3.494756 0.133764295 0.133764 15. 4.7213115 13.03278689 0.144953 7.823235 4.370591157 0.144953 Dan pengalokasian kembali nilai tersebut kedalam cluster masing-masing dapat dilihat pada tabel berikut ini:
Tabel 4.10 Pengalokasian Kembali Kedalam Cluster No
Pasien C1 C2 C3
1. 1
2. 1
3. 1
4. 1
5. 1
6. 1
7. 1
8. 1
9. 1
10. 1
11. 1
12. 1
13. 1
14. 1
15. 1
Dimana pada proses iterasi ke 2 mendapatkan hasil yang berbeda dengan iterasi 1 maka proses dilanjutkan kembali pada iterasi ke-3 dengan cara yang sama dengan
25
iterasi ke 2 sampai didapatkan hasil clusterisasi yang tidak berubah sehingga didapatkan hasil akhir pada iterasi ke 4 dimana hasil clusterisasi nya ditunjukkan pada tabel 4.11 dan tabel 4.12.
Tabel 4.11 Hasil Iterasi Ke 5 No
Pasien Suhu Pasien Kenyamanan
Pasien C1 C2 C3 Cn
1. 4.852459016 13.03278689 0.013805004 13.90682899 4.615850175 0.013805004 2. 4.721311475 8.68852459 4.346679897 9.888439796 0.269734673 0.269734673 3. 4.983606557 8.68852459 4.345846771 10.01632637 0.387655088 0.387655088 4. 4.852459016 13.03278689 0.013805004 13.90682899 4.615850175 0.013805004 5. 4.852459016 8.68852459 4.344284229 9.951724376 0.307110653 0.307110653 6. 5.901639344 13.03278689 1.035375324 14.3067425 4.766228162 1.035375324 7. 4.721311475 4.344262295 8.689733643 6.415870708 4.075074316 4.075074316 8. 5.639344262 8.68852459 4.412512657 10.35821719 0.9726584 0.9726584 9. 4.721311475 8.68852459 4.346679897 9.888439796 0.269734673 0.269734673 10. 4.721311475 8.68852459 4.346679897 9.888439796 0.269734673 0.269734673 11. 4.852459016 13.03278689 0.013805004 13.90682899 4.615850175 0.013805004 12. 4.852459016 8.68852459 4.344284229 9.951724376 0.307110653 0.307110653 13. 4.983606557 13.03278689 0.117342537 13.95313113 4.62190787 0.117342537 14. 4.852459016 8.68852459 4.344284229 9.951724376 0.307110653 0.307110653 15. 4.721311475 13.03278689 0.144952545 13.86161304 4.613514136 0.144952545
Tabel 4.12 Pengalokasian Ke Dalam Cluster No
Pasien C1 C2 C3 1. 1
2. 1
3. 1
4. 1
5. 1
6. 1
7. 1
8. 1
9. 1
10. 1
11. 1
12. 1
26
13. 1
14. 1
15. 1 4.2.2. K-Means standar
Penentuan nilai bobot awal pada k-means standar dilakukan dengan mengambil data acak dalam dataset pada setiap kelasnya. Untuk selengkapnya akan ditampilkan pada table 4.3. Maka hasil clusteirng yang dihasilkan dapat dilihat pada Tabel 4.9.
Tabel 4.13 Penentuan Pusat Awal Centroid
Centroid Kordinat 1 Kordinat 2
C1 (data ke 43) 45 15
C2 (data ke 7) 36 5
C3 (data ke 83) 23 10
Sehingga dari nilai awal centroid diatas dengan proses perhitungan yang sama dengan pembahasan sebelumnya yang sudah dibahas didapatkan hasil yang ditunjukkan pada tabel 4.14 dan tabel 4.15
Tabel 4.14 Hasil akhir Iterasi K-Means Standar
No.
Pasien
Suhu Pasien
Kenyamanan
Pasien C1 C2 C3 Cn
1. 37 15 0.5 5.37359175 9.22293 0.5
2. 36 10 5.22015 0.70745196 6.75 0.70745
3. 38 10 5.02494 1.43631065 8.75 1.43631
4. 37 15 0.5 5.37359175 9.22293 0.5
5. 37 10 5.02494 0.53079024 7.75 0.53079
6. 45 15 7.5 9.9561784 16.5246 7.5
7. 36 5 10.1119 4.68046347 8.40015 4.68046
8. 43 10 7.43303 6.4007217 13.75 6.40072
9. 36 10 5.22015 0.70745196 6.75 0.70745
10. 36 10 5.22015 0.70745196 6.75 0.70745
11. 37 15 0.5 5.37359175 9.22293 0.5
12. 37 10 5.02494 0.53079024 7.75 0.53079
13. 38 15 0.5 5.53685274 10.0778 0.5
14. 37 10 5.02494 0.53079024 7.75 0.53079
27
15. 36 15 1.5 5.39390752 8.40015 1.5
Tabel 4.15 Hasil Clustering Dengan K-Means Standar
No.
Pasien C1 C2 C3
1. 1
2. 1
3. 1
4. 1
5. 1
6. 1
7. 1
8. 1
9. 1
10. 1
11. 1
12. 1
13. 1
14. 1
15. 1
4.3. Hasil Penelitian
Dalam melakukan pengujian pada penelitian ini dilakukan sebanyak 4 kali pengujian pada k-means standar dimana dengan berbeda-beda pusat centroid awal nya dan didapatkan bahwa setiap kali pengujian berbeda-beda hasilnya pada setiap centroid awal sedangkan dengan menggunakan entropy untuk menentukan nilai centroid nya terhadap 2 atribut yang ada, terbukti hanya butuh 1 kali pengujian saja dengan sudah ditentukan nya nilai centroid awal dengan entropy tersebut.
Adapun hasil pengujian dilakukan dengan menggunakan parameter pada tabel terhadap pengclusteran pasien pasca operasi ditampilkan pada Tabel 4.16
Tabel 4.16 Hasil Perbandingan
28
Dari tabel di atas bisa dilihat bahwa nilai centroid diperoleh dari cara entropy memiliki tingkat efektifitas yang lebih baik dalam mengclusterkan jika dibandingkan cara yang lain yakni berbeda-beda di setiap iterasi. Sehingga apabila dilakukan perhitungan berkali-kali dengan berbeda-beda centroid awalnya berbeda pula hasil clusterisasi nya.
4.4. Pembahasan (Perbandingan)
Dari hasil penelitian yang telah dilakukan bahwa metode entropy dapat digunakan sebagai penentu nilai centroid awal pada k-means. Nilai centroid yang diperoleh dari metode entropy menunjukkan kinerja yang baik dalam mempelajari data pada saat proses training. Metode entropy menghasilkan nilai centroid yang dapat mewakili
No Pasien
K-means Dengan Entropy K-means Standar
Iterasi C1 C2 C3 Iterasi C1 C2 C3
1. 4 1 4 1
2. 4 1 4 1
3. 4 1 4 1
4. 4 1 4 1
5. 4 1 4 1
6. 4 1 4 1
7. 4 1 4 1
8. 4 1 4 1
9. 4 1 4 1
10. 4 1 4 1
11. 4 1 4 1
12. 4 1 4 1
29
keseluruhan data dengan jumlah data training yang walaupun dengan penentuan centroid awal tertentu jumlah iterasinya sama yaitu sebanyak 4 kali. Namun pada proses penghitungan keseluruhan data, metode entropy dapat mendapatkan hasil yang optimal dibandingkan dengan k-means standar.
Namun secara keseluruhan pengujian, nilai centroid awal yang dihasilkan dengan metode entropy memiliki tingkat keberhasilan dalam pengclusteran data dibandingkan dengan cara yang lainnya. Maka dapat disimpulkan bahwa nilai centroid awal sangatlah mempengaruhi dari proses pembelajaran data dan tingkat akurasi yang didapat. Kemudian penentuan nilai centroid awal pada k-means dengan menggunakan metode entropy bisa dikatakan lebih baik jika dibandingkan dengan penentuan nilai centroid awal dengan cara k-means standar.
30
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Kesimpulan dari hasil penelitian yang telah dilakukan yaitu :
1. Metode entropy dalam penentuan nilai bobot awal pada penentuan pusat cluster membantu kinerja proses dalam clustering dan menghasilkan tingkat hasil yang lebih baik dalam proses klasterisasi.
2. Nilai bobot awal yang dihasilkan metode entropy mampu mempelajari data dengan baik dan menghasilkan tingkat akurasi lebih tinggi, hal ini disebabkan sifat metode entropy mampu menyelidiki keserasian dari sekumpulan dataset sehingga menghasilkan nilai bobot yang dapat mewakili setiap dataset pada setiap kelas.
5.2. Saran
Adapun saran yang diberikan oleh penulis yaitu :
1. Untuk hasil yang lebih akurat lagi dapat menggunakan metode penentuan bobot selain metode entropy ataupun mengkombinasikan k-means dengan metode lainnya.
2. Perlu diimplementasikan dengan data kasus yang lain atau dengan data set yang lebih banyak.
31
DAFTAR PUSTAKA
Abbas, A.R. 2004. Entropy Methode for Adaptive Utility Elicitation. IEEE Transaction on System, Man, and Cybernetics 34(2): 169-178.
Agusta, Yudi PhD, “K-Means – Penerapan, Permasalahan dan Metode Terkait”, Jurnal Sistem dan Informatika Vol. 3 (Pebruari 2007), 47-60
Chen , Bernard, Phang C. Tai, R. Harrison and Yi Pan, “Novel Hybrid
Hierarchical-K-means Clustering Method (H-K-means) for Microarray Analysis” Department of Computer Science, Department of Biology, Georgia State University, Atlanta, USA 2005
Chen , Bernard, Phang C. Tai, R. Harrison and Yi Pan, “Novel Hybrid
Hierarchical-K-means Clustering Method (H-K-means) for Microarray Analysis” Department of Computer Science, Department of Biology, Georgia State University, Atlanta, USA 2005
Jamila. 2012. Sistem Pendukung Keputusan Pemilihan Subkontrak Produksi Sarung Tangan Menggunakan Metode Entropy dan TOPSIS. Seminar Nasional Informatika UPN Yogyakarta. 1(2).
Nurul C., Wiharto, & Umi S. 2012. Pengaruh Normalisasi Data pada Jaringan Syaraf Tiruan Backpropation Gradient Descent Adaptive Gain (BPGDAG) untuk Klasifikasi. JURNAL ITSMART. 2301-7201.
Xia, Shu-yin, Zhong-yang Xiong, Yue-guo Luo, Wei-Xu, “Effectiveness of the Euclidean distance in high dimensional spaces”, College of Computer Science, 2015
32
LAMPIRAN
Lampiran 1 Tabel Dataset Pasien Pasca Operasi No
Pasien
Suhu Pasien
Kenyamanan Pasien
No Pasien
Suhu Pasien
Kenyamanan Pasien
1. 37 15 31. 37 10
2. 36 10 32. 30 10
3. 38 10 33. 37 10
4. 37 15 34. 37 10
5. 37 10 35. 31 10
6. 45 15 36. 37 10
7. 36 5 37. 35 10
8. 43 10 38. 35 10
9. 36 10 39. 35 7
10. 36 10 40. 37 10
11. 37 15 41. 33 10
12. 37 10 42. 35 15
13. 38 15 43. 45 15
14. 37 10 44. 36 10
15. 36 15 45. 33 10
16. 39 10 46. 35 10
17. 30 15 47. 25 5
18. 37 10 48. 37 10
19. 37 15 49. 39 8
20. 37 10 50. 37 10
21. 33 15 51. 37 10
22. 35 10 52. 33 10
23. 37 15 53. 37 10
24. 37 10 54. 36 10
25. 38 10 55. 38 10
26. 32 10 56. 37 15
27. 38 10 57. 38 15
28. 33 10 58. 37 10
29. 37 15 59. 33 10
30. 36 10 60. 37 10
Sumber: Sumber: http://archive.ics.uci.edu
33
Lampiran 1 Tabel Dataset Pasien Pasca Operasi (Lanjutan) No
Pasien
Suhu Pasien
Kenyamanan Pasien
No Pasien
Suhu Pasien
Kenyamanan Pasien
61. 37 10 76. 31 10
62. 37 10 77. 37 10
63. 37 10 78. 37 10
64. 36 10 79. 36 10
65. 39 10 80. 37 10
66. 36 10 81. 37 15
67. 37 10 82. 36 10
68. 37 10 83. 23 10
69. 37 10 84. 38 5
70. 37 10 85. 37 10
71. 37 8 86. 37 10
72. 32 10 87. 36 15
73. 36 10 88. 37 15
74. 37 10 89. 37 10
75. 37 10 90. 36 15
Sumber: http://archive.ics.uci.edu
Lampiran 2 Tabel Titik Awal Centroid
Kordinat 1 Kordinat 2 Nilai C1 5.901639344 13.03278689
Nilai C2 4.852459016 8.68852459
Nilai C3 3.016393443 4.344262295 Lampiran 3 Tabel Iterasi Ke 1
No
Pasien Suhu Pasien
Kenyamanan
Pasien C1 C2 C3 Cn
1. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 2. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 3. 4.983606557 8.68852459 4.440202595 0.131148 4.768914 0.131148 4. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 5. 4.852459016 8.68852459 4.469160352 0 4.716328 0 6. 5.901639344 13.03278689 0 4.46916 9.155059 0 7. 4.721311475 4.344262295 8.76833128 4.346241 1.704918 1.704918 8. 5.639344262 8.68852459 4.352173434 0.786885 5.074691 0.786885
34
Lampiran 3 Tabel Iterasi Ke 1 (Lanjutan)
9. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 10. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 11. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 12. 4.852459016 8.68852459 4.469160352 0 4.716328 0 13. 4.983606557 13.03278689 0.918032787 4.346241 8.908445 0.918033 14. 4.852459016 8.68852459 4.469160352 0 4.716328 0 15. 4.721311475 13.03278689 1.180327869 4.346241 8.85422 1.180328 16. 5.114754098 8.68852459 4.41495224 0.262295 4.824493 0.262295 17. 3.93442623 13.03278689 1.967213115 4.440203 8.73689 1.967213 18. 4.852459016 8.68852459 4.469160352 0 4.716328 0 19. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 20. 4.852459016 8.68852459 4.469160352 0 4.716328 0 21. 4.327868852 13.03278689 1.573770492 4.375821 8.786946 1.57377 22. 4.590163934 8.68852459 4.537905094 0.262295 4.620538 0.262295 23. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 24. 4.852459016 8.68852459 4.469160352 0 4.716328 0 25. 4.983606557 8.68852459 4.440202595 0.131148 4.768914 0.131148 26. 4.196721311 8.68852459 4.666836229 0.655738 4.501754 0.655738 27. 4.983606557 8.68852459 4.440202595 0.131148 4.768914 0.131148 28. 4.327868852 8.68852459 4.62053768 0.52459 4.537905 0.52459 29. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 30. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 31. 4.852459016 8.68852459 4.469160352 0 4.716328 0 32. 3.93442623 8.68852459 4.768914166 0.918033 4.440203 0.918033 33. 4.852459016 8.68852459 4.469160352 0 4.716328 0 34. 4.852459016 8.68852459 4.469160352 0 4.716328 0 35. 4.06557377 8.68852459 4.716328199 0.786885 4.46916 0.786885 36. 4.852459016 8.68852459 4.469160352 0 4.716328 0 37. 4.590163934 8.68852459 4.537905094 0.262295 4.620538 0.262295 38. 4.590163934 8.68852459 4.537905094 0.262295 4.620538 0.262295 39. 4.590163934 6.081967213 7.073461802 2.619721 2.344434 2.344434 40. 4.852459016 8.68852459 4.469160352 0 4.716328 0 41. 4.327868852 8.68852459 4.62053768 0.52459 4.537905 0.52459 42. 4.590163934 13.03278689 1.31147541 4.352173 8.829904 1.311475 43. 5.901639344 13.03278689 0 4.46916 9.155059 0 44. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 45. 4.327868852 8.68852459 4.62053768 0.52459 4.537905 0.52459
35
46. 4.590163934 8.68852459 4.537905094 0.262295 4.620538 0.262295 Lampiran 3 Tabel Iterasi Ke 1 (Lanjutan)
47. 3.278688525 4.344262295 9.075810187 4.620538 0.262295 0.262295 48. 4.852459016 8.68852459 4.469160352 0 4.716328 0 49. 5.114754098 6.950819672 6.132659584 1.757389 3.346231 1.757389 50. 4.852459016 8.68852459 4.469160352 0 4.716328 0 51. 4.852459016 8.68852459 4.469160352 0 4.716328 0 52. 4.327868852 8.68852459 4.62053768 0.52459 4.537905 0.52459 53. 4.852459016 8.68852459 4.469160352 0 4.716328 0 54. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 55. 4.983606557 8.68852459 4.440202595 0.131148 4.768914 0.131148 56. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 57. 4.983606557 13.03278689 0.918032787 4.346241 8.908445 0.918033 58. 4.852459016 8.68852459 4.469160352 0 4.716328 0 59. 4.327868852 8.68852459 4.62053768 0.52459 4.537905 0.52459 60. 4.852459016 8.68852459 4.469160352 0 4.716328 0 61. 4.852459016 8.68852459 4.469160352 0 4.716328 0 62. 4.852459016 8.68852459 4.469160352 0 4.716328 0 63. 4.852459016 8.68852459 4.469160352 0 4.716328 0 64. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 65. 5.114754098 8.68852459 4.41495224 0.262295 4.824493 0.262295 66. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 67. 4.852459016 8.68852459 4.469160352 0 4.716328 0 68. 4.852459016 8.68852459 4.469160352 0 4.716328 0 69. 4.852459016 8.68852459 4.469160352 0 4.716328 0 70. 4.852459016 8.68852459 4.469160352 0 4.716328 0 71. 4.852459016 6.950819672 6.171799133 1.737705 3.188303 1.737705 72. 4.196721311 8.68852459 4.666836229 0.655738 4.501754 0.655738 73. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 74. 4.852459016 8.68852459 4.469160352 0 4.716328 0 75. 4.852459016 8.68852459 4.469160352 0 4.716328 0 76. 4.06557377 8.68852459 4.716328199 0.786885 4.46916 0.786885 77. 4.852459016 8.68852459 4.469160352 0 4.716328 0 78. 4.852459016 8.68852459 4.469160352 0 4.716328 0 79. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148 80. 4.852459016 8.68852459 4.469160352 0 4.716328 0 81. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 82. 4.721311475 8.68852459 4.501753966 0.131148 4.666836 0.131148
36
83. 3.016393443 8.68852459 5.215099117 1.836066 4.344262 1.836066 84. 4.983606557 4.344262295 8.736889821 4.346241 1.967213 1.967213
Lampiran 3 Tabel Iterasi Ke 1 (Lanjutan)
85. 4.852459016 8.68852459 4.469160352 0 4.716328 0 86. 4.852459016 8.68852459 4.469160352 0 4.716328 0 87. 4.721311475 13.03278689 1.180327869 4.346241 8.85422 1.180328 88. 4.852459016 13.03278689 1.049180328 4.344262 8.880405 1.04918 89. 4.852459016 8.68852459 4.469160352 0 4.716328 0 90. 4.721311475 13.03278689 1.180327869 4.346241 8.85422 1.180328
Lampiran 4 Tabel Pengalokasian Ke Dalam Cluster
No Pasien C1 C2 C3 No Pasien C1 C2 C3
1. 1 31. 1
2. 1 32. 1
3. 1 33. 1
4. 1 34. 1
5. 1 35. 1
6. 1 36. 1
7. 1 37. 1
8. 1 38. 1
9. 1 39. 1
10. 1 40. 1
11. 1 41. 1
12. 1 42. 1
13. 1 43. 1
14. 1 44. 1
15. 1 45. 1
16. 1 46. 1
17. 1 47. 1
18. 1 48. 1
19. 1 49. 1
20. 1 50. 1
21. 1 51. 1
22. 1 52. 1
23. 1 53. 1
24. 1 54. 1
25. 1 55. 1
26. 1 56. 1
27. 1 57. 1
37
28. 1 58. 1
29. 1 59. 1
30. 1 60. 1
Lampiran 4 Tabel Pengalokasian Ke Dalam Cluster (Lanjutan)
No Pasien C1 C2 C3 No Pasien C1 C2 C3
61. 1 76. 1
62. 1 77. 1
63. 1 78. 1
64. 1 79. 1
65. 1 80. 1
66. 1 81. 1
67. 1 82. 1
68. 1 83. 1
69. 1 84. 1
70. 1 85. 1
71. 1 86. 1
72. 1 87. 1
73. 1 88. 1
74. 1 89. 1
75. 1 90. 1
Lampiran 5 Tabel Penentuan Centroid Baru
C1 C2 C3
Kordinat 1 4.866264 4.721311 4.485245902 Kordinat 2 13.03279 8.635867 5.560655738
Lampiran 6 Tabel Iterasi Ke 2 No
Pasien Suhu Pasien
Kenyamanan
Pasien C1 C2 C3 Cn
1. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 2. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 3. 4.9836066 8.68852459 4.345847 0.267529 3.167321724 0.267529 4. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805
38
5. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 6. 5.9016393 13.03278689 1.035375 4.55259 7.605189956 1.035375 7. 4.7213115 4.344262295 8.689734 4.291605 1.239088359 1.239088 8. 5.6393443 8.68852459 4.412513 0.919542 3.333992589 0.919542
Lampiran 6 Tabel Iterasi Ke 2 (Lanjutan)
9. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 10. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 11. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 12. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 13. 4.9836066 13.03278689 0.117343 4.404737 7.488732017 0.117343 14. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 15. 4.7213115 13.03278689 0.144953 4.39692 7.475859204 0.144953 16. 5.1147541 8.68852459 4.351363 0.396951 3.1905868 0.396951 17. 3.9344262 13.03278689 0.931838 4.466777 7.492405902 0.931838 18. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 19. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 20. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 21. 4.3278689 13.03278689 0.538395 4.414488 7.473788291 0.538395 22. 4.5901639 8.68852459 4.353027 0.141324 3.129627989 0.141324 23. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 24. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 25. 4.9836066 8.68852459 4.345847 0.267529 3.167321724 0.267529 26. 4.1967213 8.68852459 4.395555 0.527226 3.141147879 0.527226 27. 4.9836066 8.68852459 4.345847 0.267529 3.167321724 0.267529 28. 4.3278689 8.68852459 4.377497 0.396951 3.131825521 0.396951 29. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 30. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 31. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 32. 3.9344262 8.68852459 4.443077 0.788645 3.175998405 0.788645 33. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 34. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 35. 4.0655738 8.68852459 4.417434 0.657849 3.155897377 0.657849 36. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 37. 4.5901639 8.68852459 4.353027 0.141324 3.129627989 0.141324 38. 4.5901639 8.68852459 4.353027 0.141324 3.129627989 0.141324 39. 4.5901639 6.081967213 6.956301 2.557265 0.531764467 0.531764 40. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 41. 4.3278689 8.68852459 4.377497 0.396951 3.131825521 0.396951
39
42. 4.5901639 13.03278689 0.2761 4.398875 7.472867701 0.2761 43. 5.9016393 13.03278689 1.035375 4.55259 7.605189956 1.035375 44. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 45. 4.3278689 8.68852459 4.377497 0.396951 3.131825521 0.396951 46. 4.5901639 8.68852459 4.353027 0.141324 3.129627989 0.141324
Lampiran 6 Tabel Iterasi Ke 2 (Lanjutan)
47. 3.2786885 4.344262295 8.832375 4.527586 1.713299072 1.713299 48. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 49. 5.1147541 6.950819672 6.087041 1.73037 1.526052533 1.526053 50. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 51. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 52. 4.3278689 8.68852459 4.377497 0.396951 3.131825521 0.396951 53. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 54. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 55. 4.9836066 8.68852459 4.345847 0.267529 3.167321724 0.267529 56. 4.852459 13.03278689 0.013805 4.398875 7.481148933 0.013805 57. 4.9836066 13.03278689 0.117343 4.404737 7.488732017 0.117343 58. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 59. 4.3278689 8.68852459 4.377497 0.396951 3.131825521 0.396951 60. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 61. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 62. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 63. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 64. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 65. 5.1147541 8.68852459 4.351363 0.396951 3.1905868 0.396951 66. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 67. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 68. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 69. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 70. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 71. 4.852459 6.950819672 6.081983 1.690143 1.437846041 1.437846 72. 4.1967213 8.68852459 4.395555 0.527226 3.141147879 0.527226 73. 4.7213115 8.68852459 4.34668 0.052658 3.136764338 0.052658 74. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 75. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 76. 4.0655738 8.68852459 4.417434 0.657849 3.155897377 0.657849 77. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324 78. 4.852459 8.68852459 4.344284 0.141324 3.149350573 0.141324