PENERAPAN METODE
CLUSTERING
K-MEANS
UNTUK
MENENTUKAN KATEGORI STOK BARANG
Elly Muningsih
Program Sudi Manajemen Informatika, AMIK BSI Yogyakarta Email : [email protected]
Abstract - Good and accurate stock management is needed in institutions and organizations which carry out transaction of purchases and sales of products. This is for efficiency of stocks in order to reduce storage costs, make more effective and fulfil customer satisfaction. The results of this research make 3 groups which are, the first group is the most interesting product for the number of stock, the second group is the medium stock for the more interesting product and the last group is the few stock for the less interesting product. Data processing used the clustering method which is K-Means method based on historical data of sales which contain products code, the number of transactions, sales volume and average sales. The measurement of validation and accuracy in this research use precision, recall and F1 methods which are counted base on new data sales. Based on this research it is resulted 3 members of product group for the number of stock, 11 members of product group for the medium stock and 17 members of product group for the few stock.
Keywords : stock, clustering, K-Means methods, validation, accuracy
Manajemen stok yang baik dan akurat sangat diperlukan pada suatu lembaga atau organisasi yang melakukan transaksi pembelian dan penjualan produk. Hal ini dilakukan untuk efisiensi stok agar bisa mengurangi biaya penyimpanan, lebih efektif dan memenuhi kepuasan pelanggan. Penelitian ini menghasilkan 3 kelompok produk paling diminati untuk jumlah stok banyak, jumlah stok sedang untuk produk diminati dan jumlah stok sedikit untuk produk yang kurang atau tidak diminati. Pengolahan data dilakukan menggunakan metode clustering yaitu metode K-Means berdasarkan data historis penjualan yang memuat kode produk, jumlah transaksi, volume penjualan dan rata-rata penjualan. Pengukuran validasi dan akurasi dalam penelitian ini menggunakan metode precision, recall dan F1 yang dihitung berdasrkan data baru penjualan. Dari penelitian dihasilkan 3 anggota kelompok produk untuk stok banyak, 11 anggota kelompok untuk jumlah stok sedang, dan 17 anggota kelompok stok sedikit.
Kata kunci : stok, clustering, metode K-Means, validasi, akurasi
1. PENDAHULUAN
Teknologi internet saat ini berkembang sangat pesat terutama dalam dunia bisnis, hal ini dapat dilihat dengan munculnya electronic commerce (e-commerce) [1]. E-commerce
memberikan manfaat bagi perusahaan sehingga akan menjadi keunggulan kompetitif bagi perusahaan yang mengaplikasikannya [2]. Lembaga atau perusahaan yang mengaplikasikan
E-commerce dalam kegiatan penjualan atau perdagangannya biasa dikenal dengan nama Toko Online atau Online Shop.
tidak efektif dan seringkali mengecewakan konsumen karena kekosongan suatu produk tertentu.
Persediaan atau stok dapat didefinisikan sebagai suatu aktivitas yang meliputi barang pemilik organisasi dengan maksud untuk dijual dalam suatu waktu atau periode usaha tertentu atau persediaan barang-barang yang masih dalam pengerjaan proses produksi ataupun persediaan bahan baku yang menunggu penggunanya dalam proses produksi [3]
Penentuan jumlah stok produk yang kurang akurat karena harus berdasarkan pengetahuan dari jumlah data transaksi penjualan yang besar [4]. Karena hal itu untuk mendapatkan pengetahuan tersebut maka diperlukan suatu proses pengolahan data historis transaksi besar yaitu dengsn teknik data mining. Data mining
merupakan sebuah inti dari proses Knowledge Discovery in Database (KDD) yang meliputi dugaan algoritma yang mengeksplor data, membangun model dan menemukan pola yang belum diketahui [5]. Metode K-Means
merupakan salah satu metode dalam fungsi clustering atau pengelompokan [6]. K-Means
adalah salah satu metode data clustering non hirarki yang mempartisi data ke dalam bentuk satu atau lebih cluster/kelompok, sehingga data yang memiliki karakteristik yang sama dikelompokkan dalam satu cluster yang sama dan data yang memiliki karakteristik berbeda dikelompokkan ke dalam kelompok lain [7]. Algoritma dalam metode K-Means yaitu : [7]
1. Tentukan jumlah cluster
2. Tentukan pusat cluster secara acak atau alokasikan data sesuai dengan jumlah
cluster yang telah ditentukan
3. Hitung nilai centroid pada tiap-tiap cluster
4. Alokasikan masing-masing data ke centroid
terdekat
5. Kembali ke step 3, apabila masih terdapat perpindahan data dari satu cluster ke cluster
lainnya, atau apabila perubahan pada nilai
centroid masih di atas nilai threshold yang ditentukan, atau apabila perubahan pada nilai objective function masih di atas nilai threshold yang ditentukan.
Untuk menghitung centroid cluster ke-i, vi, digunakan rumus sebagai berikut [7]:
dimana :
Ni : Jumlah data yang menjadi anggota
cluster ke-i
vi : Nilai centroid cluster ke-i
Penelitian ini mengacu pada beberapa penelitian sebelumnya, diantaranya :
a. Penelitian Wahid, dkk menggunakan model matematika yang disusun dengan rumusan logika Fuzzy, dimana untuk menentukan jumlah pemesanan barang maka dilakukan perhitungan menggunakan Logika Fuzzy
model Sugeno. Dari penelitian ini diketahui hasil keputusan jumlah pemesanan, persediaan tersisa sehingga diketahui jumlah persediaan periode selanjutnya [8]
b. Penelitian Wijaya dkk, menerapkan metode
Economic Order Quantity (EQQ) untuk menentukan stok minimum tiap barang yang harus dipenuhi, menentukan waktu pemesanan kembali dan menentukan berapa jumlah pesanan barang yang sesuai. Hasil dari penelitian ini adalah sebuah aplikasi berdasarkan metode EQQ yang dapat memberikan solusi kepada perusahaan untuk menentukan jumlah pemesanan barang yang optimal dan ekonomis untuk menentukan kapan harus melakukan pemesanan barang [9].
2. METODE PENELITIAN Rancangan Penelitian
Gambar 1. Tahapan Proses KDD
Bahan dan Alat
Bahan yang digunakan dalam penelitian ini adalah data-data tentang produk jenis Batik saja yang meliputi kode produk, jumlah transaksi, volume penjualan dan rata-rata penjualan yang berasal dari transaksi penjualan.
Metode Analisis
Tahapan Proses KDD
1. Domain Understanding & KDD Goal
Penentuan kategori stok yang tidak akurat menjadikan biaya penyimpanan tinggi, tidak efektif dan sering mengecewakan konsumen, sehingga dibutuhkan metode K-Means yang bisa meng-cluster produk menjadi kelompok jumlah stok banyak, sedang dan sedikit/kurang.
2. Selection & Addition
Data historis diambil dari data transaksi penjualan dari bulan Januari 2011 – Mei 2012 sebanyak 235 tarnsaksi. Penelitian ini memfokuskan pada produk kategori Batik dimana kode produk yang digunakan terdiri dari 31 jenis produk.
3. Preprocessing
Preprocessing data pada tahap ini adalah mengambil data sample sebanyak 148 dengan metode simple random sampling.
4. Transformation
Proses transformasi data dengan cara merubah kode produk yang terjual sebagai atribut lama dengan kode produk baru untuk memudahkan pemrosesan data. Dalam proses ini dihasilkan atribut yang digunakan dalam pengolahan data yaitu kode produk, jumlah transaksi, volume penjualan dan rata-rata penjualan.
5. Data Mining
Metode yang digunakan dalam penelitian ini adalah metode clustering K-Means. Dan tools
pendukung penelitian menggunakan
RapidMiner.
6. Evaluation and Interpretation
Pengukuran hasil penelitian ini menggunakan metode precision, recall dan F1. Data yang digunakan dalam melakukan pengukuran didapatkan dari 5 data transaksi baru untuk masing-masing cluster yang dipilih dengan metode purposive dimana pengambilan sampel dilakukan secara sengaja sesuai dengan persyaratan sampel yang diperlukan..
7. Discovered Knowledge
Pengolahan data menghasilkan 3 kelompok atau cluster yaitu cluster 1 untuk produk jumlah stok banyak, cluster 2 untuk produk jumlah stok sedang dan cluster 3 untuk produk jumlah stok sedikit.
3. HASIL DAN PEMBAHASAN
a. Pengolahan Data
Dari data yang sudah diperoleh pada tahapan ke-4 proses KDD, kemudian diolah menggunakan metode clustering K-Means. Adapun langkah dari pengelompokkan data adalah sebagai berikut :
1. Tentukan jumlah cluster. Jumlah cluster
dalam penelitian ini adalah 3.
2. Tentukan pusat cluster secara acak, misalkan ditentukan pusat cluster c1 (18; 65; 4), c2 (9; 35; 2,5) dan c3 (3; 10; 5)
3. Hitung jarak setiap data yang ada terhadap setiap pusat cluster. Misalkan untuk menghitung jarak data produk pertama dengan pusat cluster pertama adalah :
�11 =
(16−18)2+ (22−65)2+ (1,38−4)2
= 43,13
Jarak data produk pertama dengan pusat
cluster kedua :
�12
= (16−9)2+ (22−35)2+ (1,38−5)2
Jarak data produk pertama dengan pusat
cluster ketiga :
�12
= (16−3)2+ (22−10)2+ (1,38−1,5)2
= 17,69
Berdasarkan hasil ketiga perhitungan diatas dapat disimpulkan bahwa jarak data kode produk p1 yang paling dekat adalah dengan
cluster 2, sehingga produk p1 dimasukkan ke dalam cluster 2. Hasil perhitungan selengkapnya bisa dilihat pada tabel 1 berikut :
Tabel 1. Data Hasil Iterasi 1 kode
produk
jml transaksi
volume penjualan
rata-rata penjualan
cluster cluster
1 2 3 1 2 3
p1 16 22 1,38 43,13 14,81 17,69 *
p2 23 54 2,35 12,20 23,60 48,34 *
p3 2 5 2,50 62,11 30,81 5,20 *
p4 2 3 1,50 64,08 32,77 7,07 *
p5 6 13 2,17 53,40 22,21 4,29 *
p6 15 40 2,67 25,21 7,81 32,33 *
p7 15 32 2,13 33,19 6,72 25,07 *
p8 32 72 2,25 15,75 43,57 68,45 *
p9 4 8 2,00 58,73 27,46 2,29 *
p10 22 65 2,95 4,13 32,70 58,21 *
p11 6 13 2,17 53,40 22,21 4,29 *
p12 4 10 2,50 56,77 25,50 1,41 *
p13 1 2 2,00 65,28 33,96 8,26 *
p14 25 91 3,64 26,93 58,25 83,96 *
p15 14 20 1,43 45,25 15,85 14,87 *
p16 6 10 1,67 56,34 25,19 3,00 *
p17 14 106 7,57 41,35 71,36 96,82 *
p18 39 173 4,44 110,02 141,24 166,95 *
p19 2 8 4,00 59,20 27,93 3,35 *
p20 14 39 2,79 26,33 6,41 31,04 *
p21 1 2 2,00 65,28 33,96 8,26 *
p22 28 62 2,21 10,59 33,02 57,70 *
p23 12 22 1,83 43,47 13,36 15,00 *
p24 20 35 1,75 30,15 11,03 30,23 *
p25 9 17 1,89 48,88 18,01 9,23 *
p26 18 36 2,00 29,07 9,07 30,02 *
p27 14 42 3,00 23,37 8,62 33,87 *
p28 19 38 2,00 27,09 10,45 32,25 *
p29 2 3 1,50 64,08 32,77 7,07 *
p30 3 9 3,00 57,98 26,69 1,80 *
p31 4 8 2,00 58,73 27,46 2,29 *
4. Setelah semua data ditempatkan ke dalam
cluster dengan titik pusat terdekat, kemudian hitung kembali pusat cluster yang baru berdasarkan rata-rata angggota produk yang ada pada cluster tersebut.
5. Setelah didapatkan titik pusat yang baru dari setiap cluster, lakukan kembali dari langkah kedua hingga titik pusat dari setiap cluster
tidak berubah lagi dan tidak ada lagi data yang berpindah dari satu cluster ke cluster
Dalam penelitian ini, iterasi clustering data produk terjadi sebanyak 4 kali iterasi. Pada iterasi ke-4 ini, titik pusat dari setiap cluster
sudah tidak berubah dan tidak ada lagi data
yang berpindah dari satu
clusterke
clusteryang lain.
b. Hasil Clustering
Karena pada iterasi ke-4 posisi cluster tidak berubah, maka iterasi dihentikan dan hasil akhir yang diperoleh dalam 3 cluster :
1. Cluster pertama memiliki pusat (26, 123.33, 5.22) yang dapat diartikan sebagai kelompok produk paling diminati sehingga jumlah stok yang ada harus banyak. Produk yang termasuk dalam kelompok ini adalah produk dengan kode p14, p17 dan p18. Volume rata-rata penjualan untuk masing-masing produk anggota cluster ini adalah 124. 2. Cluster kedua memiliki pusat (20,
46.82, 2.37) yang dapat diartikan sebagai kelompok produk diminati sehingga jumlah stok sedang. Produk yang termasuk dalam kelompok ini adalah produk dengan kode p2, p6, p7, p8, p10, p20, p22, p24, p26, p27 dan p28. Volume rata-rata penjualan untuk masing-masing produk anggota cluster
ini adalah 47.
3. Cluster ketiga memiliki pusat (5.53, 10.29, 2.09) yang dapat diartikan sebagai kelompok produk kurang diminati sehingga jumlah stok sedikit. Produk yang termasuk dalam kelompok ini adalah produk dengan kode p1, p3, p4, p5, p9, p11, p12, p13, p15, p16, p19, p21, p23, p25, p29, p30 dan p31. Volume rata-rata penjualan untuk masing-masing produk anggota cluster
ini adalah 10.
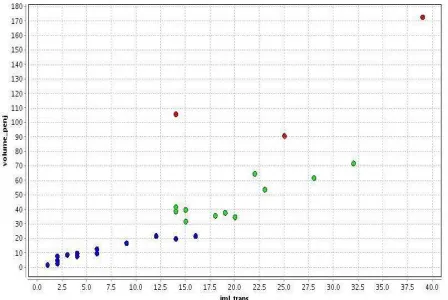
Hasil clustering yang diolah dengan software RapidMiner menghasilkan Plot View untuk masing-masing kategori stok ditampilkan pada gambar 2.
Gambar 2 Plot View Hasil Clustering di
RapidMiner
c. Pengukuran dan Evaluasi
Data yang digunakan untuk pengukuran hasil penelitian adalah data baru adalah data transaksi setelah tanggal 31 Mei 2012. Untuk perhitungan pada cluster 1 adalah sebagai berikut :
Data 1 : p14, p18, p25 X=2, Y=1, Z=1;
Sehingga F1 dapat dihitung :
Precision = X/(X+Y) = 2/(2+1) = 0,67 Recall = X/(X+Z) = 2/(2+1) = 0,67
F1 = 2 PR /(P+R)
= (2 x 0.67 x 0.67) / (0.67 + 0.67)
= 0,67
Dengan nilai F1 = 0.67 maka tingkat akurasi sistem menentukan kategori stok barang adalah tinggi. Pengukuran lainnya bisa dilihat pada tabel 3.
Tabel 3. Pengukuran dan Evaluasi Cluster 1
Data P R F1 Akurasi
X/(X+Y) X(X+Z) 2PR/(P+R)
1 0.67 0.67 0.67 Tinggi
2 0.33 0.50 0.40 Rendah
3 1.00 1.00 0.86 Tinggi
4 1.00 1.00 0.86 Tinggi
5 0.50 0.67 0.57 Tinggi
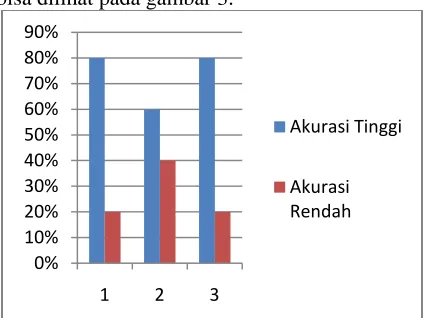
Secara keseluruhan hasil perhitungan akurasi masing-masing cluster ditampilkan pada tabel 4.
Tabel 4. Hasil Akurasi Tiga Cluster
Akurasi Cluster
1 2 3
Akurasi Tinggi 80% 60% 80%
Akurasi Rendah 20% 40% 20%
Perbandingan akurasi masing-masing cluster
bisa dilihat pada gambar 3.
Gambar 3. Perbandingan Akurasi Tiap Cluster
4. KESIMPULAN
Dari hasil penelitian ini menunjukkan bahwa penerapan metode K-Means dapat mengcluster produk menjadi 3 kelompok yaitu jumlah stok banyak, sedang dan sedikit. Dan dari hasil pengukuran menggunakan precision, recall, dan F1 didapati tingkat akurasi yang tinggi pada masing-masing cluster. Sehingga dapat diambil kesimpulan bahwa penerapan metode K-Means terbukti akurat untuk penentuan kategori stok produk.
5. SARAN
Beberapa saran untuk perbaikan penelitian berikutnya, disini ada beberapa saran yang bisa disampaikan :
a. Data yang digunakan sebaiknya adalah data transaksi terbaru, sehingga bisa dihasilkan
role yang maksimal.
b. Penelitian ini bisa dikembangkan untuk diimplementasikan dalam suatu program aplikasi, agar penentuan stok menjadi lebih mudah dan bisa diterapkan oleh banyak pelaku usaha.
DAFTAR PUSTAKA
[1] Ustadiyanto, R., 2001, Framework e-Commerce. Yogyakarta, Penerbit Andi.
[2] Rudy, Wahyudiarti, R., Megaputri, V., & Wihardini, R., 2008, Analisis Dan Perancangan E-Commerce (Studi Kasus : Roemah Soetera Batik Dan Bordir).
Seminar Nasional Informatika 2008 (semnasIF 2008) UPN "Veteran" Yogyakarta, 24 Mei.
[3] Rusdah., 2011, Analisa Dan Rancangan Sistem Informasi Persediaan Obat. Studi Kasus Puskesmas Kecamatan Kebon Jeruk.
Jurnal TELAMATIKA M.KOM, 3. No. 2.
hal51-59.
[4] Setiawan, F. H., 2011, Penerapan Fuzzy C-Means Dan Apriori Untuk Rekomendasi Promosi Produk Berdasarkan Segmentasi Konsumen. Tesis, Program Pasca Sarjana Teknik Informatika, Univ. Dian Nuswantoro, Semarang.
[5] Maimon, O., & Rokach, L., 2010, Data Mining and Knowledge Discovery Handbook. London: Springer Science+Business Media.
[6] Larose, D. T., 2005, Discovering Knowledge in Data : An Introduction to Data Mining. Hoboken, New Jersey: John Wiley & Sons, Inc.
[7] Agusta, Y., 2007, K-Means - Penerapan, Permasalahan dan Metode Terkait, Jurnal Sistem dan Informatika, vol 3, hal 47-60.
[8] Wahid, A. A., Ikhwana, A., & Partono., 2012, Sistem Pendukung Keputusan Penentuan Jumlah Pemesanan Barang,
Jurnal Algoritma, Sekolah TinggiTeknologi Garut, No 2, hal. 1-8
[9] Wijaya, A., Arifin, M., & Soebijono, T., 2013, Sistem Informasi Perencanaan Persediaan Barang, Jurnal Sistem Informasi, STIKOM Surabaya, JSIKA 2, hal 14-20
0% 10% 20% 30% 40% 50% 60% 70% 80% 90%
1 2 3
Akurasi Tinggi