Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 96
Penerapan Data Mining Metode Clustering Pada
CV. Secom Infotech Menggunakan Algoritma
K-Means
Dicky Juliawan1, Faisal Amir2, Efani Desi3 Universitas Potensi Utama, Medan
[email protected], [email protected], [email protected]
Abstract -Grouping sales data at the Secom Infotech Computer Store is still done manually in
Excel. How to group it takes time and allows data to be lost. Clustering is one of the data mining methods that are unsupervised and K-Means is a non-hierarchical clustering method that attempts to divide existing data into one or more groups. The K-Means clustering method can be applied to classify a sales data based on the type of item, type of customer, number of items. The data used is sales data in January-June 2018 as many as 30 data. The results of the tests were carried out using the RapidMiner application where the results contained 2 clusters, namely cluster 0 totaling 14 data and cluster 1 totaling 16 data. K-Means clustering method can be used for data processing using the concept of data mining in grouping data according to attributes.
Keywords: Clustering, Data Mining, K-Means, Secom Infotech Abstrak
Pengelompokan data penjualan pada Toko Komputer Secom Infotech masih dilakukan dengan cara manual di excel. Cara pengelompokkan tersebut membutuhkan waktu dan memungkinkan data hilang. Clustering merupakan salah satu metode data mining yang bersifat unsupervised dan K-Means adalah salah satu metode clustering non-hirarki yang berusaha membagi data yang ada ke dalam bentuk satu atau lebih kelompok. Metode K-Means clustering dapat diterapkan untuk mengelompokan suatu data penjualan berdasarkan jenis barang, tipe pelanggan, jumlah barang. Data yang digunakan adalah data penjualan pada bulan januari-juni 2018 sebanyak 30 data. Hasil pengujian dilakukan dengan menggunakan aplikasi RapidMiner dimana hasilnya terdapat 2 cluster yaitu cluster 0 berjumlah 14 data dan cluster 1 berjumlah 16 data. Metode K-Means clustering dapat digunakan untuk proses pengolahan data menggunakan konsep data mining dalam mengelompokkan data sesuai atribut.
Kata kunci: Clustering, Data Mining, K-Means, Secom Infotech 1. PENDAHULUAN
Dengan kemajuan teknologi informasi saat ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi akan menjadi suatu elemen penting dalam perkembangan masyarakat saat ini dan waktu mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, sering kali informasi tersebut masih harus digali ulang dari data yang jumlahnya sangat besar. Secom Infotech merupakan toko komputer yang bergerak dalam penjualan perangkat komputer seperti laptop, printer, PC dan perangkat pendukung lainnya. Dalam rangka menghadapi persaingan bisnis terdapat beberapa permasalahan yang
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 97 muncul mengenai penjualan barang. Secom Infotech sulit mendapat informasi-informasi strategis seperti tingkat penjualan per periode. Ketersediaan data penjualan yang besar di toko tidak digunakan semaksimal mungkin, sehingga data penjualan tersebut tidak dimanfaatkan secara optimal. Clustering merupakan salah satu teknik dalam data mining dimana pengguna dapat mengelompokkan sejumlah data atau objek ke dalam suatu cluster (group). Diakhir proses, cluster tersebut akan berisi data yang mirip dan berbeda dengan objek pada cluster yang lainnya [8].
Algoritma data mining yang banyak digunakan untuk Teknik clustering adalah K-Means[8]. K-Means merupakan algoritma pengelompokan inratif yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan diawal [9]. Algoritma K-Means sederhana untuk diimplementasikan dan dijalankan, relatif cepat, mudan beradaptasi, umum penggunaannya dalam praktek [9]. Algoritma K-Means merupakan model centroid, dimana model tersebut digunakan untuk membuat cluster. Centroid adalah titik tengah suatu cluster.
Centroid berupa nilai random. Centroid digunakan untuk menghitung jarak objek
data. Suatu objek data termasuk dalam cluster jika memiliki jarak terpendek terhadap centroid cluster tersebut. Algoritma K-Means dapat diartikan sebagai algoritma pembelajaran yang sederhana untuk memecahkan suatu permasalahan pengelompokkan yang bertujuan untuk meminimalkan kesalahan ganda [6]. Dalam uraian yang telah dikemukakan diatas, penulis mengemukakan lebih lanjut tentang sistem pengolahan data penjualan khususnya masalah mengenai clustering yang diajukan dengan judul Penerapan Data Mining Metode Clustering Pada CV. Secom Infotech Menggunakan Algoritma K-Means.
2. METODOLOGI PENELITIAN
Metodologi penelitian ini menggunakan Algoritma K-Means Clustering. Tujuan dari data yang akan di cluster adalah meminimalisasi objective function yang diset dalam clustering. Pada umum meminimalisasi variasi di dalam suatu
cluster dan memaksimalkan variasi antar cluster. Tiap cluster dihubungkan dengan
sebuah centroid. Tiap centroid ditempatkan ke dalam cluster dengan centroid terdekat. Jumlah cluster harus ditentukan.
2.1. Data
Dalam proses Knowledge Discovery in Database (KDD) seleksi data merupakan proses himpunan data dan menciptakan data target pada sampel data, dimana penemuan akan dilakukan selanjutnya hasil seleksi disimpan dalam suatu berkas yang terpisah dari data basis data operasional. Setelah data didapatkan dari pihak Secom Infotech seperti data awal diatas maka dilakukan proses seleksi data, proses ini dilakukan agar memudahkan proses perhitungan algoritma K-Means
Clustering . Adapun data yang digunakan adalah data pada bulan Januari-Juni 2018
yang dapat dilihat pada tabel 1.
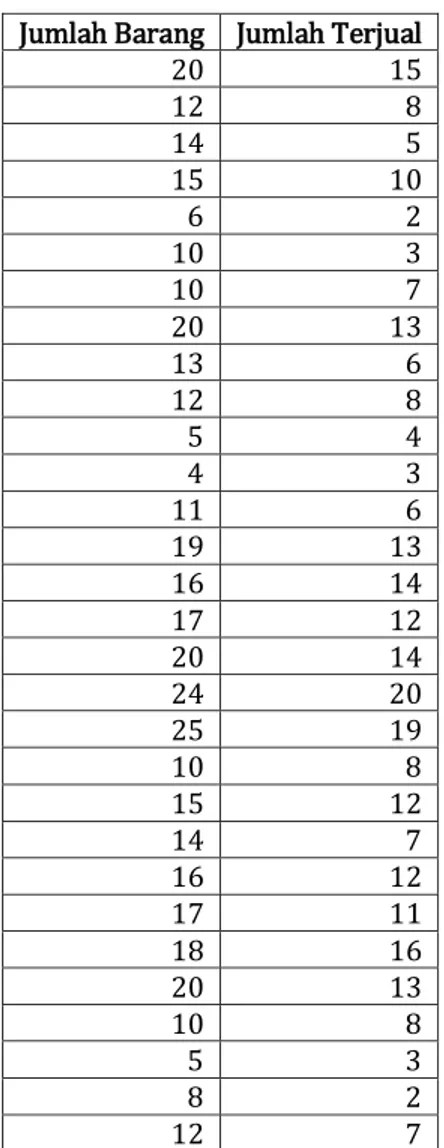
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 98 Jumlah Barang Jumlah Terjual
20 15 12 8 14 5 15 10 6 2 10 3 10 7 20 13 13 6 12 8 5 4 4 3 11 6 19 13 16 14 17 12 20 14 24 20 25 19 10 8 15 12 14 7 16 12 17 11 18 16 20 13 10 8 5 3 8 2 12 7
Pada tahap ini dilakukan proses utama yaitu pengelompokan data penjualan barang yang diakses dari database, yaitu metode clustering algoritma K-Means. Dari banyak data penjualan yang diperoleh, percobaan dilakukan dengan menggunakan parameter-parameter berikut :
a. Jumlah cluster : 2 b. Jumlah data : 30 c. Jumlah atribut : 2
2.2. Menentukan Titik Pusat Centroid Secara Random
Setelah menentukan cluster sebanyak 2 cluster, selanjutnya ditentukan titik pusat secara random. C0 diambil dari nomor 1, C1 diambil dari nomor 7 dapat
dilihat pada tabel 2.
Tabel 2. Nilai Centroid Random Centroid Jumlah Barang Jumlah Terjual
C0 20 15
C1 10 7
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 99 Rumus jarak euclidean distance digunakan untuk menghitung jarak-jarak objek kepusat terhadap masing-masing centroid sehingga ditemukan jarak yang paling terdekat dari setiap data dengan centroid. Berikut rumus persamaan Mengelompokkan data masing-masing cluster Mengklasifikasikan setiap data berdasarkan kedekatannya dengan centroid jarak terpendek. Adapun proses iterasi yang dilakukan diulang-ulang sampai iterasi tersebut tidak berubah nilai
centroid pada iterasi sebelum dan sesudahnya, pada penelitian ini berhenti pada
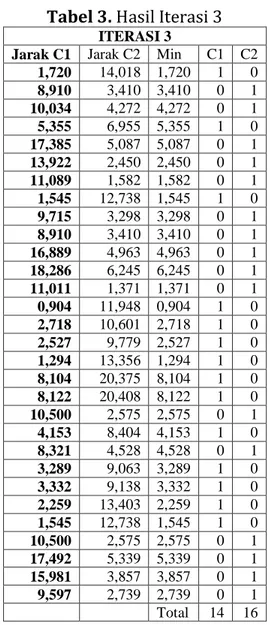
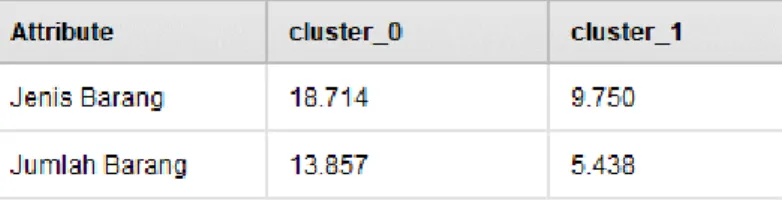
iterasi ke-3 setelah nilai centroid tidak berubah. Maka hasilnya didapatkan cluster 0 (C0) terdapat 14 data dan cluster 1 (C1) terdapat 16 data. Dapat dilihat pada tabel 3.
Tabel 3. Hasil Iterasi 3 ITERASI 3
Jarak C1 Jarak C2 Min C1 C2
1,720 14,018 1,720 1 0 8,910 3,410 3,410 0 1 10,034 4,272 4,272 0 1 5,355 6,955 5,355 1 0 17,385 5,087 5,087 0 1 13,922 2,450 2,450 0 1 11,089 1,582 1,582 0 1 1,545 12,738 1,545 1 0 9,715 3,298 3,298 0 1 8,910 3,410 3,410 0 1 16,889 4,963 4,963 0 1 18,286 6,245 6,245 0 1 11,011 1,371 1,371 0 1 0,904 11,948 0,904 1 0 2,718 10,601 2,718 1 0 2,527 9,779 2,527 1 0 1,294 13,356 1,294 1 0 8,104 20,375 8,104 1 0 8,122 20,408 8,122 1 0 10,500 2,575 2,575 0 1 4,153 8,404 4,153 1 0 8,321 4,528 4,528 0 1 3,289 9,063 3,289 1 0 3,332 9,138 3,332 1 0 2,259 13,403 2,259 1 0 1,545 12,738 1,545 1 0 10,500 2,575 2,575 0 1 17,492 5,339 5,339 0 1 15,981 3,857 3,857 0 1 9,597 2,739 2,739 0 1 Total 14 16
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 100 Berdasarkan hasil analisis yang telah dilakukan, maka tahap selanjutnya dilakukan pengujian menggunakan Software Rapidminer. Data di import dari excel, kemudian tentukan jumlah cluster dan hubungkan data penjualan ke clustering
K-Means. Dapat dilihat pada gambar 1.
Gambar 1. Proses Pengaturan K-Means
Setelah program dijalankan, otomatis sistem akan menampilkan hasil data penjualan berdasarkan cluster per data. Gambar 2 menampilkan cluster berdasarkan tabel.
Gambar 2. Tabel Cluster
Gambar 3 menampilkan hasil data penjualan dalam bentuk text view, dapat dilihat bahwa cluster 0 berjumlah 14 items dan cluster 1 berjumlah 16 items, dari total data penjualan 30 items.
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 101 Gambar 3. Cluster Model
Gambar 4 menampilkan hasil tabel centroid data pengujian berdasarkan iterasi terakhir.
Gambar 4. Centroid Tabel Data Pengujian 4. KESIMPULAN
Metode K-Means Clustering berhasil diterapkan untuk mengelompokkan data penjualan. Hasil dari penelitian ini dapat mempermudah CV Secom Infotech dalam menentukan data penjualan. Berdasarkan data yang digunakan untuk mengelompokan data penjualan pada bulan Januari-Juni 2018 dengan jumlah 30 data. Mendapatkan hasil pengelompokkkan bahwa cluster 0 (C0) terdapat 14 data,
cluster 1 (C1) untuk terdapat 16 data. Iterasi clustering pada data penjualan terjadi
sebanyak 3 kali iterasi. DAFTAR PUSTAKA
[1] Nelson Butarbutar, dkk, “Komparasi Kinerja Algoritma Fuzzy C-Means dan K-Means Dalam Pengelompokan Data Siswa Berdasarkan Prestasi Nilai Akademik Siswa (Studi Kasus : SMP Negeri 2 Pematang Siantar)”, Jurnal Riset Sistem Informasi & Teknik Informatika, Vol. 1, No. 1, Juli 2016.
[2] Mhd Gading Sadewo, dkk, “Pemanfaatan Algoritma Clustering Dalam Mengelompokkan Jumlah Desa/Kelurahan Yang Memiliki Saran Kesehatan Menurut Provinsi Dengan K-Means”, Konferensi Nasional Teknologi Informasi dan Komputer, Vol. 1, No. 1, Oktober 2017.
[3] Nurul Rofiqo, Agus Perdana Windarto dan Dedy Hartama, “Penerapan Clustering Pada Penduduk Yang Mempunyai Keluhan Kesehatan Dengan Data Mining K-Means”, Konferensi Nasional Teknologi Informasi dan Komputer, Vol. 2, No. 1, Oktober 2018.
[4] Riyani Wulan Sari, Anjar Wanto dan Agus Perdana Windarto, “Implementasi RapidMiner Dengan Metode K-Means (Studi Kasus : Imunisasi Campak Pada Balita Berdasarkan Provinsi)”, Konferensi Nasional Teknologi Informasi dan Komputer, Vol. 2, No. 1, Oktober 2018.
[5] Mhd Gading Sadewo, Agus Perdana Windarto dan Anjar Wanto, “Penerapan Algoritma Clustering Dalam Mengelompokkan Banyaknya Desa/Kelurahan Menurut Upaya Antisipasi/Mitigasi Bencana Alam Menurut Provinsi Dengan K-Means”, Konferensi Nasional Teknologi Informasi dan Komputer, Vol. 2, No. 1, Oktober 2018.
Penerapan Data Mining Clustering Pada CV. Secom Infotech (Dicky Juliawan) | 102 [6] Aldi Nurzahputra, Much Aziz Muslim dan Miranita Khusniati, “Penerapan Algoritma K-Means Untuk Clustering Penilaian Dosen Berdasarkan Indeks Kepuasan Mahasiswa”, Techno COM, Vol. 16, No. 1, 17-24, Februari 2017.
[7] Agus Perdana Windarto, “Penerapan Data Mining Pada Ekspor Buah-Buahan Menurut Negara Tujuan Menggunakan K-Means Clustering ”, Techno.COM, Vol. 16, No.4, 348-357, November 2017.
[8] Ahmad Luky Ramdani dan Hafiz Budi Firmansyah, “Clustering Application For UKT Determination Using Pillar K-Means Clustering Algorithm and Flask Web Framework”, Indonesian Journal of Artificial Intelligence and Data Mining, Vol. 1, No. 2, pp. 53-59, September 2018.
[9] Iin Parlina, dkk, “Memanfaatkan Algoritma K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Center Untuk Clustering Program SDP”, Journal of Computer Engineering System and Science, Vol. 3, No. 1, Januari 2018.