KLASIFIKASI BAHASA DOKUMEN DENGAN MENGGUNAKAN
JARINGAN SARAF TIRUAN
Esa Prakasa, Edi Kurniawan, Purnomo Husnul Khotimah, Taufiq Wirahman
{esa_prakasa, kurniawan, hkhotimah, taufiq}@informatika.lipi.go.id
Bidang Komputer, Bidang Otomasi, Bidang Sistem Informasi
Pusat Penelitian Informatika
Lembaga Ilmu Pengetahuan Indonesia, Bandung ABSTRAK
Sistem klasifikasi bahasa ini adalah hanya bagian dari sebuah sistem yang bisa digunakan sebagai sistem penerjemah bahasa secara automatis. Sistem mampu mengidentifikasi bahasa yang digunakan pada dokumen teks. Identifikasi yang dilakukan tidak berdasarkan label dokumen, tanda hyperlink, atau pun pengetahuan pembaca mengenai bahasa, tapi berdasarkan isi yang terdapat dalam dokumen. Dengan menggunakan beberapa variabel yaitu: distribusi vokal per kalimat, distrubusi konsonan per kalimat, rata-rata jumlah vokal per kata, dan rata-rata jumlah konsonan per kata. Keempat ciri ini diharapkan menjadi variabel pembeda yang cukup signifikan dalam mengenali jenis bahasa. Algoritma jaringan saraf tiruan diterapkan untuk mengolah data keempat variabel tersebut, segingga diperoleh keluaran yang mampu mengenali 6 jenis bahasa, yaitu: Indonesia, Malaysia, Inggris, Jerman, Italia, dan Portugis. Keenam bahasa tersebut juga dikelompokkan menjadi 3 kelompok yang serumpun berdasarkan asal mula bahasa yaitu rumpun: Austronesian (Indonesia & Malaysia), West-Germanic (Inggris & Jerman), dan Italo-Romance (Italia & Portugis). Pelatihan dan pengujian jaringan saraf tiruan membagi kelompok bahasa menjadi 3 grup, 2 grup terdiri atas bahasa tidak serumpun dan 1 grup adalah campuran antara bahasa serumpun dan tidak serumpun. Hasil pengujian menunjukan hanya 1 grup bahasa tidak serumpun, yiatu grup A saja yang memberikan hasil akhir memuaskan, karena mampu mengenali 3 bahasa anggota grupnya (Indonesia, Inggris, dan Portugis) dengan rata-rata prosentase keakuratan 88 %. Sisa grup yang lain masing-masing 43 % dan 57 %. Fenomena bahwa jumlah kalimat uji makin banyak maka prosentase keakuratan makin baik juga hanya ditunjukkan oleh grup A.
Kata kunci: identifikasi bahasa, dokumen teks, serumpun-tidak serumpun, jaringan saraf tiruan
1. PENDAHULUAN 1.1. Latar Belakang
Perkembangan teknologi informasi, terutama perkembangan internet memungkinkan ketersediaan data yang sangat melimpah. Data-data berupa dokumen teks juga banyak tersedia dalam beragam bahasa, seiring dengan makin meluasnya kemampuan ke berbagai penjuru dunia dalam hal mengolah, menyimpan, dan mendistribusikan dokumen teks. Kebutuhan mengakses dokumen yang berbeda bahasa termasuk salah satu kebutuhan dalam interaksi lintas bahasa dan budaya.
Metode klasifikasi yang dibuat dalam penelitian ini kelak bisa dirangkaikan ke dalam aplikasi penerjemah dokumen teks automatis. Selama ini untuk menerjemahkan dokumen teks dari suatu bahasa X ke bahasa Y, maka sedikit banyak seseorang harus mempunyai pengetahuan pada kedua bahasa tersebut. Pengetahuan dalam hal paham terhadap jenis bahasa tersebut, atau pun karena ada
label atau keterangan pada dokumen yang menjelaskan mengenai jenis bahasa yang sedang digunakan. Mesin-mesin pencari pada internet yang ada saat ini, jika diperintahkan untuk mencari dokumen dengan bahasa tertentu, lebih memilih keterangan tambahan pada dokumen sebagai acuan mengenal jenis bahasa, dibandingkan benar-benar paham atas bahasa pada isi dokumen tersebut. 1.2. Tujuan Penelitian
Penelitian ini bertujuan menemukan cara yang lebih handal dalam melakukan identifikasi jenis bahasa dokumen teks. Kehandalan yang diharapkan bisa diperoleh adalah, dalam kemampuan membedakan jenis bahasa walaupun bahasa-bahasa tersebut masih tergolog serumpun. Penelitian ini juga bertujuan memperoleh fakta terdapatnya korelasi antara jumlah kata yang harus diberikan saat pengujian dengan tingkat kehandalan sistem mengidentifikasi bahasa.
1.3. Tinjauan Pustaka
Esa Prakasa (2003) telah membuat sistem identifikasi bahasa dengan menggunakan fungsi jarak untuk mengenali 2 bahasa yang tidak serumpun yaitu bahasa Indonesia dan bahasa Inggris. Dengan menggunakan dokumen teks yang berasal dari internet, diekstraksi pola distribusi karakter abjad ‘A’ sampai dengan ‘Z’ pada kedua bahasa. Pola karakter kedua bahasa disimpan sebagai pola acuan. Dengan menggunakan 6 dokumen uji, terdiri atas 3 dokumen bahasa Indonesia dan Inggris, sistem mampu mengenali bahasa semua dokumen secara tepat 100%. Jumlah karakter yang terdapat di dalam setiap dokumen rata-rata lebih dari 1.000 karakter.
Gary Adams dan Philip Resnik (2002) mengembangkan aplikasi berbasis pemrograman Java yang mampu memberikan label jenis bahasa pada sat suatu dokumen internet sedang dibuka di browser. Kemampuan identifikasi bahasa diperoleh dengan memakai algoritma n-gram. Aplikasi awal ini juga diharapkan mampu menjadi awal pembuatan sistem penerjemah dan perangkum multi bahasa pada dokumen teks yang tersedia di internet. Mereka juga menemukan fakta bahwa identifikasi bahasa dengan memanfaatkan model bahasa berbasis karakter lebi baik dibandingkan model bahasa berbasis kata.
Hidayet Takci and Ibrahim Soukpınar (2004) merumuskan metode klasifikasi dokumen dengan menggunakan metode klasifikasi berbasis-centroid. Data-data frekuensi penggunaan huruf (letter
frequencies) menjadi acuan untuk menemukan pola
penggunaan kata. Jenis-jenis kata yang dipakai kemudian bisa menjadi acuan dalam menentukan isi dokumen. Penelitian ini menunjukkan peluang penggunaan distribusi huruf sebagai indikator identifikasi bahasa.
2. LANDASAN TEORI 2.1. Karakteristik Bahasa
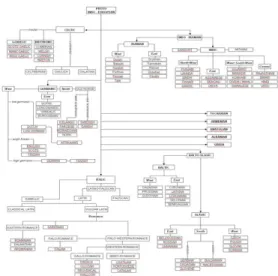
Bahasa-bahasa yang digunakan sebagai data penelitian secara umum dapat dipahami mempunyai silsilah asal bahasa, jenis vokal serta konsonan. Setiap bahasa biasa dituliskan dalam bentuk tulisan dengan menggunakan karakter-karakter latin. Bahasa-bahasa tertentu juga menggunakan karakter khusus selain karakter latin. Bahasa Indonesia adalah bahasa yang digunakan oleh warga Indonesia. Bahasa Indonesia juga dapat dikatakan sangat modern: diresmikan pada kemerdekaan Indonesia, yaitu pada tahun 1945, dan bahasa Indonesia juga adalah bahasa dinamis yang terus menyerap kata-kata dari bahasa asing. Berasal dari rumpun yang sama, Bahasa Indonesia adalah dialek terstandardisasi dari bahasa Melayu, dan keduanya cukup mirip. Silsilah asal mula bahasa Indonesia dapat dituliskan mulai dari
Austronesia, Melayu-Polinesia, Melayu-Polinesia Barat, Sundik, Malayik, Rumpun Melayu, Melayu Lokal, Bahasa Indonesia. Malaysia menggunakan bahasa Melayu sebagai bahasa formal dalam kehidupan sehari-hari. Bahasa Melayu merupakan bahasa keempat terbesar yang dituturkan di dunia. Penutur bahasa Melayu diperkirakan berjumlah lebih kurang 250 juta jiwa yang merupakan bahasa keempat dalam urutan jumlah penutur terpenting bagi bahasa-bahasa di dunia. Bahasa Malaysia mempunyai akar yang sama dengan bahasa Indonesia mengikuti jalur berikut ini: Austronesia, Melayu-Polinesia, Melayu-Polinesia Barat, Sundik, Malayik, Malayan, Melayu Lokal, hingga behasa Melayu.
Bahasa Inggris adalah bahasa Jermanik Barat, yang berasal dari Inggris. Bahasa ini merupakan kombinasi antara beberapa bahasa lokal yang dipakai oleh orang-orang Norwegia, Denmark, Saxon dan Angel dari abad ke 6 sampai 10. Lalu sejak tahun 1066 bahasa Inggris dengan sangat intensif mulai dipengaruhi bahasa Latin dan bahasa Perancis. Kosakata bahasa Inggris modern, diperkirakan terdiri atas ± 50 % berasal dari bahasa Perancis dan Latin. Rangkaian silsilah bahasa Inggris adalah: Indo-Eropa, Jermanik, Jermanik Barat, dan kemudian Bahasa Inggris. Bahasa Jerman, adalah nama sebuah bahasa Jermanik barat yang telah mengalami pergeseran bunyi Jermanik kedua. Bahasa ini adalah salah satu bahasa yang luas dipertuturkan di Eropa. Bahasa Jerman masih dekat dengan Bahasa Belanda dan lebih jauh juga Bahasa Inggris. Bahasa Jerman masih serumpun dengan bahasa Inggris karena sama-sama berakar dari bahasa Jermanik Barat, sesuai dengan urutan Indo-Eropa, Jermanik, Jermanik Barat, Bahasa Jerman hulu, dan kemudian Bahasa Jerman.
GAMBAR 2.1. CONTOH SILSILAH BAHASA INDO-EROPA.
Bahasa Italia adalah sejenis bahasa Roman yang dituturkan oleh sekitar 70 juta orang, mayoritas di
Italia. Bahasa Italia Standar adalah berdasarkan dialek Toscana dan semacam campuran bahasa-bahasa di Italia Selatan dan bahasa-bahasa Gallo-Roman di Utara. Urutan sejarah bahasa Italia dapat diurutkan seperti berikut ini Indo-Eropa, Italik, Roman, Italo-Barat, Italo-Dalmasia, hingga Bahasa Italia. Bahasa Portugis adalah sebuah bahasa Roman yang serumpun dengan bahasa Italia. Bahasa Portugis banyak dituturkan di Portugal, Brasil, Angola, Mozambik, Tanjung Verde, dan Timor Timur. Banyak ahli bahasa yang menganggap bahasa Galisia, bahasa daerah di Galisia, Spanyol, sebenarnya adalah sejenis Portugis yang telah dipengaruhi dengan kuat oleh bahasa Spanyol. Sejarat bahasa Portugis dapat dirunutkan seperti berikut ini, Indo-Eropa, Italik, Roman, Italo-Barat, Gallo-Iberia, Ibero-Roman, Iberia-Barat, Portugis-Galisia, dan kemudian sampai pada Bahasa Portugis. 2.2. Pengenalan Pola
Kemampuan untuk mengenali sesuatu adalah salah satu kemampuan yang dipunyai manusia, sebagaimana mahluk hidup lainnya. Informasi bisa dikenali dengan menggunakan indera yang dimiliki setelah terlebih dahulu melakukan pengolahan atas ciri-ciri objek yang diamati. Masalah yang umum dijumpai pada sistem pengenalan pola adalah bagaimana cara menemukan data ciri tepat yang bisa membedakan satu objek dengan objek lainnya. Cara membedakan atau dikenal dengan metode klasifikasi pola juga harus dipertimbangkan.
Dengan berbagai teknik ekstraksi pola atas suatu objek dapat diperoleh bentuk matriks vektor pola. Teknik klasifikasi pola bisa dilakukan dengan beberapa pendekatan seperti secara statistik hingg pendekatan iteratif misal dengan menggunakan algoritma jaringan saraf tiruan. Klasifikasi secara statistik ditempuh melalui pencari nilai error yang terkecil antara pola input dengan pola-pola yang sudah tersimpan di database sebelumnya. Cara pencarian paling sederhana ini dikenal dengan nama fungsi jarak.
Penelitian ini akan menggunakan jaringan saraf tiruan sebagai metode pengenalan pola. Jumlah data latih dan tingkat keragaman data latih sangat berperan pada kehandalan jaringan saraf tiruan. 2.3. Jaringan Saraf Tiruan
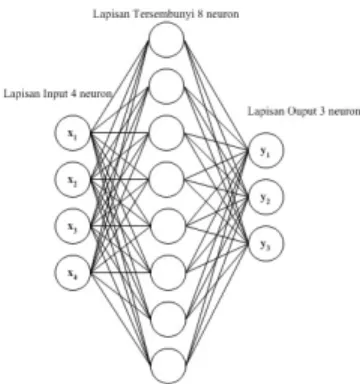
Jaringan saraf tiruan adalah sistem pengolah informasi yang mempunyai sifat sebagaimana jaringan saraf biologis. Jaringan saraf tiruan merupakan model tiruan bagaimana mahluk hidup memahami dan mengenali informasi disekitarnya. Sifat-sifat utama dari jarangan saraf tiruan antara lain: mempunyai terminal-terminal input data yang disebut sebagai neuron. Kumpulan input data
berbentuk pola yang dianggap cukup mempunyai ciri fenomena atau pun objek yang akan diamati. Neuron pada lapisan input terhubung dengan neuron-neuron lain pada lapisan tersembunyi, hingga lapisan output. Antar neuron saling terhubung, dan terdapat nilai bobot diantara neuron-neuron tersebut. Nilai bobot ditemukan melalui proses pembelajaran, hingga tercapai kesesuaian anatara nilai output hasil olahan dengan nilai yang diinginkan. Algoritma jaringan saraf tiruan banyak digunakan untuk mengatasi masalah-masalah penyimpanan dan pemanggilan data, klasifikasi dan identifikasi pola, pemetaan pola input dan output, pengelompokan pola, hingga pada pencarian nilai-nilai optimasi.
GAMBAR 2.2. ARSITEKTUR JARINGAN SARAF TIRUAN.
3. METODOLOGI PENELITIAN 3.1. Ekstraksi Data
Pola yang diekstraksi pada penelitian ini adalah: rasio karakter vokal dan konsonan pada satu kalimat dan rata-rata jumlah vokal dan konsonan per kata yang telah dinormalisasi pada satu kalimat. Pola pelatihan dan pengujian diekstraksi dari dokumen teks yang berasal dari berbagai sumber di internet. Karakter-karakter selain karakter latin pada bahasa Jerman, Italia, dan Portugis seperti: ä, ö, ü, ã, dan õ digolongkan sebagai vokal sesuai dengan aturan tata bahasa bahasa, dan selain karakter tersebut dianggap sebagai konsonan. Implementasi parsing karakter dari sebuah dokumen beserta pengelompokan dan penghitungan hasil parsing menggunakan program yang ditulis dalam program PHP.
3.2. Pelatihan dan Pengujian Sistem
Jaringan saraf tiruan diimplementasikan dengan menggunakan pemrograman Matlab. Metode yang dipilih adalah Feed Foward Propagation, fungsi pelatihan yang digunakan adalah trainlm(). Rata-rata jumlah iterasi selama pelatihan adalah 10.000 dengan nilai mean square erorr ditetapkan agar tercapai 10-5.
Fungsi transfer yag dipakai adalah logsig (). Pelatihan serta pengujian dibagi menjadi 3 tahap, 2 tahap
pertama untuk kelompok bahasa yang tidak serumpun, sedangkan tahap ketiga untuk campuran antara kelompok bahasa yang serumpun dan tidak serumpun. Dua tahap terdiri atas, tahap 1 dengan menggunakan bahasa Indonesia, Inggris, dan Portugis. Tahap 2 dengan bahasa Malaysia, Jerman, dan Italia. Sistem dilatih dan diuji dengan menggunakan kelompok bahasa yang sama untuk setiap tahapnya. Jumlah data pelatihan adalah 100 kalimat untuk setiap bahasa, jadi untuk tahap pertama akan terdapat 300 kalimat, yang masing-masing berasal dari bahasa Indonesia, Inggris, dan Portugis. Demikian pula untuk pelatihan tahap 2 menggunakan cara yang sama. Pengujian dilakukan dengan memberikan input pola hasil ekstraksi data dari 1, 3, dan 5 kalimat. Semakin banyak kalimat yang digunakan diharapkan menghasilkan pola input yang lebih representatif secara statistik. Tahap 3 data seluruh bahasa dilatihkan pada jaringan saraf tiruan sehingga ditemukan konfigurasi bobot yang baru, setelah dianggap konvergen, sistem kemudian diuji dengan menggunakan bahasa-bahasa yang sama dengan bahasa saat pelatihan. Ektsraksi data pengujian juga dilakukan dengan cara yang sama, yaitu melalui 1, 3, dan 5 kalimat.
4. HASIL DAN PEMBAHASAN 4.1. Data Penelitian
Berikut ini adalah hasil pengujian masing-masing grup. Setiap pengujian bahasa diinputkan satu kelompok kata, yang berasal dari 1, 3, atau pun 5 kalimat. Dengan demkian dilakukan pengujian sebanyak 3.600 kali. Bobot jaringan saraf tiruan antara ketiga grup tidak ada yang sama mengingat data latih yang diberikan disesuaikan dengan keanggotaan grup.
TABEL 4.1. HASIL UJI GRUP A.
Grup A Prosentase Keakuratan Identifikasi dengankalimat uji sebanyak: Bahasa 1 Kalimat 3 Kalimat 5 Kalimat
Indonesia 70% 90% 90%
Inggris 70% 80% 100%
Portugis 90% 100% 100%
TABEL 4.2. HASIL UJI GRUP B.
Grup B Prosentase Keakuratan Identifikasi dengankalimat uji sebanyak: Bahasa 1 Kalimat 3 Kalimat 5 Kalimat
Malaysia 0% 0% 0%
Jerman 40% 60% 70%
Italia 50% 90% 80%
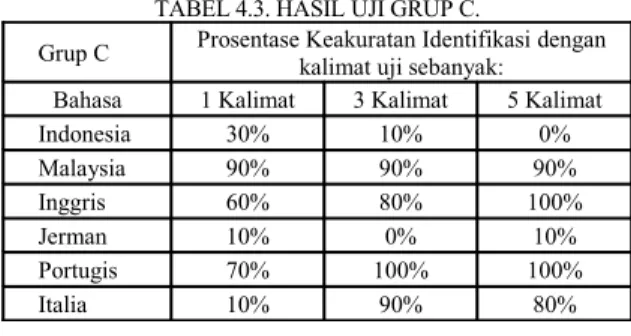
TABEL 4.3. HASIL UJI GRUP C.
Grup C Prosentase Keakuratan Identifikasi dengankalimat uji sebanyak: Bahasa 1 Kalimat 3 Kalimat 5 Kalimat
Indonesia 30% 10% 0% Malaysia 90% 90% 90% Inggris 60% 80% 100% Jerman 10% 0% 10% Portugis 70% 100% 100% Italia 10% 90% 80% 4.2. Pembahasan
Berdasrkan data pelatihan dan pengujian, grup A mempunyai kehandalan yang cukup bagus dibandingkan dengan grup yang lain, rata-rata ketepatan dalam menetapkan jenis bahasa adalah 88 %. Grup B dan C masing-masing 43 % dan 57 %. Hal ini wajar karena ketiga bahasa anggota grup A adalah bahasa yang berasal dari rumpun yang berbeda, atau berujung pada asal usul yang sama (Inggris dan Portugis sama-sama Indo-Eropa) bahasa-bahasa tersebut telah mengalami penurunan panjang sehingga kekerabatannya cukup jauh. Grup B, seharusnya juga mempunyai sifat pelatihan dan pengujian yang sama dengan grup A. Namun hasil akhir yang diperoleh justru sistem mengalami ketidakhandalan yang cukup besar. Ditunjukkan sangat menguji bahasa Malaysia, tidak ada satu pun data input yang dikenali dengan baik. Demikian grup C, tidak ada keteraturan pola yang terlihat, sehingga bisa disimpulkan fakta-fakta tertentu. Tantangan grup C juga lebih berat dibandingkan 2 grup sebelumnya, mengingat sistem harus mengenali bahasa-bahasa yang masih serumpun.
Kemudian dengan melihat tabel 4.1 hingga 4.3 juga dapat dilihat bahwa penambahan jumlah kalimat uji, atau bisa diebut juga menambah data sampel uji, bisa membantu meningkatkan prosesntase keakuratan identifikasi. Seperti diketahui, semakin banyak jumlah kalimat, maka semakin banyak jumlah kata hingga jumlah karakter yang digunakan. Namun sayangnya fenomena ini hanya tampak pada tabel 4.1 dan sebagian tabel 4.2. Angka-angkat tabel 4.3 menunjukkan bahawa tidak ada pengaruh yang cukup penting antara jumlah kalimat uji dan kenaikan prosentase keakuratan identifikasi bahasa.
Ketidaksempurnaan ini sangat mungkin disebabkan oleh jumlah variabel data input yang terlalu sedikit. Dengan 4 variabel sistem dilatih agar mengenali 3 hingga 6 objek jenis bahasa. Jika ditinjau dari jumlah pelatihan dan pengujian jaringan saraf tiruan relatif sudah cukup. Saat pelatihan memang rata-rata jaringan saraf tiruan mula-mula konvergen, namun nilai MSE stabil pada nilai tertentu. Nilai tersebut rata-rata adalah 0,02, suatu
nilai MSE cukup besar, mengingat tujuan akhir MSE yang ingin dicapai adalah 10-5.
5. PENUTUP 5.1. Kesimpulan
Jaringan saraf tiruan masih mempunyai peluang yang cukup besar pada implementasi indentifikasi serta klasifikasi jenis bahasa dokumen teks. Empat variabel yang digunakan pada paper ini, prosentase konsonan per kata, serta prosentase vokal-konsonan per kalimat belum cukup handal. Kondisi ini ditunjukkan pada pelatihan dan pengujian grup B dan C. Kehandalan metode hanya ditunjukkan pada hasil pelatihan dan pengujian grup A. Dengan demikian sistem mampu mengidentifikasi cukup baik, hanya untuk kasus 3 bahasa tidak serumpun yaitu Indonesia, Inggris, dan Portugis. Berapa banyak jumlah kalimat yang harus digunakan agar identifikasi bisa dilakukan secara tepat, belum ada batasan, namun ada kecenderungan makin banyak makin baik (tabel 4.1). Namun fakta ini tidak terjadi pada grup lainnya (tabel 4.2 dan 4.3).
5.2. Saran
Pengembangan lanjutan yang bisa dilakukan antara lain dengan menambah jumlah variabel input, tidak terbatas pada 4 variabel saja. Variabel distribusi masing-masing karakter vokal, konsonan, serta karakter asing adalah variabel tambahan yang sangat potensial mewakili ciri suatu bahasa. Keseragaman isi berita dalam dokumen teks juga harus lebih dipertimbangkan, terutama adanya kosa kata nama sesorang, tempat, kota dsb., juga kosa kata serapan dari bahasa asing lainnya.
6. REFERENSI
[1] Adams, G., Resnik, P., "A Language Identificatiaon Application on the Java Client/Server Platform", Sun Microsystem Laboratories, USA, 2002.
[2] Fausett, L., Fundamentals of Neural Networks, Prentice Hall, New Jersey, USA, 1994.
[3] Prakasa, E., "Sistem Identifikasi Bahasa Dokumen dengan Berdasarkan pada Distribusi Huruf", Seminar Nasional Teknik Informatika, Universitas Atma Jaya, Yogyakarta, 16 September 2003.
[4] Takci, H., Soukpınar, I., "Centroid-Based Language Identification Using Letter Feature Set", Department of Computer Engineering, Gebze Institute of Technology, 2004.
[5] Tou, J.T., Gonzalez, R.C., Pattern Recognition Principles, Addison-Wesley, Massachusetts, USA, 1974.