Fakultas Ilmu Komputer
Universitas Brawijaya
2509
Peramalan Siaga Banjir dengan Menganalisis Data Curah Hujan (ARR)
dan Tinggi Muka Air (AWLR) Menggunakan Metode Support Vector
Regression (Studi Kasus: Perum Jasa Tirta I)
Laila Diana Khulyati1, Muhammad Tanzil Furqon2, Bayu Rahayudi3Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Banjir merupakan bencana alam yang menjadi permasalahan umum dan sulit diprediksi kapan terjadinya. Penyebab banjir sejauh ini yaitu adanya proses kenaikan curah hujan dan tinggi muka air di Daerah Aliran Sungai, sehingga perlu adanya penelitian untuk melakukan monitoring terhadap siaga banjir. Dari hal tersebut, diperlukan sistem yang dapat melakukan peramalan untuk memudahkan dalam menganalisa status siaga banjir di masa mendatang. Untuk dapat meramalkan hasil di masa mendatang, terdapat metode yang penggunaannya didasari ketersediaan data mentah, serta dengan teknik analisis statistik yang dinamakan metode regresi. Metode regresi yang digunakan dalam penelitian ini yaitu Support Vector Regression. Metode SVR sering digunakan dalam peramalan, namun tidak banyak yang menggunakan data curah hujan dan tinggi muka air secara bersamaan. Penelitian ini memiliki tujuan untuk melakukan peramalan siaga banjir di Stasiun Kambing pada DAS Brantas. Hasil dari pengujian menunjukkan peramalan siaga banjir pada bulan Desember 2016, pada data tinggi muka air (AWLR) didapatkan nilai error rate terkecil sebesar 9.584849544 dan data curah hujan (ARR) didapatkan nilai error rate terkecil sebesar 10.52259887. Dengan nilai parameter yang digunakan yaitu 𝜀 = 0.09, 𝜆 = 0.005, 𝜎 = 0.2, 𝐶 = 0.08 dan 𝑐𝐿𝑅 = 0.08. Kedua data tersebut menghasilkan peramalan siaga banjir berupa Siaga Normal.
Kata kunci: banjir, curah hujan, tinggi muka air, peramalan, siaga, SVR
Abstract
Flood is a natural disaster that used to be general cause and hard to predict when it will happened. So far, the cause of flood is there’s process when rainfall and waterlevel is rise, so there’s required some research to do a monitoring on flood alert. From that point, system is required to be able to forecast and make it easier to analyze flood alert status in a future. To forecast a future results, there is a method that based on the availability of raw data, also with statistical analysis technique called regression method. Regression method that used in this research is Support Vector Regression. This SVR method is frequently used in forecasting, but not many of them use rainfall and waterlevel data in a same time. The purpose of this research is to do flood alert forecasting in Kambing Station DAS Brantas. The results represent flood alert forecasting at December 2016, with waterlevel data resulted minimal value of 9.584849544 in error rate and rainfall data resulted minimal value of 10.52259887 in error rate. By using values of parameters 𝜀 = 0.09, 𝜆 = 0.005, 𝜎 = 0.2, 𝐶 = 0.08 and 𝑐𝐿𝑅 = 0.08. Both data resulted flood alert forecasting that shows Normal.
Keywords: flood, rainfall, waterlevel, forecasting, alert, SVR
1. PENDAHULUAN
Salah satu jenis bencana alam yang menjadi permasalahan umum di masyarakat sekitar dan sulit diprediksi kapan kejadiannya adalah bencana banjir. Banjir merupakan salah satu bencana alam yang berpengaruh paling luas dan
menyebabkan kerugian yang besar (Ma, 2010). Penyebab banjir sejauh ini yaitu adanya proses yang berhubungan dengan tingkat curah hujan dan tinggi permukaan air. Perum Jasa Tirta I adalah sebuah Badan Usaha Milik Negara
(BUMN) yang ditugasi untuk
dan sumber-sumber air yang bermutu dan memadai bagi pemenuhan hajat hidup orang banyak, serta melaksanakan tugas-tugas tertentu yang diberikan Pemerintah dalam pengelolaan wilayah daerah aliran sungai (DAS). Salah satu unsur yang berkaitan dengan pelayanan sosial, kesejahteraan dan keselamatan umum yang dilakukan oleh Perum Jasa Tirta I adalah unsur pengendalian banjir.
Objek yang digunakan dalam penelitian ini adalah Curah Hujan (ARR) dan Tinggi Muka Air (AWLR). Kenaikan curah hujan dan muka air di Daerah Aliran Sungai menyebabkan adanya banjir, sehingga perlu adanya penelitian untuk melakukan monitoring terhadap siaga banjir pada Daerah Aliran Sungai. Dari hal tersebut, dibutuhkan solusi yang rasional melihat dari sisi teknologi sehingga diharapkan dapat menyelesaikan permasalahan ini.
Dalam menganalisis data curah hujan dan tinggi muka air dapat dilakukan peramalan untuk memudahkan dalam menganalisa status siaga banjir di masa yang akan datang. Metode dan periode peramalan bisa beragam tergantung pada waktu dan informasi yang digunakan di masa lalu yang mana metode prediksi yang teratur akan memberikan keyakinan pada penggunanya karena dapat dievaluasi secara ilmiah (Syafruddin, 2004). Jangka waktu yang dapat digunakan untuk menganalisis curah hujan dan tinggi muka air dibedakan menjadi tahunan, bulanan, mingguan, dan harian, berdasarkan tingkat curah hujan dan tinggi muka air dengan cakupan tinggi dan rendah di tiap hitungan jamnya. Untuk dapat meramalkan hasil di masa yang akan datang, terdapat metode yang penggunaannya didasari ketersediaan data mentah, serta dengan teknik analisis statistik untuk menggambarkan hubungan antara satu variabel respon dengan satu atau lebih variabel penjelas yang dinamakan metode regresi. Support Vector Regression adalah metode yang mengumpulkan solusi optimal dengan iterasi sangat cepat dibandingkan dengan SVM dan sangat sederhana untuk diimplementasikan bahkan untuk masalah dengan ukuran data yang besar. (Vijayakumar & Wu, 1999)
2. DASAR TEORI
2.1 Peramalan (Forecasting)
Peramalan (forecasting) adalah proses untuk memperkirakan beberapa kebutuhan di masa datang yang meliputi kebutuhan dalam
ukuran kuantitas, kualitas, waktu dan lokasi yang dibutuhkan dalam rangka memenuhi permintaan barang ataupun jasa (Nasution, 2003). Dalam pengambilan keputusan manajemen, peramalan yang akurat sangat dibutuhkan. Dengan berkembangnya industri, peramalan membantu keputusan panduan manajemen dalam manajemen persediaan, permintaan, manajemen tenaga, dan perencanaan produksi serta perencanaan strategis mengenai produk.
Definisi lain tentang Peramalan (forecasting) adalah ilmu untuk memperkirakan kejadian di masa yang akan datang. Hal ini dapat dilakukan dengan melibatkan pengambilan data historis dari sebuah variabel dan memproyeksikan ke masa mendatang dengan suatu bentuk model matematis (kuantitatif) atau bisa juga merupakan prediksi intuisi yang bersifat subjektif (kualitatif).
2.2 Banjir
Banjir adalah proses alam yang biasa dan merupakan bagian penting dari mekanisme pembentukan dataran di Bumi. Melalui banjir muatan sedimen terus masuk ke laut dan mengendap di dasar laut. Banjir yang terjadi sangat ditentukan oleh curah hujan. Terdapat tiga hal yang mempengaruhi banjir yaitu, air, udara, dan bumi. Air mengalir dari atas ke bawah, apabila air ditampung di suatu tempat dan tempat itu penuh dan ternyata air terus menerus masuk maka air akan meluap. Karena manusia dapat mempengaruhi debit aliran permukaan dan dapat mempelajari karakter aliran sungai, maka dapat dikatakan bahwa manusia dapat berkaitan dengan hal banjir ini. (Ratmaniar, 2013). Penyebab utama yang sangat mempengaruhi terjadinya banjir adalah curah hujan. Jika turun hujan lebat dan lama, maka air tidak dapat segera masuk ke dalam tempatnya secara lancar, tergantung penampungan dan drainase di lokasi tersebut. Sehingga terjadilah banyak antrian air yang panjang dan tinggi muka air yang semakin naik dan mengakibatkan genangan yang besar dan terjadilah banjir. 2.3 ARR dan AWLR
Dalam penelitian yang telah dilakukan oleh Setyawan yang membahas tentang sistem pemantau kondisi hidrologi, dalam hal ini peralatan pemantau debit dan tinggi muka air atau disebut AWLR (waterlevel) serta peralatan pemantau curah hujan atau disebut ARR
(rainfall) mulai dioperasikan di wilayah kerja Perum Jasa Tirta, khususnya di DAS Kali Brantas, sejak tahun 1991 dengan rincian sebanyak 11 AWLR di bendungan; 10 AWLR di sungai; dan sebanyak 24 ARR di bendungan. Di tahun 1993 dilakukan penambahan 2 ARR dan 1 AWLR di bendungan sehingga total peralatan AWLR dan ARR yang terpasang yaitu 12 AWLR di waduk dan bendungan; 10 AWLR di sungai dan 26 ARR di bendungan. Dengan terpasangnya sistem telemetri tersebut, diharapkan mampu memberikan informasi dini, khususnya untuk kegiatan pengendalian banjir (Setyawan, 2012).
Keberadaan peralatan pemantau kondisi hidrologi yang telah terpasang tersebut, baik AWLR maupun ARR, dianggap masih belum mampu meng-cover lokasi dikarenakan luas area yang memang cukup besar, sehingga pada lokasi-lokasi tertentu masih sering terjadi hujan lebat dan banjir yang tidak dapat terpantau/tercatat oleh peralatan AWLR dan ARR yang telah terpasang tersebut.
2.4 Metode Kernel
Metode kernel dapat diterapkan dalam SVR karena metode kernel fleksibel untuk mengatasi non-linear (Scholkopf et al., 2002). Fungsi kernel adalah untuk memetakan data input ke ruang dimensi yang lebih tinggi dengan harapan dalam ruang yang lebih tinggi, dimensi data dapat lebih terstruktur (Tonde, 2014). Banyak penelitian sebelumnya berpendapat bahwa SVR akan memberikan kinerja yang baik dengan menggunakan fungsi kernel Gaussian RBF (Li, et al., 2005). Kernel yang paling sering digunakan adalah Kernel Gaussian Radial Basic Function (RBF). RBF memiliki kinerja terbaik saat dibandingkan dengan fungsi kernel yang lain. Kernel RBF dapat dijabarkan melalui Persamaan (1)
𝐾(𝑥, 𝑥𝑖) = exp(− ‖𝑥−𝑥𝑖‖2
2𝜎2 ) (1) 2.5 Support Vector Regression
Support Vector Regression merupakan pengembangan dari metode Support Vector Machine (SVM) untuk kasus regresi. SVR merupakan metode yang dapat mengatasi overfitting, sehingga akan menghasilkan performansi yang bagus (Scholkopf et al., 2002). Konsep SVR didasarkan pada risk minimization, yaitu untuk mengestimasi suatu fungsi dengan cara meminimalkan batas dari error rate. Sebuah
algoritma sekuensial untuk regresi non-linear dapat menghasilkan solusi optimal dengan iterasi yang lebih cepat dibandingkan metode konvensional (Vijayakumar & Wu, 1999). Berikut tahap-tahap mengenai algoritma SVR. 1. Inisialisasi data dan parameter, data yang
digunakan terdiri dari dua tipe data yaitu data latih dan data uji, terdapat parameter-parameter yang digunakan yaitu 𝜀, 𝜆, 𝜎 untuk Kernel Gaussian RBF, 𝐶, dan cLR. 2. Normalisasi Data, proses normalisasi data
yang digunakan adalah min-max normalization. Normalisasi data memiliki tujuan untuk standarisasi semua data yang digunakan dalam perhitungan sehingga data berada pada jarak tertentu. Normalisasi data dapat dijabarkan melalui Persamaan (2) 𝑥′= 𝑥−𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥−𝑥𝑚𝑖𝑛 (2)
3. Matriks Hessian, dapat dijabarkan melalui Persamaan (3)
[𝑅]𝑖𝑗= 𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2 (3)
Kemudian hasil dari matriks hessian digunakan untuk mencari nilai parameter gamma yang dijabarkan melalui Persamaan (4)
𝛾 = 𝑐𝐿𝑅
max(𝑚𝑎𝑡𝑟𝑖𝑘𝑠𝐻𝑒𝑠𝑠𝑖𝑎𝑛) (4)
4. Sequential Learning adalah langkah menghitung nilai error 𝐸𝑖, perubahan nilai lagrange multiplier (𝛼𝑖∗ dan 𝛼𝑖), dan mendapatkan nilai lagrange multiplier baru dari data latih. Sebelum memulai langkah ini, inisialisasikan dulu nilai lagrange multiplier (𝛼𝑖∗ dan 𝛼𝑖) yakni 0. Berikut langkah-langkah beserta persamaannya Menghitung nilai error 𝐸𝑖
𝐸𝑖= 𝑦𝑖− ∑𝑙𝑗=1(𝛼𝑗∗− 𝛼𝑗)𝑅𝑖𝑗 (5)
Menghitung perubahan nilai Lagrange Multiplier
𝛿𝛼𝑖∗= min{max(𝛾(𝐸𝑖− 𝜀), −𝛼𝑖∗) , 𝐶 − 𝛼𝑖∗} (6)
𝛿𝛼𝑖= min{max(𝛾(−𝐸𝑖− 𝜀), −𝛼𝑖) , 𝐶 − 𝛼𝑖} (7)
Menghitung nilai baru Lagrange Multiplier 𝛼𝑖∗(𝑏𝑎𝑟𝑢) = 𝛿𝛼𝑖∗+ 𝛼𝑖∗(𝑙𝑎𝑚𝑎) (8)
𝛼𝑖(𝑏𝑎𝑟𝑢) = 𝛿𝛼𝑖+ 𝛼𝑖(𝑙𝑎𝑚𝑎) (9)
5. Langkah perulangan (mengulangi langkah no. 4) dilakukan hingga mencapai batas iterasi maksimal yang telah diinisialisasikan sebelumnya, atau hingga
memenuhi syarat max (|𝛿𝛼𝑖|) < 𝜀 dan max (|𝛿𝛼𝑖∗|) < 𝜀.
6. Menghitung nilai peramalan, dapat dijabarkan melalui Persamaan (10)
𝑓(𝑥) = ∑𝑛𝑖=1(𝛼𝑖∗− 𝛼𝑖)(𝐾(𝑥𝑖, 𝑥) + 𝜆2) (10)
7. Denormalisasi, dilakukan dengan tujuan mendapatkan data yang asli melalui cara mengembalikan ukuran data yang telah dinormalisasikan sebelumnya. Dapat dijabarkan melalui Persamaan (11)
𝑥 = 𝑥′(𝑥
𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛) + 𝑥𝑚𝑖𝑛 (11)
2.6 MAPE
Rata-rata presentase kesalahan Mean Absolute Percentage Error (MAPE) adalah ukuran akurasi dari hasil peramalan merupakan ukuran tentang tingkat perbedaan antara hasil peramalan dengan permintaan yang sebenarnya terjadi. MAPE menyatakan persentase kesalahan hasil peramalan terhadap permintaan aktual selama periode tertentu yang akan memberikan informasi persentase kesalahan terlalu tinggi atau terlalu rendah (Wu et al., 2009). Nilai evaluasi diukur dalam bentuk error rate menggunakan MAPE, dapat dijabarkan melalui Persamaan (12) 𝑀𝐴𝑃𝐸 =1 𝑛∑ | 𝑦̂𝑖−𝑦𝑖 𝑦𝑖 × 100| 𝑛 𝑖=1 (12) 3. PERANCANGAN DAN IMPLEMENTASI
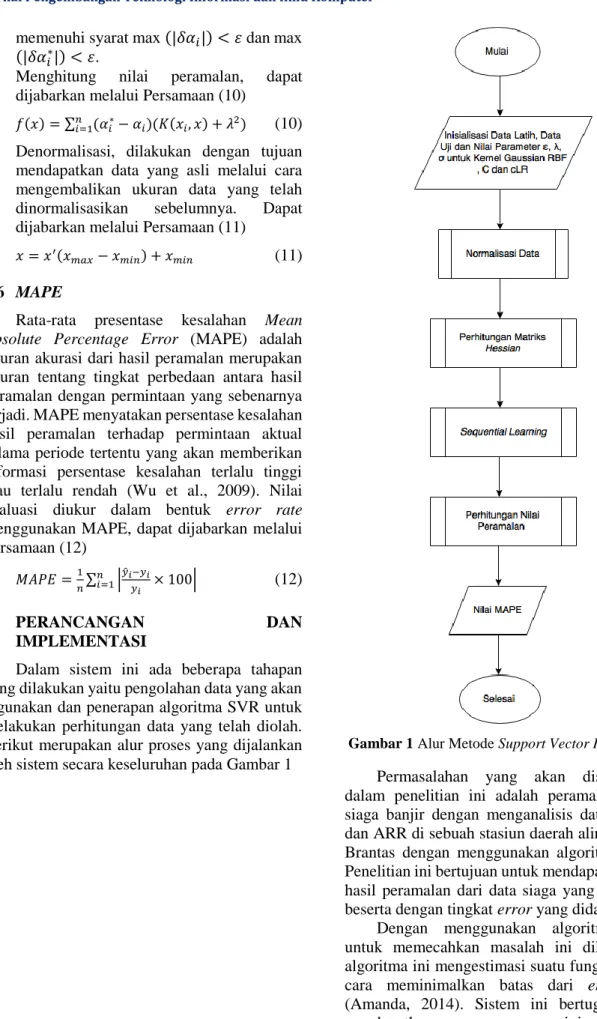
Dalam sistem ini ada beberapa tahapan yang dilakukan yaitu pengolahan data yang akan digunakan dan penerapan algoritma SVR untuk melakukan perhitungan data yang telah diolah. Berikut merupakan alur proses yang dijalankan oleh sistem secara keseluruhan pada Gambar 1
Gambar 1 Alur Metode Support Vector Regression
Permasalahan yang akan diselesaikan dalam penelitian ini adalah peramalan status siaga banjir dengan menganalisis data AWLR dan ARR di sebuah stasiun daerah aliran sungai Brantas dengan menggunakan algoritma SVR. Penelitian ini bertujuan untuk mendapatkan nilai hasil peramalan dari data siaga yang dianalisis beserta dengan tingkat error yang didapat.
Dengan menggunakan algoritma SVR untuk memecahkan masalah ini dikarenakan algoritma ini mengestimasi suatu fungsi dengan cara meminimalkan batas dari error rate (Amanda, 2014). Sistem ini bertugas untuk mendapatkan error rate yang minimal dimulai dengan menginisialisasi data menjadi data latih dan data uji serta parameter yang digunakan.
Lalu membuat tabel fitur yang diambil dari inisialisasi data secara random sebagai sampel perhitungan awal. Selanjutnya fitur-fitur tersebut dihitung nilai normalisasi datanya. Kemudian mengikuti proses-proses seperti dijelaskan pada Gambar 1 dengan menghitung nilai dari proses matriks hessian, memperoleh nilai lagrange multiplier yang baru pada proses sequential learning, menghitung nilai peramalan dan proses terakhir untuk mendapatkan nilai error rate menggunakan metode MAPE.
4. PENGUJIAN DAN ANALISIS
Pada penelitian ini dilakukan beberapa pengujian terhadap hasil error rate yang terdiri dari pengujian nilai parameter dan sistem k-fold cross validation untuk Data AWLR dan ARR. 4.1 Pengujian Nilai Parameter untuk Data
AWLR
Pada pengujian data AWLR ini menggunakan data di St. Kambing dengan jumlah data sebanyak 657. Data yang digunakan merupakan data pada bulan Desember 2016 untuk meramalkan status siaga untuk bulan selanjutnya. Data dibagi menjadi 2 bagian yaitu 457 data latih dan 200 data uji. Pengujian ini bertujuan untuk mengetahui nilai error rate paling minimal dari parameter SVR. Pengujian pertama yaitu pengujian parameter 𝜀. Untuk hasil pengujian nilai parameter 𝜀 ditunjukkan pada Gambar 2
Gambar 2 Grafik Pengujian Nilai Parameter 𝜀 untuk Data AWLR
Berdasarkan Gambar 2 menunjukkan bahwa nilai error rate mengalami penurunan mengikuti range nilai 𝜀 yang semakin tinggi.
Semakin kecil nilai 𝜀, maka nilai error rate yang dihasilkan akan semakin tinggi. Begitu pula sebaliknya, semakin besar nilai 𝜀 maka akan semakin kecil nilai error rate yang dihasilkan. Pada pengujian yang dilakukan, nilai 𝜀 akan mengalami perubahan sesuai dengan range yang ditentukan dan mencapai nilai error rate terkecil sebesar 10.5167 pada range 0.1-1.
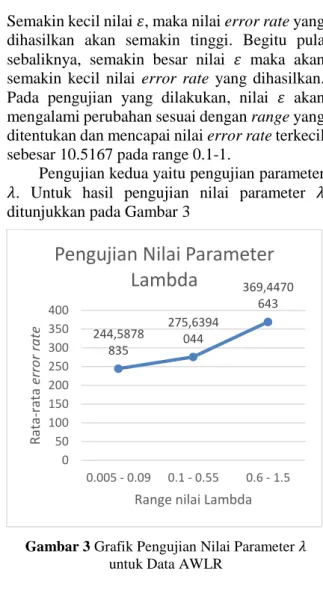
Pengujian kedua yaitu pengujian parameter 𝜆. Untuk hasil pengujian nilai parameter 𝜆 ditunjukkan pada Gambar 3
Gambar 3 Grafik Pengujian Nilai Parameter 𝜆 untuk Data AWLR
Berdasarkan Gambar 3 menunjukkan bahwa nilai error rate mengalami peningkatan mengikuti range nilai 𝜆 yang semakin tinggi. Semakin tinggi nilai parameter ini maka semakin besar nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , nilai 𝜆 akan mengalami perubahan sesuai dengan range yang ditentukan dan mencapai nilai error rate terkecil sebesar 243.741 pada range 0.005-1.
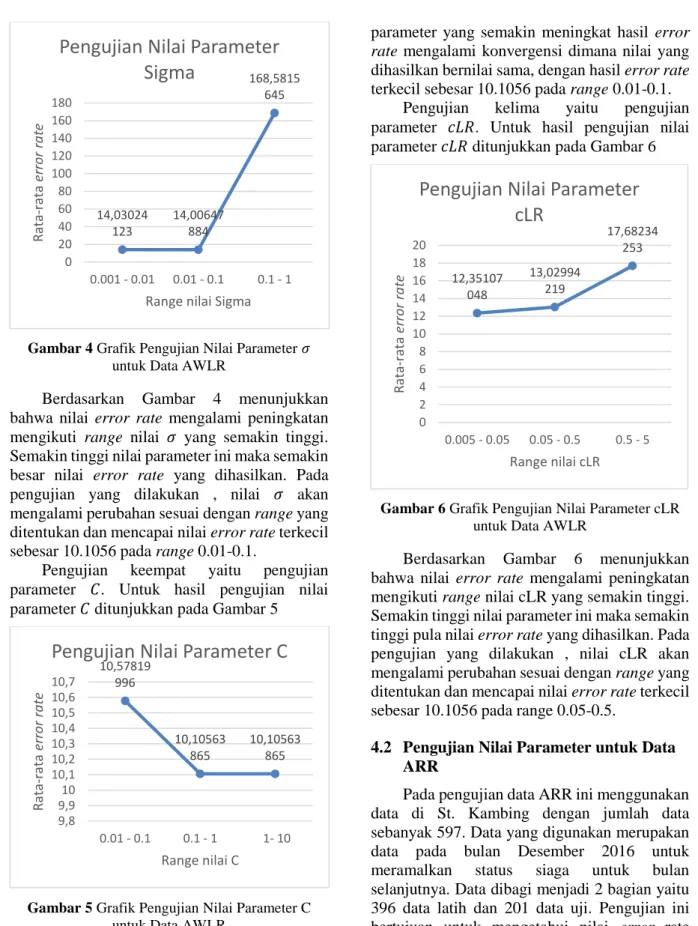
Pengujian ketiga yaitu pengujian parameter 𝜎. Untuk hasil pengujian nilai parameter 𝜎 ditunjukkan pada Gambar 4
68309,90 338 103,0755 994 14,04421 438 0 10000 20000 30000 40000 50000 60000 70000 80000 0.01 - 0.1 0.1 - 1 1- 10 Rat a-ra ta e rr o r ra te
Range nilai Epsilon
Pengujian Nilai Parameter
Epsilon
244,5878 835 275,6394 044 369,4470 643 0 50 100 150 200 250 300 350 400 0.005 - 0.09 0.1 - 0.55 0.6 - 1.5 Rat a-ra ta e rr o r ra teRange nilai Lambda
Pengujian Nilai Parameter
Gambar 4 Grafik Pengujian Nilai Parameter 𝜎 untuk Data AWLR
Berdasarkan Gambar 4 menunjukkan bahwa nilai error rate mengalami peningkatan mengikuti range nilai 𝜎 yang semakin tinggi. Semakin tinggi nilai parameter ini maka semakin besar nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , nilai 𝜎 akan mengalami perubahan sesuai dengan range yang ditentukan dan mencapai nilai error rate terkecil sebesar 10.1056 pada range 0.01-0.1.
Pengujian keempat yaitu pengujian parameter 𝐶. Untuk hasil pengujian nilai parameter 𝐶 ditunjukkan pada Gambar 5
Gambar 5 Grafik Pengujian Nilai Parameter C
untuk Data AWLR
Berdasarkan Gambar 5 menunjukkan bahwa nilai error rate mengalami penurunan mengikuti range nilai C yang semakin tinggi. Semakin tinggi nilai parameter ini maka semakin kecil nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , dengan nilai
parameter yang semakin meningkat hasil error rate mengalami konvergensi dimana nilai yang dihasilkan bernilai sama, dengan hasil error rate terkecil sebesar 10.1056 pada range 0.01-0.1.
Pengujian kelima yaitu pengujian parameter 𝑐𝐿𝑅. Untuk hasil pengujian nilai parameter 𝑐𝐿𝑅 ditunjukkan pada Gambar 6
Gambar 6 Grafik Pengujian Nilai Parameter cLR
untuk Data AWLR
Berdasarkan Gambar 6 menunjukkan bahwa nilai error rate mengalami peningkatan mengikuti range nilai cLR yang semakin tinggi. Semakin tinggi nilai parameter ini maka semakin tinggi pula nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , nilai cLR akan mengalami perubahan sesuai dengan range yang ditentukan dan mencapai nilai error rate terkecil sebesar 10.1056 pada range 0.05-0.5.
4.2 Pengujian Nilai Parameter untuk Data ARR
Pada pengujian data ARR ini menggunakan data di St. Kambing dengan jumlah data sebanyak 597. Data yang digunakan merupakan data pada bulan Desember 2016 untuk meramalkan status siaga untuk bulan selanjutnya. Data dibagi menjadi 2 bagian yaitu 396 data latih dan 201 data uji. Pengujian ini bertujuan untuk mengetahui nilai error rate paling minimal dari parameter SVR. Pengujian pertama yaitu pengujian parameter 𝜀. Untuk hasil pengujian nilai parameter 𝜀 ditunjukkan pada Gambar 7 14,03024 123 14,00647 884 168,5815 645 0 20 40 60 80 100 120 140 160 180 0.001 - 0.01 0.01 - 0.1 0.1 - 1 Rat a-ra ta e rr o r ra te
Range nilai Sigma
Pengujian Nilai Parameter
Sigma
10,57819 996 10,10563 865 10,10563 865 9,8 9,9 10 10,1 10,2 10,3 10,4 10,5 10,6 10,7 0.01 - 0.1 0.1 - 1 1- 10 Rat a-ra ta e rr o r ra te Range nilai CPengujian Nilai Parameter C
12,35107 048 13,02994 219 17,68234 253 0 2 4 6 8 10 12 14 16 18 20 0.005 - 0.05 0.05 - 0.5 0.5 - 5 Rat a-ra ta e rr o r ra te Range nilai cLR
Pengujian Nilai Parameter
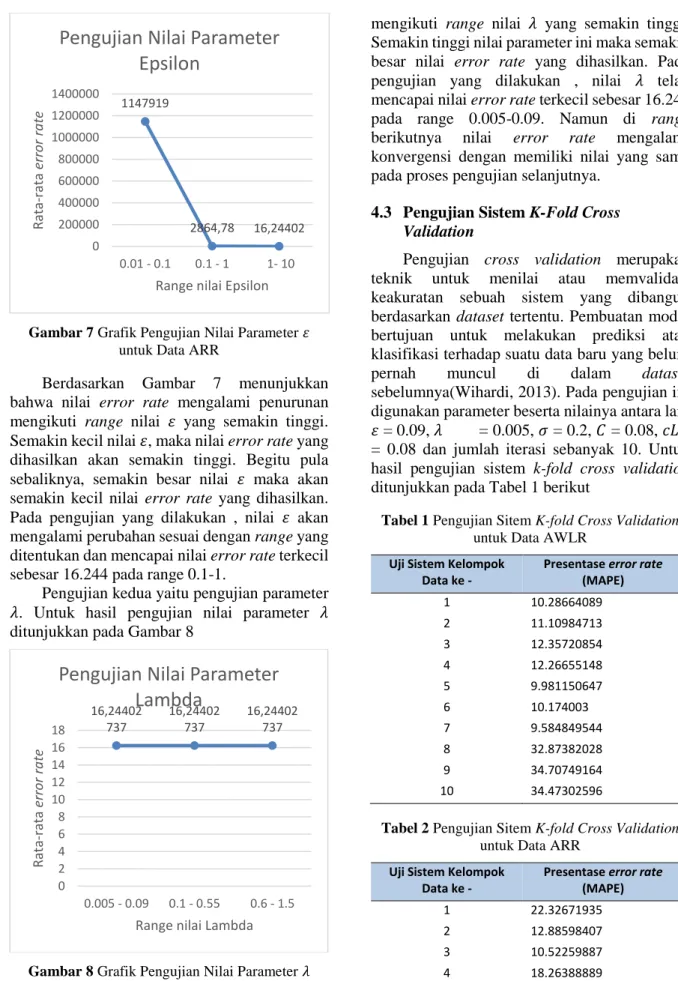
Gambar 7 Grafik Pengujian Nilai Parameter 𝜀 untuk Data ARR
Berdasarkan Gambar 7 menunjukkan bahwa nilai error rate mengalami penurunan mengikuti range nilai 𝜀 yang semakin tinggi. Semakin kecil nilai 𝜀, maka nilai error rate yang dihasilkan akan semakin tinggi. Begitu pula sebaliknya, semakin besar nilai 𝜀 maka akan semakin kecil nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , nilai 𝜀 akan mengalami perubahan sesuai dengan range yang ditentukan dan mencapai nilai error rate terkecil sebesar 16.244 pada range 0.1-1.
Pengujian kedua yaitu pengujian parameter 𝜆. Untuk hasil pengujian nilai parameter 𝜆 ditunjukkan pada Gambar 8
Gambar 8 Grafik Pengujian Nilai Parameter 𝜆 untuk Data ARR
Berdasarkan Gambar 8 menunjukkan bahwa nilai error rate mengalami peningkatan
mengikuti range nilai 𝜆 yang semakin tinggi. Semakin tinggi nilai parameter ini maka semakin besar nilai error rate yang dihasilkan. Pada pengujian yang dilakukan , nilai 𝜆 telah mencapai nilai error rate terkecil sebesar 16.244 pada range 0.005-0.09. Namun di range berikutnya nilai error rate mengalami konvergensi dengan memiliki nilai yang sama pada proses pengujian selanjutnya.
4.3 Pengujian Sistem K-Fold Cross
Validation
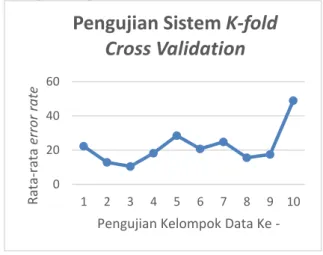
Pengujian cross validation merupakan teknik untuk menilai atau memvalidasi keakuratan sebuah sistem yang dibangun berdasarkan dataset tertentu. Pembuatan model bertujuan untuk melakukan prediksi atau klasifikasi terhadap suatu data baru yang belum pernah muncul di dalam dataset sebelumnya(Wihardi, 2013). Pada pengujian ini digunakan parameter beserta nilainya antara lain 𝜀 = 0.09, 𝜆 = 0.005, 𝜎 = 0.2, 𝐶 = 0.08, 𝑐𝐿𝑅 = 0.08 dan jumlah iterasi sebanyak 10. Untuk hasil pengujian sistem k-fold cross validation ditunjukkan pada Tabel 1 berikut
Tabel 1 Pengujian Sitem K-fold Cross Validation
untuk Data AWLR
Uji Sistem Kelompok Data ke -
Presentase error rate (MAPE) 1 2 3 4 5 6 7 8 9 10 10.28664089 11.10984713 12.35720854 12.26655148 9.981150647 10.174003 9.584849544 32.87382028 34.70749164 34.47302596
Tabel 2 Pengujian Sitem K-fold Cross Validation
untuk Data ARR
Uji Sistem Kelompok Data ke -
Presentase error rate (MAPE) 1 2 3 4 5 6 7 22.32671935 12.88598407 10.52259887 18.26388889 28.47368421 20.73759202 24.87613642 1147919 2864,78 16,24402 0 200000 400000 600000 800000 1000000 1200000 1400000 0.01 - 0.1 0.1 - 1 1- 10 Rat a-ra ta e rr o r ra te
Range nilai Epsilon
Pengujian Nilai Parameter
Epsilon
16,24402 737 16,24402 737 16,24402 737 0 2 4 6 8 10 12 14 16 18 0.005 - 0.09 0.1 - 0.55 0.6 - 1.5 Rat a-ra ta e rr o r ra teRange nilai Lambda
Pengujian Nilai Parameter
8 9 10 15.61111111 17.54740495 48.98667052
Dalam pengujian cross validation ini dibagi data menjadi dua bagian, yaitu data latih dan data uji. Setelah data diuji dilakukan proses silang dimana data uji dijadikan data latih maupun sebaliknya, data latih sebelumnya akan menjadi data uji. Hasil pengujian menunjukkan bahwa pengujian sistem menggunakan k-fold cross validation memiliki hasil yang berbeda di tiap varian data. Dari Tabel 1 dapat dilihat bahwa hasil pengujian sistem mengalami proses yang tidak menentu dengan bergantung dengan variasi data yang digunakan. Pada kelompok data yang pertama memiliki presentase error rate sebesar 10.28664089 kemudian mengalami kenaikan di pengujian sistem selanjutnya. Namun pada kelompok data ke-5 mengalami penurunan hasil error rate sebesar 9.981150647. Hasil untuk presentasi nilai error rate terkecil diperoleh pada pengujian kelompok data ke-7 dengan nilai error rate sebesar 9.584849544 dan mengalami peningkatan yang cukup jauh pada proses pengujian kelompok data selanjutnya. Grafik hasil pengujian sistem menggunakan k-fold cross validation ditunjukkan pada Gambar 9
Gambar 9 Pengujian Sistem K-fold Cross
Validation untuk Data AWLR
Untuk data ARR Dari Tabel 2 dapat dilihat bahwa hasil pengujian sistem mengalami proses yang tidak menentu dengan bergantung dengan variasi data yang digunakan. Pada kelompok data yang pertama memiliki presentase error rate sebesar 22.32671935 kemudian mengalami kenaikan di pengujian sistem selanjutnya. Namun pada kelompok data ke-10 mengalami kenaikan yang cukup tinggi dengan hasil error
rate sebesar 48.98667052. Hasil untuk presentasi nilai error rate terkecil diperoleh pada pengujian kelompok data ke-3 dengan nilai error rate sebesar 10.52259887. Grafik hasil pengujian sistem menggunakan k-fold cross validation ditunjukkan pada Gambar 10
Gambar 10 Pengujian Sistem K-fold Cross
Validation untuk Data ARR 5. KESIMPULAN
Berdasarkan hasil pengujian pada penelitian “Sistem Peramalan Siaga Banjir dengan Menganalisis Data Curah Hujan (ARR) dan Tinggi Muka Air (AWLR) Menggunakan Metode Suppor Vector Regression” maka dapat disimpulkan bahwa, Dalam mengimplementasi metode SVR untuk meramalkan status siaga banjir terdapat beberapa langkah yang dilakukan. Langkah pertama adalah menginisialisasi data yang digunakan menjadi dua tipe data yaitu data latih dan data uji dengan fitur yang telah ditentukan. Langkah kedua adalah melakukan normalisasi data menggunakan min-max normalization. Langkah ketiga adalah melakukan perhitungan kernel menggunakan Kernel Gaussian RBF dan matriks hessian untuk mendapatkan nilai parameter gamma. Langkah keempat adalah melakukan proses sequential learning yang digunakan untuk melakukan proses iterasi dan mencari nilai alpha dan alphaStar yang nantinya digunakan untuk memperoleh nilai peramalan. Langkah kelima adalah mencari nilai peramalan dan melakukan denormalisasi nilai peramalan siaga banjir. Langkah terakhir adalah mencari nilai error rate terkecil dari sistem peramalan siaga banjir menggunakan MAPE.
Berdasarkan pengujian yang telah dilakukan, pada data tinggi muka air (AWLR) dengan jumlah data latih sebanyak 591 data dan data uji sebanyak 66 data didapatkan nilai error 0 10 20 30 40 1 2 3 4 5 6 7 8 9 10 Pres en ta se e rr o r ra te
Pengujian Kelompok Data Ke
-Pengujian Sistem K-fold
Cross Validation
0 20 40 60 1 2 3 4 5 6 7 8 9 10 Rat a-ra ta e rr o r ra tePengujian Kelompok Data Ke
-Pengujian Sistem K-fold
rate terkecil sebesar 9.584849544. Dan pada data curah hujan (ARR) dengan jumlah data latih sebanyak 538 data dan data uji sebanyak 59 data didapatkan nilai error rate terkecil sebesar 10.52259887. Dengan nilai parameter yang digunakan yaitu 𝜀 = 0.09, 𝜆 = 0.005, 𝜎 = 0.2, 𝐶 = 0.08, 𝑐𝐿𝑅 = 0.08 dan jumlah Iterasi sebesar 10. Kedua data tersebut menghasilkan peramalan siaga banjir berupa Siaga NORMAL.
Pada penelitian mengenai peramalan siaga banjir dengan menganalisis data curah hujan dan tinggi muka air ini masih belum sempurna dan memiliki banyak kekurangan. Saran yang diberikan untuk penelitian selanjutnya adalah dibutuhkannya penambahan metode lain dengan algoritma optimasi karena perlunya dilakukan optimasi pada nilai parameter yang ada di metode SVR.Dan diperlukannya pengoptimalan data ARR menggunakan perhitungan atau balancing data berdasarkan jamnya sebelum melakukan proses dari metode yang diimplementasikan dikarenakan jarak antar data yang tidak seimbang.
DAFTAR PUSTAKA
Amanda, R., 2014. Analisis Support Vector Regression (SVR) Dalam Meramalkan Kurs Rupiah Terhadap Dolar Amerika Serikat. Semarang: Universitas Diponegoro. Li , C.-H., Lu, Z.-d. & Zhou, K., 2005.
SVR-Parameters Selection For Image Watermaking. Wuhan, IEEE.
Ma, D., Ding, N., Wang, J. & Cui J. 2010. Research on Flood Submergence Analysis System Based on ArcEngine Component Library. Ministry of Construction P.R. China Science & Technology Planning Project (2010-K9-24).
Nasution. 2003. Metode Research. Jakarta: PT. Bumi Aksara.
Ratmaniar, Sunadi R. & Rosminar. 2013. Jurnal Tentang Banjir. Jurusan Pendidikan Fisika: UIN Alauddin Makassar. Link: http://www.slideshare.net/mHynarLhybra/j urnal-28489176
Scholkopf, B. & Smola, A.J., 2002. Learning With Kernels : Support Vector Machine, Regularization, Opmitization & Beyond. MIT Press.
Setyawan, P., 2012. Pengembangan Sistem Monitoring Telemetri GSM Berbasis Desktop, Web dan Mobile.
Syafruddin, M., 2014. Prediksi Kebutuhan Energi Listrik Jangka Panjang untuk Provinsi Lampung hingga Tahun 2030, Bandar Lampung: Universitas Lampung. Tonde, C. & Elgammal, A., 2014. Simultaneous
Twin Kernel Learning using Polynomial Transformations for Structured Prediction. 2014 IEEE Conference on Computer Vision and Pattern Recognition.
Wihardi, Y., 2013. K-Folds Cross Validation. Link : http://blog.yayaw.web.id/riset/k-folds-cross-validation
Wu, CH., Tzeng, GH. & Lin, RH., 2009. A Novel Hybird Genetic Algorithm For Kernel Function And Parameter Optimization In Support Vector Regression.
Vijayakumar, S. & Wu, S., 1999. Sequential Support Vector Classifiers and Regression. Genoa, Italy, Saitama: RIKEN Brain Science Institute, The Institute for Physical and Chemical Research, pp. 610-619.