Abstrak— Salah satu cara berkomunikasi dengan penderita tunarungu adalah Bahasa Isyarat, namun pada umumnya Bahasa Isyarat tidak dipahami oleh orang normal . Bahasa isyarat adalah hal yang pokok bagi penderita tunarungu dalam berkomunikasi, beda halnya dengan orang normal. Pada penelitian ini dibuat sistem yang dapat membantu orang normal dalam berkomunikasi dengan penderita tunarungu. Masukan dalam sistem yang dibuat adalah berupa ucapan yang kemudian divisualisasikan berupa video Bahasa Isyarat dan standard Bahasa Isyarat yang digunakan adalah bahasa isyarat yang sesuai dengan Sistem Isyarat Bahasa Indonesia (SIBI), Penjelasan lebih detail tentang SIBI bisa dilihat pada [1]. Masukan berupa ucapan tersebut diproses dengan speaker independent speech recognition dan kalimat hasil proses speaker independent speech recognition dipenggal tiap kata menggunakan top-down parser yang kemudian divisualisasikan berupa video Bahasa Isyarat. Hasil yang dicapai dalam penelitian ini adalah semakin banyak data training dengan orang dan variasi umur yang banyak sebagai referensi maka akan semakin baik hasil speech recognition yang akan didapatkan. Hasil pengujian menunjukkan bahwa sistem dapat mengenali kata yaitu sekitar 89.84%, apabila data uji yang digunakan sama dengan data referensi. Dan sistem bisa mengenali kata sekitar 48.75%, apabila data uji yang digunakan berbeda dengan data referensi. Video Bahasa Isyarat bisa dimunculkan dengan benar dari teks hasil speech recognition maupun teks hasil pengetikan.
Kata Kunci—Bahasa Isyarat, SIBI.
I. PENDAHULUAN
AHASA isyarat merupakan bahasa natural yang digunakan dalam komunitas tunarungu. Bahasa isyarat digunakan sebagai cara utama untuk bertukar informasi. Penderita tunarungu, terutama mereka yang sudah tuli sejak lahir adalah native speaker dari bahasa isyarat. Penderita tunarungu mengalami kesulitan dalam belajar bahasa oral. Sama halnya dengan orang normal yang mencoba untuk belajar bahasa isyarat. Hal ini membuat visualisasi bahasa isyarat itu sangat penting. Visualisasi bahasa isyarat diharapkan dapat membantu meningkatkan integrasi sosial antara orang normal dengan penderita tunarungu. Dengan adanya visualisasi bahasa isyarat, orang normal tidak perlu belajar bahasa isyarat dalam berkomunikasi dengan penderita tunarungu dan sebaliknya, penderita tunarungu tidak perlu mengerti bahasa oral. Menggunakan bahasa isyarat yang baku dan seragam adalah hal yang lebih baik. Sehingga di
diperlukan media untuk mengenalkan bahasa isyarat yang baku kepada masyarakat.
II. URAIANPENELITIAN
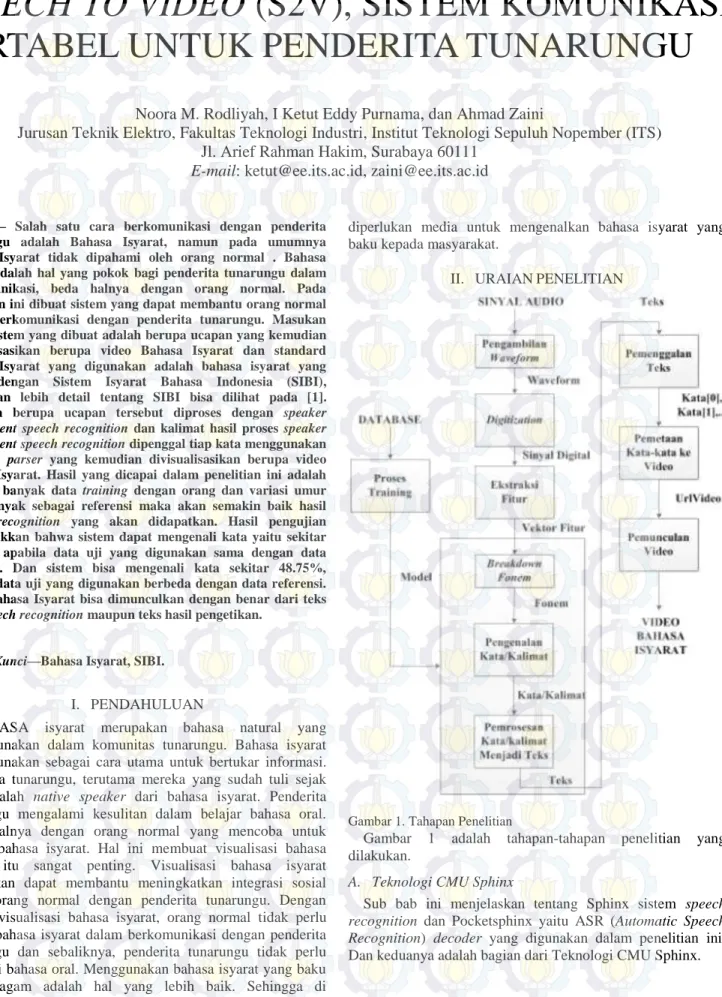
Gambar 1. Tahapan Penelitian
Gambar 1 adalah tahapan-tahapan penelitian yang dilakukan.
A. Teknologi CMU Sphinx
Sub bab ini menjelaskan tentang Sphinx sistem speech recognition dan Pocketsphinx yaitu ASR (Automatic Speech Recognition) decoder yang digunakan dalam penelitian ini. Dan keduanya adalah bagian dari Teknologi CMU Sphinx.
SPEECH TO VIDEO (S2V), SISTEM KOMUNIKASI
PORTABEL UNTUK PENDERITA TUNARUNGU
Noora M. Rodliyah, I Ketut Eddy Purnama, dan Ahmad Zaini
Jurusan Teknik Elektro, Fakultas Teknologi Industri, Institut Teknologi Sepuluh Nopember (ITS)
Jl. Arief Rahman Hakim, Surabaya 60111
E-mail: [email protected], [email protected]
1) Sphinx
Sphinx1 adalah sistem pengenalan continuous-speech dan speaker independent yang dikembangkan untuk mengatasi beberapa permasalahan dalam speech recognition yaitu speaker independence, continuous-speech, dan kosa kata yang besar. Sistem ini adalah teknologi yang menyediakan sistem pengenal ucapan dan tools untuk mengembangkan sistem speech recognition. Sphinx adalah sistem speech recognition yang biasa digunakan untuk aplikasi desktop.
Gambar 2 Metodologi
2) Pocketsphinx
Pocketsphinx adalah sistem speech recognition yang digunakan untuk hand-held devices atau untuk aplikasi mobile. Pocketsphinx digunakan pada penelitian ini karena pocketsphinx bisa digunakan pada sistem operasi android. Untuk menjalankan Pocketsphinx pada suatu device, ada 3 input yang dibutuhkan yaitu language model, acoustic model, dan dictionary file. Secara default, Pocketsphinx toolkit menyediakan satu language model (wsj0vp.5000), satu acoustic model (hub4wsj_sc_8k) dan satu dictionary file (cmu07a.dic). File-file tersebut berisikan kosa kata yang besar yaitu sekitar 125.000 kata. Untuk dokumentasi yang menjelaskan tentang bagaimana mengunduh ,compile source
1Sphinx adalah bagian dari CMU Sphinx dan open source speech
recognition system dan bisa diunduh di
http://cmusphinx.sourceforge.net/.
code dan juga cara membuat contoh aplikasi bisa dilihat di official web page Pocketsphinx2.
B. Eclipse
Eclipse adalah sebuah IDE (Integrated Development Environment) untuk mengembangkan perangkat lunak dan dapat dijalankan di semua platform. Pada penelitian ini digunakan eclipse untuk membuat aplikasi secara keseluruhan. Beberapa class yang digunakan pada penelitian ini adalah Hashmap dan Videoview. Hashmap digunakan untuk pemetaan kata ke alamat video. Dan Videoview digunakan untuk memunculkan video Bahasa Isyarat.
C. Gambaran Sistem
Penelitian ini bertujuan agar media atau aplikasi yang dibuat bisa digunakan orang normal dalam berkomunikasi dengan penderita tunarungu. Orang normal bisa berbicara dan kalimat yang dikenali oleh sistem speech recognition akan dipenggal perkata karena video Bahasa Isyarat yang akan dimunculkan adalah perkata dan setelah itu aplikasi akan memunculkan video Bahasa Isyarat perkata. Kosa kata yang diucapkan harus sesuai dengan kosa kata yang dilatih. Jadi apabila pengguna mengucapkan kosa kata yang tidak dilatih, aplikasi tidak akan mengenali kata tersebut.
D. Kosa kata
Kosa kata yang digunakan pada penelitian ini adalah kosa kata yang bisa digunakan dalam berkomunikasi sehari-hari. Pada penelitian ini kosa kata yang dibuat membentuk beberapa kalimat yang kemudian dilatih agar sistem bisa mengenali kalimat tersebut.
E. Video Bahasa Isyarat
1) 3.5.1 Kata ke Alamat Video
Video Bahasa Isyarat yang digunakan diambil dari aplikasi web i-CHAT. Pada proses ini dilakukan pemetaan kata ke alamat video. Hal perlu dilakukan adalah membuat daftar semua kata yang akan dimunculkan video Bahasa Isyarat, dan daftar alamat video Bahasa Isyarat dari semua kata. Kemudian dilakukan pemetaan kata ke alamat video menggunakan Hashmap. Kode 1 adalah kode yang digunakan untuk memetakan kata ke alamat video. KumpulanKata pada kode 1 adalah daftar semua kata dan indexVideo adalah daftar semua alamat video. Jadi urutan daftar semua kata dan alamat videonya harus sama.
Kode 1 Pemetaan Kata ke Video
2) Memunculkan Video Bahasa Isyarat
Setelah semua kata dipetakan ke video Bahasa Isyarat. Proses selanjutnya yaitu memunculkan video Bahasa Isyarat. kode 2 adalah kode yang digunakan untuk mendapatkan alamat video. urlVideo pada kode 2 adalah nama variable untuk alamat video. Dan kata2 adalah kata-kata hasil proses pemenggalan kalimat (hasil yang dikenali oleh sistem speech recognition). Jadi apabila kata2 sama dengan kata yang ada di
daftar KumpulanKata maka akan didapatkan alamat video sesuai dengan yang telah dipetakan. Jadi Videoview akan menampilkan video sesuai dengan urlVideo yang didapatkan.
Kode 2 Cara mendapatkan alamat video F. Language Model dan Dictionary File
1) Language Model
CMU Sphinx toolkit menyediakan aplikasi-aplikasi yang
bisa digunakan untuk membantu developer dalam membuat language model yang baru. Aplikasi-aplikasi ini disebut Statistical Language Model Toolkit (CMUCLMTK). Tujuan toolkit ini adalah untuk mengambil text corpus sebagai masukan dan menghasilkan suatu language model. Text corpus adalah daftar kalimat yang ingin dikenali oleh sistem speech recognition dan digunakan untuk menentukan stuktur bahasa serta bagaimana tiap kata berhubungan satu sama lain. langkah-langkah pembuatan language model dengan CMUCLMTK bisa dilihat pada [6].
Cara lain untuk membuat language model selain CMUCMLTK toolkit adalah lmtool. Untuk menggunakan tool ini, pengguna harus upload text corpus ke server menggunakan web browser dan tool akan menghasilkan language model. Tool ini digunakan untuk text corpus yang kecil yaitu maksimal berisikan ratusan kalimat saja. Pada penelitian ini menggunakan puluhan kalimat, jadi bisa menggunakan kedua tools.
CMUCLMTK toolkit menghasilkan beberapa file yang berguna seperti vocab file yang berisikan daftar semua kata yang ditemukan dalam text corpus, wfreq file yaitu file yang berisikan daftar semua kata yang ada dalam text corpus dan jumlah tiap kata yang muncul di text corpus. Dan CMUCLMTK toolkit juga menghasilkan file yang digunakan dalam penelitian ini yaitu language model, yang pertama language model dengan format arpa (.arpa) dan yang kedua language model dengan format binary (.DMP). Kedua format file bisa digunakan oleh Pocketsphinx tetapi dalam penelitian ini menggunakan format binary karena file dengan format binary lebih rapi.
Ada beberapa cara untuk membuat text corpus. Yang paling simple adalah dengan menulis beberapa kalimat secara manual. Cara ini yang digunakan pada penelitian ini. Pada penelitian ini dibuat text corpus dengan cara menulis beberapa kalimat yang ingin dikenali oleh sistem speech recognition menggunakan notepad. Gambar 4 adalah salah satu text corpus yang dibuat pada penelitian ini.
Gambar 3 Text Corpus
Pada penelitian ini dibuat empat macam language model yaitu ina6 dengan 38 kosa kata yang membentuk 15 kalimat dan ina7, ina8, ina9 dengan 64 kosa kata yang membentuk 24 kalimat.
2) Dictionary File
Dictionary file dengan menggunakan lmtool. Cara yang
dilakukan sama seperti membuat language model yaitu dengan membuat text corpus dan upload ke server menggunakan web browser. Dan lmtool akan menghasilkan beberapa file, salah satunya yaitu dictionary file. Untuk penjelasan yang yang lebih detail bisa dilihat pada [5]. Dictionary file berisikan kosa kata yang digunakan dalam text corpus dan cara pengucapan tiap kosa kata yang terdiri dari fonem-fonem. Lmtool ini hanya bisa menghasilkadictionary file dengan cara pengucapan Bahasa Inggris. Jadi pada penelitian ini, cara pengucapan dictionary file diubah sesuai dengan cara pengucapan kosa kata dalam Bahasa Indonesia. Gambar 5 adalah salah satu Dictionary File yang dibuat dalam penelitian ini.
Gambar 5 Dictionary File
Pada penelitian ini dibuat empat macam dictionary file yaitu ina6 dengan 38 kosa kata yang membentuk 15 kalimat dan ina7, ina8, ina9 dengan 64 kosa kata yang membentuk 24 kalimat.
G. Acoustic Model
Pocketsphinx menyediakan tools untuk membuat acoustic model yang baru yaitu Sphinxtrain. Sphinxtrain berfungsi untuk melatih acoustic model yang baru. Hal perlu disediakan adalah rekaman suara yang cukup dan transcript dari setiap kalimat yang diucapkan dalam rekaman suara. Tools ini menerima input seperti yang bisa dilihat pada gambar 6
Gambar 6 Input untuk Pembuatan Acoustic Model Input pada Sphinxtrain adalah:
a. Kumpulan rekaman suara dengan format .wav. Setiap file berisikan satu kalimat dengan satu pembicara.
b. Transcription file yang berisikan setiap kalimat yang diucapkan pada rekaman suara. File yang sama bisa digunakan untuk pembicara yang berbeda. c. Dictionary file yang berisikan kosa kata yang
digunakan dalam rekaman suara.
d. Filler file yang berisikan suara non-speech dalam rekaman. Seperti silence sebelum kalimat diucapkan, silence diantara kata dan silence setelah kalimat selesai diucapakan.
Pada penelitian ini dibuat empat macam acoustic model yaitu ina6 dengan data rekaman suara 1 orang perempuan dewasa dan jumlah data rekamannya adalah 802 file, ina7 dengan data rekaman suara 5 orang perempuan dewasa dan 2 orang laki-laki dan jumlah data rekamannya adalah 1011 file, ina8 dengan data rekaman suara 5 orang perempuan dewasa dan jumlah data rekamannya adalah 817 file, dan ina9 dengan data rekaman suara 2 orang laki-laki dewasa dan jumlah data rekamannya adalah 194 file. Untuk langkah-langkah pembuatan acoustic model yang lebih detail bisa dilihat pada [7].
H. Sistem Aplikasi 1) Input
Input pada sistem ini adalah model lingusitik (acoustic model, language model dan dictionary file) dan suara pengguna aplikasi. Model linguistik yang digunakan untuk proses decoding dari sinyal suara yang masuk. Model linguistik ini yang akan memberikan informasi ke decoder speech recognition kalimat yang dibentuk dari sinya suara yang masuk.
2) Output
Output dari sistem ini adalah video Bahasa Isyarat. pada penelitian ini kalimat yang dikenali oleh sistem speech recognition yang dibuat akan dipenggal menjadi kata-kata. Dan setiap kata yang telah dipenggal akan dimunculkan video Bahasa Isyaratnya.
3) Algoritma
Sub bab ini menjelaskan tentang proses Pocketsphinx mengenali suatu kalimat dan proses pemunculan video
Bahasa Isyarat dari kalimat yang dikenali. proses-prosesnya adalah sebagai berikut:
a. Ready, pada awalnya sistem speech recognition menginisialisasi audio input device agar mulai mendengarkan pembicara. Sistem juga akan memuat acoustic model, language model dan dictionary file untuk proses selanjutnya yaitu decoding input suara. b. Listening, saat pembicara mulai berbicara, sistem
speech recognition akan mendengarkan ucapan yang masuk dan akan melakukan proses ekstraksi fitur sampai pembicara selesai berbicara.
c. Decoding, pada proses ini masukan sinyal suara dikenali dengan informasi dari vektor fitur hasil prose ekstraksi fitur dan model lingustik (acoustic model, language model dan dictionary file). Acoustic model berisikan informasi yang digunakan untuk memetakan sinyal suara yang masuk ke fonem-fonem dan kata-kata. Language model berisikan informasi yang digunakan untuk memprediksi kata selanjutnya yang muncul berdasarkan kata sebelumnya yang dikenali. Dan dictionary file menyediakan representasi fonetik dari kata-kata dalam language model dan digunakan untuk memetakan fonem ke kata yang dibentuk oleh fonem-fonem.
d. Kata ke Video, setelah kalimat dikenali oleh sistem speech recognition, kalimat tersebut dipenggal perkata untuk memunculkan video Bahasa Isyaratnya. Kalimat dipenggal berdasarkan spasi, jadi setiap kata yang terpisah oleh spasi akan dipenggal. Kata-kata hasil proses pemenggalan akan dipetakan ke alamat video Bahasa Isyarat. Dan alamat video Bahasa Isyarat akan dimunculkan videonya oleh Videoview pada eclipse.
III. HASILPERCOBAAN
A. Model (Acoustic Model, Language Model dan Statistical Model)
1. Acoustic Model
Pengujian ini dilakukan untuk mendapatkan akurasi yang baik dalam pengenalan ucapan yang dilakukan. Pengujian ini dilakukan dengan menggunakan decoder yang ada pada library trainer acoustic model. Acoustic model ini diuji dan analisa dengan metode perbandingan. Perbandingan dilakukan antata data rekaman suara yang diambil menggunakan alat perekam komputer (laptop) dengan data rekaman suara yang di ambil menggunakan alat perekam Zoom Handy Recorder. Akurasi kebenaran untuk alat perekam Zoom Handy Recorder adalah 52,11% dan akurasi kebenaran untuk alat perekam komputer (laptop) adalah 25.35%.
2. Language Model
Pengujian ini dilakukan untuk mendapatkan akurasi yang baik dalam pengenalan ucapan yang dilakukan. Pengujian ini dilakukan dengan menggunakan decoder yang ada pada library trainer acoustic model. Language model ini diuji dan analisa dengan metode perbandingan. Pembuatan Language Model menggunakan CMUCLMTK, cara pembuatannya bisa dilihat pada [5] dengan pembuatan language model menggunakan web service (lmtool) yang kemudian diubah formatnya menjadi DMP, cara pembuatannya bisa dilihat pada
[4]. Untuk menghasilkan akurasi kebenaran yang baik dalam pengenalan ucapan yang dilakukan, bisa menggunakan Language Model dari CMUCLMTK atau web service karena keduanya menghasilkan akurasi yang sama.
3. Statistical Model (Dictionary File)
Pengujian ini dilakukan untuk mendapatkan akurasi yang baik dalam pengenalan ucapan yang dilakukan. Pengujian ini dilakukan dengan menggunakan decoder yang ada pada library trainer acoustic model. Statistical model ini diuji dan analisa dengan metode perbandingan. Statistical model yang menggunakan ejaan vokal Bahasa Indonesia yang meniru ejaan Bahasa Inggris dengan ejaan Bahasa Indonesia yang normal. Untuk menghasilkan akurasi kebenaran yang baik dalam pengenalan ucapan yang dilakukan, bisa menggunakan Statistical Model dengan ejaan vokal Bahasa Inggris atau Bahasa Indonesia karena keduanya menghasilkan akurasi yang sama.
B. Speech ke Teks 1. Model ina6
Pada penelitian ini dilakukan pengujian pengenalan ucapan dengan menggunakan perangkat android. Data training pada model ina6 terdiri dari suara 1 orang perempuan dewasa. Pengujian ini dilakukan dengan suara 1 orang perempuan dewasa yang digunakan juga sebagai data training, 4 orang perempuan dewasa, 3 orang laki-laki dengan usia dewasa antara 15-23 tahun, dan 1 anak laki-laki dengan usia anak 10 tahun sebagai data uji. Dan ada 15 kalimat dengan total 38 kata yang diucapkan dalam pengujian. Contoh kalimatnya adalah “saya makan”, “aku makan”, “kita pergi makan”, “dia pulang”dll.
Gambar 3 adalah hasil pengujian model ina6. Diagram ini dibuat dengan akurasi yang didapatkan dari pengujian yang telah dilakukan. Akurasi dihitung berdasarkan total kata yang benar dikenali oleh speech recognition dibagi dengan total kata yang diucapkan kemudian hasil perhitungan tersebut dihitung rata-ratanya sesuai jumlah data uji. Nilai persentase pada Gambar 3 menunjukkan porsi kebenaran speech recognition yang diberikan dalam skala 100%. Input sinyal yang sama dari seorang perempuan dewasa dengan data rekaman pada data training memberikan tingkat kebenaran speech recognition (pengenalan ucapan yang dibuat dalam penelitian ini) yang paling bagus yaitu 44%.
Gambar 3. Diagram Pengujian Model ina6
Hasil percobaan menunjukkan bahwa sistem dapat mengenali kata sekitar 81,5%, kalau diucapkan pembicara yang suaranya disertakan dalam pembuatan model. Dan sistem bisa mengenali kata sekitar 34,3%, kalau diucapkan pembicara yang suaranya tidak disertakan dalam pembuatan model. Persentase dihitung dari akurasi pengenalan ucapan yang didapat dan apabila data uji lebih dari satu maka akurasinya dirata-rata.
Kata-kata bisa dikenali ketika user berbicara dengan tempo yang normal (sekitar 0.9 detik tiap kata), dengan jarak mikrofon 7-10 cm dan dalam ruangan yang tenang (tidak orang lain yang berbicara). Kata-kata banyak bisa dikenali apabila pengguna aplikasi adalah seorang perempuan.
2. Model ina7
Pada penelitian ini dilakukan pengujian pengenalan ucapan dengan menggunakan perangkat android. Data training pada model ina7 terdiri dari suara 5 orang perempuan dewasa dan 2 orang laki-laki dewasa. Pengujian ini dilakukan dengan suara 3 orang perempuan dewasa yang digunakan juga sebagai data training, 2 orang perempuan dewasa, 1 orang laki-laki dewasa yang digunakan juga sebagai data training, 2 orang laki-laki dewasa dengan usia dewasa diantara 15-23 tahun, dan 1 anak laki-laki bukan dengan usia anak 10 tahun sebagai data uji. Dan ada 24 kalimat dengan total 66 kata yang diucapkan dalam pengujian. Contoh kalimatnya adalah “saya makan”, “aku makan”, “dia mandi”, “kita pergi makan” dll.
Gambar 4 adalah hasil pengujian model ina7. Diagram ini dibuat dengan akurasi yang didapatkan dari pengujian yang telah dilakukan. Akurasi dihitung berdasarkan total kata yang benar dikenali oleh speech recognition dibagi dengan total kata yang diucapkan kemudian hasil perhitungan tersebut dihitung rata-ratanya sesuai jumlah data uji. Nilai persentase pada Gambar 4 menunjukkan porsi kebenaran speech recognition yang diberikan dalam skala 100%. Input sinyal yang sama dari orang perempuan dewasa dengan data rekaman pada data training memberikan tingkat kebenaran speech recognition (pengenalan ucapan yang dibuat dalam penelitian ini) yang paling bagus yaitu 25%.
Gambar 4. Diagram Pengujian Model ina7
Hasil percobaan menunjukkan bahwa sistem dapat mengenali kata sekitar 88,8%, Kalau diucapkan pembicara yang suaranya disertakan dalam pembuatan model. Dan sistem bisa mengenali kata sekitar 69,4%, kalau diucapkan pembicara yang suaranya tidak disertakan dalam pembuatan model. Input (Pr,dewasa) = data training, 44 % Input (Pr,dewasa) ≠ data training, 26 % Input (Lk,dewasa) ≠ data training, 11 % Input (Lk, anak) ≠ data training, 19 % 1 2 3 4 Input (Pr,dewasa) = data training, 25 % Input (Lk,dewasa) = data Training, 21 % Input (Lk,dewasa) ≠ data training, 22 % Input (Pr,dewasa) ≠ data training, 22 % Input (Lk,anak) ≠ data training, 10 % 1 2 3 4 5
Persentase dihitung dari akurasi pengenalan ucapan yang didapat dan apabila data uji lebih dari satu maka akurasinya dirata-rata.
Kata-kata bisa dikenali Ketika user berbicara dengan tempo yang normal (sekitar 0.9 detik tiap kata), dengan jarak mikrofon 7-10 cm dan dalam ruangan yang tenang (tidak orang lain yang berbicara). Kata-kata banyak bisa dikenali apabila pengguna aplikasi adalah seorang perempuan maupun laki-laki. Tetapi akurasi speech recognition untuk laki-laki lebih jelek dari pada speech recognition untuk perempuan karena jumlah data training laki-laki lebih sedikit dari pada perempuan.
3. Model ina8
Pada penelitian ini dilakukan pengujian pengenalan ucapan dengan menggunakan perangkat android. Data training model ina8 terdiri dari suara 5 orang perempuan dewasa. Pengujian ini dilakukan dengan suara 2 orang perempuan dewasa yang digunakan juga sebagai data training, 2 orang perempuan dewasa, 3 orang laki-laki dewasa dengan usia dewasa diantara 15-23 tahun, dan 1 anak laki-laki dengan usia anak 10 tahun sebagai data uji. Dan ada 24 kalimat dengan total 66 kata yang diucapkan dalam pengujian. Contoh kalimatnya adalah “saya makan”, “aku makan”, “dia mandi”, “kita pergi makan” dll. Gambar 5 adalah hasil pengujian model ina8. Diagram ini dibuat dengan akurasi yang didapatkan dari pengujian yang telah dilakukan. Akurasi dihitung berdasarkan total kata yang benar dikenali oleh speech recognition dibagi dengan total kata yang diucapkan kemudian hasil perhitungan tersebut dihitung rata-ratanya sesuai jumlah data uji. Nilai persentase pada Gambar 5 menunjukkan porsi kebenaran speech recognition yang diberikan dalam skala 100%. Input sinyal yang sama dari seorang perempuan dewasa dengan data rekaman pada data training memberikan tingkat kebenaran speech recognition (pengenalan ucapan yang dibuat dalam penelitian ini) yang paling bagus yaitu 35%.
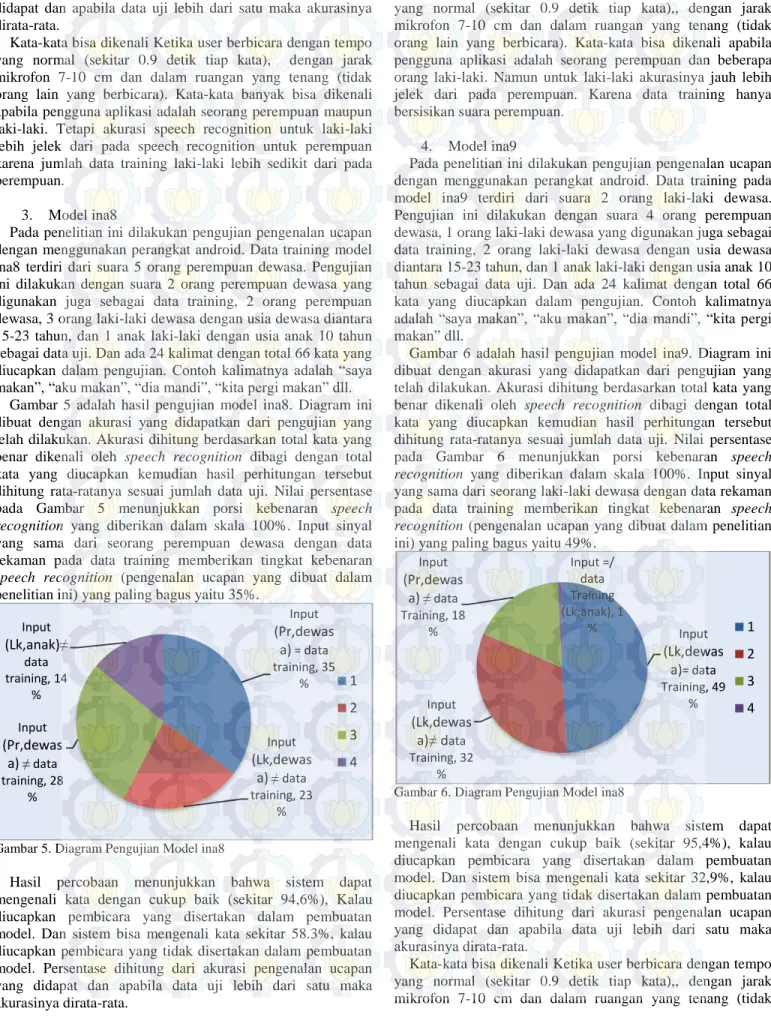
Gambar 5. Diagram Pengujian Model ina8
Hasil percobaan menunjukkan bahwa sistem dapat mengenali kata dengan cukup baik (sekitar 94,6%), Kalau diucapkan pembicara yang disertakan dalam pembuatan model. Dan sistem bisa mengenali kata sekitar 58.3%, kalau diucapkan pembicara yang tidak disertakan dalam pembuatan model. Persentase dihitung dari akurasi pengenalan ucapan yang didapat dan apabila data uji lebih dari satu maka akurasinya dirata-rata.
Kata-kata bisa dikenali Ketika user berbicara dengan tempo yang normal (sekitar 0.9 detik tiap kata),, dengan jarak mikrofon 7-10 cm dan dalam ruangan yang tenang (tidak orang lain yang berbicara). Kata-kata bisa dikenali apabila pengguna aplikasi adalah seorang perempuan dan beberapa orang laki-laki. Namun untuk laki-laki akurasinya jauh lebih jelek dari pada perempuan. Karena data training hanya bersisikan suara perempuan.
4. Model ina9
Pada penelitian ini dilakukan pengujian pengenalan ucapan dengan menggunakan perangkat android. Data training pada model ina9 terdiri dari suara 2 orang laki-laki dewasa. Pengujian ini dilakukan dengan suara 4 orang perempuan dewasa, 1 orang laki-laki dewasa yang digunakan juga sebagai data training, 2 orang laki-laki dewasa dengan usia dewasa diantara 15-23 tahun, dan 1 anak laki-laki dengan usia anak 10 tahun sebagai data uji. Dan ada 24 kalimat dengan total 66 kata yang diucapkan dalam pengujian. Contoh kalimatnya adalah “saya makan”, “aku makan”, “dia mandi”, “kita pergi makan” dll.
Gambar 6 adalah hasil pengujian model ina9. Diagram ini dibuat dengan akurasi yang didapatkan dari pengujian yang telah dilakukan. Akurasi dihitung berdasarkan total kata yang benar dikenali oleh speech recognition dibagi dengan total kata yang diucapkan kemudian hasil perhitungan tersebut dihitung rata-ratanya sesuai jumlah data uji. Nilai persentase pada Gambar 6 menunjukkan porsi kebenaran speech recognition yang diberikan dalam skala 100%. Input sinyal yang sama dari seorang laki-laki dewasa dengan data rekaman pada data training memberikan tingkat kebenaran speech recognition (pengenalan ucapan yang dibuat dalam penelitian ini) yang paling bagus yaitu 49%.
Gambar 6. Diagram Pengujian Model ina8
Hasil percobaan menunjukkan bahwa sistem dapat mengenali kata dengan cukup baik (sekitar 95,4%), kalau diucapkan pembicara yang disertakan dalam pembuatan model. Dan sistem bisa mengenali kata sekitar 32,9%, kalau diucapkan pembicara yang tidak disertakan dalam pembuatan model. Persentase dihitung dari akurasi pengenalan ucapan yang didapat dan apabila data uji lebih dari satu maka akurasinya dirata-rata.
Kata-kata bisa dikenali Ketika user berbicara dengan tempo yang normal (sekitar 0.9 detik tiap kata),, dengan jarak mikrofon 7-10 cm dan dalam ruangan yang tenang (tidak Input (Pr,dewas a)= data training, 35 % Input (Lk,dewas a)≠ data training, 23 % Input (Pr,dewas a) ≠ data training, 28 % Input (Lk,anak)≠ data training, 14 % 1 2 3 4 Input (Lk,dewas a)= data Training, 49 % Input (Lk,dewas a)≠ data Training, 32 % Input (Pr,dewas a) ≠ data Training, 18 % Input =/ data Training (Lk,anak), 1 % 1 2 3 4
orang lain yang berbicara). Kata-kata banyak bisa dikenali apabila pengguna aplikasi adalah seorang orang laki-laki. Karena data training hanya berisikan suara laki-laki.
C. Pengujian dan Analisa Kata ke Video 1. TEKS DARI SPEECH
Pada penelitian ini dilakukan pengujian pemunculan video dari teks menggunakan perangkat android. Aplikasi yang dibuat diinstall pada perangkat android dan diuji langsung dengan suara beberapa orang. Pengujian ini dilakukan empat kali sesuai dengan model yang ada.
Model ina6 memiliki 38 kosa kata yang bisa diucapkan. Dan semua video Bahasa Isyaratnya sesuai kata yang dikenali oleh sistem pengenalan ucapan. Dan apabila input berupa kalimat, maka semua video Bahasa Isyarat suatu kata dari kalimat tersebut bisa dimunculkan semuanya sesuai dengan kalimat yang dikenali oleh sistem pengenalan ucapan.
Model ina7 memiliki 66 kosa kata yang bisa diucapkan. Dan semua video Bahasa Isyaratnya bisa sesuai kata yang dikenali oleh sistem pengenalan ucapan. Dan apabila input berupa kalimat, maka semua video Bahasa Isyarat suatu kata dari kalimat tersebut bisa dimunculkan semuanya sesuai dengan kalimat yang dikenali oleh sistem pengenalan ucapan. Model ina8 memiliki 66 kosa kata yang bisa diucapkan. Dan semua video Bahasa Isyaratnya bisa muncul sesuai kata yang dikenali oleh sistem pengenalan ucapan. Dan apabila input berupa kalimat, maka semua video Bahasa Isyarat suatu kata dari kalimat tersebut bisa dimunculkan semuanya sesuai dengan kalimat yang dikenali oleh sistem pengenalan ucapan. Model ina9 memiliki 66 kosa kata yang bisa diucapkan. Dan semua video Bahasa Isyaratnya bisa muncul sesuai kata yang dikenali oleh sistem pengenalan ucapan. Dan apabila input berupa kalimat, maka semua video Bahasa Isyarat suatu kata dari kalimat tersebut bisa dimunculkan semuanya sesuai dengan kalimat yang dikenali oleh sistem pengenalan ucapan.
2. TEKS DARI PENGETIKAN
Pada penelitian ini juga dilakukan pengujian pemunculan video dari teks menggunakan perangkat android. Aplikasi yang dibuat diinstall pada perangkat android dan diuji langsung dengan mengetik beberapa kalimat sederhana. Pengujian ini dilakukan dengan 57 kalimat (231 kata) dengan rincian sebagai berikut:
a. Kalimat Tak Lengkap
Berdasarkan pengujian yang dilakukan dengan 12 kalimat dan 25 kata. Hasilnya adalah ada 5 kata yang video Bahasa Isyaratnya tidak ada dan 20 kata bisa dimunculkan video Bahasa Isyarat. Jadi ada 5 kalimat yang tidak bisa dimunculkan video Bahasa Isyaratnya dengan benar dan 7 kalimat yang bisa dimunculkan video Bahasa Isyaratnya dengan benar. Jadi untuk pemunculan video Bahasa Isyarat berhasil dilakukan dengan benar, tetapi tidak semua kata memiliki video Bahasa Isyarat.
b. Kalimat Lengkap
Berdasarkan pengujian yang dilakukan dengan 19 kalimat dan 117 kata. Hasilnya adalah ada 4 kata yang video Bahasa Isyaratnya tidak ada dan 113 kata bisa dimunculkan video Bahasa Isyarat. Jadi ada 3 kalimat yang tidak bisa
dimunculkan video Bahasa Isyaratnya dengan benar dan 16 kalimat yang bisa dimunculkan video Bahasa Isyaratnya dengan benar. Jadi untuk pemunculan video Bahasa Isyarat berhasil dilakukan dengan benar, tetapi tidak semua kata memiliki video Bahasa Isyarat.
c. Kalimat Percakapan Sederhana
Berdasarkan pengujian yang dilakukan dengan 26 kalimat dan 89 kata. Hasilnya adalah tidak ada kata yang video Bahasa Isyaratnya tidak ada dan 89 kata bisa dimunculkan video Bahasa Isyarat. Jadi tidak ada kalimat yang tidak bisa dimunculkan video Bahasa Isyaratnya dengan benar dan 26 kalimat yang bisa dimunculkan video Bahasa Isyaratnya dengan benar. Jadi untuk pemunculan video Bahasa Isyarat berhasil dilakukan dengan benar.
Dalam aplikasi ini ada 3600 kata yang bisa dimunculkan video Bahasa Isyaratnya. Kata-kata tersebut adalah kata baku Bahasa Indonesia, tidak ada kata ganti orang, kata depan untuk keterangan tempat dll. Waktu yang dibutuhkan untuk memunculkan video Bahasa Isyarat dari teks adalah kurang lebih 0,7 detik. Dan waktu di antara munculnya video Bahasa Isyarat apabila kata yang diucapkan lebih dari satu adalah kurang lebih 0,5detik. Hal ini membuat adanya sedikit jeda di antara munculnya video Bahasa Isyarat
D. Pengujian Data Training
Pengujian ini dilakukan untuk mendapatkan akurasi yang bagus pada pengenalan ucapan yang dilakukan. Pengujian ini dilakukan dengan menggunakan decoder yang ada pada library trainer acoustic model. Hasil pengujian dengan data training yang diedit secara manual sehingga silence disekitar kata kurang lebih 0.25 detik dan dengan data uji suara yang direkam sebagai berikut
TOTAL Words: 114 Correct: 114 Errors: 0 TOTAL Percent correct = 100.00% Error = 0.00% Accuracy = 100.00%
TOTAL Insertions: 0 Deletions: 0 Substitutions: 0
Dari data ini dapat dilihat bahwa kata-kata yang berhasil dikenali dengan benar ada 114 kata dari total kata 114 dan tidak kata yang salah dikenali.Dan didapatkan akurasi 100%. Dan hasil pengujian dengan data training yang tidak diedit silence disekitar katanya dan dengan data uji suara yang direkam adalah
TOTAL Words: 114 Correct: 114 Errors: 10 TOTAL Percent correct = 100.00% Error = 8.77% Accuracy = 91.23%
TOTAL Insertions: 10 Deletions: 0 Substitutions: 0
Dari data ini dapat dilihat bahwa kata-kata yang berhasil dikenali dengan benar ada 104 kata dari total kata 114 dan kata yang salah dikenali ada 10 dari 114 kata. Dengan kesalahan yaitu adanya selipan 10 kata. Dan didapatkan akurasi 91.23%.
Hasil yang didapat menunjukkan akurasi yang lebih bagus adalah ketika data training diedit silence disekitar kata kurang lebih 0.25 detik.
IV. KESIMPULAN/RINGKASAN
1. Untuk mendapatkan acoustic model yang bagus diperlukan silence di sekitar kata/ucapan pada data audio kurang lebih 0,25 detik.
2. Pengenalan ucapan yang dilakukan hanya bisa mengenali sinyal input (ucapan) dengan tempo yang normal (tidak terlalu pelan ataupun cepat), mikrofon tidak terlalu dekat (jarak 10 cm), dan suasana ruangan tenang (tidak ada orang lain yang berbicara).
UCAPANTERIMAKASIH
Penulis N.R. mengucapkan terima kasih kepada dosen-dosen pembimbing yang telah memberikan bimbingan selama pengerjaan penelitian ini.
DAFTARPUSTAKA
[1] Departemen Pendidikan dan Kebudayaan, Kamus Sistem Isyarat Bahasa Indonesia, Jakarta, 1995.
[2] Ivan Fransisco Castro Ceron, Andrea Graciela Garcia Badillo, “A Keyword Based Interactive Speech recognition System for Embedded Applications”, School of Innovation, Design and Engineering Malardalen University, Vasteras, Sweden, June, 2011.
[3] PT. Telekomunikasi Indonesia, Tbk, “i-CHAT I Can Hear And Talk”
<URL:app.i-chat.web.id>. Diakses 21 Oktober 2013 [4] Carnegie Mellon University, “Sphinx Knowledge Base
Tool”
<URL:http://www.speech.cs.cmu.edu/tools/lmtool-adv.html>. Diakses 21 Oktober 2013
[5] Carnegie Mellon University, “Building Language Model”
<URL:http://cmusphinx.sourceforge.net/wiki/tutoriallm> . Diakses 21 Oktober 2013
[6] Carnegie Mellon University, “Training Acoustic Model for CMUSphinx”
<URL:http://cmusphinx.sourceforge.net/wiki/tutorialam> . Diakses 21 Oktober 2013
[7] David Huggins-Daines, Mohit Kumar, Arthur Chan, Alan W Black, Mosur Ravishankar, and Alex I. Rudnicky, “Pocketsphinx: a Free, Real-Time Continuous Speech recognition System for hand - Held devices”, Carnegie Mellon University Language Technologies Institute 5000 Forbes Avenue, Pittsburgh, PA, USA 15213.