berhubungan dengan sistem yang akan dibangun.
2.1. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data mining merupakan suatu proses kegiatan yang meliputi pengumpulan dan pemakaian data historis untuk menemukan keteraturan pola maupun hubungan dalam suatu set data berukuran besar (Santosa, 2007). Data mining adalah tentang memecahkan suatu masalah dengan menganalisis data yang sudah ada. Data mining juga didefinisikan sebagai proses menemukan pola dalam data, dimana pola yang didapat harus memiliki beberapa keuntungan (Witten & Frank 2005).
Data mining sering disebut knowledge discovery in database (KDD), yaitu kegiatan yang meliputi kumpulan pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data
mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga istilah pattern recognition sekarang jarang digunakan karena ia termasuk bagian dari datamining (Santosa, 2007).
2.1.1. Knowledge discovery in database (KDD)
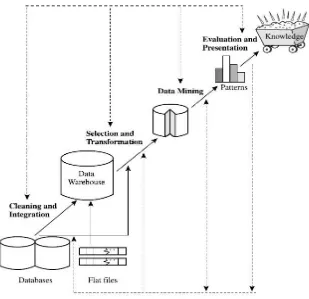
Menurut Han & Kamber (2006) proses KDD secara garis besar terdiri dari urutan yang berulang dari langkah-langkah berikut.
1. Data Cleaning (untuk menghilangkan noise dan data yang tidak konsisten) 2. Data Integration (mengkombinasikan beberapa dari sumber data)
4. Data Transformation (pengubahan data atau mengkonsolidasikan data kedalam bentuk yang sesuai untuk dilakukannya proses mining, seperti ringkasan atau agregasi operasi)
5. Data Mining (proses penting dimana metode cerdas diterapkan untuk mengekstrak pola)
6. Pattern Evaluation (mengidentifikasi pola-pola menarik yang mewakili pengetahuan berdasarkan proses data mining sebelumnya)
7. Knowledge presentation (menggunakan pengetahuan teknik representasi dan visualisasi untuk menyajikan pengetahuan kepada pengguna)
Gambar 2.1 Proses KDD (Han & Kamber 2006)
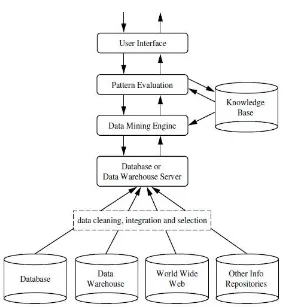
Gambar 2.2 Arsitektur sistem data mining (Han & Kamber 2006)
Database, Data Warehouse, World Wide Web, dan Other Info Repositories
merupakan satu atau kumpulan dari database, gudang data, spreadsheet atau jenis lain dari informasi repository. Cleaning data, integrasi data dan pemilihan data dapat dilakukan pada data.
Database atau Data Warehouse Server: bertanggung jawab untuk mengambil data yang relevan berdasarkan permintaan data mining pengguna.
Data Mining Engine : penting untuk sistem data mining seperti untuk tugas-tugas karakteristik, asosiasi dan analisis korelasi, klasifikasi, prediksi, analisis cluster, analisis outlier, dan analisis evolusi.
Pattern Evaluation : melakukan pemfokusan pencarian terhadap pola yang menarik dengan berinteraksi dengan modul data mining, atau dapat diintegrasikan dengan modul pertambangan, tergantung pada pelaksanaan metode data mining yang digunakan.
User Interface : diperlukan sebagai perantara pengguna dengan sistem untuk berkomunikasi yang memungkinkan pengguna untuk berinteraksi dengan sistem dengan menentukan pemberian tugas, memberi informasi untuk membantu memfokuskan pencarian. Selain itu juga memungkinkan pengguna untuk menelursuri
database dan skema data warehouse atau struktur data, mengevaluasi pola, dan memvisualisasikan pola dalam bentuk yang berbeda.
2.1.2. Teknik data mining
Terdapat beberapa teknik dan sifat data mining sebagai berikut (Hermawati, 2009) :
1. Klasifikasi (clasification)
Klasifikasi adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori (atau klas) yang telah didefinisikan sebelumnya. Contoh aplikasinya adalah pada penjualan langsung, yaitu untuk mengurangi cost surat menyurat dengan menentukan satu set konsumen yang mempunyai kesamaandalam membeli produk telepon selular baru.
2. Regresi (regression)
3. Klasterisasi (clustering)
Mempartisi data-set menjadi beberapa sub-set atau kelompok sedemikian rupa sehingga elemen-elemen dari suatu kelompok tertentu memiliki set property yang dishare bersama dengan tingkat similaritas yang tinggi dalam satu kelompok dan tingkat similaritas kelompok yang rendah. Contoh aplikasinya adalah : document clustering, dengan tujuan untuk mendapatkan kelompok dokumen yang mempunyai kesamaan berdasarkan kata-kata penting yang muncul dalam dokumen.
4. Kaidah Asosiasi (association rules)
Mendeteksi kumpulan atribut-atribut yang muncul bersamaan (co-occur) dalam frekuensi yang sering, dan membentuk sejumlah kaidah dari kumpulan-kumpulan tersebut. Contoh aplikasinya adalah pada supermarket shelf management, dengan tujuan untuk mengenali item-item yang dibeli bersama-sama oleh cukup banyak pelanggan.
5. Pencarian Pola sekuensial (sequence mining)
Mencari sejumlah event yang secara umum terjadi bersama-sama. Sebagai contoh dalam suatu set urutan DNA, ACGTC diikuti oleh GTCA setelah suatu celah selebar 9 dengan probabilitas sebesar 30 %.
2.2 Association Rule Mining
Assotiation rule mining atau aturan asosiasi sering dinamakan market basket analysis, karena awalnya berasal dari studi tentang database transaksi pelanggan uantuk menentukan kebiasaan suatu produk dibeli bersama produk apa (Santosa,2007). Sebagai contoh studi transaksi di supermarket, seseorang yang membeli susu bayi juga membeli sabun mandi. Disini berarti susu bayi bersama dengan sabun mandi.
1. Support (nilai penunjang/pendukung): suatu ukuran yang menunjukkan seberapa besar tingkat kemunculan suatu item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu itemset layak untuk dicari confidence pada tahapan selanjutnya.
2. Confidence (nilai kepastian/keyakinan): suatu ukuran yang menunjukkan hubungan antara 2 item secara conditional.
Keduan ukuran tersebut akan digunakan dalam menentukan interesting association rules, yaitu untuk dibandingkan dengan batasan (threshold) yang ditentukan oleh user. Batasan tersebut umumnya terdiri dari minimum support dan minimum confidence, yang digunakan pada proses pencarian association rules. Menurut Hermawati (2009), tujuan dari association rules mining adalah untuk menentukan semua aturan yang mempunyai support >= min_support dan confidence
>= min_confidence. Sebuah association rule dengan confidence sama atau lebih besar dari minimum confidence dapat dikatakan sebagai valid association rule (Agrawal & Srikant, 1994).
Proses pencarian association rules terbagi menjadi dua tahap yaitu analisis
frequent itemset dan pembentukan association rules (Han & Kamber 2006).
1. Analisis Frequent Item
Sedangkan nilai support dari 2 item diperoleh dengan rumus sebagai berikut: 𝑆𝑢𝑝𝑝𝑜𝑟𝑡 𝐴,𝐵 =Jumlah Transaksi yang Mengandung A dan B
2. Pembentukan Asosiation Rules
Setelah semua pola frekuensi tinggi ditemukan, kemudian dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence
aturan asositif A→B. Nilai confidencedari aturan A→B diperoleh dari rumus 2.3,
𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 𝐴 → 𝐵 = Jumlah Transaksi yang Mengandung A dan B
Jumlah Transaksi yang Mengandung A 𝑥 100%
(2.3)
2.2.1. Algoritma FP-growth
Algoritma FP-Growth mempresentasikan transaksi dengan menggunakan struktur data FP-Tree (Han, et al. 2000). FP-growth adalah salah satu alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang sering muncul (frequent itemset) dalam sebuah kumpulan data (Samuel, 2008).
FP-Tree merupakan struktur penyimpanan data yang dibentuk oleh sebuah akar yang diberi label null (Han & Kamber 2006). Pada FP-Tree, item dipetakan ke
item lainnya pada setiap lintasan. Pada setiap itemset yang dipetakan mungkin saja terdapat item yang sama, sehingga pada FP-Tree ini memungkinkan untuk saling menimpa. FP-Tree akan semakin efektif apabila semakin banyak pula item yang sama pada setiap itemset (Samuel, 2008).
2.2.2. Pencarian association rules dengan algoritma FP-growth
Proses pencarian association rules terbagi menjadi dua tahap yaitu analisis pola frekuensi tinggi dan pembentukan aturan assosiasi (Han & Kamber 2006).
1. Analisis frequent itemset, atau analisis pola frekuensi tinggi untuk mencari kombinasi item yang memenuhi syarat minimum dari nilai support itemset, dimana nilai support menunjukkan perhitungan frekuensi kemunculan pada suatu data. Proses pencarian frequent itemset pada sistem ini menggunakan algoritma
FP-Growth yang melalui tiga tahapan. a. Pencarian frequent item
frequent atau kemunculan sedikit maka item akan dibuang. Nilai support
dapat diperoleh dengan rumus (2.1) b. Pembangunan FP-Tree
Pembangunan FP-tree diawali dengan pembangunan tree pada setiap itemset. Pembangunan tree diawali dengan prefix atau awalan yang sama dari setiap
itemset. Apabila terdapat itemset yang memiliki prefix berbeda, maka itemset
berikutnya dibangun pada lintasan berbeda (Tan, et al. 2005).
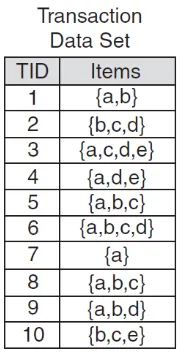
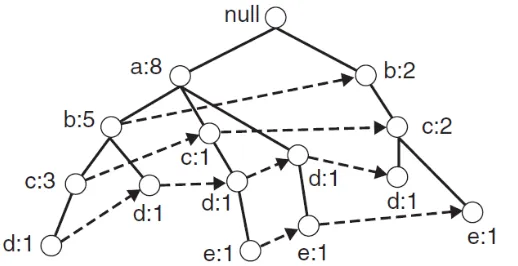
Sebagai contoh dapat dilihat pada Gambar 2.3, Gambar 2.4 dan Gambar 2.5.
Gambar 2.3 Transaction data set (Tan, et al. 2005)
FP-tree yang dapat dibangun dari itemset yang ada adalah sebagai berikut :
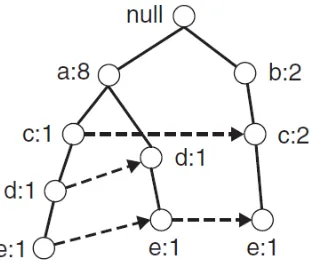
Gambar 2.5 Setelah membaca TID 2 (Tan, et al. 2005)
Setiap item pada setiap lintasan diberi nilai awal 1 sebagai support count, apabila itemset berikutnya memiliki prefix yang sama maka akan ditambahkan nilai support count pada item yang sama. Walaupun b ada pada lintasan pertama, namun karena berbeda prefix, maka penambahan support count tidak bisa dilakukan. Proses terus dilanjutkan sampai semua itemset
selesai dibaca seperti pada Gambar 2.5.
Gambar 2.6 Setelah membaca TID 10 (Tan, et al. 2005) c. Pencarian frequent itemset
Frequent itemset didapat melalui tiga tahapan (Tan, et al. 2005).
Gambar 2.7 Tree yang mengandung suffix e (Tan, et al. 2005)
Gambar 2.8 Tree yang mengandung suffix d (Tan, et al. 2005) 2. Mengecek kembali nilai support dari suffix item lebih besar atau tidak dari
minimum support yang telah diinput oleh pengguna sebelumnya. Apabila memenuhi, maka item tersebut termasuk frequent itemset. Nilai support
setiap itemnya pada tahap ini dihitung dengan rumus (2.1).
3. Apabila terdapat item yang frequent, maka akan dilanjutkan dengan metode divide and conquer untuk memecahkan subproblem yang lebih kecil, yaitu untuk menemukan frequent itemset yang berakhir dengan dua
item dari frequent item yang didapat sebelumnya. Kemudian membangun kembali tree yang diakhiri dengan dua item kombinasinya, dimana nilai
support pada itemset hanya mengandung nilai yang diakhiri dari frequent item. Begitu pula selanjutnya sampai prefix dari kombinasi.
2. Pembentukan association rules atau aturan assosiasi untuk mencari aturan assositif
A→B yang memenuhi syarat minimum nilai confidence. Pencarian nilai
confidence dapat dihitung dengan rumus (2.3)
Dimana A adalah antecendent (item setelah jika) dan B adalah consequent (item
setelah maka). Untuk antecendent dapat terdiri lebih dari satu unsur, akan tetapi
consequent hanya terdiri dari satu unsur. Ini digunakan untuk mengetahui keterhubungan anatr item dalam suatu itemset. Sebagai contoh, pada penelitian ini akan mencari seberapa keterhubungannya jalur masuk, asal pendidikan, fakultas, dan IPK terhadap masa studi seorang mahasiswa.
Rules yang telah didapat dilakukan pencocokan untuk memberikan saran kepada pengguna, dengan kata lain rules yang didapat akan diterjemahkan kedalam informasi yang dapat dimengerti oleh pengguna, yaitu berupa informasi kategori apa saja yang paling banyak muncul dan memiliki keterhubungan pada data lulusan mahasiswa perguruan tinggi serta saran/arahan yang dapat dilakukan oleh perguruan tinggi maupun fakultas.
2.3 Penelitian Terdahulu
Terdapat beberapa penelitian pada data mahasiswa yang telah dilakukan, yaitu penentu keterhubungan antara data mahasiswa dan masa studi dengan algoritma regresi linier berganda (Siregar, 2011). Pada penelitian ini menghasilkan sebanyak 61% keterhubungan antara data mahasiswa terhadap masa studi, Parameter yang digunakan dalam penentu keterhubungan adalah IPK, rata-rata UN, jumlah SKS, dan pendidikan orang tua. Data yang digunakan sebanyak 500 data mahasiswa, dan mengahasilkan sebuah prediksi tanpa belum mengetahui kombinasi dari parameter mana yang sering muncul.
Penelitian selanjutya oleh Ma’ruf (2013) yaitu aplikasi data mining untuk
keberhasilan proses masuk mahasiswa itu berasal dari mana untuk menjadi acuan dalam memaksimalkan iklan pada daerah tertentu, pada penelitian ini algoritma yang digunakan adalah algoritma apriori yang melakukan candidate generate dari setiap
item sehingga memerlukan banyak perulangan pencarian ke database, juga data yang digunakan pada penilitian ini belum menggunakan data yang cukup banyak, sehingga hasil yang diperoleh masih belum signifikan.
Selanjutnya Huda (2010) membangun aplikasi data mining untuk menampilkan informasi tingkat kelulusan mahasiswa. Pada penelitian ini juga menggunakan algoritma apriori, hasil dari proses data mining pada penelitian ini dapat digunakan sebagai pertimbangan dalam mengambil keputusan lebih lanjut tentang faktor yang mempengaruhi tingkat kelulusan khususnya faktor dalam data induk mahasiswa pada satu fakultas. Data induk mahasiswa yang diproses mining meliputi data proses masuk, data asal sekolah, data kota mahasiswa, dan data program studi. Pada penelitian ini menganjurkan peneliti selanjutnya untuk menggunakan algoritma FP-Growth, dikarenakan algoritma apriori memerlukan banyak perulangan pencarian ke
database. Ringkasan penelitian terdahulu dapat dilihat pada Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
No Peneliti (Tahun)
Teknik yang
digunakan Keterangan