Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 144
DATA MINING UNTUK ANALISA TINGKAT KEJAHATAN JALANAN
DENGAN ALGORITMA ASSOCIATION RULE METODE APRIORI
(Studi Kasus Di Polsekta Medan Sunggal)
Fadlina
Pasca Sarjana Ilmu Komputer Universitas Putra Indonesia “YPTK” PADANG Alamat : Jl. Raya Lubuk Begalung Padang, Sumatera Barat
No. Telepon : (0751) 776666-72472-730000, Fax : (0751) 71973 Website : http://upi-yptk.ac.id // Email : [email protected]
Abstrack
Data mining, or often referred to as knowledge discovery in databases (KDD) is acollection of activities that include, the use of historical data to discoverregularities,patterns or relationships in large data. In this thesis data mining is used to analyze the level of street crime. This technique aims to provide information about the area and the potential for street crime that can assist the police in anticipation of a crime that often appears, was done by using analysis of habit how often do street crimes. Detection of crime which often occur simultaneously called association rule (association rules). Algorithm that can be used to find Apriori association rule is. Apriori algorithm is the association rule mining through multiple scan data sets, find a relationship between the variables and present a strong rule in a large database. The data is taken as a case study of street crime data Polsekta Sunggal Medan. Test data using data mining software Tanagra and Microsoft Excel for data storage. Results from a combination of patterns and rules obtained to provide information that could be followed up or contain important information that can be utilized to enhance the security and sensitivity of street crime.
Keywords: Data mining, Association rules, Apriori, Knowledge Discovery in Database
1. Pendahuluan
1.1. Latar Belakang Masalah
Perkembangan jaman berdampak pada perkembangan masyarakat, perilaku, maupun pergeseran budaya. Terjadinya peningkatan kepadatan penduduk, pengangguran bertambah, kemiskinan yang mengakibatkan tingginya angka kriminalitas terutama di daerah urban yang padat.
Makaampoh, (2013) dalam penelitiannya menyatakan tindak kekerasan dalam KUHP salah satunya adalah aksi kejahatan jalanan (Street Crime) seperti pencurian, pemerasan, pemerkosaan, penganiayaan, tindak kekerasan terhadap orang atau barang, perilaku Mabuk dimuka umum, yang tentunya dapat mengganggu ketertiban umum serta menimbulkan keresahan di masyarakat
Kepolisian berkaitan dengan fungsinya sebagai pengayom masyarakat diharapkan mampu mengambil tindakan dalam menyikapi fenomena kejahatan jalanan dengan melakukan operasi razia dalam mengungkap kejahatan yang dapat dilakukan dengan menggunakan teknik analisis dari kebiasaan seberapa sering kejahatan jalanan dilakukan. Pendeteksian kejahatan yang sering terjadi secara bersamaan disebut association rule (aturan asosiasi).
Wakabi-Waiswa dan Baryamureeba, (2008) menggunakan Association rule untuk mengekstrak atau menarik korelasi dari pola yang sering muncul atau struktur kasual antara set item dalam transaksi database atau repository data lainnya.
Umarani dan Punithavalli, (2011) menggunakan Proses pertambangan aturan asosiasi
dari database yang besar menjadi dua langkah yaitu generasi itemset sering yang disebut minsupport dan association rule generation dari itemset sering, menghasilkan semua aturan asosiasi yang disebut minconfidence. Algoritma yang dapat digunakan untuk menemukan association rule adalah Apriori.
Algoritma Apriori adalah aturan asosiasi pertambangan melalui beberapa scan set data, menemukan hubungan antara variabel dan menyajikan aturan yang kuat dalam database yang besar (Padmaja dan Poongodai, 2011).
Dalam penelitian Prasad dan Malik, (2011) juga mengimplementasikan algoritma apriori untuk aturan dari dataset yang berisi transaksi penjualan toko ritel. Sedangkan dalam penelitian ini akan dilakukan pengujian apakah metode Association Rule dapat digunakan untuk menyelesaikan permasalahan pada data kejahatan jalanan. Data yang digunakan adalah daerah dan jenis kejahatan jalanan dari data statistik Polsek Medan Sunggal. Hasil dari penelitian ini diharapkan dapat memberikan informasi mengenai daerah dan potensi kejahatan jalanan yang dapat membantu pihak kepolisian dalam mengantisipasi kejahatan yang sering muncul.
1.2. Perumusan Masalah
Berdasarkan uraian latar belakang, maka penulis merumuskan suatu permasalahan yaitu sebagai berikut:
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule pola kombinasi itemsets dengan menggunakan
algoritma apriori?
2. Bagaimana mengimplementasikan Data Mining dengan algoritma Association Rule untuk menganalisa tingkat kejahatan jalanan?
3. Bagaimana faktor pendukung tersebut bisa dijadikan sebagai informasi dalam meningkatkan kewaspadaan masyarakat agar terhindar dari kejahatan di jalanan (Street Crime)?
1.3 Batasan Masalah
Agar penulisan tesis tidak lepas dari latar belakang dan perumusan masalah, maka penulis membuat batasan masalahnya yaitu sebagai berikut : 1. Menggunakan data mining Association Rule
untuk menghasilkan rules dan algoritma Apriori untuk menemukan pola kombinasi itemset
2. Data yang digunakan adalah data kejahatan jalanan (Street Crime) dan daerah kejahatan pada Polsekta Medan Sunggal.
3. Menggunakan aplikasi atau tools data mining Tanagra sebagai pengujian data.
1.4 Tujuan Penelitian
Beberapa tujuan yang ingin dicapai dalam penelitian ini yaitu sebagai berikut:
1. Mengimplementasikan data mining Association Rule dan Algoritma Apriori pada kejahatan jalanan untuk mengekstrak ilmu pengetahuan, informasi penting dan menarik dari database. 2. Membentuk pola kombinasi itemsets dari data
kejahatan jalanan dengan menggunakan algoritma Apriori .
3. Menghasilkan rules dari pola kombinasi itemsets yang interesting, sehingga dapat diketahui tingkat kejahatan jalanan apa yang sering dilakukan. 4. Merancang metode Association Rule untuk
penanganan kejahatan jalanan sehingga dapat meningkatkan efektifitas dan efesiensi kinerja kepolisian.
5. Membangun suatu pengetahuan baru dalam menganalisa tingkat kejahatan sehingga dapat meningkatkan keamanan dan sensitifitas kejahatan.
6. Menguji Data kejahatan jalanan dengan menggunakan Tools Tanagra sehingga informasi ini dapat membantu kepolisian dalam mengatasi tingkat kriminaliatas.
2. Landasan Teori
Landasan teori merupakan panduan untuk membahas tentang teori pemecahan masalah yang dihadapi. Dalam hal ini akan dikemukakan beberapa teori yang berhubungan dan relevan dengan masalah yang dibahas dalam penelitian ini.
Teori-teori yang menjadi landasan dalam penulisan tesis ini antara lain teori Data Mining, Algoritma Appriori, dan pada tesis ini juga penulis
juga menyampaikan jenis dan bentuk dari algoritma Association Rule.
2.1 Data Mining
Tahun 90-an telah melahirkan “gunungan” data di bidang ilmu pengetahuan, bisnis dan pemerintah. Kemampuan teknologi informasi untuk mengumpulkan dan menyimpan berbagai tipe data jauh meninggalkan kemampuan untuk menganalisis, meringkas dan mengekstraksi “pengetahuan” dari data. Metodologi tradisional untuk menganalisis data yang ada, tidak dapat menangani data dalam jumlah besar. Sementara para pelaku bisnis memiliki kebutuhan-kebutuhan untuk memanfaatkan gudang data yang sudah dimiliki, para peneliti melihat peluang untuk melahirkan sebuah teknologi baru yang menjawab kebutuhan ini, yaitu data mining. Teknologi ini sekarang sudah ada dan diaplikasikan oleh perusahaan perusahaan untuk memecahkan berbagai permasalahan bisnis dan juga untuk menggali pengetahuan baru dari bongkahan data
2.2. Defenisi Data Mining
Data mining atau sering disebut sebagai knowledge discovery in database (KDD) adalah
kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam data berukuran besar. Keluaran data
mining ini bisa dipakai untuk membantu
pengambilan keputusan di masa depan. Pengembangan KDD ini menyebabkan penggunaan
pattern recognition semakin berkurang karena telah
menjadi bagian data mining (Subekti Mujiasih, 2011).
Metode ini merupakan gabungan 4 (empat) disiplin ilmu yakni statistik, visualisasi, database, dan machine learning). Adapun machine learning adalah suatu area dalam artificial intelligence atau kecerdasan buatan yang berhubungan dengan pengembangan teknik-teknik pemrograman berdasarkan pembelajaran masa lalu dan bersinggungan dengan ilmu statistika dan juga optimasi.
2.3. Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Kusrini dan Emha Taufiq Luthfi, 2009): 1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari data untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menentukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden.
2. Estimasi
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 146 pada kearah kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel predikasi. Sebagai contoh akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi.
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang.
Contoh prediksi bisnis dan penelitian adalah: a. Prediksi harga beras dalam tiga bulan yang
akan datang.
b. Prediksi persentasi kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Klasifikasi adalah fungsi pembelajaran yang memetakan (mengklasifikasi) sebuah unsur (item) data ke dalam salah satu dari beberapa kelas yang sudah didefinisikan. Contoh lain klasifikasi dalam bisnis dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau tidak.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa.
5. Pengklusteran
Pengelompokan (clustering) merupakan tugas deskripsi yang banyak digunakan dalam mengidentifikasi sebuah himpunan terbatas pada kategori atau cluster untuk mendeskripsikan data yang ditelaah. Kategori-kategori ini dapat bersifat eksklusif dan ekshaustif mutual, atau mengandung representasi yang lebih kaya seperti kategori yang hirarkis atau saling menumpu (overlapping). Contoh pengklusteran dalam bisnis dan penelitian adalah:
a. Mendapatkan kelompok-kelompok
konsumen untuk target pemasaran dari satu suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
b. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku financial dalam baik dan mencurigakan. c. Melakukan pengklusteran terhadap ekspresi
dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
6. Asosiasi.
Tugas asosiasi dalam data mining adalah menemukan attribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan. b. Menentukan barang dalam supermarket yang
dibeli secara bersamaan dan yang tidak pernah dibeli secara bersamaan.
2.4. Association Rule
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Algoritma aturan asosiasi akan menggunakan data latihan, sesuai dengan pengertian data mining, untuk menghasilkan pengetahuan. Pengetahuan apakah yang hendak dihasilkan dalam aturan asosiasi? Pengetahuan untuk mengetahuan item-item belanja yang sering dibeli secara bersamaan dalam suatu waktu. Aturan asosiasi yang berbentuk “if…then…” atau “jika…maka…” merupakan pengetahuan yang dihasilkan dari fungsi aturan asosiasi (Seni Susanto dan Dedy Suryadi, 2010).
2.5. Tahapan Association Rules
Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknik data mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frequensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu persentase kombinasi item tersebut dalam database dan confidence (Nugroho Wandi, et al. 2012).
A. Data Preparation.
Pada banyak bidang keilmuan, terutama komputer sains, diperlukan data
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 1. Data real world merupakan data kotor. Data
real world bisa mengandung data yang tidak, terdapat noise, tidak konsisten, yang dikarenakan:
a. Tidak lengkap (incomplete), yaitu kekurangan nilai atribut atau hanya
mengandung agregat data (contoh : address = " ")
b. Noise, yaitu masih mengandung error dan outliers.
c. Tidak konsisten (inconsistent), yaitu data yang mengandung discrepansi dalam code dan nama atau singkatnya datanya tidak konsisten. 2. Sistem mining dengan performa tinggi
membutuhkan data yang berkualitas. Data preparation atau preparation menghasilkan dataset yang lebih sedikit daripada dataset yang asli, ini bias meningkatkan efisiensi dari data mining. Langkah ini mengandung:
a. Memilih data yang relevan b. Mengurangi data
3. Data yang berkualitas menghasilkan pola yang berkualitas. Dengan data preparation, maka data yang dihasilkan adalah data yang berkualitas, yang mengarah pada pola yang berkualitas pula, dengan:
a. Mengembalikan data yang tidak lengkap b. Membenarkan eror, atau menghilangkan outliers
c. Membenahi data yang bertentangan.
B. Association Rules
Association rule merupakan salah satu metode yang bertujuan mencari pola yang sering muncul di antara banyak transaksi, dimana setiap transaksi terdiri dari beberapa item sehingga metode ini akan mendukung system rekomendasi melalui penemuan pola antar item dalam transaksi-transaksi yang terjadi
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap :
1. Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut:
2. Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A _B Nilai confidence dari aturan A _B diperoleh dari rumus berikut:
C. Frequent Itemset
Langkah pertama pada association rule adalah menghasilkan semua itemset yang memungkinkan dengan kemungkinan itemset yang muncul dengan m-item adalah 2m. Karena besarnya komputasi untuk menghitung frequent itemset, yang membandingkan setiap kandidat itemset dengan setiap transaksi, maka ada beberapa pendekatan untuk mengurangi komputasi tersebut, salah satunya dengan algoritma apriori.
D. Apriori
Algoritma apriori digunakan untuk mencari frequent itemset yang memenuhi minsup kemudian mendapatkan rule yang memenuhi minconf dari frequent itemset tadi. Algoritma ini mengontrol berkembangnya kandidat itemset dari hasil frequent itemset dengan support-based pruning untuk menghilangkan itemset yang tidak menarik dengan menetapkan minsup. Prinsip dari apriori ini adalah bila itemset digolongkan sebagai frequent itemset, yang memiliki support lebih dari yang ditetapkan sebelumnya, maka semua subsetnya juga termasuk golongan frequent itemset, dan sebaliknya.
E. Rule Generation
Setelah mendapatkan frequent itemset menggunakan algoritma apriori, langkah selanjutnya adalah mendapatkan rule yang memenuhi confidence. Karena rule yang dihasilkan berasal dari frequent itemset, dengan kata lain, dalam menghitung rule menggunakan confidence, tidak perlu lagi menghitung support-nya karena semua calon rules yang dihasilkan telah memenuhi minsup sesuai yang ditentukan. Penghitungan ini juga tidak perlu melakukan perulangan scanning pada database untuk menghitung confidence, cukup dengan mengambil itemset dari hasil support.
1.5.Algoritma Apriori
Algoritma apriori yaitu langkah yang membutuhkan pemrosesan lebih adalah frequent itemset berdasarkan sifat frequent itemset yaitu setiap subset frequent itemset harus menjadi frequent itemset (Dana Sulistiyo Kusumo, et al. 2003).
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 148 dari k-itemset dari frequent itemset pada langkah
sebelumnya dan menghitung nilai support k-itemset tersebut. Itemset yang memiliki nilai support di bawah dari minsup akan dihapus. Algortima berhenti ketika tidak ada lagi frequent itemset baru yang dihasilkan.
Kedua, dari hasil frequent itemset tersebut, langkah selanjutnya dihitung minconf mengikuti rumus sesuai yang telah ditentukan. Support tidak perlu dilihat lagi, karena generate frequent itemset didapatkan dari melihat minsup-nya. Bila rule yang didapatkan memenuhi batasan yang ditentukan dan batasan itu tinggi, maka rule tersebut tergolong strong rules.
Prinsip algoritma apriori terbagi dalam beberapa tahap (Leo Wilyanto Santoso, 2003)
1. Kumpulkan jumlah item tunggal, dapatkan item besar
2. Dapatkan candidate pairs, hitung => large paris dari item-item
3. Dapatkan candidate triplets, hitung => large triplets dari item-item seterusnya.
4. Sebagai petunjuk : setiap subset dari sebuah frequent itemsets harus menjadi frequent. Contoh dari penerapan algoritma apriori adalah diilustrasikan digambar berikut:
Gambar 1 : Ilustrasi Algoritma Apriori
Gambar 1menunjukkan bahwa algoritma akan menghasilkan kandidat baru dari 1-itemset dari frequent itemset dan menghitung nilai support 1-itemset tersebut. Selanjutnya masuk ke 2-1-itemset dan dihitung lagi support 2-itemset. Kemudian Itemset yang memiliki nilai support di bawah dari minsup akan dihapus. Algortima berhenti jika tidak ada lagi frequent itemset baru yang dihasilkan dan menetapkan minimum support nya = 3.
3. Analisa Dan Pembahasan 3.1. Analisa
Data administrasi Reskrim pada Polseka Medan Sunggal sudah menggunakan komputerisasi. Salah satu output adalah data kejahatan jalanan (Street Crime). Untuk mencapai tujuan yang
diinginkan di dalam penelitian ini, maka data tersebut di export ke dalam bentuk Microsoft excel.
Data mining digunakan pada data kejahatan jalanan (street crime) adalah untuk mengekstrak ilmu pengetahuan seperti mengetahui tingkat kejahatan jalanan khususnya pada Polsekta Medan Sunggal, untuk mengetahui jenis kejahatan apa yang sering muncul secara bersamaan, untuk mengetahui modus kejahatan apa saja yang banyak dilakukan dan menghasilkan rules antar jenis item yang berkombinasi.
Data mining ialah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Dalam data mining ada beberapa teknik menganalisis data, salah satunya adalah dengan algoritma apriori. Algoritma apriori adalah algoritma untuk menemukan frekuensi dan kombinasi frekuensi itemsets yang dijalankan pada sekumpulan data, sedangkan teknik untuk menemukan hubungan antara satu item dengan item yang lain, dan antara pola kombinasi itemsest yang satu dengan pola kombinasi itemsets yang lain disebut association rules.
3.2. Pembahasan
Proses pembentukan pola kombinasi itemsets dan pembuatan rules dimulai dari analisis data. Data yang digunakan adalah data kejahatan jalanan, kemudian dilanjutkan dengan pembentukan pola kombinasi itemsets dan dari pola kombinasi itemsets yang menarik terbentuk association rules.
3.3. Analisis Data
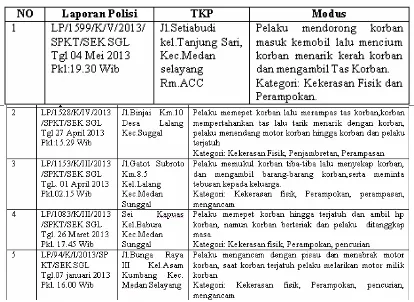
Dengan studi kasus pada Polsekta Medan Sunggal, dapat dilakukan analisa terhadap data kejahatan jalanan dengan salah satu tujuan adalah untuk menemukan pola kombinasi dan hubungan antar item jenis kejahatan. Berikut ini adalah tabel 1 yaitu beberapa data yang akan dijadikan sampel untuk analisis dan juga untuk pengujian.
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 3.4. Data Tabular Kejahatan Jalanan
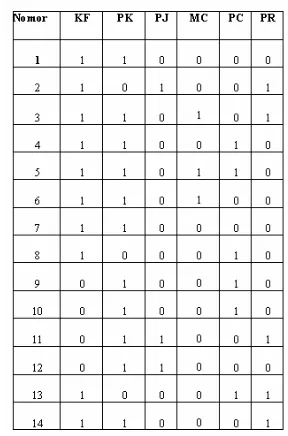
Untuk melakukan pengujian, menggunakan salah satu database Microsoft Excel dalam bentuk tabular yang dikonversi ke dalam bentuk biner, yaitu format data dalam bentuk 1 dan 0. Hasil proses konversi data kejahatan ke format data dalam bentuk biner adalah seperti pada tabel 2berikut ini:
Tabel 2 Data Dalam Bentuk Tabular Data
Untuk mempermudah dalam melakukan pengujian data maka tabel real data kejahatan jalanan dibuat dalam bentuk kode atau tabel alias untuk menerangkan atribute yang digunakan sehingga data bisa lebih dimengerti.
Tabel 3 Tabel Alias Data Kejahatan jalanan
Data table 3adalah bentuk transaksi data real terdiri atas attribute nomor, laporan polisi, tkp dan modus dalam bentuk kode atau tabel alias
3.5. Analisa Pola Frekuensi Tinggi
Untuk mencari pola kombinasi terlebih dulu dicari semua nama jenis item kejahatan yang ada seperti pada seperti pada tabel diatas sekaligus menentukan support per item jenis kejahatan, di mana tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database, nilai support sebuah item diperoleh dengan rumus 1 sebagai berikut:
Support (KF) = %
%
Tabel berikut merupakan tabel semua jenis item seperti pada tabel 4 berikut ini:
Tabel 4 : Keterangan Jenis Items Kejahatan Kejalanan
Data di atas menggambar bentuk data satu item, yang terdiri atas attribute item sebagai nama item jenis semua yang ada, support yaitu jumlah setiap item yang
ada di semua data, sedangkan support (%) adalah presentasi jumlah item yang ada di dalam data kejahatan, yang didapat dari jumlah item dibagi jumlah semua transaksi dikali seratus persen. Tabel berikut adalah item data yang memenuhi support minimal, nilai support minimal sama dengan 20 persen (%). Seperti yang terlihat pada tabel 5 berikut ini:
Tabel 5: Jenis Items Kejahatan jalanan yang Memenuhi Support Minimal
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 150 3.6. Pembentukan Pola Kombinasi Dua Itemsets
Pembentukan pola frekuensi dua itemsets, dibentuk dari items-items jenis yang memenuhi support minimal yaitu dengan cara mengkombinasi semua item kedalam pola dua kombinasi, hasil pembentukan pola kombinasi dua itemsets yang dibentuk dari tabel 5 adalah seperti pada tabel 4 berikut ini:
Tabel 6 : Pola Kombinasi Dua Itemsets
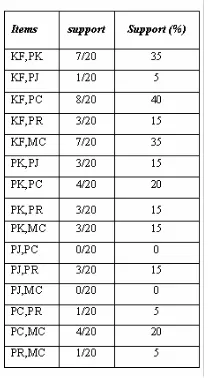
Data tabel 6 merupakan kombinasi dua itemsets yang merupakan hasil dari semua kombinasi semua jenis items. Dengan menetapkan support minimal sama dengan 20 persen (%), maka data yang memenuhi support minimal adalah seperti pada tabel 7 berikut ini:
Tabel 7 : Pola Kombinasi Dua Itemsets yang Memenuhi Support Minimal
Data table 7 adalah pola kombinasi dua itemsets yang memenuhi support minimal, terlihat data kombinasi jenis kejahatan KF dan PK, KF dan PC, KF dan PR, KF dan MC, PK dan PC, PK dan PR, PC dan MC memiliki support yang terbanyak, itu menandakan bahwa pola kombinasi dua itemsets tersebut paling banyak di dalam transaksi data.
3.7. Pembentukan Pola Kombinasi Tiga Itemsets Pembentukan pola kombinasi tiga itemsets dibentuk dari pola kombinasi dua itemsets yang memenuhi support minimal. Pembentukan kombinasi tiga itemsets dibentuk dengan dasar kombinasi dua itemsets, kemudian dikombinasikan dengan salah satu item dari pola kombinasi dua itemsets yang lain, dengan ketentuan bahwa pola kombinasi item tersebut ada di dalam kombinasi dua
itemsets yang memenuhi suppor minimal. Hasil pembentukan pola kombinasi tiga itemsets yang dibentuk dari tabel 6 adalah seperti pada tabel 7 berikut ini:
Tabel 7 : Pola Kombinasi Tiga Itemsets
Data tabel 7 merupakan pola hasil kombinasi tiga itemsets yang dibentuk dari kombinasi itemsets dua. Dengan support minimal sama dengan 20 persen(%), maka data yang memenuhi support minimal seperti pada tabel 8 berikut ini:
Tabel 8 : Pola Tiga Itemsets yang memenuhi support minimal
Itemsets Support Support (%)
KF,PC,MC 4/20 20
Data tabel 8 diatas merupakan hasil pola kombinasi tiga items yang dibentuk dari pola kombinasi dua itemsets, data terlihat hanya memiliki satu pola kombinasi item. Berhubung karena pola kombinasi lima itemsets hanya satu pola kombinasi itemsets maka pembentukan pola kombinasi itemsets berikutnya tidak akan terbentuk.
3.8. Pembentukan Association Rules
Setelah semua pola frekuensi tinggi ditemukan, baru dicari association rules yang memenuhi syarat minimum confidence, dengan menghitung confidence aturan asosiasi A ke B.
Untuk melihat kuat tidaknya aturan asosiasi adalah membandingkannya dengan nilai benchmark, dimana diasumsikan kejadian item dari consequent dalam suatu transaksi adalah independent dengan kejadian dari antecedent dari suatu aturan asosiasi. Nilai estimasi dari confidence benchmark dihitung dari data suatu aturan dengan rumus 4 , seperti berikut:
database dalam transaksi Jumlah
Consequent dalam
items transaksi Jumlah
benchmark Confidence
_ _ _
_ _ _ _
_ =
Confidence_benchmark = % Lift rasio adalah perbandingan antara confidence untuk suatu aturan dibagi dengan confidence, dimana diasumsikan consequent dan antecedent saling independent. Rumus untuk mendapat lift sebagai berikut:
Confidence benchmark
Confidence Lift
_ =
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule Jika nilai lift rasio lebih besar dari pada 1
menunjukkan adanya manfaat dari aturan tersebut. Lebih tinggi nilai lift rasio, lebih besar kekuatan asosiasi. Dari tabel yaitu tabel pola kombinasi dua itemsets, dapat dilihat besarnya nilai support dan confidence dari calon association rules seperti tampak pada tabel 9 berikut ini:
Tabel 9 Calon Association Rules
Tabel 4.8 merupakan tabel calon association rules dari kombinasi dua itemsets, tabel diatas terdiri atas rules dari pola kombinasi dua items, lift sebagai yang tingkat kekuatan rules atas kejadian acak dari antecedent dan consequent berdasarkan support masing-masing, support (itemsets) sebagai nilai support antara itemsets yang berkombinasi, support sebagai nilai support item yang mengandung antecedent. Dengan menetapkan nilai confidence minimal adalah 40 persen (%), maka rules interesting yang dihasilkan adalah seperti pada tabel 10 berikut ini:
Tabel 10 : Association Rules yang Memenuhi Confidence Minimal
Association rules menunjukkan bahwa setiap kejahatan jalanan yang dilakukan baik itu perampokan, penjambretan, pencurian dan perampasan maka juga akan melakukan kekerasan fisik dan mengancam. Dari hasil tabel diatas juga dapat dijadikan satu ilmu pengetahuan baru atau informasi kejahatan jalanan apa yang sering
dilakukan. Informasi tersebut dapat dijadikan acuan bagi pihak kepolisian dan masyarakat sehingga dapat mengatasi tingkat kriminalitas dalam meningkatkan keamanan dan sensitifitas kejahatan jalanan (Street Crime).
4. Implementasi Dan Pengujian 4.1 Implementasi
Langkah-langkah implementasi proses algoritma apriori pada aplikasi Tanagra merupakan tahap penerapan software tanagra untuk dioperasikan.
4.2 . Data Tabular Kejahatan Jalanan
Aplikasi yang digunakan dalam pengujian adalah aplikasi yang menggunakan salah satu database Microsoft Exel dengan data dalam bentuk tabular data, maka data kejahatan jalanan, dikonversi ke dalam bentuk biner. Format tabular data adalah format data dalam bentuk 1 dan 0 atau format data dalam bentuk biner. Hasil proses konversi data kejahatan ke format data dalam bentuk tabular data adalah seperti pada lampiran B
4.3. Pengujian
Untuk membuktikan data-data yang telah dihasilkan berupa pola hubungan kombinasi antar items dan rules-rules asosiasi sesuai dengan algoritma apriori maka perlu dilakukan pengujian dengan menggunakan aplikasi. Aplikasi yang digunakan adalah Tanagra versi 1.4.48 sebagai berikut :
Gambar 1 : Tampilan Utama Tanagra
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 152
Gambar 2 : Pemilihan Datasheet
Gambar 2 menjelaskan untuk membuat atau mengambil database pada textbox datasheet diketik nama datasheet yang akan kita gunakan untuk pengujian software.
4.4. Pengujian Untuk Menghasilkan Pola Kombinasi Itemsets
Pada Aplikasi Tanagra pengujian yang pertama dilakukan adalah menghitung frekuensi items atau frequent itemsets. Untuk menghasilkan pola kombinasi itemsets yaitu dengan cara klik menu icon define status dan masukkan komponen frequent itemsets dan masukkan parameters nya, kemudian execute, pilih view untuk melihat hasilnya.
Gambar 3 : Jendela Frequent Itemset
Gambar 3 diatas menunjukkan dengan paremeters adalah minimal support sama dengan 20 persen (%), maksimal support sama dengan 100 persen (%), minimal length sama dengan satu, maksimal length sama dengan dua, dan itemset type sama dengan frequent. Seperti pada gambar 4 berikut ini:
Gambar 4 : Penetapan Parameter
Tabel 11 di bawah ini adalah hasil dari pola kombinasi itemset yang dihasilkan dengan minimum support sebesar 20%.
Tabel 11 :Jenis Items yang Memenuhi Support Minimal 20%
Items support Support (%)
KF-PC 28/100 28
KF-PK 34/100 34
PK-PC 39/100 39
Setelah dilakukan pengujian dengan penentuan nilai parameters, maka dihasilkan jenis item dan pola kombinasi dua items seperti pada gambar 5 berikut ini:
Gambar 5 : Hasil Pengujian Dengan Satu Item dan Pola Kombinasi Dua Itemsets
Gambar 5 : yaitu tampilan pengujian dengan untuk menghasilkan jenis item dan pola kombinasi dua itemset. Ada dua attribute yang digunakan, yaitu Description dan Support. Description menggambarkan jenis items dan bentuk pola kombinasi dua items, Sedangkan support adalah nilai presentasi banyak jumlah jenis items, dan jumlah presentasi banyak items dan pola kombinasi dua items di dalam data.
4.5. Pengujian Untuk Menghasilkan Rules
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule dilakukan selanjutnya adalah pengujian untuk
menghasilkan rules-rules, di mana rules-rules tersebut terbentuk dari pola kombinasi items pada pengujian sebelumnya.
4.6. Hasil Pengujian pertama
Pengujian yang dilakukan pertama adalah pengujian untuk menghasilkan rules-rules yang terbentuk dari pola kombinasi dua items dan penentuan parameter dari Apriori. Jendela Parameter Association rules adalah seperti pada gambar 6 : berikut:
Gambar 6 : Jendela Association Rules Paremeters Gambar 5.6 menunjukkan paremeters yang harus di isi adalah support sama dengan 20 persen (%), Confidence sama dengan 45 persen (%), maksimal card itemsets sama dengan enam. Association rules yang memenuhi syarat minimum confidence, dengan menghitung confidence aturan asosiasi A ke B terlihat pada tabel 12 dibawah ini:
Tabel 12 : Calon Association Rules dari tabel 11
Setelah dilakukan pengujian dengan penentuan nilai parameters, maka rules-rules yang dihasilkan dari parameters di atas adalah seperti pada gambar 7 berikut ini:
Gambar 7 : Pengujian Dengan Rules Dari Pola Kombinasi Dua Itemset
Hasil pengujian gambar 7 di atas menggunakan 100 data kejahatan untuk menghasil rules dari pola kombinasi dua items yang
menghasilkan maximum confidence 65% yaitu PC dan PK. Rules di atas terdiri atas Antecedent, consequent, lift, support(%), Confidence. Jumlah rule yang dihasilkan dari pengujian di atas adalah sebanyak 6 rules.
4.7. Hasil Pengujian kedua
Pengujian kedua dilakukan dengan menetapkan minimum support 30% dan Maximum confidence sebesar 50% maka rules yang dihasilkan adalah seperti pada tabel 13 dibawah ini
Tabel 13 Calon Association Rules dari tabel
Dengan merubah nilai minimum Support dan minimum confidence menjadi lebih tinggi dan dari pengujian rule yang dihasilkan menjadi lebih sedikit yaitu 3 rules seperti terlihat pada gambar 8 dibawah ini
Gambar 8 Hasil Pengujian kedua Dengan Rules Gambar 8 diatas merupakan hasil dari pengujian dengan meningkatkan minimal support dan confidence dari 100 data kejahatan jalanan dan menghasilkan 3 rules itu artinya jumlah rules yang dihasilkan akan lebih sedikit apabila minimum support dan confidence nya di naikkan.
4.8. Hasil Pengujian ketiga
Pengujian ketiga digunakan untuk menghasilkan rules dari kombinasi 2 item dimana parameter adalah minimum support 35% confidence 55% sedangkan lift rasio nya adalah 0 maka rules yang dihasilkan sebagai berikut:
Tabel 14 : Calon Association Rules dari tabel
Data Mining Untuk Analisa Tingkat Kejahatan Jalanan Dengan Algoritma Association Rule 154 Gambar 9 : Hasil Pengujian ketiga
Dengan Rules
Gambar 9 : diatas menunjukkan rules dari hasil pengujian yang dilakukan dengan minimum support dan minimum confidence lebih besar maka rules yang dihasilkan semakin sedikit yaitu 2 rules.
5. Kesimpulan Dan Saran 5.1 Kesimpulan
Berdasarkan penelitian dan pembahasan yang dilakukan, maka dapat disimpulkan beberapa hal sebagai berikut :
1. Data mining adalah proses menemukan pola-pola didalam data, dimana proses penemuan tersebut dilakukan secara otomatis atau semi otomatis dan pola-pola yang ditemukan harus bermanfaat sebagai ilmu pengetahuan yang baru dan informasi penting dari data kejahatan jalanan (Street Crime) bagi kepolisian dan masyarakat dalam menanggulangi tingkat kejahatan jalanan dan sensitifitas kejahatan. 2. Program Tanagra 1.4.48 adalah salah satu tools
Data Mining yang mampu menangani persoalan mengeksplorasi data dengan size yang sangat besar yang dapat menghasilkan pola kombinasi itemsets dan rules.
3. Hasil dari perancangan data mining dengan algoritma apriori ini diperoleh informasi yang dibutuhkan oleh pihak kepolisian berupa prosentase yang digunakan oleh bagian reskrim untuk mengetahui kejahatan jalanan apa yang sering terjadi sehingga persoalan tingkat kejahatan jalanan dapat di minimalisasi.
4. Kelemahan data mining dengan algoritma apriori yaitu harus melakukan scan database setiap kali iterasi, sehingga dalam pencarian pola kombinasi itemset dan rule yang interesting membutuhkan waktu yang lama.
5.2 Saran
Untuk perkembangan lebih lanjut dari penulisan tesis ini maka penulis memberikan beberapa saran sebagai berikut :
1. Agar hasil dari pengujian dapat lebih dikembangkan yaitu dengan menambah jumlah data dan penentuan tingkat support dan confidence yang lebih bervariasi sehingga menghasilkan asosiasi antara data yang lebih banyak dan menghasilkan Knowledge (pengetahuan baru) dan informasi penting untuk
dapat dimanfaatkan dalam menanggulangi tingkat kejahatan jalanan.
2. Dari kelemahan data mining dengan algoritma apriori yaitu membutuhkan waktu yang lama maka perlu pengembangan dari algoritma apriori untuk menemukan pola hubungan (asosiasi) antar item dari suatu data yang besar.
6. Daftar Pustaka
[1] Beta Noranita dan Nurdin Bahtiar (2010). Implementasi Data Mining Untuk Menemukan Pola Hubungan Tingkat Kelulusan Mahasiswa Denga Data Induk Mahasiswa.
[2] Budi Santosa (2007). Data Mining, Teknik Pemanfaatan Data Untuk Keperluan Bisnis. Yogyakarta. Penerbit Graha Ilmu.10.
[3] Eko Prasetyo (2012). Data Mining Konsep Dan Aplikasi Menggunakan Matlab. Yogyakarta.Penerbit Andi.1
[4] Eko Wahyu Tyas D (2008). Penerapan Metode Association Rules Menggunakan Algoritma Apriori Untuk Analisa Pola Data Hasil Tangkapan Ikan.
[5] Feri Sulianto dan Dominikus Juju (2010). Data Mining, Meramalkan Bisnis Perusahaan. Jakarta. Penerbit Elex Media Komputindo.19-22.
[6] Kusrini dan Emha Taufig Luthfi (2009). Algoritma Data Mining. Yogyakarta. Penerbit Andi.3-12.
[7] Leo Wilyanto Santoso (2003). Pembuatan Perangkat Lunak Data Mining Untuk Penggalian Kaidah Asosiasi Menggunakan Metode Apriori
[8] Makaampoh (2013). Kedudukan Dan Tugas Polri Untuk Memberantas Aksi Premanisme Serta Kaitannya Dengan Tindak Pidana Kekerasan Dalam KUHP
[9] Nugroho Wandi. et all (2012). Pengembangan Sistem Rekomendasi Penelusuran Buku dengan Pengendalian Association Rule Menggunakan Algoritma Apriori (Studi Kasus Badan Perpustakaan dan Kearsipan Provinsi Jawa Timur)
[10] Padmaja dan Poongodai (2011). Mining Weighted Association Rules
[11] Prasad dan Malik, (2011). Using Association Rule Mining for Extracting Product Sales Patterns in Retail Store Transactions.
[12] Sani Susanto dan Dedy Suryadi (2010). Pengantar Data Mining. Yogyakarta. Penerbit Andi.97.
[13] Subekti Mujiasih (2011). Pemanfatan Data Mining Untuk Prakiraan Cuaca