BAB 2
LANDAS AN TEORI
Pada bab ini akan dibahas mengenai teori-teori yang mendukung dalam perancangan aplikasi pengenalan karakter Korea pada Android. Hal-hal yang dibahas mengenai struktur karakter Korea, Computer Vision, Optical Character Recognition (OCR), Tesseract OCR open source engine, image processing, Android, Sqlite, dan Unicode,.
2.1 Pengenalan Karakter Korea
Lee, Ramsey (2000, p13) menyatakan “The Korean writing system is a true alphabet, with a symbol available for each consonant and vocal in the languge”.
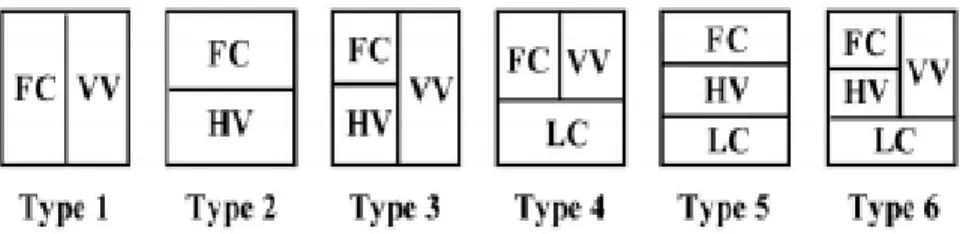
Bahasa Korea yang juga disebut sebagai Hangeul terdiri dari unsur vokal dan konsonan yang direpresentasikan dengan simbol-simbol. Tetapi masing-masing unsur vokal dan konsonan tidak dapat berdiri sendiri, karena untuk membentuk satu kata yang memiliki arti diperlukan beberapa simbol seperti halnya bahasa Indonesia yang membutuhkan beberapa huruf untuk membentuk satu kata. Setiap karakter Korea pada dasarnya dibentuk dari dua, tiga atau empat simbol yang merupakan gabungan dari unsur vokal dan konsonan (Sofyan, 2010, h3; Yeung, Kwok, Fred, Roli, Ridder, 2006, p432) yang diatur pada ruang dua dimensi (Yeung et al., 2006; Jung, Kim, 2000). Pada Gambar 2.1 berikut ini menunjukkan struktur karakter Korea (Jung et al, 2000).
Gambar 2.1 Enam Jenis Aturan Komposisi Grafem Bahasa Korea
Gambar 2.2 Grafem Bahasa Korea
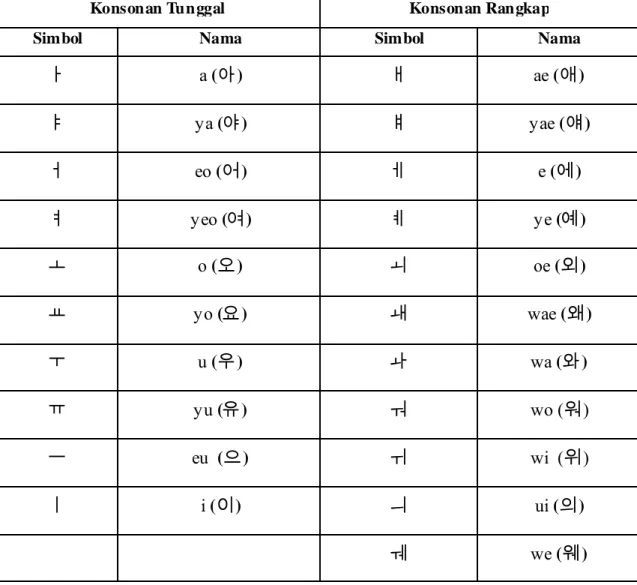
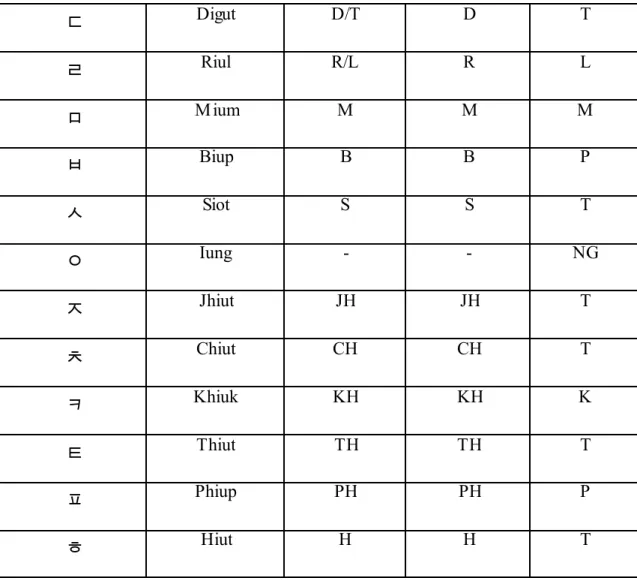
Komponen huruf Korea terdiri dari 14 konsonan tunggal, 10 vokal tunggal, 5 konsonan rangkap, 11 vokal rangkap, 7 bunyi konsonan akhir, dan 11 konsonan akhir kompleks (Putra, 2011). Karakter yang dapat dibentuk dari penggabungan keseluruhan konsonan dan vokal ada sebanyak 11.728 karakter (Yeung et al., 2006). Namun pada prakteknya hanya sekitar 2.350 karakter yang digunakan dan secara umum hanya 520 karakter yang sering digunakan (Yeung et al., 2006). Untuk simbol-simbol konsonan dan vokal disajikan dalam Tabel 2.1, Tabel 2.2, dan Tabel 2.3.
Tabel 2.1 Daftar Vokal Tunggal dan Rangkap dalam Bahasa Korea
Tabel 2.2 Daftar Konsonan Tunggal dalam Bahasa Korea
Simbol Nama Pengucapan
Awal Tengah/Akhir Bawah
ㄱ Giuk G/K G K
ㄴ Niun N N N
Konsonan Tunggal Konsonan Rangkap
Simbol Nama Simbol Nama
ㅏ a (아) ㅐ ae (애) ㅑ ya (야) ㅒ yae (얘) ㅓ eo (어) ㅔ e (에) ㅕ yeo (여) ㅖ ye (예) ㅗ o (오) ㅚ oe (외) ㅛ yo (요) ㅙ wae (왜) ㅜ u (우) ㅘ wa (와) ㅠ yu (유) ㅝ wo (워) ㅡ eu (으) ㅟ wi (위) ㅣ i (이) ㅢ ui (의) ㅞ we (웨)
ㄷ Digut D/T D T ㄹ Riul R/L R L ㅁ M ium M M M ㅂ Biup B B P ㅅ Siot S S T ㅇ Iung - - NG ㅈ Jhiut JH JH T ㅊ Chiut CH CH T ㅋ Khiuk KH KH K ㅌ Thiut TH TH T ㅍ Phiup PH PH P ㅎ Hiut H H T
Tabel 2.3 Daftar Konsonan Rangkap dalam Bahasa Korea
Simbol Nama Pengucapan
Awal Tengah/Akhir Bawah
ㄲ Ssangkiuk K K K
ㄸ Ssangdigut T T -
ㅆ Ssangbiup P P -
ㅉ Ssangjhiut C C -
Dalam penulisan bahasa Korea hampir mirip dengan bahasa Indonesia. Penulisan bahasa Indonesia merupakan gabungan huruf vokal dan konsonan dalam bentuk alfabet, pada penulisan bahasa Korea juga menggabungkan vokal dan konsonan yang direpresentasikan dengan simbol-simbol. Pada penulisan huruf vokal, baik vokal tunggal maupun rangkap setiap simbol vokal ditambahkan dengan simbol ㅇ(ieung). Simbol ini
berbunyi “ng” seperti pada kata “uang”, namun pada penulisan huruf vokal bunyi “ng” tidak dibacakan. Untuk membentuk karakter “a” diperlukan dua simbol “ㅇ” (ieung) dan
“ㅏ” (a) yang bila digabungkan akan membentuk karakter “아” yang dibaca “a” seperti
dalam bahasa Indonesia. Pada penulisan huruf konsonan tidak perlu ditambahkan dengan simbol “ㅇ” (ieung).
Pada penggabungan huruf vokal dan konsonan, posisi “ㅇ” (ieung) ini yang
digantikan oleh huruf konsonan (Sofyan, 2010, h2) jika huruf konsonan mendahului huruf vokal seperti pada kata “da”. Untuk membentuk kata “da” perlu menggabungkan konsonan “ㄷ” dan vokal “아” sehingga menjadi “다”. Pada kata “da” konsonan “ㄷ”
menggantikan posisi ieung pada vokal “아”. Namun, jika huruf vokal mendahului
(ieung) tetapi diletakkan dibawah simbol vokal. Untuk membentuk kata “il” diperlukan vokal “이” dan konsonan “ㄹ“ menjadi “일”. Pada kata “일”, posisi simbol simbol ”ㄹ”
berada di bawah karakter “이“. Seperti halnya penggabungan tiga simbol seperti kata
“sam”. Pada kata “sam”, simbol “s” menggantikan posisi “ㅇ” (ieung) pada simbol “a”
sedangkan simbol “m” diletakkan dibawah hasil penggabungan simbol “s” dan “a” sehingga terbentuklah kata “sam”.
2.2 Computer Vision
Computer Vision merupakan salah satu cabang ilmu pengetahuan dalam teknik informatika yang mempelajari bagaimana komputer dapat menganalisis dan mengenali objek yang diamati (Apristandi, 2010). Seperti halnya penglihatan manusia, Computer Vision diharapkan dapat mengekstrak informasi dari objek yang dilihat untuk melakukan tugas tertentu.
Pengenalan karakter optik atau OCR dalam skripsi ini merupakan bagian dari Computer Vision. Dalam OCR, komputer diminta untuk melihat teks yang terdapat pada gambar, kemudian mendeskripsikan objek yang dilihat tersebut sebagai objek keluaran atau output yang berupa teks. Untuk mempermudah penglihatan komputer terhadap objek yang terdapat pada gambar dan mendeskripsikan objek yang dilihat, Computer Vision mengkombinasikan pengolahan gambar dan pengenalan pola. Pengolahan gambar bertujuan untuk menghasilkan kualitas gambar yang baik agar pola objek yang terdapat pada gambar lebih mudah dikenali. Pengolahan gambar dan pengenalan pola (dalam hal ini karakter) akan dijelaskan pada subbab berikutnya.
2.3 Optical Character Recognition (OCR)
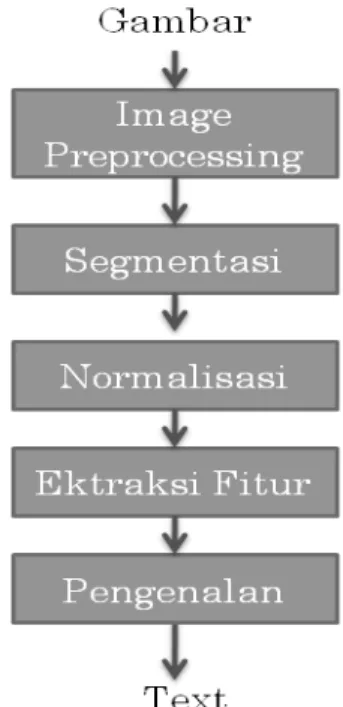
Optical Character Recognition (OCR) merupakan suatu proses mengkonversi scanned image ke dalam suatu editable text (Somers, 2003). Scanned image yang dimaksudkan di sini yaitu gambar/image yang dimasukkan ke dalam komputer melalui sebuah alat scanner maupun hasil pemotretan melalui kamera. Gambar/image ini berisi karakter-karakter, teks, atau simbol yang akan diproses oleh komputer, dikenali dan kemudian dikonversikan ke kode-kode karakter seperti ASCII maupun unicode lainnya seperti UTF-8. Setelah pengkonversian ini, karakter-karakter dalam image tersebut bukan lagi berbentuk image yang tidak dapat di-edit, namun sebaliknya telah menjadi teks yang dapat di-edit, disalin dan digunakan untuk keperluan apapun, salah satunya yaitu untuk diterjemahkan ke bahasa lain. Gambar 2.3 menjelaskan proses umum yang dilakukan oleh OCR.
Dalam sistem OCR, input yang dimasukkan adalah gambar yang berisi karakter yang ingin dikenali. Sebelum karakter pada gambar dapat dikenali, gambar tersebut harus terlebih dahulu dilakukan preprocessing. Tujuan dari proses ini ialah menghilangkan bagian-bagian dari gambar yang tidak diinginkan (bukan bagian dari karakter yang ingin dikenali) dan untuk memperbaiki kualitas gambar sehingga objek pada gambar lebih mudah untuk dikenali. Preprocessing pada gambar biasanya meliputi grayscaling, noise removal, dan thresholding. Grayscaling merupakan tahap awal dalam image preprocessing, yaitu mengubah gambar berwarna menjadi gambar yang hanya memiliki derajat keabuan saja. Selanjutnya dilakukan proses noise filtering, yaitu proses meredukti atau mengurangi noise. Proses akhir dari image preprocessing adalah thresholding, yaitu suatu proses untuk memisahkan background dengan objek yang ingin diamati dengan mengubah gambar menjadi hitam putih.
Setelah preprocessing selesai dilakukan, maka tahap selanjutnya ialah segmentasi. Proses ini digunakan untuk memisahkan area-area pengamatan dari setiap karakter yang ingin dikenali, seperti pemisahan kalimat ke dalam kata-kata dan pemisahan kata ke dalam karakter-karakter. Tahap selanjutnya ialah normalisasi karakter hasil segmentasi, yaitu proses untuk mengubah dimensi region dari setiap karakter, seperti ketebalan karakter. Hal yang biasa dilakukan untuk proses normalisasi pada OCR adalah scaling dan thinning. Setelah normalisasi dilakukan, kemudian akan dilakukan ektraksi fitur untuk mendapatkan karakteristik dari masing-masing karakter yang membedakannya dengan karakter lain. Tahap akhir dari proses OCR adalah pengenalan atau recognising, dalam tahap ini algoritma akan membandingkan ciri-ciri fitur yang
ingin dikenali dengan data yang tersimpan sebelumnya. Hasil pengenalan berupa teks dengan kemiripan paling besar antara fitur karakter yang ingin dikenali dengan informasi yang tersimpan.
2.4 Tesseract OCR Engine
Tesseract merupakan sebuah mesin Optical Character Recognition (OCR) open source yang dapat digunakan oleh berbagai sistem operasi. M esin OCR ini awalnya dikembangkan di Hewlett-Packard (HP) antara tahun 1984 dan 1994 (Smith, 2007) . Kemudian pada tahun 2005, Tesseract OCR direlease menjadi open source oleh HP dan UNLV. Pengembangan Tesseract OCR disponsori oleh Google sejak tahun 2006 dan direlease di bawah lisensi Apache versi 2.0.
2.4.1 Arsitektur
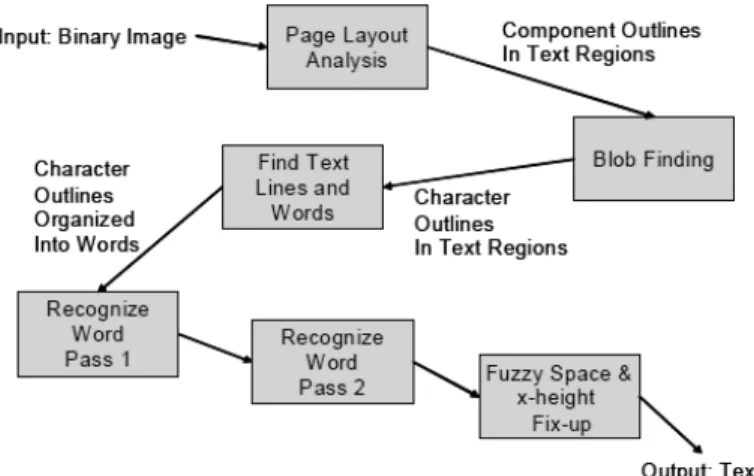
Tesseract OCR mengasumsikan input yang diterima berupa sebuah binary image. Pertama, analisis dilakukan pada komponen terhubung/Connected Component (CC) untuk menemukan di mana outline komponen disimpan. Pada tahap ini outlines dikumpulkan bersama menjadi blob. Blob disusun menjadi baris teks, sedangkan garis dan region dianalisis untuk pitch tetap dan teks proporsional. Baris teks dipecah menjadi kata-kata berbeda menurut jenis spasi karakter. Teks dengan pitch tetap dibagi menjadi sel-sel karakter. Teks proporsional dipecah menjadi kata-kata dengan menggunakan ruang pasti dan ruang fuzzy. Pengenalan kata pada image dilakukan pada dua tahap proses yang disebut pass-two (Smith, 2007). Pada pass pertama dilakukan untuk mengenali masing-masing kata pada gilirannya. Kata-kata yang sukses pada pass pertama yaitu kata-kata yang terdapat di kamus dan tidak ambigu kemudian diteruskan
ke classifier adaptif sebagai data pelatihan. Begitu classifier adaptif memiliki sampel yang cukup, classifier adaptif ini dapat memberikan hasil klasifikasi bahkan pada pass pertama. Proses pass kedua dilakukan untuk mengenali kata-kata yang mungkin saja kurang dikenali atau terlewatkan pada pass pertama, pada tahap ini classifier adaptif telah memperoleh informasi lebih dari pass pertama. Tahap terakhir menyelesaikan ruang fuzzy dan memeriksa hipotesis alternatif pada ketinggian-x untuk mencari teks dengan smallcap.
Gambar 2.4 Arsitektur Tesseract OCR
Gambar 2.4 merupakan blok diagram komponen-komponen dasar Tesseract. Tesseract dirancang untuk mengenali teks putih di atas latar hitam dan teks hitam di atas latar putih. Hal ini menyebabkan rancangan mengarah pada analisis komponen terhubung/connected component (CC) dan operasi pada outline komponen. Langkah pertama setelah analisis CC ialah menemukan blob pada region teks. Sebuah blob merupakan unit putatif yang dapat diklasifikasikan, yang mana bisa satu atau lebih komponen-komponen yang saling tumpang tindih secara horizontal. Dalam bahasa
Inggris, terdapat beberapa karakter (misalnya © dan ®) yang memiliki lebih dari 2 level outline.
Setelah memutuskan outline mana yang membentuk blob, pencari baris teks mendeteksi (hanya horizontal) baris teks berdasarkan karakter-karakter yang berdekatan saling tumpang tindih secara vertikal pada sebuah baris teks. Setelah menemukan baris teks, pendeteksi fixed-pitch memeriksa fixed pitch layout karakter, dan menjalankan satu dari dua algoritma segmentasi yang berbeda berdasarkan keputusan fixed pitch. Sebagian besar proses pengenalan berjalan pada setiap kata secara independen, diikuti tahap resolusi fuzzy-space akhir, di mana ruang tidak pasti diputuskan.
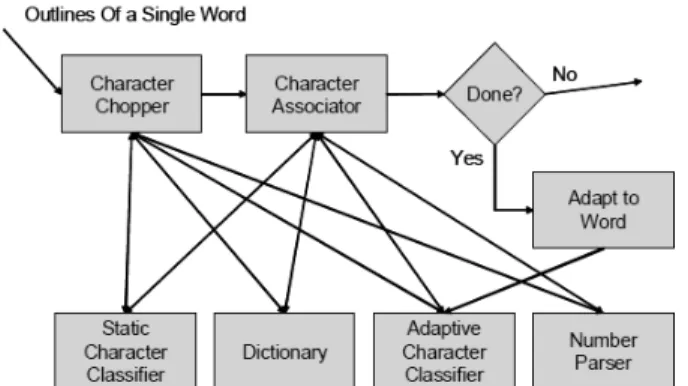
Gambar 2.5 Blok Diagram Pengenalan Kata Tesseract
M enurut Smith (2007) ada beberapa langkah yang dilakukan oleh Tesseract untuk pengenalan karakter adalah sebagai berikut :
2.4.2 Pencarian Teks-Line dan Kata
Algoritma line finding dirancang supaya halaman yang miring dapat dikenali tanpa harus de-skew (proses untuk mengubah halaman yang miring menjadi tegak lurus)
sehingga tidak menurunkan kualitas gambar (Smith, 2007). Kunci proses dari algoritma ini adalah blob filtering dan line construction (konstruksi baris).
Algoritma pencarian text-line bekerja secara independen untuk setiap region teks dari analisis layout dan dimulai dengan mencari ketetanggan dari CC kecil (relatif terhadap perkiraan ukuran huruf) untuk menemukan body-text-sized CC terdekat. Jika tidak ada yang dekat dengan body-text-sized CC, maka CC kecil ini akan dianggap sebagai noise dan dibuang (pengecualian harus dilakukan untuk titik-titik/garis putus-putus yang biasanya ditemukan pada daftar isi). Jika tidak, sebuah bounding box yang berisi CC kecil dan neighbor yang lebih besar dibangun dan digunakan di bounding box CC kecil pada projeksi selanjutnya.
Sebuah profil projeksi horizontal dibangun, paralel terhadap kemiringan horizontal yang diperkirakan, dari bounding box CC menggunakan boxes yang sudah dimodifikasi untuk CC kecil. Algoritma dynamic programming kemudian memilih set terbaik dari titik-titik segmentasi pada profil projeksi. Setelah garis-garis potong telah ditentukan, seluruh CC ditempatkan pada text-line untuk CC yang saling tumpang tindih secara vertikal.
Setelah baris teks diekstrak, blob pada garis disusun menjadi unit-unit pengenalan. Untuk bahasa latin, unit pengenalan berkorespondensi dengan kata-kata yang dipisahkan oleh spasi, yang secara alami cocok untuk model bahasa yang berdasarkan kamus. Untuk bahasa yang tidak dipisahkan oleh spasi, seperti Chinese, Jepang dan Korea (CJK), simbol-simbol pada CJK dianggap sebagai satu unit pengenalan. Namun, mengingat simbol-simbol CJK dibentuk dari beberapa radikal, akan lebih sulit untuk mendapatkan segmentasi karakter yang benar tanpa bantuan
pengenalan. M engingat jumlah informasi yang terbatas yang tersedia pada tahap awal proses, solusinya ialah memecah ururan blob pada tanda baca yang dapat dideteksi cukup handal berdasarkan ukuran dan spasi terhadap blob selanjutnya. Walaupun hal ini tidak sepenuhnya menyelesaikan masalah untuk urutan blob yang sangat panjang, namun merupakan faktor penting dalam menentukan kualitas dan efisiensi ketika melakukan pencarian terhadap graf segmentasi, paling tidak ini akan mereduksi panjang dari unit-unit pengenalan ke dalam ukuran yang lebih bisa dikelola.
2.4.3 Baseline Fitting
Setelah text-line ditemukan, baseline (garis pangkal) dicocokan secara lebih tepat menggunakan sebuah quadratic spline. Hal ini merupakan salah satu kelebihan Tesseract sehingga Tesseract dapat menangani halaman dengan garis pangkal (baseline) yang miring. Baseline dicocokan dengan partisi blob ke dalam group dengan suatu perpindahan kontinu untuk baseline lurus. Sebuah Quadratic spline dicookan pada partisi yang paling padat (diasumsikan sebagai baseline). Quadratic spline memiliki kelebihan karena perhitungan yang stabil, namun kelemahannya adalah diskonitinuitas dapat muncul pada saat beberapa segmen spline diperlukan. Dalam hal ini, cubic spline yang lebih tradisional dapat bekerja lebih baik.
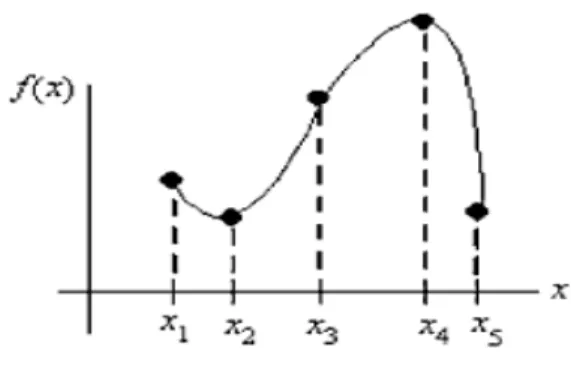
M enurut Cohen (2011), interpolasi quadratic spline dibangun dengan menuliskan fungsi sebagai sebuah polinomial orde kedua diantara kumpulan tiga titik yang berurutan, secara matematis dapat dideskripsikan sebagai:
2 2
)
(x = kx + kx+ k xk ≤x≤xk+
f α β γ (2.1)
Sebuah quadratic spline dibangun dengan mencocokan f(x) terhadap sebuah section parabolic pada tiga titik consecutive. Konstan αk,βk,dan γkditentukan dari nilai
) (xk
f , )f(xk+1 , dan f(xk+2)secara berturut-turut.
Gambar 2.7 Interpolasi Quadratic Spline
2.4.4 Perkiraan Ketinggian-x Teks
Setelah menemukan baris teks dan menyusun blok blob menjadi baris-baris, Tesseract mengestimasi ketinggian-x untuk setiap baris teks. Pertama, algoritma estimasi x menentukan batas-batas maksimum dan minimum dari ketinggian-x yang dapat diterima berdasarkan ukuruan garis inisial yang dihitung untuk blok. Kemudian, setiap baris secara terpisah, ketinggian bounding box blob terjadi pada garis dikuantisasi dan dikumpulkan menjadi sebuah histogram. Dari histogram ini, algoritma pencarian ketinggian-x mencari ketinggian dua mode yang paling sering terjadi yang
cukup jauh terpisah untuk menjadi ketinggian-x dan ketinggian-ascender. Untuk mengantisipasi noise, algoritma memastikan mode ketinggian yang diambil menjadi ketinggian-x dan ketinggian-ascender memiliki jumlah yang cukup atau kejadian-kejadian relatif terhadap jumlah keseluruhan blob pada baris.
2.4.5 Pengenalan Karakter dan Kata
Bagian dari proses pengenalan untuk mesin pengenalan karakter apapun ialah untuk mengidentifikasi bagaimana sebuah kata atau karakter sebaiknya disegmentasi menjadi karakter atau simbol-simbol. Output segmentasi awal dari pencarian baris diklasifikasikan. Sisa langkah pengenalan kata hanya dilakukan pada teks yang non-fixed-pitch.
1. Pemisahan Karakter Terhubung
Apabila hasil dari pengenalan kata tidak memuaskan, Tesseract berusaha untuk memperbaiki hasil dengan memisahkan blob dengan keyakinan terburuk dari classifier karakter (Smith, 2007). Kandidat untuk titik-titik pemisahan ditemukan dari simpul cekung dari pendekatan poligonal outline dan mungkin saja terdapat titik cekung berlawanan lainnya atau segmen garis. Ini akan menghabiskan sampai 3 pasang titik pemotongan untuk memisahkan karakter yang terhubung dari set ASCII.
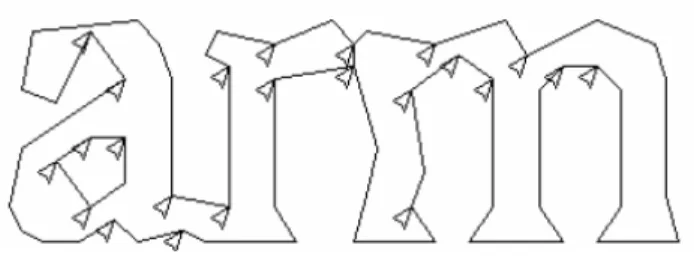
Gambar 2.8 Kandidat Titik Pemotongan
Gambar 2.8 menunjukkan kumpulan kandidat titik pemisahan dengan panah dan pemotongan terpilih sebagai sebuah garis melewati outline di mana huruf ‘r’ menyentuh huruf ‘m’. Pemotongan dilakukan sesuai dengan urutan prioritas. Setiap pemotongan yang gagal memperbaiki hasil keyakinan dibatalkan, namun tidak sepenuhnya dibuang sehingga pemotongan dapat digunakan kembali oleh asosiator jika dibutuhkan.
2. Asosiasi Karakter Patah
Pada tahap pemisahan karakter terhubung tidak menghasilkan karakter atau kata yang cukup bagus, kemudian dilanjutkan ke asosiator. Asosiator ini membuat pencarian A* (best first search) dari graf segmentasi untuk kemungkinan kombinasi dari maksimal pemisahan blob menjadi karakter kandidat. Hal itu dilakukan tanpa secara nyata membangun graf segmentasi, melainkan membangun tabel hash dari state yang dikunjungi. Hasil pencarian A* dengan menarik kandidat state baru dari antrian prioritas dan mengevaluasi kandidat dengan mengklasifikasikan kombinasi fragmen yang belum terklasifikasi.
Gambar 2.9 Karakter Terputus yang dapat dikenali dengan baik
Segmentasi pencarian A* pertama kali diimplementasikan sekitar pada tahun 1989. Dengan algoritma pencarian A* ini, Tesseract dengan mudah mengenali karakter patah seperti pada Gambar 2.9.
3. Klafisikasi Bentuk
a. Static Classifier
Versi awal Tesseract menggunakan feature topologikal yang dikembangkan dari karya Shillman. Kemudian ide selanjutnya melibatkan penggunaan segmen dari pendekatan poligonal sebagai feature, namun pendekatan ini tidak terlalu kuat untuk karakter yang rusak. Solusi terobosan yang digunakan adalah feature yang tidak ketahui tidak perlu sama dengan feature yang terdapat data training.
Selama pelatihan, segmen dari pendekatan poligonal digunakan untuk feature, namun pada proses pengenalan, feature kecil yang panjangnya tetap (dalam unit ternormalisasi) diekstraksi dari outline dan dicocokan secara many-to-one terhadap prototipe feature yang ter-cluster pada data pelatihan.
b. Adaptive Classifier
Tesseract tidak menggunakan template classifier, tetapi menggunakan feature yang sama seperti static classifier. Perbedaan yang signifikan antara static
classifier dan adaptiver classifier, terlepas dari data pelatihan, adaptive classifier menggunakan normalisasi isotropic baseline/x-height, sedangkan static classifier menormalisasi karakter oleh centroid (momen pertama) untuk posisi dan momen kedua untuk normalisasi ukuran yang anisotropic.
Classifier bentuk Tesseract bekerja sangat baik pada 5000 karakter Chinese tanpa memerlukan modifikasi besar, sehingga cocok untuk ukuran kelas besar. Feature merupakan komponen pendekatan poligonal dari outline sebuah bentuk. Pada training, vektor fitur 4 dimensi (x,posisi-y, arah, panjang) diturunkan dari setiap elemen pendekatan poligonal dan dikelompokkan untuk membentuk prototipikal vektor fitur. Pada pengenalan, elemen-elemen poligon dipecah menjadi bagian-bagian yang lebih pendek dengan panjang yang sama, sehingga dimensi panjang dieliminasi dari vektor fitur. Beberapa fitur pendek dicocokkan dengan setiap fitur prototipikal dari training, hal ini membuat proses klasifikasi lebih kuat terhadap karakter yang terputus.
(a) (b)
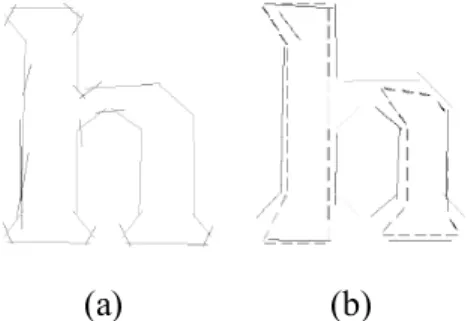
Gambar 2.10 (a) Prototipe huruf h untuk font Times New Roman (b) Pencocokan huruf h yang terputus terhadap prototipe
Gambar 2.10 (a) menujukkan sebuah contoh prototipe dari huruf ‘h’ untuk huruf Time New Roman. Segmen garis warna hijau merepresentasikan cluster dari cluster
signifikan yang berisi sampel hampir dari setiap sampel huruf ‘h’ pada Times New Roman. Segmen biru merupakan cluster yang digabung dengan cluster lainnya untuk membentuk cluster signifikan. Segmen magenta tidak digunakan karena cocok dengan cluster signifikan yang ada. Segmen merah tidak mengandung cukup sampel untuk signifikan dan tidak dapat digabung dengan cluster tetangga manapun untuk membentuk cluster signifikan.
Gambar 2.10 (b) menunjukkan bagaimana fitur lebih pendek yang tidak diketahui dicocokkan terhadap prototipe untuk mencapai intensitas dari karakter yang rusak. Garis pendek tebal merupakn fitur yang tidak diketahui, menjadi ‘h’ yang rusak dan garis yang lebih panjang merupakan fitur prototipe. Warna merepresentasikan kualitas pencocokan : hitam > bagus, magenta > lumayan, cyan > buruk, dan kuning -> tidak cocok. Prototipe vertikal semua memiliki kecocokan yang baik, meskipun fakta bahwa ‘h’ rusak.
Klasifikasi bentuk beroperasi dalam dua tahap. Tahap pertama, disebut class pruner yang mereduksi karakter set menjadi list pendek dari 1-10 karakter, menggunakan metode yang erat kaitannya dengan Locality Sensitive Hashing (LSH). Tahap terakhir menghitung jarak yang tidak diketahui dari prototipe karakter dalam list pendek.
Pada tabel hash terdapat tabel look-up sederhana yang mengembalikan sebuah vektor bilangan bulat dalam range [0,3], satu dari setiap kelas dalam karakter set, dengan nilai yang mewakili perkiraan kebaikan perbandingan suatu fitur terhadap prototipe dari karakter set. Hasil vektor dijumlahkan untuk seluruh fitur yang tidak
diketahui, dan kelas-kelas yang memiliki nilai total dalam pecahan tertinggi dikembalikan sebagai list yang akan diklasifikasikan oleh tahap kedua.
Tahap classifier kedua menghitung jarak df dari setiap fitur dari prototipe terdekat dari fitur tersebut, sebagai jarak d euclid berpangkat dari koordinat (x,y) fitur dari garis prototipe dalam ruang 2-D, ditambah dengan weight (w) perbedaan sudut θ dari prototipe : 2 2 θ w d df = + (2.2)
Pada dasarnya ialah sebuah classifier generatif, artinya classifier menghitung jarak dari ideal. Jarak fitur dikonversikan ke evidence fitur Ef menggunakan persamaan berikut :
2 1 1 f kd Ef + = (2.3)
Konstan k digunakan untuk mengendalikan rate di mana evidence meluruh dengan jarak. Sebagai fitur-fitur yang cocok dengan prototipe, evidence fitur Ef disalin ke prototipe Ep. Jumlah dari evidence prototipe dan fitur dapat berbeda dikarenakan prototipe memperkirakan ada beberapa fitur yang akan dicocokkan dan kumpulan “paling cocok” dilakukan secara independen. Jumlah evidence prototipe dinormalisasi dengan jumlah fitur dan jumlah panjang prototipe Lp, dan hasilnya dikonversikan kembali menjadi jarak :
∑
∑
∑
+ + − = p p f p p f f final L N E E d 1 (2.4) 4. Contextual Post-PreprocessingProces training Tesseract mendukung sebagian perluasan model bahasa dengan menyediakan suatu cara menghasilkan kamus untuk bahasa baru dari daftar kata. Untuk kekompakan dan pencarian yang cepat, kamus ini diwakili oleh directed acyclic word graphs (DAWGs). Pada implementasi, data struktur DAWG digunakan secara sekuensial mencari beberapa kamus termasuk sistem kamus pre-generated, kamus dokumen (secara dinamis dikontruksi dari kata-kata pada dokumen yang dilakukan OCR) dan daftar kata yang disediakan oleh user sendiri.
Pada mulanya setiap edge pada DAWG menyimpan karakter 8-bit untuk mewakili huruf atau karakter yang digunakan untuk transisi huruf yang sesuai dalam DAWG. Struktur data DAWG kemudian dimodifikasi untuk menyimpan ID unicharset yang digunakan oleh classifier karakter sehingga dapat digunakan oleh bahasa dengan karakter multi-byte termasuk bahasa Korea sendiri. Hal ini secara signifikan menyederhanakan proses konstruksi dan pencarian DAWG, selain itu pencarian dapat dilakukan secara paralel untuk keseluruhan DAWG yang ada. Untuk menemukan string yang diberikan merupakan kata yang valid dalam kamus, pencarian dimulai dengan inisial set dari DAWG yang “aktif”. Karena setiap huruf dalam kata dianggap, set ini direduksi menjadi hanya berisi sebagian string yang “diterima”. Pada akhir proses, set dari “aktif” DAWG berisi DAWG yang berisi kata.
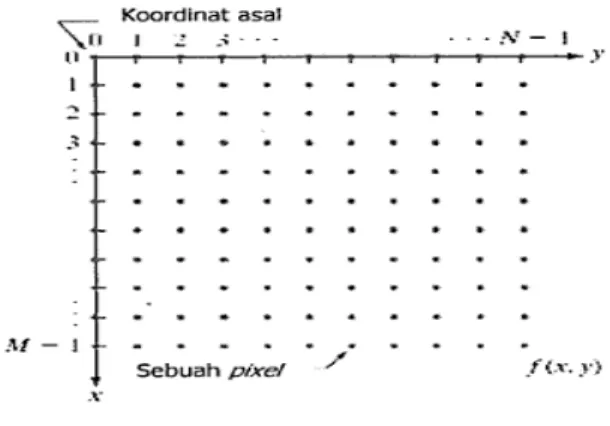
2.5 Citra Digital
Digital image atau citra digital menurut Putra (2010) didefinisikan sebagai sebuah fungsi f(x,y) berukuran M baris dan N kolom dengan koordinat spasial x,y dan amplitudo f di titik koordinat (x,y) di mana nilai x,y dan nilai amplitudo f secara
keseluruhan berhingga (finite) dan bernilai diskrit. Amplitudo f pada titik koordinat (x,y) merupakan tingkat intensitas atau tingkat keabuan image pada titik tersebut.
Gambar 2.11 Koordinat Citra Digital
Citra digital yang tingginya N, lebarnya M , dan memiliki L derajat keabuan dapat dianggap sebagai fungsi :
∞ ≤ ≤ ( , ) 0 f x y (2.5) ) , ( ). , ( ) , (x y i x y r x y f = (2.6) ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ ≤ ≤ ≤ ≤ ≤ ≤ M x N y L f y x f 0 0 0 ) , ( (2.7) Dimana :
i(x,y) = jumlah cahaya yang masuk dari sumbernya r(x,y) = derajat kemampuan objek untuk memantulkan M = jumlah kolom
L = derajat keabuan
Citra digital yang berukuran N x M umumnya dinyatakan dengan matriks berukuran N baris dan M kolom, dan masing-masing elemen matriks pada citra digital disebut pixel (picture element). ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − = ) 1 , 0 ( ) 1 , 0 ( ) 0 , 0 ( ) 1 , 1 ( ) 1 , 1 ( ) 0 , 1 ( ) 1 , 0 ( ) 1 , 1 ( ) 1 , 1 ( ) 0 , 1 ( ) , ( N f f f N f f f N f N M f M f M f y x f L L M M L Gambar 2.12 M atriks Citra Digital
2.6 Image Processing
Preprocessing atau praproses merupakan tahapan awal yang dilakukan terhadap image sebelum dilakukan segmentasi terhadap karakter yang ingin dikenali. Untuk menghasilkan image yang dapat diproses oleh Tesseract OCR engine dan supaya karakter-karakter Korea dalam image dapat dikenali dengan sebaik mungkin, perlu dilakukan beberapa tahapan. Tahapan preprocessing yang dilakukan dalam skripsi ini meliputi : pengkonversian gambar berwarna RGB menjadi grayscale, penghalusan image, dan thresholding.
2.6.1 Pengkonversian Gambar RGB menjadi Gambar Grayscale
Gambar berwarna RGB merupakan sebuah gambar multi-spectral dengan satu band atau pita untuk setiap warna red, green, dan blue, sehingga menghasilkan
kombinasi berbobot tiga warna utama untuk setiap pixel (Fisher, Perkins, Walker, Erik Wolfart, 2003).
Pengkonversian gambar berwarna menjadi grayscale perlu dilakukan agar lebih mudah untuk menghilangkan noise pada gambar. Grayscale image merupakan gambar digital yang hanya memiliki satu nilai kanal pada setiap pixel-nya dengan kedalaman warna 8 bit (Putra, 2010).
Pada awalnya gambar terdiri dari 3 layer matriks yaitu R-layer, G-layer dan B-layer. Ketiga layer tersebut akan diubah menjadi 1 layer matriks grayscale dan hasilnya adalah gambar grayscale. Untuk mengubah gambar berwarna yang mempunyai nilai matriks masing-masing r, g dan b menjadi gambar grayscale dengan nilai gs, maka konversi dapat dilakukan dengan persamaan berikut (CzachÓrski, Kozielski, Stańczyk, 2011, p191).
b g
r
gs=0.299* +0.587* +0.114* (2.8) Dengan format warna gray ini maka dihasilkan RED = GREEN = BLUE, nilai ini digunakan untuk menunjukkan tingkat intensitas. Sehingga warna yang dimiliki pada jenis gambar ini adalah hitam, keabuan dan putih.
Gambar 2.13 (a) Gambar asli sebelum konversi ke gambar grayscale (b) Gambar sesudah konversi ke grayscale
2.6.2 Penghalusan Gambar
Setelah mengubah gambar berwarna menjadi gambar grayscale yang hanya memiliki derajat keabuan saja, selanjutnya dilakukan penghalusan image/gambar. Penghalusan dalam hal ini adalah menghilangkan/mereduksi noise (Aryan, 2007) yang muncul pada saat gambar diambil baik dengan scanner maupun kamera. Banyak teknik filter yang bisa dilakukan berkaitan dengan hal ini seperti, Median Filter, Weighted Median, Center Weighted Median, Switching Median Filter, Gaussian Smoothing, dan Mean Filter.
Pada skripsi ini akan digunakan Gaussian Smoothing atau dikenal juga dengan Gaussian Blur.
Gaussian Smoothing
Operator Gaussian Smoothing merupakan sebuah operator konvolusi 2 dimensi yang digunakan untuk mem-blur gambar dan menghilangkan detail serta noise (Fisher et al, 2003). Hal ini dapat digunakan dalam image processing untuk mengimplementasikan operator-operator yang memiliki output nilai pixel yang merupakan kombinasi linear sederhana dari nilai input pixel tertentu. Dalam konteks image processing, salah satu dari array biasanya merupakan sebuah gambar grayscale.
Gaussian Smoothing mirip dengan mean filter, namun menggunakan kernel yang berbeda yang mewakili bentuk dari sebuah punuk (bentuk lonceng) Gaussian. Kernel ini memiliki beberapa sifat khusus seperti di bawah ini.
Distribusi Gaussian pada 1-D mempunyai bentuk :
e
x x G σ πσ 2 2 2 2 1 ) ( = − (2.9)di mana σmerupakan parameter standar deviasi dari distribusi. Parameter σ mengatur lebar dari blur kernel (Rocholl, 2009). Di sini diasumsikan distribusi ini memiliki rata-rata 0 ( misalnya pada pusat garis x=0 ). Ilustrasi distribusi ini ditunjukkan oleh Gambar 2.14.
Gambar 2.14 Distrubusi Gaussian 1-D dengan rata-rata 0 dan σ =1
Sedangkan dalam 2-D, distribusi Gaussian memiliki bentuk :
e
y x y x G σ πσ 2 2 2 2 2 1 ) , ( = − + (2.10)Ilustrasi distibrusi ini ditunjukkan oleh Gambar 2.5
Gambar 2.15 Distrubusi Gaussian 2-D dengan rata-rata (0,0) dan σ =1.0
Ide dasar dari Gaussian smoothing adalah menggunakan distribusi 2-D sebagai fungsi ‘titik penyebaran’ yang dicapai dengan konvolusi. Karena gambar digital disimpan sebagai kumpulan pixel diskrit, perlu dilakukan pendekatan diskrit untuk fungsi Gaussian sebelum dilakukan konvolusi. Gambar 2.16 menunjukkan kernel konvolusi bilangan bulat yang mendekati Gaussian dengan standar deviasi σ =1.0.
Gambar 2.16 Pendekatan Diskrit Fungsi Gaussian dengan σ =1.0
Setelah kernel yang sesuai dihitung, kemudian Gaussian smoothing dapat dilakukan menggunakan metode konvolusi standar (Fisher et al, 2003). Konvolusi sebenarnya dapat dilakukan dengan cukup cepat karena persamaan isotropik Gaussian 2-D pada persamaan (2.10) dipisahkan menjadi komponen x dan y.
2.6.3 Thresholding Gambar
Thresholding merupakan sebuah teknik untuk segmentasi gambar baik grayscale maupun gambar berwarna berdasarkan nilai warna pada gambar berwarna dan derajat keabuan pada gambar grayscale yang mengubah image menjadi sebuah binary image dengan mengubah masing-masing pixel menurut apakah nilai pixel tersebut di dalam atau di luar kisaran tertentu (Huang, Chau, 2008).
Kisaran tertentu yang dimaksudkan ialah nilai ambang batas (threshold). Thresholding mengatur semua pixel yang memiliki nilai intensitas di atas threshold (ambang batas) ke nilai foreground (latar depan) dengan warna putih 255 dan semua pixel yang tersisa ke nilai background/latar belakang dengan warna hitam 0 (Fisher et al, 2003). Gambar hasil thresholding digunakan untuk ekstraksi fitur dan proses pegenalan objek pada gambar.
Basic Global dan Local Thresholding
Global thresholding menggunakan threshold tetap untuk semua pixel dalam gambar dan karenanya bekerja hanya jika histogram intensitas dari gambar input berisi puncak rapi dipisahkan sesuai subjek yang diinginkan (Fisher et al, 2003). Oleh karena itu teknik ini tidak dapat digunakan pada gambar yang memiliki gradien iluminasi yang kuat. Namun jika dibandingkan dengan adaptive thresholding, waktu proses yang digunakan untuk global thresholding lebih cepat karena tidak seperti pada adaptive thresholding yang harus mencari nilai threshold berdasarkan ukuran neighborhood pada
setiap pixel. Semakin besar neigborhood yang digunakan, maka akan semakin lama proses untuk menentukan nilai threshold.
M enurut Huang dan Chau (2008), thresholding dapat dilihat sebagai sebuah operasi yang melibatkan pengujian terhadap fungsi T dari bentuk :
)] , ( ), , ( , , [x y p x y f x y T T = (2.11)
Dimana f (x, y) merupakan tingkat keabuan dari titik (x, y) dan p(x, y) menunjukkan beberapa sifat lokal titik tersebut, misalnya tingkat keabuan rata-rata dari lingkungan ketetanggaan (neighborhood). Bagian yang sebenarnya dari thresholding terdiri dari pengaturan nilai background untuk pixel yang di bawah sebuah nilai threshold dan set berbeda dari nilai-nilai untuk foreground. Sebuah gambar yang telah dilakukan threshold g(x, y) didefinisikan sebagai : ⎪ ⎩ ⎪ ⎨ ⎧ < = T y x f if otherwise y x g ) , ( 0 1 ) , ( (2.12)
Skema thresholding sederhana membandingkan setiap pixel level abu dengan sebuah threshold global tunggal. Ini yang disebut dengan Global Thresholding. Jika T bergantung pada f(x,y) dan p(x,y) maka disebut Local Thresholding. Algoritma yang digunakan untuk mendapatkan Threshold untuk global thresholding ialah :
1. Pilih estimasi awal untuk T.
2. Segmentasi gambar menggunakan T. Pada langkah ini akan menghasilkan dua grup pixel : G1 berisi semua pixel dengan nilai abu > T dan G2 berisi pixel-pixel dengan nilai < T.
3. Hitung rata-rata nilai level abu μ1dan μ2 untuk setiap pixel di region G1 dan G2.
4. Hitung threshold baru dengan nilai
[
1 2]
21 μ +μ =
T
5. Ulangi langkah 2 hingga 4 sampai perbedaan T pada iterasi yang berurutan lebih kecil dari parameter To yang telah ditetapkan pada langkah 1.
Salah satu contoh metode yang menggunakan global thresholding yaitu metode Otsu. M etode ini juga digunakan oleh Tesseract untuk binerisasi gambar. Tujuan dari metode ini ialah membagi histogram gambar gray level kedalam dua daerah yang berbeda secara otomatis tanpa membutuhkan bantuan user untuk memasukkan nilai ambang. Pendekatan yang dilakukan oleh metode otsu adalah dengan melakukan analisis diskriminan yaitu menentukan suatu variabel yang dapat membedakan antara dua atau lebih kelompok yang muncul secara alami. Analisis Diskriminan akan memaksimumkanvariable tersebut agar dapat membagi objeklatardepan (foreground) dan latarbelakang (background).
Nilai Ambang yang akan dicari dari suatu gambar gray level dinyatakan dengan k. Nilai k berkisar antara 1 sampai dengan L, dengan nilai L = 255. Probabilitas setiap pixel pada level ke i dapat dinyatakan:
N n
pi = i / (2.13)
dengan :
ni menyatakan jumlah pixel pada level ke i N menyatakan total jumlah pixel pada gambar.
Nilai Zeroth cumulative moment, First cumulative moment, dan total nilai mean berturut-turut dapat dinyatakan dengan rumus berikut.
∑
= = k i t p k 1 ) ( ω (2.14)∑
= = k i i p i k 1 . ) ( μ (2.15)∑
= = L i i p i T 1 . ) ( μ (2.16)Nilai ambang k dapat ditentukan dengan memaksimumkan persamaan : ) ( ) ( * 2 2
max
1 k k B B L k σ σ < ≤ = (2.17) dengan )] ( 1 )[ ( )] ( ) ( [ ) ( 2 2 k k k k k T B ω ω μ ω μ σ − − = (2.18)Berikut algoritma untuk mencari nilai threshold pada metode Otsu : 1. Hitung histogram dan probabilitas untuk setiap level intensitas 2. Tentukan nilai awal ωi(0) dan μi(0)
3. Lewati semua intensitas maksimum threshold yang mungkin a) Perbarui ωidan μi
b) Hitung
4. Sesuaikan ambang batas (threshold) yang diinginkan dengan maksimum 2(k) B σ
Gambar 2.17 (a) Gambar RGB (b) Gambar hasil thresholding dengan M etode
Otsu
2.7 Unicode
Proses analisis gambar masukan barupa huruf cetak karakter Korea akan menghasilkan kode, kode ini akan digunakan untuk melakukan pencarian pada box files Tesseract yang berisi data yang sudah ditraining sebelumnya untuk mendapatnya kode yang bersesuaian. Hasil pengenalan akan berupa kode yang dikenali oleh mesin. Komputer memberikan kode-kode untuk setiap karakter atau huruf yang dikenalinya. Kode ini mempunyai relasi satu terhadap satu karakter atau satu huruf berdasarkan character set yang digunakan. Unicode biasanya dalam bentuk hexadecimal yaitu antara 0 sampai 9 dan A sampai F.
Unicode merupakan character set paling lengkap diantara karakter set yang ada dan dapat mengatasi sistem multilingual seperti bahasa CJK yang merupakan karakter multi byte. Unicode standard telah banyak diadopsi luas oleh perbagai software sehingga pertukaran informasi semakin mudah tanpa harus mengubah informasi ke dalam bentuk lain karena hampir semua platform telah mendukung Unicode. Unicode sendiri terdiri
dari berbagai jenis yaitu UTF-8, UTF-16 dan UTF-32. Dalam perancangan aplikasi pengenalan karakter Hangeul Korea ini menggunakan UTF-8.
2.8 Android
Android merupakan sistem operasi open source untuk mobile berbasis Linux yang dikembangkan oleh Android Inc dan kemudian diakuisisi oleh Google (Enterprise, 2010). Sistem operasi yang open source ini sangat mempermudah para programmer dalam mengembangkan aplikasi Android. Salah satu keunggulan sistem operasi ini ialah banyaknya produk mobile yang mengadopsi sistem operasi ini seperti LG, Samsung, HTC dan lain sebagainya. Google sendiri selaku pemilik dari sistem operasi ini juga merilis ponsel dengan nama Google Nexus One. Fenomena tersebut membuat para konsumen memiliki pilihan dalam menggunakan ponsel yang berbasis sistem operasi Android.
Sistem operasi Android memiliki fitur-fitur yang dimiliki oleh smart phone dan berbagai aplikasi yang melimpah lainnya yang dapat di-download melalui Android Market.
Gambar 2.18 Arsitektur Sistem Operasi Android
Berikut penjelasan mengenai arsitektur Android mulai dari lapisan paling atas hingga lapisan paling bawah.
1. Application dan Widgets
Lapisan ini merupakan lapisan paling atas dari sistem operasi Android yang berinteraksi langsung dengan pengguna. Aplikasi-aplikasi Android berada di lapisan ini.
2. Application Framework
Application Framework mencakup kelas-kelas yang digunakan untuk menciptakan aplikasi Android. Lapisan ini membantu dalam pengaksesan perangkat keras dan mengelola sumber daya user interface dan aplikasi.
Android runtime merupakan mesin yang mendayai aplikasi dan bersama dengan libraries membentuk dasar dari kerangka kerja aplikasi. Android runtime mencakup Dalvik virtual machine dan core libraries.
a) Dalvik virtual machine
Dalvik merupakan mesin virtual berbasis register yang telah dioptimalkan sehingga perangkat dapat menjalankan beberapa aplikasi secara efisien. b) Core Libraries
Core libraries menyediakan sebagian besar fungsi yang ada pada core Java libraries dan libraries khusus Android lainnya.
4. Libraries (Native Labriaries)
Native libraries merupakan libraries yang ditulis dalam bahasa C/C++, di-compile untuk arsitektur perangkat keras yang digunakan oleh ponsel.
Beberapa contoh native libraries yang penting adalah
a) Surface Manager digunakan untuk mengatur hak akses pada subsistem tampilan dan menggabungkan lapisan grafis 2D dan 3D dari berbagai aplikasi.
b) Graphic libraries mencakup SGL dan OpenGL untuk grafik 2D dan 3D. c) Media libraries untuk pemutaran dan perekaman media audio dan video. 5. SQLite database engine untuk pengelolaan database.
6. Web Kit untuk web browser dan SSL untuk keamanan internet.
M enurut Haldar (2007), SQLite merupakan sebuah relational Database Management System (RDMS) berbasis SQL (Structured Query Language) yang memiliki karakteristik sebagai berikut.
1. Zero Configuration
Tidak ada instalasi terpisah atau pengaturan prosedur untuk inisialisasi SQLite sebelum digunakan. Source code SQLite dapat di-download kemudian di-compile dengan di-compiler C. Setelah itu library hasil kompilasi dapat digunakan. 2. Embeddable
Tidak perlu melakukan pemeliharan terhadap proses server terpisah yang didedikasikan untuk SQLite karena library tertanam dalam aplikasi.
3. Application Interface
SQLite menyediakan lingkungan SQL untuk aplikasi-aplikasi bahasa C guna untuk memanipulasi database.
4. Transcational Support
SQLite mendukung transaksi-transaksi inti, yaitu atomicity, consistency, isolation dan durability (ACID). SQLite tidak memerlukan tindakan pemulihan database dari database administrator untuk crash dan kegagalan sistem karena SQLite secara otomatis melakukan pemulihan atau recovery terhadap database secara transparan kepada user.
5. Thread Safe
SQLite merupakan thread-safe library, dan beberapa thread dalam proses aplikasi dapat mengakses secara bersamaan database yang sama atau berbeda. 6. Lightweight
SQLite memiliki ukuran yang kecil, yaitu hanya sekitar 250 KB, dan ukuran ini masih dapat diperkecil dengan menonaktifkan beberapa fitur-fitur lanjut pada saat kompilasi dari source code. SQLite beroperasi pada Linux, Windows, M ac OS X, OpenBSD dan beberapa sistem operasi lainnya.
7. Customizable
SQLite menyediakan framework yang bagus sehingga pengguna dapat mendefinisikan dan menggunakan fungsi-fungsi SQL dan fungsi aggregate. Selain itu, SQLite juga mendukung encoding standar UTF-8 dan UTF-16 untuk teks Unicode.
8. Cross-platform
SQLite memungkinkan pengguna memindahkan file dabatabase dari satu platform ke platform lainnya tanpa adanya perubahan karena database berperilaku sama untuk semua platform yang didukung oleh SQLite.
SQLite berbeda dari kebanyakan database SQL modern lainnya dalam arti bahwa tujuan utama desainnya harus sederhana. SQLite mudah dalam hal pemeliharaan, pengoperasian, penyesuaian (customizeable), pengelolaan dan penggunaan dalam bahasa C. Selain itu, SQLite juga menggunakan teknik sederhana untuk mengimplementasikan properti ACID.
SQLite mendukung subset besar fitur-fitur data manipulation dan data definition SQL-92, dan beberapa perintah-perintah khusus SQLite. Pengguna dapat membuat
table,, trigger, index, view menggunakan standar data definition SQL. Berikut ini merupakan fitur-fitur tambahan yang didukung oleh SQLite realase 3.6.6.
a. Dukungan parsial untuk ALTER TABLE (mengganti nama table dan menambah column)
b. Konstrain UNIQUE, NOT NULL, CHECK
c. Subquery, Subquery berkolerasi, INNER JOIN, OUTER JOIN, LEFT JOIN, NATURAL JOIN, UNION, UNION ALL, INSERSECT, EXCEPT
d. Perintah transaksional : BEGIN, COMMIT, ROLLBACK e. Perintah SQLite meliputi reindex, attach, detach, dan pragma.
Berikut ini merupakan fitur-fitur SQL-92 yang tidak didukung oleh SQLite release 3.6.6.
a. Konstrain foreign key
b. Beberapa fitur ALTER TABLE
c. Beberapa fitur yang berhubungan dengan TRIGGER d. RIGH dan FULL OUTER JOIN
e. M emperbarui VIEW f. GRANT dan REVOKE