4 BAB II LANDASAN TEORI
2.1 Aksara Lampung
Aksara Lampung sangat terpengaruh oleh Aksara Pallawa serta Huruf Arab[3].
Aksara Lampung memiliki beberapa bagian yaitu induk aksara, anak aksara serta tanda baca. Adapun induk aksara Lampung berjumlah 20. Induk aksara dan anak aksara Lampung ditunjukkan pada Gambar 2.1 berikut:
Gambar 2.1 Aksara Lampung[3]
2.2 Pengolahan Citra Digital
Pengolahan citra digital merupakan seluruh proses yang wajib dilalui untuk dapat mengidentifikasi citra digital tertentu. Pengolahan citra digital dimulai dari mengakuisisi citra digital sampai tahapan terakhir yaitu klasifikasi citra[6].
2.2.1 Akuisisi Data
Akuisisi data adalah tahap awal dalam proses pengolahan citra digital. Akuisisi data merupakan kegiatan untuk mengumpulkan dataset citra[7]. Pengumpulan dataset dapat dilakukan dengan berbagai cara seperti menggunakan kamera ataupun scanner. Citra yang diakuisisi dapat disimpan dalam format file seperti JPG ataupun PNG.
5 2.2.2 Preprocessing Citra
Preprocessing citra merupakan tahapan selanjutnya dalam pengolahan citra digital setelah data didapatkan pada tahap sebelumnya. Preprocessing citra melibatkan berbagai pemrosesan antara lain resizing citra, mengonversi citra menjadi citra grayscale dan binerisasi citra. Resizing merupakan proses mengubah ukuran baris dan kolom piksel citra[8]. Terdapat dua jenis resize yaitu memperbesar dan memperkecil ukuran citra.
Konversi citra grayscale merupakan proses mengubah nilai 3 kanal warna menjadi memiliki tingkat intensitas yang sama menjadi hanya memiliki satu nilai kanal piksel. Nilai intensitas yang dimiliki oleh citra grayscale 256 kombinasi warna.
Rentang nilai intensitas dimulai dari 0 – 255, semakin besar nilai intensitas semakin cerah warna yang dihasilkan[9]. Dalam mengonversi suatu citra untuk dijadikan citra grayscale digunakan persamaan berikut:
𝛾 = 0.2999𝑅 + 0.587𝐺 + 0.114𝐵 (2.1)
Binerisasi citra adalah proses mengubah citra menjadi citra biner atau citra yang memiliki dua buah nilai saja dengan representasi warna hitam dan warna putih.
Citra biner memudahkan dalam membedakan antara objek citra dengan latar citra.
Dalam mengonversi citra menjadi citra biner, salah satu metode yang digunakan adalah metode thresholding[6]. Metode ini dapat dilakukan dengan menggunakan grayscale dari citra yang dalam prosesnya memerlukan nilai threshold. Nilai intensitas grayscale citra jika kurang dari atau sama dengan nilai threshold maka nilai intensitas dikonversi menjadi 255 atau warna putih dan untuk nilai intensitas grayscale citra lebih besar dari nilai threshold dikonversi menjadi 0 atau warna hitam.
2.2.3 Ekstraksi Fitur Citra
Ekstraksi fitur citra adalah tahapan yang bertujuan memperoleh fitur unik yang dimiliki oleh citra tertentu. Fitur unik inilah yang akan menjadi dasar untuk tahap selanjutnya yaitu klasifikasi[10]. Ada beberapa metode untuk memperoleh fitur cita yaitu: bentuk, ukuran, warna, dan lain-lain.
6 2.2.4 Klasifikasi Citra
Klasifikasi citra merupakan proses akhir dalam pengolahan citra untuk membangun model identifikasi citra. Klasifikasi citra merupakan proses untuk mengelompokkan data berdasarkan fitur-fitur ciri tertentu hasil dari ekstraksi fitur kedalam kelas yang bersesuaian[11]. Ada beberapa algoritma untuk klasifikasi, antara lain K-Means, KNN, Decision Trees, SVM, dan lain-lain.
2.3 Freeman Chain Code
Freeman pertama kali memperkenalkan kode rantai untuk pengenalan bentuk objek citra pada tahun 1961 yang dikenal dengan nama Freeman Chain Code. Freeman chain code adalah representasi dari kontur citra dengan memakai prinsip delapan ketetanggaan [12]. Freeman Chain Code mampu untuk melakukan penelusuran piksel objek citra mengikuti searah atau melawan arah jarum jam dengan delapan arah mata angin. Berikut contoh representasi kontur dari objek citra pada Gambar 2.2:
Gambar 2.2 Representasi Freeman chain code[12]
Panjang hasil chain code dapat berbeda untuk setiap citra, faktor yang dapat mempengaruhi panjang chain code antara lain bentuk objek dan kontur dari citra yang digunakan. Memerlukan proses normalisasi untuk menyamakan panjang fitur untuk setiap citra yang akan diklasifikasi. Berikut persamaan yang dapat digunakan menormalisasikan panjang chain code.
7 𝑉 = 𝑉𝑖
∑7𝑖=1𝑉𝑖 (2.2)
Keterangan
i = kode arah 1,2,3,…..,7 Vi = Frekuensi kode arah ke-i
Hasil dari persamaan diatas ditampung dalam variabel V untuk membentuk fitur yang menjadi pembeda setiap citra.
2.4 Support Vektor Machine
Support Vector Machine (SVM) ditemukan Vapnik saat melakukan penelitian sekitar tahun 1963. SVM merupakan algoritma supervised machine learning yang bisa digunakan dalam permasalahan klasifikasi maupun regresi. Klasifikasi hampir mirip dengan regresi, yang membedakan adalah outputnya. Output klasifikasi adalah suatu objek pada himpunan sedangkan output regresi adalah nilai kontinu[13].
Adapun target dari SVM yaitu mendapatkan hyperplane terbaik yang kedua kelas pada data masukkan terpisah. Proses menemukan hyperplane dapat dilihat pada Gambar 2.3.
Gambar 2.3 Proses Menemukan Hyperplane[14]
Hyperplane terbaik untuk memisahkan antar kedua kelas didapatkan dengan cara mengukur margin. Margin adalah panjang antara objek terdekat dari kedua kelas.
Objek terdekat terdekat dari kelas inilah yang dikenal sebagai Support vector[14].
Hyperplane. Data yang ada dilambangkankan dengan 𝑥⃗𝑖 ∈ ℜ𝑑 untuk kelas
8
dilambangkankan 𝑦𝑖 ∈ {−1, +1} dimana i = 1,2,…,l dimana l merupakan jumlah data. Dimisalkan kedua kelas -1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d didefinisikan dengan:
𝑤⃗⃗⃗ 𝑥⃗ + 𝑏 = 0 (2.3)
Pola 𝑥⃗1 pada kelas -1 (negatif) dirumuskan dengan pola yang memenuhi pertidaksamaan
𝑤⃗⃗⃗ 𝑥⃗ + 𝑏 ≤ −1 (2.4)
untuk pola 𝑥⃗𝑖 pada kelas +1 (positif)
𝑤⃗⃗⃗ 𝑥⃗ + 𝑏 ≥ +1 (2.5)
Keterangan:
w = bobot vector x = nilai dari atribut b = bias
dari memaksimalkan panjang di antara hyperplane dengan titik paling dekat maka dapat ditemukan nilai margin terbesar yakni 1/‖𝑤⃗⃗⃗‖. Hal ini bisa dirumuskan sebagai Quadric Programming (QP) problem, yakni menemukan titik minimal persamaan (2.6), dengan melihat constraint pada persamaan (2.7).
min𝑤⃗⃗⃗ 𝜏(𝑤) =1
2‖𝑤⃗⃗⃗‖2 (2.6)
𝑦𝑖(𝑥⃗𝑖. 𝑤⃗⃗⃗ + 𝑏) − 1 ≥ 0, ∀𝑖 (2.7) Permasalahan ini bisa diselesaikan menggunakan Lagrange Multiplier.
𝐿(𝑤⃗⃗⃗, 𝑏, 𝛼) =1
2‖𝑤⃗⃗⃗‖2− ∑ 𝛼𝑖
𝑙
𝑖=1
(𝑦𝑖((𝑥⃗𝑖𝑤⃗⃗⃗ + 𝑏) − 1)) (2.8) 𝛼𝑖 merupakan Lagrange multipliers, yang bernilai nol atau positif (𝛼𝑖 ≥ 0). Nilai optimal dari persamaan (2.8) dihitung meminimalkan 𝐿 terhadap 𝑤⃗⃗⃗ dan 𝑏, dan memaksimalkan nilai 𝐿 terhadap 𝛼𝑖. Pada titik optimal gradient 𝐿 = 0, persamaan (2.8) ditransformasi untuk memaksimalisasi problem yang hanya memiliki 𝛼𝑖 saja.
9
∑ 𝛼𝑖 −1 2
𝑙
𝑖=1
∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝑥⃗𝑖𝑦⃗𝑗
𝑙
𝑖,𝑗=0
(2.9)
𝛼𝑖 ≥ 0 (𝑖 = 1,2, … . , 𝑙) ∑ 𝛼𝑖𝑦𝑖 = 0
𝑙
𝑖=0
Support vector adalah data yang berkolerasi dengan 𝛼𝑖 positif. Umumnya kedua kelas tidak dapat terpisah dengan sempurna. Hal tersebut mengakibatkan constraint pada persamaan 2.7 tidak dapat dipenuhi. Teknik soft margin bisa digunakan dalam memecahkan permasalahan tersebut dengan memasukkan slack variable pada persamaan 2.7.
𝑦𝑖(𝑥⃗𝑖. 𝑤⃗⃗⃗ + 𝑏) ≥ 1 − ξ𝑖, ∀𝑖 (2.10) Persamaan 2.6 dikonversi dengan:
min𝑤⃗⃗⃗ 𝜏(𝑤⃗⃗⃗ , ξ) =1
2‖𝑤⃗⃗⃗‖2+ 𝐶 ∑ ξ𝑖
𝑙
𝑖=0
(2.11) Parameter C digunakan mengendalikan tradeoff antar margin dengan error klasifikasi ξ. Nilai C yang lebih besar akan menghasilkan penalty yang lebih besar terhadap error klasifikasi. Permasalahan selanjutnya adalah data pada umumnya bersifat non-linear. Ketidakmampuan Support Vector Machine untuk memisahkan berbentuk non-linear menggunakan persamaan linear, sehingga formula SVM diubah melalui fungsi-non linear. Yang dilakukan ketika mendapatkan data yang tidak linear adalah pemetaan dimensi data menjadi lebih tinggi dinotasikan dengan:
𝜙: ℜ𝑑 → ℜ𝑞, (𝑑 < 𝑞)
10
Gambar 2.4 Pemetaan Data ke Ruang Vektor Berdimensi Lebih Tinggi Tahap traning di SVM untuk mendapatkan support vector hanya mengandalkan kepada dot product yaitu 𝜙(𝑥⃗𝑖). 𝜙(𝑥⃗𝑗). Sejalan dengan teori Mercer dot product bisa disubstitusi memakai fungsi kernel dengan persamaan berikut:
𝐾𝑥⃗𝑖𝑥⃗𝑗 = 𝜙(𝑥⃗𝑖). 𝜙(𝑥⃗𝑗) (2.12) Berikut merupakan beberapa jenis kernel yang umum digunakan untuk menyelesaikan permasalahan SVM[15][16]:
1) Linear
Kernel Linear adalah jenis kernel yang paling dasar. Kernel Linear digunakan pada data yang bersifat linear. Berikut adalah persamaan kernel Linear:
𝐾𝑥⃗𝑖𝑥⃗𝑗 = 𝑥⃗𝑖. 𝑥⃗𝑗 (2.13) 2) Polynomial
Kernel Polynomial digunakan saat data non-linear. Kernel Polynomial menggunakan dot product untuk transformasi data ke dimensi yang lebih tinggi.[15] Berikut adalah persamaan kernel Polynomial:
𝐾𝑥⃗𝑖𝑥⃗𝑗 = (𝑥⃗𝑖. 𝑥⃗𝑗 + 1)𝑑 (2.14) Semakin besar parameter nilai degree (d) dapat menyebabkan overfitting.
Overfitting adalah keadaan dimana model sulit untuk mengidentifikasi data testing baru atau berbeda dari data training yang berakibat dapat mengurangi tingkat akurasi[17].
11 3) Radial Basis Function (RBF)
Kernel RBF digunakan saat data non-linear. Kernel RBF mentransformasi data ke dalam dimensi dengan jumlah tidak terbatas[15]. Berikut adalah persamaan kernel RBF:
𝐾𝑥⃗𝑖𝑥⃗𝑗 = exp (−𝛾‖𝑥⃗𝑖 − 𝑥⃗𝑗‖2 (2.15) Semakin besar parameter nilai gamma (𝛾) dapat menyebabkan overfitting.
Sehingga untuk mendapatkan hasil dari klasifikasi 𝑥⃗ data didapatkan menggunakan persamaan 2.16.
𝑓(𝑥) = ∑ 𝛼𝑖𝑦𝑖𝐾(𝑥⃗𝑥⃗𝑖)
𝑛
𝑖=1,𝑥⃗𝑖∈𝑆𝑉
+ 𝑏 (2.16)
2.5 Multi Class SVM
SVM seiring perkembangannya bukan hanya memecahkan permasalahan klasifikasi biner saja, tetapi dapat juga menyelesaikan permasalahan klasifikasi non biner. Metode yang umum digunakan untuk permasalahan non biner adalah one- against-all dan one-against-one.
2.5.1 One-Against-All
Metode one-against-all bekerja dengan cara membandingkan setiap kelas dengan seluruh sisa kelas lainnya[18].
Gambar 2.5 Metode One-Against-All[19]
12
Pada Gambar 2.5 terdapat tiga buah kelas yang berbeda. Asumsikan kelas 1 adalah data yang berwarna merah, kelas 2 adalah data yang berwarna biru, kelas 3 adalah data yang berwarna hijau. Saat mengklasifikasikan data untuk kelas 1 maka semua kelas yang bukan kelas 1 akan digabung membentuk klasifikasi kelas biner, setelah terbentuk kelas biner maka hyperplane dapat ditemukan. Langkah yang sama untuk setiap kelas berikutnya.
2.5.2 One-Against-One
Metode one-against-one bekerja dengan cara membanding setiap kelas dengan setiap kelas lainnya. Metode ini membentuk sebanyak k(k-1)/2 klasifikasi kelas biner[18].
Gambar 2.6 Metode One-Against-One[19]
Pada Gambar 2.6 terdapat tiga buah kelas yang berbeda. Asumsikan kelas 1 adalah data yang berwarna merah, kelas 2 adalah data yang berwarna biru, kelas 3 adalah data yang berwarna hijau. Pada saat proses klasifikasi dari ketiga kelas akan terbentuk sebanyak tiga klasifikasi kelas biner. Hasil klasifikasi dapat dilihat pada Gambar 2.6
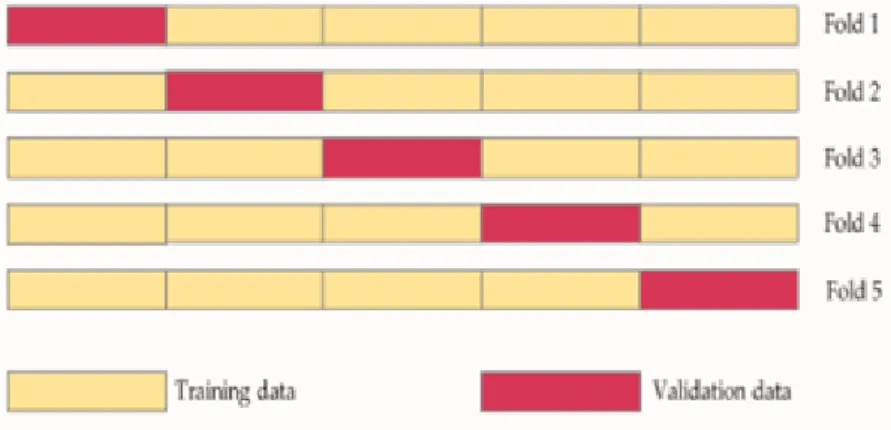
2.6 K-Fold Cross Validation
K-fold cross validation adalah salah satu cara dalam memisahkan dataset menjadi data training dengan data testing, seluruh dataset dibagi menjadi sebesar K kelompok. Kemudian K-1 kelompok digunakan sebagai data training dan satu kelompok lainnya digunakan sebagai data testing[20]. Contoh K-fold cross validation dapat dilihat pada Gambar 2.7.
13
Gambar 2.7 K-Fold Cross Validation dengan K = 5 2.7 Confusion Matrix
Confusion matrix merupakan alat dalam mengukur kinerja dari suatu model pembelajaran[21]. Pengukuran kinerja model atau evaluasi model pada umumnya dilakukan pada proses akhir pengembangan model. Langkah ini perlu diperhatikan untuk mengukur sudah seberapa baik kinerja model pada permasalahan yang diangkat.
Tabel 2.1 Confusion Matrix True Value Positive Negative Prediction Positive TP FP
Negative FN TN
Keterangan:
1. True Positive (TP) adalah data positive yang diprediksi benar pada kelas positive.
2. False Positive (FP) adalah data negative yang diprediksi salah pada kelas positive.
3. False Negative (FN) adalah data positive yang diprediksi salah pada kelas negative.
4. True Negative (TN) adalah data negative yang diprediksi benar pada kelas negative.
14
Berikut beberapa perhitungan untuk mengukur kinerja model klasifikasi dari confusion matrix[20][21]:
1. Accuracy. Accuracy adalah jumlah data prediksi benar terhadap seluruh data prediksi. Adapun persamaan untuk menghitung accuracy dapat dilihat pada persamaan 2.17.
𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁 (2.17)
2. Precision. Precision adalah jumlah data prediksi benar positif terhadap jumlah data prediksi positif. Adapun persamaan dalam menghitung precision dapat dilihat pada persamaan 2.18.
𝑇𝑃
𝑇𝑃 + 𝐹𝑃 (2.18)
3. Recall. Recall adalah jumlah data prediksi benar positif terhadap jumlah data positif. Adapun persamaan dalam menghitung recall dapat dilihat pada persamaan 2.19.
𝑇𝑃
𝑇𝑃 + 𝐹𝑁 (2.19)
4. F-1 Score. F-1 Score adalah harmonic mean dari precision dan recall.
Adapun persamaan untuk menghitung F-1 Score dapat dilihat pada persamaan 2.20.
2 𝑃𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙 (2.20)
2.8 Penelitian Terkait
Penelitian terkait identifikasi atau pengenalan aksara atau huruf sudah sangat berkembang. Berbagai macam algoritma maupun metode telah digunakan dengan hasil tingkat akurasi mengidentifikasi suatu aksara yang bervariasi. Berikut beberapa penelitian terkait diantaranya yaitu penelitian yang dilakukan oleh
15
Pradika,dkk[22]. Penelitian ini membuat model pengenalan tulisan tangan huruf Hijaiyah menggunakan metode convolutional Neural Network (CNN) dengan augmentasi data. Akurasi yang dihasilkan pada penelitian tersebut sebesar 99,7%.
Penelitian berikutnya yang dilakukan oleh Riadi,dkk[23]. Penelitian ini bertujuan mengidentifikasi tulisan tangan huruf Katakana menggunakan ekstraksi ciri Chain Code dan metode Euclidean. Akurasi yang didapatkan dari penelitian tersebut sebesar 78%.
Penelitian yang dilakukan oleh Riska Yulianti,dkk[4]. Penelitian ini bertujuan untuk membuat model pembelajaran yang dapat mengenali tulisan tangan aksara Sasak dengan metode Moment Invariant dan Support Vector Machine. Akurasi yang didapatkan dari penelitian tersebut sebesar 89,76%.
Penelitian lainnya dilakukan oleh Faturrahman,dkk[24]. Penelitian dengan tujuan membuat sistem pengenalan pola huruf Hijaiyah khat Kufi dengan metode deteksi tepi Sobel berbasis jaringan syaraf tiruan. Akurasi yang didapatkan pada penelitian ini sebesar 100% dari delapan skenario pelatihan.
Penelitian yang dilakukan oleh Sholeh,dkk[25]. Penelitian ini membandingkan metode deteksi tepi Robert dengan Sobel menggunakan klasifikasi jaringan syaraf tiruan untuk pengenalan karakter aksara Lampung. Hasil dari penelitian ini yaitu dengan menggunakan metode Robert presentase error sebesar 28,5% dan untuk metode Sobel presentase error sebesar 14,5%. Penelitian ini menyimpulkan bahwa metode deteksi tepi Sobel lebih akurat dibandingkan dengan Sobel.
Penelitian yang dilakukan oleh Riansyah,dkk[26]. Penelitian ini membuat sistem pengenalan aksara Sunda dengan metode Modified Direction Feature dan klasifikasi Learning Vector Quantization. Penelitian ini menghasilkan akurasi sebesar 78,67%. Akurasi pada penelitian ini dipengaruhi oleh ukuran aksara dan Teknik pengambilan citra.
16
Tabel 2.2 Penelitian-Penelitian Terkait Nama Peneliti judul Penelitian Metode
Penelitian Hasil Sunu Ilham
Pradika, Budi Nugroho, Eva Yulia
Puspaningrum [2020]
Pengenalan Tulisan Tangan Huruf Hijaiyah Menggunakan
Convolutional Neural Network Dengan Augmentasi Data
Convolutional Neural
Network
Akurasi data uji sebesar 99,7%
Imam Riadi, Abdul Fadlil, Putri Annisa [2020]
Identifikasi Tulisan Tangan Huruf Katakana Jepang Dengan Metode Euclidean
Chain code dan Euclidean
Akurasi yang dihasilkan sebesar 78%
Riska Yulianti, I Gede Pasek Suta Wijaya, Fitri
Bimantoro [2019]
Pengenalan Pola Tulisan Tangan Aksara Sasak Menggunakan Metode Moment Invariant dan Support Vector Machine
Moment Invariant dan Support Vector Machine
Akurasi yang dihasilkan sebesar 89,76%
Irvan
Faturrahman, Arini, Fitri Mintarsih [2018]
Pengenalan Pola huruf Hijaiyah Khat Kufi Dengan Metode Deteksi Tepi Sobel Berbasis Jaringan Syarat Tiruan Backpropagation
Deteksi Tepi Sobel dan Jaringan Syarat Tiruan Backpropagati- on
Akurasi yang dihasilkan sebesar 100%
Halim Abdillah Sholeh, Yessi mulyani, Hery Dian Septana [2018]
Studi Perbandingan Pengenalan Karakter Aksara Lampung Dengan Metode deteksi Tepi Robert dan Sobel
deteksi Tepi Robert, deteksi Tepi Sobel dan ANN
Backpropagati- on
dihasilkan error sebesar 28,5%
ada deteksi tepi Robert dan error sebesar 15,5%
pada Sobel
17
Nama Peneliti judul Penelitian Metode
Penelitian Hasil Rizki Rahmat
Riansyah, Youllia Indrawaty Nurhasanah, Irma Amelia Dewi
[2017]
Sistem Pengenalan Aksara Sunda
Menggunakan Metode Modified Direction Feature dan Learning Vector Quantization
Modified Direction Feature dan Learning Vector Quantization
Akurasi yang dihasilkan sebesar 68,68%
![Gambar 2.1 Aksara Lampung[3]](https://thumb-ap.123doks.com/thumbv2/123dok/3845149.3958494/1.892.174.763.409.741/gambar-aksara-lampung.webp)
![Gambar 2.2 Representasi Freeman chain code[12]](https://thumb-ap.123doks.com/thumbv2/123dok/3845149.3958494/3.892.249.685.604.874/gambar-representasi-freeman-chain-code.webp)
![Gambar 2.3 Proses Menemukan Hyperplane[14]](https://thumb-ap.123doks.com/thumbv2/123dok/3845149.3958494/4.892.211.724.736.955/gambar-proses-menemukan-hyperplane.webp)

![Gambar 2.5 Metode One-Against-All[19]](https://thumb-ap.123doks.com/thumbv2/123dok/3845149.3958494/8.892.348.575.867.1087/gambar-metode-one-against-all.webp)
![Gambar 2.6 Metode One-Against-One[19]](https://thumb-ap.123doks.com/thumbv2/123dok/3845149.3958494/9.892.368.559.476.665/gambar-metode-one-against-one.webp)