commit to user
3
BAB II
LANDASAN TEORI
2.1. Kajian Pustaka
HCCI (homogeneous charge compression ignition) adalah teknologi
pembakaran yang memiliki efisiensi yang tinggi dan dapat mengurangi kadar emisi. Pembakaran HCCI dikarakteristikan oleh dinamika nonlinier yang komplek yang memharuskan penggunaan model prediksi pada desain kontrolnya. Membangun sebuah model HCCI membutuhkan waktu dan biaya yang tidak sedikit. Neural network digunakan sebagai dasar metodologi untuk memprediksi perilaku pembakaran HCCI selama operasi transien. Dengan demikian, waktu dan biaya yang diperlukan menjadi lebih sedikit. Pemodelan banyak input dengan satu output dirancang untuk memprediksi tekanan efektif rata-rata, tahapan pembakaran, kenaikan tekanan dalam silinder dan AFR ekuivalen. Ketika dibandingkan hasil prediksi dan data eksperimen, dapat disimpulkan jaringan saraf tiruan dapat dijadikan pendekatan untuk mengidentifikasi pembakaran pada mesin HCCI. (Janakiraman dkk. 2012)
Jaringan syaraf tiruan dapat digunakan untuk menentukan torsi pada mesin diesel dengan satu silinder dengan data posisi sudut poros dan pengukuran kecepatan. Pengukuran dua input (posisi sudut poros dan kecepatan) dapat dilakukan dengan mudah dan memerlukan dana yang sedikit. Dengan demikian, penentuan torsi dapat mudah dilakukan untuk melakukan kontrol atau strategi diagnostik pada mesin. Hasilnya, perbandingan hasil eksperimen dengan hasil dari jaringan mempunyai nilai yang cukup mendekati. (Zweiri. 2006)
Jaringan syaraf tiruan digunakan untuk memprediksi jumlah emisi NOx suatu mesin dengan menggunakan 12 inputan berbeda. Mesin dijalankan selama 1200 detik. Hasil akhir menunjukkan hasil prediksi dengan data eksperimen yang hampir berdekatan. Nilai R untuk data training adalah 0.96 sedangkan untuk data validasi adalah 0.94. R menunukkan korelasi antara nilai prediksi dan output target. Nilai 1 berarti nilai prediksi sangat akurat dengan output target sedangkan
commit to user
nilai 0 menunjukkan tidak ada korelasi antara output jaringan dengan output target. (Deng dkk. 2011)
Prediksi umur pahat dapat dilakukan dengan menggunakan metode
Support Vector Machine yang dapat bermanfaat dalam perencanaan proses permesinan. Parameter yang digunakan dlam penelitian ini adalah variasi putaran poros, diameter benda kerja dan waktu pemotongan yang diambil secara langsung melalui praktek konvensional dan umur pahat dihitung menggunakan rumus. Data yang diambil sebanyak 50 data. Dengan menggunakan SVM semua data tersebut dibagi menjadi 35 data training dan 15 data testing dengan memanfaatkan 3
variasi kernel yaitu Multilayer Percepteron (MLP), Radial Basic Function (RBF)
dan Polynomial Data. Hasil dan analisa menunjukkan bahwa hasil pelatihan menunjukkan hasil yang mendekati target yaitu 90,03%(MLP), 98,17%(RBF) dan 98,98%(Polynomial). Berdasarkan hasil tersebut bisa disimpulkan bahwa prediksi umur pahat dengan menggunakan algoritma polynomial dapat digunakan secara tepat dan akurat untuk memprediksi umur pahat. (Agus Winoto. 2011)
2.2. Dasar Teori
2.2.1. Kecerdasan Buatan
Istilah kecerdasan buatan mempunyai beberapa definisi menurut beberapa peneliti. Right and Knight (1991) mendefinisikan kecerdasan buatan sebagai studi tentang bagaimana membuat komputer melakukan hal-hal yang pada saaat ini dapat dilakakukan lebih baik oleh manusia. Menurut Encyclopedia Brittanica, kecerdasan merupakan cabang dari ilmu komputer yang dalam mempresentasikan ilmu lebih banyak menggunakan bentuk simbol-simbol daripada bilangan, dan memproses informasi berdasarkan metode heuristic atau dengan berdasarkan sejumlah aturan. Alan Turing, amtematikawan asal Inggris yang pertama kali melakuka uji coba untuk melihat apakah mesin dapat dikatakan cerdas, mendefinisikan kecerdasan buatan sebagai bidang yang memodelkan proses-proses berpikir manusia dan mendesain mesin agar dapat menirukan kelakuan manusia. Dari beberapa penjelasan di atas, dapat disimpulkan bahwa kecerdasan buatan erat kaitannya dengan usaha dalam menciptakan komputer atau mesin yang dapat berpikir atau menalar layaknya manusia.
commit to user
Layaknya manusia, agar komputer dapat berpikir atau menalar seperti manusia, komputer atau mesin juga harus diberi bekal pengetahuan dan pegalaman agar dapat menyelesaikan masalah-masalah yang diberikan. Menurut Winsto dan Prendergast (1984) terdapat 3 tujuan yaitu membuat mesin menjadi lebih pintar, memahami apa itu kecerdasan dan membuat mesin lebih bermanfaat (Yui Jayusman. 2012)
Ada beberapa bahasa pemrograman yang digunakan dalam penerapan kecerdasan buatan
1. LISP, dikembangkan awal tahun 1950-an, bahasa pemrograman
pertama yang diasosiakan dengan AI
2. PROLOG, dikembangkan tahun 1970-an
3. Bahasa pemrograman berorientasi obyek (Oject Oriented
Programming) seperti C, C++, Smalltalk, Java dll
Soft computing merupakan inovasi baru dalam membangun sistem kecerdasan buatan yaitu sistem yang memiliki keahlian seperti manusia pada domain tertentu, mampu beradaptasi dan belajar agar dapat bekerja lebih baik jika
terjadi perubahan lingkungan. Soft computing mengeksplorasi adanya toleransi
terhadap ketidaktepatan, ketidakpastian, dan kebenaran parsial untuk diselesaikan dan dikendalikan dengan mudah agar sesuai realita (Zadeh. 1992).
Metodologi-metodologi yang digunakan dalam soft computing yaitu
1. Sistem fuzzy (mengakomodasi ketidaktepatan)
2. Jaringan saraf tiruan (menggunakan pembelajaran)
3. Probabilistic reasoning (mengakomodasi ketidakpastian)
4. Evolutionary computing (optimasi)
Semakin pesatnya teknologi masa kini tak lepas dari berkembangnya kecerdasan buatan. Hal ini karena karakteristik cerdas sudah mulai dibutuhkan di berbagai disiplin ilmu dan teknologi. Lingkup utama kecerdasan buatan yaitu
1. Sistem pakar. Kecerdasan buatan digunakan untuk menyimpan
pengetahuan atau penalaran para pakar dalam menyelesaikan suatu persoalan
commit to user
2. Pengolahan bahasa alami (Natural Language Processing).
Memberikan pengetahuan kepada komputer agar dapat berkomunikasi dengan pengguna komputer menggunakan bahasa sehari-hari.
3. Pengenalan ucapan (speech Recognition). Memberikan kemampuan
kepada komputer agar dapat mengenali dan memahami bahasa ucapan.
4. Robotika & Sistem Sensor.
5. Computer Vision. Mencoba untuk dapat menginterpretasikan gambar
atau obyek-obyek tampak melalui komputer.
6. Intelligent Computer-aided Instruction. Komputer dapat digunakan sebagai tutor yang dapat melatih dan mengajar.
7. Game playing.
Jika dibandingkan dengan kecerdasan manusia/kecerdasan alami, kecerdasan buatan memiliki keuntungan komersial, antara lain:
1. Kecerdasan buatan lebih bersifat permanen. Kecerdasan alami akan
cepat mengalami perubahan.
2. Kecerdasan buatan lebih mudah diduplikasi dan disebarkan
3. Kecerdasan bautan bersifat konsisten
4. Kecerdasan buatan dapat didokumentasi
5. Kecerdasan buatan dapat mengerjakan pekerjaan lebih cepat dibanding
dengan kecerdasan alami
6. Kecerdasan buatan dapat mengerjakan pekerjaan lebih baik dibanding
dengan kecerdasan alami.
Sedangkan kecerdasan alami memiliki keuntungan sebagai berikut:
1. Kreatif
2. Kecerdasan alami memungkinkan orang untuk menggunakan
pengalaman secara langsung. Sedangkan kecerdasan buatan harus bekerja dengan input-input simbolik
3. Pemikiran manusia dapat digunakan secara luas sedangkan kecerdasan
commit to user
2.2.2. Jaringan Saraf Tiruan
Otak manusia tersusun oleh sel-sel syaraf yang terhubung satu sama lain yang berfungsi untuk menyalurkan rangsangan dan memberikan tanggapan terhadap rangsangan tersebut. Tangapan-tanggapan yang muncul berbeda-beda tergantung pada jenis rangsangan yang mengenainya.
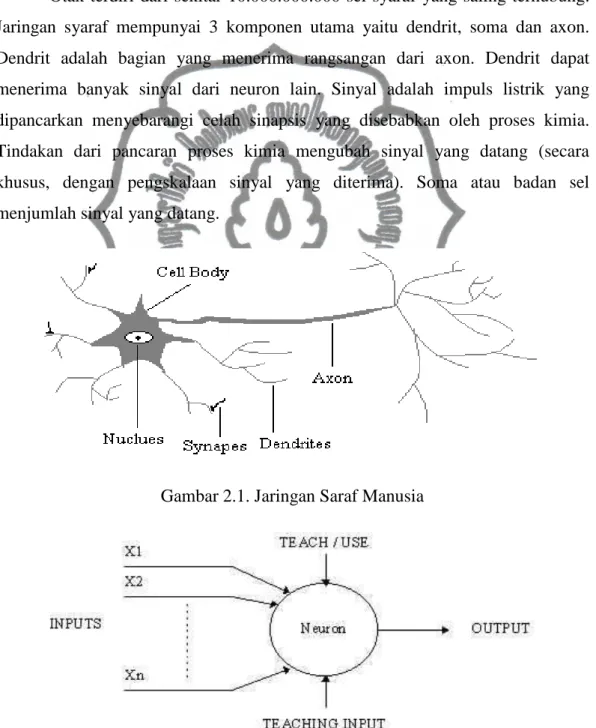
Otak terdiri dari sekitar 10.000.000.000 sel syaraf yang saling terhubung. Jaringan syaraf mempunyai 3 komponen utama yaitu dendrit, soma dan axon. Dendrit adalah bagian yang menerima rangsangan dari axon. Dendrit dapat menerima banyak sinyal dari neuron lain. Sinyal adalah impuls listrik yang dipancarkan menyebarangi celah sinapsis yang disebabkan oleh proses kimia. Tindakan dari pancaran proses kimia mengubah sinyal yang datang (secara khusus, dengan pengskalaan sinyal yang diterima). Soma atau badan sel menjumlah sinyal yang datang.
Gambar 2.1. Jaringan Saraf Manusia
commit to user
Jaringan saraf tiruan mengadopsi cara kerja jaringan saraf manusia. Jaringan saraf juga memiliki neuron yang terhubung melalui layer dengan bobot tertentu. Pada jaringan saraf manusia, bobot tersebut dianalogikan dengan aksi
pada proses kimia yang terjadi pada synaptic gap. Input dan output sesuai dengan
sensor dan saraf motorik seperti sinyal datang dari mata kemudian diteruskan ke tangan. Sinyal input atau masukan diterima ditraining atau di beri pelatihan untuk
membentuk sebuah jaringan berdasarkan input. Neuron memiliki internal state
yang disebut aktivasi. Aktivasi merupakan fungsi dari input yang diterima. Pada jaringan saraf, neuron-neuron akan dikumpulkan dalam
lapisan-lapisan tersembunyi (hidden layers). Informasi atau output yang telah diberikan
bobot akan dilewatkan pada lapisan-lapisan tempat dimana input-input tersebut diproses. Input-input yang telah diproses tersebut akan menghasilkan sebuah output. Beberapa saraf ada juga yang tidak memiliki lapisan tersembunyi, dan ada juga jaringan saraf dimana neuron-neuronnya disusun dalam bentuk matriks.
Jaringan saraf tiruan ditentukan oleh 3 hal, yaitu
a. Pola hubungan antar neuron (disebut arsitektur jaringan)
b. Metode untuk menentukan bobot penghubung (disebut metode
training/learning)
c. Fungsi aktivasi
Penyelesaian masalah dengan jaringan saraf tiruan tidak memerlukan pemrograman. Jaringan saraf tiruan menyelesaikan masalah melalui proses belajar
atau training dari contoh-contoh. Biasanya pada jaringan saraf tiruan diberikan
sebuah himpunan pola pelatihan yang terdiri atas sekumpulan contoh pola.
Sebagai tanggapan atas pola masukan-sasaran yang disajikan tersebut, jaringan akan menyesuaikan nilai bobotnya. Jika pelatihan telah berhasil, bobot-bobot yang dihasilkan selama pelatihan jaringan akan memberikan tanggapan yang benar terhadap masukan yang diberikan. (STMIK Triguna Dharma,Buku Panduan Belajar Kecerdasan Buatan)
commit to user
1.) Arsitektur Jaringan Syaraf Tiruan
Berdasarkan dari arsitektur (pola koneksi), Jaringan saraf tiruan dapat dibagi kedalam dua kategori
a. Struktur feedforward
Sebuah jaringan yang sederhana mempunyai struktur feedforward dimana sinyal bergerak dari input kemudian melalui lapisan tersembunyi dan akhirnya mencapai unit output.
Tipe jaringan feedforward mempunyai jaringan yang mempunyai beberapa lapisan. Sinyal input bukanlah merupakan sel saraf. Sinyal input kemudian dikenalkan ke bagian lapisan tersembunyi dengan nilai bobot yang telah ditentukan oleh jaringan.
Gambar 2.3. Jaringan Syaraf Tiruan Feedforward
(elektronika-dasar.web.id) Yang termasuk dalam struktur feedforward adalah
1. Single-layer percepteron 2. Multilayer percepteron 3. Radial-basis function network 4. Higher-order networks
5. Polynomial learning networks
b. Struktur Recurrent
Jaringan reccurent menggunakan koneksi kembali output ke input. Hal ini akan menimbulkan ketidakstabilan dan dapat menghasilkan dinamika yang komplek. Yang termasuk struktur reccurent adalah
commit to user 1. Competitive networks
2. Self-organizing maps 3. Hopfield networks
4. Adaptive-resonanse theory models
2.) Fungsi Aktivasi
Fungsi aktivasi dipakai untuk menentukan keluaran suatu neuron. Fungsi
aktivasi menggambarkan hubungan antara tingkat aktivasi internal (summation
function) yang mungkin berbentuk linier atau nonlinier. (STMIK Triguna Dharma, Buku Panduan Belajar Kecerdasan Buatan).
Fungsi aktivasi digunakan untuk mengupdate nilai-nilai bobot per iterasi. Fungsi aktivasi sederhana adalah mengkalikan input dengan bobotnya dan kemudia menjumlahkannya.
N i i iw x a 1 ...(2.1)Gambar 2.4. Fungsi Aktivasi Sederhana
wn adalah bobot, b adalah bias dan F adalah fungsi aktivasi. Hasil
penjumlahan inputan kemudian akan diaktivasi oleh sebuah fungsi yang kemudian akan menghasilkan output.
commit to user
3.) Proses Pembelajaran
Ada beberapa metode untuk proses pembelajaran pada jaringan saraf tiruan ini, yaitu
1. Pembelajaran terawasi
Pembelajaran terawasi berlaku jika nilai output dari suatu pola telah diketahui. Pada prosesnya, nilai input akan di berikan ke suatu neuron pada lapisan input. Pola ini akan dirambatkan ke semua lapisan sehingga akan tebentuk sebuah otuput dari jaringan tersebut. Output dari jaringan tersebut akan dicocokkan dengan output target. Apabila terjadi perbedaan
antara output jaringan dengan output target, maka akan muncul error.
Apabila error masih cukup besar, maka pembelajaran harus dilakukan
lebih banyak lagi.
2. Pembelajaran tak terawasi
Pada pembelajaran tipe ini, tidak diperlukan output target. Pada metode ini, tidak dapat ditentukan hasil seperti apakah yang diharapkan selama proses pembelajaran. Selama pembelajaran, nilai bobot disusun dalam satu jarak tertentu pada nilai input yang diberikan. Biasanya, pembelajaran tipe ini digunakan untuk membentuk suatu klasifikasi atau pengelompokkan pola.
4.) Algoritma Jaringan Saraf Tiruan
Jaringan saraf tiruan terdiri dari elemen-elemen pemrosesan sederhana
yang disebut neuron. Setiap neuron dihubungkan ke neuron lain dengan link
komunikasi yang disebut arsitektur jaringan. Bobot koneksi mewakili besarnya informasi yang digunakan. Operasi dasar sebuah neuron buatan meliputi jumlah dari hasil perkalian sinyal input dengan bobot antar neuron, kemudian menggunakan fungsi aktivasi untuk menghasilkan output. Pada setiap pelatihan, jaringan menghitung respon dari unit output dan kesalahan dnegan membandingkan output terhitung dengan nilai target.
Misalnya ambil contoh pelatihan pada jaringan dilakukan dengan
menggunakan jaringan backpropogation. Pelatihan jaringan dengan
commit to user
input, perhitungan dan propagasi balik dari error dan penyesuaian bobot. Pada
tahap umpan maju setiap unit input menerima sinyal input (xi) dan
menyebarkannya ke unit tersembunyi z1,...,zp. Setiap unit tersembunyi menghitung aktivasinya menghitung aktivasinya dan jumlah terboboti dari input-inputnya dalam bentuk
i bj i ji j w x w in z_ ...(2.2)Dengan xi aktivasi dari unit input ke-i yang mengirimkan sinyal ke unit hidden ke j, wj adalah bobot dari sinyal yang terkirim. Hasil penjumlahan ditransformasi dengan fungsi aktivasi non linier
j
j f z in
z _ ...(2.3) Setelah semua unit tersembunyi menghitung aktivasinya kemudian
mengirim sinyal (zj) ke unit output. Kemudian unit output menghitung aktivasinya
dalam bentuk
j bo j joz w w z w g( , ) ...(2.4)Fungsi pada 2.5 merupakan nilai output dari jaringan yaitu
j bo j jof a w w o ( ) ...(2.5)commit to user
Dengan wbo adalah bobot dari bias ke unit output. Model NN dengan satu
hidden dan input xt1,,xtp ditulis dalam bentuk
n no n cn i in t j co t w w w w x i xˆ 0 ...(2.6)Dengan {wcn} adalah bobot antara unit konstan dan neuron dan wco adalah bobot
antara unit konstan dan output. {win} dengan {wcn} adalah bobot antara unit
konstan dan neuron dan wco adalah bobot antara unit konstan dan output. {win} dan
{wno} masing-masing menyatakan bobot koneksi input dengan neuron dan antara
neuron dengan output. Kedua fungsi
n dan o masing-masing fungsi aktivasiyang digunakan pada neuron dan output. (Budi Warsito. 2005)
2.2.3. Support Vector Machine
Support vector machine merupakan teknik untuk memprediksi, baik dalam kasus kalsifikasi maupun regresi, yang relatif baru karena baru dikembangkan pada tahun 1995 oleh Boser, Guyon dan Vapnik. SVM mempunyai kerja yang
hampir sama dengan Artificial Neural Network dalam hal fungsi dan kondisi
permasalahan yang ingin diselesaikan. Keduanya masuk dalam kelas supervised
learning. SVM dan ANN telah banyak digunakan oleh para ilmuan untuk
menyelesaikan permasalahan di berbagai bidang seperti gene expression analysis,
finansial, cuaca hingga bidang kedokteran. Perbedaan keduanya adalah ANN
menemukan solusi berupa local optimal yang artinya setiap kita menjalankan
ANN solusi yang kita temukan akan selalu berbeda. Hal ini disebabkan local
optimal yang dicapai tidak selalu sama. Berbeda dengan SVM yang yang
menemukan solusi secara global optimal. SVM akan menghsilkan output yang
selalu sama setiap kali running.
Baik SVM dan ANN digunakan sebagai metode untuk pengenalan metode. Pembelajaran dilakukan dengan cara menyediakan data input dan data ouput. Pembelajaran dengan cara ini disebut dengan pembelajaran terarah. Dengan adanya data input dan data output tersebut akan tergambar sebuah ketergantungan antara input terhadap output. Selanjutnya, diharapkan fungsi yang terbentuk mempunyai kemampuan generalisasi yang baik, dengan kata lain fungsi tersebut dapat digunakan walaupun data inupt yang digunakan nantinya di luar data pembelajaran.
commit to user
Konsep dasar SVM adalah berusaha menemukan hyperplane atau garis
pemisah dua kelas pada input space. Ilustrasi dari kerja SVM dapat dilihat pada
gambar 2.4 dibawah ini.
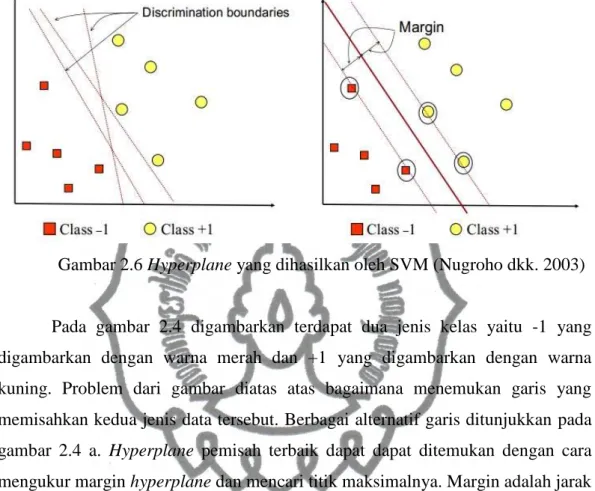
Gambar 2.6 Hyperplane yang dihasilkan oleh SVM (Nugroho dkk. 2003)
Pada gambar 2.4 digambarkan terdapat dua jenis kelas yaitu -1 yang digambarkan dengan warna merah dan +1 yang digambarkan dengan warna kuning. Problem dari gambar diatas atas bagaimana menemukan garis yang memisahkan kedua jenis data tersebut. Berbagai alternatif garis ditunjukkan pada
gambar 2.4 a. Hyperplane pemisah terbaik dapat dapat ditemukan dengan cara
mengukur margin hyperplane dan mencari titik maksimalnya. Margin adalah jarak
hyperplane dengan data paling dekat dengan hyperplane dari masing-masing
kelas. Data yang paling dekat dengan hyperplane disebut support vector. Gambar
2.4 b menunjukkan hyperplane terbaik yang memisahkan kedua data. Usaha untuk
menemukan hyperplane terbaik ini merupakan inti dari proses pembelajaran
SVM.(Nugroho dkk. 2003)
Pada permasalahan nyata, sangatlah sulit untuk menemukan data yang dapat dipisahkan secara linier. Oleh karena itu digunakanlah fungsi kernel untuk mengatasi permasalahan non-linier. Dengan memasukkan fungsi kernel, maka
problem data non-linier menjadi linier dalam space baru. Ilustrasi dari fungsi
commit to user
Gambar 2.7 Ilustrasi Fungsi Kernel Ada 4 jenis kernel yang biasanya digunakan, yaitu
1. Linier Kernel 2. Polynomial Kernel
3. Radial Basis Function (RBF) Kernel 4. Tangent Hyperbolic (sigmoid) Kernel
1.) Kelebihan dan Kelemahan Support Vector Machine
Walaupun berbagai studi telah menunjukkan kelebihan SVM dengan metode-metode lain, SVM juga memiliki beberapa kelemahan. Kelebihan SVM antara lain
1. Generalisasi
Generalisasi adalah kemampuan suatu metode (SVM, Neural Network
dll) untuk mengklasifikasikan suatu pola yang tidak termasuk data yang dipakai dalam fase training atau pembelajaran metode itu. Vapnik menjelaskan bahwa generalization error dipengaruhi oleh dua faktor; 1) error terhadap training set dan 2) dimensi VC
(Vapnik-Chervokinensis). Strategi pembeljaran pada neural network dan
umumnya metode learning machine difokuskan pada usaha untuk
meminimalkan error pada training-set. Strategi ini disebut Empirical
Risk Minimalization (ERM). Adapun SVM selain meminimalkan error
pada training-set, juga meminimalkan faktor kedua. Strategi ini disebut
Structural Risk Minimalization (SRM), dan dalam SVM diwujudkan
commit to user
empiris menunjukkan bahwa pendekatan SRM pada SVM memberikan error generalisasi yang lebih kecil daripada yang diperoleh dari strategi
ERM pada Neural Network maupun metode yang lain.
2. Curse of Dimensionality
Curse of dimensionality adalah masalah yang dihadapi suatu metoda
pattern recognition dalam mengestimasikan parameter dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional
ruang vektor data tersebut. Curse of dimensionality sering dialami
dalam aplikasi di bidang biomedical engineering, karena biasanya data biologi yang tersedia sangat terbatas dan penyediaanya memerlukan biaya yang besar. Vapnik membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh dimensi dari input vektor. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat untuk dipakai guna memecahkan masalah berdimensi tinggi dalam keterbatasan sample data yang ada.
3. Feasibility
SVM dapat diimplementasikan relatif mudah, karena proses penentuan support vector dapat dirumuskan dengan QP problem. Dengan demikian jika kita memiliki library untuk menyelesaikan QP problem, dengan sendirinya SVM dapat diimplementasikan dengan mudah.
Disamping kelebihan-kelebihan di atas, SVM juga memiliki beberapa kekurangan, antara lain
1. Sulit dipakai dalam problem berskala besar. Skala besar dalam hal
ini adalah jumlah sampel yang diolah
2. SVM secara teoritikdikembangkan untuk problem kalsifikasi
dengan dua kelas. Dewasa ini SVM telah dimodifikasi agar dapat
menyelesaikan masalah dengan class lebih dari dua, antara lain
strategi one versus rest dan strategi tree structure. Namun
demikian, masing-masing strategi ini memiliki kelemahan sehigga dapat dikatakan penelitian dan pengembangan SVM pada
commit to user
multiclass-problem masih merupakan tema penelitian yang masih terbuka.
2.) Algoritma Support Vector Machine
Support Vector Machine (SVM) adalah salah satu teknik klasifikasi data dengan proses pelatihan. Salah satu ciri dari metode SVM adalah menemukan
garis hyperplane atau garis pemisah terbaik sehingga diperoleh ukuran margin
yang maksimal. Titik yang terdekat dengan hyperplane disebut support vector.
Margin adalah dua kali jarak antara hyperplane dengan support vector. Ilustrasi
SVM untuk data yang terpisahkan secara linier dapat dilihat pada gambar 2.6
Gambar 2.8. Hyperplane Alternatif dan Hyperplane Terbaik Dengan Data Yang
Dapat Dipisahkan Secara Linier (Krisantus Sembiring. 2007)
Dalam contoh diatas dua kelas dipisahkan oleh dua garis sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang kedua membatasi kelas kedua, sehingga diperoleh:
1 .wb xi untuk yi=+1...(2.7) 1 .wb xi untuk yi=-1
Dengan w adalah normal bidang dan b adalah posisi bidang relatif
terhadap puast kooordinat. Nilai margin (jarak) antara bidang pembatas (berdasarkan rumus jarak ke garis pusat) adalah
w w b b ( 1 ) 2 1
Nilai margin ini dimaksimalkan dengan tetap memenuhi persamaan 2.7.
Dengan mengalikan b dan w dengan sebuah konstanta, akan dihasilkan nilai
commit to user
pada persamaan (2.7) merupakan scaling constant yang dapat dipenuhi dengan
rescaling b dan w. Selain itu, karena memaksimalkan
w
1
sama dengan
meminimumkan w2dan jika kedua bidang pembatas persamaan (2.7)
dipresentasikan ke dalam pertidaksamaan 0 1 ) . (x wb yi i ...(2.8) Maka pencarian bidang pemisah terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi konstrain, yaitu
2
2 1
min w ...(2.9)
s,t yi(xi.wb)10
Persoalan ini akan lebih mudah diselesaikan jika diubah ke dalam formula
lagrangian yang menggunakan lagrange multiplier. Dengan demikian permasalahan optimasi konstrain dapat diubah menjadi
n i n i i i i i p b w L w b a w a y x w b a 1 1 2 , 2 . 1 , , min ...(2.10)Dengan tambahan konstrain, ai≥ 0 (nilai dari koefisien lagrange). Dengan
meminimumkan Lp terhadap w dan b, maka dari
, ,
0 a b w L b p diperoleh (2.11) dan dari
, ,
0 a b w L w p diperoleh (2.12)
n i i iy a 1 0...(2.11)
n i i i iy x a w 1 ...(2.12)Vektor w seringkali bernilai besar (mungkin tak terhingga), tetapi nilai αi
terhingga. Untuk itu, formula lagrangian Lp (primal problem) diubah ke dalam
dual problem Ld. Dengan mensubstitusikan persamaan (2.11) ke Lp diperoleh
dual problem Ld dengan konstrain berbeda
n i n j i j i j i j i i D y y x x L 0 2 1, 1 1 ) ( ...(2.13)commit to user S,t. 0, 0 1
i n i i iy a ...(2.14)Dengan demikian, dapat diperoleh nilai αi yang nantinya digunakan untuk
menemukan w. Terdapat nilai αi untuk setiap data pelatihan. Data pelatihan yang
memiliki nilai αi>0 adalah support vector sedangkan sisanya memiliki nilai αi=0.
Dengan demikian fungsi keputusan yang dihasilkan hanya dipengaruhi oleh
support vector.
Formula pencarian bidang pemisah terbaik ini adalah permasalahan
quadratic programming sehingga nilai maksimum global dari αi selalu dapat
ditemukan. Setelah solusi permasalahan quadratic programming ditemukan (nilai
αi), maka kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari
fungsi keputusan:
ns i d i i i d y x x b x f 0 ) ( ...(2.15)Xi adalah support vector, ns= jumlah support vector dan xd adalah data
yang akan diklasifikasi.
3.) SVM pada Nonliniarly Separable Data
Metode untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier adalah dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
Gambar 2.9. Feature Space(Krisantus Sembiring. 2007)
Caranya, data dipetakan dengan menggunakan fungsi pemetaan
(transformasi) xk
xk ke dalam feature space sehingga terdapat bidangcommit to user
data set yang datanya memiliki dua atribut dan dua kelas yaitu kelas positif dan kelas negatif. Data yang memiliki kelas positif {(2,2),(2,-2),(-2,2),(-2,-2)}, dan data yang memiliki kelas negatif {91,1),(1,-1),(-1,1),(-1,-1)}. Apabila data ini digambarkan dalam ruang dua dimensi (gambar 2.9) dapat dilihat data ini tidak dapat dipisah secara linier. Oleh karena itu, digunakan fungsi transformasi berikut
) , ( 2 ) , ( ) 4 , 4 ( 2 ) , ( 2 1 2 2 2 1 2 1 2 1 1 2 1 2 2 2 2 1 2 1 x x x x x x x x x x x x x x x x ...(2.16)
Data sesudah transformasi adalah {(2,2),(6,2),(6,6),(2,6)} untuk kelas negatif, dan {(1,1),(1,-1),(-1,1),(-1,-1)} untuk kelas positif. Selanjutnya pencarian bidang pemisah terbaik dilakukan pada data ini.
Gambar 2.10. Transformasi ke Feature Space (Krisantus Sembiring. 2007)
Dengan menggunakan transformasi xk
xk , maka nilai
ns i i i iy x w 1 ) ( dan fungsi hasil pembelajaran yang dihasilkan adalah
ns i d i i i d y x x b x f 1 ) ( ) ( ...(2.17)Feature space dalam prakteknya biasanya memiliki dimensi yang lebih
tinggi dari vektor input (input space). Hal ini mengakibatkan komputasi pada
feature space mungkin sangat besar, karena ada kemungkinan feature space dapat
memiliki jumlah feature yang tak terhingga. Selain itu, sulit mengetahui fungsi
transformasi yang tepat. Untuk mengatasi masalah ini, pada SVM digunakan ‘kernel trick’. Dari persamaan 2.11 dapat dilihat terdapat dot product (xi)(xd).
Jika terdapat sebuah fungsi kernel K sehingga K(xixd)(xi)(xd), maka fungsi
transformasi (xk)tidak perlu diketahui secara persis. Dengan demikian fungsi
commit to user
ns i d i i i d y K x x b x f 1 ) , ( (xi= support vector)...(2.18)
Syarat sebuah fungsi untuk menjadi fungsi kernel adalah memenuhi teorema Mercer yang menyatakan bahwa matriks kernel yang dihasilkan harus
bersifat positive semi-definite. Fungsi kernel yang umum digunakan adalah
sebagai berikut: a. Kernel linier x x x x K T i i ) ( ...(2.19) b. Polynomial kernel 0 , ) . ( ) (xix xTi xr p K ...(2.20)
c. Radial Basis Function (RBF)
0 ), exp( ) (x x x x2 K i i ...(2.21) d. Sigmoid kernel ) tanh( ) (x x x x r K i iT ...(2.22) Fungsi kernel yang direkomendasikan untuk diuji pertama klai adalah kernel RBF karena memiliki performasi yang sama dengan kernel linier pada parameter tertentu, memiliki perilaku seperti fungsi kernel sigmoid dengan parameter tertentu dan rentang nilainya kecil. (Krisantus Sembiring. 2007)