Sistem Pakar Diagnosa Penyakit Diabetes Melitus Menggunakan Algoritma Iterative Dichotomiser Three (ID3) Berbasis Android
Artikel Ilmiah
Diajukan kepada
Fakultas Teknologi Informasi
Untuk memperoleh Gelar Sarjana Komputer
Oleh:
Ardi Pratama Patengko
NIM: 672014603
Program Studi Teknik Informatika Fakultas Teknologi Informasi Universitas Kristen Satya Wacana
1
1. Pendahuluan
Sistem pakar (expert system) adalah sistem yang menggunakan pengetahuan seorang pakar untuk menyelesaikan masalah terkait dengan bidang tertentu seperti yang biasa dilakukan oleh seorang pakar. Sistem pakar yang baik dirancang agar dapat menyelesaikan suatu permasalahan tertentu dengan meniru kerja dari para ahli. Dengan sistem pakar, orang awam pun dapat menyelesaikan masalah yang cukup rumit yang sebenarnya hanya dapat diselesaikan dengan bantuan para ahli. Bagi para ahli, sistem pakar juga akan memabntu aktivitasnya sebagai asisten yang sangat berpengalaman [1].
Penelitian ini menggunakan algoritma ID3 karena dapat membangun sebuah pohon keputusan dengan cepat dan mudah dipahami. Penanganan penyakit diabetes melitus menjadi lebih mudah apabila menggunakan pohon keputusan karena hanya membutuhkan masukan berupa data gejala. Dataset yang digunakan dalam penelitian ini diambil dari repositori database Pima Indians, UCI [2]. Dataset Pima ini terdiri dari 768 data yang pasiennya berjenis kelamin perempuan dengan umur sekurang – kurangnya 21 tahun. Berdasarkan dataset ini penulis membangun aplikasi berbasis Android yang bisa menghasilkan pohon keputusan berdasarkan fakta-fakta yang ada dan bisa digunakan untuk menguji apakah pasien menderita penyakit diabetes mellitus.
2. Kajian Pustaka
Penelitian oleh Lesmana [3] yang juga menggunakan dataset Pima Indians, ada beberapa attribut yang memiliki nilai tidak lengkap. Dari sembilan attribut yaitu Pregnant (Pregnant),
Plasma-Glucose (Glucose), Diastolic Blood-Pressure (DBP), Tricepts Skin Fold Thickness
(TSFT), Insulin (INS), Body Mass Index (BMI), Diabetes Pedigree Function (DPF), Age (Age), dan Class Variable (Class) hanya tujuh attribut yang digunakan dan siap diolah lebih lanjut dalam penelitian tersebut antara lain Pregnant, Glucose, DBP, BMI, DPF, Age, dan Class. ID3 adalah algoritma yang akan digunakan dalam penelitian ini untuk membuat pohon keputusan berdasarkan dataset Pima Indians. Untuk menghitung dan membuat pohon keputusan menggunakan algoritma ID3 dibutuhkan data yang bersifat kategorial sedangkan dataset yang digunakan bersifat nominal. Oleh karena itu diskritisasi atribut pada dataset dibutuhkan untuk mempermudah pengelompokan nilai berdasarkan kriteria yang telah ditetapkan.
Tabel 1 Diskritisasi atribut dataset diabetes Pima Indians [3]
Atribut Diskritisasi
Pregnant Low (0,1), Medium (2,3,4,5), High ( > 6) Glucose Low (< 95 ), Medium (95-140), High (> 140)
DBP Normal (< 80), Normal-to-High (80-90), High (> 90)
BMI Low (< 24.9), Normal (25-29.9), Obese (30-34.9), Severely-Obese (> 35) DPF Low (< 0.5275), High (> 0.5275)
Age Young (<40), Medium (40-59), Old (> 60)
2
Untuk mendapatkan pohon keputusan menggunakan algoritma ID3, Entropy dan Gain harus dihitung terlebih dahulu.
Entropy
Untuk menghitung gain ratio, terlebih dahulu harus diketahui nilai entropy-nya. Entropy merupakan suatu parameter untuk mengukur heterogenitas (keberagaman) dari suatu kumpulan sampel data. Jika kumpulan sampel data semakin heterogen, maka nilai entropynya semakin besar. Secara matematis, entropy dirumuskan pada persamaan (1).
Entropy(S) = -p + log2 p + -p - log2 p- (1)
Keterangan persamaan (1) :
S : 700 ruang (data) sampel yang digunakan untuk training.
P+ : 241 sampel yang bersolusi positif (mendukung). P- : 459 sampel yang bersolusi negatif (tidak mendukung). Gain ratio
Setelah nilai entropy didapatkan dari suatu kumpulan sampel data, maka kita dapat mengukur efektifitas suatu atribut dalam mengklasifikasikan data. Ukuran efektivitas ini disebut gain ratio. Gain ratio dihitung berdasarkan split information yang dirumuskan pada persamaan (2).
Gain(S, A) = Entropy(S) - ∑|��|| � |� �� � �� (2)
Keterangan persamaan (2) :
A : atribut yang digunakan yaitu Pregnant, Plasma-Glucose, Diastolic Blood-Pressure, Body Mass Index, Diabetes Predigree Function, Age, dan Class
v : menyatakan suatu nilai yang mungkin untuk atribut yang digunakan Values(A) : himpunan yang mungkin untuk atribut A
|Sv| : jumlah sampel untuk nilai v |S| : jumlah seluruh sampel data
Entropy(Sv) : entropy untuk sampel-sampel yang memiliki nilai v
3. Perancangan Sistem
4
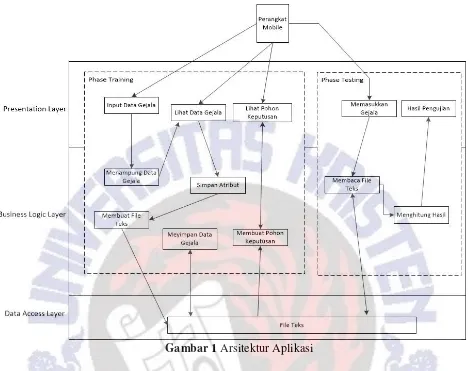
Gambar 1 Arsitektur Aplikasi
Presentation Layer adalah apa yang dilihat oleh pengguna dan tempat untuk berinteraksi dengan sistem. Activity Gejala, Data Gejala, Pohon Keputusan, dan Pengujian adalah tempat pengguna untuk berinteraksi dengan sistem dan merupakan representasi dari presentation layer.
Business Logic Layer merupakan aturan bisnis yang diterapkan pada sistem melalui logika pemograman dan bagaimana aturan itu dapat dijalankan. Cara menyimpan data gejala, menggunakan library, mmebuat dan membaca file text, membentuk pohon keputusan sampai menguji pohon keputusan merupakan tugas dari business logic layer. Lapisan yang terakhir yaitu
data access layer merupakan sebuah tempat untuk menyimpan dan mengambil informasi. Data yang disimpan berupa file teks yang menyimpan atribut dan data penyakit diabetes melitus.
5 menggunakan instance dengan 6 nilai atribut yang tersedia untuk menguji pohon keputusan. Hasil pengujian dari pohon keputusan berupa nilai 0 (Negatif) atau 1 (Positif).
Metode pengembangan perangkat lunak yang dipakai dalam penelitian ini adalah model
prototyping. Model prototyping adalah salah satu metode pengembangan perangkat lunak yang dibuat dengan pendekatan aspek desain, fungsi, dan user-interface. Bagan mengenai prototype model dapat dilihat pada Gambar 1.
Gambar 1Bagan Prototype Model [4]
Tahap-tahap dalam prototype model adalah sebagai berikut: (1) Listen to Customer, (2) Build, (3) Customer Test. Dari tahap pertama didapatkan bahwa kebutuhan dari sistem adalah sebagai berikut: aplikasi menampilkan menu utama yaitu data gejala, rules ID3, dan pengujian ID3. Data gejala adalah tempat untuk memasukkan data-data dari dataset yang ada. Rules ID3 adalah tempat untuk melihat pohon keputusan yang telah dibentuk berdasarkan dataset yang ada. Dan pengujian ID3 adalah tempat untuk menguji pohon keputusan yang telah dibuat menggunakan atribut yang ada. Tahap build meliputi tahap perancangan dan pengimplementasian aplikasi. Aplikasi Sistem Pakar Diagnosa Penyakit Diabetes Melitus Menggunakan Algoritma ID3 menggunakan pendekatan Object Oriented. Sedangkan aplikasi diimplementasikan menggunakan bahasa pemograman Java.
6
Aplikasi sistem pakar diagnosa penyakit diabetes mellitus menggunakan algoritma ID3 mempunyai beberapa fungsi utama yaitu : (1) Data gejala dimasukkan oleh user pada activity
Gejala kemudian bisa dilihat pada expendable list view, dan selanjutnya akan disimpan menjadi sebuah file text pada tempat penyimpanan internal android yang akan digunakan untuk membentuk pohon keputusan; (2) Pohon keputusan yang telah dibuat berbentuk teks yang menunjukkan atribut dan nilai atribut; (3) Pengujian menggunakan radio button yang menampilkan nilai masing-masing atribut dan hasil dari pohon keputusan akan ditampilkan melalui alert dialog pada android.
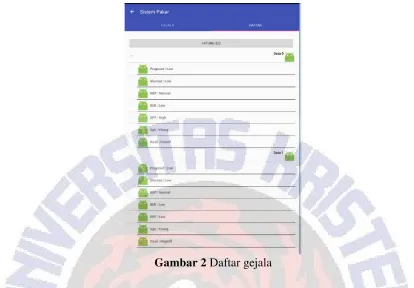
Data gejala harus dimasukkan terlebih dahulu melalui activity Data Gejala oleh pengguna sebagai acuan untuk membangun pohon keputusan. Pengguna juga dapat melihat data gejala yang telah dimasukkan sebelumnya dengan melakukan swipe pada activity data gejala. Nilai atribut ditampilkan pada komponen spinner android dan daftar gejala disimpan pada komponen
expandable list view. Gambar 2 menunjukkan data gejala pada halaman daftar gejala.
Pseudocode 1 Untuk memasukkan gejala kedalam expandable list view
1. Start
2. Input List
3. Read value pregnat
4. Add List child (value pregnant)
5. Read value glucose
6. Add List child (value glucose)
7. Read value dbp
8. Add List child (value dbp)
9. Read value bmi
10.Add List child (value bmi)
11.Read value dpf
12.Add List child (value dpf)
13.Read value age
14.Add List child (value age)
15.Read value class
16.Add List child (value class)
17.Input ExpandableListView
18.Set ExpandableListView = List
7
Gambar 2 Daftar gejala
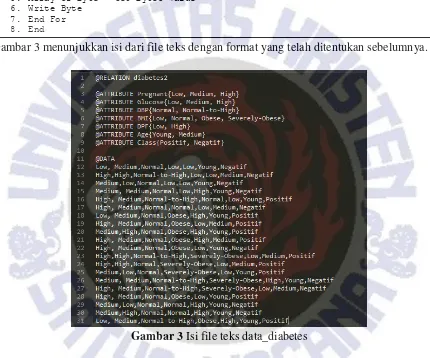
Informasi yang dibutuhkan oleh library weka untuk membangun pohon keputusan menggunakan algoritma ID3 adalah sebuah file teks yang berisi informasi tentang nama instances, atribut, dan dataset. Aplikasi akan mencari file dengan nama data_diabetes.txt pada direktori internal android. Jika file sudah ada sebelumnya maka file tersebut akan dihapus dan akan dibuat sebuah file baru dengan nama yang sama.
Pseudocode 2Untuk membuat file teks pada penyimpanan internal android
Setelah file teks dibuat program akan mengisi file teks tersebut dengan format yang telah ditentukan. Nama instances, atribut, dan dataset disimpan pada array bertipe data String yang akan
1. Start
8. Write to File = “@RELATION diabetes”
9. Write to File = “@ATTRIBUTE Pregnant{Low, Medium, High}”
10.Write to File = “@ATTRIBUTE Glucose{Low, Medium, High}”
11.Write to File = “@ATTRIBUTE DBP{Normal, High}”
12.Write to File = “@ATTRIBUTE BMI{Low, Normal, Obese, Severely-Obese}”
13.Write to File = “@ATTRIBUTE DPF{Low, High}”
14.Write to File = “@ATTRIBUTE Age{Young, Medium}”
15.Write to File = “@ATTRIBUTE Class{Positif, Negatif}”
16.Write to File = “@DATA”
17.End Function
8
diubah menjadi Byte array dan disimpan pada file teks menggunakan fungsi write dan flush pada kelas FileOutputStream.
Pseudocode 3 Untuk mengisi file teks
Gambar 3 menunjukkan isi dari file teks dengan format yang telah ditentukan sebelumnya.
Gambar 3 Isi file teks data_diabetes
Setelah file teks terisi dengan data yang dibutuhkan untuk membangun pohon keputusan, aplikasi akan mengisi instances menggunakan file tersebut melalui variabel trainingData.
Pseudocode 4 Untuk membaca file teks
1. Start
2. Read Data Diabetes
3. For i = 1 to Data Diabetes Length Do
4. String value = “Pregnat Value,Glucose Value,DBP Value,BMI Value,Age Value,
Class Value”
5. Array of Byte = Get Bytes value
6. Write Byte
7. End For
9
Setelah instances dibuat melalui variabel trainingData aplikasi akan membangun pohon keputusan ID3 menggunakan class Id3 dengan fungsi buildClassifier dengan 1 parameter
instances. Gambar 4 menunjukkan bentuk pohon keputusan yang telah dibuat dengan atribut BMI sebagai root.
Gambar 4 Bentuk Pohon Keputusan
Pseudocode 5 Untuk membuat pohon keputusan
Hasil dari metode prototyping pada penelitian ini menghasilkan dua hasil prototype. Dari hasil
prototype pertama, sistem menulis semua nilai atribut pada file teks dan menampilkan semua atribut pada activity pengujian ID3. Dengan cara seperti ini sistem hampir berjalan dengan baik
1. Start
2. Input File Reader
3. Try
4. File Reader = filename
5. Training Data = Reader Instances
6. Catch
5. Tree Build Classifier = Training Data
10
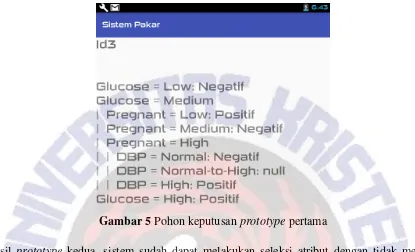
tapi ada masalah yang terjadi yaitu pada beberapa pengujian menghasilkan pohon keputusan dengan sebuah cabang yang mempunyai nilai atribut null atau kosong.
Gambar 5 Pohon keputusan prototype pertama
Hasil prototype kedua, sistem sudah dapat melakukan seleksi atribut dengan tidak menulis semua atribut yang ada tetapi menulis hanya pada atribut yang digunakan. Atribut akan disimpan dan digunakan nanti pada saat proses penulisan pada file teks. Pohon keputusan yang dihasilkan tidak mempunyai cabang dengan nilai atribut null atau kosong.
Gambar 6 Pohon keputusan prototype kedua
Cross validation yang merupakan salah satu teknik untuk menilai/memvalidasi keakuratan sebuah model yang dibangun berdasarkan dataset tertentu [6]. Pada pengujian ini menggunakan
11
yang digunakan sebanyak 700 data. Hasil dari pengujian didapatkan data yaitu jumlah instances
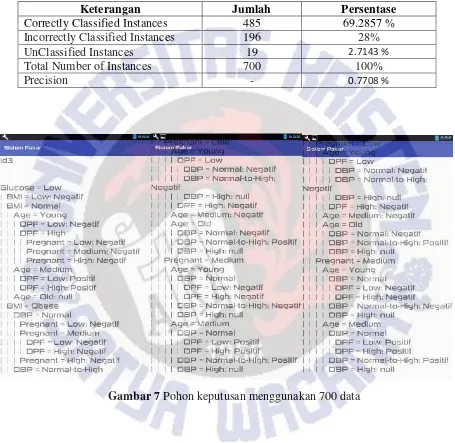
yang berhasil diklasifikasi ada 485 data, 196 data yang salah diklasifikasi, dan 19 data yang tidak dapat diklasifikasi dengan presisi 0.7708 %. Gambar 7, 8, 9, dan 10 menunjukkan hasil pohon keputusan dengan menggunakan 700 data.
Tabel 2 Hasil pengujian cross validation 10 fold
Keterangan Jumlah Persentase
Correctly Classified Instances 485 69.2857 %
Incorrectly Classified Instances 196 28%
UnClassified Instances 19 2.7143 %
Total Number of Instances 700 100%
Precision - 0.7708 %
12
Gambar 8 Pohon keputusan menggunakan 700 data
13
Gambar 10 Pohon keputusan menggunakan 700 data
5. Simpulan
Dalam penelitian ini dibuat aplikasi sistem pakar diagnosa penyakit diabetes melitus menggunakan algoritma ID3 berbasis Android dengan metode prototyping untuk menghasilkan pohon keputusan menggunakan dataset Pima Indians. Aplikasi menerima masukan berupa data gejala dari penyakit diabetes melitus. Sistem akan membentuk pohon keputusan berdasarkan data gejala, kemudian dibentuk sebuah pohon keputusan menggunakan library dari aplikasi data mining weka, dan melakukan pengujian terhadap pohon keputusan tersebut. Berdasarkan hasil pengujian menggunakan cross validation jumlah data yang berhasil diklasifikasi ada 485 data (69.2857 %), 196 data (28%) yang salah diklasifikasi, dan 19 data (2.7143 %) yang tidak dapat diklasifikasi dengan presisi 0.7708 %.
Pengembangan yang dapat dilakukan pada penelitian ini di kemudian hari adalah memperbaiki pohon keputusan yang dihasilkan karena pohon keputusan yang terbentuk menggunakan 700 dataset masih mempunyai cabang dengan nilai null dan menghasilkan data yang tidak dapat diklasifikasikan dan memperbaiki sistem jika ditemukan bug.
6. Daftar Pustaka
[1] Dahria, Muhammad. 2011. Pengembangan Sistem Pakar Dalam Membangun Aplikasi. Jurnal SAINTIKOM. 10 : 3
[2] Pima Indians Diabetes Dataset, UCI Machine Learning Repository, diambil dari http://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
14
Informatika (Teknomatika) 2:2,
http://news.palcomtech.com/wp-content/uploads/2012/08/DODY_TE020220121.pdf. (diakses tanggal 20 Juli 2016). [4] Pressman, Roger S., 2001, Software Engineering a Practitioner’s Approach, New York :
McGraw-Hill Higher Education
[5] Gill, Amandeep Kaur & Charanjit Singh. 2014. Implementation of NTRU Algorithm for the Security of N-Tier Architecture. International Journal of Computer Science and Information Technologies. 5 : 6
![Gambar 1 Bagan Prototype Model [4]](https://thumb-ap.123doks.com/thumbv2/123dok/3578844.1450911/11.612.96.521.275.523/gambar-bagan-prototype-model.webp)