1
UNIVERSITAS GADJAH MADA
JURUSAN ILMU KOMPUTER DAN ELEKTRONIKA
FAKULTAS MATEMATIKA DAN ILMU
PENGETAHUAN ALAM
Buku 3: BAHAN AJAR
ALGORITMA DAN STRUKTUR DATA II
Semester Ganjil/3 sks/MIK 2201
oleh
1. Drs. Janoe Hendarto, M.Kom.
2. Anifuddin Azis, S.Si., M.Kom.
Didanai dengan dana BOPTN P3-UGM
Tahun Anggaran 2013
2
TINJAUAN MATA KULIAH
Matakuliah ini adalah matakuliah wajib inti dan merupakan lanjutan dari matakuliah Algoritma dan Struktur Data I, matakuliah ini memberikan pengetahuan dan ketrampilan kepada mahasiswa untuk melakukan analisa terhadap permasalahan, perancangan algoritma dan menentukan struktur data yang tepat agar program komputer yang dihasilkan terstruktur dan efisien.
Pada matakuliah Algoritma dan Struktur Data II ini, lebih menitik beratkan pada struktur datanya, yaitu membahas macam-macam struktur data baik yang linear maupun yang non-linear dan melihat kelebihan dan kekurangannya serta membahas contoh permasalahannya, dan juga membahas paradigma pemrograman object oriented programming (OOP) yang merupakan paradigma pemrograman baru yang dikembangkan dari fasilitas tipe data turunan di dalam pemrograman terstruktur.
Object oriented di masa sekarang menjadi pilihan cara pemrograman yang sering digunakan karena pendekatannya yang cenderung lebih deskriptif dan terorganisir dengan baik. Hasilnya saat ini, banyak software-software yang lahir menggunakan prinsip OOP sehingga membuat metode ini menjadi sebuah metode yang umum dalam dunia pemrograman. Oleh sebab itu, OOP menjadi sebuah topik bahasan di dalam mata kuliah algoritma dan struktur data untuk memberikan perkembangan teknologi pemrograman yang teraktual kepada mahasiswa.
Tujuan Pembelajaran : Memberikan bekal kepada mahasiswa agar dapat melakukan perancangan dan pemilihan struktur data yang sesuai, implementasi dan melakukan analisis secara umum pada algoritma yang dibuat serta menguasai prinsip dasar pemrograman OOP.
Luaran/outcome : 1. Memiliki pengetahuan mengenai teori dan konsep dasar algoritma dan struktur data.
2. Dapat menganalisis, merancang dan meng-implementasikan struktur data linear seperti linked list, stack dan queue.
3. Dapat menganalisis, merancang dan meng-implementasikan struktur data non linear seperti matriks, multiple linked list dan tree.
4. Memiliki pengetahuan mengenai algoritma searching dan sorting serta dapat mengimple-mentasikan dalam program komputer.
3
5. Memiliki pengetahuan mengenai teori dan konsep dasar Object Oriented Programming (OOP).
6. Dapat membangun program komputer berbasis OOP.
Isi Materi :
BAB BahasanI Pengantar
1. Struktur data statis dan dinamis 2. Tipe data abstrak
II Linked List linear
1. Definisi Linked List 2. Operasi pada linked list 3. Penggunaan linked list 4. Variasi linked list III Stack
1. Definisi Stack 2. Operasi pada stack 3. Implementasi stack 4. Aplikasi stack
IV Queue
1. Definisi queue 2. Operasi pada queue 3. Implementasi queue 4. Aplikasi queue
V Struktur data non linear
1. Matriks, Array 2 Dimensi 2. Multiple linked list VI Struktur data Tree
1. Konsep dan implementasi 2. BST
3. AVL
VII Algoritma Sorting
1. Merge Sort dan Quick Sort 2. Heap Sort
VIII Algoritma Searching
1. Linear search dan Binary Search 2. Searching dengan fungsi hashing IX Pengenalan OOP
1. Pengenalan Bahasa Pemrograman Java 2. Prinsip dasar OOP
4
BAB I
PENGANTAR
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data statis dan dinamis serta tipe data abstrak yang merupakan konsep dasar dari matakuliah ini.
Manfaat
Dengan memahami struktur data statis dan dinamis serta tipe data abstrak, mahasiswa akan dapat memilih struktur data yang efisien dan sesuai dengan kebutuhan.
Relevansi
Materi ini menjadi dasar untuk mempelajari berbagai macam struktur data yang lebih kompleks baik yang linear maupun non linear.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memiliki pengetahuan tentang struktur data statis, dinamis dan tipe data abstrak dan mampu membuat program menggunakan tipe data array dan pointer untuk membangun struktur data linear.
Penyajian
1.1 Struktur Data Statis dan Dinamis
Struktur data dilihat dari kebutuhan memorynya dapat dikelompokan menjadi 2 macam yaitu struktur data statis dan dinamis, dimana
Struktur data statis : Struktur data yang kebutuhan/alokasi memorinya tetap (fixed size), tidak dapat dikembangkan atau diciutkan, biasanya menggunakan tipe data array
Struktur data dinamis : Struktur data yang kebutuhan memorynya sesuai data yang ada, dimana dapat dikembangkan atau diciutkan sesuai dengan kebutuhan. Pengelolaan alamat secara dinamis (dynamic address) dapat dilakukan dengan menggunakan tipe data pointer.
Array adalah suatu struktur data statis yang terdiri dari sejumlah elemen yang memiliki tipe data yang sama. Elemen-elemen array tersusun secara sekuensial dalam memori komputer. Array dapat berupa satu dimensi, dua dimensi, tiga dimensi ataupun banyak dimensi (multi dimensi).
Larikan dibentuk menggunakan Array Satu dimensi, yaitu tidak lain adalah kumpulan elemen-elemen identik yang tersusun dalam satu baris. Elemen-elemen tersebut memiliki tipe
5
data yang sama, tetapi isi dari elemen tersebut bisa berbeda.
Elemen ke- 0 1 2 3 4 5 6 7 8 9 Nilai 23 34 32 12 25 14 23 12 11 10
Berikut contoh program mengisi larik X dengan bilangan random kemudian menentukan maximum dan minimum.
#include<iostream> #include<stdlib.h> #include<conio.h> using namespace std; main() {
int i, n, max, min, x[100];
cout<<"masukkan banyak data : ";cin>>n; srand((unsigned)time(NULL)); for (i=1;i<=n;i++) { x[i]=rand()%100+1; cout<<x[i]<<" "; if (i%10==0) cout<<endl; } cout<<endl; max=x[1];min=x[1]; for (i=2;i<=n;i++){ if (x[i]>max) max=x[i]; else if(x[i]<min) min=x[i]; }
cout<<"data max adalah : "<<max<<endl; cout<<"data min adalah : "<<min<<endl; }
Pemakaian array tidak selalu tepat untuk program-program terapan yang kebutuhan pengingatnya selalu bertambah selama eksekusi program tersebut. Untuk itu diperlukan satu tipe data yang dapat digunakan untuk mengalokasikan (membentuk) dan mendealokasikan (menghapus) pengingat secara dinamis, yaitu sesuai dengan kebutuhan pada saat suatu program dieksekusi. Oleh karena itu akan dijelaskan suatu tipe data yang dinamakan sebagai
tipe Data Pointer.
Nama peubah yang kita gunakan untuk mewakili suatu nilai data sebenarnya merupakan / menunjukkan suatu lokasi tertentu dalam pengingat komputer di mana data yang diwakili oleh tipe data tersebut disimpan. Pada saat sebuah program dikompilasi maka
6
compiler akan melihat pada bagian deklarasi peubah untuk mengetahui nama-nama peubah apa saja yang digunakan, sekaligus mengalokasikan atau menyediakan tempat dalam memory untuk menyimpan nilai data tersebut. Dari sini kita bisa melihat bahwa sebelum program dieksekusi, maka lokasi-lokasi data dalam memory sudah ditentukan dan tidak dapat diubah selama program tersebut dieksekusi. Peubah-peubah yang demikian itu dinamakan sebagai
Peubah Statis (Static Variable).
Dari pengertian diatas kita perhatikan bahwa sesudah suatu lokasi pengingat ditentukan untuk suatu nama peubah maka dalam program tersebut peubah yang dimaksud akan tetap menempati lokasi yang telah ditentukan dan tidak mungkin diubah. Dengan melihat pada sifat-sifat peubah statis maka bisa dikatakan bahwa banyaknya data yang bisa diolah adalah sangat terbatas. Misalnya peubah dalam bentuk Array yang dideklarasikan sbb : int matriks[100][100], maka peubah tersebut hanya mampu menyimpan data sebanyak 100x100=10000 buah data. Jika kita tetap nekat memasukkan data pada peubah tersebut setelah semua ruangnya penuh maka eksekusi program akan terhenti dan muncul error. Memang kita dapat mengubah deklarasi program diatas dengan memperbesar ukurannya. Tetapi jika setiap kali kita harus mengubah deklarasi dari tipe daa tersebut sementara, banyaknya data tidak dapat ditentukan lebih dahulu, maka hal ini tentu merupakan pekerjaan yang membosankan.
Sekarang bagaimana jika kita ingin mengolah data yang banyaknya kita tidak yakin sebelumnya bahwa larik yang telah kita deklarasikan sebelumnya mampu menampung data yang kita miliki ? Untuk menjawab pertanyaan di atas maka bahasa pemrograman menyediakan satu fasilitas yang memungkinkan kita untuk menggunakan suatu peubah yang disebut dengan Peubah Dinamis (Dynamic Variable). Peubah dinamis adalah peubah yang dialokasikan hanya pada saat diperlukan, yaitu setelah program dieksekusi. Dengan kata lain, pada saat program dikompilasi, lokasi untuk peubah belum ditentukan sebagai peubah dinamis. Hal ini membawa keuntungan pula, bahwa peubah-peubah dinamis tersebut dapat dihapus pada saat program dieksekusi sehingga ukuran memory selalu berubah. Hal inilah yang menyebabkan peubah tersebut dinamakan sebagai peubah dinamis.
Pada peubah statis, isi dari peubah adalah data sesungguhnya yang akan diolah. Pada peubah dinamis nilai peubah adalah alamat lokasi lain yang menyimpan data sesungguhnya. Dengan demikian data yang sesungguhnya tidak dapat dimasup secara langsung. Oleh karena itu, peubah dinamis dikenal dengan sebutan POINTER yang artinya menunjuk ke sesuatu, yang berisi adress/alamat dalam RAM.
7
Deklarasi variabel bertipe pointer : tipe data *namavariabel;
Contoh : int *p
Maka variabel p menunjuk suatu alamat pada memori. Jika ada variabel A bertipe integer, maka alamat variabel tersebut pada memori bisa diketahui dengan pernyataan &A. Variabel pointer p, bisa menunjuk ke alamat variabel A, yaitu dengan pernyataan :
p = &A;
atau dengan memesan sendiri memory baru yaitu dengan perintah p = new int;
Sedangkan untuk mengetahui isi dari variabel yang alamatnya ditunjuk oleh p, dengan pernyataan *p;
Contoh Program menuliskan alamat dan nilai dari suatu variabel pointer :
#include<iostream> using namespace std; main(){ int a,*b; a=10; b=&a; c=new int; *c=25; cout<<b<<" "<<*b<<" "<<c; getchar(); }
1.2 Tipe Data Abstrak
Menurut Wikipedia, Tipe data abstrak (TDA) atau lebih dikenal dalam bahasa Inggris sebagai Abstract data type (ADT) merupakan model matematika yang merujuk pada sejumlah bentuk struktur data yang memiliki kegunaan atau perilaku yang serupa; atau suatu tipe data dari suatu bahasa pemrograman yang memiliki semantik yang serupa. Tipe data abstrak umumnya didefinisikan tidak secara langsung, melainkan hanya melalui operasi matematis tertentu sehingga membutuhkan penggunaan tipe data tersebut meski dengan resiko kompleksitas yang lebih tinggi atas operasi tersebut.
Dengan kata lain Tipe data abstrak (ADT) dapat didefinisikan sebagai model matematika dari objek data yang menyempurnakan tipe data dengan cara mengaitkannya dengan fungsi-fungsi yang beroprasi pada data yang bersangkutan. Merupakan hal yang sangat penting untuk mengenali bahwa operasi-operasi yang akan dimanipulasi data pada objek yang bersangkutan termuat dalam spesifikasi ADT. Sebagai contoh, ADT HIMPUNAN didefinisikan sebagai koleksi data yang diakses oleh operasi-operasi
8
himpunan seperti penggabungan (UNION), irisan (INTERSECTION), dan selisih antar-himpunan (SET DIFFERENCE).
Implementasi dari ADT harus menyediakan cara tertentu untuk merepresentasikan unsur tipe data (seperti matrix) dan cara untuk mengimplementasikan operasi -operasi matrix. Secara tipikal, kita akan mendeskripsikan operasi-operasi pada ADT dengan algoritma (logika berfikir) tertentu. Algoritma ini biasanya berupa urutan instruksi yang menspesifikasi secara tepat bagaimana operasi-operasi akan dilakukan/dieksekusi oleh komputer.
Kita sekarang akan membahas lebih konkret tentang apa itu ADT. Pada dasarnya, ADT adalah tipe data tertentu yang didefinisikan oleh pemrogram untuk kemudahan pemrograman serta untuk mengakomodasi tipe-tipe data yang tidak secara spesifik diakomodasi oleh bahasa pemrograman yang digunakan. Maka, secara informal dapat dinyatakan bahwa ADT adalah :
1. Tipe data abstrak ADT pertama kali ditemukan oleh para ilmuan komputer utuk memisahkan struktur penyimpanan dari perilaku tipe data yang abstrak seperti misalnya, Tumpukan(Stack) serta antrian(Queue). Seperti kita duga, pemrogram tidak perlu tahu bagaimana Tumpukan(Stack) perubahan inplementasi ADT tidak mengubah program yang menggunakannya secara keseluruhan, dengan catatan bahwa interface ADT tersebut dengan ‘dunia luar’ tetap dipertahankan.
2. Pemakaian dan pembuatan ADT dapat dilakukan secara terpisah. yang perlu dibicarakan antara pembuat dan pengguna ADT adalah interface ADT yang bersangkutan.
3. ADT merupakan sarana pengembangan sistem yang bersifat modular, memungkinkan suatu sistem dikembangkan oleh beberapa orang anggota tim kerja dimana masing-masing anggota tim bisa melakukan bagiannya sendiri-sendiri dengan tetap mempertahankan keterpaduannya dengan anggota tim yang lain.
Dalam hal ini perlu dibedakan antara pengertian struktur data dan ADT. Struktur data hanya memperlihatkan bagaimana data-data di organisir, sedangkan ADT bercakupan lebih luas, yaitu memuat/mengemas struktur data tertentu sekaligus dengan operasi-operasi yang dapat dilakukan pada struktur data tersebut. Dengan demikian, definisi umum tentang ADT di atas dapat diperluas sebagai berikut :
9 Implementasi ADT = {Struktur Data (Operasi-operasi yang dapat dilakukan terhadap Struktur Data)}
Contoh ADT
Tipe jadi (built-in): boolean, integer, real, array, dll
Tipe buatan (user-defined): stack, queue, tree, dll
ADT Built-in:
Boolean
Nilai: true dan false
Operasi: and, or, not, xor, dll Integer
Nilai: Semua bilangan
Operasi: tambah, kurang, kali,bagi, dll
ADT buatan (user-defined) : Stack (tumpukan)
Nilai : elemen dalam stack Operasi: Initstack, Push, Pop
Queue (antrian)
Nilai: elemen dalam Queue
Operasi: InitQueue, Enqueue, Dequeue.
Tree (pohon)
Nilai: elemen dalam pohon
Operasi: insert, delete, find, traverse
10 Penutup
Latihan Soal
1. Tulislah output dari cuplikan program berikut :
#include<iostream> using namespace std; main(){ int a,*b, *c; a=10; b=&a; cout<<*b<<endl; c=new int; *c=25; b=c; cout<<*b<<endl; getchar(); }
2. Diketahui subprogram berikut : void buatA(list &l)
{ int i,n; list b,t; n=10;
for (i=1;i<=n;i++){
b=new node; b->next=NULL; b->data=(i+i*i*2)%40; cout<<b->data<<" "; if (l==NULL) l=b;
else if (b->data%2==0) {b->next=l;l=b;} else {
t=l;
while (t->next!=NULL) t=t->next; t->next=b; } } } Jika dipanggil list p; BuatA(p); cetakdata(p); Maka tulis outputnya.
11
BAB II
LINKED LIST LINEAR
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data linked list, operasi-operasi pada linked list, dan contoh penggunaannnya.
Manfaat
Dengan memahami linked list, mahasiswa akan mudah mengimplementasikan struktur data yang lain, seperti stack, queue, dan tree.
Relevansi
Materi ini menjadi dasar untuk mempelajari struktur data yang lain, seperti stack, queue, dan tree.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memahami dan mampu membuat program operasi-operasi pada linked list.
Penyajian
Struktur data linear adalah kumpulan komponen-komponen yang tersusun membentuk satu garis linear. Bila komponen-komponen ditambahkan (atau dikurangi), maka struktur-struktur tersebut berkembang (atau menyusut). Pemakaian struktur-struktur data yang tepat di dalam proses pemrograman akan menghasilkan algoritma yang lebih jelas dan tepat , sehingga menjadikan program secara keseluruhan lebih efisien dan sederhana.
Struktur data linear yang akan dibahas pada bab ini dan bab-bab selanjutnya adalah linear linked list serta stack dan queue.
2.1 Definisi Linked List
Linked list adalah kumpulan data yang bertipe sama dengan setiap elemen berisi dua bagian, yaitu : data and link (next). Nama linked list sama dengan nama suatu variable bertipe pointer.
Gambar 2.1 menunjukkan linked list nilai yang memiliki empat elemen (node). Linked list kosong adalah pointer null, seperti pada Gambar 1.1.
12
Gambar 2.1 Linked List
Contoh deklarasi linked list yang berisi nilai integer : typedef struct elmt {
int isi; elmt *next; }elemen, nodptr; typedef struct { elemen *first; }list;
2.2 Operasi pada linked list
Operasi-operasi pada linked list adalah : 1. Buat linked list
2. Sisip node pada linked list 3. Hapus node pada linked list 4. Kunjungi node pada linked list 1. Operasi Buat list
Operasi ini untuk membuat sebuah linked list. Linked list yang dideklarasikan merupakan list yang masih kosong.
Prosedurnya :
void buatList(list *L) { (*L).first = NULL; }
2. Operasi sisip node pada linked list.
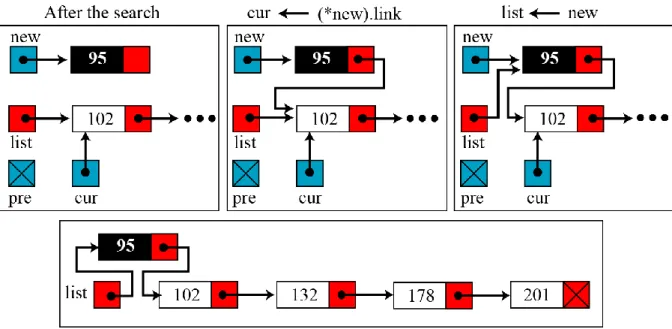
Operasi ini untuk menambkan data baru ke dalam linked list. Data tersimpan di dalam node baru. Ada 3 cara penambahan data baru ke dalam list, yaitu :
13
a. Penambahan di depan
Pada cara ini, node baru akan diletakkan di tempat paling depan pada linked list. Gambar 2.2 menunjukkan proses penambahan node di awal list.
Gambar 2.2 Penyisipan node di awal list (Sisip depan) Prosedurnya :
void sisipDepan (list *L, int IB) { elemen *NB;
NB = (elemen *) malloc (sizeof (elemen)); NB->isi = IB; NB->next = (*L).first; (*L).first = NB; NB = NULL; free(NB); }
b. Penambahan node di belakang
Pada cara ini, node baru akan diletakkan di akhir list. Untuk menyisipkan node di akhir list, diperlukan pointer bantu untuk mencari alamat node yang terakhir (paling belakang). Proses penambahan node di akhir list, setelah node paling akhir ditemukan, ditunjukkan pada Gambar 2.3.
14
Gambar 2.3 Penyisipan di akhir list Prosedurnya :
void sisipBlk (list *L, int IB) { elemen *NB;
NB = (elemen *) malloc (sizeof (elemen)); NB->isi = IB; NB->next = NULL; if ((*L).first==NULL){ (*L).first =NB; } else { elemen *p;
p = (elemen *) malloc (sizeof (elemen)); p=(*L).first;
while (p->next != NULL){ p = p->next; } p->next=NB; NB->next=NULL; } }
15
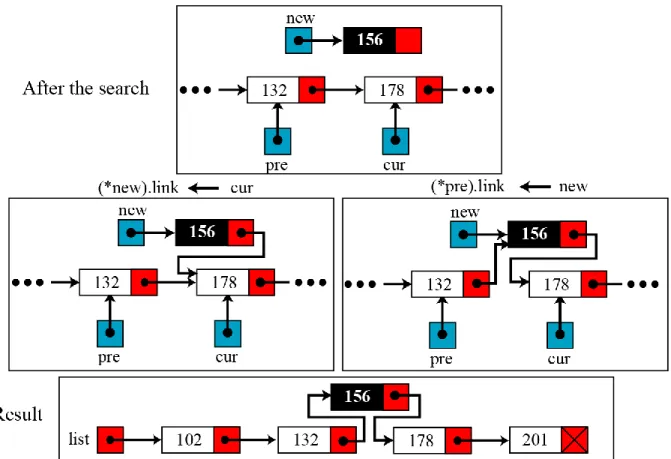
c. Penyisipan node di tempat tertentu
Pada penyisipan ini, node baru akan diletakkan setelah node tertentu, misalkan setelah node yang datanya terbesar yang lebih dari data node baru (pada kasus linked list dengan data diletakkan secara terurut naik). Proses penyisipan seperti pada Gambar 2.4.
Gambar 2.4 Proses penyisipan node secara terurut naik Prosedurnya :
void sisipUrut(list *L, int IB) { elemen *NB;
NB = (elemen *) malloc (sizeof (elemen)); NB->isi = IB;
NB->next = NULL;
if (((*L).first == NULL) ||(IB < (*L).first->isi)){ NB->next = (*L).first;
(*L).first = NB; }
else {
elemen *p ;
p = (nodptr *) malloc (sizeof (nodptr)); p=(*L).first;
while ((p->next != NULL) && (p->next->isi < IB)){ p = p->next;
16
NB->next = p->next; p->next = NB; }
}
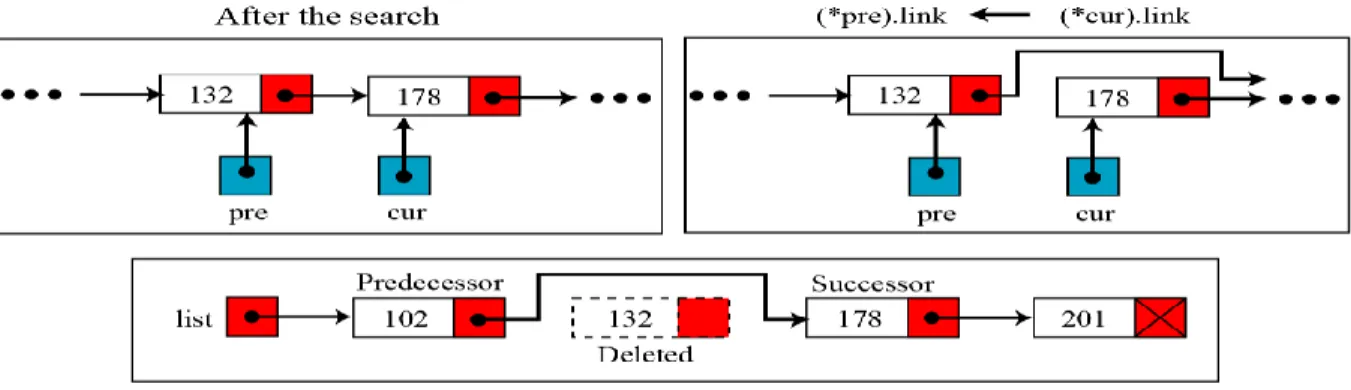
3. Operasi Hapus Node
Operasi ini untuk menghapus node pada linked list. Sebelum node dihapus, ada proses pencarian untuk mencari node yang dihapus. Sehingga diperlukan pointer bantu, yang akan menunjukkan alamat di depan alamat node yang akan dihapus. Gambar 2.5 berikut ini menunjukkan prose penghapusan node. Sebelum dihapus, alamat yang ditunjuk oleh node yang akan dihapus, akan ditunjuk pula oleh pointer bantu.
Gambar 2.5 Proses penghapusan node
Jika setelah dihapus, linked list jadi kosong, maka linked list diset null. 4. Operasi Kunjungi Node
Pada operasi ini, dilakukan kunjungan pada linked list, dari node paling depan ke node paling akhir.
Gambar 2.6 Kunjungan pada linked list Prosedurnya :
void cetakList (list L) { if (L.first != NULL) { elemen *p;
17 while (p != NULL){ cout<<p->isi<<endl; p = p->next; } } }
2.3 Penggunaan Linked List
Linked list adalah struktur data yang sangat efisien untuk pengurutan list. Linked list adalah stuktur data dinamis yang bisa ditambah elemen dengan mudah. Node juga dengan mudah dihaus tanpa menukar tempat, seperti pada array.
Struktur data linked list digunakan juga sebagai implementasi pada struktur data stack, queue, tree, dan graph.
2.4 Variasi Linked List
1. Doubly-linked lists: Tiap list node menyimpan referensi node sebelum dan sesudahnya. Berguna bila perlu melakukan pembacaan linked list dari dua arah.
Gambar 2.7 Doubly-linked list Deklarasi struktur data Doubly-linked list :
struct Node { int isi;
Node *prev, *next; };
A. Operasi Menambah Data
a. Menambah data pada Doubly linked list yang kosong : pNew = (struct node *) malloc(sizeof(struct dllnode)); pNew -> data = 39;
pNew -> prev = pHead; pNew -> next = pHead;
18
pHead = pNew;
b. Menambah data di tengah Doubly linked list
pNew = (struct node *) malloc(sizeof(struct dllnode)); pNew -> data = 64;
pNew -> prev = pCur;
pNew -> next = pCur -> next; pCur -> next -> prev = pNew; pCur -> next = pNew;
c. Menambah data di akhir Doubly linked list
pNew = (struct node *) malloc(sizeof(struct dllnode)); pNew -> data = 84;
pNew -> prev = pCur;
pNew -> next = pCur -> next; pCur -> next = pNew;
B. Menghapus node pada Doubly linked list if (pCur -> left == NULL){
//menghapus node paling depan pHead = pCur -> next;
pCur -> next -> prev = NULL; {
else {
//menghapus node di tengah atau belakang linked list pCur -> prev -> next = pCur -> next;
pCur -> next -> prev = pCur -> prev; }
free(pCur).
2. Circular-linked lists: Node terakhir menyimpan referensi node pertama. Dapat diterapkan dengan atau tanpa header node.
19
Gambar 2.8 Circular-linked list
Penutup Latihan Soal
1. Jelaskan tentang linked list linear!
2. Apa yang dibutuhkan pada linked list linear dan apa keunggulannya dibanding struktur data larikan/menggunakan tipe array ?
3. Tuliskan program untuk menyisipkan node baru setelah suatu node tertentu. 4. Tuliskan program untuk menyisipkan node baru sebelum suatu node tertentu..
20
BAB III
STACK
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data stack, operasi-operasi pada stack, dan contoh penggunaannnya.
Manfaat
Dengan memahami stack, maka mahasiswa akan bisa menerapkan stack pada suatu permasalahan, seperti antara lain pada algoritma pelacakan DFS (Depth First Search).
Relevansi
Materi ini terkait dengan materi berikutnya seperti struktur data Tree dan juga pada materi kuliah Analisis dan Desain Algoritma 1 dan 2, seperti algoritma DFS.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memahami dan mampu membuat program untuk operasi-operasi pada stack dan mampu menggunakan stack untuk mengkonversi notasi infix menjadi postfix.
Penyajian
3.1 Definisi Stack
Stack adalah struktur data linear di mana penambahan/pengurangan elemen dilakukan di satu ujung saja, sehingga elemen yang pertama ditambahkan, akan diambil terakhir. Sehingga stack dikenal jug sebagai struktur last in first out (LIFO). Contoh stack (tumpukan) dalam kehidupa sehari-hari seperti pada Gambar 3.1
Gambar 3.1 Contoh stack (tumpukan) dalam kehidupan sehari-hari
3.2 Operasi pada Stack
21
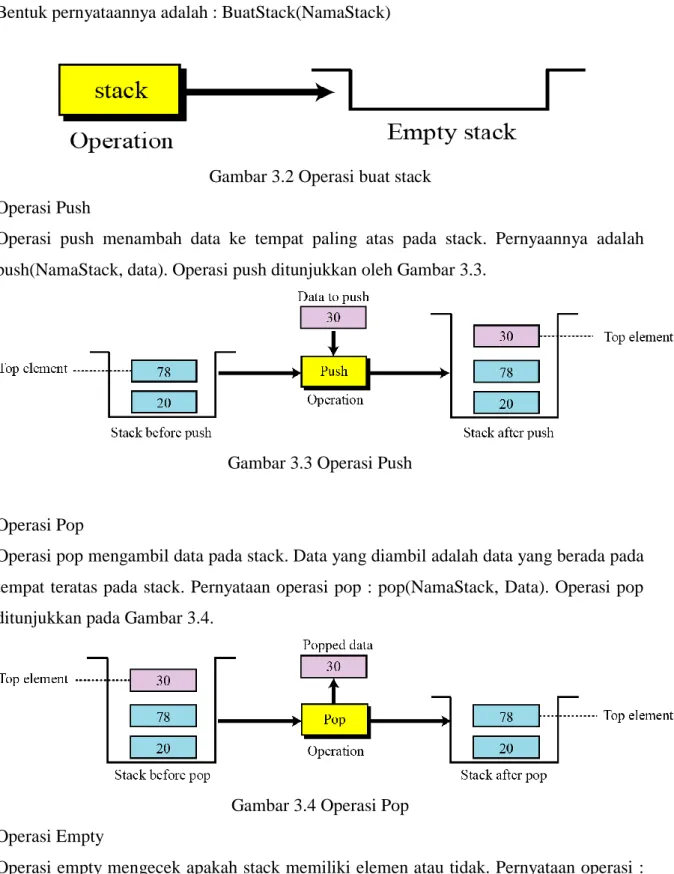
1. Operasi Buat Stack
Operasi buat stack menciptakan stack kosong, yaitu stack yang belum memiliki elemen. Bentuk pernyataannya adalah : BuatStack(NamaStack)
Gambar 3.2 Operasi buat stack 2. Operasi Push
Operasi push menambah data ke tempat paling atas pada stack. Pernyaannya adalah push(NamaStack, data). Operasi push ditunjukkan oleh Gambar 3.3.
Gambar 3.3 Operasi Push
3. Operasi Pop
Operasi pop mengambil data pada stack. Data yang diambil adalah data yang berada pada tempat teratas pada stack. Pernyataan operasi pop : pop(NamaStack, Data). Operasi pop ditunjukkan pada Gambar 3.4.
Gambar 3.4 Operasi Pop 4. Operasi Empty
Operasi empty mengecek apakah stack memiliki elemen atau tidak. Pernyataan operasi : empty(NamaStack). Jika stack kosong, maka operasi akan mengembalikan nilai true, jika tidak maka nilainya false.
22 3.3 Implementasi Stack
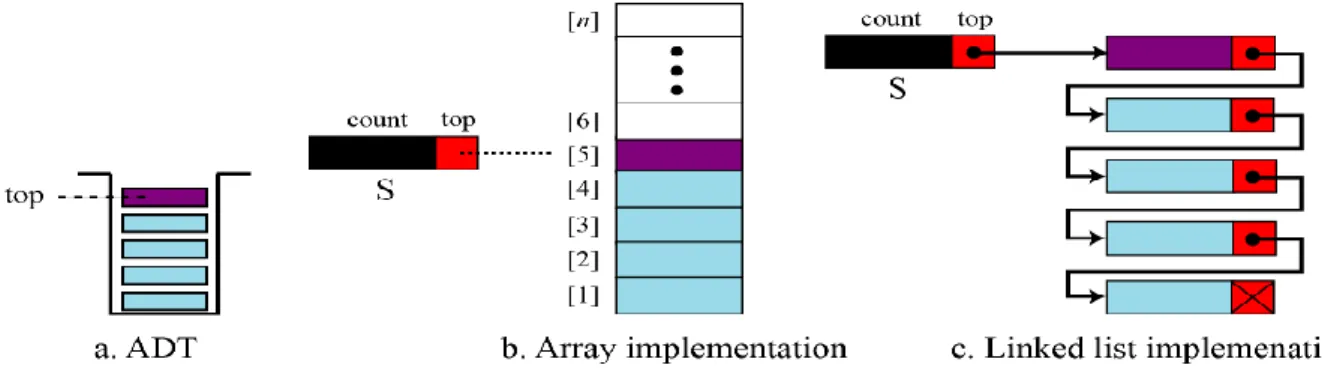
Struktur Data Stack bisa diimplementasikan dengan 2 cara, yaitu dengan array dan dengan linked list. Pada implementasi dengan array, digunakan array of record. Setiap record memiliki dua field yaitu field data, untuk menyimpan nilai data, dan top untuk menyimpan indeks tempat paling atas pada stack. Sedangkan pada implementasi dengan linked list, setiap node juga berupa record untuk menyimpan data dan penunjuk ke alamat node lain. Implementasi stack ditunjukkan pada Gambar 3.5.
Gambar 3.5 Implementasi Stack
1. Implementasi dengan array
Stack dapat diimplementasi dengan suatu array dan suatu integer top yang mencatat indeks dalam array dari top of the stack. Untuk stack kosong maka top berharga -1. Saat terjadi push, lakukan dengan increment counter top, dan tulis ke dalam posisi top tsb dalam array. Saat terjadi pop, lakukan dengan decrement counter top.
Deklarasi struktur data stack menggunakan array, missal stack berisi data integer dengan maksimum banyaknya elemen 100 :
typedef struct{ int TOP; int data[99]; }stack;
A. Prosedur Buat Stack
void buatStack(stack &S){ int i;
S.TOP=-1; }
B. Prosedur Push
23
S.TOP= S.TOP + 1; S.data[S.TOP] = IB; }
C. Prosedur Pop
void pop(stack &S, int &EB){ if (stackKosong(S)!= 1){ EB = S.data[S.TOP]; S.TOP= S.TOP-1; } } D. Fungsi Empty int stackKosong(stack S){ int hasil; if (S.TOP== -1) { hasil = 1; } else hasil = 0; return hasil; }
2. Implementasi dengan linked list
Secara lojik, sebuah STACK dapat digambarkan sebagai list linier yang setiap elemennya adalah :
Type ElemenStack <Info : InfoType, Next : address >
Type Stack <top : address>
Dalam bahasa C, deklarasi stack dengan linked list adalah : typedef struct elmt *alamatelmt;
typedef struct elmt { int isi;
alamatelmt next; }Tstack;
24
A. Prosedur Buat Stack void buatStack(stack *S){ (*S) = NULL;
}
B. Prosedur Push
void push(stack *S, int IB){ Tstack *NB;
NB = (Tstack *) malloc (sizeof (Tstack)); NB->isi = IB; NB->next = NULL; if ((*S) == NULL) { (*S)=NB; } else { NB->next=(*S); (*S)=NB; } } C. Prosedur Pop
void pop(stack *S,int &EB){ Tstack *p; EB = (*S)->isi; p = (*S); if ((*S)!=NULL){ (*S)=(*S)->next;} free(p); }
D. Fungsi Stack Kosong
int stackKosong(stack S){ int hasil;
if (S == NULL) { hasil = 1; }
25
else hasil = 0; return hasil; }
3.4 Aplikasi Stack
Terdapat banyak penggunaan stack dalam algoritma atau suatu permasalahan. Misal pada algoritma pelacakan DFS (Depth First Search), untuk mengevaluasi suatu ekspresi dalam notasi postfix/prefix, untuk mengubah suatu ekspresi dalam notasi infix menjadi postfix/prefix.
A. Algoritma evaluasi ekspresi dalam notasi postfix
Berikut adalah langkah-langkah mengevaluasi ekspresi dalam notasi postfix. 1. Inisialisasi stack
2. Ulangi langkah berikut sampai akhir ekspresi
a) Ambil token (const, var, operator) pada ekspresi b) Jika operan, push ke dalam stack
c) Jika operator Lakukan :
i. Pop 2 nilai dari stack
ii. Operasikan denga operator ke dua nilai tersebut iii. Hasilnya di push ke stack
3. Pada saat ekspresi sudah habis, maka nilai terakhir yang ada di stack adalah nilai dari ekspresi tersebut.
B. Algoritma konversi ekspresi dalam infix ke postfix 1. Inisialisasi stack operator
2. Selama ekspresi masih ada :
a. Ambil token dari ekspresi infix b. Jika token :
i. "(" : push ke dalam stack
ii. “)” : pop dan tampilkan elemen stack sampai ditemui “(“, jangan ditampilkan
26
Jika operator memiliki prioritas lebih tinggi daripada top stack, maka push token ke dalam stack, jika tidak pop dan tampilkan top stack dan ulangi perbandingan dengan top stack
iv. operand tampilkan
3. Ketika akhir dari infix sudah diperoleh, pop dan tampilkan stack sampai stack kosong.
Penutup Latihan Soal
1. Tulis program non-rekursif untuk membalik string menggunakan stack. 2. Jelaskan ekspresi prefix, infix, and postfix dengan contoh.
27
BAB IV
QUEUE
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data queue, operasi-operasi pada queue, dan contoh penggunaannnya.
Manfaat
Dengan memahami queue, maka mahasiswa akan bisa menerapkan queue pada suatu permasalahan, seperti antara lain pada algoritma pelacakan BFS (Breadth First Search) dan pada masalah antrian yang lain.
Relevansi
Materi ini terkait dengan materi selanjutnya seperti Tree dan juga materi pada kuliah Analisis dan Desain Algoritma 1 dan 2, seperti algoritma BFS.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memahami dan mampu membuat program untuk operasi-operasi pada queue dan mampu menggunakan queue pada suatu permasalahan.
Penyajian
4.1 Definisi Queue
Queue adalah struktur data linear seperti Stack, hanya saja penambahan dan penghapusan elemen dilakukan pada tempat yang berbeda. Penambahan elemen dilakukan pada bagian belakang Queue, sedangkan penghapusan elemen dilakukan pada bagian depan Queue. Mekanisme ini dikenal sebagai First-In-First-Out (FIFO). Beberapa contoh aplikasi queue atau antrian adalah : antrian printer, antrian kasir, dsb.
4.2 Operasi pada Queue
Terdapat lima operasi dasar pada queue : Buat Queue, enqueue, dequeue, kosong, dan penuh.
1. Buat Queue
Operasi ini untuk membuat queue kosong. Formatnya adalah : BuatQueue(NamaQueue)
28
2. Queue Kosong
Operasi ini untuk mengecek apakah queue kosong atau tidak. Formatnya : Kosong(NamaQueue).
3. QueuePenuh
Operasi ini untuk mengecek apakah queue penuh atau tidak (dalam hal ini, queue yang diimplementasikan dengan array). Formatnya : Penuh(NamaQueue).
4. Operasi Enqueue
Operasi ini untuk menambahelemen baru pada queue, dan diletakkan di posisi paling belakang dari queue. Formatnya : Enqueue(NamaQueue, Nilai).
Gambar 4.2 Operasi Enqueue 5. DeQueue
Operasi ini untuk mengambil elemen queue yang berada di posisi paling depan. Formatnya : Dequeue(NamaQueue, Nilai).
Gambar 4.3 Operasi Dequeue
4.3 Implementasi Queue
Struktur data queue dapat diimplementasikan menggunakan array atau linked list .Gambar 3.4 menggambarkan implementasi queue dengan array dan linked list. Pada implementasi dengan array, digunakan sebuah array of record dengan setiap record terdiri dari 3 field, dan salah satu field untuk menyimpan data.
Pada implementasi dengan linked list juga mirip: terdapat node yang berupa record yang memiliki dua field berupa pointer untuk menunjuk elemen depan dan belakang.
29
Gambar 4.4 Implementasi Queue dengan array dan llinked list
1. Implementasi dengan Array – cara naive
Pada metode ini, elemen pada suatu array disimpan dengan item terdepan pada index nol dan item terbelakang pada index belakang. Dengan cara ini, operasi Enqueue mudah & cepat, yaitu dengan menaikkan nilai belakang. Sedangkan Dequeue tidak efisien, karena setiap elemen harus digeserkan ke depan. Akibatnya: waktu menjadi O(N).
Deklarasi struktur data queue dengan array :
typedef struct {
int depan; int blk; int data[30]; }queue;
A. Operasi Buat Queue.
Operasi ini untuk membuat queue kosong, yaitu queue yang belum memiliki elemen. void buatQueue(queue *Q){
(*Q).depan =-1; (*Q).blk =-1; }
B. Fungsi Kosong
Fungsi ini untuk mengecek apakah suatu queue kosong atau tidak. Jika kosong, maka fungsi akan mengembalikan nilai 1, jika tidak kosong akan mengembalikan nilai 0.
30 int kosongQueue(queue Q){ int hasil =0; if (Q.depan==-1) { hasil =1; } return hasil; } C. Fungsi Penuh
Fungsi ini untuk mengecek apakah queue penuh, yaitu indeks belakang sudah mencapai maksimum atau tidak.
int penuhQueue(queue Q){ int hasil =0; if (Q.blk==29) { hasil =1; } return hasil; } D. Operasi Enqueue
Operasi ini untuk menambahkan elemen baru ke dalam queue. Elemen baru diletakkan di belakang, sehingga indeks belakang dinaikkan 1.
void enQueue(queue *Q,int db){ if (kosongQueue(*Q)==1){ (*Q).depan =0; (*Q).blk =0; (*Q).data[0]=db; } else { if (penuhQueue(*Q)!= 1){ (*Q).blk =(*Q).blk +1; (*Q).data[(*Q).blk]=db; }
31
else {
cout<<"Queue penuh "<<endl; }
} }
E. Operasi Dequeue
Operasi ini untuk mengambil elemen pada queue, yaitu elemen pada posisi depan. Setelah elemen diambil, dilakukan pergeseran elemen queue pada array.
void deQueue(queue *Q, int *da){ if (kosongQueue(*Q)==1){
cout<<"Queue kosong, tdk bisa diambil"<<endl; } else { if ((*Q).blk == 0){ *da =(*Q).data[0]; (*Q).depan =-1; (*Q).blk =-1; } else { int i; *da =(*Q).data[(*Q).depan]; for (i=((*Q).depan+1);i<=(*Q).blk;i++){ (*Q).data[i-1]=(*Q).data[i]; } (*Q).blk=(*Q).blk-1; } } }
Sehingga terjadi pergeseran pada semua elemen queue, Terdapat ide lain, yaitu menggunakan indeks depan untuk mencatat indeks terdepan, sehingga Dequeue dilakukan dengan menaikkan depan dan waktu Dequeue tetap O(1). Namun permasalahan yang timbul
32
adalah, ada suatu keadaan setelah proses Dequeue, indeks belakang = panjang array -1, sehingga queue seperti kosong, padahal masih bias diisi.
Solusinya adalah dengan menggunakan wraparound untuk menggunakan kembali sel-sel di awal array yang sudah kosong akibat dequeue. Jadi setelah increment, jika index depan atau belakang keluar dari array maka ia kembali ke 0.
2. Implementasi dengan List Linear
Pada implementasi Queue (Antrian) dengan list linier, maka : 1. Dikenali elemen pertama (depan) dan elemen terakhirnya (belakang).
2. Aturan penyisipan dan penghapusan elemennya didefinisikan sebagai berikut : - Penyisipan selalu dilakukan setelah elemen terakhir.
- Penghapusan selalu dilakukan pada elemen pertama.
3. Satu elemen dengan elemen lain dapat diakses melalui informasi Next. Deklarasi Queue (Antrian) dengan list linier :
typedef struct node { int isi; node *next; }Tqueue; typedef struct { Tqueue *depan; Tqueue *blk; }Queue;
A. Operasi Buat Queue void buatQueue(Queue *Q){ (*Q).depan = NULL; (*Q).blk = NULL; }
B. Operasi Enqueue
void enQueue(Queue *Q, int IB){ Tqueue *NB;
NB = (Tqueue *) malloc (sizeof (Tqueue)); NB->isi = IB;
33 if ((*Q).depan == NULL) { (*Q).depan=NB;} else {(*Q).blk->next = NB;} (*Q).blk =NB; NB= NULL; } C. Operasi Dequeue
void deQueue(Queue *Q,int &X){ Tqueue *p; if ((*Q).depan!=NULL){ X = (*Q).depan->isi; p = (*Q).depan; (*Q).depan=(*Q).depan->next;} free(p); } 4.4 Aplikasi Queue
Aplikasi queue pada dunia nyata dapat dijumpai pada semua jenis antrian, seperti antrian pelanggan, antrian pembeli tiket. Sedangkan antrian pada sistem komputer misalnya antrian job yang ditangani sistem operasi, antrian layanan cetak pada mesin printer. Struktur data queue juga digunakan pada bucket sort dan implementasi algoritma pelacakan BFS.
Penutup Latihan Soal
1. Apakah queue linear? Apa keterbatasan queue linear?
2. Jelaskan perbedaaan antara linear queue and circular queue, mana yang lebih baik dan mengapa?
3. Misalkan dimiliki queue integer, dan queue q telah berisi 3 data nilai : 5 12 7
depan belakang
Gambarkan urutan diagram yang menunjukkan isi dari queue q, setelah setiap baris perintah ini dikerjakan.
enqueue(q,1); dequeue(q,x);enqueue(q,x); dequeue(q,y); dequeue(q,z);enqueue(q, y-z);
34
BAB V
STRUKTUR DATA NON LINEAR
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data non linear yaitu matriks dan multiple linked list beserta contoh aplikasinya.
Manfaat
Dengan memahami struktur data matriks dan multiple linked list, mahasiswa akan dapat membangun struktur data yang lebih kompleks seperti Tree dan Graf.
Relevansi
Materi ini menjadi dasar untuk mempelajari berbagai macam struktur data yang lebih kompleks terutama struktur data non linear.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memiliki pengetahuan tentang struktur data non linear yaitu matriks dan multiple linked list serta mampu membuat program menggunakan tipe data array dan pointer untuk membangun struktur data non linear.
Penyajian
Pada bab-bab sebelumnya telah kita bahas tentang beberapa struktur data linear yaitu linked list linear, stack dan queue. Struktur data non linear adalah struktur data yang tidak linear, yaitu antara lain yang akan dibahas dalam bab ini adalah matriks, menggunakan array 2 dimensi, dan multiple linked list.
5.1 Matriks, Array Dua Dimensi
Array dua dimensi sering digambarkan sebagai sebuah matriks, merupakan perluasan dari array satu dimensi. Jika array satu dimensi hanya terdiri dari sebuah baris dan beberapa kolom elemen, maka array dua dimensi terdiri dari beberapa baris dan beberapa kolom elemen yang bertipe sama sehingga dapat digambarkan sebagai berikut:
35 0 1 2 3 4 5 6 0 10 21 23 43 45 78 65 1 45 43 65 12 21 12 21 2 32 34 23 56 54 34 45 3 11 12 32 23 56 76 45 Bentuk umum:
<tipe data> NamaArray [m][n];
Atau
<tipe data> NamaArray [m][n] = { {a,b,..z},{1,2,...,n-1} };
Contoh:
double matrix[4][7];
Pendeklarasian array dua dimensi hampir sama dengan pendeklarasian array satu dimensi, kecuali bahwa array dua dimensi terdapat dua jumlah elemen yang terdapat di dalam kurung siku dan keduanya boleh tidak sama.
Elemen array dua dimensi diakses dengan menuliskan kedua indeks elemennya dalam kurung siku seperti pada contoh berikut:
matrix[1][2] = 65; matrix[3][6] = 45;
Berikut contoh program tentang penggunaan array 2 dimensi. #include<iostream>
#include<conio.h> #include<stdio.h> using namespace std;
int cost[10][10],dist[20],i,j,n,k,m,S[20],v,totcost,path[20],p; int shortest(int v,int n)
{int min; for(i=1;i<=n;i++) { S[i]=0; dist[i]=cost[v][i]; } path[++p]=v;
36 S[v]=1; dist[v]=0; for(i=2;i<=n-1;i++) { k=-1; min=9999; for(j=1;j<=n;j++) { if(dist[j]<min && S[j]!=1) { min=dist[j]; k=j; } } if(cost[v][k]<=dist[k]) p=1; path[++p]=k; for(j=1;j<=p;j++) cout<<path[j]<<" "; // cout <<"\n"; // cout <<k; S[k]=1; for(j=1;j<=n;j++)
if(cost[k][j]!=9999 && dist[j]>=dist[k]+cost[k][j] && S[j]!=1) dist[j]=dist[k]+cost[k][j]; cout<<dist[j]<<endl; } } main() { int c;
cout <<"enter no of vertices :"; cin >> n;
cout <<"enter no of edges :"; cin >>m;
cout <<"\nenter\nEDGE Cost\n"; for(k=1;k<=m;k++) { cin >> i >> j >>c; cost[i][j]=c; } for(i=1;i<=n;i++) for(j=1;j<=n;j++)
if(cost[i][j]==0 && i!=j) cost[i][j]=9999; cout <<"enter initial vertex :";
cin >>v;
cout << v<<"\n"; shortest(v,n); getch(); }
37
5.2 Multiple Linked list
Multiple linked list adalah linked list dengan linked field lebih dari satu dan bentuknya tidak linear. Multiple linked sangat beragam strukturnya, berikut adalah sebagai ilustrasi dari salah satu bentuk multiple linked list.
Implementasi dari multiple linked untuk menyimpan data peserta suatu pelatihan dimana banyak pelatihan dan pesertanya bisa dinamis dapat dilihat pada program berikut.
#include<iostream> #include<conio.h> using namespace std; typedef struct nodep { char nama[20]; struct nodep *next; } *peserta;
typedef struct node
{ char pelatihan[20]; struct node *next; peserta down; } *list;
list L;
void InsertPelatihan(list &l) {
int i,n; list b;
cout<<"banyak pelatihan : ";cin>>n; for (i=1;i<=n;i++){
b=new node;
b->next=NULL;b->down=NULL;
cout<<"Nama Pelatihan : ";cin>>b->pelatihan; if (l==NULL) l=b;
else {b->next=l; l=b;}
} }
38 void cetakdata(list l) {list p;peserta q; if (l!=NULL) { p=l;cout<<endl; while (p!=NULL) { cout<<p->pelatihan<<" : "; q=p->down; while (q!=NULL) { cout<<q->nama<<", ";q=q->next;} p=p->next;cout<<endl; } } else cout<<"kosong"; }
void InsertPeserta(list &l) {
int i,n;char namapelatihan[20]; list p;peserta b;
cout<<"Insert Peserta "<<endl;
cout<<"Nama pelatihan: ";cin>>namapelatihan; p=l;
while (p!=NULL && strcmp(p->pelatihan,namapelatihan)!=0) p=p->next; if (p==NULL) cout<<"nama pelatihan belum ada\n"; else
if(strcmp(p->pelatihan,namapelatihan)==0) { cout<<"banyak peserta : ";cin>>n;
for (i=1;i<=n;i++){
b=new nodep; b->next=NULL;
cout<<"Nama peserta : ";cin>>b->nama; if (p->down==NULL) p->down=b; else {b->next=p->down; p->down=b; } } } }
void HapusPeserta(list &l) {
char namapelatihan[20],namapeserta[20]; list p;peserta b,c;
cout<<"Hapus Peserta "<<endl;
cout<<"Nama pelatihan: ";cin>>namapelatihan; p=l;
while (p!=NULL && strcmp(p->pelatihan,namapelatihan)!=0) p=p->next; if (p==NULL) cout<<"nama pelatihan tidak ada\n";
else if(strcmp(p->pelatihan,namapelatihan)==0) { b=p->down;
if(b==NULL)cout<<"tidak ada pesertanya"; else{
39
cin>>namapeserta;
if (strcmp(b->nama,namapeserta)==0) {c=p->down;p->down=c->next;free(c);} else {
while(b->next!=NULL && strcmp(b->next->nama,namapeserta) !=0)b=b->next;
if (b->next==NULL) cout<<"peserta tidak ada"; else if(strcmp(b->next->nama,namapeserta)==0){ c=b->next;b->next=c->next;free(c); } } } } } main() { int x; L=NULL; InsertPelatihan(L); InsertPeserta(L); cetakdata(L); HapusPeserta(L); cetakdata(L); HapusPeserta(L); cetakdata(L); getch(); } Penutup Latihan Soal
1. Dengan menggunakan struktur data matriks, buatlah program untuk membuat matriks gambar yang nilai elemennya 0..255 dan kemudian tentukan nilai dominan yaitu nilai 0..255 yang paling sering muncul.
2. Buatlah program untuk menyimpan data menu utama, submenu dan sub submenu dalam multiple linkedlist, Program minimal mempunyai subprogram insertmenu, deletemenu dan cetak menu.
40
BAB VI
STRUKTUR DATA POHON ( TREE )
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan struktur data Tree yaitu Binary Search Tree (BST) dan AVL-Tree beserta implementasinya.
Manfaat
Dengan memahami struktur data Tree, mahasiswa akan dapat menyelesaikan berbagai permasalahan yang menggunakan struktur data Tree, antara lain pada searching, sorting dan kompresi data.
Relevansi
Materi ini menjadi dasar untuk mempelajari berbagai permasalahan seperti pada searching, sorting dan kompresi data.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memiliki pengetahuan tentang struktur data Tree yaitu BST dan AVL serta mampu membuat program menggunakan tipe data array dan pointer untuk membangun struktur data Tree.
Penyajian
Struktur data Tree atau pohon adalah struktur data yang tidak linear dan berbentuk herarki, atau dapat didefinisikan sebagai kumpulan node atau simpul (mulai pada simpul akar), di mana setiap node adalah struktur data yang terdiri dari nilai, bersama dengan daftar referensi ke node anak-anaknya atau cabang-cabangnya.
Sebagai tipe data, pohon memiliki nilai dan anak-anak, dan anak-anak itu sendiri bisa berupa pohon, nilai dan anak-anak dari pohon diinterpretasikan sebagai nilai dari simpul akar dan subpohon anak-anak dari simpul akar. dalam hal ini daftar anak-anak dapat menjadi ukuran tetap (percabangan faktor, terutama 2 atau "biner"), jika diinginkan.
Sebagai struktur data, pohon adalah sekelompok node, dimana setiap node memiliki nilai dan daftar referensi ke node lain (anak-anaknya). Struktur data Tree yang akan dibahas adalah struktur data binary tree (pohon biner).
41
Pohon biner merupakan pohon yang memiliki ketentuan setiap node hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Sesuai dengan definisi tersebut, maka tiap node dalam binary tree hanya boleh memiliki paling banyak dua anak.
Berikut ini adalah ilustrasi pohon biner :
Implementasi Tree dalam program, ada beberapa hal yang perlu diperhatikan yaitu :
1. deklarasi pohon
2. membuat pohon
3. memeriksa apakah pohon kosong
4. membuat node baru
5. menambah node ke pohon
6. membaca sebuah node
7. mengunjungi pohon secara In Order
(Kunjungi Left Child, cetak isi node yang dikunjungi, kunjungi Right Child)
8. mengunjungi pohon secara Pre Order
(Cetak isi node yang dikunjungi, kunjung Left Child, kunjungi Right Child)
9. mengunjungi pohon secara Post Order
(Kunjungi Lift Child, kunjungi Right Child, cetak node yang dikunjungi)
42
Berikut contoh implementasi program tentang Pohon Biner. #include<iostream>
#include<stdio.h> #include<conio.h> using namespace std; typedef struct node { char data;
struct node *kanan,*kiri; } simpul;
typedef simpul *tree; tree T;
void BST(tree *T,char x) { tree b;
if (*T==NULL) { b=new simpul;
b->data=x;b->kanan=NULL;b->kiri=NULL; *T=b;}
else if(x<(*T)->data) BST(&(*T)->kiri,x); else BST(&(*T)->kanan,x); } void PRE(tree T) { if (T!=NULL) { cout<<T->data<<" "; PRE(T->kiri); PRE(T->kanan); } } void IN(tree T) { if (T!=NULL) { IN(T->kiri); cout<<T->data<<" "; IN(T->kanan); } } void POST(tree T) { if (T!=NULL) { POST(T->kiri); POST(T->kanan); cout<<T->data<<" "; } }
43
main (){
tree P;char x;int i,n; P=NULL;
cout<<"banyak data : ";cin>>n; for (i=1;i<=n;i++) {
x=(65+rand()%26); cout<<x<<" "; BST(&P,x);
}
cout<<"pre : "; PRE(P); cout<<endl; cout<<"In : "; IN(P); cout<<endl; cout<<"post : "; POST(P);
getch(); }
Sebuah binary search tree (BST) adalah sebuah pohon biner yang boleh kosong, dan setiap nodenya harus memiliki identifier/value. value pada semua node subpohon sebelah kiri adalah selalu lebih kecil dari value dari parent/root, sedangkan value subpohon di sebelah kanan adalah sama atau lebih besar dari value pada parent/root, masing – masing subpohon tersebut (kiri&kanan) itu sendiri adalah juga BST. Sebagai gambaran berikut adalah sebuah BST.
Operasi penambahan node/insert pada BST :
44
Sebuah BST, pada dasarnya adalah sebuah pohon biner (binary tree), oleh karena itu, kita dapat melakukan traversal pada setiap node dengan metode inorder, preorder maupun postorder. dan jika kita melakukan traversal dengan metode inorder, pada dasarnya kita telah melakukan traversal valuenya secara terurut dari kecil ke besar, jadi ini sebagai sorting algoritma.
Struktur data BST sangat penting dalam struktur pencarian, misalkan, dalam kasus pencarian dalam sebuah larik, jika larik sudah dalam keadaan terurut maka proses pencarian akan sangat cepat, jika kita menggunanan pencarian biner. Akan tetapi, jika kita ingin melakukan perubahan isi larik (insert atau delete), menggunakan larik/array akan sangat lambat, karena proses insert dan delete dalam larik butuh memindahkan banyak elemen setiap saat. Sebaliknya binary tree memberikan jawaban sempurna atas semua permasalahan ini, dengan memanfaatkan binary tree kita dapat melakukan pencarian elemen/node value dalam kompleksitas algorimta O(n log n) langkah saja.
Kebanyakan aplikasi saat ini melakukan operasi penambahan dan penghapusan elemen secara terus-menerus tanpa urutan yang jelas urutannya. Oleh karena itu sangatlah penting untuk mengoptimasi waktu pencarian dengan menjaga agar pohon tersebut mendekati seimbang/balance sepanjang waktu. Dan hal ini telah diwujudkan oleh 2 orang matematikawan Russia , G.M. Adel’son-Vel’skii dan E.M. Landis. Oleh karena itu Binary
Search Tree ini disebut AVLtree yang diambil dari nama kedua matematikawan Russia
tersebut. Tujuan utama dari pembuatan AVL-Tree ini adalah agar operasi pencarian, penambahan, dan penghapusan elemen dapat dilakukan dalam waktu O(log n) bahkan untuk kasus terburuk pun. Tidak seperti Binary Search Tree biasa yang dapat mencapai waktu O(1.44 log n) untuk kasus terburuk.
Dalam pohon yang benar-benar seimbang, subpohon kiri dan kanan dari setiap node mempunyai tinggi yang sama. Walaupun kita tidak dapat mencapai tujuan ini secara sempurna, setidaknya dengan membangun Binary Search Tree dengan metode penambahan elemen yang nantinya akan kita bahas, kita dapat meyakinkan bahwa setiap subpohon kiri dan kanan tidak akan pernah berselisih lebih dari 1. Jadi, sebuah AVL-Tree merupakan Binary
Search Tree yang subpohon kiri dan kanan dari akarnya tidak akan berselisih lebih dari 1 dan
setiap subpohon dari AVL-Tree juga merupakan AVL-Tree. Dan setiap simpul di AVL-Tree mempunyai faktor penyeimbang (balance factor) yang bernilai left-higher (subpohon kiri > kanan), equal-height (subpohon kiri = kanan), righthigher (subpohon kiri < kanan).
45
Proses balancing pada AVL-Tree dilakukan dengan cara :
Single Rotation (kiri dan kanan) Double Rotation (kiri dan kanan) Berikut contoh kedua proses tersebut :
AVL-Tree sebelum dilakukan insert 20 AVL-Tree setelah insert 20 dan single rotation kanan
AVL-Tree sebelum dilakukan insert 95 AVL-Tree setelah insert 95 dan double rotation kanan
Penutup Latihan Soal
1. Gambarlah Pohon Biner yang memenuhi informasi berikut :
Inorder P B S K R A I U H E O
Preorder A K P S B R U I O E H
2. Diberikan deretan data sebagai berikut:
50, 70, 60, 55, 65, 58, 68, 40, 80, 30, 75
Buatlah Binary Search Tree berdasarkan urutan data tersebut.
46
BAB VII
ALGORITMA SORTING
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan tentang algoritma untuk mengurutkan data (Sorting) yaitu Merge Sort dan Quick Sort serta Heap Sort beserta analisis algoritmanya.
Manfaat
Dengan memahami algoritma sorting yang termasuk kategori cepat dan efisien, mahasiswa dapat menerapkan algoritma sorting untuk menyelesaikan permasalahan yang lebih kompleks.
Relevansi
Materi ini memberi bekal untuk menyelesaikan permasalahan yang menggunakan proses pengurutan data.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memiliki pengetahuan tentang algoritma sorting yang cepat dan efisien serta mampu membuat program implementasinya.
Penyajian
Pada bab ini dijelaskan beberapa algoritma pengurutan data (sorting), yaitu : Merge Sort, Quick Sort (review) dan Heap Sort. Pengurutan atau sorting merupakan proses untuk menyusun kembali kumpulan entri-entri yang telah dimasukkan dengan suatu aturan tertentu. Secara umum ada 2 macam pengurutan yaitu pengurutan secara menaik (ascenden) dan pengurutan secara menurun (descenden).
7.1 Algoritma Merge Sort dan Quick Sort
Algoritma Merge Sort dan Quick Sort algoritma yang dirancang dengan teknik devide and conquer, yang paling optimal dan sangat cepat untuk mengurutkan data.
Algoritma merge sort membagi tabel menjadi dua tabel yang sama besar. Masing-masing tabel diurutkan secara rekursif, dan kemudian digabungkan kembali untuk membentuk tabel yang terurut. Implementasi dasar dari algoritma merge sort memakai tiga buah tabel, dua untuk menyimpan elemen dari tabel yang telah di bagi dua dan satu untuk
47
menyimpan elemen yang telah terurut. Namun algoritma ini dapat juga dilakukan langsung pada dua tabel, sehingga menghemat ruang atau memori yang dibutuhkan.
Quick Sort adalah algoritma yang proses pembagian data dengan cara partisi berdasarkan data pivot, biasanya data pertama, tanpa menggunakan memory tambahan sehingga diharapkan lebih efisien dalam penggunaan memory.
Berikut adalah program tentang Merge Sort dan Quick Sort.
#include<iostream> #include<stdlib.h> #include<conio.h> using namespace std; typedef int larik[250001]; long long c=0;
int n,cc=0;
void cetakdata(larik x,int n) {int i; for (i=1;i<=n;i++) { cout<<x[i]<<" "; } cout<<endl; cout<<endl;getch(); }
void partisi(larik x,int aw,int ak,int &j) { int i,t,pivot;
pivot=x[aw]; i=aw;j=ak; while (i<j){
while ((i<ak)&&(x[i]<=pivot)) {i++;cc++;}if(i<ak) cc++; while ((j>aw)&&(x[j]>pivot)) {j--;cc++;}if(j>aw) cc++;
if (i<j) {t=x[i];x[i]=x[j];x[j]=t;} }
x[aw]=x[j];x[j]=pivot; }
void qsort(larik x,int aw,int ak) {int j; if (aw<ak) { partisi(x,aw,ak,j);//cetakdata(x,n); qsort(x,aw,j-1); qsort(x,j+1,ak); } }
48 {larik z;
int i,j,k,l;
i=aw; j=mid+1; k=aw; do {
if(x[i]<=x[j]) {z[k]=x[i];i++;} else {z[k]=x[j];j++;}
k++;}
while ((i<=mid) && (j<=ak));
if (i>mid) for (l=j;l<=ak;l++) {z[k]=x[l];k++;} else for (l=i;l<=mid;l++) {z[k]=x[l];k++;} for (k=aw;k<=ak;k++) x[k]=z[k]; }
void mergesort(larik x,int aw,int ak) {int mid; if(aw<ak) { mid =(aw+ak)/2; mergesort(x,aw,mid); mergesort(x,mid+1,ak); merge(x,aw,mid,ak); } }
void buatdata(larik x,int &n) {int i;
cout<<"banyak data :";cin>>n; // srand(time(NULL)); for (i=1;i<=n;i++) { x[i]= rand()%100+1; // cout<<x[i]<<" "; } cout<<endl; // cout<<endl; } main() { int i,j; larik x; buatdata(x,n); cetakdata(x,n);
clock_t begin_time = clock(); mergesort1(x,1,n);
cout << float( clock () - begin_time )/CLOCKS_PER_SEC; cetakdata(x,n);
49
7.2 Algoritma Heap Sort
HeapSort adalah algoritma pengurutan data berdasarkan perbandingan, dan termasuk golongan selection sort. Walaupun lebih lambat daripada quick sort pada kebanyakan mesin , tetapi heap sort mempunyai keunggulan yaitu kompleksitas algoritma pada kasus terburuk adalah n log n.
Algoritma pengurutan heap sort ini mengurutkan isi suatu larik masukan dengan memandang larik masukan sebagai suatu Complete Binary Tree (CBT).
Setelah itu Complete Binary Tree (CBT) ini dapat dikonversi menjadi suatu heap tree. Setelah itu Complete Binary Tree (CBT) diubah menjadi suatu priority queue.
Algoritma pengurutan heap dimulai dari membangun sebuah heap dari kumpulan data yang ingin diurutkan, dan kemudian menghapus data yang mempunyai nilai tertinggi dan menempatkan dalam akhir dari larik yang telah terurut.
Setelah memindahkan data dengan nilai terbesar, proses berikutnya adalah membangun ulang heap dan memindahkan nilai terbesar pada heap tersebut dan menempatkannya dalam tempat terakhir pada larik terurut yang belum diisi data lain.
Proses ini berulang sampai tidak ada lagi data yang tersisa dalam heap dan larik yang terurut penuh. Dalam implementasinya kita membutuhkan dua larik – satu untuk menyimpan heap dan satu lagi untuk menyimpan data yang sudah terurut.
Tetapi untuk optimasi memori, kita dapat menggunakan hanya satu larik saja. Yaitu dengan cara menukar isi akar dengan elemen terakhir dalam heap tree. Jika memori tidak menjadi masalah maka dapat tetap menggunakan dua larik yaitu larik masukan dan larik hasil.
50 Heap Sort memasukkan data masukan ke dalam struktur data heap.
Nilai terbesar (dalam max-heap) atau nilai terkecil (dalam min-heap) diambil satu per satu sampai habis, nilai tersebut diambil dalam urutan yang terurut.
Algoritma untuk heap sort :
function heapSort(a, count)
input: sebuah larik tidak terurut a dengan panjang length (pertama letakkan a dalam max-heap) heapify(a, count) end = count -1 while end > 0 { remove ( ) reheapify ( ) end = end – 1 } Algoritma Heapify
Algoritma Heapify adalah membangun sebuah heap dari bawah ke atas, secara berturut-turut berubah ke bawah untuk membangun heap. Permasalahan pertama yang harus kita pertimbangkan dalam melakukan operasi heapify adalah dari bagian mana kita harus memulai.
Bila kita mencoba operasi heapify dari akar maka akan terjadi operasi runut-naik seperti algoritma bubble sort yang akan menyebabkan kompleksitas waktu yang ada akan berlipat ganda. Sebuah versi lain adalah membangun heap secara atas-bawah dan berganti-ganti ke atas untuk secara konseptual lebih sederhana untuk ditangani. Versi ini mulai dengan sebuah heap kosong dan secara berturut-turut memasukkan data.
Versi lainnya lagi adalah dengan membentuk pohon heap-pohon heap mulai dari subtree-subtree yang paling bawah. Jika subtree-subtree suatu simpul sudah membentuk heap maka pohon dari simpul tersebut mudah dijadikan pohon heap dengan mengalirkannya ke bawah. Setelah diuji, maka ide yang paling efisien adalah versi yang terakhir, yang kompleksitas algoritmanya pada kasus terburuk adalah O(n), sedangkan versi membentuk heap tree-heap tree dari atas ke bawah kompleksitas nya O(n log n).
Jadi, algoritma utama heapify adalah melakukan iterasi mulai dari internal simpul paling kanan bawah (pada representasi larik, adalah elemen yang berada di indeks paling besar) hingga akar, kemudian kearah kiri dan naik ke level di atasnya, dan seterusnya hingga
51
mencapai akar (sebagai larik [0..N-1]). Oleh karena itu, iterasi dilakukan mulai dari j= N/2 dan berkurang satu-satu hingga mencapai j=0. Pada simpul internal tersebut, pemeriksaan hanya dilakukan pada simpul anaknya langsung (tidak pada level-level lain di bawahnya). Pada saat iterasi berada di level yang lebih tinggi, subtree subtree selalu sudah membentuk heap. Jadi, kasus akan mengalirkan simpul tersebut kearah bawah. Dengan demikian, heapify versi ini melakukan sebanyak N/2 kali iterasi, dan pada kasus yang paling buruk akan melakukan iterasi sebanyak log (N) kali.
Algoritma Remove
Algoritma remove ini menukar akar (yang berisi nilai maksimum) dari heap dengan elemen terakhir. Secara logika, simpul yang berada paling kanabawah dipindahkan ke akar untuk menggantikan simpul akar yang akan diambil.
Algoritma Reheapify
Algoritma reheapify ini melakukan pembuatan ulang heap dari atas ke bawah seperti halnya iterasi terakhir dari algoritma metoda heapify. Perbedaan antara metode heapify dengan metode reheapify ada pada iterasi yang dilakukan oleh kedua algoritma tersebut. Algoritma metode reheapify ini hanya melakukan iterasi terakhir dari algoritma heapify. Hal ini disebabkan baik subtree kiri maupun subtree kanannya sudah merupakan heap, sehingga tidak perlu dilakukan iterasi lengkap seperti algoritma heapify. Dan setelah reheapify maka simpul yang akan diiterasikan berikutnya akan berkurang satu.
Perbandingan Dengan Algoritma Pengurutan Lain
Heapsort hampir setara dengan quick sort, algoritma pengurutan data lain berdasarkan perbandingan yang sangat efisien. Quick sort sedikit lebih cepat, karena cache dan faktor-faktor lain, tetapi pada kasus terburuk kompleksitasnya O(n), yang sangat lambat untuk data yang berukuran sangat besar. Lalu karena heap sort memiliki (N log N) maka sistem yang memerlukan pengamanan yang ketat biasa memakai heap sort sebagai algoritma pengurutannya. Heap sort juga sering dibandingkan dengan merge sort, yang mempunyaikompleksitas algoritma yang sama, tetapi kompleksitas ruang nya (n) yang lebih besar dari heap sort. Heap sort juga lebih cepat pada mesin dengancache data yang kecil atau lambat.
52
pengurutan data yang mangkus yang bisa dimanfaatkan untuk membangun program aplikasi yang baik. Algoritma pengurutan heap sort bisa dimasukkan ke dalam algoritma divide and conquer yang disebabkan pembagian dilakukan dengan terlebih dahulu menerapkan algoritma metoda heapify sebagai inisialisasi untuk mentransformasi suatu tree menjadi heap tree, dan pada setiap tahapan diterapkan algoritma metoda reheapify untuk menyusun ulang heap tree.
Penutup Latihan Soal
1. Dengan menggunakan data input di bawah ini, Tuliskan urutan data sampai terurut (acending) dan hitung berapa kali operasi perbandingan dilakukan, juga tentukan set data tsb termasuk best, worst atau avaragecase?
42, 68, 35, 1, 70, 25, 79, 59, 63, 65, 6, 46, 82, 28, 62 jika digunakan algoritma :
a. Merge sort b. Quick sort c. Heap sort
53
BAB VIII
ALGORITMA SEARCHING
PendahuluanDeskripsi Singkat
Pada bab ini akan dijelaskan tentang algoritma untuk mengurutkan data (Sorting) yaitu Merge Sort dan Quick Sort serta Heap Sort beserta analisis algoritmanya.
Manfaat
Dengan memahami algoritma sorting yang termasuk kategori cepat dan efisien, mahasiswa dapat menerapkan algoritma sorting untuk menyelesaikan permasalahan yang lebih kompleks.
Relevansi
Materi ini memberi bekal untuk menyelesaikan permasalahan yang menggunakan proses pengurutan data.
Learning Outcomes
Setelah mempelajari materi ini, mahasiswa memiliki pengetahuan tentang algoritma sorting yang cepat dan efisien serta mampu membuat program implementasinya.
Penyajian
Pertama akan dibahas 2 algoritma pencarian data (Searching) yang biasa dilakukan, yaitu pencarian sekuensial (sequential search) dan pencarian biner (binary search). Pencarian sekuensial lebih cocok digunakan untuk mencari data pada sejumlah data yang belum terurut sedangkan pencarian biner digunakan pada sejumlah data yang sudah terurut. Kemudian dibahas metode pencarian dengan fungsi hashing.
8.1 Pencarian Sekuensial
Pada pencarian sekuensial, data yang dicari, dibandingkan satu per satu dengan data pada suatu larik data.
Algoritmanya adalah sebagai berikut :
Misalkan dimiliki N data integer yang disimpan pada larik A, dan data yang dicari adalah X. 1. Ketemu = 0, indeks = 1.
2. Selama data belum ketemu (ketemu = 0) dan indeks N : a. Jika X = A[indeks], maka data ketemu, lalu nilai ketemu =1.