12 2.1. State of The Art
Sistem backup dengan virtualisasi sekarang telah dikembangkan untuk banyak aplikasi terutama untuk aplikasi-aplikasi keamanan. Virtualisasi server sebagai pengganti bentuk fisik dari sebuah server mempunyai banyak manfaat, terutama kepraktisannya karena tidak perlu membeli peralatan komputer server untuk membangun sebuah server. Sistem backup juga memiliki banyak fungsi, diantaranya adalah dapat berperan sebagai alternatif jika data center utama sedang mengalami pemeliharaan (maintenance), manipulasi data, ataupun terjadi kerusakan mesin (down). Masalah utamanya adalah jika data center memiliki jumlah data yang sangat banyak, sistem backup pada umumnya akan mem-backup seluruh data yang sudah ditentukan oleh administrator dengan intensitas waktu tertentu. Dikarenakan ukuran data relatif besar, dapat mengakibatkan jalur transmisi (bandwidth) semakin padat, dan aktifitas jaringan pun semakin menurun. Ada beberapa teknik untuk memanipulasi ukuran data yang relatif besar yang akan diproses, salah satunya adalah dengan menggunakan pemisahan data.
Beberapa penelitian yang telah dilakukan sebelumnya terkait dengan judul yang diangkat diantaranya peneliti J. Wei, H. Jiang, K. Zhou, and D. Feng (2010) melakukan penelitian “MAD2: A scala'ble high-throughput exact deduplication approach for network backup services”. Dalam penelitian ini mengusulkan metode pendekatan MAD2, pendekatan deduplication yang tepat dan scalable untuk
layanan backup jaringan berdasarkan tingginya trafik throughput. MAD2 menghilangkan data ganda baik ditingkat file dan ditingkat potongan data dengan menggunakan empat teknik untuk mempercepat proses duplikasi dan perataan distribusi data. Pertama, MAD2 mengatur sidik jari (fingerprint) menjadi Bucket Matrix Hash (HBM), dapat digunakan untuk menjaga area data backup. Kedua, MAD2 menggunakan Bloom Filter Array (BFA) sebagai indeks cepat untuk mengidentifikasi non-duplikat objek data yang masuk atau menunjukkan dimana kemungkinan menemukan duplikat. Ketiga, Dual Cache terintegrasi dalam MAD2 secara efektif menangkap dan memanfaatkan data secara lokal. Akhirnya, MAD2 menggunakan teknik Load- Balance berbasis DHT (Distributed Hash Tables) untuk mendistribusikan secara merata objek data antara beberapa node storage sesuai urutan cadangan objek data untuk lebih meningkatkan kinerja dengan beban yang seimbang. Hasil evaluasi menunjukkan MAD2 secara signifikan melakukan perkiraan pendekatan yang efisiensi dalam hal deduplication, dan mendukung throughput deduplication minimal 100MB/s untuk setiap komponen penyimpanan dalam sistem backup.
Penelitian yang dilakukan oleh Okafor Kennedy, Udeze Chidiebele. C.C, Prof. H. C. Inyiama, dan Dr. C.C Okezie (2012) dengan judul “Virtualization: A Cost Effective Approach to Infrastructure Management in Data Center Networks” menjelaskan tentang langkah terbaik menggunakan redundansi infrastruktur untuk membangun beberapa pusat data dengan sistem operasi, aplikasi dan layanan data yang independent. Penelitian tersebut mengadopsi skema virtualisasi data center sebagai arsitektur server yang dinamis untuk memperbaiki tantangan duplikasi
infrastruktur di jaringan data center sehingga menghemat biaya. Tetapi masalah yang dihadapi jika menggunakan pemisahan data adalah adanya data yang merupakan data integrasi akan bercampur aduk dengan data biasa dan terjadinya duplikasi data, hal ini akan menyulitkan proses pembalikan (restore) data. Hal tersebutlah yang akan coba dicarikan solusi dalam penelitian ini.
Penelitian dari I Putu Eka Suparwita (2012) yang berjudul “Implementasi Sistem Backup Otomatis Virtual Private Server Dengan Crontab” menjelaskan tentang backup server otomatis dalam Virtual Private Server (VPS) dengan menggunakan sistem penjadwalan dari CRONTAB. Backup otomatis Virtual Private Server yang telah dibuat sudah dapat beroperasi sesuai tujuan pembuatannya yaitu mampu melakukan backup secara otomatis pada Virtual Private Server. Akan tetapi backup yang dilakukan tidak menggunakan teknik apapun untuk memilah file yang di-backup, hanya menggunakan sistem penjadwalan dari CRONTAB.
Dalam penelitian selanjutnya Velvizhi J. dan Balaji C. G. (2012) dengan judul “Fingerprint Lookup-An Effective and Efficient Backup Using Deduplication Technique” menjelaskan bahwa data deduplication menghindari data yang berlebihan dalam penyimpanan cadangan operasi. Dalam sistem ini, file yang berisi data dibagi menjadi potongan (chunk) dengan menggunakan konteks pendekatan potongan dan pencarian sidik jari (fingerprint) untuk setiap potongan. Hasil penelitian tersebut menunjukkan bahwa ruang penyimpanan yang digunakan untuk backup lebih efisien dan kinerja backup lebih meningkat.
Stephen Mkandawire (2012) melakukan penelitian “Improving Backup and Restore Performance for Deduplication-based Cloud Backup Services”. Penelitian ini hampir sama dengan penelitian Velvizhi J. dan Balaji C. G, tapi diimplementasikan pada teknologi Cloud Computing. Data deduplication bergantung pada perbandingan sidik jari (fingerprints) dari potongan data, dan menyimpannya dalam potongan indeks untuk mengidentifikasi dan menghapus data yang berlebihan, dengan tujuan akhir menghemat ruang penyimpanan dan bandwidth jaringan pada teknologi cloud computing.
Penelitian Iswahyudi Hulukati, Arip Mulyanto dan Rochmad M. Thohir Jassin (2013) yang berjudul “Model Server Cluster Sebagai Redundant System” yang menghasilkan model server cluster dengan menerapkan metode replikasi data dan failover yang dapat menyediakan pelayanan kepada client yang dikhususkan untuk penyimpanan database. Dalam penelitian ini menerapkan sistem backup menggunakan mirror dari server dengan menggandakan file server secara keseluruhan, dengan kata lain penelitian ini mengimplementasikan full backup.
Melihat penelitian yang dilakukan oleh Stephen Mkandawire, dan penelitian-penelitian lainnya khususnya dibidang pengolahan data center, diusulkan metode Neural Network dengan Iterative Dychotomizer version 3 (ID3) dan Backpropagation untuk melakukan proses backup. Dengan menggunakan metode Neural Network akan diambil data yang akan di-backup hanya pada data yang mengalami perubahan dengan mencocokkan dengan metadata dan kode identitas (algoritma hash) dari setiap data guna mendapatkan data yang benar-benar harus di-backup untuk menanggulagi metode sebelumnya yang sangat rentan
terhadap duplikasi data yang terlalu besar dan proses backup data yang memerlukan waktu yang lama sehingga dapat menyebabkan dampak penggunaan resource komputer server yang terlalu tinggi. Disamping itu metode ini juga akan diimplementasikan untuk virtualisasi server karena pada metode konvensional yang diangkat memiliki kerentanan terhadap safety data dan memakan banyak resource perangkat keras seperti penggunaan memori dan CPU untuk setiap proses backup yang berjalan. Diharapkan dengan menggunakan metode Neural Network menggunakan Iterative Dychotomizer version 3 (ID3) dan Backpropagation ini bisa handal dalam melakukan proses backup data dalam setiap server yang ada pada data center.
17 1 MAD2: A scala'ble
high-throughput exact deduplication approach for network backup services, J. Wei, dkk (2010) √ √ √ √ 2 Virtualization: A Cost Effective Approach to Infrastructure Management in Data Center Networks, Okafor Kennedy, dkk (2012) √ √ √ √ 3 Implementasi Sistem Backup Otomatis Virtual Private Server dengan Crontab, I Putu Eka Suparwita (2012)
√ √ √ √
4 Fingerprint Lookup-An Effective and Efficient Backup Using
Deduplication
Technique, Velvizhi J. dan Balaji C. G. (2012)
18 for
Deduplication-based Cloud Backup Services, Stephen Mkandawire (2012)
√ √ √ √
6 Model Server Cluster sebagai Redundant System, Iswahyudi Hulukati, Arip
Mulyanto dan Rochmad M. Thohir Jassin (2013)
√ √ √ √
2.2. Data Center
Data center menjadi salah satu komponen penting dalam lingkungan bisnis yang ada saat ini. Sebagai inti dari layanan bisnis, data center diharapkan mampu memberikan pelayanan yang maksimal, sekalipun dalam keadaan terjadinya suatu bencana sehingga bisnis dalam perusahaan tersebut tetap bertahan dan keuntungan bagi perusahaan akan terus mengalir. Berangkat dari peran data center yang begitu signifikan, kemudian dikaitkan dengan berbagai isu yang ada pada data center akhir-akhir ini, terutama masalah Disaster Recovery Planning, kajian mengenai data center menjadi salah satu topik menarik dalam lingkungan bisnis (Yulianti, 2008).
Mengolah data dalam jumlah yang banyak tentulah tidak mudah. Sehingga pada sebuah organisasi yang besar untuk pengelolaan data, mereka memusatkan data pada data center. Data center menyimpan semua data yang dibutuhkan oleh organisasi. Data tersebut diambil, diolah dan disimpan kembali pada data center. Data yang disimpan pada data center merupakan data yang memiliki nilai bagi organisasi, dengan pengelolaan data yang baik akan membuat data terlindungi (Wood, 2011).
Pengelolaan data perlu didukung dengan proteksi data. Pengamanan data perlu dilakukan apalagi pada data center yang menyimpan semua data organisasi. Pusat data atau yang lebih dikenal data center adalah suatu fasilitas yang digunakan untuk menempatkan sistem komputer dan komponen-komponen terkaitnya, seperti sistem telekomunikasi dan penyimpanan data. Fasilitas ini biasanya mencakup juga catu daya redundan atau cadangan, koneksi komunikasi data redundan, pengontrol
lingkungan (misalnya AC dan ventilasi), pencegah bahaya kebakaran, serta piranti keamanan fisik dan salah satu penempatan server untuk website atau database (Kochhar, 2011).
Pada data center terdapat ratusan bahkan ribuan server yang tersusun pada rak server yang ditata sesuai bentuk fisiknya. Di setiap ruang memiliki pendingin, sistem catu daya (power supply), Uninteruptable Power System (UPS), security dan jaringan terkoneksi yang ditata dengan detail. Bahkan lantai dimana server dibangun memiliki karakteristik yakni terdapat upaya peredam dan selokan tempat jaringan kabel listrik maupun komputer (Greenberg, 2009).
Disain dan perencanaan data center harus memperhatikan minimum aspek-aspek berikut (Sun Microsystem, 2008):
1. Lokasi aman, memenuhi syarat sipil bangunan, geologi, vulkanologi, topografi.
2. Terproteksi dengan sistem cadangan, untuk sistem catu daya, pengatur udara/lingkungan, komunikasi data.
3. Menerapkan tata kelola standar data center meliputi: a. Standar Prosedur Operasi
b. Standar Prosedur Perawatan
c. Standar dan Rencana Pemulihan dan Mitigasi Bencana d. Standar Jaminan Kelangsungan Bisnis
Masalah keamanan dan kerahasiaan data juga merupakan salah satu aspek penting dari suatu sistem informasi. Dalam hal ini, sangat terkait dengan betapa pentingnya informasi tersebut dikelola oleh orang yang berkepentingan. Informasi
akan tidak berguna lagi apabila informasi itu dimanipulasi oleh orang yang tidak berhak, dan informasi tersebut tidak memiliki salinan (backup) dari informasi aslinya, sehingga informasi tersebut tidak sah (valid). Banyak teknik dan metode yang digunakan untuk melakukan pengamanan pada sebuah data center, diantaranya adalah dengan membuat sistem backup yang baik (Mkandawire, 2012). Layanan utama data center seperti yang digambarkan pada gambar 2.1 yang terdiri dari 5 (lima) komponen.
Gambar 2.1 Layanan utama data center (Yulianti, 2008)
Menurut Yulianti dan Nanda (2008), sesuai dengan gambar 2.1 layanan utama data center adalah sebagai berikut:
1. Business Continuance Infrastructure (Infrastruktur yang Menjamin Kelangsungan Bisnis) merupakan aspek-aspek yang mendukung kelangsungan bisnis ketika terjadi suatu kondisi kritis terhadap data center. Aspek-aspek tersebut meliputi kriteria pemilihan lokasi data center, kuantifikasi ruang data center, laying-out ruang dan instalasi data center, sistem elektrik yang dibutuhkan, pengaturan infrastruktur
jaringan yang scalable, pengaturan sistem pendingan dan fire suppression.
2. Data Center Security (Infrastruktur Keamanan Data Center) terdiri dari sistem pengamanan fisik dan non-fisik pada data center. Fitur sistem pengamanan fisik meliputi akses user ke data center berupa kunci akses memasuki ruangan (kartu akses atau biometrik) dan segenap petugas keamanan yang mengawasi keadaan data center (baik di dalam maupun di luar), pengamanan fisik juga dapat diterapkan pada seperangkat infrastruktur dengan melakukan penguncian dengan kunci gembok tertentu. Pengamanan non-fisik dilakukan terhadap bagian software atau sistem yang berjalan pada perangkat tersebut, antara lain dengan memasang beberapa perangkat lunak keamanan seperti access control list, firewall, (Intrusion Detection System) IDS dan host IDS, fitur-fitur keamanan pada layer ke-2 (datalink layer) dan layer ke-3 (network layer) disertai dengan pengelolaan keamanan.
3. Application Optimization (Optimasi Aplikasi) berkaitan dengan layer ke-4 (transport layer) dan layer ke-5 (session layer) untuk meningkatkan waktu respon suatu server. Layer ke-4 adalah layer end-to-end yang paling bawah antara aplikasi sumber dan tujuan, menyediakan end-to-end flow control, end-to-end error detection dan correction, mungkin juga menyediakan congestion control tambahan. Sedangkan layer ke-5 menyediakan riteri dialog (siapa yang memiliki giliran berbicara/mengirim data), token management (siapa yang
memiliki akses ke resource bersama) serta sinkronisasi data (status terakhir sebelum link terputus). Berbagai isu yang terkait dengan hal ini adalah load balancing, caching, dan terminasi Secure Sockets Layer (SSL), yang bertujuan untuk mengoptimalkan jalannya suatu aplikasi dalam suatu sistem.
4. IP Infrastrucrure (Infrastruktur Internet Protocol – IP) merupakan infrastruktur IP menjadi layanan utama pada data center. Layanan ini disediakan pada layer ke-2 dan layer ke-3. Isu yang harus diperhatikan terkait dengan layer ke-2 adalah hubungan antara server dan perangkat layanan, memungkinkan akses ke media, mendukung sentralisasi yang reliable, loop-free, predictable, dan scalable. Sedangkan pada layer ke-3, isu yang terkait adalah memungkinkan fast-convergence routed network (seperti dukungan terhadap default gateway). Kemudian juga tersedia layanan tambahan yang disebut Intelligent Network Services, meliputi fitur-fitur yang memungkinkan application services network-wide, fitur yang paling umum adalah mengenai QoS (Quality of Services), multicast (memungkinkan kemampuan untuk menangani banyak user secara konkuren), private LAN dan policy-based routing. 5. Storage Infrastructure (Infrastruktur Penyimpanan) terkait dengan
segala infrastruktur penyimpanan. Isu yang diangkat antara lain adalah arsitektur Storage Area Network (SAN), fibre channel switching, replikasi, backup serta archival.
2.3. Virtualisasi Server
Virtualisasi adalah sebuah teknologi yang memungkinkan untuk membuat versi virtual dari sesuatu yang bersifat fisik, misalnya sistem operasi, storage data atau sumber daya jaringan. Proses tersebut dilakukan oleh sebuah software atau firmware bernama Hypervisor. Hypervisor adalah layer yang seakan-akan menjadi sebuah infrastruktur untuk menjalankan beberapa virtual machine (Calzolari, 2009). Dalam prakteknya, dengan membeli dan memiliki satu buah mesin, seolah-olah memiliki banyak server, sehingga bisa mengurangi pengeluaran Information Technology (IT) untuk pembelian server baru, komponen, storage, dan software pendukung lainnya (Greenberg, 2009).
Konsep virtualisasi sesungguhnya bukan konsep yang baru. Mainframe IBM sudah menggunakan sistem operasi Virtual Machine (VM) yang sudah menerapkan teknologi virtualisasi selama beberapa dekade. Saat ini sistem operasi VM memungkinkan untuk menjalankan beberapa sistem Linux pada sebuah mesin mainframe (Golden, 2008). Dengan kata lain, sejumlah mesin Linux dapat dikonsolidasikan pada sebuah mainframe menggunakan sistem operasi VM.
Sistem komputer modern tersusun atas beberapa layer, yaitu layer hardware, layer operating system, dan layer program aplikasi seperti yang tergambar dalam gambar 2.2.
Gambar 2.2 Layer pada sistem komputer modern (Vmware, Inc., 2007) Pada gambar 2.2 software virtualisasi melakukan abstraksi dari mesin virtual dengan cara menambahkan layer baru di antara 3 layer di atas. Posisi dari layer baru tersebut menentukan level dari virtualisasi. Secara umum terdapat 3 level virtualisasi (Vmware, Inc., 2007), yaitu:
1. Level hardware
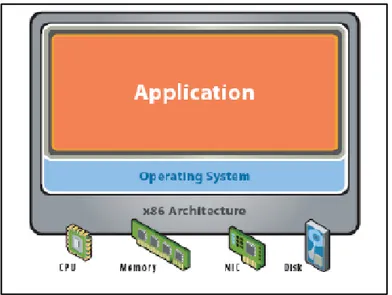
Pada tahun 1970 mainframe IBM menjadi pionir dalam virtualisasi secara hardware. Mainframe tersebut menjalankan sistem operasi VM yang berfungsi untuk menyediakan servis virtualisasi, sehingga mainframe tersebut dapat dipartisi dimana masing-masing partisi dapat menjalankan sistem operasi dan aplikasi sendiri. Layer virtualisasi berada tepat di atas layer hardware, sehingga akses ke hardware dari mesin virtual dapat dilakukan secara efisien. Seperti terlihat dalam gambar 2.3 arsitektur virtualisasi pada level hardware disebut juga sebagai arsitektur hypervisor (Kennedy, 2012).
Gambar 2.3 Virtualisasi pada level hardware (Vmware, Inc., 2007) Pada gambar 2.3 virtualisasi pada level hardware dipengaruhi dari jenis arsitektur platform seperti misalnya x86 dan AMD64, platform ini nanti yang menggunakan CPU (Central Processing Unit), memori, NIC (Network Interface Card) dan disk secara bersama.
2. Level sistem operasi
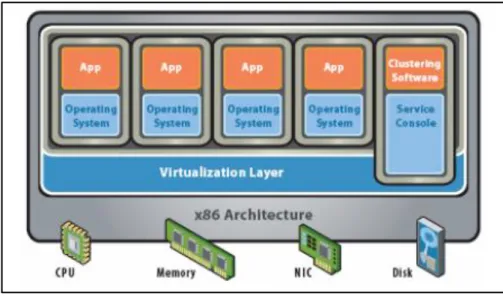
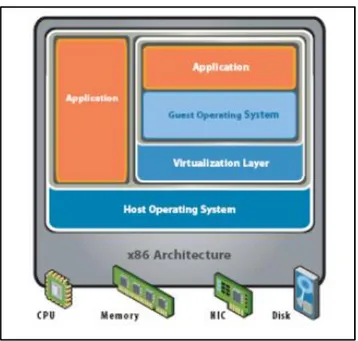
Layer virtualisasi diletakkan di atas layer sistem operasi. Program aplikasi dijalankan di atas sistem operasi pada mesin virtual. Akses ke hardware dari mesin virtual harus melalui sistem operasi dari mesin fisik, sehingga tidak terlalu efisien pada arsitektur hypervisor. Seperti terlihat dalam gambar 2.4 arsitektur virtualisasi pada level sistem operasi disebut juga sebagai arsitektur hosted.
Gambar 2.4 Virtualisasi level sistem operasi (Vmware, Inc., 2007) Pada gambar 2.4 virtualisasi pada level sistem operasi ini berada diatas level hardware, menjembatani application dan guest operating system. 3. Level bahasa tingkat tinggi
Layer virtualisasi berada di atas layer program aplikasi, berfungsi untuk melakukan abstraksi mesin virtual yang dapat menjalankan program yang ditulis dan dikompilasi sesuai dengan definisi abstrak mesin virtual yang akan menjalankan program tersebut.
2.4. Sistem Backup
Menurut Mkandawire (2012) backup adalah suatu copy dari file system atau bagian dari file system (seperti data atau file) yang disimpan pada media penyimpanan lain yang dapat digunakan sewaktu-waktu untuk me-restore (mengembalikan) data atau file tersebut jika dibutuhkan. Data yang di-backup akan tersimpan dalam replika dari data center utama, replika tersebut dapat berperan
sebagai alternatif jika data center utama sedang mengalami pemeliharaan (maintenance), manipulasi data, ataupun terjadi kerusakan mesin (down).
Dalam melakukan backup data, perlu adanya pengecekan kekosistenan data, yaitu dengan membandingkan data pada struktur direktori dengan data pada blok, lalu apabila ditemukan kesalahan, maka program tersebut akan mencoba memperbaikinya (Stephano, 2009). Ada tiga jenis backup data, diantaranya adalah (Vice, 2013):
1. Backup Penuh (Full Backup)
Full backup adalah menyalin semua data termasuk direktori ke media lain. Oleh karena itu, hasil full backup lebih cepat dan mudah saat operasi restore. Namun pada saat pembuatannya membutuhkan waktu yang lama dan ruang yang sangat besar.
2. Backup Peningkatan (Incremental Backup)
Incremental backup adalah menyalin semua data yang berubah sejak terakhir kali melakukan full backup. Incremental backup sering juga disebut differential backup.
3. Backup Cermin (Mirror Backup)
Mirror backup sama dengan full backup, tetapi data tidak dipadatkan atau dikompress (dengan format .tar, .zip, atau yang lain) dan tidak bisa dilindungi dengan password. Dapat juga diakses dengan menggunakan tools seperti Windows Explorer. Mirror backup adalah metode backup yang paling cepat bila dibandingkan dengan metode yang lain karena
menyalin data dan folder ke media tujuan tanpa melakukan pemadatan. Tapi hal itu menyebabkan media penyimpanannya harus cukup besar. Beberapa sebab kerusakan atau kegagalan operasi backup adalah sebagai berikut (Vice, 2013):
1. Aliran listrik terputus, yang dapat mengakibatkan hilangnya informasi yang ada di memori utama dan register.
2. Kesalahan operator (human error), dimana operator atau manusia melakukan kesalahan operasi yang tidak disengaja.
3. Kesalahan perangkat lunak, yang dapat mengakibatkan hasil pengolahan tidak benar, informasi yang disajikan ke user salah, dan basisdata menjadi tidak konsisten.
4. Disk rusak, yang dapat mengakibatkan hilangnya informasi atau rusaknya basis data yang ada dalam disk.
Beberapa jenis kerusakan yang dapat terjadi diantaranya sebagai berikut (Ashar, 2010):
1. Kegagalan transaksi (transaksi failure)
Ada beberapa jenis kesalahan yang dapat menyebabkan sebuah transaksi menjadi gagal, yaitu:
a. Kesalahan logika (logical error), dimana program tidak dapat melanjutkan eksekusi normalnya karena adanya kondisi internal tertentu seperti masukan yang salah atau rusak, data yang tidak tersedia, nilai data di luar batas domain yang diperbolehkan (overflow), logika program yang tidak tepat.
b. Kesalahan sistem (system error), dimana program atau sistem telah memasuki kondisi yang tidak diharapkan (seperti deadlock), sebagai hasil dari tidak tereksekusinya program atau sistem secara normal.
2. Kerusakan sistem (system crash)
Perangkat keras yang macet (hang), menyebabkan isi media penyimpanan sementara hilang.
3. Kegagalan atau kerusakan disk (disk failure)
Terjadinya bad sector atau disk yang macet pada saat berlangsungnya operasi input-output (I/O) ke disk.
Ada beberapa jenis media penyimpanan (storage) yang digunakan untuk sistem backup, yang dapat dibedakan dari segi kecepatan, kapasitas dan juga ketahanannya terhadap kerusakan (Ross, 2009):
1. Media penyimpanan sementara (volatile storage)
Informasi yang ada di media penyimpanan ini hanya ada selama catuan listrik mengalir. Jika catuan listriknya terputus, maka informasi/data yang tersimpan akan hilang. Akan tetapi kelebihan media penyimpanan ini terletak pada kecepatannya yang sangat tinggi. Contoh media penyimpananya adalah RAM (Random Access Memory), cache dan register.
2. Media penyimpanan permanen (non-volatile storage)
Informasi yang ada dalam media penyimpanan ini tetap ada walaupun catuan listrik tidak mengalir lagi.
3. Media penyimpanan stabil (stable storage)
Informasi yang ada di media penyimpanan ini tidak pernah hilang atau rusak (secara fisik oleh faktor-faktor internal).
Kerusakan terhadap disk (yang merupakan jenis media penyimpanan permanen yang paling umum), kerusakan data karena aktivitas pemakai ataupun kerusakan data oleh aplikasi eksternal, dapat diantisipasi dengan melakukan operasi backup secara periodik.
Berdasarkan waktu pelaksanaan atau strateginya ada 2 (dua) jenis operasi backup yang dapat dipilih, yaitu:
1. Backup Statis, dimana backup dilakukan oleh administrator secara manual.
2. Backup Dinamis, dimana backup dilakukan oleh mesin yang terjadwal dengan baik.
2.4.1. Sistem Remote Backup
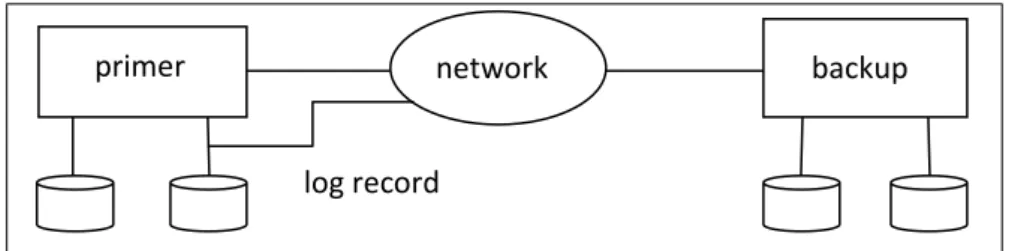
Sebuah alternatif lain di samping penerapan data terdistribusi adalah dengan menjalankan pengolahan transaksi pada sebuah server yang disebut sebagai server utama atau server primer, tetapi dengan memiliki sebuah server untuk backup jarak jauh (remote backup), dimana semua data dari server utama direplikasi. Server remote backup sering kali disebut juga sebagai server sekunder. Server remote backup tersebut harus terus disinkronisasi dengan server primer, begitu terjadi perubahan pada server primer (Ross, 2009). Server remote backup secara fisik harus terpisah dari server primer seperti pada gambar 2.5.
Gambar 2.5 Arsitektur Remote Backup
Pada gambar 2.5 remote backup bisa dilakukan melalui network dari server primer dan proses backup nantinya akan tersimpan log-nya dalam log record pada server primer.
2.4.2. Rsync
Rsync adalah utilitas untuk mentransfer dan menyinkronkan file secara efisien ke seluruh sistem komputer, dengan memeriksa timestamp dan ukuran file. Rsync adalah utilitas perangkat lunak gratis untuk sistem mirip Unix dan Linux yang menyalin file dan direktori dari satu host ke host lainnya. Algoritma rsync adalah jenis delta encoding, dan digunakan untuk meminimalkan penggunaan jaringan (Ross, 2009). Rsync biasanya digunakan untuk menyinkronkan file dan direktori di antara dua sistem yang berbeda. Rsync akan menggunakan SSH untuk terhubung dari user ke host. Setelah terhubung, Rsync akan memanggil rsync remote-host dan kemudian kedua program akan menentukan bagian file mana yang perlu ditransfer melalui koneksi. Rsync dianggap sebagai aplikasi yang ringan karena transfer filenya bersifat incremental, setelah transfer file secara penuh pada awal backup, selanjutnya hanya file yang telah diubah yang akan ditransfer. Rsync sering digunakan untuk menyediakan backup offsite dengan menyinkronkan data ke mesin remote di luar firewall.
primer network backup
2.4.3. Bacula File Daemon
Bacula adalah software opensource untuk mengelola dan verifikasi data komputer di jaringan komputer dengan berbagai jenis. Bacula relatif mudah digunakan dan efisien, sambil menawarkan banyak fitur pengelolaan penyimpanan yang canggih sehingga memudahkan pencarian dan pemulihan file yang hilang atau rusak. Bacula dapat digunakan di sistem komputer tunggal sampai sistem di jaringan yang luas. Bacula digunakan disisi klien, bersifat multiplatform sistem operasi, dijalankan oleh "file daemon" yang berjalan disisi klien untuk membuat session di jaringan. File Daemon adalah perangkat lunak yang menyediakan akses server-client ke data yang akan dibackup (Vice, 2013).
2.4.4. Restore
Restore adalah proses pengembalian data dari file backup yang dilakukan sebelum atau pada saat terjadi kerusakan, kecelakaan, atau bencana alam yang merusak data utama. Ketika melakukan restore mengembalikan komputer atau perangkat elektronik lainnya ke keadaan sebelumnya, dengan kata lain data yang dikembalikan adalah posisi data pada saat di-backup (Vice, 2013).
Mengembalikan data komputer sering dilakukan sebagai upaya terakhir untuk memperbaiki mesin yang bermasalah. Sebagai contoh, jika virus telah menginfeksi sejumlah besar file system, sistem restore adalah cara untuk mendapatkan komputer dapat bekerja kembali. Jika hard drive telah rusak dan tidak dapat diperbaiki dengan menggunakan utilitas disk, perlu untuk meng-format hard drive dan mengembalikan komputer dari disk instalasi sistem operasi yang asli.
2.5. Artificial Intelligence
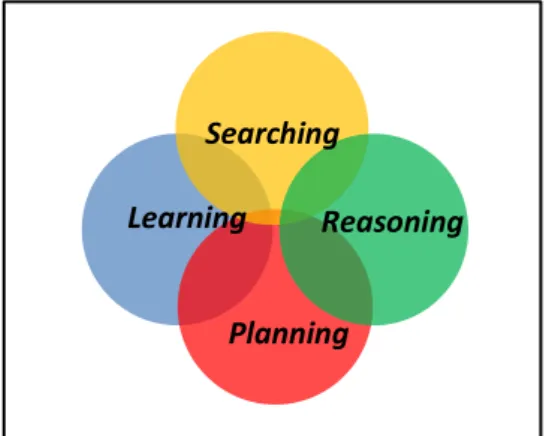
Kecerdasan Buatan atau Intelegensi Artifisial (disingkat AI) didefinisikan sebagai kecerdasan entitas ilmiah. Kecerdasan diciptakan dan dimasukkan ke dalam suatu mesin (komputer) agar dapat melakukan pekerjaan seperti yang dapat dilakukan manusia. Beberapa macam bidang yang menggunakan kecerdasan buatan antara lain sistem pakar, permainan komputer (games), logika fuzzy, jaringan syaraf tiruan dan robotika. Dalam Artificial Intelligence terdapat empat teknik dasar pemecahan masalah, yaitu: searching, reasoning, planning dan learning (gambar 2.6). Keempat teknik dasar ini memiliki karakteristik yang unik dan dapat digunakan sendiri-sendiri secara terpisah atau digabungkan (Suyanto, 2014).
Gambar 2.6 Empat teknik dasar dalam Artificial Intelligence
Pada gambar 2.6 yang menunjukkan teknik dasar dalam Artificial Intelligence dengan penjelasan sebagai berikut:
1. Searching
Teknik penyelesaian masalah dengan cara melakukan searching atau pencarian. Langkah pertama adalah mendefinisikan ruang masalah yang digambarkan sebagai himpunan keadaan (state) atau dapat juga
Searching Learning
Planning
sebagai himpunan rute dari keadaan awal (initial state) menuju keadaan tujuan (goal state) untuk suatu masalah yang dihadapi. Langkah kedua adalah mendefinisikan aturan produksi yang digunakan untuk mengubah suatu state ke state yang lain. Langkah terakhir adalah memilih metode pencarian yang tepat sehingga dapat menemukan solusi terbaik dengan usaha yang minimal. Terdapat dua jenis pencarian yang dapat dilakukan yakni:
a. Blind/Un-informed Search
Dapat dikatakan juga pencarian buta karena tidak ada informasi awal yang digunakan dalam proses pencarian. Metode yang tergolong Blind Search adalah:
1) Breadth First Search (BFS) 2) Uniform Cost Search (UCS) 3) Depth First Search (DFS)
4) Iterative Deepening Search (IDS) 5) Bi-directional Search (BDS) b. Heuristic / Informed Search
Metode ini menggunakan suatu fungsi yang menghitung biaya perkiraan dari suatu simpul tertentu menuju ke simpul tujuan. Heuristic disini diartikan sebagai suatu proses yang mungkin dapat menyelesaikan masalah tetapi tidak ada jaminan bahwa solusi yang dicari selalu dapat ditemukan.
Metode yang termasuk dalam heuristic adalah: 1) Generate and Test
2) Hill Climbing 3) Simulate Annealing 4) Best First Search. 2. Reasoning
Teknik penyelesaian masalah dengan cara merepresentasikan masalah ke dalam basis pengetahuan (knowledge base) menggunakan logic atau bahasa formal (bahasa yang dipahami komputer). Metode yang digunakan untuk merepresentasikan pengetahuan dan melakukan penalaran diantaranya:
a. Propositional Logic (Logika Proposisi)
b. First Order Logic atau Predicate Calculus (Kalkulus Predikat) c. Fuzzy Logic (Logika Samar)
3. Planning
Teknik penyelesaian masalah dengan cara memecah masalah ke dalam sub-sub masalah yang lebih kecil, menyelesaikan sub-sub masalah satu demi satu, kemudian menggabungkan solusi-solusi dari sub-sub masalah tersebut menjadi sebuah solusi lengkap dengan tetap mengingat dan menangani interaksi yang terdapat pada sub-sub masalah tersebut. Dua metode dasar yang digunakan adalah:
a. Goal Stack Planning (GSP) b. Constraint Posting (CP)
4. Learning
Teknik Learning ini berbeda dengan ketiga teknik sebelumnya, yaitu searching, reasoning, dan planning. Ketiga teknik tersebut harus mendefinisikan aturan yang benar dan lengkap untuk sistem yang akan dibangun, akan tetapi terkadang pada masalah tertentu tidak bisa didefinisikan aturan secara benar dan lengkap karena data-data yang didapatkan tidak lengkap. Teknik learning inilah solusi untuk secara otomatis menemukan aturan yang diharapkan dapat berlaku secara umum untuk data-data yang belum pernah diketahui. Metode yang menggunakan teknik learning adalah:
a. Neural Network b. Algoritma Genetika
2.6. Fuzzy System
Terori fuzzy set atau himpunan samar pertama kali dikemukakan oleh Lotfi A. Zadeh sekitar tahun 1965 pada sebuah makalah yang berjudul “Fuzzy Sets”. Dengan teori fuzzy set, dapat dipresentasikan dan dapat menangani masalah ketidakpastian yang dalam hal ini bisa berarti keraguan, ketidakpastian, ketidaktepatan, kekurang lengkapan informasi, dan kebenaran yang bersifat sebagian (Suyanto, 2014). Dalam dunia nyata seringkali menghadapi suatu masalah yang informasinya sangat sulit diterjemahkan ke dalam suatu rumus atau angka yang tepat karena informasi tersebut bersifat kualitatif (tidak bisa diukur secara kuantitatif).
2.6.1. Fuzzy Set
Misalkan U adalah universe (semesta) objek dan x adalah anggota U. Suatu fuzzy set A di U didefinisikan sebagai suatu fungsi keanggotaan
µ
A (x), yangmemetakan setiap objek di U menjadi suatu nilai real dalam interval [0,1]. Nilai-nilai
µ
A(x) menyatakan derajat keanggotaan x di dalam A. Himpunan yangmembedakan anggota dan non anggotanya dengan batasan yang jelas disebut crisp set. Misalnya, jika C = {x|x integer, x > 2}, maka anggota C adalah 3, 4, 5, dan seterusnya. Sedangkan yang bukan anggota C adalah 2, 1, 0, -1, dan seterusnya.
Konvensi untuk menuliskan fuzzy set yang dihasilkan dari U yang diskrit adalah sebagai berikut:
A = + + … =
∑
…………...(2.1) sedangkan jika U adalah kontinu, maka fuzzy set A dinotasikan sebagai:A =
ʃ
………....(2.2)Penulisan notasi tersebut hanyalah deskripsi formal dan tanda “ ” menyatakan pasangan (bukan operasi pembagian). Sedangkan tanda “+” menyatakan simbol function-theoritic union (bukan operasi penjumlahan).
Di dalam fuzzy system, fungsi keanggotaan memainkan peranan yang sangat penting untuk merepresentasikan masalah dan menghasilkan keputusan yang akurat. i
µ
A (x1) x1µ
A (x2) x2µ
A (xi) xi xϵUµ
A (x) xTerdapat banyak sekali fungsi keanggotaan yang dapat digunakan, diantaranya adalah:
1. Fungsi Sigmoid
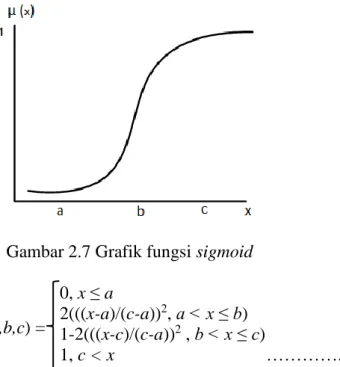
Sesuai dengan namanya, fungsi ini berbentuk kurva sigmoidal seperti huruf S. Setiap nilai x (anggota crisp set) dipetakan ke dalam interval [0, 1]. Grafik (gambar 2.7) dan notasi matematika (rumus 2.3) untuk fungsi ini adalah sebagai berikut:
Gambar 2.7 Grafik fungsi sigmoid 0, x ≤ a
2(((x-a)/(c-a))2, a < x ≤ b) 1-2(((x-c)/(c-a))2 , b < x ≤ c)
1, c < x …………..(2.3)
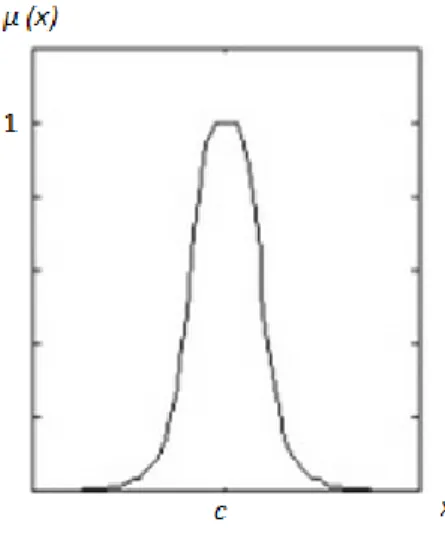
2. Fungsi Phi
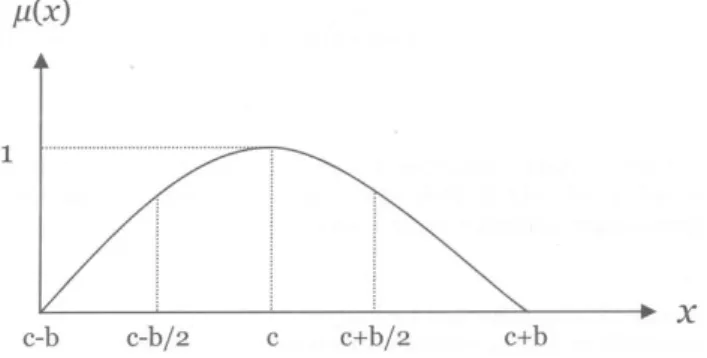
Disebut fungsi Phi karena bentuk seperti simbol phi. Pada fungsi keanggotaan ini, hanya terdapat satu nilai x yang memiliki derajat keanggotaan sama dengan 1, yaitu ketika x = c. Nilai-nilai disekitar c memiliki derajat keanggotaan yang masih mendekati 1. Grafik (gambar
2.8) dan notasi matematika (rumus 2.4) dari fungsi ini adalah sebagai berikut:
Gambar 2.8 Grafik fungsi phi Phi (x, c-b, c-b/2, c), x ≤ c
1-Phi (x, c, c+b/2, c+b), x > c ...(2.4)
3. Fungsi Segitiga
Pada fungsi ini juga terdapat hanya satu nilai x yang memiliki derajat keanggotaan sama dengan 1, yaitu ketika x=b. Tetapi nilai-nilai di sekitar b memiliki derajat keanggotaan yang turun cukup tajam (menjauhi 1). Grafik (gambar 2.9) dan notasi matematika (rumus 2.5) dari fungsi segitiga adalah sebagi berikut:
Gambar 2.9 Grafik fungsi segitiga 0, x ≤ a, x ≥ c
(x-a)/(b-a), a < x ≤ b
-(x-c)/(c-b), b < x ≤ c ……….(2.5) Phi (x,b,c) =
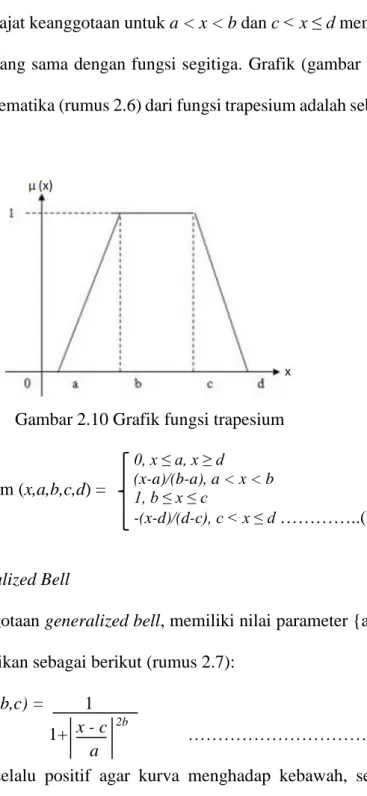
4. Fungsi Trapesium
Berbeda dengan fungsi segitiga, pada fungsi ini terdapat beberapa nilai x yang memiliki derajat keanggotaan sama dengan 1, yaitu ketika b ≤ x ≤ c. Tetapi derajat keanggotaan untuk a < x < b dan c < x ≤ d memiliki karakteristik yang sama dengan fungsi segitiga. Grafik (gambar 2.10) dan notasi matematika (rumus 2.6) dari fungsi trapesium adalah sebagai berikut:
Gambar 2.10 Grafik fungsi trapesium 0, x ≤ a, x ≥ d
(x-a)/(b-a), a < x < b 1, b ≤ x ≤ c
-(x-d)/(d-c), c < x ≤ d …………..(2.6)
5. Fungsi Generalized Bell
Fungsi keanggotaan generalized bell, memiliki nilai parameter {a,b,c} yang didefinisikan sebagai berikut (rumus 2.7):
bell (x,a,b,c) = 1
1+ ………(2.7)
Parameter b selalu positif agar kurva menghadap kebawah, seperti terlihat pada gambar 2.11.
Trapesium (x,a,b,c,d) =
x - c 2b a
Gambar 2.11 Grafik fungsi Generalized Bell 6. Fungsi Gaussian
Fungsi keanggotaan berbentuk Gaussian didefinisikan oleh 2 parameter σ dan c dengan persamaan sebagai berikut (rumus 2.8):
gaussian (x: σ,c) = e ……….………...(2.8) Fungsi keanggotaan Gauss ditentukan oleh parameter σ dan c yang menunjukan titik tengah dan lebar fungsi, seperti terlihat pada gambar 2.12.
Gambar 2.12 Grafik fungsi Gaussian - x – c 2
2.6.2. Fuzzy Logic
Fuzzy logic didefinisikan sebagai suatu jenis logic yang bernilai ganda dan berhubungan dengan ketidakpastian dan kebenaran parsial. Objek dasar dari suatu logic adalah proposition (proposisi) atau pernyataan yang menyatakan suatu fakta. Fuzzy logic memiliki derajat keanggotaan dalam rentang 0 (nol) hingga 1 (satu), berbeda dengan logika digital yang hanya memiliki dua nilai yaitu 1 (satu) atau 0 (nol). Logika fuzzy digunakan untuk menerjemahkan suatu besaran yang diekspresikan menggunakan bahasa (linguistic), misalkan besaran kecepatan laju kendaraan yang diekspresikan dengan pelan, agak cepat, cepat dan sangat cepat. Secara umum dalam sistem logika fuzzy terdapat empat buah elemen dasar, yaitu:
1. Basis kaidah (rule base), yang berisi aturan-aturan secara linguistik yang bersumber dari para pakar.
2. Suatu mekanisme pengambilan keputusan (inference engine), yang memperagakan bagaimana para pakar mengambil suatu keputusan dengan menerapkan pengetahuan (knowledge).
3. Proses fuzzifikasi (fuzzification), yang mengubah besaran tegas (crisp) ke besaran fuzzy.
4. Proses defuzzifikasi (defuzzification), yang mengubah besaran fuzzy hasil dari inference engine, menjadi besaran tegas (crisp).
2.6.3. Sistem Berbasis Aturan Fuzzy
Membangun sistem yang menggunakan aturan fuzzy dapat dilakukan dengan 4 buah elemen dasar yang disebutkan sebelumnya yaitu (Suyanto, 2014):
1. Variabel Linguistik
Variabel linguistik adalah suatu interval numerik dan mempunyai nilai-nilai linguistik, yang semantiknya didefinisikan oleh fungsi keanggotaannya. Misalnya, suhu adalah suatu variable linguistik yang bisa memiliki nilai-nilai linguistik seperti ‘Dingin’, ‘Hangat, ‘Panas’ yang semantiknya didefinisikan oleh fungsi-fungsi keanggotaan tertentu.
Suatu sistem berbasis aturan fuzzy yang lengkap terdiri dari tiga komponen utama: Fuzzyfication, Inference dan Defuzzification. Fuzzification mengubah masukan-masukan yang nilai kebenarannya bersifat pasti (crisp input) ke dalam bentuk fuzzy input, yang berupa nilai linguistik yang semantiknya ditentukan berdasarkan fungsi keanggotaan tertentu. Inference melakukan penalaran menggunakan fuzzy input dan fuzzy rules yang telah ditentukan sehingga menghasilkan fuzzy output. Sedangkan Deffuzification mengubah fuzzy output menjadi crisp rule berdasarkan fungsi keanggotaan yang telah ditentukan. 2. Fuzzification
Masukan-masukan yang nilai kebenarannya bersifat pasti (crisp input) dikonversi ke bentuk fuzzy input, yang berupa nilai linguistik yang semantiknya ditentukan berdasarkan fungsi keanggotaannya. Misalnya,
suhu 200C dikonversikan menjadi Hangat dengan derajat keanggotaan sama dengan 0,7.
3. Inference
Suatu aturan fuzzy dituliskan sebagai (rumus 2.9):
IF antecendent THEN consequent ………(2.9) Dalam suatu sistem berbasis aturan fuzzy, proses inference memperhitungkan semua aturan yang ada dalam basis pengetahuan. Hasil dari proses inference direpresentasikan oleh suatu fuzzy set untuk setiap variabel bebas (pada consequent). Derajat keanggotaan untuk setiap nilai variabel tidak bebas menyatakan ukuran kompatibilitas terhadap variabel bebas (pada antecendent). Misalkan, terdapat suatu sistem dengan n variable bebas x1, …, xn dan m variabel tidak bebas y1,
…, ym. Misalkan R adalah suatu basis dari sejumlah r aturan fuzzy
(rumus 2.10)
IF P1(x1, …, xn) THEN Q1(y1, …, ym)
… …
IF Pr(x1, …, xn) THEN Qr(y1, …, ym) ………...(2.10)
Dimana P1, …, Pr menyatakan fuzzy predicate untuk variabel bebas, dan
Terdapat dua model aturan fuzzy yang digunakan secara luas dalam berbagai aplikasi, yaitu:
a. Model Mamdani
Pada model ini, aturan fuzzy didefinisikan sebagai (rumus 2.11): IFx1 is A1 AND … AND xn is An THEN y is B …...(2.11)
Dimana A1, …, An, dan B adalah nilai-nilai linguistik (atau fuzzy set)
dan “x1 is A1” menyatakan bahwa nilai variable x1 adalah anggota
fuzzy set A1.
b. Model Sugeno
Model ini dikenal juga sebagai Takagi-Sugeno-Kang (TSK) model, yaitu suatu varian dari model Mamdani. Model ini menggunakan aturan yang berbentuk rumus 2.12.
IF x1 is A1 AND…AND xn is An THEN y = f (x1,…,xn)...(2.12)
Dimana f bisa berupa sembarang fungsi dari variabel-variabel input yang nilainya berada dalam interval veriabel output. Biasanya, fungsi ini dibatasi dengan menyatakan f sebagai kombinasi linier dari variabel-variabel input (rumus 2.13):
f (x1,…,xn)=w0+ w1 x1+…+ wn xn ……….(2.13)
Dimana w0, w1, …, wn adalah konstanta yang berupa bilangan real
4. Defuzzification
Terdapat berbagai metode defuzzification yang telah berhasil diaplikasikan untuk berbagai macam masalah, diantaranya adalah: a. Centroid method
Metode ini disebut juga sebagai Centre of Area atau Centre of Gravity. Metode ini merupakan metode yang paling penting dan menarik diantara semua metode yang ada. Metode ini menghitung nilai crisp menggunakan rumus 2.14.
y
* =ʃ
yµ
R (y)dy
ʃ
µ
R (y)dy ……….(2.14)Dimana y* suatu nilai crisp. Fungsi integration dapat diganti dengan fungsi summation jika y bernilai diskrit, sehingga menjadi rumus 2.15.
y
* =∑
yµ
R (y)
∑
µ
R (y) ………..(2.15)Dimana y adalah nilai crisp dan
µ
R (y) adalah derajat keanggotaandari y.
b. Height method
Metode ini dikenal juga sebagai prinsip keanggotaan maksimum karena metode ini secara sederhana memilih nilai crisp yang memiliki derajat keanggotaan maksimum. Oleh karena itu, metode ini hanya bisa dipakai untuk fungsi keanggotaan yang memiliki
derajat keanggotaan 1 pada suatu nilai crisp tunggal dan 0 pada semua nilai crisp yang lain. Fungsi seperti ini sering disebut sebagai singleton.
c. First (or last) of Maxima
Metode ini juga merupakan generalisasi dari height method untuk kasus dimana fungsi keanggotaan output memiliki lebih dari satu nilai maksimum. Sehingga, nilai crisp yang digunakan adalah salah satu dari nilai yang dihasilkan dari maksimum pertama atau maksimum terakhir (tergantung pada aplikasi yang akan dibangun). d. Mean-Max method
Metode ini disebut juga sebagai Middle of Maxima. Metode ini merupakan generalisasi dari height method untuk kasus dimana terdapat lebih dari satu nilai crisp yang memiliki derajat keanggotaan maksimum. Sehingga y* didefinisikan sebagai titik tengah antara nilai crisp terkecil dan nilai crisp terbesar (rumus 2.16).
y
* =m + M
2
………..(2.16) Dimana m adalah nilai crisp yang paling kecil dan M adalah nilai crisp yang paling besar.e. Weighted Average
Metode ini mengambil nila rata-rata dengan menggunakan pembobotan berupa derajat keanggotaan. Sehingga y* didefinisikan sebagai (rumus 2.17).
y
* =µ
(y) y
µ
(y) ………..(2.17)Dimana y adalah nilai crisp dan µ(y) adalah derajat keanggotaan dari nilai crisp y.
2.6.4. Permasalahan Dalam Fuzzy System
Pada sebagian masalah, dimana terdapat seorang ahli yang sangat memahami tingkah laku variabel-variabel linguistik dan aturan yang ada, maka pendefinisian fungsi keanggotaan dan aturan fuzzy bisa dilakukan dengan mudah dan cepat.
Tetapi ketika tidak bisa memahami masalah dan tidak bisa menemukan ahli yang memahami masalah yang dihadapi, maka pendefinisian fungsi keanggotaan dan aturan fuzzy memerlukan usaha keras dan waktu yang lama. Jika fungsi keanggotaan atau aturan fuzzy yang didefinisikan tidak tepat, maka performansi dari sistem fuzzy yang dibangun menjadi tidak optimal. Tetapi dalam bidang Soft Computing telah ditemukan cara pendefinisian kedua hal tersebut, yaitu menggunakan Evolutionary Algorithm (EA) atau Artificial Neural Network (ANN). Kedua metode tersebut, baik EA maupun ANN, berusaha menemukan fungsi keanggotaan ataupun aturan fuzzy yang paling optimum untuk masalah yang dihadapi.
2.7. Neural Network
Jaringan Syaraf Tiruan (Artificial Neural Network) adalah sebuah model matematik yang berupa kumpulan unit yang terhubung secara parallel yang bentuknya menyerupai jaringan saraf pada otak manusia (neural). Jaringan syaraf tiruan sering digunakan juga dalam bidang kecerdasan buatan (Yegnanarayana, 2009).
Neural Network merupakan kategori ilmu Soft Computing. Neural Network sebenarnya mengadopsi dari kemampuan otak manusia yang mampu memberikan stimulasi atau rangsangan, melakukan proses, dan memberikan output. Output diperoleh dari variasi stimulasi dan proses yang terjadi di dalam otak manusia. Kemampuan manusia dalam memproses informasi merupakan hasil kompleksitas proses di dalam otak. Misalnya, yang terjadi pada anak-anak, mereka mampu belajar untuk melakukan pengenalan meskipun mereka tidak mengetahui algoritma apa yang digunakan. Kekuatan komputasi yang luar biasa dari otak manusia ini merupakan sebuah keunggulan di dalam kajian ilmu pengetahuan.
Dari struktur neuron pada otak manusia, dan proses kerja yang dijelaskan di atas, maka konsep dasar pembangunan neural network buatan terbentuk. Ide mendasar dari Artificial Neural Network (ANN) adalah mengadopsi mekanisme berpikir sebuah sistem atau aplikasi yang menyerupai otak manusia, baik untuk pemrosesan berbagai sinyal elemen yang diterima, toleransi terhadap kesalahan atau error, dan juga parallel processing. Karakteristik dari ANN dilihat dari pola hubungan antar neuron, metode penentuan bobot dari tiap koneksi, dan fungsi
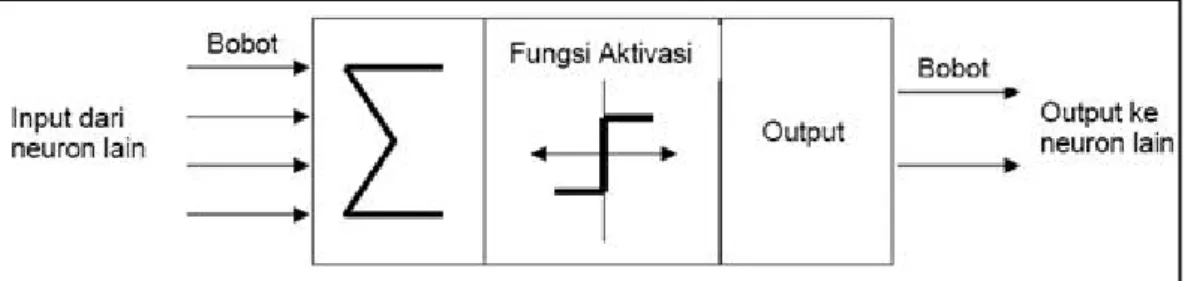
aktivasinya. Gambar 2.13 menjelaskan struktur ANN secara mendasar yang terdiri dari 3 (tiga) komponen.
Gambar 2.13 Struktur ANN (Yegnanarayana, 2009)
Seperti terlihat dalam gambar 2.13, struktur ANN diantaranya adalah sebagai berikut (Puspitaningrum, 2007):
1. Input, berfungsi seperti dendrite. 2. Output, berfungsi seperti akson.
3. Fungsi aktivasi, berfungsi seperti sinapsis.
Neural network dibangun dari banyak node atau unit yang dihubungkan oleh link secara langsung. Link dari unit yang satu ke unit yang lainnya digunakan untuk melakukan propagasi aktivasi dari unit pertama ke unit selanjutnya. Setiap link memiliki bobot numerik. Bobot ini menentukan kekuatan serta penanda dari sebuah konektivitas.
Proses pada ANN dimulai dari input yang diterima oleh neuron beserta dengan nilai bobot dari tiap-tiap input yang ada. Setelah masuk ke dalam neuron, nilai input yang ada akan dijumlahkan oleh suatu fungsi perambatan (summing function), yang bisa dilihat seperti pada di gambar 2.13 dengan lambang sigma (∑). Hasil penjumlahan akan diproses oleh fungsi aktivasi setiap neuron, disini akan dibandingkan hasil penjumlahan dengan threshold (nilai ambang) tertentu. Jika
nilai melebihi threshold, maka aktivasi neuron akan dibatalkan, sebaliknya jika masih dibawah nilai threshold, neuron akan diaktifkan. Setelah aktif, neuron akan mengirimkan nilai output melalui bobot-bobot outputnya ke semua neuron yang berhubungan dengannya. Proses ini akan terus berulang pada input-input selanjutnya (Puspitaningrum, 2007).
ANN terdiri dari banyak neuron di dalamnya. Neuron-neuron ini akan dikelompokkan ke dalam beberapa layer. Neuron yang terdapat pada tiap layer dihubungkan dengan neuron pada layer lainnya. Hal ini tentunya tidak berlaku pada layer input dan output, tapi hanya layer yang berada di antaranya. Informasi yang diterima di layer input dilanjutkan ke layer-layer dalam ANN secara satu persatu hingga mencapai layer terakhir atau layer output. Layer yang terletak di antara input dan output disebut sebagai hidden layer. Namun, tidak semua ANN memiliki hidden layer, ada juga yang hanya terdapat layer input dan output saja.
2.7.1. Decision Tree Learning
Decision tree learning adalah salah satu metode belajar yang sangat populer dan banyak digunakan secara praktis. Metode ini merupakan metode yang berusaha menemukan fungsi-fungsi pendekatan yang bernilai diskrit dan tahan terhadap data-data yang terdapat kesalahan (noisy data-data) serta mampu mempelajari ekspresi-ekspresi disjunctive (ekspresi-ekspresi OR). Iterative Dychotomizer version 3 (ID3) adalah salah satu jenis decision tree yang sangat populer.
Konsep Decision Tree adalah mengubah data menjadi pohon keputusan (decision tree) dan aturan-aturan keputusan (rule) yang terlihat pada gambar 2.14.
Gambar 2.14 Konsep Decision Tree
Decision tree adalah struktur flowcart yang mempunyai tree (pohon), dimana setiap simpul internal menandakan suatu tes atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree ditelusuri dari simpul akar ke simpul daun yang memegang prediksi kelas untuk contoh tersebut. Decision tree mudah untuk dikonversi ke aturan klasifikasi (classification rule). Konsep data dalam decision tree dinyatakan dalam bentuk tabel dengan atribut dan record (Suyanto, 2014).
Pohon (tree) merupakan sebuah graf terhubung yang tidak mengandung sirkuit. Konsep pohon (tree) dalam teori graf merupakan konsep yang sangat penting, karena terapannya diberbagai bidang ilmu. Oleh karenanya antara pohon (tree) sangat erat hubungannya dengan teori graf. Definisi pohon adalah graf tak berarah terhubung yang tidak mengandung sirkuit, menurut definisi tersebut, ada dua sifat penting pada pohon yaitu terhubung dan tidak mengandung sirkuit. Pohon (tree) merupakan graf dimana dua simpul memiliki paling banyak satu lintasan yang menghubungkannya. Pohon seringkali memiliki akar, karena setiap simpul pada pohon hanya memiliki satu lintasan akses dari setiap simpul lainnya, maka tidak mungkin bagi sebuah lintasan untuk membentuk simpul (loop) atau siklus (cycle) yang secara berkesinambungan melalui serangkaian simpul seperti terlihat pada gambar 2.15 (Suyanto, 2014).
Gambar 2.15 Konsep Tree (Suyanto, 2014)
Komponen dalam pencarian Decision tree learning adalah sebagai berikut: a. Entropy dan Information Gain
Sebuah obyek yang diklasifikasikan dalam pohon harus dites nilai entropinya. Entropy adalah ukuran dari teori informasi yang dapat mengetahui karakteristik dari impuryt, dan homogenity dari kumpulan data yaitu dengan mengatur heterogenitas (keberagaman) dari suatu sampel data. Jika kumpulan sampel data semakin heterogen, maka nilai entropy-nya semakin besar. Dari nilai entropy tersebut kemudian dihitung nilai information gain (IG) masing-masing atribut. Secara matematis, entropy dirumuskan sebagai berikut (rumus 2.18):
Entropy(S) = - (pi log2 pi ) – (pj log2 pj) ………(2.18)
dimana (1) S adalah ruang/data sampel yang digunakan untuk training. (2) Pi adalah
jumlah yang bersolusi positif (mendukung) pada data sampel untuk kriteria tertentu. (3) Pj adalah jumlah yang bersolusi negatif (tidak mendukung) pada data sampel
untuk kriteria tertentu.
Dari rumus entropy 2.18 tersebut dapat disimpulkan bahwa definisi entropy (S) adalah jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (i atau j) dari sejumlah data acak pada suatu ruang sampel S. Entropy bisa dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas. Semakin kecil nilai entropy maka semakin baik digunakan dalam mengekstraksi suatu kelas.
Setelah mendapat nilai entropy untuk suatu kumpulan data, maka kita dapat mengukur efektivitas suatu atribut dalam mengklasifikasikan data. Ukuran efektifitas ini disebut information gain. Secara matematis, infomation gain dari suatu atribut A, dituliskan sebagai berikut (rumus 2.19):
Gain (S, A) = Entropy (S) -
∑
Entropy (Sv) ………… (2.19)dimana (1) A adalah atribut, (2) V menyatakan suatu nilai yang mungkin untuk atribut A, (3) Values (A) merupakan himpunan nilai-nilai yang mungkin untuk atribut A, (4) | Sv | adalah jumlah sampel untuk nilai v, (5) | S | merupakan jumlah
seluruh sampel data, dan (6) Entropy (Sv) adalah entropy untuk sampel-sampel yang
dimiliki v.
b. Algoritma ID3
Iterative Dychotomizer version 3 (ID3) adalah algoritma decision tree learning (algoritma pembelajaran pohon keputusan) yang paling dasar. Algoritma ini melakukan pencarian secara menyeluruh (greedy) pada semua kemungkinan pohon keputusan. Salah satu algoritma induksi pohon keputusan yaitu Iterative Dychotomizer version 3 (ID3). ID3 dikembangkan oleh J. Ross Quinlan. Algoritma ID3 dapat diimplementasikan menggunakan fungsi rekursif (fungsi yang memanggil dirinya sendiri). Algoritma ID3 berusaha membangun decision tree (pohon keputusan) secara top-down (dari atas ke bawah), mulai dengan pertanyaan “atribut mana yang pertama kali harus dicek dan diletakkan pada root?”, pertanyaan ini dijawab dengan mengevaluasi semua atribut yang ada dengan menggunakan suatu ukuran statistik (yang banyak digunakan adalah information gain) untuk
v ϵValues (A)
|Sv|
mengukur efektivitas suatu atribut dalam mengklasifikasikan kumpulan sampel data.
Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah decision tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu.
Berikut ini adalah algoritma ID3 (Suyanto, 2014):
Function ID3 (KumpulanSampel, AtributTarget, KumpulanAtribut) 1. Buat simpul Root
2. If semua sampel adalah kelas i, maka Return pohon satu simpul Root dengan label = i
3. If KumpulanAtribut kosong, Return pohon satu simpul Root dengan label = nilai atribut target yang paling umum (yang paling sering muncul)
Else
a. A Atribut yang merupakan the best classifer (dengan information gain terbesar)
b. Atribut keputusan untuk Root A c. For vi (setiap nilai pada A)
2) Buat suatu variable, misalnya Sampelvi, sebagai himpunan
bagian (subset) dari KumpulanSampel yang bernilai vi pada
atribut A.
3) If Sampelvi kosong
a) Then dibawah cabang ini tambahkan suatu simpul daun (leaf node, simpul yang tidak punya anak dibawahnya) dengan label = nilai atribut target yang paling umum (yang paling sering muncul)
b) Else dibawah cabang ini tambahkan subtree dengan memanggil fungsi ID3 (Sampelvi,
AtributTarget,Atribut-{A}) End End End 4. Return Root 2.7.2. Backpropagation
Artificial Neural Network (ANN) merupakan salah satu sistem pemrosesan informasi atau data yang didisain dengan menirukan cara kerja otak manusia dalam menyelesaikan suatu masalah dengan melakukan proses belajar melalui perubahan bobot sinapsisnya (Puspitaningrum, 2007). Salah satu metode yang digunakan dalam ANN adalah Backpropagation. Backpropagation adalah algoritma pembelajaran untuk memperkecil tingkat error dengan cara menyesuaikan bobotnya berdasarkan perbedaan output dan target yang diinginkan.
Backpropagation juga merupakan sebuah metode sistematik untuk pelatihan multilayer ANN karena backpropagation memiliki tiga layer dalam proses pelatihannya, yaitu input layer, hidden layer dan output layer, dimana backpropagation ini merupakan perkembangan dari single layer network (jaringan layar tunggal) yang memiliki dua layer, yaitu input layer dan output layer. Dengan adanya hidden layer pada backpropagation dapat menyebabkan tingkat error pada backpropagation lebih kecil dibanding tingkat error pada single layer network, karena hidden layer pada backpropagation berfungsi sebagai tempat untuk meng-update dan menyesuaikan bobot, sehingga didapatkan nilai bobot yang baru yang bisa diarahkan mendekati dengan target output yang diinginkan. Gambar 2.16 menggambarkan tentang arsitektur backpropagation.
Gambar 2.16 Arsitektur Backpropagation (Chauvin, 2013)
Pada gambar 2.16 yang menjelaskan tentang arsitektur backpropagation dimana:
X = Masukan (input).
Wij = Bobot pada lapisan keluaran. Voj = Bias pada lapisan tersembunyi.
Woj = Bias pada lapisan tersembunyi dan lapisan keluaran. J = 1, 2, 3,….., n.
n = Jumlah unit pengolah pada lapisan tersembunyi. k = Jumlah unit pengolah pada lapisan keluaran. Y = Keluaran hasil.
Pada input layer tidak terjadi proses komputasi, namun terjadi pengiriman sinyal input X ke hidden layer. Pada hidden dan output layer terjadi proses komputasi terhadap bobot dan bias, serta dihitung pula besarnya output dari hidden dan output layer tersebut berdasarkan fungsi aktivasi tertentu. Dalam algoritma backpropagation ini digunakan fungsi aktivasi sigmoid biner, karena output yang diharapkan bernilai antara 0 sampai 1 (Chauvin, 2013).
Beberapa faktor yang mempengaruhi keberhasilan algoritma backpropagation adalah sebagai berikut (Puspitaningrum, 2007):
a. Inisialisasi bobot
Bobot awal menentukan apakah jaringan akan mencapai global minimal atau lokal minimal kesalahan, dan seberapa cepat jaringan akan konvergen.
b. Laju pembelajaran
Laju pembelajaran merupakan parameter jaringan dalam mengendalikan proses penyesuaian bobot. Nilai laju pembelajaran yang optimal bergantung pada kasus yang dihadapi. Laju pembelajaran yang
terlalu kecil menyebabkan konvergensi jaringan menjadi lebih lambat, sedang laju pembelajaran yang terlalu besar dapat menyebabkan ketidakstabilan pada jaringan.
c. Momentum
Momentum digunakan untuk mempercepat pelatihan jaringan. Metode momentum melibatkan penyesuaian bobot ditambah dengan faktor tertentu dari penyesuaian sebelumnya.
Sebelum diproses, data master dinormalisasi terlebih dahulu. Normalisasi data adalah proses penskalaan data input sesuai dengan range fungsi aktifasi yang digunakan. Normalisasi data dilakukan apabila data input bernilai besar (melebihi nilai maksimum fungsi aktifasi yang digunakan) dan prosesnya sebelum perhitungan keluaran jaringan. Jadi, keluaran jaringan yang merupakan jumlah perkalian antara bobot dan data input menggunakan data input yang sudah melalui normalisasi data. Sedangkan denormalisasi data adalah proses pengembalian data yang diskala menjadi data yang sebenarnya. Denormalisasi data dilakukan pada data hasil keluaran jaringan.
Persamaan 2.20, 2.21 dan 2.22 adalah persamaan untuk normalisasi data, sedangkan persamaan 2.23 untuk denormalisasi data.
x’ = α * x + β ……… (2.20) α = Upperbound – Lowerbound ………. (2.21) max(x) – min(x) β = Upperbound – (α * max(x) ) ……… (2.22) x = (x’ – β) ………. (2.23) α
Dengan x’ adalah data diskala, x adalah data asli, upperbound adalah batas atas nilai data, lowerbound adalah batas bawah nilai data. Pada Backpropagation menggunakan fungsi aktifasi sigmoid biner dengan interval [0,1] dimana upperbound=1 dan lowerbound=0.
Algoritma pelatihan backpropagation pada dasarnya terbagi menjadi 2 (dua) langkah, yaitu langkah maju (feed forward) dan propagasi balik (back propagation). Pada feed forward, perhitungan bobot-bobot neuron hanya didasarkan pada vektor masukan, perhitungan ini untuk menghitung error antara keluaran aktual dan target. Sedangkan pada backpropagation bobot-bobot diperhalus dengan memperbaiki bobot-bobot sinaptik pada semua neuron yang ada. Algoritma pelatihan feedforward dan backpropagation adalah sebagai berikut (Suyanto, 2014):
1. Definisikan masalah, misalkan matriks masukan (P) dan matriks target (T).
2. Inisialisasi, menentukan arsitektur jaringan, nilai ambang MSE sebagai kondisi berhenti, learning rate, serta menetapkan nilai-nilai bobot sinaptik melalui pembangkitan nilai acak dengan interval nilai sembarang. Pembangkitan nilai acak dapat dilakukan dalam interval [0,+1]. Nilai Mean Square Error (MSE) pada satu siklus pelatihan adalah nilai kesalahan (error = nilai keluaran - nilai masukan) rata-rata dari seluruh record (tupple) yang dipresentasikan ke ANN dan dirumuskan seperti rumus 2.24:
MSE = ∑ error2
Semakin kecil MSE, ANN semakin kecil kesalahannya dalam memprediksi kelas dari record yang baru. Maka, pelatihan ANN ditujukan untuk memperkecil MSE dari satu siklus ke siklus berikutnya sampai selisih nilai MSE pada siklus ini dengan siklus sebelumnya lebih kecil atau sama dengan batas minimal yang diberikan (epsilon). 3. Pelatihan jaringan
a. Perhitungan Maju (feed forward)
Dengan menggunakan bobot-bobot yang telah ditentukan pada inisialisasi awal (W1), dapat dihitung keluaran dari hidden layer berdasarkan persamaan berikut (misalnya digunakan fungsi aktivasi sigmoid seperti rumus persamaan 2.25).
A1 = 1
1 + e (W1*P+B1) ………..(2.25) Hasil dari keluaran hidden layer (A1) dipakai untuk mendapatkan keluaran dari output layer seperti pada rumus persamaan 2.26.
A2 = W2 * A1 + B2 ………(2.26) Keluaran dari jaringan (A2) dibandingkan dengan target yang diinginkan. Selisih nilai tersebut adalah error dari jaringan seperti pada rumus persamaan 2.27.
E = T – A2 ……….(2.27) Sedangkan nilai error keseluruhan dinyatakan oleh rumus persamaan 2.28 berikut ini :
b. Perhitungan Mundur (back propagation)
Nilai error yang didapat dipakai sebagai parameter dalam pelatihan. Pelatihan akan selesai jika error yang diperoleh sudah dapat diterima. Error yang didapat dikembalikan lagi ke lapis-lapis yang berada di depannya. Selanjutnya, neuron pada lapis tersebut akan memperbaiki nilai-nilai bobotnya. Perhitungan perbaikan bobot diberikan pada rumus-rumus persamaan (2.29-2.34) berikut: D2 = (1 – A22) * E ………(2.29) D1 = (1 – A12) * (W2 * D2) ……….(2.30) dW1 = dW1 + (lr * D1 * P) ……….(2.31) dB1 = dB1 + (lr * D1) ……….(2.32) dW2 = dW2 + (lr * D2 * P) ……….(2.33) dB2 = dB2 + (lr * D2) ……….(2.34) c. Perbaikan Bobot Jaringan
Setelah neuron-neuron mendapatkan nilai yang sesuai dengan kontribusinya pada error keluaran, maka bobot-bobot jaringan akan diperbaiki agar error dapat diperkecil. Perbaikan bobot jaringan diberikan oleh rumus-rumus persamaan (2.35-2.38) berikut:
TW1 = W1 + dW1……….(2.35) TB1 = B1 + dB1 ………...(2.36) TW2 = W2 + dW2 ………(2.37) TB2 = B2 + dB2 ………...(2.38)
d. Presentasi Bobot Jaringan
Bobot-bobot yang baru, hasil dari perbaikan, dipakai kembali untuk mengetahui apakah bobot-bobot tersebut sudah cukup baik bagi jaringan. Baik bagi jaringan berarti bahwa dengan bobot-bobot tersebut, error yang akan dihasilkan sudah cukup kecil. Pemakaian nilai bobot-bobot yang baru diperlihatkan pada rumus-rumus persamaan (2.39-2.42) berikut:
TA1 = 1
1 + e (TW1*P+TB1) ………(2.39) TA2 = TW2 * TA1 + TB2 ……….(2.40) TE = T – TA2 ………...(2.41) TSSE = ∑ TE2 ………..(2.42)
Kemudian bobot sinapsis jaringan diubah menjadi bobot-bobot baru:
W1 = TW1; B1=TB1; W2=TW2; B2=TB2; A1=TA1; A2=TA2; E=TE; SSE=TSSE; 4. Langkah-langkah diatas adalah untuk satu kali siklus pelatihan (satu
epoch). Bisanya, pelatihan harus diulang-ulang lagi hingga jumlah siklus tertentu atau telah tercapai SSE (Sum Square Error) atau MSE (Mean Square Error) yang diinginkan.
5. Hasil akhir dari pelatihan jaringan adalah bobot-bobot W1, W2, B1, dan B2.