OPTIMISASI
QUERY
CITRA DENGAN
RELEVANCE FEEDBACK
DAN
SUPPORT VECTOR MACHINE
WILLIAM SURYA JAYA
G64104026
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2009
ABSTRAK
WILLIAM SURYA JAYA. Optimisasi Query Citra dengan Relevance Feedback dan Support Vector Machine. Dibimbing oleh YENI HERDIYENI dan ARIEF RAMADHAN.
Temu kembali citra dilakukan berdasarkan isi citra (CBIR). masing-masing citra memiliki warna, bentuk dan tekstur yang beragam sehingga perlu digunakan teknik klasifikasi agar proses pencarian dapat bekerja optimal. Relevance Feedback (RF) digunakan untuk lebih memaksimalkan hasil temu kembali citra. Penelitian ini menitikberatkan pada temu kembali citra berdasarkan ciri warna. Citra query disegmentasi menggunakan Expectation Maximization kemudian diekstraksi dengan Fuzzy Color Histogram (FCH). Kelas dari citra query diperoleh dari model klasifikasi yang dibentuk menggunakan Support Vector Machine (SVM). RF akan melakukan update pada FCH query sesuai masukan dari pengguna. Penelitian ini mengukur peningkatan yang terjadi pada temu kembali citra dengan SVM dan RF dibandingkan dengan SVM tanpa RF.
Evaluasi hasil temu kembali menggunakan rataan precision untuk tiap tingkatan recall. Berdasarkan penelitian ini, hasil temu kembali citra menggunakan SVM tanpa RF memiliki rataan precision 0.74, sedangkan hasil temu kembali ctra menggunakan SVM dan RF memiliki rataan precision 0.82.
Kata Kunci: image retrieval, support vector machine, relevance feedback, expectation maximization, fuzzy color histogram.
Judul Skripsi : Optimisasi
Query
Citra dengan
Relevance Feedback
dan
Support
Vector Machine
Nama
: William Surya Jaya
NIM
: G64104026
Menyetujui:
Pembimbing I,
Pembimbing II,
Yeni Herdiyeni, S.Si, M.Kom.
Arief Ramadhan, S.Kom.
NIP 132282665
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA
NIP 131578806
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 5 Maret 1986 dari pasangan Simon Bong dan Yuliana. Penulis merupakan anak kedua dari empat bersaudara.
Tahun 2004 penulis lulus dari SMU Negri 1 Ciputat dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB. Penulis memilih Program Studi Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis menjadi asisten mata kuliah Agama Kristen Protestan pada tahun ajaran 2005/2006. Pada tahun 2006, penulis terpilih menjadi ketua Komisi Literatur UKM PMK IPB.
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga skripsi dengan judul Optimisasi Query Citra dengan Relevance Feedback dan Support Vector Machine berhasil diselesaikan.
Penulis mengucapkan terima kasih kepada Ibu Yeni Herdiyeni, S.Si, M.Kom dan Bapak Arief Ramadhan, S.Kom selaku pembimbing I dan pembimbing II yang telah banyak memberikan saran, masukan dan ide-ide kepada penulis. Penulis juga mengucapkan terima kasih kepada Bapak Ir. Agus Buono, M.Si, M.Kom selaku penguji yang telah memberikan kritik dan saran kepada penulis. Selanjutnya, penulis ingin mengucapkan terima kasih kepada:
1. Ibu, Bapak, Adik, dan Cici Vivi yang selalu memberikan dukungan dan bimbingan serta kasih sayang.
2. Clara Larasati atas segalanya dalam penelitian hingga penulisan skripsi ini.
3. Martin, Didit, Yohan, Jefry, Afris, Samuel, Edo, dan semua penghuni Wisma Emperor yang telah membantu dalam banyak hal.
4. Rizki, Imam, Kak Gibta, dan semua teman-teman Lab CI atas dukungannya dalam menyelesaikan skripsi ini.
5. Ilkomerz 41 yang telah memberikan kesan terindah selama masa perkuliahan.
6. Komisi Literatur UKM PMK IPB yang telah menjadi wadah melayani selama masa perkuliahan. 7. Departemen Ilmu Komputer, dosen dan staf yang telah banyak membantu penulis dalam
perkuliahan dan penelitian.
Penulis berharap hasil penelitian ini dapat bermanfaat dan dapat menjadi acuan bagi penelitian berikutnya.
Bogor, Januari 2009
DAFTAR ISI Halaman DAFTAR TABEL ……... v DAFTAR GAMBAR………. v DAFTAR LAMPIRAN ... v PENDAHULUAN Latar Belakang ... 1 Tujuan Penelitian ... 1
Ruang Lingkup Penelitian... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Content-Based Image Retrieval ... 1
Expectation-Maximization ... 1
Relevance Feedback ... 1
Fuzzy Color Histogram ... 2
Fungsi Cauchy ... 2
K-Fold Cross Validation ... 3
Sequential Minimal Optimization ... 3
Support Vector Machine ... 3
Precission and Recall ... 5
METODE PENELITIAN Segmentasi Warna Dengan EM ... 5
Ekstraksi Ciri Warna Dengan FCH ... 6
Data Latihan dan Data Uji... 6
Support Vector Machine ... 6
Model Klasifikasi ………... 7
Relevance Feedback……… 7
Evaluasi Hasil Temu Kembali………. 7
HASIL DAN PEMBAHASAN Segmentasi Citra ... 7
Ekstraksi Ciri Warna ... 8
Data Latih dan Data Uji ... 8
Klasifikasi dengan SVM ... 8
Hasil Temu Kembali dengan RF... 8
Evaluasi Hasil Temu Kembali ... 10
KESIMPULAN DAN SARAN Kesimpulan ... 11
Saran ... 11
DAFTAR PUSTAKA... 12
DAFTAR TABEL
Halaman
1 Rataan akurasi hasil pengujian pasangan C dan σ ... 8
2 Hasil pengujian dengan SVM ... 8
3 Nilai rataan precision hasil temu kembali citra... 10
4 Nilai rataan precision hasil temu kembali citra SVM dengan RF dan tanpa RF ……. 11
DAFTAR GAMBAR
Halaman 1 Data terpisah secara linear... 32 Metode SVM dalam mengklasifikasikan data ... 3
3 Grafik precision-recall... 5
4 Metode penelitian... 5
5 Contoh citra sebelum dan sesudah segmentasi menggunakan algoritme EM……….. 7
6 Hasil FCH dengan FCM 25 bin……… 8
7 Contoh hasil temu kembali dengan SVM tanpa RF………. 9
8 Contoh hasil temu kembali menggunakan SVM dengan RF ……….… 9
9 Contoh hasil temu kembali citra yang gagal menemukan kelas query ……… 10
10 Grafik hasil precision and recall sistem untuk setiap iterasi ………... 11
11 Grafik hasil precision and recall………. 11
DAFTAR LAMPIRAN
Halaman 1 Citra query yang diujicobakan pada proses temu kembali citra ... 142 Contoh hasil temu kembali citra berdasarkan ciri warna menggunakan SVM tanpa RF dan SVM dengan RF ………. 15
3 Nilai recall-precision hasil temu kembali citra menggunakan SVM dengan RF untuk setiap citra query ... 25
4 Nilai recall-precision hasil temu kembali citra menggunakan SVM tanpa RF untuk setiap citra query ... 26
PENDAHULUAN
Latar BerlakangSaat ini, pencarian citra dilakukan berdasarkan isi citra atau sering disebut dengan Content Based Image Retrieval (CBIR). Tingkat kemiripan diukur berdasarkan jarak Euclidean antara query dengan citra dalam basis data. Proses ini sangat tidak efektif karena banyak kendala yang dihadapi seperti waktu yang dibutuhkan untuk proses pencariannya. Hal ini mendorong berkembangnya teknik klasifikasi citra.
Beberapa teknik klasifikasi citra diantaranya adalah Bayesian Network, K-Nearest Neighbours, Radial Basis Function (RBF) dan Support Vector Machine (SVM). Zang et al. (2001) telah menggunakan Support Vector Machine (SVM) untuk klasifikasi pada sistem temu kembali citra ciri warna. Berdasarkan penelitian Gosselin dan Cord (2004), metode Support Vector Machine (SVM) memberikan hasil yang lebih baik dibandingkan dengan metode klasifikasi Bayes dan K-Nearest Neighbours. Platt (1998) telah menggunakan algoritme Sequential Minimal Optimization (SMO) untuk proses pelatihan dalam metode Support Vector Machine (SVM) dengan waktu komputasi yang lebih cepat.
Pencarian citra menggunakan klasifikasi ternyata belum dapat menyelesaikan permasalahan temu kembali citra. Sering kali citra yang ditemukembalikan tidak sesuai dengan kelas dari query. Hal ini disebabkan adanya perbedaan antara persepsi pengguna dengan hasil CBIR (semantic gap). Setia, et al. (2002) menggunakan Relevance Feedback (RF) dan Support Vector Machine (SVM) untuk meningkatkan hasil temu kembali citra. Setia et al. (2002) membuktikan bahwa RF mampu mengurangi semantic gap pada CBIR sehingga hasil temu kembali citra menjadi lebih baik. Oleh karena itu pada penelitian ini dikembangkan sebuah sistem temu kembali citra berdasarkan ciri warna menggunakan Relevance Feedback (RF) dan Support Vector Machine (SVM).
Tujuan Penelitian
Penelitian ini bertujuan untuk mendapatkan hasil query citra yang lebih baik menggunakan Support Vector Machine dan Relevance Feedback.
Ruang Lingkup Penelitian
Penelitian ini hanya menitikberatkan pada temu kembali citra berdasarkan ciri warna. Manfaat Penelitian
Manfaat dari penelitian ini adalah mendapatkan hasil temu kembali yang sesuai dengan keinginan pengguna.
TINJAUAN PUSTAKA
Content-Based Image RetrievalContent-based image retrieval (CBIR) merupakan pendekatan untuk masalah temu kembali citra yang didasarkan kepada ciri yang terkandung dalam citra tersebut seperti warna, bentuk dan tekstur (Zhang R & Zhang Z 2003).
Expectation-Maximization
Expectation-Maximation digunakan untuk mencari dugaan parameter maximum likelihood ketika ada data yang hilang atau tidak lengkap. Proses ini terdiri dari perhitungan dugaan kemungkinan untuk mengisi data yang tidak lengkap (E-Step) dan perhitungan dugaan parameter maximum likelihood menggunakan parameter yang diperoleh dari tahap E-Step (M-Step). Proses ini akan berulang hingga mencapai konvergensi nilai likelihood (Belongie et al. 1998).
Relevance Feedback
Relevance Feedback digunakan dalam Image Retrieval (IR) sebagai metode untuk menyelesaikan permasalahan klasifikasi yang bergantung kepada pengguna dan tidak mudah untuk digambarkan dalam term (vektor warna hasil ekstraksi). Relevance Feedback merupakan cara yang interaktif dimana pengguna ikut menentukan manakah citra yang relevan dengan query atau tidak.
Keberhasilan Relevance Feedback (RF) sebagai salah satu metode query expansion yang interaktif sangat tergantung dari kemampuan mesin pembelajaran dalam memilih fungsi yang digunakan untuk mempropagasi kata kunci dari query pengguna dalam melabelkan citra yang sesuai (Crucuianu et al. 2004).
Tehnik RF pertama kali dikenalkan oleh Roccio. Formula awal Roccio adalah sebagai berikut: dengan
= vektor query yang telah dimodifikasi
= vektor query asli α,β,γ = bobot (ditentukan) = vektor citra relevan = vektor citra tidak relevan
Query baru yang termodifikasi merupakan query awal ditambah dengan nilai determinan antara rataan vektor citra relevan dengan vektor citra tidak relevan. Query baru memiliki term baru dan bobot yang baru untuk setiap term sebelumnya. Jika bobot term dalam proses RF turun hingga mendekati nol maka term tersebut dihilangkan.
Ide (1971) melakukan modifikasi terhadap formula Roccio yang kemudian dinamakan Ide-Dec-Hi. Formula ini hanya menggunakan dokumen tidak relevan pertama yang ditemukembalikan. Formula Ide-Dec-Hi adalah sebagai berikut:
dengan
= jumlah citra ralevan = vektor citra relevan ke-i
= vektor citra tidak relevan pertama Ide-Dec-Hi tidak meningkatkan hasil temu kembali secara signifikan namun Ide-Dec-Hi sangat konsisten untuk berbagai Query. Selain Ide-Dec-Hi, Ide juga melakukan modifikasi lain yang dikenal dengan Ide-regular. Ide-regular diperoleh dari formula Roccio yang dinormalisasikan. Formula Ide-regular adalah sebagai berikut: dengan
= jumlah citra relevan = jumlah citra tidak relevan Fuzzy Color Histogram
Fuzzy Color Histogram adalah salah satu metode yang merepresentasikan informasi warna dalam citra digital ke dalam bentuk histogram. Di dalam Fuzzy Color Histogram (FCH), setiap warna direpresentasikan dengan
himpunan fuzzy (fuzzy set). Hubungan antar warna dimodelkan dengan fungsi keanggotaan (membership function) terhadap fuzzy set. Fuzzy set F pada ruang ciri Rn didefinisikan oleh µF : R
n
→[0,1] yang biasa disebut membership function. Untuk setiap vektor ciri f Є Rn, nilai dari µF (f) disebut derajat
keanggotaan dari f terhadap fuzzy set F (Zang R & Zang Z 2002).
Fuzzy C-Means
Fuzzy C-Means adalah suatu teknik menentukan pusat cluster pada metode clustering tanpa proses pelatihan (unsupervised learning). Algoritme Fuzzy C-Means (FCM) adalah sebagai berikut (Han & Ma 2002):
1. Masukan jumlah cluster c, konstanta pembobot m, dan toleransi nilai error e. 2. Inisialisasi pusat cluster vi, untuk 1≤ i≤ c.
3. Data input X = {x1,x2,…,xn}.
4. Menghitung c pusat cluster {vi(l)} dengan
!"#$%(+"&'($)*(
%(+"&'($) , -.-/0 1 2 1 34
5. Perbaharui nilai keanggotaan u(l) dengan
-5 % 678(9:'7; <8(9:<;= )9 > + 6. Jika 7-"#$ -"#?$7 @ A maka l = l + l dan kembali ke tahap 4. Jika tidak maka berhenti.
Hasil dari Fuzzy C-Means (FCM) adalah sejumlah pusat cluster dengan derajat keanggotaan setiap titik data terhadap cluster tersebut yang digambarkan sebagai matriks U = [uik]nxn’.
Fungsi Cauchy
Beberapa fungsi keanggotaan adalah fungsi Cauchy, Cone, dan Trapezoidal. Berdasarkan hasil penelitian Zhang R & Zhang Z (2002), fungsi Cauchy lebih baik daripada fungsi keanggotaan yang lain. Fungsi Cauchy C : Rn → [0,1] didefinisikan sebagai berikut:
3"BC$ D"E*C?FGCEHI$ JK
dengan
!C = titik tengah dari lokasi fuzzy set L = lebar dari fungsi
α = tingkat fuzziness (kekaburan). !C M , L, N M , L @ O, M
K-Fold Cross Validation
K-Fold Cross Validation dilakukan untuk membagi data penelitian dan data pengujian. K-Fold Cross Validation membagi data contoh secara acak ke dalam K subset yang saling bebas. Satu subset digunakan sebagai data pengujian dan K-1 subset sebagai data pelatihan. Proses cross validation akan diulang sampai K kali. Data awal dibagi menjadi K subset yang saling bebas secara acak, yaitu S1, S2, …, Sk, dengan ukuran setiap
subset kira-kira sama. Pelatihan dan pengujian dilakukan sebanyak K kali. Pada proses ke-i, subset Si diperlakukan sebagai data pengujian
dan subset lainnya diperlakukan sebagai data pelatihan. Pada proses pertama S2, …, Sk
menjadi data pelatihan dan S1 menjadi data
pengujian, Pada proses kedua S1, S3, …, Sk
menjadi data pelatihan dan S2 menjadi data
pengujian, dan seterusnya. (Fu 1994, diacu dalam Noorniawati 2007).
Sequential Minimal Optimization
Sequential Minimal Optimization digunakan untuk mempercepat proses Support Vector Machine (SVM) yang bersifat Quadratic Programming (QP). Penggunaan Support Vector Machine (SVM) hanya dapat menyelesaikan masalah yang berukuran kecil karena algoritme pelatihan Support Vector Machine (SVM) cenderung lambat, kompleks dan sulit untuk diimplementasikan. Sequential Minimal Optimization mampu membagi proses SVM yang bersifat QP kedalam bagian yang lebih sederhana (Platt 1998).
Sequential Minimal Optimization (SMO) memilih menyelesaikan masalah optimisasi dengan cara memilih dua Lagrange multipliers αi untuk dioptimisasi
bersama-sama, mencari nilai yang paling optimal untuk lagrange multiplier tersebut, dan memperbaharui Support Vector Machine (SVM) dengan nilai optimal yang baru. Support Vector Machine
Metode ini diperkenalkan dalam bidang pengkelasan teks oleh Joachims dan digunakan oleh Dumais et al.(1998), Drucker et al. (1999), Yang & Liu (1999) serta Klinkenberg & Joachims (2000). Support Vector Machine (SVM) memiliki dua sifat yang tidak dimiliki algoritme pembelajaran pada umumnya yaitu proses memaksimumkan margin antara ruang input bukan-linear dengan ruang ciri menggunakan kaidah kernel (Cortes & Vapnik, 1995). Algoritme Support Vector Machine (SVM) beroperasi
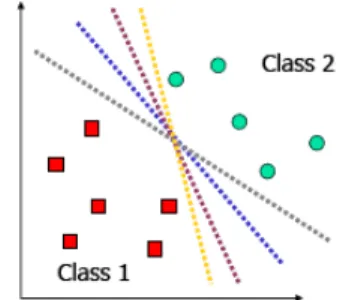
memetakan set latihan yang diberikan ke dalam satu ruang ciri yang berdimensi tinggi dengan menempatkan satu pembagi yang memisahkan model positif dengan model negatif. Ilustrasi Support Vector Machine (SVM) untuk data yang dipisahkan secara linear dapat dilihat pada Gambar 1 dan Gambar 2.
Gambar 1 Data terpisah secara linear.
Gambar 2 Metode SVM dalam mengklasifikasikan data.
Data yang berada pada bidang pembatas ini disebut support vector. Contoh di atas menunjukan bahwa kedua kelas dapat dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh:
B4 P Q R 0ST0U
B4 P Q 1 0ST0U
dengan
w = normal bidang
b = posisi bidang relatif terhadap pusat koordinat
Nilai margin (jarak) antara bidang pembatas (berdasarkan rumus jarak garis ke titik pusat) adalah
?V?"??V$
W W
Nilai margin ini dimaksimalkan dengan tetap memenuhi persamaan di atas. Dengan
XYZW,V[\"P, Q, $ ]^ P _ ` a b cU"B4 P Q$ ad ea mengalikan b dan w dengan sebuah konstanta,
akan dihasilkan nilai margin yang dikalikan dengan konstanta yang sama. Oleh karena itu, constraint di atas merupakan scaling constraint yang dapat dipenuhi dengan rescaling b dan w. Selain itu, karena memaksimalkan
P
sama dengan meminimumkan P dan jika kedua bidang pembatas direpresentasikan dalam pertidaksamaan
U"B4 P Q$ R O
maka pencarian bidang pemisah terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi constraint, yaitu
XYZ^ P 4 .0U"B4 P Q$ R O
Permasalahan ini dapat diselesaikan dengan formula lagrangian menggunakan lagrange multiplier XYZW,V[\"P, Q, $ ]^ P U"B4P Q$ dengan constraint R O (nilai koefisien lagrange) dengan meminimumkan [\terhadap w dan b, maka diperoleh persamaan
U O0LfZ UB P Vektor w sering bernilai besar sehingga persamaan ini diubah kedalam bentuk dual problem [I [I"$ ] ^ UUBB ,
sehingga bidang pemisah terbaik dapat dirumuskan menjadi: Xfg h [I"$ ] ^ UUBB , 4 .4 U O, R O
α yang dihasilkan digunakan untuk mencari w. Data yang memiliki nilai α = 0 merupakan support vector. Dengan demikian, fungsi keputusan hanya dipengaruhi oleh support vector.
Formula bidang pemisah terbaik bersifat quadratic programming, sehingga nilai maksimum global dari dapat dengan mudah ditemukan. Setelah bidang pemisah ditemukan maka formula untuk mencari kelas dari data pengujian adalah S"BI$ UB i BI Q dengan B = support vector
BI = data yang akan diklasifikasikan
ns = jumlah support vector
Untuk data yang tidak dapat dipisahkan secara linear, persamaan SVM dimodifikasi dengan menambahkan variabel a"aR O, jk a
O0lm/n0B0om/2nmSm/nm/n0oApn0QAn$menjadi: B4 P Q R 0ST0U a
B4 P Q 1 0ST0U a
sehingga formula pencarian bidang pemisah terbaik menjadi: XYZ^ P _ ` a b 4 .4 U"B4 P Q$ R a a R O
C merupakan besarnya penalty akibat kesalahan dalam klasifikasi. Selanjutnya primal problemnya menjadi:
Dual problem yang dihasilkan pada non linear problem sama dengan dual problem yang dihasilkan pada linear problem, tetapi rentang antara O R R _. Data pelatihan yang memiliki nilai R _ disebut bounded support vector.
Metode lain yang digunakan untuk memisahkan data yang tidak dapat dipisahkan secara linear adalah dengan mentransformasikannya kedalam feature space. Feature space dalam prakteknya memiliki dimensi yang lebih tinggi dari data masukannya sehingga dilakukan kernel trick. Beberapa fungsi kernel yang biasa digunakan adalah:
1. Linear kernel q"B, B$ Br4 B
2. Polinomial kernel
3. Radial basis function
q"B, B$ sgt" B B $ , @ O
4. Sigmoid kernel
q"B, B$ ufZv"4 Br4 B $
Precision dan Recall
Precision adalah perbandingan antara jumlah dokumen yang relevan yang berhasil dicapai dengan jumlah dokumen yang berhasil dicapai baik yang relevan maupun yang tidak relevan.
wA3mmT 0l-x2ny0oT/-xA0A2A!n0Unp0.AnxQm2l-x2ny0oT/-xA0Unp0.AnxQm2
Recall adalah perbandingan antara jumlah dokumen yang relevan yang berhasil dicapai dengan jumlah dokumen yang relevan dalam basis data.
A3n22 0l-x2ny0oT/-xA0A2A!n0on2nx0on.nQnAl-x2ny0oT/-xA0A2A!n0Unp0.AnxQm2
Menurut Frakes (1992), hubungan antara precision dan recall dapat digambarkan dalam grafik recall-precision (Gambar 3). Grafik menunjukan bahwa nilai precision berbanding terbalik dengan recall.
0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Recall P r e c is io n
Gambar 3 Grafik precision-recall.
METODOLOGI PENELITIAN
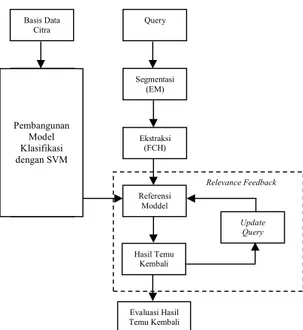
Tahapan yang dilakukan pada penelitian ini secara garis besar dapat dilihat pada Gambar 4. Data yang digunakan diambil dari basis data Caltech dan www.flowers.vg sebanyak 300 citra yang terdiri dari berbagai macam objek dengan format JPEG berukuran 50x50 piksel. Data citra disegmentasi menggunakan metode EM (Expectation Maximization) yang kemudian diekstraksi menggunakan metode FCH (Fuzzy Color Histogram).Gambar 4 Metode penelitian. Segmentasi Warna dengan EM
Setiap citra akan disegmentasi untuk dikelompokan berdasarkan warna yang dikandung oleh setiap piksel dari citra ke dalam beberapa cluster yang sudah ditentukan jumlahnya, yaitu dua, tiga, empat dan lima. Penetapan jumlah cluster dilakukan berdasarkan penelitian Yuni (2007). Cluster ini merupakan representasi dari warna-warna dominan citra. Setiap piksel dari citra dibangkitkan dari salah satu g cluster dengan formula sebagai berikut:
z"B {$ z"B |#$}~
#
Masing-masing cluster diasumsikan mempunyai distribusi normal Gauss, sehingga peluang piksel dari cluster f dapat dihitung dengan formula sebagai berikut:
z"B {$ "^$IoA."#$
ABz ^ B e#r#"B e#$ Algoritme Expectation-Maximization (EM) mempunyai dua tahapan utama yaitu tahapan Expectation (E-Step) dan Maximization (M-Step). Data X diasumsikan sebagai data yang tidak lengkap dengan missing value berupa label yang menyatakan keanggotaan tiap piksel dari X ke dalam salah satu dari G segmen (expectation step). Proses ini dilanjutkan dengan menghitung peluang dari tiap piksel dari tiap segmen sehingga membentuk matriks Z yang akan melengkapi data X. Data yang telah dilengkapi dapat
Evaluasi Hasil Temu Kembali Referensi Moddel Update Query Hasil Temu Kembali SVM Query Ekstraksi (FCH) Segmentasi (EM) Basis Data Citra Ekstraksi (FCH) Segmentasi (EM) Relevance Feedback Pembangunan Model Klasifikasi dengan SVM
dinyatakan sebagai Y = (X,Z). Label tiap piksel didapat dari segmen yang mempunyai peluang tertinggi dalam Z. Nilai likelihood dari data yang tidak lengkap adalah:
z" {$ z" {$
#
Tahapan Maximization diawali dengan menentukan parameter untuk iterasi berikutnya sesuai dugaan variabel dari z. Formulasi untuk menduga kembali parameter segmen adalah sebagai berikut:
# D # # e# D% # # B % # # # D% # # "B e# ?$"B e# ?$r % # #
Nilai parameter yang baru dari M-Step ini akan digunakan kembali untuk E-Step pada iterasi berikutnya. Proses E-Step dan M-Step akan terus berulang sampai didapat nilai likelihood yang kecil sehingga hasil perhitungan sudah tidak terlalu banyak mengalami perubahan. Ketika nilai likelihood hanya sedikit berubah, maka hasil dianggap konvergen.
Ekstraksi Ciri Warna dengan FCH
Hasil ekstraksi warna dengan Fuzzy Color Histogram (FCH) tidak terlalu beragam pada ruang warna RGB, HSV, dan Lab (Vertan & Boujemaa 2000). Oleh karena itu, untuk mempermudah pengolahan citra digunakan ruang warna RGB (Red Green Blue) yang sudah tersedia.
Langkah pertama yang dilakukan untuk menghitung FCH (Fuzzy Color Histogram) adalah menghitung histogram awal. Noorniawati (2007) menghitung nilai kuantisasi awal berdasarkan sebaran citra pada basis data yang memiliki 10 kelas citra dengan jenis dan variasi yang berbeda. Setiap kelas citra diambil 10 warna piksel yang memiliki frekuensi kemunculan tertinggi sehingga dihasilkan 100 warna semesta tanpa ada warna yang sama.
Histogram awal menghasilkan jumlah ciri yang terlalu banyak sehingga diperlukan waktu komputasi yang besar untuk ekstraksi sebuah citra. Oleh karena itu perlu dilakukan pengelompokan warna (clustering) dari 100 warna semesta tersebut kedalam beberapa
pusat cluster warna menggunakan Fuzzy C-Means (FCM). Setiap pusat cluster FCM merepresentasikan bin Fuzzy Color Histogram (FCH). Balqis (2006) membuktikan bahwa FCH dengan 25 bin, α = 2 dan σ = 15 menghasilkan rataan precision dan recall yang paling optimal.
Perhitungan Fuzzy Color Histogram (FCH) selanjutnya memerlukan matriks derajat keanggotaan yang nilai keanggotaaannya dapat diperoleh menggunakan fungsi Cauchy:
eK"3$
D"I"K4$H$J , dengan d(c’,c) = Jarak Euclid antara warna c dengan
c’,
c’ = warna pada bin FCH, c = warna semesta,
α = untuk menentukan kehalusan dari fungsi,
σ = untuk menentukan lebar dari fungsi keanggotaan.
Perhitungan akhir Fuzzy Color Histogram (FCH) dengan Fuzzy C-Means (FCM) dinotasikan sebagai berikut:
y "3$ % e K"3$ y"3$, dengan
h2 = fuzzy color histogram,
h(c) = conventional color histogram, µc’(c) = nilai keanggotaan dari warna c ke
warna c’. Data Latihan dan Data Uji
Data hasil ekstraksi ciri warna yang terdapat di dalam basis data kemudian dibagi kedalam 10 subset (S1, S2, …, S10)
menggunakan metode 10-fold cross validation.. Setiap subset memiliki ukuran yang sama. Pembagian data dilakukan secara acak dengan mempertahankan perbandingan jumlah citra pada setiap kelas. Pada proses pertama S1 menjadi data uji sedangkan S2, S3,
…, S10 menjadi data pelatihan. Pada proses
kedua S2 menjadi data uji sedangkan S1, S3,…,
S10 menjadi data pelatihan dan seterusnya.
Support Vector Machine
Pelatihan Support Vector Machine (SVM) menggunakan algoritme Sequential Minimal Optimization (SMO) dengan fungsi Kernel Gaussian Radial Basis Function (RBF) dan parameter σ untuk memperluas dimensi agar dapat membangun model klasifikasi. Noorniawati (2007) melakukan perhitungan tingkat akurasi untuk setiap pasang variasi nilai C (konstanta pada algoritme SMO) yaitu 20, 21,…, 29 dan variasi nilai σ yaitu 2-2, 2-1
dan 20. Pasangan nilai C dan σ yang menghasilkan model terbaiklah yang akan dipilih.
Data latih adalah data citra yang telah ditentukan sebelumnya (data latih hasil 10-fold cross validation) dan telah diberi label mengenai relevan atau tidaknya terhadap suatu query. Setiap citra mengandung vektor ciri citra dan label kelas karena Support Vector Machine (SVM) bersifat supervised learning.
Model Klasifikasi
Metode 10-fold cross validation menghasilkan 10 data latih dan data uji yang saling berpasangan. Setiap pasang data latih dan data uji kemudian dilatih dan dilakukan pengujian sehingga dihasilkan model klasifikasi SVM. Setiap model klasifikasi yang terbentuk kemudian dihitung tingkat akurasinya. Model yang memiliki tingkat akurasi tertinggi dijadikan model klasifikasi pada sistem ini.
Relevance Feedback
Hasil temu kembali kemudian ditingkakan menggunakan Relevance Feedback (RF). FCH query akan diformulasikan menggunakan fungsi Roccio dan Ide-Dec-Hi. sehingga dihasilkan FCH query yang lebih mirip dengan rataan vektor citra relevan. Vektor query yang baru merupakan vektor query yang telah ditambah dengan determinan antara vektor rataan citra relevan dengan vektor rataan citra tidak relevan. Jumlah iterasi tidak ditentukan.
Untuk melihat pengaruh Relevance Feedback (RF) terhadap sistem dilakukan pengukuran average precision pada lima dokumen teratas dan sepuluh dokumen teratas yang ditemu kembalikan oleh kedua metode RF.
Evaluasi Hasil Temu Kembali
Hasil temu kembali citra yang menggunakan Relevance Feedback (RF) kemudian dihitung nilai precision dan recallnya yang kemudian dibandingkan dengan nilai precision dan recall sistem tanpa menggunakan Relevance Feedback (RF).
Penelitian ini diimplementasikan pada perangkat yang dapat digunakan untuk mengolah data citra dengan spesifikasi perangkat keras:
• Prosessor Intel Pentium 4 • RAM 1 GB,
• Harddisk 40 GB, • VGA Card.
Perangkat lunak yang digunakan adalah: • Microsoft Visual C++ 2005.Net • Matlab 7 R2007
• Windows XP sebagai operating sistemnya
HASIL DAN PEMBAHASAN
Penelitian ini menekankan pada penerapan Relevance Feedback (RF) untuk optimasi query citra menggunakan metode Support Vector Machine (SVM). Metode ini digunakan untuk mengklasifikasikan citra berdasarkan ciri warna citra tersebut. Citra yang digunakan adalah citra dengan format JPEG ukuran 50 x 50 piksel sebanyak 300 citra. Terdapat 10 kelas citra yang berbeda yaitu buaya, bonsai, macan, pesawat terbang, kapal laut, wajah, bunga, kura-kura, gentong dan budha. Masing-masing kelas terdiri dari 30 citra.Segmentasi Citra
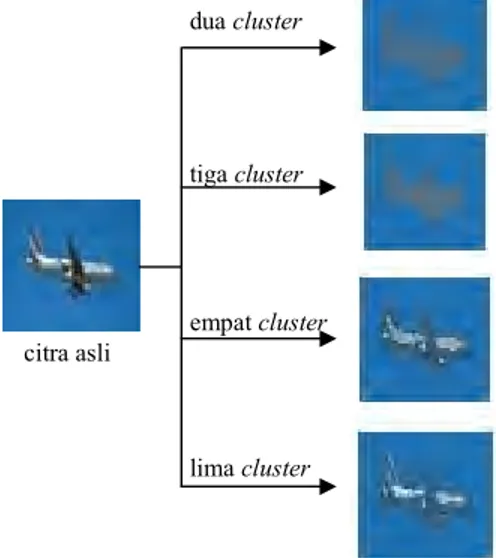
Proses ini diawali dengan mengelompokan warna yang dikandung oleh setiap piksel dari setiap citra kedalam beberapa kelompok warna (cluster). Jumlah cluster sudah ditentukan jumlahnya yaitu dua, tiga, empat, dan lima. Cluster ini merupakan representasi warna dominan yang terdapat dalam citra tersebut sehingga warna citra asli berkurang seperti pada Gambar 5.
Gambar 5 Contoh citra sebelum dan sesudah segmentasi menggunakan algoritme EM. dua cluster tiga cluster empat cluster lima cluster citra asli
Ekstraksi Ciri Warna
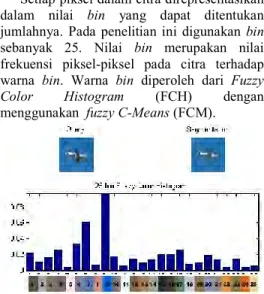
Setiap piksel dalam citra direpresentasikan dalam nilai bin yang dapat ditentukan jumlahnya. Pada penelitian ini digunakan bin sebanyak 25. Nilai bin merupakan nilai frekuensi piksel-piksel pada citra terhadap warna bin. Warna bin diperoleh dari Fuzzy Color Histogram (FCH) dengan menggunakan fuzzy C-Means (FCM).
Gambar 6 Hasil FCH dengan FCM 25 bin. Pada Gambar 6, dapat dilihat bahwa warna yang paling banyak muncul adalah warna biru. Hal ini disebabkan oleh frekuensi warna biru dalam citra query lebih tinggi daripada warna lainnya.
Data Latih dan Data Uji
Seluruh citra hasil ekstraksi ciri warna di dalam basis data sebanyak 300 citra, dibagi kedalam 10 subset. Setiap subset memiliki jumlah citra yang sama yaitu 30 citra. Pembagian 300 citra tersebut ke dalam 10 subset dilakukan secara acak. Subset-subset tersebut akan digunakan sebagai data latih dan data uji sesuai dengan metode 10-fold cross validation.
Klasifikasi dengan SVM
Metode Support Vector Machine (SVM) digunakan untuk mengklasifikasikan setiap citra dalam basis data. Tabel 1 menunjukan rataan akurasi dari setiap pasangan C (20, 21, …, 29) dan σ (2-2, 2-1 dan 20).
Berdasarkan Tabel 1, hasil terbaik diperoleh pasangan nilai C dan σ sebesar 26 dan 2-1 . Nilai C dan σ ini kemudian digunakan pada pengujian SVM. Pengujian dilakukan sebanyak 10 kali sesuai dengan metode 10-fold cross validation.
Tabel 1 Rataan akurasi hasil pengujian pasangan C dan σ σ C 2 -2 2-1 20 20 0.53 0.52 0.51 21 0.54 0.52 0.51 22 0.53 0.53 0.52 23 0.54 0.53 0.53 24 0.51 0.53 0.53 25 0.51 0.53 0.52 26 0.51 0.56 0.54 27 0.52 0.53 0.55 28 0.52 0.51 0.52 29 0.52 0.51 0.54
Tabel 2 menunjukan hasil pengukuran tingkat akurasi untuk setiap model SVM yang dibentuk pada pengujian SVM. Model klasifikasi yang dihasilkan oleh pasangan data latih dan data uji ke-10 merupakan model terbaik dengan tingkat akurasi tertinggi yaitu sebesar 0.86.
Tabel 2 Hasil pengujian dengan SVM Pengujian Akurasi 1 0.43 2 0.56 3 0.56 4 0.63 5 0.53 6 0.40 7 0.53 8 0.46 9 0.56 10 0.86 Rataan 0.55
Hasil Temu Kembali dengan RF
Pada penelitian ini, digunakan 30 citra query (Lampiran 1) yang diperoleh dari metode 10-fold cross validation. Query tersebut diujicobakan ke dalam dua metode yang berbeda untuk melihat perbedaan tingkat keefektifan hasil temu kembali. Metode pertama menggunakan SVM tanpa RF dan metode kedua menggunakan SVM dengan RF.
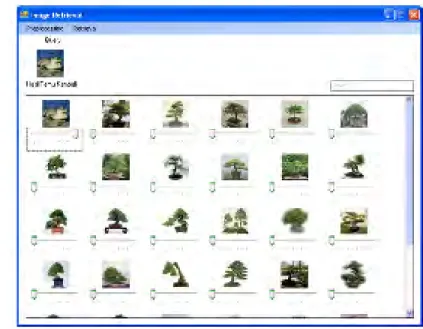
Gambar 7 Contoh hasil temu kembali dengan SVM tanpa RF. Gambar 7 memperlihatkan bahwa citra
hasil temu kembali tidak sepenuhnya sama dengan citra query. Hal ini disebabkan oleh kemiripan warna pada citra tidak relevan dari hasil temu kembali dengan citra query. Oleh karena itu, digunakan Relevance Feedback (RF) untuk memperbaiki hasil temu kembali citra tersebut.
Gambar 8 memperlihatkan bahwa hasil yang diperoleh dari SVM dengan RF lebih baik dibandingkan dengan SVM tanpa RF. Hal ini menunjukan bahwa RF mampu memperbaiki query sehingga citra yang ditemukembalikan menjadi lebih baik. Query yang telah diperbaiki memiliki kemiripan yang lebih tinggi dengan citra-citra pada kelas yang bersesuaian dengan citra query.
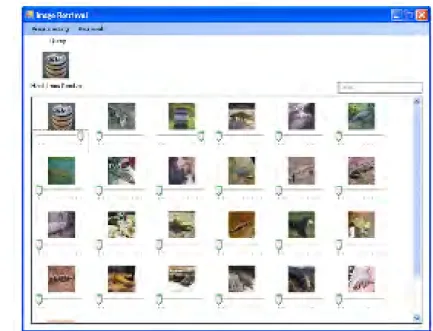
Gambar 9 Contoh hasil temu kembali citra yang gagal menemukan kelas query. Tidak semua citra query dapat berhasil
seperti pada Gambar 8. Gambar 9 adalah hasil temu kembali citra menggunakan Support Vector Machine (SVM) dengan RF yang gagal menemukan kelas yang bersesuaian dengan citra query. Query citra tidak memiliki warna yang mirip dengan kelasnya sehingga Relevance Feedback (RF) gagal memperbaiki hasil temu kembali citra tersebut.
Query yang dimasukan berasal dari kelas gentong tetapi warna yang paling dominan (warna abu-abu) tidak sesuai dengan kelas gentong. Warna dominan ini mirip dengan kelas buaya sehingga Support Vector Machine (SVM) dan Relevance Feedback (RF) gagal menemukembalikan citra yang bersesuaian. Oleh karena itu, perlu dilakukan pengukuran berdasarkan ciri bentuk dan tekstur.
Evaluasi Hasil Temu Kembali
Pada tahap evaluasi dilakukan penilaian tingkat keefektifan metode Relevance Feedback (RF) terhadap sejumlah koleksi pengujian dengan menghitung nilai recall dan precision dari proses temu kembali citra berdasarkan relevansinya. Penilaian relevansi didasarkan atas kesamaan kelas citra. Penilaian tersebut kemudian digunakan sebagai acuan pada saat melakukan evaluasi terhadap hasil temu kembali untuk setiap citra query.
Tabel 3 menunjukan hasil evaluasi rataan precision dari sistem untuk setiap iterasi.Tingkat pengukuran recall yang digunakan adalah 0, 0.1, 0.2, …, 1. Seluruh
citra hasil temu kembali diberikan label yang menyatakan relevan atau tidaknya citra tersebut terhadap query yang dimasukan.
Pada penelitian ini, iterasi RF dilakukan sebanyak tiga kali. Pengujian ini bertujuan mengukur tingkat keberhasilan RF dalam menemukembalikan citra relevan dalam basis data. RF dikatakan optimal jika berhasil menemukan citra relevan dalam basis data dengan sekali iterasi.
Tabel 3 Nilai rataan precision hasil temu kembali citra
Pada iterasi kedua, dihasilkan rataan nilai precision yang lebih baik daripada iterasi pertama dan ketiga. Hal ini menunjukan bahwa pada penelitian ini jumlah iterasi RF yang terbaik adalah dua yaitu sebesar 0.78. Peningkatan rataan recall dan precision SVM
Recall
SVM Tanpa RF
SVM dengan RF dengan jumlah iterasi
1 2 3 0 1 0.83 0.9 0.73 0.1 0.83 0.81 0.89 0.70 0.2 0.80 0.78 0.87 0.69 0.3 0.80 0.77 0.88 0.70 0.4 0.79 0.78 0.88 0.70 0.5 0.80 0.77 0.88 0.70 0.6 0.80 0.77 0.86 0.69 0.7 0.72 0.70 0.76 0.59 0.8 0.63 0.54 0.61 0.47 0.9 0.55 0.52 0.58 0.46 1 0.47 0.43 0.47 0.40 Rataan 0.74 0.70 0.78 0.62
dan RF jika dibandingkan dengan SVM adalah sebesar 0.04. Visualisasi dari peningkatan SVM dan RF ditampilkan pada Gambar 10. 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall P re ci si o n
SVM RF Iterasi 1 RF Iterasi 2 RF Iterasi 3
Gambar 10 Grafik hasil precision and recall sistem untuk setiap iterasi. Tabel 4 menunjukan hasil evaluasi dari tiap tingkat pengukuran recall. Pengukuran ini mengabaikan iterasi dari Relevance Feedback (RF). Hasil terbaik dari tiap iterasi digunakan pada pengukuran ini.
Tabel 4 Nilai rataan precision hasil temu kembali citra SVM dengan RF dan tanpa RF
Recall SVM tanpa RF SVM dengan RF
0 1 1 0.1 0.83 0.95 0.2 0.80 0.92 0.3 0.80 0.92 0.4 0.79 0.92 0.5 0.80 0.92 0.6 0.80 0.89 0.7 0.72 0.80 0.8 0.63 0.64 0.9 0.55 0.58 1 0.47 0.47 Rataan 0.74 0.82
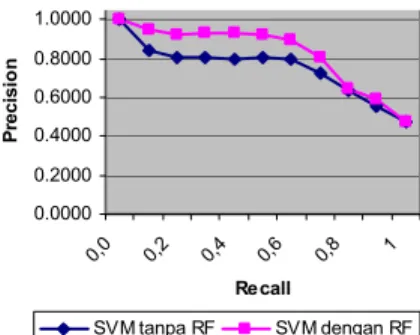
Rataan nilai precision Support Vector Machine (SVM) tanpa Relevance Feedback (RF) sebesar 0.74 sedangkan rataan nilai precision Support Vector Machine (SVM) dengan Relevance Feedback (RF) sebesar 0.82. Visualisasi dari Tabel 4 ditampilkan dalam grafik pada Gambar 11.
Gambar 11 menunjukan bahwa setiap tingkat pengukuran recall menunjukan bahwa Support Vector Machine (SVM) dengan Relevance Feedback (RF) menemukembalikan kelas citra query lebih baik daripada Support Vector Machine (SVM) tanpa Relevance Feedback (RF). Penurunan grafik perbandingan recall dan precision yang terjadi disebabkan oleh beberapa citra dalam basis data gagal diklasifikasikan pada kelas yang
sesuai. Hal ini mengakibatkan sistem tidak dapat mencapai tingkat pengukuran recall maksimum. 0.0000 0.2000 0.4000 0.6000 0.8000 1.0000 0,0 0,2 0,4 0,6 0,8 1 Re call P re c is io n SVM tanpa RF SVM dengan RF Gambar 11 Grafik hasil precision and recall.
KESIMPULAN DAN SARAN
KesimpulanRelevance Feedback (RF) dapat meningkatkan hasil temu kembali citra. Model klasifikasi yang dibentuk menggunakan metode Support Vector Machine (SVM) memiliki tingkat akurasi sebesar 0.86.
Pada penelitian ini, hasil temu kembali citra terbaik dari metode SVM dan RF diperoleh pada saat jumlah iterasi sebanyak dua. Semakin sedikit warna yang dimiliki oleh citra asli maka semakin sedikit jumlah iterasi dari RF.
Rataan nilai precision SVM tanpa Relevance Feedback (RF) sebesar 0.74 sedangkan rataan nilai precision Support Vector Machine (SVM) dengan Relevance Feedback (RF) sebesar 0.82. peningkatan yang diperoleh adalah 0.08.
Saran
Penelitian ini menggunakan ciri warna sebagai pengukuran tingkat kemiripan citra query dengan citra dalam basis data. Citra query yang gagal menemukembalikan kelasnya disebabkan karena citra query memiliki warna yang mirip dengan kelas lain sehingga perlu dilakukan pendekatan melalui ciri bentuk dan tekstur.
Data yang digunakan pada penelitian ini adalah data yang berasal dari Caltech dan www.flowers.vg sebanyak 300 citra dengan format JPEG ukuran 50 x 50 piksel. Gambar yang digunakan memiliki tingkat noise yang kecil sehingga perlu dilakukan pengujian pada data yang relatif besar dan memiliki noise yang cukup besar untuk menguji tingkat efektifitas hasil temu kembali.
DAFTAR PUSTAKA
Agusetyawan AW. Relevance Feedback pada Temu Kembali Teks Berbahasa Indonesia dengan Metode Dec-Hi dan Ide-Regular [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor; 2006.
Balqis DP. Metode Fuzzy Color Histogram Untuk Temu Kembali Citra Bunga [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor; 2006.
Belongie S, et al. 1998. Color–and Texture– Based Image Segmentation Using EM and Its Application to Content-Based image Retrieval.
http://elib.cs.berkeley.edu/carson/papers/I CCV98.pdf [6 Mei 2007].
Crucianu M, Tarel JP, Ferecatu M. 2004. A comparison of user strategies in image retrieval with relevance feedback.
http://perso.lcpc.fr/tarel.jean-philippe/publis/jpt-delos05.pdf [23 Januari 2009].
Ferecatu M, Crucianu M, Boujemma. Tuning SVM-based relevance feedback for the interactive classification of Images. Gosselin PH, Cord M. 2004. A Comparison of
Active Clasification Methods for Content Based Image Retrieval. http://perso-etis.ensea.fr/~gosselin/gosselin04cvdb.pdf [28 Oktober 2006].
Huang TS, Zhou XS. Image retrieval with relevance feedback: from heuristic weight adjustment to optimal learning method. Noorniawati VY. Metode Support Vector
Machine untuk Klasifikasi pada Sistem Temu Kembali Citra [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor; 2007.
Platt JC. 1998. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. http://reseach.microsoft.com/users/jplatt/s moTR.pdf [28 Oktober 2006].
Ruthven I, Lalmas M. 2003. A Survey on The Use of Relevance Feedback for Information Access System.
Setia L, Ick J, Burkhardt. 2002. SVM-based relevance feedback in image retrieval using invariant feature histogram.
Zhang Lei, et al. 2001. Support Vector Machine Learning for Image Retrieval. http://research.microsoft.com/users/leizhan g/Paper/ICIP01.pdf [28 Oktober 2006]. Zhang R, Zhang Z. 2003. Robust Color Object
Analysis Approach to Efficient Image Retrieval.
http://www.fortune.binghamton.edu/public ations/EURASIP.pdf [28 Oktober 2006].
Lampiran 1 Citra query yang diujicobakan pada proses temu kembali citra No Kueri Citra ID Citra No Kueri Citra ID Citra No Kueri Citra ID Citra 1 6 11 102 21 206 2 10 12 104 22 214 3 15 13 129 23 220 4 33 14 133 24 233 5 37 15 150 25 246 6 43 16 158 26 255 7 62 17 175 27 264 8 66 18 177 28 276 9 85 19 185 29 282 10 96 20 200 30 287
Lampiran 2 Contoh hasil temu kembali citra berdasarkan ciri warna menggunakan SVM tanpa RF dan SVM dengan RF
(a) Hasil temu kembali dengan SVM tanpa RF untuk kelas buaya
Lampiran 2 Lanjutan
(c) Hasil temu kembali dengan SVM tanpa RF untuk kelas bonsai
Lampiran 2 Lanjutan
(e) Hasil temu kembali dengan SVM tanpa RF untuk kelas macan
Lampiran 2 Lanjutan
(g) Hasil temu kembali dengan SVM tanpa RF untuk kelas pesawat terbang
Lampiran 2 Lanjutan
(i) Hasil temu kembali dengan SVM tanpa RF untuk kelas kapal laut
Lampiran 2 Lanjutan
(k) Hasil temu kembali dengan SVM tanpa RF untuk kelas wajah
Lampiran 2 Lanjutan
(m)Hasil temu kembali dengan SVM tanpa RF untuk kelas bunga
Lampiran 2 Lanjutan
(o) Hasil temu kembali dengan SVM tanpa RF untuk kelas kura-kura
Lampiran 2 Lanjutan
(q) Hasil temu kembali dengan SVM tanpa RF untuk kelas gentong
Lampiran 2 Lanjutan
(s) Hasil temu kembali dengan SVM tanpa RF untuk kelas budha
Lampiran 3 Nilai recall-precision hasil temu kembali citra menggunakan SVM dengan RF untuk setiap citra query
id kueri Recall (dalam %) Kelas 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 6 1.00 1.00 1.00 1.00 1.00 0.93 0.90 0.91 0.00 0.00 0.00 buaya 10 1.00 1.00 1.00 1.00 1.00 1.00 0.90 0.91 0.00 0.00 0.00 15 1.00 1.00 0.85 0.90 0.92 0.88 0.90 0.91 0.00 0.00 0.00 33 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 bonsai 37 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.93 43 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 62 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.92 0.90 0.90 macan 66 1.00 1.00 1.00 1.00 1.00 0.93 0.90 0.91 0.92 0.90 0.90 85 1.00 1.00 1.00 1.00 1.00 0.93 0.94 0.95 0.92 0.93 0.90 96 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.00 0.00 0.00 0.00 pesawat 102 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.00 0.00 0.00 0.00 104 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.00 0.00 0.00 0.00 129 1.00 1.00 0.85 0.90 0.92 0.93 0.90 0.84 0.85 0.84 0.00 kapal 133 1.00 1.00 0.85 0.81 0.80 0.88 0.81 0.84 0.82 0.84 0.00 150 1.00 1.00 0.85 0.90 0.92 0.88 0.90 0.91 0.88 0.84 0.00 158 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 wajah 175 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 177 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 185 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 bunga 200 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 206 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 214 1.00 1.00 1.00 1.00 0.92 0.88 0.75 0.72 0.75 0.00 0.00 kura-kura 220 1.00 1.00 0.66 0.64 0.66 0.71 0.75 0.77 0.77 0.00 0.00 233 1.00 0.60 0.66 0.69 0.70 0.75 0.75 0.77 0.80 0.81 0.00 246 1.00 1.00 1.00 1.00 1.00 0.93 0.94 0.95 0.00 0.00 0.00 gentong 255 1.00 1.00 1.00 1.00 1.00 0.93 0.94 0.95 0.00 0.00 0.00 264 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 276 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.95 0.92 0.93 0.93 budha 282 1.00 1.00 1.00 1.00 1.00 1.00 0.90 0.91 0.92 0.93 0.93 287 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.92 0.93 0.93 Rataan 1.00 0.95 0.92 0.92 0.92 0.92 0.90 0.80 0.64 0.58 0.47 Keterangan:
Lampiran 4 Nilai recall-precision hasil temu kembali citra menggunakan SVM tanpa RF untuk setiap citra query
id kueri Recall (dalam %) Kelas
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 6 1.00 1.00 1.00 1.00 1.00 0.88 0.90 0.91 0.00 0.00 0.00 buaya 10 1.00 0.60 0.75 0.81 0.85 0.88 0.90 0.91 0.00 0.00 0.00 15 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 33 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.91 0.93 bonsai 37 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.93 43 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 62 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.88 0.90 0.90 macan 66 1.00 1.00 1.00 0.90 0.85 0.88 0.90 0.87 0.88 0.90 0.90 85 1.00 1.00 0.85 0.90 0.85 0.88 0.90 0.91 0.92 0.93 0.90 96 1.00 0.75 0.54 0.90 0.92 0.93 0.94 0.00 0.00 0.00 0.00 pesawat 102 1.00 0.60 0.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 104 1.00 1.00 1.00 0.90 0.92 0.93 0.94 0.00 0.00 0.00 0.00 129 1.00 1.00 0.85 0.90 0.92 0.93 0.90 0.80 0.82 0.84 0.0 kapal 133 1.00 1.00 0.75 0.81 0.75 0.78 0.81 0.84 0.85 0.84 0.00 150 1.00 1.00 0.85 0.90 0.85 0.83 0.85 0.84 0.85 0.84 0.00 158 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 wajah 175 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.96 0.96 0.96 177 1.00 1.00 1.00 0.90 0.92 0.93 0.94 0.95 0.96 0.96 0.96 185 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 bunga 200 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 0.96 206 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.96 0.96 214 1.00 1.00 1.00 1.00 0.85 0.88 0.78 0.75 0.75 0.00 0.00 kura-kura 220 1.00 0.75 0.60 0.69 0.66 0.68 0.72 0.72 0.72 0.00 0.00 233 1.00 0.42 0.54 0.64 0.66 0.71 0.72 0.72 0.75 0.00 0.00 246 1.00 1.00 1.00 1.00 0.92 0.93 0.94 0.95 0.00 0.00 0.00 gentong 255 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 264 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 276 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.91 0.92 0.93 0.93 budha 282 1.00 1.00 1.00 1.00 1.00 1.00 0.94 0.91 0.92 0.93 0.93 287 1.00 1.00 1.00 1.00 1.00 0.93 0.94 0.91 0.92 0.93 0.93 Rataan 1.00 0.83 0.80 0.80 0.79 0.80 0.80 0.72 0.63 0.55 0.47 Keterangan: