ALGORITMA COMPANION DAN COCITATION UNTUK
PENCARIAN HALAMAN WEB YANG TERKAIT
Gunawan
Sekolah Tinggi Teknik Surabaya gunawan@stts.edu
ABSTRACT
It is very often that an internet user wants to find some alternative websites which are similar or related with the website he or she is visiting. The process to find web pages which are related with a URL is very helpful to give more information from resulted web pages. An internet user can compare these web pages and find alternative web pages which are appropriate with his or her needs.The project explained in this paper uses link analysis approach to find related web pages. Link analysis ranks pages according to the relationship among those pages. There are two algorithms used, namely Companion and Cocitation algorithms. Both these algorithms start with creating a graph.
Companion algorithm ranks web pages according to the highest authority value. Authority computation uses Imp algorithm which is based on HITS algorithm. Imp algorithm use edge weight when computing hub and authority values to solve HITS’ lack in TKC (Tightly-Knit Community). Assigning edge weights depends on host relationship among the nodes in the graph. Cocitation algorithm ranks web pages according to the highest degree of cocitation. The degree of cocitation is the number of same parents as with the web pages which are used as the query.
From the test, it is proven that Companion algorithm performance is better than Cocitation algorithm. Companion algorithm works better in a graph which has many same hosts than Cocitation algorithm. The execution process of Cocitation algorithm is faster than that of Companion algorithm. Generally the URL results from these two algorithms are almost similar using Google for the comparison.
Keywords: companion, cocitation, related web pages, web structure mining, link analysis.
INTISARI
Seringkali seorang pengguna internet ingin mencari beberapa alternatif website lain mirip atau terkait dengan website yang sedang ia kunjungi. Proses pencarian halaman web yang terkait dengan suatu URL berguna untuk memberikan tambahan informasi dari halaman – halaman web yang dihasilkan, pengguna internet dapat membandingkan antar halaman web tersebut dan mencari alternatif halaman web lain yang sesuai dengan kebutuhannya. Software yang pengembangannya dipaparkan dalam tulisan ini menggunakan pendekatan analisis link untuk mencari halaman web yang terkait. Pendekatan ini meranking halaman berdasarkan hubungan yang dimiliki antara halaman satu dengan halaman lainnya. Terdapat dua algoritma yang digunakan yaitu algoritma Companion dan Cocitation. Kedua algoritma ini diawali prosesnya dengan pembentukan sebuah graph.
berdasarkan nilai degree of cocitation yang tertinggi. Degree of cocitation adalah jumlah parent yang sama dengan halaman web yang digunakan sebagai query.
Dari hasil percobaan dapat dibuktikan performansi algoritma companion lebih baik dari algoritma cocitation. Algoritma companion berkerja lebih baik pada graph yang memiliki banyak host yang sama dibandingkan dengan algoritma cocitation. Proses eksekusi dari algoritma cocitation lebih cepat dibandingkan dengan algoritma companion. Secara umum hasil kedua algoritma ini hampir sama dengan menggunakan Google sebegai pembanding.
Kata kunci: companion, cocitation, halaman web terkait, penambangan struktur web, analisis link.
PENDAHULUAN
Informasi yang terdapat dalam World Wide Web tumbuh dan berubah dengan sangat cepat dari tahun ke tahun. Kebutuhan untuk mendapatkan informasi yang cepat dan mudah sangat diperlukan saat ini. Tidak semua informasi yang terdapat dalam web dibutuhkan oleh user; karena itulah banyak terdapat search engine yang membantu untuk mencari informasi dalam web seperti Google, Yahoo, Altavista, dll. Banyak penelitian yang telah diarahkan untuk membantu pencarian informasi dengan cepat dan mudah. Banyak tantangan yang dibutuhkan dalam berinteraksi dengan web, antara lain menemukan informasi yang relevan, mendapatkan pengetahuan dari informasi yang tersedia, dan mempelajari perilaku dari user. Web Mining berperan penting dalam hal ini.
Search engine yang tradisional menggunakan kumpulan term sebagai query dan menghasilkan kumpulan halaman yang relevan dengan term yang dicari pada query. Ketika informasi yang penting diperlukan dalam berbagai keadaan, search engine memiliki kekurangan dimana user menentukan query yang sesuai dengan informasi yang dibutuhkan, dimana masih mudah terjadi error. Jika pengguna Internet ingin mendapatkan sekumpulan halaman yang mirip dengan halaman yang sedang ia kunjungi maka ia harus memikirkan kumpulan term sebagai query yang akan digunakan untuk mendapatkan halaman yang diinginkan. Karena itu, pendekatan baru yang menggunakan URL suatu halaman web sebagai query akan lebih mudah untuk diterima.
Pada penelitian ini akan dibahas bagaimana mendapatkan halaman web yang terkait dengan pendekatan yang berbeda. Dengan pendekatan ini, input yang diberikan bukan kumpulan dari term, melainkan URL dari suatu halaman web, dan outputnya berupa kumpulan halaman web yang terkait dengan input yang diberikan. Suatu halaman dikatakan terkait apabila memiliki topik yang sama dengan halaman digunakan sebagai input, tetapi tidak perlu sama secara semantik (struktur). Sebagai contoh apabila diberikan input www.jawapos.co.id, dimana URL ini adalah suatu halaman surat kabar di Indonesia, maka nantinya progam harus mendapatkan halaman surat kabar atau orgranisasi berita lain yang berada di Indonesia.
ALGORITMA COMPANION
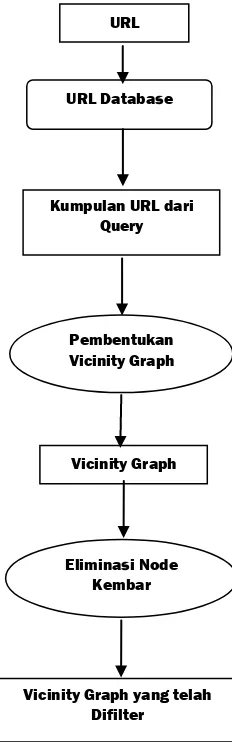
Algoritma Companion terdiri atas 4 tahap utama. Tahap yang pertama dari algoritma Companion adalah proses pembentukan Vicinity Graph. Tahap ke dua adalah eliminasi node yang kembar. Tahap yang ke tiga adalah proses pemberian bobot pada edge. Tahap ke empat adalah proses perhitungan nilai hub dan authority untuk tiap-tiap node.
A. Pembentukan Vicinity Graph
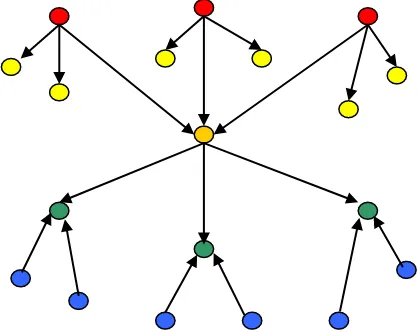
Pada penjelasan di bawah ini, yang dimaksud dengan parent adalah halaman web yang menunjuk u (memiliki outlink menuju u) dan children adalah halaman yang ditunjuk oleh suatu parent. Vicinity Graph nantinya akan berisi node-node dan edge yang menghubungkan node satu dengan yang lain, dan semuanya terpusat pada u.
1. Tentukan u (URL input).
2. Dari u dicari sejumlah Back (B) parents dari u dan untuk setiap parent dicari sejumlah Back Forward (BF) children tiap parent yang berbeda dari u.
3. Dari u dicari sejumlah F children dari u dan untuk setiap child dicari sejumlah Forward Back (FB)parent yang berbeda dari u.
Gambar 1. Proses Pembentukan Vicinity Graph URL
Vicinity Graph URL Database
Vicinity Graph yang telah Difilter
Kumpulan URL dari Query
Pembentukan Vicinity Graph
Dalam pembentukan Vicinity Graph ini terdapat daftar stoplist URL yang tidak terkait dengan kebanyakan query dan memiliki indegree yang sangat tinggi. Sebagai contoh adalah halaman search engine www.google.com, www.altavista.com, atau website terkenal seperti www.microsoft.com.
Jika starting URLu bukan merupakan salah satu node pada stoplist maka semua URL yang terdapat pada stoplist diabaikan pada saat pembentukan Vicinity Graph. Jika u muncul pada stoplist maka stoplist diset menjadi list kosong dan semua node dapat dengan bebas membentuk Vicinity Graph. Stoplist diabaikan ketika URL input tidak muncul pada stoplist karena banyak node pada stoplist adalah search engine dan portal yang populer, namun node ini diproses jika URL input ada pada stoplist.
Pembentukan graph dimulai dari parentu. Jika u memiliki lebih dari B parent maka pada graph ditambahkan sejumlah B parent secara acak yang tidak terdapat pada stoplist. Sebaliknya, jika jumlah parent yang dimiliki u kurang dari B maka semua parent tersebut akan ditambahkan pada graph. Jika suatu parent dari u memiliki lebih dari BF+1 outlink maka ditambahkan sejumlah BF/2 children yang dihubungkan oleh BF/2 link yang terdapat pada parent tersebut. Namun jika parent dari u tersebut memiliki jumlah children yang lebih kecil dari nilai BF maka semua children yang dimiliki oleh parent tersebut akan ditambahkan pada graph.
Setelah menambahkan parent yang dimiliki u pada graph maka selanjutnya akan ditambahkan children yang dimiliki oleh u dengan ketentuan sebagai berikut. Jika u memiliki lebih dari F children maka pada graph ditambahkan children yang ditunjuk oleh sejumlah F link pertama dari u, sebaliknya jika jumlah children dari u lebih kecil dari nilai F maka pada graph ditambahkan semua children yang dimiliki oleh u. Jika child dari u memiliki lebih dari sejumlah BF parent maka pada graph ditambahkan sejumlah BF parent yang tidak terdapat pada stoplist. Sebaliknya, jika jumlah parent lebih kecil dari nilai BF maka semua parent dari child akan ditambahkan pada graph.
B. Eliminasi Node Kembar
Setelah Vicinity Graph terbentuk maka langkah selanjutnya adalah menghapus node yang kembar dengan menggunakan kombinasi near-duplicate. Dua buah node dikatakan near-duplicate jika pada setiap node tersebut memiliki 10 link dan memiliki sedikitnya 95% link yang sama satu dengan yang lain. Untuk melakukan kombinasi dua near-duplicate maka dua node digantikan dengan node yang link-linknya adalah union dari link-link dari dua nodenear-duplicate.
Menghapus node yang kembar merupakan fase yang cukup penting, sebab dalam Internet terdapat banyak halaman yang identik, misalnya melalui mirror site atau memiliki nama yang berbeda untuk halaman yang sama.
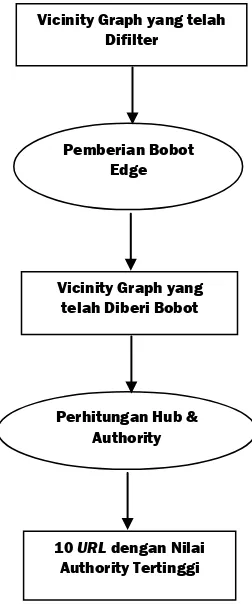
C. Pemberian Bobot Edge
Setelah penghapusan node yang kembar selesai dilakukan maka berikutnya akan dilakukan proses pemberian bobot. Penetapan bobot ini dilakukan dengan melihat host antar edge. Edge yang terdapat diantara dua node pada host yang sama diberi bobot 0. Jika terdapat k edge dari sejumlah dokumen pada host yang pertama ke suatu dokumen pada host yang ke dua maka setiap edge diberikan bobot authority sebesar 1/k. Bobot ini akan digunakan ketika menghitung nilai authority dari dokumen pada host kedua. Jika terdapat l edge dari suatu dokumen pada host yang pertama ke kumpulan dokumen pada host yang ke dua, maka pada setiap edge diberikan bobot hub sebesar 1/l. Pemberian bobot ini dilakukan untuk mencegah suatu host memiliki terlalu banyak pengaruh pada perhitungan.
Gambar 3. Mekanisme Pemberian Bobot dan Perhitungan Hub dan Authority
D. Perhitungan Hub dan Authority
Sebagai langkah terakhir, setelah pemberian bobot, dilakukan perhitungan hub dan authority untuk melakukan ranking pada URL yang ada pada graph. Untuk melakukan perhitungan hub dan authority pada graph digunakan algoritma Imp.
Algoritma Imp merupakan perkembangan dari algoritma HITS yang diperkenalkan oleh Kleinberg. Algoritma Imp memperhitungkan bobot edge yang dimiliki oleh suatu node pada graph. Pada Algoritma 1 ditunjukkan mekanisme perhitungan hub dan authority untuk sebuah vicinity graph.
10 URL dengan Nilai Authority Tertinggi Vicinity Graph yang telah Diberi Bobot Pemberian Bobot
Edge
Perhitungan Hub & Authority Vicinity Graph yang telah
Algoritma 1. Algoritma Imp
1: Inisialisasi semua elemen dari vektor hub H menjadi 1
2: Inisialisasi semua elemen dari vektor authority A menjadi 1
3: WHILE vektor H dan A tidak konvergen
4: FOR semua node n pada Vicinity Graph N
6: Normalisasi vektor H dan A
7: EXIT
ALGORITMA COCITATION
Algoritma Cocitation merupakan alternatif yang dapat digunakan untuk mencari halaman web yang terkait. Algoritma ini cukup sederhana bila dibandingkan dengan algoritma Companion.
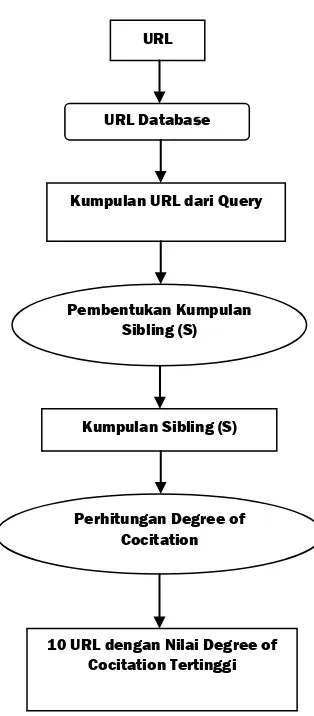
Gambar 4. Mekanisme Algoritma Cocitation
)
10 URL dengan Nilai Degree of Cocitation Tertinggi Perhitungan Degree of
Pada algoritma ini diberikan input berupa URL, kemudian input tersebut akan diberikan oleh sistem kepada database sebagai query dan hasil dari query tersebut akan digunakan untuk membentuk graph yang berisi kumpulan sibling dari URL input. Setelah selesai membentuk kumpulan sibling maka proses penghapusan node yang kembar pada algoritma Companion dapat dipakai agar kumpulan sibling dapat difilter lagi sehingga nantinya perhitungan yang dilakukan lebih valid.
Algoritma Cocitation pertama-tama memilih sejumlah B parents dari u secara acak. Kemudian dimulai dengan membentuk kumpulan S yang kosong, dan untuk semua node (p) pada P dipilih sejumlah K link dari p dan ditambahkan pada kumpulan S sehingga mengelilingi linku pada p. Elemen dari S merupakan siblings dari u. Untuk setiap node s pada S, ditentukan degree of cocitation dari s dengan u. Berikut adalah urutan algoritma Cocitation.
Algoritma 2. Algoritma Cocitation
1: Cari sejumlah B parent dari u(P) secara acak
2: Mulai dengan kumpulan S kosong,
3: FOR semua node (p) yang terdapat pada P do :
4: Pilih sejumlah K link dari p dan tambahkan pada S (sejumlah K link dipilih sehingga mengelilingi link u pada p)
5: Node yang terdapat pada S merupakan siblings dari u
6: FOR setiap node s pada S
Hitung degree of cocitation=jumlah parent yang umum antara s dan p pada P
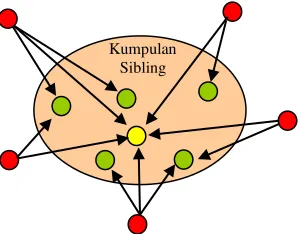
Gambar 5. Kumpulan Sibling
Proses pembentukan kumpulan sibling dari URL input hampir sama dengan proses pencarian inlink yang terhubung dengan URL input, yang kemudian dari inlink tersebut akan dicari outlinknya yang merupakan sibling dari URL input. Suatu URL disebut sebagai sibling dari URL u apabila URL tersebut terletak mengelilingi URL u. Setelah kumpulan sibling terbentuk maka akan dihitung nilai degree of cocitation untuk setiap sibling pada S dengan menggunakan parent dari node u sebagai acuan.
UJICOBA
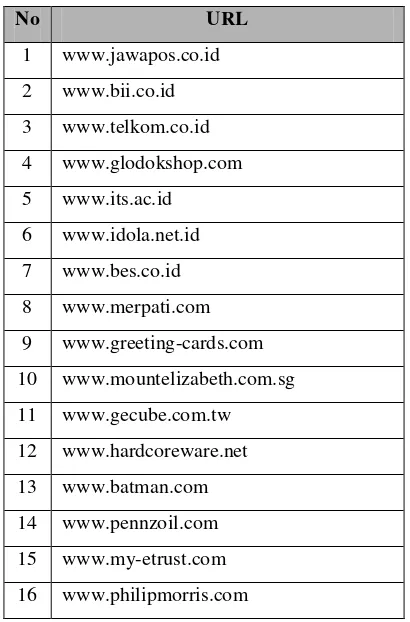
Implementasi untuk keseluruhan uji coba dilakukan dengan menggunakan bahasa pemrograman Java. Ujicoba yang digunakan menggunakan bantuan search engine Google, dimana Google juga memiliki fasilitas untuk mencari halaman web yang terkait dengan URL yang diberikan. Untuk menggunakan fasilitas Google tersebut, query input harus menggunakan keyword tertentu, yaitu dengan format “related:nama URL”, dimana pada penggunaan query ini tidak boleh ada spasi diantara keyword “related:” dengan nama URL yang diberikan. Pada ujicoba, hasil yang diberikan oleh Google akan dianggap sebagai acuan hasil yang relevan. Akan dibandingkan 20 hasil dari Google dengan 20 hasil dari kedua algoritma tersebut. Ujicoba dilakukan pada 16 URL yang dipilih; 8 website dipilih dari Indonesia, sedangkan 8 lainnya dari luar Indonesia (Tabel 1).
Meskipun percobaan dilakukan untuk 16 URL website seperti yang ditunjukkan pada tabel 1, penjelasan pada uji coba ini hanya menggunakan 4 (empat) website, dua dari Indonesia dan dua lainnya darui luar Indonesia. Namun demikian kesimpulan yang diberikan pada akhir tulisan ini menunjuk kepada hasil uji coba dari 16 website.
Berikut adalah hasil ujicoba algoritma Companion dan Cocitation untuk beberapa URL input. Untuk setiap grafik Recall/Precision yang disertakan pada setiap URL yang dipakai, garis berwarna merah menandakan hasil algoritma Cocitation sedangkan garis hitam menandakan hasil algoritma Companion.
Tabel 1. Daftar URL yang Digunakan untuk Uji Coba
No URL
1 www.jawapos.co.id
2 www.bii.co.id
3 www.telkom.co.id
4 www.glodokshop.com
5 www.its.ac.id
6 www.idola.net.id
7 www.bes.co.id
8 www.merpati.com
9 www.greeting-cards.com
10 www.mountelizabeth.com.sg
11 www.gecube.com.tw
12 www.hardcoreware.net
13 www.batman.com
14 www.pennzoil.com
15 www.my-etrust.com
www.bii.co.id
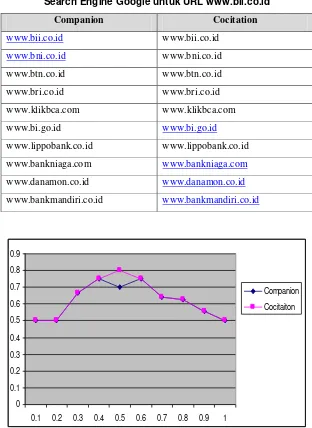
Pada percobaan dengan algoritma Companion, node yang terbentuk sebanyak 275 node dan edge yang terbentuk sebanyak 377 edge. Terdapat 53 inlink yang menunjuk URL ini.
Pada query ini, algoritma Companion memiliki nilai presisi 0.5. Dari 20 URL yang dihasilkan, ada 10 URL yang sama dengan hasil dari Google.
Pada algoritma Cocitation, node yang terbentuk sebanyak 275 node dan edge yang terbentuk sebanyak 377 edge. Nilai presisi Algoritma Cocitation untuk query ini secara keseluruhan adalah 0.5.
Secara keseluruhan, algoritma Companion dan Cocitation memiliki nilai presisi yang sama, yaitu 0.5. Dari 10 URL yang dihasilkan oleh algoritma Companion, semuanya sama dengan yang dihasilkan algoritma Cocitation.
Tabel 2. Hasil Algoritma Companion dan Cocitation yang sama dengan Hasil Pencarian Search Engine Google untuk URL www.bii.co.id
Companion Cocitation
www.bii.co.id www.bii.co.id
www.bni.co.id www.bni.co.id
www.btn.co.id www.btn.co.id
www.bri.co.id www.bri.co.id
www.klikbca.com www.klikbca.com
www.bi.go.id www.bi.go.id
www.lippobank.co.id www.lippobank.co.id
www.bankniaga.com www.bankniaga.com
www.danamon.co.id www.danamon.co.id
www.bankmandiri.co.id www.bankmandiri.co.id
Gambar 6. Recall/Precision untuk URL www.bii.co.id
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Companion
www.jawapos.co.id
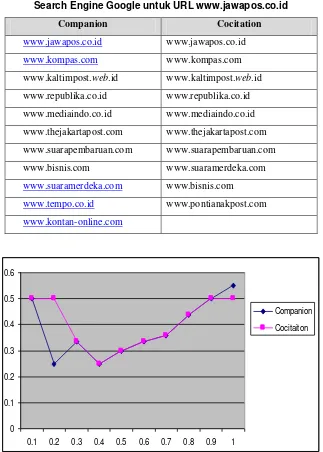
Pada percobaan algoritma Companion untuk URL www.jawapos.co.id, node yang terbentuk sebanyak 456 node dan edge yang terbentuk sebanyak 903 edge.
Sedangkan pada algoritma Cocitation, dengan URL input yang sama, jumlah node yang terbentuk sebanyak 450 node dan edge yang terbentuk sebanyak 898 edge.
Pada query ini, algoritma Companion memiliki nilai presisi 0.55 sedangkan algoritma Cocitation 0.5. Terdapat 11 URL hasil algoritma Companion yang sama dengan yang dihasilkan Google, sedangkan pada algoritma Cocitation hanya ada 10 URL yang sama.
Tabel 3. Hasil Algoritma Companion dan Cocitation yang sama dengan Hasil Pencarian Search Engine Google untuk URL www.jawapos.co.id
Companion Cocitation
www.jawapos.co.id www.jawapos.co.id
www.kompas.com www.kompas.com
www.kaltimpost.web.id www.kaltimpost.web.id
www.republika.co.id www.republika.co.id
www.mediaindo.co.id www.mediaindo.co.id
www.thejakartapost.com www.thejakartapost.com
www.suarapembaruan.com www.suarapembaruan.com
www.bisnis.com www.suaramerdeka.com
www.suaramerdeka.com www.bisnis.com
www.tempo.co.id www.pontianakpost.com
www.kontan-online.com
Gambar 7. Recall/Precision untuk URL www.jawapos.co.id 0
0.1 0.2 0.3 0.4 0.5 0.6
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
www.greeting-cards.com
Pada percobaan dengan algoritma Companion, node yang terbentuk sebanyak 760 node dan edge yang terbentuk sebanyak 1038 edge.
Pada algoritma Cocitation, jumlah node yang terbentuk sebanyak 755 node dan edge yang terbentuk sebanyak 1018 edge.
Pada query ini, kedua algoritma memiliki nilai presisi 0.55 untuk algoritma Companion dan 0.5 untuk algoritma Cocitation. Hasil dari algoritma Companion ada 11 URL yang sama dengan Google sedangkan pada algoritma Cocitation ada 10 URL yang sama dengan Google.
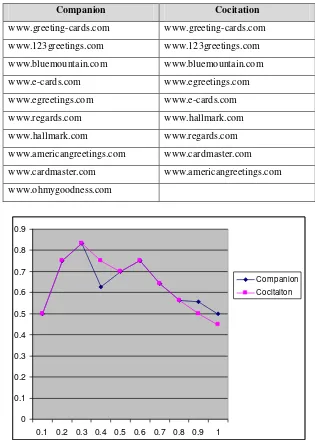
Tabel 4. Hasil Algoritma Companion dan Cocitation yang sama dengan Hasil Pencarian Search Engine Google untuk URL www.greeting-cards.com
Companion Cocitation
www.greeting-cards.com www.greeting-cards.com
www.123greetings.com www.123greetings.com
www.bluemountain.com www.bluemountain.com
www.e-cards.com www.egreetings.com
www.egreetings.com www.e-cards.com
www.regards.com www.hallmark.com
www.hallmark.com www.regards.com
www.americangreetings.com www.cardmaster.com
www.cardmaster.com www.americangreetings.com
www.ohmygoodness.com
Gambar 8. Recall/Precision untuk URL www.greeting-cards.com
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
www.pennzoil.com
Pada percobaan dengan algoritma Companion, node yang terbentuk 610 node dan edge yang terbentuk 786 edge.
Pada algoritma Cocitation untuk URL www.pennzoil.com, jumlah node yang terbentuk sebanyak 600 node dan edge yang terbentuk sebanyak 776 edge.
Pada query ini, kedua algoritma memiliki nilai presisi 0.4. Dari hasil dari algoritma Companion dan Cocitation, ada 8 URL yang sama dengan Google.
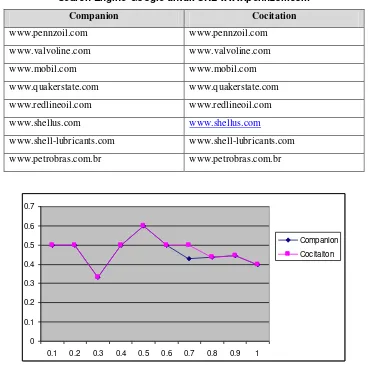
Tabel 5. Hasil Algoritma Companion dan Cocitation yang sama dengan Hasil Pencarian Search Engine Google untuk URL www.pennzoil.com
Companion Cocitation
www.pennzoil.com www.pennzoil.com
www.valvoline.com www.valvoline.com
www.mobil.com www.mobil.com
www.quakerstate.com www.quakerstate.com
www.redlineoil.com www.redlineoil.com
www.shellus.com www.shellus.com
www.shell-lubricants.com www.shell-lubricants.com
www.petrobras.com.br www.petrobras.com.br
Gambar 9. Recall/Precision untuk URL www.pennzoil.com
KESIMPULAN
Dari hasil ujicoba yang telah dilakukan melalui 16 website yang disebutkan pada tabel 1, dapat diberikan beberapa kesimpulan sebagai berikut:
1. Proses pengambilan URL sebagai node child pada graph ikut mendukung tercapainya hasil yang diharapkan, dimana proses pengambilan ini dilakukan dengan memilih node child yang berada sekitar URL input. Kebanyakan susunan halaman web mengelompokkan link halaman yang saling terkait secara berurutan.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Companion
2. Proses eliminasi node yang kembar dan penggantiannya dengan satu node gabungan pada proses pembentukan graph dapat meningkatkan precision pada algoritma Companion untuk menghindari output yang sama muncul beberapa kali.
3. Pada algoritma Companion, pemberian bobot edge dengan mempertimbangkan host suatu URL dan menggunakannya pada perhitungan hub dan authority membuat algoritma ini bekerja lebih baik dari algoritma Cocitation pada graph dengan struktur node yang memiliki banyak host yang sama. Hal ini dapat menghindari dominasi suatu host pada ranking yang dihasilkan.
4. Dari hasil pengamatan ujicoba, nilai presisi algoritma Companion lebih baik dibandingkan dengan algoritma Cocitation. Namun algoritma Cocitation dapat dijadikan sebagai salah satu alternatif karena memiliki proses yang cukup cepat jika dibandingkan dengan algoritma Companion dan presisinya juga cukup baik.
5. Penggunakan link analisis dapat menjadi pertimbangan sebagai alternatif untuk mencari halaman web yang terkait, dengan melihat waktu yang dibutuhkan untuk proses eksekusi lebih cepat.
DAFTAR PUSTAKA
Bharat, Krishna, dan Henzinger, Monika R., 1998, Improved Algorithms for Topic Distillation in Hyperlinked Environments, Proceeding of the 21st ACM SIGIR Conference on Research and Development in Information Retrieval, http://gatekeeper.dec.com/pub/DEC/SRC/ publications/monika/sigir98.pdf.
Brin, Sergei, dan Page, Lawrence, 1998, The Anatomy of a Large-Scale Hypertextual Web Search Engine, http://www.site.uottawa.ca/~stan/csi5389/readings/google.pdf.
Chakrabarti, Soumen, 2003, Mining the Web: Discovering Knowledge from Hypertext Data, Morgan-Kaufmann Publisher, San Francisco-CA, USA.
Dean, Jeffrey, dan Henzinger, Monika R., 1999, Finding Related Pages in the World Wide Web, Compact Western Research Laboratory, http://www.unizh.ch/home/mazzo/reports/ www8conf/2148/pdf/pd1.pdf .
Deo, Narsingh, dan Gupta, Pankaj, 2001, World Wide Web: A Graph-Theoretic Perspective, School of Computer Science, University of Central Florida, http://cui.unige.ch/tcs/course/ algoweb/Documents/lecturenotes.pdf.
Kleinberg, Jon M., 1998, Authoritative Sources in a Hyperlinked Environment, Proceeding of the ACM-SIAM Symposium of Discrete Algorithms, http://www.cs.cornell.edu/home/kleinber/ auth.pdf .