Page | 1
Metode Observasi Terhadap Data Mobil Dengan Menggunakan
Klasifikasi dan Decision Tree Pada Matlab 7.8.0 (R2009a)
Eva Syamrosbania Lelana
11
Jurusan Teknik Elektro, Universitas Haluoleo
[email protected]
Abstract — The method of “Observation car data use classification and decision tree” . intended as a task of data
mining wich for early trials. In this study using data already provided in matlab. Classification is a method for compiling data or group data systematicall or according to some rule or rules that have been set. The decision tree is a classification method that uses the representation to a tree structure that contains alternative to solving a problem. The research uses matlab 7.8.0 (R2009a) application.
Keyword — Statistic Toolbox, Observation, Classification
Trees, Decision Tree, Matlab 7.8.0 (R2009a).
Abstrak — Pada Metode “Observasi Data Mobil Menggunakan Klasifikasi Dan Pohon Keputusan”. Bertujuan sebagai tugas dari Data Mining dimana untuk awal percobaan-percobaan. Dalam penelitian ini menggunakan data yang sudah disediakan di matlab. Klasifikasi adalah sebuah metode untuk menyusun data atau mengelompokkan data secara sistematis atau menurut beberapa aturan atau kaidah yang telah ditetapkan. Pohon Keputusan adalah suatu metode klasifikasi yang menggunakan representasi untuk struktur pohon yang berisi alternative-alternatif untuk pemecahan suatu masalah. Penelitian ini menggunakan aplikasi matlab 7.8.0 (R2009a).
Kata kunci —Statistik Toolbox, Observasi, Klasifikasi, Pohon Keputusan, Matlab 7.8.0 (R2009a).
I. PENDAHULUAN
Berkembangnya penggunaan computer dalam bidang manajemen data menyebabkan akumulasi data dalam jumlah sangat besar dibeberapa organisasi. Apalagi dengan berkembangnya persepsi bahwa analisa terhadap data yang besar ini akan mengubah data pasif menjadi informasi yang berguna. Salah satu cara untuk melakukan hal itu adalah denggan menggunakan metode Data Mining atau Knowledge Discovery in Database.
II. LATAR BELAKANG
Di dalam konsep Data Mining terdapat berbagai cara dan metode untuk mengekstrak informasi dari data yang besar. Klasifikasi adalah salah satu metode untuk melakukan ekstraksi informasi. Tujuan dari klasifikasi ini adalah untuk menganalisa data input dan membuat model yang akurat untuk setiap kelasnya berdasarkan data yang ada. Model kelas tersebut juga digunakan untuk mengklasifikasikan data tes lain/data tes baru untuk ditentukan label kelasnya.
Terdapat banyak algoritma yang dapat digunakan untuk melakukan klasifikasi data mining, salah satunya dengan Jaringan Syaraf Tiruan (JST). JST merupakan suatu arsitektur jaringan untuk memodelkan cara kerja sistem syaraf manusia (otak) dalam melaksanakan tugas tertentu. Pemodelan ini didasari oleh kemampuan otak manusia dalam mengorganisasi sel-sel penyusunnya atau neuron,
sehingga memiliki kemampuan untuk melaksanakan tugas-tugas tertentu khususnya pengenalan pola dengan efektivitas jaringan sangat tinggi[9]. Dalam mencari arsitektur yang optimal bukanlah hal yang mudah dalam penggunaan JST. Salah satu kelemahan JST adalah penentuan arsitektur yang optimal. Yang dimaksud arsitektur adalah penentuan struktur dan bobot-bobot koneksi dalam JST.
Evolutionary Algorithms (EAs) adalah algoritma-algoritma optimasi yang berbasis evolusi dalam dunia nyata. Oleh karena itu EAs dapat digunakan dalam optimasi pencarian arsitektur yang optimal dari JST. Algoritma EAs yang digunakan dalam penelitian ini adalah Evolution Strategies (ES). Pemilihan algoritma ES disebabkan kecepatan proses ES lebih baik dibandingkan dengan Genetic Algorithm[9].
Setiap atribut data memiliki pengaruh yang berbeda-beda dalam pengklasifikasian data. Hal ini tergantung pada seberapa besar nilai keinformatifan atau kontribusi suatu atribut dalam pengklasifikasian data. Sehingga diperlukan feature selection terhadap atribut yang akan dijadikan sebagai input dalam pengklasfikasian data menggunakan JST. Penelitian ini menganalisis metode klasifikasi JST, yang dipadukan dengan ES dan dengan melakukan proses feature selection pada saat preprocessing. Metode JST yang digunakan adalah Feedforward Networks dengan Supervised Learning.
III. LANDASAN TEORI
A. Data Mining
Data mining adalah suatu proses mengekplorasi dan menganalisis data dalam jumlah besar baik secara otomatis maupun semi otomatis untuk mendapatkan suatu pola yang bermakna dari data. Data mining menjadi penting karena banyaknya data yang terkumpul saat ini, cepatnya transfer data yang terjadi pada saat ini serta adanya kebutuhan untuk dapat mengolah data mentah menjadi data yang bernilai dengan cepat dan tepat.
B. Matlab
Page | 2 kemampuan aljabar komputer. Sebuah paket tambahan,
Simulink, menambahkan simulasi grafis multiranah dan Desain Berdasar-Model untuk sistem terlekat dan dinamik. Misalkan sistem 2 persamaan dengan 2 variabel seperti persamaan dibawah ini :
2x–y = 12
...(1) 5x + 12 y = 12
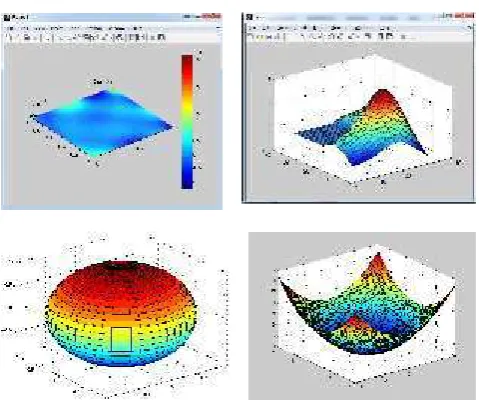
Gambar 1.1 Tampilan Awal Matlab 7.8.0 (R2009a) Hingga yang kompleks, seperti mencari akar-akar polinomial, interpolasi dari sejumlah data, perhitungan dengan matriks, pengolahan sinyal, dan metoda numerik.Salah satu aspek yang sangat berguna dari MATLAB ialah kemampuannya untuk menggambarkan berbagai jenis grafik, sehingga kita bisa memvisualisasikan data dan fungsi yang kompleks.Sebagai contoh, tiga gambar berikut diciptakan dengan command surf di MATLAB[2]
Gambar 1.2 Dimensi Command Surf Pada Matlab
C. Klasifikasi
Klasifikasi adalah suatu proses untuk mengelompokkan sejumlah data ke dalam kelas-kelas tertentu yang sudah diberikan berdasarkan kesamaan sifat dan pola yang terdapat dalam data-data tersebut[4]. Secara umum, proses klasifikasi dimulai dengan diberikannya sejumlah data yang menjadi acuan untuk membuat aturan klasifikasi data. Data-data ini biasa disebut dengan training sets. Dari training sets
tersebut kemudian dibuat suatu model untuk mengklasifikasikan data. Model tersebut kemudian digunakan sebagai acuan untuk mengklasifikasikan data-data yang belum diketahui kelasnya yang biasa disebut dengan test sets. Beberapa metode klasifikasi adalah dengan menggunakan pohon keputusan, kaidah (rule), memory based reasoning, neural networks, Naïve Bayes, dan support vector machine.
D. Information Gain
Untuk Menghitung information gain, terlebih dahulu kita harus memahami suatu ukuran yang disebut entropy. Didalam bidang information theory, kita menggunakan entropy sebagai suatu parameter untuk mengukur keberagaman dari suatu kumpulan sampel data Secara matematis, entropy dirumuskan sebagai berikut :
……….(2) dimana c adalah jumlah nilai yang ada pada atribut target (jumlah kelas). Sedangkan, pi menyatakan jumlah sampel untuk kelas i.
Setelah kita mendapatkan nilai entropy untuk suatu kumpulan sampel data, maka kita dapat mengukur efektivitas suatu atribut dalam mengklasifikasikan data. Ukuran efektivitas ini disebut sebagai information gain. Secara matematis, information gain dari suatu atribut A, dituliskan sebagai berikut:
…(3) Dimana :
A : Atribut
v : menyatakan suatu nilai yang mungkin untuk atribut A
Values (A) : himpunan nilai-nilai yang mungkin untuk atribut A
|Sv| : jumlah sampel untuk nilai v
|S| : jumlah seluruh sampel data
Entropy (Sv) : entropy untuk sampel-sampel yang
memiliki nilai v
E. Decision Tree (Pohon Keputusan)
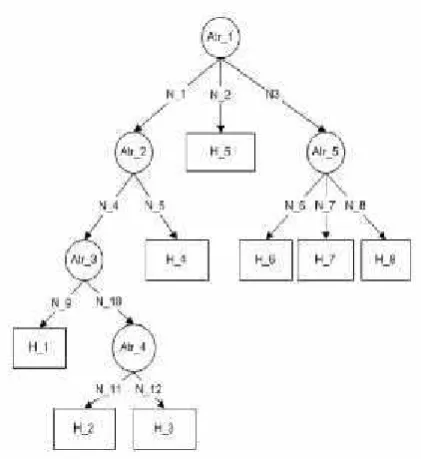
Pohon keputusan atau decision tree merupakan teknik data mining yang digunakan untuk mengeksplorasi data dengan membagi kumpulan data yang besar menjadi himpunan record yang lebih kecil dan memperhatikan variabel tujuannya.[5].
Page | 3 Gambar 1.3 Decision Tree (Pohon Keputusan)
IV. METODE PENELITIAN
Metode yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Studi Pustaka, yaitu peneliti mencari materi dengan browsing dan searching lewat internet.
2. Data yang digunakan sebagai percobaan sudah disediakan di matlab sehingga penulis hanya menganalisa saja, tidak merekap data dilapangan. 3. Penulis mendesain penulisan jurnal berdasarkan
template yang telah diberikan oleh dosen pemateri. A. Alat Dan Bahan Yang Digunakan
Penelitian ini menggunakan Notebook toshiba 64 bit dengan kapasitas RAM 2 GB serta hard disk 320 GB dengan kecepatan processor 1.86 GHz. Notebook Toshiba sudah terinstal dengan windows 7, microsoft office 2007, dan terinstal aplikasi matlab 7.8.0 (R2009a). Perkembangan terbaru dari matlab adalah 2016b, Namun penulis tidak menggunakan matlab 2016b, dikarenakan aplikasi yang terdownload tidak bisa diinstall. Sehingga dengan kendala seperti itu penulis tidak bisa menggunakan versi matlab terbaru.
B. Pengujian Alat Dan Bahan
Tahap Selanjutnya adalah pengujian alat dan bahan. Dimana jika computer atau notebook Toshiba yang digunakan tidak ada kendala sampai selesai menganalisa atau dalam penelitian maka computer atau notebook Toshiba dalam keadaan normal. Dalam system operasi matlab 7.8.0 (R2009a) yang terinstall dengan baik dan benar, maka akan seperti pada gambar berikut :
Gambar 1.4 Tampilan Matlab saat Terinstal Dengan Benar
C. Flowchart Dan Program
Tidak
Ya
Ya Tidak
Keterangan :
Langkah awal adalah dengan membuka matlab dengan mengklik 2 kali pada aplikasi matlab, kemudian masukkan data yang sudah tersedia di statistic toolbox pada matlab, setelah memasukkan data maka data itu akan diklasifikasikan atau dipengelompokkan, setelah data diklafikasi maka data tersebut akan dianalisa, jika tidak ingin menganalisa data maka bisa kembali menginput data baru. Setelah menganalisa data, maka terbentuk pohon keputusan atau decision tree, jika ingin membuat kesimpulan maka bisa memilih pilihan “Ya” jika tidak maka akan langsung berakhir “END”.
START
Input Data
Klasifikasi Data
Menganalisa Data
Decision Tree
Kesimpulan
Page | 4
V. HASIL DAN PEMBAHASAN
A. Hasil klasifikasi data mobil
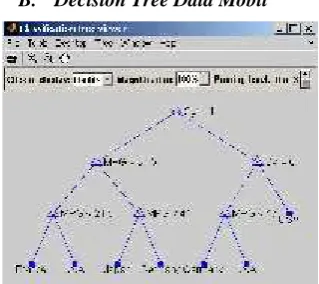
Load carsmall
t = classregtree ([MPG Cylinders], origin,……
‘ names’ ,{‘ MPG’ ‘ Cyl’ }, ‘ cat’ ,2).
t =
Decision tree for classification
1. If Cyl = 4 then node 2 else node 3
2. If MPG<31.5 then node 4 else node 5
3. If Cyl=6 then node 6 else node 7
4. If MPG<21.5 then node 8 else node 9
5. If MPG <41 then node 10 else node 11
6. If MPG<17 then node 12 else node 13
7. Class = USA
8. Class = France
9. Class = USA
10. Class = Japan
11. Class = Germany
12. Class = Germany
13. Class = USA
View (t)
Ket : Fungsi load adalah memanggil data untuk ditampilkan. B. Decision Tree Data Mobil
Gambar 1.4 Hasil Decision Tree pada data mobil
VI. KESIMPULAN
Perancangan aplikasi (Application design) adalah rancangan interface dan program aplikasi yang menggunakan data base[7].
Flowchart adalah suatu skema atau bagan yang menggambarkan urutan-urutan dari kegiatan mulai dari proses awal sampai akhir proses[8].
Data mining adalah suatu proses mengekplorasi dan menganalisis data dalam jumlah besar baik secara otomatis maupun semi otomatis untuk mendapatkan suatu pola yang bermakna dari data.
Decision tree merupakan teknik data mining yang digunakan untuk mengeksplorasi data dengan membagi kumpulan data yang besar menjadi himpunan record yang lebih kecil dan memperhatikan variabel tujuannya.[5].
A. Ucapan Terimakasih
Penulis mengucapkan terimakasih kepada dosen pembimbing yang telah membimbing penulis, kepada orang tua yang selalu mensupport penulis, dan kepada teman-teman elektro yang telah membantu dalam penelitian ini
B. Daftar Pustaka
[1] Conolly; dkk. (2010). A Practical Approach to Design, Implementation, an Management, (Vol. 5). Boston: Pearson Education.
[2] Turban, E. (2001). Decision Support Systems and Expert Systems and Intelligent Systems, 6th Ed. New Jersey: Prentice Hall Internasional, Inc
[3] Aris Saputra Laode, Pramono Bambang, & Natalis Ransi, Web Usage Mining menggunakan algoritma k-means clustering, Jurusan Teknik Informatika F. Teknik UHO 2016, Jurnal
[4] Jogiyanto. (2005 ). Analisis dan Desain Sistem Informasi . Yogyakarta : AndiOffseet
[5] AriadniRatih, IsyeArieshanti, Impelementasi metode pohon keputusan untuk klasifikasi data dengan niaifitur yang tidak pasti.
[6] on-line :http://ejournal.undip.ac.id/index.php/jsinbis hal. 77. Pdf
[7] Turban, E. (2001). Decision Support Systems and Expert Systems and Intelligent Systems, 6th Ed. New Jersey: Prentice Hall Internasional, Inc.