BAB II DASAR TEORI
2.1 Citra Digital
Citra digital didefinisikan sebagai fungsi f (x,y) dua dimensi,dimana x dan y adalah koordinat spasial dan f(x,y) adalah disebut dengan intensitas atau tingkat keabuan citra pada koordinat x dan y (R.C.Gonzales, R.E.Woods,2002). Jika x, y, dan nilai f terbatas dalam diskrit, maka disebut dengan citra digital. Citra digital dibentuk dari sejumlah elemen terbatas, yang masing-masing elemen tersebut memiliki nilai dan koordinat tertentu. Pixel adalah elemen citra yang memiliki nilai yang menunjukkan intensitas warna (R.C.Gonzales, R.E.Woods, Woods,2002).
Citra digital diperoleh melalui proses penangkapan atau akuisisi pada objek pada lingkungan nyata melalui perangkat yang dilengkapi dengan sensor optic yang mampu mendeteksi intensitas cahaya dan merepresentasikan intensitas tersebut menjadi nilai diskrit (Sutoyo, 2009).
Gambar 2.1 Proses Akuisisi Citra (Sutoyo, 2009)
2.2 Sifat Citra Digital
Citra digital bersifat diskrit yang dapat diolah oleh komputer. Citra ini dapat dihasilkan melalui
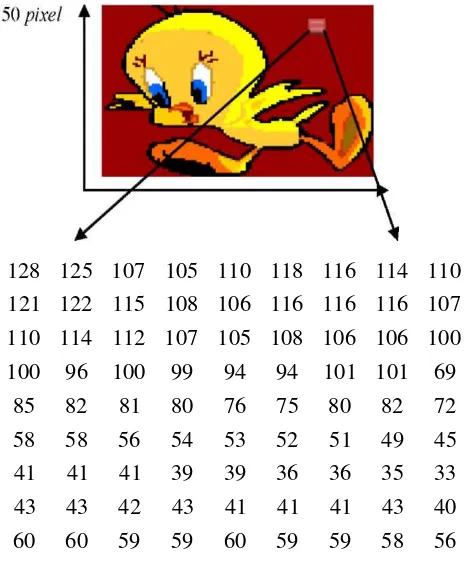
pikselnya atau biasa dinyatakan dalam ukuran N x M dimana N untuk baris dan M untuk kolom.
Misalnya diambil suatu kotak kecil dari bagian citra direpresentasikan dengan matriks berukuran 9
x 9, seperti terlihat pada Gambar 2.1
Gambar 2.2 Representasi Citra Digital
Sumber : R.C.Gonzales,R.E.Woods ( 2002 )
2.3 Citra Grayscale
Citra yang ditampilkan dari citra jenis ini terdiri atas warna abu-abu, bervariasi pada warna hitam
pada bagian yang intensitas terlemah dan warna putih pada intensitas terkuat. Citra grayscale
berbeda dengan citra "hitam-putih", dimana pada konteks komputer, citra hitam putih hanya terdiri
atas 2 warna saja yaitu "hitam" dan "putih" saja. Pada citra grayscale warna bervariasi antara hitam dan putih, tetapi variasi warna diantaranya sangat banyak. Citra grayscale seringkali merupakan perhitungan dari intensitas cahaya pada setiap pixel pada spektrum elektromagnetik
single band.
2.4 Image Thinning
Thinning (biasa disebut juga skeletonizing) adalah suatu metode untuk merepresentasikan transformasi suatu bentuk gambar ke bentuk graph dengan mereduksi informasi tertentu dalam gambar tersebut. Thinning ini biasa digunakan mencari bentuk dasar/rangka/skeleton dari suatu gambar. Contohnya pada PCB (printed circuit boards) untuk mengetahui aliran/arus data pada PCB tersebut. Selain untuk kompresi suatu gambar, kegunaan lain dari thinning adalah untuk mencari informasi tertentu dari suatu gambar dengan menghilangkan informasi yang tidak
diperlukan. Misalnya saja untuk mencari dataran tinggi dalam peta geografis.
Algoritma thinning binary regions memberikan aspek sebagai berikut :
1. thinning tidak menghapus point terakhir
2. thinning tidak merusak konektivitas
3. thinning tidak menyebabkan pengikisan berlebihan dari region. Diasumsikan region points memiliki nilai 1 dan background points memiliki nilai 0. Metode ini terdiri dari 2 langkah dasar yang dikenakan terhadap contour points dari suatu region, dimana
contour points adalah sembarang piksel dengan nilai 1 dan memiliki paling sedikit satu dari 8-tetangga bernilai 0. Algoritma ini menggunakan tanda untuk memilih piksel mana
yang akan dihapus. Aturannya, 8-tetangga terdekat dari setiap piksel P1 dinomori P2
(untuk piksel di atas P1) sampai dengan P9 sesuai dengan arah jarum jam.
(a) 2 < N(Pi) < 6;
Langkah 2 Hampir sama dengan langkah 1, hanya saja pada langkah 2 ini bagian (c) dan (d) berubah menjadi sebagai berikut :
(c) P2 . P4 . P8 = 0;
(d)P2 . P6 . P8 = 0;
Langkah 1 diterapkan untuk border pixel pada binary region. Jika satu atau lebih dari kondisi (a) sampai dengan (d) tidak dipenuhi, maka nilai dari point yang diperiksa tidak berubah (tidak perlu diberi tanda). Points yang diperiksa tidak akan dihapus sampai semua border points
selesai diproses. Hal ini dilakukan untuk mencegah agar tidak terjadi perubahan pada struktur data
saat pengeksekusian algoritma. Setelah langkah 1 telah selesai dilakukan terhadap semua border points , semua yang telah diberi tanda dihapus (diubah ke 0). Lalu, langkah 2 baru dijalankan terhadap hasil data persis sama seperti pada langkah 1.
Jadi, satu iterasi dalam algoritma thinning ini terdiri dari :
1. Pengerjaan langkah 1 untuk memberi tanda pada border points untuk dihapus. 2. Penghapusan points yang telah diberi tanda.
3. Pengerjaan langkah 2 untuk memberi tanda border points yang tersisa untuk dihapus.
4. Penghapusan points yang telah diberi tanda.
Prosedur dasar ini akan beriterasi hingga tidak ada points yang dapat dihapus lagi, sehingga hasil yang didapat adalah skeleton (kerangka) dari region. Proses thinning ini, menghilangkan informasi-informasi tertentu dalam gambar, dengan tetap mempertahankan
informasi yang paling utama atau kerangka utama gambar tersebut. Jadi misalnya terdapat suatu
2.5 Jaringan Syaraf Tiruan
Hermawan,A.2006 mendefinisikan Jaringan Syaraf Tiruan adalah suatu struktur pemroses informasi yang terdistribusi dan bekerja secara paralel, yang terdiri atas elemen pemroses (yang memiliki memori lokal dan beroperasi dengan informasi lokal) yang diinterkoneksi bersama dengan alur sinyal searah yang disebut koneksi. Setiap elemen pemroses memiliki koneksi keluaran tunggal yang bercabang (fan out) ke sejumlah koneksi kolateral yang diinginkan (setiap koneksi membawa sinyal yang sama dari keluaran elemen pemroses tersebut). Keluaran dari elemen pemroses tersebut dapat merupakan sebarang jenis persamaan matematis yang diinginkan. Seluruh proses yang berlangsung pada setiap elemen pemroses harus benar-benar dilakukan secara lokal, yaitu keluaran hanya bergantung pada nilai masukan pada saat itu yang diperoleh melalui koneksi dan nilai yang tersimpan dalam memori lokal.
Jaringan neuron buatan terdiri atas kumpulan grup neuron yang tersusun dalam lapisan :
1. Lapisan input (Input Layer): berfungsi sebagai penghubung jaringan ke dunia luar (sumber data).
2. Lapisan tersembunyi (hidden Layer): Suatu jaringan dapat memiliki lebih dari satu hidden layer atau bahkan bisa juga tidak memilikinya sama sekali.
3. Lapisan Output (Output Layer): Prinsip kerja neuron pada lapisan ini sama dengan prinsip kerja neuron-neuron pada lapisan tersembunyi (hidden layer) dan di sini juga digunakan fungsi Sigmoid, tapi keluaran dari
neuron pada lapisan ini sudah dianggap sebagai hasildari proses
Secara umum, terdapat tiga jenis neural network yang sering digunakan berdasarkan jenis network-nya, yaitu : 1. Single-Layer Neural adalah jaringan syaraf tiruan yang memiliki koneksi pada inputnya secara langsung ke
jaringan output.
2. Multilayer Perceptron Neural Network adalah jaringan syaraf tiruan yang mempunyai layer yang dinamakan "'hidden', ditengah layer input dan output. Hidden ini bersifat variabel, dapat digunakan lebih dari satu
hidden layer.
3. Recurrent Neural Networks Neural network adalah jaringan syaraf tiruan yang memiliki ciri, yaitu adanya koneksi umpan balik dari output ke input
2.6 Jaringan Syaraf Tiruan Backpropagation
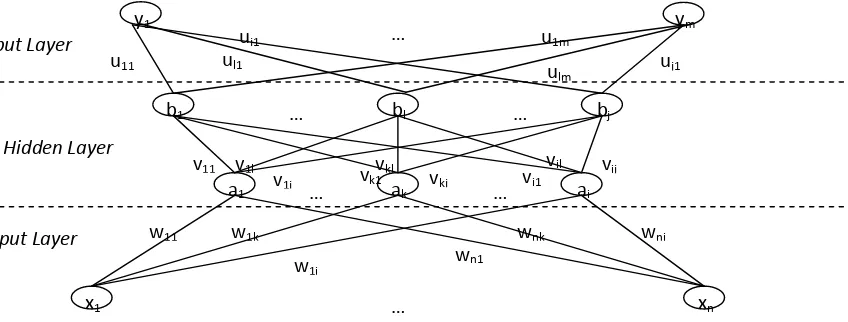
Backpropagation adalah salah satu pengembangan dari arsitektur Single Layer Neural Network. Arsitektur ini terdiri dari input layer, hidden layer dan output layer, dan setiap
layer terdiri dari satu atau lebih aritificial neuron. Nama umum dari arsitektur ini adalah
Gambar 2.3 : Arsitektur Multilayer Neural Network
Sumber : Hermawan, A ( 2006
Dengan menggunakan arsitektur jenis ini, maka metode pelatihan yang digunakan
adalahBackpropagation yang biasanya disebut juga sebagai feedforward networks.
Algoritma selengkapnya elatihan jaringan backpropagation adalah sebagai berikut :
Langkah 0 :Inisialisasi bobot (ambil bobot awal dengan nilai random yang
cukup kecil).
Langkah 1 :Bila syarat berhenti adalah salah, kerjakan langkah 2 sampai 9
Langkah 2 :Untuk setiap pasangan pelatihan, kerjakan langkah 3-8.
Feedforward:
Langkah 3 : Tiap-tiap unit input (Xi, i=1,2,3,...,n) menerima sinyal xi dan
meneruskan sinyal ke semua unit pada lapisan hidden (lapisan
tersembunyi).
Langkah 4 : Tiap-tiap unit lapisan tersembunyi (Zj, j=1,2,3,...,p) menjumlahkan
sinyal-sinyal input terbobot:
v=Bobot awal input ke hidden.
Gunakan fungsi aktivasi untuk menghitung sinyal outputnya:
zj = f(z_inj) (2.2)
Langkah 5 : Tiap-tiap output (Yk, k=1,2,3,...,m) menjumlahkan sinyal-sinyal input
gunakan fungsi aktivasi untuk menghitung sinyal outputnya:
yk = f(y_ink) (2.4)
dan kirimkan sinyal tersebut ke semua unit di lapisan hidden (lapisan tersembunyi).
Catatan: Langkah (b) dilakukan sebanyak jumlah lapisan tersembunyi.
Backpropagation
Langkah 6 : Tiap-tiap unit output (Yk, k=1,2,3,...,m) menerima target pola yang
berhubungan dengan pola input pembelajaran, hitung informasi errornya
δk = (tk-yk) f’(y_ink) (2.5)
Kemudian hitung koreksi bobot (yang nantinya akan digunakan
untuk memperbaiki nilai wjk):
∆wjk = αδkzj (2.6)
Hitung juga koreksi bias
∆w0k = αδk (2.7)
Langkah 7 : Tiap-tiap unit lapisan tersembunyi (Zj, j=1,2,3,...,p) menjumlahkan delta inputnya (dari unit-unit yang berada dilapisan hidden).
δ_inj =
Kalikan nilai ini dengan turunan dari fungsi aktivasi untuk menghitung informasi error:
kemudian hitung koreksi bobot:
∆vij = αδjxi (2.10)
Langkah 8 :Tiap-tiap unit ouput (Yk, k=1,2,3,...,m) memperbaiki bias dan bobotnya
(j=1,2,3,...,p):
wjk(baru) = wjk(lama) + ∆wjk (2.11)
Tiap-tiap unit lapisan tersembunyi (Zj, j=1,2,3,...,p) memperbaiki nilai bias dan bobotnya (i=1,2,3,...,n. ):
vij(baru) = vij(lama) + ∆vij (2.12)
Langkah 9 : Uji syarat berhenti.
2.7 Adaptive Learning Rate
Adaptive Learning Rate merupakan pendekatan atau metode yang bertujuan untuk
meningkatkan efektifitas dari parameter tingkat pembelajaran atau learning rate, dimana
tingkat pembelajaran merupakan parameter yang berfungsi untuk meningkatkan kecepatan belajar dari jaringan backpropagation.
Adaptive learning rate muncul karena penelitian yang dilakukan pada nilai yang
konstan pada tingkat pembelajaran menyebabkan metode jaringan backpropagation
menjadi tidak efisien, dikarenakan sangat bergantung pada nilai tingkat pembelajaran yang dipilih (Plagianakos, 1998). Pemilihan tingkat pembelajaran yang tidak tepat akan menyebabkan jaringan sangat lambat mencapai local optima. Karena alasan tersebut maka muncullah pendekatan adaptive learning rate.
Implementasi adaptive learning rate adalah mengganti nilai learning rate yang digunakan dalam koreksi bobot pada jaringan pada tiap iterasi menggunakan persamaan yang diusulkan oleh (Plagianakos, 1998) sebagai berikut.
(2.13)
= Bobot baru untuk iterasi berikutnya (t+1)
= Bobot pada iterasi saat (t)
= Adaptive Learning Rate
= Fungsi Error pada bobot iterasi saat (t)
Nilai dapat diperoleh dari persamaan berikut.
(2.14)
Dimana :
=
= Faktor Pertumbuhan Maksimum
2.8 Perbandingan Backpropagation Konvensional dan Adaptive Learning Rate
Algoritma backpropagation merupakan algoritma yang digunakan dalam mengidentifikasi
karakter huruf atau angka yang terdapat pada citra input. Secara garis besar, algoritma
backpropagation dibagi menjadi dua tahap, yaitu tahap forward propagation dan
Gambar 2.4 Ilustrasi Pembelajaran Karakter Angka.
Backward propagation melakukan koreksi nilai bobot pada tiap lapisan mulai dari lapisan output menuju ke lapisan input, koreksi bobot didasarkan atas selisih antara output yang dihasilkan oleh jaringan dengan output yang diharapkan. Setelah proses koreksi bobot selesai maka tahap forward propagation akan di lakukan kembali dengan bobot baru yang telah dikoreksi.
Proses forward dan backward propagation terus dilakukan sampai jaringan mampu menghasilkan output yang diharapkan atau dianggap mampu mengenali
karakter yang diberikan. Secara normal metode backpropagation membutuhkan waktu
yang sangat lama dalam proses pembelajarannya dimana waktu yang dibutuhkan berbanding lurus dengan banyaknya data pelatihan, yang artinya semakin besar data pelatihan maka akan semakin lama proses pembelajaran yang dilakukan.
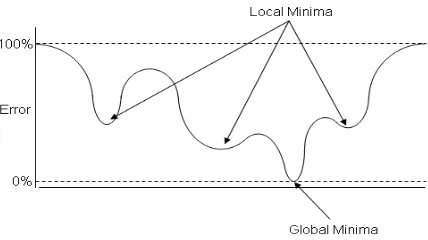
Gambar 2.5 Ilustrasi Lokal Minimal dan Global Minimal
(Sumber : http://mnemstudio.org/neural-networks-multilayer-perceptron-design.html,2013)
Suatu jaringan dikatakan sudah belajar jika jaringan tersebut sudah mencapai kondisi global minima atau kondisi dimana jaringan telah mencapai nilai error terendah. Untuk mempercepat jaringan menuju ke global minima maka diperlukan beberapa
pengembangan terhadap metode backpropagation tersebut, yang dalam penelitian ini salah
satu pengembangan yang diusulkan adalah adaptive learning rate.
backpropagation. Metode adaptive learning rate dilakukan pada saat koreksi bobot
berlangsung. Algoritma backpropagation normal menggunakan parameter learning rate
sebagai konstanta, dimana parameter tersebut digunakan terus menerus selama proses
iterasi pembelajaran tanpa mengalami perubahan. Dengan menggunakan adaptive
learning rate, parameter learning rate atau tingkat pembelajaran terus mengalami perubahan seiring proses pembelajaran yang perubahan nilainya bergantung pada selisih error pada tiap iterasi pembelajaran.
Pada operasi backpropagation normal, operasi koreksi bobot dilakukan dengan perhitungan fungsi error terlebih dahulu dengan persamaan berikut.
(2.15)
Dimana :
=
Fungsi Error pada iterasi ke - k=
Target Output pada node ke - k=
Output jaringan pada node ke – kSedangkan untuk mencari fungsi error pada bobot ke-k dapat dilihat pada persamaan berikut. Penggunaan fungsi error pada operasi koreksi bobot menggunakan persamaan berikut.
(2.16)
Dimana :
=
Bobot baru untuk iterasi k+1=
Learning Rate=
Fungsi Error pada iterasi ke –kPada operasi backpropagation normal, parameter learning rate bernilai statis dimana nilai parameter dipilih pada awal pembelajaran dan terus digunakan pada setiap iterasi tanpa mengalami perubahan.
Penggunaan adaptive learning rate memberikan dampak positif dimana proses
menuju local optima akan semakin cepat. Dimana dengan tingkat pembelajaran yang selalu menyesuaikan diri dengan nilai error yang dihasilkan mampu memberikan stabilitas dalam proses pembelajaran dibandingkan dengan tingkat pembelajaran yang konstan atau statis.
Berdasarkan penelitian yang dilakukan oleh Plagianakos, berikut usulan persamaan dalam menghitung nilai learning rate pada tiap iterasi (Plagianakos, 1998).
(2.17)
Dimana :
=
Learning Rate pada iterasi ke – k=
=
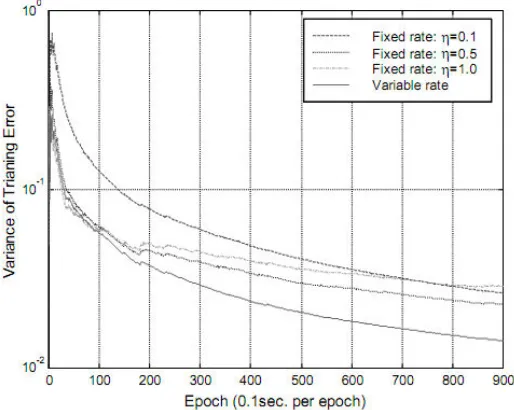
Pada penelitian yang dilakukan oleh Daohang Sha dan Vladimir mengenai
adaptive learning rate, mereka melakukan perbandingan performa dari learning rate statis dan penggunaan adaptive learning rate yang dapat dilihat pada gambar berikut.
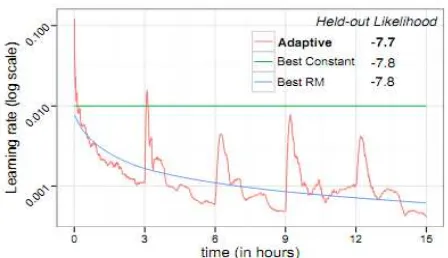
Gambar 2.6 Perbandingan Laju Error Pada Percobaan Learning Rate
(Sumber : Sha & Bajic, 2000)
Pada gambar 2.6 dapat dilihat lajur error dari Variable rate atau dengan kata lain
Adaptive learning rate memiliki laju eror yang paling baik dibandingkan dengan Fixed rate atau nilai learning rate statis. Pada penelitian lain yang dilakukan oleh Rajesh et al,
penggunaan metode adaptive learning rate memberikan kecepatan laju pembelajaran yang
Gambar 2.7 Grafik Perbandingan Implementasi Learning Rate.
(Sumber : Ranganath, 2013)
2.9 Parallel Training
Parallel training merupakan pendekatan implementasi pelatihan jaringan
Backpropagation dimana proses pelatihan dilakukan secara parallel. Dipandang dari sudut
pandang perangkat keras, parallel training dapat dibagi menjadi dua kategori yang mana
kategori pertama adalah pelatihan parallel dengan memanfaatkan unit pengolah atau CPU lebih dari satu sedangkan kategori kedua adalah pelatihan parallel dengan menggunakan
teknologi multithreading (Mumtazimah, 2012).
Jaringan backpropagation adalah sebuah proses berulang yang seringkali
menbutuhkan waktu yang sangat lama dalam prosesnya. Ketika proses pelatihan dibagi menjadi beberapa unit dan diproses secara bersamaan maka waktu yang dibutuhkan juga akan jauh lebih sedikit. Berikut tahap – tahap dalam implementasi Parallel Training pada jaringan Backpropagation (Schuessler & Loyola, 2011).
1. Partisi set data pelatihan T menjadi bagian – bagian yang sama besar (T1, T2,…, Tn). Pada penelitian ini objek yang akan di-identifikasi adalah objek karakter huruf dan angka dimana jumlah karakter huruf dan angka dapat dijabarkan menjadi :
Jumlah Huruf Biasa = 26
Jumlah Angka = 10
Total Karakter = 62
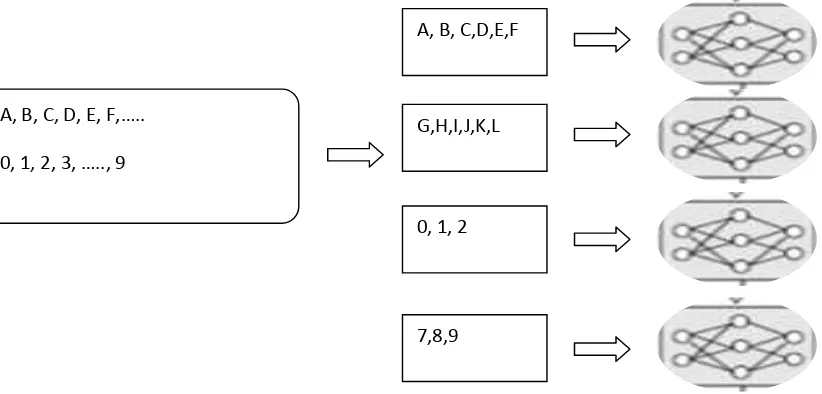
Jika terdapat sepuluh unit jaringan backpropagation maka data karakter akan dipartisi menjadi sepuluh partisi dengan rincian sebagai berikut.
T1 = 6 Karakter (A,B,C,D,E,F) T2 = 6 Karakter (G,H,I,J,K,L) T3 = 6 Karakter (M,N,O,P,Q,R) T4 = 6 Karakter (S,T,U,V,W,X) T5 = 6 Karakter (Y,Z,a,b,c,d) T6 = 6 Karakter (e,f,g,h,i,j) T7 = 6 Karakter (k,l,m,n,o,p) T8 = 6 Karakter (q,r,s,t,u,v) T9 = 6 Karakter (w,x,y,z,0,1) T10 = 8 Karakter (2,3,4,5,6,7,8,9)
2. Masukkan partisi – partisi data pelatihan ke dalam unit – unit jaringan
Gambar 2.8 Ilustrasi Parallel Training pada Data Input Karakter dan Angka
3. Lakukan proses forward propagation pada tiap unit.
4. Hitung total perubahan bobot dari semua unit jaringan, dan terapkan koreksi perubahan bobot pada tiap jaringan.
Perhitungan fungsi error dilakukan dengan menghitung rata-rata dari jumlah
fungsi error pada tiap unit backpropagation menggunakan persamaan berikut.
(2.18)
Dimana :
=
Fungsi Error total ke - k=
fungsi error pada unit backpropagation ke - i=
Jumlah unit backpropagationBerdasarkan persamaan diatas nilai fungsi error total digunakan dalam menghitung nilai learning rate seperti yang telah dibahas pada sub bab analisis sebelumnya, dan dilanjutkan dengan perhitungan bobot baru atau . Nilai perubahan bobot
akan dikirimkan ke setiap unit backpropagation untuk mengoreksi bobot pada setiap unit.
5. Ulangi langkah tiga sampai kondisi berhenti tercapai.
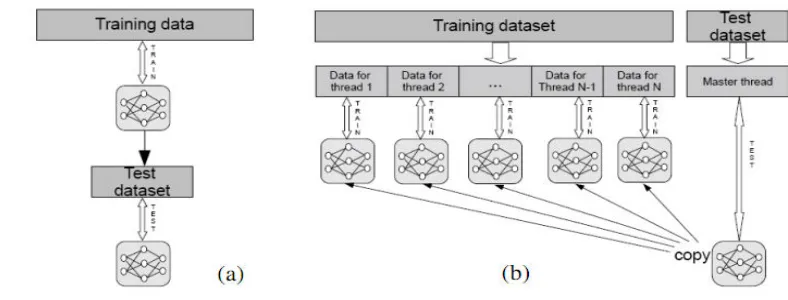
! " # $$
% & ' $$ (
! " #
) * + , - .
% &
Gambar 2.9 Presentasi skema pelatihan pada jaringan (a) Pelatihan tanpa implementasi parallel, (b) Pelatihan dengan implementasi parallel.