ABSTRAK
DIAGNOSA PENGAMATAN BERPENGARUH MENGGUNAKAN DFBETAS DAN KONSTRUKSI VARIABEL PADA ANALISIS REGRESI
LINIER BERGANDA
Oleh
DWI MARDIANA
Pengamatan berpengaruh adalah pengamatan yang berpengaruh terhadap
kesesuaian fungsi regresi dan terdapat pengaruh yang berubah nyata pada model regresi ketika pengamatan dimasukkan dengan ketika tidak dimasukkan.
Mendeteksi pengamatan berpengaruh antara lain dengan mendeteksi pengamatan ke-i yang berpengaruh terhadap masing-masing koefisien regresi ke-j
menggunakan DFBETAS.
Pada penelitian ini bertujuan untuk mendiagnosa adanya pengamatan berpengaruh pada regresi linier berganda menggunakan metode DFBETAS dan menyeleksi model regresi terbaik yang dihasilkan dari beberapa pengamatan berpengaruh yang dihilangkan pada konstruksi variabel. Langkah yang dilakukan pada data penelitian yang mengandung pengamatan berpengaruh yaitu mendiagnosa pengamatan yang berpengaruh dengan menggunakan DFBETAS, mencobakan konstruksi variabel pada tiap kombinasi pengamatan berpengaruh yang
dihilangkan dan menyeleksi model yang terbaik dengan kriteria nilai S2 dan Adjusted-R2.
Hasil penelitian menunjukkan bahwa pegamatan yang berpengaruh dikaitkan dengan nilai residual dan leverage. Leverage yang tinggi dan pencilan belum tentu pengamatan berpengaruh. Sebaliknya, pengamatan berpengaruh belum tentu pencilan atau leverage yang tinggi. Pada konstruksi variabel diperoleh bahwa bila beberapa pengamatan berpengaruh dihilangkan menghasilkan dugaan model regresi yang terbaik.
I. PENDAHULUAN
1.1 Latar Belakang dan Masalah
Analisis regresi merupakan metode statistika yang digunakan untuk mencari hubungan antara dua variabel atau lebih, dimana variabel yang dijelaskan disebut variabel tak bebas Y dan variabel penjelasnya disebut variabel bebas X. Seringkali di dalam penerapan analisis regresi terdapat satu atau lebih kasus pengamatan ekstrim yang memencil atau keadaan tidak biasa pada sekumpulan data.
Pengamatan yang tidak biasa itu dapat terdiri dari pencilan, leverage tinggi, dan pengamatan berpengaruh. Pencilan adalah suatu data yang menyimpang dari sekumpulan data lainnya. Suatu pengamatan dikatakan leverage tinggi apabila pengamatan berada jauh dari pusat data X. Sedangkan pengamatan berpengaruh adalah pengamatan yang berpengaruh terhadap kesesuaian fungsi regresi. Suatu pengamatan dikatakan berpengaruh jika terdapat pengaruh yang berubah nyata pada model regresi ketika pengamatan dimasukkan dengan ketika tidak
dimasukkan.
termasuk pencilan, leverage tinggi atau pengamatan berpengaruh. Bila pada grafik visual menunjukkan leverage yang tinggi dan residual yang besar, belum dapat dipastikan pengamatan tersebut pengamatan berpengaruh. Oleh karena itu sangat penting untuk menyelidiki kasus pengamatan seperti ini dengan terperinci dan lebih lanjut secara statistik.
Suatu pengamatan tidak mempunyai dampak yang sama pada semua hasil regresi. Satu pengamatan mungkin mempunyai pengaruh pada ̂, pengaruh pada varian S2, pengaruh pada ̂. Masing-masing alat pendiagnosa pengamatan berpengaruh memiliki karakteristik tersendiri dalam mendeteksi pengamatan berpengaruh antara lain dengan mendeteksi pengamatan ke-i yang berpengaruh terhadap masing-masing koefisien regresi menggunakan DFBETAS.
Pengamatan berpengaruh yang dideteksi menggunakan DFBETAS merupakan pengamatan yang berpengaruh terhadap koefisien regresi. Dikatakan berpengaruh jika ada perubahan nyata pada saat pengamatan tersebut dihilangkan dengan tidak dihilangkan. Besarnya perubahan pada koefisien regresi dapat dilihat dari perbandingan antara semua kemungkinan pengamatan berpengaruh yang dihilangkan dengan semua pengamatan tanpa dihilangkan. Besarnya perubahan koefisien regresi ke-j menunjukkan pengaruh pengamatan sangat besar.
Dalam analisis regresi adakalanya tidak semua variabel bebas dapat dimasukkan kedalam model. Variabel bebas yang berpengaruh dimasukkan dalam model akan memperoleh model regresi yang terbaik. Dalam menentukan variabel yang akan dimasukkan dalam regresi ada beberapa hal yang bertentangan. Persamaan yang diperoleh bermanfaat bagi tujuan peramalan, maka dimasukkan sebanyak mungkin variabel X sehingga diperoleh nilai ramalan yang terandalkan. Sedangkan untuk memperoleh informasi dari banyak variabel bebas X serta pemonitorannya seringkali diperlukan biaya yang tinggi, maka diinginkan persamaan regresinya mencakup sedikit mungkin variabel X.
1.2 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah
1. Mendiagnosa adanya pengamatan berpengaruh pada regresi linier berganda menggunakan metode DFBETAS.
2. Menyeleksi model regresi terbaik yang dihasilkan dari beberapa pengamatan berpengaruh yang dihilangkan pada konstruksi variabel.
1.3 Manfaat Penelitian
II. TINJAUAN PUSTAKA
2.1 Konsep Dasar Matriks
2.1.1 Matriks
Matriks adalah suatu susunan bilangan berbentuk segi empat. Bilangan-bilangan dalam susunan itu disebut anggota dalam matriks tersebut. Suatu matriks A mempunyai unsur yang dilambangkan dengan dengan i menyatakan banyaknya baris dan j menyatakan banyak kolom. Suatu matriks A dapat juga dilambangkan dengan A= (Anton, 1987).
2.1.2 Transpose Matriks
Jika A adalah sebarang matriks m x n, maka transpose A dinyatakan dengan AT, didefinisikan dengan matriks n x m yang didapatkan dengan mempertukarkan baris dan kolom dari A, yaitu kolom pertama dari AT adalah baris pertama dari A, kolom kedua dari AT adalah baris kedua dari A, dan seterusnya (Anton, 1987).
2.1.3 Matriks Simetris
2.1.4 Invers Matriks
Jika A adalah matriks bujur sangkar, dan jika sebuah matriks B yang berukuran sama bisa didapat sedemikian sehingga AB=BA=I, maka A disebut bisa dibalik dan B disebut invers dari A (Anton, 1987).
2.1.5 Matriks Diagonal
Jika adalah elemen pada diagonal ke-i dari matriks A berukuran n x n, dan misalkan adalah unsur-unsur diluar diagonal, jika untuk semua , maka A dinamakan matriks diagonal. Biasanya matriks diagonal dilambangkan dengan D (Anton, 1987).
2.2 Analisis Regresi Linier
Analisis regresi linier adalah salah satu analisis statistika yang dapat digunakan untuk menyelidiki atau membangun model hubungan linier antara beberapa variabel. Analisis regresi yang mempelajari pola hubungan antara satu variabel tak bebas dan satu variabel bebas disebut analisis regresi linier sederhana (simple linear regression).
Model regresi linier sederhana biasa ditulis sebagai berikut :
Dimana : adalah intersep atau perpotongan dengan sumbu tegak. adalah kemiringan atau gradiennya.
Y adalah variabel tak bebas. X adalah variabel bebas. adalah galat (error term) .
Regresi linier berganda (multiple linear regression) merupakan suatu model regresi yang melibatkan satu variabel tak bebas dan lebih dari satu variabel bebas. Model regresi linier berganda dalam bentuk umum yaitu :
, i=1,2,..,n
Bila dirinci untuk setiap pengamatan :
Dengan cara matriks dapat ditulis sebagai berikut :
Dalam notasi matriks ditulis sebagai berikut:
Dengan: Y adalah vektor n x 1 variabel tak bebas.
X adalah matriks n x (p+1) variabel bebas.
adalah vektor (p+1) x 1 parameter yang diduga.
adalah n x 1 vektor galat atau error term
(Myers, 1990).
2.3 Matriks HAT
Alat pendiagnosa yang memberikan informasi titik data yang mengandung leverage tinggi adalah matriks HAT. Matriks HAT didefinisikan berikut :
Matriks HAT memainkan peranan penting dalam mengidentifikasi pengamatan berpengaruh. H menentukan varian dan kovarian dari ̂ dan e, dimana Var ( ̂) =
dan var (e) = ( Montgomery, Peck & Vinning, 2006 ).
Elemen diagonal dari matriks Hdidefinisikan sebagai
Diagonal HAT memberikan ukuran jarak yang terbakukan dari titik ke pusat data dari x yaitu ̅. Nilai diagonal HAT yang tinggi menunjukkan pengamatan yang ekstrim pada x (Myers, 1990).
Nilai diagonal HAT berada antara 0 dan 1, . Jika X memiliki rank penuh, maka ∑ . Sehingga rata-rata dari elemen diagonal adalah p/n. Disarankan menggunakan 2p/n sebagai titik kritis untuk . memiliki potensi untuk berpengaruh kuat pada hasil regresi. Jika pengamatan ke-i mempunyai nilai yang melebihi 2p/n, maka pengamatan tersebut dikatakan titik leverage yang tinggi (Belsley, Kuh, & Welsch, 1980).
2.4 Analisis Residual
2.4.1 Residual
Salah satu dari metode pendiagnosa gangguan pada model (pencilan) adalah dengan kuadrat terkecil residual ̂. Dugaan parameter regresi dengan metode kuadrat terkecil dari adalah ̂ .
Vektor residual adalah ̂ ̂
=
Matriks varian-kovarian dari residual adalah
=
=
=
Karena bersifat idempoten , maka (Myers,1990).
2.4.2 R-Student
Diberikan penduga alternatif yaitu akar nilai tengah kuadrat galat yang dihitung dengan menghilangkan pengamatan ke-i . Ini dinotasikan dengan S-i, yaitu
√
Jumlah kuadrat galat tanpa menggunakan pengamatan ke-i berbeda dari jumlah
kuadrat galat menggunakan semua data dengan kuantitas
.
Penduga S-idigunakan menggantikan menghasilkan eksternal residual student yang sering disebut R-student, dengan rumus
Daerah kritis untuk R- student yaitu membandingkannya dengan distribusi-t berderajat bebas n-p-1yang dapat dilihat pada tabel distribusi-t. Nilai R-student lebih besar dari nilai t-tabel menunjukkan pengamatan merupakan suatu pencilan (Myers, 1990).
2.5 Pengamatan Berpengaruh
Menurut Belsley, Kuh, & Welsch (1980), suatu pengamatan berpengaruh adalah sesuatu yang secara individu atau bersama-sama dengan beberapa pengamatan lain, mempengaruhi nilai terhitung dari berbagai pendugaan (koefisien regresi, standar galat, nilai-t dan lain-lain) dibandingkan pada pengamatan yang lain.
Untuk menguji pengaruhnya satu demi satu pengamatan berpengaruh tersebut dihilangkan. Baris-baris pengamatan yang dihilangkan relatif menghasilkan perubahan besar pada nilai terhitung dan dianggap berpengaruh. Dengan pengujian dari prosedur ini, dapat dilihat dampak masing-masing baris
pengamatan pada koefisien dugaan dan nilai prediksi ( ̂) , residual dan dugaan parameter varian-kovarian matriks.
Suatu pengamatan tidak mempunyai dampak yang sama pada semua hasil regresi. Suatu pengamatan mungkin mempunyai pengaruh pada ̂, pengaruh pada
2.6 DFBETAS
Diberikan matriks berukuran p x p dan jika baris ke-i pada X.
adalah matriks dengan baris ke-i dihilangkan.
Atau dapat ditulis sebagai
Dimana diperoleh dengan menghapus baris ke-i dari X. Juga diberikan dan diasumsikan hii < 1.
Dari formula di atas dihasilkan berikut
( )
… (*)
Diketahui bahwa
̂
̂
Sehingga
Substitusi (**) ke dalam (*), sehingga dihasilkan
̂ ̂
[ ̂]
Sehingga ukuran jarak antara b dan b-i sebagai berikut:
(Belsley, Kuh & Welsch, 1980).
Untuk setiap koefisien regresi, pendiagnosa pengaruh menyediakan satu statistik, yang memberikan nilai standar galat perubahan koefisien jika pengamatan ke-i dihilangkan. Rumusnya
Dimana Cjj adalah elemen diagonal ke-j dari .
bj adalah koefisien regresi ke-j.
bj.–i adalah koefisien regresi ke-j yang dihitung tanpa pengamatan ke-i.
Besarnya nilai DFBETASj.i mengindikasikan bahwa pengamatan ke-i mempunyai
pengaruh pada koefisien regresi ke-j. Untuk menghitung nilai DFBETASj.i
dibutuhkan suatu matriks p x n, matriks . Dari konversi formula diatas didapat
√
√∑
=
√∑
=
√
=
√ √ (R-student)
2.7 Regresi Himpunan Bagian ( Subset)
Ada beberapa prosedur statistik tertentu yang dapat menentukan variabel yang akan dimasukkan dalam regresi, misal ingin menentukan suatu persamaan regresi linier variabel respon tertentu Y terhadap variabel bebas X. Dalam kaitannya ada dua kriteria yang saling bertentangan:
1. Agar persamaannya bermanfaat bagi tujuan peramalan, dimasukkan sebanyak mungkin variabel X sehingga diperoleh nilai ramalan yang terandalkan.
2. Karena untuk memperoleh informasi dari banyak variabel bebas X serta pemonitorannya seringkali diperlukan biaya yang tinggi, maka diinginkan persamaan regresinya mencakup sedikit mungkin variabel X.
Ada beberapa algoritma yang dapat dipergunakan untuk pemilihan himpunan bagian terbaik peubah peramal dalam regresi. Algoritma dapat menghitung hanya sebagian dari semua kemungkinan regresi dalam menentukan himpunan bagian “K terbaik”. Beberapa kriteria yang dapat digunakan untuk menentukan himpunan bagian “K terbaik” yaitu adj-R2 maksimum dan S2 minimum. Algoritma yang digunakan dapat menghasilkan K regresi terbaik dengan satu peubah peramal, K regresi terbaik dengan dua peubah peramal, dan seterusnya sampai persamaan regresi yang mencakup semua peubah peramal.
Misalkan ada 3 variabel X1, X2dan X3 , kelompokkan persamaan regresi kedalam
Kelompok yang terdiri atas persamaan regresi dengan 1 peubah peramal, dengan model :
Kelompok yang terdiri atas persamaan regresi dengan 2 peubah peramal, dengan model :
Kelompok yang terdiri atas persamaan regresi dengan 3 peubah peramal, dengan model :
2.8 Kriteria Seleksi Model
2.8.1 Mean Square Error (MSE)
Mean Square Error (MSE) dapat didefinisikan sebagai perbandingan antara Sum Square Error (SSE) dan derajat bebas suatu galat. Misalnya diketahui model regresi sederhana sebagai berikut.
̂
̂
Maka SSE dapat ditulis dalam persamaan berikut.
∑
∑ ̂
Sehingga SSE mempunyai n-2 derajat bebas. Kuadrat tengah galat (Mean Square Error) yang tepat dinotasikan oleh MSE atau S2, dapat ditulis dalam persamaan berikut.
Hal ini juga ditunjukan bahwa MSE adalah penduga tak bias dari , sehingga:
E(MSE)=
Sebagai nilai standar deviasi penduga adalah √
MSE yang disimbolkan dengn S2 merupakan salah satu patokan yang baik digunakan dalam menilai kecocokan suatu model. Semakin kecil MSE maka model semakin baik. Ukuran ini memperhitungkan banyaknya parameter dalam model melalui pembagian dengan derajat bebasnya. S2 mungkin membesar bila penurunan dalam SSE akibat pemasukan suatu variabel tambahan ke dalam model tidak dapat mengimbangi penurunan dalam derajat bebasnya. Menurut Sembiring (1995), rumus umum dari MSE diberikan sebagai berikut:
∑
2.8.2 R2 disesuaikan (Adjusted- R2)
Adj-R2 =
( )
Statistik Adj-R2p belum tentu meningkat seiring pertambahan variabel ke dalam
model. Faktanya bahwa jika k variabel x (regresor) ditambahkan pada model , Adj-R2p+k akan melebihi Adj-R2p jika dan hanya jika statistik parsial-F untuk uji
signifikan pada penambahan k variabel x (regresor) melebihi 1. Konsekuen, satu kriteria seleksi pada model himpunan bagian (subset) optimum adalah dengan memilih model yang memiliki maksimum Adj-R2p.
Kriteria seleksi model regresi himpunan bagian selain dengan minimum MSE dapat juga dengan maksimum Adj-R2. Hubungan keduanya sebagai berikut :
Adj-R2 =
III. METODOLOGI PENELITIAN
3.1 Tempat dan Waktu Penelitian
Penelitian ini dilakukan di Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Lampung pada semester genap tahun ajaran 2009/2010.
3.2 Metode Penelitian
Penelitian ini dilakukan secara studi pustaka, yaitu dengan mempelajari buku-buku teks penunjang dan karya ilmiah yang disajikan dalam jurnal. Untuk mempermudah perhitungan dan hasil yang akurat, penelitian ini menggunakan software SAS 9.
Adapun langkah-langkah yang dilakukan dalam penelitian ini adalah:
1. Mendapatkan data penelitian yang mengandung pengamatan berpengaruh. 2. Menganalisis data dengan semua pengamatan untuk mendapatkan nilai
dugaan parameter, nilai statistik-T, nilai residual, leverage serta hasil statistik lainnya.
4. Menguji dampak dari semua kombinasi pengamatan berpengaruh yang dihilangkan. Gunanya mendapatkan nilai koefisien regresi, statistik-T pada masing-masing variabel, dan nilai statistik lainnya yang dapat
dibandingkan dengan hasil regresi dari semua pengamatan.
5. Mencobakan semua kombinasi variabel pada tiap kombinasi pengamatan berpengaruh yang dihilangkan.
IV. HASIL DAN PEMBAHASAN
4.1 Data Penelitian
Data yang digunakan dalam penelitian bersumber dari “Spray congealing: particle size relationships using a centrifugal wheel atomizer oleh Scott, et al, tahun 1964. Data yang digunakan tentang spray congealing yaitu nilai-nilai peubah pengoperasian dan besarnya nilai partikel rata-rata. Data penelitian dapat dilihat pada lampiran. Dimana variabel bebas X1 adalah Feed Rate per satuan Whetted Wheel Periphery (gm/det/cm), X2 adalah kecepatan Peripheral Wheel (cm/det), X3 adalah Feed Viscosity (poise), dan variabel tak bebas Y adalah rata-rata besar partikel produk ( ).
4.2 Hasil dan Pembahasan
4.2.1 Mendiagnosa Pengamatan Berpengaruh
Nilai R-student mengindikasikan pengamatan yang memencil (pencilan)
sedangkan nilai leverage mengindikasikan pengamatan berpengaruh. Nilai kritis dengan taraf nyata 5% untuk R-student yaitu | ti | > . Nilai pada tabel-t
sebesar 1.697. Nilai kritis untuk hii yaitu 2p/n = 0.2286. Nilai yang melebihi nilai
1.697 pada pengamatan ke-6, 15, 19, 31, dan 33. Pengamatan tersebut merupakan pencilan yang dapat dilihat juga pada nilai residualnya yang tinggi. Nilai yang melebihi 0.2286 pada pengamatan ke-34 dan 35. Pengamatan tersebut merupakan leverage yang tinggi. Simpangan baku galat berkaitan dengan nilai residual dan diagonal HAT hii-nya. Simpangan baku galat yang dihitung tanpa
pengamatan ke-i digunakan dalam perhitungan DFBETAS yang dapat mendeteksi pengamatan ke-i yang berpengaruh terhadap dugaan parameter ke-j.
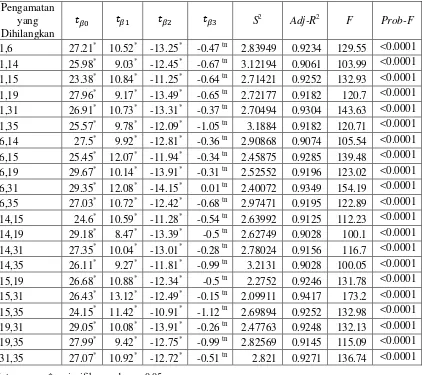
Tabel 2. Nilai dugaan parameter dengan pengamatan ke-i dihilangkan
Tabel 2. (lanjutan)
Menghitung nilai DFBETASj.i dengan formula berikut:
√
Dimana adalah elemen diagonal ke-j dari .
Perkalian silang matriks X
Nilai invers dari
Nilai DFBETAS pengamatan ke-1 pada koefisien regresi ̂
√
Nilai DFBETAS pengamatan ke-1 pada koefisien regresi ̂
√
Nilai DFBETAS pengamatan ke-1 pada koefisien regresi ̂
√
Nilai DFBETAS pengamatan ke-1 pada koefisien regresi ̂
√
Nilai kritis untuk DFBETAS adalah 2/√ = 2/√ = 0.3381. Nilai | DFBETAS | > 0.3381 maka dianggap pengamatan tersebut adalah pengamatan yang
berpengaruh.
Pengamatan yang merupakan pencilan sebagian menjadi pengamatan berpengaruh. Pengamatan ke-33 tidak memiliki pengaruh terhadap dugaan parameter sedangkan pengamatan ke-6,15,19,dan 31 berpengaruh terhadap dugaan parameter. Pengamatan dengan leverage yang tinggi sebagian menjadi pengamatan berpengaruh. Pengamatan ke-35 berpengaruh terhadap dugaan parameter sedangkan pengamatan ke-34 tidak berpengaruh.
Pada Tabel 3, pengamatan yang berpengaruh ditandai dengan tanda bintang. Pengamatan yang berpengaruh terhadap ̂ (intersep) adalah pengamatan ke- 1, 6, 15, dan 31. Pengamatan yang berpengaruh terhadap ̂ adalah pengamatan ke- 14, 15, 19, dan 31. Pengamatan yang berpengaruh terhadap ̂ adalah
pengamatan ke- 6 dan 15. Pengamatan yang berpengaruh terhadap ̂ adalah pengamatan ke-31 dan 35. Sehingga terdapat 7 pengamatan yang berpengaruh yaitu pengamatan ke-1,6,14,15,19,31,35.
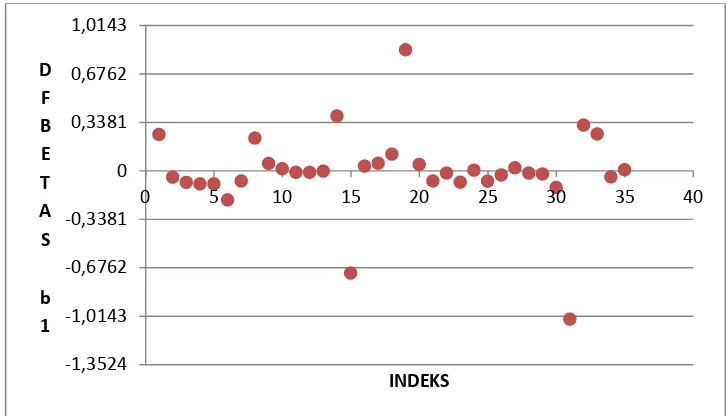
Gambar 1. Diagram pencar nilai DFBETAS pada ̂ untuk setiap pengamatan
Titik pengamatan yang melebihi batas 0.3381 yaitu titik pengamatan ke-1, 6, 15 dan 31.
Gambar 2. Diagram pencar nilai DFBETAS pada ̂ untuk setiap pengamatan
Gambar 3. Diagram pencar nilai DFBETAS pada ̂ untuk setiap pengamatan
Titik pengamatan yang melebihi batas 0.3381 yaitu pengamatan ke- 6 dan 15.
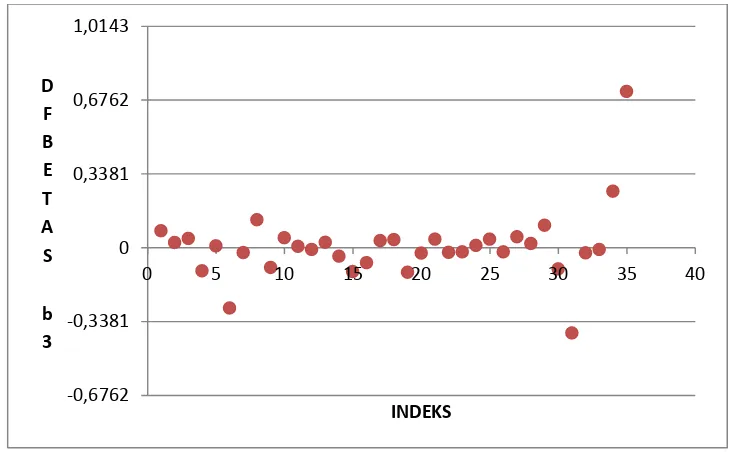
Gambar 4. Diagram pencar nilai DFBETAS pada ̂ untuk setiap pengamatan
Dari diagram pencar diatas dapat terlihat jelas titik-titik pengamatan yang berbeda letaknya dengan titik pengamatan lain. Titik pengamatan yang melebihi garis batas nilai 0.3381 dan -0.3381 adalah pengamatan yang berpengaruh. Sedangkan, titik pengamatan yang berada antara garis batas nilai -0.3381 sampai 0.3381 bukan pengamatan yang berpengaruh.
Untuk mengetahui sebaran titik pengamatan pada variabel X yang berpengaruh terhadap koefisian regresinya, disajikan pula diagaram pencar berikut:
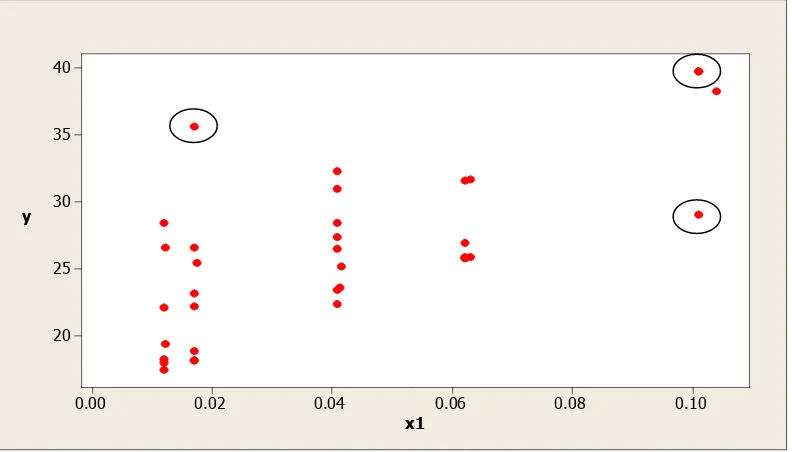
Gambar 5. Diagram pencar antara X1 dan Y
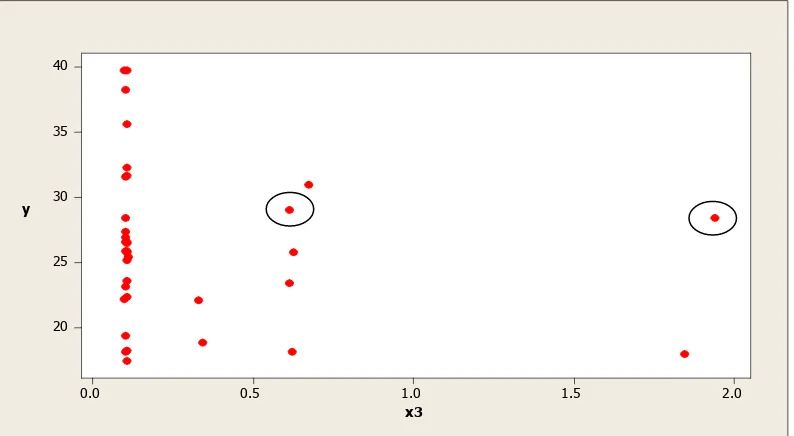
Gambar 6. Diagram pencar antara X2 dan Y
Pengamatan yang berpengaruh terhadap ̂ adalah pengamatan ke-6 dan 15. Pada Gambar 6 diatas titik-titik pengamatan ke-6 dan 15 ditunjukan oleh lingkaran.
Pengamatan yang berpengaruh terhadap ̂ adalah pengamatan ke-6 dan 15. Pada Gambar 7 diatas titik-titik pengamatan ke-6 dan 15 ditunjukan oleh lingkaran.
4.2.2 Efek Kombinasi Pengamatan Berpengaruh yang Dihilangkan
Suatu pengamatan dikatakan berpengaruh jika terdapat pengaruh yang berubah nyata pada model regresi ketika pengamatan dimasukkan dibandingkan ketika tidak dimasukkan (dihilangkan). Pengamatan yang dihilangkan relatif
menghasilkan perubahan besar pada nilai-nilai statistik dan dianggap berpengaruh. Semua kemungkinan kombinasi pengamatan yang berpengaruh satu per satu akan dihilangkan dari data. Sebanyak 7 pengamatan berpengaruh akan dikombinasikan. Kombinasi 0 dari 7 ditulis , dan seterusnya sampai kombinasi 7 dari 7 atau
dengan rumus :
berarti dari n pengamatan yang berpengaruh sebanyak r pengamatan akan dihilangkan.
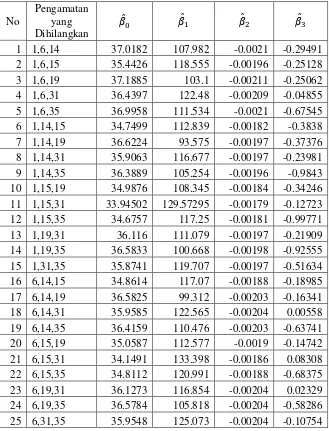
Tabel 4. Nilai dugaan parameter hasil regresi dan
Tabel 5. Nilai statistik pendugaan parameter dan model hasil regresi dan
Pengamatan
Uji hipotesis :
H0 : ̂ ; tidak signifikan (tidak nyata) H1 : ̂ ; signifikan
Jika t-hitung > t-tabel maka tolak H0. Pada kolom , , dan nilainya relatif besar dari 6.314, sehingga tolak H0 yang berarti signifikan pada taraf nyata 5%. Nilai pada kolom relatif kecil sehingga terima H0 yang berarti pengaruhnya tidak signifikan dan penggunaan variabel X3 pada model tidak informatif.
Pada Tabel 5 diatas terlihat bahwa peluang untuk nilai F yang diperoleh < 0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
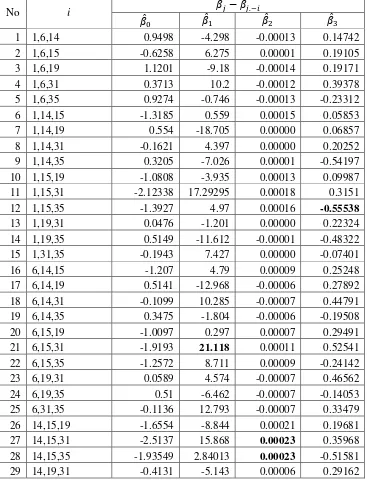
Tabel 6. Selisih dugaan parameter hasil regresi dan
No i ̂ ̂
Pada Tabel 6 terlihat bahwa pengamatan ke-15 yang dihilangkan mengalami penurunan maksimum pada ̂ sebesar 1.67113 dibanding pengamatan ke-1,6, dan 31 yang juga berpengaruh pada ̂ . Pengamatan ke-31 dihilangkan dari data mengalami perubahan peningkatan maksimum pada ̂ sebesar 10.55418
Pengamatan ke-15 yang dihilangkan mengalami peningkatan maksimum pada ̂ sebesar 0.00016 dibanding dengan pengamatan ke-6 yang juga berpengaruh terhadap ̂ .
Pengamatan ke-35 dihilangkan dari data mengalami perubahan penurunan maksimum pada ̂ sebesar 0.50582 dibanding pengamatan ke-31 yang juga berpengaruh terhadap ̂ .
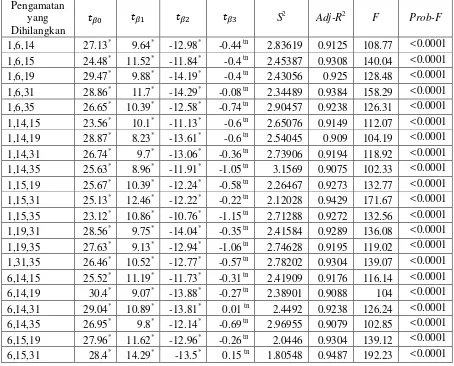
Tabel 7. Nilai dugaan parameter hasil regresi
Tabel 8. Nilai statistik pendugaan parameter dan model hasil regresi
Nilai-nilai statistik-T yang disajikan pada Tabel 8, digunakan untuk uji signifikan dari variabel bebas X pada dugaan parameter model regresi ̂ . Nilai kritis yaitu dibandingkan dengan T tabel dengan derajat bebas 1 dan pada taraf nyata 5% yang nilainya 6.314.
Uji hipotesis :
Jika t-hitung > t-tabel maka tolak H0. Pada kolom , , dan nilainya relatif besar, sehingga tolak H0 yang berarti signifikan pada taraf nyata 5%. Nilai pada kolom relatif kecil sehingga terima H0 yang berarti pengaruhnya tidak signifikan dan penggunaan variabel X3 pada model tidak informatif.
Pada Tabel 8 terlihat bahwa peluang untuk nilai F yang diperoleh < 0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi. Tabel 9. Selisih dugaan parameter hasil regresi dengan semua pengamatan
Kombinasi pengamatan (15,31) yang dihilangkan mengalami perubahan
penurunan maksimum pada ̂ sebesar 2.4965, perubahan peningkatan maksimum pada ̂ sebesar 19.423 dan perubahan peningkatan maksimum pada ̂ sebesar 0.00021
Kombinasi pengamatan (1,35) yang dihilangkan mengalami perubahan penurunan maksimum pada ̂ sebesar 0.55096.
Tabel 10. Nilai dugaan parameter hasil regresi
Tabel 10. (lanjutan)
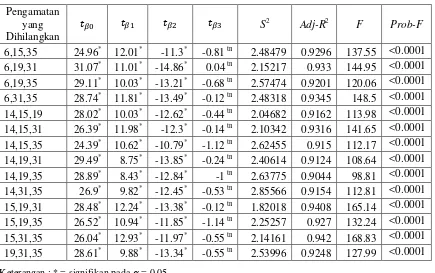
Tabel 11. Nilai statistik pendugaan parameter dan model hasil regresi
Tabel 11. (lanjutan)
Nilai-nilai statistik-T yang disajikan pada Tabel 11, digunakan untuk uji
signifikan dari variabel bebas X pada dugaan parameter model regresi ̂ . Nilai kritis yaitu dibandingkan dengan T tabel dengan derajat bebas 1 dan pada taraf nyata 5% yang nilainya 6.314.
Uji hipotesis :
H0 : ̂ ; tidak signifikan (tidak nyata) H1 : ̂ ; signifikan
Pada Tabel 11 terlihat bahwa peluang untuk nilai F yang diperoleh <0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
Tabel 12. Selisih dugaan parameter hasil regresi dengan semua pengamatan
Tabel 12. (lanjutan)
No i ̂ ̂
̂ ̂ ̂ ̂
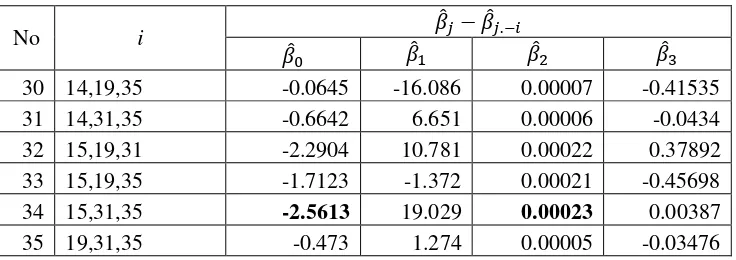
30 14,19,35 -0.0645 -16.086 0.00007 -0.41535
31 14,31,35 -0.6642 6.651 0.00006 -0.0434
32 15,19,31 -2.2904 10.781 0.00022 0.37892
33 15,19,35 -1.7123 -1.372 0.00021 -0.45698
34 15,31,35 -2.5613 19.029 0.00023 0.00387
35 19,31,35 -0.473 1.274 0.00005 -0.03476
Kombinasi pengamatan (15,31,35) yang dihilangkan mengalami perubahan penurunan maksimum pada ̂ sebesar 2.5613 dan perubahan peningkatan maksimum pada ̂ sebesar 0.00023.
Kombinasi pengamatan (6,15,31) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 21.118.
Kombinasi pengamatan (14,15,31), (14,15,35) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 0.00023.
Nilai-nilai statistik-T yang disajikan pada Tabel 14, digunakan untuk uji
signifikan dari variabel bebas X pada dugaan parameter model regresi ̂ . Nilai kritis yaitu dibandingkan dengan T tabel dengan derajat bebas 1 dan pada taraf nyata 5% yang nilainya 6.314.
Uji hipotesis :
H0 : ̂ ; tidak signifikan (tidak nyata) H1 : ̂ ; signifikan
Jika t-hitung > t-tabel maka tolak H0. Pada kolom , , dan nilainya relatif besar, sehingga tolak H0 yang berarti signifikan pada taraf nyata 5%. Nilai pada kolom relatif kecil sehingga terima H0 yang berarti pengaruhnya tidak signifikan dan penggunaan variabel X3 pada model tidak informatif.
Pada Tabel 14 terlihat bahwa peluang untuk nilai F yang diperoleh < 0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
Tabel 15. Selisih dugaan parameter hasil regresi dengan semua pengamatan
No i ̂ ̂
̂ ̂ ̂ ̂
1 1,6,14,15 -0.741 2.419 0.00004 0.21036
2 1,6,14,19 1.0229 -15.803 -0.00010 0.22455
3 1,6,14,31 0.3549 7.493 -0.00011 0.39235
4 1,6,14,35 0.846 -4.503 -0.00010 -0.23902
Tabel 15. (lanjutan)
Kombinasi pengamatan (6,15,31,35) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 20.853.
Kombinasi pengamatan (14,15,19,35), dan(14,15,31,35) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 0.00025.
Kombinasi pengamatan (1,14,15,35) yang dihilangkan mengalami perubahan penurunan maksimum pada ̂ sebesar 0.54581.
Tabel 16. Nilai dugaan parameter hasil regresi
No
9 1,6,15,31,35 34.49198 130.93653 -0.00188 -0.15829
10 1,6,19,31,35 36.5812 113.559 -0.00207 -0.19658
11 1,14,15,19,31 34.1891 113.552 -0.00176 -0.09327
12 1,14,15,19,35 34.68596 101.00819 -0.00176 -0.90694
13 1,14,15,31,35 33.8547 125.458 -0.00175 -0.49947
20 6,15,19,31,35 34.21452 118.08994 -0.00181 -0.21498
Tabel 17. Nilai statistik pendugaan parameter dan model hasil regresi
Nilai-nilai statistik-T yang disajikan pada Tabel 17, digunakan untuk uji
signifikan dari variabel bebas X pada dugaan parameter model regresi ̂ . Nilai kritis yaitu dibandingkan dengan T tabel dengan derajat bebas 1 dan pada taraf nyata 5% nilainya 6.314.
Uji hipotesis :
Jika t-hitung > t-tabel maka tolak H0. Pada kolom , , dan nilainya relatif besar, sehingga tolak H0 yang berarti signifikan pada taraf nyata 5%. Nilai pada kolom relatif kecil sehingga terima H0 yang berarti pengaruhnya tidak signifikan dan penggunaan variabel X3 pada model tidak informatif.
Pada Tabel 17 terlihat bahwa peluang untuk nilai F yang diperoleh <0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
Tabel 18. Selisih dugaan parameter hasil regresi dengan semua pengamatan
Kombinasi pengamatan (14,15,19,31,35) yang dihilangkan mengalami perubahan penurunan maksimum pada ̂ sebesar 2.3637 dan perubahan peningkatan
maksimum pada ̂ sebesar 0.00027.Kombinasi pengamatan (1,6,15,31,35) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 18.65653. Kombinasi pengamatan (6,14,15,19,31) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 0.54123.
Tabel 19. Nilai dugaan parameter hasil regresi dan
No Pengamatan yang
6 1,14,15,19,31,35 34.1073 112.693 -0.00174 -0.53575
7 6,14,15,19,31,35 34.2145 118.09 -0.00181 -0.21498
8 1,6,14,15,19,31,35 34.63484 115.63832 -0.00184 -0.25228
Tabel 20. Nilai statistik pendugaan parameter dan model hasil regresi dan
Nilai-nilai statistik-T yang disajikan pada Tabel 20, digunakan untuk uji
signifikan dari variabel bebas X pada dugaan parameter model regresi ̂ . Nilai kritis yaitu dibandingkan dengan T tabel dengan derajat bebas 1 dan pada taraf nyata 5% yang nilainya 6.314.
Uji hipotesis :
H0 : ̂ ; tidak signifikan (tidak nyata) H1 : ̂ ; signifikan
Jika t-hitung > t-tabel maka tolak H0. Pada kolom , , dan nilainya relatif besar, sehingga tolak H0 yang berarti signifikan pada taraf nyata 5%. Nilai pada kolom relatif kecil sehingga terima H0 yang berarti pengaruhnya tidak signifikan dan penggunaan variabel X3 pada model tidak informatif.
Pada Tabel 20, terlihat bahwa peluang untuk nilai F yang diperoleh < 0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
Tabel 21. Selisih dugaan parameter hasil regresi dan dengan semua pengamatan
Kombinasi pengamatan (1,14,15,19,31,35) yang dihilangkan mengalami perubahan penurunan maksimum pada ̂ sebesar 1.9611 dan perubahan peningkatan maksimum pada ̂ sebesar 0.00023.
Kombinasi pengamatan (1,6,14,15,31,35) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 15.58.
Kombinasi pengamatan (1,6,14,15,19,31) yang dihilangkan mengalami perubahan peningkatan maksimum pada ̂ sebesar 0.49878.
4.2.3 Konstruksi Variabel pada Semua Kombinasi Pengamatan yang Berpengaruh dan Pemilihan Model Terbaik
Konstruksi variabel digunakan untuk membangun sebuah model dari variabel bebas yang berpengaruh terhadap variabel responnya. Mengkonstruksi variabel dapat dilakukan dengan cara mencobakan satu per satu kombinasi variabel dengan menyimpulkan nilai S2, Adj-R2 dan statistik-F. Hasil yang ingin diperoleh yaitu mendapatkan model yang terbaik dengan kriteria nilai S2 yang minimum.
Tabel 22. Konstruksi variabel untuk data dengan seluruh pengamatan
Model dengan 1 variabel :
Model dengan 3 variabel:
Dengan kriteria nilai S2 yang minimum dan adj-R2 yang maksimum, maka model terbaik yang digunakan pada semua data tanpa pengamatan berpengaruh
dihilangkan adalah
Pada Tabel 22 terlihat bahwa peluang untuk nilai F yang diperoleh < 0.0001, berarti sangat signifikan pada taraf nyata 5%. Ini menunjukkan model dugaan yang diperoleh secara statistik dapat digunakan sebagai model populasi.
Konstruksi variabel dengan kombinasi pengamatan berpengaruh yang dihilangkan dapat dilihat pada lampiran. Berikut disajikan hasil dari konstruksi variabel yang terbaik dari tiap kombinasi pengamatan berpengaruh yang dihilangkan :
Tabel 23. Hasil subset terbaik proses konstruksi variabel
Tabel 23. (Lanjutan)
Model terbaik berdasarkan tabel diatas yaitu pada saat pengamatan 1, 6, 14, 15, 19, dan 31 tidak dimasukkan (dihilangkan) dengan 2 variabel X1 dan X2 , modelnya sebagai berikut sebagai berikut :
Berikut disajikan tabel nilai dugaan parameter dan analisis ragam :
Tabel 24. Nilai dugaan parameter
Tabel 25. Analisis Ragam
Sumber Keragaman
Derajat Bebas
Jumlah Kuadart
Kuadrat
Tengah F F-prob
Model 2 658.1659 329.083 236.36 <0.0001
Galat 26 36.19961 1.39229
Total 28 694.3655
Dengan nilai dugaan parameter yang tersedia, model regresi nya adalah :
̂
Dari 7 pengamatan berpengaruh yaitu pengamatan ke-1, 6, 14, 15, 19, 31, dan 35, hanya pengamatan ke-1, 6, 14, 15, 19, dan 31 yang dihilangkan sehingga
V. KESIMPULAN
Dari hasil penelitian dan pembahasan dapat disimpulkan bahwa :
1. Pegamatan yang berpengaruh dikaitkan dengan nilai residual dan leverage. 2. Leverage yang tinggi belum tentu pengamatan berpengaruh. Nilai residual
yang tinggi (pencilan) belum tentu pengamatan berpengaruh. Sebaliknya, pengamatan berpengaruh belum tentu pencilan atau leverage yang tinggi. 3. Dari konstruksi variabel bila beberapa pengamatan berpengaruh dihilangkan
DAFTAR PUSTAKA
Anton, H. 1987. Dasar - dasar Aljabar Linier. Erlangga, Jakarta.
Belsley, D.A., Kuh, E. & Welsch, R.E. 1980. Regression Diagnostics:
Identifying Influential Data and Sources of Collinearity. John Wiley & Sons, New York.
Chatterjee, S. & Hadi, A.S. 1986. Influential Observations, High Leverage Points, and Outliers in Linear Regression. Statistical Science 1(3), 379-393.
Draper, N.R. & Smith, H. 1992. Analisis Regresi Terapan Edisi kedua. PT. Gramedia Pustaka Utama, Jakarta.
Montgomery, D.C., Peck, E.A. & Vinning, G.G . 2006. Intoduction to Linear Regression Analysis. 4th Edition. A Wiley-Interscience Publication, New York.
Myers, R.H. 1990. Classical and Modern Regression with Applications. PWS-KENT Publishing Company, Boston.
Neter, J.W. & Kutner, M. H. 1990. Applied linear Statistical Model. 3rd Ed. Homewood : Richard D. Irwin. Inc., Illinois.
Sembiring, R.K. 1995. Analisis Regresi . Penerbit ITB, Bandung.
SANWACANA
Alhamdulillahirobbil’alamin, puji dan syukur penulis panjatkan atas kehadirat ALLAH SWT yang telah melimpahkan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Diagnosa Pengamatan Berpengaruh Menggunakan DFBETAS dan Konstruksi Variabel pada Analisis Regresi Linier Berganda”. Sholawat serta salam semoga selalu tercurah kepada Nabi
Muhammad SAW.
Pada kesempatan ini, penulis mengucapkan terima kasih kepada :
1. Ibu Khoirin Nisa, S.Si., M.Si. selaku Pembimbing Utama untuk perhatian, bimbingan dan motivasi yang berharga;
2. Ibu Notiragayu, S.Si., M.Si. selaku Pembimbing kedua untuk perhatian, bimbingan, saran dan semangatnya;
3. Ibu Dr. Netti Herawati selaku Pembahas untuk kritik dan saran yang membangun;
4. Bapak Drs. Rudi Ruswandi, M.Si. selaku Pembimbing Akademik; 5. Ibu Dra. Dorrah Aziz, M.Si. selaku Ketua Program Studi matematika
FMIPA Unila;
9. Mamak dan Bapak tercinta yang telah memberikan kasih sayang,
perhatiannya dan selalu mendo’akanku untuk menjadi anak yang sholeh dan sukses;
10.Mas Eko, Abi dan Catur tersayang;
11.Saudaraku: Jamrud, Yudi, Bayu, Nduk, Tia, Rani, Mbak Ana, Mas Edi, Mbak Hartini, Mas Yanto, Bibie, Meutia, Diaz, keponakanku Rama dan Rido;
12.Sahabat-sahabatku : Tewe, Sari, Debi, Yuni, Eka Fitri, teteh Maya, Restu, Amel, Andi, Septian, Hendra;
13.Sahabat Alumni IPA 1 ’06 lainnya yang tetap menjaga silaturahminya: Rachel, Dina, Jaka, Puji, Septiyani, Adi, Nur’arini, Uni, Ayink, Ika, Harly, Caca, Retno, Wani, Mumun, Nesia, Titin, Erni, Cory, mamen Sanz, Dewa; 14.Sahabat cosmix : Aida (Alm), mbak Dian, Gustini, Leni, Okta, Uli, Siti,
Pipit, Febri, Uci, Dewi, Mei, Umi, Nova, Muha, Cika, Erna, Weni, Atma, Ita, Eka, Ike, Neng, Yuli, Nur Rohmah, Emir, Wawan, Anwar, Dayat, Joni, Haposan, Ferdy, Gema, Anjas, Yudo, Rudi, Septa, Crismes, Tomy, Beni, Jhon, Rohim, Yusuf, Markus;
15.Mbak dan Kakak tingkat: Kak Adi, Mbak Maria, Mbak Nelly, Mbak Yusnaeni, Mbak Deka, Mbak Icha, Mbak Ayu Pepi;
Akhir kata, semoga skripsi ini dapat memberikan manfaat bagi pembaca dan penulis.
Bandar Lampung, Mei 2010
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 17 Juli 1988 di kecamatan Natar kabupaten
Lampung Selatan, sebagai anak kedua dari empat bersaudara dari pasangan Bapak Sumarwoto dan Ibu Supinah yang berkediaman di kecamatan Natar, Lampung Selatan.
Pendidikan Sekolah Dasar (SD) diselesaikan di SD Negeri 1 Merak Batin pada tahun 2000, Sekolah Menengah Pertama (SMP) di SMP Negeri 1 Natar pada tahun 2003 dan Sekolah Menengah Atas (SMA) di SMA Negeri 1 Natar pada tahun 2006.
2006-2007, sebagai anggota Bidang IV dan Humas (reshuffle) periode 2007-2008 serta pernah berorganisasi di Badan Eksekutif Mahasiswa (BEM) sebagai anggota Biro Kestari (Kesekretariatan) periode 2007-2008.
Pada tahun 2009, penulis melakukan Kerja Praktik di PT. Kereta Api (Persero) Sub Divisi Regional III.2 Tanjung Karang. Selama masa kerja, penulis