PENANGANAN DATA KATEGORIK
MENGGUNAKAN ALGORITMA GIFI
PADA MODEL PERSAMAAN STRUKTURAL BERHIRARKI
ALFATIHAH RENO MAULANI NURYANINGSIH
SOEKRI PUTRI MUNAF
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI DISERTASI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa disertasi berjudul Penanganan Data Kategorik dengan Algoritma Gifi pada Model Persamaan Struktural Berhirarki adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari disertasi saya kepada Institut Pertanian Bogor.
Bogor, Pebruari 2017
RINGKASAN
ALFATIHAH RENO MAULANI NURYANINGSIH SOEKRI PUTRI MUNAF.
Penanganan Data Kategorik dengan Algoritma Gifi pada Model Persamaan Struktural Berhirarki. Dibimbing oleh HARI WIJAYANTO, ASEP SAEFUDDIN, dan I WAYAN MANGKU.
Kajian mengenai metode statistik bisa berawal dari pembelajaran terhadap teori yang ada atau upaya untuk memecahkan permasalahan yang ada. Penelitian ini berupaya menemukan penyelesaian dari permasalahan sosial dengan data kategorik yang memiliki struktur bersarang atau berkelompok.
Structural Equation Model (SEM) dipilih untuk menjelaskan hubungan sebab akibat pada suatu permasalahan. Pemodelan menggunakan SEM dengan metode pendugaan kemungkinan maksimum memerlukan data untuk mengikuti sebaran tertentu. Ketika data mengandung peubah kategorik, maka perlu dilakukan penanganan terlebih dahulu. Salah satu pilihannya adalah transformasi data sehingga data mengikuti suatu sebaran kontinu tertentu. Penelitan ini mengkaji keunggulan metode transformasi data menggunakan Algoritma Gifi. Seratus set peubah dengan transformasi Gifi digunakan dalam memodelkan SEM untuk menjelaskan kepuasan terhadap kondisi kesehatan di Pulau Jawa, kemudian hasil ukuran kesesuaian model dibandingkan dengan ukuran kesesuaian model pada peubah tanpa transformasi. Hasil yang didapatkan adalah peubah hasil transformasi Gifi menunjukkan adanya peningkatan performa pada model SEM yang terbentuk, utamanya pada efisiensi waktu yang diperlukan untuk komputasi.
Perbedaan pola pembentuk kepuasan terhadap kondisi kesehatan antara provinsi di Pulau Jawa dijelaskan menggunakan analisis SEM Mutigrup. Pemeriksaan keragaman model antar kelompok menunjukkan indikasi terdapat perbedaan model untuk setiap provinsi. Pendugaan menggunakan Generalized Least Squares dilakukan untuk mengatasi adanya ragam negatif pada Provinsi DI Yogyakarta.
Bagian utama dari penelitian ini adalah pemodelan SEM berhirarki dengan data kategorik yang diaplikasikan pada penilaian kepuasan terhadap kondisi kesehatan. Sumber data yang digunakan adalah Indikator Kesehatan dari Survey Pengukuran Tingkat Kebahagiaan (SPTK) yang diselenggarakan Badan Pusat Statistik (BPS) pada tahun 2014 dan fasilitas kesehatan yang disediakan pemerintah di tahun yang sama berdasarkan catatan Kementrian Kesehatan Republik Indonesia. Tingkat pertama, gambaran di tingkat individu, menggunakan data SPTK. Tingkat kedua, gambaran di tingkat provinsi, menggunakan data fasilitas kesehatan. Tahapan ini menjelaskan bahwa pengaruh fasilitas kesehatan yang disediakan oleh pemerintah lebih besar daripada penilaian seseorang akan kondisinya di dalam menentukan kepuasan terhadap kondisi kesehatan. Kepuasan terhadap kondisi kesehatan pada tingkat individu ditentukan oleh kebiasaan menjaga kesehatan (1,000) dan pada tingkat provinsi ditentukan oleh fasilitas kesehatan (1,025).
SUMMARY
ALFATIHAH RENO MAULANI NURYANINGSIH SOEKRI PUTRI MUNAF. Handling Categorical Data Using Gifi’s Algorithm in Multilevel Structural Equation Model. Supervised by HARI WIJAYANTO, ASEP SAEFUDDIN, and I WAYAN MANGKU.
The study of statistical methods can be started from learning the existing theory or solving the existing problems. This study seeks to find a solution to social problems with categorical data that has nested structure or in groups.
SEM was chosen to explain the causal relationship of the problem. However, modeling using SEM with maximum likelihood estimation method requires data to follow certain distribution. In categorical data, it is necessary to handle the data first. One of the choice is data transformation so that the data follow a certain continuous distribution. This research examines the advantages of data transformation method using Gifi Algorithm. A hundred sets of variables with the transformation of Gifi used in SEM model to explain satisfaction of health conditions in Java. We compare the goodness of fit of SEM-Gifi model versus the goodness of fit of SEM model without data transformation. The obtained results Gifi transformed variables improved performance of SEM, especially the efficiency of the time needed for computation. A macro program for Gifi transformations are written in MATLAB.
Multi-group SEM analysis performed to see the differences in the pattern forming of satisfaction of health conditions in each province in Java. Examination of the diversity of models among the groups indicate that models cannot be said to be uniform, there are different models for each province. Estimation using Generalized Least Squares was used to overcome the negative variance in Yogyakarta Province.
The main part of this research is applying Multilevel SEM with categorical data to the assessment of satisfaction of health conditions. Two data sources are used: Health Indicators of Happiness Level Measurement Survey held by Statistics Indonesia (BPS) in 2014, to explain individual level; and health facilities provided by the government in 2014 based on records of the Ministry of Health of the Republic of Indonesia, to explain the provincial level. The first level, the picture at the individual level, using the data SPTK. The second level, picturing the provincial level, using health facilities. The result explains that health facilities provided by the government is more influential than one's judgment about his condition in determining satisfaction of health conditions. Satisfaction of health conditions at the individual level is determined by the maintaining healthy habits (1,000), and at the provincial level is determined by the health facilities (1,025).
© Hak Cipta Milik IPB, Tahun 2017
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Disertasi
sebagai salah satu syarat untuk memperoleh gelar Doktor
pada
Program Studi Statistika
PENANGANAN DATA KATEGORIK
MENGGUNAKAN ALGORITMA GIFI
PADA MODEL PERSAMAAN STRUKTURAL BERHIRARKI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2017
Penguji pada Ujian Tertutup: Dr. Ir. I Made Sumertajaya, MS Dr. Heru Margono M.Sc
Judul Disertasi : Penanganan Data Kategorik dengan Algoritma Gifi pada Model Persamaan Struktural Berhirarki
Nama Mahasiswa : Alfatihah Reno Maulani Nuryaningsih Soekri Putri Munaf
NIM : G161110071
Disetujui oleh: Komisi Pembimbing
Dr Ir Hari Wijayanto, MSi Ketua
Prof Dr Ir Asep Saefuddin, M.Sc
Anggota Prof Dr Ir I Wayan Mangku, M.Sc Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr. Ir. I Made Sumertajaya, MS
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MSc Agr
Ujian Tertutup: 6 Pebruari 2017
PRAKATA
Alhamdulillahi Rabbil Alamin, puji dan syukur kepada Allah SWT, dengan ijin dan kuasa-Nya penulis dapat menyelesaikan penulisan disertasi dengan judul “Penanganan Data Kategorik dengan Algoritma Gifi pada Structural Equation Model Berhirarki”. Disertasi ini disusun sebagai salah satu syarat untuk memperoleh gelar Doktor pada Program Mayor Statistika (STK), Institut Pertanian Bogor.
Penulis mengucapkan banyak terima kasih dan memberikan penghargaan yang setinggi-tingginya kepada semua pihak yang telah terlibat baik langsung maupun tidak langsung dalam penyelesaian disertasi ini, di antaranya:
1. Jajaran pimpinan Badan Pusat Statistik, yang telah memberikan izin dan kesempatan kepada penulis untuk belajar di Institut Pertanian Bogor.
2. “Elwindra”, “Alif Bintang Elfandra” serta “Alwie Attar Elfandra”, ketiga lelaki penting dalam kehidupan penulis, atas kesabaran dan keikhlasan dalam penantiannya.
3. Komisi pembimbing atas kesabaran, bimbingan, masukan, arahan, dan semangat yang diberikan: Dr. Ir. Hari Wijayanto, M.Si, Prof. Dr. Ir. Asep Saefuddin, M.Sc, dan Prof. Dr. Ir. I Wayan Mangku, M.Sc.
4. Penguji luar komisi yang juga komisi promosi Dr. Ir. I Made Sumertajaya, MS, Dr. Heru Margono M.Sc, dan Dr. Ir. Sasmito Hadi Wibowo M.Sc. yang telah memberikan banyak masukan untuk perbaikan disertasi ini.
5. Sekolah pasca sarjana IPB beserta jajarannya yang telah membantu memfasilitasi studi penulis.
6. Sekretariat Mayor Statistika dan staf yang selalu membantu selama proses studi. 7. Bu Herlina, Mbak Siti Muchlisoh, Mbak Khairunnisa, atas kebersamaannya
selama 5.5 tahun ini.
8. Dan banyak pihak yang tidak dapat disebutkan satu-persatu, yang turut berkontribusi dalam penyelesaian penelitian ini.
Penulis menyadari bahwa terdapat kekurangan dalam penulisan disertasi ini, oleh karena itu kritik dan saran yang membangun sangat diharapkan. Akhirnya penulis berharap semoga apa yang telah ditulis ini dapat bermanfaat dan berguna bagi semua pihak.
Bogor, Pebruari 2017 Penulis,
DAFTAR ISI
DAFTAR GAMBAR xvi
DAFTAR TABEL xvii
DAFTAR LAMPIRAN xviii
DAFTAR NOTASI xix
1 PENDAHULUAN 1
Latar Belakang 1
Rumusan Permasalahan 3
Tujuan Penelitian 3
Manfaat Penelitian 4
Ruang Lingkup Penelitian 4
Kebaruan Penelitian 5
2 TINJAUAN PUSTAKA 7
Transformasi Gifi 7
Penyajian Data ke Dalam Bentuk Matriks 8
Kuantifikasi 11
Algoritma Gifi 11
Structural Equation Model (SEM) 13
Penyusunan Model SEM 14
Metode Pendugaan Parameter Model SEM 14
Uji Kesesuaian Model SEM 15
3 PENANGANAN DATA KATEGORIK PADA SEM 19
Pendahuluan 19
Bahan dan Metode 20
Data 20
Structural Equation Model (SEM) 22
Hasil dan Pembahasan 25
4 ANALISIS MULTIGRUP SEM PADA PENGUKURAN
KEPUASAN TERHADAP KONDISI KESEHATAN DI PULAU JAWA 31
Pendahuluan 31
Bahan dan Metode 32
Hasil dan Pembahasan 33
5 KEPUASAN TERHADAP KONDISI KESEHATAN DI PULAU
JAWA DENGAN PENDEKATAN SEM BERHIRARKI 37
Pendahuluan 37
Bahan dan Metode 38
Model Hirarki (Multilevel Modeling) 38
SEM Berhirarki (Multilevel Structural Equation Model) 39
Hasil dan Pembahasan 45
6 PEMBAHASAN UMUM 47
7 SIMPULAN DAN SARAN 51
Simpulan 51
Saran 52
DAFTAR PUSTAKA 53
LAMPIRAN 57
DAFTAR GAMBAR
Gambar 1. Kerangka pikir penelitian 5
Gambar 2. Sejarah perkembangan Structural Equation Model (Karimi dan
Meyer 2014) 13
Gambar 3. Kerangka teori penyusunan model SEM untuk kepuasan terhadap
kondisi kesehatan 22
Gambar 4. Model SEM untuk pengukuran kepuasan terhadap kondisi
kesehatan 23
Gambar 5. Model struktural SEM untuk kepuasan terhadap kondisi kesehatan. 28 Gambar 6. Model SEM untuk kepuasan terhadap kondisi kesehatan 29 Gambar 7. Model SEM dua tingkat dengan peubah indikator dan peubah laten
pada setiap tingkatannya 40
DAFTAR TABEL
Tabel 1. Contoh data kategorik pada matriks 8
Tabel 2. Profil matriks frekuensi 9
Tabel 3. Ringkasan profil matriks frekuensi 9
Tabel 4. Matriks indikator 9
Tabel 5. Matriks pada data matriks 10
Tabel 6. Matriks pada data matriks 10
Tabel 7. Sebaran responden berdasarkan provinsi pada SPTK 2014 20 Tabel 8. Peubah yang digunakan untuk menjelaskan kepuasan terhadap
kondisi kesehatan 21
Tabel 9. Hubungan antara peubah laten 22
Tabel 10. Kriteria menentukan kebaikan model 24
Tabel 11. Ringkasan ukuran kesesuaian model awal 26 Tabel 12. Ringkasan ukuran kebaikan model pada model awal dan model
dengan Algoritma Gifi 27
Tabel 13. Ringkasan ukuran kesesuaian model SEM dengan GIFI 28 Tabel 14. Perbedaan model di dalam SEM Multigrup 33 Tabel 15. Ringkasan ukuran kesesuaian model dasar pada SEM Multigrup 33 Tabel 16. Ringkasan ukuran kesesuaian model pada pemeriksaan keragaman 34 Tabel 17. Loading faktor model SEM Multigrup dengan keragaman lemah
(Loading invarian) 34
Tabel 18. Model SEM Multigrup dengan jalur hubungan kausal invarian 35 Tabel 19. Ringkasan matriks yang digunakan untuk spesifikasi model SEM 44 Tabel 20. Perbandingan hasil pendugaan parameter model pada SEM dan SEM
berhirarki 49
DAFTAR LAMPIRAN
Lampiran 1. Korelasi antara Peubah Indikator dengan Kepuasan terhadap Kondisi Kesehatan59
Lampiran 2. Macro Matlab untuk Algoritma Gifi ... 60
Lampiran 3. Karakteristik peubah hasil transformasi GIFI ... 61
Lampiran 4. Model SEM dengan Menggunakan Data Awal (Tanpa Modifikasi Data) ... 63
Lampiran 5. Simulasi Model SEM dengan Seratus Set Peubah Hasil Transformasi Gifi ... 66
Lampiran 6. Model SEM dengan GIFI ... 67
Lampiran 7. Model SEM-GIFI Multigrup setelah Modifikasi ... 70
DAFTAR NOTASI
ℎ = Peubah kategorik dengan = 1, … ,
= Setiap kategori jawaban dari ℎ
= Observasi dengan = 1, … ,
= Matriks indikator
= Vektor dari jumlah total di dalam matriks
= Matriks diagonal dimana elemen diagonal ke akan sama dengan elemen ke- dari
= Matriks diagonal dari jumlah setiap baris pada = Tabulasi dua arah dari peubah ℎ dan ℎ
= Peubah hasil kuantifikasi = Skor untuk kuantifikasi = Vektor rerata dari
= Jumlah peubah tertimbang dengan bobot = Jumlah peubah tertimbang dengan bobot
( , ) = Nilai korelasi terkecil pada matriks (matriks korelasi
antara ℎ dan ℎ )
= Eta, menunjukkan peubah laten endogen = Beta, menunjukkan koefisien regresi
= Gamma, matriks koefisien untuk peubah laten eksogen = Xi, menunjukkan peubah laten eksogen
= Zeta, galat untuk peubah laten endogen = Lamda, menunjukkan faktor loading = Delta, galat untuk X
= Epsilon, galat untuk Y = Peubah indikator untuk = Peubah indikator untuk = Intersep untuk
, = Intersep untuk X, Y = Kappa, ( ) =
( ) = Matriks peragam yang didapatkan dari model = Matriks peragam populasi
= Phi, matriks peragam dari = Psi, matriks peragam dari
Θ = Theta, Matriks peragam
1 PENDAHULUAN
Latar Belakang
Model Persamaan Struktutal atau Structural Equation Model (SEM) merupakan metode yang biasa digunakan dalam menjelaskan hubungan antara peubah indikator dan peubah laten secara menyeluruh. Peubah laten di dalam SEM merupakan peubah yang tidak dapat diukur secara langsung keberadaannya. Agar dapat mengukur peubah laten, digunakan peubah manifes atau peubah indikator yang merupakan hasil pengukuran langsung, untuk kemudian dipelajari bagaimana hubungannya dengan peubah laten.
Metode yang umum digunakan dalam menduga parameter dari SEM adalah metode kemungkinan maksimum. Metode kemungkinan maksimum memerlukan asumsi data haruslah mengikuti sebaran kontinu tertentu. Pada saat berhadapan dengan data kategorik, harus ada upaya penanganan data terlebih dahulu untuk tetap dapat melakukan estimasi menggunakan metode kemungkinan maksimum. Salah satu upayanya adalah melakukan transformasi data.
Ada beberapa metode yang dapat digunakan dalam transformasi data, di antaranya adalah transformasi Box Cox, Succesive Intervals, dan transformasi Gifi.
Pertimbangan yang perlu dilakukan dalam memilih metode transformasi adalah apakah data dapat dipetakan ke dalam bentuk aslinya. Kondisi ini dipenuhi jika transformasi yang dilakukan merupakan transformasi satu-satu. Selain itu, pertimbangan selanjutnya adalah metode transformasi yang digunakan sedapat mungkin dapat mempertahankan karakteristik awal dari data aslinya. Metode transformasi Gifi (Gifi 1990) merupakan metode transformasi satu-satu yang selain dapat dikembalikan ke bentuk aslinya, dapat mempertahankan karakteristik awal dari data, dan dikenal memiliki kemampuan untuk menangani kompleksitas informasi yang baik pada saat diaplikasikan pada berbagai macam model regresi (Katragadda 2008; Howe et al. 2011).
Setelah tahap persiapan data, perlu dipertimbangkan apakah luasan wilayah penelitian dapat mempengaruhi model SEM yang akan digunakan. Semakin luas wilayahnya, semakin besar kemungkinan terdapat kecenderungan data untuk memiliki struktur bersarang atau berkelompok. Kelompok ini dibentuk ketika data yang merupakan hasil pengamatan terhadap individu ternyata merupakan bagian dari komunitas, wilayah bagian, hingga negara, sehingga dapat dikatakan membentuk suatu hirarki (tingkatan). Ketika terdapat data yang bersarang pada suatu kelompok, maka pemodelan menggunakan regresi konvensional dengan satu level tidak lagi sesuai untuk digunakan, karena tidak lagi independen (Congdon 2010). Congdon menemukan bahwa ada pengaruh pembentukan kelompok terhadap model yang dihasilkan. Dengan demikian, perlu dilakukan uji apakah pembentukan kelompok memiliki pengaruh terhadap model yang akan dianalisis.
dari analisis SEM Multigrup adalah untuk menjelaskan apakah terdapat keinvarianan (kestabilan) pendugaan laten di antara kelompok yang ada (Byrne 1998). Tetapi, pemodelan dengan menggunakan SEM Multigrup tidak dapat digunakan untuk mengetahui bagaimana hubungan peubah antar tingkat, dan tidak mengizinkan adanya keberagaman pada tingkat yang lebih tinggi (Rabe-Hesketh et al. 2007).
Struktur data yang memiliki hirarki membutuhkan penyelesaian model yang bisa menjelaskan keragaman pada hirarkinya. Pendekatan model hirarki dapat digunakan pada dua kondisi. Kondisi pertama adalah pada saat terdapat kelompok pada data dan kelompok ini membentuk hirarki. Kondisi kedua adalah pada saat penyusunan persamaan regresi untuk menjelaskan model didapatkan parameter regresi yang memiliki tingkatan karena keberadaan hiperparameter pada level di atasnya (Gelman 2006b).
Ketika diketahui model SEM yang dibangun memiliki kelompok di dalam struktur datanya, dapat dilakukan kombinasi pendekatan SEM dan pendekatan model berhirarki, sehingga menghasilkan pendekatan SEM berhirarki (Multilevel
SEM/ Hierarchical SEM). Model SEM berhirarki baik digunakan pada saat melibatkan unit observasi yang memiliki tingkatan dalam struktur data dan peubah yang diukur dengan menggunakan beberapa indikator (Rabe-Hesketh et al. 2007; Congdon 2014).
Kajian mengenai SEM berhirarki sendiri masih sangat terbatas. Diawali dengan pengembangan model berhirarki oleh Hox (2002) dan pengembangan perangkat aplikasinya menggunakan M-Plus. Curran (2003) mengkaji SEM dan
Multilevel Modeling, kemudian menyimpulkan potensi dari SEM berhirarki untuk dikembangkan pada penelitian selanjutnya. Aplikasinya pada SEM mulai diperkenalkan oleh Rabe-Hesketh et al. (2004), dengan menjelaskan model persamaan struktural dengan adanya hubungan antara peubah indikator dan peubah laten pada tingkat yang berbeda. Mehta (2013) mengembangkannya lagi sampai ke sejumlah N tingkat. Semakin banyak tingkatan yang dilibatkan, maka modelnya akan semakin kompleks. Semakin kompleks modelnya, maka diperlukan upaya lebih di dalam melakukan pendugaan terhadap parameternya, di antaranya adalah meningkatnya waktu yang diperlukan pada tahapan komputasi. Algoritma Gifi menjadi pertimbangan utama untuk digunakan dalam mengatasi kekompleksan informasi dan diharapkan mampu meningkatkan performa model.
Indikator kepuasan terhadap kondisi kesehatan merupakan salah satu dari empat belas indikator yang digunakan di dalam menilai tingkat kebahagiaan seseorang. 8 kelompok pertanyaan diajukan untuk menilai kondisi kesehatan seseorang, berkaitan dengan kesehatan fisik (status kesehatan dan kesulitan fungsional) dan kesehatan mental (intensitas emosi positif dan gejala depresi). Pernyataan akan kondisi kesehatan fisik dan mental ini kemudian divalidasi dengan pertanyaan kepuasan terhadap kondisi kesehatan secara umum. Pertanyaan kepuasan terhadap kondisi kesehatan secara umum merupakan peubah kategorik dengan tipe data ordinal dalam rentang 0-10 dengan 0 menunjukkan sangat tidak puas terhadap kondisi kesehatannya, dan 10 menunjukkan sangat puas akan kondisi kesehatannya (BPS 2014).
Balas (2011) telah menggunakan pemodelan berhirarki untuk dapat menggambarkan keterbandingan pemodelan kebahagiaan antar wilayah. Dengan memperhatikan kebutuhan untuk menjelaskan hubungan kausal dan adanya keberadaan kelompok pada data SPTK, maka penggunaan pendekatan SEM Berhirarki tepat untuk digunakan.
Rumusan Permasalahan
Data SPTK sebagian besar merupakan data kategorik. Indikator kepuasan terhadap kondisi kesehatan di dalam rangkaian SPTK ini keseluruhannya merupakan peubah dengan tipe data kategorik. Analisis terhadap data melibatkan 26 peubah dengan 13.684 amatan. Permasalahan komputasi menjadi salah satu hal yang harus dipertimbangkan di dalam memodelkan data.
Konsekuensi dari mengaplikasikan SEM pada data SPTK adalah tidak dapat digunakannya metode pendugaan maksimum likelihood. Dalam menanganinya, dapat dipilih metode pendugaan yang lain, misalnya Generalized Least Square, atau melakukan tahapan transformasi data terlebih dahulu. Pada saat mempertimbangkan adanya kelompok di dalam data, maka pemodelan SEM menjadi lebih kompleks. Semakin kompleks model yang disusun, maka diperlukan waktu yang lebih lama dalam pemrosesannya.
Kedua permasalahan untuk dapat mengaplikasikan pendekatan SEM berhirarki (persiapan data dan kemampuan untuk mengatasi kekompleksan informasi yang terdapat di dalam data) diharapkan dapat diatasi dengan transformasi Gifi. Model SEM berhirarki sendiri tidak dapat menjelaskan bagaimana signifikansi peubah di dalam model. Menghadapi keterbatasan ini, maka penggunaan transformasi Gifi diharapkan dapat meningkatkan performa model SEM berhirarki dengan ukuran kesesuaian yang baik.
Tujuan Penelitian
Secara keseluruhan tujuan utama dari penelitian ini adalah pemodelan SEM berhirarki dengan data kategorik. Kajian yang dilakukan dalam penelitian ini adalah
1. Pengangan data kategorik dengan transformasi Gifi pada SEM.
Manfaat Penelitian
Manfaat utama dari penelitian ini adalah memperkaya kajian penanganan data kategorik di dalam memodelkan SEM dan memperkaya kajian SEM berhirarki. Manfaat tambahan adalah aplikasi pada permasalahan di dunia nyata, yaitu menjelaskan hubungan antara kepuasan kesehatan di tingkat individu dan pengaruh layanan kesehatan di tingkat provinsi terhadap kepuasan kesehatan.
Ruang Lingkup Penelitian
Transformasi data merupakan salah satu metode yang dapat dilakukan pada saat pemodelan dengan menggunakan data dengan peubah kategorik. Transformasi satu-satu dilakukan agar dapat menjaga karakteristik pada data (Gifi 1990). Gifi menjelaskan konsep pemetaan dengan bantuan pembentukan matriks indikator. Pengembangannya dalam analisis multivariate digagas oleh Michailidis dan Leeuw (1998) dalam membantu mendeskripsikan analisis multivariate. Eriksson et al.
(2000) mengaplikasikan Algoritma Gifi pada Partial Least Squares (PLS). PLS adalah salah satu metode pendugaan yang bisa dilakukan di dalam SEM, yang dapat mengatasi keterbatasan SEM yang mengharuskan data mengikuti sebaran normal, jumlah sampel yang relatif besar dan tidak adanya multikoLinearitas. PLS memungkinkan untuk diaplikasikan pada jumlah sampel kecil, dan tidak mengharuskan data untuk mengikuti suatu sebaran tertentu. Penggunaan algorima GIFI juga dilakukan oleh Katragadda (2008) dalam berbagai model regresi, dan menyatakan bahwa Algoritma Gifi ini memiliki keunggulan di dalam mengatasi kekompleksan informasi. De Leeuw (2009) menggunakan pengembangan Algoritma Gifi untuk penskalaan optimal, dan Howe (2011) menjadi yang pertama mengaplikasikannya pada SEM.
Structural Equation Model (SEM) merupakan metode yang biasa digunakan untuk mencari hubungan antara peubah manifes (dapat diukur secara langsung) dan peubah laten (tidak dapat diukur secara langsung). Tujuan utama dari SEM adalah menemukan model yang relatif masuk akal untuk digunakan dalam membuat kesimpulan dan menghasilkan keputusan yang benar. Perkembangan SEM berihirarki sebagaimana digambarkan oleh Karimi dan Meyer (2014)baru dimulai di tahun 2000-an. Curran (2003) menjadi yang pertama mengkaji SEM dan Model berhirarki, dan kemudian menyimpulkan potensi dari SEM berhirarki untuk dikembangkan pada penelitian selanjutnya.
Model berhirarki digunakan ketika terjadi tingkatan pada data. Pemodelan berhirarki juga membuka kemungkinan untuk melakukan analisis terhadap peubah yang berbeda di setiap tingkatannya, misalnya penelitian Gelman (2006a), yang meneliti sebaran kandungan radon, karsinogen penyebab kanker, di mana level pertamanya adalah pengukuran radon di ruang bawah tanah rumah, dan level keduanya adalah kandungan uranium yang dimiliki suatu daerah.
Aplikasi SEM berhirarki mulai dikaji oleh Rabe-Hesketh et al. (2004), penelitiannya mengkombinasikan GLM dan SEM, menghasilkan metode
tingkatnya, pada kasus pemodelan mengenai kemampuan memahami bacaan pada siswa yang dilakukan yang mengukur kemampuan siswa di tingkat pertamanya, dan kinerja guru di sekolah pada tingkat keduanya. Preacher et al. (2010) dalam penelitannya membandingkan Model Berhirarki dan SEM berhirarki di dalam menyelesaikan pemodelan yang menggunakan mediasi. Hasil penelitiannya, Model Berhirarki tidak dapat mengakomodasi mediasi yang terjadi di antara tingkatan, dan SEM berhirarki lebih bisa diandalkan dalam menangani kemungkinan adanya mediasi di antara tingkatan. Mehta (2013) melanjutkan dengan mengkaji berbagai bentuk model SEM berhirarki, dan mengaplikasikannya ke dalam paket pemrograman yang dapat digunakan untuk pendugaan parameter di dalam model SEM berhirarki.
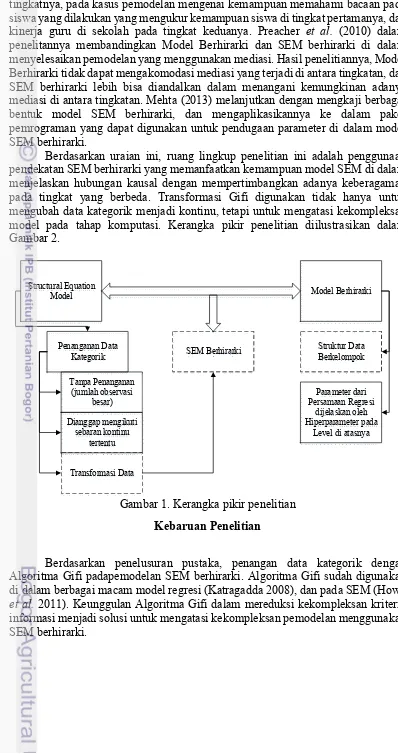
Berdasarkan uraian ini, ruang lingkup penelitian ini adalah penggunaan pendekatan SEM berhirarki yang memanfaatkan kemampuan model SEM di dalam menjelaskan hubungan kausal dengan mempertimbangkan adanya keberagaman pada tingkat yang berbeda. Transformasi Gifi digunakan tidak hanya untuk mengubah data kategorik menjadi kontinu, tetapi untuk mengatasi kekompleksan model pada tahap komputasi. Kerangka pikir penelitian diilustrasikan dalam Gambar 2.
Structural Equation
Model Model Berhirarki
Penanganan Data Kategorik
Tanpa Penanganan (jumlah observasi
besar)
Dianggap mengikuti sebaran kontinu
tertentu
Transformasi Data
SEM Berhirarki Struktur Data Berkelompok
Parameter dari Persamaan Regresi
dijelaskan oleh Hiperparameter pada
Level di atasnya
Gambar 1. Kerangka pikir penelitian
Kebaruan Penelitian
Berdasarkan penelusuran pustaka, penangan data kategorik dengan Algoritma Gifi padapemodelan SEM berhirarki. Algoritma Gifi sudah digunakan di dalam berbagai macam model regresi (Katragadda 2008), dan pada SEM (Howe
2 TINJAUAN PUSTAKA
Transformasi Gifi
Pada penelitian sosial, peubah yang digunakan bisa berasal dari peubah kategorik, baik yang memiliki tingkatan pada kategorinya (skala data ordinal) atau pilihan biasa (skala data nominal). Bollen (1989) menyatakan bahwa pada saat peubah laten merupakan data kategorik dapat mengakibatkan terjadinya pelanggaran asumsi seperti model pengukuran yang dihasilkan tidak mencerminkan ukuran yang sebenarnya (Y pada SEM kontinu); sebaran dari peubah ordinal berbeda dengan indikator peubah laten kontinu, pada saat peubah laten ataupun peubah indikatornya bersifat data kategorik akan sangat mungkin sebarannya tidak normal; dan terjadinya pelanggaran pada hipotesis struktur kovarian. Asumsi bahwa data mengikuti suatu sebaran kontinu tertentu diperlukan pada saat akan memodelkan SEM dan memilih metode pendugaan kemungkinan maksimum.
Salah satu bentuk penanganan data kategorik di dalam memodelkan SEM adalah dengan memilih metode pendugaan parameter yang tidak memerlukan persyaratan data untuk mengikuti sebaran tertentu, atau melakukan transformasi terlebih dahulu. Pemodelan SEM dengan data dikotomi dan data berskala ordinal dilakukan oleh Skrondal dan Rabe-Hesketh (2005), dengan menggunakan
Generalized Linear Model yang mampu menangani tipe data yang lebih beragam. Bentuk lain dari penanganan data kategorik di dalam memodelkan SEM adalah dengan melakukan transformasi data. Di dalam melakukan transformasi data ada beberapa pertimbangan yang perlu diperhatikan. Pertama, hubungan antara peubah awal dan peubah hasil haruslah merupakan hubungan pemetaan satu-satu, tujuannya agar data dapat dikembalikan ke dalam bentuk aslinya. Metode transformasi data yang memenuhi hubungan pemetaan satu-satu di antaranya adalah transformasi Box Cox dan transformasi Gifi. Kedua, perlu diperhatikan bahwa karakteristik dari peubah awal tidak hilang, dan peubah hasil memiliki kemiripan yang baik dengan peubah awal. Transformasi Gifi menggunakan prinsip dari analisis kehomogenan, sehingga peubah hasil yang didapatkan diharapkan karakteristiknya tidak berbeda dari peubah asalnya. Alasan ini dijelaskan Howe et al. (2011) pada saat memilih transformasi Gifi dalam tahap persiapan data untuk memodelkan SEM.
Ide dasar dari Algoritma Gifi adalah mengkuantifikasikan peubah kategorik (proses mengubah data kategorik menjadi data kontinu). Peubah hasil transformasi Gifi melibatkan matriks indikator dari peubah asal dan bobot yang akan dicari dan dioptimasi menggunakan Algoritma Gifi. Optimasi dari peubah hasil dan bobot yang digunakan secara bergantian sampai tercapai kondisi optimum tertentu, yaitu meminimumkan loss function, dilakukan dengan menggunakan prinsip Alternating Least Squares.
dan data deret waktu (Heijden dan Buuren 2016). Peubah hasil transformasi dengan Algoritma Gifi selain bersifat dapat dikembalikan (hasil pemetaan), juga memiliki kemiripan yang sangat tinggi dengan peubah hasilnya (diperoleh dari proses kuantifikasi).
Pengembangan Algoritma Gifi dalam analisis multivariat dimulai oleh Michailidis dan Leeuw (1998), hasil penelitiannya menjelaskan tentang penggunaan Algoritma Gifi pada analisis multivariat nonlinear. Aplikasi pada model PLS dilakukan oleh Eriksson et al. (2000). Kajian yang cukup lengkap mengenai aplikasi Algoritma Gifi dilakukan oleh Katragadda (2008) dalam berbagai model regresi, dan menyatakan bahwa Algoritma Gifi ini memiliki keunggulan di dalam mengatasi kekompleksan informasi. De Leeuw (2009) menggunakan pengembangan Algoritma Gifi untuk penskalaan optimal, dan Howe (2011) menjadi yang pertama mengaplikasikannya pada SEM.
Penyajian Data ke Dalam Bentuk Matriks
Langkah awal dalam melakukan transformasi data adalah dengan menganggap data sebagai suatu matriks. Misalkan ada sejumlah peubah kategorik ( = 1, … , ). Misalkan pula pada setiap peubah memiliki sebanyak kategori jawaban. Kemudian terdapat sejumlah amatan. Maka data dapat disajikan ke dalam bentuk matriks yang memiliki dimensi × dengan elemen matriks dinyatakan dalam , ( = 1, … , ). Contoh data kategorik pada matriks
disajikan pada Tabel 1.
Tabel 1. Contoh data kategorik pada matriks
Amatan Peubah 1 Peubah 2 Peubah 3
1 a d h
2 a e g
3 b f h
4 b d g
5 c d h
6 c d h
7 c e g
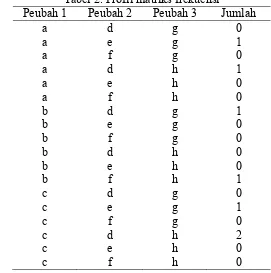
Tabel 1 di atas merupakan ilustrasi jawaban yang diberikan oleh tujuh responden terhadap tiga pertanyaan yang keseluruhannya memiliki jawaban dalam bentuk kategori. Pertanyaan pertama memiliki tiga kategori jawaban (a, b, dan c). Pertanyaan kedua memiliki tiga kategori jawaban (d, e, dan f). Pertanyaan ketiga memiliki dua kategori jawaban (g dan h). Jumlah dari kemungkinan jawaban bagi setiap amatan akan sama dengan ∏ . Pada ilustrasi di Tabel 1, jumlah kemungkinan jawaban responden adalah delapan belas, yang diperoleh dari perkalian dari jumlah kategori pada masing-masing peubah. Data pada Tabel 1 bisa disajikan ke dalam bentuk profil matriks frekuensi seperti disajikan di Tabel 2.
Tabel 2. Profil matriks frekuensi
Peubah 1 Peubah 2 Peubah 3 Jumlah
a d g 0
a e g 1
a f g 0
a d h 1
a e h 0
a f h 0
b d g 1
b e g 0
b f g 0
b d h 0
b e h 0
b f h 1
c d g 0
c e g 1
c f g 0
c d h 2
c e h 0
c f h 0
Tabel 3. Ringkasan profil matriks frekuensi Peubah 1 Peubah 2 Peubah 3 Jumlah
a e g 1
a d h 1
b d g 1
b f h 1
c e g 1
c d h 2
Kemudian, dari matriks frekuensi pada Tabel 3 dibuatlah matriks indikator , sebagaimana disajikan pada Tabel 4.
Tabel 4. Matriks indikator
Amatan a Peubah 1 b c d Peubah 2 e f Peubah 3 g h
1 1 0 0 1 0 0 0 1
2 1 0 0 0 1 0 1 0
3 0 1 0 0 0 1 0 1
4 0 1 0 1 0 0 1 0
5 0 0 1 1 0 0 0 1
6 0 0 1 1 0 0 0 1
Matriks indikator dikatakan lengkap jika setiap baris dari hanya memiliki satu elemen yang sama dengan satu dan nol di tempat lain, sehingga jumlah deretan sama dengan satu, dan matriks indikator yang lengkap memiliki sifat-sifat sebagai berikut (Gifi 1990):
1. Misalkan adalah vektor dari jumlah total di dalam matriks . Elemen ke akan menunjukkan kategori ke dari setiap peubah ℎ . Jumlah dari elemen haruslah sama dengan . Secara matematis, dapat dinyatakan dengan ′ =
, dengan merupakan vector berelemenkan 1.
2. Dalam setiap peubah, setiap observasi akan berkorespondensi dengan 1 kategori, karenanya, kolom dari matriks ortogonal.
3. Misalkan = ′ merupakan matriks diagonal dimana elemen diagonal ke akan sama dengan elemen ke- dari . Kemudian didefinisikan sebagai matriks diagonal dari jumlah setiap baris pada . Agar menjadi matriks indikator yang lengkap, = dengan merupakan matriks identitas. 4. Misalkan = ′ merupakan tabulasi dua arah dari peubah ℎ dan ℎ .
Elemen dari akan sesuai dengan frekuensi dari observasi yang ditandai dengan kombinasi tertentu pada salah satu kategori di ℎ dan salah satu kategori di ℎ . Didefinisikan sebagai kombinasi dari setiap . Elemen diagonal
dari sub-matriks sesuai dengan matriks diagonal pada peubah ℎ .
5. Didefinisikan sebagai matriks partisi dari , dalam arti bahwa unsur dan adalah identik dalam diagonal sub-matriks = , dimana memiliki elemen pada diagonal sub-matriksnya. Contoh matriks dan diberikan dalam Tabel 5 dan Tabel 7.
Tabel 5. Matriks pada data matriks
A b c d e f g h
a 2 0 0 1 1 0 1 1
b 0 2 0 1 0 1 1 1
c 0 0 3 2 1 0 1 2
d 1 1 2 4 0 0 1 3
e 1 0 1 0 2 0 2 0
f 0 1 0 0 0 1 0 1
g 1 1 1 1 2 0 3 0
h 1 1 2 3 0 1 0 4
Tabel 6. Matriks pada data matriks
A b c d e f g h
a 2 0 0 0 0 0 0 0
b 0 2 0 0 0 0 0 0
c 0 0 3 0 0 0 0 0
d 0 0 0 4 0 0 0 0
e 0 0 0 0 2 0 0 0
f 0 0 0 0 0 1 0 0
g 0 0 0 0 0 0 3 0
Kuantifikasi
Kuantifikasi merupakan upaya untuk mengubah elemen dari yang terdiri dari kategori-kategori menjadi kontinu, sehingga teknik analisis multivatiat yang memerlukan asumsi data mengikuti sebaran kontinu bisa dilakukan. Peubah hasil kuantifikasi didefinisikan sebagai = .
Didefinisikan sebagai vektor rata-rata dari sebagaimana dinyatakan pada persamaan (2.3), maka vektor akan menyederhanakan kuantifikasi dari amatan. Didefinisikan sebagai bobot dan dinyatakan pada persamaan (2.3). Vektor akan memiliki dimensi × 1 dan vektor akan memiliki dimensi × 1.
Algoritma Gifi
Prinsip dasar pada Algoritma Gifi adalah metode transformasi data yang menghasilkan peubah dengan kemiripan yang tinggi dengan peubah aslinya, dengan menggunakan suatu ukuran optimasi (loss function) tertentu. Kondisi optimal didapatkan pada saat loss function minimal/ mendekati konvergen.
Misalkan ℎ merupakan peubah acak, dengan ℎ = 0, dengan ragam
ℎ = 1. Didefinisikan = ℎ ℎ . Misalkan = ∑ ℎ dan = ∑ ℎ , sehingga dan merupakan jumlah peubah tertimbang dengan bobot yang berbeda, dan . Sehingga pada ( , ), korelasi antara dan akan bernilai antara -1 dan 1. Bobot dari dan harus positif, dengan batas bawah
( , )merupakan nilai korelasi terkecil pada matriks (matriks korelasi antara ℎ
dan ℎ ).
Diasumsikan semua distandarkan, dan merupakan kandidat pengganti dari . Penggantian ini akan mengakibatkan adanya bagian informasi yang hilang, yang dinyatakan dengan loss function pada persamaan (2.1)
( ) ≡ ∑ ( − ). (2.1)
Konsep ( ) yang digunakan pada persamaan (2.1) dan persamaan-persamaan setelahnya menyatakan jumlah kuadrat dari elemen-elemen di vektor .
( ) = 0 pada saat = pada setiap . Misalkan berdimensi dengan nilai harapan 0. Dan merupakan vektor dari bobot . Kuantifikasi bisa dinyatakan dengan mengubah menjadi , sehingga loss function-nya dapat dinyatakan pada persamaan (2.2)
( , ) ≡ ( − ). (2.2)
Analisis kehomogenan adalah bentuk tertentu dari analisis komponen utama
nonlinear berbasiskan matriks indikator. Tujuan dari analisis ini adalah untuk memaksimumkan kehomogenan di dalam data. Kuantifikasi dari amatan dan kategori membentuk matriks indikator yang lengkap ( , … , ) yang akan memenuhi persamaan (2.3) dan (2.4), dan adaptasi loss function pada persamaan (2.5)
~ (2.3)
( ; , … , ) ≡ ∑ ( − ). (2.5) Algoritma kehomogenan yang diusulkan Gifi bertujuan untuk menemukan nilai optimal bagi ∗ dan ∗, yang menggunakan prinsip dasar alternating least
square Gifi (1990).
Algoritma ini bertujuan untuk memenuhi = 1, dan memerlukan inisiasi awal ( ≠ 0), dengan rerata 0, dan akan dinormalisasikan pada jumlah kuadrat dari (sehingga diharapkan akan memiliki keragaman sebesar 1). Prosedurnya dijelaskan sebagai berikut:
(1) Perbarui skor ← / .
(2) Tahap normalisasi ← √ ( ) . (3) Perbarui bobot ← ′ .
(4) Uji konvergensi Ulangi langkah (1), dengan mengganti ← , sampai dan konvergen (selisihnya lebih kecil dari nilai keakuratan yang telah ditentukan sebelumnya).
Dalam memetakan peubah asal pada peubah hasil di transformasi Gifi, terdapat dua algoritma. Algoritma Optimal Scaling Method (OSM) dan algoritma
Linear Combination Method (LCM). Misalkan banyak dimensi peubah dinyatakan dengan m. Algoritma OSM akan memetakan set peubah asal berdimensi m ke pada set peubah hasil berdimensi m juga. Sedangkan algoritma LCM memetakan set peubah asal berdimensi m ke pada peubah hasil berdimensi 1. Umumnya, algoritma LCM digunakan untuk meringkas peubah. Penelitian ini akan menggunakan algoritma OSM.
Teknis dari Algoritma Gifi pada uraian sebelumnya dijelaskan sebagai berikut:
1. Data disajikan ke dalam matriks berukuran x .
2. Untuk setiap peubah dalam , buatlah matriks indikator , dan matriks diagonal .
3. Banyak kategori pada masing-masing pertanyaan bisa berbeda. Algoritma OSM diterapkan bertahap, dengan mentransformasikan peubah pertama terlebih dahulu, sampai peubah ke-m sehingga peubah hasil transformasi memiliki dimensi yang sama dengan peubah awalnya.
4. Untuk setiap ℎ , diawali dari = 1, inisiasi peubah dengan membangkitkan peubah ∗ ~ ( , 1). Untuk menjamin bahwa ∗ = 0, dilakukan pengaturan parameter pada bangkitan peubah acak. Dalam paket program matlab pengaturannya diberikan sebagai berikut: x = -b + (a-b).*rand(n,1)
5. Selanjutnya untuk menjamin ∗ = 1 adalah dengan normalisasi jumlah kuadrat pada n. Dalam paket program matlab pengaturannya diberikan sebagai berikut: x = (sqrt(n))*(x)*(sqrt(x'*x))^-1
6. Kemudian hitung bobot awal ∗ = ( ′ ∗)/ . 7. Perbarui peubah ∗, dengan = ( )/ . 8. Normalisasikan peubah , = √ ( ). 9. Perbarui bobot = ( ′ )/ .
11. Jika ( ) − ( − 1) < 0.001, dikatakan sudah konvergen, peubah pada poin 8 menjadi hasil. Jika belum, kembali ke poin 7. Setiap peubah yang sudah konvergen disimpan dalam set peubah hasil .
12. Tahapan ini diulangi sebamyak m kali sehingga dimensi = dimensi .
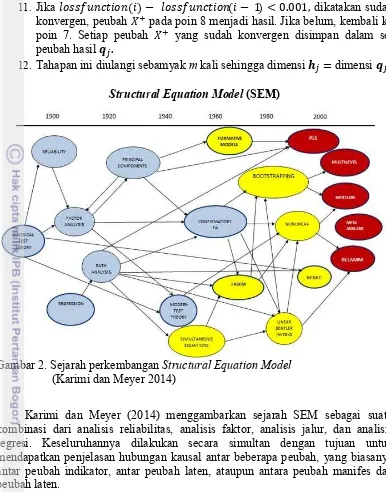
Structural Equation Model (SEM)
Gambar 2. Sejarah perkembangan Structural Equation Model
(Karimi dan Meyer 2014)
Karimi dan Meyer (2014) menggambarkan sejarah SEM sebagai suatu kombinasi dari analisis reliabilitas, analisis faktor, analisis jalur, dan analisis regresi. Keseluruhannya dilakukan secara simultan dengan tujuan untuk mendapatkan penjelasan hubungan kausal antar beberapa peubah, yang biasanya antar peubah indikator, antar peubah laten, ataupun antara peubah manifes dan peubah laten.
Hair et al. (2010) merumuskan bahwa dalam menggunakan SEM, ada tahapan pemodelan yang dijadikan acuan, yaitu sebagai berikut.
1. Pengembangan model secara teoritis. 2. Penyusunan diagram jalur.
3. Penyusunan persamaan struktural dari diagram jalur yang terbentuk. 4. Pemilihan matriks input untuk analisis data (matriks peragam atau matriks
korelasi).
5. Penilaian identifikasi model.
Penyusunan Model SEM
Bollen (1989) menjelaskan bahwa dalam persamaan SEM terdapat: 1. Peubah acak yang terdiri dari peubah indikator, peubah laten, dan galat. 2. Peubah tak acak yang merupakan peubah yang telah ditentukan nilainya. 3. Struktur parameter yang menyatakan hubungan sebab akibat antar peubah
indikator, antar peubah laten, ataupun antara peubah manifes dan peubah laten.
Lebih lanjut, Bollen menjelaskan konsep dan notasi yang digunakan dalam SEM dinyatakan sebagai berikut:
a. Peubah laten
Peubah tidak terobservasi dalam SEM dikenal juga dengan peubah laten, peubah tak terukur, atau faktor. Peubah ini tidak mengandung galat, dan biasanya akan menjadi peubah yang akan diuji. Peubah ini memiliki sifat abstrak (tidak dapat diukur langsung), sehingga diukur dengan menggunakan hubungan antar beberapa peubah yang menjadi indikatornya. Menurut jenisnya, terdapat peubah laten eksogen, yang merupakan peubah laten bebas (tidak dipengaruhi peubah laten lain), dan peubah laten endogen, yang merupakan peubah yang dipengaruhi peubah laten eksogen dan akan dihitung berdasarkan hubungan dengan peubah laten yang lainnya. Model persamaan dan notasi untuk peubah laten dituliskan sebagai berikut.
= + + . (2.6)
Asumsi yang digunakan dalam persamaan (2.6) adalah sebagai berikut. 1. ( ) = ( ) = ( ) = 0.
2. dan tidak saling berkorelasi.
3. diasumsikan homoskedastik dan tidak memiliki autokorelasi. 4. Matriks (I-B) adalah nonsingular (memiliki invers).
b. Peubah indikator/ peubah manifes
Peubah terobservasi dalam SEM dikenal juga sebagai peubah indikator/ peubah manifes. Asumsi yang digunakan dalam menyusun model SEM adalah bahwa peubah manifes memiliki korelasi sempurna (atau hampir sempurna) dengan peubah laten yang akan diukurnya. Model persamaan untuk peubah manifes dituliskan sebagai berikut.
= + (2.7)
= + . (2.8)
Asumsi yang digunakan dalam persamaan (2.7) dan (2.8) adalah sebagai berikut.
1. Rata-rata vektor dan vektor sama dengan 0. 2. , dan tidak saling berkorelasi.
Metode Pendugaan Parameter Model SEM
1. Pendugaan kemungkinan maksimum
Metode pendugaan kemungkinan maksimum merupakan metode pendugaan yang paling umum digunakan. Pendugaan parameter dilakukan dengan meminimumkan fungsi yang terdapat pada persamaan (2.9).
= log| ( )| + ( ) − | | − ( + ) (2.9)
dengan asumsi bahwa S dan () adalah matriks definit potitif/matriks non singular, p merupakan banyak indikator pada peubah laten endogen, dan q merupakan banyak indikator pada peubah laten eksogen. Untuk dapat menggunakan metode pendugaan kemungkinan maksimum juga diperlukan asumsi bahwa peubah indikator adalah peubah yang memiliki sebaran normal ganda sehingga menghasilkan penduga kemungkinan maksimum yang efisien untuk ukuran contoh yang cukup besar.
Sifat-sifat pendugaan kemungkinan maksimum menurut Bollen (1989) adalah tidak bias secara asimtotik (pada saat ukuran contoh terlalu kecil mungkin terjadi bias), konsisten, efisien secara asimtotik, dan invarian terhadap skala pengukuran (nilai dugaan parameter model tidak dipengaruhi oleh satuan pengukuran).
2. Generalized Least Squares (GLS)
Metode GLS merupakan metode yang umum digunakan setelah metode kemungkinan maksimum. Metode GLS digunakan untuk mengatasi keheterogenan ragam ralat yang biasanya menjadi masalah ketika asumsi kehomogenan ragam tidak terpenuhi. Pendugaan parameter dilakukan dengan meminimumkan fungsi yang terdapat pada persamaan (2.10).
= 12 tr[{( − ) } ] (2.10)
dengan merupakan matriks pembobot bagi matriks sisaan yang dipilih semirip mungkin dengan . Sifat pendugaan GLS konsisten, tetapi pengaruh dari pemilihan bobot dapat menghasilkan penduga yang tidak efisien.
Uji Kesesuaian Model SEM
Hasil dari pendugaan parameter dalam model SEM adalah nilai akhir dari parameter yang diduga. Kriteria kebaikan model ditentukan oleh ukuran kesesuaian model. Ukuran kesesuaian ini akan menyatakan seberapa baik model yang dihasilkan di dalam merepresentasikan data. Di dalam SEM, ukuran kebaikan model tidak dilihat berdasarkan hasil pengujian statistik tertentu, melainkan beberapa ukuran kesesuaian model untuk kemudian mengambil keputusan apakah model dapat dikatakan baik. Berikut ini beberapa uji kesesuaian yang biasa digunakan pada saat menentukan kebaikan model.
1. Chi-Square 2
H0 : Σ= Σ(θ)
H1 : Σ Σ(θ).
Statistik uji yang digunakan untuk menguji hipotesis tersebut adalah .
ˆ 1
2 =(n )xF(θ)
χhitung
) θ
F(ˆ adalah nilai minimum untuk θ=θˆ pada metode pendugaan kemungkinan
maksimum dengan besarnya derajat bebas. Model dikatakan baik jika memiliki nilai χ2 yang rendah dan memiliki signifikansi lebih besar atau sama dengan 0.05 (p≥0.05).
2. Goodness of Fit Indice (GFI)
GFI digunakan untuk menguji kesesuaian model dengan melakukan evaluasi secara deskriptif.Indeks kesesuaian ini akan menghitung proporsi tertimbang dari ragam dalam matriks kovarian sampel yang dijelaskan oleh matriks kovarian populasi yang diduga. GFI membandingkan model yang dihipotesiskan dengan model null (∑(θ)). Rumus dari GFI adalah sebagai berikut:
= 1 − (2.11)
dengan merupakan nilai minimum dari F untuk model yang dihipotesiskan, dan nilai minimum dari F untuk model null. Nilai GFI berada pada kisaran antara 0
dan 1, model dapat dikatakan memiliki kesesuaian yang baik pada saat nilai GF1 ≥ 0.90, dan cukup baik pada saat 0,80 ≤ GFI < 0.
3. Root Mean Square of Approximation (RMSEA)
RMSEA merupakan ukuran kesesuaian yang dalam penggunaanya dalam menilai kesesuaian model harus didampingi oleh statistik 2.
= ( − 1) − ( − 1)
(2.12)
dengan 2 adalah nilai dari chi-square model, df adalah derajat kebebasan model dan n adalah ukuran contoh. Kesesuaian model yang baik dinyatakan dengan nilai RMSEA ≤ 0.05, sedangkan kesesuaian model yang cukup baik dan masih dapat diterima didapatkan pada 0.05 < RMSEA ≤ 0.08.
4. Root Mean Square Residual ( RMR)
RMR merupakan ukuran rata-rata dari kuadrat sisaan yang diperoleh dari mencocokan matriks kovarian dari model yang dihipotesiskan dengan matriks kovarian dari data sampel. Sisaan ini adalah relatif terhadap ukuran dari kovarian indikator sehingga sukar diinterpretasikan. RMR yang distandarkan (SRMR)
= ( + )( + + 1)/2.∑ ∑ −
(2.13)
5. Akaike’s Information Criterion (AIC)
AIC bukanlah suatu tes hipotesis karena tidak memiliki signifikansi. AIC memberikan ukuran ketidakpastian untuk setiap model. Pada pemodelan konvensional, seleksi peubah dapat mengakibatkan peubah tidak disertakan ke dalam model. Akibatnya, teknik ini sering menghasilkan kesimpulan yang berbeda tergantung pada urutan di mana model dihitung. Pendekatan AIC menghasilkan hasil yang konsisten dan independen dari urutan model dihitung.
= − 2( ℎ ) + 2 (2.14)
dengan adalah banyak parameter yang akan diestimasi di dalam model. Model yang baik dinyatakan dengan ukuran AIC yang lebih kecil.
6. Bayesian Information Criterion (BIC)
Seperti juga AIC, BIC bukanlah suatu hipotesis. Meningkatnya keragaman pada model akan meningkatkan nilai BIC. Karenanya, model yang baik ditentukan dengan model yang memiliki nilai BIC minimum. Pendekatan BIC diformulasikan pada persamaan (2.15)
= log( ) − 2( ℎ ) (2.15)
3 PENANGANAN DATA KATEGORIK PADA SEM
Pendahuluan
Structural Equation Model (SEM) merupakan metode yang biasa digunakan untuk mencari hubungan antara peubah indikator dan peubah laten secara menyeluruh. Tujuan utama dari SEM adalah menemukan model yang relatif masuk akal untuk digunakan dalam membuat kesimpulan dan menghasilkan keputusan yang benar. Untuk mencapai tujuan ini, analisis statistik seperti pendugaan parameter, pemilihan model dan uji kesesuaian model dilakukan dalam SEM, dan dapat dilakukan pada berbagai campuran jenis data.
SEM merupakan metode analisis yang banyak digunakan pada penelitian di bidang ilmu sosial. Pengukuran fenomena sosial banyak melibatkan peubah kategorik, baik itu peubah dengan skala data nominal maupun interval. Kebutuhan untuk menganalisis fenomena ini memerlukan penanganan tersendiri dalam pemodelannya. Metode analisis data kategorik bertujuan untuk menjawab tiga pertanyaan yang saling berkaitan, siapa/apa yang sedang dipelajari, bagaimana karakteristik dari objek yang sedang dipelajari, dan ada unsur apa sajakah dari karakteristik objek yang sedang dipelajari (Freeman 1987). Secara ringkas, analisis data kategorik merupakan suatu metode yang mampu menjelaskan unit analisisnya, peubah yang digunakan untuk mengukur analisis, dan bagaimana menjelaskan keterkaitan antar peubah sehingga menjadi suatu fakta.
Dalam melakukan analisis, masing-masing metode analisis memerlukan asumsi yang berbeda. Asumsi bahwa peubah mengikuti sebaran normal adalah asumsi yang biasa digunakan dalam metode analisis yang mendasarkan pada teori normalitas. Bollen (1989) menyatakan bahwa pada saat peubah laten merupakan data kategorik dapat mengakibatkan terjadinya pelanggaran asumsi seperti model pengukuran yang dihasilkan tidak mencerminkan ukuran yang sebenarnya (Y pada SEM kontinu); sebaran dari peubah ordinal berbeda dengan indikator peubah laten kontinu, pada saat peubah laten ataupun peubah indikatornya bersifat data kategorik akan sangat mungkin sebarannya tidak normal; dan terjadinya pelanggaran pada hipotesis struktur kovarian. Asumsi normal diperlukan untuk pendugaan parameter menggunakan Maximum Likelihood Estimator (MLE), jika asumsi ini dilanggar, tidak dapat dilakukan pendugaan parameter menggunakan MLE.
Salah satu upaya agar data yang digunakan dapat dianalisis dengan metode yang mendasarkan pada teori normalitas adalah dengan melakukan transformasi data. Ada beberapa metode yang dapat digunakan dalam transformasi data. Beberapa contohnya adalah transformasi Box Cox, Succesive Intervals, dan transformasi Gifi. Di dalam menggunakan transformasi di dalam melakukan analisis perlu mempertimbangkan apakah transformasi yang dilakukan merupakan transformasi satu-satu, sehingga data dapat dipetakan kembali ke bentuk aslinya. Pengembalian ini penting di dalam melakukan interpretasi dari model yang dihasilkan.
Bahan dan Metode Data
Set data Kepuasan terhadap kondisi Kesehatan di Pulau Jawa merupakan bagian set data dari Survei Pengukuran Tingkat Kebahagiaan 2014. Penelitian ini menggunakan 60% dari keseluruhan responden SPTK di Pulau Jawa, yaitu sebanyak 13.684 responden, dengan sebaran seperti disajikan pada Tabel 7. Penggunaan 60% responden dari keseluruhan responden yang ada merupakan salah satu batasan dari penelitian ini, karena ketersediaan data yang ada. Pemilihan Pulau Jawa memperhatikan kelengkapan data yang ada di dalam suatu pulau, dan ketersediaan data pembanding dari Kementrian Kesehatan untuk data fasilitas kesehatan. Pemekaran Provinsi mengakibatkan data fasilitas kesehatan beberapa Provinsi hasil pemekaran tidak tersedia di Kementrian Kesehatan untuk tahun yang sama (2014). Responden di dalam penelitian ini adalah Kepala Rumah Tangga/ Pasangan Kepala Rumah Tangga dari rumah tangga terpilih di dalam SPTK (BPS 2014).
Tabel 7. Sebaran responden berdasarkan provinsi pada SPTK 2014 Provinsi Jumlah Responden
(1) (2)
DKI JAKARTA 667
JAWA BARAT 3.263
JAWA TENGAH 3.932
D I YOGYAKARTA 512
JAWA TIMUR 4.355
BANTEN 955
Total 13.684
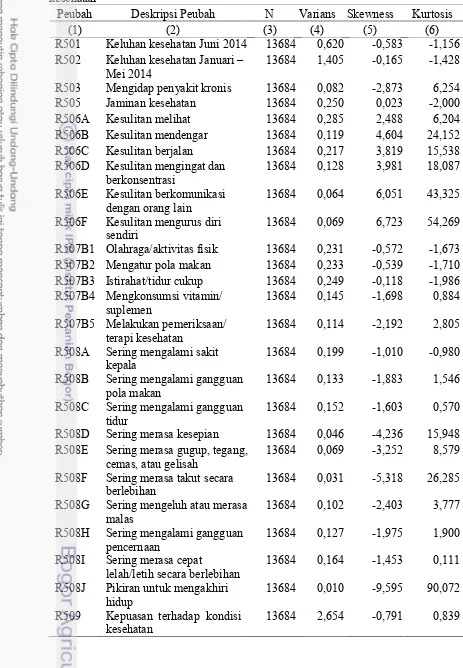
Hasil pemeriksaan pada peubah dalam data SPTK ini memberikan rasio kemiringan dan keruncingan dari masing-masing peubah yang menunjukkan bahwa tidak ada satupun peubah yang mengikuti sebaran normal. Ketidaknormalan ini dapat dijelaskan dengan kondisi data yang keseluruhannya memang merupakan peubah kategorik. Lebih lengkapnya, deskripsi data dapat dilihat pada Tabel 8. Peubah R509 menjelaskan kepuasan terhadap kondisi kesehatan yang dirasakan sekarang, dengan bentuk pertanyaan yang merupakan skala likert dengan interval 0 (sangat tidak puas) sampai dengan 10 (sangat puas). Peubah R501 dan R502 pada dataset merupakan peubah ordinal, sedangkan peubah lainnya merupakan peubah dikotomi dengan kategori jawaban Ya dan Tidak.
Tabel 8. Peubah yang digunakan untuk menjelaskan kepuasan terhadap kondisi kesehatan
Peubah Deskripsi Peubah N Varians Skewness Kurtosis
(1) (2) (3) (4) (5) (6)
R501 Keluhan kesehatan Juni 2014 13684 0,620 -0,583 -1,156 R502 Keluhan kesehatan Januari –
Mei 2014 13684 1,405 -0,165 -1,428
R503 Mengidap penyakit kronis 13684 0,082 -2,873 6,254 R505 Jaminan kesehatan 13684 0,250 0,023 -2,000 R506A Kesulitan melihat 13684 0,285 2,488 6,204 R506B Kesulitan mendengar 13684 0,119 4,604 24,152 R506C Kesulitan berjalan 13684 0,217 3,819 15,538 R506D Kesulitan mengingat dan
berkonsentrasi 13684 0,128 3,981 18,087
R506E Kesulitan berkomunikasi
dengan orang lain 13684 0,064 6,051 43,325 R506F Kesulitan mengurus diri
sendiri 13684 0,069 6,723 54,269
R507B1 Olahraga/aktivitas fisik 13684 0,231 -0,572 -1,673 R507B2 Mengatur pola makan 13684 0,233 -0,539 -1,710 R507B3 Istirahat/tidur cukup 13684 0,249 -0,118 -1,986 R507B4 Mengkonsumsi vitamin/
suplemen 13684 0,145 -1,698 0,884
R507B5 Melakukan pemeriksaan/
terapi kesehatan 13684 0,114 -2,192 2,805
R508A Sering mengalami sakit
kepala 13684 0,199 -1,010 -0,980
R508B Sering mengalami gangguan
pola makan 13684 0,133 -1,883 1,546
R508C Sering mengalami gangguan
tidur 13684 0,152 -1,603 0,570
R508D Sering merasa kesepian 13684 0,046 -4,236 15,948 R508E Sering merasa gugup, tegang,
cemas, atau gelisah 13684 0,069 -3,252 8,579 R508F Sering merasa takut secara
berlebihan 13684 0,031 -5,318 26,285
R508G Sering mengeluh atau merasa
malas 13684 0,102 -2,403 3,777
R508H Sering mengalami gangguan
pencernaan 13684 0,127 -1,975 1,900
R508I Sering merasa cepat
lelah/letih secara berlebihan 13684 0,164 -1,453 0,111 R508J Pikiran untuk mengakhiri
hidup 13684 0,010 -9,595 90,072
R509 Kepuasan terhadap kondisi
Tabel 9. Hubungan antara peubah laten
Peubah Laten Indikator Peubah Laten Hubungan ke Kepuasan
terhadap kondisi kesehatan
R506D, R506E, R506F Respoden yang tidak memiliki keterbatasan fisik cenderung lebih tinggi kepuasan terhadap
R507B4, R507B5 Respoden kesehatan cenderung lebih yang menjaga tinggi kepuasan terhadap kondisi kesehatannya
Structural Equation Model (SEM)
Kerangka teori yang digunakan dalam penyusunan model SEM diadaptasi dari New Economic Foundation dan Office for National Statistics. Adapun kerangka teori yang disampaikan New Economic Foundation dan Office for National Statistics adalah sebagai berikut.
Bollen (1989) menggambarkan urutan pemodelan sebagai berikut: 1) Spesifikasi Model.
Pada spesifikasi model, hubungan dalam diagram jalur diterjemahkan ke dalam persamaan matematika, di mana model struktural yang diberikan dalam persamaan (3.1), dan model pengukuran diberikan dalam persamaan (3.2) dan (3.3).
= + + + (3.1)
= + + (3.2)
= + + (3.3)
, , adalah vektor intersep yang memenuhi asumsi:
Tidak ada korelasi antara dan
Tidak ada korelasi antara dan
Tidak ada korelasi antara dan
( ) = ( ) = ( ) = 0
( ) = , sehingga ( ) = ( − ) ( + );
( ) = + ;
( ) = + ( − ) ( + ).
Kerangka teori yang diilustrasikan pada Gambar 3 kemudian diadopsi dalam menyusun model SEM untuk mengukur kepuasan terhadap kondisi kesehatan di level individu (Gambar 4), seperti yang diuraikan pada Tabel 9.
External Factor dijelaskan menggunakan laten (Kepemilikan asuransi/
Insurance (I)), Personal Resources dinyatakan dengan tiga beubah laten, yaitu: (Kondisi kesehatan/Health Condition (HC)), (Keterbatasan Fisik/ Physical Limitations (PL)), dan (Gejala depresi/ Symptom of Depresi (SS)). Functioning
(Kebiasaan Menjaga Kesehatan/ Healthcare Behavior (HB)), dinyatakan dengan laten , dan Satisfaction (Kepuasan terhadap Kondisi Kesehatan/ Health Satisfaction (HS)) dinyatakan dengan laten .
Gambar 4. Model SEM untuk pengukuran kepuasan terhadap kondisi kesehatan 2) Identifikasi Model.
Tahapan ini diperlukan untuk memeriksa apakah model memiliki solusi yang unik. Sebelum melakukan tahapan pendugaan model, model diidentifikasi terlebih dahulu apakah bisa mendapatkan solusi. Identifikasi model dapat dijelaskan dapat menggunakan derajat bebas dari model. Nilai derajat bebas model dihitung dari banyaknya data dikurangi dengan banyaknya parameter yang diduga.
Insurance
Healthcare
Behavior Satisfaction Health Health
Condition
Physical Limitation
Hasil identifikasi dalam SEM terdiri atas tiga kategori, yaitu:
a. Under-Identified, terjadi ketika banyak parameter yang akan diduga lebih besar dari banyak data yang diketahui (derajat bebas < 0).
b. Just-Identified, terjadi ketika banyak parameter yang diduga sama dengan data yang diketahui (derajat bebas = 0).
c. Over-Identified, terjadi ketika banyak parameter yang diduga lebih kecil dari banyak data yang diketahui (derajat bebas > 0).
Solusi unik untuk setiap parameter dapat dicapai ketika identifikasi menunjukkan minimal just-identified.
3) Pendugaan Model
Kita perlu menemukan nilai pendugaan parameter yang meminimumkan perbedaan antara unsur-unsur dalam ( ) (matriks peragam yang didapatkan dari model) dengan elemen pada (matriks peragam populasi). Ragam yang tidak diketahui akan diduga sedemikian sehingga ( ) = . Dengan asumsi = 0 pada persamaan (3.2) and (3.3), kita akan mendapatkan:
( ) = ( − ) ( [( − ) ]′ ′+ )[( − ) ]′ ′ + ( − )′ + ′
dan
= ( )( ) ( )( ) . Ditentukan pula ( , ( )) sebagai fitting function. 4) Pengujian model.
Hair et al. (2006) menjelaskan bahwa uji kebaikan model dapat dilakukan dengan beberapa tahap.
a) Overall Model Fit. Hooper et al. (2008) memberikan beberapa ukuran yang dapat digunakan dalam menilai kebaikan model, sebagaimana dijelaskan pada Tabel 10.
b) Kesesuaian model pengukuran. Pengukuran dilakukan pada semua konstruk, amatan diharapkan valid dan reliable.
c) Kesesuaian model struktural. Tahapan ini memperhatikan signifikansi dari setiap peubah terhadap model.
Tabel 10. Kriteria menentukan kebaikan model
Indikator Kriteria Nilai
Absolute fit indices Chi-Square Antara 2.0 sampai 5.0. Root Mean Square of
Approximation (RMSEA) Antara 0.0 sampai 0.08 Root mean square residual
(RMR) dan standardized root mean square residual (SRMR)
Antara 0.0 sampai 1.00, model dikatakan fit jika nilainya kurang dari 0.05
Incremental fit
5) Respesifikasi.
Respesifikasi merupakan sebuah cara untuk meningkatkan performa model. Pilihan cara dalam melakukan respesifikasi akan bergantung kepada strategi pemodelan yang dilakukan. Di dalam SEM, terdapattiga strategi pemodelan (Jöreskog dan Sörbom 1996; Hair et al. 2006) yaitu:
a. Strategi pemodelan konfirmatori.
Strategi pemodelan ini menggunakan satu model tunggal, kemudian dilakukan pengumpulan data empiris untuk diuji signifikansinya. Pengujian ini akan menghasilkan suatu penerimaan atau penolakan terhadap model tersebut. Strategi ini tidak memerlukan respesifikasi.
b. Strategi kompetisi model.
Strategi pemodelan ini memungkinkan ada beberapa model yang dikembangkan dari data, dan akan dipilih salah satu model yang paling sesuai. Tahapan respesifikasi pada strategi ini dilakukan pada semua alternative model yang ada.
c. Strategi pengembangan model.
Strategi pemodelan ini menggunakan model awal yang ditentukan terlebih dahulu. Jika model awal tidak cocok dengan data empiris yang ada, maka modifikasi model dilakukan dan diuji kembali dengan data yang sama. Beberapa model dapat diuji dalam proses ini dengan tujuan untuk mencari satu model yang memiliki kesesuaian yang baik dengan data dan setiap parameternya dapat diartikan dengan baik.
Hasil dan Pembahasan
Karakteristik data SPTK sebagian besar merupakan peubah dengan tipe kategorik. Untuk mengubahnya menjadi kontinu, digunakan transformasi Gifi. Transformasi Gifi dipilih karena kemampuannya dalam menghasilkan model yang memiliki kriteria kekompleksan informasi yang baik. Ini akan sangat membantu pada saat memodelkan SEM Multigrup dan SEM berhirarki yang modelnya lebih kompleks.
Pada bab ini akan dilakukan perbandingan model SEM tanpa transformasi data dan model SEM dengan transformasi Gifi, untuk kemudian dievaluasi mana yang memiliki kesesuaian lebih baik secara empiris.
Tahapan kajian perbandingan Model SEM tanpa transformasi data dan Model SEM dengan sistem GIFI dijelaskan sebagai berikut:
1. Lakukan pendugaan model SEM dengan data awal sebelum transformasi data.
2. Lakukan transformasi data dengan Algoritma Gifi sebanyak 100 kali. 3. Pendugaan model SEM dilakukan dengan 100 data hasil transformasi Gifi
pada poin 2.
4. Evaluasi ukuran kesesuaian model berdasarkan hasil yang diperoleh pada poin 3.
Tahapan dalam pemodelan SEM dijelaskan sebagai berikut: 1) Spesifikasi Model
Berdasarkan model SEM yang diilustrasikan pada Gambar 4, disusun persamaan struktural (persamaan (3.4) dan persamaan (3.5)) dan persamaan pengukuran (persamaan (3.6) dan (3.7)).
= + (3.4)
= + + + + (3.5)
, = ( , )+ ( , ) + , (3.6)
= + + (3.7)
Pada persamaan (3.6), , menyatakan pebah manifes ke-i dari peubah laten ke h.
2) Identifikasi Model
Hasil penghitungan menunjukkan bahwa banyak parameter yang diduga lebih kecil dari banyak data yang diketahui (derajat bebas > 0). Dengan demikian model over-identified, dan pendugaan memiliki solusi yang unik.
3) Pendugaan Model
Pada tahap awal, pendugaan dilakukan pada data tanpa transformasi. Paket program yang digunakan adalah Lavaan, dengan susunan model SEM terdapat pada Lampiran 3.
4) Pengujian Model
Hasil lengkap pengujian model SEM dengan data awal tanpa transformasi disajikan pada Lampiran 3.
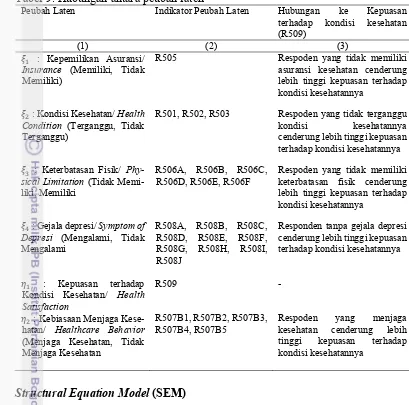
Tabel 11. Ringkasan ukuran kesesuaian model awal Indikator Kriteria Nilai
Sebelum
Modifikasi Setelah Modifikasi
Absolute fit indices Chi-Square 13788,520;
p = 0,000 6040,928; p = 0,000
RMSEA 0.058* 0.039*
SRMR 0.068* 0.042*
Incremental fit
indices CFI 0.822 0.924*
TLI 0.801 0.911*
dan tidak mengalami gejala depresi memiliki kecenderungan untuk menjaga kesehatan.
Sebagai pembanding, dibuat 100 set peubah yang transformasikan dengan Algoritma Gifi. Kemudian, terhadap 100 peubah ini dilakukan pemodelan SEM dengan mengulangi tahap sebelumnya. Ringkasan hasil pengulangan disajikan pada Tabel 12.
Tabel 12. Ringkasan ukuran kebaikan model pada model awal dan model dengan Algoritma Gifi
Rata-rata Model Awal Simulasi 100 kali
Jumlah Iterasi 142 67,510
Chi-square 13788,52 12018,209
CFI 0,822 0,748
TLI 0,801 0,717
RMSEA 0,058 0,054
SRMR 0,068 0,062
Berdasarkan hasil yang diperoleh pada Tabel 12, pengaruh dari penggunaan Algoritma Gifi pada tahap persiapan data utamanya dirasakan pada berkurangnya jumlah iterasi. Jika model awal memerlukan lebih dari 100 iterasi untuk mendapatkan model, maka model dengan peubah hasil transformasi Gifi dicapai dalam waktu setengahnya saja, berada di kisaran 67-68 kali iterasi. Untuk model yang kompleks ini menjadi keuntungan tersendiri, karena dapat menyingkat waktu komputasi yang diperlukan. Tetapi, untuk ukuran Incremental Fit Index (CFI dan TLI), performa dari model SEM dengan Algoritma Gifi tidak sebaik pada model awal. Ukuran kebaikan model lainnya masih dalam rentang yang dapat diterima untuk dapat mengindikasikan model memiliki kesesuaian yang cukup baik. Nilai
Chi-Square berkurang, tetapi masih belum cukup baik, masih di angka yang cukup besar, namun ini juga merupakan salah satu akibat dari besarnya jumlah sampel. Ringkasan model disajikan pada Tabel 13, dan hasil lengkap pemodelan pada Lampiran 5.
Ringkasan pada Tabel 13 menunjukkan bahwa terjadi perubahan pada ukuran
Chi-Square yang signifikan, tetapi belum cukup baik untuk dapat dikatakan model baik secara keseluruhan (p-value untuk nilai Chi-Square signifikan, <0,001). Memperhatikan ukuran kesesuaian lainnya (RMSEA, SRMR, CFI dan TLI), dapat dikatakan model sudah baik.
yang baik (tidak sakit), tidak merasakan adanya gejala depresi, dan memiliki kebiasaan menjaga kesehatan yang baik. Hasil ini masih menunjukkan pola yang sejalan dengan apa yang disampaikan pada model awal (tanpa transformasi data), hanya saja dengan nilai parameter yang berbeda.
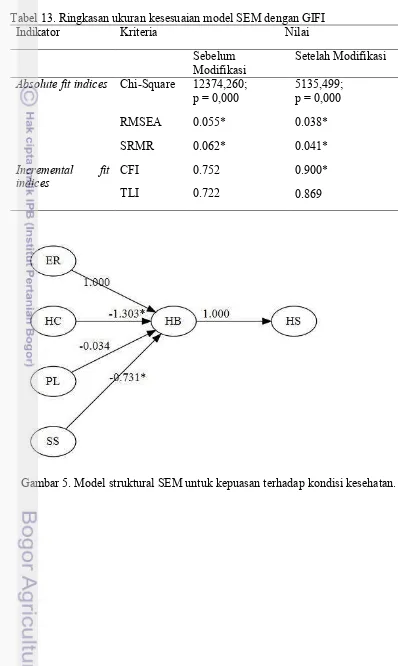
Tabel 13. Ringkasan ukuran kesesuaian model SEM dengan GIFI
Indikator Kriteria Nilai
Sebelum
Modifikasi Setelah Modifikasi
Absolute fit indices Chi-Square 12374,260;
p = 0,000 5135,499; p = 0,000
RMSEA 0.055* 0.038*
SRMR 0.062* 0.041*
Incremental fit
indices CFI 0.752 0.900*
TLI 0.722 0.869